Apache Tajo - Câu lệnh SQL
Trong chương trước, bạn đã hiểu cách tạo bảng trong Tajo. Chương này giải thích về câu lệnh SQL trong Tajo.
Tạo Báo cáo Bảng
Trước khi chuyển sang tạo bảng, hãy tạo tệp văn bản “student.csv” trong đường dẫn thư mục cài đặt Tajo như sau:
students.csv
| Tôi | Tên | Địa chỉ | Tuổi tác | Điểm |
|---|---|---|---|---|
| 1 | Adam | 23 Phố Mới | 21 | 90 |
| 2 | Amit | 12 Phố Cổ | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Đại lộ Express | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 đường phía nam | 12 | 70 |
| 9 | Mary | 5 phố tây | 12 | 75 |
| 10 | Peter | 16 Đại lộ Park | 12 | 95 |
Sau khi tệp đã được tạo, di chuyển đến thiết bị đầu cuối và khởi động máy chủ Tajo và trình bao từng cái một.
Tạo nên cơ sở dữ liệu
Tạo cơ sở dữ liệu mới bằng lệnh sau:
Truy vấn
default> create database sampledb;
OKKết nối với cơ sở dữ liệu “sa Sampleb” hiện đã được tạo.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Sau đó, tạo một bảng trong “sa Sampleb” như sau:
Truy vấn
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
OKTại đây, bảng bên ngoài được tạo. Bây giờ, bạn chỉ cần nhập vị trí tệp. Nếu bạn phải gán bảng từ hdfs thì hãy sử dụng hdfs thay vì tệp.
Tiếp theo, “students.csv”tệp chứa các giá trị được phân tách bằng dấu phẩy. Cáctext.delimiter trường được gán với ','.
Bây giờ bạn đã tạo thành công “mytable” trong “sackedb”.
Hiển thị bảng
Để hiển thị các bảng trong Tajo, hãy sử dụng truy vấn sau.
Truy vấn
sampledb> \d
mytable
sampledb> \d mytableKết quả
Truy vấn trên sẽ tạo ra kết quả sau.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4Bảng liệt kê
Để tìm nạp tất cả các bản ghi trong bảng, hãy nhập truy vấn sau:
Truy vấn
sampledb> select * from mytable;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.

Chèn tuyên bố bảng
Tajo sử dụng cú pháp sau để chèn các bản ghi trong bảng.
Cú pháp
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Câu lệnh chèn của Tajo tương tự như câu lệnh INSERT INTO SELECT câu lệnh của SQL.
Truy vấn
Hãy tạo một bảng để ghi đè dữ liệu bảng của một bảng hiện có.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dKết quả
Truy vấn trên sẽ tạo ra kết quả sau.
mytable
testChèn hồ sơ
Để chèn các bản ghi trong bảng "kiểm tra", hãy nhập truy vấn sau.
Truy vấn
sampledb> insert overwrite into test select * from mytable;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
Progress: 100%, response time: 0.518 secTại đây, các bản ghi “mytable” ghi đè lên bảng “test”. Nếu bạn không muốn tạo bảng “test”, hãy chỉ định ngay vị trí đường dẫn thực như đã đề cập trong một tùy chọn thay thế cho truy vấn chèn.
Tìm nạp hồ sơ
Sử dụng truy vấn sau để liệt kê tất cả các bản ghi trong bảng "kiểm tra" -
Truy vấn
sampledb> select * from test;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.

Câu lệnh này được sử dụng để thêm, xóa hoặc sửa đổi các cột của một bảng hiện có.
Để đổi tên bảng, hãy sử dụng cú pháp sau:
Alter table table1 RENAME TO table2;Truy vấn
sampledb> alter table test rename to students;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
OKĐể kiểm tra tên bảng đã thay đổi, hãy sử dụng truy vấn sau.
sampledb> \d
mytable
studentsBây giờ bảng “kiểm tra” được đổi thành bảng “học sinh”.
Thêm cột
Để chèn cột mới trong bảng "sinh viên", hãy nhập cú pháp sau:
Alter table <table_name> ADD COLUMN <column_name> <data_type>Truy vấn
sampledb> alter table students add column grade text;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
OKĐặt thuộc tính
Thuộc tính này được sử dụng để thay đổi thuộc tính của bảng.
Truy vấn
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKỞ đây, loại nén và thuộc tính codec được gán.
Để thay đổi thuộc tính dấu phân cách văn bản, hãy sử dụng như sau:
Truy vấn
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKKết quả
Truy vấn trên sẽ tạo ra kết quả sau.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTKết quả trên cho thấy các thuộc tính của bảng được thay đổi bằng thuộc tính “SET”.
Chọn câu lệnh
Câu lệnh SELECT được sử dụng để chọn dữ liệu từ cơ sở dữ liệu.
Cú pháp cho câu lệnh Select như sau:
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Mệnh đề Where
Mệnh đề Where được sử dụng để lọc các bản ghi khỏi bảng.
Truy vấn
sampledb> select * from mytable where id > 5;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
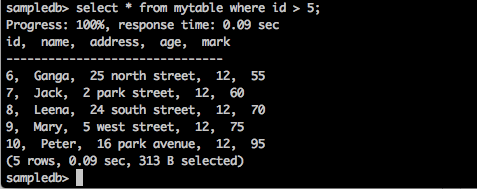
Truy vấn trả về bản ghi của những sinh viên có id lớn hơn 5.
Truy vấn
sampledb> select * from mytable where name = ‘Peter’;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Kết quả chỉ lọc hồ sơ của Peter.
Mệnh đề riêng biệt
Một cột trong bảng có thể chứa các giá trị trùng lặp. Từ khóa DISTINCT chỉ có thể được sử dụng để trả về các giá trị riêng biệt (khác nhau).
Cú pháp
SELECT DISTINCT column1,column2 FROM table_name;Truy vấn
sampledb> select distinct age from mytable;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12Truy vấn trả về độ tuổi khác biệt của sinh viên từ mytable.
Nhóm theo mệnh đề
Mệnh đề GROUP BY được sử dụng phối hợp với câu lệnh SELECT để sắp xếp dữ liệu giống nhau thành các nhóm.
Cú pháp
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Truy vấn
select age,sum(mark) as sumofmarks from mytable group by age;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
age, sumofmarks
-------------------------------
13, 145
12, 610Ở đây, cột “mytable” có hai loại tuổi - 12 và 13. Bây giờ truy vấn nhóm các bản ghi theo độ tuổi và tạo ra tổng điểm cho các độ tuổi tương ứng của học sinh.
Có mệnh đề
Mệnh đề HAVING cho phép bạn chỉ định các điều kiện lọc kết quả nhóm nào xuất hiện trong kết quả cuối cùng. Mệnh đề WHERE đặt điều kiện vào các cột đã chọn, trong khi mệnh đề HAVING đặt điều kiện vào các nhóm được tạo bởi mệnh đề GROUP BY.
Cú pháp
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Truy vấn
sampledb> select age from mytable group by age having sum(mark) > 200;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
age
-------------------------------
12Truy vấn nhóm các bản ghi theo độ tuổi và trả về độ tuổi khi kết quả điều kiện sum (dấu)> 200.
Đặt hàng theo mệnh đề
Mệnh đề ORDER BY được sử dụng để sắp xếp dữ liệu theo thứ tự tăng dần hoặc giảm dần, dựa trên một hoặc nhiều cột. Cơ sở dữ liệu Tajo sắp xếp các kết quả truy vấn theo thứ tự tăng dần theo mặc định.
Cú pháp
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Truy vấn
sampledb> select * from mytable where mark > 60 order by name desc;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.

Truy vấn trả về tên của những sinh viên đó theo thứ tự giảm dần có điểm lớn hơn 60.
Tạo Tuyên bố Chỉ mục
Câu lệnh CREATE INDEX được sử dụng để tạo chỉ mục trong bảng. Chỉ mục được sử dụng để truy xuất dữ liệu nhanh chóng. Phiên bản hiện tại chỉ hỗ trợ lập chỉ mục cho các định dạng TEXT thuần túy được lưu trữ trên HDFS.
Cú pháp
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Truy vấn
create index student_index on mytable(id);Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
id
———————————————Để xem chỉ mục được chỉ định cho cột, hãy nhập truy vấn sau.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Ở đây, phương pháp TWO_LEVEL_BIN_TREE được sử dụng theo mặc định trong Tajo.
Tuyên bố bảng thả
Câu lệnh Drop Table được sử dụng để loại bỏ một bảng từ cơ sở dữ liệu.
Cú pháp
drop table table name;Truy vấn
sampledb> drop table mytable;Để kiểm tra xem bảng có bị xóa khỏi bảng hay không, hãy nhập truy vấn sau.
sampledb> \d mytable;Kết quả
Truy vấn trên sẽ tạo ra kết quả sau.
ERROR: relation 'mytable' does not existBạn cũng có thể kiểm tra truy vấn bằng lệnh “\ d” để liệt kê các bảng Tajo có sẵn.