Kiến trúc máy tính song song - Hướng dẫn nhanh
Trong 50 năm qua, đã có những bước phát triển to lớn về hiệu suất và khả năng của một hệ thống máy tính. Điều này có thể thực hiện được với sự trợ giúp của công nghệ Tích hợp Quy mô Rất lớn (VLSI). Công nghệ VLSI cho phép một số lượng lớn các thành phần được chứa trên một chip duy nhất và tốc độ xung nhịp tăng lên. Do đó, có thể thực hiện song song nhiều thao tác cùng một lúc.
Xử lý song song cũng được liên kết với dữ liệu cục bộ và truyền thông dữ liệu. Parallel Computer Architecture là phương pháp tổ chức tất cả các nguồn lực để tối đa hóa hiệu suất và khả năng lập trình trong giới hạn do công nghệ đưa ra và chi phí tại bất kỳ thời điểm nào.
Tại sao Kiến trúc song song?
Kiến trúc máy tính song song thêm một chiều hướng mới trong sự phát triển của hệ thống máy tính bằng cách sử dụng ngày càng nhiều bộ vi xử lý. Về nguyên tắc, hiệu suất đạt được khi sử dụng số lượng lớn bộ xử lý cao hơn hiệu suất của một bộ xử lý đơn lẻ tại một thời điểm nhất định.
Xu hướng ứng dụng
Với sự tiến bộ của năng lực phần cứng, nhu cầu về một ứng dụng hoạt động tốt cũng tăng lên, điều này đặt ra yêu cầu đối với sự phát triển của kiến trúc máy tính.
Trước kỷ nguyên vi xử lý, hệ thống máy tính hiệu suất cao có được nhờ công nghệ mạch điện và tổ chức máy kỳ lạ, khiến chúng trở nên đắt đỏ. Giờ đây, hệ thống máy tính có hiệu suất cao có được bằng cách sử dụng nhiều bộ xử lý, và hầu hết các ứng dụng quan trọng và đòi hỏi cao được viết dưới dạng chương trình song song. Do đó, để có hiệu suất cao hơn, cả kiến trúc song song và ứng dụng song song đều cần được phát triển.
Để tăng hiệu suất của ứng dụng, Tốc độ là yếu tố chính cần được xem xét. Speedup trên bộ xử lý p được định nghĩa là -
$$Speedup(p \ processors)\equiv\frac{Performance(p \ processors)}{Performance(1 \ processor)}$$Đối với một vấn đề đã được khắc phục,
$$performance \ of \ a \ computer \ system = \frac{1}{Time \ needed \ to \ complete \ the \ problem}$$ $$Speedup \ _{fixed \ problem} (p \ processors) =\frac{Time(1 \ processor)}{Time(p \ processor)}$$Máy tính Khoa học và Kỹ thuật
Kiến trúc song song đã trở nên không thể thiếu trong tính toán khoa học (như vật lý, hóa học, sinh học, thiên văn học, v.v.) và các ứng dụng kỹ thuật (như mô hình hồ chứa, phân tích luồng không khí, hiệu suất đốt cháy, v.v.). Trong hầu hết các ứng dụng, nhu cầu trực quan hóa đầu ra tính toán là rất lớn dẫn đến nhu cầu phát triển tính toán song song để tăng tốc độ tính toán.
Máy tính thương mại
Trong máy tính thương mại (như video, đồ họa, cơ sở dữ liệu, OLTP, v.v.) cũng cần máy tính tốc độ cao để xử lý một lượng lớn dữ liệu trong một thời gian nhất định. Máy tính để bàn sử dụng các chương trình đa luồng gần giống như các chương trình song song. Điều này lại đòi hỏi phải phát triển kiến trúc song song.
Xu hướng công nghệ
Với sự phát triển của công nghệ và kiến trúc, nhu cầu phát triển của các ứng dụng hiệu suất cao là rất lớn. Các thí nghiệm cho thấy các máy tính song song có thể hoạt động nhanh hơn nhiều so với bộ xử lý đơn được phát triển tối đa. Hơn nữa, máy tính song song có thể được phát triển trong giới hạn của công nghệ và chi phí.
Công nghệ chính được sử dụng ở đây là công nghệ VLSI. Do đó, ngày nay ngày càng nhiều bóng bán dẫn, cổng và mạch có thể được lắp trong cùng một khu vực. Với việc giảm kích thước tính năng VLSI cơ bản, tốc độ xung nhịp cũng cải thiện tương ứng với nó, trong khi số lượng bóng bán dẫn tăng lên theo hình vuông. Việc sử dụng nhiều bóng bán dẫn cùng một lúc (song song) có thể hoạt động tốt hơn nhiều so với việc tăng tốc độ xung nhịp
Xu hướng công nghệ cho thấy khối xây dựng chip đơn cơ bản sẽ cho công suất ngày càng lớn. Do đó, khả năng đặt nhiều bộ xử lý trên một chip sẽ tăng lên.
Xu hướng kiến trúc
Sự phát triển trong công nghệ quyết định điều gì là khả thi; kiến trúc chuyển đổi tiềm năng của công nghệ thành hiệu suất và khả năng.Parallelism và localitylà hai phương pháp mà khối lượng tài nguyên lớn hơn và nhiều bóng bán dẫn hơn sẽ nâng cao hiệu suất. Tuy nhiên, hai phương pháp này cạnh tranh vì các nguồn lực giống nhau. Khi nhiều thao tác được thực hiện song song, số chu kỳ cần thiết để thực hiện chương trình sẽ giảm xuống.
Tuy nhiên, cần có các nguồn lực để hỗ trợ từng hoạt động đồng thời. Tài nguyên cũng cần thiết để phân bổ lưu trữ cục bộ. Hiệu suất tốt nhất đạt được nhờ một kế hoạch hành động trung gian sử dụng các nguồn lực để tận dụng mức độ song song và mức độ địa phương.
Nói chung, lịch sử của kiến trúc máy tính đã được chia thành bốn thế hệ với các công nghệ cơ bản sau:
- Ống chân không
- Transistors
- Mạch tích hợp
- VLSI
Cho đến năm 1985, thời lượng bị chi phối bởi sự phát triển song song mức bit. Bộ vi xử lý 4-bit, tiếp theo là 8-bit, 16-bit, v.v. Để giảm số chu kỳ cần thiết để thực hiện đầy đủ hoạt động 32 bit, độ rộng của đường dẫn dữ liệu đã được tăng gấp đôi. Sau đó, các hoạt động 64-bit đã được giới thiệu.
Sự phát triển trong instruction-level-parallelismthống trị giữa những năm 80 đến giữa những năm 90. Cách tiếp cận RISC cho thấy rằng việc xây dựng các bước xử lý lệnh rất đơn giản để trung bình một lệnh được thực thi trong hầu hết mọi chu kỳ. Sự phát triển trong công nghệ trình biên dịch đã làm cho các đường dẫn hướng dẫn hoạt động hiệu quả hơn.
Vào giữa những năm 80, máy tính dựa trên bộ vi xử lý bao gồm
- Một đơn vị xử lý số nguyên
- Một đơn vị dấu phẩy động
- Bộ điều khiển bộ nhớ cache
- SRAM cho dữ liệu bộ nhớ cache
- Thẻ lưu trữ
Khi dung lượng chip tăng lên, tất cả các thành phần này được hợp nhất thành một chip duy nhất. Do đó, một con chip bao gồm các phần cứng riêng biệt cho phép toán số học số nguyên, dấu phẩy động, phép toán bộ nhớ và phép toán nhánh. Khác với các hướng dẫn riêng lẻ, nó tìm nạp nhiều lệnh cùng một lúc và gửi chúng song song đến các đơn vị chức năng khác nhau bất cứ khi nào có thể. Loại song song mức hướng dẫn này được gọi làsuperscalar execution.
Máy song song đã được phát triển với một số kiến trúc riêng biệt. Trong phần này, chúng ta sẽ thảo luận về kiến trúc máy tính song song khác nhau và bản chất của sự hội tụ của chúng.
Kiến trúc truyền thông
Kiến trúc song song nâng cao các khái niệm thông thường về kiến trúc máy tính với kiến trúc truyền thông. Kiến trúc máy tính xác định các yếu tố trừu tượng quan trọng (như ranh giới hệ thống người dùng và ranh giới phần cứng-phần mềm) và cấu trúc tổ chức, trong khi kiến trúc truyền thông xác định các hoạt động giao tiếp và đồng bộ hóa cơ bản. Nó cũng đề cập đến cơ cấu tổ chức.
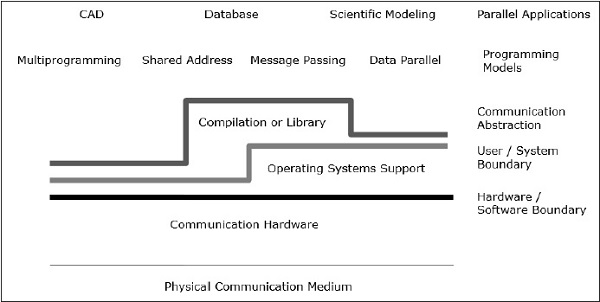
Mô hình lập trình là lớp trên cùng. Các ứng dụng được viết bằng mô hình lập trình. Các mô hình lập trình song song bao gồm:
- Không gian địa chỉ được chia sẻ
- Thông qua
- Lập trình song song dữ liệu
Shared addresslập trình cũng giống như sử dụng một bảng thông báo, nơi người ta có thể giao tiếp với một hoặc nhiều cá nhân bằng cách đăng thông tin tại một địa điểm cụ thể, thông tin này được chia sẻ bởi tất cả các cá nhân khác. Hoạt động cá nhân được điều phối bằng cách để ý xem ai đang làm nhiệm vụ gì.
Message passing giống như một cuộc gọi điện thoại hoặc các bức thư trong đó một người nhận cụ thể nhận được thông tin từ một người gửi cụ thể.
Data parallellập trình là một hình thức hợp tác có tổ chức. Tại đây, một số cá nhân thực hiện đồng thời một hành động trên các phần tử riêng biệt của tập dữ liệu và chia sẻ thông tin trên toàn cầu.
Bộ nhớ dùng chung
Bộ nhớ dùng chung đa xử lý là một trong những lớp quan trọng nhất của máy song song. Nó cung cấp thông lượng tốt hơn trên khối lượng công việc đa chương trình và hỗ trợ các chương trình song song.
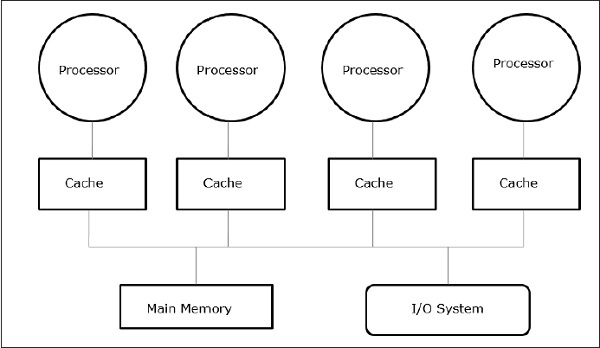
Trong trường hợp này, tất cả các hệ thống máy tính đều cho phép một bộ xử lý và một bộ điều khiển I / O truy cập vào một tập hợp các mô-đun bộ nhớ bằng một số kết nối phần cứng. Dung lượng bộ nhớ được tăng lên bằng cách thêm mô-đun bộ nhớ và dung lượng I / O được tăng lên bằng cách thêm thiết bị vào bộ điều khiển I / O hoặc bằng cách thêm bộ điều khiển I / O bổ sung. Khả năng xử lý có thể được tăng lên bằng cách chờ sẵn một bộ xử lý nhanh hơn hoặc bằng cách thêm nhiều bộ xử lý hơn.
Tất cả các tài nguyên được tổ chức xung quanh một bus bộ nhớ trung tâm. Thông qua cơ chế truy cập bus, bất kỳ bộ xử lý nào cũng có thể truy cập bất kỳ địa chỉ vật lý nào trong hệ thống. Vì tất cả các bộ xử lý cách đều tất cả các vị trí bộ nhớ nên thời gian truy cập hoặc độ trễ của tất cả các bộ xử lý là như nhau trên một vị trí bộ nhớ. Đây được gọi làsymmetric multiprocessor.
Kiến trúc truyền thông điệp
Kiến trúc truyền thông điệp cũng là một lớp quan trọng của các máy song song. Nó cung cấp thông tin liên lạc giữa các bộ xử lý như các hoạt động I / O rõ ràng. Trong trường hợp này, giao tiếp được kết hợp ở mức I / O, thay vì hệ thống bộ nhớ.
Trong kiến trúc truyền thông điệp, giao tiếp người dùng được thực thi bằng cách sử dụng hệ điều hành hoặc lệnh gọi thư viện thực hiện nhiều hành động cấp thấp hơn, bao gồm cả hoạt động giao tiếp thực tế. Kết quả là, có một khoảng cách giữa mô hình lập trình và các hoạt động giao tiếp ở cấp phần cứng vật lý.
Send và receivelà hoạt động giao tiếp cấp người dùng phổ biến nhất trong hệ thống truyền thông điệp. Gửi chỉ định bộ đệm dữ liệu cục bộ (sẽ được truyền) và bộ xử lý từ xa nhận. Nhận chỉ định một quá trình gửi và một bộ đệm dữ liệu cục bộ trong đó dữ liệu được truyền sẽ được đặt. Trong hoạt động gửi, mộtidentifier hoặc một tag được đính kèm vào thông báo và hoạt động nhận chỉ định quy tắc đối sánh như thẻ cụ thể từ một bộ xử lý cụ thể hoặc bất kỳ thẻ nào từ bất kỳ bộ xử lý nào.
Sự kết hợp giữa một gửi và một nhận phù hợp sẽ hoàn thành một bản sao từ bộ nhớ vào bộ nhớ. Mỗi đầu chỉ định địa chỉ dữ liệu cục bộ của nó và một sự kiện đồng bộ hóa cặp đôi.
Sự hội tụ
Sự phát triển của phần cứng và phần mềm đã xóa nhòa ranh giới rõ ràng giữa bộ nhớ dùng chung và trại truyền thông điệp. Truyền thông điệp và không gian địa chỉ dùng chung đại diện cho hai mô hình lập trình riêng biệt; mỗi bên cung cấp một mô hình minh bạch để chia sẻ, đồng bộ hóa và giao tiếp. Tuy nhiên, các cấu trúc máy cơ bản đã hội tụ về một tổ chức chung.
Xử lý song song dữ liệu
Một lớp quan trọng khác của máy song song được gọi một cách đa dạng - mảng bộ xử lý, kiến trúc song song dữ liệu và máy đa dữ liệu một lệnh. Đặc điểm chính của mô hình lập trình là các phép toán có thể được thực hiện song song trên từng phần tử của cấu trúc dữ liệu thông thường lớn (như mảng hoặc ma trận).
Ngôn ngữ lập trình song song dữ liệu thường được thực thi bằng cách xem không gian địa chỉ cục bộ của một nhóm các quy trình, mỗi quy trình trên mỗi bộ xử lý, tạo thành một không gian toàn cục rõ ràng. Vì tất cả các bộ xử lý giao tiếp với nhau và có một cái nhìn toàn cục về tất cả các hoạt động, vì vậy có thể sử dụng không gian địa chỉ dùng chung hoặc chuyển thông điệp.
Các vấn đề cơ bản về thiết kế
Chỉ phát triển mô hình lập trình không thể làm tăng hiệu quả của máy tính cũng như chỉ phát triển phần cứng không thể làm được. Tuy nhiên, sự phát triển trong kiến trúc máy tính có thể tạo ra sự khác biệt trong hiệu suất của máy tính. Chúng ta có thể hiểu được vấn đề thiết kế bằng cách tập trung vào cách các chương trình sử dụng máy và những công nghệ cơ bản nào được cung cấp.
Trong phần này, chúng ta sẽ thảo luận về tính trừu tượng của giao tiếp và các yêu cầu cơ bản của mô hình lập trình.
Giao tiếp trừu tượng
Sự trừu tượng hóa giao tiếp là giao diện chính giữa mô hình lập trình và việc triển khai hệ thống. Nó giống như tập lệnh cung cấp nền tảng để cùng một chương trình có thể chạy chính xác trên nhiều triển khai. Các hoạt động ở cấp độ này phải đơn giản.
Sự trừu tượng hóa giao tiếp giống như một hợp đồng giữa phần cứng và phần mềm, cho phép nhau cải thiện tính linh hoạt mà không ảnh hưởng đến công việc.
Yêu cầu về mô hình lập trình
Một chương trình song song có một hoặc nhiều luồng hoạt động trên dữ liệu. Mô hình lập trình song song xác định dữ liệu nào mà các luồng có thểname, cái nào operations có thể được thực hiện trên dữ liệu được đặt tên, và thứ tự nào được tuân theo bởi các hoạt động.
Để xác nhận rằng các phụ thuộc giữa các chương trình được thực thi, một chương trình song song phải điều phối hoạt động của các luồng của nó.
Xử lý song song đã được phát triển như một công nghệ hiệu quả trong máy tính hiện đại để đáp ứng nhu cầu về hiệu suất cao hơn, chi phí thấp hơn và kết quả chính xác trong các ứng dụng thực tế. Các sự kiện đồng thời phổ biến trong các máy tính ngày nay do thực hành đa chương trình, đa xử lý hoặc đa máy tính.
Máy tính hiện đại có các gói phần mềm mạnh mẽ và phong phú. Để phân tích sự phát triển hiệu suất của máy tính, trước hết chúng ta phải hiểu sự phát triển cơ bản của phần cứng và phần mềm.
Computer Development Milestones - Có hai giai đoạn phát triển chính của máy tính - mechanical hoặc là electromechanicalcác bộ phận. Máy tính hiện đại phát triển sau sự ra đời của các thành phần điện tử. Các electron có tính di động cao trong máy tính điện tử đã thay thế các bộ phận hoạt động trong máy tính cơ khí. Để truyền thông tin, tín hiệu điện truyền gần như bằng tốc độ ánh sáng đã thay thế các bánh răng hoặc đòn bẩy cơ học.
Elements of Modern computers - Một hệ thống máy tính hiện đại bao gồm phần cứng máy tính, tập lệnh, chương trình ứng dụng, phần mềm hệ thống và giao diện người dùng.

Các vấn đề tính toán được phân loại là tính toán số, suy luận logic và xử lý giao dịch. Một số vấn đề phức tạp có thể cần sự kết hợp của cả ba chế độ xử lý.
Evolution of Computer Architecture- Trong bốn thập kỷ qua, kiến trúc máy tính đã trải qua những thay đổi mang tính cách mạng. Chúng tôi bắt đầu với kiến trúc Von Neumann và bây giờ chúng tôi có đa máy tính và đa xử lý.
Performance of a computer system- Hiệu suất của hệ thống máy tính phụ thuộc cả vào khả năng của máy và hành vi của chương trình. Khả năng của máy có thể được cải thiện với công nghệ phần cứng tốt hơn, các tính năng kiến trúc tiên tiến và quản lý tài nguyên hiệu quả. Hành vi của chương trình là không thể đoán trước vì nó phụ thuộc vào ứng dụng và điều kiện thời gian chạy
Đa xử lý và Đa máy tính
Trong phần này, chúng ta sẽ thảo luận về hai loại máy tính song song -
- Multiprocessors
- Multicomputers
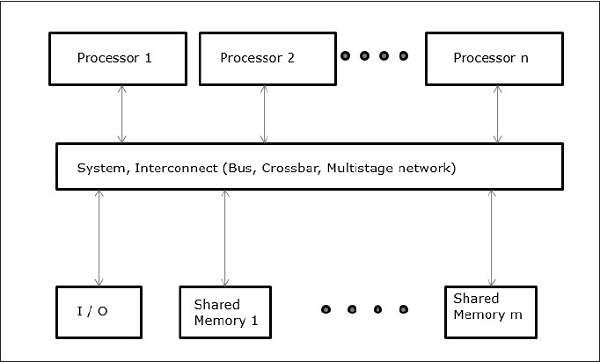
Máy tính đa bộ nhớ dùng chung
Ba mô hình đa xử lý bộ nhớ dùng chung phổ biến nhất là:
Truy cập bộ nhớ thống nhất (UMA)
Trong mô hình này, tất cả các bộ xử lý chia sẻ bộ nhớ vật lý một cách đồng nhất. Tất cả các bộ xử lý có thời gian truy cập bằng nhau đến tất cả các từ bộ nhớ. Mỗi bộ xử lý có thể có một bộ nhớ đệm riêng. Quy tắc tương tự cũng được tuân theo đối với các thiết bị ngoại vi.
Khi tất cả các bộ xử lý có quyền truy cập như nhau vào tất cả các thiết bị ngoại vi, hệ thống được gọi là symmetric multiprocessor. Khi chỉ một hoặc một vài bộ xử lý có thể truy cập vào các thiết bị ngoại vi, hệ thống được gọi làasymmetric multiprocessor.
Quyền truy cập bộ nhớ không đồng nhất (NUMA)
Trong mô hình đa xử lý NUMA, thời gian truy cập thay đổi theo vị trí của từ bộ nhớ. Tại đây, bộ nhớ dùng chung được phân phối vật lý giữa tất cả các bộ xử lý, được gọi là bộ nhớ cục bộ. Tập hợp tất cả các bộ nhớ cục bộ tạo thành một không gian địa chỉ chung mà tất cả các bộ xử lý có thể truy cập.
Kiến trúc bộ nhớ chỉ bộ nhớ đệm (COMA)
Mô hình COMA là một trường hợp đặc biệt của mô hình NUMA. Tại đây, tất cả các bộ nhớ chính được phân phối được chuyển đổi thành bộ nhớ đệm.

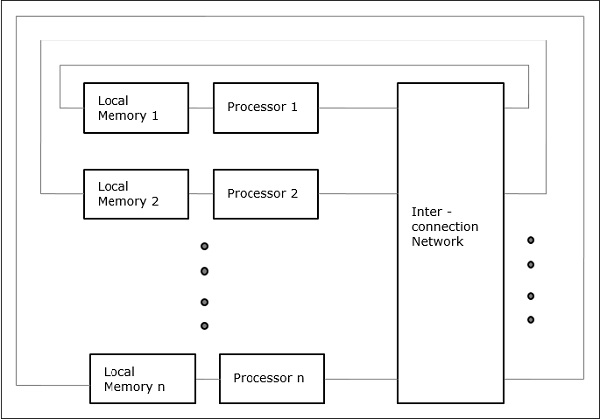
Distributed - Memory Multicomputers- Một hệ thống đa máy tính bộ nhớ phân tán bao gồm nhiều máy tính, được gọi là các nút, được kết nối với nhau bằng mạng truyền thông điệp. Mỗi nút hoạt động như một máy tính tự trị có bộ xử lý, bộ nhớ cục bộ và đôi khi là thiết bị I / O. Trong trường hợp này, tất cả các bộ nhớ cục bộ là riêng tư và chỉ bộ xử lý cục bộ mới có thể truy cập được. Đây là lý do tại sao, các máy truyền thống được gọi làno-remote-memory-access (NORMA) máy móc.

Máy tính đa vũ trụ và SIMD
Trong phần này, chúng ta sẽ thảo luận về siêu máy tính và bộ xử lý song song để xử lý vectơ và song song dữ liệu.
Siêu máy tính vector
Trong máy tính vectơ, bộ xử lý vectơ được gắn vào bộ xử lý vô hướng như một tính năng tùy chọn. Đầu tiên máy tính chủ sẽ tải chương trình và dữ liệu vào bộ nhớ chính. Sau đó, bộ điều khiển vô hướng giải mã tất cả các hướng dẫn. Nếu các lệnh được giải mã là hoạt động vô hướng hoặc hoạt động chương trình, bộ xử lý vô hướng thực hiện các hoạt động đó bằng cách sử dụng các đường ống chức năng vô hướng.
Mặt khác, nếu các lệnh được giải mã là các phép toán vector thì các lệnh sẽ được gửi đến đơn vị điều khiển vector.
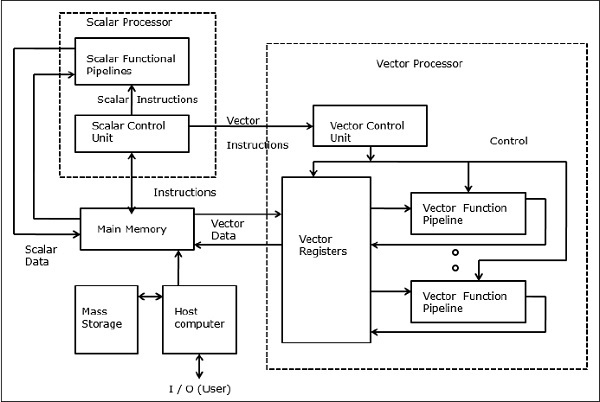
Siêu máy tính SIMD
Trong máy tính SIMD, số 'N' bộ xử lý được kết nối với một bộ điều khiển và tất cả các bộ xử lý đều có bộ nhớ riêng. Tất cả các bộ vi xử lý được kết nối bằng một mạng kết nối.
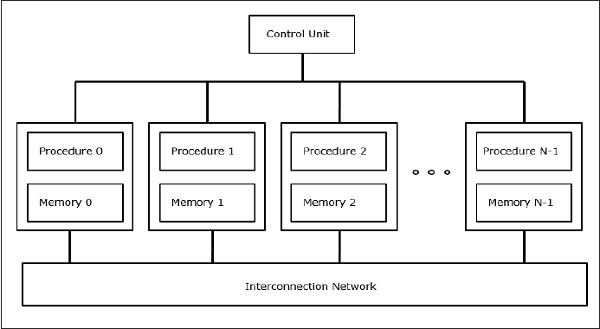
Mô hình PRAM và VLSI
Mô hình lý tưởng đưa ra một khuôn khổ phù hợp để phát triển các thuật toán song song mà không cần xem xét các ràng buộc vật lý hoặc chi tiết triển khai.
Các mô hình có thể được thực thi để đạt được giới hạn hiệu suất lý thuyết trên các máy tính song song hoặc để đánh giá độ phức tạp của VLSI trên diện tích chip và thời gian hoạt động trước khi chip được chế tạo.
Máy truy cập ngẫu nhiên song song
Sheperdson và Sturgis (1963) đã mô hình hóa các máy tính Uniprocessor thông thường như các máy truy cập ngẫu nhiên (RAM). Fortune và Wyllie (1978) đã phát triển mô hình máy truy cập ngẫu nhiên song song (PRAM) để mô hình hóa một máy tính song song lý tưởng với chi phí truy cập bộ nhớ và đồng bộ hóa bằng không.

Một PRAM bộ xử lý N có một bộ nhớ dùng chung. Bộ nhớ dùng chung này có thể được tập trung hoặc phân phối giữa các bộ xử lý. Các bộ xử lý này hoạt động trên một chu trình đồng bộ bộ nhớ đọc, bộ nhớ ghi và tính toán. Vì vậy, các mô hình này chỉ định cách xử lý các hoạt động đọc và ghi đồng thời.
Sau đây là các thao tác cập nhật bộ nhớ có thể thực hiện:
Exclusive read (ER) - Trong phương pháp này, trong mỗi chu kỳ chỉ có một bộ xử lý được phép đọc từ bất kỳ vị trí bộ nhớ nào.
Exclusive write (EW) - Trong phương pháp này, ít nhất một bộ xử lý được phép ghi vào một vị trí bộ nhớ tại một thời điểm.
Concurrent read (CR) - Nó cho phép nhiều bộ xử lý đọc cùng một thông tin từ cùng một vị trí bộ nhớ trong cùng một chu kỳ.
Concurrent write (CW)- Nó cho phép các thao tác ghi đồng thời vào cùng một vị trí bộ nhớ. Để tránh xung đột ghi, một số chính sách được thiết lập.
Mô hình độ phức tạp VLSI
Máy tính song song sử dụng chip VLSI để chế tạo mảng bộ xử lý, mảng bộ nhớ và mạng chuyển mạch quy mô lớn.
Ngày nay, công nghệ VLSI là 2 chiều. Kích thước của chip VLSI tỷ lệ thuận với dung lượng lưu trữ (bộ nhớ) có sẵn trong chip đó.
Chúng ta có thể tính toán độ phức tạp không gian của một thuật toán bằng diện tích chip (A) của việc thực thi chip VLSI của thuật toán đó. Nếu T là thời gian (độ trễ) cần thiết để thực thi thuật toán, thì AT đưa ra giới hạn trên về tổng số bit được xử lý qua chip (hoặc I / O). Đối với một số máy tính nhất định, tồn tại một giới hạn dưới, f (s), sao cho
AT 2 > = O (f (s))
Trong đó A = diện tích chip và T = thời gian
Theo dõi phát triển kiến trúc
Sự phát triển của máy tính song song tôi đã truyền bá theo các bài sau:
- Nhiều bản nhạc bộ xử lý
- Theo dõi đa xử lý
- Theo dõi đa máy tính
- Nhiều dữ liệu theo dõi
- Theo dõi vector
- Theo dõi SIMD
- Theo dõi nhiều chủ đề
- Bài hát đa luồng
- Theo dõi luồng dữ liệu
Trong multiple processor track, giả định rằng các luồng khác nhau thực thi đồng thời trên các bộ xử lý khác nhau và giao tiếp thông qua bộ nhớ dùng chung (theo dõi đa xử lý) hoặc hệ thống truyền thông báo (theo dõi đa máy tính).
Trong multiple data track, giả định rằng cùng một đoạn mã được thực thi trên một lượng lớn dữ liệu. Nó được thực hiện bằng cách thực hiện các hướng dẫn giống nhau trên một chuỗi các phần tử dữ liệu (theo dõi vectơ) hoặc thông qua việc thực hiện cùng một chuỗi hướng dẫn trên một tập dữ liệu tương tự (theo dõi SIMD).
Trong multiple threads track, giả định rằng việc thực thi xen kẽ các luồng khác nhau trên cùng một bộ xử lý để ẩn sự chậm trễ đồng bộ hóa giữa các luồng thực thi trên các bộ xử lý khác nhau. Luồng xen kẽ có thể là thô (theo dõi đa luồng) hoặc tốt (theo dõi luồng dữ liệu).
Vào những năm 80, một bộ xử lý có mục đích đặc biệt rất phổ biến để tạo ra nhiều máy tính được gọi là Transputer. Một máy phát bao gồm một bộ xử lý lõi, một bộ nhớ SRAM nhỏ, một giao diện bộ nhớ chính DRAM và bốn kênh giao tiếp, tất cả đều nằm trên một con chip. Để thực hiện giao tiếp máy tính song song, các kênh được kết nối để tạo thành một mạng các Bộ truyền. Nhưng nó thiếu sức mạnh tính toán và do đó không thể đáp ứng nhu cầu ngày càng tăng của các ứng dụng song song. Vấn đề này đã được giải quyết bằng sự phát triển của bộ vi xử lý RISC và nó cũng rẻ.
Máy tính song song hiện đại sử dụng bộ vi xử lý sử dụng song song ở một số cấp độ như song song cấp lệnh và song song cấp dữ liệu.
Bộ xử lý hiệu suất cao
Bộ vi xử lý RISC và RISCy thống trị thị trường máy tính song song ngày nay.
Đặc điểm của RISC truyền thống là -
- Có ít chế độ địa chỉ.
- Có định dạng cố định cho các lệnh, thường là 32 hoặc 64 bit.
- Có hướng dẫn tải / lưu trữ chuyên dụng để tải dữ liệu từ bộ nhớ vào thanh ghi và lưu trữ dữ liệu từ thanh ghi vào bộ nhớ.
- Các phép toán số học luôn được thực hiện trên các thanh ghi.
- Sử dụng pipelining.
Hầu hết các bộ vi xử lý ngày nay là superscalar, tức là trong một máy tính song song nhiều đường dẫn lệnh được sử dụng. Do đó, bộ xử lý siêu phương có thể thực hiện nhiều hơn một lệnh cùng một lúc. Hiệu quả của bộ xử lý siêu cực phụ thuộc vào lượng song song mức lệnh (ILP) có sẵn trong các ứng dụng. Để giữ cho các đường ống được lấp đầy, các lệnh ở cấp phần cứng được thực hiện theo một thứ tự khác với thứ tự chương trình.
Nhiều bộ vi xử lý hiện đại sử dụng cách tiếp cận siêu pipelining . Trong siêu đường ống , để tăng tần số xung nhịp, công việc được thực hiện trong một giai đoạn đường ống được giảm xuống và số lượng các giai đoạn đường ống được tăng lên.
Bộ xử lý từ hướng dẫn rất lớn (VLIW)
Chúng có nguồn gốc từ vi lập trình ngang và xử lý siêu quang. Các lệnh trong bộ xử lý VLIW rất lớn. Các hoạt động trong một lệnh đơn được thực hiện song song và được chuyển tiếp đến các đơn vị chức năng thích hợp để thực thi. Vì vậy, sau khi tìm nạp một lệnh VLIW, các hoạt động của nó sẽ được giải mã. Sau đó, các hoạt động được gửi đến các đơn vị chức năng mà chúng được thực hiện song song.
Bộ xử lý vector
Bộ xử lý vectơ là bộ đồng xử lý với bộ vi xử lý đa năng. Bộ xử lý vectơ thường là thanh ghi thanh ghi hoặc bộ nhớ-bộ nhớ. Một lệnh vectơ được tìm nạp và giải mã, sau đó một thao tác nhất định được thực hiện cho mỗi phần tử của vectơ toán hạng, trong khi trong bộ xử lý thông thường, thao tác vectơ cần có cấu trúc vòng lặp trong mã. Để làm cho nó hiệu quả hơn, bộ xử lý vectơ chuỗi một số phép toán vectơ với nhau, tức là, kết quả từ một phép toán vectơ được chuyển tiếp sang một phép toán khác dưới dạng toán hạng.
Bộ nhớ đệm
Bộ nhớ đệm là yếu tố quan trọng của bộ vi xử lý hiệu suất cao. Sau mỗi 18 tháng, tốc độ của bộ vi xử lý tăng gấp đôi, nhưng chip DRAM cho bộ nhớ chính không thể cạnh tranh với tốc độ này. Vì vậy, bộ nhớ đệm được giới thiệu để thu hẹp khoảng cách tốc độ giữa bộ xử lý và bộ nhớ. Bộ nhớ đệm là một bộ nhớ SRAM nhanh và nhỏ. Nhiều bộ đệm khác được áp dụng trong các bộ xử lý hiện đại như bộ đệm Dịch nhìn sang một bên (TLB), bộ nhớ đệm hướng dẫn và dữ liệu, v.v.
Bộ nhớ đệm được ánh xạ trực tiếp
Trong bộ nhớ đệm được ánh xạ trực tiếp, hàm 'modulo' được sử dụng để ánh xạ một - một các địa chỉ trong bộ nhớ chính đến các vị trí trong bộ đệm. Vì cùng một mục nhập bộ đệm có thể có nhiều khối bộ nhớ chính được ánh xạ tới nó, bộ xử lý phải có khả năng xác định xem khối dữ liệu trong bộ đệm có phải là khối dữ liệu thực sự cần thiết hay không. Việc nhận dạng này được thực hiện bằng cách lưu trữ một thẻ cùng với một khối bộ nhớ cache.
Bộ nhớ đệm hoàn toàn liên kết
Một ánh xạ liên kết đầy đủ cho phép đặt một khối bộ nhớ cache ở bất kỳ đâu trong bộ nhớ cache. Bằng cách sử dụng một số chính sách thay thế, bộ đệm sẽ xác định một mục nhập bộ đệm trong đó nó lưu trữ một khối bộ đệm. Bộ nhớ đệm hoàn toàn liên kết có ánh xạ linh hoạt, giúp giảm thiểu số lượng xung đột mục nhập bộ đệm. Vì việc triển khai liên kết đầy đủ là tốn kém, chúng không bao giờ được sử dụng trên quy mô lớn.
Bộ đệm ẩn liên kết đặt
Ánh xạ liên kết tập hợp là sự kết hợp của ánh xạ trực tiếp và ánh xạ liên kết đầy đủ. Trong trường hợp này, các mục trong bộ đệm được chia thành các bộ bộ đệm. Như trong ánh xạ trực tiếp, có một ánh xạ cố định của các khối bộ nhớ vào một tập hợp trong bộ đệm. Nhưng bên trong một tập hợp bộ đệm, một khối bộ nhớ được ánh xạ theo cách liên kết hoàn toàn.
Chiến lược bộ nhớ đệm
Ngoài cơ chế ánh xạ, bộ nhớ đệm cũng cần một loạt các chiến lược chỉ định điều gì sẽ xảy ra trong trường hợp các sự kiện nhất định. Trong trường hợp (set-) bộ đệm kết hợp, bộ đệm phải xác định khối bộ đệm nào sẽ được thay thế bằng một khối mới vào bộ đệm.
Một số chiến lược thay thế nổi tiếng là:
- Nhập trước xuất trước (FIFO)
- Ít được sử dụng gần đây (LRU)
Chúng ta sẽ thảo luận về đa xử lý và đa máy tính trong chương này.
Kết nối hệ thống đa xử lý
Xử lý song song cần sử dụng các kết nối hệ thống hiệu quả để giao tiếp nhanh chóng giữa Đầu vào / Đầu ra và các thiết bị ngoại vi, bộ đa xử lý và bộ nhớ dùng chung.
Hệ thống xe buýt phân cấp
Hệ thống bus phân cấp bao gồm một hệ thống bus phân cấp kết nối các hệ thống và hệ thống con / thành phần khác nhau trong máy tính. Mỗi xe buýt được tạo thành từ một số đường dây tín hiệu, điều khiển và nguồn điện. Các xe buýt khác nhau như xe buýt địa phương, xe buýt bảng nối đa năng và xe buýt I / O được sử dụng để thực hiện các chức năng kết nối khác nhau.
Xe buýt địa phương là xe buýt được thực hiện trên bảng mạch in. Xe buýt bảng nối đa năng là một mạch in trên đó có nhiều đầu nối được sử dụng để cắm vào các bảng chức năng. Các xe buýt kết nối thiết bị đầu vào / đầu ra với hệ thống máy tính được gọi là xe buýt I / O.
Công tắc thanh ngang và Bộ nhớ đa cổng
Mạng chuyển mạch cung cấp kết nối động giữa các đầu vào và đầu ra. Các hệ thống cỡ vừa hoặc nhỏ hầu hết sử dụng mạng thanh ngang. Mạng đa tầng có thể được mở rộng cho các hệ thống lớn hơn, nếu vấn đề độ trễ tăng lên có thể được giải quyết.
Cả công tắc thanh ngang và tổ chức bộ nhớ đa cổng đều là một mạng một giai đoạn. Mặc dù mạng một giai đoạn rẻ hơn để xây dựng, nhưng có thể cần nhiều lần để thiết lập các kết nối nhất định. Một mạng nhiều tầng có nhiều hơn một tầng hộp chuyển mạch. Các mạng này sẽ có thể kết nối mọi đầu vào với bất kỳ đầu ra nào.
Mạng đa tầng và kết hợp
Mạng đa tầng hay mạng liên kết nhiều tầng là một loại mạng máy tính tốc độ cao, chủ yếu bao gồm các phần tử xử lý ở một đầu của mạng và các phần tử bộ nhớ ở đầu kia, được kết nối bằng các phần tử chuyển mạch.
Các mạng này được áp dụng để xây dựng các hệ thống đa xử lý lớn hơn. Điều này bao gồm Mạng Omega, Mạng Bướm và nhiều hơn nữa.
Đa máy tính
Đa máy tính là kiến trúc MIMD bộ nhớ phân tán. Sơ đồ sau đây cho thấy một mô hình khái niệm của một máy tính đa năng:
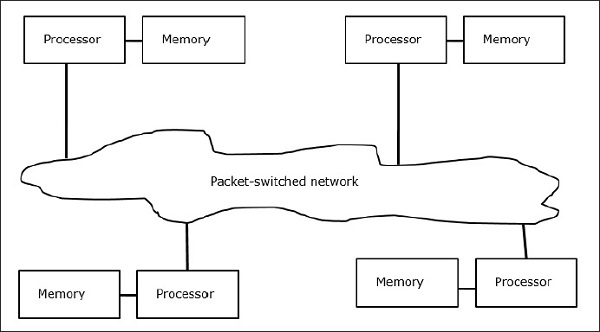
Đa máy tính là máy truyền thông điệp áp dụng phương pháp chuyển mạch gói để trao đổi dữ liệu. Ở đây, mỗi bộ xử lý có một bộ nhớ riêng, nhưng không có không gian địa chỉ chung vì bộ xử lý chỉ có thể truy cập bộ nhớ cục bộ của chính nó. Vì vậy, giao tiếp không minh bạch: ở đây các lập trình viên phải đưa các nguyên tắc giao tiếp vào mã của họ một cách rõ ràng.
Không có bộ nhớ có thể truy cập toàn cầu là một nhược điểm của đa máy tính. Điều này có thể được giải quyết bằng cách sử dụng hai lược đồ sau:
- Bộ nhớ chia sẻ ảo (VSM)
- Bộ nhớ ảo dùng chung (SVM)
Trong các lược đồ này, người lập trình ứng dụng giả định một bộ nhớ dùng chung lớn có thể xử lý được trên toàn cầu. Nếu được yêu cầu, các tham chiếu bộ nhớ do các ứng dụng tạo ra sẽ được dịch sang mô hình truyền thông báo.
Bộ nhớ chia sẻ ảo (VSM)
VSM là một triển khai phần cứng. Vì vậy, hệ thống bộ nhớ ảo của Hệ điều hành được thực hiện một cách minh bạch trên VSM. Vì vậy, hệ điều hành nghĩ rằng nó đang chạy trên máy có bộ nhớ dùng chung.
Bộ nhớ ảo dùng chung (SVM)
SVM là một triển khai phần mềm ở cấp Hệ điều hành với sự hỗ trợ phần cứng từ Đơn vị quản lý bộ nhớ (MMU) của bộ xử lý. Ở đây, đơn vị chia sẻ là các trang bộ nhớ Hệ điều hành.
Nếu một bộ xử lý giải quyết một vị trí bộ nhớ cụ thể, MMU sẽ xác định xem trang bộ nhớ được liên kết với quyền truy cập bộ nhớ có nằm trong bộ nhớ cục bộ hay không. Nếu trang không có trong bộ nhớ, trong hệ thống máy tính bình thường, nó sẽ được Hệ điều hành hoán đổi từ đĩa. Tuy nhiên, trong SVM, Hệ điều hành tìm nạp trang từ nút từ xa sở hữu trang cụ thể đó.
Ba thế hệ của đa máy tính
Trong phần này, chúng ta sẽ thảo luận về ba thế hệ đa máy tính.
Lựa chọn thiết kế trong quá khứ
Trong khi lựa chọn công nghệ bộ xử lý, một nhà thiết kế đa máy tính chọn các bộ xử lý hạt trung bình chi phí thấp làm khối xây dựng. Đa số các máy tính song song được xây dựng với bộ vi xử lý tiêu chuẩn hiện có. Bộ nhớ phân tán được chọn cho nhiều máy tính hơn là sử dụng bộ nhớ dùng chung, điều này sẽ hạn chế khả năng mở rộng. Mỗi bộ xử lý có bộ nhớ cục bộ riêng.
Đối với sơ đồ kết nối, đa máy tính có các mạng trực tiếp truyền thông điệp, điểm-điểm thay vì mạng chuyển mạch địa chỉ. Đối với chiến lược điều khiển, nhà thiết kế nhiều máy tính chọn các hoạt động MIMD, MPMD và SMPD không đồng bộ. Khối lập phương vũ trụ của Caltech (Seitz, 1983) là máy tính đa năng thế hệ đầu tiên.
Phát triển hiện tại và tương lai
Các máy tính thế hệ tiếp theo đã phát triển từ các máy tính đa năng hạt nhỏ đến trung bình sử dụng bộ nhớ ảo được chia sẻ toàn cầu. Hiện tại, nhiều máy tính thế hệ thứ hai vẫn đang được sử dụng. Nhưng sử dụng bộ vi xử lý tốt hơn như i386, i860,… máy tính thế hệ thứ hai đã phát triển rất nhiều.
Máy tính thế hệ thứ ba là máy tính thế hệ tiếp theo mà các nút được triển khai VLSI sẽ được sử dụng. Mỗi nút có thể có bộ xử lý 14-MIPS, các kênh định tuyến 20-Mbyte / s và 16 Kbyte RAM được tích hợp trên một chip.
Hệ thống Intel Paragon
Trước đây, các nút đồng nhất được sử dụng để tạo đa máy tính siêu khối, vì tất cả các chức năng được giao cho máy chủ. Vì vậy, điều này đã hạn chế băng thông I / O. Vì vậy, để giải quyết các vấn đề quy mô lớn một cách hiệu quả hoặc với thông lượng cao, các máy tính này không thể được sử dụng. Hệ thống Intel Paragon được thiết kế để khắc phục khó khăn này. Nó biến máy tính đa năng thành một máy chủ ứng dụng với quyền truy cập đa người dùng trong môi trường mạng.
Cơ chế chuyển thông báo
Cơ chế truyền thông điệp trong mạng đa máy tính cần hỗ trợ phần cứng và phần mềm đặc biệt. Trong phần này, chúng ta sẽ thảo luận về một số phương án.
Lược đồ định tuyến tin nhắn
Trong đa máy tính với lược đồ định tuyến lưu trữ và chuyển tiếp, gói tin là đơn vị truyền thông tin nhỏ nhất. Trong các mạng định tuyến theo lỗ sâu, các gói được chia thành nhiều phần. Chiều dài gói được xác định bởi sơ đồ định tuyến và triển khai mạng, trong khi chiều dài ống bị ảnh hưởng bởi kích thước mạng.
Trong Store and forward routing, gói tin là đơn vị cơ bản của truyền thông tin. Trong trường hợp này, mỗi nút sử dụng một bộ đệm gói. Một gói được truyền từ một nút nguồn đến một nút đích thông qua một chuỗi các nút trung gian. Độ trễ tỷ lệ thuận với khoảng cách giữa nguồn và đích.
Trong wormhole routing, quá trình truyền từ nút nguồn đến nút đích được thực hiện thông qua một chuỗi các bộ định tuyến. Tất cả các phần của cùng một gói được truyền theo một trình tự không thể tách rời theo kiểu pipelined. Trong trường hợp này, chỉ có phần tiêu đề mới biết gói tin đang đi đâu.
Bế tắc và kênh ảo
Kênh ảo là một liên kết hợp lý giữa hai nút. Nó được hình thành bởi bộ đệm flit trong nút nguồn và nút thu, và một kênh vật lý giữa chúng. Khi một kênh vật lý được cấp phát cho một cặp, một bộ đệm nguồn sẽ được ghép nối với một bộ đệm thu để tạo thành một kênh ảo.
Khi tất cả các kênh bị chiếm bởi tin nhắn và không có kênh nào trong chu kỳ được giải phóng, tình trạng bế tắc sẽ xảy ra. Để tránh điều này, một kế hoạch tránh bế tắc phải được tuân theo.
Trong chương này, chúng ta sẽ thảo luận về các giao thức liên kết bộ đệm để đối phó với các vấn đề không nhất quán đa bộ đệm.
Vấn đề liên kết bộ nhớ cache
Trong hệ thống đa xử lý, sự không nhất quán dữ liệu có thể xảy ra giữa các cấp liền kề hoặc trong cùng một cấp của hệ thống phân cấp bộ nhớ. Ví dụ, bộ nhớ đệm và bộ nhớ chính có thể có các bản sao không nhất quán của cùng một đối tượng.
Vì nhiều bộ xử lý hoạt động song song và nhiều bộ đệm độc lập có thể sở hữu các bản sao khác nhau của cùng một khối bộ nhớ, điều này tạo ra cache coherence problem. Cache coherence schemes giúp tránh vấn đề này bằng cách duy trì trạng thái thống nhất cho mỗi khối dữ liệu được lưu trong bộ nhớ cache.
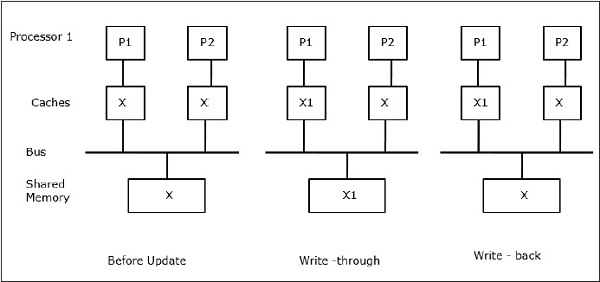
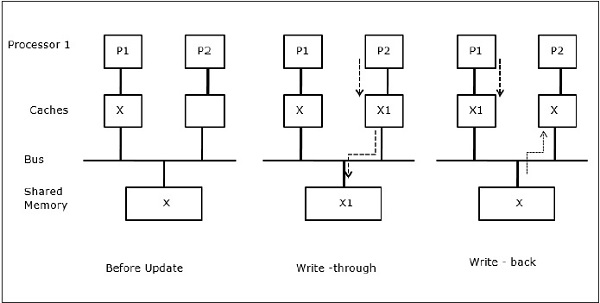
Gọi X là một phần tử của dữ liệu được chia sẻ đã được tham chiếu bởi hai bộ xử lý, P1 và P2. Ban đầu, ba bản sao của X là nhất quán. Nếu bộ xử lý P1 ghi một dữ liệu mới X1 vào bộ nhớ đệm, bằng cách sử dụngwrite-through policy, cùng một bản sao sẽ được ghi ngay vào bộ nhớ dùng chung. Trong trường hợp này, sự không nhất quán xảy ra giữa bộ nhớ đệm và bộ nhớ chính. Khi mộtwrite-back policy được sử dụng, bộ nhớ chính sẽ được cập nhật khi dữ liệu sửa đổi trong bộ đệm được thay thế hoặc mất hiệu lực.
Nói chung, có ba nguồn gốc của vấn đề không nhất quán -
- Chia sẻ dữ liệu có thể ghi
- Quá trình di chuyển
- Hoạt động I / O
Giao thức xe buýt Snoopy
Các giao thức Snoopy đạt được tính nhất quán dữ liệu giữa bộ nhớ đệm và bộ nhớ dùng chung thông qua hệ thống bộ nhớ dựa trên bus. Write-invalidate và write-update chính sách được sử dụng để duy trì tính nhất quán của bộ nhớ cache.
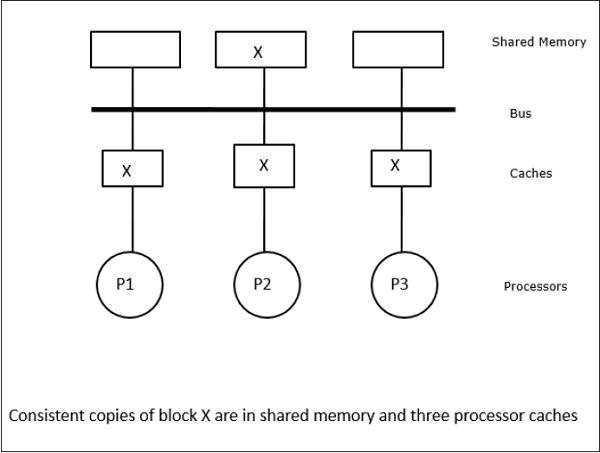
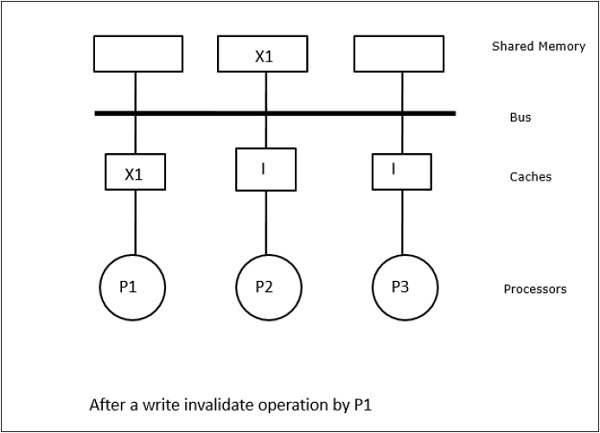
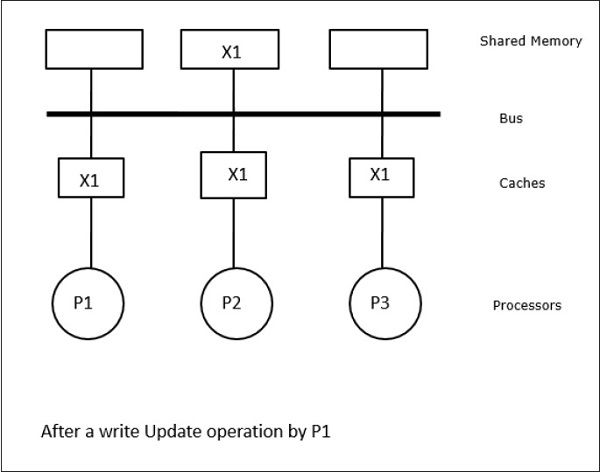
Trong trường hợp này, chúng ta có ba bộ xử lý P1, P2 và P3 có một bản sao nhất quán của phần tử dữ liệu 'X' trong bộ nhớ đệm cục bộ của chúng và trong bộ nhớ dùng chung (Hình-a). Bộ xử lý P1 ghi X1 vào bộ nhớ đệm của nó bằng cách sử dụngwrite-invalidate protocol. Vì vậy, tất cả các bản sao khác đều bị vô hiệu qua xe buýt. Nó được ký hiệu là 'I' (Hình-b). Các khối không hợp lệ còn được gọi làdirty, tức là chúng không nên được sử dụng. Cácwrite-update protocolcập nhật tất cả các bản sao bộ nhớ cache thông qua bus. Bằng cách sử dụngwrite back cache, bản sao bộ nhớ cũng được cập nhật (Hình-c).
Các sự kiện và hành động trong bộ nhớ cache
Các sự kiện và hành động sau xảy ra khi thực hiện các lệnh truy cập bộ nhớ và lệnh hủy bỏ hiệu lực:
Read-miss- Khi một bộ xử lý muốn đọc một khối và khối đó không có trong bộ đệm, thì xảy ra hiện tượng bỏ sót đọc. Điều này bắt đầu mộtbus-readhoạt động. Nếu không có bản sao bẩn nào tồn tại, thì bộ nhớ chính có bản sao nhất quán sẽ cung cấp bản sao cho bộ nhớ đệm yêu cầu. Nếu bản sao bẩn tồn tại trong bộ nhớ đệm từ xa, bộ nhớ đệm đó sẽ hạn chế bộ nhớ chính và gửi bản sao đến bộ nhớ đệm yêu cầu. Trong cả hai trường hợp, bản sao bộ nhớ cache sẽ vào trạng thái hợp lệ sau khi bỏ lỡ lần đọc.
Write-hit - Nếu bản sao bị bẩn hoặc reservedtrạng thái, viết được thực hiện cục bộ và trạng thái mới là bẩn. Nếu trạng thái mới là hợp lệ, lệnh ghi-vô hiệu hóa được phát tới tất cả các bộ nhớ đệm, làm mất hiệu lực các bản sao của chúng. Khi bộ nhớ chia sẻ được ghi qua, trạng thái kết quả được bảo lưu sau lần ghi đầu tiên này.
Write-miss- Nếu bộ xử lý không ghi được trong bộ nhớ đệm cục bộ, bản sao phải đến từ bộ nhớ chính hoặc từ bộ nhớ đệm từ xa có khối bẩn. Điều này được thực hiện bằng cách gửi mộtread-invalidatelệnh này sẽ làm mất hiệu lực của tất cả các bản sao bộ nhớ cache. Sau đó, bản sao cục bộ được cập nhật với trạng thái bẩn.
Read-hit - Read-hit luôn được thực hiện trong bộ nhớ đệm cục bộ mà không gây ra chuyển đổi trạng thái hoặc sử dụng bus snoopy để làm mất hiệu lực.
Block replacement- Khi một bản sao bị bẩn, nó phải được ghi trở lại bộ nhớ chính bằng phương pháp thay thế khối. Tuy nhiên, khi bản sao ở trạng thái hợp lệ hoặc bảo lưu hoặc không hợp lệ, sẽ không có sự thay thế nào được thực hiện.
Giao thức dựa trên thư mục
Bằng cách sử dụng một mạng đa tầng để xây dựng một bộ xử lý lớn với hàng trăm bộ xử lý, các giao thức bộ nhớ cache rình mò cần được sửa đổi cho phù hợp với khả năng của mạng. Việc truyền phát rất tốn kém để thực hiện trong một mạng nhiều tầng, các lệnh nhất quán chỉ được gửi đến những bộ đệm lưu giữ một bản sao của khối. Đây là lý do phát triển các giao thức dựa trên thư mục cho các bộ đa xử lý được kết nối mạng.
Trong hệ thống giao thức dựa trên thư mục, dữ liệu được chia sẻ được đặt trong một thư mục chung để duy trì sự gắn kết giữa các bộ nhớ đệm. Tại đây, thư mục hoạt động như một bộ lọc nơi bộ xử lý yêu cầu quyền tải một mục nhập từ bộ nhớ chính vào bộ nhớ đệm của nó. Nếu một mục nhập bị thay đổi, thư mục sẽ cập nhật nó hoặc làm mất hiệu lực các bộ nhớ đệm khác có mục nhập đó.
Cơ chế đồng bộ hóa phần cứng
Đồng bộ hóa là một hình thức giao tiếp đặc biệt mà thay vì kiểm soát dữ liệu, thông tin được trao đổi giữa các quá trình giao tiếp nằm trong cùng một bộ xử lý hoặc khác nhau.
Hệ thống đa xử lý sử dụng cơ chế phần cứng để thực hiện các hoạt động đồng bộ hóa mức thấp. Hầu hết các bộ đa xử lý đều có cơ chế phần cứng để áp đặt các hoạt động nguyên tử như thao tác đọc, ghi hoặc đọc-sửa-ghi trong bộ nhớ để thực hiện một số nguyên thuỷ đồng bộ hoá. Ngoài các hoạt động của bộ nhớ nguyên tử, một số ngắt của bộ xử lý cũng được sử dụng cho mục đích đồng bộ hóa.
Đồng tiền trong bộ nhớ đệm trong máy bộ nhớ dùng chung
Duy trì đồng tiền bộ nhớ đệm là một vấn đề trong hệ thống đa xử lý khi các bộ xử lý chứa bộ nhớ đệm cục bộ. Sự mâu thuẫn dữ liệu giữa các bộ nhớ đệm khác nhau dễ dàng xảy ra trong hệ thống này.
Các lĩnh vực quan tâm chính là -
- Chia sẻ dữ liệu có thể ghi
- Quá trình di chuyển
- Hoạt động I / O
Chia sẻ dữ liệu có thể ghi
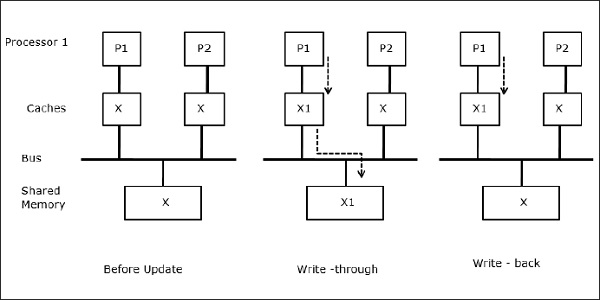
Khi hai bộ xử lý (P1 và P2) có cùng phần tử dữ liệu (X) trong bộ nhớ đệm cục bộ của chúng và một quá trình (P1) ghi vào phần tử dữ liệu (X), vì bộ nhớ đệm là bộ nhớ đệm cục bộ ghi qua P1, bộ nhớ chính sẽ cũng được cập nhật. Bây giờ khi P2 cố gắng đọc phần tử dữ liệu (X), nó không tìm thấy X vì phần tử dữ liệu trong bộ nhớ cache của P2 đã trở nên lỗi thời.
Quá trình di chuyển
Trong giai đoạn đầu, bộ nhớ đệm của P1 có phần tử dữ liệu X, trong khi P2 không có phần tử dữ liệu nào. Một quá trình trên P2 đầu tiên ghi trên X và sau đó chuyển sang P1. Bây giờ, quá trình bắt đầu đọc phần tử dữ liệu X, nhưng vì bộ xử lý P1 có dữ liệu lỗi thời nên quá trình không thể đọc nó. Vì vậy, một quá trình trên P1 ghi vào phần tử dữ liệu X và sau đó chuyển sang P2. Sau khi di chuyển, một quá trình trên P2 bắt đầu đọc phần tử dữ liệu X nhưng nó tìm thấy phiên bản X đã lỗi thời trong bộ nhớ chính.
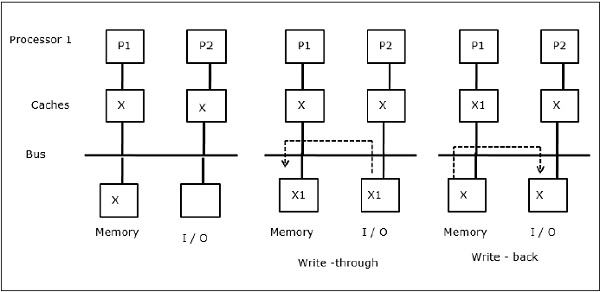
Hoạt động I / O
Như minh họa trong hình, thiết bị I / O được thêm vào bus trong kiến trúc đa xử lý hai bộ xử lý. Lúc đầu, cả hai cache đều chứa phần tử dữ liệu X. Khi thiết bị I / O nhận phần tử mới X, nó sẽ lưu phần tử mới trực tiếp vào bộ nhớ chính. Bây giờ, khi P1 hoặc P2 (giả sử P1) cố gắng đọc phần tử X, nó sẽ nhận được một bản sao lỗi thời. Vì vậy, P1 ghi vào phần tử X. Bây giờ, nếu thiết bị I / O cố gắng truyền X, nó sẽ nhận được một bản sao lỗi thời.
Truy cập bộ nhớ thống nhất (UMA)
Kiến trúc Truy cập Bộ nhớ Đồng nhất (UMA) có nghĩa là bộ nhớ dùng chung là giống nhau cho tất cả các bộ xử lý trong hệ thống. Các lớp phổ biến của máy UMA, thường được sử dụng cho máy chủ (file-), được gọi là Bộ xử lý đa đối xứng (SMP). Trong một SMP, tất cả các tài nguyên hệ thống như bộ nhớ, đĩa, các thiết bị I / O khác, v.v. đều có thể được bộ xử lý truy cập theo cách thống nhất.
Quyền truy cập bộ nhớ không thống nhất (NUMA)
Trong kiến trúc NUMA, có nhiều cụm SMP có mạng gián tiếp / chia sẻ nội bộ, được kết nối trong mạng truyền thông báo có thể mở rộng. Vì vậy, kiến trúc NUMA là kiến trúc bộ nhớ phân tán vật lý được chia sẻ một cách hợp lý.
Trong máy NUMA, bộ điều khiển bộ nhớ đệm của bộ xử lý xác định xem một tham chiếu bộ nhớ là cục bộ trong bộ nhớ của SMP hay nó là từ xa. Để giảm số lần truy cập bộ nhớ từ xa, kiến trúc NUMA thường áp dụng bộ xử lý bộ nhớ đệm có thể lưu vào bộ đệm dữ liệu từ xa. Nhưng khi có liên quan đến bộ nhớ đệm, đồng tiền của bộ đệm cần được duy trì. Vì vậy, các hệ thống này còn được gọi là CC-NUMA (Cache kết hợp NUMA).
Kiến trúc bộ nhớ chỉ bộ nhớ đệm (COMA)
Máy COMA tương tự như máy NUMA, với điểm khác biệt duy nhất là bộ nhớ chính của máy COMA hoạt động như bộ nhớ đệm được ánh xạ trực tiếp hoặc bộ nhớ đệm kết hợp tập hợp. Các khối dữ liệu được băm đến một vị trí trong bộ đệm DRAM theo địa chỉ của chúng. Dữ liệu được tìm nạp từ xa thực sự được lưu trữ trong bộ nhớ chính cục bộ. Hơn nữa, khối dữ liệu không có vị trí cố định tại nhà, chúng có thể tự do di chuyển trong toàn hệ thống.
Các kiến trúc COMA hầu hết đều có một mạng truyền thông điệp phân cấp. Một công tắc trong một cây như vậy chứa một thư mục với các phần tử dữ liệu là cây con của nó. Vì dữ liệu không có vị trí nhà riêng, nó phải được tìm kiếm một cách rõ ràng. Điều này có nghĩa là truy cập từ xa yêu cầu một đường truyền dọc theo các công tắc trong cây để tìm kiếm dữ liệu cần thiết trong thư mục của chúng. Vì vậy, nếu một switch trong mạng nhận được nhiều yêu cầu từ cây con của nó cho cùng một dữ liệu, nó sẽ kết hợp chúng thành một yêu cầu duy nhất được gửi đến cha mẹ của switch. Khi dữ liệu được yêu cầu trả về, công tắc sẽ gửi nhiều bản sao của dữ liệu đó xuống cây con của nó.
COMA so với CC-NUMA
Sau đây là sự khác biệt giữa COMA và CC-NUMA.
COMA có xu hướng linh hoạt hơn CC-NUMA vì COMA hỗ trợ một cách minh bạch việc di chuyển và sao chép dữ liệu mà không cần hệ điều hành.
Máy COMA rất tốn kém và phức tạp để xây dựng vì chúng cần phần cứng quản lý bộ nhớ không theo tiêu chuẩn và giao thức coherency khó thực hiện hơn.
Truy cập từ xa trong COMA thường chậm hơn so với truy cập trong CC-NUMA vì mạng cây cần được duyệt để tìm dữ liệu.
Có nhiều phương pháp để giảm chi phí phần cứng. Một phương pháp là tích hợp hệ thống hỗ trợ giao tiếp và mạng ít chặt chẽ hơn vào nút xử lý, đồng thời tăng độ trễ và chiếm dụng giao tiếp.
Một phương pháp khác là cung cấp tính năng sao chép tự động và tính liên kết trong phần mềm hơn là phần cứng. Phương thức thứ hai cung cấp tính năng sao chép và tính liên kết trong bộ nhớ chính và có thể thực thi ở nhiều mức độ chi tiết khác nhau. Nó cho phép sử dụng các bộ phận hàng hóa có sẵn cho các nút và kết nối với nhau, giảm thiểu chi phí phần cứng. Điều này tạo áp lực cho lập trình viên để đạt được hiệu suất tốt.
Các mô hình nhất quán về bộ nhớ được thư giãn
Mô hình nhất quán bộ nhớ cho một không gian địa chỉ dùng chung xác định các ràng buộc theo thứ tự mà các hoạt động bộ nhớ ở cùng một vị trí hoặc các vị trí khác nhau dường như đang thực thi đối với nhau. Trên thực tế, bất kỳ lớp hệ thống nào hỗ trợ mô hình đặt tên không gian địa chỉ dùng chung phải có mô hình nhất quán bộ nhớ bao gồm giao diện lập trình viên, giao diện hệ thống người dùng và giao diện phần cứng-phần mềm. Phần mềm tương tác với lớp đó phải nhận thức được mô hình nhất quán bộ nhớ của chính nó.
Thông số kỹ thuật
Đặc tả hệ thống của một kiến trúc xác định thứ tự và sắp xếp lại các hoạt động của bộ nhớ và hiệu suất thực sự có thể đạt được từ nó.
Sau đây là một số mô hình đặc điểm kỹ thuật sử dụng các thư giãn theo thứ tự chương trình -
Relaxing the Write-to-Read Program Order- Loại mô hình này cho phép phần cứng loại bỏ độ trễ của các hoạt động ghi đã bị bỏ lỡ trong bộ nhớ đệm cấp một. Khi lỗi ghi nằm trong bộ đệm ghi và không hiển thị với các bộ xử lý khác, bộ xử lý có thể hoàn thành các lần đọc được ghi trong bộ nhớ đệm của nó hoặc thậm chí một lần đọc bị bỏ sót trong bộ nhớ đệm của nó.
Relaxing the Write-to-Read and Write-to-Write Program Orders- Cho phép ghi để bỏ qua các lần ghi chưa xuất hiện trước đó đến các vị trí khác nhau cho phép nhiều lần ghi được hợp nhất trong bộ đệm ghi trước khi cập nhật bộ nhớ chính. Do đó, nhiều lần ghi nhầm sẽ bị chồng chéo và có thể nhìn thấy không theo thứ tự. Động lực là để giảm thiểu hơn nữa tác động của độ trễ ghi lên thời gian nghỉ của bộ xử lý và nâng cao hiệu quả giao tiếp giữa các bộ xử lý bằng cách hiển thị các giá trị dữ liệu mới cho các bộ xử lý khác.
Relaxing All Program Orders- Không có lệnh chương trình nào được đảm bảo theo mặc định ngoại trừ dữ liệu và điều khiển phụ thuộc trong một quy trình. Do đó, lợi ích là nhiều yêu cầu đọc có thể được thực hiện cùng một lúc và theo thứ tự chương trình có thể được bỏ qua bằng cách ghi sau và bản thân chúng có thể hoàn thành không theo thứ tự, cho phép chúng tôi ẩn độ trễ đọc. Loại mô hình này đặc biệt hữu ích cho các bộ xử lý được lập lịch động, có thể tiếp tục các lần đọc trước đây đến các tham chiếu bộ nhớ khác. Chúng cho phép nhiều lần lặp lại, thậm chí loại bỏ các truy cập được thực hiện bởi tối ưu hóa trình biên dịch.
Giao diện lập trình
Các giao diện lập trình giả định rằng các lệnh chương trình không cần phải được duy trì giữa các hoạt động đồng bộ hóa. Nó được đảm bảo rằng tất cả các hoạt động đồng bộ hóa được dán nhãn rõ ràng hoặc được xác định như vậy. Thư viện thời gian chạy hoặc trình biên dịch chuyển các hoạt động đồng bộ hóa này thành các hoạt động bảo toàn thứ tự phù hợp được yêu cầu bởi đặc tả hệ thống.
Sau đó, hệ thống đảm bảo thực thi nhất quán tuần tự mặc dù nó có thể sắp xếp lại các hoạt động giữa các hoạt động đồng bộ hóa theo bất kỳ cách nào nó mong muốn mà không làm gián đoạn các phụ thuộc vào một vị trí trong một quy trình. Điều này cho phép trình biên dịch đủ linh hoạt giữa các điểm đồng bộ hóa để sắp xếp lại thứ tự mà nó mong muốn, đồng thời cho phép bộ xử lý thực hiện nhiều sắp xếp lại theo mô hình bộ nhớ của nó cho phép. Ở giao diện của lập trình viên, mô hình nhất quán ít nhất phải yếu bằng mô hình của giao diện phần cứng, nhưng không cần giống nhau.
Cơ chế dịch
Trong hầu hết các bộ vi xử lý, việc dịch nhãn theo thứ tự các cơ chế duy trì tương đương với việc chèn một lệnh rào cản bộ nhớ phù hợp trước và / hoặc sau mỗi thao tác được gắn nhãn là đồng bộ hóa. Nó sẽ lưu các hướng dẫn với các lần tải / cửa hàng riêng lẻ cho biết những khó khăn cần thực thi và tránh các hướng dẫn bổ sung. Tuy nhiên, vì các hoạt động thường không thường xuyên, đây không phải là cách mà hầu hết các bộ vi xử lý thực hiện cho đến nay.
Khắc phục giới hạn năng lực
Chúng tôi đã ngụy biện các hệ thống cung cấp tính năng sao chép tự động và tính liên kết trong phần cứng chỉ trong bộ nhớ đệm của bộ xử lý. Bộ nhớ đệm của bộ xử lý, không cần sao chép trước trong bộ nhớ chính cục bộ, sẽ sao chép dữ liệu được cấp phát từ xa trực tiếp khi tham chiếu.
Một vấn đề với các hệ thống này là phạm vi sao chép cục bộ bị giới hạn trong bộ nhớ cache phần cứng. Nếu một khối được thay thế từ bộ nhớ đệm, khối đó phải được tìm nạp từ bộ nhớ từ xa khi cần lại. Mục đích chính của các hệ thống được thảo luận trong phần này là giải quyết vấn đề dung lượng sao chép nhưng vẫn cung cấp tính nhất quán trong phần cứng và ở mức độ chi tiết tốt của các khối bộ nhớ cache để đạt hiệu quả.
Bộ nhớ đệm cấp ba
Để giải quyết vấn đề dung lượng sao chép, một phương pháp là sử dụng bộ nhớ đệm truy cập từ xa lớn nhưng chậm hơn. Điều này là cần thiết cho chức năng, khi các nút của máy tự là bộ xử lý đa xử lý quy mô nhỏ và có thể đơn giản là lớn hơn để đạt hiệu suất. Nó cũng sẽ giữ các khối từ xa được sao chép đã được thay thế từ bộ nhớ đệm bộ xử lý cục bộ.
Kiến trúc bộ nhớ chỉ sử dụng bộ nhớ đệm (COMA)
Trong các máy COMA, mọi khối bộ nhớ trong toàn bộ bộ nhớ chính đều có một thẻ phần cứng được liên kết với nó. Không có nút cố định nào luôn đảm bảo được cấp phát không gian cho khối bộ nhớ. Dữ liệu tự động di chuyển đến hoặc được sao chép trong bộ nhớ chính của các nút truy cập / thu hút chúng. Khi một khối từ xa được truy cập, nó được sao chép trong bộ nhớ thu hút và được đưa vào bộ nhớ cache, và được phần cứng giữ nhất quán ở cả hai nơi. Một khối dữ liệu có thể nằm trong bất kỳ bộ nhớ thu hút nào và có thể di chuyển dễ dàng từ khối này sang khối khác.
Giảm chi phí phần cứng
Giảm chi phí có nghĩa là chuyển một số chức năng của phần cứng chuyên dụng sang phần mềm chạy trên phần cứng hiện có. Phần mềm quản lý sao chép và gắn kết trong bộ nhớ chính dễ dàng hơn nhiều so với trong bộ nhớ cache phần cứng. Các phương pháp chi phí thấp có xu hướng cung cấp sự sao chép và tính liên kết trong bộ nhớ chính. Để sự gắn kết được kiểm soát một cách hiệu quả, mỗi thành phần chức năng khác của trợ giúp có thể được hưởng lợi từ việc chuyên môn hóa và tích hợp phần cứng.
Các nỗ lực nghiên cứu nhằm giảm chi phí bằng các cách tiếp cận khác nhau, như bằng cách thực hiện kiểm soát truy cập trong phần cứng chuyên dụng, nhưng chỉ định các hoạt động khác cho phần mềm và phần cứng hàng hóa. Một cách tiếp cận khác là thực hiện kiểm soát truy cập trong phần mềm và được thiết kế để phân bổ trừu tượng không gian địa chỉ chia sẻ nhất quán trên các nút hàng hóa và mạng không có hỗ trợ phần cứng chuyên dụng.
Hàm ý cho phần mềm song song
Mô hình nhất quán bộ nhớ thư giãn cần các chương trình song song gắn nhãn các truy cập xung đột mong muốn làm điểm đồng bộ hóa. Một ngôn ngữ lập trình cung cấp hỗ trợ để gắn nhãn một số biến là đồng bộ hóa, sau đó sẽ được trình biên dịch dịch sang lệnh bảo toàn thứ tự phù hợp. Để hạn chế việc sắp xếp lại thứ tự của các trình biên dịch đối với các quyền truy cập vào bộ nhớ dùng chung, trình biên dịch có thể sử dụng các nhãn của chính nó.
An interconnection networktrong một máy song song chuyển thông tin từ bất kỳ nút nguồn nào đến bất kỳ nút đích mong muốn nào. Tác vụ này phải được hoàn thành với độ trễ càng nhỏ càng tốt. Nó sẽ cho phép một số lượng lớn các chuyển nhượng như vậy diễn ra đồng thời. Hơn nữa, nó sẽ không đắt so với chi phí của phần còn lại của máy.
Mạng bao gồm các liên kết và chuyển mạch, giúp gửi thông tin từ nút nguồn đến nút đích. Mạng được xác định bởi cấu trúc liên kết, thuật toán định tuyến, chiến lược chuyển mạch và cơ chế điều khiển luồng.
Cơ cấu tổ chức
Mạng kết nối bao gồm ba thành phần cơ bản sau:
Links- Liên kết là cáp gồm một hoặc nhiều sợi quang hoặc dây dẫn điện có đầu nối ở mỗi đầu được gắn với công tắc hoặc cổng giao diện mạng. Thông qua đó, một tín hiệu tương tự được truyền từ một đầu, nhận ở đầu kia để có được dòng thông tin số ban đầu.
Switches- Một công tắc bao gồm một tập hợp các cổng đầu vào và đầu ra, một “thanh ngang” bên trong kết nối tất cả đầu vào với tất cả đầu ra, bộ đệm bên trong và logic điều khiển để thực hiện kết nối đầu vào - đầu ra tại từng thời điểm. Nói chung, số lượng cổng đầu vào bằng số lượng cổng đầu ra.
Network Interfaces- Giao diện mạng hoạt động khá khác so với các nút chuyển đổi và có thể được kết nối thông qua các liên kết đặc biệt. Giao diện mạng định dạng các gói và xây dựng thông tin điều khiển và định tuyến. Nó có thể có bộ đệm đầu vào và đầu ra, so với một công tắc. Nó có thể thực hiện kiểm tra lỗi đầu cuối và kiểm soát luồng. Do đó, chi phí của nó bị ảnh hưởng bởi độ phức tạp xử lý, dung lượng lưu trữ và số lượng cổng.
Mạng kết nối
Mạng liên kết bao gồm các phần tử chuyển mạch. Cấu trúc liên kết là mô hình để kết nối các công tắc riêng lẻ với các phần tử khác, như bộ xử lý, bộ nhớ và các công tắc khác. Một mạng cho phép trao đổi dữ liệu giữa các bộ xử lý trong hệ thống song song.
Direct connection networks- Mạng trực tiếp có kết nối điểm - điểm giữa các nút lân cận. Các mạng này là tĩnh, có nghĩa là các kết nối điểm-điểm là cố định. Một số ví dụ về mạng trực tiếp là vòng, mắt lưới và hình khối.
Indirect connection networks- Mạng gián tiếp không có hàng xóm cố định. Cấu trúc liên kết truyền thông có thể được thay đổi động dựa trên nhu cầu ứng dụng. Mạng gián tiếp có thể được chia thành ba phần: mạng bus, mạng nhiều tầng và chuyển mạch thanh ngang.
Bus networks- Mạng bus bao gồm một số dòng bit trên đó một số tài nguyên được gắn vào. Khi các bus sử dụng các đường vật lý giống nhau cho dữ liệu và địa chỉ, dữ liệu và các đường địa chỉ được ghép kênh theo thời gian. Khi có nhiều bus-master gắn vào bus, cần có trọng tài.
Multistage networks- Một mạng nhiều tầng bao gồm nhiều tầng chuyển mạch. Nó bao gồm các thiết bị chuyển mạch 'axb' được kết nối bằng một mẫu kết nối giữa các tiểu bang (ISC) cụ thể. Các phần tử chuyển mạch 2x2 nhỏ là lựa chọn phổ biến cho nhiều mạng đa tầng. Số lượng các giai đoạn xác định độ trễ của mạng. Bằng cách chọn các mẫu kết nối giữa các tiểu bang khác nhau, có thể tạo ra nhiều loại mạng đa tầng khác nhau.
Crossbar switches- Một công tắc xà ngang chứa một ma trận các phần tử công tắc đơn giản có thể bật và tắt để tạo hoặc ngắt kết nối. Bật một phần tử chuyển mạch trong ma trận, kết nối giữa bộ xử lý và bộ nhớ có thể được thực hiện. Công tắc thanh ngang là không chặn, đó là tất cả các hoán vị giao tiếp có thể được thực hiện mà không bị chặn.
Đánh giá sự cân bằng thiết kế trong cấu trúc liên kết mạng
Nếu mối quan tâm chính là khoảng cách định tuyến, thì kích thước phải được tối đa hóa và tạo ra một siêu khối. Trong định tuyến cửa hàng và chuyển tiếp, giả sử rằng mức độ của chuyển đổi và số lượng liên kết không phải là một yếu tố chi phí đáng kể và số lượng liên kết hoặc mức độ chuyển đổi là chi phí chính, thì kích thước phải được giảm thiểu và lưới được xây dựng.
Trong trường hợp xấu nhất, mô hình lưu lượng cho mỗi mạng, ưu tiên các mạng có chiều cao, nơi tất cả các đường dẫn đều ngắn. Trong các mẫu mà mỗi nút chỉ giao tiếp với một hoặc hai nút lân cận, thì mạng có chiều thấp được ưu tiên hơn, vì chỉ một số kích thước thực sự được sử dụng.
định tuyến
Thuật toán định tuyến của mạng xác định đường nào trong số các đường có thể từ nguồn đến đích được sử dụng làm các tuyến và cách xác định tuyến theo từng gói cụ thể. Định tuyến thứ tự thứ nguyên giới hạn tập hợp các đường dẫn hợp pháp để có chính xác một tuyến đường từ mỗi nguồn đến mỗi đích. Người có được bằng cách đi đúng khoảng cách đầu tiên trong chiều thứ tự cao, sau đó đến chiều tiếp theo, v.v.
Cơ chế định tuyến
Số học, chọn cổng dựa trên nguồn và tra cứu bảng là ba cơ chế mà bộ chuyển mạch tốc độ cao sử dụng để xác định kênh đầu ra từ thông tin trong tiêu đề gói. Tất cả các cơ chế này đơn giản hơn so với kiểu tính toán định tuyến chung được thực hiện trong các bộ định tuyến LAN và WAN truyền thống. Trong các mạng máy tính song song, bộ chuyển mạch cần đưa ra quyết định định tuyến cho tất cả các đầu vào của nó trong mọi chu kỳ, do đó cơ chế cần đơn giản và nhanh chóng.
Định tuyến xác định
Thuật toán định tuyến là xác định nếu lộ trình được thực hiện bởi một thông điệp được xác định riêng bởi nguồn và đích của nó, chứ không phải bởi lưu lượng truy cập khác trong mạng. Nếu một thuật toán định tuyến chỉ chọn các đường đi ngắn nhất đến đích thì nó là tối thiểu, ngược lại thì nó là không tối thiểu.
Tự do bế tắc
Bế tắc có thể xảy ra trong nhiều tình huống khác nhau. Khi hai nút cố gắng gửi dữ liệu cho nhau và mỗi nút bắt đầu gửi trước khi một trong hai nhận được, có thể xảy ra bế tắc 'đối đầu'. Một trường hợp deadlock khác xảy ra, khi có nhiều thông báo cạnh tranh tài nguyên trong mạng.
Kỹ thuật cơ bản để chứng minh một mạng là không có bế tắc, là xóa các phụ thuộc có thể xảy ra giữa các kênh do kết quả của các thông báo di chuyển qua các mạng và chỉ ra rằng không có chu kỳ nào trong biểu đồ phụ thuộc kênh tổng thể; do đó không có mẫu lưu lượng nào có thể dẫn đến bế tắc. Cách phổ biến của việc này là đánh số tài nguyên kênh sao cho tất cả các tuyến tuân theo một trình tự tăng hoặc giảm cụ thể, để không phát sinh các chu kỳ phụ thuộc.
Thiết kế chuyển đổi
Thiết kế của một mạng phụ thuộc vào thiết kế của công tắc và cách các công tắc được nối dây với nhau. Mức độ của công tắc, cơ chế định tuyến bên trong và bộ đệm bên trong của nó quyết định những cấu trúc liên kết nào có thể được hỗ trợ và những thuật toán định tuyến nào có thể được triển khai. Giống như bất kỳ thành phần phần cứng nào khác của hệ thống máy tính, bộ chuyển mạch mạng chứa đường dẫn dữ liệu, điều khiển và lưu trữ.
Các cổng
Tổng số chân thực sự là tổng số cổng đầu vào và đầu ra nhân với chiều rộng kênh. Khi chu vi của chip phát triển chậm so với diện tích, các công tắc có xu hướng bị giới hạn.
Đường dẫn dữ liệu nội bộ
Đường dữ liệu là kết nối giữa mỗi tập hợp các cổng đầu vào và mọi cổng đầu ra. Nó thường được gọi là thanh ngang bên trong. Một thanh chéo không chặn là một thanh mà mỗi cổng đầu vào có thể được kết nối với một đầu ra riêng biệt trong bất kỳ hoán vị nào đồng thời.
Bộ đệm kênh
Việc tổ chức lưu trữ bộ đệm trong bộ chuyển mạch có tác động quan trọng đến hiệu suất của bộ chuyển mạch. Các bộ định tuyến và bộ chuyển mạch truyền thống có xu hướng có bộ đệm SRAM hoặc DRAM lớn bên ngoài kết cấu bộ chuyển mạch, trong khi trong VLSI chuyển mạch bộ đệm nằm bên trong bộ chuyển mạch và xuất phát từ cùng một ngân sách silicon như đường dữ liệu và phần điều khiển. Khi kích thước và mật độ chip tăng lên, nhiều bộ đệm hơn có sẵn và nhà thiết kế mạng có nhiều lựa chọn hơn, nhưng bất động sản bộ đệm vẫn là lựa chọn hàng đầu và tổ chức của nó rất quan trọng.
Kiểm soát lưu lượng
Khi nhiều luồng dữ liệu trong mạng cố gắng sử dụng cùng một lúc các tài nguyên mạng dùng chung, thì phải thực hiện một số hành động để kiểm soát các luồng này. Nếu chúng tôi không muốn mất bất kỳ dữ liệu nào, một số luồng phải bị chặn trong khi các luồng khác vẫn tiếp tục.
Vấn đề kiểm soát luồng phát sinh trong tất cả các mạng và ở nhiều cấp. Nhưng nó khác về chất trong mạng máy tính song song so với mạng cục bộ và mạng diện rộng. Trong các máy tính song song, lưu lượng mạng cần được phân phối chính xác như lưu lượng qua một xe buýt và có một số lượng rất lớn các luồng song song trên quy mô thời gian rất nhỏ.
Tốc độ của bộ vi xử lý đã tăng hơn 10 lần mỗi thập kỷ, nhưng tốc độ của bộ nhớ hàng hóa (DRAM) chỉ tăng gấp đôi, tức là thời gian truy cập giảm một nửa. Do đó, độ trễ của truy cập bộ nhớ tính theo chu kỳ xung nhịp của bộ xử lý tăng lên 6 trong 10 năm. Các bộ xử lý đa xử lý đã làm tăng thêm vấn đề.
Trong các hệ thống dựa trên bus, việc thiết lập bus băng thông cao giữa bộ xử lý và bộ nhớ có xu hướng làm tăng độ trễ của việc lấy dữ liệu từ bộ nhớ. Khi bộ nhớ được phân phối vật lý, độ trễ của mạng và giao diện mạng được thêm vào độ trễ của việc truy cập bộ nhớ cục bộ trên nút.
Độ trễ thường tăng theo kích thước của máy, vì nhiều nút hơn ngụ ý nhiều giao tiếp hơn so với tính toán, nhiều bước nhảy hơn trong mạng để giao tiếp chung và có nhiều khả năng tranh chấp hơn. Mục tiêu chính của thiết kế phần cứng là giảm độ trễ của truy cập dữ liệu trong khi duy trì băng thông cao, có thể mở rộng.
Tổng quan về Dung sai độ trễ
Cách xử lý khả năng chịu độ trễ được hiểu rõ nhất bằng cách xem xét các tài nguyên trong máy và cách chúng được sử dụng. Theo quan điểm của bộ xử lý, kiến trúc truyền thông từ nút này sang nút khác có thể được xem như một đường ống. Các giai đoạn của đường ống bao gồm các giao diện mạng tại nguồn và đích, cũng như trong các liên kết và chuyển mạch mạng trên đường đi. Ngoài ra còn có các giai đoạn trong hỗ trợ giao tiếp, hệ thống bộ nhớ / bộ đệm cục bộ và bộ xử lý chính, tùy thuộc vào cách kiến trúc quản lý giao tiếp.
Vấn đề sử dụng trong cấu trúc giao tiếp cơ sở là bộ xử lý hoặc kiến trúc truyền thông đang bận tại một thời điểm nhất định và trong đường ống truyền thông chỉ có một giai đoạn bận tại một thời điểm khi một từ được truyền đi từ nguồn đến đích. Mục đích của khả năng chịu độ trễ là chồng chéo việc sử dụng các tài nguyên này càng nhiều càng tốt.
Dung sai độ trễ khi chuyển thông báo rõ ràng
Quá trình truyền dữ liệu thực tế trong quá trình truyền thông điệp thường do người gửi khởi tạo, sử dụng thao tác gửi. Bản thân hoạt động nhận không thúc đẩy dữ liệu được giao tiếp, mà là sao chép dữ liệu từ bộ đệm đến vào không gian địa chỉ ứng dụng. Giao tiếp do người nhận khởi tạo được thực hiện bằng cách đưa ra một thông báo yêu cầu tới tiến trình là nguồn dữ liệu. Sau đó, quá trình sẽ gửi dữ liệu trở lại thông qua một lần gửi khác.
Hoạt động gửi đồng bộ có độ trễ giao tiếp bằng với thời gian cần thiết để giao tiếp tất cả dữ liệu trong thông báo đến đích, và thời gian xử lý nhận và thời gian trả lại báo nhận. Độ trễ của hoạt động nhận đồng bộ là chi phí xử lý của nó; trong đó bao gồm việc sao chép dữ liệu vào ứng dụng và độ trễ bổ sung nếu dữ liệu chưa đến. Chúng tôi muốn ẩn những độ trễ này, bao gồm cả chi phí nếu có thể, ở cả hai đầu.
Dung sai độ trễ trong không gian địa chỉ dùng chung
Giao tiếp cơ bản thông qua việc đọc và ghi trong một không gian địa chỉ dùng chung. Để thuận tiện, nó được gọi là giao tiếp đọc-ghi. Giao tiếp do máy thu khởi tạo được thực hiện với các hoạt động đọc dẫn đến dữ liệu từ bộ nhớ hoặc bộ đệm của bộ xử lý khác được truy cập. Nếu không có bộ nhớ đệm của dữ liệu được chia sẻ, giao tiếp do người gửi khởi xướng có thể được thực hiện thông qua việc ghi vào dữ liệu được cấp phát trong bộ nhớ từ xa.
Với tính liên kết trong bộ nhớ cache, ảnh hưởng của việc ghi phức tạp hơn: việc ghi dẫn đến giao tiếp do người gửi hoặc người nhận bắt đầu phụ thuộc vào giao thức kết hợp bộ nhớ cache. Dù do người nhận khởi tạo hoặc do người gửi khởi tạo, giao tiếp trong không gian địa chỉ chia sẻ đọc ghi được hỗ trợ phần cứng là chi tiết tự nhiên, điều này làm cho độ trễ dung sai trở nên rất quan trọng.
Chặn truyền dữ liệu trong không gian địa chỉ dùng chung
Trong không gian địa chỉ dùng chung, bằng phần cứng hoặc phần mềm, việc kết hợp dữ liệu và bắt đầu chuyển khối có thể được thực hiện một cách rõ ràng trong chương trình người dùng hoặc hệ thống một cách minh bạch. Chuyển khối rõ ràng được bắt đầu bằng cách thực hiện một lệnh tương tự như gửi trong chương trình người dùng. Lệnh gửi được giải thích bởi bộ phận hỗ trợ truyền thông, nó chuyển dữ liệu theo cách thức tổng hợp từ nút nguồn đến đích. Tại điểm đến, bộ phận hỗ trợ giao tiếp kéo các từ dữ liệu vào từ giao diện mạng và lưu trữ chúng ở các vị trí được chỉ định.
Có hai điểm khác biệt cơ bản so với việc truyền thông điệp gửi-nhận, cả hai đều phát sinh từ thực tế là quá trình gửi có thể chỉ định trực tiếp cấu trúc dữ liệu chương trình nơi dữ liệu sẽ được đặt tại đích, vì các vị trí này nằm trong không gian địa chỉ dùng chung .
Tiếp tục các sự kiện có độ trễ dài trong quá khứ trong không gian địa chỉ dùng chung
Nếu hoạt động bộ nhớ được thực hiện không chặn, bộ xử lý có thể tiếp tục hoạt động bộ nhớ qua các lệnh khác. Đối với việc ghi, điều này thường khá đơn giản để thực hiện nếu quá trình ghi được đặt trong bộ đệm ghi, và bộ xử lý tiếp tục trong khi bộ đệm xử lý việc cấp lệnh ghi vào hệ thống bộ nhớ và theo dõi quá trình hoàn thành theo yêu cầu. Sự khác biệt là không giống như ghi, một lần đọc thường được theo sau rất sớm bởi một lệnh cần giá trị được trả về bởi lần đọc.
Giao tiếp trước trong Không gian địa chỉ dùng chung
Giao tiếp trước là một kỹ thuật đã được áp dụng rộng rãi trong các bộ vi xử lý thương mại và tầm quan trọng của nó có thể sẽ tăng lên trong tương lai. Một lệnh tìm nạp trước không thay thế việc đọc thực tế của mục dữ liệu và bản thân lệnh tìm nạp trước phải không bị chặn, nếu nó đạt được mục tiêu là ẩn độ trễ thông qua chồng chéo.
Trong trường hợp này, vì dữ liệu được chia sẻ không được lưu vào bộ nhớ đệm, nên dữ liệu đã tìm nạp trước được đưa vào một cấu trúc phần cứng đặc biệt được gọi là bộ đệm tìm nạp trước. Khi từ thực sự được đọc vào một thanh ghi trong lần lặp tiếp theo, nó sẽ được đọc từ phần đầu của bộ đệm tìm nạp trước chứ không phải từ bộ nhớ. Nếu độ trễ cần ẩn lớn hơn nhiều so với thời gian tính toán lặp lại vòng lặp đơn, chúng tôi sẽ tìm nạp trước một số lần lặp trước và có khả năng sẽ có một số từ trong bộ đệm tìm nạp trước tại một thời điểm.
Đa luồng trong không gian địa chỉ dùng chung
Về mặt ẩn các loại độ trễ khác nhau, đa luồng hỗ trợ phần cứng có lẽ là kỹ thuật linh hoạt. Nó có những ưu điểm khái niệm sau so với các cách tiếp cận khác:
Nó không yêu cầu phân tích hoặc hỗ trợ phần mềm đặc biệt.
Vì nó được gọi động, nó có thể xử lý các tình huống không thể đoán trước, chẳng hạn như xung đột bộ nhớ cache, v.v. cũng như những tình huống có thể dự đoán được.
Giống như tìm nạp trước, nó không thay đổi mô hình nhất quán bộ nhớ vì nó không sắp xếp lại các truy cập trong một luồng.
Mặc dù các kỹ thuật trước đây được nhắm mục tiêu vào việc ẩn độ trễ truy cập bộ nhớ, nhưng đa luồng có thể có khả năng ẩn độ trễ của bất kỳ sự kiện có độ trễ dài nào một cách dễ dàng, miễn là sự kiện có thể được phát hiện trong thời gian chạy. Điều này bao gồm đồng bộ hóa và độ trễ hướng dẫn.
Xu hướng này có thể thay đổi trong tương lai, vì độ trễ ngày càng trở nên dài hơn so với tốc độ của bộ xử lý. Ngoài ra với các bộ vi xử lý phức tạp hơn đã cung cấp các phương pháp có thể mở rộng cho đa luồng và với các kỹ thuật đa luồng mới đang được phát triển để kết hợp đa luồng với song song mức chỉ lệnh, xu hướng này chắc chắn sẽ có một số thay đổi trong tương lai.