Sqoop - Giới thiệu
Hệ thống quản lý ứng dụng truyền thống, nghĩa là, sự tương tác của các ứng dụng với cơ sở dữ liệu quan hệ sử dụng RDBMS, là một trong những nguồn tạo ra Dữ liệu lớn. Dữ liệu lớn như vậy, được tạo bởi RDBMS, được lưu trữ trong Quan hệDatabase Servers trong cấu trúc cơ sở dữ liệu quan hệ.
Khi các bộ lưu trữ và phân tích Dữ liệu lớn như MapReduce, Hive, HBase, Cassandra, Pig, v.v. của hệ sinh thái Hadoop đi vào hoạt động, chúng yêu cầu một công cụ tương tác với các máy chủ cơ sở dữ liệu quan hệ để nhập và xuất Dữ liệu lớn nằm trong đó. Ở đây, Sqoop chiếm một vị trí trong hệ sinh thái Hadoop để cung cấp sự tương tác khả thi giữa máy chủ cơ sở dữ liệu quan hệ và HDFS của Hadoop.
Sqoop - “SQL thành Hadoop và Hadoop thành SQL”
Sqoop là một công cụ được thiết kế để truyền dữ liệu giữa Hadoop và các máy chủ cơ sở dữ liệu quan hệ. Nó được sử dụng để nhập dữ liệu từ cơ sở dữ liệu quan hệ như MySQL, Oracle sang Hadoop HDFS và xuất từ hệ thống tệp Hadoop sang cơ sở dữ liệu quan hệ. Nó được cung cấp bởi Apache Software Foundation.
Sqoop hoạt động như thế nào?
Hình ảnh sau đây mô tả quy trình làm việc của Sqoop.
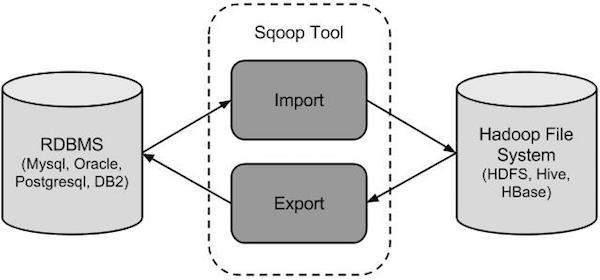
Nhập Sqoop
Công cụ nhập nhập các bảng riêng lẻ từ RDBMS sang HDFS. Mỗi hàng trong bảng được coi như một bản ghi trong HDFS. Tất cả các bản ghi được lưu trữ dưới dạng dữ liệu văn bản trong tệp văn bản hoặc dữ liệu nhị phân trong tệp Avro và Sequence.
Xuất khẩu Sqoop
Công cụ xuất xuất một tập hợp các tệp từ HDFS trở lại RDBMS. Các tệp được cung cấp làm đầu vào cho Sqoop chứa các bản ghi, được gọi là hàng trong bảng. Chúng được đọc và phân tích cú pháp thành một tập hợp các bản ghi và được phân tách bằng dấu phân cách do người dùng chỉ định.