Apache Solr - Indizierung von Daten
Im Allgemeinen, indexingist eine systematische Anordnung von Dokumenten oder (anderen Entitäten). Durch die Indizierung können Benutzer Informationen in einem Dokument suchen.
Durch die Indizierung werden Dokumente gesammelt, analysiert und gespeichert.
Die Indizierung wird durchgeführt, um die Geschwindigkeit und Leistung einer Suchabfrage zu erhöhen und gleichzeitig ein erforderliches Dokument zu finden.
Indizierung in Apache Solr
In Apache Solr können wir verschiedene Dokumentformate wie XML, CSV, PDF usw. indizieren (hinzufügen, löschen, ändern). Wir können dem Solr-Index auf verschiedene Arten Daten hinzufügen.
In diesem Kapitel werden wir die Indizierung diskutieren -
- Verwenden des Solr-Webinterfaces.
- Verwenden einer der Client-APIs wie Java, Python usw.
- Verwendung der post tool.
In diesem Kapitel wird erläutert, wie Sie mithilfe verschiedener Schnittstellen (Befehlszeile, Webschnittstelle und Java-Client-API) Daten zum Index von Apache Solr hinzufügen.
Hinzufügen von Dokumenten mit dem Post-Befehl
Solr hat eine post Befehl in seiner bin/Verzeichnis. Mit diesem Befehl können Sie verschiedene Dateiformate wie JSON, XML, CSV in Apache Solr indizieren.
Durchsuchen Sie die bin Verzeichnis von Apache Solr und führen Sie die –h option des post-Befehls, wie im folgenden Codeblock gezeigt.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hWenn Sie den obigen Befehl ausführen, erhalten Sie eine Liste der Optionen von post command, Wie nachfolgend dargestellt.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Beispiel
Angenommen, wir haben eine Datei mit dem Namen sample.csv mit folgendem Inhalt (in der bin Verzeichnis).
| Studenten ID | Vorname | Nachname | Telefon | Stadt |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Kolkata |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Der obige Datensatz enthält persönliche Daten wie Studenten-ID, Vorname, Nachname, Telefon und Stadt. Die CSV-Datei des Datensatzes wird unten angezeigt. Hier müssen Sie beachten, dass Sie das Schema erwähnen und seine erste Zeile dokumentieren müssen.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiSie können diese Daten unter dem genannten Kern indizieren sample_Solr Verwendung der post Befehl wie folgt -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvBei Ausführung des obigen Befehls wird das angegebene Dokument unter dem angegebenen Kern indiziert, wodurch die folgende Ausgabe generiert wird.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Besuchen Sie die Homepage von Solr Web UI unter der folgenden URL:
http://localhost:8983/
Wählen Sie den Kern aus Solr_sample. Standardmäßig ist der Anforderungshandler/selectund die Abfrage lautet ":". Klicken Sie ohne Änderungen aufExecuteQuery Schaltfläche am unteren Rand der Seite.
Beim Ausführen der Abfrage können Sie den Inhalt des indizierten CSV-Dokuments im JSON-Format (Standard) beobachten, wie im folgenden Screenshot gezeigt.
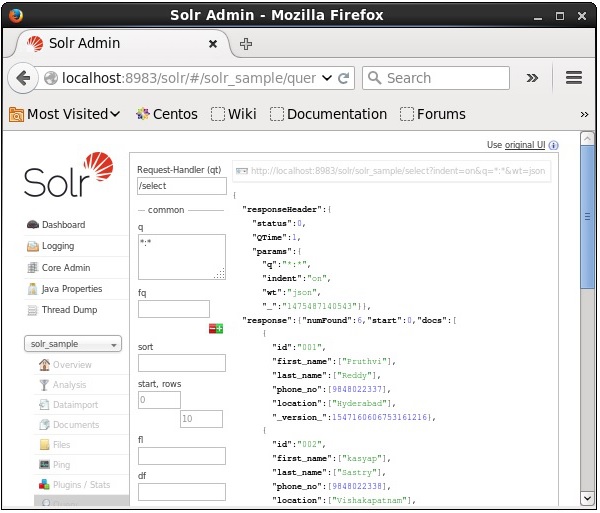
Note - Auf die gleiche Weise können Sie andere Dateiformate wie JSON, XML, CSV usw. indizieren.
Hinzufügen von Dokumenten über das Solr-Webinterface
Sie können Dokumente auch über die von Solr bereitgestellte Weboberfläche indizieren. Lassen Sie uns sehen, wie das folgende JSON-Dokument indiziert wird.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Schritt 1
Öffnen Sie die Solr-Weboberfläche unter der folgenden URL:
http://localhost:8983/
Step 2
Wählen Sie den Kern aus Solr_sample. Standardmäßig sind die Werte der Felder Anforderungshandler, Common Within, Overwrite und Boost / update, 1000, true und 1.0, wie im folgenden Screenshot gezeigt.
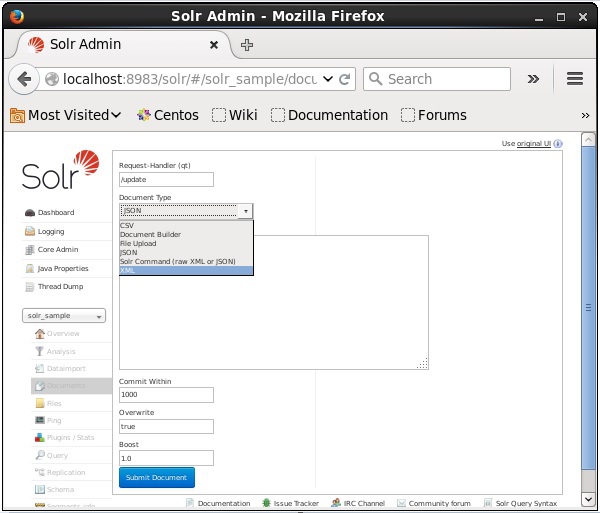
Wählen Sie nun das gewünschte Dokumentformat aus JSON, CSV, XML usw. aus. Geben Sie das zu indizierende Dokument in den Textbereich ein und klicken Sie auf Submit Document Schaltfläche, wie im folgenden Screenshot gezeigt.
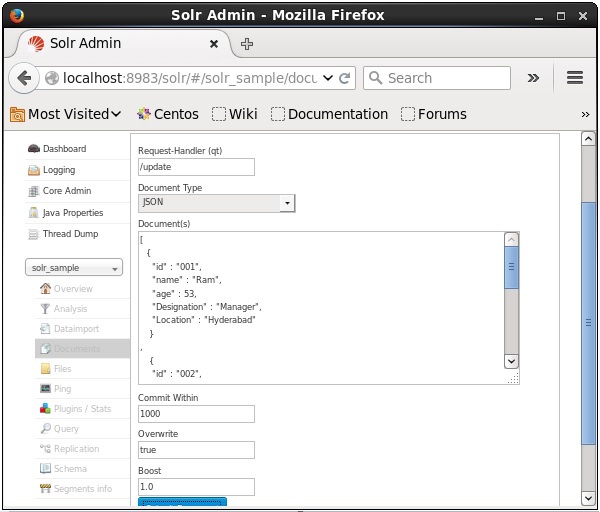
Hinzufügen von Dokumenten mithilfe der Java Client-API
Im Folgenden finden Sie das Java-Programm zum Hinzufügen von Dokumenten zum Apache Solr-Index. Speichern Sie diesen Code in einer Datei mit dem NamenAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Kompilieren Sie den obigen Code, indem Sie die folgenden Befehle im Terminal ausführen:
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentWenn Sie den obigen Befehl ausführen, erhalten Sie die folgende Ausgabe.
Documents added