Elasticsearch - Hướng dẫn nhanh
Elasticsearch là một máy chủ tìm kiếm dựa trên Apache Lucene. Nó được phát triển bởi Shay Banon và xuất bản vào năm 2010. Hiện nó được duy trì bởi Elasticsearch BV. Phiên bản mới nhất của nó là 7.0.0.
Elasticsearch là một công cụ phân tích và tìm kiếm toàn văn mã nguồn mở và được phân phối theo thời gian thực. Nó có thể truy cập từ giao diện dịch vụ web RESTful và sử dụng lược đồ ít tài liệu JSON (JavaScript Object Notation) để lưu trữ dữ liệu. Nó được xây dựng trên ngôn ngữ lập trình Java và do đó Elasticsearch có thể chạy trên các nền tảng khác nhau. Nó cho phép người dùng khám phá một lượng lớn dữ liệu với tốc độ rất cao.
Các tính năng chung
Các tính năng chung của Elasticsearch như sau:
Elasticsearch có thể mở rộng đến petabyte dữ liệu có cấu trúc và không có cấu trúc.
Elasticsearch có thể được sử dụng để thay thế các kho tài liệu như MongoDB và RavenDB.
Elasticsearch sử dụng chức năng không chuẩn hóa để cải thiện hiệu suất tìm kiếm.
Elasticsearch là một trong những công cụ tìm kiếm doanh nghiệp phổ biến và hiện đang được sử dụng bởi nhiều tổ chức lớn như Wikipedia, The Guardian, StackOverflow, GitHub, v.v.
Elasticsearch là một mã nguồn mở và có sẵn theo giấy phép Apache phiên bản 2.0.
Ý chính
Các khái niệm chính của Elasticsearch như sau:
Nút
Nó đề cập đến một phiên bản đang chạy của Elasticsearch. Một máy chủ vật lý và ảo chứa nhiều nút tùy thuộc vào khả năng của tài nguyên vật lý của chúng như RAM, khả năng lưu trữ và xử lý.
Cụm
Nó là một tập hợp của một hoặc nhiều nút. Cluster cung cấp khả năng lập chỉ mục và tìm kiếm tập thể trên tất cả các nút cho toàn bộ dữ liệu.
Mục lục
Nó là một tập hợp các loại tài liệu khác nhau và thuộc tính của chúng. Chỉ mục cũng sử dụng khái niệm phân đoạn để cải thiện hiệu suất. Ví dụ, một tập hợp tài liệu chứa dữ liệu của một ứng dụng mạng xã hội.
Tài liệu
Nó là một tập hợp các trường theo một cách cụ thể được xác định ở định dạng JSON. Mỗi tài liệu thuộc về một loại và nằm bên trong một chỉ mục. Mọi tài liệu được liên kết với một số nhận dạng duy nhất được gọi là UID.
Mảnh vỡ
Chỉ mục được chia nhỏ theo chiều ngang thành các phân đoạn. Điều này có nghĩa là mỗi phân đoạn chứa tất cả các thuộc tính của tài liệu nhưng chứa ít đối tượng JSON hơn chỉ mục. Sự phân tách theo chiều ngang làm cho phân đoạn trở thành một nút độc lập, có thể được lưu trữ trong bất kỳ nút nào. Phân đoạn chính là phần nằm ngang ban đầu của một chỉ mục và sau đó các phân đoạn chính này được sao chép thành các phân đoạn sao chép.
Bản sao
Elasticsearch cho phép người dùng tạo bản sao các chỉ mục và phân đoạn của họ. Việc sao chép không chỉ giúp tăng tính khả dụng của dữ liệu trong trường hợp bị lỗi mà còn cải thiện hiệu suất tìm kiếm bằng cách thực hiện thao tác tìm kiếm song song trong các bản sao này.
Ưu điểm
Elasticsearch được phát triển trên Java, giúp nó tương thích trên hầu hết mọi nền tảng.
Elasticsearch là thời gian thực, nói cách khác là sau một giây, tài liệu được thêm vào có thể tìm kiếm được trong công cụ này
Elasticsearch được phân phối, giúp dễ dàng mở rộng quy mô và tích hợp trong bất kỳ tổ chức lớn nào.
Dễ dàng tạo các bản sao lưu đầy đủ bằng cách sử dụng khái niệm gateway, có trong Elasticsearch.
Việc xử lý nhiều hợp đồng thuê nhà rất dễ dàng trong Elasticsearch khi so sánh với Apache Solr.
Elasticsearch sử dụng các đối tượng JSON làm phản hồi, điều này giúp bạn có thể gọi máy chủ Elasticsearch với một số lượng lớn các ngôn ngữ lập trình khác nhau.
Elasticsearch hỗ trợ hầu hết mọi loại tài liệu ngoại trừ những tài liệu không hỗ trợ kết xuất văn bản.
Nhược điểm
Elasticsearch không có hỗ trợ đa ngôn ngữ về mặt xử lý dữ liệu yêu cầu và phản hồi (chỉ có thể trong JSON) không giống như trong Apache Solr, nơi có thể ở các định dạng CSV, XML và JSON.
Đôi khi, Elasticsearch gặp sự cố Chia rẽ tình huống não.
So sánh giữa Elasticsearch và RDBMS
Trong Elasticsearch, chỉ mục tương tự như các bảng trong RDBMS (Hệ quản trị cơ sở dữ liệu quan hệ). Mỗi bảng là một tập hợp các hàng giống như mọi chỉ mục là một tập hợp các tài liệu trong Elasticsearch.
Bảng sau đây đưa ra so sánh trực tiếp giữa các thuật ngữ này
| Elasticsearch | RDBMS |
|---|---|
| Cụm | Cơ sở dữ liệu |
| Mảnh vỡ | Mảnh vỡ |
| Mục lục | Bàn |
| Cánh đồng | Cột |
| Tài liệu | Hàng |
Trong chương này, chúng ta sẽ hiểu chi tiết quy trình cài đặt của Elasticsearch.
Để cài đặt Elasticsearch trên máy tính cục bộ của bạn, bạn sẽ phải làm theo các bước dưới đây:
Step 1- Kiểm tra phiên bản java được cài đặt trên máy tính của bạn. Nó phải là java 7 hoặc cao hơn. Bạn có thể kiểm tra bằng cách làm như sau:
Trong Hệ điều hành Windows (OS) (sử dụng dấu nhắc lệnh) -
> java -versionTrong hệ điều hành UNIX (Sử dụng thiết bị đầu cuối) -
$ echo $JAVA_HOMEStep 2 - Tùy thuộc vào hệ điều hành của bạn, tải xuống Elasticsearch từ www.elastic.co như được đề cập bên dưới -
Đối với hệ điều hành windows, tải xuống tệp ZIP.
Đối với HĐH UNIX, hãy tải xuống tệp TAR.
Đối với HĐH Debian, hãy tải xuống tệp DEB.
Đối với Red Hat và các bản phân phối Linux khác, hãy tải xuống tệp RPN.
Các tiện ích APT và Yum cũng có thể được sử dụng để cài đặt Elasticsearch trong nhiều bản phân phối Linux.
Step 3 - Quá trình cài đặt Elasticsearch rất đơn giản và được mô tả bên dưới cho các hệ điều hành khác nhau -
Windows OS- Giải nén gói zip và Elasticsearch đã được cài đặt.
UNIX OS- Giải nén tệp tar ở bất kỳ vị trí nào và Elasticsearch đã được cài đặt.
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gzUsing APT utility for Linux OS- Tải xuống và cài đặt Khóa ký công khai
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -Lưu định nghĩa kho lưu trữ như hình dưới đây -
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listChạy cập nhật bằng lệnh sau:
$ sudo apt-get updateBây giờ bạn có thể cài đặt bằng cách sử dụng lệnh sau:
$ sudo apt-get install elasticsearchDownload and install the Debian package manually using the command given here −
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0Using YUM utility for Debian Linux OS
Tải xuống và cài đặt Khóa ký công khai -
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchTHÊM văn bản sau vào tệp có hậu tố .repo trong thư mục “/etc/yum.repos.d/” của bạn. Ví dụ :asticsearch.repo
elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdBây giờ bạn có thể cài đặt Elasticsearch bằng cách sử dụng lệnh sau
sudo yum install elasticsearchStep 4- Vào thư mục chính Elasticsearch và bên trong thư mục bin. Chạy tệp thunsearch.bat trong trường hợp Windows hoặc bạn có thể thực hiện tương tự bằng cách sử dụng dấu nhắc lệnh và thông qua thiết bị đầu cuối trong trường hợp tệp UNIX rum Elasticsearch.
Trong Windows
> cd elasticsearch-2.1.0/bin
> elasticsearchTrong Linux
$ cd elasticsearch-2.1.0/bin
$ ./elasticsearchNote - Trong trường hợp windows, bạn có thể gặp lỗi cho biết JAVA_HOME chưa được đặt, vui lòng đặt nó trong biến môi trường thành “C: \ Program Files \ Java \ jre1.8.0_31” hoặc vị trí bạn đã cài đặt java.
Step 5- Cổng mặc định cho giao diện web Elasticsearch là 9200 hoặc bạn có thể thay đổi nó bằng cách thay đổi http.port bên trong tệp đàn hồi.yml có trong thư mục bin. Bạn có thể kiểm tra xem máy chủ có hoạt động hay không bằng cách duyệthttp://localhost:9200. Nó sẽ trả về một đối tượng JSON, chứa thông tin về Elasticsearch đã cài đặt theo cách sau:
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Step 6- Ở bước này, chúng ta hãy cài đặt Kibana. Làm theo mã tương ứng được cung cấp bên dưới để cài đặt trên Linux và Windows -
For Installation on Linux −
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz
tar -xzf kibana-7.0.0-linux-x86_64.tar.gz
cd kibana-7.0.0-linux-x86_64/
./bin/kibanaFor Installation on Windows −
Tải xuống Kibana cho Windows từ https://www.elastic.co/products/kibana. Khi bạn nhấp vào liên kết, bạn sẽ tìm thấy trang chủ như hình dưới đây -
Giải nén và đi đến thư mục chính của Kibana và sau đó chạy nó.
CD c:\kibana-7.0.0-windows-x86_64
.\bin\kibana.batTrong chương này, chúng ta hãy tìm hiểu cách thêm một số chỉ mục, ánh xạ và dữ liệu vào Elasticsearch. Lưu ý rằng một số dữ liệu này sẽ được sử dụng trong các ví dụ được giải thích trong hướng dẫn này.
Tạo chỉ mục
Bạn có thể sử dụng lệnh sau để tạo chỉ mục:
PUT schoolPhản ứng
Nếu chỉ mục được tạo, bạn có thể thấy kết quả sau:
{"acknowledged": true}Thêm dữ liệu
Elasticsearch sẽ lưu trữ các tài liệu mà chúng tôi thêm vào chỉ mục như được hiển thị trong đoạn mã sau. Các tài liệu được cung cấp một số ID được sử dụng để xác định tài liệu.
Nội dung yêu cầu
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}Phản ứng
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Ở đây, chúng tôi đang thêm một tài liệu tương tự khác.
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}Phản ứng
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}Bằng cách này, chúng tôi sẽ tiếp tục bổ sung bất kỳ dữ liệu mẫu nào mà chúng tôi cần để làm việc trong các chương sắp tới.
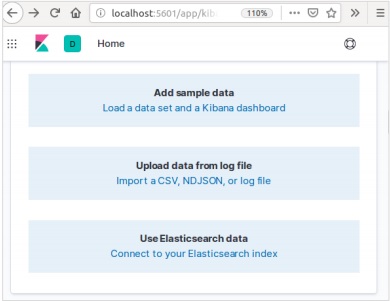
Thêm dữ liệu mẫu trong Kibana
Kibana là một công cụ điều khiển GUI để truy cập dữ liệu và tạo hình ảnh trực quan. Trong phần này, hãy cho chúng tôi hiểu cách chúng tôi có thể thêm dữ liệu mẫu vào đó.
Trong trang chủ Kibana, hãy chọn tùy chọn sau để thêm dữ liệu thương mại điện tử mẫu:
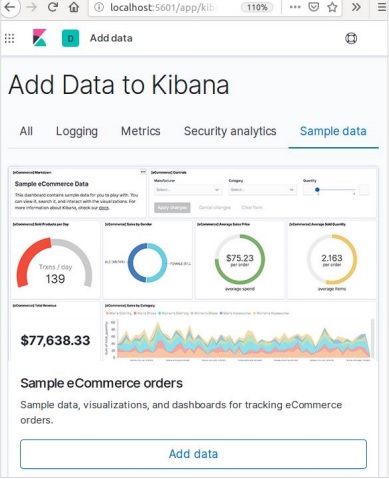
Màn hình tiếp theo sẽ hiển thị một số hình ảnh trực quan và một nút để Thêm dữ liệu -
Nhấp vào Thêm dữ liệu sẽ hiển thị màn hình sau xác nhận dữ liệu đã được thêm vào chỉ mục có tên Thương mại điện tử.
Trong bất kỳ hệ thống hoặc phần mềm nào, khi chúng tôi nâng cấp lên phiên bản mới hơn, chúng tôi cần làm theo một vài bước để duy trì cài đặt ứng dụng, cấu hình, dữ liệu và những thứ khác. Các bước này được yêu cầu để làm cho ứng dụng ổn định trong hệ thống mới hoặc để duy trì tính toàn vẹn của dữ liệu (ngăn dữ liệu bị hỏng).
Bạn cần làm theo các bước sau để nâng cấp Elasticsearch -
Đọc tài liệu Nâng cấp từ https://www.elastic.co/
Kiểm tra phiên bản đã nâng cấp trong môi trường không sản xuất của bạn như trong môi trường UAT, E2E, SIT hoặc DEV.
Lưu ý rằng không thể khôi phục về phiên bản Elasticsearch trước đó nếu không có sao lưu dữ liệu. Do đó, nên sao lưu dữ liệu trước khi nâng cấp lên phiên bản cao hơn.
Chúng tôi có thể nâng cấp bằng cách khởi động lại toàn bộ cụm hoặc nâng cấp luân phiên. Nâng cấp cuộn dành cho các phiên bản mới. Lưu ý rằng không xảy ra tình trạng ngừng hoạt động dịch vụ khi bạn đang sử dụng phương pháp nâng cấp luân phiên để di chuyển.
Các bước nâng cấp
Kiểm tra nâng cấp trong môi trường nhà phát triển trước khi nâng cấp cụm sản xuất của bạn.
Sao lưu dữ liệu của bạn. Bạn không thể quay trở lại phiên bản cũ hơn trừ khi bạn có ảnh chụp nhanh dữ liệu của mình.
Cân nhắc đóng các công việc máy học trước khi bạn bắt đầu quá trình nâng cấp. Trong khi các công việc học máy có thể tiếp tục chạy trong quá trình nâng cấp luân phiên, nó sẽ làm tăng chi phí trên cụm trong quá trình nâng cấp.
Nâng cấp các thành phần của Ngăn xếp đàn hồi của bạn theo thứ tự sau:
- Elasticsearch
- Kibana
- Logstash
- Beats
- Máy chủ APM
Nâng cấp từ 6.6 trở lên
Để nâng cấp trực tiếp lên Elasticsearch 7.1.0 từ phiên bản 6.0-6.6, bạn phải lập chỉ mục lại theo cách thủ công bất kỳ chỉ số 5.x nào mà bạn cần để tiếp tục và thực hiện khởi động lại toàn bộ cụm.
Khởi động lại toàn bộ cụm
Quá trình khởi động lại toàn bộ cụm liên quan đến việc tắt từng nút trong cụm, nâng cấp từng nút lên 7x và sau đó khởi động lại cụm.
Sau đây là các bước cấp cao cần được thực hiện để khởi động lại toàn bộ cụm -
- Tắt phân bổ phân đoạn
- Ngừng lập chỉ mục và thực hiện xả đồng bộ hóa
- Tắt tất cả các nút
- Nâng cấp tất cả các nút
- Nâng cấp bất kỳ plugin nào
- Bắt đầu mỗi nút được nâng cấp
- Chờ cho tất cả các nút tham gia cụm và báo cáo trạng thái màu vàng
- Bật lại phân bổ
Khi phân bổ được bật lại, cụm bắt đầu phân bổ các phân đoạn bản sao cho các nút dữ liệu. Tại thời điểm này, có thể an toàn để tiếp tục lập chỉ mục và tìm kiếm, nhưng cụm của bạn sẽ phục hồi nhanh hơn nếu bạn có thể đợi cho đến khi tất cả các phân đoạn chính và bản sao được phân bổ thành công và trạng thái của tất cả các nút có màu xanh lục.
Giao diện lập trình ứng dụng (API) trong web là một nhóm các lệnh gọi hàm hoặc hướng dẫn lập trình khác để truy cập thành phần phần mềm trong ứng dụng web cụ thể đó. Ví dụ, Facebook API giúp nhà phát triển tạo ứng dụng bằng cách truy cập dữ liệu hoặc các chức năng khác từ Facebook; nó có thể là ngày sinh hoặc cập nhật trạng thái.
Elasticsearch cung cấp API REST, được truy cập bởi JSON qua HTTP. Elasticsearch sử dụng một số quy ước mà chúng ta sẽ thảo luận ngay bây giờ.
Nhiều chỉ số
Hầu hết các hoạt động, chủ yếu là tìm kiếm và các hoạt động khác, trong API dành cho một hoặc nhiều chỉ số. Điều này giúp người dùng tìm kiếm ở nhiều nơi hoặc tất cả dữ liệu có sẵn bằng cách thực hiện truy vấn một lần. Nhiều ký hiệu khác nhau được sử dụng để thực hiện các hoạt động trong nhiều chỉ số. Chúng ta sẽ thảo luận một vài trong số chúng ở đây trong chương này.
Ký hiệu được phân tách bằng dấu phẩy
POST /index1,index2,index3/_searchNội dung yêu cầu
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Phản ứng
Các đối tượng JSON từ index1, index2, index3 có any_string trong đó.
_tất cả từ khóa cho tất cả chỉ số
POST /_all/_searchNội dung yêu cầu
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Phản ứng
Các đối tượng JSON từ tất cả các chỉ số và có any_string trong đó.
Các ký tự đại diện (*, +, -)
POST /school*/_searchNội dung yêu cầu
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Phản ứng
Các đối tượng JSON từ tất cả các chỉ số bắt đầu với trường học có CBSE trong đó.
Ngoài ra, bạn cũng có thể sử dụng mã sau:
POST /school*,-schools_gov /_searchNội dung yêu cầu
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Phản ứng
Các đối tượng JSON từ tất cả các chỉ số bắt đầu bằng “school” nhưng không phải từ school_gov và có CBSE trong đó.
Ngoài ra còn có một số tham số chuỗi truy vấn URL -
- ignore_unavailable- Sẽ không có lỗi nào xảy ra hoặc không có hoạt động nào bị dừng, nếu một hoặc nhiều chỉ mục có trong URL không tồn tại. Ví dụ, chỉ mục trường học tồn tại, nhưng hiệu sách không tồn tại.
POST /school*,book_shops/_searchNội dung yêu cầu
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Nội dung yêu cầu
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}Hãy xem xét đoạn mã sau:
POST /school*,book_shops/_search?ignore_unavailable = trueNội dung yêu cầu
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Phản hồi (không có lỗi)
Các đối tượng JSON từ tất cả các chỉ số bắt đầu với trường học có CBSE trong đó.
allow_no_indices
truegiá trị của thông số này sẽ ngăn lỗi, nếu một URL có ký tự đại diện dẫn đến không có chỉ số. Ví dụ: không có chỉ mục nào bắt đầu bằng school_pri -
POST /schools_pri*/_search?allow_no_indices = trueNội dung yêu cầu
{
"query":{
"match_all":{}
}
}Phản hồi (Không có lỗi)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}expand_wildcards
Tham số này quyết định xem các ký tự đại diện có cần được mở rộng cho các chỉ số mở hay chỉ số đóng hay thực hiện cả hai. Giá trị của tham số này có thể mở và đóng hoặc không có và tất cả.
Ví dụ: đóng các trường chỉ mục -
POST /schools/_closePhản ứng
{"acknowledged":true}Hãy xem xét đoạn mã sau:
POST /school*/_search?expand_wildcards = closedNội dung yêu cầu
{
"query":{
"match_all":{}
}
}Phản ứng
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}Hỗ trợ toán ngày trong tên chỉ mục
Elasticsearch cung cấp chức năng tìm kiếm các chỉ mục theo ngày và giờ. Chúng ta cần chỉ định ngày và giờ theo một định dạng cụ thể. Ví dụ: accountdetail-2015.12.30, chỉ mục sẽ lưu trữ chi tiết tài khoản ngân hàng của ngày 30 tháng 12 năm 2015. Các phép toán có thể được thực hiện để lấy thông tin chi tiết cho một ngày cụ thể hoặc một phạm vi ngày và giờ.
Định dạng cho tên chỉ mục toán học ngày -
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_searchstatic_name là một phần của biểu thức được giữ nguyên trong mọi chỉ mục toán ngày như chi tiết tài khoản. date_math_expr chứa biểu thức toán học xác định ngày và giờ động như now-2d. date_format chứa định dạng trong đó ngày được viết trong chỉ mục như YYYY.MM.dd. Nếu ngày hôm nay là ngày 30 tháng 12 năm 2015, thì <accountdetail- {now-2d {YYYY.MM.dd}}> sẽ trả về accountdetail-2015.12.28.
| Biểu hiện | Giải quyết cho |
|---|---|
| <accountdetail- {now-d}> | accountdetail-2015.12.29 |
| <accountdetail- {now-M}> | accountdetail-2015.11.30 |
| <accountdetail- {now {YYYY.MM}}> | accountdetail-2015.12 |
Bây giờ chúng ta sẽ thấy một số tùy chọn phổ biến có sẵn trong Elasticsearch có thể được sử dụng để nhận phản hồi ở định dạng được chỉ định.
Kết quả khá
Chúng tôi có thể nhận được phản hồi trong một đối tượng JSON được định dạng tốt bằng cách thêm một tham số truy vấn URL, tức là khá = true.
POST /schools/_search?pretty = trueNội dung yêu cầu
{
"query":{
"match_all":{}
}
}Phản ứng
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….Đầu ra có thể đọc được của con người
Tùy chọn này có thể thay đổi các phản hồi thống kê thành dạng con người có thể đọc được (Nếu con người = true) hoặc dạng máy tính có thể đọc được (nếu con người = sai). Ví dụ: nếu human = true thì distance_kilometer = 20KM và nếu human = false thì distance_meter = 20000, khi phản hồi cần được sử dụng bởi một chương trình máy tính khác.
Lọc phản hồi
Chúng ta có thể lọc phản hồi cho ít trường hơn bằng cách thêm chúng vào tham số field_path. Ví dụ,
POST /schools/_search?filter_path = hits.totalNội dung yêu cầu
{
"query":{
"match_all":{}
}
}Phản ứng
{"hits":{"total":3}}Elasticsearch cung cấp các API tài liệu đơn lẻ và API đa tài liệu, nơi lệnh gọi API nhắm mục tiêu một tài liệu và nhiều tài liệu tương ứng.
API chỉ mục
Nó giúp thêm hoặc cập nhật tài liệu JSON trong một chỉ mục khi có yêu cầu đối với chỉ mục tương ứng đó với ánh xạ cụ thể. Ví dụ: yêu cầu sau sẽ thêm đối tượng JSON vào lập chỉ mục trường học và ánh xạ trường học -
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Tạo chỉ mục tự động
Khi một yêu cầu được thực hiện để thêm đối tượng JSON vào một chỉ mục cụ thể và nếu chỉ mục đó không tồn tại, thì API này sẽ tự động tạo chỉ mục đó và cũng là ánh xạ cơ bản cho đối tượng JSON cụ thể đó. Chức năng này có thể bị vô hiệu hóa bằng cách thay đổi các giá trị của các tham số sau thành false, có trong tệp tin đàn hồi.yml.
action.auto_create_index:false
index.mapper.dynamic:falseBạn cũng có thể hạn chế việc tự động tạo chỉ mục, trong đó chỉ cho phép tên chỉ mục với các mẫu cụ thể bằng cách thay đổi giá trị của tham số sau:
action.auto_create_index:+acc*,-bank*Note - Ở đây + biểu thị được phép và - biểu thị không được phép.
Phiên bản
Elasticsearch cũng cung cấp cơ sở kiểm soát phiên bản. Chúng ta có thể sử dụng tham số truy vấn phiên bản để chỉ định phiên bản của một tài liệu cụ thể.
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}Tạo phiên bản là một quá trình thời gian thực và nó không bị ảnh hưởng bởi các hoạt động tìm kiếm thời gian thực.
Có hai kiểu lập phiên bản quan trọng nhất -
Phiên bản nội bộ
Phiên bản nội bộ là phiên bản mặc định bắt đầu bằng 1 và tăng dần với mỗi lần cập nhật, xóa bao gồm.
Phiên bản bên ngoài
Nó được sử dụng khi phiên bản của tài liệu được lưu trữ trong một hệ thống bên ngoài như hệ thống lập phiên bản của bên thứ ba. Để kích hoạt chức năng này, chúng tôi cần đặt version_type thành bên ngoài. Tại đây Elasticsearch sẽ lưu trữ số phiên bản theo chỉ định của hệ thống bên ngoài và sẽ không tự động tăng chúng.
Loại hoạt động
Loại hoạt động được sử dụng để buộc một hoạt động tạo. Điều này giúp tránh ghi đè tài liệu hiện có.
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Tạo ID tự động
Khi ID không được chỉ định trong thao tác lập chỉ mục, thì Elasticsearch sẽ tự động tạo id cho tài liệu đó.
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Nhận API
API giúp trích xuất đối tượng JSON kiểu bằng cách thực hiện yêu cầu nhận đối với một tài liệu cụ thể.
pre class="prettyprint notranslate" > GET schools/_doc/5Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Hoạt động này là thời gian thực và không bị ảnh hưởng bởi tốc độ làm mới của Chỉ mục.
Bạn cũng có thể chỉ định phiên bản, sau đó Elasticsearch sẽ chỉ tìm nạp phiên bản tài liệu đó.
Bạn cũng có thể chỉ định _all trong yêu cầu, để Elasticsearch có thể tìm kiếm id tài liệu đó ở mọi loại và nó sẽ trả về tài liệu phù hợp đầu tiên.
Bạn cũng có thể chỉ định các trường bạn muốn trong kết quả của mình từ tài liệu cụ thể đó.
GET schools/_doc/5?_source_includes=name,feesKhi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}Bạn cũng có thể tìm nạp phần nguồn trong kết quả của mình bằng cách thêm phần _source vào yêu cầu nhận của bạn.
GET schools/_doc/5?_sourceKhi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Bạn cũng có thể làm mới phân đoạn trước khi thực hiện thao tác nhận bằng cách đặt tham số làm mới thành true.
Xóa API
Bạn có thể xóa một chỉ mục, ánh xạ hoặc một tài liệu cụ thể bằng cách gửi một yêu cầu HTTP DELETE tới Elasticsearch.
DELETE schools/_doc/4Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}Phiên bản của tài liệu có thể được chỉ định để xóa phiên bản cụ thể đó. Tham số định tuyến có thể được chỉ định để xóa tài liệu khỏi một người dùng cụ thể và hoạt động không thành công nếu tài liệu không thuộc về người dùng cụ thể đó. Trong thao tác này, bạn có thể chỉ định tùy chọn làm mới và thời gian chờ giống như API GET.
Cập nhật API
Tập lệnh được sử dụng để thực hiện thao tác này và việc lập phiên bản được sử dụng để đảm bảo rằng không có cập nhật nào xảy ra trong quá trình lấy và lập chỉ mục lại. Ví dụ: bạn có thể cập nhật học phí của trường học bằng cách sử dụng script -
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}Bạn có thể kiểm tra bản cập nhật bằng cách gửi yêu cầu đến tài liệu được cập nhật.
API này được sử dụng để tìm kiếm nội dung trong Elasticsearch. Người dùng có thể tìm kiếm bằng cách gửi yêu cầu nhận với chuỗi truy vấn dưới dạng tham số hoặc họ có thể đăng truy vấn trong nội dung thư của yêu cầu đăng. Chủ yếu tất cả các APIS tìm kiếm là đa chỉ mục, đa loại.
Đa chỉ mục
Elasticsearch cho phép chúng tôi tìm kiếm các tài liệu có trong tất cả các chỉ số hoặc trong một số chỉ số cụ thể. Ví dụ: nếu chúng tôi cần tìm kiếm tất cả các tài liệu có tên chứa trung tâm, chúng tôi có thể làm như được hiển thị ở đây -
GET /_all/_search?q=city:paprolaKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi sau:
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Tìm kiếm URI
Nhiều tham số có thể được chuyển trong một thao tác tìm kiếm sử dụng Mã định danh tài nguyên đồng nhất -
| S.Không | Mô tả về Thông Số |
|---|---|
| 1 | Q Tham số này được sử dụng để chỉ định chuỗi truy vấn. |
| 2 | lenient Tham số này được sử dụng để chỉ định chuỗi truy vấn. Các lỗi dựa trên định dạng có thể được bỏ qua bằng cách đặt tham số này thành true. Nó là sai theo mặc định. |
| 3 | fields Tham số này được sử dụng để chỉ định chuỗi truy vấn. |
| 4 | sort Chúng ta có thể nhận được kết quả được sắp xếp bằng cách sử dụng tham số này, các giá trị có thể có cho tham số này là fieldName, fieldName: asc / fieldname: desc |
| 5 | timeout Chúng tôi có thể giới hạn thời gian tìm kiếm bằng cách sử dụng thông số này và phản hồi chỉ chứa các lần truy cập trong thời gian được chỉ định đó. Theo mặc định, không có thời gian chờ. |
| 6 | terminate_after Chúng tôi có thể hạn chế phản hồi đối với một số tài liệu cụ thể cho mỗi phân đoạn, khi đạt đến đó truy vấn sẽ kết thúc sớm. Theo mặc định, không có cuối cùng |
| 7 | from Bắt đầu từ chỉ mục của các lần truy cập để trả về. Mặc định là 0. |
| số 8 | size Nó biểu thị số lần truy cập cần trả lại. Mặc định là 10. |
Yêu cầu tìm kiếm cơ thể
Chúng tôi cũng có thể chỉ định truy vấn bằng cách sử dụng truy vấn DSL trong phần thân yêu cầu và có nhiều ví dụ đã được đưa ra trong các chương trước. Một ví dụ như vậy được đưa ra ở đây -
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi sau:
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Khung tổng hợp thu thập tất cả dữ liệu được chọn bởi truy vấn tìm kiếm và bao gồm nhiều khối xây dựng, giúp xây dựng các bản tóm tắt phức tạp của dữ liệu. Cấu trúc cơ bản của một tập hợp được hiển thị ở đây:
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}Có nhiều loại tổng hợp khác nhau, mỗi loại có mục đích riêng. Chúng được thảo luận chi tiết trong chương này.
Tổng hợp số liệu
Các tổng hợp này giúp tính toán ma trận từ các giá trị của trường của các tài liệu tổng hợp và đôi khi một số giá trị có thể được tạo từ các tập lệnh.
Ma trận số có giá trị đơn như tổng hợp trung bình hoặc đa giá trị như thống kê.
Tổng hợp Trung bình
Tổng hợp này được sử dụng để lấy giá trị trung bình của bất kỳ trường số nào có trong các tài liệu tổng hợp. Ví dụ,
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}Cardinality Aggregation
Tổng hợp này cung cấp số lượng các giá trị riêng biệt của một trường cụ thể.
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}Note - Giá trị của cardinality là 2 vì có hai giá trị khác biệt trong phí.
Tổng hợp số liệu thống kê mở rộng
Tổng hợp này tạo ra tất cả các thống kê về một trường số cụ thể trong các tài liệu tổng hợp.
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}Tổng hợp tối đa
Tổng hợp này tìm giá trị tối đa của một trường số cụ thể trong các tài liệu được tổng hợp.
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}Tổng hợp tối thiểu
Tổng hợp này tìm giá trị nhỏ nhất của một trường số cụ thể trong các tài liệu tổng hợp.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}Tổng hợp
Tập hợp này tính tổng của một trường số cụ thể trong các tài liệu được tổng hợp.
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}Có một số tổng hợp số liệu khác được sử dụng trong các trường hợp đặc biệt như tổng hợp giới hạn địa lý và tổng hợp trung tâm địa lý cho mục đích xác định vị trí địa lý.
Tổng hợp số liệu thống kê
Tổng hợp chỉ số nhiều giá trị tính toán thống kê trên các giá trị số được trích xuất từ các tài liệu tổng hợp.
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}Siêu dữ liệu tổng hợp
Bạn có thể thêm một số dữ liệu về tập hợp tại thời điểm được yêu cầu bằng cách sử dụng thẻ meta và có thể lấy dữ liệu đó để phản hồi.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}Các API này chịu trách nhiệm quản lý tất cả các khía cạnh của chỉ mục như cài đặt, bí danh, ánh xạ, mẫu chỉ mục.
Tạo chỉ mục
API này giúp bạn tạo chỉ mục. Chỉ mục có thể được tạo tự động khi người dùng chuyển các đối tượng JSON đến bất kỳ chỉ mục nào hoặc nó có thể được tạo trước đó. Để tạo chỉ mục, bạn chỉ cần gửi một yêu cầu PUT với cài đặt, ánh xạ và bí danh hoặc chỉ một yêu cầu đơn giản không có nội dung.
PUT collegesKhi chạy đoạn mã trên, chúng tôi nhận được kết quả như hình dưới đây:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Chúng ta cũng có thể thêm một số cài đặt vào lệnh trên -
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả như hình dưới đây:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Xóa chỉ mục
API này giúp bạn xóa bất kỳ chỉ mục nào. Bạn chỉ cần chuyển một yêu cầu xóa với tên của Chỉ mục cụ thể đó.
DELETE /collegesBạn có thể xóa tất cả các chỉ số bằng cách sử dụng _all hoặc *.
Nhận chỉ mục
API này có thể được gọi bằng cách chỉ gửi yêu cầu nhận đến một hoặc nhiều chỉ số. Điều này trả về thông tin về chỉ mục.
GET collegesKhi chạy đoạn mã trên, chúng tôi nhận được kết quả như hình dưới đây:
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Bạn có thể lấy thông tin của tất cả các chỉ số bằng cách sử dụng _all hoặc *.
Chỉ mục tồn tại
Sự tồn tại của một chỉ mục có thể được xác định bằng cách chỉ gửi một yêu cầu nhận đến chỉ mục đó. Nếu phản hồi HTTP là 200, nó tồn tại; nếu nó là 404, nó không tồn tại.
HEAD collegesKhi chạy đoạn mã trên, chúng tôi nhận được kết quả như hình dưới đây:
200-OKCài đặt chỉ mục
Bạn có thể nhận cài đặt chỉ mục bằng cách thêm từ khóa _settings vào cuối URL.
GET /colleges/_settingsKhi chạy đoạn mã trên, chúng tôi nhận được kết quả như hình dưới đây:
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Số liệu thống kê
API này giúp bạn trích xuất số liệu thống kê về một chỉ mục cụ thể. Bạn chỉ cần gửi yêu cầu nhận với URL chỉ mục và từ khóa _stats ở cuối.
GET /_statsKhi chạy đoạn mã trên, chúng tôi nhận được kết quả như hình dưới đây:
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………Tuôn ra
Quá trình xóa chỉ mục đảm bảo rằng bất kỳ dữ liệu nào hiện chỉ tồn tại trong nhật ký giao dịch cũng được lưu giữ vĩnh viễn trong Lucene. Điều này làm giảm thời gian khôi phục vì dữ liệu đó không cần được lập chỉ mục lại từ nhật ký giao dịch sau khi Lucene được lập chỉ mục được mở.
POST colleges/_flushKhi chạy đoạn mã trên, chúng tôi nhận được kết quả như hình dưới đây:
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}Thông thường, kết quả từ các API Elasticsearch khác nhau được hiển thị ở định dạng JSON. Nhưng JSON không phải lúc nào cũng dễ đọc. Vì vậy, tính năng API mèo có sẵn trong Elasticsearch giúp quản lý việc đưa ra định dạng in kết quả dễ đọc và dễ hiểu hơn. Có nhiều tham số khác nhau được sử dụng trong API cat mà máy chủ có mục đích khác nhau, chẳng hạn - thuật ngữ V làm cho đầu ra dài dòng.
Hãy để chúng tôi tìm hiểu về API mèo chi tiết hơn trong chương này.
Dài dòng
Đầu ra dài dòng cung cấp một màn hình hiển thị đẹp mắt về kết quả của lệnh mèo. Trong ví dụ được đưa ra bên dưới, chúng tôi nhận được chi tiết của các chỉ số khác nhau có trong cụm.
GET /_cat/indices?vKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb
yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b
yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb
yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283bTiêu đề
Tham số h, còn được gọi là tiêu đề, được sử dụng để chỉ hiển thị các cột được đề cập trong lệnh.
GET /_cat/nodes?h=ip,portKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
127.0.0.1 9300Sắp xếp
Lệnh sắp xếp chấp nhận chuỗi truy vấn có thể sắp xếp bảng theo cột được chỉ định trong truy vấn. Sắp xếp mặc định là tăng dần nhưng điều này có thể được thay đổi bằng cách thêm: desc vào một cột.
Ví dụ dưới đây, đưa ra kết quả của các mẫu được sắp xếp theo thứ tự giảm dần của các mẫu chỉ mục đã phân loại.
GET _cat/templates?v&s=order:desc,index_patternsKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
name index_patterns order version
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-9 [.watcher-history-9*] 2147483647
.watches [.watches*] 2147483647
.kibana_task_manager [.kibana_task_manager] 0 7000099Đếm
Tham số đếm cung cấp số lượng tổng số tài liệu trong toàn bộ cụm.
GET /_cat/count?vKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
epoch timestamp count
1557633536 03:58:56 17809API cụm được sử dụng để lấy thông tin về cụm và các nút của nó và thực hiện các thay đổi trong chúng. Để gọi API này, chúng ta cần chỉ định tên nút, địa chỉ hoặc _local.
GET /_nodes/_localKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………Tình trạng cụm
API này được sử dụng để nhận trạng thái về tình trạng của cụm bằng cách thêm từ khóa 'sức khỏe'.
GET /_cluster/healthKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}Trạng thái cụm
API này được sử dụng để nhận thông tin trạng thái về một cụm bằng cách thêm URL từ khóa 'trạng thái'. Thông tin trạng thái chứa phiên bản, nút chính, các nút khác, bảng định tuyến, siêu dữ liệu và các khối.
GET /_cluster/stateKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………Thống kê cụm
API này giúp lấy thống kê về cụm bằng cách sử dụng từ khóa 'thống kê'. API này trả về số phân đoạn, kích thước lưu trữ, mức sử dụng bộ nhớ, số lượng nút, vai trò, hệ điều hành và hệ thống tệp.
GET /_cluster/statsKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….Cài đặt cập nhật cụm
API này cho phép bạn cập nhật cài đặt của một cụm bằng cách sử dụng từ khóa 'cài đặt'. Có hai loại cài đặt - liên tục (áp dụng khi khởi động lại) và tạm thời (không tồn tại khi khởi động lại toàn bộ cụm).
Số liệu thống kê về nút
API này được sử dụng để truy xuất số liệu thống kê của một nút khác của cụm. Số liệu thống kê của nút gần giống như cụm.
GET /_nodes/statsKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….Nút hot_threads
API này giúp bạn truy xuất thông tin về các luồng nóng hiện tại trên mỗi nút trong cụm.
GET /_nodes/hot_threadsKhi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:Trong Elasticsearch, tìm kiếm được thực hiện bằng cách sử dụng truy vấn dựa trên JSON. Một truy vấn được tạo thành từ hai mệnh đề -
Leaf Query Clauses - Các mệnh đề này là đối sánh, thuật ngữ hoặc phạm vi, tìm kiếm một giá trị cụ thể trong trường cụ thể.
Compound Query Clauses - Các truy vấn này là sự kết hợp của các mệnh đề truy vấn lá và các truy vấn ghép khác để trích xuất thông tin mong muốn.
Elasticsearch hỗ trợ một số lượng lớn các truy vấn. Một truy vấn bắt đầu bằng một từ khóa truy vấn và sau đó có các điều kiện và bộ lọc bên trong dưới dạng đối tượng JSON. Các loại truy vấn khác nhau đã được mô tả bên dưới.
Khớp tất cả truy vấn
Đây là truy vấn cơ bản nhất; nó trả về tất cả nội dung và với điểm 1,0 cho mọi đối tượng.
POST /schools/_search
{
"query":{
"match_all":{}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Truy vấn văn bản đầy đủ
Các truy vấn này được sử dụng để tìm kiếm toàn bộ nội dung như một chương hoặc một bài báo. Truy vấn này hoạt động theo trình phân tích được liên kết với chỉ mục hoặc tài liệu cụ thể đó. Trong phần này, chúng ta sẽ thảo luận về các loại truy vấn toàn văn khác nhau.
Khớp truy vấn
Truy vấn này khớp một văn bản hoặc cụm từ với các giá trị của một hoặc nhiều trường.
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Truy vấn nhiều đối sánh
Truy vấn này khớp với một văn bản hoặc cụm từ với nhiều trường.
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Truy vấn Chuỗi truy vấn
Truy vấn này sử dụng trình phân tích cú pháp truy vấn và từ khóa query_string.
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….Truy vấn cấp độ kỳ hạn
Các truy vấn này chủ yếu xử lý dữ liệu có cấu trúc như số, ngày tháng và enums.
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..Truy vấn phạm vi
Truy vấn này được sử dụng để tìm các đối tượng có giá trị giữa các phạm vi giá trị đã cho. Để làm được điều này, chúng ta cần sử dụng các toán tử như -
- gte - lớn hơn bằng
- gt - lớn hơn
- lte - nhỏ hơn bằng
- lt - nhỏ hơn
Ví dụ, hãy quan sát đoạn mã dưới đây:
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Tồn tại các loại truy vấn cấp thuật ngữ khác, chẳng hạn như -
Exists query - Nếu một trường nào đó có giá trị khác rỗng.
Missing query - Điều này hoàn toàn ngược lại với truy vấn tồn tại, truy vấn này tìm kiếm các đối tượng không có trường cụ thể hoặc trường có giá trị null.
Wildcard or regexp query - Truy vấn này sử dụng biểu thức chính quy để tìm các mẫu trong các đối tượng.
Truy vấn phức hợp
Các truy vấn này là tập hợp các truy vấn khác nhau được hợp nhất với nhau bằng cách sử dụng các toán tử Boolean như và, hoặc, không hoặc cho các chỉ số khác nhau hoặc có các lệnh gọi hàm, v.v.
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}Truy vấn địa lý
Các truy vấn này liên quan đến vị trí địa lý và điểm địa lý. Những truy vấn này giúp tìm ra trường học hoặc bất kỳ đối tượng địa lý nào khác gần bất kỳ vị trí nào. Bạn cần sử dụng kiểu dữ liệu điểm địa lý.
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}Bây giờ chúng ta đăng dữ liệu trong chỉ mục đã tạo ở trên.
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}Ánh xạ là phác thảo của các tài liệu được lưu trữ trong một chỉ mục. Nó xác định kiểu dữ liệu như geo_point hoặc chuỗi và định dạng của các trường có trong tài liệu và quy tắc để kiểm soát ánh xạ các trường được thêm động.
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}Khi chúng tôi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}Các loại dữ liệu trường
Elasticsearch hỗ trợ một số kiểu dữ liệu khác nhau cho các trường trong tài liệu. Các kiểu dữ liệu được sử dụng để lưu trữ các trường trong Elasticsearch được thảo luận chi tiết tại đây.
Các loại dữ liệu cốt lõi
Đây là các kiểu dữ liệu cơ bản như văn bản, từ khóa, ngày, dài, kép, boolean hoặc ip, được hầu hết các hệ thống hỗ trợ.
Các kiểu dữ liệu phức tạp
Các kiểu dữ liệu này là sự kết hợp của các kiểu dữ liệu cốt lõi. Chúng bao gồm mảng, đối tượng JSON và kiểu dữ liệu lồng nhau. Ví dụ về kiểu dữ liệu lồng nhau được hiển thị bên dưới & dấu trừ
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}Khi chúng tôi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Một mã mẫu khác được hiển thị bên dưới -
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}Khi chúng tôi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Chúng ta có thể kiểm tra tài liệu trên bằng cách sử dụng lệnh sau:
GET /accountdetails/_mappings?include_type_name=falseLoại bỏ các loại ánh xạ
Các chỉ số được tạo trong Elasticsearch 7.0.0 trở lên không còn chấp nhận ánh xạ _default_. Các chỉ số được tạo trong 6.x sẽ tiếp tục hoạt động như trước trong Elasticsearch 6.x. Các loại không được chấp nhận trong API phiên bản 7.0.
Khi một truy vấn được xử lý trong một hoạt động tìm kiếm, nội dung trong bất kỳ chỉ mục nào sẽ được phân tích bởi mô-đun phân tích. Mô-đun này bao gồm bộ phân tích, bộ tách sóng, bộ lọc mã thông báo và bộ lọc bộ lọc. Nếu không có bộ phân tích nào được xác định, thì theo mặc định, các bộ phân tích, mã thông báo, bộ lọc và bộ phân tích tích hợp sẽ được đăng ký với mô-đun phân tích.
Trong ví dụ sau, chúng tôi sử dụng máy phân tích chuẩn được sử dụng khi không có máy phân tích nào khác được chỉ định. Nó sẽ phân tích câu dựa trên ngữ pháp và đưa ra các từ được sử dụng trong câu.
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}Cấu hình máy phân tích chuẩn
Chúng tôi có thể định cấu hình bộ phân tích tiêu chuẩn với các thông số khác nhau để nhận được các yêu cầu tùy chỉnh của chúng tôi.
Trong ví dụ sau, chúng tôi định cấu hình trình phân tích tiêu chuẩn để có max_token_length là 5.
Đối với điều này, trước tiên chúng tôi tạo một chỉ mục với trình phân tích có tham số max_length_token.
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}Tiếp theo, chúng tôi áp dụng bộ phân tích với một văn bản như hình dưới đây. Xin lưu ý cách mã thông báo không xuất hiện vì nó có hai dấu cách ở đầu và hai dấu cách ở cuối. Đối với từ “là”, có một khoảng trắng ở đầu và một khoảng trắng ở cuối từ. Lấy tất cả chúng, nó trở thành 4 chữ cái có dấu cách và điều đó không biến nó thành một từ. Ít nhất phải có một ký tự nonspace ở đầu hoặc cuối, để làm cho nó trở thành một từ được đếm.
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}Danh sách các máy phân tích khác nhau và mô tả của chúng được đưa ra trong bảng dưới đây:
| S.Không | Trình phân tích & Mô tả |
|---|---|
| 1 | Standard analyzer (standard) stopwords và cài đặt max_token_length có thể được đặt cho máy phân tích này. Theo mặc định, danh sách từ dừng trống và max_token_length là 255. |
| 2 | Simple analyzer (simple) Máy phân tích này được cấu tạo bởi tokenizer chữ thường. |
| 3 | Whitespace analyzer (whitespace) Bộ phân tích này bao gồm bộ tách khoảng trắng. |
| 4 | Stop analyzer (stop) stopwords và stopwords_path có thể được định cấu hình. Theo mặc định, các từ dừng được khởi tạo thành các từ dừng tiếng Anh và stopwords_path chứa đường dẫn đến tệp văn bản có các từ dừng. |
Tokenizers
Tokenizers được sử dụng để tạo mã thông báo từ một văn bản trong Elasticsearch. Văn bản có thể được chia thành các mã thông báo bằng cách tính đến khoảng trắng hoặc các dấu câu khác. Elasticsearch có rất nhiều công cụ phân tích mã hóa tích hợp, có thể được sử dụng trong bộ phân tích tùy chỉnh.
Dưới đây là một ví dụ về tokenizer ngắt văn bản thành các thuật ngữ bất cứ khi nào nó gặp một ký tự không phải là chữ cái, nhưng nó cũng viết thường tất cả các thuật ngữ:
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}Danh sách các Tokenizers và mô tả của chúng được hiển thị ở đây trong bảng dưới đây -
| S.Không | Tokenizer & Mô tả |
|---|---|
| 1 | Standard tokenizer (standard) Điều này được xây dựng dựa trên tokenizer dựa trên ngữ pháp và max_token_length có thể được định cấu hình cho tokenizer này. |
| 2 | Edge NGram tokenizer (edgeNGram) Có thể đặt các cài đặt như min_gram, max_gram, token_chars cho tokenizer này. |
| 3 | Keyword tokenizer (keyword) Điều này tạo ra toàn bộ đầu vào dưới dạng đầu ra và có thể đặt buffer_size cho việc này. |
| 4 | Letter tokenizer (letter) Thao tác này sẽ ghi lại toàn bộ từ cho đến khi gặp một ký tự không phải chữ cái. |
Elasticsearch bao gồm một số mô-đun, chịu trách nhiệm về chức năng của nó. Các mô-đun này có hai loại cài đặt như sau:
Static Settings- Các cài đặt này cần được định cấu hình trong tệp config (asticsearch.yml) trước khi khởi động Elasticsearch. Bạn cần cập nhật tất cả các nút quan tâm trong cụm để phản ánh những thay đổi của các cài đặt này.
Dynamic Settings - Các cài đặt này có thể được đặt trên Elasticsearch trực tiếp.
Chúng ta sẽ thảo luận về các mô-đun khác nhau của Elasticsearch trong các phần sau của chương này.
Định tuyến cấp độ cụm và phân bổ mảnh
Cài đặt cấp độ cụm quyết định việc phân bổ các phân đoạn cho các nút khác nhau và phân bổ lại các phân đoạn để cân bằng lại cụm. Đây là các cài đặt sau để kiểm soát phân bổ phân đoạn.
Phân bổ mảnh cấp độ cụm
| Cài đặt | Giá trị có thể | Sự miêu tả |
|---|---|---|
| cluster.routing.allocation.enable | ||
| tất cả | Giá trị mặc định này cho phép phân bổ phân đoạn cho tất cả các loại phân đoạn. | |
| bầu cử sơ bộ | Điều này chỉ cho phép phân bổ phân đoạn cho các phân đoạn chính. | |
| new_primaries | Điều này chỉ cho phép phân bổ phân đoạn cho các phân đoạn chính cho các chỉ số mới. | |
| không ai | Điều này không cho phép bất kỳ phân bổ phân đoạn nào. | |
| cluster.routing.allocation .node_concurrent_recoveries | Giá trị số (theo mặc định là 2) | Điều này hạn chế số lượng phục hồi phân đoạn đồng thời. |
| cluster.routing.allocation .node_initial_primaries_recoveries | Giá trị số (theo mặc định là 4) | Điều này hạn chế số lần khôi phục chính ban đầu song song. |
| cluster.routing.allocation .same_shard.host | Giá trị boolean (theo mặc định là false) | Điều này hạn chế việc phân bổ nhiều hơn một bản sao của cùng một phân đoạn trong cùng một nút vật lý. |
| indices.recovery.concurrent _streams | Giá trị số (theo mặc định là 3) | Điều này kiểm soát số lượng luồng mạng mở trên mỗi nút tại thời điểm khôi phục phân đoạn từ các phân đoạn ngang hàng. |
| indices.recovery.concurrent _small_file_streams | Giá trị số (theo mặc định là 2) | Điều này kiểm soát số luồng mở trên mỗi nút đối với các tệp nhỏ có kích thước dưới 5mb tại thời điểm khôi phục phân đoạn. |
| cluster.routing.rebalance.enable | ||
| tất cả | Giá trị mặc định này cho phép cân bằng cho tất cả các loại phân đoạn. | |
| bầu cử sơ bộ | Điều này chỉ cho phép cân bằng phân đoạn cho các phân đoạn chính. | |
| bản sao | Điều này cho phép cân bằng phân đoạn chỉ cho các phân đoạn bản sao. | |
| không ai | Điều này không cho phép bất kỳ loại cân bằng phân đoạn nào. | |
| cluster.routing.allocation .allow_rebalance | ||
| luôn luôn | Giá trị mặc định này luôn cho phép cân bằng lại. | |
| indices_primaries _active | Điều này cho phép tái cân bằng khi tất cả các phân đoạn chính trong cụm được phân bổ. | |
| Indices_all_active | Điều này cho phép tái cân bằng khi tất cả các phân đoạn chính và bản sao được phân bổ. | |
| cluster.routing.allocation.cluster _concurrent_rebalance | Giá trị số (theo mặc định là 2) | Điều này hạn chế số lượng cân bằng phân đoạn đồng thời trong cụm. |
| cluster.routing.allocation .balance.shard | Giá trị nổi (theo mặc định là 0,45f) | Điều này xác định hệ số trọng số cho các phân đoạn được phân bổ trên mọi nút. |
| cluster.routing.allocation .balance.index | Giá trị nổi (theo mặc định là 0,55f) | Điều này xác định tỷ lệ số phân đoạn trên mỗi chỉ mục được phân bổ trên một nút cụ thể. |
| cluster.routing.allocation .balance.threshold | Giá trị float không âm (theo mặc định là 1.0f) | Đây là giá trị tối ưu hóa tối thiểu của các hoạt động nên được thực hiện. |
Phân bổ mảnh dựa trên đĩa
| Cài đặt | Giá trị có thể | Sự miêu tả |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | Giá trị Boolean (theo mặc định là true) | Điều này cho phép và vô hiệu hóa trình quyết định phân bổ đĩa. |
| cluster.routing.allocation.disk.watermark.low | Giá trị chuỗi (theo mặc định là 85%) | Điều này biểu thị mức sử dụng tối đa của đĩa; sau thời điểm này, không có phân đoạn nào khác có thể được cấp phát cho đĩa đó. |
| cluster.routing.allocation.disk.watermark.high | Giá trị chuỗi (theo mặc định là 90%) | Điều này biểu thị mức sử dụng tối đa tại thời điểm phân bổ; nếu đạt đến điểm này tại thời điểm phân bổ, thì Elasticsearch sẽ phân bổ phân đoạn đó vào một đĩa khác. |
| cluster.info.update.interval | Giá trị chuỗi (theo mặc định là 30 giây) | Đây là khoảng thời gian giữa các lần kiểm tra việc sử dụng ổ đĩa. |
| cluster.routing.allocation.disk.include_relocations | Giá trị Boolean (theo mặc định là true) | Điều này quyết định xem có nên xem xét các phân đoạn hiện đang được cấp phát hay không trong khi tính toán mức sử dụng đĩa. |
Khám phá
Mô-đun này giúp một cụm phát hiện và duy trì trạng thái của tất cả các nút trong đó. Trạng thái của cụm thay đổi khi một nút được thêm vào hoặc xóa khỏi nó. Cài đặt tên cụm được sử dụng để tạo ra sự khác biệt hợp lý giữa các cụm khác nhau. Có một số mô-đun giúp bạn sử dụng các API được cung cấp bởi các nhà cung cấp đám mây và những mô-đun đó như được cung cấp bên dưới -
- Khám phá Azure
- Khám phá EC2
- Khám phá công cụ máy tính của Google
- Khám phá Zen
Cổng vào
Mô-đun này duy trì trạng thái cụm và dữ liệu phân đoạn trên toàn bộ cụm khởi động lại. Sau đây là các cài đặt tĩnh của mô-đun này:
| Cài đặt | Giá trị có thể | Sự miêu tả |
|---|---|---|
| gateway.emplete_nodes | giá trị số (theo mặc định là 0) | Số lượng nút dự kiến sẽ có trong cụm để khôi phục các phân đoạn cục bộ. |
| gateway.eosystem_master_nodes | giá trị số (theo mặc định là 0) | Số lượng nút chính dự kiến sẽ có trong cụm trước khi bắt đầu khôi phục. |
| gateway.eosystem_data_nodes | giá trị số (theo mặc định là 0) | Số lượng nút dữ liệu dự kiến trong cụm trước khi bắt đầu khôi phục. |
| gateway.recover_ after_time | Giá trị chuỗi (theo mặc định là 5m) | Đây là khoảng thời gian giữa các lần kiểm tra việc sử dụng ổ đĩa. |
| cluster.routing.allocation. disk.include_relocations | Giá trị Boolean (theo mặc định là true) | Điều này chỉ định thời gian mà quá trình khôi phục sẽ đợi để bắt đầu bất kể số lượng nút đã tham gia trong cụm. gateway.recover_ after_nodes |
HTTP
Mô-đun này quản lý giao tiếp giữa máy khách HTTP và các API Elasticsearch. Mô-đun này có thể bị vô hiệu hóa bằng cách thay đổi giá trị của http.enabled thành false.
Sau đây là các cài đặt (được định cấu hình trongasticsearch.yml) để điều khiển mô-đun này:
| S.Không | Cài đặt & Mô tả |
|---|---|
| 1 | http.port Đây là một cổng để truy cập Elasticsearch và nó nằm trong khoảng từ 9200-9300. |
| 2 | http.publish_port Cổng này dành cho máy khách http và cũng hữu ích trong trường hợp tường lửa. |
| 3 | http.bind_host Đây là một địa chỉ máy chủ cho dịch vụ http. |
| 4 | http.publish_host Đây là địa chỉ máy chủ cho ứng dụng khách http. |
| 5 | http.max_content_length Đây là kích thước tối đa của nội dung trong một yêu cầu http. Giá trị mặc định của nó là 100mb. |
| 6 | http.max_initial_line_length Đây là kích thước tối đa của URL và giá trị mặc định của nó là 4kb. |
| 7 | http.max_header_size Đây là kích thước tiêu đề http tối đa và giá trị mặc định của nó là 8kb. |
| số 8 | http.compression Điều này cho phép hoặc tắt hỗ trợ nén và giá trị mặc định của nó là false. |
| 9 | http.pipelinig Điều này cho phép hoặc vô hiệu hóa đường dẫn HTTP. |
| 10 | http.pipelining.max_events Điều này hạn chế số lượng sự kiện được xếp hàng trước khi đóng một yêu cầu HTTP. |
Chỉ số
Mô-đun này duy trì các cài đặt, được đặt chung cho mọi chỉ mục. Các cài đặt sau chủ yếu liên quan đến việc sử dụng bộ nhớ -
Ngắt mạch
Điều này được sử dụng để ngăn hoạt động gây ra lỗi OutOfMemroyError. Cài đặt chủ yếu hạn chế kích thước heap JVM. Ví dụ: cài đặt indices.breaker.total.limit, mặc định là 70% heap JVM.
Fielddata Cache
Điều này được sử dụng chủ yếu khi tập hợp trên một lĩnh vực. Bạn nên có đủ bộ nhớ để cấp phát nó. Có thể kiểm soát dung lượng bộ nhớ được sử dụng cho bộ đệm dữ liệu trường bằng cài đặt indices.fielddata.cache.size.
Node Query Cache
Bộ nhớ này được sử dụng để lưu kết quả truy vấn vào bộ nhớ đệm. Bộ nhớ cache này sử dụng chính sách loại bỏ Ít được Sử dụng Gần đây (LRU). Cài đặt Indices.queries.cahce.size kiểm soát kích thước bộ nhớ của bộ đệm này.
Bộ đệm lập chỉ mục
Bộ đệm này lưu trữ các tài liệu mới được tạo trong chỉ mục và xóa chúng khi bộ đệm đầy. Cài đặt như indices.memory.index_buffer_size kiểm soát số lượng heap được phân bổ cho bộ đệm này.
Shard Request Cache
Bộ nhớ cache này được sử dụng để lưu trữ dữ liệu tìm kiếm cục bộ cho mọi phân đoạn. Bộ nhớ đệm có thể được kích hoạt trong quá trình tạo chỉ mục hoặc có thể bị vô hiệu hóa bằng cách gửi tham số URL.
Disable cache - ?request_cache = true
Enable cache "index.requests.cache.enable": truePhục hồi các chỉ số
Nó kiểm soát các tài nguyên trong quá trình khôi phục. Sau đây là các cài đặt -
| Cài đặt | Giá trị mặc định |
|---|---|
| indices.recovery.concurrent_streams | 3 |
| indices.recovery.concurrent_small_file_streams | 2 |
| indices.recovery.file_chunk_size | 512kb |
| indices.recovery.translog_ops | 1000 |
| indices.recovery.translog_size | 512kb |
| indices.recovery.compress | thật |
| indices.recovery.max_bytes_per_sec | 40mb |
Khoảng thời gian TTL
Khoảng thời gian tồn tại (TTL) xác định thời gian của tài liệu, sau đó tài liệu sẽ bị xóa. Sau đây là các cài đặt động để kiểm soát quá trình này:
| Cài đặt | Giá trị mặc định |
|---|---|
| indices.ttl.interval | 60s |
| indices.ttl.bulk_size | 1000 |
Nút
Mỗi nút có một tùy chọn là nút dữ liệu hoặc không. Bạn có thể thay đổi thuộc tính này bằng cách thay đổinode.datacài đặt. Đặt giá trị làfalse xác định rằng nút không phải là một nút dữ liệu.
Đây là các mô-đun được tạo cho mọi chỉ mục và kiểm soát cài đặt và hành vi của các chỉ số. Ví dụ: có bao nhiêu phân đoạn mà một chỉ mục có thể sử dụng hoặc số lượng bản sao mà một phân đoạn chính có thể có cho chỉ mục đó, v.v. Có hai loại cài đặt chỉ mục -
- Static - Chúng chỉ có thể được đặt tại thời điểm tạo chỉ mục hoặc trên một chỉ mục đã đóng.
- Dynamic - Những thứ này có thể được thay đổi trên chỉ mục trực tiếp.
Cài đặt chỉ mục tĩnh
Bảng sau đây hiển thị danh sách các cài đặt chỉ mục tĩnh:
| Cài đặt | Giá trị có thể | Sự miêu tả |
|---|---|---|
| index.number_of_shards | Mặc định là 5, tối đa 1024 | Số lượng phân đoạn chính mà một chỉ mục phải có. |
| index.shard.check_on_startup | Giá trị mặc định là false. Có thể đúng | Nên kiểm tra xem các mảnh vỡ có bị hỏng hay không trước khi mở. |
| index.codec | Nén LZ4. | Loại nén được sử dụng để lưu trữ dữ liệu. |
| index.routing_partition_size | 1 | Số lượng phân đoạn mà một giá trị định tuyến tùy chỉnh có thể chuyển đến. |
| index.load_fixed_bitset_filters_eagerly | sai | Cho biết liệu các bộ lọc được lưu trong bộ nhớ cache có được tải trước cho các truy vấn lồng nhau hay không |
Cài đặt chỉ mục động
Bảng sau đây hiển thị danh sách các cài đặt chỉ mục động:
| Cài đặt | Giá trị có thể | Sự miêu tả |
|---|---|---|
| index.number_of_replicas | Mặc định là 1 | Số lượng bản sao mà mỗi phân đoạn chính có. |
| index.auto_expand_replicas | Một dấu gạch ngang được phân tách giới hạn dưới và trên (0-5) | Tự động mở rộng số lượng bản sao dựa trên số lượng nút dữ liệu trong cụm. |
| index.search.idle. after | 30 giây | Thời gian một phân đoạn không thể nhận được tìm kiếm hoặc nhận được yêu cầu cho đến khi nó được coi là không tìm kiếm. |
| index.refresh_interval | 1 giây | Tần suất thực hiện thao tác làm mới, thao tác này làm cho các thay đổi gần đây đối với chỉ mục hiển thị cho tìm kiếm. |
| index.blocks.read_only | 1 đúng / sai | Đặt thành true để chỉ đọc chỉ mục và siêu dữ liệu, false để cho phép ghi và thay đổi siêu dữ liệu. |
Đôi khi chúng ta cần chuyển đổi một tài liệu trước khi lập chỉ mục cho nó. Ví dụ: chúng tôi muốn xóa một trường khỏi tài liệu hoặc đổi tên một trường và sau đó lập chỉ mục nó. Điều này được xử lý bởi nút Ingest.
Mọi nút trong cụm đều có khả năng nhập nhưng nó cũng có thể được tùy chỉnh để chỉ được xử lý bởi các nút cụ thể.
Các bước liên quan
Có hai bước liên quan đến hoạt động của nút nhập:
- Tạo đường dẫn
- Tạo tài liệu
Tạo một đường ống
Đầu tiên, tạo một đường dẫn chứa các bộ xử lý và sau đó thực hiện đường dẫn, như được hiển thị bên dưới:
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"acknowledged" : true
}Tạo tài liệu
Tiếp theo, chúng tôi tạo một tài liệu bằng cách sử dụng bộ chuyển đổi đường ống.
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Tiếp theo, chúng tôi tìm kiếm tài liệu đã tạo ở trên bằng cách sử dụng lệnh GET như hình dưới đây:
GET /logs/_doc/1Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}Bạn có thể thấy ở trên rằng 21 đã trở thành một số nguyên.
Không có đường ống
Bây giờ chúng ta tạo một tài liệu mà không cần sử dụng đường dẫn.
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}Bạn có thể thấy ở trên rằng 11 là một chuỗi không có đường ống được sử dụng.
Quản lý vòng đời chỉ mục liên quan đến việc thực hiện các hành động quản lý dựa trên các yếu tố như kích thước phân đoạn và yêu cầu hiệu suất. Các API quản lý vòng đời chỉ mục (ILM) cho phép bạn tự động hóa cách bạn muốn quản lý các chỉ số của mình theo thời gian.
Chương này cung cấp danh sách các API ILM và cách sử dụng chúng.
API quản lý chính sách
| Tên API | Mục đích | Thí dụ |
|---|---|---|
| Tạo chính sách vòng đời. | Tạo chính sách vòng đời. Nếu chính sách được chỉ định tồn tại, chính sách sẽ được thay thế và phiên bản chính sách được tăng lên. | PUT_ilm / policy / policy_id |
| Nhận chính sách vòng đời. | Trả về định nghĩa chính sách đã chỉ định. Bao gồm phiên bản chính sách và ngày sửa đổi cuối cùng. Nếu không có chính sách nào được chỉ định, trả về tất cả các chính sách đã xác định. | GET_ilm / policy / policy_id |
| Xóa chính sách vòng đời | Xóa định nghĩa chính sách vòng đời đã chỉ định. Bạn không thể xóa các chính sách hiện đang được sử dụng. Nếu chính sách đang được sử dụng để quản lý bất kỳ chỉ số nào, yêu cầu không thành công và trả về lỗi. | DELETE_ilm / policy / policy_id |
API quản lý chỉ mục
| Tên API | Mục đích | Thí dụ |
|---|---|---|
| Chuyển sang API bước vòng đời. | Di chuyển thủ công một chỉ mục vào bước đã chỉ định và thực hiện bước đó. | POST_ilm / move / index |
| Thử lại chính sách. | Đặt chính sách trở lại bước xảy ra lỗi và thực hiện bước đó. | POST index / _ilm / retry |
| Xóa chính sách khỏi chỉnh sửa API chỉ mục. | Loại bỏ chính sách vòng đời được chỉ định và ngừng quản lý chỉ mục được chỉ định. Nếu một mẫu chỉ mục được chỉ định, hãy xóa các chính sách đã chỉ định khỏi tất cả các chỉ số phù hợp. | POST index / _ilm / remove |
API quản lý hoạt động
| Tên API | Mục đích | Thí dụ |
|---|---|---|
| Nhận API trạng thái quản lý vòng đời của chỉ mục. | Trả về trạng thái của plugin ILM. Trường chế độ hoạt động trong phản hồi hiển thị một trong ba trạng thái: BẮT ĐẦU, DỪNG hoặc DỪNG. | GET / _ilm / trạng thái |
| Khởi động API quản lý vòng đời chỉ mục. | Khởi động plugin ILM nếu nó hiện đang bị dừng. ILM được khởi động tự động khi cụm được hình thành. | POST / _ilm / start |
| Dừng API quản lý vòng đời của chỉ mục. | Tạm dừng tất cả các hoạt động quản lý vòng đời và dừng plugin ILM. Điều này hữu ích khi bạn đang thực hiện bảo trì trên cụm và cần ngăn ILM thực hiện bất kỳ hành động nào trên các chỉ số của bạn. | ĐĂNG / _ilm / dừng |
| Giải thích về vòng đời API. | Truy xuất thông tin về trạng thái vòng đời hiện tại của chỉ mục, chẳng hạn như giai đoạn, hành động và bước hiện đang thực thi. Hiển thị thời điểm nhập chỉ mục, định nghĩa của giai đoạn chạy và thông tin về bất kỳ lỗi nào. | GET chỉ mục / _ilm / giải thích |
Nó là một thành phần cho phép các truy vấn giống SQL được thực thi trong thời gian thực chống lại Elasticsearch. Bạn có thể coi Elasticsearch SQL như một trình dịch, một trình dịch hiểu cả SQL và Elasticsearch, đồng thời giúp bạn dễ dàng đọc và xử lý dữ liệu trong thời gian thực, trên quy mô lớn bằng cách tận dụng các khả năng của Elasticsearch.
Ưu điểm của Elasticsearch SQL
It has native integration - Mỗi và mọi truy vấn được thực thi hiệu quả đối với các nút có liên quan theo bộ nhớ cơ bản.
No external parts - Không cần phần cứng, quy trình, thời gian chạy hoặc thư viện bổ sung để truy vấn Elasticsearch.
Lightweight and efficient - nó bao gồm và bộc lộ SQL để cho phép tìm kiếm toàn văn phù hợp, trong thời gian thực.
Thí dụ
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}Truy vấn SQL
Ví dụ sau đây cho thấy cách chúng tôi đóng khung truy vấn SQL:
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}Khi chạy đoạn mã trên, chúng tôi nhận được phản hồi như hình dưới đây:
Address | name | start_date | student_count
--------------------+---------------+------------------------+---------------
Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482
Main Street |Sunshine |1965-06-01T00:00:00.000Z|604Note - Bằng cách thay đổi truy vấn SQL ở trên, bạn có thể nhận được các tập kết quả khác nhau.
Để theo dõi tình trạng của cụm, tính năng giám sát thu thập số liệu từ mỗi nút và lưu trữ chúng trong Chỉ số Elasticsearch. Tất cả các cài đặt liên quan đến giám sát trong Elasticsearch phải được đặt trong tệpasticsearch.yml cho mỗi nút hoặc, nếu có thể, trong cài đặt cụm động.
Để bắt đầu giám sát, chúng ta cần kiểm tra cài đặt cụm, có thể thực hiện theo cách sau:
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}Mỗi thành phần trong ngăn xếp có trách nhiệm tự giám sát và sau đó chuyển tiếp các tài liệu đó đến cụm sản xuất Elasticsearch để định tuyến và lập chỉ mục (lưu trữ). Các quy trình định tuyến và lập chỉ mục trong Elasticsearch được xử lý bởi những người được gọi là bộ sưu tập và nhà xuất khẩu.
Người sưu tầm
Collector chạy một lần cho mỗi khoảng thời gian thu thập để lấy dữ liệu từ các API công khai trong Elasticsearch mà nó chọn để theo dõi. Khi việc thu thập dữ liệu kết thúc, dữ liệu được giao hàng loạt cho người xuất để gửi đến cụm giám sát.
Chỉ có một bộ thu thập cho mỗi loại dữ liệu được thu thập. Mỗi người thu thập có thể tạo không hoặc nhiều tài liệu giám sát.
Nhà xuất khẩu
Các nhà xuất khẩu lấy dữ liệu được thu thập từ bất kỳ nguồn Elastic Stack nào và định tuyến nó đến cụm giám sát. Có thể định cấu hình nhiều hơn một nhà xuất khẩu, nhưng thiết lập chung và mặc định là sử dụng một nhà xuất khẩu duy nhất. Các nhà xuất khẩu có thể định cấu hình ở cả cấp độ nút và cụm.
Có hai loại nhà xuất khẩu trong Elasticsearch -
local - Nhà xuất khẩu này định tuyến dữ liệu trở lại cùng một cụm
http - Trình xuất ưu tiên, mà bạn có thể sử dụng để định tuyến dữ liệu vào bất kỳ cụm Elasticsearch được hỗ trợ nào có thể truy cập qua HTTP.
Trước khi nhà xuất khẩu có thể định tuyến dữ liệu giám sát, họ phải thiết lập một số tài nguyên Elasticsearch nhất định. Các tài nguyên này bao gồm các mẫu và đường ống nhập
Công việc tổng hợp là một công việc định kỳ tóm tắt dữ liệu từ các chỉ số được chỉ định bởi một mẫu chỉ mục và cuộn nó vào một chỉ mục mới. Trong ví dụ sau, chúng tôi tạo một chỉ mục có tên là cảm biến với các dấu thời gian ngày tháng khác nhau. Sau đó, chúng tôi tạo một công việc cuộn lên để cuộn dữ liệu từ các chỉ số này theo định kỳ bằng cách sử dụng công việc cron.
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}Khi chạy đoạn mã trên, chúng tôi nhận được kết quả sau:
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Bây giờ, thêm tài liệu thứ hai, v.v. cho các tài liệu khác.
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}Tạo một công việc tổng hợp
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}Tham số cron kiểm soát thời gian và tần suất công việc kích hoạt. Khi lịch biểu cron của công việc cuộn lên kích hoạt, nó sẽ bắt đầu cuộn lên từ vị trí đã dừng lại sau lần kích hoạt cuối cùng
Sau khi công việc đã chạy và xử lý một số dữ liệu, chúng ta có thể sử dụng DSL Query để thực hiện một số tìm kiếm.
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}Các chỉ mục được tìm kiếm thường xuyên được lưu giữ trong bộ nhớ vì cần có thời gian để xây dựng lại chúng và giúp tìm kiếm hiệu quả. Mặt khác, có thể có các chỉ số mà chúng tôi hiếm khi truy cập. Các chỉ mục đó không cần chiếm bộ nhớ và có thể được xây dựng lại khi cần thiết. Các chỉ số như vậy được gọi là chỉ số cố định.
Elasticsearch xây dựng cấu trúc dữ liệu tạm thời của từng phân đoạn của chỉ mục cố định mỗi khi phân đoạn đó được tìm kiếm và loại bỏ các cấu trúc dữ liệu này ngay sau khi tìm kiếm hoàn tất. Bởi vì Elasticsearch không duy trì các cấu trúc dữ liệu tạm thời này trong bộ nhớ, các chỉ số cố định tiêu thụ ít đống hơn nhiều so với các chỉ số bình thường. Điều này cho phép tỷ lệ đĩa trên heap cao hơn nhiều so với khả năng có thể.
Ví dụ về đông lạnh và không đông lạnh
Ví dụ sau đây đóng băng và mở một chỉ mục -
POST /index_name/_freeze
POST /index_name/_unfreezeCác tìm kiếm trên các chỉ số cố định sẽ thực thi chậm. Các chỉ số cố định không dành cho tải tìm kiếm cao. Có thể mất vài giây hoặc vài phút để hoàn thành việc tìm kiếm một chỉ mục bị cố định, ngay cả khi các tìm kiếm tương tự được hoàn thành trong mili giây khi các chỉ mục không được đóng băng.
Tìm kiếm Chỉ mục Đông lạnh
Số lượng chỉ số cố định được tải đồng thời trên mỗi nút bị giới hạn bởi số luồng trong nhóm luồng tìm kiếm_throttled, theo mặc định là 1. Để bao gồm các chỉ số cố định, một yêu cầu tìm kiếm phải được thực hiện với tham số truy vấn - ignore_throttled = false.
GET /index_name/_search?q=user:tpoint&ignore_throttled=falseTheo dõi các chỉ số đông lạnh
Các chỉ số cố định là các chỉ số thông thường sử dụng điều chỉnh tìm kiếm và triển khai phân đoạn hiệu quả trong bộ nhớ.
GET /_cat/indices/index_name?v&h=i,sthElasticsearch cung cấp một tệp jar, có thể được thêm vào bất kỳ IDE java nào và có thể được sử dụng để kiểm tra mã có liên quan đến Elasticsearch. Một loạt các thử nghiệm có thể được thực hiện bằng cách sử dụng khung do Elasticsearch cung cấp. Trong chương này, chúng ta sẽ thảo luận chi tiết về các bài kiểm tra này -
- Kiểm tra đơn vị
- Thử nghiệm hội nhập
- Thử nghiệm ngẫu nhiên
Điều kiện tiên quyết
Để bắt đầu thử nghiệm, bạn cần thêm phần phụ thuộc thử nghiệm Elasticsearch vào chương trình của mình. Bạn có thể sử dụng maven cho mục đích này và có thể thêm phần sau vào pom.xml.
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.1.0</version>
</dependency>EsSetup đã được khởi tạo để bắt đầu và dừng nút Elasticsearch và cũng để tạo các chỉ mục.
EsSetup esSetup = new EsSetup();Hàm esSetup.execute () với createIndex sẽ tạo các chỉ mục, bạn cần chỉ định cài đặt, kiểu và dữ liệu.
Kiểm tra đơn vị
Bài kiểm tra đơn vị được thực hiện bằng cách sử dụng khung kiểm tra JUnit và Elasticsearch. Nút và chỉ mục có thể được tạo bằng cách sử dụng các lớp Elasticsearch và trong phương pháp thử nghiệm có thể được sử dụng để thực hiện thử nghiệm. Các lớp ESTestCase và ESTokenStreamTestCase được sử dụng cho thử nghiệm này.
Thử nghiệm hội nhập
Kiểm tra tích hợp sử dụng nhiều nút trong một cụm. Lớp ESIntegTestCase được sử dụng cho thử nghiệm này. Có nhiều phương pháp giúp công việc chuẩn bị test case dễ dàng hơn.
| S.Không | Phương pháp & Mô tả |
|---|---|
| 1 | refresh() Tất cả các chỉ số trong một cụm được làm mới |
| 2 | ensureGreen() Đảm bảo trạng thái cụm sức khỏe xanh |
| 3 | ensureYellow() Đảm bảo trạng thái cụm sức khỏe màu vàng |
| 4 | createIndex(name) Tạo chỉ mục với tên được truyền cho phương thức này |
| 5 | flush() Tất cả các chỉ số trong cụm được xóa |
| 6 | flushAndRefresh() flush () và refresh () |
| 7 | indexExists(name) Xác minh sự tồn tại của chỉ mục được chỉ định |
| số 8 | clusterService() Trả về lớp java dịch vụ cụm |
| 9 | cluster() Trả về lớp cụm kiểm tra |
Phương pháp cụm kiểm tra
| S.Không | Phương pháp & Mô tả |
|---|---|
| 1 | ensureAtLeastNumNodes(n) Đảm bảo số lượng nút tối thiểu trong một cụm nhiều hơn hoặc bằng số lượng đã chỉ định. |
| 2 | ensureAtMostNumNodes(n) Đảm bảo số lượng nút tối đa trong một cụm nhỏ hơn hoặc bằng số lượng đã chỉ định. |
| 3 | stopRandomNode() Để dừng một nút ngẫu nhiên trong một cụm |
| 4 | stopCurrentMasterNode() Để dừng nút chính |
| 5 | stopRandomNonMaster() Để dừng một nút ngẫu nhiên trong một cụm không phải là nút chính. |
| 6 | buildNode() Tạo một nút mới |
| 7 | startNode(settings) Bắt đầu một nút mới |
| số 8 | nodeSettings() Ghi đè phương pháp này để thay đổi cài đặt nút. |
Tiếp cận khách hàng
Máy khách được sử dụng để truy cập các nút khác nhau trong một cụm và thực hiện một số hành động. Phương thức ESIntegTestCase.client () được sử dụng để lấy một máy khách ngẫu nhiên. Elasticsearch cũng cung cấp các phương thức khác để truy cập máy khách và những phương thức đó có thể được truy cập bằng phương thức ESIntegTestCase.internalCluster ().
| S.Không | Phương pháp & Mô tả |
|---|---|
| 1 | iterator() Điều này giúp bạn tiếp cận tất cả các khách hàng có sẵn. |
| 2 | masterClient() Điều này trả về một máy khách đang giao tiếp với nút chính. |
| 3 | nonMasterClient() Điều này trả về một ứng dụng khách không giao tiếp với nút chính. |
| 4 | clientNodeClient() Điều này trả về một máy khách hiện đang ở trên nút máy khách. |
Thử nghiệm ngẫu nhiên
Thử nghiệm này được sử dụng để kiểm tra mã của người dùng với mọi dữ liệu có thể có, để không xảy ra lỗi trong tương lai với bất kỳ loại dữ liệu nào. Dữ liệu ngẫu nhiên là lựa chọn tốt nhất để thực hiện thử nghiệm này.
Tạo dữ liệu ngẫu nhiên
Trong thử nghiệm này, lớp Random được khởi tạo bởi phiên bản do RandomizedTest cung cấp và cung cấp nhiều phương pháp để lấy các loại dữ liệu khác nhau.
| phương pháp | Giá trị trả lại |
|---|---|
| getRandom () | Phiên bản của lớp ngẫu nhiên |
| randomBoolean () | Boolean ngẫu nhiên |
| randomByte () | Byte ngẫu nhiên |
| randomShort () | Ngắn ngẫu nhiên |
| randomInt () | Số nguyên ngẫu nhiên |
| randomLong () | Ngẫu nhiên dài |
| randomFloat () | Phao ngẫu nhiên |
| randomDouble () | Đôi ngẫu nhiên |
| randomLocale () | Ngôn ngữ ngẫu nhiên |
| randomTimeZone () | Múi giờ ngẫu nhiên |
| randomFrom () | Phần tử ngẫu nhiên từ mảng |
Khẳng định
Các lớp ElasticsearchAssertions và ElasticsearchGeoAssertions chứa các xác nhận, được sử dụng để thực hiện một số kiểm tra phổ biến tại thời điểm kiểm tra. Ví dụ, hãy quan sát đoạn mã được đưa ra ở đây -
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);Trang tổng quan Kibana là một tập hợp các hình ảnh và tìm kiếm. Bạn có thể sắp xếp, thay đổi kích thước và chỉnh sửa nội dung trang tổng quan, sau đó lưu trang tổng quan để bạn có thể chia sẻ. Trong chương này, chúng ta sẽ xem cách tạo và chỉnh sửa trang tổng quan.
Tạo trang tổng quan
Từ Trang chủ Kibana, chọn tùy chọn bảng điều khiển từ các thanh điều khiển bên trái như hình dưới đây. Điều này sẽ nhắc bạn tạo một trang tổng quan mới.
Để Thêm hình ảnh trực quan vào trang tổng quan, chúng tôi chọn menu Thêm và chọn từ các hình ảnh trực quan được tạo sẵn có sẵn. Chúng tôi đã chọn các tùy chọn hình ảnh hóa sau đây từ danh sách.
Khi chọn các hình ảnh trực quan ở trên, chúng tôi nhận được bảng điều khiển như được hiển thị ở đây. Sau đó, chúng tôi có thể thêm và chỉnh sửa trang tổng quan để thay đổi các phần tử và thêm các phần tử mới.
Kiểm tra các yếu tố
Chúng tôi có thể kiểm tra các phần tử của Bảng điều khiển bằng cách chọn menu bảng điều khiển hình ảnh hóa và chọn Inspect. Điều này sẽ hiển thị dữ liệu đằng sau phần tử mà cũng có thể được tải xuống.
Chia sẻ trang tổng quan
Chúng ta có thể chia sẻ trang tổng quan bằng cách chọn menu chia sẻ và chọn tùy chọn để lấy siêu liên kết như hình dưới đây -

Chức năng khám phá có sẵn trong trang chủ Kibana cho phép chúng tôi khám phá các tập dữ liệu từ nhiều góc độ khác nhau. Bạn có thể tìm kiếm và lọc dữ liệu cho các mẫu chỉ mục đã chọn. Dữ liệu thường có sẵn dưới dạng phân phối các giá trị trong một khoảng thời gian.
Để khám phá mẫu dữ liệu thương mại điện tử, chúng tôi nhấp vào Discoverbiểu tượng như trong hình dưới đây. Điều này sẽ hiển thị dữ liệu cùng với biểu đồ.
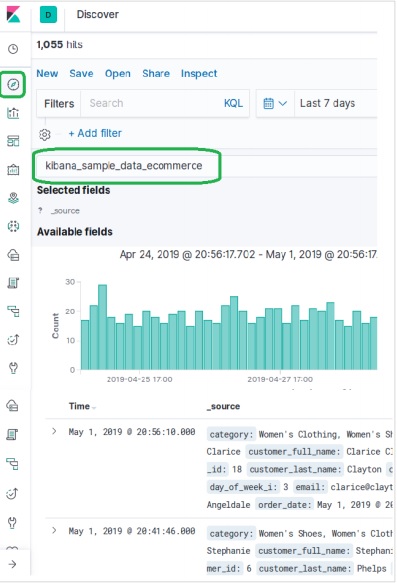
Lọc theo thời gian
Để lọc ra dữ liệu theo khoảng thời gian cụ thể, chúng tôi sử dụng tùy chọn bộ lọc thời gian như hình dưới đây. Theo mặc định, bộ lọc được đặt ở 15 phút.
Lọc theo trường
Tập dữ liệu cũng có thể được lọc theo các trường bằng cách sử dụng Add Filtertùy chọn như hình dưới đây. Ở đây chúng tôi thêm một hoặc nhiều trường và nhận được kết quả tương ứng sau khi các bộ lọc được áp dụng. Trong ví dụ của chúng tôi, chúng tôi chọn trườngday_of_week và sau đó là toán tử cho trường đó như is và giá trị như Sunday.
Tiếp theo, chúng tôi nhấp vào Lưu với các điều kiện lọc ở trên. Tập hợp kết quả chứa các điều kiện lọc được áp dụng được hiển thị bên dưới.
Bảng dữ liệu là kiểu trực quan được sử dụng để hiển thị dữ liệu thô của một tổng hợp đã tổng hợp. Có nhiều loại tổng hợp khác nhau được trình bày bằng cách sử dụng bảng Dữ liệu. Để tạo Bảng dữ liệu, chúng ta nên thực hiện chi tiết các bước được thảo luận ở đây.
Hình dung
Trong Màn hình chính Kibana, chúng tôi tìm thấy tên tùy chọn Visualize cho phép chúng tôi tạo trực quan hóa và tổng hợp từ các chỉ số được lưu trữ trong Elasticsearch. Hình ảnh sau đây cho thấy tùy chọn.
Chọn bảng dữ liệu
Tiếp theo, chúng tôi chọn tùy chọn Bảng Dữ liệu trong số các tùy chọn trực quan hóa khác nhau có sẵn. Tùy chọn được hiển thị trong hình ảnh sau & miuns;
Chọn số liệu
Sau đó, chúng tôi chọn các chỉ số cần thiết để tạo trực quan hóa bảng dữ liệu. Sự lựa chọn này quyết định loại tập hợp mà chúng tôi sẽ sử dụng. Chúng tôi chọn các trường cụ thể được hiển thị bên dưới từ tập dữ liệu thương mại điện tử cho việc này.
Khi chạy cấu hình trên cho Bảng dữ liệu, chúng tôi nhận được kết quả như trong hình ở đây -
Bản đồ khu vực hiển thị số liệu trên Bản đồ địa lý. Nó rất hữu ích trong việc xem xét dữ liệu được gắn vào các vùng địa lý khác nhau với cường độ khác nhau. Các sắc thái tối hơn thường biểu thị các giá trị cao hơn và các sắc thái sáng hơn biểu thị các giá trị thấp hơn.
Các bước để tạo hình ảnh trực quan này được giải thích chi tiết như sau:
Hình dung
Trong bước này, chúng ta chuyển đến nút trực quan hóa có sẵn trong thanh bên trái của Màn hình chính Kibana và sau đó chọn tùy chọn để thêm một Hình ảnh hóa mới.
Màn hình sau đây cho thấy cách chúng tôi chọn tùy chọn Bản đồ khu vực.
Chọn các chỉ số
Màn hình tiếp theo nhắc chúng tôi chọn các số liệu sẽ được sử dụng để tạo Bản đồ khu vực. Ở đây, chúng tôi chọn Giá trung bình làm chỉ số và country_iso_code làm trường trong nhóm sẽ được sử dụng để tạo hình ảnh trực quan.
Kết quả cuối cùng bên dưới hiển thị Bản đồ khu vực sau khi chúng tôi áp dụng lựa chọn. Vui lòng lưu ý các sắc thái của màu và giá trị của chúng được đề cập trong nhãn.
Biểu đồ hình tròn là một trong những công cụ trực quan đơn giản và nổi tiếng. Nó biểu thị dữ liệu dưới dạng các lát của một vòng tròn, mỗi phần được tô màu khác nhau. Các nhãn cùng với các giá trị dữ liệu phần trăm có thể được trình bày cùng với vòng tròn. Hình tròn cũng có thể có hình dạng của một chiếc bánh rán.
Hình dung
Trong Màn hình chính của Kibana, chúng tôi tìm thấy tên tùy chọn Visualize cho phép chúng tôi tạo trực quan hóa và tổng hợp từ các chỉ số được lưu trữ trong Elasticsearch. Chúng tôi chọn thêm hình ảnh trực quan mới và chọn biểu đồ hình tròn như tùy chọn được hiển thị bên dưới.
Chọn các chỉ số
Màn hình tiếp theo sẽ nhắc chúng tôi chọn các số liệu sẽ được sử dụng để tạo Biểu đồ hình tròn. Ở đây, chúng tôi chọn số lượng đơn giá cơ sở làm chỉ số và Tổng hợp nhóm làm biểu đồ. Ngoài ra, khoảng thời gian tối thiểu được chọn là 20. Vì vậy, giá sẽ được hiển thị dưới dạng các khối giá trị với 20 là một phạm vi.
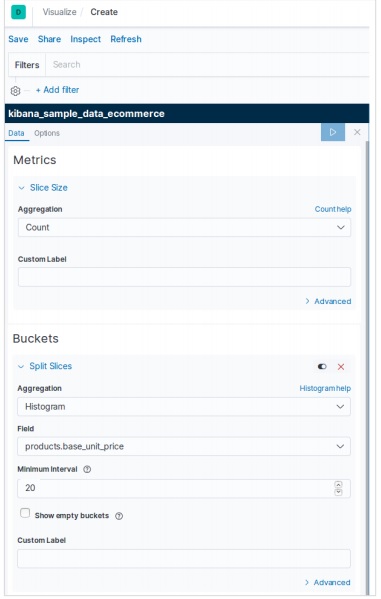
Kết quả dưới đây cho thấy biểu đồ hình tròn sau khi chúng tôi áp dụng lựa chọn. Vui lòng lưu ý các sắc thái của màu và giá trị của chúng được đề cập trong nhãn.

Tùy chọn biểu đồ hình tròn
Khi di chuyển đến tab tùy chọn dưới biểu đồ hình tròn, chúng ta có thể thấy các tùy chọn cấu hình khác nhau để thay đổi giao diện cũng như cách sắp xếp hiển thị dữ liệu trong biểu đồ hình tròn. Trong ví dụ sau, biểu đồ hình tròn xuất hiện dưới dạng bánh rán và các nhãn xuất hiện ở trên cùng.
Biểu đồ vùng là phần mở rộng của biểu đồ đường trong đó vùng giữa biểu đồ đường và các trục được đánh dấu bằng một số màu. Biểu đồ thanh đại diện cho dữ liệu được tổ chức thành một dải giá trị và sau đó được vẽ dựa trên các trục. Nó có thể bao gồm thanh ngang hoặc thanh dọc.
Trong chương này, chúng ta sẽ thấy tất cả ba loại đồ thị này được tạo ra bằng cách sử dụng Kibana. Như đã thảo luận trong các chương trước, chúng tôi sẽ tiếp tục sử dụng dữ liệu trong chỉ mục thương mại điện tử.
Biểu đồ khu vực
Trong Màn hình chính của Kibana, chúng tôi tìm thấy tên tùy chọn Visualize cho phép chúng tôi tạo trực quan hóa và tổng hợp từ các chỉ số được lưu trữ trong Elasticsearch. Chúng tôi chọn thêm một hình ảnh trực quan mới và chọn Biểu đồ Khu vực như tùy chọn được hiển thị trong hình ảnh bên dưới.
Chọn các chỉ số
Màn hình tiếp theo nhắc chúng tôi chọn các số liệu sẽ được sử dụng để tạo Biểu đồ khu vực. Ở đây chúng tôi chọn tổng làm loại số liệu tổng hợp. Sau đó, chúng tôi chọn trường total_quantity làm trường được sử dụng làm số liệu. Trên trục X, chúng tôi chọn trường order_date và chia chuỗi với số liệu đã cho ở kích thước 5.

Khi chạy cấu hình trên, chúng tôi nhận được biểu đồ vùng sau làm đầu ra:
Biểu đồ thanh ngang
Tương tự, đối với biểu đồ thanh Ngang, chúng tôi chọn trực quan hóa mới từ Màn hình chính của Kibana và chọn tùy chọn cho Thanh ngang. Sau đó, chúng tôi chọn các số liệu như trong hình ảnh bên dưới. Ở đây chúng tôi chọn Sum làm tổng số lượng sản phẩm đã đặt tên. Sau đó, chúng tôi chọn các nhóm có biểu đồ ngày cho ngày đặt hàng của trường.
Khi chạy cấu hình trên, chúng ta có thể thấy biểu đồ thanh ngang như hình dưới đây:
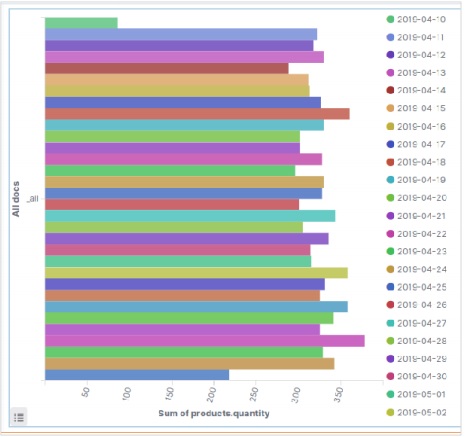
Biểu đồ thanh dọc
Đối với biểu đồ thanh dọc, chúng tôi chọn trực quan hóa mới từ Màn hình chính của Kibana và chọn tùy chọn cho Thanh dọc. Sau đó, chúng tôi chọn các số liệu như trong hình ảnh bên dưới.
Ở đây chúng tôi chọn Sum làm tập hợp cho trường có tên số lượng sản phẩm. Sau đó, chúng tôi chọn các nhóm có biểu đồ ngày cho ngày đặt hàng trường với khoảng thời gian hàng tuần.
Khi chạy cấu hình trên, một biểu đồ sẽ được tạo như hình dưới đây:
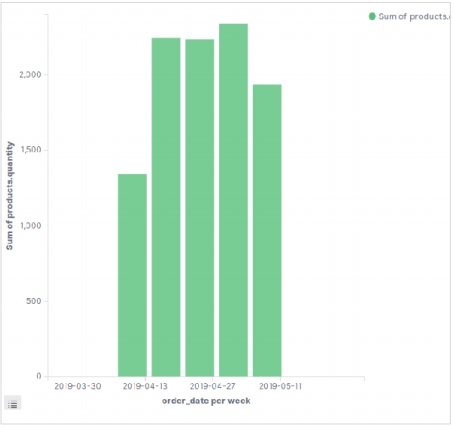
Chuỗi thời gian là biểu diễn chuỗi dữ liệu trong một chuỗi thời gian cụ thể. Ví dụ: dữ liệu cho mỗi ngày bắt đầu từ ngày đầu tiên của tháng đến ngày cuối cùng. Khoảng thời gian giữa các điểm dữ liệu không đổi. Bất kỳ tập dữ liệu nào có thành phần thời gian trong đó đều có thể được biểu diễn dưới dạng chuỗi thời gian.
Trong chương này, chúng tôi sẽ sử dụng tập dữ liệu thương mại điện tử mẫu và vẽ biểu đồ đếm số lượng đơn đặt hàng cho mỗi ngày để tạo chuỗi thời gian.
Chọn số liệu
Đầu tiên, chúng tôi chọn mẫu chỉ mục, trường dữ liệu và khoảng thời gian sẽ được sử dụng để tạo chuỗi thời gian. Từ tập dữ liệu thương mại điện tử mẫu, chúng tôi chọn order_date làm trường và 1d làm khoảng thời gian. Chúng tôi sử dụngPanel Optionsđể thực hiện các lựa chọn này. Ngoài ra, chúng tôi để các giá trị khác trong tab này làm mặc định để lấy màu và định dạng mặc định cho chuỗi thời gian.
bên trong Data , chúng tôi chọn tính là tùy chọn tổng hợp, nhóm theo tùy chọn làm mọi thứ và đặt nhãn cho biểu đồ chuỗi thời gian.
Kết quả
Kết quả cuối cùng của cấu hình này xuất hiện như sau. Xin lưu ý rằng chúng tôi đang sử dụng khoảng thời gianMonth to Datecho đồ thị này. Khoảng thời gian khác nhau sẽ cho kết quả khác nhau.
Một đám mây thẻ đại diện cho văn bản, chủ yếu là từ khóa và siêu dữ liệu ở dạng trực quan hấp dẫn. Chúng được căn chỉnh theo các góc độ khác nhau và được thể hiện bằng các màu sắc và cỡ chữ khác nhau. Nó giúp tìm ra các thuật ngữ nổi bật nhất trong dữ liệu. Mức độ nổi bật có thể được quyết định bởi một hoặc nhiều yếu tố như tần suất của cụm từ, tính duy nhất của thẻ hoặc dựa trên một số trọng số gắn với các cụm từ cụ thể, v.v. Dưới đây, chúng tôi xem các bước để tạo Đám mây thẻ.
Hình dung
Trong Màn hình chính của Kibana, chúng tôi tìm thấy tên tùy chọn Visualize cho phép chúng tôi tạo trực quan hóa và tổng hợp từ các chỉ số được lưu trữ trong Elasticsearch. Chúng tôi chọn thêm hình ảnh trực quan mới và chọn Đám mây thẻ như tùy chọn được hiển thị bên dưới -
Chọn các chỉ số
Màn hình tiếp theo nhắc chúng tôi chọn các chỉ số sẽ được sử dụng để tạo Đám mây thẻ. Ở đây chúng tôi chọn số lượng làm loại chỉ số tổng hợp. Sau đó, chúng tôi chọn trường tên sản phẩm làm từ khóa được sử dụng làm thẻ.
Kết quả hiển thị ở đây cho thấy biểu đồ hình tròn sau khi chúng tôi áp dụng lựa chọn. Vui lòng lưu ý các sắc thái của màu và giá trị của chúng được đề cập trong nhãn.

Tag Cloud Options
Đang chuyển đến optionstrong Tag Cloud, chúng ta có thể thấy các tùy chọn cấu hình khác nhau để thay đổi giao diện cũng như cách sắp xếp hiển thị dữ liệu trong Tag Cloud. Trong ví dụ dưới đây, Đám mây thẻ xuất hiện với các thẻ nằm dọc theo cả chiều ngang và chiều dọc.
Bản đồ nhiệt là một loại trực quan trong đó các sắc thái màu khác nhau thể hiện các khu vực khác nhau trong biểu đồ. Các giá trị có thể liên tục thay đổi và do đó r màu của một màu thay đổi theo các giá trị. Chúng rất hữu ích để thể hiện cả dữ liệu thay đổi liên tục cũng như dữ liệu rời rạc.
Trong chương này, chúng ta sẽ sử dụng tập dữ liệu có tên là sample_data_flights để xây dựng biểu đồ bản đồ nhiệt. Trong đó, chúng tôi xem xét các biến có tên quốc gia xuất phát và quốc gia đích của các chuyến bay và tính toán.
Trong Màn hình chính của Kibana, chúng tôi tìm thấy tên tùy chọn Visualize cho phép chúng tôi tạo trực quan hóa và tổng hợp từ các chỉ số được lưu trữ trong Elasticsearch. Chúng tôi chọn thêm hình ảnh trực quan mới và chọn Bản đồ nhiệt như tùy chọn được hiển thị bên dưới & mimus;
Chọn các chỉ số
Màn hình tiếp theo nhắc chúng tôi chọn các chỉ số sẽ được sử dụng để tạo Biểu đồ Bản đồ Nhiệt. Ở đây chúng tôi chọn số lượng làm loại chỉ số tổng hợp. Sau đó, đối với các nhóm trong Y-Axis, chúng tôi chọn Điều khoản làm tập hợp cho trường OriginCountry. Đối với Trục X, chúng tôi chọn cùng một tập hợp nhưng DestCountry làm trường được sử dụng. Trong cả hai trường hợp, chúng tôi chọn kích thước của thùng là 5.

Khi chạy cấu hình hiển thị ở trên, chúng tôi nhận được biểu đồ bản đồ nhiệt được tạo ra như sau.
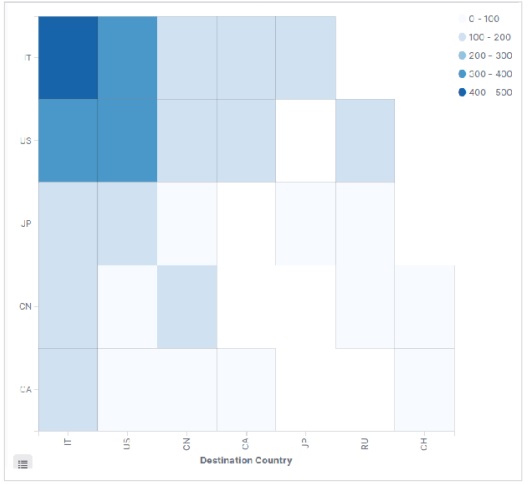
Note - Bạn phải cho phép phạm vi ngày là Năm nay để biểu đồ thu thập dữ liệu trong một năm để tạo ra biểu đồ nhiệt hiệu quả.
Ứng dụng Canvas là một phần của Kibana, cho phép chúng tôi tạo hiển thị dữ liệu động, nhiều trang và pixel hoàn hảo. Khả năng tạo đồ họa thông tin chứ không chỉ biểu đồ và số liệu là điều khiến nó trở nên độc đáo và hấp dẫn. Trong chương này, chúng ta sẽ thấy các tính năng khác nhau của canvas và cách sử dụng các tấm làm việc canvas.
Mở Canvas
Truy cập trang chủ Kibana và chọn tùy chọn như trong sơ đồ bên dưới. Nó mở ra danh sách các miếng đệm làm việc canvas mà bạn có. Chúng tôi chọn theo dõi Doanh thu từ thương mại điện tử cho nghiên cứu của mình.
Nhân bản một Workpad
Chúng tôi sao chép [eCommerce] Revenue Trackingbàn làm việc sẽ được sử dụng trong nghiên cứu của chúng tôi. Để sao chép nó, chúng tôi đánh dấu hàng có tên của bàn làm việc này và sau đó sử dụng nút sao chép như thể hiện trong sơ đồ bên dưới -
Theo kết quả của bản sao ở trên, chúng ta sẽ nhận được một bảng công việc mới có tên là [eCommerce] Revenue Tracking – Copy khi mở sẽ hiển thị đồ họa thông tin bên dưới.
Nó mô tả tổng doanh số và Doanh thu theo danh mục cùng với hình ảnh và biểu đồ đẹp mắt.
Sửa đổi Workpad
Chúng ta có thể thay đổi kiểu và số liệu trong bảng làm việc bằng cách sử dụng các tùy chọn có sẵn trong tab bên tay phải. Ở đây chúng tôi mong muốn thay đổi màu nền của bàn làm việc bằng cách chọn một màu khác như thể hiện trong sơ đồ bên dưới. Lựa chọn màu có hiệu lực ngay lập tức và chúng ta nhận được kết quả như hình dưới đây -

Kibana cũng có thể giúp trực quan hóa dữ liệu nhật ký từ nhiều nguồn khác nhau. Nhật ký là nguồn phân tích quan trọng về tình trạng cơ sở hạ tầng, nhu cầu hiệu suất và phân tích vi phạm bảo mật, v.v. Kibana có thể kết nối với các nhật ký khác nhau như nhật ký máy chủ web, nhật ký tìm kiếm đàn hồi và nhật ký đồng hồ đám mây, v.v.
Nhật ký Logstash
Trong Kibana, chúng ta có thể kết nối với nhật ký logstash để trực quan hóa. Đầu tiên, chúng tôi chọn nút Nhật ký từ màn hình chính của Kibana như hình dưới đây -
Sau đó, chúng tôi chọn tùy chọn Thay đổi cấu hình nguồn mang đến cho chúng tôi tùy chọn chọn Logstash làm nguồn. Màn hình bên dưới cũng hiển thị các loại tùy chọn khác mà chúng tôi có làm nguồn nhật ký.
Bạn có thể phát trực tuyến dữ liệu để theo dõi nhật ký trực tiếp hoặc tạm dừng phát trực tuyến để tập trung vào dữ liệu nhật ký lịch sử. Khi bạn đang phát trực tuyến nhật ký, nhật ký gần đây nhất sẽ xuất hiện ở cuối bảng điều khiển.
Để tham khảo thêm, bạn có thể tham khảo hướng dẫn Logstash của chúng tôi .