Apache Tajo - Hướng dẫn nhanh
Hệ thống kho dữ liệu phân tán
Kho dữ liệu là một cơ sở dữ liệu quan hệ được thiết kế để truy vấn và phân tích hơn là để xử lý giao dịch. Đây là một bộ sưu tập dữ liệu theo định hướng chủ đề, tích hợp, biến thể theo thời gian và không thay đổi. Dữ liệu này giúp các nhà phân tích đưa ra các quyết định sáng suốt trong một tổ chức nhưng khối lượng dữ liệu quan hệ được tăng lên từng ngày.
Để vượt qua những thách thức, hệ thống kho dữ liệu phân tán chia sẻ dữ liệu trên nhiều kho dữ liệu cho mục đích Xử lý Phân tích Trực tuyến (OLAP). Mỗi kho dữ liệu có thể thuộc về một hoặc nhiều tổ chức. Nó thực hiện cân bằng tải và khả năng mở rộng. Siêu dữ liệu được sao chép và phân phối tập trung.
Apache Tajo là một hệ thống kho dữ liệu phân tán sử dụng Hệ thống tệp phân tán Hadoop (HDFS) làm lớp lưu trữ và có công cụ thực thi truy vấn riêng thay vì khung MapReduce.
Tổng quan về SQL trên Hadoop
Hadoop là một khung công tác mã nguồn mở cho phép lưu trữ và xử lý dữ liệu lớn trong một môi trường phân tán. Nó cực kỳ nhanh và mạnh mẽ. Tuy nhiên, Hadoop có khả năng truy vấn hạn chế nên hiệu suất của nó có thể được cải thiện tốt hơn nữa với sự trợ giúp của SQL trên Hadoop. Điều này cho phép người dùng tương tác với Hadoop thông qua các lệnh SQL dễ dàng.
Một số ví dụ về ứng dụng SQL trên Hadoop là Hive, Impala, Drill, Presto, Spark, HAWQ và Apache Tajo.
Apache Tajo là gì
Apache Tajo là một khung xử lý dữ liệu quan hệ và phân tán. Nó được thiết kế để có độ trễ thấp và phân tích truy vấn đặc biệt có thể mở rộng.
Tajo hỗ trợ SQL tiêu chuẩn và các định dạng dữ liệu khác nhau. Hầu hết các truy vấn Tajo có thể được thực hiện mà không cần sửa đổi.
Tajo có fault-tolerance thông qua cơ chế khởi động lại cho các tác vụ không thành công và công cụ ghi lại truy vấn có thể mở rộng.
Tajo thực hiện những điều cần thiết ETL (Extract Transform and Load process)hoạt động để tóm tắt các tập dữ liệu lớn được lưu trữ trên HDFS. Nó là một lựa chọn thay thế cho Hive / Pig.
Phiên bản mới nhất của Tajo có khả năng kết nối cao hơn với các chương trình Java và cơ sở dữ liệu của bên thứ ba như Oracle và PostGreSQL.
Đặc điểm của Apache Tajo
Apache Tajo có các tính năng sau:
- Khả năng mở rộng vượt trội và hiệu suất tối ưu hóa
- Độ trễ thấp
- Các chức năng do người dùng xác định
- Khung xử lý lưu trữ hàng / cột.
- Khả năng tương thích với HiveQL và Hive MetaStore
- Luồng dữ liệu đơn giản và bảo trì dễ dàng.
Lợi ích của Apache Tajo
Apache Tajo mang lại những lợi ích sau:
- Dễ sử dụng
- Kiến trúc đơn giản
- Tối ưu hóa truy vấn dựa trên chi phí
- Kế hoạch thực thi truy vấn được vector hóa
- Chuyển phát nhanh
- Cơ chế I / O đơn giản và hỗ trợ nhiều loại lưu trữ.
- Khả năng chịu lỗi
Các trường hợp sử dụng của Apache Tajo
Sau đây là một số trường hợp sử dụng của Apache Tajo:
Lưu trữ và phân tích dữ liệu
Công ty SK Telecom của Hàn Quốc đã chạy Tajo dựa trên dữ liệu trị giá 1,7 terabyte và nhận thấy nó có thể hoàn thành các truy vấn với tốc độ cao hơn cả Hive hoặc Impala.
Khám phá dữ liệu
Dịch vụ phát trực tuyến nhạc Hàn Quốc Melon sử dụng Tajo để xử lý phân tích. Tajo thực hiện các công việc ETL (giải nén-chuyển đổi-tải) nhanh hơn từ 1,5 đến 10 lần so với Hive.
Phân tích nhật ký
Bluehole Studio, một công ty có trụ sở tại Hàn Quốc đã phát triển TERA - một trò chơi trực tuyến nhiều người chơi giả tưởng. Công ty sử dụng Tajo để phân tích nhật ký trò chơi và tìm ra nguyên nhân chính gây ra gián đoạn chất lượng dịch vụ.
Định dạng dữ liệu và lưu trữ
Apache Tajo hỗ trợ các định dạng dữ liệu sau:
- JSON
- Tệp văn bản (CSV)
- Parquet
- Tệp trình tự
- AVRO
- Bộ đệm giao thức
- Apache Orc
Tajo hỗ trợ các định dạng lưu trữ sau:
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
Hình minh họa sau đây mô tả kiến trúc của Apache Tajo.

Bảng sau đây mô tả chi tiết từng thành phần.
| Không. | Thành phần & Mô tả |
|---|---|
| 1 | Client Client gửi câu lệnh SQL cho Tajo Master để nhận kết quả. |
| 2 | Master Master là daemon chính. Nó chịu trách nhiệm lập kế hoạch truy vấn và là người điều phối cho người lao động. |
| 3 | Catalog server Duy trì các mô tả bảng và chỉ mục. Nó được nhúng trong daemon Master. Máy chủ danh mục sử dụng Apache Derby làm lớp lưu trữ và kết nối qua máy khách JDBC. |
| 4 | Worker Nút chính giao nhiệm vụ cho các nút công nhân. TajoWorker xử lý dữ liệu. Khi số lượng TajoWorker tăng lên, khả năng xử lý cũng tăng tuyến tính. |
| 5 | Query Master Tajo master gán truy vấn cho Query Master. Query Master chịu trách nhiệm kiểm soát một kế hoạch thực thi phân tán. Nó khởi chạy TaskRunner và lên lịch các tác vụ cho TaskRunner. Vai trò chính của Query Master là giám sát các tác vụ đang chạy và báo cáo chúng cho nút Master. |
| 6 | Node Managers Quản lý tài nguyên của nút công nhân. Nó quyết định việc phân bổ các yêu cầu tới nút. |
| 7 | TaskRunner Hoạt động như một công cụ thực thi truy vấn cục bộ. Nó được sử dụng để chạy và giám sát quá trình truy vấn. TaskRunner xử lý từng tác vụ một. Nó có ba thuộc tính chính sau:
|
| số 8 | Query Executor Nó được sử dụng để thực hiện một truy vấn. |
| 9 | Storage service Kết nối bộ lưu trữ dữ liệu cơ bản với Tajo. |
Quy trình làm việc
Tajo sử dụng Hệ thống tệp phân tán Hadoop (HDFS) làm lớp lưu trữ và có công cụ thực thi truy vấn riêng thay vì khung MapReduce. Một cụm Tajo bao gồm một nút chính và một số nhân công trên các nút cụm.
Người chủ chịu trách nhiệm chính về việc lập kế hoạch truy vấn và người điều phối cho người lao động. Master chia một truy vấn thành các nhiệm vụ nhỏ và giao cho các worker. Mỗi công nhân có một công cụ truy vấn cục bộ thực thi một đồ thị xoay chiều có hướng của các toán tử vật lý.
Ngoài ra, Tajo có thể kiểm soát luồng dữ liệu phân tán linh hoạt hơn so với MapReduce và hỗ trợ kỹ thuật lập chỉ mục.
Giao diện dựa trên web của Tajo có các khả năng sau:
- Tùy chọn để tìm cách lập kế hoạch cho các truy vấn đã gửi
- Tùy chọn để tìm cách phân phối các truy vấn trên các nút
- Tùy chọn để kiểm tra trạng thái của cụm và các nút
Để cài đặt Apache Tajo, bạn phải có phần mềm sau trên hệ thống của mình:
- Hadoop phiên bản 2.3 trở lên
- Java phiên bản 1.7 trở lên
- Linux hoặc Mac OS
Bây giờ chúng ta hãy tiếp tục với các bước sau để cài đặt Tajo.
Xác minh cài đặt Java
Hy vọng rằng bạn đã cài đặt Java phiên bản 8 trên máy của mình. Bây giờ, bạn chỉ cần tiếp tục bằng cách xác minh nó.
Để xác minh, hãy sử dụng lệnh sau:
$ java -versionNếu Java được cài đặt thành công trên máy của bạn, bạn có thể thấy phiên bản Java hiện tại đã được cài đặt. Nếu Java chưa được cài đặt, hãy làm theo các bước sau để cài đặt Java 8 trên máy của bạn.
Tải xuống JDK
Tải xuống phiên bản mới nhất của JDK bằng cách truy cập liên kết sau và sau đó, tải xuống phiên bản mới nhất.
https://www.oracle.com
Phiên bản mới nhất là JDK 8u 92 và tệp là “jdk-8u92-linux-x64.tar.gz”. Vui lòng tải xuống tệp trên máy của bạn. Sau đó, giải nén các tệp và chuyển chúng vào một thư mục cụ thể. Bây giờ, hãy đặt các lựa chọn thay thế Java. Cuối cùng, Java đã được cài đặt trên máy của bạn.
Xác minh cài đặt Hadoop
Bạn đã cài đặt Hadooptrên hệ thống của bạn. Bây giờ, hãy xác minh nó bằng lệnh sau:
$ hadoop versionNếu mọi thứ đều ổn với thiết lập của bạn, thì bạn có thể thấy phiên bản của Hadoop. Nếu Hadoop chưa được cài đặt, hãy tải xuống và cài đặt Hadoop bằng cách truy cập liên kết sau:https://www.apache.org
Cài đặt Apache Tajo
Apache Tajo cung cấp hai chế độ thực thi - chế độ cục bộ và chế độ phân tán hoàn toàn. Sau khi xác minh cài đặt Java và Hadoop, hãy tiến hành các bước sau để cài đặt cụm Tajo trên máy của bạn. Một phiên bản Tajo ở chế độ cục bộ yêu cầu cấu hình rất dễ dàng.
Tải xuống phiên bản mới nhất của Tajo bằng cách truy cập liên kết sau: https://www.apache.org/dyn/closer.cgi/tajo
Bây giờ bạn có thể tải xuống tệp “tajo-0.11.3.tar.gz” từ máy của bạn.
Giải nén tệp Tar
Giải nén tệp tar bằng cách sử dụng lệnh sau:
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3Đặt biến môi trường
Thêm các thay đổi sau vào “conf/tajo-env.sh” tập tin
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/Ở đây, bạn phải chỉ định đường dẫn Hadoop và Java đến “tajo-env.sh”tập tin. Sau khi các thay đổi được thực hiện, hãy lưu tệp và thoát khỏi thiết bị đầu cuối.
Khởi động máy chủ Tajo
Để khởi chạy máy chủ Tajo, hãy thực hiện lệnh sau:
$ bin/start-tajo.shBạn sẽ nhận được phản hồi tương tự như sau:
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002Bây giờ, gõ lệnh “jps” để xem các trình duyệt đang chạy.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterKhởi chạy Tajo Shell (Tsql)
Để khởi chạy ứng dụng khách Tajo shell, hãy sử dụng lệnh sau:
$ bin/tsqlBạn sẽ nhận được kết quả sau:
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Thoát vỏ Tajo
Thực hiện lệnh sau để thoát khỏi Tsql -
default> \q
bye!Ở đây, mặc định đề cập đến danh mục trong Tajo.
Giao diện người dùng web
Nhập URL sau để khởi chạy giao diện người dùng web Tajo - http://localhost:26080/
Bây giờ bạn sẽ thấy màn hình sau tương tự như tùy chọn ExecuteQuery.

Dừng Tajo
Để dừng máy chủ Tajo, hãy sử dụng lệnh sau:
$ bin/stop-tajo.shBạn sẽ nhận được phản hồi sau:
localhost: stopping worker
stopping masterCấu hình của Tajo dựa trên hệ thống cấu hình của Hadoop. Chương này giải thích chi tiết về cài đặt cấu hình Tajo.
Cài đặt cơ bản
Tajo sử dụng hai tệp cấu hình sau:
- catalog-site.xml - cấu hình cho máy chủ danh mục.
- tajo-site.xml - cấu hình cho các mô-đun Tajo khác.
Cấu hình chế độ phân tán
Thiết lập chế độ phân tán chạy trên Hệ thống tệp phân tán Hadoop (HDFS). Hãy làm theo các bước để cấu hình thiết lập chế độ phân tán Tajo.
tajo-site.xml
Tệp này có sẵn @ /path/to/tajo/confthư mục và hoạt động như cấu hình cho các mô-đun Tajo khác. Để truy cập Tajo ở chế độ phân tán, hãy áp dụng các thay đổi sau đối với“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>Cấu hình nút chính
Tajo sử dụng HDFS làm loại lưu trữ chính. Cấu hình như sau và sẽ được thêm vào“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>Cấu hình danh mục
Nếu bạn muốn tùy chỉnh dịch vụ danh mục, hãy sao chép $path/to/Tajo/conf/catalogsite.xml.template đến $path/to/Tajo/conf/catalog-site.xml và thêm bất kỳ cấu hình nào sau đây nếu cần.
Ví dụ, nếu bạn sử dụng “Hive catalog store” để truy cập Tajo, thì cấu hình phải như sau:
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>Nếu bạn cần lưu trữ MySQL danh mục, sau đó áp dụng các thay đổi sau:
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>Tương tự, bạn có thể đăng ký các danh mục hỗ trợ Tajo khác trong tệp cấu hình.
Cấu hình công nhân
Theo mặc định, TajoWorker lưu trữ dữ liệu tạm thời trên hệ thống tệp cục bộ. Nó được định nghĩa trong tệp “tajo-site.xml” như sau:
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>Để tăng khả năng chạy các tác vụ của từng tài nguyên công nhân, hãy chọn cấu hình sau:
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Để làm cho công nhân Tajo chạy ở chế độ chuyên dụng, hãy chọn cấu hình sau:
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>Trong chương này, chúng ta sẽ hiểu chi tiết các lệnh của Tajo Shell.
Để thực hiện các lệnh của Tajo shell, bạn cần khởi động máy chủ Tajo và Tajo shell bằng các lệnh sau:
Khởi động máy chủ
$ bin/start-tajo.shKhởi động Shell
$ bin/tsqlCác lệnh trên đã sẵn sàng để thực thi.
Lệnh Meta
Bây giờ chúng ta hãy thảo luận về Meta Commands. Các lệnh meta Tsql bắt đầu bằng dấu gạch chéo ngược(‘\’).
Lệnh trợ giúp
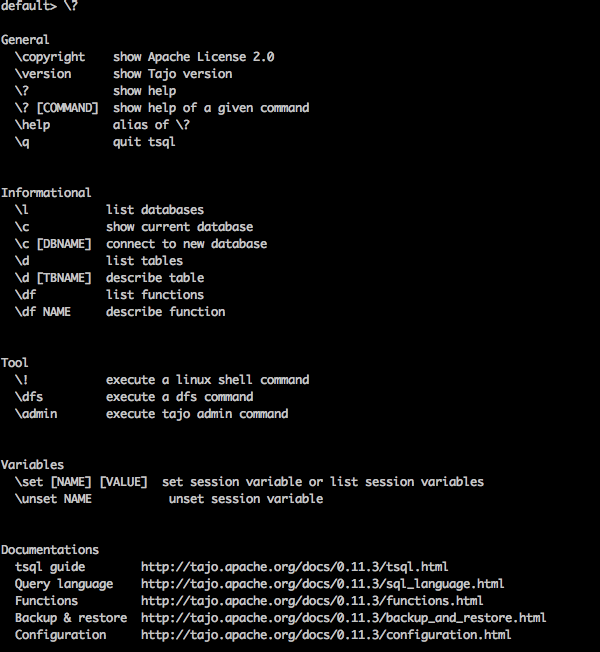
“\?” Lệnh được sử dụng để hiển thị tùy chọn trợ giúp.
Query
default> \?Result
Trên \?Lệnh liệt kê tất cả các tùy chọn sử dụng cơ bản trong Tajo. Bạn sẽ nhận được kết quả sau:
Cơ sở dữ liệu danh sách
Để liệt kê tất cả các cơ sở dữ liệu trong Tajo, hãy sử dụng lệnh sau:
Query
default> \lResult
Bạn sẽ nhận được kết quả sau:
information_schema
defaultHiện tại, chúng tôi chưa tạo bất kỳ cơ sở dữ liệu nào nên nó hiển thị hai cơ sở dữ liệu được xây dựng trong Tajo.
Cơ sở dữ liệu hiện tại
\c tùy chọn được sử dụng để hiển thị tên cơ sở dữ liệu hiện tại.
Query
default> \cResult
Bây giờ bạn được kết nối với cơ sở dữ liệu "mặc định" là "tên người dùng" của người dùng.
Liệt kê các chức năng tích hợp
Để liệt kê tất cả hàm tích hợp, hãy nhập truy vấn như sau:
Query
default> \dfResult
Bạn sẽ nhận được kết quả sau:

Mô tả chức năng
\df function name - Truy vấn này trả về mô tả đầy đủ của hàm đã cho.
Query
default> \df sqrtResult
Bạn sẽ nhận được kết quả sau:

Quit Terminal
Để thoát khỏi thiết bị đầu cuối, hãy nhập truy vấn sau:
Query
default> \qResult
Bạn sẽ nhận được kết quả sau:
bye!Lệnh quản trị
Tajo shell cung cấp \admin tùy chọn để liệt kê tất cả các tính năng quản trị.
Query
default> \adminResult
Bạn sẽ nhận được kết quả sau:

Thông tin cụm
Để hiển thị thông tin cụm trong Tajo, hãy sử dụng truy vấn sau
Query
default> \admin -clusterResult
Bạn sẽ nhận được kết quả sau:

Hiển thị chủ
Truy vấn sau đây hiển thị thông tin chính hiện tại.
Query
default> \admin -showmastersResult
localhostTương tự, bạn có thể thử các lệnh quản trị khác.
Các biến phiên
Máy khách Tajo kết nối với Master thông qua một id phiên duy nhất. Phiên hoạt động cho đến khi máy khách bị ngắt kết nối hoặc hết hạn.
Lệnh sau được sử dụng để liệt kê tất cả các biến phiên.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'Các \set key val sẽ đặt biến phiên có tên key với giá trị val. Ví dụ,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]Tại đây, bạn có thể gán khóa và giá trị trong \setchỉ huy. Nếu bạn cần hoàn nguyên các thay đổi, hãy sử dụng\unset chỉ huy.
Để thực hiện một truy vấn trong Tajo shell, hãy mở terminal của bạn và di chuyển đến thư mục đã cài đặt Tajo, sau đó gõ lệnh sau:
$ bin/tsqlBây giờ bạn sẽ thấy phản hồi như được hiển thị trong chương trình sau:
default>Bây giờ bạn có thể thực hiện các truy vấn của mình. Nếu không, bạn có thể chạy các truy vấn của mình thông qua ứng dụng bảng điều khiển web tới URL sau:http://localhost:26080/
Các kiểu dữ liệu ban đầu
Apache Tajo hỗ trợ danh sách các kiểu dữ liệu nguyên thủy sau:
| Không. | Kiểu dữ liệu & Mô tả |
|---|---|
| 1 | integer Được sử dụng để lưu trữ giá trị số nguyên với bộ nhớ 4 byte. |
| 2 | tinyint Giá trị số nguyên nhỏ là 1 byte |
| 3 | smallint Được sử dụng để lưu trữ giá trị số nguyên kích thước nhỏ 2 byte. |
| 4 | bigint Giá trị số nguyên phạm vi lớn có 8 byte lưu trữ. |
| 5 | boolean Trả về true / false. |
| 6 | real Được sử dụng để lưu trữ giá trị thực. Kích thước là 4 byte. |
| 7 | float Giá trị chính xác dấu chấm động có không gian lưu trữ 4 hoặc 8 byte. |
| số 8 | double Giá trị chính xác điểm kép được lưu trữ trong 8 byte. |
| 9 | char[(n)] Giá trị ký tự. |
| 10 | varchar[(n)] Dữ liệu không phải Unicode có độ dài thay đổi. |
| 11 | number Giá trị thập phân. |
| 12 | binary Giá trị nhị phân. |
| 13 | date Lịch ngày (năm, tháng, ngày). Example - DATE '2016-08-22' |
| 14 | time Thời gian trong ngày (giờ, phút, giây, mili giây) không có múi giờ. Các giá trị thuộc loại này được phân tích cú pháp và hiển thị trong múi giờ của phiên. |
| 15 | timezone Thời gian trong ngày (giờ, phút, giây, mili giây) với một múi giờ. Các giá trị thuộc loại này được hiển thị bằng cách sử dụng múi giờ từ giá trị. Example - TIME '01: 02: 03.456 Châu Á / kolkata' |
| 16 | timestamp Thời gian tức thì bao gồm ngày và giờ trong ngày mà không có múi giờ. Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text Văn bản Unicode có độ dài thay đổi. |
Các toán tử sau đây được sử dụng trong Tajo để thực hiện các thao tác mong muốn.
| Không. | Nhà điều hành & Mô tả |
|---|---|
| 1 | Toán tử số học Presto hỗ trợ các toán tử số học như +, -, *, /,%. |
| 2 | Toán tử quan hệ <,>, <=,> =, =, <> |
| 3 | Toán tử logic VÀ, HOẶC, KHÔNG |
| 4 | Toán tử chuỗi Dấu '||' toán tử thực hiện nối chuỗi. |
| 5 | Toán tử phạm vi Toán tử phạm vi được sử dụng để kiểm tra giá trị trong một phạm vi cụ thể. Tajo hỗ trợ toán tử GIỮA, KHÔNG ĐỦ, KHÔNG ĐỦ. |
Hiện tại, bạn đã biết về việc chạy các truy vấn cơ bản đơn giản trên Tajo. Trong vài chương tiếp theo, chúng ta sẽ thảo luận về các hàm SQL sau:
- Các hàm toán học
- Hàm chuỗi
- Các hàm DateTime
- Các hàm JSON
Các hàm toán học hoạt động dựa trên các công thức toán học. Bảng sau đây mô tả chi tiết danh sách các chức năng.
| Không. | Mô tả chức năng |
|---|---|
| 1 | abs (x) Trả về giá trị tuyệt đối của x. |
| 2 | cbrt (x) Trả về căn bậc hai của x. |
| 3 | ceil (x) Trả về giá trị x được làm tròn đến số nguyên gần nhất. |
| 4 | tầng (x) Trả về x làm tròn xuống số nguyên gần nhất. |
| 5 | số Pi() Trả về giá trị pi. Kết quả sẽ được trả về dưới dạng giá trị kép. |
| 6 | radian (x) chuyển đổi góc x tính bằng radian độ. |
| 7 | độ (x) Trả về giá trị độ cho x. |
| số 8 | pow (x, p) Trả về lũy thừa của value'p 'cho giá trị x. |
| 9 | div (x, y) Trả về kết quả phép chia cho hai giá trị nguyên x, y đã cho. |
| 10 | exp (x) Trả về số của Euler e nâng lên thành lũy thừa của một số. |
| 11 | sqrt (x) Trả về căn bậc hai của x. |
| 12 | dấu (x) Trả về hàm dấu hiệu của x, nghĩa là -
|
| 13 | mod (n, m) Trả về môđun (phần dư) của n chia cho m. |
| 14 | vòng (x) Trả về giá trị làm tròn cho x. |
| 15 | cos (x) Trả về giá trị cosine (x). |
| 16 | asin(x) Returns the inverse sine value(x). |
| 17 | acos(x) Returns the inverse cosine value(x). |
| 18 | atan(x) Returns the inverse tangent value(x). |
| 19 | atan2(y,x) Returns the inverse tangent value(y/x). |
Data Type Functions
The following table lists out the data type functions available in Apache Tajo.
| S.No. | Function & Description |
|---|---|
| 1 | to_bin(x) Returns the binary representation of integer. |
| 2 | to_char(int,text) Converts integer to string. |
| 3 | to_hex(x) Converts the x value into hexadecimal. |
The following table lists out the string functions in Tajo.
| S.No. | Function & Description |
|---|---|
| 1 | concat(string1, ..., stringN) Concatenate the given strings. |
| 2 | length(string) Returns the length of the given string. |
| 3 | lower(string) Returns the lowercase format for the string. |
| 4 | upper(string) Returns the uppercase format for the given string. |
| 5 | ascii(string text) Returns the ASCII code of the first character of the text. |
| 6 | bit_length(string text) Returns the number of bits in a string. |
| 7 | char_length(string text) Returns the number of characters in a string. |
| 8 | octet_length(string text) Returns the number of bytes in a string. |
| 9 | digest(input text, method text) Calculates the Digest hash of string. Here, the second arg method refers to the hash method. |
| 10 | initcap(string text) Converts the first letter of each word to upper case. |
| 11 | md5(string text) Calculates the MD5 hash of string. |
| 12 | left(string text, int size) Returns the first n characters in the string. |
| 13 | right(string text, int size) Returns the last n characters in the string. |
| 14 | locate(source text, target text, start_index) Returns the location of specified substring. |
| 15 | strposb(source text, target text) Returns the binary location of specified substring. |
| 16 | substr(source text, start index, length) Returns the substring for the specified length. |
| 17 | trim(string text[, characters text]) Removes the characters (a space by default) from the start/end/both ends of the string. |
| 18 | split_part(string text, delimiter text, field int) Splits a string on delimiter and returns the given field (counting from one). |
| 19 | regexp_replace(string text, pattern text, replacement text) Replaces substrings matched to a given regular expression pattern. |
| 20 | reverse(string) Reverse operation performed for the string. |
Apache Tajo supports the following DateTime functions.
| S.No. | Function & Description |
|---|---|
| 1 | add_days(date date or timestamp, int day Returns date added by the given day value. |
| 2 | add_months(date date or timestamp, int month) Returns date added by the given month value. |
| 3 | current_date() Returns today’s date. |
| 4 | current_time() Returns today’s time. |
| 5 | extract(century from date/timestamp) Extracts century from the given parameter. |
| 6 | extract(day from date/timestamp) Extracts day from the given parameter. |
| 7 | extract(decade from date/timestamp) Extracts decade from the given parameter. |
| 8 | extract(day dow date/timestamp) Extracts day of week from the given parameter. |
| 9 | extract(doy from date/timestamp) Extracts day of year from the given parameter. |
| 10 | select extract(hour from timestamp) Extracts hour from the given parameter. |
| 11 | select extract(isodow from timestamp) Extracts day of week from the given parameter. This is identical to dow except for Sunday. This matches the ISO 8601 day of the week numbering. |
| 12 | select extract(isoyear from date) Extracts ISO year from the specified date. ISO year may be different from the Gregorian year. |
| 13 | extract(microseconds from time) Extracts microseconds from the given parameter. The seconds field, including fractional parts, multiplied by 1 000 000; |
| 14 | extract(millennium from timestamp ) Extracts millennium from the given parameter.one millennium corresponds to 1000 years. Hence, the third millennium started January 1, 2001. |
| 15 | extract(milliseconds from time) Extracts milliseconds from the given parameter. |
| 16 | extract(minute from timestamp ) Extracts minute from the given parameter. |
| 17 | extract(quarter from timestamp) Extracts quarter of the year(1 - 4) from the given parameter. |
| 18 | date_part(field text, source date or timestamp or time) Extracts date field from text. |
| 19 | now() Returns current timestamp. |
| 20 | to_char(timestamp, format text) Converts timestamp to text. |
| 21 | to_date(src text, format text) Converts text to date. |
| 22 | to_timestamp(src text, format text) Converts text to timestamp. |
The JSON functions are listed in the following table −
| S.No. | Function & Description |
|---|---|
| 1 | json_extract_path_text(js on text, json_path text) Extracts JSON string from a JSON string based on json path specified. |
| 2 | json_array_get(json_array text, index int4) Returns the element at the specified index into the JSON array. |
| 3 | json_array_contains(json_ array text, value any) Determine if the given value exists in the JSON array. |
| 4 | json_array_length(json_ar ray text) Returns the length of json array. |
This section explains the Tajo DDL commands. Tajo has a built-in database named default.
Create Database Statement
Create Database is a statement used to create a database in Tajo. The syntax for this statement is as follows −
CREATE DATABASE [IF NOT EXISTS] <database_name>Query
default> default> create database if not exists test;Result
The above query will generate the following result.
OKDatabase is the namespace in Tajo. A database can contain multiple tables with a unique name.
Show Current Database
To check the current database name, issue the following command −
Query
default> \cResult
The above query will generate the following result.
You are now connected to database "default" as user “user1".
default>Connect to Database
As of now, you have created a database named “test”. The following syntax is used to connect the “test” database.
\c <database name>Query
default> \c testResult
The above query will generate the following result.
You are now connected to database "test" as user “user1”.
test>You can now see the prompt changes from default database to test database.
Drop Database
To drop a database, use the following syntax −
DROP DATABASE <database-name>Query
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;Result
The above query will generate the following result.
OKA table is a logical view of one data source. It consists of a logical schema, partitions, URL, and various properties. A Tajo table can be a directory in HDFS, a single file, one HBase table, or a RDBMS table.
Tajo supports the following two types of tables −
- external table
- internal table
External Table
External table needs the location property when the table is created. For example, if your data is already there as Text/JSON files or HBase table, you can register it as Tajo external table.
The following query is an example of external table creation.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';Here,
External keyword − This is used to create an external table. This helps to create a table in the specified location.
Sample refers to the table name.
Location − It is a directory for HDFS,Amazon S3, HBase or local file system. To assign a location property for directories, use the below URI examples −
HDFS − hdfs://localhost:port/path/to/table
Amazon S3 − s3://bucket-name/table
local file system − file:///path/to/table
Openstack Swift − swift://bucket-name/table
Table Properties
An external table has the following properties −
TimeZone − Users can specify a time zone for reading or writing a table.
Compression format − Used to make data size compact. For example, the text/json file uses compression.codec property.
Internal Table
A Internal table is also called an Managed Table. It is created in a pre-defined physical location called the Tablespace.
Syntax
create table table1(col1 int,col2 text);By default, Tajo uses “tajo.warehouse.directory” located in “conf/tajo-site.xml” . To assign new location for the table, you can use Tablespace configuration.
Tablespace
Tablespace is used to define locations in the storage system. It is supported for only internal tables. You can access the tablespaces by their names. Each tablespace can use a different storage type. If you don’t specify tablespaces then, Tajo uses the default tablespace in the root directory.
Tablespace Configuration
You have “conf/tajo-site.xml.template” in Tajo. Copy the file and rename it to “storagesite.json”. This file will act as a configuration for Tablespaces. Tajo data formats uses the following configuration −
HDFS Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}HBase Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}Text File Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}Tablespace Creation
Tajo’s internal table records can be accessed from another table only. You can configure it with tablespace.
Syntax
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]Here,
IF NOT EXISTS − This avoids an error if the same table has not been created already.
TABLESPACE − This clause is used to assign the tablespace name.
Storage type − Tajo data supports formats like text,JSON,HBase,Parquet,Sequencefile and ORC.
AS select statement − Select records from another table.
Configure Tablespace
Start your Hadoop services and open the file “conf/storage-site.json”, then add the following changes −
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Here, Tajo will refer to the data from HDFS location and space1 is the tablespace name. If you do not start Hadoop services, you can’t register tablespace.
Query
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;The above query creates a table named “table1” and “space1” refers to the tablespace name.
Data formats
Tajo supports data formats. Let’s go through each of the formats one by one in detail.
Text
A character-separated values’ plain text file represents a tabular data set consisting of rows and columns. Each row is a plain text line.
Creating Table
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;Here, “customers.csv” file refers to a comma separated value file located in the Tajo installation directory.
To create internal table using text format, use the following query −
default> create table customer(id int,name text,address text,age int) using text;In the above query, you have not assigned any tablespace so it will take Tajo’s default tablespace.
Properties
A text file format has the following properties −
text.delimiter − This is a delimiter character. Default is ‘|’.
compression.codec − This is a compression format. By default, it is disabled. you can change the settings using specified algorithm.
timezone − The table used for reading or writing.
text.error-tolerance.max-num − The maximum number of tolerance levels.
text.skip.headerlines − The number of header lines per skipped.
text.serde − This is serialization property.
JSON
Apache Tajo supports JSON format for querying data. Tajo treats a JSON object as SQL record. One object equals one row in a Tajo table. Let’s consider “array.json” as follows −
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}After you create this file, switch to the Tajo shell and type the following query to create a table using the JSON format.
Query
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;Always remember that the file data must match with the table schema. Otherwise, you can omit the column names and use * which doesn’t require columns list.
To create an internal table, use the following query −
default> create table sample (num1 int,num2 text,num3 float) using json;Parquet
Parquet is a columnar storage format. Tajo uses Parquet format for easy, fast and efficient access.
Table creation
The following query is an example for table creation −
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;Parquet file format has the following properties −
parquet.block.size − size of a row group being buffered in memory.
parquet.page.size − The page size is for compression.
parquet.compression − The compression algorithm used to compress pages.
parquet.enable.dictionary − The boolean value is to enable/disable dictionary encoding.
RCFile
RCFile is the Record Columnar File. It consists of binary key/value pairs.
Table creation
The following query is an example for table creation −
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile has the following properties −
rcfile.serde − custom deserializer class.
compression.codec − compression algorithm.
rcfile.null − NULL character.
SequenceFile
SequenceFile is a basic file format in Hadoop which consists of key/value pairs.
Table creation
The following query is an example for table creation −
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;This sequence file has Hive compatibility. This can be written in Hive as,
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar) is a columnar storage format from Hive.
Table creation
The following query is an example for table creation −
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;The ORC format has the following properties −
orc.max.merge.distance − ORC file is read, it merges when the distance is lower.
orc.stripe.size − This is the size of each stripe.
orc.buffer.size − The default is 256KB.
orc.rowindex.stride − This is the ORC index stride in number of rows.
In the previous chapter, you have understood how to create tables in Tajo. This chapter explains about the SQL statement in Tajo.
Create Table Statement
Before moving to create a table, create a text file “students.csv” in Tajo installation directory path as follows −
students.csv
| Id | Name | Address | Age | Marks |
|---|---|---|---|---|
| 1 | Adam | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
After the file has been created, move to the terminal and start the Tajo server and shell one by one.
Create Database
Create a new database using the following command −
Query
default> create database sampledb;
OKConnect to the database “sampledb” which is now created.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Then, create a table in “sampledb” as follows −
Query
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Result
The above query will generate the following result.
OKHere, the external table is created. Now, you just have to enter the file location. If you have to assign the table from hdfs then use hdfs instead of file.
Next, the “students.csv” file contains comma separated values. The text.delimiter field is assigned with ‘,’.
You have now created “mytable” successfully in “sampledb”.
Show Table
To show tables in Tajo, use the following query.
Query
sampledb> \d
mytable
sampledb> \d mytableResult
The above query will generate the following result.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4List table
To fetch all the records in the table, type the following query −
Query
sampledb> select * from mytable;Result
The above query will generate the following result.

Insert Table Statement
Tajo uses the following syntax to insert records in table.
Syntax
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Tajo’s insert statement is similar to the INSERT INTO SELECT statement of SQL.
Query
Let’s create a table to overwrite table data of an existing table.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dResult
The above query will generate the following result.
mytable
testInsert Records
To insert records in the “test” table, type the following query.
Query
sampledb> insert overwrite into test select * from mytable;Result
The above query will generate the following result.
Progress: 100%, response time: 0.518 secHere, “mytable" records overwrite the “test” table. If you don’t want to create the “test” table, then straight away assign the physical path location as mentioned in an alternative option for insert query.
Fetch records
Use the following query to list out all the records in the “test” table −
Query
sampledb> select * from test;Result
The above query will generate the following result.

This statement is used to add, remove or modify columns of an existing table.
To rename the table use the following syntax −
Alter table table1 RENAME TO table2;Query
sampledb> alter table test rename to students;Result
The above query will generate the following result.
OKTo check the changed table name, use the following query.
sampledb> \d
mytable
studentsNow the table “test” is changed to “students” table.
Add Column
To insert new column in the “students” table, type the following syntax −
Alter table <table_name> ADD COLUMN <column_name> <data_type>Query
sampledb> alter table students add column grade text;Result
The above query will generate the following result.
OKSet Property
This property is used to change the table’s property.
Query
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKHere, compression type and codec properties are assigned.
To change the text delimiter property, use the following −
Query
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKResult
The above query will generate the following result.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTThe above result shows that the table’s properties are changed using the “SET” property.
Select Statement
The SELECT statement is used to select data from a database.
The syntax for the Select statement is as follows −
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Mệnh đề Where
Mệnh đề Where được sử dụng để lọc các bản ghi khỏi bảng.
Truy vấn
sampledb> select * from mytable where id > 5;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
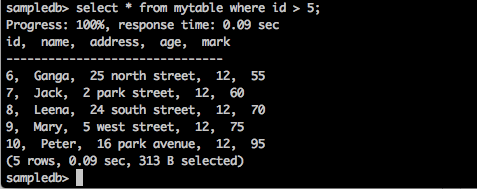
Truy vấn trả về bản ghi của những sinh viên có id lớn hơn 5.
Truy vấn
sampledb> select * from mytable where name = ‘Peter’;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Kết quả chỉ lọc hồ sơ của Peter.
Mệnh đề riêng biệt
Một cột trong bảng có thể chứa các giá trị trùng lặp. Từ khóa DISTINCT chỉ có thể được sử dụng để trả về các giá trị riêng biệt (khác nhau).
Cú pháp
SELECT DISTINCT column1,column2 FROM table_name;Truy vấn
sampledb> select distinct age from mytable;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12Truy vấn trả về độ tuổi khác biệt của sinh viên từ mytable.
Nhóm theo mệnh đề
Mệnh đề GROUP BY được sử dụng phối hợp với câu lệnh SELECT để sắp xếp dữ liệu giống nhau thành các nhóm.
Cú pháp
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Truy vấn
select age,sum(mark) as sumofmarks from mytable group by age;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
age, sumofmarks
-------------------------------
13, 145
12, 610Ở đây, cột “mytable” có hai loại tuổi - 12 và 13. Bây giờ truy vấn nhóm các bản ghi theo độ tuổi và tạo ra tổng điểm cho các độ tuổi tương ứng của học sinh.
Có mệnh đề
Mệnh đề HAVING cho phép bạn chỉ định các điều kiện lọc kết quả nhóm nào xuất hiện trong kết quả cuối cùng. Mệnh đề WHERE đặt điều kiện vào các cột đã chọn, trong khi mệnh đề HAVING đặt điều kiện vào các nhóm được tạo bởi mệnh đề GROUP BY.
Cú pháp
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Truy vấn
sampledb> select age from mytable group by age having sum(mark) > 200;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
age
-------------------------------
12Truy vấn nhóm các bản ghi theo độ tuổi và trả về độ tuổi khi kết quả điều kiện sum (dấu)> 200.
Đặt hàng theo mệnh đề
Mệnh đề ORDER BY được sử dụng để sắp xếp dữ liệu theo thứ tự tăng dần hoặc giảm dần, dựa trên một hoặc nhiều cột. Cơ sở dữ liệu Tajo sắp xếp các kết quả truy vấn theo thứ tự tăng dần theo mặc định.
Cú pháp
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Truy vấn
sampledb> select * from mytable where mark > 60 order by name desc;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.

Truy vấn trả về tên của những sinh viên đó theo thứ tự giảm dần có điểm lớn hơn 60.
Tạo Tuyên bố Chỉ mục
Câu lệnh CREATE INDEX được sử dụng để tạo chỉ mục trong bảng. Chỉ mục được sử dụng để truy xuất dữ liệu nhanh chóng. Phiên bản hiện tại chỉ hỗ trợ lập chỉ mục cho các định dạng TEXT thuần túy được lưu trữ trên HDFS.
Cú pháp
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Truy vấn
create index student_index on mytable(id);Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
id
———————————————Để xem chỉ mục được chỉ định cho cột, hãy nhập truy vấn sau.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Ở đây, phương pháp TWO_LEVEL_BIN_TREE được sử dụng theo mặc định trong Tajo.
Tuyên bố bảng thả
Câu lệnh Drop Table được sử dụng để loại bỏ một bảng từ cơ sở dữ liệu.
Cú pháp
drop table table name;Truy vấn
sampledb> drop table mytable;Để kiểm tra xem bảng có bị xóa khỏi bảng hay không, hãy nhập truy vấn sau.
sampledb> \d mytable;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
ERROR: relation 'mytable' does not existBạn cũng có thể kiểm tra truy vấn bằng lệnh “\ d” để liệt kê các bảng Tajo có sẵn.
Chương này giải thích chi tiết các hàm tổng hợp và cửa sổ.
Chức năng tổng hợp
Các hàm tổng hợp tạo ra một kết quả duy nhất từ một tập hợp các giá trị đầu vào. Bảng sau đây mô tả chi tiết danh sách các hàm tổng hợp.
| Không. | Mô tả chức năng |
|---|---|
| 1 | AVG (exp) Tính trung bình một cột của tất cả các bản ghi trong một nguồn dữ liệu. |
| 2 | CORR (biểu thức1, biểu thức2) Trả về hệ số tương quan giữa một tập hợp các cặp số. |
| 3 | ĐẾM() Trả về các hàng số. |
| 4 | MAX (biểu thức) Trả về giá trị lớn nhất của cột đã chọn. |
| 5 | MIN (biểu thức) Trả về giá trị nhỏ nhất của cột đã chọn. |
| 6 | SUM (biểu thức) Trả về tổng của cột đã cho. |
| 7 | LAST_VALUE (biểu thức) Trả về giá trị cuối cùng của cột đã cho. |
Chức năng cửa sổ
Các hàm Window thực thi trên một tập hợp các hàng và trả về một giá trị duy nhất cho mỗi hàng từ truy vấn. Cửa sổ thuật ngữ có ý nghĩa là tập hợp hàng cho hàm.
Hàm Window trong một truy vấn, xác định cửa sổ bằng mệnh đề OVER ().
Các OVER() mệnh đề có các khả năng sau:
- Xác định các phân vùng cửa sổ để tạo thành các nhóm hàng. (Mệnh đề PARTITION BY)
- Sắp xếp các hàng trong một phân vùng. (Mệnh đề ORDER BY)
Bảng sau đây mô tả chi tiết các chức năng của cửa sổ.
| Chức năng | Loại trả lại | Sự miêu tả |
|---|---|---|
| cấp() | int | Trả về thứ hạng của hàng hiện tại có khoảng trống. |
| row_num () | int | Trả về hàng hiện tại trong phân vùng của nó, đếm từ 1. |
| lead (giá trị [, số nguyên bù [, mặc định bất kỳ]]) | Giống như kiểu đầu vào | Trả về giá trị được đánh giá tại hàng được bù đắp hàng sau hàng hiện tại trong phân vùng. Nếu không có hàng như vậy, giá trị mặc định sẽ được trả về. |
| lag (giá trị [, số nguyên bù [, mặc định bất kỳ]]) | Giống như kiểu đầu vào | Trả về giá trị được đánh giá tại hàng được bù đắp hàng trước hàng hiện tại trong phân vùng. |
| first_value (giá trị) | Giống như kiểu đầu vào | Trả về giá trị đầu tiên của các hàng đầu vào. |
| last_value (giá trị) | Giống như kiểu đầu vào | Trả về giá trị cuối cùng của các hàng đầu vào. |
Chương này giải thích về các Truy vấn quan trọng sau đây.
- Predicates
- Explain
- Join
Hãy để chúng tôi tiến hành và thực hiện các truy vấn.
Dự đoán
Vị từ là một biểu thức được sử dụng để đánh giá các giá trị true / false và UNKNOWN. Các vị từ được sử dụng trong điều kiện tìm kiếm của mệnh đề WHERE và mệnh đề HAVING và các cấu trúc khác mà giá trị Boolean được yêu cầu.
Vị ngữ IN
Xác định xem giá trị của biểu thức cần kiểm tra có khớp với bất kỳ giá trị nào trong truy vấn con hoặc danh sách hay không. Truy vấn con là một câu lệnh SELECT thông thường có tập kết quả gồm một cột và một hoặc nhiều hàng. Cột này hoặc tất cả các biểu thức trong danh sách phải có cùng kiểu dữ liệu với biểu thức để kiểm tra.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
Truy vấn trên sẽ tạo ra kết quả sau.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueTruy vấn trả về các bản ghi từ mytable cho id sinh viên 2,3 và 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
Truy vấn trên sẽ tạo ra kết quả sau.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueTruy vấn trên trả về các bản ghi từ mytable nơi mà học sinh không thuộc khối 2,3 và 4.
Giống như Vị từ
Vị từ LIKE so sánh chuỗi được chỉ định trong biểu thức đầu tiên để tính giá trị chuỗi, được coi là giá trị để kiểm tra, với mẫu được xác định trong biểu thức thứ hai để tính toán giá trị chuỗi.
Mẫu có thể chứa bất kỳ sự kết hợp nào của các ký tự đại diện như -
Biểu tượng gạch chân (_), có thể được sử dụng thay cho bất kỳ ký tự đơn nào trong giá trị để kiểm tra.
Dấu phần trăm (%), thay thế bất kỳ chuỗi nào không hoặc nhiều ký tự trong giá trị cần kiểm tra.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
Truy vấn trên sẽ tạo ra kết quả sau.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95Truy vấn trả về các bản ghi từ bảng của tôi về những sinh viên có tên bắt đầu bằng 'A'.
Query
select * from mytable where name like ‘_a%';Result
Truy vấn trên sẽ tạo ra kết quả sau.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75Truy vấn trả về các bản ghi từ mytable của những học sinh có tên bắt đầu bằng 'a' làm ký tự thứ hai.
Sử dụng giá trị NULL trong điều kiện tìm kiếm
Bây giờ chúng ta hãy hiểu cách sử dụng Giá trị NULL trong các điều kiện tìm kiếm.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
Truy vấn trên sẽ tạo ra kết quả sau.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Ở đây, kết quả là true nên nó trả về tất cả các tên từ bảng.
Query
Bây giờ chúng ta hãy kiểm tra truy vấn với điều kiện NULL.
default> select name from mytable where name is null;Result
Truy vấn trên sẽ tạo ra kết quả sau.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Giải thích
Explainđược sử dụng để có được một kế hoạch thực thi truy vấn. Nó cho thấy một kế hoạch hợp lý và toàn cầu thực hiện một câu lệnh.
Truy vấn kế hoạch logic
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
Truy vấn trên sẽ tạo ra kết quả sau.

Kết quả truy vấn hiển thị một định dạng kế hoạch hợp lý cho bảng đã cho. Phương án lôgic trả về ba kết quả sau:
- Danh sách mục tiêu
- Ra ngoài lược đồ
- Trong lược đồ
Truy vấn kế hoạch toàn cầu
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
Truy vấn trên sẽ tạo ra kết quả sau.

Ở đây, kế hoạch toàn cầu hiển thị ID khối thực thi, thứ tự thực hiện và thông tin của nó.
Tham gia
Các phép nối SQL được sử dụng để kết hợp các hàng từ hai hoặc nhiều bảng. Sau đây là các loại SQL Joins khác nhau:
- Tham gia bên trong
- {TRÁI | QUYẾN RŨ | FULL} THAM GIA NGOÀI TRỜI
- Tham gia chéo
- Tự tham gia
- Tham gia tự nhiên
Hãy xem xét hai bảng sau để thực hiện các thao tác nối.
Bảng 1 - Khách hàng
| Tôi | Tên | Địa chỉ | Tuổi tác |
|---|---|---|---|
| 1 | Khách hàng 1 | 23 Phố Cổ | 21 |
| 2 | Khách hàng 2 | 12 Phố Mới | 23 |
| 3 | Khách hàng 3 | 10 Đại lộ Express | 22 |
| 4 | Khách hàng 4 | 15 Đại lộ Express | 22 |
| 5 | Khách hàng 5 | 20 Garden Street | 33 |
| 6 | Khách hàng 6 | 21 North Street | 25 |
Table2 - customer_order
| Tôi | Mã đơn hàng | Id trống |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Bây giờ chúng ta hãy tiếp tục và thực hiện các phép nối SQL trên hai bảng trên.
Tham gia bên trong
Phép nối bên trong chọn tất cả các hàng từ cả hai bảng khi có sự khớp giữa các cột trong cả hai bảng.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
Truy vấn trên sẽ tạo ra kết quả sau.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105Truy vấn khớp với năm hàng từ cả hai bảng. Do đó, nó trả về tuổi của các hàng phù hợp từ bảng đầu tiên.
Tham gia bên ngoài bên trái
Một phép nối ngoài cùng bên trái giữ lại tất cả các hàng của bảng “bên trái”, bất kể có hàng nào khớp trên bảng “bên phải” hay không.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
Truy vấn trên sẽ tạo ra kết quả sau.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Ở đây, phép nối ngoài cùng bên trái trả về các hàng cột tên từ bảng khách hàng (bên trái) và cột rỗng các hàng khớp với bảng khách hàng (bên phải).
Tham gia bên ngoài bên phải
Một phép nối ngoài cùng bên phải giữ lại tất cả các hàng của bảng “bên phải”, bất kể có hàng nào khớp trên bảng “bên trái” hay không.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
Truy vấn trên sẽ tạo ra kết quả sau.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Ở đây, phép nối bên phải trả về các hàng trống từ bảng customer_order (bên phải) và cột tên khớp với các hàng từ bảng khách hàng.
Tham gia đầy đủ bên ngoài
Tham gia bên ngoài đầy đủ giữ lại tất cả các hàng từ cả bảng bên trái và bên phải.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
Truy vấn trên sẽ tạo ra kết quả sau.

Truy vấn trả về tất cả các hàng phù hợp và không khớp từ cả bảng khách hàng và bảng customer_order.
Tham gia chéo
Điều này trả về tích Descartes của các tập hợp các bản ghi từ hai hoặc nhiều bảng được nối.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
Truy vấn trên sẽ tạo ra kết quả sau.
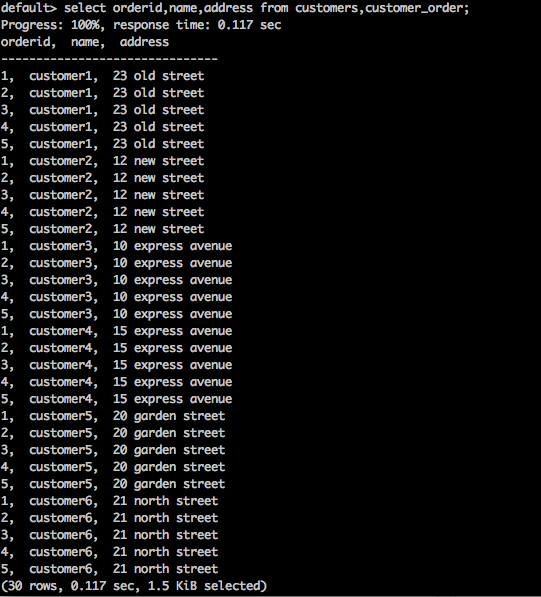
Truy vấn trên trả về tích Descartes của bảng.
Tham gia tự nhiên
Một phép nối tự nhiên không sử dụng bất kỳ toán tử so sánh nào. Nó không kết hợp theo cách một tích Descartes làm. Chúng ta chỉ có thể thực hiện phép nối tự nhiên nếu có ít nhất một thuộc tính chung tồn tại giữa hai mối quan hệ.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
Truy vấn trên sẽ tạo ra kết quả sau.

Ở đây, có một id cột chung tồn tại giữa hai bảng. Sử dụng cột chung đó,Natural Join tham gia cả hai bảng.
Tự tham gia
SQL SELF JOIN được sử dụng để nối một bảng với chính nó như thể bảng là hai bảng, tạm thời đổi tên ít nhất một bảng trong câu lệnh SQL.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
Truy vấn trên sẽ tạo ra kết quả sau.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6Truy vấn kết hợp một bảng khách hàng với chính nó.
Tajo hỗ trợ nhiều định dạng lưu trữ khác nhau. Để đăng ký cấu hình plugin lưu trữ, bạn nên thêm các thay đổi vào tệp cấu hình “storage-site.json”.
Storage-site.json
Cấu trúc được xác định như sau:
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}Mỗi cá thể lưu trữ được xác định bởi URI.
Trình xử lý lưu trữ PostgreSQL
Tajo hỗ trợ trình xử lý lưu trữ PostgreSQL. Nó cho phép các truy vấn của người dùng truy cập các đối tượng cơ sở dữ liệu trong PostgreSQL. Nó là trình xử lý lưu trữ mặc định trong Tajo nên bạn có thể dễ dàng cấu hình nó.
cấu hình
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}Đây, “database1” đề cập đến postgreSQL cơ sở dữ liệu được ánh xạ tới cơ sở dữ liệu “sampledb” trong Tajo.
Apache Tajo hỗ trợ tích hợp HBase. Điều này cho phép chúng tôi truy cập các bảng HBase trong Tajo. HBase là một cơ sở dữ liệu hướng cột phân tán được xây dựng trên hệ thống tệp Hadoop. Đây là một phần của hệ sinh thái Hadoop cung cấp quyền truy cập đọc / ghi ngẫu nhiên theo thời gian thực vào dữ liệu trong Hệ thống tệp Hadoop. Các bước sau là bắt buộc để cấu hình tích hợp HBase.
Đặt biến môi trường
Thêm các thay đổi sau vào tệp “conf / tajo-env.sh”.
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseSau khi bạn đã bao gồm đường dẫn HBase, Tajo sẽ đặt tệp thư viện HBase thành classpath.
Tạo bảng bên ngoài
Tạo một bảng bên ngoài bằng cú pháp sau:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;Để truy cập bảng HBase, bạn phải cấu hình vị trí vùng bảng.
Đây,
Table- Đặt tên bảng gốc hbase. Nếu bạn muốn tạo một bảng bên ngoài, bảng đó phải tồn tại trên HBase.
Columns- Phím đề cập đến phím hàng HBase. Số lượng mục nhập cột cần phải bằng số cột của bảng Tajo.
hbase.zookeeper.quorum - Đặt địa chỉ túc số người giữ vườn thú.
hbase.zookeeper.property.clientPort - Đặt cổng khách hàng của người giữ vườn thú.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';Tại đây, trường Đường dẫn vị trí đặt id cổng ứng dụng của người giữ vườn thú. Nếu bạn không đặt cổng, Tajo sẽ tham chiếu đến thuộc tính của tệp hbase-site.xml.
Tạo bảng trong HBase
Bạn có thể khởi động trình bao tương tác HBase bằng lệnh “hbase shell” như được hiển thị trong truy vấn sau.
Query
/bin/hbase shellResult
Truy vấn trên sẽ tạo ra kết quả sau.
hbase(main):001:0>Các bước truy vấn HBase
Để truy vấn HBase, bạn nên hoàn thành các bước sau:
Step 1 - Đưa các lệnh sau vào vỏ HBase để tạo bảng “hướng dẫn”.
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - Bây giờ, sử dụng lệnh sau trong hbase shell để tải dữ liệu vào một bảng.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - Bây giờ, quay lại trình bao Tajo và thực hiện lệnh sau để xem siêu dữ liệu của bảng -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - Để tìm nạp kết quả từ bảng, hãy sử dụng truy vấn sau:
Query
default> select * from studentsResult
Truy vấn trên sẽ lấy kết quả sau:
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo hỗ trợ HiveCatalogStore để tích hợp với Apache Hive. Sự tích hợp này cho phép Tajo truy cập các bảng trong Apache Hive.
Đặt biến môi trường
Thêm các thay đổi sau vào tệp “conf / tajo-env.sh”.
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveSau khi bạn đã bao gồm đường dẫn Hive, Tajo sẽ đặt tệp thư viện Hive thành đường dẫn classpath.
Cấu hình danh mục
Thêm các thay đổi sau vào tệp “conf / catalog-site.xml”.
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>Sau khi HiveCatalogStore được cấu hình, bạn có thể truy cập bảng của Hive trong Tajo.
Swift là một cửa hàng đối tượng / blob phân tán và nhất quán. Swift cung cấp phần mềm lưu trữ đám mây để bạn có thể lưu trữ và truy xuất nhiều dữ liệu với một API đơn giản. Tajo hỗ trợ tích hợp Swift.
Sau đây là các điều kiện tiên quyết của Tích hợp Swift:
- Swift
- Hadoop
Core-site.xml
Thêm các thay đổi sau vào tệp hadoop “core-site.xml” -
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>Điều này sẽ được sử dụng để Hadoop truy cập các đối tượng Swift. Sau khi bạn thực hiện tất cả các thay đổi, hãy chuyển đến thư mục Tajo để đặt biến môi trường Swift.
conf / tajo-env.h
Mở tệp cấu hình Tajo và thêm thiết lập biến môi trường như sau:
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarBây giờ, Tajo sẽ có thể truy vấn dữ liệu bằng Swift.
Tạo bảng
Hãy tạo một bảng bên ngoài để truy cập các đối tượng Swift trong Tajo như sau:
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';Sau khi bảng đã được tạo, bạn có thể chạy các truy vấn SQL.
Apache Tajo cung cấp giao diện JDBC để kết nối và thực thi các truy vấn. Chúng ta có thể sử dụng cùng một giao diện JDBC để kết nối Tajo từ ứng dụng dựa trên Java của chúng ta. Bây giờ chúng ta hãy hiểu cách kết nối Tajo và thực thi các lệnh trong ứng dụng Java mẫu của chúng ta bằng giao diện JDBC trong phần này.
Tải xuống trình điều khiển JDBC
Tải xuống trình điều khiển JDBC bằng cách truy cập liên kết sau: http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
Bây giờ, tệp “tajo-jdbc-0.11.3.jar” đã được tải xuống máy của bạn.
Đặt đường dẫn lớp
Để sử dụng trình điều khiển JDBC trong chương trình của bạn, hãy đặt đường dẫn lớp như sau:
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHKết nối với Tajo
Apache Tajo cung cấp trình điều khiển JDBC dưới dạng một tệp jar duy nhất và nó có sẵn @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
Chuỗi kết nối để kết nối Apache Tajo có định dạng sau:
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseĐây,
host - Tên máy chủ của TajoMaster.
port- Số cổng mà máy chủ đang nghe. Số cổng mặc định là 26002.
database- Tên cơ sở dữ liệu. Tên cơ sở dữ liệu mặc định là mặc định.
Ứng dụng Java
Bây giờ chúng ta hãy hiểu ứng dụng Java.
Mã hóa
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Ứng dụng có thể được biên dịch và chạy bằng các lệnh sau.
Tổng hợp
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaChấp hành
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleKết quả
Các lệnh trên sẽ tạo ra kết quả sau:
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo hỗ trợ các chức năng tùy chỉnh / do người dùng xác định (UDF). Các chức năng tùy chỉnh có thể được tạo trong python.
Các chức năng tùy chỉnh chỉ là các chức năng python đơn giản với trình trang trí “@output_type(<tajo sql datatype>)” như sau -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;Các tập lệnh python với UDF có thể được đăng ký bằng cách thêm cấu hình bên dưới vào “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>Sau khi các tập lệnh được đăng ký, hãy khởi động lại cụm và các UDF sẽ có sẵn ngay trong truy vấn SQL như sau:
select sum_py(10, 10) as pyfn;Apache Tajo cũng hỗ trợ các hàm tổng hợp do người dùng xác định nhưng không hỗ trợ các hàm cửa sổ do người dùng xác định.