AI với Python - Nhận dạng giọng nói
Trong chương này, chúng ta sẽ tìm hiểu về nhận dạng giọng nói bằng AI với Python.
Lời nói là phương tiện giao tiếp cơ bản nhất của con người khi trưởng thành. Mục tiêu cơ bản của xử lý giọng nói là cung cấp sự tương tác giữa con người và máy móc.
Hệ thống xử lý giọng nói chủ yếu có ba tác vụ:
First, nhận dạng giọng nói cho phép máy bắt các từ, cụm từ và câu mà chúng ta nói
Second, xử lý ngôn ngữ tự nhiên để cho phép máy hiểu những gì chúng ta nói và
Third, tổng hợp giọng nói để cho phép máy nói.
Chương này tập trung vào speech recognition, quá trình hiểu những lời nói của con người. Hãy nhớ rằng các tín hiệu giọng nói được ghi lại với sự trợ giúp của micrô và sau đó nó phải được hệ thống hiểu.
Xây dựng Trình nhận dạng giọng nói
Nhận dạng giọng nói hoặc Nhận dạng giọng nói tự động (ASR) là trung tâm của sự chú ý đối với các dự án AI như robot. Nếu không có ASR, không thể tưởng tượng một robot nhận thức tương tác với con người. Tuy nhiên, không hoàn toàn dễ dàng để xây dựng một trình nhận dạng giọng nói.
Khó khăn trong việc phát triển hệ thống nhận dạng giọng nói
Phát triển một hệ thống nhận dạng giọng nói chất lượng cao thực sự là một bài toán khó. Khó khăn của công nghệ nhận dạng giọng nói có thể được mô tả chung theo một số khía cạnh như được thảo luận dưới đây:
Size of the vocabulary- Kích thước của từ vựng ảnh hưởng đến việc dễ dàng phát triển một ASR. Hãy xem xét các kích thước từ vựng sau để hiểu rõ hơn.
Ví dụ, một từ vựng kích thước nhỏ bao gồm 2-100 từ, như trong hệ thống menu giọng nói
Ví dụ, một từ vựng cỡ trung bình bao gồm một số từ 100 đến 1.000 từ, chẳng hạn như trong tác vụ truy xuất cơ sở dữ liệu
Một từ vựng kích thước lớn bao gồm khoảng 10.000 từ, như trong một nhiệm vụ chính tả chung.
Channel characteristics- Chất lượng kênh cũng là một yếu tố quan trọng. Ví dụ, lời nói của con người có băng thông cao với dải tần đầy đủ, trong khi lời nói qua điện thoại bao gồm băng thông thấp với dải tần hạn chế. Lưu ý rằng nó khó hơn trong phần sau.
Speaking mode- Việc dễ dàng phát triển ASR cũng phụ thuộc vào chế độ nói, đó là liệu bài phát biểu có ở chế độ từ tách biệt, hoặc chế độ từ được kết nối hay ở chế độ nói liên tục. Lưu ý rằng một bài phát biểu liên tục khó nhận ra hơn.
Speaking style- Bài phát biểu được đọc có thể theo phong cách trang trọng, hoặc tự phát và đối thoại với phong cách bình thường. Cái sau khó nhận ra hơn.
Speaker dependency- Lời nói có thể phụ thuộc vào người nói, thích ứng với người nói hoặc độc lập với người nói. Một diễn giả độc lập là khó nhất để xây dựng.
Type of noise- Tiếng ồn là một yếu tố khác cần xem xét khi phát triển ASR. Tỷ lệ tín hiệu trên tiếng ồn có thể nằm trong nhiều phạm vi khác nhau, tùy thuộc vào môi trường âm thanh quan sát ít hơn so với nhiều tiếng ồn xung quanh -
Nếu tỷ lệ tín hiệu trên nhiễu lớn hơn 30dB, nó được coi là dải cao
Nếu tỷ lệ tín hiệu trên nhiễu nằm trong khoảng từ 30dB đến 10db, nó được coi là SNR trung bình
Nếu tỷ lệ tín hiệu trên nhiễu nhỏ hơn 10dB, nó được coi là dải thấp
Microphone characteristics- Chất lượng của micrô có thể tốt, trung bình hoặc dưới trung bình. Ngoài ra, khoảng cách giữa miệng và micro phone có thể khác nhau. Các yếu tố này cũng cần được xem xét đối với hệ thống công nhận.
Lưu ý rằng, kích thước từ vựng càng lớn thì việc nhận dạng càng khó.
Ví dụ, loại tiếng ồn xung quanh như tiếng ồn cố định, tiếng ồn không phải của con người, tiếng nói nền và nhiễu xuyên âm của những người nói khác cũng góp phần vào độ khó của bài toán.
Bất chấp những khó khăn này, các nhà nghiên cứu đã làm việc rất nhiều trên các khía cạnh khác nhau của lời nói như hiểu tín hiệu giọng nói, người nói và xác định các trọng âm.
Bạn sẽ phải làm theo các bước dưới đây để tạo trình nhận dạng giọng nói -
Hình dung tín hiệu âm thanh - Đọc từ tệp và làm việc trên đó
Đây là bước đầu tiên trong việc xây dựng hệ thống nhận dạng giọng nói vì nó cung cấp hiểu biết về cách một tín hiệu âm thanh được cấu trúc. Một số bước phổ biến có thể được làm theo để làm việc với tín hiệu âm thanh như sau:
ghi âm
Đầu tiên, khi bạn phải đọc tín hiệu âm thanh từ một tệp, sau đó ghi lại bằng micrô.
Lấy mẫu
Khi ghi âm bằng micrô, các tín hiệu được lưu trữ dưới dạng số hóa. Nhưng để hoạt động, máy cần chúng ở dạng số rời rạc. Do đó, chúng ta nên thực hiện lấy mẫu ở một tần số nhất định và chuyển đổi tín hiệu thành dạng số rời rạc. Việc chọn tần số cao để lấy mẫu ngụ ý rằng khi con người nghe tín hiệu, họ cảm thấy nó như một tín hiệu âm thanh liên tục.
Thí dụ
Ví dụ sau đây cho thấy một cách tiếp cận từng bước để phân tích tín hiệu âm thanh, sử dụng Python, được lưu trữ trong một tệp. Tần số của tín hiệu âm thanh này là 44.100 HZ.
Nhập các gói cần thiết như được hiển thị ở đây -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileBây giờ, hãy đọc tệp âm thanh được lưu trữ. Nó sẽ trả về hai giá trị: tần số lấy mẫu và tín hiệu âm thanh. Cung cấp đường dẫn của tệp âm thanh nơi nó được lưu trữ, như được hiển thị ở đây -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Hiển thị các thông số như tần số lấy mẫu của tín hiệu âm thanh, loại dữ liệu của tín hiệu và thời lượng của nó, sử dụng các lệnh được hiển thị:
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Bước này liên quan đến việc chuẩn hóa tín hiệu như hình dưới đây -
audio_signal = audio_signal / np.power(2, 15)Trong bước này, chúng tôi sẽ trích xuất 100 giá trị đầu tiên từ tín hiệu này để hình dung. Sử dụng các lệnh sau cho mục đích này:
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)Bây giờ, hãy hình dung tín hiệu bằng các lệnh dưới đây:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()Bạn sẽ có thể thấy đồ thị đầu ra và dữ liệu được trích xuất cho tín hiệu âm thanh ở trên như trong hình ảnh tại đây

Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 secondsĐặc trưng cho tín hiệu âm thanh: Chuyển đổi sang miền tần số
Đặc trưng cho một tín hiệu âm thanh liên quan đến việc chuyển đổi tín hiệu miền thời gian thành miền tần số và hiểu các thành phần tần số của nó, bằng cách. Đây là bước quan trọng vì nó cho biết nhiều thông tin về tín hiệu. Bạn có thể sử dụng một công cụ toán học như Fourier Transform để thực hiện phép biến đổi này.
Thí dụ
Ví dụ sau đây cho thấy, từng bước, cách mô tả đặc tính của tín hiệu, sử dụng Python, được lưu trữ trong một tệp. Lưu ý rằng ở đây chúng tôi đang sử dụng công cụ toán học Fourier Transform để chuyển đổi nó thành miền tần số.
Nhập các gói cần thiết, như được hiển thị ở đây -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileBây giờ, hãy đọc tệp âm thanh được lưu trữ. Nó sẽ trả về hai giá trị: tần số lấy mẫu và tín hiệu âm thanh. Cung cấp đường dẫn của tệp âm thanh nơi nó được lưu trữ như được hiển thị trong lệnh ở đây -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")Trong bước này, chúng tôi sẽ hiển thị các thông số như tần số lấy mẫu của tín hiệu âm thanh, loại dữ liệu của tín hiệu và thời lượng của nó, bằng cách sử dụng các lệnh được đưa ra bên dưới:
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Trong bước này, chúng ta cần chuẩn hóa tín hiệu, như được hiển thị trong lệnh sau:
audio_signal = audio_signal / np.power(2, 15)Bước này liên quan đến việc trích xuất độ dài và nửa độ dài của tín hiệu. Sử dụng các lệnh sau cho mục đích này:
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)Bây giờ, chúng ta cần áp dụng các công cụ toán học để biến đổi thành miền tần số. Ở đây chúng tôi đang sử dụng Biến đổi Fourier.
signal_frequency = np.fft.fft(audio_signal)Bây giờ, hãy chuẩn hóa tín hiệu miền tần số và bình phương nó -
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal
signal_frequency **= 2Tiếp theo, trích xuất độ dài và nửa độ dài của tín hiệu được biến đổi tần số -
len_fts = len(signal_frequency)Lưu ý rằng tín hiệu biến đổi Fourier phải được điều chỉnh cho trường hợp chẵn cũng như lẻ.
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2Bây giờ, trích xuất công suất theo decibal (dB) -
signal_power = 10 * np.log10(signal_frequency)Điều chỉnh tần số tính bằng kHz cho trục X -
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0Bây giờ, hãy hình dung đặc tính của tín hiệu như sau:
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()Bạn có thể quan sát đồ thị đầu ra của đoạn mã trên như trong hình bên dưới:

Tạo tín hiệu âm thanh đơn điệu
Hai bước mà bạn đã thấy cho đến giờ rất quan trọng để tìm hiểu về các tín hiệu. Bây giờ, bước này sẽ hữu ích nếu bạn muốn tạo tín hiệu âm thanh với một số thông số được xác định trước. Lưu ý rằng bước này sẽ lưu tín hiệu âm thanh trong một tệp đầu ra.
Thí dụ
Trong ví dụ sau, chúng ta sẽ tạo một tín hiệu đơn điệu, sử dụng Python, sẽ được lưu trữ trong một tệp. Đối với điều này, bạn sẽ phải thực hiện các bước sau:
Nhập các gói cần thiết như được hiển thị -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import writeCung cấp tệp nơi tệp đầu ra sẽ được lưu
output_file = 'audio_signal_generated.wav'Bây giờ, hãy chỉ định các tham số bạn chọn, như minh họa -
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piTrong bước này, chúng ta có thể tạo ra tín hiệu âm thanh, như minh họa -
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)Bây giờ, lưu tệp âm thanh trong tệp đầu ra -
write(output_file, frequency_sampling, signal_scaled)Trích xuất 100 giá trị đầu tiên cho biểu đồ của chúng tôi, như được hiển thị:
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)Bây giờ, hãy hình dung tín hiệu âm thanh được tạo ra như sau:
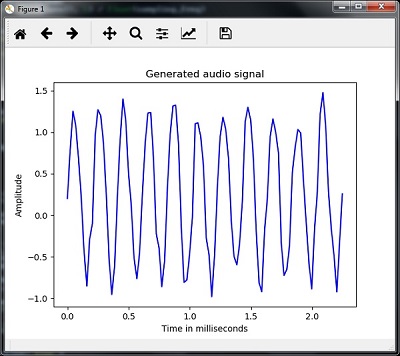
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()Bạn có thể quan sát cốt truyện như trong hình ở đây -
Tính năng trích xuất từ giọng nói
Đây là bước quan trọng nhất trong việc xây dựng một bộ nhận dạng giọng nói vì sau khi chuyển đổi tín hiệu giọng nói sang miền tần số, chúng ta phải chuyển nó thành dạng có thể sử dụng được của vector đặc trưng. Chúng tôi có thể sử dụng các kỹ thuật trích xuất tính năng khác nhau như MFCC, PLP, PLP-RASTA, v.v. cho mục đích này.
Thí dụ
Trong ví dụ sau, chúng tôi sẽ trích xuất các tính năng từ tín hiệu, từng bước, sử dụng Python, bằng cách sử dụng kỹ thuật MFCC.
Nhập các gói cần thiết, như được hiển thị ở đây -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbankBây giờ, hãy đọc tệp âm thanh được lưu trữ. Nó sẽ trả về hai giá trị - tần số lấy mẫu và tín hiệu âm thanh. Cung cấp đường dẫn của tệp âm thanh nơi nó được lưu trữ.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Lưu ý rằng ở đây chúng tôi đang lấy 15000 mẫu đầu tiên để phân tích.
audio_signal = audio_signal[:15000]Sử dụng các kỹ thuật của MFCC và thực hiện lệnh sau để trích xuất các tính năng của MFCC -
features_mfcc = mfcc(audio_signal, frequency_sampling)Bây giờ, in các thông số MFCC, như được hiển thị -
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])Bây giờ, vẽ và hình dung các tính năng của MFCC bằng các lệnh dưới đây:
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')Trong bước này, chúng tôi làm việc với các tính năng của ngân hàng bộ lọc như minh họa -
Trích xuất các tính năng của ngân hàng bộ lọc -
filterbank_features = logfbank(audio_signal, frequency_sampling)Bây giờ, in các thông số của ngân hàng bộ lọc.
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])Bây giờ, vẽ và hình dung các tính năng của ngân hàng lọc.
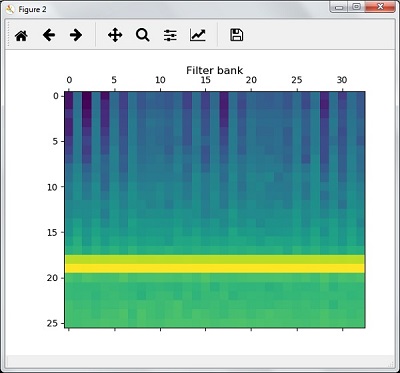
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()Theo kết quả của các bước trên, bạn có thể quan sát các đầu ra sau: Hình1 cho MFCC và Hình2 cho Ngân hàng bộ lọc

Nhận biết các từ đã nói
Nhận dạng giọng nói có nghĩa là khi con người đang nói, một cỗ máy sẽ hiểu nó. Ở đây, chúng tôi đang sử dụng Google Speech API bằng Python để biến điều đó thành hiện thực. Chúng tôi cần cài đặt các gói sau cho việc này -
Pyaudio - Nó có thể được cài đặt bằng cách sử dụng pip install Pyaudio chỉ huy.
SpeechRecognition - Gói này có thể được cài đặt bằng cách sử dụng pip install SpeechRecognition.
Google-Speech-API - Nó có thể được cài đặt bằng cách sử dụng lệnh pip install google-api-python-client.
Thí dụ
Quan sát ví dụ sau để hiểu về nhận dạng lời nói -
Nhập các gói cần thiết như được hiển thị -
import speech_recognition as srTạo một đối tượng như hình dưới đây -
recording = sr.Recognizer()Bây giờ, Microphone() mô-đun sẽ lấy giọng nói làm đầu vào -
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)Bây giờ Google API sẽ nhận dạng giọng nói và đưa ra đầu ra.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)Bạn có thể xem kết quả sau:
Please Say Something:
You said:Ví dụ, nếu bạn nói tutorialspoint.com, sau đó hệ thống nhận dạng nó một cách chính xác như sau:
tutorialspoint.com