Apache Kafka - Kurzanleitung
In Big Data wird ein enormes Datenvolumen verwendet. In Bezug auf Daten haben wir zwei Hauptherausforderungen. Die erste Herausforderung besteht darin, große Datenmengen zu erfassen, und die zweite darin, die gesammelten Daten zu analysieren. Um diese Herausforderungen zu bewältigen, benötigen Sie ein Nachrichtensystem.
Kafka ist für verteilte Hochdurchsatzsysteme konzipiert. Kafka eignet sich sehr gut als Ersatz für einen traditionelleren Nachrichtenbroker. Im Vergleich zu anderen Messagingsystemen bietet Kafka einen besseren Durchsatz, eine integrierte Partitionierung, Replikation und eine inhärente Fehlertoleranz, wodurch es sich gut für große Nachrichtenverarbeitungsanwendungen eignet.
Was ist ein Messaging-System?
Ein Messaging-System ist für die Übertragung von Daten von einer Anwendung zu einer anderen verantwortlich, sodass sich die Anwendungen auf Daten konzentrieren können, sich jedoch nicht um die Freigabe kümmern müssen. Distributed Messaging basiert auf dem Konzept einer zuverlässigen Nachrichtenwarteschlange. Nachrichten werden asynchron zwischen Clientanwendungen und Nachrichtensystem in die Warteschlange gestellt. Es stehen zwei Arten von Messaging-Mustern zur Verfügung - eines ist Punkt-zu-Punkt und das andere ist das Publish-Subscribe-Messaging-System (Pub-Sub). Die meisten Nachrichtenmuster folgenpub-sub.
Punkt-zu-Punkt-Messaging-System
In einem Punkt-zu-Punkt-System bleiben Nachrichten in einer Warteschlange erhalten. Ein oder mehrere Verbraucher können die Nachrichten in der Warteschlange verwenden, eine bestimmte Nachricht kann jedoch nur von maximal einem Verbraucher verwendet werden. Sobald ein Verbraucher eine Nachricht in der Warteschlange liest, verschwindet sie aus dieser Warteschlange. Das typische Beispiel für dieses System ist ein Auftragsabwicklungssystem, bei dem jeder Auftrag von einem Auftragsabwickler bearbeitet wird, aber auch mehrere Auftragsabwickler gleichzeitig arbeiten können. Das folgende Diagramm zeigt die Struktur.

Publish-Subscribe-Messaging-System
Im Publish-Subscribe-System bleiben Nachrichten in einem Thema erhalten. Im Gegensatz zum Punkt-zu-Punkt-System können Verbraucher ein oder mehrere Themen abonnieren und alle Nachrichten in diesem Thema verwenden. Im Publish-Subscribe-System werden Nachrichtenproduzenten als Herausgeber und Nachrichtenkonsumenten als Abonnenten bezeichnet. Ein Beispiel aus der Praxis ist Dish TV, das verschiedene Kanäle wie Sport, Filme, Musik usw. veröffentlicht. Jeder kann seine eigenen Kanäle abonnieren und diese abrufen, sobald seine abonnierten Kanäle verfügbar sind.

Was ist Kafka?
Apache Kafka ist ein verteiltes Publish-Subscribe-Messaging-System und eine robuste Warteschlange, die ein hohes Datenvolumen verarbeiten kann und es Ihnen ermöglicht, Nachrichten von einem Endpunkt an einen anderen weiterzuleiten. Kafka eignet sich sowohl für den Offline- als auch für den Online-Nachrichtenverbrauch. Kafka-Nachrichten bleiben auf der Festplatte erhalten und werden im Cluster repliziert, um Datenverlust zu vermeiden. Kafka basiert auf dem ZooKeeper-Synchronisierungsdienst. Es lässt sich sehr gut in Apache Storm und Spark für die Echtzeit-Streaming-Datenanalyse integrieren.
Leistungen
Im Folgenden sind einige Vorteile von Kafka aufgeführt:
Reliability - Kafka ist verteilt, partitioniert, repliziert und fehlertolerant.
Scalability - Das Kafka-Messaging-System lässt sich ohne Ausfallzeiten problemlos skalieren.
Durability- Kafka verwendet das
verteilte Festschreibungsprotokoll,
was bedeutet, dass Nachrichten so schnell wie möglich auf der Festplatte gespeichert werden und daher dauerhaft sind.Performance- Kafka hat einen hohen Durchsatz beim Veröffentlichen und Abonnieren von Nachrichten. Es behält eine stabile Leistung bei, selbst wenn viele TB Nachrichten gespeichert sind.
Kafka ist sehr schnell und garantiert keine Ausfallzeiten und keinen Datenverlust.
Anwendungsfälle
Kafka kann in vielen Anwendungsfällen verwendet werden. Einige von ihnen sind unten aufgeführt -
Metrics- Kafka wird häufig für Betriebsüberwachungsdaten verwendet. Dies beinhaltet das Aggregieren von Statistiken aus verteilten Anwendungen, um zentralisierte Feeds mit Betriebsdaten zu erstellen.
Log Aggregation Solution - Kafka kann unternehmensweit verwendet werden, um Protokolle von mehreren Diensten zu sammeln und sie mehreren Verbrauchern in einem Standardformat zur Verfügung zu stellen.
Stream Processing- Beliebte Frameworks wie Storm und Spark Streaming lesen Daten aus einem Thema, verarbeiten sie und schreiben verarbeitete Daten in ein neues Thema, wo sie für Benutzer und Anwendungen verfügbar werden. Die starke Haltbarkeit von Kafka ist auch im Zusammenhang mit der Stream-Verarbeitung sehr nützlich.
Notwendigkeit für Kafka
Kafka ist eine einheitliche Plattform für die Verarbeitung aller Echtzeit-Datenfeeds. Kafka unterstützt die Zustellung von Nachrichten mit geringer Latenz und garantiert die Fehlertoleranz bei Maschinenfehlern. Es hat die Fähigkeit, eine große Anzahl unterschiedlicher Verbraucher zu behandeln. Kafka ist sehr schnell und führt 2 Millionen Schreibvorgänge pro Sekunde aus. Kafka speichert alle Daten auf der Festplatte, was im Wesentlichen bedeutet, dass alle Schreibvorgänge in den Seitencache des Betriebssystems (RAM) verschoben werden. Dies macht es sehr effizient, Daten vom Seiten-Cache zu einem Netzwerk-Socket zu übertragen.
Bevor Sie tief in die Kafka einsteigen, müssen Sie die wichtigsten Begriffe wie Themen, Makler, Produzenten und Verbraucher kennen. Das folgende Diagramm zeigt die Hauptterminologien und die Tabelle beschreibt die Diagrammkomponenten im Detail.
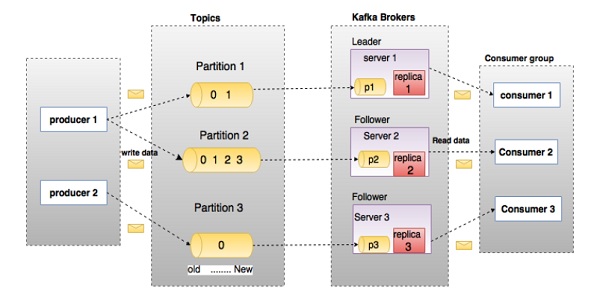
Im obigen Diagramm ist ein Thema in drei Partitionen konfiguriert. Partition 1 hat zwei Versatzfaktoren 0 und 1. Partition 2 hat vier Versatzfaktoren 0, 1, 2 und 3. Partition 3 hat einen Versatzfaktor 0. Die ID des Replikats entspricht der ID des Servers, auf dem es gehostet wird.
Angenommen, wenn der Replikationsfaktor des Themas auf 3 festgelegt ist, erstellt Kafka 3 identische Replikate jeder Partition und platziert sie im Cluster, um sie für alle ihre Vorgänge verfügbar zu machen. Um eine Last im Cluster auszugleichen, speichert jeder Broker eine oder mehrere dieser Partitionen. Mehrere Hersteller und Verbraucher können gleichzeitig Nachrichten veröffentlichen und abrufen.
| S.No. | Komponenten und Beschreibung |
|---|---|
| 1 | Topics Ein Nachrichtenstrom, der zu einer bestimmten Kategorie gehört, wird als Thema bezeichnet. Daten werden in Themen gespeichert. Themen sind in Partitionen unterteilt. Für jedes Thema behält Kafka eine Mini-Mutter von einer Partition. Jede solche Partition enthält Nachrichten in einer unveränderlichen Reihenfolge. Eine Partition wird als Satz von Segmentdateien gleicher Größe implementiert. |
| 2 | Partition Themen können viele Partitionen haben, sodass sie eine beliebige Datenmenge verarbeiten können. |
| 3 | Partition offset Jede partitionierte Nachricht hat eine eindeutige Sequenz-ID, die als |
| 4 | Replicas of partition Replikate sind nichts anderes als |
| 5 | Brokers
|
| 6 | Kafka Cluster Kafkas mit mehr als einem Broker werden als Kafka-Cluster bezeichnet. Ein Kafka-Cluster kann ohne Ausfallzeiten erweitert werden. Diese Cluster werden verwendet, um die Persistenz und Replikation von Nachrichtendaten zu verwalten. |
| 7 | Producers Produzenten sind Herausgeber von Nachrichten zu einem oder mehreren Kafka-Themen. Produzenten senden Daten an Kafka-Broker. Jedes Mal, wenn ein Produzent eine Nachricht an einen Broker veröffentlicht, hängt der Broker die Nachricht einfach an die letzte Segmentdatei an. Tatsächlich wird die Nachricht an eine Partition angehängt. Der Produzent kann auch Nachrichten an eine Partition seiner Wahl senden. |
| 8 | Consumers Verbraucher lesen Daten von Maklern. Verbraucher abonnieren ein oder mehrere Themen und konsumieren veröffentlichte Nachrichten, indem sie Daten von den Brokern abrufen. |
| 9 | Leader
|
| 10 | Follower Knoten, die den Anweisungen des Leiters folgen, werden als Follower bezeichnet. Wenn der Anführer ausfällt, wird einer der Anhänger automatisch zum neuen Anführer. Ein Follower fungiert als normaler Verbraucher, ruft Nachrichten ab und aktualisiert seinen eigenen Datenspeicher. |
Schauen Sie sich die folgende Abbildung an. Es zeigt das Clusterdiagramm von Kafka.

In der folgenden Tabelle werden die im obigen Diagramm gezeigten Komponenten beschrieben.
| S.No. | Komponenten und Beschreibung |
|---|---|
| 1 | Broker Der Kafka-Cluster besteht normalerweise aus mehreren Brokern, um den Lastausgleich aufrechtzuerhalten. Kafka-Broker sind zustandslos und verwenden ZooKeeper, um ihren Clusterstatus beizubehalten. Eine Kafka-Broker-Instanz kann Hunderttausende von Lese- und Schreibvorgängen pro Sekunde verarbeiten, und jeder Broker kann TB-Nachrichten ohne Auswirkungen auf die Leistung verarbeiten. Die Wahl des Kafka-Maklerführers kann von ZooKeeper durchgeführt werden. |
| 2 | ZooKeeper ZooKeeper wird zur Verwaltung und Koordination des Kafka-Brokers verwendet. Der ZooKeeper-Dienst wird hauptsächlich verwendet, um Hersteller und Verbraucher über das Vorhandensein eines neuen Brokers im Kafka-System oder den Ausfall des Brokers im Kafka-System zu informieren. Gemäß der Benachrichtigung, die der Tierpfleger über das Vorhandensein oder Versagen des Maklers erhalten hat, treffen Hersteller und Verbraucher die Entscheidung und beginnen, ihre Aufgabe mit einem anderen Makler zu koordinieren. |
| 3 | Producers Produzenten senden Daten an Makler. Wenn der neue Broker gestartet wird, durchsuchen ihn alle Hersteller und senden automatisch eine Nachricht an diesen neuen Broker. Der Kafka-Produzent wartet nicht auf Bestätigungen vom Broker und sendet Nachrichten so schnell, wie der Broker sie verarbeiten kann. |
| 4 | Consumers Da Kafka-Broker zustandslos sind, muss der Verbraucher mithilfe des Partitionsversatzes festlegen, wie viele Nachrichten verbraucht wurden. Wenn der Verbraucher einen bestimmten Nachrichtenoffset bestätigt, bedeutet dies, dass der Verbraucher alle vorherigen Nachrichten verbraucht hat. Der Verbraucher gibt eine asynchrone Pull-Anforderung an den Broker aus, damit ein Puffer mit Bytes zum Verzehr bereitsteht. Die Verbraucher können zu jedem Punkt in einer Partition zurückspulen oder springen, indem sie einfach einen Versatzwert angeben. Der Verbraucher-Offset-Wert wird von ZooKeeper benachrichtigt. |
Ab sofort haben wir die Kernkonzepte von Kafka diskutiert. Lassen Sie uns nun etwas Licht auf den Workflow von Kafka werfen.
Kafka ist einfach eine Sammlung von Themen, die in eine oder mehrere Partitionen unterteilt sind. Eine Kafka-Partition ist eine linear geordnete Folge von Nachrichten, wobei jede Nachricht durch ihren Index (als Offset bezeichnet) identifiziert wird. Alle Daten in einem Kafka-Cluster sind die getrennte Vereinigung von Partitionen. Eingehende Nachrichten werden am Ende einer Partition geschrieben und Nachrichten werden von Verbrauchern nacheinander gelesen. Die Haltbarkeit wird durch das Replizieren von Nachrichten an verschiedene Broker gewährleistet.
Kafka bietet sowohl Pub-Sub- als auch Warteschlangen-basierte Messaging-Systeme schnell, zuverlässig, dauerhaft, fehlertolerant und ohne Ausfallzeiten. In beiden Fällen senden die Hersteller die Nachricht einfach an ein Thema, und der Verbraucher kann je nach Bedarf einen beliebigen Typ eines Nachrichtensystems auswählen. Befolgen Sie die Schritte im nächsten Abschnitt, um zu verstehen, wie der Verbraucher das Nachrichtensystem seiner Wahl auswählen kann.
Workflow für Pub-Sub-Messaging
Es folgt der schrittweise Workflow des Pub-Sub-Messaging -
Produzenten senden in regelmäßigen Abständen Nachrichten an ein Thema.
Kafka Broker speichert alle Nachrichten in den Partitionen, die für das jeweilige Thema konfiguriert sind. Es stellt sicher, dass die Nachrichten gleichmäßig zwischen Partitionen geteilt werden. Wenn der Produzent zwei Nachrichten sendet und zwei Partitionen vorhanden sind, speichert Kafka eine Nachricht in der ersten Partition und die zweite Nachricht in der zweiten Partition.
Der Verbraucher abonniert ein bestimmtes Thema.
Sobald der Verbraucher ein Thema abonniert hat, stellt Kafka dem Verbraucher den aktuellen Versatz des Themas zur Verfügung und speichert den Versatz auch im Zookeeper-Ensemble.
Der Verbraucher wird die Kafka in regelmäßigen Abständen (z. B. 100 ms) nach neuen Nachrichten fragen.
Sobald Kafka die Nachrichten von den Herstellern erhalten hat, leitet er diese Nachrichten an die Verbraucher weiter.
Der Verbraucher erhält die Nachricht und verarbeitet sie.
Sobald die Nachrichten verarbeitet sind, sendet der Verbraucher eine Bestätigung an den Kafka-Broker.
Sobald Kafka eine Bestätigung erhält, ändert er den Offset auf den neuen Wert und aktualisiert ihn im Zookeeper. Da Offsets im Zookeeper verwaltet werden, kann der Verbraucher die nächste Nachricht auch bei Serverausfällen korrekt lesen.
Dieser obige Ablauf wird wiederholt, bis der Verbraucher die Anforderung beendet.
Der Verbraucher hat die Möglichkeit, jederzeit zum gewünschten Versatz eines Themas zurückzuspulen / zu springen und alle nachfolgenden Nachrichten zu lesen.
Workflow von Queue Messaging / Consumer Group
In einem Warteschlangennachrichtensystem anstelle eines einzelnen Verbrauchers abonniert eine Gruppe von Verbrauchern mit derselben Gruppen-ID
ein Thema. In einfachen Worten, Verbraucher, die ein Thema mit derselben Gruppen-ID
abonnieren, werden als eine einzelne Gruppe betrachtet und die Nachrichten werden zwischen ihnen geteilt. Lassen Sie uns den tatsächlichen Workflow dieses Systems überprüfen.
Produzenten senden in regelmäßigen Abständen Nachrichten an ein Thema.
Kafka speichert alle Nachrichten in den Partitionen, die für das jeweilige Thema konfiguriert sind, ähnlich wie im vorherigen Szenario.
Ein einzelner Verbraucher abonniert ein bestimmtes Thema. Nehmen Sie
Thema-01
mit derGruppen-ID
alsGruppe-1 an
.Kafka interagiert mit dem Verbraucher auf die gleiche Weise wie Pub-Sub Messaging, bis der neue Verbraucher dasselbe Thema abonniert,
Thema-01
mit derselbenGruppen-ID
wieGruppe-1
.Sobald der neue Verbraucher eintrifft, wechselt Kafka seinen Betrieb in den Freigabemodus und teilt die Daten zwischen den beiden Verbrauchern. Diese Freigabe wird fortgesetzt, bis die Anzahl der Verbraucher die Anzahl der für dieses bestimmte Thema konfigurierten Partitionen erreicht hat.
Sobald die Anzahl der Verbraucher die Anzahl der Partitionen überschreitet, erhält der neue Verbraucher keine weitere Nachricht, bis sich einer der vorhandenen Verbraucher abmeldet. Dieses Szenario tritt auf, weil jedem Verbraucher in Kafka mindestens eine Partition zugewiesen wird. Sobald alle Partitionen den vorhandenen Verbrauchern zugewiesen sind, müssen die neuen Verbraucher warten.
Diese Funktion wird auch als
Verbrauchergruppe bezeichnet
. Auf die gleiche Weise wird Kafka auf sehr einfache und effiziente Weise das Beste aus beiden Systemen bereitstellen.
Rolle von ZooKeeper
Eine kritische Abhängigkeit von Apache Kafka ist Apache Zookeeper, ein verteilter Konfigurations- und Synchronisierungsdienst. Zookeeper dient als Koordinationsschnittstelle zwischen den Kafka-Maklern und den Verbrauchern. Die Kafka-Server teilen Informationen über einen Zookeeper-Cluster. Kafka speichert grundlegende Metadaten in Zookeeper, z. B. Informationen zu Themen, Brokern, Verbraucher-Offsets (Warteschlangenlesern) usw.
Da alle kritischen Informationen im Zookeeper gespeichert sind und diese Daten normalerweise im gesamten Ensemble repliziert werden, wirkt sich ein Ausfall des Kafka-Brokers / Zookeepers nicht auf den Status des Kafka-Clusters aus. Kafka wird den Zustand wiederherstellen, sobald der Zookeeper neu startet. Dies gibt Kafka keine Ausfallzeiten. Die Wahl des Führers zwischen dem Kafka-Makler erfolgt auch unter Verwendung von Zookeeper im Falle eines Versagens des Führers.
Um mehr über Zookeeper zu erfahren, wenden Sie sich bitte an zookeeper
Lassen Sie uns im nächsten Kapitel weiter mit der Installation von Java, ZooKeeper und Kafka auf Ihrem Computer fortfahren.
Im Folgenden finden Sie die Schritte zum Installieren von Java auf Ihrem Computer.
Schritt 1 - Überprüfen der Java-Installation
Hoffentlich haben Sie Java bereits auf Ihrem Computer installiert, also überprüfen Sie es einfach mit dem folgenden Befehl.
$ java -versionWenn Java erfolgreich auf Ihrem Computer installiert wurde, wird möglicherweise die Version des installierten Java angezeigt.
Schritt 1.1 - JDK herunterladen
Wenn Java nicht heruntergeladen wird, laden Sie bitte die neueste Version von JDK herunter, indem Sie den folgenden Link besuchen und die neueste Version herunterladen.
http://www.oracle.com/technetwork/java/javase/downloads/index.htmlJetzt ist die neueste Version JDK 8u 60 und die Datei lautet "jdk-8u60-linux-x64.tar.gz". Bitte laden Sie die Datei auf Ihren Computer herunter.
Schritt 1.2 - Dateien extrahieren
Im Allgemeinen werden heruntergeladene Dateien im Download-Ordner gespeichert. Überprüfen Sie diese und extrahieren Sie das Tar-Setup mit den folgenden Befehlen.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzSchritt 1.3 - Zum Opt-Verzeichnis wechseln
Um Java für alle Benutzer verfügbar zu machen, verschieben Sie den extrahierten Java-Inhalt in den Ordner usr / local / java
/.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Schritt 1.4 - Pfad festlegen
Fügen Sie der Datei ~ / .bashrc die folgenden Befehle hinzu, um Pfad- und JAVA_HOME-Variablen festzulegen.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binÜbernehmen Sie nun alle Änderungen in das aktuell laufende System.
$ source ~/.bashrcSchritt 1.5 - Java-Alternativen
Verwenden Sie den folgenden Befehl, um Java-Alternativen zu ändern.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Step 1.6 - Überprüfen Sie nun Java mit dem in Schritt 1 erläuterten Überprüfungsbefehl (Java-Version).
Schritt 2 - Installation von ZooKeeper Framework
Schritt 2.1 - Laden Sie ZooKeeper herunter
Um das ZooKeeper-Framework auf Ihrem Computer zu installieren, besuchen Sie den folgenden Link und laden Sie die neueste Version von ZooKeeper herunter.
http://zookeeper.apache.org/releases.htmlDie neueste Version von ZooKeeper ist ab sofort 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Schritt 2.2 - Teerdatei extrahieren
Extrahieren Sie die TAR-Datei mit dem folgenden Befehl
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataSchritt 2.3 - Konfigurationsdatei erstellen
Öffnen Sie die Konfigurationsdatei mit dem Namen conf / zoo.cfg
mit dem Befehl vi „conf / zoo.cfg“ und allen folgenden Parametern, die als Ausgangspunkt festgelegt werden sollen.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Sobald die Konfigurationsdatei erfolgreich gespeichert wurde und Sie wieder zum Terminal zurückkehren, können Sie den Zookeeper-Server starten.
Schritt 2.4 - Starten Sie ZooKeeper Server
$ bin/zkServer.sh startNach Ausführung dieses Befehls erhalten Sie eine Antwort wie unten gezeigt -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDSchritt 2.5 - Starten Sie die CLI
$ bin/zkCli.shNachdem Sie den obigen Befehl eingegeben haben, werden Sie mit dem Zookeeper-Server verbunden und erhalten die folgende Antwort.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Schritt 2.6 - Stoppen Sie Zookeeper Server
Nachdem Sie den Server verbunden und alle Vorgänge ausgeführt haben, können Sie den Zookeeper-Server mit dem folgenden Befehl stoppen:
$ bin/zkServer.sh stopJetzt haben Sie Java und ZooKeeper erfolgreich auf Ihrem Computer installiert. Sehen wir uns die Schritte zur Installation von Apache Kafka an.
Schritt 3 - Apache Kafka Installation
Fahren Sie mit den folgenden Schritten fort, um Kafka auf Ihrem Computer zu installieren.
Schritt 3.1 - Kafka herunterladen
Um Kafka auf Ihrem Computer zu installieren, klicken Sie auf den folgenden Link:
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgzJetzt die neueste Version dh - kafka_2.11_0.9.0.0.tgz wird auf Ihren Computer heruntergeladen.
Schritt 3.2 - Extrahieren Sie die TAR-Datei
Extrahieren Sie die TAR-Datei mit dem folgenden Befehl:
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$ cd kafka_2.11.0.9.0.0Jetzt haben Sie die neueste Version von Kafka auf Ihren Computer heruntergeladen.
Schritt 3.3 - Server starten
Sie können den Server starten, indem Sie den folgenden Befehl eingeben:
$ bin/kafka-server-start.sh config/server.propertiesNach dem Start des Servers wird die folgende Antwort auf Ihrem Bildschirm angezeigt:
$ bin/kafka-server-start.sh config/server.properties
[2016-01-02 15:37:30,410] INFO KafkaConfig values:
request.timeout.ms = 30000
log.roll.hours = 168
inter.broker.protocol.version = 0.9.0.X
log.preallocate = false
security.inter.broker.protocol = PLAINTEXT
…………………………………………….
…………………………………………….Schritt 4 - Stoppen Sie den Server
Nachdem Sie alle Vorgänge ausgeführt haben, können Sie den Server mit dem folgenden Befehl stoppen:
$ bin/kafka-server-stop.sh config/server.propertiesNachdem wir die Kafka-Installation bereits besprochen haben, können wir im nächsten Kapitel lernen, wie grundlegende Operationen an Kafka ausgeführt werden.
Beginnen wir zunächst mit der Implementierung der Konfiguration eines einzelnen Knotens und eines einzelnen Brokers.
Anschließend migrieren wir unser Setup auf die Konfiguration eines einzelnen Knotens und mehrerer Broker.
Hoffentlich hätten Sie Java, ZooKeeper und Kafka jetzt auf Ihrem Computer installiert. Bevor Sie zum Kafka Cluster-Setup wechseln, müssen Sie zuerst Ihren ZooKeeper starten, da Kafka Cluster ZooKeeper verwendet.
Starten Sie ZooKeeper
Öffnen Sie ein neues Terminal und geben Sie den folgenden Befehl ein:
bin/zookeeper-server-start.sh config/zookeeper.propertiesGeben Sie den folgenden Befehl ein, um Kafka Broker zu starten:
bin/kafka-server-start.sh config/server.propertiesGeben Sie nach dem Starten von Kafka Broker den Befehl jps
am ZooKeeper-Terminal ein, und Sie sehen die folgende Antwort:
821 QuorumPeerMain
928 Kafka
931 JpsJetzt konnten Sie zwei Daemons auf dem Terminal sehen, auf denen QuorumPeerMain der ZooKeeper-Daemon und ein weiterer der Kafka-Daemon ist.
Einzelknoten-Einzelbroker-Konfiguration
In dieser Konfiguration haben Sie eine einzelne ZooKeeper- und Broker-ID-Instanz. Im Folgenden finden Sie die Schritte zum Konfigurieren:
Creating a Kafka Topic- Kafka bietet ein Befehlszeilenprogramm namens kafka-topics.sh
zum Erstellen von Themen auf dem Server. Öffnen Sie ein neues Terminal und geben Sie das folgende Beispiel ein.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-KafkaWir haben gerade ein Thema namens Hello-Kafka
mit einer einzelnen Partition und einem Replikationsfaktor erstellt. Die oben erstellte Ausgabe ähnelt der folgenden Ausgabe:
Output- Erstelltes Thema Hello-Kafka
Sobald das Thema erstellt wurde, können Sie die Benachrichtigung im Kafka-Broker-Terminalfenster und das Protokoll für das erstellte Thema erhalten, das in der Datei config / server.properties unter „/ tmp / kafka-logs /“ angegeben ist.
Liste der Themen
Um eine Liste der Themen auf dem Kafka-Server abzurufen, können Sie den folgenden Befehl verwenden:
Syntax
bin/kafka-topics.sh --list --zookeeper localhost:2181Output
Hello-KafkaDa wir ein Thema erstellt haben, wird nur Hello-Kafka
aufgelistet. Angenommen, wenn Sie mehr als ein Thema erstellen, erhalten Sie die Themennamen in der Ausgabe.
Starten Sie den Produzenten, um Nachrichten zu senden
Syntax
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-nameAus der obigen Syntax sind zwei Hauptparameter für den Producer-Befehlszeilenclient erforderlich -
Broker-list- Die Liste der Broker, an die wir die Nachrichten senden möchten. In diesem Fall haben wir nur einen Broker. Die Datei Config / server.properties enthält die Broker-Port-ID, da wir wissen, dass unser Broker Port 9092 überwacht, sodass Sie ihn direkt angeben können.
Themenname - Hier ist ein Beispiel für den Themennamen.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-KafkaDer Produzent wartet auf Eingaben von stdin und veröffentlicht im Kafka-Cluster. Standardmäßig wird jede neue Zeile als neue Nachricht veröffentlicht. Anschließend werden die Standardproduzenteneigenschaften in der Datei config / Producer.properties angegeben
. Jetzt können Sie einige Zeilen mit Nachrichten in das Terminal eingeben, wie unten gezeigt.
Output
$ bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Hello-Kafka[2016-01-16 13:50:45,931]
WARN property topic is not valid (kafka.utils.Verifia-bleProperties)
Hello
My first messageMy second messageStarten Sie Consumer, um Nachrichten zu empfangen
Ähnlich wie bei Producer werden die Standard-Consumer-Eigenschaften in der Datei config / consumer.proper-tie angegeben
. Öffnen Sie ein neues Terminal und geben Sie die folgende Syntax ein, um Nachrichten zu konsumieren.
Syntax
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginningExample
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginningOutput
Hello
My first message
My second messageSchließlich können Sie Nachrichten vom Terminal des Herstellers eingeben und sehen, wie sie im Terminal des Verbrauchers angezeigt werden. Ab sofort haben Sie ein sehr gutes Verständnis für den einzelnen Knotencluster mit einem einzelnen Broker. Kommen wir nun zur Konfiguration mit mehreren Brokern.
Konfiguration mit mehreren Knoten und mehreren Brokern
Starten Sie zunächst Ihren ZooKeeper-Server, bevor Sie mit dem Cluster-Setup für mehrere Broker fortfahren.
Create Multiple Kafka Brokers- Wir haben bereits eine Kafka-Broker-Instanz in con-fig / server.properties. Jetzt benötigen wir mehrere Brokerinstanzen. Kopieren Sie die vorhandene Datei server.prop-erties in zwei neue Konfigurationsdateien und benennen Sie sie in server -one.properties und server-two.prop-erties um. Bearbeiten Sie dann beide neuen Dateien und weisen Sie die folgenden Änderungen zu:
config / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# The port the socket server listens on
port=9093
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-1config / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# The port the socket server listens on
port=9094
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-2Start Multiple Brokers- Nachdem alle Änderungen auf drei Servern vorgenommen wurden, öffnen Sie drei neue Terminals, um jeden Broker einzeln zu starten.
Broker1
bin/kafka-server-start.sh config/server.properties
Broker2
bin/kafka-server-start.sh config/server-one.properties
Broker3
bin/kafka-server-start.sh config/server-two.propertiesJetzt laufen drei verschiedene Broker auf der Maschine. Probieren Sie es selbst aus, um alle Dämonen durch Eingabe zu überprüfenjps Auf dem ZooKeeper-Terminal wird dann die Antwort angezeigt.
Ein Thema erstellen
Weisen Sie dem Replikationsfaktor für dieses Thema drei zu, da drei verschiedene Broker ausgeführt werden. Wenn Sie zwei Broker haben, beträgt der zugewiesene Replikatwert zwei.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic MultibrokerapplicationOutput
created topic “Multibrokerapplication”Mit dem Befehl Beschreiben
können Sie überprüfen, welcher Broker das aktuell erstellte Thema abhört (siehe unten).
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cationOutput
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cation
Topic:Multibrokerapplication PartitionCount:1
ReplicationFactor:3 Configs:
Topic:Multibrokerapplication Partition:0 Leader:0
Replicas:0,2,1 Isr:0,2,1Aus der obigen Ausgabe können wir schließen, dass die erste Zeile eine Zusammenfassung aller Partitionen enthält, die den Themennamen, die Partitionsanzahl und den Replikationsfaktor enthält, den wir bereits ausgewählt haben. In der zweiten Zeile ist jeder Knoten der Anführer für einen zufällig ausgewählten Teil der Partitionen.
In unserem Fall sehen wir, dass unser erster Broker (mit broker.id 0) der Anführer ist. Dann Replikate: 0,2,1 bedeutet, dass alle Broker das Thema replizieren. Schließlich ist Isr
die Menge der synchronisierten
Replikate. Nun, dies ist die Teilmenge der Repliken, die derzeit am Leben sind und vom Anführer eingeholt werden.
Starten Sie den Produzenten, um Nachrichten zu senden
Dieser Vorgang bleibt derselbe wie beim Setup eines einzelnen Brokers.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092
--topic MultibrokerapplicationOutput
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
[2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties)
This is single node-multi broker demo
This is the second messageStarten Sie Consumer, um Nachrichten zu empfangen
Dieses Verfahren bleibt das gleiche wie im Einzelbroker-Setup.
Example
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion --from-beginningOutput
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion —from-beginning
This is single node-multi broker demo
This is the second messageGrundlegende Themenoperationen
In diesem Kapitel werden wir die verschiedenen grundlegenden Themenoperationen diskutieren.
Ein Thema ändern
Wie Sie bereits verstanden haben, erstellen Sie ein Thema in Kafka Cluster. Lassen Sie uns nun ein erstelltes Thema mit dem folgenden Befehl ändern
Syntax
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name
--parti-tions countExample
We have already created a topic “Hello-Kafka” with single partition count and one replica factor.
Now using “alter” command we have changed the partition count.
bin/kafka-topics.sh --zookeeper localhost:2181
--alter --topic Hello-kafka --parti-tions 2Output
WARNING: If partitions are increased for a topic that has a key,
the partition logic or ordering of the messages will be affected
Adding partitions succeeded!Ein Thema löschen
Um ein Thema zu löschen, können Sie die folgende Syntax verwenden.
Syntax
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_nameExample
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafkaOutput
> Topic Hello-kafka marked for deletionNote −Dies hat keine Auswirkungen, wenn delete.topic.enable ist nicht auf true gesetzt
Lassen Sie uns eine Anwendung zum Veröffentlichen und Konsumieren von Nachrichten mit einem Java-Client erstellen. Der Kafka Producer Client besteht aus den folgenden APIs.
KafkaProducer API
Lassen Sie uns den wichtigsten Satz der Kafka-Produzenten-API in diesem Abschnitt verstehen. Der zentrale Teil der KafkaProducer-API ist die KafkaProducer-
Klasse. Die KafkaProducer-Klasse bietet die Möglichkeit, einen Kafka-Broker in seinem Konstruktor mit den folgenden Methoden zu verbinden.
Die KafkaProducer-Klasse bietet eine Sendemethode zum asynchronen Senden von Nachrichten an ein Thema. Die Signatur von send () lautet wie folgt
producer.send(new ProducerRecord<byte[],byte[]>(topic,
partition, key1, value1) , callback);ProducerRecord - Der Produzent verwaltet einen Puffer mit Datensätzen, die darauf warten, gesendet zu werden.
Callback - Ein vom Benutzer angegebener Rückruf, der ausgeführt wird, wenn der Datensatz vom Server bestätigt wurde (null bedeutet, dass kein Rückruf erfolgt).
Die KafkaProducer-Klasse bietet eine Flush-Methode, um sicherzustellen, dass alle zuvor gesendeten Nachrichten tatsächlich abgeschlossen wurden. Die Syntax der Flush-Methode lautet wie folgt:
public void flush()Die KafkaProducer-Klasse bietet die partitionFor-Methode, mit deren Hilfe die Partitionsmetadaten für ein bestimmtes Thema abgerufen werden können. Dies kann für die benutzerdefinierte Partitionierung verwendet werden. Die Signatur dieser Methode lautet wie folgt:
public Map metrics()Es gibt die Karte der internen Metriken zurück, die vom Hersteller verwaltet werden.
public void close () - Die KafkaProducer-Klasse stellt enge Methodenblöcke bereit, bis alle zuvor gesendeten Anforderungen abgeschlossen sind.
Hersteller-API
Der zentrale Teil der Producer-API ist die Producer-
Klasse. Die Producer-Klasse bietet eine Option zum Verbinden des Kafka-Brokers in seinem Konstruktor mit den folgenden Methoden.
Die Produzentenklasse
Die Producer-Klasse bietet die Sendemethode an send Nachrichten zu einzelnen oder mehreren Themen mit den folgenden Signaturen.
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,”async”)
ProducerConfig config = new ProducerConfig(prop);Es gibt zwei Arten von Produzenten - Sync und Async.
Die gleiche API-Konfiguration gilt auch für Sync
Producer. Der Unterschied zwischen ihnen besteht darin, dass ein Synchronisierungsproduzent Nachrichten direkt sendet, Nachrichten jedoch im Hintergrund. Async-Produzent wird bevorzugt, wenn Sie einen höheren Durchsatz wünschen. In früheren Versionen wie 0.8 hat ein asynchroner Produzent keinen Rückruf für send (), um Fehlerbehandlungsroutinen zu registrieren. Dies ist nur in der aktuellen Version von 0.9 verfügbar.
public void close ()
Produzentenklasse bietet close Methode zum Schließen der Produzentenpoolverbindungen zu allen Kafka-Brokern.
Konfigurationseinstellungen
Die Hauptkonfigurationseinstellungen der Producer-API sind zum besseren Verständnis in der folgenden Tabelle aufgeführt.
| S.No. | Konfigurationseinstellungen und Beschreibung |
|---|---|
| 1 | client.id identifiziert die Herstelleranwendung |
| 2 | producer.type entweder synchron oder asynchron |
| 3 | acks Die acks-Konfiguration steuert die Kriterien, unter denen Herstelleranforderungen als vollständig betrachtet werden. |
| 4 | retries Wenn die Herstelleranforderung fehlschlägt, wiederholen Sie den Vorgang automatisch mit einem bestimmten Wert. |
| 5 | bootstrap.servers Bootstrapping-Liste der Broker. |
| 6 | linger.ms Wenn Sie die Anzahl der Anforderungen reduzieren möchten, können Sie verweilen.ms auf einen Wert setzen, der größer als ein Wert ist. |
| 7 | key.serializer Schlüssel für die Serializer-Schnittstelle. |
| 8 | value.serializer Wert für die Serializer-Schnittstelle. |
| 9 | batch.size Puffergröße. |
| 10 | buffer.memory Steuert die Gesamtmenge an Speicher, die dem Produzenten zum Puffern zur Verfügung steht. |
ProducerRecord API
ProducerRecord ist ein Schlüssel / Wert-Paar, das an den Kafka-Cluster gesendet wird. ProducerRecord-Klassenkonstruktor zum Erstellen eines Datensatzes mit Partitions-, Schlüssel- und Wertepaaren unter Verwendung der folgenden Signatur.
public ProducerRecord (string topic, int partition, k key, v value)Topic - Benutzerdefinierter Themenname, der an die Aufzeichnung angehängt wird.
Partition - Anzahl der Partitionen
Key - Der Schlüssel, der in den Datensatz aufgenommen wird.
- Value - Inhalt aufzeichnen
public ProducerRecord (string topic, k key, v value)Der ProducerRecord-Klassenkonstruktor wird verwendet, um einen Datensatz mit Schlüssel-, Wertepaaren und ohne Partition zu erstellen.
Topic - Erstellen Sie ein Thema, um einen Datensatz zuzuweisen.
Key - Schlüssel für die Aufzeichnung.
Value - Inhalte aufzeichnen.
public ProducerRecord (string topic, v value)Die ProducerRecord-Klasse erstellt einen Datensatz ohne Partition und Schlüssel.
Topic - ein Thema erstellen.
Value - Inhalte aufzeichnen.
Die ProducerRecord-Klassenmethoden sind in der folgenden Tabelle aufgeführt:
| S.No. | Klassenmethoden und Beschreibung |
|---|---|
| 1 | public string topic() Das Thema wird an den Datensatz angehängt. |
| 2 | public K key() Schlüssel, der in den Datensatz aufgenommen wird. Wenn kein solcher Schlüssel vorhanden ist, wird hier erneut null gesetzt. |
| 3 | public V value() Inhalt aufzeichnen. |
| 4 | partition() Partitionsanzahl für den Datensatz |
SimpleProducer-Anwendung
Starten Sie vor dem Erstellen der Anwendung zunächst ZooKeeper und Kafka Broker und erstellen Sie dann mit dem Befehl create topic ein eigenes Thema in Kafka Broker. Erstellen Sie anschließend eine Java-Klasse mit dem Namen Sim-pleProducer.java
und geben Sie die folgende Codierung ein.
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name”);
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}Compilation - Die Anwendung kann mit dem folgenden Befehl kompiliert werden.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution - Die Anwendung kann mit dem folgenden Befehl ausgeführt werden.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>Output
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10Einfaches Verbraucherbeispiel
Ab sofort haben wir einen Produzenten erstellt, der Nachrichten an den Kafka-Cluster sendet. Lassen Sie uns nun einen Konsumenten erstellen, der Nachrichten aus dem Kafka-Cluster konsumiert. Die KafkaConsumer-API wird verwendet, um Nachrichten aus dem Kafka-Cluster zu konsumieren. Der KafkaConsumer-Klassenkonstruktor ist unten definiert.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)configs - Geben Sie eine Karte mit Verbraucherkonfigurationen zurück.
Die KafkaConsumer-Klasse verfügt über die folgenden wichtigen Methoden, die in der folgenden Tabelle aufgeführt sind.
| S.No. | Methode und Beschreibung |
|---|---|
| 1 | public java.util.Set<TopicPar-tition> assignment() Rufen Sie die Partitionen ab, die derzeit vom Verbraucher zugewiesen wurden. |
| 2 | public string subscription() Abonnieren Sie die angegebene Themenliste, um dynamisch signierte Partitionen zu erhalten. |
| 3 | public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener) Abonnieren Sie die angegebene Themenliste, um dynamisch signierte Partitionen zu erhalten. |
| 4 | public void unsubscribe() Deaktivieren Sie die Themen aus der angegebenen Liste der Partitionen. |
| 5 | public void sub-scribe(java.util.List<java.lang.String> topics) Abonnieren Sie die angegebene Themenliste, um dynamisch signierte Partitionen zu erhalten. Wenn die angegebene Themenliste leer ist, wird sie genauso behandelt wie das Abbestellen (). |
| 6 | public void sub-scribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener) Das Argumentmuster bezieht sich auf das Abonnementmuster im Format des regulären Ausdrucks, und das Listener-Argument erhält Benachrichtigungen vom Abonnementmuster. |
| 7 | public void as-sign(java.util.List<TopicParti-tion> partitions) Weisen Sie dem Kunden manuell eine Liste von Partitionen zu. |
| 8 | poll() Abrufen von Daten für die angegebenen Themen oder Partitionen mithilfe einer der Abonnement- / Zuweisungs-APIs. Dies gibt einen Fehler zurück, wenn die Themen vor dem Abrufen von Daten nicht abonniert wurden. |
| 9 | public void commitSync() Übernehmen Sie Offsets, die bei der letzten Umfrage () für die gesamte unterzeichnete Liste von Themen und Partitionen zurückgegeben wurden. Die gleiche Operation wird auf commitAsyn () angewendet. |
| 10 | public void seek(TopicPartition partition, long offset) Rufen Sie den aktuellen Versatzwert ab, den der Verbraucher bei der nächsten poll () -Methode verwendet. |
| 11 | public void resume() Setzen Sie die angehaltenen Partitionen fort. |
| 12 | public void wakeup() Wecken Sie den Verbraucher. |
ConsumerRecord-API
Die ConsumerRecord-API wird zum Empfangen von Datensätzen vom Kafka-Cluster verwendet. Diese API besteht aus einem Themennamen, einer Partitionsnummer, von der der Datensatz empfangen wird, und einem Offset, der auf den Datensatz in einer Kafka-Partition verweist. Die ConsumerRecord-Klasse wird verwendet, um einen Consumer-Datensatz mit bestimmten Themennamen, Partitionsanzahl und <Schlüssel, Wert> -Paaren zu erstellen. Es hat die folgende Signatur.
public ConsumerRecord(string topic,int partition, long offset,K key, V value)Topic - Der Themenname für den vom Kafka-Cluster empfangenen Verbraucherdatensatz.
Partition - Partition für das Thema.
Key - Der Schlüssel des Datensatzes, wenn kein Schlüssel vorhanden ist, wird null zurückgegeben.
Value - Inhalt aufzeichnen.
ConsumerRecords-API
Die ConsumerRecords-API fungiert als Container für ConsumerRecord. Diese API wird verwendet, um die Liste von ConsumerRecord pro Partition für ein bestimmtes Thema zu speichern. Sein Konstruktor ist unten definiert.
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)TopicPartition - Geben Sie eine Partitionskarte für ein bestimmtes Thema zurück.
Records - Rückgabeliste von ConsumerRecord.
In der ConsumerRecords-Klasse sind die folgenden Methoden definiert.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | public int count() Die Anzahl der Datensätze für alle Themen. |
| 2 | public Set partitions() Der Satz von Partitionen mit Daten in diesem Datensatz (wenn keine Daten zurückgegeben wurden, ist der Satz leer). |
| 3 | public Iterator iterator() Mit Iterator können Sie eine Sammlung durchlaufen, Elemente abrufen oder verschieben. |
| 4 | public List records() Liste der Datensätze für die angegebene Partition abrufen. |
Konfigurationseinstellungen
Die Konfigurationseinstellungen für die Hauptkonfigurationseinstellungen der Consumer-Client-API sind unten aufgeführt:
| S.No. | Einstellungen und Beschreibung |
|---|---|
| 1 | bootstrap.servers Bootstrapping-Liste der Broker. |
| 2 | group.id Weist einer Gruppe einen einzelnen Verbraucher zu. |
| 3 | enable.auto.commit Aktivieren Sie die automatische Festschreibung für Offsets, wenn der Wert true ist, andernfalls nicht festgeschrieben. |
| 4 | auto.commit.interval.ms Gibt zurück, wie oft aktualisierte verbrauchte Offsets in ZooKeeper geschrieben werden. |
| 5 | session.timeout.ms Gibt an, wie viele Millisekunden Kafka darauf wartet, dass der ZooKeeper auf eine Anfrage (Lesen oder Schreiben) antwortet, bevor er aufgibt und weiterhin Nachrichten konsumiert. |
SimpleConsumer-Anwendung
Die Herstelleranwendungsschritte bleiben hier gleich. Starten Sie zuerst Ihren ZooKeeper- und Kafka-Broker. Erstellen Sie dann eine SimpleConsumer-
Anwendung mit der Java-Klasse SimpleCon-sumer.java
und geben Sie den folgenden Code ein.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilation - Die Anwendung kann mit dem folgenden Befehl kompiliert werden.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution − Die Anwendung kann mit dem folgenden Befehl ausgeführt werden
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>Input- Öffnen Sie die Produzenten-CLI und senden Sie einige Nachrichten an das Thema. Sie können die kleine Eingabe als "Hallo Verbraucher" eingeben.
Output - Es folgt die Ausgabe.
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello ConsumerDie Verbrauchergruppe ist ein Multithread- oder Multimaschinenverbrauch aus Kafka-Themen.
Verbrauchergruppe
Verbraucher können einer Gruppe mit derselben
group.id beitreten.
Die maximale Parallelität einer Gruppe besteht darin, dass die Anzahl der Verbraucher in der Gruppe ← Anzahl der Partitionen beträgt.
Kafka weist dem Verbraucher in einer Gruppe die Partitionen eines Themas zu, sodass jede Partition von genau einem Verbraucher in der Gruppe verwendet wird.
Kafka garantiert, dass eine Nachricht immer nur von einem einzelnen Verbraucher in der Gruppe gelesen wird.
Verbraucher können die Nachricht in der Reihenfolge sehen, in der sie im Protokoll gespeichert wurden.
Neuausgleich eines Verbrauchers
Durch Hinzufügen weiterer Prozesse / Threads wird Kafka neu ausgeglichen. Wenn ein Verbraucher oder Broker keinen Heartbeat an ZooKeeper sendet, kann er über den Kafka-Cluster neu konfiguriert werden. Während dieser Neuausrichtung weist Kafka den verfügbaren Threads verfügbare Partitionen zu und verschiebt möglicherweise eine Partition in einen anderen Prozess.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Zusammenstellung
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.javaAusführung
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-groupHier haben wir einen Beispielgruppennamen als meine Gruppe
mit zwei Verbrauchern erstellt. Ebenso können Sie Ihre Gruppe und die Anzahl der Verbraucher in der Gruppe erstellen.
Eingang
Öffnen Sie die Produzenten-CLI und senden Sie einige Nachrichten wie -
Test consumer group 01
Test consumer group 02Ausgabe des ersten Prozesses
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 01Ausgabe des zweiten Prozesses
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02Hoffentlich hätten Sie SimpleConsumer und ConsumeGroup mithilfe der Java-Client-Demo verstanden. Jetzt haben Sie eine Idee, wie Sie Nachrichten mit einem Java-Client senden und empfangen können. Lassen Sie uns die Kafka-Integration mit Big-Data-Technologien im nächsten Kapitel fortsetzen.
In diesem Kapitel erfahren Sie, wie Sie Kafka in Apache Storm integrieren.
Über Sturm
Storm wurde ursprünglich von Nathan Marz und dem Team von BackType erstellt. In kurzer Zeit wurde Apache Storm zum Standard für verteilte Echtzeitverarbeitungssysteme, mit denen Sie ein großes Datenvolumen verarbeiten können. Storm ist sehr schnell und wurde von einem Benchmark mit über einer Million Tupeln pro Sekunde und Knoten verarbeitet. Apache Storm wird kontinuierlich ausgeführt, verbraucht Daten aus den konfigurierten Quellen (Spouts) und leitet die Daten über die Verarbeitungspipeline (Bolts) weiter. Kombiniert bilden Ausgüsse und Schrauben eine Topologie.
Integration mit Storm
Kafka und Storm ergänzen sich auf natürliche Weise, und ihre leistungsstarke Zusammenarbeit ermöglicht Echtzeit-Streaming-Analysen für sich schnell bewegende Big Data. Die Integration von Kafka und Storm soll Entwicklern das Aufnehmen und Veröffentlichen von Datenströmen aus Storm-Topologien erleichtern.
Konzeptioneller Ablauf
Ein Auslauf ist eine Quelle von Strömen. Zum Beispiel kann ein Auslauf Tupel von einem Kafka-Thema lesen und sie als Stream ausgeben. Ein Bolzen verbraucht Eingabestreams, verarbeitet sie und gibt möglicherweise neue Streams aus. Bolts können alles tun, von der Ausführung von Funktionen über das Filtern von Tupeln bis hin zu Streaming-Aggregationen, Streaming-Joins, Gesprächen mit Datenbanken und vielem mehr. Jeder Knoten in einer Storm-Topologie wird parallel ausgeführt. Eine Topologie wird unbegrenzt ausgeführt, bis Sie sie beenden. Storm weist fehlgeschlagene Aufgaben automatisch neu zu. Darüber hinaus garantiert Storm, dass kein Datenverlust auftritt, selbst wenn die Computer ausfallen und Nachrichten gelöscht werden.
Lassen Sie uns die Kafka-Storm-Integrations-APIs im Detail durchgehen. Es gibt drei Hauptklassen, um Kafka in Storm zu integrieren. Sie sind wie folgt -
BrokerHosts - ZkHosts & StaticHosts
BrokerHosts ist eine Schnittstelle und ZkHosts und StaticHosts sind die beiden Hauptimplementierungen. ZkHosts wird verwendet, um die Kafka-Broker dynamisch zu verfolgen, indem die Details in ZooKeeper verwaltet werden, während StaticHosts verwendet wird, um die Kafka-Broker und ihre Details manuell / statisch festzulegen. ZkHosts ist der einfache und schnelle Weg, um auf den Kafka-Broker zuzugreifen.
Die Signatur von ZkHosts lautet wie folgt:
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)Dabei ist BrokerZkStr der ZooKeeper-Host und BrokerZkPath der ZooKeeper-Pfad zum Verwalten der Kafka-Brokerdetails.
KafkaConfig API
Diese API wird verwendet, um Konfigurationseinstellungen für den Kafka-Cluster zu definieren. Die Signatur von Kafka Con-fig ist wie folgt definiert
public KafkaConfig(BrokerHosts hosts, string topic)Hosts - Die BrokerHosts können ZkHosts / StaticHosts sein.
Topic - Themenname.
SpoutConfig API
Spoutconfig ist eine Erweiterung von KafkaConfig, die zusätzliche ZooKeeper-Informationen unterstützt.
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)Hosts - Die BrokerHosts können eine beliebige Implementierung der BrokerHosts-Schnittstelle sein
Topic - Themenname.
zkRoot - ZooKeeper-Stammpfad.
id −Der Auslauf speichert den Status der Offsets, die in Zookeeper verbraucht werden. Die ID sollte Ihren Auslauf eindeutig identifizieren.
SchemeAsMultiScheme
SchemeAsMultiScheme ist eine Schnittstelle, die vorschreibt, wie der von Kafka verbrauchte ByteBuffer in ein Sturmtupel umgewandelt wird. Es ist von MultiScheme abgeleitet und akzeptiert die Implementierung der Scheme-Klasse. Es gibt viele Implementierungen der Scheme-Klasse und eine solche Implementierung ist StringScheme, die das Byte als einfachen String analysiert. Es steuert auch die Benennung Ihres Ausgabefeldes. Die Signatur ist wie folgt definiert.
public SchemeAsMultiScheme(Scheme scheme)Scheme - Byte-Puffer aus Kafka verbraucht.
KafkaSpout API
KafkaSpout ist unsere Auslaufimplementierung, die in Storm integriert wird. Es holt die Nachrichten aus dem Kafka-Thema und gibt sie als Tupel an das Storm-Ökosystem ab. KafkaSpout erhält seine Konfigurationsdetails von SpoutConfig.
Unten finden Sie einen Beispielcode zum Erstellen eines einfachen Kafka-Auslaufs.
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);
//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts,
topicName, "/" + topicName UUID.randomUUID().toString());
//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);Bolzenerstellung
Bolt ist eine Komponente, die Tupel als Eingabe verwendet, das Tupel verarbeitet und neue Tupel als Ausgabe erzeugt. Bolzen implementieren die IRichBolt-Schnittstelle. In diesem Programm werden zwei Schraubenklassen WordSplitter-Bolt und WordCounterBolt verwendet, um die Operationen auszuführen.
Die IRichBolt-Schnittstelle verfügt über die folgenden Methoden:
Prepare- Versorgt den Bolzen mit einer auszuführenden Umgebung. Die Ausführenden führen diese Methode aus, um den Auslauf zu initialisieren.
Execute - Verarbeiten Sie ein einzelnes Tupel der Eingabe.
Cleanup - Wird aufgerufen, wenn ein Bolzen abgeschaltet wird.
declareOutputFields - Deklariert das Ausgabeschema des Tupels.
Erstellen wir SplitBolt.java, das die Logik zum Aufteilen eines Satzes in Wörter implementiert, und CountBolt.java, das die Logik implementiert, um eindeutige Wörter zu trennen und deren Auftreten zu zählen.
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}CountBolt.java
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Senden an die Topologie
Die Storm-Topologie ist im Grunde eine Thrift-Struktur. Die TopologyBuilder-Klasse bietet einfache Methoden zum Erstellen komplexer Topologien. Die TopologyBuilder-Klasse verfügt über Methoden zum Setzen von Ausgüssen (setSpout) und zum Setzen von Bolzen (setBolt). Schließlich verfügt TopologyBuilder über createTopology zum Erstellen von to-pology. shuffleGrouping- und fieldsGrouping-Methoden helfen beim Festlegen der Stream-Gruppierung für Auslauf und Schrauben.
Local Cluster- Zu Entwicklungszwecken können wir mit dem LocalCluster-
Objekt einen lokalen Cluster erstellen
und dann die Topologie mit der submitTopology-
Methode der LocalCluster-
Klasse senden
.
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}Vor dem Verschieben der Kompilierung benötigt die Kakfa-Storm-Integration die Java-Bibliothek des Kurators ZooKeeper. Curator Version 2.9.1 unterstützt Apache Storm Version 0.9.5 (die wir in diesem Tutorial verwenden). Laden Sie die unten angegebenen JAR-Dateien herunter und platzieren Sie sie im Java-Klassenpfad.
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
Kompilieren Sie das Programm nach dem Einfügen von Abhängigkeitsdateien mit dem folgenden Befehl:
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.javaAusführung
Starten Sie die Kafka Producer CLI (im vorherigen Kapitel erläutert), erstellen Sie ein neues Thema mit dem Namen " Mein erstes Thema"
und geben Sie einige Beispielnachrichten an, wie unten gezeigt.
hello
kafka
storm
spark
test message
another test messageFühren Sie nun die Anwendung mit dem folgenden Befehl aus:
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSampleDie Beispielausgabe dieser Anwendung ist unten angegeben -
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2In diesem Kapitel werden wir diskutieren, wie Apache Kafka in die Spark Streaming API integriert wird.
Über Spark
Die Spark-Streaming-API ermöglicht die skalierbare, fehlertolerante Stream-Verarbeitung von Live-Datenströmen mit hohem Durchsatz. Daten können aus vielen Quellen wie Kafka, Flume, Twitter usw. aufgenommen und mit komplexen Algorithmen wie übergeordneten Funktionen wie Map, Reduce, Join und Window verarbeitet werden. Schließlich können verarbeitete Daten in Dateisysteme, Datenbanken und Live-Dashboards übertragen werden. Resilient Distributed Datasets (RDD) ist eine grundlegende Datenstruktur von Spark. Es ist eine unveränderliche verteilte Sammlung von Objekten. Jeder Datensatz in RDD ist in logische Partitionen unterteilt, die auf verschiedenen Knoten des Clusters berechnet werden können.
Integration mit Spark
Kafka ist eine potenzielle Messaging- und Integrationsplattform für Spark-Streaming. Kafka fungiert als zentraler Hub für Echtzeit-Datenströme und wird mithilfe komplexer Algorithmen in Spark Streaming verarbeitet. Sobald die Daten verarbeitet sind, veröffentlicht Spark Streaming möglicherweise Ergebnisse in einem weiteren Kafka-Thema oder speichert sie in HDFS, Datenbanken oder Dashboards. Das folgende Diagramm zeigt den konzeptionellen Ablauf.

Lassen Sie uns nun die Kafka-Spark-APIs im Detail durchgehen.
SparkConf API
Es repräsentiert die Konfiguration für eine Spark-Anwendung. Wird verwendet, um verschiedene Spark-Parameter als Schlüssel-Wert-Paare festzulegen.
Die SparkConf-
Klasse verfügt über die folgenden Methoden:
set(string key, string value) - Konfigurationsvariable setzen.
remove(string key) - Schlüssel aus der Konfiguration entfernen.
setAppName(string name) - Legen Sie den Anwendungsnamen für Ihre Anwendung fest.
get(string key) - Schlüssel holen
StreamingContext-API
Dies ist der Haupteinstiegspunkt für die Spark-Funktionalität. Ein SparkContext stellt die Verbindung zu einem Spark-Cluster dar und kann zum Erstellen von RDDs, Akkumulatoren und Broadcast-Variablen im Cluster verwendet werden. Die Signatur wird wie unten gezeigt definiert.
public StreamingContext(String master, String appName, Duration batchDuration,
String sparkHome, scala.collection.Seq<String> jars,
scala.collection.Map<String,String> environment)master - Cluster-URL, zu der eine Verbindung hergestellt werden soll (z. B. mesos: // host: port, spark: // host: port, local [4]).
appName - Ein Name für Ihren Job, der auf der Cluster-Web-Benutzeroberfläche angezeigt wird
batchDuration - das Zeitintervall, in dem Streaming-Daten in Stapel aufgeteilt werden
public StreamingContext(SparkConf conf, Duration batchDuration)Erstellen Sie einen StreamingContext, indem Sie die für einen neuen SparkContext erforderliche Konfiguration bereitstellen.
conf - Funkenparameter
batchDuration - das Zeitintervall, in dem Streaming-Daten in Stapel aufgeteilt werden
KafkaUtils API
Die KafkaUtils-API wird verwendet, um den Kafka-Cluster mit dem Spark-Streaming zu verbinden. Diese API verfügt über die unten definierte signifikante Methode createStream-
Signatur.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
StreamingContext ssc, String zkQuorum, String groupId,
scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)Die oben gezeigte Methode wird verwendet, um einen Eingabestream zu erstellen, der Nachrichten von Kafka Brokers abruft.
ssc - StreamingContext-Objekt.
zkQuorum - Zookeeper-Quorum.
groupId - Die Gruppen-ID für diesen Verbraucher.
topics - Geben Sie eine Karte mit den zu konsumierenden Themen zurück.
storageLevel - Speicherebene zum Speichern der empfangenen Objekte.
Die KafkaUtils-API verfügt über eine andere Methode createDirectStream, mit der ein Eingabestream erstellt wird, der Nachrichten direkt von Kafka Brokers abruft, ohne einen Empfänger zu verwenden. Dieser Stream kann garantieren, dass jede Nachricht von Kafka genau einmal in Transformationen enthalten ist.
Die Beispielanwendung erfolgt in Scala. Um die Anwendung zu kompilieren, laden Sie bitte das sbt
, scala build tool (ähnlich wie maven) herunter und installieren Sie es
. Der Hauptanwendungscode ist unten dargestellt.
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}Skript erstellen
Die Spark-Kafka-Integration hängt vom Spark-, Spark-Streaming- und Spark-Kafka-Integrationsglas ab. Erstellen Sie eine neue Datei build.sbt
und geben Sie die Anwendungsdetails und deren Abhängigkeit an. Der sbt
lädt das erforderliche JAR herunter, während er die Anwendung kompiliert und packt.
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"Zusammenstellung / Verpackung
Führen Sie den folgenden Befehl aus, um die JAR-Datei der Anwendung zu kompilieren und zu verpacken. Wir müssen die JAR-Datei an die Spark-Konsole senden, um die Anwendung auszuführen.
sbt packageSubmiting to Spark
Start Kafka Producer CLI (explained in the previous chapter), create a new topic called my-first-topic
and provide some sample messages as shown below.
Another spark test messageRun the following command to submit the application to spark console.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>The sample output of this application is shown below.
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..Let us analyze a real time application to get the latest twitter feeds and its hashtags. Earlier, we have seen integration of Storm and Spark with Kafka. In both the scenarios, we created a Kafka Producer (using cli) to send message to the Kafka ecosystem. Then, the storm and spark inte-gration reads the messages by using the Kafka consumer and injects it into storm and spark ecosystem respectively. So, practically we need to create a Kafka Producer, which should −
- Read the twitter feeds using “Twitter Streaming API”,
- Process the feeds,
- Extract the HashTags and
- Send it to Kafka.
Once the HashTags
are received by Kafka, the Storm / Spark integration receive the infor-mation and send it to Storm / Spark ecosystem.
Twitter Streaming API
The “Twitter Streaming API” can be accessed in any programming language. The “twitter4j” is an open source, unofficial Java library, which provides a Java based module to easily access the “Twitter Streaming API”. The “twitter4j” provides a listener based framework to access the tweets. To access the “Twitter Streaming API”, we need to sign in for Twitter developer account and should get the following OAuth authentication details.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Once the developer account is created, download the “twitter4j” jar files and place it in the java class path.
The Complete Twitter Kafka producer coding (KafkaTwitterProducer.java) is listed below −
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.*;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaTwitterProducer {
public static void main(String[] args) throws Exception {
LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);
if(args.length < 5){
System.out.println(
"Usage: KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret> <twitter-access-token>
<twitter-access-token-secret>
<topic-name> <twitter-search-keywords>");
return;
}
String consumerKey = args[0].toString();
String consumerSecret = args[1].toString();
String accessToken = args[2].toString();
String accessTokenSecret = args[3].toString();
String topicName = args[4].toString();
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
// System.out.println("@" + status.getUser().getScreenName()
+ " - " + status.getText());
// System.out.println("@" + status.getUser().getScreen-Name());
/*for(URLEntity urle : status.getURLEntities()) {
System.out.println(urle.getDisplayURL());
}*/
/*for(HashtagEntity hashtage : status.getHashtagEntities()) {
System.out.println(hashtage.getText());
}*/
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {
// System.out.println("Got a status deletion notice id:"
+ statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
// System.out.println("Got track limitation notice:" +
num-berOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
// System.out.println("Got scrub_geo event userId:" + userId +
"upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
// System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
Thread.sleep(5000);
//Add Kafka producer config settings
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int i = 0;
int j = 0;
while(i < 10) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
i++;
}else {
for(HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord<String, String>(
top-icName, Integer.toString(j++), hashtage.getText()));
}
}
}
producer.close();
Thread.sleep(5000);
twitterStream.shutdown();
}
}Compilation
Compile the application using the following command −
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.javaExecution
Open two consoles. Run the above compiled application as shown below in one console.
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:
. KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret>
<twitter-access-token>
<twitter-ac-cess-token-secret>
my-first-topic foodRun any one of the Spark / Storm application explained in the previous chapter in another win-dow. The main point to note is that the topic used should be same in both cases. Here, we have used “my-first-topic” as the topic name.
Output
The output of this application will depend on the keywords and the current feed of the twitter. A sample output is specified below (storm integration).
. . .
food : 1
foodie : 2
burger : 1
. . .Kafka Tool packaged under “org.apache.kafka.tools.*. Tools are categorized into system tools and replication tools.
System Tools
System tools can be run from the command line using the run class script. The syntax is as follows −
bin/kafka-run-class.sh package.class - - optionsSome of the system tools are mentioned below −
Kafka Migration Tool − This tool is used to migrate a broker from one version to an-other.
Mirror Maker − This tool is used to provide mirroring of one Kafka cluster to another.
Consumer Offset Checker − This tool displays Consumer Group, Topic, Partitions, Off-set, logSize, Owner for the specified set of Topics and Consumer Group.
Replication Tool
Kafka replication is a high level design tool. The purpose of adding replication tool is for stronger durability and higher availability. Some of the replication tools are mentioned below −
Create Topic Tool − This creates a topic with a default number of partitions, replication factor and uses Kafka's default scheme to do replica assignment.
List Topic Tool − This tool lists the information for a given list of topics. If no topics are provided in the command line, the tool queries Zookeeper to get all the topics and lists the information for them. The fields that the tool displays are topic name, partition, leader, replicas, isr.
Add Partition Tool − Creation of a topic, the number of partitions for topic has to be specified. Later on, more partitions may be needed for the topic, when the volume of the topic will increase. This tool helps to add more partitions for a specific topic and also allows manual replica assignment of the added partitions.
Kafka supports many of today's best industrial applications. We will provide a very brief overview of some of the most notable applications of Kafka in this chapter.
Twitter is an online social networking service that provides a platform to send and receive user tweets. Registered users can read and post tweets, but unregistered users can only read tweets. Twitter uses Storm-Kafka as a part of their stream processing infrastructure.
Apache Kafka is used at LinkedIn for activity stream data and operational metrics. Kafka mes-saging system helps LinkedIn with various products like LinkedIn Newsfeed, LinkedIn Today for online message consumption and in addition to offline analytics systems like Hadoop. Kafka’s strong durability is also one of the key factors in connection with LinkedIn.
Netflix
Netflix is an American multinational provider of on-demand Internet streaming media. Netflix uses Kafka for real-time monitoring and event processing.
Mozilla
Mozilla is a free-software community, created in 1998 by members of Netscape. Kafka will soon be replacing a part of Mozilla current production system to collect performance and usage data from the end-user’s browser for projects like Telemetry, Test Pilot, etc.
Oracle
Oracle provides native connectivity to Kafka from its Enterprise Service Bus product called OSB (Oracle Service Bus) which allows developers to leverage OSB built-in mediation capabilities to implement staged data pipelines.