Sqoop - Hướng dẫn nhanh
Hệ thống quản lý ứng dụng truyền thống, nghĩa là, sự tương tác của các ứng dụng với cơ sở dữ liệu quan hệ sử dụng RDBMS, là một trong những nguồn tạo ra Dữ liệu lớn. Dữ liệu lớn như vậy, được tạo bởi RDBMS, được lưu trữ trong Quan hệDatabase Servers trong cấu trúc cơ sở dữ liệu quan hệ.
Khi các bộ lưu trữ và phân tích Dữ liệu lớn như MapReduce, Hive, HBase, Cassandra, Pig, v.v. của hệ sinh thái Hadoop đi vào hoạt động, chúng yêu cầu một công cụ tương tác với các máy chủ cơ sở dữ liệu quan hệ để nhập và xuất Dữ liệu lớn nằm trong đó. Ở đây, Sqoop chiếm một vị trí trong hệ sinh thái Hadoop để cung cấp sự tương tác khả thi giữa máy chủ cơ sở dữ liệu quan hệ và HDFS của Hadoop.
Sqoop - “SQL thành Hadoop và Hadoop thành SQL”
Sqoop là một công cụ được thiết kế để truyền dữ liệu giữa Hadoop và các máy chủ cơ sở dữ liệu quan hệ. Nó được sử dụng để nhập dữ liệu từ cơ sở dữ liệu quan hệ như MySQL, Oracle sang Hadoop HDFS và xuất từ hệ thống tệp Hadoop sang cơ sở dữ liệu quan hệ. Nó được cung cấp bởi Apache Software Foundation.
Sqoop hoạt động như thế nào?
Hình ảnh sau đây mô tả quy trình làm việc của Sqoop.
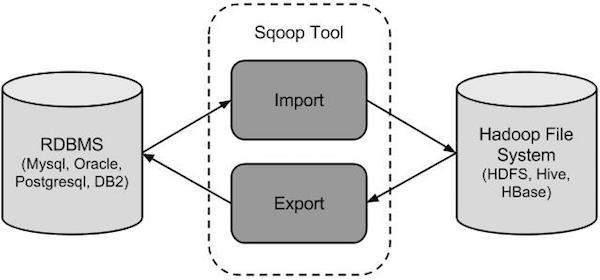
Nhập Sqoop
Công cụ nhập nhập các bảng riêng lẻ từ RDBMS sang HDFS. Mỗi hàng trong bảng được coi như một bản ghi trong HDFS. Tất cả các bản ghi được lưu trữ dưới dạng dữ liệu văn bản trong tệp văn bản hoặc dữ liệu nhị phân trong tệp Avro và Sequence.
Xuất khẩu Sqoop
Công cụ xuất xuất một tập hợp các tệp từ HDFS trở lại RDBMS. Các tệp được cung cấp làm đầu vào cho Sqoop chứa các bản ghi, được gọi là hàng trong bảng. Chúng được đọc và phân tích cú pháp thành một tập hợp các bản ghi và được phân tách bằng dấu phân cách do người dùng chỉ định.
Vì Sqoop là một dự án con của Hadoop nên nó chỉ có thể hoạt động trên hệ điều hành Linux. Làm theo các bước dưới đây để cài đặt Sqoop trên hệ thống của bạn.
Bước 1: Xác minh cài đặt JAVA
Bạn cần cài đặt Java trên hệ thống của mình trước khi cài đặt Sqoop. Hãy để chúng tôi xác minh cài đặt Java bằng lệnh sau:
$ java –versionNếu Java đã được cài đặt trên hệ thống của bạn, bạn sẽ thấy phản hồi sau:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Nếu Java chưa được cài đặt trên hệ thống của bạn, hãy làm theo các bước dưới đây.
Cài đặt Java
Làm theo các bước đơn giản dưới đây để cài đặt Java trên hệ thống của bạn.
Bước 1
Tải xuống Java (JDK <phiên bản mới nhất> - X64.tar.gz) bằng cách truy cập liên kết sau .
Sau đó, jdk-7u71-linux-x64.tar.gz sẽ được tải xuống hệ thống của bạn.
Bước 2
Nói chung, bạn có thể tìm thấy tệp Java đã tải xuống trong thư mục Tải xuống. Xác minh nó và giải nén tệp jdk-7u71-linux-x64.gz bằng các lệnh sau.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzBước 3
Để cung cấp Java cho tất cả người dùng, bạn phải chuyển nó đến vị trí “/ usr / local /”. Mở thư mục gốc và gõ các lệnh sau.
$ su
password:
# mv jdk1.7.0_71 /usr/local/java
# exitStep IV:Bước 4
Để thiết lập các biến PATH và JAVA_HOME, hãy thêm các lệnh sau vào tệp ~ / .bashrc.
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/binBây giờ áp dụng tất cả các thay đổi vào hệ thống đang chạy hiện tại.
$ source ~/.bashrcBước 5
Sử dụng các lệnh sau để định cấu hình các lựa chọn thay thế Java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarBây giờ hãy xác minh cài đặt bằng lệnh java -version từ thiết bị đầu cuối như đã giải thích ở trên.
Bước 2: Xác minh cài đặt Hadoop
Hadoop phải được cài đặt trên hệ thống của bạn trước khi cài đặt Sqoop. Hãy để chúng tôi xác minh cài đặt Hadoop bằng lệnh sau:
$ hadoop versionNếu Hadoop đã được cài đặt trên hệ thống của bạn, thì bạn sẽ nhận được phản hồi sau:
Hadoop 2.4.1
--
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Nếu Hadoop chưa được cài đặt trên hệ thống của bạn, hãy tiến hành các bước sau:
Tải xuống Hadoop
Tải xuống và giải nén Hadoop 2.4.1 từ Apache Software Foundation bằng các lệnh sau.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitCài đặt Hadoop trong Chế độ phân tán giả
Làm theo các bước dưới đây để cài đặt Hadoop 2.4.1 ở chế độ phân phối giả.
Bước 1: Thiết lập Hadoop
Bạn có thể đặt các biến môi trường Hadoop bằng cách thêm các lệnh sau vào tệp ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binBây giờ, hãy áp dụng tất cả các thay đổi vào hệ thống đang chạy hiện tại.
$ source ~/.bashrcBước 2: Cấu hình Hadoop
Bạn có thể tìm thấy tất cả các tệp cấu hình Hadoop ở vị trí “$ HADOOP_HOME / etc / hadoop”. Bạn cần thực hiện các thay đổi phù hợp trong các tệp cấu hình đó theo cơ sở hạ tầng Hadoop của mình.
$ cd $HADOOP_HOME/etc/hadoopĐể phát triển các chương trình Hadoop bằng java, bạn phải đặt lại các biến môi trường java trong hadoop-env.sh bằng cách thay thế giá trị JAVA_HOME bằng vị trí của java trong hệ thống của bạn.
export JAVA_HOME=/usr/local/javaDưới đây là danh sách các tệp mà bạn cần chỉnh sửa để định cấu hình Hadoop.
core-site.xml
Tệp core-site.xml chứa thông tin như số cổng được sử dụng cho phiên bản Hadoop, bộ nhớ được cấp cho hệ thống tệp, giới hạn bộ nhớ để lưu trữ dữ liệu và kích thước của bộ đệm Đọc / Ghi.
Mở core-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration> và </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000 </value>
</property>
</configuration>hdfs-site.xml
Tệp hdfs-site.xml chứa thông tin như giá trị của dữ liệu sao chép, đường dẫn nút tên và đường dẫn nút dữ liệu của hệ thống tệp cục bộ của bạn. Nó có nghĩa là nơi bạn muốn lưu trữ cơ sở hạ tầng Hadoop.
Hãy để chúng tôi giả sử dữ liệu sau đây.
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeMở tệp này và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration> trong tệp này.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - Trong tệp trên, tất cả các giá trị thuộc tính đều do người dùng xác định và bạn có thể thực hiện thay đổi theo cơ sở hạ tầng Hadoop của mình.
yarn-site.xml
Tệp này được sử dụng để cấu hình sợi thành Hadoop. Mở tệp fiber-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration> trong tệp này.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Tệp này được sử dụng để chỉ định khung MapReduce mà chúng tôi đang sử dụng. Theo mặc định, Hadoop chứa một mẫu sợi-site.xml. Trước hết, bạn cần sao chép tệp từ mapred-site.xml.template sang tệp mapred-site.xml bằng lệnh sau.
$ cp mapred-site.xml.template mapred-site.xmlMở tệp mapred-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration> trong tệp này.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Xác minh cài đặt Hadoop
Các bước sau được sử dụng để xác minh cài đặt Hadoop.
Bước 1: Đặt tên cho thiết lập nút
Thiết lập nút tên bằng lệnh “hdfs namenode -format” như sau.
$ cd ~
$ hdfs namenode -formatKết quả mong đợi như sau.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Bước 2: Xác minh dfs Hadoop
Lệnh sau được sử dụng để bắt đầu dfs. Thực thi lệnh này sẽ khởi động hệ thống tệp Hadoop của bạn.
$ start-dfs.shSản lượng dự kiến như sau:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Bước 3: Xác minh Tập lệnh Sợi
Lệnh sau được sử dụng để bắt đầu tập lệnh sợi. Việc thực thi lệnh này sẽ bắt đầu các daemon sợi của bạn.
$ start-yarn.shSản lượng dự kiến như sau:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outBước 4: Truy cập Hadoop trên trình duyệt
Số cổng mặc định để truy cập Hadoop là 50070. Sử dụng URL sau để tải các dịch vụ Hadoop trên trình duyệt của bạn.
http://localhost:50070/Hình ảnh sau đây mô tả trình duyệt Hadoop.

Bước 5: Xác minh tất cả các ứng dụng cho cụm
Số cổng mặc định để truy cập tất cả các ứng dụng của cụm là 8088. Sử dụng url sau để truy cập dịch vụ này.
http://localhost:8088/Hình ảnh sau đây mô tả trình duyệt cụm Hadoop.

Bước 3: Tải xuống Sqoop
Chúng tôi có thể tải xuống phiên bản mới nhất của Sqoop từ liên kết sau Đối với hướng dẫn này, chúng tôi đang sử dụng phiên bản 1.4.5, nghĩa làsqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz.
Bước 4: Cài đặt Sqoop
Các lệnh sau được sử dụng để giải nén bóng tar Sqoop và di chuyển nó vào thư mục “/ usr / lib / sqoop”.
$tar -xvf sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz
$ su
password:
# mv sqoop-1.4.4.bin__hadoop-2.0.4-alpha /usr/lib/sqoop
#exitBước 5: Định cấu hình bashrc
Bạn phải thiết lập môi trường Sqoop bằng cách nối các dòng sau vào ~ /.bashrc tập tin -
#Sqoop
export SQOOP_HOME=/usr/lib/sqoop export PATH=$PATH:$SQOOP_HOME/binLệnh sau được sử dụng để thực thi ~ /.bashrc tập tin.
$ source ~/.bashrcBước 6: Định cấu hình Sqoop
Để định cấu hình Sqoop với Hadoop, bạn cần chỉnh sửa sqoop-env.sh tệp, được đặt trong $SQOOP_HOME/confdanh mục. Trước hết, chuyển hướng đến thư mục cấu hình Sqoop và sao chép tệp mẫu bằng lệnh sau:
$ cd $SQOOP_HOME/conf
$ mv sqoop-env-template.sh sqoop-env.shMở sqoop-env.sh và chỉnh sửa các dòng sau -
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoopBước 7: Tải xuống và định cấu hình mysql-connector-java
Chúng tôi có thể tải xuống mysql-connector-java-5.1.30.tar.gztập tin từ liên kết sau .
Các lệnh sau được sử dụng để giải nén tarball mysql-connector-java và di chuyển mysql-connector-java-5.1.30-bin.jar đến thư mục / usr / lib / sqoop / lib.
$ tar -zxf mysql-connector-java-5.1.30.tar.gz
$ su
password:
# cd mysql-connector-java-5.1.30
# mv mysql-connector-java-5.1.30-bin.jar /usr/lib/sqoop/libBước 8: Xác minh Sqoop
Lệnh sau được sử dụng để xác minh phiên bản Sqoop.
$ cd $SQOOP_HOME/bin
$ sqoop-versionSản lượng mong đợi -
14/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
Sqoop 1.4.5 git commit id 5b34accaca7de251fc91161733f906af2eddbe83
Compiled by abe on Fri Aug 1 11:19:26 PDT 2014Cài đặt Sqoop hoàn tất.
Chương này mô tả cách nhập dữ liệu từ cơ sở dữ liệu MySQL sang Hadoop HDFS. 'Công cụ nhập' nhập các bảng riêng lẻ từ RDBMS sang HDFS. Mỗi hàng trong bảng được coi như một bản ghi trong HDFS. Tất cả các bản ghi được lưu trữ dưới dạng dữ liệu văn bản trong tệp văn bản hoặc dưới dạng dữ liệu nhị phân trong tệp Avro và Sequence.
Cú pháp
Cú pháp sau được sử dụng để nhập dữ liệu vào HDFS.
$ sqoop import (generic-args) (import-args)
$ sqoop-import (generic-args) (import-args)Thí dụ
Chúng ta hãy lấy một ví dụ về ba bảng có tên là emp, emp_addvà emp_contact, nằm trong cơ sở dữ liệu được gọi là userdb trong máy chủ cơ sở dữ liệu MySQL.
Ba bảng và dữ liệu của chúng như sau.
trống rỗng:
| Tôi | Tên | độ | tiền lương | nợ |
|---|---|---|---|---|
| 1201 | gopal | giám đốc | 50.000 | TP. |
| 1202 | manisha | Trình đọc bằng chứng | 50.000 | TP. |
| 1203 | khalil | php dev | 30.000 | AC |
| 1204 | prasanth | php dev | 30.000 | AC |
| 1204 | kranthi | quản trị viên | 20.000 | TP. |
emp_add:
| Tôi | hno | đường phố | thành phố |
|---|---|---|---|
| 1201 | 288A | vgiri | jublee |
| 1202 | 108I | aoc | tồi tệ |
| 1203 | 144Z | pgutta | hydrat hóa |
| 1204 | 78B | thành phố cổ | tồi tệ |
| 1205 | 720X | hitec | tồi tệ |
emp_contact:
| Tôi | phno | |
|---|---|---|
| 1201 | 2356742 | [email protected] |
| 1202 | 1661663 | [email protected] |
| 1203 | 8887776 | [email protected] |
| 1204 | 9988774 | [email protected] |
| 1205 | 1231231 | [email protected] |
Nhập một bảng
Công cụ Sqoop 'nhập' được sử dụng để nhập dữ liệu bảng từ bảng vào hệ thống tệp Hadoop dưới dạng tệp văn bản hoặc tệp nhị phân.
Lệnh sau được sử dụng để nhập emp bảng từ máy chủ cơ sở dữ liệu MySQL sang HDFS.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp --m 1Nếu nó được thực thi thành công, thì bạn sẽ nhận được kết quả sau.
14/12/22 15:24:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
14/12/22 15:24:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
14/12/22 15:24:56 INFO tool.CodeGenTool: Beginning code generation
14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM `emp` AS t LIMIT 1
14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM `emp` AS t LIMIT 1
14/12/22 15:24:58 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
14/12/22 15:25:11 INFO orm.CompilationManager: Writing jar file:
/tmp/sqoop-hadoop/compile/cebe706d23ebb1fd99c1f063ad51ebd7/emp.jar
-----------------------------------------------------
-----------------------------------------------------
14/12/22 15:25:40 INFO mapreduce.Job: The url to track the job:
http://localhost:8088/proxy/application_1419242001831_0001/
14/12/22 15:26:45 INFO mapreduce.Job: Job job_1419242001831_0001 running in uber mode :
false
14/12/22 15:26:45 INFO mapreduce.Job: map 0% reduce 0%
14/12/22 15:28:08 INFO mapreduce.Job: map 100% reduce 0%
14/12/22 15:28:16 INFO mapreduce.Job: Job job_1419242001831_0001 completed successfully
-----------------------------------------------------
-----------------------------------------------------
14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Transferred 145 bytes in 177.5849 seconds
(0.8165 bytes/sec)
14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Retrieved 5 records.Để xác minh dữ liệu đã nhập trong HDFS, hãy sử dụng lệnh sau.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*Nó cho bạn thấy emp dữ liệu bảng và các trường được phân tách bằng dấu phẩy (,).
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TPNhập vào Thư mục đích
Chúng ta có thể chỉ định thư mục đích trong khi nhập dữ liệu bảng vào HDFS bằng công cụ nhập Sqoop.
Sau đây là cú pháp để chỉ định thư mục đích làm tùy chọn cho lệnh nhập Sqoop.
--target-dir <new or exist directory in HDFS>Lệnh sau được sử dụng để nhập emp_add dữ liệu bảng vào thư mục '/ queryresult'.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp_add \
--m 1 \
--target-dir /queryresultLệnh sau được sử dụng để xác minh dữ liệu đã nhập trong biểu mẫu thư mục / queryresult emp_add bàn.
$ $HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-*Nó sẽ hiển thị cho bạn dữ liệu bảng emp_add với các trường được phân tách bằng dấu phẩy (,).
1201, 288A, vgiri, jublee
1202, 108I, aoc, sec-bad
1203, 144Z, pgutta, hyd
1204, 78B, oldcity, sec-bad
1205, 720C, hitech, sec-badNhập tập hợp con dữ liệu bảng
Chúng ta có thể nhập một tập hợp con của một bảng bằng mệnh đề 'where' trong công cụ nhập Sqoop. Nó thực hiện truy vấn SQL tương ứng trong máy chủ cơ sở dữ liệu tương ứng và lưu trữ kết quả trong thư mục đích trong HDFS.
Cú pháp cho mệnh đề where như sau.
--where <condition>Lệnh sau được sử dụng để nhập một tập hợp con của emp_addbảng dữ liệu. Truy vấn tập hợp con là truy xuất id và địa chỉ của nhân viên, người sống ở thành phố Secunderabad.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp_add \
--m 1 \
--where “city =’sec-bad’” \
--target-dir /wherequeryLệnh sau được sử dụng để xác minh dữ liệu đã nhập trong thư mục / wherequery từ emp_add bàn.
$ $HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-*Nó sẽ cho bạn thấy emp_add dữ liệu bảng với các trường được phân tách bằng dấu phẩy (,).
1202, 108I, aoc, sec-bad
1204, 78B, oldcity, sec-bad
1205, 720C, hitech, sec-badNhập gia tăng
Nhập tăng dần là một kỹ thuật chỉ nhập các hàng mới được thêm vào trong bảng. Bắt buộc phải thêm các tùy chọn 'tăng dần', 'cột kiểm' và 'giá trị cuối cùng' để thực hiện nhập tăng dần.
Cú pháp sau được sử dụng cho tùy chọn tăng dần trong lệnh nhập Sqoop.
--incremental <mode>
--check-column <column name>
--last value <last check column value>Hãy để chúng tôi giả sử dữ liệu mới được thêm vào emp bảng như sau -
1206, satish p, grp des, 20000, GRLệnh sau được sử dụng để thực hiện nhập gia tăng trong emp bàn.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp \
--m 1 \
--incremental append \
--check-column id \
-last value 1205Lệnh sau được sử dụng để xác minh dữ liệu đã nhập từ emp bảng vào thư mục HDFS emp /.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*Nó cho bạn thấy emp dữ liệu bảng với các trường được phân tách bằng dấu phẩy (,).
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TP
1206, satish p, grp des, 20000, GRLệnh sau được sử dụng để xem các hàng đã sửa đổi hoặc mới được thêm vào từ emp bàn.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1Nó hiển thị cho bạn các hàng mới được thêm vào emp bảng với các trường được phân tách bằng dấu phẩy (,).
1206, satish p, grp des, 20000, GRChương này mô tả cách nhập tất cả các bảng từ máy chủ cơ sở dữ liệu RDBMS sang HDFS. Mỗi dữ liệu bảng được lưu trữ trong một thư mục riêng biệt và tên thư mục giống như tên bảng.
Cú pháp
Cú pháp sau được sử dụng để nhập tất cả các bảng.
$ sqoop import-all-tables (generic-args) (import-args)
$ sqoop-import-all-tables (generic-args) (import-args)Thí dụ
Hãy để chúng tôi lấy một ví dụ về việc nhập tất cả các bảng từ userdbcơ sở dữ liệu. Danh sách các bảng mà cơ sở dữ liệuuserdb chứa như sau.
+--------------------+
| Tables |
+--------------------+
| emp |
| emp_add |
| emp_contact |
+--------------------+Lệnh sau được sử dụng để nhập tất cả các bảng từ userdb cơ sở dữ liệu.
$ sqoop import-all-tables \
--connect jdbc:mysql://localhost/userdb \
--username rootNote - Nếu bạn đang sử dụng import-all-table, thì bắt buộc mỗi bảng trong cơ sở dữ liệu đó phải có trường khóa chính.
Lệnh sau được sử dụng để xác minh tất cả dữ liệu bảng vào cơ sở dữ liệu userdb trong HDFS.
$ $HADOOP_HOME/bin/hadoop fs -lsNó sẽ hiển thị cho bạn danh sách các tên bảng trong cơ sở dữ liệu userdb dưới dạng thư mục.
Đầu ra
drwxr-xr-x - hadoop supergroup 0 2014-12-22 22:50 _sqoop
drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:46 emp
drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:50 emp_add
drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:52 emp_contactChương này mô tả cách xuất dữ liệu trở lại từ HDFS sang cơ sở dữ liệu RDBMS. Bảng đích phải tồn tại trong cơ sở dữ liệu đích. Các tệp được cung cấp làm đầu vào cho Sqoop chứa các bản ghi, được gọi là các hàng trong bảng. Chúng được đọc và phân tích cú pháp thành một tập hợp các bản ghi và được phân tách bằng dấu phân cách do người dùng chỉ định.
Hoạt động mặc định là chèn tất cả bản ghi từ tệp đầu vào vào bảng cơ sở dữ liệu bằng cách sử dụng câu lệnh INSERT. Trong chế độ cập nhật, Sqoop tạo câu lệnh UPDATE thay thế bản ghi hiện có vào cơ sở dữ liệu.
Cú pháp
Sau đây là cú pháp cho lệnh xuất.
$ sqoop export (generic-args) (export-args)
$ sqoop-export (generic-args) (export-args)Thí dụ
Hãy để chúng tôi lấy một ví dụ về dữ liệu nhân viên trong tệp, trong HDFS. Dữ liệu nhân viên có sẵn trongemp_datatệp trong thư mục 'emp /' trong HDFS. Cácemp_data là như sau.
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TP
1206, satish p, grp des, 20000, GRBắt buộc phải xuất bảng được tạo theo cách thủ công và có mặt trong cơ sở dữ liệu từ nơi nó phải được xuất.
Truy vấn sau được sử dụng để tạo bảng 'nhân viên' trong dòng lệnh mysql.
$ mysql
mysql> USE db;
mysql> CREATE TABLE employee (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20),
deg VARCHAR(20),
salary INT,
dept VARCHAR(10));Lệnh sau được sử dụng để xuất dữ liệu bảng (trong emp_data trên HDFS) vào bảng nhân viên trong cơ sở dữ liệu db của máy chủ cơ sở dữ liệu Mysql.
$ sqoop export \
--connect jdbc:mysql://localhost/db \
--username root \
--table employee \
--export-dir /emp/emp_dataLệnh sau được sử dụng để xác minh bảng trong dòng lệnh mysql.
mysql>select * from employee;Nếu dữ liệu đã cho được lưu trữ thành công, thì bạn có thể tìm thấy bảng dữ liệu nhân viên nhất định sau đây.
+------+--------------+-------------+-------------------+--------+
| Id | Name | Designation | Salary | Dept |
+------+--------------+-------------+-------------------+--------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | preader | 50000 | TP |
| 1203 | kalil | php dev | 30000 | AC |
| 1204 | prasanth | php dev | 30000 | AC |
| 1205 | kranthi | admin | 20000 | TP |
| 1206 | satish p | grp des | 20000 | GR |
+------+--------------+-------------+-------------------+--------+Chương này mô tả cách tạo và duy trì các công việc Sqoop. Công việc Sqoop tạo và lưu các lệnh nhập và xuất. Nó chỉ định các tham số để xác định và gọi lại công việc đã lưu. Việc gọi lại hoặc thực thi lại này được sử dụng trong quá trình nhập tăng dần, có thể nhập các hàng đã cập nhật từ bảng RDBMS sang HDFS.
Cú pháp
Sau đây là cú pháp để tạo một công việc Sqoop.
$ sqoop job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]
$ sqoop-job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]Tạo công việc (--create)
Ở đây chúng tôi đang tạo một công việc với tên myjob, có thể nhập dữ liệu bảng từ bảng RDBMS sang HDFS. Lệnh sau được sử dụng để tạo một công việc đang nhập dữ liệu từemployee bàn trong db cơ sở dữ liệu vào tệp HDFS.
$ sqoop job --create myjob \
-- import \
--connect jdbc:mysql://localhost/db \
--username root \
--table employee --m 1Xác minh công việc (- danh sách)
‘--list’đối số được sử dụng để xác minh các công việc đã lưu. Lệnh sau được sử dụng để xác minh danh sách các công việc Sqoop đã lưu.
$ sqoop job --listNó hiển thị danh sách các công việc đã lưu.
Available jobs:
myjobKiểm tra công việc (--show)
‘--show’đối số được sử dụng để kiểm tra hoặc xác minh các công việc cụ thể và chi tiết của chúng. Lệnh sau và đầu ra mẫu được sử dụng để xác minh một công việc được gọi làmyjob.
$ sqoop job --show myjobNó hiển thị các công cụ và tùy chọn của chúng, được sử dụng trong myjob.
Job: myjob
Tool: import Options:
----------------------------
direct.import = true
codegen.input.delimiters.record = 0
hdfs.append.dir = false
db.table = employee
...
incremental.last.value = 1206
...Thực thi công việc (--exec)
‘--exec’tùy chọn được sử dụng để thực hiện một công việc đã lưu. Lệnh sau được sử dụng để thực hiện một công việc đã lưu được gọi làmyjob.
$ sqoop job --exec myjobNó cho bạn thấy kết quả sau.
10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation
...Chương này mô tả tầm quan trọng của công cụ 'codegen'. Từ quan điểm của ứng dụng hướng đối tượng, mỗi bảng cơ sở dữ liệu có một lớp DAO chứa các phương thức 'getter' và 'setter' để khởi tạo các đối tượng. Công cụ này (-codegen) tạo lớp DAO tự động.
Nó tạo ra lớp DAO trong Java, dựa trên cấu trúc Lược đồ bảng. Định nghĩa Java được khởi tạo như một phần của quá trình nhập. Công dụng chính của công cụ này là kiểm tra xem Java có bị mất mã Java hay không. Nếu vậy, nó sẽ tạo một phiên bản Java mới với dấu phân cách mặc định giữa các trường.
Cú pháp
Sau đây là cú pháp cho lệnh Sqoop codegen.
$ sqoop codegen (generic-args) (codegen-args)
$ sqoop-codegen (generic-args) (codegen-args)Thí dụ
Hãy để chúng tôi lấy một ví dụ tạo mã Java cho emp bàn trong userdb cơ sở dữ liệu.
Lệnh sau được sử dụng để thực hiện ví dụ đã cho.
$ sqoop codegen \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table empNếu lệnh thực thi thành công, thì nó sẽ tạo ra kết quả sau trên thiết bị đầu cuối.
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation
……………….
14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or
overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file:
/tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jarxác minh
Hãy để chúng tôi xem xét đầu ra. Đường dẫn được in đậm, là vị trí mà mã Java củaemptạo bảng và lưu trữ. Hãy để chúng tôi xác minh các tệp ở vị trí đó bằng các lệnh sau.
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/
$ ls
emp.class
emp.jar
emp.javaNếu bạn muốn xác minh sâu, hãy so sánh emp bàn trong userdb cơ sở dữ liệu và emp.java trong thư mục sau
/ tmp / sqoop-hadoop / biên dịch / 9a300a1f94899df4a9b10f9935ed9f91 /.
Chương này mô tả cách sử dụng công cụ Sqoop 'eval'. Nó cho phép người dùng thực thi các truy vấn do người dùng xác định dựa trên các máy chủ cơ sở dữ liệu tương ứng và xem trước kết quả trong bảng điều khiển. Vì vậy, người dùng có thể mong đợi dữ liệu bảng kết quả được nhập. Sử dụng eval, chúng ta có thể đánh giá bất kỳ loại truy vấn SQL nào có thể là câu lệnh DDL hoặc DML.
Cú pháp
Cú pháp sau được sử dụng cho lệnh eval của Sqoop.
$ sqoop eval (generic-args) (eval-args)
$ sqoop-eval (generic-args) (eval-args)Chọn Đánh giá Truy vấn
Sử dụng công cụ eval, chúng ta có thể đánh giá bất kỳ loại truy vấn SQL nào. Hãy để chúng tôi lấy một ví dụ về việc chọn các hàng giới hạn trongemployee bảng của dbcơ sở dữ liệu. Lệnh sau được sử dụng để đánh giá ví dụ đã cho bằng cách sử dụng truy vấn SQL.
$ sqoop eval \
--connect jdbc:mysql://localhost/db \
--username root \
--query “SELECT * FROM employee LIMIT 3”Nếu lệnh thực thi thành công, thì nó sẽ tạo ra kết quả sau trên thiết bị đầu cuối.
+------+--------------+-------------+-------------------+--------+
| Id | Name | Designation | Salary | Dept |
+------+--------------+-------------+-------------------+--------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | preader | 50000 | TP |
| 1203 | khalil | php dev | 30000 | AC |
+------+--------------+-------------+-------------------+--------+Chèn đánh giá truy vấn
Công cụ eval của Sqoop có thể áp dụng cho cả mô hình hóa và định nghĩa các câu lệnh SQL. Điều đó có nghĩa là, chúng ta cũng có thể sử dụng eval cho các câu lệnh chèn. Lệnh sau được sử dụng để chèn một hàng mới trongemployee bảng của db cơ sở dữ liệu.
$ sqoop eval \
--connect jdbc:mysql://localhost/db \
--username root \
-e “INSERT INTO employee VALUES(1207,‘Raju’,‘UI dev’,15000,‘TP’)”Nếu lệnh thực thi thành công, thì nó sẽ hiển thị trạng thái của các hàng được cập nhật trên bảng điều khiển.
Hoặc nếu không, bạn có thể xác minh bảng nhân viên trên bảng điều khiển MySQL. Lệnh sau được sử dụng để xác minh các hàng củaemployee bảng của db cơ sở dữ liệu sử dụng truy vấn select '.
mysql>
mysql> use db;
mysql> SELECT * FROM employee;
+------+--------------+-------------+-------------------+--------+
| Id | Name | Designation | Salary | Dept |
+------+--------------+-------------+-------------------+--------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | preader | 50000 | TP |
| 1203 | khalil | php dev | 30000 | AC |
| 1204 | prasanth | php dev | 30000 | AC |
| 1205 | kranthi | admin | 20000 | TP |
| 1206 | satish p | grp des | 20000 | GR |
| 1207 | Raju | UI dev | 15000 | TP |
+------+--------------+-------------+-------------------+--------+Chương này mô tả cách liệt kê các cơ sở dữ liệu bằng Sqoop. Công cụ cơ sở dữ liệu danh sách Sqoop phân tích cú pháp và thực hiện truy vấn 'HIỂN THỊ DỮ LIỆU' đối với máy chủ cơ sở dữ liệu. Sau đó, nó liệt kê ra các cơ sở dữ liệu hiện tại trên máy chủ.
Cú pháp
Cú pháp sau đây được sử dụng cho lệnh Sqoop list-database.
$ sqoop list-databases (generic-args) (list-databases-args)
$ sqoop-list-databases (generic-args) (list-databases-args)Truy vấn mẫu
Lệnh sau được sử dụng để liệt kê tất cả các cơ sở dữ liệu trong máy chủ cơ sở dữ liệu MySQL.
$ sqoop list-databases \
--connect jdbc:mysql://localhost/ \
--username rootNếu lệnh thực thi thành công, thì nó sẽ hiển thị danh sách cơ sở dữ liệu trong máy chủ cơ sở dữ liệu MySQL của bạn như sau.
...
13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
mysql
test
userdb
dbChương này mô tả cách liệt kê các bảng của một cơ sở dữ liệu cụ thể trong máy chủ cơ sở dữ liệu MySQL bằng Sqoop. Công cụ bảng danh sách Sqoop phân tích cú pháp và thực hiện truy vấn 'HIỂN THỊ BẢNG BIỂU' dựa trên một cơ sở dữ liệu cụ thể. Sau đó, nó liệt kê các bảng hiện tại trong cơ sở dữ liệu.
Cú pháp
Cú pháp sau được sử dụng cho lệnh Sqoop list-table.
$ sqoop list-tables (generic-args) (list-tables-args)
$ sqoop-list-tables (generic-args) (list-tables-args)Truy vấn mẫu
Lệnh sau được sử dụng để liệt kê tất cả các bảng trong userdb cơ sở dữ liệu của máy chủ cơ sở dữ liệu MySQL.
$ sqoop list-tables \
--connect jdbc:mysql://localhost/userdb \
--username rootNếu lệnh được thực thi thành công, thì nó sẽ hiển thị danh sách các bảng trong userdb cơ sở dữ liệu như sau.
...
13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
emp
emp_add
emp_contactChương này mô tả cách liệt kê các bảng của một cơ sở dữ liệu cụ thể trong máy chủ cơ sở dữ liệu MySQL bằng Sqoop. Công cụ bảng danh sách Sqoop phân tích cú pháp và thực hiện truy vấn 'HIỂN THỊ BẢNG BIỂU' dựa trên một cơ sở dữ liệu cụ thể. Sau đó, nó liệt kê các bảng hiện tại trong cơ sở dữ liệu.
Cú pháp
Cú pháp sau được sử dụng cho lệnh Sqoop list-table.
$ sqoop list-tables (generic-args) (list-tables-args)
$ sqoop-list-tables (generic-args) (list-tables-args)Truy vấn mẫu
Lệnh sau được sử dụng để liệt kê tất cả các bảng trong userdb cơ sở dữ liệu của máy chủ cơ sở dữ liệu MySQL.
$ sqoop list-tables \
--connect jdbc:mysql://localhost/userdb \
--username rootNếu lệnh được thực thi thành công, thì nó sẽ hiển thị danh sách các bảng trong userdb cơ sở dữ liệu như sau.
...
13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
emp
emp_add
emp_contact