Lập trình chức năng - Hướng dẫn nhanh
Các ngôn ngữ lập trình hàm được thiết kế đặc biệt để xử lý các ứng dụng tính toán biểu tượng và xử lý danh sách. Lập trình hàm dựa trên các hàm toán học. Một số ngôn ngữ lập trình chức năng phổ biến bao gồm: Lisp, Python, Erlang, Haskell, Clojure, v.v.
Các ngôn ngữ lập trình hàm được phân loại thành hai nhóm, tức là -
Pure Functional Languages- Các loại ngôn ngữ chức năng này chỉ hỗ trợ các mô hình chức năng. Ví dụ - Haskell.
Impure Functional Languages- Các loại ngôn ngữ chức năng này hỗ trợ các mô hình chức năng và lập trình kiểu mệnh lệnh. Ví dụ - LISP.
Lập trình chức năng - Đặc điểm
Các đặc điểm nổi bật nhất của lập trình hàm như sau:
Các ngôn ngữ lập trình hàm được thiết kế dựa trên khái niệm về các hàm toán học sử dụng các biểu thức điều kiện và đệ quy để thực hiện tính toán.
Hỗ trợ lập trình chức năng higher-order functions và lazy evaluation đặc trưng.
Các ngôn ngữ lập trình hàm không hỗ trợ Điều khiển luồng như câu lệnh lặp và câu lệnh điều kiện như Câu lệnh If-Else và Câu lệnh chuyển đổi. Họ trực tiếp sử dụng các chức năng và lời gọi chức năng.
Giống như OOP, các ngôn ngữ lập trình chức năng hỗ trợ các khái niệm phổ biến như Trừu tượng hóa, Đóng gói, Kế thừa và Đa hình.
Lập trình chức năng - Ưu điểm
Lập trình hàm cung cấp những ưu điểm sau:
Bugs-Free Code - Lập trình chức năng không hỗ trợ state, vì vậy không có kết quả tác dụng phụ và chúng tôi có thể viết mã không có lỗi.
Efficient Parallel Programming- Các ngôn ngữ lập trình hàm KHÔNG có trạng thái có thể thay đổi, vì vậy không có vấn đề thay đổi trạng thái. Người ta có thể lập trình "Functions" hoạt động song song như "hướng dẫn". Những mã như vậy hỗ trợ khả năng tái sử dụng và kiểm tra dễ dàng.
Efficiency- Các chương trình chức năng bao gồm các đơn vị độc lập có thể chạy đồng thời. Kết quả là, các chương trình như vậy hiệu quả hơn.
Supports Nested Functions - Lập trình chức năng hỗ trợ Chức năng lồng nhau.
Lazy Evaluation - Lập trình chức năng hỗ trợ các cấu trúc chức năng lười biếng như Lazy Lists, Lazy Maps, v.v.
Một nhược điểm là lập trình chức năng yêu cầu không gian bộ nhớ lớn. Vì nó không có trạng thái, bạn cần tạo các đối tượng mới mỗi lần để thực hiện các hành động.
Lập trình Chức năng được sử dụng trong các tình huống mà chúng ta phải thực hiện nhiều thao tác khác nhau trên cùng một tập dữ liệu.
Lisp được sử dụng cho các ứng dụng trí tuệ nhân tạo như Máy học, xử lý ngôn ngữ, Lập mô hình giọng nói và thị giác, v.v.
Trình thông dịch Lisp được nhúng bổ sung khả năng lập trình cho một số hệ thống như Emacs.
Lập trình chức năng so với Lập trình hướng đối tượng
Bảng sau đây nêu rõ những điểm khác biệt chính giữa lập trình hàm và lập trình hướng đối tượng:
| Lập trình chức năng | OOP |
|---|---|
| Sử dụng dữ liệu bất biến. | Sử dụng dữ liệu có thể thay đổi. |
| Tuân theo Mô hình Lập trình Khai báo. | Tuân theo mô hình lập trình mệnh lệnh. |
| Tập trung vào: "Bạn đang làm gì" | Tập trung vào "Bạn đang làm như thế nào" |
| Hỗ trợ lập trình song song | Không thích hợp cho lập trình song song |
| Các chức năng của nó không có tác dụng phụ | Các phương pháp của nó có thể tạo ra các tác dụng phụ nghiêm trọng. |
| Kiểm soát luồng được thực hiện bằng cách sử dụng các lệnh gọi hàm & lệnh gọi hàm với đệ quy | Điều khiển luồng được thực hiện bằng cách sử dụng vòng lặp và câu lệnh điều kiện. |
| Nó sử dụng khái niệm "Đệ quy" để lặp lại Dữ liệu Bộ sưu tập. | Nó sử dụng khái niệm "Vòng lặp" để lặp lại Dữ liệu Bộ sưu tập. Ví dụ: For-each loop trong Java |
| Thứ tự thực hiện các câu lệnh không quá quan trọng. | Thứ tự thực hiện các câu lệnh là rất quan trọng. |
| Hỗ trợ cả "Trừu tượng trên dữ liệu" và "Trừu tượng trên hành vi". | Chỉ hỗ trợ "Tóm tắt trên dữ liệu". |
Hiệu quả của mã chương trình
Hiệu quả của mã lập trình tỷ lệ thuận với hiệu quả thuật toán và tốc độ thực thi. Hiệu quả tốt đảm bảo hiệu suất cao hơn.
Các yếu tố ảnh hưởng đến hiệu quả của một chương trình bao gồm:
- Tốc độ của máy
- Tốc độ biên dịch
- Hệ điều hành
- Chọn ngôn ngữ lập trình phù hợp
- Cách sắp xếp dữ liệu trong chương trình
- Thuật toán được sử dụng để giải quyết vấn đề
Hiệu quả của một ngôn ngữ lập trình có thể được cải thiện bằng cách thực hiện các tác vụ sau:
Bằng cách loại bỏ mã không cần thiết hoặc mã được xử lý dư thừa.
Bằng cách sử dụng bộ nhớ tối ưu và bộ nhớ không linh hoạt
Bằng cách sử dụng các thành phần có thể tái sử dụng nếu có.
Bằng cách sử dụng xử lý lỗi và ngoại lệ ở tất cả các lớp của chương trình.
Bằng cách tạo mã lập trình đảm bảo tính toàn vẹn và nhất quán của dữ liệu.
Bằng cách phát triển mã chương trình tuân thủ logic và luồng thiết kế.
Một mã lập trình hiệu quả có thể giảm tiêu thụ tài nguyên và thời gian hoàn thành nhiều nhất có thể với rủi ro tối thiểu đối với môi trường hoạt động.
Theo thuật ngữ lập trình, a functionlà một khối các câu lệnh thực hiện một nhiệm vụ cụ thể. Các hàm chấp nhận dữ liệu, xử lý nó và trả về một kết quả. Các hàm được viết chủ yếu để hỗ trợ khái niệm khả năng tái sử dụng. Khi một hàm được viết, nó có thể được gọi một cách dễ dàng mà không cần phải viết lại cùng một đoạn mã.
Các ngôn ngữ hàm khác nhau sử dụng cú pháp khác nhau để viết một hàm.
Điều kiện tiên quyết để viết một hàm
Trước khi viết một hàm, một lập trình viên phải biết những điểm sau:
Mục đích của chức năng phải được lập trình viên biết.
Lập trình viên phải biết thuật toán của hàm.
Các biến dữ liệu hàm và mục tiêu của chúng phải được lập trình viên biết.
Dữ liệu của hàm phải được lập trình viên biết và được người dùng gọi.
Kiểm soát luồng của một chức năng
Khi một hàm được "gọi", chương trình "chuyển" điều khiển để thực thi chức năng và "luồng điều khiển" của nó như sau:
Chương trình đến câu lệnh có chứa "hàm gọi".
Dòng đầu tiên bên trong hàm được thực thi.
Tất cả các câu lệnh bên trong hàm được thực thi từ trên xuống dưới.
Khi hàm được thực thi thành công, điều khiển quay trở lại câu lệnh bắt đầu từ đâu.
Mọi dữ liệu được hàm tính toán và trả về đều được sử dụng thay cho hàm trong dòng mã gốc.
Cú pháp của một hàm
Cú pháp chung của một hàm trông như sau:
returnType functionName(type1 argument1, type2 argument2, . . . ) {
// function body
}Định nghĩa một hàm trong C ++
Hãy lấy một ví dụ để hiểu cách một hàm có thể được định nghĩa trong C ++, một ngôn ngữ lập trình hướng đối tượng. Đoạn mã sau có một hàm thêm hai số và cung cấp kết quả của nó dưới dạng đầu ra.
#include <stdio.h>
int addNum(int a, int b); // function prototype
int main() {
int sum;
sum = addNum(5,6); // function call
printf("sum = %d",sum);
return 0;
}
int addNum (int a,int b) { // function definition
int result;
result = a + b;
return result; // return statement
}Nó sẽ tạo ra kết quả sau:
Sum = 11Định nghĩa một hàm trong Erlang
Hãy xem cách định nghĩa hàm tương tự trong Erlang, một ngôn ngữ lập trình hàm.
-module(helloworld).
-export([add/2,start/0]).
add(A,B) ->
C = A + B,
io:fwrite("~w~n",[C]).
start() ->
add(5,6).Nó sẽ tạo ra kết quả sau:
11Nguyên mẫu hàm
Nguyên mẫu hàm là một khai báo của hàm bao gồm kiểu trả về, tên hàm & danh sách đối số. Nó tương tự như định nghĩa hàm mà không có hàm-body.
For Example - Một số ngôn ngữ lập trình hỗ trợ tạo mẫu hàm và một số thì không.
Trong C ++, chúng ta có thể tạo nguyên mẫu hàm của hàm 'sum' như thế này:
int sum(int a, int b)Note - Các ngôn ngữ lập trình như Python, Erlang, v.v. không hỗ trợ tạo mẫu hàm, chúng ta cần khai báo hàm hoàn chỉnh.
Việc sử dụng nguyên mẫu hàm là gì?
Nguyên mẫu hàm được trình biên dịch sử dụng khi hàm được gọi. Trình biên dịch sử dụng nó để đảm bảo kiểu trả về chính xác, danh sách đối số thích hợp được chuyển vào và kiểu trả về của chúng là chính xác.
Chữ ký chức năng
Chữ ký hàm tương tự như nguyên mẫu hàm trong đó số lượng tham số, kiểu dữ liệu của tham số và thứ tự xuất hiện phải theo thứ tự tương tự. Ví dụ -
void Sum(int a, int b, int c); // function 1
void Sum(float a, float b, float c); // function 2
void Sum(float a, float b, float c); // function 3Function1 và Function2 có các chữ ký khác nhau. Function2 và Function3 có cùng chữ ký.
Note - Nạp chồng hàm và ghi đè hàm mà chúng ta sẽ thảo luận trong các chương tiếp theo dựa trên khái niệm về chữ ký hàm.
Quá tải hàm có thể xảy ra khi một lớp có nhiều hàm có cùng tên nhưng khác chữ ký.
Có thể ghi đè hàm khi một hàm lớp dẫn xuất có cùng tên và chữ ký với lớp cơ sở của nó.
Các chức năng có hai loại -
- Các chức năng được xác định trước
- Các chức năng do người dùng xác định
Trong chương này, chúng ta sẽ thảo luận chi tiết về các hàm.
Chức năng được xác định trước
Đây là những hàm được tích hợp sẵn trong Ngôn ngữ để thực hiện các thao tác & được lưu trữ trong Thư viện Hàm Chuẩn.
For Example - 'Strcat' trong C ++ & 'concat' trong Haskell được sử dụng để nối hai chuỗi, 'strlen' trong C ++ & 'len' trong Python được sử dụng để tính độ dài chuỗi.
Chương trình in độ dài chuỗi trong C ++
Chương trình sau đây cho thấy cách bạn có thể in độ dài của một chuỗi bằng C ++:
#include <iostream>
#include <string.h>
#include <stdio.h>
using namespace std;
int main() {
char str[20] = "Hello World";
int len;
len = strlen(str);
cout<<"String length is: "<<len;
return 0;
}Nó sẽ tạo ra kết quả sau:
String length is: 11Chương trình in độ dài chuỗi bằng Python
Chương trình sau đây cho thấy cách in độ dài của một chuỗi bằng Python, là một ngôn ngữ lập trình hàm:
str = "Hello World";
print("String length is: ", len(str))Nó sẽ tạo ra kết quả sau:
('String length is: ', 11)Chức năng do người dùng xác định
Các chức năng do người dùng định nghĩa được xác định bởi người dùng để thực hiện các tác vụ cụ thể. Có bốn mẫu khác nhau để xác định một hàm -
- Các hàm không có đối số và không có giá trị trả về
- Các hàm không có đối số nhưng có giá trị trả về
- Các hàm có đối số nhưng không có giá trị trả về
- Các hàm có đối số và giá trị trả về
Các hàm không có đối số và không có giá trị trả về
Chương trình sau đây chỉ ra cách xác định một hàm không có đối số và không có giá trị trả về trong C++ -
#include <iostream>
using namespace std;
void function1() {
cout <<"Hello World";
}
int main() {
function1();
return 0;
}Nó sẽ tạo ra kết quả sau:
Hello WorldChương trình sau đây cho thấy cách bạn có thể xác định một hàm tương tự (không có đối số và không có giá trị trả về) trong Python -
def function1():
print ("Hello World")
function1()Nó sẽ tạo ra kết quả sau:
Hello WorldCác hàm không có đối số nhưng có giá trị trả về
Chương trình sau đây chỉ ra cách xác định một hàm không có đối số nhưng có giá trị trả về trong C++ -
#include <iostream>
using namespace std;
string function1() {
return("Hello World");
}
int main() {
cout<<function1();
return 0;
}Nó sẽ tạo ra kết quả sau:
Hello WorldChương trình sau đây cho thấy cách bạn có thể xác định một hàm tương tự (không có đối số nhưng có giá trị trả về) trong Python -
def function1():
return "Hello World"
res = function1()
print(res)Nó sẽ tạo ra kết quả sau:
Hello WorldCác hàm có đối số nhưng không có giá trị trả về
Chương trình sau đây chỉ ra cách xác định một hàm có đối số nhưng không có giá trị trả về trong C++ -
#include <iostream>
using namespace std;
void function1(int x, int y) {
int c;
c = x+y;
cout<<"Sum is: "<<c;
}
int main() {
function1(4,5);
return 0;
}Nó sẽ tạo ra kết quả sau:
Sum is: 9Chương trình sau đây cho thấy cách bạn có thể xác định một hàm tương tự trong Python -
def function1(x,y):
c = x + y
print("Sum is:",c)
function1(4,5)Nó sẽ tạo ra kết quả sau:
('Sum is:', 9)Các hàm có đối số và giá trị trả về
Chương trình sau đây chỉ ra cách xác định một hàm trong C ++ không có đối số nhưng có giá trị trả về:
#include <iostream>
using namespace std;
int function1(int x, int y) {
int c;
c = x + y;
return c;
}
int main() {
int res;
res = function1(4,5);
cout<<"Sum is: "<<res;
return 0;
}Nó sẽ tạo ra kết quả sau:
Sum is: 9Chương trình sau đây trình bày cách xác định một hàm tương tự (với đối số và giá trị trả về) trong Python -
def function1(x,y):
c = x + y
return c
res = function1(4,5)
print("Sum is ",res)Nó sẽ tạo ra kết quả sau:
('Sum is ', 9)Sau khi xác định một hàm, chúng ta cần chuyển các đối số vào nó để có được kết quả mong muốn. Hầu hết các ngôn ngữ lập trình đều hỗ trợcall by value và call by reference các phương thức truyền đối số vào hàm.
Trong chương này, chúng ta sẽ tìm hiểu "call by value" hoạt động trong ngôn ngữ lập trình hướng đối tượng như C ++ và ngôn ngữ lập trình chức năng như Python.
Trong phương pháp Gọi theo giá trị, original value cannot be changed. Khi chúng ta truyền một đối số cho một hàm, nó sẽ được lưu trữ cục bộ bởi tham số hàm trong bộ nhớ ngăn xếp. Do đó, các giá trị chỉ được thay đổi bên trong hàm và nó sẽ không có tác dụng bên ngoài hàm.
Gọi theo giá trị trong C ++
Chương trình sau đây cho thấy cách Call by Value hoạt động trong C ++:
#include <iostream>
using namespace std;
void swap(int a, int b) {
int temp;
temp = a;
a = b;
b = temp;
cout<<"\n"<<"value of a inside the function: "<<a;
cout<<"\n"<<"value of b inside the function: "<<b;
}
int main() {
int a = 50, b = 70;
cout<<"value of a before sending to function: "<<a;
cout<<"\n"<<"value of b before sending to function: "<<b;
swap(a, b); // passing value to function
cout<<"\n"<<"value of a after sending to function: "<<a;
cout<<"\n"<<"value of b after sending to function: "<<b;
return 0;
}Nó sẽ tạo ra kết quả sau:
value of a before sending to function: 50
value of b before sending to function: 70
value of a inside the function: 70
value of b inside the function: 50
value of a after sending to function: 50
value of b after sending to function: 70Gọi theo giá trị trong Python
Chương trình sau đây cho thấy cách Call by Value hoạt động trong Python:
def swap(a,b):
t = a;
a = b;
b = t;
print "value of a inside the function: :",a
print "value of b inside the function: ",b
# Now we can call the swap function
a = 50
b = 75
print "value of a before sending to function: ",a
print "value of b before sending to function: ",b
swap(a,b)
print "value of a after sending to function: ", a
print "value of b after sending to function: ",bNó sẽ tạo ra kết quả sau:
value of a before sending to function: 50
value of b before sending to function: 75
value of a inside the function: : 75
value of b inside the function: 50
value of a after sending to function: 50
value of b after sending to function: 75Trong Cuộc gọi bằng Tham chiếu, original value is changedbởi vì chúng tôi chuyển địa chỉ tham chiếu của các đối số. Các đối số thực tế và chính thức chia sẻ cùng một không gian địa chỉ, vì vậy bất kỳ sự thay đổi giá trị nào bên trong hàm đều được phản ánh bên trong cũng như bên ngoài hàm.
Gọi bằng tham chiếu trong C ++
Chương trình sau đây cho thấy cách Call by Value hoạt động trong C ++:
#include <iostream>
using namespace std;
void swap(int *a, int *b) {
int temp;
temp = *a;
*a = *b;
*b = temp;
cout<<"\n"<<"value of a inside the function: "<<*a;
cout<<"\n"<<"value of b inside the function: "<<*b;
}
int main() {
int a = 50, b = 75;
cout<<"\n"<<"value of a before sending to function: "<<a;
cout<<"\n"<<"value of b before sending to function: "<<b;
swap(&a, &b); // passing value to function
cout<<"\n"<<"value of a after sending to function: "<<a;
cout<<"\n"<<"value of b after sending to function: "<<b;
return 0;
}Nó sẽ tạo ra kết quả sau:
value of a before sending to function: 50
value of b before sending to function: 75
value of a inside the function: 75
value of b inside the function: 50
value of a after sending to function: 75
value of b after sending to function: 50Gọi bằng tham chiếu trong Python
Chương trình sau đây cho thấy cách Call by Value hoạt động trong Python:
def swap(a,b):
t = a;
a = b;
b = t;
print "value of a inside the function: :",a
print "value of b inside the function: ",b
return(a,b)
# Now we can call swap function
a = 50
b =75
print "value of a before sending to function: ",a
print "value of b before sending to function: ",b
x = swap(a,b)
print "value of a after sending to function: ", x[0]
print "value of b after sending to function: ",x[1]Nó sẽ tạo ra kết quả sau:
value of a before sending to function: 50
value of b before sending to function: 75
value of a inside the function: 75
value of b inside the function: 50
value of a after sending to function: 75
value of b after sending to function: 50Khi chúng ta có nhiều hàm có cùng tên nhưng khác tham số, thì chúng được cho là quá tải. Kỹ thuật này được sử dụng để nâng cao khả năng đọc của chương trình.
Có hai cách để nạp chồng một hàm, tức là -
- Có số lượng đối số khác nhau
- Có các loại đối số khác nhau
Nạp chồng hàm thường được thực hiện khi chúng ta phải thực hiện một thao tác đơn lẻ với số lượng hoặc kiểu đối số khác nhau.
Nạp chồng hàm trong C ++
Ví dụ sau đây cho thấy cách thực hiện nạp chồng hàm trong C ++, một ngôn ngữ lập trình hướng đối tượng:
#include <iostream>
using namespace std;
void addnum(int,int);
void addnum(int,int,int);
int main() {
addnum (5,5);
addnum (5,2,8);
return 0;
}
void addnum (int x, int y) {
cout<<"Integer number: "<<x+y<<endl;
}
void addnum (int x, int y, int z) {
cout<<"Float number: "<<x+y+z<<endl;
}Nó sẽ tạo ra kết quả sau:
Integer number: 10
Float number: 15Nạp chồng hàm trong Erlang
Ví dụ sau đây cho thấy cách thực hiện nạp chồng hàm trong Erlang, là một ngôn ngữ lập trình hàm:
-module(helloworld).
-export([addnum/2,addnum/3,start/0]).
addnum(X,Y) ->
Z = X+Y,
io:fwrite("~w~n",[Z]).
addnum(X,Y,Z) ->
A = X+Y+Z,
io:fwrite("~w~n",[A]).
start() ->
addnum(5,5), addnum(5,2,8).Nó sẽ tạo ra kết quả sau:
10
15Khi lớp cơ sở và lớp dẫn xuất có các hàm thành viên có cùng tên, cùng kiểu trả về và danh sách đối số giống nhau, thì nó được cho là ghi đè hàm.
Ghi đè hàm bằng C ++
Ví dụ sau đây cho thấy cách ghi đè hàm được thực hiện trong C ++, một ngôn ngữ lập trình hướng đối tượng -
#include <iostream>
using namespace std;
class A {
public:
void display() {
cout<<"Base class";
}
};
class B:public A {
public:
void display() {
cout<<"Derived Class";
}
};
int main() {
B obj;
obj.display();
return 0;
}Nó sẽ tạo ra kết quả sau
Derived ClassGhi đè hàm bằng Python
Ví dụ sau đây cho thấy cách thực hiện ghi đè hàm trong Python, là một ngôn ngữ lập trình hàm:
class A(object):
def disp(self):
print "Base Class"
class B(A):
def disp(self):
print "Derived Class"
x = A()
y = B()
x.disp()
y.disp()Nó sẽ tạo ra kết quả sau:
Base Class
Derived ClassMột hàm gọi chính nó được gọi là một hàm đệ quy và kỹ thuật này được gọi là đệ quy. Một lệnh đệ quy tiếp tục cho đến khi một lệnh khác ngăn cản nó.
Đệ quy trong C ++
Ví dụ sau cho thấy cách hoạt động của đệ quy trong C ++, một ngôn ngữ lập trình hướng đối tượng -
#include <stdio.h>
long int fact(int n);
int main() {
int n;
printf("Enter a positive integer: ");
scanf("%d", &n);
printf("Factorial of %d = %ld", n, fact(n));
return 0;
}
long int fact(int n) {
if (n >= 1)
return n*fact(n-1);
else
return 1;
}Nó sẽ tạo ra kết quả sau
Enter a positive integer: 5
Factorial of 5 = 120Đệ quy trong Python
Ví dụ sau cho thấy cách hoạt động của đệ quy trong Python, là một ngôn ngữ lập trình hàm:
def fact(n):
if n == 1:
return n
else:
return n* fact (n-1)
# accepts input from user
num = int(input("Enter a number: "))
# check whether number is positive or not
if num < 0:
print("Sorry, factorial does not exist for negative numbers")
else:
print("The factorial of " + str(num) + " is " + str(fact(num)))Nó sẽ tạo ra kết quả sau:
Enter a number: 6
The factorial of 6 is 720Hàm bậc cao hơn (HOF) là một hàm tuân theo ít nhất một trong các điều kiện sau:
- Sử dụng hoặc nhiều chức năng làm đối số
- Trả về một hàm dưới dạng kết quả của nó
HOF bằng PHP
Ví dụ sau đây cho thấy cách viết một hàm bậc cao hơn trong PHP, là một ngôn ngữ lập trình hướng đối tượng:
<?php
$twice = function($f, $v) { return $f($f($v));
};
$f = function($v) {
return $v + 3; }; echo($twice($f, 7));Nó sẽ tạo ra kết quả sau:
13HOF bằng Python
Ví dụ sau đây cho thấy cách viết một hàm bậc cao hơn trong Python, là một ngôn ngữ lập trình hướng đối tượng:
def twice(function):
return lambda x: function(function(x))
def f(x):
return x + 3
g = twice(f)
print g(7)Nó sẽ tạo ra kết quả sau:
13Kiểu dữ liệu xác định kiểu giá trị mà một đối tượng có thể có và những thao tác nào có thể được thực hiện trên nó. Một kiểu dữ liệu nên được khai báo trước khi được sử dụng. Các ngôn ngữ lập trình khác nhau hỗ trợ các kiểu dữ liệu khác nhau. Ví dụ,
- C hỗ trợ char, int, float, long, v.v.
- Python hỗ trợ Chuỗi, Danh sách, Tuple, v.v.
Theo nghĩa rộng, có ba loại kiểu dữ liệu -
Fundamental data types- Đây là các kiểu dữ liệu được xác định trước được người lập trình sử dụng trực tiếp để lưu trữ chỉ một giá trị theo yêu cầu, tức là kiểu số nguyên, kiểu ký tự hoặc kiểu động. Ví dụ - int, char, float, v.v.
Derived data types- Các kiểu dữ liệu này được tạo ra bằng cách sử dụng kiểu dữ liệu tích hợp được lập trình viên thiết kế để lưu trữ nhiều giá trị cùng kiểu theo yêu cầu của chúng. Ví dụ - Mảng, Con trỏ, hàm, danh sách, v.v.
User-defined data types- Các kiểu dữ liệu này được tạo ra bằng cách sử dụng các kiểu dữ liệu tích hợp được bao bọc thành một kiểu dữ liệu duy nhất để lưu trữ nhiều giá trị cùng loại hoặc khác kiểu hoặc cả hai theo yêu cầu. Ví dụ - Lớp, Cấu trúc, v.v.
Các kiểu dữ liệu được hỗ trợ bởi C ++
Bảng sau liệt kê các kiểu dữ liệu được hỗ trợ bởi C ++:
| Loại dữ liệu | Kích thước | Phạm vi |
|---|---|---|
| char | 1 byte | -128 đến 127 hoặc 0 đến 255 |
| ký tự không dấu | 1 byte | 0 đến 255 |
| ký char | 1 byte | -128 đến 127 |
| int | 4 byte | -2147483648 đến 2147483647 |
| int không dấu | 4 byte | 0 đến 4294967295 |
| int đã ký | 4 byte | -2147483648 đến 2147483647 |
| int ngắn | 2 byte | -32768 đến 32767 |
| int ngắn không dấu | 2 byte | 0 đến 65,535 |
| ký ngắn int | 2 byte | -32768 đến 32767 |
| int dài | 4 byte | -2.147.483.648 đến 2.147.483.647 |
| ký dài hạn | 4 byte | -2.147.483.648 đến 2.147.483.647 |
| int dài unsigned | 4 byte | 0 đến 4,294,967,295 |
| Phao nổi | 4 byte | +/- 3.4e +/- 38 (~ 7 chữ số) |
| gấp đôi | 8 byte | +/- 1.7e +/- 308 (~ 15 chữ số) |
| dài đôi | 8 byte | +/- 1.7e +/- 308 (~ 15 chữ số) |
Các kiểu dữ liệu được Java hỗ trợ
Các kiểu dữ liệu sau được Java hỗ trợ:
| Loại dữ liệu | Kích thước | Phạm vi |
|---|---|---|
| byte | 1 byte | -128 đến 127 |
| char | 2 byte | 0 đến 65,536 |
| ngắn | 2 byte | -32,7688 đến 32,767 |
| int | 4 byte | -2.147.483.648 đến 2.147.483.647 |
| Dài | 8 byte | -9,223,372,036,854,775,808 đến 9,223,372,036,854,775,807 |
| Phao nổi | 4 byte | -2147483648 đến 2147483647 |
| gấp đôi | 8 byte | + 9.223 * 1018 |
| Boolean | 1 chút | Đúng hay sai |
Các loại dữ liệu được hỗ trợ bởi Erlang
Trong phần này, chúng ta sẽ thảo luận về các kiểu dữ liệu được hỗ trợ bởi Erlang, một ngôn ngữ lập trình chức năng.
Con số
Erlang hỗ trợ hai loại chữ số, tức là integer và float. Hãy xem ví dụ sau đây cho thấy cách thêm hai giá trị số nguyên:
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[5+4]).Nó sẽ tạo ra sản lượng sau:
9Atom
An atomlà một chuỗi có giá trị không thể thay đổi. Nó phải bắt đầu bằng một chữ cái thường và có thể chứa bất kỳ ký tự chữ và số và ký tự đặc biệt nào. Khi một nguyên tử chứa các ký tự đặc biệt, thì nó phải được đặt bên trong dấu nháy đơn ('). Hãy xem ví dụ sau để hiểu rõ hơn.
-module(helloworld).
-export([start/0]).
start()->
io:fwrite(monday).Nó sẽ tạo ra kết quả sau:
mondayNote- Hãy thử thay đổi nguyên tử thành "Thứ hai" với chữ "M" viết hoa. Chương trình sẽ tạo ra một lỗi.
Boolean
Kiểu dữ liệu này được sử dụng để hiển thị kết quả true hoặc là false. Hãy xem ví dụ sau. Nó chỉ ra cách so sánh hai số nguyên.
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite(5 =< 9).Nó sẽ tạo ra kết quả sau:
trueChuỗi bit
Một chuỗi bit được sử dụng để lưu trữ một vùng của bộ nhớ chưa được nhập. Hãy xem ví dụ sau. Nó chỉ ra cách chuyển 2 bit của một chuỗi bit thành một danh sách.
-module(helloworld).
-export([start/0]).
start() ->
Bin2 = <<15,25>>,
P = binary_to_list(Bin2),
io:fwrite("~w",[P]).Nó sẽ tạo ra kết quả sau:
[15,25]Tuple
Tuple là một kiểu dữ liệu phức hợp có số hạng cố định. Mỗi thuật ngữ của một tuple được gọi là mộtelement. Số phần tử là kích thước của bộ tuple. Ví dụ sau đây cho thấy cách xác định một bộ 5 thuật ngữ và in kích thước của nó.
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} ,
io:fwrite("~w",[tuple_size(K)]).Nó sẽ tạo ra kết quả sau:
5Bản đồ
Bản đồ là một kiểu dữ liệu kết hợp với một số lượng biến các liên kết khóa-giá trị. Mỗi liên kết khóa-giá trị trong bản đồ được gọi làassociation-pair. Cáckey và value các bộ phận của cặp được gọi là elements. Số lượng các cặp liên kết được cho là kích thước của bản đồ. Ví dụ sau đây cho thấy cách xác định một bản đồ gồm 3 ánh xạ và in kích thước của nó.
-module(helloworld).
-export([start/0]).
start() ->
Map1 = #{name => 'abc',age => 40, gender => 'M'},
io:fwrite("~w",[map_size(Map1)]).Nó sẽ tạo ra kết quả sau:
3Danh sách
Danh sách là một kiểu dữ liệu phức hợp có số hạng thay đổi. Mỗi thuật ngữ trong danh sách được gọi là một phần tử. Số phần tử được cho là độ dài của danh sách. Ví dụ sau đây cho thấy cách xác định danh sách 5 mục và in kích thước của nó.
-module(helloworld).
-export([start/0]).
start() ->
List1 = [10,15,20,25,30] ,
io:fwrite("~w",[length(List1)]).Nó sẽ tạo ra kết quả sau:
5Note - Kiểu dữ liệu 'chuỗi' không được xác định trong Erlang.
Đa hình, về mặt lập trình, có nghĩa là sử dụng lại nhiều lần một đoạn mã. Cụ thể hơn, đó là khả năng của một chương trình xử lý các đối tượng khác nhau tùy thuộc vào kiểu dữ liệu hoặc lớp của chúng.
Đa hình có hai loại -
Compile-time Polymorphism - Loại đa hình này có thể đạt được bằng cách sử dụng nạp chồng phương thức.
Run-time Polymorphism - Loại đa hình này có thể đạt được bằng cách sử dụng ghi đè phương thức và các hàm ảo.
Ưu điểm của Đa hình
Tính đa hình mang lại những ưu điểm sau:
Nó giúp lập trình viên sử dụng lại các mã, tức là các lớp sau khi được viết, kiểm tra và triển khai có thể được sử dụng lại theo yêu cầu. Tiết kiệm được nhiều thời gian.
Một biến có thể được sử dụng để lưu trữ nhiều kiểu dữ liệu.
Dễ dàng gỡ lỗi các mã.
Các kiểu dữ liệu đa hình
Các kiểu dữ liệu đa hình có thể được thực hiện bằng cách sử dụng các con trỏ chung chỉ lưu một địa chỉ byte, không có kiểu dữ liệu được lưu trữ tại địa chỉ bộ nhớ đó. Ví dụ,
function1(void *p, void *q)Ở đâu p và q là những con trỏ chung có thể giữ int, float (hoặc bất kỳ giá trị nào khác) làm đối số.
Hàm đa hình trong C ++
Chương trình sau đây trình bày cách sử dụng các hàm đa hình trong C ++, là một ngôn ngữ lập trình hướng đối tượng.
#include <iostream>
Using namespace std:
class A {
public:
void show() {
cout << "A class method is called/n";
}
};
class B:public A {
public:
void show() {
cout << "B class method is called/n";
}
};
int main() {
A x; // Base class object
B y; // Derived class object
x.show(); // A class method is called
y.show(); // B class method is called
return 0;
}Nó sẽ tạo ra kết quả sau:
A class method is called
B class method is calledHàm đa hình trong Python
Chương trình sau đây trình bày cách sử dụng các hàm đa hình trong Python, là một ngôn ngữ lập trình hàm.
class A(object):
def show(self):
print "A class method is called"
class B(A):
def show(self):
print "B class method is called"
def checkmethod(clasmethod):
clasmethod.show()
AObj = A()
BObj = B()
checkmethod(AObj)
checkmethod(BObj)Nó sẽ tạo ra kết quả sau:
A class method is called
B class method is calledA stringlà một nhóm các ký tự bao gồm khoảng trắng. Có thể nói nó là một mảng một chiều các ký tự được kết thúc bởi một ký tự NULL ('\ 0'). Một chuỗi cũng có thể được coi là một lớp được xác định trước được hỗ trợ bởi hầu hết các ngôn ngữ lập trình như C, C ++, Java, PHP, Erlang, Haskell, Lisp, v.v.
Hình ảnh sau đây cho thấy chuỗi "Hướng dẫn" sẽ trông như thế nào trong bộ nhớ.
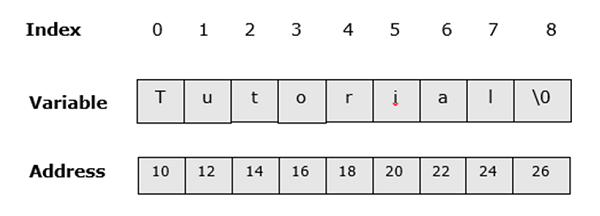
Tạo một chuỗi trong C ++
Chương trình sau đây là một ví dụ cho thấy cách tạo một chuỗi trong C ++, là một ngôn ngữ lập trình hướng đối tượng.
#include <iostream>
using namespace std;
int main () {
char greeting[20] = {'H', 'o', 'l', 'i', 'd', 'a', 'y', '\0'};
cout << "Today is: ";
cout << greeting << endl;
return 0;
}Nó sẽ tạo ra kết quả sau:
Today is: HolidayChuỗi trong Erlang
Chương trình sau đây là một ví dụ cho thấy cách tạo một chuỗi trong Erlang, là một ngôn ngữ lập trình chức năng.
-module(helloworld).
-export([start/0]).
start() ->
Str = "Today is: Holiday",
io:fwrite("~p~n",[Str]).Nó sẽ tạo ra kết quả sau:
"Today is: Holiday"Hoạt động chuỗi trong C ++
Các ngôn ngữ lập trình khác nhau hỗ trợ các phương thức khác nhau trên chuỗi. Bảng sau đây cho thấy một vài phương thức chuỗi được xác định trước được hỗ trợ bởi C ++.
| Không. | Phương pháp & Mô tả |
|---|---|
| 1 | Strcpy(s1,s2) Nó sao chép chuỗi s2 thành chuỗi s1 |
| 2 | Strcat(s1,s2) Nó thêm chuỗi s2 vào cuối s1 |
| 3 | Strlen(s1) Nó cung cấp độ dài của chuỗi s1 |
| 4 | Strcmp(s1,s2) Nó trả về 0 khi chuỗi s1 & s2 giống nhau |
| 5 | Strchr(s1,ch) Nó trả về một con trỏ đến lần xuất hiện đầu tiên của ký tự ch trong chuỗi s1 |
| 6 | Strstr(s1,s2) Nó trả về một con trỏ đến lần xuất hiện đầu tiên của chuỗi s2 trong chuỗi s1 |
Chương trình sau đây cho thấy cách các phương thức trên có thể được sử dụng trong C ++:
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[20] = "Today is ";
char str2[20] = "Monday";
char str3[20];
int len ;
strcpy( str3, str1); // copy str1 into str3
cout << "strcpy( str3, str1) : " << str3 << endl;
strcat( str1, str2); // concatenates str1 and str2
cout << "strcat( str1, str2): " << str1 << endl;
len = strlen(str1); // String length after concatenation
cout << "strlen(str1) : " << len << endl;
return 0;
}Nó sẽ tạo ra kết quả sau:
strcpy(str3, str1) : Today is
strcat(str1, str2) : Today is Monday
strlen(str1) : 15Hoạt động chuỗi trong Erlang
Bảng sau đây hiển thị danh sách các phương thức chuỗi được xác định trước được hỗ trợ bởi Erlang.
| Không. | Phương pháp & Mô tả |
|---|---|
| 1 | len(s1) Trả về số ký tự trong chuỗi đã cho. |
| 2 | equal(s1,s2) Nó trả về true khi chuỗi s1 & s2 bằng nhau, ngược lại trả về false |
| 3 | concat(s1,s2) Nó thêm chuỗi s2 vào cuối chuỗi s1 |
| 4 | str(s1,ch) Nó trả về vị trí chỉ mục của ký tự ch trong chuỗi s1 |
| 5 | str (s1,s2) Nó trả về vị trí chỉ mục của s2 trong chuỗi s1 |
| 6 | substr(s1,s2,num) Phương thức này trả về chuỗi s2 từ chuỗi s1 dựa trên vị trí bắt đầu và số ký tự từ vị trí bắt đầu |
| 7 | to_lower(s1) Phương thức này trả về chuỗi bằng chữ thường |
Chương trình sau đây cho thấy các phương pháp trên có thể được sử dụng như thế nào trong Erlang.
-module(helloworld).
-import(string,[concat/2]).
-export([start/0]).
start() ->
S1 = "Today is ",
S2 = "Monday",
S3 = concat(S1,S2),
io:fwrite("~p~n",[S3]).Nó sẽ tạo ra kết quả sau:
"Today is Monday"Listlà kiểu dữ liệu linh hoạt nhất có sẵn trong các ngôn ngữ lập trình chức năng được sử dụng để lưu trữ một tập hợp các mục dữ liệu tương tự. Khái niệm tương tự như mảng trong lập trình hướng đối tượng. Các mục danh sách có thể được viết trong một dấu ngoặc vuông được phân tách bằng dấu phẩy. Cách ghi dữ liệu vào danh sách khác nhau giữa các ngôn ngữ.
Chương trình tạo danh sách các số trong Java
Danh sách không phải là một kiểu dữ liệu trong Java / C / C ++, nhưng chúng tôi có những cách thay thế để tạo danh sách trong Java, tức là bằng cách sử dụng ArrayList và LinkedList.
Ví dụ sau đây cho thấy cách tạo một danh sách trong Java. Ở đây chúng tôi đang sử dụng phương pháp Danh sách liên kết để tạo danh sách các số.
import java.util.*;
import java.lang.*;
import java.io.*;
/* Name of the class has to be "Main" only if the class is public. */
public class HelloWorld {
public static void main (String[] args) throws java.lang.Exception {
List<String> listStrings = new LinkedList<String>();
listStrings.add("1");
listStrings.add("2");
listStrings.add("3");
listStrings.add("4");
listStrings.add("5");
System.out.println(listStrings);
}
}Nó sẽ tạo ra kết quả sau:
[1, 2, 3, 4, 5]Chương trình tạo danh sách các số trong Erlang
-module(helloworld).
-export([start/0]).
start() ->
Lst = [1,2,3,4,5],
io:fwrite("~w~n",[Lst]).Nó sẽ tạo ra kết quả sau:
[1 2 3 4 5]Liệt kê các hoạt động trong Java
Trong phần này, chúng ta sẽ thảo luận về một số thao tác có thể được thực hiện trên danh sách trong Java.
Thêm phần tử vào danh sách
Các phương thức add (Object), add (index, Object), addAll () được sử dụng để thêm các phần tử vào một danh sách. Ví dụ,
ListStrings.add(3, “three”)Xóa các phần tử khỏi danh sách
Các phương thức remove (chỉ mục) hoặc removeobject () được sử dụng để xóa các phần tử khỏi danh sách. Ví dụ,
ListStrings.remove(3,”three”)Note - Để xóa tất cả các phần tử khỏi danh sách, phương thức clear () được sử dụng.
Lấy các phần tử từ một danh sách
Phương thức get () được sử dụng để lấy các phần tử từ một danh sách tại một vị trí được chỉ định. Phương thức getfirst () & getlast () có thể được sử dụng trong lớp LinkedList. Ví dụ,
String str = ListStrings.get(2)Cập nhật các phần tử trong một danh sách
Phương thức set (index, element) được sử dụng để cập nhật một phần tử tại một chỉ mục xác định với một phần tử được chỉ định. Ví dụ,
listStrings.set(2,”to”)Sắp xếp các phần tử trong một danh sách
Các phương thức collection.sort () và collection.reverse () được sử dụng để sắp xếp danh sách theo thứ tự tăng dần hoặc giảm dần. Ví dụ,
Collection.sort(listStrings)Tìm kiếm các phần tử trong một danh sách
Ba phương pháp sau được sử dụng theo yêu cầu:
Boolean contains(Object) phương thức trả về true nếu danh sách chứa phần tử được chỉ định, nếu không nó sẽ trả về false.
int indexOf(Object) phương thức trả về chỉ số của lần xuất hiện đầu tiên của một phần tử được chỉ định trong danh sách, nếu không nó trả về -1 khi phần tử không được tìm thấy.
int lastIndexOf(Object) trả về chỉ số của lần xuất hiện cuối cùng của một phần tử được chỉ định trong danh sách, nếu không nó trả về -1 khi phần tử không được tìm thấy.
Liệt kê các hoạt động trong Erlang
Trong phần này, chúng ta sẽ thảo luận về một số thao tác có thể được thực hiện trên danh sách trong Erlang.
Thêm hai danh sách
Phương thức append (listfirst, listecond) được sử dụng để tạo một danh sách mới bằng cách thêm hai danh sách. Ví dụ,
append(list1,list2)Xóa một phần tử
Phương thức xóa (phần tử, tên danh sách) được sử dụng để xóa phần tử đã chỉ định khỏi danh sách và nó trả về danh sách mới. Ví dụ,
delete(5,list1)Xóa phần tử cuối cùng khỏi danh sách
Phương thức droplast (listname) được sử dụng để xóa phần tử cuối cùng khỏi danh sách và trả về một danh sách mới. Ví dụ,
droplast(list1)Tìm kiếm một phần tử
Phương thức member (element, listname) được sử dụng để tìm kiếm phần tử trong danh sách, nếu tìm thấy nó trả về true, nếu không nó sẽ trả về false. Ví dụ,
member(5,list1)Nhận giá trị tối đa và tối thiểu
Phương thức max (listname) và min (listname) được sử dụng để tìm các giá trị lớn nhất và nhỏ nhất trong danh sách. Ví dụ,
max(list1)Sắp xếp các phần tử danh sách
Các phương thức sort (tên danh sách) và đảo ngược (tên danh sách) được sử dụng để sắp xếp danh sách theo thứ tự tăng dần hoặc giảm dần. Ví dụ,
sort(list1)Thêm phần tử danh sách
Phương thức sum (listname) được sử dụng để thêm tất cả các phần tử của danh sách và trả về tổng của chúng. Ví dụ,
sum(list1)Sắp xếp danh sách theo thứ tự tăng dần và giảm dần bằng Java
Chương trình sau đây cho thấy cách sắp xếp danh sách theo thứ tự tăng dần và giảm dần bằng Java:
import java.util.*;
import java.lang.*;
import java.io.*;
public class SortList {
public static void main (String[] args) throws java.lang.Exception {
List<String> list1 = new ArrayList<String>();
list1.add("5");
list1.add("3");
list1.add("1");
list1.add("4");
list1.add("2");
System.out.println("list before sorting: " + list1);
Collections.sort(list1);
System.out.println("list in ascending order: " + list1);
Collections.reverse(list1);
System.out.println("list in dsending order: " + list1);
}
}Nó sẽ tạo ra kết quả sau:
list before sorting : [5, 3, 1, 4, 2]
list in ascending order : [1, 2, 3, 4, 5]
list in dsending order : [5, 4, 3, 2, 1]Sắp xếp danh sách theo thứ tự tăng dần bằng Erlang
Chương trình sau đây cho thấy cách sắp xếp danh sách theo thứ tự tăng dần và giảm dần bằng cách sử dụng Erlang, là một ngôn ngữ lập trình chức năng:
-module(helloworld).
-import(lists,[sort/1]).
-export([start/0]).
start() ->
List1 = [5,3,4,2,1],
io:fwrite("~p~n",[sort(List1)]),Nó sẽ tạo ra kết quả sau:
[1,2,3,4,5]Tuple là một kiểu dữ liệu phức hợp có một số thuật ngữ cố định. Mỗi thuật ngữ trong một bộ được gọi là mộtelement. Số phần tử là kích thước của bộ tuple.
Chương trình xác định một bộ giá trị trong C #
Chương trình sau đây trình bày cách xác định một bộ bốn thuật ngữ và in chúng bằng C #, một ngôn ngữ lập trình hướng đối tượng.
using System;
public class Test {
public static void Main() {
var t1 = Tuple.Create(1, 2, 3, new Tuple<int, int>(4, 5));
Console.WriteLine("Tuple:" + t1);
}
}Nó sẽ tạo ra kết quả sau:
Tuple :(1, 2, 3, (4, 5))Chương trình xác định một tuple trong Erlang
Chương trình sau đây trình bày cách xác định một bộ bốn thuật ngữ và in chúng bằng Erlang, một ngôn ngữ lập trình chức năng.
-module(helloworld).
-export([start/0]).
start() ->
P = {1,2,3,{4,5}} ,
io:fwrite("~w",[P]).Nó sẽ tạo ra kết quả sau:
{1, 2, 3, {4, 5}}Ưu điểm của Tuple
Tuples cung cấp những ưu điểm sau:
Tuple có kích thước nhỏ về bản chất, tức là chúng ta không thể thêm / xóa các phần tử vào / khỏi một bộ tuple.
Chúng tôi có thể tìm kiếm bất kỳ phần tử nào trong một bộ tuple.
Bộ giá trị nhanh hơn danh sách, bởi vì chúng có một bộ giá trị không đổi.
Tuples có thể được sử dụng làm khóa từ điển, vì chúng chứa các giá trị bất biến như chuỗi, số, v.v.
Tuples vs Lists
| Tuple | Danh sách |
|---|---|
| Tuples là immutable, tức là, chúng tôi không thể cập nhật dữ liệu của nó. | Danh sách là mutable, tức là, chúng tôi có thể cập nhật dữ liệu của nó. |
| Các phần tử trong một bộ có thể là kiểu khác nhau. | Tất cả các phần tử trong danh sách là cùng một loại. |
| Các bộ giá trị được biểu thị bằng dấu ngoặc tròn xung quanh các phần tử. | Danh sách được biểu thị bằng dấu ngoặc vuông xung quanh các phần tử. |
Hoạt động trên Tuples
Trong phần này, chúng ta sẽ thảo luận về một số thao tác có thể được thực hiện trên một bộ tuple.
Kiểm tra xem một giá trị được chèn có phải là một Tuple hay không
Phương pháp is_tuple(tuplevalues)được sử dụng để xác định xem một giá trị được chèn có phải là một bộ giá trị hay không. Nó trở lạitrue khi một giá trị được chèn là một bộ giá trị, nếu không nó sẽ trả về false. Ví dụ,
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} , io:fwrite("~w",[is_tuple(K)]).Nó sẽ tạo ra kết quả sau:
TrueChuyển đổi một danh sách thành một Tuple
Phương pháp list_to_tuple(listvalues)chuyển đổi một danh sách thành một bộ. Ví dụ,
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[list_to_tuple([1,2,3,4,5])]).Nó sẽ tạo ra kết quả sau:
{1, 2, 3, 4, 5}Chuyển đổi Tuple thành danh sách
Phương pháp tuple_to_list(tuplevalues)chuyển đổi một tuple được chỉ định sang định dạng danh sách. Ví dụ,
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w",[tuple_to_list({1,2,3,4,5})]).Nó sẽ tạo ra kết quả sau:
[1, 2, 3, 4, 5]Kiểm tra kích thước tuple
Phương pháp tuple_size(tuplename)trả về kích thước của một tuple. Ví dụ,
-module(helloworld).
-export([start/0]).
start() ->
K = {abc,50,pqr,60,{xyz,75}} ,
io:fwrite("~w",[tuple_size(K)]).Nó sẽ tạo ra kết quả sau:
5Bản ghi là một cấu trúc dữ liệu để lưu trữ một số phần tử cố định. Nó tương tự như một cấu trúc trong ngôn ngữ C. Tại thời điểm biên dịch, các biểu thức của nó được dịch sang biểu thức tuple.
Làm thế nào để tạo một bản ghi?
Từ khóa 'record' được sử dụng để tạo các bản ghi được chỉ định với tên bản ghi và các trường của nó. Cú pháp của nó như sau:
record(recodname, {field1, field2, . . fieldn})Cú pháp để chèn giá trị vào bản ghi là:
#recordname {fieldName1 = value1, fieldName2 = value2 .. fieldNamen = valuen}Chương trình tạo bản ghi bằng Erlang
Trong ví dụ sau, chúng tôi đã tạo một bản ghi tên student có hai trường, tức là, sname và sid.
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5}.Chương trình tạo bản ghi bằng C ++
Ví dụ sau cho thấy cách tạo bản ghi bằng C ++, là một ngôn ngữ lập trình hướng đối tượng:
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
15
};
int main() {
student S;
S.sname = "Sachin";
S.sid = 5;
return 0;
}Chương trình truy cập các giá trị bản ghi bằng Erlang
Chương trình sau đây cho thấy cách truy cập các giá trị bản ghi bằng Erlang, là một ngôn ngữ lập trình chức năng:
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5},
io:fwrite("~p~n",[S#student.sid]),
io:fwrite("~p~n",[S#student.sname]).Nó sẽ tạo ra kết quả sau:
5
"Sachin"Chương trình truy cập các giá trị bản ghi bằng C ++
Chương trình sau đây cho thấy cách truy cập các giá trị bản ghi bằng C ++:
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
};
int main() {
student S;
S.sname = "Sachin";
S.sid = 5;
cout<<S.sid<<"\n"<<S.sname;
return 0;
}Nó sẽ tạo ra kết quả sau:
5
SachinCác giá trị bản ghi có thể được cập nhật bằng cách thay đổi giá trị thành một trường cụ thể và sau đó gán bản ghi đó cho một tên biến mới. Hãy xem hai ví dụ sau để hiểu cách nó được thực hiện bằng cách sử dụng ngôn ngữ lập trình hướng đối tượng và chức năng.
Chương trình cập nhật giá trị bản ghi bằng Erlang
Chương trình sau đây cho thấy cách cập nhật các giá trị bản ghi bằng Erlang:
-module(helloworld).
-export([start/0]).
-record(student, {sname = "", sid}).
start() ->
S = #student{sname = "Sachin",sid = 5},
S1 = S#student{sname = "Jonny"},
io:fwrite("~p~n",[S1#student.sid]),
io:fwrite("~p~n",[S1#student.sname]).Nó sẽ tạo ra kết quả sau:
5
"Jonny"Chương trình cập nhật giá trị bản ghi bằng C ++
Chương trình sau đây cho biết cách cập nhật các giá trị bản ghi bằng C ++:
#include<iostream>
#include<string>
using namespace std;
class student {
public:
string sname;
int sid;
};
int main() {
student S;
S.sname = "Jonny";
S.sid = 5;
cout<<S.sname<<"\n"<<S.sid;
cout<<"\n"<< "value after updating"<<"\n";
S.sid = 10;
cout<<S.sname<<"\n"<<S.sid;
return 0;
}Nó sẽ tạo ra kết quả sau:
Jonny
5
value after updating
Jonny
10Giải tích Lambda là một khung được phát triển bởi Alonzo Church vào những năm 1930 để nghiên cứu các phép tính với các hàm.
Function creation - Church giới thiệu ký hiệu λx.Eđể biểu thị một hàm trong đó 'x' là đối số chính thức và 'E' là phần thân của hàm. Các hàm này có thể không có tên và đối số đơn lẻ.
Function application - Church sử dụng ký hiệu E1.E2 để biểu thị ứng dụng của chức năng E1 đối số thực tế E2. Và tất cả các hàm đều nằm trên một đối số.
Cú pháp của Lambda Calculus
Phép tính Lamdba bao gồm ba loại biểu thức khác nhau, tức là
E :: = x (biến)
| E 1 E 2 (ứng dụng chức năng)
| λx.E (tạo hàm)
Ở đâu λx.E được gọi là trừu tượng Lambda và E được gọi là biểu thức λ.
Đánh giá Lambda Calculus
Giải tích lambda thuần túy không có hàm tích hợp sẵn. Chúng ta hãy đánh giá biểu thức sau:
(+ (* 5 6) (* 8 3))Ở đây, chúng ta không thể bắt đầu bằng '+' vì nó chỉ hoạt động trên các con số. Có hai biểu thức rút gọn: (* 5 6) và (* 8 3).
Chúng tôi có thể giảm một trong hai trước. Ví dụ -
(+ (* 5 6) (* 8 3))
(+ 30 (* 8 3))
(+ 30 24)
= 54Quy tắc giảm β
Chúng ta cần một quy tắc giảm để xử lý λs
(λx . * 2 x) 4
(* 2 4)
= 8Đây được gọi là quá trình khử β.
Tham số chính thức có thể được sử dụng nhiều lần -
(λx . + x x) 4
(+ 4 4)
= 8Khi có nhiều điều khoản, chúng tôi có thể xử lý chúng như sau:
(λx . (λx . + (− x 1)) x 3) 9Bên trong x thuộc về bên trong λ còn x ngoài cùng thuộc x ngoài cùng.
(λx . + (− x 1)) 9 3
+ (− 9 1) 3
+ 8 3
= 11Các biến miễn phí và ràng buộc
Trong một biểu thức, mỗi lần xuất hiện của một biến là "tự do" (với λ) hoặc "bị ràng buộc" (với λ).
β-giảm của (λx . E) y thay thế mọi x điều đó xảy ra miễn phí trong E với y. Ví dụ -

Giảm Alpha
Việc khử alpha rất đơn giản và nó có thể được thực hiện mà không làm thay đổi ý nghĩa của biểu thức lambda.
λx . (λx . x) (+ 1 x) ↔ α λx . (λy . y) (+ 1 x)Ví dụ -
(λx . (λx . + (− x 1)) x 3) 9
(λx . (λy . + (− y 1)) x 3) 9
(λy . + (− y 1)) 9 3
+ (− 9 1) 3
+ 8 3
11Định lý Church-Rosser
Định lý Church-Rosser phát biểu như sau:
Nếu E1 ↔ E2, thì tồn tại một E sao cho E1 → E và E2 → E. "Giảm theo bất kỳ cách nào cuối cùng có thể tạo ra cùng một kết quả."
Nếu E1 → E2 và E2 là dạng chuẩn thì có sự giảm bậc bình thường của E1 thành E2. "Giảm bậc bình thường sẽ luôn tạo ra một dạng bình thường, nếu một dạng tồn tại."
Đánh giá lười biếng là một chiến lược đánh giá giữ đánh giá một biểu thức cho đến khi giá trị của nó là cần thiết. Nó tránh đánh giá lặp lại.Haskell là một ví dụ điển hình về một ngôn ngữ lập trình chức năng có các nguyên tắc cơ bản dựa trên Đánh giá Lười biếng.
Đánh giá lười biếng được sử dụng trong các chức năng bản đồ Unix để cải thiện hiệu suất của chúng bằng cách chỉ tải các trang được yêu cầu từ đĩa. Không có bộ nhớ nào sẽ được cấp cho các trang còn lại.
Đánh giá lười biếng - Ưu điểm
Nó cho phép thời gian chạy ngôn ngữ loại bỏ các biểu thức con không được liên kết trực tiếp với kết quả cuối cùng của biểu thức.
Nó làm giảm độ phức tạp về thời gian của một thuật toán bằng cách loại bỏ các tính toán tạm thời và các điều kiện.
Nó cho phép lập trình viên truy cập các thành phần của cấu trúc dữ liệu không theo thứ tự sau khi khởi tạo chúng, miễn là chúng không có bất kỳ phụ thuộc vòng tròn nào.
Nó phù hợp nhất để tải dữ liệu thường được truy cập.
Đánh giá lười biếng - Mặt hạn chế
Nó buộc thời gian chạy ngôn ngữ giữ đánh giá các biểu thức con cho đến khi nó được yêu cầu trong kết quả cuối cùng bằng cách tạo thunks (đối tượng bị trì hoãn).
Đôi khi nó làm tăng độ phức tạp không gian của một thuật toán.
Rất khó để tìm thấy hiệu suất của nó vì nó chứa các biểu thức thu nhỏ trước khi thực hiện.
Đánh giá lười biếng bằng Python
Các rangephương thức trong Python tuân theo khái niệm Đánh giá lười biếng. Nó tiết kiệm thời gian thực thi cho các phạm vi lớn hơn và chúng tôi không bao giờ yêu cầu tất cả các giá trị cùng một lúc, vì vậy nó cũng tiết kiệm tiêu thụ bộ nhớ. Hãy xem ví dụ sau.
r = range(10)
print(r)
range(0, 10)
print(r[3])Nó sẽ tạo ra kết quả sau:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
3Chúng ta cần các tệp để lưu trữ kết quả đầu ra của một chương trình khi chương trình kết thúc. Sử dụng tệp, chúng ta có thể truy cập thông tin liên quan bằng nhiều lệnh khác nhau bằng các ngôn ngữ khác nhau.
Đây là danh sách một số thao tác có thể được thực hiện trên một tệp:
- Tạo một tệp mới
- Mở một tệp hiện có
- Đọc nội dung tệp
- Tìm kiếm dữ liệu trên tệp
- Ghi vào một tệp mới
- Cập nhật nội dung vào tệp hiện có
- Xóa tệp
- Đóng tệp
Ghi vào tệp
Để ghi nội dung vào một tệp, trước tiên chúng ta cần mở tệp cần thiết. Nếu tệp được chỉ định không tồn tại, thì một tệp mới sẽ được tạo.
Hãy xem cách ghi nội dung vào tệp bằng C ++.
Thí dụ
#include <iostream>
#include <fstream>
using namespace std;
int main () {
ofstream myfile;
myfile.open ("Tempfile.txt", ios::out);
myfile << "Writing Contents to file.\n";
cout << "Data inserted into file";
myfile.close();
return 0;
}Note -
fstream là lớp luồng dùng để điều khiển các thao tác đọc / ghi tệp.
ofstream là lớp luồng dùng để ghi nội dung vào tệp.
Chúng ta hãy xem cách ghi nội dung vào tệp bằng Erlang, một ngôn ngữ lập trình chức năng.
-module(helloworld).
-export([start/0]).
start() ->
{ok, File1} = file:open("Tempfile.txt", [write]),
file:write(File1,"Writting contents to file"),
io:fwrite("Data inserted into file\n").Note -
Để mở một tệp, chúng tôi phải sử dụng, open(filename,mode).
Cú pháp ghi nội dung vào tệp: write(filemode,file_content).
Output - Khi chúng ta chạy đoạn mã này, "Ghi nội dung vào tệp" sẽ được ghi vào tệp Tempfile.txt. Nếu tệp có bất kỳ nội dung hiện có nào, thì tệp đó sẽ bị ghi đè.
Đọc từ một tệp
Để đọc từ một tệp, trước tiên chúng ta phải mở tệp được chỉ định trong reading mode. Nếu tệp không tồn tại, thì phương thức tương ứng của nó sẽ trả về NULL.
Chương trình sau đây cho biết cách đọc nội dung của tệp trong C++ -
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main () {
string readfile;
ifstream myfile ("Tempfile.txt",ios::in);
if (myfile.is_open()) {
while ( getline (myfile,readfile) ) {
cout << readfile << '\n';
}
myfile.close();
} else
cout << "file doesn't exist";
return 0;
}Nó sẽ tạo ra kết quả sau:
Writing contents to fileNote- Trong chương trình này, chúng tôi đã mở một tệp văn bản ở chế độ đọc bằng cách sử dụng “ios :: in” và sau đó in nội dung của nó trên màn hình. Chúng tôi vừa dùngwhile vòng lặp để đọc nội dung tệp từng dòng bằng cách sử dụng phương thức "getline".
Chương trình sau đây chỉ ra cách thực hiện thao tác tương tự bằng cách sử dụng Erlang. Ở đây, chúng tôi sẽ sử dụngread_file(filename) để đọc tất cả nội dung từ tệp được chỉ định.
-module(helloworld).
-export([start/0]).
start() ->
rdfile = file:read_file("Tempfile.txt"),
io:fwrite("~p~n",[rdfile]).Nó sẽ tạo ra kết quả sau:
ok, Writing contents to fileXóa một tệp hiện có
Chúng tôi có thể xóa một tệp hiện có bằng các thao tác với tệp. Chương trình sau đây cho biết cách xóa một tệp hiện cóusing C++ -
#include <stdio.h>
int main () {
if(remove( "Tempfile.txt" ) != 0 )
perror( "File doesn’t exist, can’t delete" );
else
puts( "file deleted successfully " );
return 0;
}Nó sẽ tạo ra kết quả sau:
file deleted successfullyChương trình sau đây cho biết cách bạn có thể thực hiện thao tác tương tự trong Erlang. Ở đây, chúng ta sẽ sử dụng phương phápdelete(filename) để xóa một tệp hiện có.
-module(helloworld).
-export([start/0]).
start() ->
file:delete("Tempfile.txt").Output - Nếu tệp “Tempfile.txt” tồn tại, thì tệp đó sẽ bị xóa.
Xác định kích thước của tệp
Chương trình sau đây cho biết cách bạn có thể xác định kích thước của tệp bằng C ++. Đây, hàmfseek đặt chỉ báo vị trí được liên kết với luồng sang vị trí mới, ngược lại ftell trả về vị trí hiện tại trong luồng.
#include <stdio.h>
int main () {
FILE * checkfile;
long size;
checkfile = fopen ("Tempfile.txt","rb");
if (checkfile == NULL)
perror ("file can’t open");
else {
fseek (checkfile, 0, SEEK_END); // non-portable
size = ftell (checkfile);
fclose (checkfile);
printf ("Size of Tempfile.txt: %ld bytes.\n",size);
}
return 0;
}Output - Nếu tệp “Tempfile.txt” tồn tại, thì nó sẽ hiển thị kích thước của nó theo byte.
Chương trình sau đây cho biết cách bạn có thể thực hiện thao tác tương tự trong Erlang. Ở đây, chúng ta sẽ sử dụng phương phápfile_size(filename) để xác định kích thước của tệp.
-module(helloworld).
-export([start/0]).
start() ->
io:fwrite("~w~n",[filelib:file_size("Tempfile.txt")]).Output- Nếu tệp “Tempfile.txt” tồn tại, thì nó sẽ hiển thị kích thước của nó theo byte. Nếu không, nó sẽ hiển thị “0”.