Apache Storm - Kernkonzepte
Apache Storm liest Rohdatenströme von Echtzeitdaten von einem Ende und leitet sie durch eine Folge kleiner Verarbeitungseinheiten und gibt die verarbeiteten / nützlichen Informationen am anderen Ende aus.
Das folgende Diagramm zeigt das Kernkonzept von Apache Storm.

Schauen wir uns nun die Komponenten von Apache Storm genauer an -
| Komponenten | Beschreibung |
|---|---|
| Tupel | Tupel ist die Hauptdatenstruktur in Storm. Es ist eine Liste der geordneten Elemente. Standardmäßig unterstützt ein Tupel alle Datentypen. Im Allgemeinen wird es als Satz von durch Kommas getrennten Werten modelliert und an einen Storm-Cluster übergeben. |
| Strom | Stream ist eine ungeordnete Folge von Tupeln. |
| Ausgüsse | Quelle des Stroms. Im Allgemeinen akzeptiert Storm Eingabedaten aus Rohdatenquellen wie der Twitter-Streaming-API, der Apache Kafka-Warteschlange, der Kestrel-Warteschlange usw. Andernfalls können Sie Ausläufe schreiben, um Daten aus Datenquellen zu lesen. "ISpout" ist die Kernschnittstelle für die Implementierung von Ausgüssen. Einige der spezifischen Schnittstellen sind IRichSpout, BaseRichSpout, KafkaSpout usw. |
| Schrauben | Schrauben sind logische Verarbeitungseinheiten. Ausläufe leiten Daten an Bolzen weiter und verarbeiten einen neuen Ausgabestrom. Bolts können die Vorgänge Filtern, Aggregieren, Verbinden und Interagieren mit Datenquellen und Datenbanken ausführen. Der Bolzen empfängt Daten und sendet an einen oder mehrere Bolzen. "IBolt" ist die Kernschnittstelle für die Implementierung von Schrauben. Einige der gängigen Schnittstellen sind IRichBolt, IBasicBolt usw. |
Nehmen wir ein Echtzeitbeispiel für „Twitter-Analyse“ und sehen, wie es in Apache Storm modelliert werden kann. Das folgende Diagramm zeigt die Struktur.

Die Eingabe für die „Twitter-Analyse“ stammt von der Twitter-Streaming-API. Spout liest die Tweets der Benutzer mithilfe der Twitter-Streaming-API und gibt sie als Stream von Tupeln aus. Ein einzelnes Tupel aus dem Auslauf hat einen Twitter-Benutzernamen und einen einzelnen Tweet als durch Kommas getrennte Werte. Dieser Dampf von Tupeln wird dann an den Bolt weitergeleitet, und der Bolt teilt den Tweet in ein einzelnes Wort auf, berechnet die Wortanzahl und speichert die Informationen in einer konfigurierten Datenquelle. Jetzt können wir das Ergebnis leicht erhalten, indem wir die Datenquelle abfragen.
Topologie
Ausgüsse und Schrauben sind miteinander verbunden und bilden eine Topologie. Die Echtzeit-Anwendungslogik wird in der Storm-Topologie angegeben. In einfachen Worten ist eine Topologie ein gerichteter Graph, in dem Eckpunkte berechnet werden und Kanten Datenströme sind.
Eine einfache Topologie beginnt mit Ausgüssen. Der Auslauf gibt die Daten an eine oder mehrere Schrauben aus. Die Schraube stellt einen Knoten in der Topologie mit der kleinsten Verarbeitungslogik dar, und die Ausgabe einer Schraube kann als Eingabe in eine andere Schraube ausgegeben werden.
Storm hält die Topologie immer am Laufen, bis Sie die Topologie beenden. Die Hauptaufgabe von Apache Storm besteht darin, die Topologie auszuführen und zu einem bestimmten Zeitpunkt eine beliebige Anzahl von Topologien auszuführen.
Aufgaben
Jetzt haben Sie eine Grundidee für Ausgüsse und Schrauben. Sie sind die kleinste logische Einheit der Topologie, und eine Topologie wird aus einem einzelnen Auslauf und einer Reihe von Schrauben erstellt. Sie sollten ordnungsgemäß in einer bestimmten Reihenfolge ausgeführt werden, damit die Topologie erfolgreich ausgeführt werden kann. Die Ausführung jedes einzelnen Auslaufs und Bolzens durch Storm wird als „Aufgaben“ bezeichnet. Mit einfachen Worten, eine Aufgabe ist entweder die Ausführung eines Ausgusses oder eines Bolzens. Zu einem bestimmten Zeitpunkt können für jeden Auslauf und jede Schraube mehrere Instanzen in mehreren separaten Gewinden ausgeführt werden.
Arbeitskräfte
Eine Topologie wird verteilt auf mehreren Arbeitsknoten ausgeführt. Storm verteilt die Aufgaben gleichmäßig auf alle Worker-Knoten. Die Rolle des Arbeitsknotens besteht darin, auf Jobs zu warten und die Prozesse zu starten oder zu stoppen, wenn ein neuer Job eintrifft.
Stream-Gruppierung
Datenstrom fließt von Ausgüssen zu Schrauben oder von einer Schraube zu einer anderen Schraube. Die Stream-Gruppierung steuert, wie die Tupel in der Topologie weitergeleitet werden, und hilft uns, den Tupelfluss in der Topologie zu verstehen. Es gibt vier eingebaute Gruppierungen, wie unten erläutert.
Shuffle-Gruppierung
Bei der Shuffle-Gruppierung wird eine gleiche Anzahl von Tupeln zufällig auf alle Arbeiter verteilt, die die Bolzen ausführen. Das folgende Diagramm zeigt die Struktur.

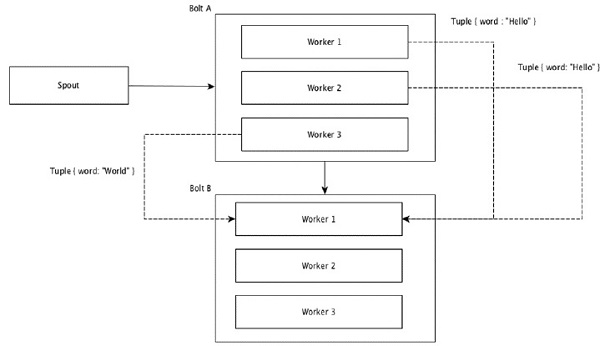
Feldgruppierung
Die Felder mit den gleichen Werten in Tupeln werden gruppiert und die verbleibenden Tupel außerhalb aufbewahrt. Dann werden die Tupel mit denselben Feldwerten an denselben Arbeiter weitergeleitet, der die Schrauben ausführt. Wenn der Stream beispielsweise nach dem Feld "Wort" gruppiert ist, werden die Tupel mit derselben Zeichenfolge "Hallo" zu demselben Worker verschoben. Das folgende Diagramm zeigt, wie die Feldgruppierung funktioniert.

Globale Gruppierung
Alle Streams können gruppiert und an eine Schraube weitergeleitet werden. Diese Gruppierung sendet Tupel, die von allen Instanzen der Quelle generiert wurden, an eine einzelne Zielinstanz (wählen Sie insbesondere den Worker mit der niedrigsten ID aus).
Alle Gruppierung
Alle Gruppierungen senden eine einzelne Kopie jedes Tupels an alle Instanzen des Empfangsbolzens. Diese Art der Gruppierung wird verwendet, um Signale an Schrauben zu senden. Alle Gruppierungen sind nützlich für Verknüpfungsvorgänge.
