Apache Solr - Trên Hadoop
Solr có thể được sử dụng cùng với Hadoop. Vì Hadoop xử lý một lượng lớn dữ liệu, Solr giúp chúng tôi tìm kiếm thông tin cần thiết từ một nguồn lớn như vậy. Trong phần này, hãy cho chúng tôi hiểu cách bạn có thể cài đặt Hadoop trên hệ thống của mình.
Tải xuống Hadoop
Dưới đây là các bước cần thực hiện để tải Hadoop xuống hệ thống của bạn.
Step 1- Vào trang chủ của Hadoop. Bạn có thể sử dụng liên kết - www.hadoop.apache.org/ . Nhấp vào liên kếtReleases, như được đánh dấu trong ảnh chụp màn hình sau.
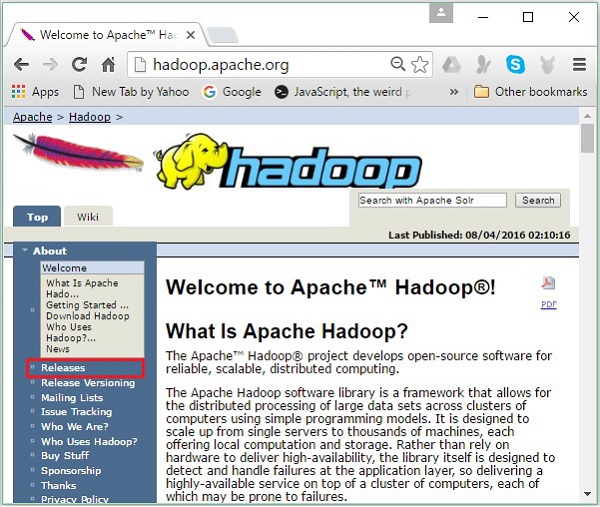
Nó sẽ chuyển hướng bạn đến Apache Hadoop Releases trang chứa các liên kết cho các bản sao của tệp nguồn và tệp nhị phân của các phiên bản Hadoop khác nhau như sau:
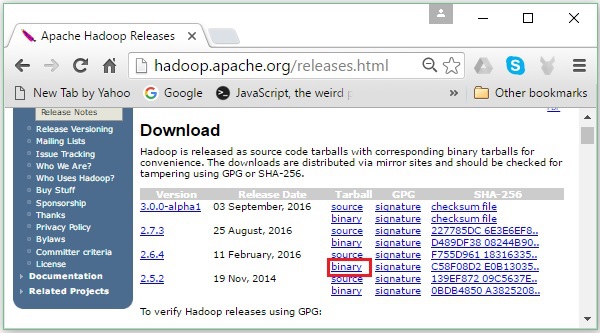
Step 2 - Chọn phiên bản mới nhất của Hadoop (trong hướng dẫn của chúng tôi là 2.6.4) và nhấp vào binary link. Nó sẽ đưa bạn đến một trang có sẵn các bản sao cho hệ nhị phân Hadoop. Nhấp vào một trong những gương này để tải xuống Hadoop.
Tải xuống Hadoop từ Command Prompt
Mở thiết bị đầu cuối Linux và đăng nhập với tư cách siêu người dùng.
$ su
password:Đi tới thư mục mà bạn cần cài đặt Hadoop và lưu tệp ở đó bằng liên kết đã sao chép trước đó, như được hiển thị trong khối mã sau.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzSau khi tải xuống Hadoop, hãy giải nén nó bằng các lệnh sau.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitCài đặt Hadoop
Làm theo các bước dưới đây để cài đặt Hadoop trong chế độ phân phối giả.
Bước 1: Thiết lập Hadoop
Bạn có thể đặt các biến môi trường Hadoop bằng cách thêm các lệnh sau vào ~/.bashrc tập tin.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMETiếp theo, áp dụng tất cả các thay đổi vào hệ thống đang chạy hiện tại.
$ source ~/.bashrcBước 2: Cấu hình Hadoop
Bạn có thể tìm thấy tất cả các tệp cấu hình Hadoop ở vị trí “$ HADOOP_HOME / etc / hadoop”. Bắt buộc phải thực hiện các thay đổi trong các tệp cấu hình đó theo cơ sở hạ tầng Hadoop của bạn.
$ cd $HADOOP_HOME/etc/hadoopĐể phát triển các chương trình Hadoop trong Java, bạn phải đặt lại các biến môi trường Java trong hadoop-env.sh tập tin bằng cách thay thế JAVA_HOME giá trị với vị trí của Java trong hệ thống của bạn.
export JAVA_HOME = /usr/local/jdk1.7.0_71Sau đây là danh sách các tệp mà bạn phải chỉnh sửa để định cấu hình Hadoop:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
Các core-site.xml tệp chứa thông tin như số cổng được sử dụng cho phiên bản Hadoop, bộ nhớ được cấp phát cho hệ thống tệp, giới hạn bộ nhớ để lưu trữ dữ liệu và kích thước của bộ đệm Đọc / Ghi.
Mở core-site.xml và thêm các thuộc tính sau vào trong các thẻ <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Các hdfs-site.xml tệp chứa thông tin như giá trị của dữ liệu sao chép, namenode con đường, và datanodeđường dẫn của hệ thống tệp cục bộ của bạn. Nó có nghĩa là nơi bạn muốn lưu trữ cơ sở hạ tầng Hadoop.
Hãy để chúng tôi giả sử dữ liệu sau đây.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeMở tệp này và thêm các thuộc tính sau vào trong các thẻ <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - Trong tệp trên, tất cả các giá trị thuộc tính đều do người dùng xác định và bạn có thể thực hiện thay đổi theo cơ sở hạ tầng Hadoop của mình.
yarn-site.xml
Tệp này được sử dụng để định cấu hình sợi thành Hadoop. Mở tệp fiber-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration> trong tệp này.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Tệp này được sử dụng để chỉ định khung MapReduce mà chúng tôi đang sử dụng. Theo mặc định, Hadoop chứa một mẫu sợi-site.xml. Trước hết, cần phải sao chép tệp từmapred-site,xml.template đến mapred-site.xml tập tin bằng lệnh sau.
$ cp mapred-site.xml.template mapred-site.xmlMở mapred-site.xml và thêm các thuộc tính sau vào trong các thẻ <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Xác minh cài đặt Hadoop
Các bước sau được sử dụng để xác minh cài đặt Hadoop.
Bước 1: Đặt tên cho Node Setup
Thiết lập nút tên bằng lệnh "hdfs namenode –format" như sau.
$ cd ~
$ hdfs namenode -formatKết quả mong đợi như sau.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Bước 2: Xác minh dfs Hadoop
Lệnh sau được sử dụng để khởi động dfs Hadoop. Thực thi lệnh này sẽ khởi động hệ thống tệp Hadoop của bạn.
$ start-dfs.shSản lượng dự kiến như sau:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Bước 3: Xác minh Tập lệnh Sợi
Lệnh sau được sử dụng để bắt đầu tập lệnh Yarn. Thực hiện lệnh này sẽ bắt đầu quỷ Sợi của bạn.
$ start-yarn.shSản lượng dự kiến như sau:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outBước 4: Truy cập Hadoop trên trình duyệt
Số cổng mặc định để truy cập Hadoop là 50070. Sử dụng URL sau để tải các dịch vụ Hadoop trên trình duyệt.
http://localhost:50070/
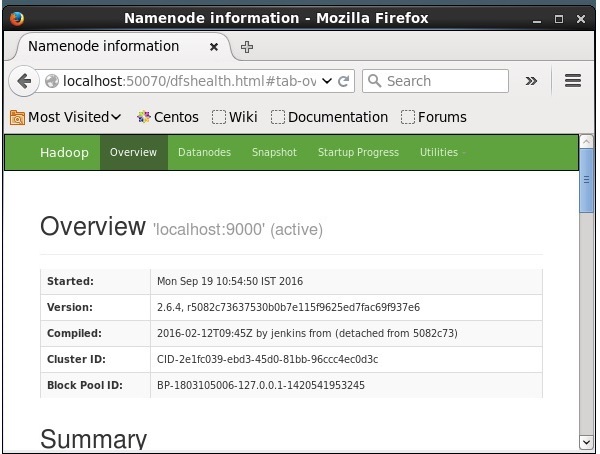
Cài đặt Solr trên Hadoop
Làm theo các bước dưới đây để tải xuống và cài đặt Solr.
Bước 1
Mở trang chủ của Apache Solr bằng cách nhấp vào liên kết sau: https://lucene.apache.org/solr/
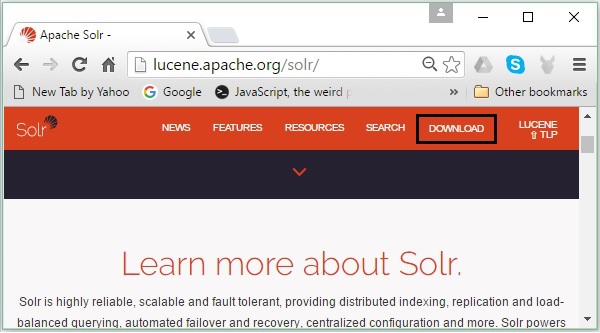
Bước 2
Nhấn vào download button(được đánh dấu trong ảnh chụp màn hình ở trên). Khi nhấp vào, bạn sẽ được chuyển hướng đến trang nơi bạn có nhiều bản sao Apache Solr. Chọn một nhân bản và nhấp vào nó, thao tác này sẽ chuyển hướng bạn đến một trang nơi bạn có thể tải xuống tệp nguồn và tệp nhị phân của Apache Solr, như được hiển thị trong ảnh chụp màn hình sau.
Bước 3
Khi nhấp vào, một thư mục có tên Solr-6.2.0.tqzsẽ được tải xuống trong thư mục tải xuống của hệ thống của bạn. Giải nén nội dung của thư mục đã tải xuống.
Bước 4
Tạo một thư mục có tên Solr trong thư mục chính Hadoop và di chuyển nội dung của thư mục đã giải nén vào đó, như hình dưới đây.
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/xác minh
Duyệt qua bin thư mục của Thư mục chính Solr và xác minh cài đặt bằng cách sử dụng version tùy chọn, như được hiển thị trong khối mã sau.
$ cd bin/
$ ./Solr version
6.2.0Đặt nhà và đường dẫn
Mở .bashrc tập tin bằng lệnh sau:
[Hadoop@localhost ~]$ source ~/.bashrcBây giờ đặt thư mục chính và đường dẫn cho Apache Solr như sau:
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Mở thiết bị đầu cuối và thực hiện lệnh sau:
[Hadoop@localhost Solr]$ source ~/.bashrcBây giờ, bạn có thể thực hiện các lệnh của Solr từ bất kỳ thư mục nào.