Học sâu với Keras - Hướng dẫn nhanh
Deep Learning đã trở thành một từ thông dụng trong những ngày gần đây trong lĩnh vực Trí tuệ nhân tạo (AI). Trong nhiều năm, chúng tôi đã sử dụng Học máy (ML) để truyền đạt trí thông minh cho máy móc. Trong những ngày gần đây, học sâu đã trở nên phổ biến hơn do tính ưu việt trong dự đoán so với các kỹ thuật ML truyền thống.
Về cơ bản, Deep Learning có nghĩa là đào tạo một Mạng thần kinh nhân tạo (ANN) với một lượng dữ liệu khổng lồ. Trong học sâu, mạng tự học và do đó yêu cầu dữ liệu khổng lồ để học. Trong khi máy học truyền thống về cơ bản là một tập hợp các thuật toán phân tích dữ liệu và học hỏi từ nó. Sau đó, họ sử dụng cách học này để đưa ra các quyết định thông minh.
Bây giờ, đến với Keras, nó là một API mạng thần kinh cấp cao chạy trên TensorFlow - một nền tảng học máy mã nguồn mở end-to-end. Sử dụng Keras, bạn dễ dàng xác định các kiến trúc ANN phức tạp để thử nghiệm trên dữ liệu lớn của mình. Keras cũng hỗ trợ GPU, thứ trở nên cần thiết để xử lý lượng dữ liệu khổng lồ và phát triển các mô hình học máy.
Trong hướng dẫn này, bạn sẽ học cách sử dụng Keras trong việc xây dựng mạng nơ-ron sâu. Chúng ta sẽ xem xét các ví dụ thực tế để giảng dạy. Vấn đề đang đặt ra là nhận dạng các chữ số viết tay bằng cách sử dụng mạng thần kinh được đào tạo với phương pháp học sâu.
Chỉ để giúp bạn hào hứng hơn trong việc học sâu, dưới đây là ảnh chụp màn hình về các xu hướng của Google về học sâu tại đây -

Như bạn có thể thấy từ biểu đồ, mối quan tâm đến học sâu đang tăng dần trong vài năm qua. Có nhiều lĩnh vực như thị giác máy tính, xử lý ngôn ngữ tự nhiên, nhận dạng giọng nói, tin sinh học, thiết kế thuốc, v.v., nơi học sâu đã được áp dụng thành công. Hướng dẫn này sẽ giúp bạn nhanh chóng bắt đầu học sâu.
Vì vậy, hãy tiếp tục đọc!
Như đã nói trong phần giới thiệu, học sâu là một quá trình đào tạo một mạng nơ-ron nhân tạo với một lượng dữ liệu khổng lồ. Sau khi được đào tạo, mạng sẽ có thể cung cấp cho chúng tôi các dự đoán về dữ liệu không nhìn thấy. Trước khi tôi đi sâu hơn trong việc giải thích học sâu là gì, chúng ta hãy nhanh chóng đi qua một số thuật ngữ được sử dụng trong đào tạo mạng nơ-ron.
Mạng thần kinh
Ý tưởng về mạng thần kinh nhân tạo được bắt nguồn từ mạng thần kinh trong não của chúng ta. Một mạng nơ-ron điển hình bao gồm ba lớp - đầu vào, đầu ra và lớp ẩn như trong hình bên dưới.

Đây còn được gọi là shallowmạng nơ-ron, vì nó chỉ chứa một lớp ẩn. Bạn thêm nhiều lớp ẩn trong kiến trúc trên để tạo ra một kiến trúc phức tạp hơn.
Mạng sâu
Sơ đồ sau đây cho thấy một mạng sâu bao gồm bốn lớp ẩn, một lớp đầu vào và một lớp đầu ra.
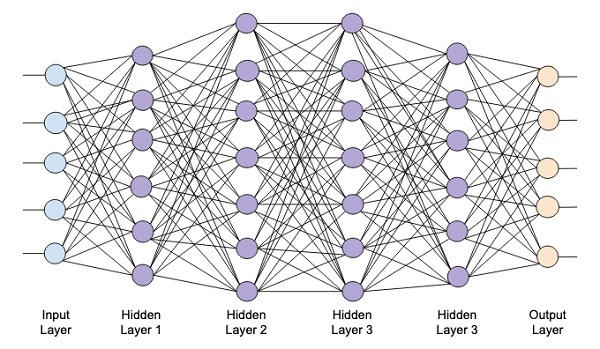
Khi số lượng lớp ẩn được thêm vào mạng, việc huấn luyện nó trở nên phức tạp hơn về tài nguyên cần thiết và thời gian cần thiết để huấn luyện toàn bộ mạng.
Đào tạo mạng
Sau khi bạn xác định kiến trúc mạng, bạn đào tạo nó để thực hiện một số loại dự đoán. Huấn luyện một mạng là một quá trình tìm kiếm các trọng số thích hợp cho mỗi liên kết trong mạng. Trong quá trình đào tạo, dữ liệu chảy từ các lớp Đầu vào đến Đầu ra thông qua các lớp ẩn khác nhau. Vì dữ liệu luôn di chuyển theo một hướng từ đầu vào đến đầu ra, chúng tôi gọi mạng này là Mạng chuyển tiếp và chúng tôi gọi việc truyền dữ liệu là Truyền chuyển tiếp.
Chức năng kích hoạt
Tại mỗi lớp, chúng tôi tính toán tổng trọng số của các đầu vào và đưa nó vào chức năng Kích hoạt. Chức năng kích hoạt mang lại tính phi tuyến cho mạng. Nó chỉ đơn giản là một số chức năng toán học làm gián đoạn kết quả đầu ra. Một số hàm kích hoạt được sử dụng phổ biến nhất là sigmoid, hyperbolic, tangent (tanh), ReLU và Softmax.
Lan truyền ngược
Backpropagation là một thuật toán để học có giám sát. Trong Backpropagation, các lỗi truyền ngược từ đầu ra đến lớp đầu vào. Với một hàm lỗi, chúng tôi tính toán độ dốc của hàm lỗi đối với trọng số được chỉ định tại mỗi kết nối. Việc tính toán gradient tiến hành ngược lại thông qua mạng. Gradient của lớp vật nặng cuối cùng được tính trước và gradient của lớp vật nặng đầu tiên được tính sau cùng.
Tại mỗi lớp, các tính toán từng phần của gradient được sử dụng lại trong việc tính toán gradient cho lớp trước đó. Đây được gọi là Gradient Descent.
Trong hướng dẫn dựa trên dự án này, bạn sẽ xác định một mạng nơ-ron sâu chuyển tiếp và đào tạo nó bằng các kỹ thuật lan truyền ngược và chuyển xuống dốc. May mắn thay, Keras cung cấp cho chúng ta tất cả các API cấp cao để xác định kiến trúc mạng và đào tạo nó bằng cách sử dụng gradient descent. Tiếp theo, bạn sẽ học cách làm điều này trong Keras.
Hệ thống nhận dạng chữ số viết tay
Trong dự án nhỏ này, bạn sẽ áp dụng các kỹ thuật được mô tả trước đó. Bạn sẽ tạo một mạng nơron học sâu sẽ được đào tạo để nhận dạng các chữ số viết tay. Trong bất kỳ dự án học máy nào, thách thức đầu tiên là thu thập dữ liệu. Đặc biệt, đối với mạng học sâu, bạn cần dữ liệu khổng lồ. May mắn thay, đối với vấn đề mà chúng tôi đang cố gắng giải quyết, ai đó đã tạo tập dữ liệu để đào tạo. Đây được gọi là mnist, có sẵn như một phần của các thư viện Keras. Tập dữ liệu bao gồm một số hình ảnh 28x28 pixel của các chữ số viết tay. Bạn sẽ đào tạo mô hình của mình trên phần chính của tập dữ liệu này và phần còn lại của dữ liệu sẽ được sử dụng để xác thực mô hình được đào tạo của bạn.
mô tả dự án
Các mnisttập dữ liệu bao gồm 70000 hình ảnh của các chữ số viết tay. Một vài hình ảnh mẫu được sao chép lại tại đây để bạn tham khảo

Mỗi hình ảnh có kích thước 28 x 28 pixel làm cho nó có tổng cộng 768 pixel ở các mức thang màu xám khác nhau. Hầu hết các điểm ảnh có xu hướng hướng tới bóng đen trong khi chỉ một số ít trong số chúng hướng tới màu trắng. Chúng tôi sẽ đặt sự phân bố của các pixel này trong một mảng hoặc một vector. Ví dụ: sự phân bố các pixel cho một hình ảnh điển hình của chữ số 4 và 5 được thể hiện trong hình bên dưới.
Mỗi hình ảnh có kích thước 28 x 28 pixel làm cho nó có tổng cộng 768 pixel ở các mức thang màu xám khác nhau. Hầu hết các điểm ảnh có xu hướng hướng tới bóng đen trong khi chỉ một số ít trong số chúng hướng tới màu trắng. Chúng tôi sẽ đặt sự phân bố của các pixel này trong một mảng hoặc một vector. Ví dụ: sự phân bố các pixel cho một hình ảnh điển hình của chữ số 4 và 5 được thể hiện trong hình bên dưới.

Rõ ràng, bạn có thể thấy rằng sự phân bố của các pixel (đặc biệt là những pixel có xu hướng thiên về tông màu trắng) khác nhau, điều này phân biệt các chữ số mà chúng đại diện. Chúng tôi sẽ cung cấp phân phối 784 pixel này cho mạng của chúng tôi làm đầu vào của nó. Đầu ra của mạng sẽ bao gồm 10 loại đại diện cho một chữ số từ 0 đến 9.
Mạng của chúng ta sẽ bao gồm 4 lớp - một lớp đầu vào, một lớp đầu ra và hai lớp ẩn. Mỗi lớp ẩn sẽ chứa 512 nút. Mỗi lớp được kết nối đầy đủ với lớp tiếp theo. Khi chúng tôi đào tạo mạng, chúng tôi sẽ tính toán trọng số cho mỗi kết nối. Chúng tôi đào tạo mạng bằng cách áp dụng lan truyền ngược và giảm độ dốc mà chúng tôi đã thảo luận trước đó.
Với nền tảng này, bây giờ chúng ta hãy bắt đầu tạo dự án.
Thiết lập dự án
Chúng tôi sẽ sử dụng Jupyter xuyên qua Anacondahoa tiêu cho dự án của chúng tôi. Vì dự án của chúng tôi sử dụng TensorFlow và Keras, bạn sẽ cần cài đặt chúng trong thiết lập Anaconda. Để cài đặt Tensorflow, hãy chạy lệnh sau trong cửa sổ bảng điều khiển của bạn:
>conda install -c anaconda tensorflowĐể cài đặt Keras, hãy sử dụng lệnh sau:
>conda install -c anaconda kerasBây giờ bạn đã sẵn sàng để bắt đầu Jupyter.
Khởi động Jupyter
Khi bạn khởi động trình điều hướng Anaconda, bạn sẽ thấy màn hình mở sau.

Nhấp chuột ‘Jupyter’để bắt đầu nó. Màn hình sẽ hiển thị các dự án hiện có, nếu có, trên ổ đĩa của bạn.
Bắt đầu một dự án mới
Bắt đầu một dự án Python 3 mới trong Anaconda bằng cách chọn tùy chọn menu sau:
File | New Notebook | Python 3Ảnh chụp màn hình của lựa chọn menu được hiển thị để bạn tham khảo nhanh -

Một dự án trống mới sẽ hiển thị trên màn hình của bạn như hình dưới đây -
Thay đổi tên dự án thành DeepLearningDigitRecognition bằng cách nhấp và chỉnh sửa tên mặc định “UntitledXX”.
Đầu tiên chúng tôi nhập các thư viện khác nhau theo yêu cầu của mã trong dự án của chúng tôi.
Xử lý mảng và vẽ đồ thị
Như điển hình, chúng tôi sử dụng numpy để xử lý mảng và matplotlibđể lập mưu. Các thư viện này được nhập vào dự án của chúng tôi bằng cách sử dụngimport các câu lệnh
import numpy as np
import matplotlib
import matplotlib.pyplot as plotCảnh báo ngăn chặn
Vì cả Tensorflow và Keras tiếp tục sửa đổi, nếu bạn không đồng bộ hóa các phiên bản thích hợp của chúng trong dự án, trong thời gian chạy, bạn sẽ thấy nhiều lỗi cảnh báo. Khi chúng làm bạn mất tập trung vào việc học, chúng tôi sẽ loại bỏ tất cả các cảnh báo trong dự án này. Điều này được thực hiện với các dòng mã sau:
# silent all warnings
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
import warnings
warnings.filterwarnings('ignore')
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = FalseKeras
Chúng tôi sử dụng các thư viện Keras để nhập tập dữ liệu. Chúng tôi sẽ sử dụngmnisttập dữ liệu cho các chữ số viết tay. Chúng tôi nhập gói bắt buộc bằng cách sử dụng câu lệnh sau
from keras.datasets import mnistChúng tôi sẽ xác định mạng nơ-ron học sâu của mình bằng cách sử dụng các gói Keras. Chúng tôi nhập khẩuSequential, Dense, Dropout và Activationcác gói để xác định kiến trúc mạng. Chúng tôi sử dụngload_modelgói để lưu và truy xuất mô hình của chúng tôi. Chúng tôi cũng dùngnp_utilscho một vài tiện ích mà chúng tôi cần trong dự án của mình. Những lần nhập này được thực hiện với các câu lệnh chương trình sau:
from keras.models import Sequential, load_model
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utilsKhi bạn chạy mã này, bạn sẽ thấy một thông báo trên bảng điều khiển cho biết rằng Keras sử dụng TensorFlow ở phần phụ trợ. Ảnh chụp màn hình ở giai đoạn này được hiển thị ở đây -

Bây giờ, khi chúng tôi có tất cả các lần nhập theo yêu cầu của dự án, chúng tôi sẽ tiến hành xác định kiến trúc cho mạng Học sâu của chúng tôi.
Mô hình mạng nơ-ron của chúng tôi sẽ bao gồm một chồng lớp tuyến tính. Để xác định một mô hình như vậy, chúng tôi gọiSequential chức năng -
model = Sequential()Lớp đầu vào
Chúng tôi xác định lớp đầu vào, là lớp đầu tiên trong mạng của chúng tôi bằng cách sử dụng câu lệnh chương trình sau:
model.add(Dense(512, input_shape=(784,)))Điều này tạo ra một lớp có 512 nút (nơ-ron) với 784 nút đầu vào. Điều này được mô tả trong hình bên dưới -

Lưu ý rằng tất cả các nút đầu vào được kết nối đầy đủ với Lớp 1, tức là mỗi nút đầu vào được kết nối với tất cả 512 nút của Lớp 1.
Tiếp theo, chúng ta cần thêm chức năng kích hoạt cho đầu ra của Lớp 1. Chúng ta sẽ sử dụng ReLU làm kích hoạt của mình. Chức năng kích hoạt được thêm vào bằng cách sử dụng câu lệnh chương trình sau:
model.add(Activation('relu'))Tiếp theo, chúng tôi thêm Số người bỏ học là 20% bằng cách sử dụng câu lệnh bên dưới. Bỏ học là một kỹ thuật được sử dụng để ngăn người mẫu trang bị quá mức.
model.add(Dropout(0.2))Tại thời điểm này, lớp đầu vào của chúng ta đã được xác định đầy đủ. Tiếp theo, chúng ta sẽ thêm một lớp ẩn.
Lớp ẩn
Lớp ẩn của chúng ta sẽ bao gồm 512 nút. Đầu vào cho lớp ẩn đến từ lớp đầu vào đã xác định trước đó của chúng ta. Tất cả các nút được kết nối đầy đủ như trong trường hợp trước đó. Đầu ra của lớp ẩn sẽ chuyển đến lớp tiếp theo trong mạng, đây sẽ là lớp cuối cùng và đầu ra của chúng ta. Chúng tôi sẽ sử dụng kích hoạt ReLU tương tự như cho lớp trước và tỷ lệ bỏ qua là 20%. Mã để thêm lớp này được đưa ra ở đây -
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))Mạng ở giai đoạn này có thể được hình dung như sau:

Tiếp theo, chúng ta sẽ thêm lớp cuối cùng vào mạng của mình, đó là lớp đầu ra. Lưu ý rằng bạn có thể thêm bất kỳ số lớp ẩn nào bằng cách sử dụng mã tương tự như mã mà bạn đã sử dụng ở đây. Thêm nhiều lớp hơn sẽ làm cho mạng phức tạp để đào tạo; tuy nhiên, mang lại lợi thế nhất định về kết quả tốt hơn trong nhiều trường hợp mặc dù không phải tất cả.
Lớp đầu ra
Lớp đầu ra chỉ bao gồm 10 nút vì chúng ta muốn phân loại các hình ảnh đã cho thành 10 chữ số khác nhau. Chúng tôi thêm lớp này, sử dụng câu lệnh sau:
model.add(Dense(10))Khi chúng tôi muốn phân loại đầu ra theo 10 đơn vị riêng biệt, chúng tôi sử dụng kích hoạt softmax. Trong trường hợp ReLU, đầu ra là nhị phân. Chúng tôi thêm kích hoạt bằng cách sử dụng câu lệnh sau:
model.add(Activation('softmax'))Tại thời điểm này, mạng của chúng ta có thể được hình dung như thể hiện trong sơ đồ dưới đây:

Tại thời điểm này, mô hình mạng của chúng tôi đã được xác định đầy đủ trong phần mềm. Chạy ô mã và nếu không có lỗi, bạn sẽ nhận được thông báo xác nhận trên màn hình như trong ảnh chụp màn hình bên dưới -

Tiếp theo, chúng ta cần biên dịch mô hình.
Quá trình biên dịch được thực hiện bằng một lệnh gọi phương thức duy nhất được gọi là compile.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')Các compilephương thức yêu cầu một số tham số. Tham số tổn thất được chỉ định để có loại'categorical_crossentropy'. Thông số chỉ số được đặt thành'accuracy' và cuối cùng chúng tôi sử dụng adamtrình tối ưu hóa để đào tạo mạng. Kết quả ở giai đoạn này được hiển thị bên dưới:

Bây giờ, chúng tôi đã sẵn sàng cung cấp dữ liệu vào mạng của mình.
Đang tải dữ liệu
Như đã nói trước đó, chúng tôi sẽ sử dụng mnisttập dữ liệu do Keras cung cấp. Khi chúng tôi tải dữ liệu vào hệ thống của mình, chúng tôi sẽ chia nhỏ dữ liệu đó trong dữ liệu đào tạo và kiểm tra. Dữ liệu được tải bằng cách gọiload_data phương pháp như sau -
(X_train, y_train), (X_test, y_test) = mnist.load_data()Đầu ra ở giai đoạn này trông giống như sau:

Bây giờ, chúng ta sẽ tìm hiểu cấu trúc của tập dữ liệu đã tải.
Dữ liệu được cung cấp cho chúng tôi là các hình ảnh đồ họa có kích thước 28 x 28 pixel, mỗi hình chứa một chữ số duy nhất từ 0 đến 9. Chúng tôi sẽ hiển thị mười hình ảnh đầu tiên trên bảng điều khiển. Mã để làm như vậy được đưa ra dưới đây:
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])Trong một vòng lặp lặp lại gồm 10 số đếm, chúng tôi tạo một biểu đồ con trên mỗi lần lặp lại và hiển thị một hình ảnh từ X_trainvector trong đó. Chúng tôi đặt tiêu đề cho mỗi hình ảnh từy_trainvectơ. Lưu ý rằngy_train vectơ chứa các giá trị thực cho hình ảnh tương ứng trong X_trainvectơ. Chúng tôi loại bỏ các đánh dấu trục x và y bằng cách gọi hai phương thứcxticks và yticksvới đối số rỗng. Khi bạn chạy mã, bạn sẽ thấy kết quả sau:

Tiếp theo, chúng tôi sẽ chuẩn bị dữ liệu để đưa nó vào mạng của chúng tôi.
Trước khi chúng tôi cung cấp dữ liệu vào mạng của mình, dữ liệu đó phải được chuyển đổi sang định dạng theo yêu cầu của mạng. Đây được gọi là chuẩn bị dữ liệu cho mạng. Nó thường bao gồm việc chuyển đổi đầu vào đa chiều thành vectơ một chiều và chuẩn hóa các điểm dữ liệu.
Định hình lại Véc tơ đầu vào
Hình ảnh trong tập dữ liệu của chúng tôi bao gồm 28 x 28 pixel. Nó phải được chuyển đổi thành một vectơ một chiều có kích thước 28 * 28 = 784 để đưa nó vào mạng của chúng tôi. Chúng tôi làm như vậy bằng cách gọireshape phương pháp trên vector.
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)Bây giờ, vectơ đào tạo của chúng tôi sẽ bao gồm 60000 điểm dữ liệu, mỗi điểm bao gồm một vectơ một chiều có kích thước 784. Tương tự, vectơ thử nghiệm của chúng tôi sẽ bao gồm 10000 điểm dữ liệu của một vectơ một chiều có kích thước 784.
Chuẩn hóa dữ liệu
Dữ liệu mà vectơ đầu vào chứa hiện có giá trị rời rạc trong khoảng từ 0 đến 255 - các mức thang màu xám. Bình thường hóa các giá trị pixel này giữa 0 và 1 giúp tăng tốc quá trình đào tạo. Vì chúng ta sẽ sử dụng descent gradient ngẫu nhiên, việc chuẩn hóa dữ liệu cũng sẽ giúp giảm nguy cơ mắc kẹt trong optima cục bộ.
Để chuẩn hóa dữ liệu, chúng tôi biểu thị nó dưới dạng kiểu float và chia nó cho 255 như được hiển thị trong đoạn mã sau:
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255Bây giờ chúng ta hãy xem dữ liệu chuẩn hóa trông như thế nào.
Kiểm tra dữ liệu chuẩn hóa
Để xem dữ liệu chuẩn hóa, chúng tôi sẽ gọi hàm biểu đồ như được hiển thị ở đây:
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))Ở đây, chúng tôi vẽ biểu đồ của phần tử đầu tiên của X_trainvectơ. Chúng tôi cũng in chữ số được đại diện bởi điểm dữ liệu này. Kết quả của việc chạy mã trên được hiển thị ở đây:

Bạn sẽ nhận thấy mật độ dày của các điểm có giá trị gần bằng không. Đây là những điểm chấm đen trong hình ảnh, rõ ràng là phần chính của hình ảnh. Phần còn lại của thang điểm màu xám, gần với màu trắng, đại diện cho chữ số. Bạn có thể kiểm tra sự phân bố các pixel cho một chữ số khác. Đoạn mã dưới đây in ra biểu đồ của một chữ số ở chỉ số 2 trong tập dữ liệu đào tạo.
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])Kết quả của việc chạy mã trên được hiển thị bên dưới:

So sánh hai hình trên, bạn sẽ nhận thấy rằng sự phân bố của các pixel màu trắng trong hai hình ảnh khác nhau cho thấy sự thể hiện của một chữ số khác - “5” và “4” trong hai hình trên.
Tiếp theo, chúng tôi sẽ kiểm tra sự phân bố dữ liệu trong tập dữ liệu đào tạo đầy đủ của chúng tôi.
Kiểm tra phân phối dữ liệu
Trước khi chúng tôi đào tạo mô hình học máy trên tập dữ liệu của mình, chúng tôi nên biết sự phân bố của các chữ số duy nhất trong tập dữ liệu của mình. Hình ảnh của chúng tôi đại diện cho 10 chữ số khác nhau từ 0 đến 9. Chúng tôi muốn biết số chữ số 0, 1, v.v., trong tập dữ liệu của chúng tôi. Chúng tôi có thể lấy thông tin này bằng cách sử dụngunique phương pháp của Numpy.
Sử dụng lệnh sau để in số lượng giá trị duy nhất và số lần xuất hiện của mỗi giá trị
print(np.unique(y_train, return_counts=True))Khi bạn chạy lệnh trên, bạn sẽ thấy kết quả sau:
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))Nó cho thấy rằng có 10 giá trị phân biệt - từ 0 đến 9. Có 5923 lần xuất hiện của chữ số 0, 6742 lần xuất hiện của chữ số 1, v.v. Ảnh chụp màn hình của đầu ra được hiển thị ở đây -

Bước cuối cùng trong quá trình chuẩn bị dữ liệu, chúng ta cần mã hóa dữ liệu của mình.
Mã hóa dữ liệu
Chúng tôi có mười danh mục trong tập dữ liệu của mình. Do đó, chúng tôi sẽ mã hóa đầu ra của mình trong mười danh mục này bằng cách sử dụng mã hóa một nóng. Chúng tôi sử dụng phương thức to_categorial của các tiện ích Numpy để thực hiện mã hóa. Sau khi dữ liệu đầu ra được mã hóa, mỗi điểm dữ liệu sẽ được chuyển đổi thành một vectơ đơn chiều có kích thước 10. Ví dụ: chữ số 5 bây giờ sẽ được biểu diễn là [0,0,0,0,0,1,0,0,0 , 0].
Mã hóa dữ liệu bằng đoạn mã sau:
n_classes = 10
Y_train = np_utils.to_categorical(y_train, n_classes)Bạn có thể kiểm tra kết quả mã hóa bằng cách in 5 phần tử đầu tiên của vectơ Y_train đã phân loại.
Sử dụng mã sau để in 5 vectơ đầu tiên -
for i in range(5):
print (Y_train[i])Bạn sẽ thấy kết quả sau:
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]Phần tử đầu tiên đại diện cho chữ số 5, phần tử thứ hai đại diện cho chữ số 0, v.v.
Cuối cùng, bạn cũng sẽ phải phân loại dữ liệu thử nghiệm, điều này được thực hiện bằng cách sử dụng câu lệnh sau:
Y_test = np_utils.to_categorical(y_test, n_classes)Ở giai đoạn này, dữ liệu của bạn đã được chuẩn bị đầy đủ để đưa vào mạng.
Tiếp theo, đến phần quan trọng nhất và đó là đào tạo mô hình mạng của chúng tôi.
Việc đào tạo mô hình được thực hiện trong một lệnh gọi phương thức duy nhất được gọi là fit có ít tham số như được thấy trong đoạn mã bên dưới:
history = model.fit(X_train, Y_train,
batch_size=128, epochs=20,
verbose=2,
validation_data=(X_test, Y_test)))Hai tham số đầu tiên của phương thức fit chỉ định các tính năng và đầu ra của tập dữ liệu huấn luyện.
Các epochsđược đặt thành 20; chúng tôi giả định rằng quá trình đào tạo sẽ hội tụ trong tối đa 20 kỷ nguyên - các lần lặp lại. Mô hình được đào tạo được xác nhận trên dữ liệu thử nghiệm như được chỉ định trong tham số cuối cùng.
Kết quả một phần của việc chạy lệnh trên được hiển thị ở đây:
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
- 9s - loss: 0.2488 - acc: 0.9252 - val_loss: 0.1059 - val_acc: 0.9665
Epoch 2/20
- 9s - loss: 0.1004 - acc: 0.9688 - val_loss: 0.0850 - val_acc: 0.9715
Epoch 3/20
- 9s - loss: 0.0723 - acc: 0.9773 - val_loss: 0.0717 - val_acc: 0.9765
Epoch 4/20
- 9s - loss: 0.0532 - acc: 0.9826 - val_loss: 0.0665 - val_acc: 0.9795
Epoch 5/20
- 9s - loss: 0.0457 - acc: 0.9856 - val_loss: 0.0695 - val_acc: 0.9792Ảnh chụp màn hình của đầu ra được đưa ra bên dưới để bạn tham khảo nhanh -

Bây giờ, khi mô hình được đào tạo dựa trên dữ liệu đào tạo của chúng tôi, chúng tôi sẽ đánh giá hiệu suất của nó.
Để đánh giá hiệu suất của mô hình, chúng tôi gọi evaluate phương pháp như sau -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)Để đánh giá hiệu suất của mô hình, chúng tôi gọi evaluate phương pháp như sau -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)Chúng tôi sẽ in ra sự mất mát và độ chính xác bằng cách sử dụng hai câu lệnh sau:
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])Khi bạn chạy các câu lệnh trên, bạn sẽ thấy kết quả sau:
Test Loss 0.08041584826191042
Test Accuracy 0.9837Điều này cho thấy độ chính xác của thử nghiệm là 98%, chúng tôi có thể chấp nhận được. Điều đó có nghĩa là gì đối với chúng tôi rằng trong 2% trường hợp, các chữ số viết tay sẽ không được phân loại chính xác. Chúng tôi cũng sẽ vẽ biểu đồ về độ chính xác và số liệu tổn thất để xem mô hình hoạt động như thế nào trên dữ liệu thử nghiệm.
Các chỉ số về độ chính xác của âm mưu
Chúng tôi sử dụng ghi lại historytrong quá trình đào tạo của chúng tôi để có được sơ đồ về số liệu chính xác. Đoạn mã sau sẽ vẽ biểu đồ độ chính xác trên mỗi kỷ nguyên. Chúng tôi lấy độ chính xác của dữ liệu đào tạo (“acc”) và độ chính xác của dữ liệu xác thực (“val_acc”) để vẽ biểu đồ.
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')Biểu đồ đầu ra được hiển thị bên dưới -

Như bạn có thể thấy trong biểu đồ, độ chính xác tăng nhanh trong hai kỷ nguyên đầu tiên, cho thấy rằng mạng đang học nhanh. Sau đó, đường cong phẳng hơn cho thấy rằng không cần quá nhiều kỷ nguyên để đào tạo mô hình thêm. Nói chung, nếu độ chính xác của dữ liệu đào tạo (“acc”) tiếp tục được cải thiện trong khi độ chính xác của dữ liệu xác thực (“val_acc”) trở nên tồi tệ hơn, thì bạn đang gặp phải tình trạng trang bị quá mức. Nó chỉ ra rằng mô hình đang bắt đầu ghi nhớ dữ liệu.
Chúng tôi cũng sẽ lập biểu đồ số liệu tổn thất để kiểm tra hiệu suất mô hình của chúng tôi.
Lập đồ thị số liệu tổn thất
Một lần nữa, chúng tôi vẽ biểu đồ tổn thất trên cả dữ liệu đào tạo (“mất mát”) và kiểm tra (“val_loss”). Điều này được thực hiện bằng cách sử dụng mã sau:
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')Đầu ra của mã này được hiển thị bên dưới:

Như bạn có thể thấy trong biểu đồ, tổn thất trên tập huấn luyện giảm nhanh chóng trong hai kỷ nguyên đầu tiên. Đối với tập thử nghiệm, tổn thất không giảm cùng tốc độ với tập huấn luyện, nhưng gần như không đổi trong nhiều kỷ nguyên. Điều này có nghĩa là mô hình của chúng tôi đang tổng quát hóa tốt cho dữ liệu không nhìn thấy.
Bây giờ, chúng tôi sẽ sử dụng mô hình được đào tạo của mình để dự đoán các chữ số trong dữ liệu thử nghiệm của chúng tôi.
Để dự đoán các chữ số trong một dữ liệu không nhìn thấy là rất dễ dàng. Bạn chỉ cần gọipredict_classes phương pháp của model bằng cách chuyển nó đến một vectơ bao gồm các điểm dữ liệu chưa biết của bạn.
predictions = model.predict_classes(X_test)Lời gọi phương thức trả về các dự đoán trong một vectơ có thể được kiểm tra các giá trị 0 và 1 so với các giá trị thực. Điều này được thực hiện bằng cách sử dụng hai câu lệnh sau:
correct_predictions = np.nonzero(predictions == y_test)[0]
incorrect_predictions = np.nonzero(predictions != y_test)[0]Cuối cùng, chúng tôi sẽ in ra số lượng các dự đoán đúng và sai bằng cách sử dụng hai câu lệnh chương trình sau:
print(len(correct_predictions)," classified correctly")
print(len(incorrect_predictions)," classified incorrectly")Khi bạn chạy mã, bạn sẽ nhận được kết quả sau:
9837 classified correctly
163 classified incorrectlyBây giờ, khi bạn đã huấn luyện mô hình một cách thỏa đáng, chúng tôi sẽ lưu nó để sử dụng trong tương lai.
Chúng tôi sẽ lưu mô hình được đào tạo trong ổ đĩa cục bộ của chúng tôi trong thư mục mô hình trong thư mục làm việc hiện tại của chúng tôi. Để lưu mô hình, hãy chạy đoạn mã sau:
directory = "./models/"
name = 'handwrittendigitrecognition.h5'
path = os.path.join(save_dir, name)
model.save(path)
print('Saved trained model at %s ' % path)Kết quả sau khi chạy mã được hiển thị bên dưới:

Bây giờ, khi bạn đã lưu một mô hình được đào tạo, bạn có thể sử dụng nó sau này để xử lý dữ liệu không xác định của mình.
Để dự đoán dữ liệu không nhìn thấy, trước tiên bạn cần tải mô hình được đào tạo vào bộ nhớ. Điều này được thực hiện bằng cách sử dụng lệnh sau:
model = load_model ('./models/handwrittendigitrecognition.h5')Lưu ý rằng chúng tôi chỉ tải tệp .h5 vào bộ nhớ. Điều này thiết lập toàn bộ mạng nơ-ron trong bộ nhớ cùng với trọng số được gán cho mỗi lớp.
Bây giờ, để thực hiện dự đoán của bạn về dữ liệu không nhìn thấy, hãy tải dữ liệu, để nó là một hoặc nhiều mục, vào bộ nhớ. Xử lý trước dữ liệu để đáp ứng các yêu cầu đầu vào của mô hình của chúng tôi như những gì bạn đã làm trên dữ liệu đào tạo và kiểm tra ở trên. Sau khi xử lý trước, hãy cấp nó vào mạng của bạn. Mô hình sẽ đưa ra dự đoán của nó.
Keras cung cấp một API cấp cao để tạo mạng thần kinh sâu. Trong hướng dẫn này, bạn đã học cách tạo một mạng nơ-ron sâu được đào tạo để tìm các chữ số trong văn bản viết tay. Một mạng nhiều lớp đã được tạo ra cho mục đích này. Keras cho phép bạn xác định một chức năng kích hoạt mà bạn chọn ở mỗi lớp. Sử dụng gradient descent, mạng được đào tạo dựa trên dữ liệu đào tạo. Độ chính xác của mạng được đào tạo trong việc dự đoán dữ liệu không nhìn thấy đã được kiểm tra trên dữ liệu thử nghiệm. Bạn đã học cách vẽ biểu đồ đo độ chính xác và sai số. Sau khi mạng được huấn luyện đầy đủ, bạn đã lưu mô hình mạng để sử dụng trong tương lai.