IMS DB - Hướng dẫn nhanh
Một tổng quan ngắn gọn
Cơ sở dữ liệu là một tập hợp các mục dữ liệu tương quan. Các mục dữ liệu này được sắp xếp và lưu trữ theo cách để cung cấp khả năng truy cập nhanh chóng và dễ dàng. Cơ sở dữ liệu IMS là cơ sở dữ liệu phân cấp, nơi dữ liệu được lưu trữ ở các cấp khác nhau và mỗi thực thể phụ thuộc vào các thực thể cấp cao hơn. Các yếu tố vật lý trên một hệ thống ứng dụng sử dụng IMS được thể hiện trong hình sau.
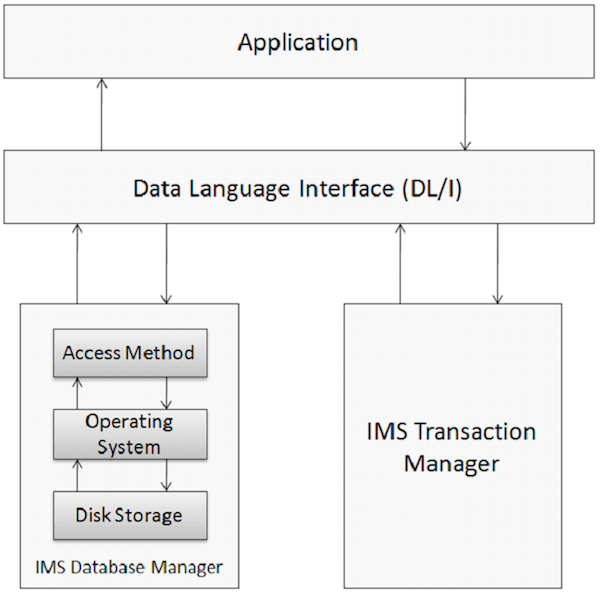
Quản lý cơ sở dữ liệu
Hệ quản trị cơ sở dữ liệu là một tập hợp các chương trình ứng dụng được sử dụng để lưu trữ, truy cập và quản lý dữ liệu trong cơ sở dữ liệu. Hệ quản trị cơ sở dữ liệu IMS duy trì tính toàn vẹn và cho phép khôi phục dữ liệu nhanh chóng bằng cách tổ chức dữ liệu theo cách dễ dàng truy xuất. IMS duy trì một lượng lớn dữ liệu doanh nghiệp trên thế giới với sự trợ giúp của hệ thống quản lý cơ sở dữ liệu.
Giám đốc giao dịch
Chức năng của quản lý giao dịch là cung cấp nền tảng giao tiếp giữa cơ sở dữ liệu và các chương trình ứng dụng. IMS hoạt động như một người quản lý giao dịch. Người quản lý giao dịch giao dịch với người dùng cuối để lưu trữ và truy xuất dữ liệu từ cơ sở dữ liệu. IMS có thể sử dụng IMS DB hoặc DB2 làm cơ sở dữ liệu phía sau của nó để lưu trữ dữ liệu.
DL / I - Giao diện ngôn ngữ dữ liệu
DL / I bao gồm các chương trình ứng dụng cấp quyền truy cập vào dữ liệu được lưu trữ trong cơ sở dữ liệu. IMS DB sử dụng DL / I dùng làm ngôn ngữ giao diện mà người lập trình sử dụng để truy cập cơ sở dữ liệu trong một chương trình ứng dụng. Chúng ta sẽ thảo luận chi tiết hơn về vấn đề này trong các chương sắp tới.
Đặc điểm của IMS
Những điểm cần lưu ý -
- IMS hỗ trợ các ứng dụng từ các ngôn ngữ khác nhau như Java và XML.
- Các ứng dụng và dữ liệu IMS có thể được truy cập trên bất kỳ nền tảng nào.
- Quá trình xử lý IMS DB rất nhanh so với DB2.
Hạn chế của IMS
Những điểm cần lưu ý -
- Việc triển khai IMS DB rất phức tạp.
- Cấu trúc cây xác định trước IMS làm giảm tính linh hoạt.
- IMS DB rất khó quản lý.
Cấu trúc phân cấp
Cơ sở dữ liệu IMS là một tập hợp dữ liệu chứa các tệp vật lý. Trong cơ sở dữ liệu phân cấp, cấp cao nhất chứa thông tin chung về thực thể. Khi chúng tôi tiến hành từ cấp cao nhất đến cấp dưới cùng trong hệ thống phân cấp, chúng tôi ngày càng nhận được nhiều thông tin hơn về thực thể.
Mỗi cấp trong hệ thống phân cấp chứa các phân đoạn. Trong các tệp tiêu chuẩn, rất khó để thực hiện phân cấp nhưng DL / I hỗ trợ phân cấp. Hình sau mô tả cấu trúc của IMS DB.
Bộ phận
Những điểm cần lưu ý -
Một phân đoạn được tạo bằng cách nhóm các dữ liệu tương tự lại với nhau.
Đây là đơn vị thông tin nhỏ nhất mà DL / I chuyển đến và từ một chương trình ứng dụng trong bất kỳ hoạt động đầu vào-đầu ra nào.
Một phân đoạn có thể có một hoặc nhiều trường dữ liệu được nhóm lại với nhau.
Trong ví dụ sau, phân đoạn Sinh viên có bốn trường dữ liệu.
| Sinh viên | |||
|---|---|---|---|
| Số cuộn | Tên | Khóa học | Số điện thoại |
Cánh đồng
Những điểm cần lưu ý−
Trường là một phần dữ liệu đơn lẻ trong một phân đoạn. Ví dụ: Số cuộn, Tên, Khóa học và Số điện thoại di động là các trường đơn lẻ trong phân khúc Sinh viên.
Một phân đoạn bao gồm các trường liên quan để thu thập thông tin của một thực thể.
Các trường có thể được sử dụng như một khóa để sắp xếp thứ tự các phân đoạn.
Các trường có thể được sử dụng như một điều kiện để tìm kiếm thông tin về một phân đoạn cụ thể.
Loại phân đoạn
Những điểm cần lưu ý -
Loại phân đoạn là một loại dữ liệu trong một phân đoạn.
Một cơ sở dữ liệu DL / I có thể có 255 kiểu phân đoạn khác nhau và 15 mức phân cấp.
Trong hình sau, có ba phân đoạn cụ thể là Thư viện, Thông tin Sách và Thông tin Sinh viên.
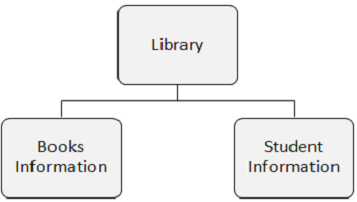
Phân đoạn xuất hiện
Những điểm cần lưu ý -
Sự xuất hiện phân đoạn là một phân đoạn riêng lẻ của một loại cụ thể có chứa dữ liệu người dùng. Trong ví dụ trên, Thông tin sách là một loại phân đoạn và có thể có bất kỳ số lần xuất hiện nào của nó, vì nó có thể lưu trữ thông tin về bất kỳ số lượng sách nào.
Trong Cơ sở dữ liệu IMS, chỉ có một lần xuất hiện của mỗi loại phân đoạn, nhưng có thể có số lần xuất hiện không giới hạn của mỗi loại phân đoạn.
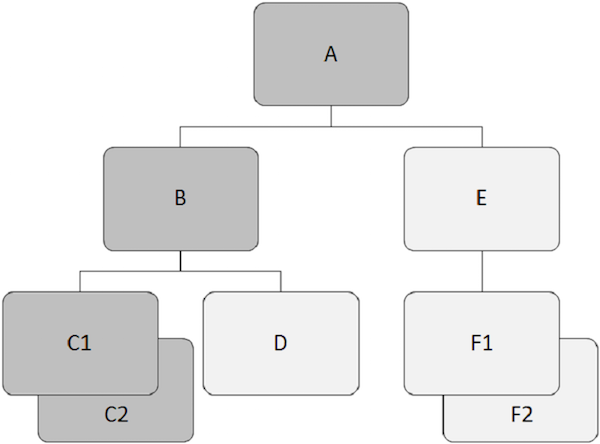
Cơ sở dữ liệu phân cấp hoạt động dựa trên mối quan hệ giữa hai hoặc nhiều phân đoạn. Ví dụ sau cho thấy các phân đoạn có liên quan với nhau như thế nào trong cấu trúc cơ sở dữ liệu IMS.
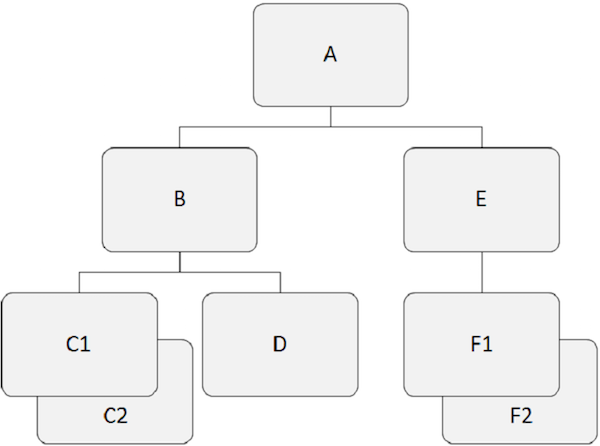
Phân đoạn gốc
Những điểm cần lưu ý -
Phân đoạn nằm trên cùng của cấu trúc phân cấp được gọi là phân đoạn gốc.
Phân đoạn gốc là phân đoạn duy nhất mà qua đó tất cả các phân đoạn phụ thuộc đều được truy cập.
Phân đoạn gốc là phân đoạn duy nhất trong cơ sở dữ liệu không bao giờ là phân đoạn con.
Chỉ có thể có một phân đoạn gốc trong cấu trúc cơ sở dữ liệu IMS.
Ví dụ, 'A' là đoạn gốc trong ví dụ trên.
Phân đoạn chính
Những điểm cần lưu ý -
Phân đoạn mẹ có một hoặc nhiều phân đoạn phụ thuộc ngay bên dưới nó.
Ví dụ, 'A', 'B'và 'E' là các phân đoạn mẹ trong ví dụ trên.
Phân đoạn phụ thuộc
Những điểm cần lưu ý -
Tất cả các phân đoạn khác với phân đoạn gốc được gọi là phân đoạn phụ thuộc.
Các phân đoạn phụ thuộc phụ thuộc vào một hoặc nhiều phân đoạn để trình bày ý nghĩa hoàn chỉnh.
Ví dụ, 'B', 'C1', 'C2', 'D', 'E', 'F1' và 'F2' là các phân đoạn phụ thuộc trong ví dụ của chúng tôi.
Phân đoạn con
Những điểm cần lưu ý -
Bất kỳ phân đoạn nào có một phân đoạn nằm ngay phía trên nó trong hệ thống phân cấp được gọi là phân đoạn con.
Mỗi phân đoạn phụ thuộc trong cấu trúc là một phân đoạn con.
Ví dụ, 'B', 'C1', 'C2', 'D', 'E', 'F1' và 'F2' là các phân đoạn con.
Phân đoạn đôi
Những điểm cần lưu ý -
Hai hoặc nhiều lần xuất hiện phân đoạn của một loại phân đoạn cụ thể trong một phân đoạn mẹ được gọi là phân đoạn sinh đôi.
Ví dụ, 'C1' và 'C2' là các phân đoạn sinh đôi, do đó 'F1' và 'F2' Chúng tôi.
Phân đoạn anh chị em
Những điểm cần lưu ý -
Các phân đoạn anh chị em ruột là các phân đoạn của các loại khác nhau và cùng cha mẹ.
Ví dụ, 'B' và 'E' là các phân đoạn anh chị em. Tương tự,'C1', 'C2', và 'D' là các phân đoạn anh chị em.
Bản ghi cơ sở dữ liệu
Những điểm cần lưu ý -
Mỗi lần xuất hiện của phân đoạn gốc, cộng với tất cả các lần xuất hiện của phân đoạn cấp dưới tạo thành một bản ghi cơ sở dữ liệu.
Mỗi bản ghi cơ sở dữ liệu chỉ có một phân đoạn gốc nhưng nó có thể có bất kỳ số lần xuất hiện phân đoạn nào.
Trong xử lý tệp tiêu chuẩn, bản ghi là một đơn vị dữ liệu mà chương trình ứng dụng sử dụng cho các hoạt động nhất định. Trong DL / I, đơn vị dữ liệu đó được gọi là phân đoạn. Một bản ghi cơ sở dữ liệu duy nhất có nhiều lần xuất hiện phân đoạn.
Đường dẫn cơ sở dữ liệu
Những điểm cần lưu ý -
Đường dẫn là một loạt các phân đoạn bắt đầu từ phân đoạn gốc của một bản ghi cơ sở dữ liệu đến bất kỳ sự kiện phân đoạn cụ thể nào.
Một đường dẫn trong cấu trúc phân cấp không cần phải hoàn chỉnh đến mức thấp nhất. Nó phụ thuộc vào lượng thông tin chúng tôi yêu cầu về một thực thể.
Một đường dẫn phải liên tục và chúng ta không thể bỏ qua các cấp độ trung gian trong cấu trúc.
Trong hình sau, bản ghi con có màu xám đậm hiển thị một đường dẫn bắt đầu từ 'A' và đi qua 'C2'.
IMS DB lưu trữ dữ liệu ở các cấp độ khác nhau. Dữ liệu được truy xuất và chèn bằng cách phát lệnh gọi DL / I từ một chương trình ứng dụng. Chúng ta sẽ thảo luận chi tiết về các cuộc gọi DL / I trong các chương sắp tới. Dữ liệu có thể được xử lý theo hai cách sau:
- Xử lý tuần tự
- Xử lý ngẫu nhiên
Xử lý tuần tự
Khi các phân đoạn được truy xuất tuần tự từ cơ sở dữ liệu, DL / I tuân theo một mẫu được xác định trước. Hãy để chúng tôi hiểu quá trình xử lý tuần tự của IMS DB.
Dưới đây là những điểm cần lưu ý về xử lý tuần tự -
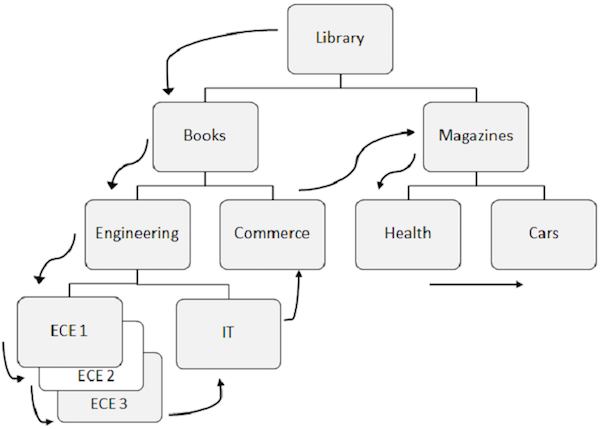
Mẫu được xác định trước để truy cập dữ liệu trong DL / I trước tiên nằm xuống phân cấp, sau đó từ trái sang phải.
Đoạn gốc được truy xuất đầu tiên, sau đó DL / I di chuyển đến phần con bên trái đầu tiên và nó đi xuống mức thấp nhất. Ở mức thấp nhất, nó truy xuất tất cả các lần xuất hiện của các phân đoạn sinh đôi. Sau đó, nó đi đến phân đoạn bên phải.
Để hiểu rõ hơn, hãy quan sát các mũi tên trong hình trên hiển thị quy trình truy cập các phân đoạn. Thư viện là phân đoạn gốc và quy trình bắt đầu từ đó và đi cho đến khi ô tô truy cập vào một bản ghi duy nhất. Quá trình tương tự được lặp lại cho tất cả các lần xuất hiện để lấy tất cả các bản ghi dữ liệu.
Trong khi truy cập dữ liệu, chương trình sử dụng position trong cơ sở dữ liệu giúp lấy và chèn các phân đoạn.
Xử lý ngẫu nhiên
Xử lý ngẫu nhiên còn được gọi là xử lý trực tiếp dữ liệu trong IMS DB. Chúng ta hãy lấy một ví dụ để hiểu quá trình xử lý ngẫu nhiên trong IMS DB -
Dưới đây là những điểm cần lưu ý về xử lý ngẫu nhiên -
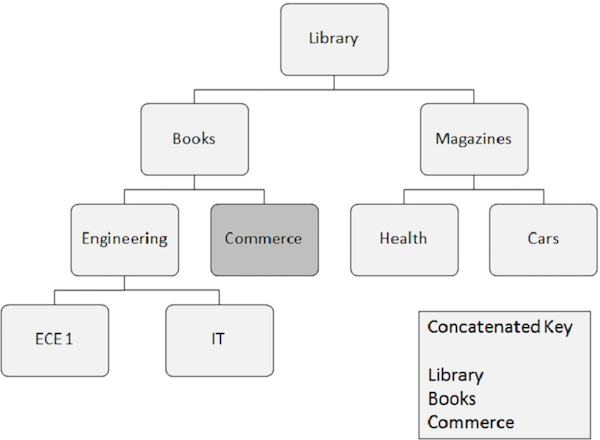
Sự xuất hiện của phân đoạn cần được truy xuất ngẫu nhiên yêu cầu các trường khóa của tất cả các phân đoạn mà nó phụ thuộc vào. Các trường chính này được cung cấp bởi chương trình ứng dụng.
Một khóa được nối hoàn toàn xác định đường dẫn từ phân đoạn gốc đến phân đoạn mà bạn muốn truy xuất.
Giả sử bạn muốn truy xuất một lần xuất hiện của phân đoạn Thương mại, thì bạn cần cung cấp các giá trị trường khóa được nối của các phân đoạn mà nó phụ thuộc vào, chẳng hạn như Thư viện, Sách và Thương mại.
Xử lý ngẫu nhiên nhanh hơn xử lý tuần tự. Trong kịch bản thế giới thực, các ứng dụng kết hợp cả phương pháp xử lý tuần tự và ngẫu nhiên với nhau để đạt được kết quả tốt nhất.
Trường chính
Những điểm cần lưu ý -
Trường khóa còn được gọi là trường trình tự.
Trường khóa có trong một phân đoạn và nó được sử dụng để truy xuất sự xuất hiện của phân đoạn.
Trường khóa quản lý sự xuất hiện của phân đoạn theo thứ tự tăng dần.
Trong mỗi phân đoạn, chỉ một trường duy nhất có thể được sử dụng làm trường khóa hoặc trường trình tự.
Trường tìm kiếm
Như đã đề cập, chỉ một trường duy nhất có thể được sử dụng làm trường khóa. Nếu bạn muốn tìm kiếm nội dung của các trường phân đoạn khác không phải là trường khóa, thì trường được sử dụng để truy xuất dữ liệu được gọi là trường tìm kiếm.
Các khối điều khiển IMS xác định cấu trúc của cơ sở dữ liệu IMS và quyền truy cập của chương trình vào chúng. Sơ đồ sau đây cho thấy cấu trúc của các khối điều khiển IMS.
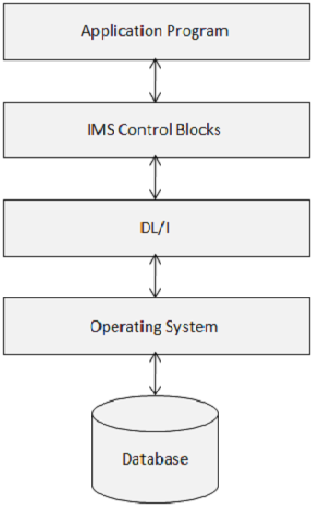
DL / I sử dụng ba loại Khối điều khiển sau:
- Bộ mô tả cơ sở dữ liệu (DBD)
- Khối đặc tả chương trình (PSB)
- Khối kiểm soát ra vào (ACB)
Bộ mô tả cơ sở dữ liệu (DBD)
Những điểm cần lưu ý -
DBD mô tả cấu trúc vật lý hoàn chỉnh của cơ sở dữ liệu khi tất cả các phân đoạn đã được xác định.
Trong khi cài đặt cơ sở dữ liệu DL / I, một DBD phải được tạo vì nó được yêu cầu để truy cập cơ sở dữ liệu IMS.
Các ứng dụng có thể sử dụng các khung nhìn khác nhau của DBD. Chúng được gọi là Cấu trúc Dữ liệu Ứng dụng và chúng được chỉ định trong Khối Đặc tả Chương trình.
Người quản trị cơ sở dữ liệu tạo DBD bằng cách mã hóa DBDGEN các câu lệnh kiểm soát.
DBDGEN
DBDGEN là một Trình tạo mô tả cơ sở dữ liệu. Tạo khối điều khiển là trách nhiệm của Người quản trị cơ sở dữ liệu. Tất cả các mô-đun tải được lưu trữ trong thư viện IMS. Hợp ngữ Các câu lệnh macro của ngôn ngữ được sử dụng để tạo các khối điều khiển. Dưới đây là một đoạn mã mẫu cho thấy cách tạo một DBD bằng cách sử dụng các câu lệnh điều khiển DBDGEN -
PRINT NOGEN
DBD NAME=LIBRARY,ACCESS=HIDAM
DATASET DD1=LIB,DEVICE=3380
SEGM NAME=LIBSEG,PARENT=0,BYTES=10
FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5
FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9
FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C
DBDGEN
FINISH
ENDHãy để chúng tôi hiểu các thuật ngữ được sử dụng trong DBDGEN ở trên -
Khi bạn thực hiện các câu lệnh điều khiển ở trên trong JCL, nó tạo ra một cấu trúc vật lý trong đó LIBRARY là phân đoạn gốc, và SÁCH và TẠP CHÍ là phân đoạn con của nó.
Câu lệnh macro DBD đầu tiên xác định cơ sở dữ liệu. Ở đây, chúng ta cần đề cập đến TÊN và TRUY CẬP được sử dụng bởi DL / I để truy cập cơ sở dữ liệu này.
Câu lệnh macro DATASET thứ hai xác định tệp chứa cơ sở dữ liệu.
Các loại phân đoạn được xác định bằng cách sử dụng câu lệnh macro SEGM. Chúng ta cần chỉ định PHỤ HUYNH của phân đoạn đó. Nếu đó là một phân đoạn gốc, hãy đề cập đến PARENT = 0.
Bảng sau đây cho thấy các tham số được sử dụng trong câu lệnh macro FIELD:
| S.Không | Mô tả về Thông Số |
|---|---|
| 1 | Name Tên của trường, thường dài từ 1 đến 8 ký tự |
| 2 | Bytes Chiều dài của trường |
| 3 | Start Vị trí của trường trong phân đoạn |
| 4 | Type Kiểu dữ liệu của trường |
| 5 | Type C Kiểu dữ liệu ký tự |
| 6 | Type P Kiểu dữ liệu thập phân được đóng gói |
| 7 | Type Z Kiểu dữ liệu thập phân được khoanh vùng |
| số 8 | Type X Kiểu dữ liệu thập lục phân |
| 9 | Type H Kiểu dữ liệu nhị phân nửa từ |
| 10 | Type F Kiểu dữ liệu nhị phân từ đầy đủ |
Khối đặc tả chương trình (PSB)
Các nguyên tắc cơ bản của PSB như dưới đây:
Cơ sở dữ liệu có một cấu trúc vật lý duy nhất được xác định bởi DBD nhưng các chương trình ứng dụng xử lý nó có thể có các khung nhìn khác nhau về cơ sở dữ liệu. Các khung nhìn này được gọi là cấu trúc dữ liệu ứng dụng và được định nghĩa trong PSB.
Không chương trình nào có thể sử dụng nhiều hơn một PSB trong một lần thực thi.
Các chương trình ứng dụng có PSB của riêng chúng và các chương trình ứng dụng có các yêu cầu xử lý cơ sở dữ liệu tương tự thường dùng chung một PSB.
PSB bao gồm một hoặc nhiều khối điều khiển được gọi là Khối truyền thông chương trình (PCB). PSB chứa một PCB cho mỗi cơ sở dữ liệu DL / I mà chương trình ứng dụng sẽ truy cập. Chúng tôi sẽ thảo luận thêm về PCB trong các mô-đun sắp tới.
PSBGEN phải được thực hiện để tạo PSB cho chương trình.
PSBGEN
PSBGEN được gọi là Bộ tạo khối đặc tả chương trình. Ví dụ sau tạo PSB bằng PSBGEN:
PRINT NOGEN
PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS
SENSEG NAME=LIBSEG
SENSEG NAME=BOOKSEG,PARENT=LIBSEG
SENSEG NAME=MAGSEG,PARENT=LIBSEG
PSBGEN PSBNAME=LIBPSB,LANG=COBOL
ENDHãy để chúng tôi hiểu các thuật ngữ được sử dụng trong DBDGEN ở trên -
Câu lệnh macro đầu tiên là Khối Giao tiếp Chương trình (PCB) mô tả Kiểu cơ sở dữ liệu, Tên, Độ dài khóa và Tùy chọn xử lý.
Tham số DBDNAME trên macro PCB chỉ định tên của DBD. KEYLEN chỉ định độ dài của khóa nối dài nhất. Chương trình có thể xử lý trong cơ sở dữ liệu. Tham số PROCOPT chỉ định các tùy chọn xử lý của chương trình. Ví dụ, LS chỉ có nghĩa là các Hoạt động TẢI.
SENSEG được gọi là Độ nhạy mức phân đoạn. Nó xác định quyền truy cập của chương trình vào các phần của cơ sở dữ liệu và nó được xác định ở cấp độ phân đoạn. Chương trình có quyền truy cập vào tất cả các trường trong các phân đoạn mà nó nhạy cảm. Một chương trình cũng có thể có độ nhạy ở mức trường. Trong phần này, chúng tôi xác định tên phân đoạn và tên gốc của phân đoạn.
Câu lệnh macro cuối cùng là PCBGEN. PSBGEN là câu lệnh cuối cùng cho biết không còn câu lệnh nào để xử lý. PSBNAME xác định tên được đặt cho mô-đun PSB đầu ra. Tham số LANG chỉ định ngôn ngữ mà chương trình ứng dụng được viết, ví dụ: COBOL.
Khối kiểm soát ra vào (ACB)
Dưới đây là những điểm cần lưu ý về các khối kiểm soát truy cập -
Khối điều khiển truy cập cho một chương trình ứng dụng kết hợp Bộ mô tả cơ sở dữ liệu và Khối đặc tả chương trình thành một biểu mẫu thực thi.
ACBGEN được gọi là Trình tạo khối kiểm soát truy cập. Nó được sử dụng để tạo ra các ACB.
Đối với các chương trình trực tuyến, chúng ta cần xây dựng trước các ACB. Do đó tiện ích ACBGEN được thực thi trước khi thực thi chương trình ứng dụng.
Đối với các chương trình hàng loạt, ACB cũng có thể được tạo tại thời điểm thực hiện.
Một chương trình ứng dụng bao gồm các lệnh gọi DL / I không thể thực thi trực tiếp. Thay vào đó, cần có JCL để kích hoạt mô-đun lô IMS DL / I. Mô-đun khởi tạo hàng loạt trong IMS là DFSRRC00. Chương trình ứng dụng và mô-đun DL / I thực thi cùng nhau. Sơ đồ sau đây cho thấy cấu trúc của một chương trình ứng dụng bao gồm các lệnh gọi DL / I để truy cập cơ sở dữ liệu.
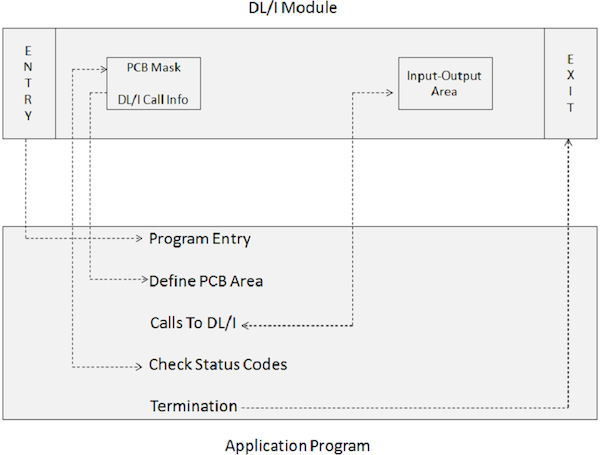
Chương trình ứng dụng giao diện với các mô-đun IMS DL / I thông qua các phần tử chương trình sau:
Một câu lệnh ENTRY chỉ định rằng PCB được chương trình sử dụng.
Mặt nạ PCB liên quan đến thông tin được lưu giữ trong PCB được xây dựng trước, nơi nhận thông tin trả về từ IMS.
Khu vực Đầu vào-Đầu ra được sử dụng để chuyển các phân đoạn dữ liệu đến và đi từ cơ sở dữ liệu IMS.
Các lệnh gọi đến DL / I chỉ định các chức năng xử lý như tìm nạp, chèn, xóa, thay thế, v.v.
Mã kiểm tra trạng thái được sử dụng để kiểm tra mã trả về SQL của tùy chọn xử lý được chỉ định để thông báo liệu hoạt động có thành công hay không.
Câu lệnh Chấm dứt được sử dụng để kết thúc quá trình xử lý chương trình ứng dụng bao gồm DL / I.
Bố cục phân đoạn
Hiện tại, chúng tôi đã biết rằng IMS bao gồm các phân đoạn được sử dụng trong các ngôn ngữ lập trình cấp cao để truy cập dữ liệu. Hãy xem xét cấu trúc cơ sở dữ liệu IMS sau đây của một Thư viện mà chúng ta đã thấy trước đó và ở đây chúng ta thấy bố cục của các phân đoạn của nó trong COBOL -
01 LIBRARY-SEGMENT.
05 BOOK-ID PIC X(5).
05 ISSUE-DATE PIC X(10).
05 RETURN-DATE PIC X(10).
05 STUDENT-ID PIC A(25).
01 BOOK-SEGMENT.
05 BOOK-ID PIC X(5).
05 BOOK-NAME PIC A(30).
05 AUTHOR PIC A(25).
01 STUDENT-SEGMENT.
05 STUDENT-ID PIC X(5).
05 STUDENT-NAME PIC A(25).
05 DIVISION PIC X(10).Tổng quan về chương trình ứng dụng
Cấu trúc của chương trình ứng dụng IMS khác với cấu trúc của chương trình ứng dụng không phải IMS. Một chương trình IMS không thể được thực thi trực tiếp; đúng hơn nó luôn được gọi như một chương trình con. Một chương trình ứng dụng IMS bao gồm các Khối đặc tả chương trình để cung cấp chế độ xem cơ sở dữ liệu IMS.
Chương trình ứng dụng và các PSB được liên kết với chương trình đó được tải khi chúng tôi thực thi một chương trình ứng dụng bao gồm các mô-đun IMS DL / I. Sau đó, các yêu cầu CALL được kích hoạt bởi các chương trình ứng dụng được thực thi bởi mô-đun IMS.
Dịch vụ IMS
Các dịch vụ IMS sau được chương trình ứng dụng sử dụng:
- Truy cập bản ghi cơ sở dữ liệu
- Ban hành lệnh IMS
- Thực hiện các cuộc gọi dịch vụ IMS
- Cuộc gọi trạm kiểm soát
- Đồng bộ hóa cuộc gọi
- Gửi hoặc nhận tin nhắn từ thiết bị đầu cuối người dùng trực tuyến
Chúng tôi bao gồm các cuộc gọi DL / I bên trong chương trình ứng dụng COBOL để giao tiếp với cơ sở dữ liệu IMS. Chúng tôi sử dụng các câu lệnh DL / I sau trong chương trình COBOL để truy cập cơ sở dữ liệu:
- Báo cáo đầu vào
- Tuyên bố quay lại
- Báo cáo cuộc gọi
Báo cáo đầu vào
Nó được sử dụng để chuyển điều khiển từ DL / I đến chương trình COBOL. Đây là cú pháp của câu lệnh nhập -
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]Câu lệnh trên được mã hóa trong Procedure Divisioncủa một chương trình COBOL. Hãy cùng chúng tôi tìm hiểu chi tiết về câu lệnh đầu vào trong chương trình COBOL -
Mô-đun khởi tạo hàng loạt kích hoạt chương trình ứng dụng và được thực thi dưới sự kiểm soát của nó.
DL / I tải các khối và mô-đun điều khiển được yêu cầu và chương trình ứng dụng, và quyền điều khiển được trao cho chương trình ứng dụng.
DLITCBL là viết tắt của DL/I to COBOL. Câu lệnh entry được sử dụng để xác định điểm vào trong chương trình.
Khi chúng tôi gọi một chương trình con trong COBOL, địa chỉ của nó cũng được cung cấp. Tương tự như vậy, khi DL / I trao quyền điều khiển cho chương trình ứng dụng, nó cũng cung cấp địa chỉ của mỗi PCB được xác định trong PSB của chương trình.
Tất cả các PCB được sử dụng trong chương trình ứng dụng phải được xác định bên trong Linkage Section của chương trình COBOL vì PCB nằm ngoài chương trình ứng dụng.
Định nghĩa PCB bên trong Phần liên kết được gọi là PCB Mask.
Mối quan hệ giữa mặt nạ PCB và PCB thực tế trong kho được tạo ra bằng cách liệt kê các PCB trong báo cáo đầu vào. Trình tự liệt kê trong câu lệnh nhập phải giống như trình tự xuất hiện trong PSBGEN.
Tuyên bố quay lại
Nó được sử dụng để chuyển điều khiển trở lại chương trình điều khiển IMS. Sau đây là cú pháp của câu lệnh Goback:
GOBACKDưới đây là những điểm cơ bản cần lưu ý về câu lệnh Goback -
GOBACK được mã hóa ở cuối chương trình ứng dụng. Nó trả về điều khiển cho DL / I từ chương trình.
Chúng ta không nên sử dụng STOP RUN vì nó trả lại quyền điều khiển cho hệ điều hành. Nếu chúng ta sử dụng STOP RUN, DL / I sẽ không bao giờ có cơ hội thực hiện các chức năng kết thúc của nó. Đó là lý do tại sao, trong các chương trình ứng dụng DL / I, câu lệnh Goback được sử dụng.
Trước khi đưa ra câu lệnh Goback, tất cả các tập dữ liệu không phải DL / I được sử dụng trong chương trình ứng dụng COBOL phải được đóng lại, nếu không chương trình sẽ kết thúc bất thường.
Báo cáo cuộc gọi
Lệnh gọi được sử dụng để yêu cầu các dịch vụ DL / I chẳng hạn như thực hiện các hoạt động nhất định trên cơ sở dữ liệu IMS. Đây là cú pháp của câu lệnh gọi -
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]Cú pháp trên hiển thị các tham số mà bạn có thể sử dụng với câu lệnh cuộc gọi. Chúng ta sẽ thảo luận về từng loại trong bảng sau:
| Không. | Mô tả về Thông Số |
|---|---|
| 1 | DLI Function Code Xác định chức năng DL / I sẽ được thực hiện. Đối số này là tên của bốn trường ký tự mô tả hoạt động I / O. |
| 2 | PCB Mask Định nghĩa PCB bên trong Phần liên kết được gọi là Mặt nạ PCB. Chúng được sử dụng trong câu lệnh nhập cảnh. Không yêu cầu câu lệnh SELECT, ASSIGN, OPEN hoặc CLOSE. |
| 3 | Segment I/O Area Tên của một khu vực làm việc đầu vào / đầu ra. Đây là một khu vực của chương trình ứng dụng mà DL / I đặt một phân đoạn được yêu cầu. |
| 4 | Segment Search Arguments Đây là các tham số tùy chọn tùy thuộc vào loại lệnh gọi được phát hành. Chúng được sử dụng để tìm kiếm các phân đoạn dữ liệu bên trong cơ sở dữ liệu IMS. |
Dưới đây là những điểm cần lưu ý về câu lệnh Call -
CBLTDLI là viết tắt của COBOL to DL/I. Nó là tên của một mô-đun giao diện được liên kết chỉnh sửa với mô-đun đối tượng của chương trình của bạn.
Sau mỗi lần gọi DL / I, DLI lưu trữ một mã trạng thái trong PCB. Chương trình có thể sử dụng mã này để xác định cuộc gọi thành công hay thất bại.
Thí dụ
Để hiểu thêm về COBOL, bạn có thể xem qua hướng dẫn về COBOL của chúng tôi tại đây . Ví dụ sau đây cho thấy cấu trúc của một chương trình COBOL sử dụng cơ sở dữ liệu IMS và các lệnh gọi DL / I. Chúng ta sẽ thảo luận chi tiết từng tham số được sử dụng trong ví dụ trong các chương sắp tới.
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST1.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.
01 SEGMENT-I-O-AREA PIC X(150).
LINKAGE SECTION.
01 STUDENT-PCB-MASK.
05 STD-DBD-NAME PIC X(8).
05 STD-SEGMENT-LEVEL PIC XX.
05 STD-STATUS-CODE PIC XX.
05 STD-PROC-OPTIONS PIC X(4).
05 FILLER PIC S9(5) COMP.
05 STD-SEGMENT-NAME PIC X(8).
05 STD-KEY-LENGTH PIC S9(5) COMP.
05 STD-NUMB-SENS-SEGS PIC S9(5) COMP.
05 STD-KEY PIC X(11).
PROCEDURE DIVISION.
ENTRY 'DLITCBL' USING STUDENT-PCB-MASK.
A000-READ-PARA.
110-GET-INVENTORY-SEGMENT.
CALL ‘CBLTDLI’ USING DLI-GN
STUDENT-PCB-MASK
SEGMENT-I-O-AREA.
GOBACK.Hàm DL / I là tham số đầu tiên được sử dụng trong lệnh gọi DL / I. Hàm này cho biết thao tác nào sẽ được thực hiện trên cơ sở dữ liệu IMS bằng lệnh gọi IMS DL / I. Cú pháp của hàm DL / I như sau:
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.Cú pháp này đại diện cho các điểm chính sau:
Đối với tham số này, chúng ta có thể cung cấp bất kỳ tên gồm bốn ký tự nào làm trường lưu trữ để lưu mã hàm.
Tham số hàm DL / I được mã hóa trong phần lưu trữ làm việc của chương trình COBOL.
Để chỉ định hàm DL / I, lập trình viên cần mã một trong 05 tên dữ liệu mức như DLI-GU trong lệnh gọi DL / I, vì COBOL không cho phép mã hóa các ký tự trên câu lệnh CALL.
Các chức năng DL / I được chia thành ba loại: Nhận, Cập nhật và Các chức năng khác. Hãy để chúng tôi thảo luận chi tiết từng người trong số họ.
Nhận chức năng
Các hàm Get tương tự như thao tác đọc được hỗ trợ bởi bất kỳ ngôn ngữ lập trình nào. Hàm Get được sử dụng để tìm nạp các phân đoạn từ cơ sở dữ liệu IMS DL / I. Các hàm Get sau được sử dụng trong IMS DB:
- Nhận duy nhất
- Tiếp theo
- Tiếp theo trong Parent
- Nắm giữ duy nhất
- Giữ tiếp theo
- Tiếp tục giữ trong vòng Parent
Chúng ta hãy xem xét cấu trúc cơ sở dữ liệu IMS sau đây để hiểu các lệnh gọi hàm DL / I:
Nhận duy nhất
Mã 'GU' được sử dụng cho chức năng Nhận duy nhất. Nó hoạt động tương tự như câu lệnh đọc ngẫu nhiên trong COBOL. Nó được sử dụng để tìm nạp một lần xuất hiện phân đoạn cụ thể dựa trên các giá trị trường. Các giá trị trường có thể được cung cấp bằng cách sử dụng các đối số tìm kiếm phân đoạn. Cú pháp của cuộc gọi GU như sau:
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Nếu bạn thực hiện lệnh gọi ở trên bằng cách cung cấp các giá trị thích hợp cho tất cả các tham số trong chương trình COBOL, bạn có thể truy xuất phân đoạn trong khu vực I / O phân đoạn từ cơ sở dữ liệu. Trong ví dụ trên, nếu bạn cung cấp các giá trị trường của Thư viện, Tạp chí và Sức khỏe, thì bạn sẽ nhận được sự xuất hiện mong muốn của phân đoạn Sức khỏe.
Tiếp theo
Mã 'GN' được sử dụng cho chức năng Get Next. Nó hoạt động tương tự như câu lệnh đã đọc tiếp theo trong COBOL. Nó được sử dụng để tìm nạp các lần xuất hiện của phân đoạn trong một trình tự. Mẫu được xác định trước để truy cập các lần xuất hiện phân đoạn dữ liệu là theo phân cấp, sau đó từ trái sang phải. Cú pháp của một cuộc gọi GN như sau:
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Nếu bạn thực hiện câu lệnh gọi ở trên bằng cách cung cấp các giá trị thích hợp cho tất cả các tham số trong chương trình COBOL, bạn có thể truy xuất sự xuất hiện phân đoạn trong khu vực I / O phân đoạn từ cơ sở dữ liệu theo thứ tự tuần tự. Trong ví dụ trên, nó bắt đầu với việc truy cập phân đoạn Thư viện, sau đó phân đoạn Sách, v.v. Chúng tôi thực hiện lệnh gọi GN lặp đi lặp lại, cho đến khi chúng tôi đạt được sự xuất hiện phân đoạn mà chúng tôi muốn.
Tiếp theo trong Parent
Mã 'GNP' được sử dụng cho Get Next trong Parent. Hàm này được sử dụng để truy xuất các lần xuất hiện của phân đoạn theo trình tự phụ với phân đoạn mẹ đã thiết lập. Cú pháp của lệnh gọi GNP như sau:
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Nắm giữ duy nhất
Mã 'GHU' được sử dụng để Nhận Giữ hàng Duy nhất. Hàm giữ chỉ định rằng chúng tôi sẽ cập nhật phân đoạn sau khi truy xuất. Chức năng Nhận Giữ Duy nhất tương ứng với cuộc gọi Nhận Duy nhất. Dưới đây là cú pháp của cuộc gọi GHU -
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Giữ tiếp theo
Mã 'GHN' được sử dụng cho Tiếp theo. Hàm giữ chỉ định rằng chúng tôi sẽ cập nhật phân đoạn sau khi truy xuất. Chức năng Nhận Giữ Tiếp theo tương ứng với cuộc gọi Tiếp theo. Dưới đây là cú pháp của lệnh gọi GHN -
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Tiếp tục giữ trong vòng Parent
Mã 'GHNP' được sử dụng để Nhận Tiếp theo trong vòng dành cho Phụ huynh. Hàm giữ chỉ định rằng chúng tôi sẽ cập nhật phân đoạn sau khi truy xuất. Chức năng Get Hold Next trong Parent tương ứng với lệnh Get Next trong Parent. Dưới đây là cú pháp của cuộc gọi GHNP -
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Cập nhật chức năng
Các chức năng cập nhật tương tự như các thao tác viết lại hoặc chèn vào bất kỳ ngôn ngữ lập trình nào khác. Các chức năng cập nhật được sử dụng để cập nhật các phân đoạn trong cơ sở dữ liệu IMS DL / I. Trước khi sử dụng chức năng cập nhật, phải có một cuộc gọi thành công với mệnh đề Giữ cho sự xuất hiện của phân đoạn. Các chức năng Cập nhật sau được sử dụng trong IMS DB -
- Insert
- Delete
- Replace
Chèn
Mã 'ISRT' được sử dụng cho chức năng Chèn. Hàm ISRT được sử dụng để thêm một phân đoạn mới vào cơ sở dữ liệu. Nó được sử dụng để thay đổi cơ sở dữ liệu hiện có hoặc tải cơ sở dữ liệu mới. Dưới đây là cú pháp của lệnh gọi ISRT -
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]Xóa bỏ
Mã 'DLET' được sử dụng cho chức năng Xóa. Nó được sử dụng để xóa một phân đoạn khỏi cơ sở dữ liệu IMS DL / I. Dưới đây là cú pháp của lệnh gọi DLET -
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]Thay thế
Mã 'REPL' được sử dụng cho Nhận Giữ Tiếp theo trong Parent. Chức năng Replace được sử dụng để thay thế một phân đoạn trong cơ sở dữ liệu IMS DL / I. Dưới đây là cú pháp của cuộc gọi REPL -
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]Cac chưc năng khac
Các chức năng khác sau đây được sử dụng trong lệnh gọi IMS DL / I:
- Checkpoint
- Restart
- PCB
Trạm kiểm soát
Mã 'CHKP' được sử dụng cho chức năng Điểm kiểm tra. Nó được sử dụng trong các tính năng khôi phục của IMS. Dưới đây là cú pháp của cuộc gọi CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Khởi động lại
Mã 'XRST' được sử dụng cho chức năng Khởi động lại. Nó được sử dụng trong các tính năng khởi động lại của IMS. Dưới đây là cú pháp của cuộc gọi XRST -
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]PCB
Chức năng PCB được sử dụng trong các chương trình CICS trong cơ sở dữ liệu IMS DL / I. Dưới đây là cú pháp của cuộc gọi PCB -
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]Bạn có thể tìm thêm thông tin chi tiết về các chức năng này trong chương khôi phục.
PCB là viết tắt của Program Communication Block. PCB Mask là tham số thứ hai được sử dụng trong lệnh gọi DL / I. Nó được khai báo trong phần liên kết. Dưới đây là cú pháp của PCB Mask -
01 PCB-NAME.
05 DBD-NAME PIC X(8).
05 SEG-LEVEL PIC XX.
05 STATUS-CODE PIC XX.
05 PROC-OPTIONS PIC X(4).
05 RESERVED-DLI PIC S9(5).
05 SEG-NAME PIC X(8).
05 LENGTH-FB-KEY PIC S9(5).
05 NUMB-SENS-SEGS PIC S9(5).
05 KEY-FB-AREA PIC X(n).Dưới đây là những điểm chính cần lưu ý -
Đối với mỗi cơ sở dữ liệu, DL / I duy trì một vùng lưu trữ được gọi là khối giao tiếp chương trình. Nó lưu trữ thông tin về cơ sở dữ liệu được truy cập bên trong các chương trình ứng dụng.
Câu lệnh ENTRY tạo kết nối giữa các mặt nạ PCB trong Phần liên kết và các PCB trong PSB của chương trình. Mặt nạ PCB được sử dụng trong lệnh gọi DL / I cho biết cơ sở dữ liệu nào sẽ sử dụng để hoạt động.
Bạn có thể cho rằng điều này tương tự như việc chỉ định tên tệp trong câu lệnh COBOL READ hoặc tên bản ghi trong câu lệnh ghi COBOL. Không yêu cầu câu lệnh SELECT, ASSIGN, OPEN hoặc CLOSE.
Sau mỗi lần gọi DL / I, DL / I lưu một mã trạng thái trong PCB và chương trình có thể sử dụng mã đó để xác định xem cuộc gọi thành công hay thất bại.
Tên PCB
Những điểm cần lưu ý -
Tên PCB là tên của khu vực đề cập đến toàn bộ cấu trúc của các trường PCB.
Tên PCB được sử dụng trong các câu lệnh của chương trình.
Tên PCB không phải là một trường trong PCB.
Tên DBD
Những điểm cần lưu ý -
Tên DBD chứa dữ liệu ký tự. Nó dài tám byte.
Trường đầu tiên trong PCB là tên của cơ sở dữ liệu đang được xử lý và nó cung cấp tên DBD từ thư viện mô tả cơ sở dữ liệu được liên kết với một cơ sở dữ liệu cụ thể.
Mức phân đoạn
Những điểm cần lưu ý -
Cấp phân đoạn được gọi là Chỉ báo cấp phân cấp phân đoạn. Nó chứa dữ liệu ký tự và dài hai byte.
Trường cấp độ phân đoạn lưu trữ cấp độ của phân đoạn đã được xử lý. Khi một phân đoạn được truy xuất thành công, số cấp của phân đoạn đã truy xuất được lưu trữ ở đây.
Trường cấp phân đoạn không bao giờ có giá trị lớn hơn 15 vì đó là số cấp tối đa được phép trong cơ sở dữ liệu DL / I.
Mã trạng thái
Những điểm cần lưu ý -
Trường mã trạng thái chứa hai byte dữ liệu ký tự.
Mã trạng thái chứa mã trạng thái DL / I.
Dấu cách được chuyển đến trường mã trạng thái khi DL / I hoàn thành xử lý lệnh gọi thành công.
Các giá trị không phải khoảng trắng cho biết rằng cuộc gọi không thành công.
Mã trạng thái GB cho biết phần cuối của tệp và mã trạng thái GE cho biết rằng không tìm thấy phân đoạn được yêu cầu.
Tùy chọn Proc
Những điểm cần lưu ý -
Tùy chọn Proc được gọi là tùy chọn xử lý có chứa các trường dữ liệu bốn ký tự.
Trường Tùy chọn xử lý cho biết loại xử lý mà chương trình được phép thực hiện trên cơ sở dữ liệu.
DL / I dành riêng
Những điểm cần lưu ý -
DL / I dành riêng được gọi là vùng dành riêng của IMS. Nó lưu trữ dữ liệu nhị phân bốn byte.
IMS sử dụng khu vực này cho liên kết nội bộ của riêng mình liên quan đến một chương trình ứng dụng.
Tên phân đoạn
Những điểm cần lưu ý -
Tên SEG được gọi là khu vực phản hồi tên phân đoạn. Nó chứa 8 byte dữ liệu ký tự.
Tên của phân đoạn được lưu trữ trong trường này sau mỗi lần gọi DL / tôi.
Khóa FB chiều dài
Những điểm cần lưu ý -
Chiều dài phím FB được gọi là chiều dài của vùng phản hồi phím. Nó lưu trữ bốn byte dữ liệu nhị phân.
Trường này được sử dụng để báo cáo độ dài của khóa nối của phân đoạn cấp thấp nhất được xử lý trong lần gọi trước.
Nó được sử dụng với khu vực phản hồi chính.
Số lượng phân đoạn nhạy cảm
Những điểm cần lưu ý -
Số lượng phân đoạn độ nhạy lưu trữ dữ liệu nhị phân bốn byte.
Nó xác định mức độ nhạy cảm của một chương trình ứng dụng. Nó đại diện cho số lượng phân đoạn trong cấu trúc dữ liệu logic.
Khu vực phản hồi chính
Những điểm cần lưu ý -
Vùng phản hồi chính có độ dài khác nhau từ PCB này sang PCB khác.
Nó chứa khóa nối dài nhất có thể có thể được sử dụng với chế độ xem cơ sở dữ liệu của chương trình.
Sau khi thao tác với cơ sở dữ liệu, DL / I trả về khóa được nối của phân đoạn cấp thấp nhất được xử lý trong trường này và nó trả về độ dài của khóa trong vùng phản hồi độ dài khóa.
SSA là viết tắt của Segment Search Arguments. SSA được sử dụng để xác định sự xuất hiện của phân đoạn đang được truy cập. Nó là một tham số tùy chọn. Chúng tôi có thể bao gồm bất kỳ số lượng SSA nào tùy thuộc vào yêu cầu. Có hai loại SSA -
- SSA không đủ tiêu chuẩn
- SSA đủ điều kiện
SSA không đủ tiêu chuẩn
SSA không đủ tiêu chuẩn cung cấp tên của phân đoạn đang được sử dụng bên trong cuộc gọi. Dưới đây là cú pháp của một SSA không đủ tiêu chuẩn -
01 UNQUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X VALUE SPACE.Các điểm chính của SSA không đủ tiêu chuẩn như sau:
Một SSA không đủ tiêu chuẩn cơ bản dài 9 byte.
8 byte đầu tiên giữ tên phân đoạn đang được sử dụng để xử lý.
Byte cuối cùng luôn chứa khoảng trắng.
DL / I sử dụng byte cuối cùng để xác định loại SSA.
Để truy cập một phân đoạn cụ thể, hãy di chuyển tên của phân đoạn trong trường TÊN PHÂN ĐOẠN.
Các hình ảnh sau đây cho thấy cấu trúc của các SSA không đủ tiêu chuẩn và đủ điều kiện -
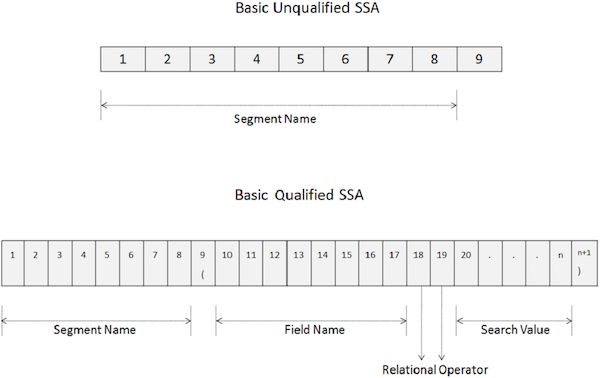
SSA đủ điều kiện
SSA Đủ điều kiện cung cấp loại phân đoạn với sự xuất hiện cơ sở dữ liệu cụ thể của một phân đoạn. Dưới đây là cú pháp của SSA Đủ điều kiện -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.Các điểm chính của SSA đủ điều kiện như sau:
8 byte đầu tiên của một SSA đủ điều kiện chứa tên phân đoạn đang được sử dụng để xử lý.
Byte thứ chín là một dấu ngoặc đơn bên trái '('.
8 byte tiếp theo bắt đầu từ vị trí thứ mười chỉ định tên trường mà chúng ta muốn tìm kiếm.
Sau khi tên trường, trong vòng 18 ngày và 19 ngày vị trí, chúng tôi chỉ định hai nhân vật đang điều hành quan hệ.
Sau đó, chúng tôi chỉ định giá trị trường và trong byte cuối cùng, có một dấu ngoặc đơn bên phải ')'.
Bảng sau đây cho thấy các toán tử quan hệ được sử dụng trong SSA Đủ điều kiện.
| Toán tử quan hệ | Biểu tượng | Sự miêu tả |
|---|---|---|
| EQ | = | Công bằng |
| NE | ~ = ˜ | Không công bằng |
| GT | > | Lớn hơn |
| GE | > = | Lớn hơn hoặc bằng |
| LT | << | Ít hơn |
| LE | <= | Nhỏ hơn hoặc bằng |
Mã lệnh
Mã lệnh được sử dụng để nâng cao chức năng của lệnh gọi DL / I. Mã lệnh làm giảm số lượng lệnh gọi DL / I, làm cho các chương trình trở nên đơn giản. Ngoài ra, nó còn cải thiện hiệu suất khi số lượng cuộc gọi giảm xuống. Hình ảnh sau đây cho thấy cách mã lệnh được sử dụng trong các SSA không đủ tiêu chuẩn và đủ điều kiện:
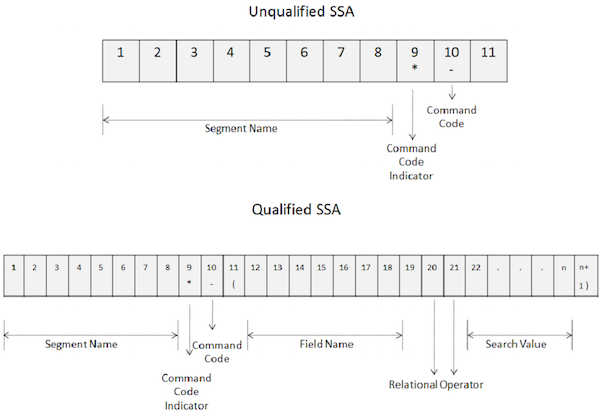
Các điểm chính của mã lệnh như sau:
Để sử dụng mã lệnh, hãy chỉ định dấu hoa thị ở vị trí thứ 9 của SSA như thể hiện trong hình trên.
Mã lệnh được mã hóa ở vị trí thứ mười.
Từ vị trí thứ 10 trở đi, DL / I coi tất cả các ký tự là mã lệnh cho đến khi nó gặp khoảng trống cho một SSA không đủ tiêu chuẩn và một dấu ngoặc đơn bên trái cho một SSA đủ điều kiện.
Bảng sau đây cho thấy danh sách các mã lệnh được sử dụng trong SSA:
| Mã lệnh | Sự miêu tả |
|---|---|
| C | Khóa liên kết |
| D | Cuộc gọi đường dẫn |
| F | Lần xuất hiện đầu tiên |
| L | Lần xuất hiện cuối cùng |
| N | Bỏ qua cuộc gọi đường dẫn |
| P | Đặt huyết thống |
| Q | Enqueue Segment |
| U | Duy trì vị trí ở cấp độ này |
| V | Duy trì Vị trí ở mức này và tất cả các cấp trên |
| - | Mã lệnh rỗng |
Nhiều bằng cấp
Các điểm cơ bản của nhiều bằng cấp như sau:
Nhiều bằng cấp được yêu cầu khi chúng ta cần sử dụng hai hoặc nhiều bằng cấp hoặc lĩnh vực để so sánh.
Chúng tôi sử dụng toán tử Boolean như AND và OR để kết nối hai hoặc nhiều trình độ.
Nhiều trình độ có thể được sử dụng khi chúng ta muốn xử lý một phân đoạn dựa trên một loạt các giá trị có thể có cho một trường.
Dưới đây là cú pháp của Nhiều Bằng cấp -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.MUL-QUAL là một thuật ngữ viết tắt của MULtiple QUALIification, trong đó chúng tôi có thể cung cấp các toán tử boolean như AND hoặc OR.
Các phương pháp truy xuất dữ liệu khác nhau được sử dụng trong lệnh gọi IMS DL / I như sau:
- Gọi GU
- Gọi GN
- Sử dụng mã lệnh
- Nhiều chế biến
Chúng ta hãy xem xét cấu trúc cơ sở dữ liệu IMS sau đây để hiểu các lệnh gọi hàm truy xuất dữ liệu:
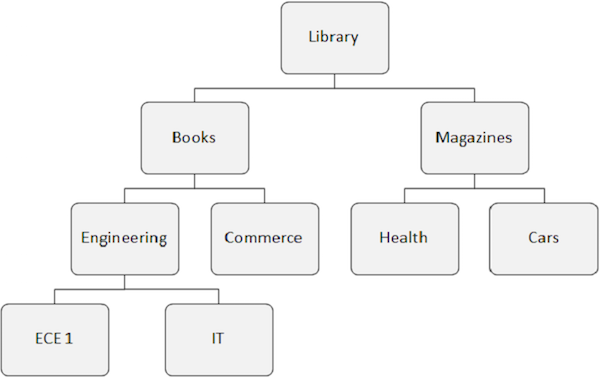
Gọi GU
Các nguyên tắc cơ bản của cuộc gọi GU như sau:
Cuộc gọi GU được gọi là cuộc gọi Nhận duy nhất. Nó được sử dụng để xử lý ngẫu nhiên.
Nếu một ứng dụng không cập nhật cơ sở dữ liệu thường xuyên hoặc nếu số lượng cập nhật cơ sở dữ liệu ít hơn, thì chúng tôi sử dụng xử lý ngẫu nhiên.
Lệnh gọi GU được sử dụng để đặt con trỏ tại một vị trí cụ thể để truy xuất tuần tự tiếp theo.
Các cuộc gọi GU độc lập với vị trí con trỏ được thiết lập bởi các cuộc gọi trước đó.
Quá trình xử lý cuộc gọi GU dựa trên các trường khóa duy nhất được cung cấp trong câu lệnh gọi.
Nếu chúng tôi cung cấp trường khóa không phải là duy nhất, thì DL / I trả về lần xuất hiện phân đoạn đầu tiên của trường khóa.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSAVí dụ trên cho thấy chúng tôi thực hiện lệnh gọi GU bằng cách cung cấp một tập hợp đầy đủ các SSA đủ điều kiện. Nó bao gồm tất cả các trường khóa bắt đầu từ cấp cơ sở cho đến sự xuất hiện của phân đoạn mà chúng ta muốn truy xuất.
Cân nhắc cuộc gọi GU
Nếu chúng tôi không cung cấp bộ đầy đủ các SSA đủ điều kiện trong cuộc gọi, thì DL / I hoạt động theo cách sau:
Khi chúng tôi sử dụng SSA không đủ tiêu chuẩn trong lệnh gọi GU, DL / I truy cập lần xuất hiện phân đoạn đầu tiên trong cơ sở dữ liệu đáp ứng các tiêu chí bạn chỉ định.
Khi chúng tôi thực hiện một cuộc gọi GU mà không có bất kỳ SSA nào, DL / I trả về lần xuất hiện đầu tiên của phân đoạn gốc trong cơ sở dữ liệu.
Nếu một số SSA ở cấp độ trung gian không được đề cập trong lệnh gọi, thì DL / I sử dụng vị trí đã thiết lập hoặc giá trị mặc định của một SSA không đủ tiêu chuẩn cho phân đoạn.
Mã trạng thái
Bảng sau đây hiển thị các mã trạng thái có liên quan sau cuộc gọi GU -
| S.Không | Mã Trạng thái & Mô tả |
|---|---|
| 1 | Spaces Cuộc gọi thành công |
| 2 | GE DL / Tôi không thể tìm thấy phân đoạn đáp ứng các tiêu chí được chỉ định trong cuộc gọi |
Gọi GN
Các nguyên tắc cơ bản của cuộc gọi GN như sau:
Cuộc gọi GN được gọi là cuộc gọi Tiếp theo. Nó được sử dụng để xử lý tuần tự cơ bản.
Vị trí ban đầu của con trỏ trong cơ sở dữ liệu là trước phân đoạn gốc của bản ghi cơ sở dữ liệu đầu tiên.
Vị trí con trỏ cơ sở dữ liệu nằm trước lần xuất hiện phân đoạn tiếp theo trong chuỗi, sau khi gọi GN thành công.
Cuộc gọi GN bắt đầu thông qua cơ sở dữ liệu từ vị trí được thiết lập bởi cuộc gọi trước đó.
Nếu một lệnh gọi GN không đủ điều kiện, nó sẽ trả về lần xuất hiện phân đoạn tiếp theo trong cơ sở dữ liệu bất kể loại của nó, theo trình tự phân cấp.
Nếu một lệnh gọi GN bao gồm các SSA, thì DL / I chỉ truy xuất các phân đoạn đáp ứng các yêu cầu của tất cả các SSA được chỉ định.
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSAVí dụ trên cho thấy chúng tôi thực hiện một cuộc gọi GN cung cấp vị trí bắt đầu để đọc các bản ghi một cách tuần tự. Nó tìm nạp lần xuất hiện đầu tiên của phân đoạn BOOKS.
Mã trạng thái
Bảng sau đây hiển thị các mã trạng thái có liên quan sau một cuộc gọi GN:
| S.Không | Mã Trạng thái & Mô tả |
|---|---|
| 1 | Spaces Cuộc gọi thành công |
| 2 | GE DL / Tôi không thể tìm thấy phân đoạn đáp ứng tiêu chí được chỉ định trong cuộc gọi. |
| 3 | GA Một lệnh gọi GN không đủ tiêu chuẩn di chuyển lên một cấp trong phân cấp cơ sở dữ liệu để tìm nạp phân đoạn. |
| 4 | GB Đã đến cuối cơ sở dữ liệu và không tìm thấy phân đoạn. |
GK Một lệnh gọi GN không đủ điều kiện cố gắng tìm nạp một phân đoạn của một loại cụ thể khác với một phân đoạn vừa được truy xuất nhưng vẫn ở cùng một mức phân cấp. |
Mã lệnh
Mã lệnh được sử dụng với các lệnh gọi để tìm nạp sự xuất hiện của phân đoạn. Các mã lệnh khác nhau được sử dụng với các cuộc gọi được thảo luận dưới đây.
Mã lệnh F
Những điểm cần lưu ý -
Khi một mã lệnh F được chỉ định trong một cuộc gọi, cuộc gọi sẽ xử lý lần xuất hiện đầu tiên của phân đoạn.
Mã lệnh F có thể được sử dụng khi chúng ta muốn xử lý tuần tự và nó có thể được sử dụng với các lệnh gọi GN và lệnh gọi GNP.
Nếu chúng ta chỉ định mã lệnh F với lệnh gọi GU, nó không có bất kỳ ý nghĩa nào, vì lệnh gọi GU tìm nạp lần xuất hiện phân đoạn đầu tiên theo mặc định.
Mã lệnh L
Những điểm cần lưu ý -
Khi một mã lệnh L được chỉ định trong một cuộc gọi, cuộc gọi sẽ xử lý lần xuất hiện cuối cùng của phân đoạn.
Mã lệnh L có thể được sử dụng khi chúng ta muốn xử lý tuần tự và nó có thể được sử dụng với các lệnh gọi GN và lệnh gọi GNP.
D Mã lệnh
Những điểm cần lưu ý -
Mã lệnh D được sử dụng để tìm nạp nhiều lần xuất hiện phân đoạn chỉ bằng một lệnh gọi.
Thông thường DL / I hoạt động trên phân đoạn cấp thấp nhất được chỉ định trong SSA, nhưng trong nhiều trường hợp, chúng tôi cũng muốn dữ liệu từ các cấp khác. Trong những trường hợp đó, chúng ta có thể sử dụng mã lệnh D.
Mã lệnh D giúp dễ dàng truy xuất toàn bộ đường dẫn của các phân đoạn.
Mã lệnh C
Những điểm cần lưu ý -
Mã lệnh C được sử dụng để nối các khóa.
Sử dụng toán tử quan hệ hơi phức tạp, vì chúng ta cần chỉ định tên trường, toán tử quan hệ và giá trị tìm kiếm. Thay vào đó, chúng ta có thể sử dụng mã lệnh C để cung cấp một khóa được nối.
Ví dụ sau cho thấy việc sử dụng mã lệnh C:
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSAMã lệnh P
Những điểm cần lưu ý -
Khi chúng ta thực hiện lệnh gọi GU hoặc GN, DL / I thiết lập nguồn gốc của nó ở phân đoạn cấp thấp nhất được truy xuất.
Nếu chúng ta bao gồm mã lệnh P, thì DL / I thiết lập nguồn gốc của nó ở một phân đoạn cấp cao hơn trong đường dẫn phân cấp.
Mã lệnh U
Những điểm cần lưu ý -
Khi mã lệnh U được chỉ định trong SSA không đủ tiêu chuẩn trong lệnh gọi GN, DL / I hạn chế tìm kiếm phân đoạn.
Mã lệnh U bị bỏ qua nếu nó được sử dụng với SSA đủ điều kiện.
Mã lệnh V
Những điểm cần lưu ý -
Mã lệnh V hoạt động tương tự như mã lệnh U, nhưng nó hạn chế việc tìm kiếm một phân đoạn ở một cấp cụ thể và tất cả các cấp trên hệ thống phân cấp.
Mã lệnh V bị bỏ qua khi được sử dụng với SSA đủ điều kiện.
Mã lệnh Q
Những điểm cần lưu ý -
Mã lệnh Q được sử dụng để xếp hàng hoặc đặt trước một phân đoạn để sử dụng riêng cho chương trình ứng dụng của bạn.
Mã lệnh Q được sử dụng trong một môi trường tương tác nơi một chương trình khác có thể thực hiện thay đổi đối với một phân đoạn.
Nhiều chế biến
Một chương trình có thể có nhiều vị trí trong cơ sở dữ liệu IMS được gọi là nhiều xử lý. Nhiều xử lý có thể được thực hiện theo hai cách:
- Nhiều PCB
- Nhiều vị trí
Nhiều PCB
Nhiều PCB có thể được xác định cho một cơ sở dữ liệu. Nếu có nhiều PCB, thì một chương trình ứng dụng có thể có các quan điểm khác nhau về nó. Phương pháp này để thực hiện nhiều quá trình xử lý là không hiệu quả vì các chi phí do PCB bổ sung gây ra.
Nhiều vị trí
Một chương trình có thể duy trì nhiều vị trí trong cơ sở dữ liệu bằng cách sử dụng một PCB duy nhất. Điều này đạt được bằng cách duy trì một vị trí riêng biệt cho mỗi đường dẫn phân cấp. Nhiều định vị được sử dụng để truy cập các phân đoạn của hai hoặc nhiều loại một cách tuần tự cùng một lúc.
Các phương pháp thao tác dữ liệu khác nhau được sử dụng trong lệnh gọi IMS DL / I như sau:
- Cuộc gọi ISRT
- Giữ cuộc gọi
- Cuộc gọi REPL
- Cuộc gọi DLET
Chúng ta hãy xem xét cấu trúc cơ sở dữ liệu IMS sau đây để hiểu các lệnh gọi hàm thao tác dữ liệu:
Cuộc gọi ISRT
Những điểm cần lưu ý -
Lệnh gọi ISRT được gọi là lệnh gọi Chèn được sử dụng để thêm các lần xuất hiện phân đoạn vào cơ sở dữ liệu.
Các lệnh gọi ISRT được sử dụng để tải một cơ sở dữ liệu mới.
Chúng tôi thực hiện lệnh gọi ISRT khi trường mô tả phân đoạn được tải với dữ liệu.
SSA không đủ điều kiện hoặc đủ điều kiện phải được chỉ định trong lệnh gọi để DL / tôi biết vị trí đặt sự cố phân đoạn.
Chúng tôi có thể sử dụng kết hợp cả SSA không đủ tiêu chuẩn và đủ điều kiện trong cuộc gọi. Một SSA đủ điều kiện có thể được chỉ định cho tất cả các cấp trên. Chúng ta hãy xem xét ví dụ sau:
CALL 'CBLTDLI' USING DLI-ISRT
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
UNQUALIFIED-ENGINEERING-SSAVí dụ trên cho thấy chúng tôi đang thực hiện lệnh gọi ISRT bằng cách cung cấp kết hợp các SSA đủ điều kiện và chưa đủ điều kiện.
Khi một phân đoạn mới mà chúng tôi đang chèn có một trường khóa duy nhất, thì nó sẽ được thêm vào ở vị trí thích hợp. Nếu trường khóa không phải là duy nhất, thì trường đó sẽ được thêm vào bởi các quy tắc do người quản trị cơ sở dữ liệu xác định.
Khi chúng ta đưa ra lệnh gọi ISRT mà không chỉ định trường khóa, thì quy tắc chèn sẽ cho biết vị trí đặt các phân đoạn so với các phân đoạn song sinh hiện có. Dưới đây là các quy tắc chèn -
First - Nếu quy tắc là trước, phân đoạn mới sẽ được thêm vào trước bất kỳ cặp song sinh nào hiện có.
Last - Nếu quy tắc là cuối cùng, phân đoạn mới được thêm vào sau tất cả các cặp song sinh hiện có.
Here - Nếu quy tắc ở đây, nó được thêm vào vị trí hiện tại so với cặp song sinh hiện có, có thể là đầu tiên, cuối cùng hoặc bất kỳ đâu.
Mã trạng thái
Bảng sau đây hiển thị các mã trạng thái có liên quan sau cuộc gọi ISRT -
| S.Không | Mã Trạng thái & Mô tả |
|---|---|
| 1 | Spaces Cuộc gọi thành công |
| 2 | GE Nhiều SSA được sử dụng và DL / I không thể đáp ứng cuộc gọi với đường dẫn được chỉ định. |
| 3 | II Cố gắng thêm một lần xuất hiện phân đoạn đã có trong cơ sở dữ liệu. |
| 4 | LB / LC LD / LE Chúng tôi nhận được các mã trạng thái này trong khi xử lý tải. Trong hầu hết các trường hợp, chúng chỉ ra rằng bạn không chèn các phân đoạn theo một trình tự phân cấp chính xác. |
Nhận giữ cuộc gọi
Những điểm cần lưu ý -
Có ba loại lệnh gọi Nhận Giữ mà chúng tôi chỉ định trong DL / tôi gọi:
Nắm giữ duy nhất (GHU)
Giữ tiếp theo (GHN)
Tiếp theo trong vòng Parent (GHNP)
Hàm giữ chỉ định rằng chúng tôi sẽ cập nhật phân đoạn sau khi truy xuất. Vì vậy, trước một cuộc gọi REPL hoặc DLET, một lệnh gọi giữ thành công phải được thực hiện cho DL / I biết ý định cập nhật cơ sở dữ liệu.
Cuộc gọi REPL
Những điểm cần lưu ý -
Sau khi gọi giữ thành công, chúng tôi thực hiện một cuộc gọi REPL để cập nhật sự xuất hiện của phân đoạn.
Chúng tôi không thể thay đổi độ dài của một đoạn bằng cách sử dụng lệnh gọi REPL.
Chúng tôi không thể thay đổi giá trị của trường khóa bằng cách gọi REPL.
Chúng tôi không thể sử dụng SSA đủ điều kiện với cuộc gọi REPL. Nếu chúng tôi chỉ định một SSA đủ điều kiện, thì cuộc gọi không thành công.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
*Move the values which you want to update in IT segment occurrence*
CALL ‘CBLTDLI’ USING DLI-REPL
PCB-NAME
IO-AREA.Ví dụ trên cập nhật sự xuất hiện của phân đoạn CNTT bằng cách sử dụng cuộc gọi REPL. Đầu tiên, chúng tôi thực hiện lệnh gọi GHU để nhận sự xuất hiện của phân đoạn mà chúng tôi muốn cập nhật. Sau đó, chúng tôi thực hiện một cuộc gọi REPL để cập nhật các giá trị của phân đoạn đó.
Cuộc gọi DLET
Những điểm cần lưu ý -
Lệnh gọi DLET hoạt động giống như cách gọi REPL.
Sau khi gọi giữ thành công, chúng tôi thực hiện một lệnh gọi DLET để xóa một sự cố phân đoạn.
Chúng tôi không thể sử dụng SSA đủ điều kiện với lệnh gọi DLET. Nếu chúng tôi chỉ định một SSA đủ điều kiện, thì cuộc gọi không thành công.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
CALL ‘CBLTDLI’ USING DLI-DLET
PCB-NAME
IO-AREA.Ví dụ trên xóa sự kiện phân đoạn CNTT bằng cách sử dụng lệnh gọi DLET. Đầu tiên, chúng tôi thực hiện một lệnh gọi GHU để nhận được sự xuất hiện của phân đoạn mà chúng tôi muốn xóa. Sau đó, chúng tôi thực hiện một cuộc gọi DLET để cập nhật các giá trị của phân đoạn đó.
Mã trạng thái
Bảng sau đây hiển thị các mã trạng thái có liên quan sau cuộc gọi REPL hoặc DLET -
| S.Không | Mã Trạng thái & Mô tả |
|---|---|
| 1 | Spaces Cuộc gọi thành công |
| 2 | AJ SSA đủ điều kiện được sử dụng trong cuộc gọi REPL hoặc DLET. |
| 3 | DJ Chương trình đưa ra một cuộc gọi thay thế mà không có một cuộc gọi nhận giữ ngay trước đó. |
| 4 | DA Chương trình thực hiện một thay đổi đối với trường khóa của phân đoạn trước khi thực hiện lệnh gọi REPL hoặc DLET |
Lập chỉ mục thứ cấp được sử dụng khi chúng ta muốn truy cập cơ sở dữ liệu mà không sử dụng khóa nối hoàn chỉnh hoặc khi chúng ta không muốn sử dụng các trường chính trình tự.
Phân đoạn con trỏ chỉ mục
DL / I lưu trữ con trỏ đến các phân đoạn của cơ sở dữ liệu được lập chỉ mục trong một cơ sở dữ liệu riêng biệt. Phân đoạn con trỏ chỉ mục là loại chỉ mục phụ duy nhất. Nó bao gồm hai phần -
- Phần tử tiền tố
- Yếu tố dữ liệu
Phần tử tiền tố
Phần tiền tố của phân đoạn con trỏ chỉ mục chứa một con trỏ đến Phân đoạn mục tiêu chỉ mục. Phân đoạn mục tiêu chỉ mục là phân đoạn có thể truy cập được bằng cách sử dụng chỉ mục phụ.
Yếu tố dữ liệu
Phần tử dữ liệu chứa giá trị khóa từ phân đoạn trong cơ sở dữ liệu được lập chỉ mục mà chỉ mục được tạo. Đây còn được gọi là phân đoạn nguồn chỉ mục.
Dưới đây là những điểm chính cần lưu ý về Lập chỉ mục phụ -
Phân khúc nguồn chỉ mục và phân khúc nguồn mục tiêu không được giống nhau.
Khi chúng tôi thiết lập một chỉ mục phụ, nó sẽ tự động được duy trì bởi DL / I.
DBA xác định nhiều chỉ mục phụ theo nhiều đường dẫn truy cập. Các chỉ mục phụ này được lưu trữ trong một cơ sở dữ liệu chỉ mục riêng biệt.
Chúng ta không nên tạo thêm chỉ mục phụ, vì chúng áp đặt thêm chi phí xử lý lên DL / I.
Phím phụ
Những điểm cần lưu ý -
Trường trong phân đoạn nguồn chỉ mục mà chỉ mục phụ được tạo được gọi là khóa phụ.
Bất kỳ trường nào cũng có thể được sử dụng làm khóa phụ. Nó không cần phải là trường trình tự phân đoạn.
Khóa phụ có thể là bất kỳ sự kết hợp nào của các trường đơn trong phân đoạn nguồn chỉ mục.
Giá trị khóa phụ không nhất thiết phải là duy nhất.
Cấu trúc dữ liệu thứ cấp
Những điểm cần lưu ý -
Khi chúng ta xây dựng một chỉ mục phụ, cấu trúc phân cấp rõ ràng của cơ sở dữ liệu cũng bị thay đổi.
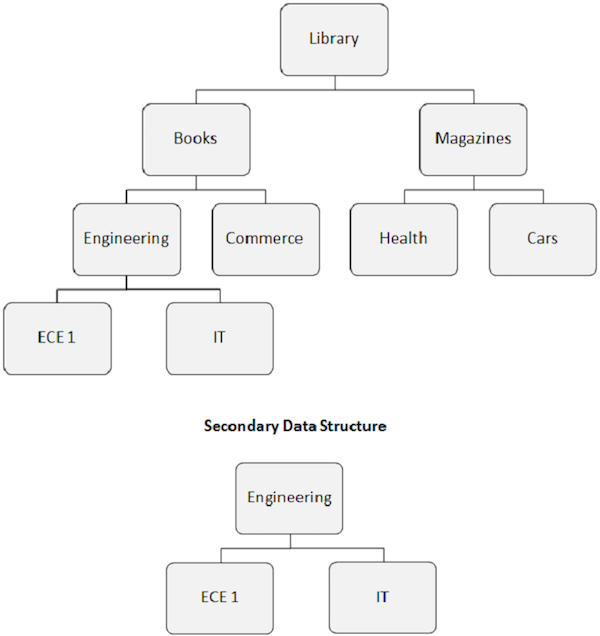
Phân đoạn mục tiêu chỉ mục trở thành phân đoạn gốc rõ ràng. Như thể hiện trong hình ảnh sau, đoạn Kỹ thuật trở thành đoạn gốc, ngay cả khi nó không phải là đoạn gốc.
Việc sắp xếp lại cấu trúc cơ sở dữ liệu do chỉ mục phụ gây ra được gọi là cấu trúc dữ liệu thứ cấp.
Cấu trúc dữ liệu thứ cấp không thực hiện bất kỳ thay đổi nào đối với cấu trúc cơ sở dữ liệu vật lý chính có trên đĩa. Nó chỉ là một cách để thay đổi cấu trúc cơ sở dữ liệu trước chương trình ứng dụng.
Nhà điều hành VÀ độc lập
Những điểm cần lưu ý -
Khi toán tử AND (* hoặc &) được sử dụng với các chỉ mục phụ, nó được gọi là toán tử AND phụ thuộc.
AND (#) độc lập cho phép chúng tôi chỉ định các điều kiện không thể với AND phụ thuộc.
Toán tử này chỉ có thể được sử dụng cho các chỉ mục phụ trong đó phân đoạn nguồn chỉ mục phụ thuộc vào phân đoạn mục tiêu chỉ mục.
Chúng tôi có thể mã hóa một SSA bằng AND độc lập để chỉ định rằng sự xuất hiện của phân đoạn đích được xử lý dựa trên các trường trong hai hoặc nhiều phân đoạn nguồn phụ thuộc.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Sắp xếp theo trình tự thưa thớt
Những điểm cần lưu ý -
Sắp xếp theo trình tự thưa thớt còn được gọi là Lập chỉ mục thưa thớt. Chúng tôi có thể xóa một số phân đoạn nguồn chỉ mục khỏi chỉ mục bằng cách sử dụng trình tự thưa thớt với cơ sở dữ liệu chỉ mục thứ cấp.
Giải trình tự thưa thớt được sử dụng để cải thiện hiệu suất. Khi một số lần xuất hiện của phân đoạn nguồn chỉ mục không được sử dụng, chúng tôi có thể loại bỏ điều đó.
DL / I sử dụng một giá trị triệt tiêu hoặc một quy trình triệt tiêu hoặc cả hai để xác định xem một phân đoạn có nên được lập chỉ mục hay không.
Nếu giá trị của trường trình tự trong phân đoạn nguồn chỉ mục khớp với giá trị triệt tiêu thì không có mối quan hệ chỉ mục nào được thiết lập.
Quy trình ngăn chặn là một chương trình do người dùng viết để đánh giá phân đoạn và xác định xem nó có nên được lập chỉ mục hay không.
Khi lập chỉ mục thưa thớt được sử dụng, các chức năng của nó được xử lý bởi DL / I. Chúng tôi không cần phải đưa ra các điều khoản đặc biệt cho nó trong chương trình ứng dụng.
Yêu cầu về DBDGEN
Như đã thảo luận trong các mô-đun trước đó, DBDGEN được sử dụng để tạo một DBD. Khi chúng tôi tạo các chỉ mục phụ, hai cơ sở dữ liệu có liên quan. Một DBA cần tạo hai DBD bằng cách sử dụng hai DBDGEN để tạo mối quan hệ giữa cơ sở dữ liệu được lập chỉ mục và cơ sở dữ liệu được lập chỉ mục thứ cấp.
Yêu cầu PSBGEN
Sau khi tạo chỉ mục phụ cho cơ sở dữ liệu, DBA cần tạo các PSB. PSBGEN cho chương trình chỉ định trình tự xử lý thích hợp cho cơ sở dữ liệu trên tham số PROCSEQ của macro PSB. Đối với tham số PROCSEQ, DBA mã tên DBD cho cơ sở dữ liệu chỉ mục phụ.
Cơ sở dữ liệu IMS có một quy tắc rằng mỗi loại phân đoạn chỉ có thể có một phụ huynh. Điều này hạn chế sự phức tạp của cơ sở dữ liệu vật lý. Nhiều ứng dụng DL / I yêu cầu cấu trúc phức tạp cho phép một phân đoạn có hai loại phân đoạn mẹ. Để khắc phục hạn chế này, DL / I cho phép DBA triển khai các mối quan hệ logic trong đó một phân đoạn có thể có cả cha mẹ vật lý và logic. Chúng ta có thể tạo thêm các mối quan hệ trong một cơ sở dữ liệu vật lý. Cấu trúc dữ liệu mới sau khi thực hiện mối quan hệ lôgic được gọi là Cơ sở dữ liệu lôgic.
Mối quan hệ logic
Mối quan hệ logic có các thuộc tính sau:
Mối quan hệ logic là một đường dẫn giữa hai phân đoạn có liên quan về mặt logic chứ không phải về mặt vật lý.
Thông thường một mối quan hệ logic được thiết lập giữa các cơ sở dữ liệu riêng biệt. Nhưng có thể có mối quan hệ giữa các phân đoạn của một cơ sở dữ liệu cụ thể.
Hình ảnh sau đây cho thấy hai cơ sở dữ liệu khác nhau. Một là cơ sở dữ liệu Sinh viên và một là cơ sở dữ liệu Thư viện. Chúng tôi tạo mối quan hệ logic giữa phân đoạn Sách đã phát hành từ cơ sở dữ liệu Sinh viên và phân đoạn Sách từ cơ sở dữ liệu Thư viện.
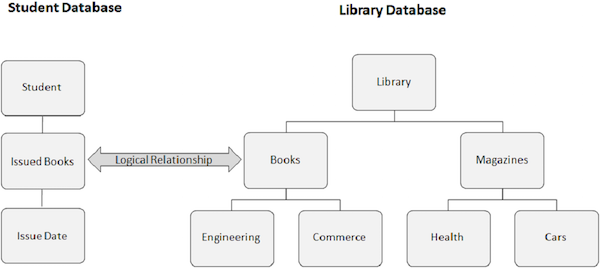
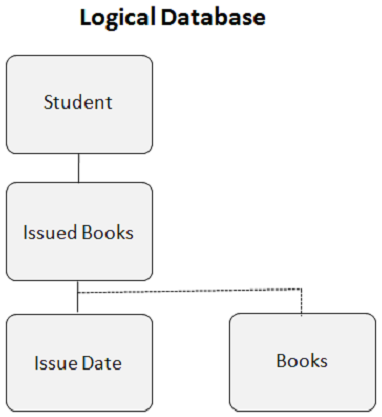
Đây là giao diện của cơ sở dữ liệu logic khi bạn tạo một mối quan hệ logic -
Phân đoạn con logic
Đoạn con logic là cơ sở của mối quan hệ logic. Nó là một phân đoạn dữ liệu vật lý nhưng đối với DL / I, nó xuất hiện như thể nó có hai cha mẹ. Phân đoạn Sách trong ví dụ trên có hai phân đoạn chính. Phân đoạn sách đã phát hành là phân khúc gốc lôgic và phân khúc Thư viện là phân khúc gốc vật lý. Một lần xuất hiện phân đoạn con logic chỉ có một lần xuất hiện đoạn cha logic và một lần xuất hiện đoạn cha logic có thể có nhiều lần xuất hiện đoạn con logic.
Cặp song sinh logic
Các cặp song sinh logic là các lần xuất hiện của loại phân đoạn con logic mà tất cả đều phụ thuộc vào một lần xuất hiện duy nhất của loại phân đoạn mẹ logic. DL / I làm cho phân đoạn con logic xuất hiện tương tự như một phân đoạn con vật lý thực tế. Đây còn được gọi là phân đoạn con logic ảo.
Các loại quan hệ lôgic
Một DBA tạo ra các mối quan hệ logic giữa các phân đoạn. Để thực hiện một mối quan hệ logic, DBA phải chỉ định nó trong DBDGEN cho các cơ sở dữ liệu vật lý liên quan. Có ba loại mối quan hệ logic -
- Unidirectional
- Ảo hai chiều
- Vật lý hai chiều
Một chiều
Kết nối logic đi từ logic con đến logic cha và nó không thể đi ngược lại.
Ảo hai chiều
Nó cho phép truy cập theo cả hai hướng. Con logic trong cấu trúc vật lý của nó và con logic ảo tương ứng có thể được xem như là các đoạn được ghép nối.
Vật lý hai chiều
Đứa trẻ hợp lý là một cấp dưới được lưu trữ về mặt vật lý đối với cha mẹ về mặt thể chất và logic của nó. Đối với các chương trình ứng dụng, nó xuất hiện giống như một con logic ảo hai chiều.
Cân nhắc lập trình
Các cân nhắc lập trình để sử dụng cơ sở dữ liệu logic như sau:
Các lệnh gọi DL / I để truy cập cơ sở dữ liệu vẫn tương tự với cơ sở dữ liệu logic.
Khối đặc tả chương trình cho biết cấu trúc mà chúng tôi sử dụng trong các cuộc gọi của mình. Trong một số trường hợp, chúng tôi không thể xác định rằng chúng tôi đang sử dụng cơ sở dữ liệu logic.
Các mối quan hệ logic thêm một chiều hướng mới cho lập trình cơ sở dữ liệu.
Bạn phải cẩn thận khi làm việc với cơ sở dữ liệu logic, vì hai cơ sở dữ liệu được tích hợp với nhau. Nếu bạn sửa đổi một cơ sở dữ liệu, các sửa đổi tương tự phải được phản ánh trong cơ sở dữ liệu kia.
Đặc tả chương trình phải chỉ ra những xử lý nào được phép trên cơ sở dữ liệu. Nếu quy tắc xử lý bị vi phạm, bạn sẽ nhận được mã trạng thái không trống.
Phân đoạn liên kết
Một phân đoạn con hợp lý luôn bắt đầu bằng khóa nối hoàn chỉnh của phần tử gốc đích. Điều này được gọi là Khóa liên kết chính đích (DPCK). Bạn cần phải luôn mã DPCK ở đầu khu vực I / O phân đoạn của bạn cho một con lôgic. Trong cơ sở dữ liệu logic, phân đoạn được nối tạo kết nối giữa các phân đoạn được xác định trong các cơ sở dữ liệu vật lý khác nhau. Một đoạn được nối bao gồm hai phần sau:
- Phân đoạn con logic
- Phân đoạn chính của điểm đến
Một phân đoạn con hợp lý bao gồm hai phần sau:
- Khóa liên kết chính của đích (DPCK)
- Dữ liệu người dùng con hợp lý

Khi chúng tôi làm việc với các phân đoạn được nối trong quá trình cập nhật, có thể thêm hoặc thay đổi dữ liệu trong cả phần tử con logic và phần tử gốc chỉ bằng một lệnh gọi. Điều này cũng phụ thuộc vào các quy tắc mà DBA chỉ định cho cơ sở dữ liệu. Để có một miếng đệm, hãy cung cấp DPCK ở đúng vị trí. Để thay thế hoặc xóa, không thay đổi DPCK hoặc dữ liệu trường trình tự trong một trong hai phần của phân đoạn được nối.
Người quản trị cơ sở dữ liệu cần lập kế hoạch khôi phục cơ sở dữ liệu trong trường hợp hệ thống bị lỗi. Các lỗi có thể có nhiều loại như treo ứng dụng, lỗi phần cứng, lỗi nguồn, v.v.
Phương pháp tiếp cận đơn giản
Một số cách tiếp cận đơn giản để khôi phục cơ sở dữ liệu như sau:
Tạo bản sao lưu định kỳ của các tập dữ liệu quan trọng để tất cả các giao dịch được đăng trên các tập dữ liệu đều được giữ lại.
Nếu tập dữ liệu bị hỏng do lỗi hệ thống, sự cố đó sẽ được khắc phục bằng cách khôi phục bản sao lưu. Sau đó, các giao dịch tích lũy được đăng lại vào bản sao lưu để cập nhật chúng.
Nhược điểm của Phương pháp Tiếp cận Đơn giản
Những nhược điểm của cách tiếp cận đơn giản để khôi phục cơ sở dữ liệu như sau:
Đăng lại các giao dịch đã tích lũy tiêu tốn rất nhiều thời gian.
Tất cả các ứng dụng khác cần phải đợi thực thi cho đến khi quá trình khôi phục hoàn tất.
Phục hồi cơ sở dữ liệu lâu hơn khôi phục tệp, nếu các mối quan hệ chỉ mục logic và phụ có liên quan.
Quy trình chấm dứt bất thường
Chương trình DL / I bị treo theo cách khác với cách chương trình chuẩn bị treo vì chương trình chuẩn được thực thi trực tiếp bởi hệ điều hành, trong khi chương trình DL / I thì không. Bằng cách sử dụng một quy trình kết thúc bất thường, hệ thống sẽ can thiệp để quá trình khôi phục có thể được thực hiện sau khi kết thúc bất thường (ABEND). Quy trình chấm dứt bất thường thực hiện các hành động sau:
- Đóng tất cả các tập dữ liệu
- Hủy tất cả các công việc đang chờ xử lý trong hàng đợi
- Tạo kết xuất lưu trữ để tìm ra nguyên nhân gốc rễ của ABEND
Hạn chế của quy trình này là nó không đảm bảo dữ liệu đang sử dụng có chính xác hay không.
DL / I Log
Khi chương trình ứng dụng TRỞ LÊN, cần phải hoàn nguyên các thay đổi do chương trình ứng dụng thực hiện, sửa lỗi và chạy lại chương trình ứng dụng. Để làm điều này, cần phải có nhật ký DL / I. Dưới đây là những điểm chính về ghi nhật ký DL / I -
Một DL / I ghi lại tất cả những thay đổi được thực hiện bởi một chương trình ứng dụng trong một tệp được gọi là tệp nhật ký.
Khi chương trình ứng dụng thay đổi một đoạn, ảnh trước và ảnh sau của nó được tạo bởi DL / I.
Những hình ảnh phân đoạn này có thể được sử dụng để khôi phục các phân đoạn, trong trường hợp chương trình ứng dụng bị treo.
DL / I sử dụng một kỹ thuật được gọi là ghi nhật ký ghi trước để ghi lại các thay đổi cơ sở dữ liệu. Với ghi nhật ký ghi trước, thay đổi cơ sở dữ liệu được ghi vào tập dữ liệu nhật ký trước khi ghi vào tập dữ liệu thực.
Vì nhật ký luôn ở trước cơ sở dữ liệu, các tiện ích khôi phục có thể xác định trạng thái của bất kỳ thay đổi cơ sở dữ liệu nào.
Khi chương trình thực hiện một lệnh gọi để thay đổi một phân đoạn cơ sở dữ liệu, DL / I sẽ xử lý phần ghi nhật ký của nó.
Phục hồi - Tiến và lùi
Hai phương pháp phục hồi cơ sở dữ liệu là:
Forward Recovery - DL / I sử dụng tệp nhật ký để lưu trữ dữ liệu thay đổi. Các giao dịch tích lũy được đăng lại bằng cách sử dụng tệp nhật ký này.
Backward Recovery- Phục hồi ngược hay còn gọi là khôi phục backout. Các bản ghi nhật ký cho chương trình được đọc ngược và tác động của chúng được đảo ngược trong cơ sở dữ liệu. Khi quá trình dự phòng hoàn tất, cơ sở dữ liệu ở trạng thái giống như trước khi bị lỗi, giả sử rằng không có chương trình ứng dụng nào khác thay đổi cơ sở dữ liệu trong thời gian đó.
Trạm kiểm soát
Điểm kiểm tra là một giai đoạn mà các thay đổi cơ sở dữ liệu được thực hiện bởi chương trình ứng dụng được coi là hoàn chỉnh và chính xác. Dưới đây là những điểm cần lưu ý về một trạm kiểm soát -
Các thay đổi cơ sở dữ liệu được thực hiện trước điểm kiểm tra gần đây nhất sẽ không bị khôi phục ngược bằng cách khôi phục.
Các thay đổi cơ sở dữ liệu được ghi lại sau điểm kiểm tra gần đây nhất không được áp dụng cho bản sao hình ảnh của cơ sở dữ liệu trong quá trình khôi phục chuyển tiếp.
Sử dụng phương pháp điểm kiểm tra, cơ sở dữ liệu được khôi phục về tình trạng của nó tại điểm kiểm tra gần đây nhất khi quá trình khôi phục hoàn tất.
Mặc định cho các chương trình hàng loạt là điểm kiểm tra là phần bắt đầu của chương trình.
Một trạm kiểm soát có thể được thiết lập bằng lệnh gọi trạm kiểm soát (CHKP).
Một lệnh gọi điểm kiểm tra gây ra một bản ghi điểm kiểm tra được ghi trên nhật ký DL / I.
Dưới đây là cú pháp của cuộc gọi CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-IDCó hai phương pháp kiểm tra -
Basic Checkpointing - Nó cho phép lập trình viên đưa ra các lệnh gọi điểm kiểm tra mà tiện ích khôi phục DL / I sử dụng trong quá trình xử lý khôi phục.
Symbolic Checkpointing- Đây là một hình thức kiểm tra nâng cao được sử dụng kết hợp với cơ sở khởi động lại mở rộng. Kết hợp điểm kiểm tra tượng trưng và khởi động lại mở rộng để lập trình viên ứng dụng mã hóa các chương trình để chúng có thể tiếp tục xử lý tại điểm ngay sau điểm kiểm tra.