ArangoDB - AQL-Beispielabfragen
In diesem Kapitel werden einige AQL-Beispielabfragen für eine Actors and MoviesDatenbank. Diese Abfragen basieren auf Diagrammen.
Problem
Gegeben eine Sammlung von Schauspielern und eine Sammlung von Filmen sowie eine Sammlung von actIn-Kanten (mit einer Jahr-Eigenschaft), um den Scheitelpunkt wie unten angegeben zu verbinden -
[Actor] <- act in -> [Movie]
Wie kommen wir -
- Alle Schauspieler, die in "movie1" ODER "movie2" mitgewirkt haben?
- Alle Schauspieler, die sowohl in "movie1" als auch in "movie2" mitgewirkt haben?
- Alle gängigen Filme zwischen "Schauspieler1" und "Schauspieler2"?
- Alle Schauspieler, die in 3 oder mehr Filmen mitgewirkt haben?
- Alle Filme, in denen genau 6 Schauspieler mitwirkten?
- Die Anzahl der Schauspieler pro Film?
- Die Anzahl der Filme nach Schauspieler?
- Die Anzahl der Filme, die zwischen 2005 und 2010 vom Schauspieler gedreht wurden?
Lösung
Während des Lösens und Erhaltens der Antworten auf die oben genannten Abfragen verwenden wir Arangosh, um das Dataset zu erstellen und Abfragen darauf auszuführen. Alle AQL-Abfragen sind Zeichenfolgen und können anstelle von Arangosh einfach auf Ihren Lieblingstreiber kopiert werden.
Beginnen wir mit der Erstellung eines Testdatensatzes in Arangosh. Laden Sie zuerst diese Datei herunter -
# wget -O dataset.js
https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharingAusgabe
...
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘dataset.js’
dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s
2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]Sie können in der obigen Ausgabe sehen, dass wir eine JavaScript-Datei heruntergeladen haben dataset.js.Diese Datei enthält die Arangosh-Befehle zum Erstellen des Datasets in der Datenbank. Anstatt die Befehle einzeln zu kopieren und einzufügen, verwenden wir die--javascript.executeOption auf Arangosh, um die mehreren Befehle nicht interaktiv auszuführen. Betrachten Sie es als den Lebensretterbefehl!
Führen Sie nun den folgenden Befehl auf der Shell aus:
$ arangosh --javascript.execute dataset.js
Geben Sie das Passwort ein, wenn Sie dazu aufgefordert werden, wie Sie im obigen Screenshot sehen können. Nachdem wir die Daten gespeichert haben, werden wir die AQL-Abfragen erstellen, um die spezifischen Fragen zu beantworten, die zu Beginn dieses Kapitels aufgeworfen wurden.
Erste Frage
Lassen Sie uns die erste Frage stellen: All actors who acted in "movie1" OR "movie2". Angenommen, wir möchten die Namen aller Schauspieler finden, die in "TheMatrix" ODER "TheDevilsAdvocate" mitgewirkt haben.
Wir werden mit jeweils einem Film beginnen, um die Namen der Schauspieler zu erhalten -
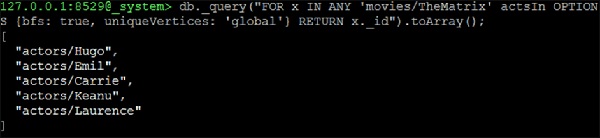
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();Ausgabe
Wir erhalten folgende Ausgabe:
[
"actors/Hugo",
"actors/Emil",
"actors/Carrie",
"actors/Keanu",
"actors/Laurence"
]
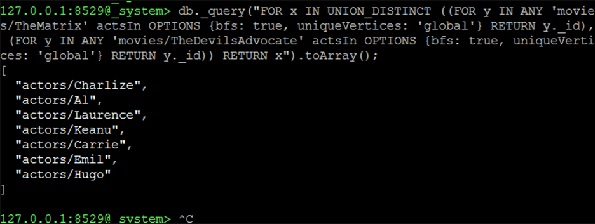
Jetzt bilden wir weiterhin eine UNION_DISTINCT aus zwei NEIGHBORS-Abfragen, die die Lösung sein werden -
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Ausgabe
[
"actors/Charlize",
"actors/Al",
"actors/Laurence",
"actors/Keanu",
"actors/Carrie",
"actors/Emil",
"actors/Hugo"
]
Zweite Frage
Betrachten wir nun die zweite Frage: All actors who acted in both "movie1" AND "movie2". Dies ist fast identisch mit der obigen Frage. Aber diesmal interessieren wir uns nicht für eine UNION, sondern für eine INTERSECTION -
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Ausgabe
Wir erhalten folgende Ausgabe:
[
"actors/Keanu"
]
Dritte Frage
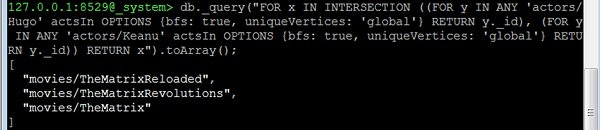
Betrachten wir nun die dritte Frage: All common movies between "actor1" and "actor2". Dies ist tatsächlich identisch mit der Frage nach gemeinsamen Schauspielern in Film1 und Film2. Wir müssen nur die Startscheitelpunkte ändern. Lassen Sie uns als Beispiel alle Filme finden, in denen Hugo Weaving ("Hugo") und Keanu Reeves die Hauptrolle spielen -
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();Ausgabe
Wir erhalten folgende Ausgabe:
[
"movies/TheMatrixReloaded",
"movies/TheMatrixRevolutions",
"movies/TheMatrix"
]
Vierte Frage
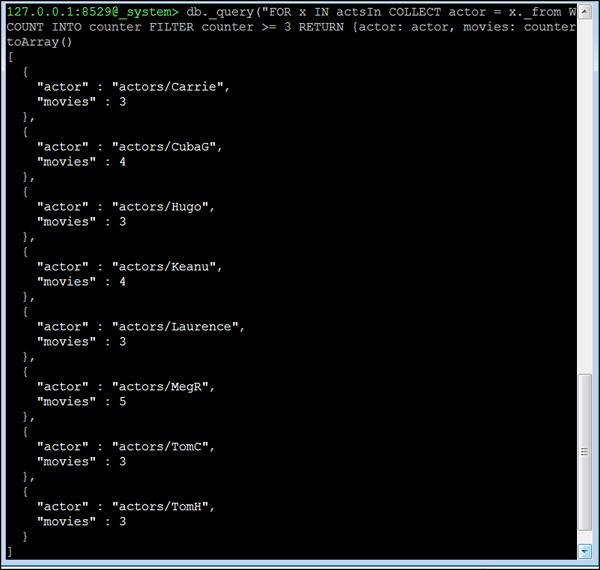
Betrachten wir nun die vierte Frage. All actors who acted in 3 or more movies. Diese Frage ist anders; Wir können die Nachbarfunktion hier nicht nutzen. Stattdessen verwenden wir den Kantenindex und die COLLECT-Anweisung von AQL für die Gruppierung. Die Grundidee ist, alle Kanten nach ihren zu gruppierenstartVertex(was in diesem Datensatz immer der Schauspieler ist). Dann entfernen wir alle Schauspieler mit weniger als 3 Filmen aus dem Ergebnis, da wir hier die Anzahl der Filme angegeben haben, in denen ein Schauspieler gespielt hat -
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()Ausgabe
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
Bei den verbleibenden Fragen werden wir die Abfragebildung diskutieren und nur die Abfragen bereitstellen. Der Leser sollte die Abfrage selbst auf dem Arangosh-Terminal ausführen.
Fünfte Frage
Betrachten wir nun die fünfte Frage: All movies where exactly 6 actors acted in. Die gleiche Idee wie in der vorherigen Abfrage, jedoch mit dem Gleichheitsfilter. Jetzt brauchen wir jedoch den Film anstelle des Schauspielers, also geben wir den zurück_to attribute - -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()Die Anzahl der Schauspieler pro Film?
Wir erinnern uns in unserem Datensatz _to am Rand entspricht dem Film, also zählen wir, wie oft das gleiche _toerscheint. Dies ist die Anzahl der Schauspieler. Die Abfrage ist aber fast identisch mit denen vorher aberwithout the FILTER after COLLECT - -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()Sechste Frage
Betrachten wir nun die sechste Frage: The number of movies by an actor.
Die Art und Weise, wie wir Lösungen für unsere oben genannten Abfragen gefunden haben, hilft Ihnen auch dabei, die Lösung für diese Abfrage zu finden.
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()