Apache Presto - Kurzanleitung
Bei der Datenanalyse werden Rohdaten analysiert, um relevante Informationen für eine bessere Entscheidungsfindung zu sammeln. Es wird hauptsächlich in vielen Organisationen verwendet, um Geschäftsentscheidungen zu treffen. Die Big-Data-Analyse umfasst eine große Datenmenge, und dieser Prozess ist recht komplex. Daher wenden Unternehmen unterschiedliche Strategien an.
Facebook ist beispielsweise eines der führenden datengesteuerten und größten Data Warehouse-Unternehmen der Welt. Facebook-Warehouse-Daten werden in Hadoop für umfangreiche Berechnungen gespeichert. Später, als die Lagerdaten auf Petabyte anstiegen, beschlossen sie, ein neues System mit geringer Latenz zu entwickeln. Im Jahr 2012 entwarfen Facebook-Teammitglieder“Presto” für interaktive Abfrageanalysen, die selbst mit Petabyte an Daten schnell funktionieren.
Was ist Apache Presto?
Apache Presto ist eine verteilte parallele Abfrageausführungs-Engine, die für geringe Latenz und interaktive Abfrageanalyse optimiert ist. Presto führt Abfragen einfach aus und skaliert ohne Ausfallzeiten von Gigabyte auf Petabyte.
Eine einzelne Presto-Abfrage kann Daten aus mehreren Quellen wie HDFS, MySQL, Cassandra, Hive und vielen weiteren Datenquellen verarbeiten. Presto ist in Java integriert und einfach in andere Dateninfrastrukturkomponenten zu integrieren. Presto ist leistungsstark und wird von führenden Unternehmen wie Airbnb, DropBox, Groupon und Netflix übernommen.
Presto - Funktionen
Presto enthält die folgenden Funktionen:
- Einfache und erweiterbare Architektur.
- Steckbare Konnektoren - Presto unterstützt steckbare Konnektoren, um Metadaten und Daten für Abfragen bereitzustellen.
- Pipeline-Ausführungen - Vermeidet unnötigen Overhead für die E / A-Latenz.
- Benutzerdefinierte Funktionen - Analysten können benutzerdefinierte Funktionen erstellen, um die Migration zu vereinfachen.
- Vektorisierte säulenförmige Verarbeitung.
Presto - Vorteile
Hier ist eine Liste der Vorteile, die Apache Presto bietet:
- Spezialisierte SQL-Operationen
- Einfach zu installieren und zu debuggen
- Einfache Speicherabstraktion
- Skaliert Petabyte-Daten schnell mit geringer Latenz
Presto - Anwendungen
Presto unterstützt die meisten der besten Industrieanwendungen von heute. Werfen wir einen Blick auf einige der bemerkenswerten Anwendungen.
Facebook- Facebook hat Presto für Datenanalyse-Anforderungen entwickelt. Presto skaliert problemlos große Datengeschwindigkeiten.
Teradata- Teradata bietet End-to-End-Lösungen für Big Data-Analysen und Data Warehousing. Der Beitrag von Teradata zu Presto erleichtert es mehr Unternehmen, alle analytischen Anforderungen zu erfüllen.
Airbnb- Presto ist ein wesentlicher Bestandteil der Airbnb-Dateninfrastruktur. Nun, Hunderte von Mitarbeitern führen täglich Abfragen mit der Technologie durch.
Warum Presto?
Presto unterstützt Standard-ANSI-SQL, was es Datenanalysten und Entwicklern sehr einfach gemacht hat. Obwohl es in Java erstellt wurde, werden typische Probleme mit Java-Code im Zusammenhang mit der Speicherzuweisung und der Speicherbereinigung vermieden. Presto verfügt über eine Hadoop-freundliche Connector-Architektur. Es ermöglicht das einfache Einstecken von Dateisystemen.
Presto läuft auf mehreren Hadoop-Distributionen. Darüber hinaus kann Presto von einer Hadoop-Plattform aus nach Cassandra, relationalen Datenbanken oder anderen Datenspeichern fragen. Diese plattformübergreifende Analysefunktion ermöglicht es Presto-Benutzern, den maximalen Geschäftswert von Gigabyte bis Petabyte an Daten zu extrahieren.
Die Architektur von Presto ähnelt fast der klassischen MPP-DBMS-Architektur (Massively Parallel Processing). Das folgende Diagramm zeigt die Architektur von Presto.

Das obige Diagramm besteht aus verschiedenen Komponenten. In der folgenden Tabelle werden die einzelnen Komponenten ausführlich beschrieben.
| S.No. | Komponentenbeschreibung |
|---|---|
| 1. | Client Der Client (Presto CLI) sendet SQL-Anweisungen an einen Koordinator, um das Ergebnis zu erhalten. |
| 2. | Coordinator Der Koordinator ist ein Master-Daemon. Der Koordinator analysiert zunächst die SQL-Abfragen, analysiert sie dann und plant die Ausführung der Abfrage. Der Scheduler führt die Pipeline-Ausführung durch, weist dem nächstgelegenen Knoten Arbeit zu und überwacht den Fortschritt. |
| 3. | Connector Speicher-Plugins werden als Konnektoren bezeichnet. Hive, HBase, MySQL, Cassandra und viele mehr fungieren als Konnektor. Andernfalls können Sie auch eine benutzerdefinierte implementieren. Der Connector stellt Metadaten und Daten für Abfragen bereit. Der Koordinator verwendet den Connector, um Metadaten zum Erstellen eines Abfrageplans abzurufen. |
| 4. | Worker Der Koordinator weist Arbeiterknoten eine Aufgabe zu. Die Arbeiter erhalten aktuelle Daten vom Konnektor. Schließlich liefert der Worker-Knoten das Ergebnis an den Client. |
Presto - Workflow
Presto ist ein verteiltes System, das auf einem Cluster von Knoten ausgeführt wird. Die verteilte Abfrage-Engine von Presto ist für interaktive Analysen optimiert und unterstützt Standard-ANSI-SQL, einschließlich komplexer Abfragen, Aggregationen, Verknüpfungen und Fensterfunktionen. Die Presto-Architektur ist einfach und erweiterbar. Presto Client (CLI) sendet SQL-Anweisungen an einen Master-Daemon-Koordinator.
Der Scheduler stellt eine Verbindung über die Ausführungspipeline her. Der Scheduler weist Knoten Knoten zu, die den Daten am nächsten liegen, und überwacht den Fortschritt. Der Koordinator weist mehreren Arbeiterknoten eine Aufgabe zu, und schließlich liefert der Arbeiterknoten das Ergebnis an den Client zurück. Der Client zieht Daten aus dem Ausgabeprozess. Erweiterbarkeit ist das Schlüsseldesign. Steckbare Konnektoren wie Hive, HBase, MySQL usw. bieten Metadaten und Daten für Abfragen. Presto wurde mit einer „einfachen Speicherabstraktion“ entwickelt, die es einfach macht, SQL-Abfragefunktionen für diese verschiedenen Arten von Datenquellen bereitzustellen.
Ausführungsmodell
Presto unterstützt benutzerdefinierte Abfrage- und Ausführungsmodule mit Operatoren, die die SQL-Semantik unterstützen. Zusätzlich zur verbesserten Planung befindet sich die gesamte Verarbeitung im Speicher und wird zwischen verschiedenen Phasen über das Netzwerk geleitet. Dies vermeidet unnötigen Overhead für die E / A-Latenz.
In diesem Kapitel wird erläutert, wie Sie Presto auf Ihrem Computer installieren. Lassen Sie uns die grundlegenden Anforderungen von Presto durchgehen.
- Linux oder Mac OS
- Java Version 8
Fahren Sie nun mit den folgenden Schritten fort, um Presto auf Ihrem Computer zu installieren.
Überprüfen der Java-Installation
Hoffentlich haben Sie Java Version 8 bereits auf Ihrem Computer installiert, also überprüfen Sie es einfach mit dem folgenden Befehl.
$ java -versionWenn Java erfolgreich auf Ihrem Computer installiert wurde, wird möglicherweise die Version von installiertem Java angezeigt. Wenn Java nicht installiert ist, führen Sie die folgenden Schritte aus, um Java 8 auf Ihrem Computer zu installieren.
Laden Sie JDK herunter. Laden Sie die neueste Version von JDK herunter, indem Sie den folgenden Link besuchen.
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Die neueste Version ist JDK 8u 92 und die Datei lautet "jdk-8u92-linux-x64.tar.gz". Bitte laden Sie die Datei auf Ihren Computer herunter.
Extrahieren Sie danach die Dateien und wechseln Sie in das jeweilige Verzeichnis.
Stellen Sie dann Java-Alternativen ein. Schließlich wird Java auf Ihrem Computer installiert.
Apache Presto Installation
Laden Sie die neueste Version von Presto herunter, indem Sie den folgenden Link besuchen:
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.149/
Jetzt wird die neueste Version von "presto-server-0.149.tar.gz" auf Ihren Computer heruntergeladen.
Teerdateien extrahieren
Extrahieren Sie die tar Datei mit dem folgenden Befehl -
$ tar -zxf presto-server-0.149.tar.gz
$ cd presto-server-0.149Konfigurationseinstellungen
Erstellen Sie ein Datenverzeichnis
Erstellen Sie ein Datenverzeichnis außerhalb des Installationsverzeichnisses, das zum Speichern von Protokollen, Metadaten usw. verwendet wird, damit es beim Upgrade von Presto problemlos beibehalten werden kann. Es wird mit dem folgenden Code definiert:
$ cd
$ mkdir dataVerwenden Sie den Befehl „pwd“, um den Pfad anzuzeigen, in dem er sich befindet. Dieser Speicherort wird in der nächsten Datei node.properties zugewiesen.
Erstellen Sie das Verzeichnis "etc"
Erstellen Sie ein etc-Verzeichnis im Presto-Installationsverzeichnis mit dem folgenden Code:
$ cd presto-server-0.149
$ mkdir etcDieses Verzeichnis enthält Konfigurationsdateien. Lassen Sie uns jede Datei einzeln erstellen.
Knoteneigenschaften
Die Eigenschaftendatei des Presto-Knotens enthält eine für jeden Knoten spezifische Umgebungskonfiguration. Es wird im Verzeichnis etc (etc / node.properties) mit dem folgenden Code erstellt:
$ cd etc
$ vi node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/../workspace/PrestoNachdem Sie alle Änderungen vorgenommen haben, speichern Sie die Datei und beenden Sie das Terminal. Hiernode.data ist der Speicherort des oben erstellten Datenverzeichnisses. node.id repräsentiert die eindeutige Kennung für jeden Knoten.
JVM-Konfiguration
Erstellen Sie eine Datei "jvm.config" im Verzeichnis etc (etc / jvm.config). Diese Datei enthält eine Liste der Befehlszeilenoptionen, die zum Starten der Java Virtual Machine verwendet werden.
$ cd etc
$ vi jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize = 32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError = kill -9 %pNachdem Sie alle Änderungen vorgenommen haben, speichern Sie die Datei und beenden Sie das Terminal.
Konfigurationseigenschaften
Erstellen Sie eine Datei "config.properties" im Verzeichnis etc (etc / config.properties). Diese Datei enthält die Konfiguration des Presto-Servers. Wenn Sie eine einzelne Maschine zum Testen einrichten, kann der Presto-Server nur als Koordinierungsprozess fungieren, wie mit dem folgenden Code definiert:
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Hier,
coordinator - Hauptknoten.
node-scheduler.include-coordinator - Ermöglicht Planungsarbeiten am Koordinator.
http-server.http.port - Gibt den Port für den HTTP-Server an.
query.max-memory=5GB - Die maximale Menge an verteiltem Speicher.
query.max-memory-per-node=1GB - Die maximale Speichermenge pro Knoten.
discovery-server.enabled - Presto verwendet den Discovery-Dienst, um alle Knoten im Cluster zu finden.
discovery.uri - Der URI zum Discovery-Server.
Wenn Sie einen Presto-Server mit mehreren Computern einrichten, fungiert Presto sowohl als Koordinierungs- als auch als Arbeitsprozess. Verwenden Sie diese Konfigurationseinstellung, um den Presto-Server auf mehreren Computern zu testen.
Konfiguration für den Koordinator
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Konfiguration für Worker
$ cd etc
$ vi config.properties
coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery.uri = http://localhost:8080Protokolleigenschaften
Erstellen Sie eine Datei "log.properties" im Verzeichnis etc (etc / log.properties). Diese Datei enthält die Mindestprotokollstufe für benannte Loggerhierarchien. Es wird mit dem folgenden Code definiert:
$ cd etc
$ vi log.properties
com.facebook.presto = INFOSpeichern Sie die Datei und beenden Sie das Terminal. Hier werden vier Protokollebenen verwendet, z. B. DEBUG, INFO, WARN und ERROR. Die Standardprotokollstufe ist INFO.
Katalogeigenschaften
Erstellen Sie ein Verzeichnis "Katalog" im Verzeichnis etc (etc / catalog). Dies wird zum Mounten von Daten verwendet. Zum Beispiel erstellenetc/catalog/jmx.properties mit dem folgenden Inhalt, um die zu montieren jmx connector als jmx katalog -
$ cd etc
$ mkdir catalog $ cd catalog
$ vi jmx.properties
connector.name = jmxStarten Sie Presto
Presto kann mit dem folgenden Befehl gestartet werden:
$ bin/launcher startDann sehen Sie eine ähnliche Antwort:
Started as 840Führen Sie Presto aus
Verwenden Sie den folgenden Befehl, um den Presto-Server zu starten:
$ bin/launcher runNach dem erfolgreichen Start des Presto-Servers finden Sie die Protokolldateien im Verzeichnis "var / log".
launcher.log - Dieses Protokoll wird vom Launcher erstellt und ist mit den Streams stdout und stderr des Servers verbunden.
server.log - Dies ist die von Presto verwendete Hauptprotokolldatei.
http-request.log - Vom Server empfangene HTTP-Anfrage.
Ab sofort haben Sie die Presto-Konfigurationseinstellungen erfolgreich auf Ihrem Computer installiert. Fahren wir mit den Schritten zur Installation von Presto CLI fort.
Installieren Sie Presto CLI
Die Presto-CLI bietet eine terminalbasierte interaktive Shell zum Ausführen von Abfragen.
Laden Sie die Presto CLI herunter, indem Sie den folgenden Link besuchen:
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.149/
Jetzt wird "presto-cli-0.149-executeable.jar" auf Ihrem Computer installiert.
Führen Sie die CLI aus
Kopieren Sie das Presto-Cli nach dem Herunterladen an den Speicherort, an dem Sie es ausführen möchten. Dieser Ort kann ein beliebiger Knoten sein, der Netzwerkzugriff auf den Koordinator hat. Ändern Sie zuerst den Namen der Jar-Datei in Presto. Dann machen Sie es ausführbar mitchmod + x Befehl mit folgendem Code -
$ mv presto-cli-0.149-executable.jar presto
$ chmod +x prestoFühren Sie nun die CLI mit dem folgenden Befehl aus:
./presto --server localhost:8080 --catalog jmx --schema default
Here jmx(Java Management Extension) refers to catalog and default referes to schema.Sie sehen die folgende Antwort:
presto:default>Geben Sie nun den Befehl "jps" in Ihr Terminal ein und Sie sehen die laufenden Dämonen.
Stoppen Sie Presto
Nachdem Sie alle Ausführungen durchgeführt haben, können Sie den Presto-Server mit dem folgenden Befehl stoppen:
$ bin/launcher stopIn diesem Kapitel werden die Konfigurationseinstellungen für Presto erläutert.
Presto Verifier
Mit dem Presto Verifier können Sie Presto gegen eine andere Datenbank (z. B. MySQL) oder zwei Presto-Cluster gegeneinander testen.
Datenbank in MySQL erstellen
Öffnen Sie den MySQL-Server und erstellen Sie eine Datenbank mit dem folgenden Befehl.
create database testJetzt haben Sie auf dem Server eine Testdatenbank erstellt. Erstellen Sie die Tabelle und laden Sie sie mit der folgenden Abfrage.
CREATE TABLE verifier_queries(
id INT NOT NULL AUTO_INCREMENT,
suite VARCHAR(256) NOT NULL,
name VARCHAR(256),
test_catalog VARCHAR(256) NOT NULL,
test_schema VARCHAR(256) NOT NULL,
test_prequeries TEXT,
test_query TEXT NOT NULL,
test_postqueries TEXT,
test_username VARCHAR(256) NOT NULL default 'verifier-test',
test_password VARCHAR(256),
control_catalog VARCHAR(256) NOT NULL,
control_schema VARCHAR(256) NOT NULL,
control_prequeries TEXT,
control_query TEXT NOT NULL,
control_postqueries TEXT,
control_username VARCHAR(256) NOT NULL default 'verifier-test',
control_password VARCHAR(256),
session_properties_json TEXT,
PRIMARY KEY (id)
);Konfigurationseinstellungen hinzufügen
Erstellen Sie eine Eigenschaftendatei, um den Verifizierer zu konfigurieren.
$ vi config.properties
suite = mysuite
query-database = jdbc:mysql://localhost:3306/tutorials?user=root&password=pwd
control.gateway = jdbc:presto://localhost:8080
test.gateway = jdbc:presto://localhost:8080
thread-count = 1Hier in der query-database Geben Sie im Feld die folgenden Details ein: Name der MySQL-Datenbank, Benutzername und Kennwort.
Laden Sie die JAR-Datei herunter
Laden Sie die Presto-Verifier-JAR-Datei herunter, indem Sie den folgenden Link besuchen:
https://repo1.maven.org/maven2/com/facebook/presto/presto-verifier/0.149/
Nun die Version “presto-verifier-0.149-executable.jar” wird auf Ihren Computer heruntergeladen.
Führen Sie JAR aus
Führen Sie die JAR-Datei mit dem folgenden Befehl aus:
$ mv presto-verifier-0.149-executable.jar verifier
$ chmod+x verifierFühren Sie Verifier aus
Führen Sie den Verifizierer mit dem folgenden Befehl aus:
$ ./verifier config.propertiesTabelle erstellen
Lassen Sie uns eine einfache Tabelle in erstellen “test” Datenbank mit der folgenden Abfrage.
create table product(id int not null, name varchar(50))Tabelle einfügen
Fügen Sie nach dem Erstellen einer Tabelle zwei Datensätze mit der folgenden Abfrage ein:
insert into product values(1,’Phone')
insert into product values(2,’Television’)Führen Sie die Verifiziererabfrage aus
Führen Sie die folgende Beispielabfrage im Verifizierer-Terminal (./verifier config.propeties) aus, um das Verifizierer-Ergebnis zu überprüfen.
Beispielabfrage
insert into verifier_queries (suite, test_catalog, test_schema, test_query,
control_catalog, control_schema, control_query) values
('mysuite', 'mysql', 'default', 'select * from mysql.test.product',
'mysql', 'default', 'select * from mysql.test.product');Hier, select * from mysql.test.product Abfrage bezieht sich auf MySQL-Katalog, test ist Datenbankname und productist Tabellenname. Auf diese Weise können Sie über den Presto-Server auf den MySQL-Connector zugreifen.
Hier werden zwei gleiche Auswahlabfragen gegeneinander getestet, um die Leistung zu sehen. Ebenso können Sie andere Abfragen ausführen, um die Leistungsergebnisse zu testen. Sie können auch zwei Presto-Cluster verbinden, um die Leistungsergebnisse zu überprüfen.
In diesem Kapitel werden die in Presto verwendeten Verwaltungstools erläutert. Beginnen wir mit dem Webinterface von Presto.
Webinterface
Presto bietet eine Webschnittstelle zum Überwachen und Verwalten von Abfragen. Der Zugriff erfolgt über die in den Eigenschaften der Koordinatorkonfiguration angegebene Portnummer.
Starten Sie den Presto-Server und die Presto-CLI. Dann können Sie über die folgende URL auf die Weboberfläche zugreifen:http://localhost:8080/
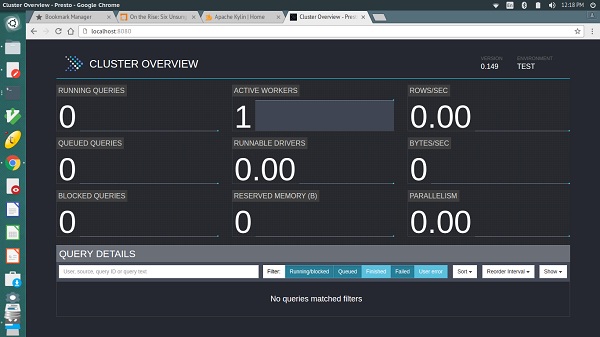
Die Ausgabe ähnelt dem obigen Bildschirm.
Hier enthält die Hauptseite eine Liste von Abfragen sowie Informationen wie eindeutige Abfrage-ID, Abfragetext, Abfragestatus, Prozentsatz der abgeschlossenen Abfragen, Benutzername und Quelle, von der diese Abfrage stammt. Die neuesten Abfragen werden zuerst ausgeführt, dann werden unten abgeschlossene oder nicht abgeschlossene Abfragen unten angezeigt.
Optimieren der Leistung auf Presto
Wenn bei Presto-Clustern Leistungsprobleme auftreten, ändern Sie Ihre Standardkonfigurationseinstellungen in die folgenden Einstellungen.
Konfigurationseigenschaften
task. info -refresh-max-wait - Reduziert die Arbeitsbelastung des Koordinators.
task.max-worker-threads - Teilt den Prozess auf und weist ihn jedem Arbeitsknoten zu.
distributed-joins-enabled - Hash-basierte verteilte Joins.
node-scheduler.network-topology - Setzt die Netzwerktopologie auf Scheduler.
JVM-Einstellungen
Ändern Sie Ihre Standard-JVM-Einstellungen in die folgenden Einstellungen. Dies ist hilfreich für die Diagnose von Speicherbereinigungsproblemen.
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCCause
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
-XX:PrintFLSStatistics = 2
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount = 1In diesem Kapitel wird erläutert, wie Sie Abfragen in Presto erstellen und ausführen. Lassen Sie uns die von Presto unterstützten Basisdatentypen durchgehen.
Grundlegende Datentypen
In der folgenden Tabelle werden die grundlegenden Datentypen von Presto beschrieben.
| S.No. | Datentyp & Beschreibung |
|---|---|
| 1. | VARCHAR Zeichendaten variabler Länge |
| 2. | BIGINT Eine 64-Bit-Ganzzahl mit Vorzeichen |
| 3. | DOUBLE Ein 64-Bit-Gleitkommawert mit doppelter Genauigkeit |
| 4. | DECIMAL Eine Dezimalzahl mit fester Genauigkeit. Zum Beispiel ist DECIMAL (10,3) - 10 die Genauigkeit, dh die Gesamtzahl der Ziffern und 3 ist der als Bruchpunkt dargestellte Skalenwert. Die Skalierung ist optional und der Standardwert ist 0 |
| 5. | BOOLEAN Boolesche Werte true und false |
| 6. | VARBINARY Binärdaten variabler Länge |
| 7. | JSON JSON-Daten |
| 8. | DATE Datumsdatentyp dargestellt als Jahr-Monat-Tag |
| 9. | TIME, TIMESTAMP, TIMESTAMP with TIME ZONE ZEIT - Uhrzeit (Stunde-Min-Sek-Millisekunde) TIMESTAMP - Datum und Uhrzeit des Tages TIMESTAMP mit ZEITZONE - Datum und Uhrzeit des Tages mit Zeitzone vom Wert |
| 10. | INTERVAL Datentypen für Datum und Uhrzeit strecken oder erweitern |
| 11. | ARRAY Array des angegebenen Komponententyps. Zum Beispiel ARRAY [5,7] |
| 12. | MAP Zuordnung zwischen den angegebenen Komponententypen. Zum Beispiel MAP (ARRAY ['eins', 'zwei'], ARRAY [5,7]) |
| 13. | ROW Zeilenstruktur aus benannten Feldern |
Presto - Betreiber
Presto-Operatoren sind in der folgenden Tabelle aufgeführt.
| S.No. | Betreiber & Beschreibung |
|---|---|
| 1. | Arithmetischer Operator Presto unterstützt arithmetische Operatoren wie +, -, *, /,% |
| 2. | Vergleichsoperator <,>, <=,> =, =, <> |
| 3. | Logischer Operator UND ODER NICHT |
| 4. | Bereichsoperator Der Bereichsoperator wird verwendet, um den Wert in einem bestimmten Bereich zu testen. Presto unterstützt ZWISCHEN, IST NULL, IST NICHT NULL, GRÖSST und MINDESTENS |
| 5. | Dezimaloperator Der binäre arithmetische Dezimaloperator führt eine binäre arithmetische Operation für den Dezimaltyp aus. Unärer Dezimaloperator - Der - operator führt Negation durch |
| 6. | String-Operator Das ‘||’ operator führt eine Zeichenfolgenverkettung durch |
| 7. | Datums- und Uhrzeitoperator Führt arithmetische Additions- und Subtraktionsoperationen für Datums- und Zeitdatentypen aus |
| 8. | Array-Operator Indexoperator [] - Zugriff auf ein Element eines Arrays Verkettungsoperator || - ein Array mit einem Array oder einem Element des gleichen Typs verketten |
| 9. | Kartenoperator Karten-Indexoperator [] - Ruft den Wert, der einem bestimmten Schlüssel entspricht, von einer Karte ab |
Ab sofort haben wir einige einfache grundlegende Abfragen für Presto besprochen. In diesem Kapitel werden die wichtigen SQL-Funktionen erläutert.
Mathematische Funktionen
Mathematische Funktionen arbeiten mit mathematischen Formeln. Die folgende Tabelle beschreibt die Liste der Funktionen im Detail.
| S.No. | Bedienungsanleitung |
|---|---|
| 1. | abs (x) Gibt den absoluten Wert von zurück x |
| 2. | cbrt (x) Gibt die Kubikwurzel von zurück x |
| 3. | Decke (x) Gibt die zurück x Wert auf die nächste ganze Zahl aufgerundet |
| 4. | ceil(x) Alias für Decke (x) |
| 5. | Grad (x) Gibt den Gradwert für zurück x |
| 6. | Ex) Gibt den doppelten Wert für Eulers Nummer zurück |
| 7. | exp(x) Gibt den Exponentenwert für die Euler-Zahl zurück |
| 8. | Boden (x) Kehrt zurück x auf die nächste ganze Zahl abgerundet |
| 9. | from_base(string,radix) Gibt den Wert der Zeichenfolge zurück, die als Basis-Radix-Zahl interpretiert wird |
| 10. | ln(x) Gibt den natürlichen Logarithmus von zurück x |
| 11. | log2 (x) Gibt den Logarithmus zur Basis 2 von zurück x |
| 12. | log10(x) Gibt den Logarithmus zur Basis 10 von zurück x |
| 13. | log(x,y) Gibt die Basis zurück y Logarithmus von x |
| 14. | mod (n, m) Gibt den Modul (Rest) von zurück n geteilt durch m |
| 15. | pi() Gibt den pi-Wert zurück. Das Ergebnis wird als doppelter Wert zurückgegeben |
| 16. | Potenz (x, p) Gibt die Wertkraft zurück ‘p’ zum x Wert |
| 17. | pow(x,p) Alias für Macht (x, p) |
| 18. | Bogenmaß (x) wandelt den Winkel um x in Grad Bogenmaß |
| 19. | rand() Alias für Bogenmaß () |
| 20. | zufällig() Gibt den Pseudozufallswert zurück |
| 21. | rand(n) Alias für random () |
| 22. | rund (x) Gibt den gerundeten Wert für x zurück |
| 23. | round(x,d) x Wert gerundet für die ‘d’ Nachkommastellen |
| 24. | sign(x) Gibt die Signumfunktion von x zurück, dh 0, wenn das Argument 0 ist 1, wenn das Argument größer als 0 ist -1, wenn das Argument kleiner als 0 ist Bei doppelten Argumenten gibt die Funktion zusätzlich - zurück NaN, wenn das Argument NaN ist 1, wenn das Argument + Unendlichkeit ist -1, wenn das Argument -Infinity ist |
| 25. | sqrt (x) Gibt die Quadratwurzel von zurück x |
| 26. | to_base (x, radix) Rückgabetyp ist Bogenschütze. Das Ergebnis wird als Basisradix für zurückgegebenx |
| 27. | abschneiden (x) Schneidet den Wert für ab x |
| 28. | width_bucket (x, bound1, bound2, n) Gibt die Bin-Nummer von zurück x angegebene Grenzen für bound1 und bound2 und n Anzahl von Buckets |
| 29. | width_bucket (x, Bins) Gibt die Bin-Nummer von zurück x gemäß den durch die Array-Bins angegebenen Bins |
Trigonometrische Funktionen
Trigonometrische Funktionsargumente werden als Bogenmaß () dargestellt. In der folgenden Tabelle sind die Funktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | acos (x) Gibt den inversen Kosinuswert (x) zurück. |
| 2. | asin(x) Gibt den inversen Sinuswert (x) zurück. |
| 3. | atan(x) Gibt den inversen Tangentenwert (x) zurück. |
| 4. | atan2 (y, x) Gibt den inversen Tangentenwert (y / x) zurück. |
| 5. | cos(x) Gibt den Kosinuswert (x) zurück. |
| 6. | cosh (x) Gibt den hyperbolischen Kosinuswert (x) zurück. |
| 7. | Sünde (x) Gibt den Sinuswert (x) zurück. |
| 8. | tan(x) Gibt den Tangentenwert (x) zurück. |
| 9. | tanh(x) Gibt den hyperbolischen Tangenswert (x) zurück. |
Bitweise Funktionen
In der folgenden Tabelle sind die bitweisen Funktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | bit_count (x, bits) Zählen Sie die Anzahl der Bits |
| 2. | bitweise_und (x, y) Führen Sie eine bitweise UND-Verknüpfung für zwei Bits durch. x und y |
| 3. | bitweise_oder (x, y) Bitweise ODER-Verknüpfung zwischen zwei Bits x, y |
| 4. | bitweise_not (x) Bitweise Nichtoperation für Bit x |
| 5. | bitweise_xor (x, y) XOR-Operation für Bits x, y |
String-Funktionen
In der folgenden Tabelle sind die String-Funktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | concat (string1, ..., stringN) Verketten Sie die angegebenen Zeichenfolgen |
| 2. | Länge (Zeichenfolge) Gibt die Länge der angegebenen Zeichenfolge zurück |
| 3. | niedriger (String) Gibt das Kleinbuchstabenformat für die Zeichenfolge zurück |
| 4. | obere (Zeichenfolge) Gibt das Großbuchstabenformat für die angegebene Zeichenfolge zurück |
| 5. | lpad (String, Größe, Padstring) Linke Polsterung für die angegebene Zeichenfolge |
| 6. | ltrim (string) Entfernt das führende Leerzeichen aus der Zeichenfolge |
| 7. | ersetzen (Zeichenfolge, suchen, ersetzen) Ersetzt den Zeichenfolgenwert |
| 8. | umgekehrt (Zeichenfolge) Kehrt die für die Zeichenfolge ausgeführte Operation um |
| 9. | rpad (String, Größe, Padstring) Richtige Auffüllung für die angegebene Zeichenfolge |
| 10. | rtrim (string) Entfernt das nachgestellte Leerzeichen aus der Zeichenfolge |
| 11. | split (Zeichenfolge, Trennzeichen) Teilt die Zeichenfolge nach dem Trennzeichen und gibt höchstens ein Array mit der Größe zurück |
| 12. | split_part (Zeichenfolge, Trennzeichen, Index) Teilt die Zeichenfolge am Trennzeichen und gibt den Feldindex zurück |
| 13. | strpos (Zeichenfolge, Teilzeichenfolge) Gibt die Startposition des Teilstrings in der Zeichenfolge zurück |
| 14. | substr (string, start) Gibt den Teilstring für die angegebene Zeichenfolge zurück |
| 15. | substr (String, Start, Länge) Gibt den Teilstring für den angegebenen String mit der spezifischen Länge zurück |
| 16. | trim (string) Entfernt das führende und das nachfolgende Leerzeichen aus der Zeichenfolge |
Datums- und Uhrzeitfunktionen
In der folgenden Tabelle sind die Funktionen Datum und Uhrzeit aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | aktuelles Datum Gibt das aktuelle Datum zurück |
| 2. | aktuelle Uhrzeit Gibt die aktuelle Zeit zurück |
| 3. | Aktueller Zeitstempel Gibt den aktuellen Zeitstempel zurück |
| 4. | current_timezone () Gibt die aktuelle Zeitzone zurück |
| 5. | jetzt() Gibt das aktuelle Datum und den Zeitstempel mit der Zeitzone zurück |
| 6. | Ortszeit Gibt die Ortszeit zurück |
| 7. | localtimestamp Gibt den lokalen Zeitstempel zurück |
Funktionen für reguläre Ausdrücke
In der folgenden Tabelle sind die Funktionen für reguläre Ausdrücke aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | regexp_extract_all (Zeichenfolge, Muster) Gibt die Zeichenfolge zurück, die mit dem regulären Ausdruck für das Muster übereinstimmt |
| 2. | regexp_extract_all (Zeichenfolge, Muster, Gruppe) Gibt die Zeichenfolge zurück, die mit dem regulären Ausdruck für das Muster und die Gruppe übereinstimmt |
| 3. | regexp_extract (Zeichenfolge, Muster) Gibt den ersten Teilstring zurück, der mit dem regulären Ausdruck für das Muster übereinstimmt |
| 4. | regexp_extract (Zeichenfolge, Muster, Gruppe) Gibt den ersten Teilstring zurück, der mit dem regulären Ausdruck für das Muster und die Gruppe übereinstimmt |
| 5. | regexp_like (Zeichenfolge, Muster) Gibt die Zeichenfolgenübereinstimmungen für das Muster zurück. Wenn die Zeichenfolge zurückgegeben wird, ist der Wert true, andernfalls false |
| 6. | regexp_replace (Zeichenfolge, Muster) Ersetzt die Instanz der Zeichenfolge, die für den Ausdruck übereinstimmt, durch das Muster |
| 7. | regexp_replace (Zeichenfolge, Muster, Ersetzung) Ersetzen Sie die Instanz der Zeichenfolge, die für den Ausdruck übereinstimmt, durch das Muster und die Ersetzung |
| 8. | regexp_split (Zeichenfolge, Muster) Teilt den regulären Ausdruck für das angegebene Muster |
JSON-Funktionen
In der folgenden Tabelle sind die JSON-Funktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | json_array_contains (json, Wert) Überprüfen Sie, ob der Wert in einem JSON-Array vorhanden ist. Wenn der Wert vorhanden ist, wird true zurückgegeben, andernfalls false |
| 2. | json_array_get (json_array, index) Holen Sie sich das Element für den Index im JSON-Array |
| 3. | json_array_length (json) Gibt die Länge im JSON-Array zurück |
| 4. | json_format (json) Gibt das JSON-Strukturformat zurück |
| 5. | json_parse (Zeichenfolge) Analysiert den String als JSON |
| 6. | json_size (json, json_path) Gibt die Größe des Werts zurück |
URL-Funktionen
In der folgenden Tabelle sind die URL-Funktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | url_extract_host (url) Gibt den Host der URL zurück |
| 2. | url_extract_path (url) Gibt den Pfad der URL zurück |
| 3. | url_extract_port (url) Gibt den Port der URL zurück |
| 4. | url_extract_protocol (url) Gibt das Protokoll der URL zurück |
| 5. | url_extract_query (url) Gibt die Abfragezeichenfolge der URL zurück |
Aggregierte Funktionen
In der folgenden Tabelle sind die Aggregatfunktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | avg(x) Gibt den Durchschnitt für den angegebenen Wert zurück |
| 2. | min (x, n) Gibt den Mindestwert aus zwei Werten zurück |
| 3. | max (x, n) Gibt den Maximalwert aus zwei Werten zurück |
| 4. | Summe (x) Gibt die Wertesumme zurück |
| 5. | Anzahl(*) Gibt die Anzahl der Eingabezeilen zurück |
| 6. | count (x) Gibt die Anzahl der Eingabewerte zurück |
| 7. | Prüfsumme (x) Gibt die Prüfsumme für zurück x |
| 8. | beliebig (x) Gibt den beliebigen Wert für zurück x |
Farbfunktionen
In der folgenden Tabelle sind die Farbfunktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | Balken (x, Breite) Rendert einen einzelnen Balken mit rgb low_color und high_color |
| 2. | Balken (x, Breite, niedrige Farbe, hohe Farbe) Rendert einen einzelnen Balken für die angegebene Breite |
| 3. | Farbe (String) Gibt den Farbwert für die eingegebene Zeichenfolge zurück |
| 4. | rendern (x, Farbe) Rendert den Wert x unter Verwendung der spezifischen Farbe unter Verwendung von ANSI-Farbcodes |
| 5. | rendern (b) Akzeptiert den Booleschen Wert b und gibt mithilfe von ANSI-Farbcodes ein Grün als wahr oder ein Rot als falsch wieder |
| 6. | rgb(red, green, blue) Gibt einen Farbwert zurück, der den RGB-Wert von drei Komponentenfarbwerten erfasst, die als int-Parameter im Bereich von 0 bis 255 angegeben werden |
Array-Funktionen
In der folgenden Tabelle sind die Array-Funktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | array_max (x) Findet das max-Element in einem Array |
| 2. | array_min (x) Findet das min-Element in einem Array |
| 3. | array_sort (x) Sortiert die Elemente in einem Array |
| 4. | array_remove (x, Element) Entfernt das bestimmte Element aus einem Array |
| 5. | concat (x, y) Verkettet zwei Arrays |
| 6. | enthält (x, Element) Findet die angegebenen Elemente in einem Array. True wird zurückgegeben, wenn es vorhanden ist, andernfalls false |
| 7. | array_position (x, element) Suchen Sie die Position des angegebenen Elements in einem Array |
| 8. | array_intersect (x, y) Führt einen Schnittpunkt zwischen zwei Arrays aus |
| 9. | element_at (Array, Index) Gibt die Position des Array-Elements zurück |
| 10. | Scheibe (x, Start, Länge) Schneidet die Array-Elemente mit der spezifischen Länge |
Teradata-Funktionen
In der folgenden Tabelle sind die Teradata-Funktionen aufgeführt.
| S.No. | Funktionen & Beschreibung |
|---|---|
| 1. | Index (Zeichenfolge, Teilzeichenfolge) Gibt den Index der Zeichenfolge mit der angegebenen Teilzeichenfolge zurück |
| 2. | Teilzeichenfolge (Zeichenfolge, Start) Gibt den Teilstring der angegebenen Zeichenfolge zurück. Hier können Sie den Startindex angeben |
| 3. | Teilzeichenfolge (Zeichenfolge, Start, Länge) Gibt den Teilstring der angegebenen Zeichenfolge für den spezifischen Startindex und die Länge der Zeichenfolge zurück |
Der MySQL-Connector wird zum Abfragen einer externen MySQL-Datenbank verwendet.
Voraussetzungen
Installation des MySQL-Servers.
Konfigurationseinstellungen
Hoffentlich haben Sie den MySQL-Server auf Ihrem Computer installiert. Um die MySQL-Eigenschaften auf dem Presto-Server zu aktivieren, müssen Sie eine Datei erstellen“mysql.properties” im “etc/catalog”Verzeichnis. Setzen Sie den folgenden Befehl ab, um eine mysql.properties-Datei zu erstellen.
$ cd etc $ cd catalog
$ vi mysql.properties
connector.name = mysql
connection-url = jdbc:mysql://localhost:3306
connection-user = root
connection-password = pwdSpeichern Sie die Datei und beenden Sie das Terminal. In der obigen Datei müssen Sie Ihr MySQL-Passwort in das Feld Verbindungskennwort eingeben.
Datenbank in MySQL Server erstellen
Öffnen Sie den MySQL-Server und erstellen Sie eine Datenbank mit dem folgenden Befehl.
create database tutorialsJetzt haben Sie auf dem Server eine Datenbank mit Tutorials erstellt. Verwenden Sie zum Aktivieren des Datenbanktyps den Befehl "Tutorials verwenden" im Abfragefenster.
Tabelle erstellen
Lassen Sie uns eine einfache Tabelle in der Datenbank "Tutorials" erstellen.
create table author(auth_id int not null, auth_name varchar(50),topic varchar(100))Tabelle einfügen
Fügen Sie nach dem Erstellen einer Tabelle drei Datensätze mit der folgenden Abfrage ein.
insert into author values(1,'Doug Cutting','Hadoop')
insert into author values(2,’James Gosling','java')
insert into author values(3,'Dennis Ritchie’,'C')Wählen Sie Datensätze
Geben Sie die folgende Abfrage ein, um alle Datensätze abzurufen.
Abfrage
select * from authorErgebnis
auth_id auth_name topic
1 Doug Cutting Hadoop
2 James Gosling java
3 Dennis Ritchie CAb sofort haben Sie Daten mit dem MySQL-Server abgefragt. Verbinden wir das MySQL-Speicher-Plugin mit dem Presto-Server.
Verbinden Sie Presto CLI
Geben Sie den folgenden Befehl ein, um das MySQL-Plugin über Presto CLI zu verbinden.
./presto --server localhost:8080 --catalog mysql --schema tutorialsSie erhalten folgende Antwort.
presto:tutorials>Hier “tutorials” verweist auf das Schema im MySQL-Server.
Listenschemata
Geben Sie die folgende Abfrage in Presto Server ein, um alle Schemas in MySQL aufzulisten.
Abfrage
presto:tutorials> show schemas from mysql;Ergebnis
Schema
--------------------
information_schema
performance_schema
sys
tutorialsAus diesem Ergebnis können wir die ersten drei Schemata als vordefiniert und das letzte als von Ihnen selbst erstellt schließen.
Listen aus dem Schema auflisten
Die folgende Abfrage listet alle Tabellen im Tutorial-Schema auf.
Abfrage
presto:tutorials> show tables from mysql.tutorials;Ergebnis
Table
--------
authorWir haben nur eine Tabelle in diesem Schema erstellt. Wenn Sie mehrere Tabellen erstellt haben, werden alle Tabellen aufgelistet.
Tabelle beschreiben
Geben Sie die folgende Abfrage ein, um die Tabellenfelder zu beschreiben.
Abfrage
presto:tutorials> describe mysql.tutorials.author;Ergebnis
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Spalten aus Tabelle anzeigen
Abfrage
presto:tutorials> show columns from mysql.tutorials.author;Ergebnis
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Zugriff auf Tabellendatensätze
Führen Sie die folgende Abfrage aus, um alle Datensätze aus der MySQL-Tabelle abzurufen.
Abfrage
presto:tutorials> select * from mysql.tutorials.author;Ergebnis
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CAus diesem Ergebnis können Sie MySQL-Serverdatensätze in Presto abrufen.
Tabelle mit Befehl erstellen
Der MySQL-Connector unterstützt keine Abfrage zum Erstellen von Tabellen, Sie können jedoch eine Tabelle mit dem Befehl as erstellen.
Abfrage
presto:tutorials> create table mysql.tutorials.sample as
select * from mysql.tutorials.author;Ergebnis
CREATE TABLE: 3 rowsSie können keine Zeilen direkt einfügen, da dieser Connector einige Einschränkungen aufweist. Die folgenden Abfragen können nicht unterstützt werden:
- create
- insert
- update
- delete
- drop
Geben Sie die folgende Abfrage ein, um die Datensätze in der neu erstellten Tabelle anzuzeigen.
Abfrage
presto:tutorials> select * from mysql.tutorials.sample;Ergebnis
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CJava Management Extensions (JMX) enthält Informationen zur Java Virtual Machine und zur Software, die in JVM ausgeführt werden. Der JMX-Connector wird zum Abfragen von JMX-Informationen auf dem Presto-Server verwendet.
Da haben wir schon aktiviert “jmx.properties” Datei unter “etc/catalog”Verzeichnis. Verbinden Sie nun die Prest-CLI, um das JMX-Plugin zu aktivieren.
Presto CLI
Abfrage
$ ./presto --server localhost:8080 --catalog jmx --schema jmxErgebnis
Sie erhalten folgende Antwort.
presto:jmx>JMX-Schema
Geben Sie die folgende Abfrage ein, um alle Schemas in "jmx" aufzulisten.
Abfrage
presto:jmx> show schemas from jmx;Ergebnis
Schema
--------------------
information_schema
currentTabellen anzeigen
Verwenden Sie den folgenden Befehl, um die Tabellen im „aktuellen“ Schema anzuzeigen.
Abfrage 1
presto:jmx> show tables from jmx.current;Ergebnis
Table
------------------------------------------------------------------------------
com.facebook.presto.execution.scheduler:name = nodescheduler
com.facebook.presto.execution:name = queryexecution
com.facebook.presto.execution:name = querymanager
com.facebook.presto.execution:name = remotetaskfactory
com.facebook.presto.execution:name = taskexecutor
com.facebook.presto.execution:name = taskmanager
com.facebook.presto.execution:type = queryqueue,name = global,expansion = global
………………
……………….Abfrage 2
presto:jmx> select * from jmx.current.”java.lang:type = compilation";Ergebnis
node | compilationtimemonitoringsupported | name | objectname | totalcompilationti
--------------------------------------+------------------------------------+--------------------------------+----------------------------+-------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | true | HotSpot 64-Bit Tiered Compilers | java.lang:type=Compilation | 1276Abfrage 3
presto:jmx> select * from jmx.current."com.facebook.presto.server:name = taskresource";Ergebnis
node | readfromoutputbuffertime.alltime.count
| readfromoutputbuffertime.alltime.max | readfromoutputbuffertime.alltime.maxer
--------------------------------------+---------------------------------------+--------------------------------------+---------------------------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | 92.0 | 1.009106149 |Der Hive-Connector ermöglicht das Abfragen von Daten, die in einem Hive-Data-Warehouse gespeichert sind.
Voraussetzungen
- Hadoop
- Hive
Hoffentlich haben Sie Hadoop und Hive auf Ihrem Computer installiert. Starten Sie alle Dienste einzeln im neuen Terminal. Starten Sie dann den Hive-Metastore mit dem folgenden Befehl:
hive --service metastorePresto verwendet den Hive-Metastore-Service, um die Details der Hive-Tabelle abzurufen.
Konfigurationseinstellungen
Erstellen Sie eine Datei “hive.properties” unter “etc/catalog”Verzeichnis. Verwenden Sie den folgenden Befehl.
$ cd etc $ cd catalog
$ vi hive.properties
connector.name = hive-cdh4
hive.metastore.uri = thrift://localhost:9083Nachdem Sie alle Änderungen vorgenommen haben, speichern Sie die Datei und beenden Sie das Terminal.
Datenbank erstellen
Erstellen Sie eine Datenbank in Hive mit der folgenden Abfrage:
Abfrage
hive> CREATE SCHEMA tutorials;Nachdem die Datenbank erstellt wurde, können Sie sie mit der überprüfen “show databases” Befehl.
Tabelle erstellen
Tabelle erstellen ist eine Anweisung zum Erstellen einer Tabelle in Hive. Verwenden Sie beispielsweise die folgende Abfrage.
hive> create table author(auth_id int, auth_name varchar(50),
topic varchar(100) STORED AS SEQUENCEFILE;Tabelle einfügen
Die folgende Abfrage wird verwendet, um Datensätze in die Tabelle des Bienenstocks einzufügen.
hive> insert into table author values (1,’ Doug Cutting’,Hadoop),
(2,’ James Gosling’,java),(3,’ Dennis Ritchie’,C);Starten Sie Presto CLI
Sie können Presto CLI starten, um das Hive-Speicher-Plugin mit dem folgenden Befehl zu verbinden.
$ ./presto --server localhost:8080 --catalog hive —schema tutorials;Sie erhalten folgende Antwort.
presto:tutorials >Listenschemata
Geben Sie den folgenden Befehl ein, um alle Schemas im Hive-Connector aufzulisten.
Abfrage
presto:tutorials > show schemas from hive;Ergebnis
default
tutorialsListet Tabellen auf
Verwenden Sie die folgende Abfrage, um alle Tabellen im Schema "Tutorials" aufzulisten.
Abfrage
presto:tutorials > show tables from hive.tutorials;Ergebnis
authorTabelle abrufen
Die folgende Abfrage wird verwendet, um alle Datensätze aus der Tabelle des Bienenstocks abzurufen.
Abfrage
presto:tutorials > select * from hive.tutorials.author;Ergebnis
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CDer Kafka Connector für Presto ermöglicht den Zugriff auf Daten von Apache Kafka mit Presto.
Voraussetzungen
Laden Sie die neueste Version der folgenden Apache-Projekte herunter und installieren Sie sie.
- Apache ZooKeeper
- Apache Kafka
Starten Sie ZooKeeper
Starten Sie den ZooKeeper-Server mit dem folgenden Befehl.
$ bin/zookeeper-server-start.sh config/zookeeper.propertiesJetzt startet ZooKeeper den Port auf 2181.
Starten Sie Kafka
Starten Sie Kafka in einem anderen Terminal mit dem folgenden Befehl.
$ bin/kafka-server-start.sh config/server.propertiesNach dem Start von kafka wird die Portnummer 9092 verwendet.
TPCH-Daten
Laden Sie tpch-kafka herunter
$ curl -o kafka-tpch
https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_
0811-1.0.shJetzt haben Sie den Loader mit dem obigen Befehl von Maven Central heruntergeladen. Sie erhalten eine ähnliche Antwort wie die folgende.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0
5 21.6M 5 1279k 0 0 83898 0 0:04:30 0:00:15 0:04:15 129k
6 21.6M 6 1407k 0 0 86656 0 0:04:21 0:00:16 0:04:05 131k
24 21.6M 24 5439k 0 0 124k 0 0:02:57 0:00:43 0:02:14 175k
24 21.6M 24 5439k 0 0 124k 0 0:02:58 0:00:43 0:02:15 160k
25 21.6M 25 5736k 0 0 128k 0 0:02:52 0:00:44 0:02:08 181k
………………………..Machen Sie es dann mit dem folgenden Befehl ausführbar:
$ chmod 755 kafka-tpchFühren Sie tpch-kafka aus
Führen Sie das Programm kafka-tpch aus, um eine Reihe von Themen mit tpch-Daten mit dem folgenden Befehl vorzuladen.
Abfrage
$ ./kafka-tpch load --brokers localhost:9092 --prefix tpch. --tpch-type tinyErgebnis
2016-07-13T16:15:52.083+0530 INFO main io.airlift.log.Logging Logging
to stderr
2016-07-13T16:15:52.124+0530 INFO main de.softwareforge.kafka.LoadCommand
Processing tables: [customer, orders, lineitem, part, partsupp, supplier,
nation, region]
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-1
de.softwareforge.kafka.LoadCommand Loading table 'customer' into topic 'tpch.customer'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-2
de.softwareforge.kafka.LoadCommand Loading table 'orders' into topic 'tpch.orders'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-3
de.softwareforge.kafka.LoadCommand Loading table 'lineitem' into topic 'tpch.lineitem'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-4
de.softwareforge.kafka.LoadCommand Loading table 'part' into topic 'tpch.part'...
………………………
……………………….Jetzt werden Kafka-Tabellen Kunden, Bestellungen, Lieferanten usw. mit tpch geladen.
Konfigurationseinstellungen hinzufügen
Fügen Sie die folgenden Konfigurationseinstellungen für den Kafka-Connector auf dem Presto-Server hinzu.
connector.name = kafka
kafka.nodes = localhost:9092
kafka.table-names = tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,
tpch.supplier,tpch.nation,tpch.region
kafka.hide-internal-columns = falseIn der obigen Konfiguration werden Kafka-Tabellen mit dem Programm Kafka-tpch geladen.
Starten Sie Presto CLI
Starten Sie Presto CLI mit dem folgenden Befehl:
$ ./presto --server localhost:8080 --catalog kafka —schema tpch;Hier “tpch" ist ein Schema für den Kafka-Connector und Sie erhalten die folgende Antwort.
presto:tpch>Listet Tabellen auf
Die folgende Abfrage listet alle Tabellen in auf “tpch” Schema.
Abfrage
presto:tpch> show tables;Ergebnis
Table
----------
customer
lineitem
nation
orders
part
partsupp
region
supplierBeschreiben Sie die Kundentabelle
Die folgende Abfrage beschreibt “customer” Tabelle.
Abfrage
presto:tpch> describe customer;Ergebnis
Column | Type | Comment
-------------------+---------+---------------------------------------------
_partition_id | bigint | Partition Id
_partition_offset | bigint | Offset for the message within the partition
_segment_start | bigint | Segment start offset
_segment_end | bigint | Segment end offset
_segment_count | bigint | Running message count per segment
_key | varchar | Key text
_key_corrupt | boolean | Key data is corrupt
_key_length | bigint | Total number of key bytes
_message | varchar | Message text
_message_corrupt | boolean | Message data is corrupt
_message_length | bigint | Total number of message bytesDie JDBC-Schnittstelle von Presto wird für den Zugriff auf Java-Anwendungen verwendet.
Voraussetzungen
Installieren Sie presto-jdbc-0.150.jar
Sie können die JDBC-JAR-Datei unter folgendem Link herunterladen:
https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.150/
Fügen Sie die JAR-Datei nach dem Herunterladen dem Klassenpfad Ihrer Java-Anwendung hinzu.
Erstellen Sie eine einfache Anwendung
Erstellen wir eine einfache Java-Anwendung mithilfe der JDBC-Schnittstelle.
Codierung - PrestoJdbcSample.java
import java.sql.*;
import com.facebook.presto.jdbc.PrestoDriver;
//import presto jdbc driver packages here.
public class PrestoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
connection = DriverManager.getConnection(
"jdbc:presto://localhost:8080/mysql/tutorials", "tutorials", “");
//connect mysql server tutorials database here
statement = connection.createStatement();
String sql;
sql = "select auth_id, auth_name from mysql.tutorials.author”;
//select mysql table author table two columns
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("auth_id");
String name = resultSet.getString(“auth_name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Speichern Sie die Datei und beenden Sie die Anwendung. Starten Sie nun den Presto-Server in einem Terminal und öffnen Sie ein neues Terminal, um das Ergebnis zu kompilieren und auszuführen. Es folgen die Schritte -
Zusammenstellung
~/Workspace/presto/presto-jdbc $ javac -cp presto-jdbc-0.149.jar PrestoJdbcSample.javaAusführung
~/Workspace/presto/presto-jdbc $ java -cp .:presto-jdbc-0.149.jar PrestoJdbcSampleAusgabe
INFO: Logging initialized @146ms
ID: 1;
Name: Doug Cutting
ID: 2;
Name: James Gosling
ID: 3;
Name: Dennis RitchieErstellen Sie ein Maven-Projekt, um die benutzerdefinierte Funktion von Presto zu entwickeln.
SimpleFunctionsFactory.java
Erstellen Sie die SimpleFunctionsFactory-Klasse, um die FunctionFactory-Schnittstelle zu implementieren.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.metadata.FunctionListBuilder;
import com.facebook.presto.metadata.SqlFunction;
import com.facebook.presto.spi.type.TypeManager;
import java.util.List;
public class SimpleFunctionFactory implements FunctionFactory {
private final TypeManager typeManager;
public SimpleFunctionFactory(TypeManager typeManager) {
this.typeManager = typeManager;
}
@Override
public List<SqlFunction> listFunctions() {
return new FunctionListBuilder(typeManager)
.scalar(SimpleFunctions.class)
.getFunctions();
}
}SimpleFunctionsPlugin.java
Erstellen Sie eine SimpleFunctionsPlugin-Klasse, um die Plugin-Schnittstelle zu implementieren.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.spi.Plugin;
import com.facebook.presto.spi.type.TypeManager;
import com.google.common.collect.ImmutableList;
import javax.inject.Inject;
import java.util.List;
import static java.util.Objects.requireNonNull;
public class SimpleFunctionsPlugin implements Plugin {
private TypeManager typeManager;
@Inject
public void setTypeManager(TypeManager typeManager) {
this.typeManager = requireNonNull(typeManager, "typeManager is null”);
//Inject TypeManager class here
}
@Override
public <T> List<T> getServices(Class<T> type){
if (type == FunctionFactory.class) {
return ImmutableList.of(type.cast(new SimpleFunctionFactory(typeManager)));
}
return ImmutableList.of();
}
}Ressourcendatei hinzufügen
Erstellen Sie eine Ressourcendatei, die im Implementierungspaket angegeben ist.
(com.tutorialspoint.simple.functions.SimpleFunctionsPlugin)Wechseln Sie nun zum Speicherort der Ressourcendatei @ / path / to / resource /
Dann fügen Sie die Änderungen hinzu,
com.facebook.presto.spi.Pluginpom.xml
Fügen Sie der Datei pom.xml die folgenden Abhängigkeiten hinzu.
<?xml version = "1.0"?>
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorialspoint.simple.functions</groupId>
<artifactId>presto-simple-functions</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>presto-simple-functions</name>
<description>Simple test functions for Presto</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-spi</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-main</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>
<build>
<finalName>presto-simple-functions</finalName>
<plugins>
<!-- Make this jar executable -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.3.2</version>
</plugin>
</plugins>
</build>
</project>SimpleFunctions.java
Erstellen Sie die SimpleFunctions-Klasse mit Presto-Attributen.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.operator.Description;
import com.facebook.presto.operator.scalar.ScalarFunction;
import com.facebook.presto.operator.scalar.StringFunctions;
import com.facebook.presto.spi.type.StandardTypes;
import com.facebook.presto.type.LiteralParameters;
import com.facebook.presto.type.SqlType;
public final class SimpleFunctions {
private SimpleFunctions() {
}
@Description("Returns summation of two numbers")
@ScalarFunction(“mysum")
//function name
@SqlType(StandardTypes.BIGINT)
public static long sum(@SqlType(StandardTypes.BIGINT) long num1,
@SqlType(StandardTypes.BIGINT) long num2) {
return num1 + num2;
}
}Nachdem die Anwendung erstellt wurde, kompilieren Sie die Anwendung und führen Sie sie aus. Es wird die JAR-Datei erstellt. Kopieren Sie die Datei und verschieben Sie die JAR-Datei in das Zielverzeichnis des Presto-Server-Plugins.
Zusammenstellung
mvn compileAusführung
mvn packageStarten Sie nun den Presto-Server neu und verbinden Sie den Presto-Client. Führen Sie dann die benutzerdefinierte Funktionsanwendung wie unten erläutert aus.
$ ./presto --catalog mysql --schema defaultAbfrage
presto:default> select mysum(10,10);Ergebnis
_col0
-------
20