Apache Spark - Kurzanleitung
Branchen nutzen Hadoop in großem Umfang, um ihre Datensätze zu analysieren. Der Grund dafür ist, dass das Hadoop-Framework auf einem einfachen Programmiermodell (MapReduce) basiert und eine Computerlösung ermöglicht, die skalierbar, flexibel, fehlertolerant und kostengünstig ist. Hierbei besteht das Hauptanliegen darin, die Geschwindigkeit bei der Verarbeitung großer Datenmengen in Bezug auf die Wartezeit zwischen Abfragen und die Wartezeit für die Ausführung des Programms aufrechtzuerhalten.
Spark wurde von der Apache Software Foundation eingeführt, um den Prozess der Hadoop-Computer-Software zu beschleunigen.
Gegen einen allgemeinen Glauben, Spark is not a modified version of Hadoopund ist nicht wirklich von Hadoop abhängig, da es über eine eigene Clusterverwaltung verfügt. Hadoop ist nur eine der Möglichkeiten, Spark zu implementieren.
Spark verwendet Hadoop auf zwei Arten - eine ist storage und zweitens ist processing. Da Spark über eine eigene Clusterverwaltungsberechnung verfügt, wird Hadoop nur zu Speicherzwecken verwendet.
Apache Spark
Apache Spark ist eine blitzschnelle Cluster-Computing-Technologie, die für schnelle Berechnungen entwickelt wurde. Es basiert auf Hadoop MapReduce und erweitert das MapReduce-Modell, um es effizient für weitere Arten von Berechnungen zu verwenden, einschließlich interaktiver Abfragen und Stream-Verarbeitung. Das Hauptmerkmal von Spark ist seinein-memory cluster computing das erhöht die Verarbeitungsgeschwindigkeit einer Anwendung.
Spark wurde entwickelt, um eine breite Palette von Workloads abzudecken, z. B. Batch-Anwendungen, iterative Algorithmen, interaktive Abfragen und Streaming. Neben der Unterstützung all dieser Workloads in einem entsprechenden System wird der Verwaltungsaufwand für die Wartung separater Tools verringert.
Entwicklung von Apache Spark
Spark ist eines von Hadoops Teilprojekten, das 2009 von Matei Zaharia in AMPLab von UC Berkeley entwickelt wurde. Es war Open Sourced im Jahr 2010 unter einer BSD-Lizenz. Es wurde 2013 an die Apache Software Foundation gespendet und jetzt ist Apache Spark seit Februar 2014 ein Apache-Projekt auf höchstem Niveau.
Funktionen von Apache Spark
Apache Spark verfügt über folgende Funktionen.
Speed- Spark hilft beim Ausführen einer Anwendung im Hadoop-Cluster, bis zu 100-mal schneller im Speicher und 10-mal schneller, wenn sie auf der Festplatte ausgeführt wird. Dies ist möglich, indem die Anzahl der Lese- / Schreibvorgänge auf die Festplatte reduziert wird. Es speichert die Zwischenverarbeitungsdaten im Speicher.
Supports multiple languages- Spark bietet integrierte APIs in Java, Scala oder Python. Daher können Sie Anwendungen in verschiedenen Sprachen schreiben. Spark bietet 80 übergeordnete Operatoren für interaktive Abfragen.
Advanced Analytics- Spark unterstützt nicht nur 'Map' und 'Reduce'. Es unterstützt auch SQL-Abfragen, Streaming-Daten, maschinelles Lernen (ML) und Graph-Algorithmen.
Funke auf Hadoop gebaut
Das folgende Diagramm zeigt drei Möglichkeiten, wie Spark mit Hadoop-Komponenten erstellt werden kann.

Es gibt drei Möglichkeiten der Spark-Bereitstellung, wie unten erläutert.
Standalone- Spark Standalone-Bereitstellung bedeutet, dass Spark den Platz über HDFS (Hadoop Distributed File System) einnimmt und explizit Speicherplatz für HDFS zugewiesen wird. Hier werden Spark und MapReduce nebeneinander ausgeführt, um alle Spark-Jobs im Cluster abzudecken.
Hadoop Yarn- Die Bereitstellung von Hadoop Yarn bedeutet einfach, dass Spark auf Yarn ausgeführt wird, ohne dass eine Vorinstallation oder ein Root-Zugriff erforderlich ist. Es hilft, Spark in das Hadoop-Ökosystem oder den Hadoop-Stack zu integrieren. Damit können andere Komponenten auf dem Stapel ausgeführt werden.
Spark in MapReduce (SIMR)- Spark in MapReduce wird verwendet, um zusätzlich zur eigenständigen Bereitstellung einen Spark-Job zu starten. Mit SIMR kann der Benutzer Spark starten und seine Shell ohne Administratorzugriff verwenden.
Komponenten von Spark
Die folgende Abbildung zeigt die verschiedenen Komponenten von Spark.

Apache Spark Core
Spark Core ist die zugrunde liegende allgemeine Ausführungs-Engine für die Spark-Plattform, auf der alle anderen Funktionen aufbauen. Es bietet In-Memory-Computing und Referenzierungsdatensätze in externen Speichersystemen.
Spark SQL
Spark SQL ist eine Komponente auf Spark Core, die eine neue Datenabstraktion namens SchemaRDD einführt, die strukturierte und halbstrukturierte Daten unterstützt.
Spark Streaming
Spark Streaming nutzt die schnelle Planungsfunktion von Spark Core, um Streaming-Analysen durchzuführen. Es nimmt Daten in Mini-Batches auf und führt RDD-Transformationen (Resilient Distributed Datasets) für diese Mini-Datenstapel durch.
MLlib (Bibliothek für maschinelles Lernen)
MLlib ist aufgrund der verteilten speicherbasierten Spark-Architektur ein Framework für verteiltes maschinelles Lernen über Spark. Laut Benchmarks wird dies von den MLlib-Entwicklern gegen die ALS-Implementierungen (Alternating Least Squares) durchgeführt. Spark MLlib ist neunmal so schnell wie die Hadoop-Festplattenversion vonApache Mahout (bevor Mahout eine Spark-Schnittstelle erhielt).
GraphX
GraphX ist ein verteiltes Framework für die Grafikverarbeitung, das auf Spark aufbaut. Es bietet eine API zum Ausdrücken der Diagrammberechnung, mit der die benutzerdefinierten Diagramme mithilfe der Pregel-Abstraktions-API modelliert werden können. Es bietet auch eine optimierte Laufzeit für diese Abstraktion.
Ausfallsichere verteilte Datensätze
Resilient Distributed Datasets (RDD) ist eine grundlegende Datenstruktur von Spark. Es ist eine unveränderliche verteilte Sammlung von Objekten. Jeder Datensatz in RDD ist in logische Partitionen unterteilt, die auf verschiedenen Knoten des Clusters berechnet werden können. RDDs können alle Arten von Python-, Java- oder Scala-Objekten enthalten, einschließlich benutzerdefinierter Klassen.
Formal ist eine RDD eine schreibgeschützte, partitionierte Sammlung von Datensätzen. RDDs können durch deterministische Operationen entweder für Daten in einem stabilen Speicher oder für andere RDDs erstellt werden. RDD ist eine fehlertolerante Sammlung von Elementen, die parallel bearbeitet werden können.
Es gibt zwei Möglichkeiten, RDDs zu erstellen: parallelizing eine vorhandene Sammlung in Ihrem Treiberprogramm oder referencing a dataset in einem externen Speichersystem, z. B. einem gemeinsam genutzten Dateisystem, HDFS, HBase oder einer Datenquelle, die ein Hadoop-Eingabeformat bietet.
Spark nutzt das RDD-Konzept, um schnellere und effizientere MapReduce-Vorgänge zu erzielen. Lassen Sie uns zunächst diskutieren, wie MapReduce-Vorgänge stattfinden und warum sie nicht so effizient sind.
Die Datenfreigabe in MapReduce ist langsam
MapReduce wird häufig zum Verarbeiten und Generieren großer Datenmengen mit einem parallelen, verteilten Algorithmus in einem Cluster eingesetzt. Benutzer können parallele Berechnungen mit einer Reihe von übergeordneten Operatoren schreiben, ohne sich um die Arbeitsverteilung und die Fehlertoleranz kümmern zu müssen.
Leider besteht in den meisten aktuellen Frameworks die einzige Möglichkeit, Daten zwischen Berechnungen (z. B. zwischen zwei MapReduce-Jobs) wiederzuverwenden, darin, sie in ein externes stabiles Speichersystem (z. B. HDFS) zu schreiben. Obwohl dieses Framework zahlreiche Abstraktionen für den Zugriff auf die Rechenressourcen eines Clusters bietet, möchten Benutzer immer noch mehr.
Beide Iterative und InteractiveAnwendungen erfordern eine schnellere gemeinsame Nutzung von Daten über parallele Jobs hinweg. Der Datenaustausch in MapReduce ist aufgrund von langsamreplication, serialization, und disk IO. In Bezug auf das Speichersystem verbringen die meisten Hadoop-Anwendungen mehr als 90% der Zeit mit HDFS-Lese- / Schreibvorgängen.
Iterative Operationen auf MapReduce
Zwischenergebnisse für mehrere Berechnungen in mehrstufigen Anwendungen wiederverwenden. In der folgenden Abbildung wird erläutert, wie das aktuelle Framework funktioniert, während die iterativen Operationen in MapReduce ausgeführt werden. Dies verursacht aufgrund der Datenreplikation, der Festplatten-E / A und der Serialisierung einen erheblichen Overhead, wodurch das System langsam wird.
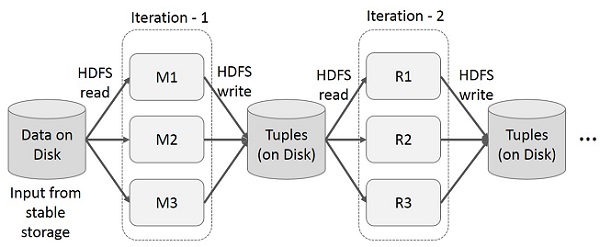
Interaktive Operationen auf MapReduce
Der Benutzer führt Ad-hoc-Abfragen für dieselbe Teilmenge von Daten aus. Bei jeder Abfrage werden die Festplatten-E / A im stabilen Speicher ausgeführt, wodurch die Ausführungszeit der Anwendung dominiert werden kann.
In der folgenden Abbildung wird erläutert, wie das aktuelle Framework beim Ausführen der interaktiven Abfragen in MapReduce funktioniert.
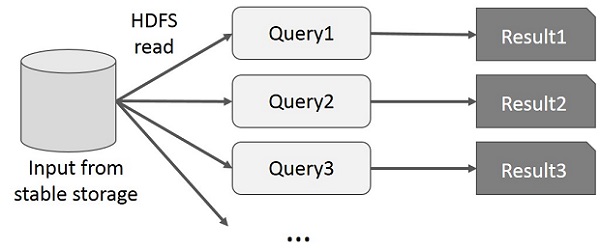
Datenaustausch mit Spark RDD
Der Datenaustausch in MapReduce ist aufgrund von langsam replication, serialization, und disk IO. Die meisten Hadoop-Anwendungen verbringen mehr als 90% der Zeit mit HDFS-Lese- / Schreibvorgängen.
Um dieses Problem zu erkennen, entwickelten die Forscher ein spezielles Framework namens Apache Spark. Die Schlüsselidee von Funken istResilient Dverteilt wird DAtasets (RDD); Es unterstützt die Berechnung der In-Memory-Verarbeitung. Dies bedeutet, dass der Speicherstatus als Objekt über die Jobs hinweg gespeichert wird und das Objekt zwischen diesen Jobs gemeinsam genutzt werden kann. Die gemeinsame Nutzung von Daten im Speicher ist 10 bis 100 Mal schneller als bei Netzwerk und Festplatte.
Versuchen wir nun herauszufinden, wie iterative und interaktive Operationen in Spark RDD stattfinden.
Iterative Operationen auf Spark RDD
Die folgende Abbildung zeigt die iterativen Operationen für Spark RDD. Es speichert Zwischenergebnisse in einem verteilten Speicher anstelle eines stabilen Speichers (Festplatte) und beschleunigt das System.
Note - Wenn der verteilte Speicher (RAM) ausreicht, um Zwischenergebnisse (Status des JOB) zu speichern, werden diese Ergebnisse auf der Festplatte gespeichert.

Interaktive Operationen auf Spark RDD
Diese Abbildung zeigt interaktive Vorgänge auf Spark RDD. Wenn verschiedene Abfragen wiederholt für denselben Datensatz ausgeführt werden, können diese bestimmten Daten für bessere Ausführungszeiten im Speicher gespeichert werden.

Standardmäßig kann jede transformierte RDD jedes Mal neu berechnet werden, wenn Sie eine Aktion darauf ausführen. Sie können jedoch auchpersisteine RDD im Speicher. In diesem Fall behält Spark die Elemente im Cluster bei, um beim nächsten Abfragen einen viel schnelleren Zugriff zu ermöglichen. Es gibt auch Unterstützung für persistente RDDs auf der Festplatte oder für die Replikation über mehrere Knoten.
Spark ist das Teilprojekt von Hadoop. Daher ist es besser, Spark auf einem Linux-basierten System zu installieren. Die folgenden Schritte zeigen, wie Sie Apache Spark installieren.
Schritt 1: Überprüfen der Java-Installation
Die Java-Installation ist eines der obligatorischen Dinge bei der Installation von Spark. Versuchen Sie den folgenden Befehl, um die JAVA-Version zu überprüfen.
$java -versionWenn Java bereits auf Ihrem System installiert ist, wird die folgende Antwort angezeigt:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Wenn auf Ihrem System kein Java installiert ist, installieren Sie Java, bevor Sie mit dem nächsten Schritt fortfahren.
Schritt 2: Überprüfen der Scala-Installation
Sie sollten die Scala-Sprache verwenden, um Spark zu implementieren. Lassen Sie uns die Scala-Installation mit dem folgenden Befehl überprüfen.
$scala -versionWenn Scala bereits auf Ihrem System installiert ist, wird die folgende Antwort angezeigt:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLWenn Sie Scala nicht auf Ihrem System installiert haben, fahren Sie mit dem nächsten Schritt für die Scala-Installation fort.
Schritt 3: Scala herunterladen
Laden Sie die neueste Version von Scala herunter, indem Sie den folgenden Link herunterladen: Scala herunterladen . Für dieses Tutorial verwenden wir die Version scala-2.11.6. Nach dem Download finden Sie die Scala-TAR-Datei im Download-Ordner.
Schritt 4: Scala installieren
Befolgen Sie die unten angegebenen Schritte zur Installation von Scala.
Extrahieren Sie die Scala-TAR-Datei
Geben Sie den folgenden Befehl zum Extrahieren der Scala-TAR-Datei ein.
$ tar xvf scala-2.11.6.tgzVerschieben Sie Scala-Softwaredateien
Verwenden Sie die folgenden Befehle, um die Scala-Softwaredateien in das entsprechende Verzeichnis zu verschieben (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitStellen Sie PATH für Scala ein
Verwenden Sie den folgenden Befehl, um PATH für Scala festzulegen.
$ export PATH = $PATH:/usr/local/scala/binÜberprüfen der Scala-Installation
Nach der Installation ist es besser, dies zu überprüfen. Verwenden Sie den folgenden Befehl, um die Scala-Installation zu überprüfen.
$scala -versionWenn Scala bereits auf Ihrem System installiert ist, wird die folgende Antwort angezeigt:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLSchritt 5: Herunterladen von Apache Spark
Laden Sie die neueste Version von Spark herunter, indem Sie den folgenden Link herunterladen: Spark herunterladen . Für dieses Tutorial verwenden wirspark-1.3.1-bin-hadoop2.6Ausführung. Nach dem Herunterladen finden Sie die Spark-Tar-Datei im Download-Ordner.
Schritt 6: Spark installieren
Führen Sie die folgenden Schritte aus, um Spark zu installieren.
Funken-Teer extrahieren
Der folgende Befehl zum Extrahieren der Spark-Tar-Datei.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzVerschieben von Spark-Softwaredateien
Die folgenden Befehle zum Verschieben der Spark-Softwaredateien in das entsprechende Verzeichnis (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitEinrichten der Umgebung für Spark
Fügen Sie die folgende Zeile zu ~ hinzu/.bashrcDatei. Dies bedeutet, dass der PATH-Variablen der Speicherort hinzugefügt wird, an dem sich die Spark-Softwaredatei befindet.
export PATH=$PATH:/usr/local/spark/binVerwenden Sie den folgenden Befehl, um die Datei ~ / .bashrc zu beziehen.
$ source ~/.bashrcSchritt 7: Überprüfen der Spark-Installation
Schreiben Sie den folgenden Befehl zum Öffnen der Spark-Shell.
$spark-shellWenn der Funke erfolgreich installiert wurde, finden Sie die folgende Ausgabe.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark Core ist die Basis des gesamten Projekts. Es bietet verteilte Aufgabenverteilung, Zeitplanung und grundlegende E / A-Funktionen. Spark verwendet eine spezielle grundlegende Datenstruktur, die als RDD (Resilient Distributed Datasets) bezeichnet wird und eine logische Sammlung von Daten darstellt, die auf mehrere Maschinen verteilt sind. RDDs können auf zwei Arten erstellt werden. Zum einen wird auf Datensätze in externen Speichersystemen verwiesen, zum anderen werden Transformationen (z. B. Map, Filter, Reducer, Join) auf vorhandene RDDs angewendet.
Die RDD-Abstraktion wird über eine sprachintegrierte API verfügbar gemacht. Dies vereinfacht die Programmierkomplexität, da die Art und Weise, wie Anwendungen RDDs manipulieren, der Manipulation lokaler Datensammlungen ähnelt.
Spark Shell
Spark bietet eine interaktive Shell - ein leistungsstarkes Tool zur interaktiven Analyse von Daten. Es ist entweder in Scala oder Python verfügbar. Die primäre Abstraktion von Spark ist eine verteilte Sammlung von Elementen, die als Resilient Distributed Dataset (RDD) bezeichnet wird. RDDs können aus Hadoop-Eingabeformaten (z. B. HDFS-Dateien) oder durch Transformieren anderer RDDs erstellt werden.
Öffnen Sie die Spark Shell
Der folgende Befehl wird zum Öffnen der Spark-Shell verwendet.
$ spark-shellErstellen Sie eine einfache RDD
Lassen Sie uns eine einfache RDD aus der Textdatei erstellen. Verwenden Sie den folgenden Befehl, um eine einfache RDD zu erstellen.
scala> val inputfile = sc.textFile(“input.txt”)Die Ausgabe für den obigen Befehl ist
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Die Spark RDD API führt nur wenige ein Transformations und wenige Actions RDD zu manipulieren.
RDD-Transformationen
RDD-Transformationen geben den Zeiger auf neues RDD zurück und ermöglichen das Erstellen von Abhängigkeiten zwischen RDDs. Jedes RDD in der Abhängigkeitskette (String of Dependencies) hat eine Funktion zur Berechnung seiner Daten und einen Zeiger (Abhängigkeit) auf sein übergeordnetes RDD.
Spark ist faul, daher wird nichts ausgeführt, es sei denn, Sie rufen eine Transformation oder Aktion auf, die die Erstellung und Ausführung von Jobs auslöst. Schauen Sie sich den folgenden Ausschnitt des Beispiels für die Wortanzahl an.
Daher ist die RDD-Transformation kein Datensatz, sondern ein Schritt in einem Programm (möglicherweise der einzige Schritt), der Spark sagt, wie Daten abgerufen werden sollen und was damit zu tun ist.
| S.No. | Transformationen & Bedeutung |
|---|---|
| 1 | map(func) Gibt ein neues verteiltes Dataset zurück, das durch Übergeben jedes Elements der Quelle durch eine Funktion gebildet wird func. |
| 2 | filter(func) Gibt ein neues Dataset zurück, das durch Auswahl der Elemente der Quelle erstellt wurde, auf denen func gibt true zurück. |
| 3 | flatMap(func) Ähnlich wie bei der Zuordnung, jedoch kann jedes Eingabeelement 0 oder mehr Ausgabeelementen zugeordnet werden (daher sollte func eine Seq anstelle eines einzelnen Elements zurückgeben). |
| 4 | mapPartitions(func) Ähnlich wie Map, wird jedoch auf jeder Partition (Block) des RDD separat ausgeführt func muss vom Typ Iterator <T> sein ⇒ Iterator <U>, wenn auf einem RDD vom Typ T ausgeführt wird. |
| 5 | mapPartitionsWithIndex(func) Ähnlich wie Map Partitions, bietet aber auch func mit einem ganzzahligen Wert, der den Index der Partition darstellt, also func muss vom Typ (Int, Iterator <T>) sein ⇒ Iterator <U>, wenn auf einem RDD vom Typ T ausgeführt wird. |
| 6 | sample(withReplacement, fraction, seed) Probe a fraction der Daten mit oder ohne Ersatz unter Verwendung eines gegebenen Zufallszahlengenerator-Startwerts. |
| 7 | union(otherDataset) Gibt ein neues Dataset zurück, das die Vereinigung der Elemente im Quelldatensatz und des Arguments enthält. |
| 8 | intersection(otherDataset) Gibt eine neue RDD zurück, die den Schnittpunkt von Elementen im Quelldatensatz und dem Argument enthält. |
| 9 | distinct([numTasks]) Gibt ein neues Dataset zurück, das die verschiedenen Elemente des Quelldatensatzes enthält. |
| 10 | groupByKey([numTasks]) Wenn ein Datensatz von (K, V) Paaren aufgerufen wird, wird ein Datensatz von (K, Iterable <V>) Paaren zurückgegeben. Note - Wenn Sie eine Gruppierung durchführen, um eine Aggregation (z. B. eine Summe oder einen Durchschnitt) für jeden Schlüssel durchzuführen, führt die Verwendung von reductByKey oder aggregateByKey zu einer wesentlich besseren Leistung. |
| 11 | reduceByKey(func, [numTasks]) Wenn ein Datensatz von (K, V) Paaren aufgerufen wird, wird ein Datensatz von (K, V) Paaren zurückgegeben, in dem die Werte für jeden Schlüssel unter Verwendung der angegebenen Reduktionsfunktion func aggregiert werden , die vom Typ (V, V) ⇒ V sein muss Wie in groupByKey kann die Anzahl der Reduzierungsaufgaben über ein optionales zweites Argument konfiguriert werden. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) Wenn ein Datensatz mit (K, V) Paaren aufgerufen wird, wird ein Datensatz mit (K, U) Paaren zurückgegeben, in dem die Werte für jeden Schlüssel unter Verwendung der angegebenen Kombinationsfunktionen und eines neutralen "Null" -Werts aggregiert werden. Ermöglicht einen aggregierten Werttyp, der sich vom Eingabewerttyp unterscheidet, wobei unnötige Zuordnungen vermieden werden. Wie in groupByKey kann die Anzahl der Reduzierungsaufgaben über ein optionales zweites Argument konfiguriert werden. |
| 13 | sortByKey([ascending], [numTasks]) Wenn ein Datensatz von (K, V) Paaren aufgerufen wird, in dem K Ordered implementiert, wird ein Datensatz von (K, V) Paaren zurückgegeben, der nach Schlüsseln in aufsteigender oder absteigender Reihenfolge sortiert ist, wie im Argument Boolean ascend angegeben. |
| 14 | join(otherDataset, [numTasks]) Beim Aufrufen von Datensätzen vom Typ (K, V) und (K, W) wird ein Datensatz von (K, (V, W)) Paaren mit allen Elementpaaren für jeden Schlüssel zurückgegeben. Äußere Verknüpfungen werden durch leftOuterJoin, rightOuterJoin und fullOuterJoin unterstützt. |
| 15 | cogroup(otherDataset, [numTasks]) Beim Aufrufen von Datensätzen vom Typ (K, V) und (K, W) wird ein Datensatz von (K, (Iterable <V>, Iterable <W>)) Tupeln zurückgegeben. Diese Operation wird auch als Gruppe mit bezeichnet. |
| 16 | cartesian(otherDataset) Gibt beim Aufrufen von Datensätzen der Typen T und U einen Datensatz von (T, U) Paaren (alle Elementpaare) zurück. |
| 17 | pipe(command, [envVars]) Leiten Sie jede Partition des RDD über einen Shell-Befehl, z. B. ein Perl- oder Bash-Skript. RDD-Elemente werden in das stdin des Prozesses geschrieben, und in das stdout ausgegebene Zeilen werden als RDD von Zeichenfolgen zurückgegeben. |
| 18 | coalesce(numPartitions) Verringern Sie die Anzahl der Partitionen in der RDD auf numPartitions. Nützlich, um Vorgänge nach dem Filtern eines großen Datensatzes effizienter auszuführen. |
| 19 | repartition(numPartitions) Mischen Sie die Daten in der RDD nach dem Zufallsprinzip neu, um mehr oder weniger Partitionen zu erstellen und über diese zu verteilen. Dadurch werden immer alle Daten über das Netzwerk gemischt. |
| 20 | repartitionAndSortWithinPartitions(partitioner) Partitionieren Sie die RDD gemäß dem angegebenen Partitionierer neu und sortieren Sie die Datensätze innerhalb jeder resultierenden Partition nach ihren Schlüsseln. Dies ist effizienter als das Aufrufen der Neupartition und das anschließende Sortieren innerhalb jeder Partition, da dadurch die Sortierung in die Shuffle-Maschinerie verschoben werden kann. |
Aktionen
| S.No. | Aktion & Bedeutung |
|---|---|
| 1 | reduce(func) Aggregieren Sie die Elemente des Datasets mithilfe einer Funktion func(das zwei Argumente akzeptiert und eines zurückgibt). Die Funktion sollte kommutativ und assoziativ sein, damit sie parallel korrekt berechnet werden kann. |
| 2 | collect() Gibt alle Elemente des Datasets als Array im Treiberprogramm zurück. Dies ist normalerweise nach einem Filter oder einer anderen Operation nützlich, die eine ausreichend kleine Teilmenge der Daten zurückgibt. |
| 3 | count() Gibt die Anzahl der Elemente im Dataset zurück. |
| 4 | first() Gibt das erste Element des Datasets zurück (ähnlich wie bei take (1)). |
| 5 | take(n) Gibt ein Array mit dem ersten zurück n Elemente des Datensatzes. |
| 6 | takeSample (withReplacement,num, [seed]) Gibt ein Array mit einer zufälligen Stichprobe von zurück num Elemente des Datensatzes, mit oder ohne Ersatz, geben optional einen Zufallszahlengenerator-Startwert vor. |
| 7 | takeOrdered(n, [ordering]) Gibt den ersten zurück n Elemente der RDD, die entweder ihre natürliche Reihenfolge oder einen benutzerdefinierten Komparator verwenden. |
| 8 | saveAsTextFile(path) Schreibt die Elemente des Datasets als Textdatei (oder als Satz von Textdateien) in ein bestimmtes Verzeichnis im lokalen Dateisystem, HDFS oder einem anderen von Hadoop unterstützten Dateisystem. Spark ruft für jedes Element toString auf, um es in eine Textzeile in der Datei zu konvertieren. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Schreibt die Elemente des Datasets als Hadoop-Sequenzdatei in einen bestimmten Pfad im lokalen Dateisystem, HDFS oder einem anderen von Hadoop unterstützten Dateisystem. Dies ist auf RDDs von Schlüssel-Wert-Paaren verfügbar, die die beschreibbare Schnittstelle von Hadoop implementieren. In Scala ist es auch für Typen verfügbar, die implizit in Writable konvertierbar sind (Spark enthält Konvertierungen für Basistypen wie Int, Double, String usw.). |
| 10 | saveAsObjectFile(path) (Java and Scala) Schreibt die Elemente des Datasets mithilfe der Java-Serialisierung in einem einfachen Format, das dann mit SparkContext.objectFile () geladen werden kann. |
| 11 | countByKey() Nur für RDDs vom Typ (K, V) verfügbar. Gibt eine Hashmap von (K, Int) Paaren mit der Anzahl der einzelnen Schlüssel zurück. |
| 12 | foreach(func) Führt eine Funktion aus funcauf jedem Element des Datensatzes. Dies geschieht normalerweise bei Nebenwirkungen wie dem Aktualisieren eines Akkus oder der Interaktion mit externen Speichersystemen. Note- Das Ändern anderer Variablen als Akkumulatoren außerhalb von foreach () kann zu undefiniertem Verhalten führen. Weitere Informationen finden Sie unter Grundlegendes zu Schließungen. |
Programmieren mit RDD
Lassen Sie uns anhand eines Beispiels die Implementierungen weniger RDD-Transformationen und -Aktionen in der RDD-Programmierung sehen.
Beispiel
Betrachten Sie ein Beispiel für die Wortanzahl - Es zählt jedes Wort, das in einem Dokument erscheint. Betrachten Sie den folgenden Text als Eingabe und wird als gespeichertinput.txt Datei in einem Home-Verzeichnis.
input.txt - Eingabedatei.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Befolgen Sie die unten angegebenen Schritte, um das angegebene Beispiel auszuführen.
Öffnen Sie die Spark-Shell
Der folgende Befehl wird zum Öffnen der Funkenschale verwendet. Im Allgemeinen wird der Funke mit Scala aufgebaut. Daher wird ein Spark-Programm in einer Scala-Umgebung ausgeführt.
$ spark-shellWenn die Spark-Shell erfolgreich geöffnet wird, finden Sie die folgende Ausgabe. Wenn Sie sich die letzte Zeile der Ausgabe ansehen, bedeutet "Spark-Kontext als sc verfügbar", dass der Spark-Container automatisch ein Spark-Kontextobjekt mit dem Namen erstelltsc. Vor dem Start des ersten Programmschritts sollte das SparkContext-Objekt erstellt werden.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Erstellen Sie eine RDD
Zuerst müssen wir die Eingabedatei mit der Spark-Scala-API lesen und eine RDD erstellen.
Der folgende Befehl wird zum Lesen einer Datei von einem bestimmten Speicherort verwendet. Hier wird eine neue RDD mit dem Namen der Eingabedatei erstellt. Der String, der in der textFile-Methode ("") als Argument angegeben wird, ist der absolute Pfad für den Namen der Eingabedatei. Wenn jedoch nur der Dateiname angegeben wird, bedeutet dies, dass sich die Eingabedatei am aktuellen Speicherort befindet.
scala> val inputfile = sc.textFile("input.txt")Führen Sie die Wortzählungstransformation aus
Unser Ziel ist es, die Wörter in einer Datei zu zählen. Erstellen Sie eine flache Karte, um jede Zeile in Wörter aufzuteilen (flatMap(line ⇒ line.split(“ ”)).
Lesen Sie als Nächstes jedes Wort als Schlüssel mit einem Wert ‘1’ (<Schlüssel, Wert> = <Wort, 1>) mit Kartenfunktion (map(word ⇒ (word, 1)).
Reduzieren Sie diese Schlüssel schließlich, indem Sie Werte ähnlicher Schlüssel hinzufügen (reduceByKey(_+_)).
Der folgende Befehl wird zum Ausführen der Wortzähllogik verwendet. Nachdem Sie dies ausgeführt haben, werden Sie keine Ausgabe finden, da dies keine Aktion, sondern eine Transformation ist. auf ein neues RDD zeigen oder Funken mitteilen, was mit den angegebenen Daten zu tun ist)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);Aktuelle RDD
Wenn Sie während der Arbeit mit dem RDD Informationen zum aktuellen RDD erhalten möchten, verwenden Sie den folgenden Befehl. Es zeigt Ihnen die Beschreibung der aktuellen RDD und ihrer Abhängigkeiten für das Debuggen.
scala> counts.toDebugStringZwischenspeichern der Transformationen
Sie können eine RDD, die beibehalten werden soll, mit den Methoden persist () oder cache () markieren. Wenn es zum ersten Mal in einer Aktion berechnet wird, wird es auf den Knoten gespeichert. Verwenden Sie den folgenden Befehl, um die Zwischentransformationen im Speicher zu speichern.
scala> counts.cache()Aktion anwenden
Das Anwenden einer Aktion, wie das Speichern aller Transformationen, führt zu einer Textdatei. Das String-Argument für die Methode saveAsTextFile ("") ist der absolute Pfad des Ausgabeordners. Versuchen Sie den folgenden Befehl, um die Ausgabe in einer Textdatei zu speichern. Im folgenden Beispiel befindet sich der Ordner "Ausgabe" am aktuellen Speicherort.
scala> counts.saveAsTextFile("output")Überprüfen der Ausgabe
Öffnen Sie ein anderes Terminal, um zum Ausgangsverzeichnis zu gelangen (wo der Funke im anderen Terminal ausgeführt wird). Verwenden Sie die folgenden Befehle, um das Ausgabeverzeichnis zu überprüfen.
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSDer folgende Befehl wird verwendet, um die Ausgabe von anzuzeigen Part-00000 Dateien.
[hadoop@localhost output]$ cat part-00000Ausgabe
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Der folgende Befehl wird verwendet, um die Ausgabe von anzuzeigen Part-00001 Dateien.
[hadoop@localhost output]$ cat part-00001Ausgabe
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)UN Behalten Sie die Lagerung bei
Wenn Sie vor dem UN-Persistent den für diese Anwendung verwendeten Speicherplatz anzeigen möchten, verwenden Sie die folgende URL in Ihrem Browser.
http://localhost:4040Der folgende Bildschirm zeigt den für die Anwendung verwendeten Speicherplatz, der auf der Spark-Shell ausgeführt wird.

Wenn Sie den Speicherplatz eines bestimmten RDD UN-persistieren möchten, verwenden Sie den folgenden Befehl.
Scala> counts.unpersist()Sie sehen die Ausgabe wie folgt:
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14Verwenden Sie die folgende URL, um den Speicherplatz im Browser zu überprüfen.
http://localhost:4040/Sie sehen den folgenden Bildschirm. Es zeigt den für die Anwendung verwendeten Speicherplatz an, der auf der Spark-Shell ausgeführt wird.
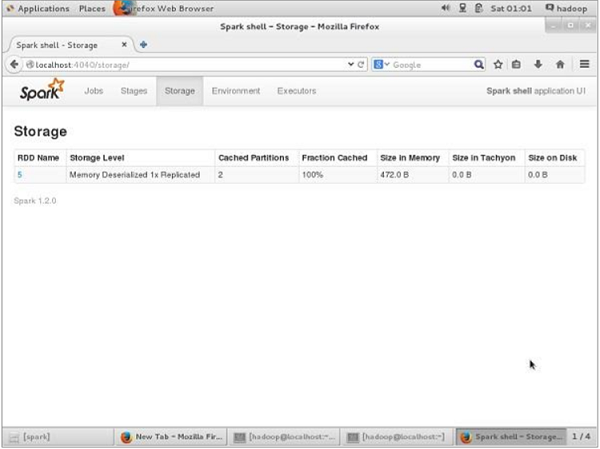
Die Spark-Anwendung, die spark-submit verwendet, ist ein Shell-Befehl, mit dem die Spark-Anwendung in einem Cluster bereitgestellt wird. Es verwendet alle jeweiligen Cluster-Manager über eine einheitliche Schnittstelle. Daher müssen Sie Ihre Anwendung nicht für jede einzelne konfigurieren.
Beispiel
Nehmen wir das gleiche Beispiel für die Wortanzahl, das wir zuvor mit Shell-Befehlen verwendet haben. Hier betrachten wir das gleiche Beispiel wie eine Funkenanwendung.
Probeneingabe
Der folgende Text enthält die Eingabedaten und die genannte Datei lautet in.txt.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Schauen Sie sich das folgende Programm an -
SparkWordCount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark._
object SparkWordCount {
def main(args: Array[String]) {
val sc = new SparkContext( "local", "Word Count", "/usr/local/spark", Nil, Map(), Map())
/* local = master URL; Word Count = application name; */
/* /usr/local/spark = Spark Home; Nil = jars; Map = environment */
/* Map = variables to work nodes */
/*creating an inputRDD to read text file (in.txt) through Spark context*/
val input = sc.textFile("in.txt")
/* Transform the inputRDD into countRDD */
val count = input.flatMap(line ⇒ line.split(" "))
.map(word ⇒ (word, 1))
.reduceByKey(_ + _)
/* saveAsTextFile method is an action that effects on the RDD */
count.saveAsTextFile("outfile")
System.out.println("OK");
}
}Speichern Sie das obige Programm in einer Datei mit dem Namen SparkWordCount.scala und legen Sie es in einem benutzerdefinierten Verzeichnis mit dem Namen spark-application.
Note - Während wir die inputRDD in countRDD umwandeln, verwenden wir flatMap () zum Tokenisieren der Zeilen (aus der Textdatei) in Wörter, die map () -Methode zum Zählen der Worthäufigkeit und die reduByKey () -Methode zum Zählen jeder Wortwiederholung.
Führen Sie die folgenden Schritte aus, um diesen Antrag einzureichen. Führen Sie alle Schritte in der ausspark-application Verzeichnis über das Terminal.
Schritt 1: Laden Sie Spark Ja herunter
Für die Kompilierung ist eine Spark-Core-JAR erforderlich. Laden Sie daher spark-core_2.10-1.3.0.jar über den folgenden Link herunter: Spark- Core-JAR und verschieben Sie die JAR-Datei aus dem Download-Verzeichnis inspark-application Verzeichnis.
Schritt 2: Programm kompilieren
Kompilieren Sie das obige Programm mit dem unten angegebenen Befehl. Dieser Befehl sollte aus dem Spark-Anwendungsverzeichnis ausgeführt werden. Hier,/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar ist ein Hadoop-Support-Jar aus der Spark-Bibliothek.
$ scalac -classpath "spark-core_2.10-1.3.0.jar:/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar" SparkPi.scalaSchritt 3: Erstellen Sie ein JAR
Erstellen Sie mit dem folgenden Befehl eine JAR-Datei der Spark-Anwendung. Hier,wordcount ist der Dateiname für die JAR-Datei.
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jarSchritt 4: Funkenantrag einreichen
Senden Sie die Funkenanwendung mit dem folgenden Befehl:
spark-submit --class SparkWordCount --master local wordcount.jarWenn es erfolgreich ausgeführt wird, finden Sie die unten angegebene Ausgabe. DasOKDas Einlassen der folgenden Ausgabe dient der Benutzeridentifikation und das ist die letzte Zeile des Programms. Wenn Sie die folgende Ausgabe sorgfältig lesen, werden Sie verschiedene Dinge finden, wie -
- Dienst 'sparkDriver' an Port 42954 wurde erfolgreich gestartet
- MemoryStore wurde mit einer Kapazität von 267,3 MB gestartet
- Startete SparkUI unter http://192.168.1.217:4040
- JAR-Datei hinzugefügt: /home/hadoop/piapplication/count.jar
- ResultStage 1 (saveAsTextFile bei SparkPi.scala: 11) wurde in 0,566 s beendet
- Die Spark-Web-Benutzeroberfläche wurde unter http://192.168.1.217:4040 gestoppt
- MemoryStore gelöscht
15/07/08 13:56:04 INFO Slf4jLogger: Slf4jLogger started
15/07/08 13:56:04 INFO Utils: Successfully started service 'sparkDriver' on port 42954.
15/07/08 13:56:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:42954]
15/07/08 13:56:04 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/07/08 13:56:05 INFO HttpServer: Starting HTTP Server
15/07/08 13:56:05 INFO Utils: Successfully started service 'HTTP file server' on port 56707.
15/07/08 13:56:06 INFO SparkUI: Started SparkUI at http://192.168.1.217:4040
15/07/08 13:56:07 INFO SparkContext: Added JAR file:/home/hadoop/piapplication/count.jar at http://192.168.1.217:56707/jars/count.jar with timestamp 1436343967029
15/07/08 13:56:11 INFO Executor: Adding file:/tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af/userFiles-df4f4c20-a368-4cdd-a2a7-39ed45eb30cf/count.jar to class loader
15/07/08 13:56:11 INFO HadoopRDD: Input split: file:/home/hadoop/piapplication/in.txt:0+54
15/07/08 13:56:12 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2001 bytes result sent to driver
(MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11), which is now runnable
15/07/08 13:56:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11)
15/07/08 13:56:13 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s
15/07/08 13:56:13 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkPi.scala:11, took 2.892996 s
OK
15/07/08 13:56:13 INFO SparkContext: Invoking stop() from shutdown hook
15/07/08 13:56:13 INFO SparkUI: Stopped Spark web UI at http://192.168.1.217:4040
15/07/08 13:56:13 INFO DAGScheduler: Stopping DAGScheduler
15/07/08 13:56:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
15/07/08 13:56:14 INFO Utils: path = /tmp/spark-45a07b83-42ed-42b3-b2c2823d8d99c5af/blockmgr-ccdda9e3-24f6-491b-b509-3d15a9e05818, already present as root for deletion.
15/07/08 13:56:14 INFO MemoryStore: MemoryStore cleared
15/07/08 13:56:14 INFO BlockManager: BlockManager stopped
15/07/08 13:56:14 INFO BlockManagerMaster: BlockManagerMaster stopped
15/07/08 13:56:14 INFO SparkContext: Successfully stopped SparkContext
15/07/08 13:56:14 INFO Utils: Shutdown hook called
15/07/08 13:56:14 INFO Utils: Deleting directory /tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af
15/07/08 13:56:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!Schritt 5: Überprüfen der Ausgabe
Nach erfolgreicher Ausführung des Programms finden Sie das Verzeichnis mit dem Namen outfile im Spark-Anwendungsverzeichnis.
Die folgenden Befehle werden zum Öffnen und Überprüfen der Liste der Dateien im Verzeichnis outfile verwendet.
$ cd outfile
$ ls
Part-00000 part-00001 _SUCCESSDie Befehle zum Einchecken der Ausgabe part-00000 Datei sind -
$ cat part-00000
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Die Befehle zum Überprüfen der Ausgabe in der Datei part-00001 lauten -
$ cat part-00001
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)Lesen Sie den folgenden Abschnitt, um mehr über den Befehl 'spark-submit' zu erfahren.
Spark-Submit-Syntax
spark-submit [options] <app jar | python file> [app arguments]Optionen
| S.No. | Möglichkeit | Beschreibung |
|---|---|---|
| 1 | --Meister | spark: // host: port, mesos: // host: port, garn oder lokal. |
| 2 | --deploy-mode | Gibt an, ob das Treiberprogramm lokal ("Client") oder auf einem der Worker-Computer im Cluster ("Cluster") gestartet werden soll (Standard: Client). |
| 3 | --Klasse | Die Hauptklasse Ihrer Anwendung (für Java / Scala-Apps). |
| 4 | --Name | Ein Name Ihrer Anwendung. |
| 5 | - Gläser | Durch Kommas getrennte Liste lokaler Jars, die in die Klassenpfade von Treiber und Executor aufgenommen werden sollen. |
| 6 | --Pakete | Durch Kommas getrennte Liste der Maven-Koordinaten von Jars, die in den Klassenpfaden von Treiber und Executor enthalten sein sollen. |
| 7 | - Repositories | Durch Kommas getrennte Liste zusätzlicher Remote-Repositorys zur Suche nach den mit --packages angegebenen Maven-Koordinaten. |
| 8 | --py-Dateien | Durch Kommas getrennte Liste von .zip-, .egg- oder .py-Dateien, die auf dem PYTHON PATH für Python-Apps abgelegt werden sollen. |
| 9 | --Dateien | Durch Kommas getrennte Liste der Dateien, die im Arbeitsverzeichnis jedes Executors abgelegt werden sollen. |
| 10 | --conf (prop = val) | Beliebige Spark-Konfigurationseigenschaft. |
| 11 | --properties-Datei | Pfad zu einer Datei, aus der zusätzliche Eigenschaften geladen werden sollen. Wenn nicht angegeben, wird nach Conf / Spark-Standardeinstellungen gesucht. |
| 12 | --Treiberspeicher | Speicher für Treiber (zB 1000M, 2G) (Standard: 512M). |
| 13 | --driver-java-options | Zusätzliche Java-Optionen, die an den Treiber übergeben werden sollen. |
| 14 | - Treiber-Bibliothek-Pfad | Zusätzliche Bibliothekspfadeinträge, die an den Treiber übergeben werden sollen. |
| 15 | --driver-class-path | Zusätzliche Klassenpfadeinträge, die an den Treiber übergeben werden sollen. Beachten Sie, dass mit --jars hinzugefügte Jars automatisch in den Klassenpfad aufgenommen werden. |
| 16 | --executor-memory | Speicher pro Executor (z. B. 1000M, 2G) (Standard: 1G). |
| 17 | --proxy-user | Benutzer, der sich beim Einreichen des Antrags ausgibt. |
| 18 | - Hilfe, -h | Diese Hilfemeldung anzeigen und beenden. |
| 19 | --verbose, -v | Zusätzliche Debug-Ausgabe drucken. |
| 20 | --Ausführung | Drucken Sie die Version des aktuellen Spark. |
| 21 | - Treiberkerne NUM | Kerne für den Treiber (Standard: 1). |
| 22 | --überwachen | Wenn angegeben, wird der Treiber bei einem Fehler neu gestartet. |
| 23 | --töten | Wenn angegeben, wird der angegebene Treiber beendet. |
| 24 | --Status | Wenn angegeben, wird der Status des angegebenen Treibers angefordert. |
| 25 | --total-executor-cores | Gesamtkerne für alle Ausführenden. |
| 26 | --Ausführerkerne | Anzahl der Kerne pro Executor. (Standard: 1 im YARN-Modus oder alle verfügbaren Kerne des Workers im Standalone-Modus). |
Spark enthält zwei verschiedene Arten von gemeinsam genutzten Variablen - eine davon broadcast variables und zweitens ist accumulators.
Broadcast variables - verwendet, um große Werte effizient zu verteilen.
Accumulators - wird verwendet, um die Informationen einer bestimmten Sammlung zusammenzufassen.
Broadcast-Variablen
Mit Broadcast-Variablen kann der Programmierer eine schreibgeschützte Variable auf jedem Computer zwischenspeichern, anstatt eine Kopie davon mit Aufgaben zu versenden. Sie können beispielsweise verwendet werden, um jedem Knoten auf effiziente Weise eine Kopie eines großen Eingabedatensatzes zu geben. Spark versucht auch, Broadcast-Variablen mithilfe effizienter Broadcast-Algorithmen zu verteilen, um die Kommunikationskosten zu senken.
Funkenaktionen werden durch eine Reihe von Stufen ausgeführt, die durch verteilte "Shuffle" -Operationen getrennt sind. Spark sendet automatisch die allgemeinen Daten, die für Aufgaben in jeder Phase benötigt werden.
Die auf diese Weise übertragenen Daten werden in serialisierter Form zwischengespeichert und vor dem Ausführen jeder Aufgabe deserialisiert. Dies bedeutet, dass das explizite Erstellen von Broadcast-Variablen nur dann nützlich ist, wenn Aufgaben in mehreren Phasen dieselben Daten benötigen oder wenn das Zwischenspeichern der Daten in deserialisierter Form wichtig ist.
Broadcast-Variablen werden aus einer Variablen erstellt v telefonisch SparkContext.broadcast(v). Die Broadcast-Variable ist ein Wrappervund auf seinen Wert kann durch Aufrufen von zugegriffen werden valueMethode. Der unten angegebene Code zeigt dies -
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))Output - -
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)Nachdem die Broadcast-Variable erstellt wurde, sollte sie anstelle des Werts verwendet werden v in allen Funktionen laufen auf dem Cluster, so dass vwird nicht mehr als einmal an die Knoten gesendet. Außerdem das Objektv sollte nach dem Broadcast nicht geändert werden, um sicherzustellen, dass alle Knoten den gleichen Wert der Broadcast-Variablen erhalten.
Akkus
Akkumulatoren sind Variablen, die nur durch eine assoziative Operation „hinzugefügt“ werden und daher parallel effizient unterstützt werden können. Sie können verwendet werden, um Zähler (wie in MapReduce) oder Summen zu implementieren. Spark unterstützt nativ Akkumulatoren numerischer Typen, und Programmierer können Unterstützung für neue Typen hinzufügen. Wenn Akkumulatoren mit einem Namen erstellt werden, werden sie in angezeigtSpark’s UI. Dies kann hilfreich sein, um den Fortschritt der laufenden Phasen zu verstehen (HINWEIS - dies wird in Python noch nicht unterstützt).
Aus einem Anfangswert wird ein Akkumulator erstellt v telefonisch SparkContext.accumulator(v). Auf dem Cluster ausgeführte Aufgaben können dann mithilfe von hinzugefügt werdenaddMethode oder der Operator + = (in Scala und Python). Sie können den Wert jedoch nicht lesen. Nur das Treiberprogramm kann den Wert des Akkumulators mit seinem lesenvalue Methode.
Der unten angegebene Code zeigt einen Akkumulator, mit dem die Elemente eines Arrays addiert werden.
scala> val accum = sc.accumulator(0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)Wenn Sie die Ausgabe des obigen Codes sehen möchten, verwenden Sie den folgenden Befehl:
scala> accum.valueAusgabe
res2: Int = 10Numerische RDD-Operationen
Mit Spark können Sie mithilfe einer der vordefinierten API-Methoden verschiedene Operationen an numerischen Daten ausführen. Die numerischen Operationen von Spark werden mit einem Streaming-Algorithmus implementiert, mit dem das Modell elementweise erstellt werden kann.
Diese Operationen werden berechnet und als a zurückgegeben StatusCounter Objekt durch Aufrufen status() Methode.
| S.No. | Methoden & Bedeutung |
|---|---|
| 1 | count() Anzahl der Elemente in der RDD. |
| 2 | Mean() Durchschnitt der Elemente in der RDD. |
| 3 | Sum() Gesamtwert der Elemente in der RDD. |
| 4 | Max() Maximalwert unter allen Elementen in der RDD. |
| 5 | Min() Mindestwert unter allen Elementen in der RDD. |
| 6 | Variance() Varianz der Elemente. |
| 7 | Stdev() Standardabweichung. |
Wenn Sie nur eine dieser Methoden verwenden möchten, können Sie die entsprechende Methode direkt auf RDD aufrufen.