Apache Flume - Sequenzgeneratorquelle
Im vorherigen Kapitel haben wir gesehen, wie Daten von der Twitter-Quelle zu HDFS abgerufen werden. In diesem Kapitel wird erläutert, wie Sie Daten abrufenSequence generator.
Voraussetzungen
Um das in diesem Kapitel bereitgestellte Beispiel auszuführen, müssen Sie es installieren HDFS zusammen mit Flume. Überprüfen Sie daher die Hadoop-Installation und starten Sie das HDFS, bevor Sie fortfahren. (Informationen zum Starten des HDFS finden Sie im vorherigen Kapitel.)
Flume konfigurieren
Wir müssen die Quelle, den Kanal und die Senke mithilfe der Konfigurationsdatei in der Konfiguration konfigurieren confMappe. Das in diesem Kapitel gegebene Beispiel verwendet asequence generator source, ein memory channel, und ein HDFS sink.
Sequenzgeneratorquelle
Es ist die Quelle, die die Ereignisse kontinuierlich generiert. Es wird ein Zähler beibehalten, der bei 0 beginnt und um 1 erhöht wird. Er wird zu Testzwecken verwendet. Bei der Konfiguration dieser Quelle müssen Sie Werte für die folgenden Eigenschaften angeben:
Channels
Source type - seq
Kanal
Wir benutzen die memoryKanal. Um den Speicherkanal zu konfigurieren, müssen Sie einen Wert für den Kanaltyp angeben. Im Folgenden finden Sie eine Liste der Eigenschaften, die Sie beim Konfigurieren des Speicherkanals angeben müssen.
type- Es enthält den Typ des Kanals. In unserem Beispiel ist der Typ MemChannel.
Capacity- Dies ist die maximale Anzahl von Ereignissen, die im Kanal gespeichert sind. Der Standardwert ist 100. (optional)
TransactionCapacity- Dies ist die maximale Anzahl von Ereignissen, die der Kanal akzeptiert oder sendet. Der Standardwert ist 100. (optional).
HDFS-Spüle
Diese Senke schreibt Daten in das HDFS. Um diese Senke zu konfigurieren, müssen Sie die folgenden Details angeben.
Channel
type - hdfs
hdfs.path - Der Pfad des Verzeichnisses in HDFS, in dem Daten gespeichert werden sollen.
Und wir können einige optionale Werte basierend auf dem Szenario bereitstellen. Im Folgenden sind die optionalen Eigenschaften der HDFS-Senke aufgeführt, die wir in unserer Anwendung konfigurieren.
fileType - Dies ist das erforderliche Dateiformat unserer HDFS-Datei. SequenceFile, DataStream und CompressedStreamsind die drei Typen, die mit diesem Stream verfügbar sind. In unserem Beispiel verwenden wir dieDataStream.
writeFormat - Könnte entweder Text oder beschreibbar sein.
batchSize- Dies ist die Anzahl der Ereignisse, die in eine Datei geschrieben werden, bevor sie in das HDFS geleert wird. Der Standardwert ist 100.
rollsize- Dies ist die Dateigröße, um eine Rolle auszulösen. Der Standardwert ist 100.
rollCount- Dies ist die Anzahl der Ereignisse, die in die Datei geschrieben wurden, bevor sie gerollt werden. Der Standardwert ist 10.
Beispiel - Konfigurationsdatei
Im Folgenden finden Sie ein Beispiel für die Konfigurationsdatei. Kopieren Sie diesen Inhalt und speichern Sie ihn unterseq_gen .conf im conf-Ordner von Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelAusführung
Durchsuchen Sie das Flume-Ausgangsverzeichnis und führen Sie die Anwendung wie unten gezeigt aus.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentWenn alles gut geht, generiert die Quelle Sequenznummern, die in Form von Protokolldateien in das HDFS übertragen werden.
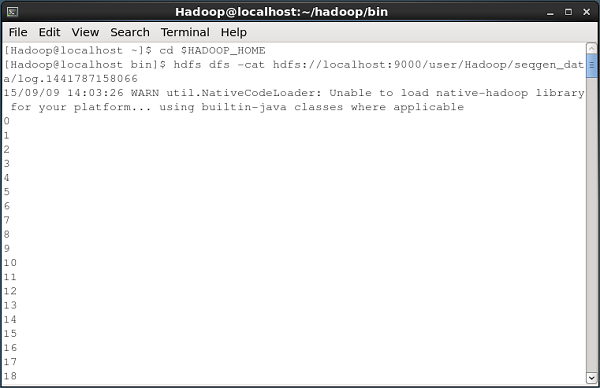
Im Folgenden finden Sie eine Momentaufnahme des Eingabeaufforderungsfensters, in dem die vom Sequenzgenerator generierten Daten in das HDFS abgerufen werden.

Überprüfen des HDFS
Sie können über die folgende URL auf die Hadoop Administration Web-Benutzeroberfläche zugreifen:
http://localhost:50070/Klicken Sie auf das Dropdown-Menü Utilitiesauf der rechten Seite der Seite. Sie können zwei Optionen sehen, wie in der folgenden Abbildung gezeigt.
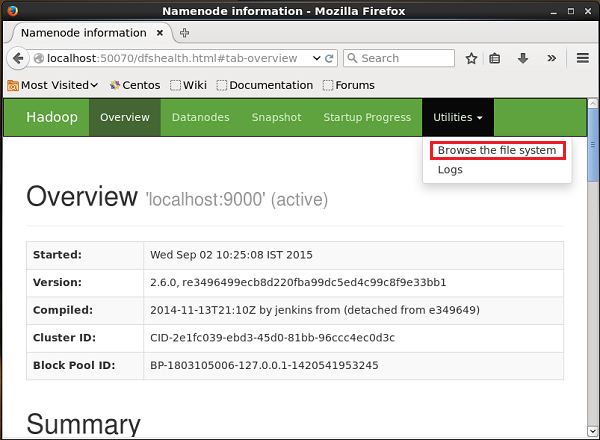
Klicke auf Browse the file system und geben Sie den Pfad des HDFS-Verzeichnisses ein, in dem Sie die vom Sequenzgenerator generierten Daten gespeichert haben.
In unserem Beispiel wird der Pfad sein /user/Hadoop/ seqgen_data /. Anschließend sehen Sie die Liste der vom Sequenzgenerator generierten Protokolldateien, die wie unten angegeben im HDFS gespeichert sind.

Überprüfen des Inhalts der Datei
Alle diese Protokolldateien enthalten Zahlen im sequentiellen Format. Sie können den Inhalt dieser Datei im Dateisystem mit überprüfencat Befehl wie unten gezeigt.