Montage - Kurzanleitung
Was ist Assemblersprache?
Jeder Personal Computer verfügt über einen Mikroprozessor, der die arithmetischen, logischen und Steuerungsaktivitäten des Computers verwaltet.
Jede Prozessorfamilie verfügt über eigene Anweisungen zum Behandeln verschiedener Vorgänge, z. B. zum Abrufen von Eingaben über die Tastatur, zum Anzeigen von Informationen auf dem Bildschirm und zum Ausführen verschiedener anderer Aufgaben. Diese Anweisungen werden als "Maschinensprachenanweisungen" bezeichnet.
Ein Prozessor versteht nur Anweisungen in Maschinensprache, die Zeichenfolgen von Einsen und Nullen sind. Die Maschinensprache ist jedoch zu dunkel und komplex für die Verwendung in der Softwareentwicklung. Daher ist die Assemblersprache auf niedriger Ebene für eine bestimmte Prozessorfamilie konzipiert, die verschiedene Anweisungen in symbolischem Code und in einer verständlicheren Form darstellt.
Vorteile der Assemblersprache
Ein Verständnis der Assemblersprache macht einen bewusst -
- Wie Programme mit Betriebssystem, Prozessor und BIOS kommunizieren;
- Wie Daten im Speicher und anderen externen Geräten dargestellt werden;
- Wie der Prozessor auf Anweisungen zugreift und diese ausführt;
- Wie Anweisungen auf Daten zugreifen und diese verarbeiten;
- Wie ein Programm auf externe Geräte zugreift.
Weitere Vorteile der Verwendung der Assemblersprache sind:
Es erfordert weniger Speicher und Ausführungszeit;
Es ermöglicht auf einfachere Weise hardwarespezifische komplexe Jobs.
Es ist für zeitkritische Jobs geeignet;
Es eignet sich am besten zum Schreiben von Interrupt-Serviceroutinen und anderen speicherresidenten Programmen.
Grundfunktionen der PC-Hardware
Die interne Haupthardware eines PCs besteht aus Prozessor, Speicher und Registern. Register sind Prozessorkomponenten, die Daten und Adressen enthalten. Um ein Programm auszuführen, kopiert das System es vom externen Gerät in den internen Speicher. Der Prozessor führt die Programmanweisungen aus.
Die grundlegende Einheit der Computerspeicherung ist ein bisschen; Es kann EIN (1) oder AUS (0) sein, und eine Gruppe von 8 verwandten Bits bildet auf den meisten modernen Computern ein Byte.
Das Paritätsbit wird also verwendet, um die Anzahl der Bits in einem Byte ungerade zu machen. Wenn die Parität gerade ist, geht das System davon aus, dass ein Paritätsfehler aufgetreten ist (obwohl selten), der möglicherweise auf einen Hardwarefehler oder eine elektrische Störung zurückzuführen ist.
Der Prozessor unterstützt die folgenden Datengrößen:
- Wort: Ein 2-Byte-Datenelement
- Doppelwort: Ein 4-Byte-Datenelement (32 Bit)
- Quadword: Ein 8-Byte-Datenelement (64 Bit)
- Absatz: Ein 16-Byte-Bereich (128 Bit)
- Kilobyte: 1024 Bytes
- Megabyte: 1.048.576 Bytes
Binärzahlensystem
Jedes Zahlensystem verwendet die Positionsnotation, dh jede Position, in die eine Ziffer geschrieben wird, hat einen anderen Positionswert. Jede Position ist die Potenz der Basis, die für das Binärzahlensystem 2 ist, und diese Potenzen beginnen bei 0 und erhöhen sich um 1.
Die folgende Tabelle zeigt die Positionswerte für eine 8-Bit-Binärzahl, bei der alle Bits auf ON gesetzt sind.
| Bitwert | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| Positionieren Sie den Wert als Potenz der Basis 2 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| Bitnummer | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Der Wert einer Binärzahl basiert auf dem Vorhandensein von 1 Bits und ihrem Positionswert. Der Wert einer bestimmten Binärzahl ist also -
1 + 2 + 4 + 8 + 16 + 32 + 64 + 128 = 255
das ist das gleiche wie 2 8 - 1.
Hexadezimalzahlensystem
Das Hexadezimalzahlensystem verwendet die Basis 16. Die Ziffern in diesem System reichen von 0 bis 15. Konventionell werden die Buchstaben A bis F verwendet, um die Hexadezimalziffern darzustellen, die den Dezimalwerten 10 bis 15 entsprechen.
Hexadezimalzahlen beim Rechnen werden zum Abkürzen langer binärer Darstellungen verwendet. Grundsätzlich stellt das Hexadezimalzahlensystem binäre Daten dar, indem jedes Byte in zwei Hälften geteilt und der Wert jedes halben Bytes ausgedrückt wird. Die folgende Tabelle enthält die Dezimal-, Binär- und Hexadezimaläquivalente.
| Dezimalzahl | Binäre Darstellung | Hexadezimale Darstellung |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | EIN |
| 11 | 1011 | B. |
| 12 | 1100 | C. |
| 13 | 1101 | D. |
| 14 | 1110 | E. |
| 15 | 1111 | F. |
Um eine Binärzahl in ihre hexadezimale Entsprechung umzuwandeln, teilen Sie sie von rechts beginnend in Gruppen von jeweils 4 aufeinanderfolgenden Gruppen auf und schreiben Sie diese Gruppen über die entsprechenden Ziffern der hexadezimalen Zahl.
Example - Die Binärzahl 1000 1100 1101 0001 entspricht hexadezimal - 8CD1
Um eine Hexadezimalzahl in eine Binärzahl umzuwandeln, schreiben Sie einfach jede Hexadezimalzahl in ihr 4-stelliges Binäräquivalent.
Example - Die Hexadezimalzahl FAD8 entspricht der Binärzahl - 1111 1010 1101 1000
Binäre Arithmetik
Die folgende Tabelle zeigt vier einfache Regeln für die binäre Addition:
| (ich) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| = 0 | = 1 | = 10 | = 11 |
Die Regeln (iii) und (iv) zeigen einen Übertrag eines 1-Bits in die nächste linke Position.
Example
| Dezimal | Binär |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
Ein negativer Binärwert wird in ausgedrückt two's complement notation. Nach dieser Regel bedeutet das Konvertieren einer Binärzahl in ihren negativen Wert das Umkehren ihrer Bitwerte und das Addieren von 1 .
Example
| Nummer 53 | 00110101 |
| Bits umkehren | 11001010 |
| Addiere 1 | 0000000 1 |
| Nummer -53 | 11001011 |
Um einen Wert von einem anderen zu subtrahieren, konvertieren Sie die zu subtrahierende Zahl in das Zweierkomplementformat und addieren Sie die Zahlen .
Example
Subtrahiere 42 von 53
| Nummer 53 | 00110101 |
| Nummer 42 | 00101010 |
| Kehren Sie die Bits von 42 um | 11010101 |
| Addiere 1 | 0000000 1 |
| Nummer -42 | 11010110 |
| 53 - 42 = 11 | 00001011 |
Der Überlauf der letzten 1 Bit geht verloren.
Adressierung von Daten im Speicher
Der Prozess, durch den der Prozessor die Ausführung von Anweisungen steuert, wird als bezeichnet fetch-decode-execute cycle oder der execution cycle. Es besteht aus drei kontinuierlichen Schritten -
- Abrufen der Anweisung aus dem Speicher
- Dekodieren oder Identifizieren der Anweisung
- Anweisung ausführen
Der Prozessor kann gleichzeitig auf ein oder mehrere Speicherbytes zugreifen. Betrachten wir eine Hexadezimalzahl 0725H. Diese Nummer benötigt zwei Bytes Speicher. Das Byte höherer Ordnung oder das höchstwertige Byte ist 07 und das Byte niedriger Ordnung ist 25.
Der Prozessor speichert Daten in umgekehrter Bytesequenz, dh ein Byte niedriger Ordnung wird in einer Adresse mit niedrigem Speicher und ein Byte höherer Ordnung in einer Adresse mit hohem Speicher gespeichert. Wenn der Prozessor also den Wert 0725H vom Register in den Speicher bringt, überträgt er 25 zuerst an die niedrigere Speicheradresse und 07 an die nächste Speicheradresse.
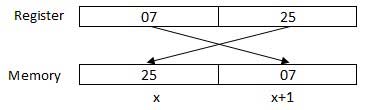
x: Speicheradresse
Wenn der Prozessor die numerischen Daten aus dem Speicher zum Registrieren erhält, kehrt er die Bytes erneut um. Es gibt zwei Arten von Speicheradressen -
Absolute Adresse - eine direkte Referenz eines bestimmten Ortes.
Segmentadresse (oder Offset) - Startadresse eines Speichersegments mit dem Offsetwert.
Einrichtung der lokalen Umgebung
Die Assemblersprache hängt vom Befehlssatz und der Architektur des Prozessors ab. In diesem Tutorial konzentrieren wir uns auf Intel-32-Prozessoren wie Pentium. Um diesem Tutorial zu folgen, benötigen Sie -
- Ein IBM PC oder ein gleichwertiger kompatibler Computer
- Eine Kopie des Linux-Betriebssystems
- Eine Kopie des NASM-Assembler-Programms
Es gibt viele gute Assembler-Programme wie -
- Microsoft Assembler (MASM)
- Borland Turbo Assembler (TASM)
- Der GNU Assembler (GAS)
Wir werden den NASM-Assembler so verwenden, wie er ist -
- Kostenlos. Sie können es aus verschiedenen Webquellen herunterladen.
- Gut dokumentiert und Sie erhalten viele Informationen im Internet.
- Kann sowohl unter Linux als auch unter Windows verwendet werden.
NASM installieren
Wenn Sie während der Installation von Linux "Entwicklungstools" auswählen, wird NASM möglicherweise zusammen mit dem Linux-Betriebssystem installiert, und Sie müssen es nicht separat herunterladen und installieren. Führen Sie die folgenden Schritte aus, um zu überprüfen, ob NASM bereits installiert ist:
Öffnen Sie ein Linux-Terminal.
Art whereis nasm und drücken Sie ENTER.
Wenn es bereits installiert ist, wird eine Zeile wie nasm: / usr / bin / nasm angezeigt. Andernfalls sehen Sie nur nasm : , dann müssen Sie NASM installieren.
Führen Sie die folgenden Schritte aus, um NASM zu installieren:
Überprüfen Sie die Netwide Assembler (NASM) Website für die neueste Version verfügbar .
Laden Sie das Linux- Quellarchiv herunter
nasm-X.XX.ta.gz, in demX.XXsich die NASM-Versionsnummer im Archiv befindet.Entpacken Sie das Archiv in ein Verzeichnis, das ein Unterverzeichnis erstellt
nasm-X. XX.CD an
nasm-X.XXund tippen./configure. Dieses Shell-Skript findet den besten C-Compiler, um Makefiles entsprechend zu verwenden und einzurichten.Art make um die Nasm- und Ndisasm-Binärdateien zu erstellen.
Art make install um nasm und ndisasm in / usr / local / bin zu installieren und die manpages zu installieren.
Dies sollte NASM auf Ihrem System installieren. Alternativ können Sie eine RPM-Distribution für Fedora Linux verwenden. Diese Version ist einfacher zu installieren. Doppelklicken Sie einfach auf die RPM-Datei.
Ein Montageprogramm kann in drei Abschnitte unterteilt werden -
Das data Sektion,
Das bss Abschnitt und
Das text Sektion.
Die Daten Abschnitt
Das dataAbschnitt wird zum Deklarieren initialisierter Daten oder Konstanten verwendet. Diese Daten ändern sich zur Laufzeit nicht. In diesem Abschnitt können Sie verschiedene konstante Werte, Dateinamen oder Puffergrößen usw. deklarieren.
Die Syntax zum Deklarieren des Datenabschnitts lautet -
section.dataDie bss Sektion
Das bssAbschnitt wird zum Deklarieren von Variablen verwendet. Die Syntax zum Deklarieren des bss-Abschnitts lautet -
section.bssDer Textabschnitt
Das textAbschnitt wird verwendet, um den tatsächlichen Code zu behalten. Dieser Abschnitt muss mit der Erklärung beginnenglobal _start, der dem Kernel mitteilt, wo die Programmausführung beginnt.
Die Syntax zum Deklarieren des Textabschnitts lautet -
section.text
global _start
_start:Bemerkungen
Der Kommentar zur Assemblersprache beginnt mit einem Semikolon (;). Es kann jedes druckbare Zeichen enthalten, einschließlich Leerzeichen. Es kann in einer eigenen Zeile erscheinen, wie -
; This program displays a message on screenoder in derselben Zeile zusammen mit einer Anweisung wie -
add eax, ebx ; adds ebx to eaxAssembler-Anweisungen
Assembler-Programme bestehen aus drei Arten von Anweisungen:
- Ausführbare Anweisungen oder Anweisungen,
- Assembler-Direktiven oder Pseudo-Ops und
- Macros.
Das executable instructions oder einfach instructionsSagen Sie dem Prozessor, was zu tun ist. Jede Anweisung besteht aus einemoperation code(Opcode). Jeder ausführbare Befehl erzeugt einen maschinensprachlichen Befehl.
Das assembler directives oder pseudo-opsInformieren Sie den Assembler über die verschiedenen Aspekte des Assemblierungsprozesses. Diese sind nicht ausführbar und generieren keine Anweisungen in Maschinensprache.
Macros sind im Grunde ein Textsubstitutionsmechanismus.
Syntax von Assembler-Anweisungen
Assembler-Anweisungen werden mit einer Anweisung pro Zeile eingegeben. Jede Anweisung folgt dem folgenden Format:
[label] mnemonic [operands] [;comment]Die Felder in eckigen Klammern sind optional. Ein Basisbefehl besteht aus zwei Teilen, der erste ist der Name des Befehls (oder der Mnemonik), der ausgeführt werden soll, und der zweite sind die Operanden oder die Parameter des Befehls.
Im Folgenden finden Sie einige Beispiele für typische Anweisungen in Assemblersprache:
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL registerDas Hello World-Programm in der Versammlung
Der folgende Assembler-Code zeigt die Zeichenfolge 'Hello World' auf dem Bildschirm an -
section .text
global _start ;must be declared for linker (ld)
_start: ;tells linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Hello, world!', 0xa ;string to be printed
len equ $ - msg ;length of the stringWenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Hello, world!Kompilieren und Verknüpfen eines Assembly-Programms in NASM
Stellen Sie sicher, dass Sie den Pfad von festgelegt haben nasm und ldBinärdateien in Ihrer Umgebungsvariablen PATH. Führen Sie nun die folgenden Schritte aus, um das obige Programm zu kompilieren und zu verknüpfen:
Geben Sie den obigen Code mit einem Texteditor ein und speichern Sie ihn als hello.asm.
Stellen Sie sicher, dass Sie sich in demselben Verzeichnis befinden, in dem Sie gespeichert haben hello.asm.
Geben Sie ein, um das Programm zusammenzustellen nasm -f elf hello.asm
Wenn ein Fehler auftritt, werden Sie zu diesem Zeitpunkt dazu aufgefordert. Andernfalls wird eine Objektdatei Ihres Programms benannthello.o wird erstellt.
Geben Sie ein, um die Objektdatei zu verknüpfen und eine ausführbare Datei mit dem Namen "Hallo" zu erstellen ld -m elf_i386 -s -o hello hello.o
Führen Sie das Programm durch Eingabe aus ./hello
Wenn Sie alles richtig gemacht haben, wird "Hallo Welt!" Angezeigt. auf dem Bildschirm.
Wir haben bereits die drei Abschnitte eines Montageprogramms besprochen. Diese Abschnitte repräsentieren auch verschiedene Speichersegmente.
Interessanterweise erhalten Sie das gleiche Ergebnis, wenn Sie das Schlüsselwort section durch segment ersetzen. Versuchen Sie den folgenden Code -
segment .text ;code segment
global _start ;must be declared for linker
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
segment .data ;data segment
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear stringWenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Hello, world!Speichersegmente
Ein segmentiertes Speichermodell unterteilt den Systemspeicher in Gruppen unabhängiger Segmente, auf die durch Zeiger in den Segmentregistern verwiesen wird. Jedes Segment wird verwendet, um einen bestimmten Datentyp zu enthalten. Ein Segment enthält Befehlscodes, ein anderes Segment speichert die Datenelemente und ein drittes Segment enthält den Programmstapel.
In Anbetracht der obigen Diskussion können wir verschiedene Speichersegmente als - spezifizieren
Data segment - Es wird vertreten durch .data Abschnitt und die .bss. Der Abschnitt .data wird verwendet, um den Speicherbereich zu deklarieren, in dem Datenelemente für das Programm gespeichert sind. Dieser Abschnitt kann nach der Deklaration der Datenelemente nicht erweitert werden und bleibt im gesamten Programm statisch.
Der Abschnitt .bss ist auch ein statischer Speicherabschnitt, der Puffer für Daten enthält, die später im Programm deklariert werden sollen. Dieser Pufferspeicher ist mit Null gefüllt.
Code segment - Es wird vertreten durch .textSektion. Dies definiert einen Bereich im Speicher, in dem die Befehlscodes gespeichert sind. Dies ist auch ein fester Bereich.
Stack - Dieses Segment enthält Datenwerte, die an Funktionen und Prozeduren innerhalb des Programms übergeben werden.
Prozessoroperationen umfassen meistens die Verarbeitung von Daten. Diese Daten können im Speicher gespeichert und von dort aus abgerufen werden. Das Lesen von Daten aus dem Speicher und das Speichern von Daten im Speicher verlangsamt jedoch den Prozessor, da komplizierte Prozesse zum Senden der Datenanforderung über den Steuerbus und in die Speichereinheit und zum Abrufen der Daten über denselben Kanal erforderlich sind.
Um die Prozessoroperationen zu beschleunigen, enthält der Prozessor einige interne Speicherstellen, die als aufgerufen bezeichnet werden registers.
Die Register speichern Datenelemente zur Verarbeitung, ohne auf den Speicher zugreifen zu müssen. Eine begrenzte Anzahl von Registern ist in den Prozessorchip eingebaut.
Prozessorregister
In der IA-32-Architektur gibt es zehn 32-Bit- und sechs 16-Bit-Prozessorregister. Die Register sind in drei Kategorien unterteilt -
- Allgemeine Register,
- Steuerregister und
- Segmentregister.
Die allgemeinen Register sind weiter in die folgenden Gruppen unterteilt:
- Datenregister,
- Zeigerregister und
- Indexregister.
Datenregister
Vier 32-Bit-Datenregister werden für arithmetische, logische und andere Operationen verwendet. Diese 32-Bit-Register können auf drei Arten verwendet werden:
Als vollständige 32-Bit-Datenregister: EAX, EBX, ECX, EDX.
Die unteren Hälften der 32-Bit-Register können als vier 16-Bit-Datenregister verwendet werden: AX, BX, CX und DX.
Die untere und die obere Hälfte der oben genannten vier 16-Bit-Register können als acht 8-Bit-Datenregister verwendet werden: AH, AL, BH, BL, CH, CL, DH und DL.

Einige dieser Datenregister werden speziell für arithmetische Operationen verwendet.
AX is the primary accumulator;; Es wird in Eingabe- / Ausgabe- und den meisten arithmetischen Anweisungen verwendet. Beispielsweise wird bei einer Multiplikationsoperation ein Operand entsprechend der Größe des Operanden im EAX- oder AX- oder AL-Register gespeichert.
BX is known as the base register, wie es bei der indizierten Adressierung verwendet werden könnte.
CX is known as the count registerAls ECX speichern CX-Register die Schleifenzahl in iterativen Operationen.
DX is known as the data register. Es wird auch bei Eingabe- / Ausgabeoperationen verwendet. Es wird auch mit dem AX-Register zusammen mit DX zum Multiplizieren und Teilen von Operationen mit großen Werten verwendet.
Zeigerregister
Die Zeigerregister sind 32-Bit-EIP-, ESP- und EBP-Register und entsprechende 16-Bit-Rechtsabschnitte IP, SP und BP. Es gibt drei Kategorien von Zeigerregistern -
Instruction Pointer (IP)- Das 16-Bit-IP-Register speichert die Offset-Adresse des nächsten auszuführenden Befehls. IP in Verbindung mit dem CS-Register (als CS: IP) gibt die vollständige Adresse des aktuellen Befehls im Codesegment an.
Stack Pointer (SP)- Das 16-Bit-SP-Register liefert den Versatzwert innerhalb des Programmstapels. SP in Verbindung mit dem SS-Register (SS: SP) bezieht sich auf die aktuelle Position von Daten oder Adressen innerhalb des Programmstapels.
Base Pointer (BP)- Das 16-Bit-BP-Register hilft hauptsächlich bei der Referenzierung der Parametervariablen, die an ein Unterprogramm übergeben werden. Die Adresse im SS-Register wird mit dem Offset in BP kombiniert, um die Position des Parameters zu erhalten. BP kann auch mit DI und SI als Basisregister für die spezielle Adressierung kombiniert werden.
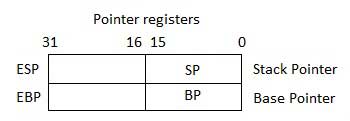
Indexregister
Die 32-Bit-Indexregister ESI und EDI sowie ihre 16-Bit-Teile ganz rechts. SI und DI werden für die indizierte Adressierung verwendet und manchmal zusätzlich und subtrahiert. Es gibt zwei Sätze von Indexzeigern -
Source Index (SI) - Es wird als Quellindex für Zeichenfolgenoperationen verwendet.
Destination Index (DI) - Es wird als Zielindex für Zeichenfolgenoperationen verwendet.

Kontrollregister
Das 32-Bit-Befehlszeigerregister und das 32-Bit-Flagsregister zusammen werden als Steuerregister betrachtet.
Viele Anweisungen umfassen Vergleiche und mathematische Berechnungen und ändern den Status der Flags. Einige andere bedingte Anweisungen testen den Wert dieser Statusflags, um den Kontrollfluss an einen anderen Ort zu leiten.
Die gemeinsamen Flag-Bits sind:
Overflow Flag (OF) - Zeigt den Überlauf eines höherwertigen Bits (Bit ganz links) nach einer vorzeichenbehafteten arithmetischen Operation an.
Direction Flag (DF)- Er bestimmt die linke oder rechte Richtung zum Verschieben oder Vergleichen von Zeichenfolgendaten. Wenn der DF-Wert 0 ist, wird die Zeichenfolgenoperation von links nach rechts ausgeführt, und wenn der Wert auf 1 gesetzt wird, wird die Zeichenfolgenoperation von rechts nach links ausgeführt.
Interrupt Flag (IF)- Hiermit wird festgelegt, ob externe Interrupts wie Tastatureingaben usw. ignoriert oder verarbeitet werden sollen. Es deaktiviert den externen Interrupt, wenn der Wert 0 ist, und aktiviert Interrupts, wenn es auf 1 gesetzt ist.
Trap Flag (TF)- Hiermit können Sie den Betrieb des Prozessors im Einzelschrittmodus einstellen. Das von uns verwendete DEBUG-Programm setzt das Trap-Flag, sodass wir die Ausführung einzeln ausführen können.
Sign Flag (SF)- Es zeigt das Vorzeichen des Ergebnisses einer arithmetischen Operation. Dieses Flag wird gemäß dem Vorzeichen eines Datenelements nach der arithmetischen Operation gesetzt. Das Vorzeichen wird durch die höhere Ordnung des Bit ganz links angezeigt. Ein positives Ergebnis löscht den Wert von SF auf 0 und ein negatives Ergebnis setzt ihn auf 1.
Zero Flag (ZF)- Zeigt das Ergebnis einer Arithmetik- oder Vergleichsoperation an. Ein Ergebnis ungleich Null löscht das Null-Flag auf 0 und ein Null-Ergebnis setzt es auf 1.
Auxiliary Carry Flag (AF)- Es enthält den Übertrag von Bit 3 nach Bit 4 nach einer arithmetischen Operation; wird für spezialisierte Arithmetik verwendet. Der AF wird gesetzt, wenn eine 1-Byte-Arithmetikoperation einen Übertrag von Bit 3 nach Bit 4 verursacht.
Parity Flag (PF)- Zeigt die Gesamtzahl der 1-Bits im Ergebnis einer arithmetischen Operation an. Eine gerade Anzahl von 1 Bits löscht das Paritätsflag auf 0 und eine ungerade Anzahl von 1 Bits setzt das Paritätsflag auf 1.
Carry Flag (CF)- Es enthält den Übertrag von 0 oder 1 von einem höherwertigen Bit (ganz links) nach einer arithmetischen Operation. Es speichert auch den Inhalt des letzten Bits einer Verschiebungs- oder Drehoperation .
Die folgende Tabelle gibt die Position der Flag-Bits im 16-Bit-Flags-Register an:
| Flagge: | Ö | D. | ich | T. | S. | Z. | EIN | P. | C. | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit Nr.: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Segmentregister
Segmente sind bestimmte Bereiche, die in einem Programm zum Enthalten von Daten, Code und Stapel definiert sind. Es gibt drei Hauptsegmente -
Code Segment- Es enthält alle auszuführenden Anweisungen. Ein 16-Bit-Codesegmentregister oder CS-Register speichert die Startadresse des Codesegments.
Data Segment- Es enthält Daten, Konstanten und Arbeitsbereiche. Ein 16-Bit-Datensegmentregister oder DS-Register speichert die Startadresse des Datensegments.
Stack Segment- Es enthält Daten und Rücksprungadressen von Prozeduren oder Unterprogrammen. Es ist als 'Stack'-Datenstruktur implementiert. Das Stapelsegmentregister oder SS-Register speichert die Startadresse des Stapels.
Neben den DS-, CS- und SS-Registern gibt es weitere zusätzliche Segmentregister - ES (zusätzliches Segment), FS und GS, die zusätzliche Segmente zum Speichern von Daten bereitstellen.
Bei der Baugruppenprogrammierung muss ein Programm auf die Speicherorte zugreifen. Alle Speicherplätze innerhalb eines Segments sind relativ zur Startadresse des Segments. Ein Segment beginnt in einer Adresse, die gleichmäßig durch 16 oder hexadezimal 10 teilbar ist. Die hexadezimale Ziffer ganz rechts in all diesen Speicheradressen ist also 0, was im Allgemeinen nicht in den Segmentregistern gespeichert ist.
In den Segmentregistern werden die Startadressen eines Segments gespeichert. Um die genaue Position von Daten oder Anweisungen innerhalb eines Segments zu erhalten, ist ein Versatzwert (oder eine Verschiebung) erforderlich. Um auf einen Speicherplatz in einem Segment zu verweisen, kombiniert der Prozessor die Segmentadresse im Segmentregister mit dem Versatzwert des Ortes.
Beispiel
Schauen Sie sich das folgende einfache Programm an, um die Verwendung von Registern in der Assembly-Programmierung zu verstehen. Dieses Programm zeigt 9 Sterne auf dem Bildschirm zusammen mit einer einfachen Meldung an -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,9 ;message length
mov ecx,s2 ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Displaying 9 stars',0xa ;a message
len equ $ - msg ;length of message
s2 times 9 db '*'Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Displaying 9 stars
*********Systemaufrufe sind APIs für die Schnittstelle zwischen dem Benutzerbereich und dem Kernelbereich. Wir haben die Systemaufrufe bereits verwendet. sys_write und sys_exit zum Schreiben in den Bildschirm bzw. zum Verlassen des Programms.
Linux-Systemaufrufe
Sie können Linux-Systemaufrufe in Ihren Assembly-Programmen verwenden. Sie müssen die folgenden Schritte ausführen, um Linux-Systemaufrufe in Ihrem Programm zu verwenden:
- Tragen Sie die Systemrufnummer in das EAX-Register ein.
- Speichern Sie die Argumente für den Systemaufruf in den Registern EBX, ECX usw.
- Rufen Sie den entsprechenden Interrupt an (80h).
- Das Ergebnis wird normalerweise im EAX-Register zurückgegeben.
Es gibt sechs Register, in denen die Argumente des verwendeten Systemaufrufs gespeichert sind. Dies sind EBX, ECX, EDX, ESI, EDI und EBP. Diese Register verwenden die aufeinander folgenden Argumente, beginnend mit dem EBX-Register. Wenn mehr als sechs Argumente vorhanden sind, wird der Speicherort des ersten Arguments im EBX-Register gespeichert.
Das folgende Codefragment zeigt die Verwendung des Systemaufrufs sys_exit -
mov eax,1 ; system call number (sys_exit)
int 0x80 ; call kernelDas folgende Codefragment zeigt die Verwendung des Systemaufrufs sys_write -
mov edx,4 ; message length
mov ecx,msg ; message to write
mov ebx,1 ; file descriptor (stdout)
mov eax,4 ; system call number (sys_write)
int 0x80 ; call kernelAlle Systemaufrufe werden in /usr/include/asm/unistd.h zusammen mit ihren Nummern aufgelistet (der Wert, der in EAX eingegeben werden muss , bevor Sie int 80h aufrufen).
Die folgende Tabelle zeigt einige der in diesem Lernprogramm verwendeten Systemaufrufe -
| % eax | Name | % ebx | % ecx | % edx | % esx | % edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - - | - - | - - | - - |
| 2 | sys_fork | struct pt_regs | - - | - - | - - | - - |
| 3 | sys_read | unsigned int | char * | size_t | - - | - - |
| 4 | sys_write | unsigned int | const char * | size_t | - - | - - |
| 5 | sys_open | const char * | int | int | - - | - - |
| 6 | sys_close | unsigned int | - - | - - | - - | - - |
Beispiel
Im folgenden Beispiel wird eine Nummer von der Tastatur gelesen und auf dem Bildschirm angezeigt.
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80hWenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Please enter a number:
1234
You have entered:1234Die meisten Assembler-Anweisungen erfordern die Verarbeitung von Operanden. Eine Operandenadresse gibt den Ort an, an dem die zu verarbeitenden Daten gespeichert werden. Einige Anweisungen erfordern keinen Operanden, während andere Anweisungen einen, zwei oder drei Operanden erfordern können.
Wenn ein Befehl zwei Operanden erfordert, ist der erste Operand im Allgemeinen das Ziel, das Daten in einem Register oder Speicherplatz enthält, und der zweite Operand ist die Quelle. Die Quelle enthält entweder die zu liefernden Daten (sofortige Adressierung) oder die Adresse (im Register oder Speicher) der Daten. Im Allgemeinen bleiben die Quelldaten nach der Operation unverändert.
Die drei grundlegenden Adressierungsmodi sind:
- Adressierung registrieren
- Sofortige Adressierung
- Speicheradressierung
Adressierung registrieren
In diesem Adressierungsmodus enthält ein Register den Operanden. Abhängig von der Anweisung kann das Register der erste Operand, der zweite Operand oder beides sein.
Zum Beispiel,
MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registersDa die Verarbeitung von Daten zwischen Registern keinen Speicher erfordert, bietet sie die schnellste Verarbeitung von Daten.
Sofortige Adressierung
Ein unmittelbarer Operand hat einen konstanten Wert oder einen Ausdruck. Wenn ein Befehl mit zwei Operanden eine sofortige Adressierung verwendet, kann der erste Operand ein Register oder ein Speicherort sein, und der zweite Operand ist eine unmittelbare Konstante. Der erste Operand definiert die Länge der Daten.
Zum Beispiel,
BYTE_VALUE DB 150 ; A byte value is defined
WORD_VALUE DW 300 ; A word value is defined
ADD BYTE_VALUE, 65 ; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AXDirekte Speicheradressierung
Wenn Operanden im Speicheradressierungsmodus angegeben werden, ist ein direkter Zugriff auf den Hauptspeicher, normalerweise auf das Datensegment, erforderlich. Diese Art der Adressierung führt zu einer langsameren Datenverarbeitung. Um den genauen Speicherort der Daten im Speicher zu ermitteln, benötigen wir die Segmentstartadresse, die normalerweise im DS-Register enthalten ist, und einen Versatzwert. Dieser Offsetwert wird auch genannteffective address.
Im direkten Adressierungsmodus wird der Versatzwert direkt als Teil des Befehls angegeben, der normalerweise durch den Variablennamen angezeigt wird. Der Assembler berechnet den Versatzwert und verwaltet eine Symboltabelle, in der die Versatzwerte aller im Programm verwendeten Variablen gespeichert sind.
Bei der direkten Speicheradressierung bezieht sich einer der Operanden auf einen Speicherort und der andere Operand auf ein Register.
Zum Beispiel,
ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to registerDirect-Offset-Adressierung
Dieser Adressierungsmodus verwendet die arithmetischen Operatoren, um eine Adresse zu ändern. Schauen Sie sich beispielsweise die folgenden Definitionen an, die Datentabellen definieren:
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of wordsDie folgenden Operationen greifen auf Daten aus den Tabellen im Speicher in Register zu -
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLEIndirekte Speicheradressierung
Dieser Adressierungsmodus nutzt die Fähigkeit des Computers zur Segmentierung: Versatzadressierung . Im Allgemeinen werden zu diesem Zweck die Basisregister EBX, EBP (oder BX, BP) und die Indexregister (DI, SI) verwendet, die in eckigen Klammern für Speicherreferenzen codiert sind.
Die indirekte Adressierung wird im Allgemeinen für Variablen verwendet, die mehrere Elemente wie Arrays enthalten. Die Startadresse des Arrays wird beispielsweise im EBX-Register gespeichert.
Das folgende Codefragment zeigt, wie auf verschiedene Elemente der Variablen zugegriffen wird.
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
ADD EBX, 2 ; EBX = EBX +2
MOV [EBX], 123 ; MY_TABLE[1] = 123Die MOV-Anweisung
Wir haben bereits den MOV-Befehl verwendet, der zum Verschieben von Daten von einem Speicherplatz in einen anderen verwendet wird. Der MOV-Befehl benötigt zwei Operanden.
Syntax
Die Syntax des MOV-Befehls lautet -
MOV destination, sourceDer MOV-Befehl kann eine der folgenden fünf Formen haben:
MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, registerBitte beachten Sie, dass -
- Beide Operanden im MOV-Betrieb sollten gleich groß sein
- Der Wert des Quelloperanden bleibt unverändert
Der MOV-Befehl verursacht manchmal Mehrdeutigkeiten. Schauen Sie sich zum Beispiel die Aussagen an -
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110Es ist nicht klar, ob Sie ein Byte-Äquivalent oder ein Wort-Äquivalent der Zahl 110 verschieben möchten. In solchen Fällen ist es ratsam, a zu verwenden type specifier.
Die folgende Tabelle zeigt einige der gängigen Typspezifizierer -
| Typspezifizierer | Bytes adressiert |
|---|---|
| BYTE | 1 |
| WORT | 2 |
| DWORD | 4 |
| QWORT | 8 |
| TBYTE | 10 |
Beispiel
Das folgende Programm veranschaulicht einige der oben diskutierten Konzepte. Es speichert einen Namen 'Zara Ali' im Datenbereich des Speichers, ändert dann programmgesteuert seinen Wert in einen anderen Namen 'Nuha Ali' und zeigt beide Namen an.
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
;writing the name 'Zara Ali'
mov edx,9 ;message length
mov ecx, name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov [name], dword 'Nuha' ; Changed the name to Nuha Ali
;writing the name 'Nuha Ali'
mov edx,8 ;message length
mov ecx,name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
name db 'Zara Ali 'Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Zara Ali Nuha AliNASM bietet verschiedene define directiveszum Reservieren von Speicherplatz für Variablen. Die Direktive define Assembler wird für die Zuweisung von Speicherplatz verwendet. Es kann verwendet werden, um ein oder mehrere Bytes zu reservieren und zu initialisieren.
Zuweisen von Speicherplatz für initialisierte Daten
Die Syntax für die Speicherzuweisungsanweisung für initialisierte Daten lautet -
[variable-name] define-directive initial-value [,initial-value]...Wobei Variablenname die Kennung für jeden Speicherplatz ist. Der Assembler ordnet jedem im Datensegment definierten Variablennamen einen Versatzwert zu.
Es gibt fünf Grundformen der Definitionsrichtlinie:
| Richtlinie | Zweck | Lagerraum |
|---|---|---|
| DB | Byte definieren | weist 1 Byte zu |
| DW | Wort definieren | weist 2 Bytes zu |
| DD | Doppelwort definieren | weist 4 Bytes zu |
| DQ | Quadword definieren | weist 8 Bytes zu |
| DT | Definieren Sie zehn Bytes | weist 10 Bytes zu |
Im Folgenden finden Sie einige Beispiele für die Verwendung von definierten Anweisungen:
choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456Bitte beachten Sie, dass -
Jedes Zeichenbyte wird als ASCII-Wert hexadezimal gespeichert.
Jeder Dezimalwert wird automatisch in sein 16-Bit-Binäräquivalent konvertiert und als Hexadezimalzahl gespeichert.
Der Prozessor verwendet die Little-Endian-Bytereihenfolge.
Negative Zahlen werden in die Zweierkomplementdarstellung umgewandelt.
Kurze und lange Gleitkommazahlen werden mit 32 bzw. 64 Bit dargestellt.
Das folgende Programm zeigt die Verwendung der define-Direktive -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,1 ;message length
mov ecx,choice ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
choice DB 'y'Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
yZuweisen von Speicherplatz für nicht initialisierte Daten
Die Reserveanweisungen werden verwendet, um Speicherplatz für nicht initialisierte Daten zu reservieren. Die Reserveanweisungen verwenden einen einzelnen Operanden, der die Anzahl der zu reservierenden Speichereinheiten angibt. Jede Definitionsrichtlinie hat eine zugehörige Reserverichtlinie.
Es gibt fünf Grundformen der Reserverichtlinie:
| Richtlinie | Zweck |
|---|---|
| RESB | Reserviere ein Byte |
| RESW | Reserviere ein Wort |
| RESD | Reserviere ein Doppelwort |
| RESQ | Reserviere ein Quadword |
| SICH AUSRUHEN | Reservieren Sie zehn Bytes |
Mehrere Definitionen
Sie können mehrere Datendefinitionsanweisungen in einem Programm haben. Zum Beispiel -
choice DB 'Y' ;ASCII of y = 79H
number1 DW 12345 ;12345D = 3039H
number2 DD 12345679 ;123456789D = 75BCD15HDer Assembler reserviert zusammenhängenden Speicher für mehrere Variablendefinitionen.
Mehrere Initialisierungen
Die TIMES-Direktive ermöglicht mehrere Initialisierungen auf denselben Wert. Beispielsweise kann ein Array mit dem Namen markierungen der Größe 9 mit der folgenden Anweisung definiert und auf Null initialisiert werden:
marks TIMES 9 DW 0Die TIMES-Direktive ist nützlich beim Definieren von Arrays und Tabellen. Das folgende Programm zeigt 9 Sternchen auf dem Bildschirm an -
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
mov edx,9 ;message length
mov ecx, stars ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
stars times 9 db '*'Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
*********Es gibt mehrere von NASM bereitgestellte Anweisungen, die Konstanten definieren. Wir haben die EQU-Richtlinie bereits in früheren Kapiteln verwendet. Wir werden insbesondere drei Richtlinien diskutieren -
- EQU
- %assign
- %define
Die EQU-Richtlinie
Das EQUDie Direktive wird zum Definieren von Konstanten verwendet. Die Syntax der EQU-Direktive lautet wie folgt:
CONSTANT_NAME EQU expressionZum Beispiel,
TOTAL_STUDENTS equ 50Sie können diesen konstanten Wert dann in Ihrem Code verwenden, wie z.
mov ecx, TOTAL_STUDENTS
cmp eax, TOTAL_STUDENTSDer Operand einer EQU-Anweisung kann ein Ausdruck sein -
LENGTH equ 20
WIDTH equ 10
AREA equ length * widthDas obige Codesegment würde AREA als 200 definieren.
Beispiel
Das folgende Beispiel zeigt die Verwendung der EQU-Direktive -
SYS_EXIT equ 1
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
mov eax,SYS_EXIT ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $ - msg2 msg3 db 'Linux assembly programming! ' len3 equ $- msg3Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Hello, programmers!
Welcome to the world of,
Linux assembly programming!Die% weisen Richtlinie zu
Das %assignDirektive kann verwendet werden, um numerische Konstanten wie die EQU-Direktive zu definieren. Diese Richtlinie ermöglicht eine Neudefinition. Beispielsweise können Sie die Konstante TOTAL als - definieren.
%assign TOTAL 10Später im Code können Sie ihn neu definieren als -
%assign TOTAL 20Diese Richtlinie unterscheidet zwischen Groß- und Kleinschreibung.
Die% definieren Richtlinie
Das %defineDie Direktive ermöglicht das Definieren von numerischen und String-Konstanten. Diese Direktive ähnelt der #define in C. Beispielsweise können Sie die Konstante PTR als - definieren
%define PTR [EBP+4]Der obige Code ersetzt PTR durch [EBP + 4].
Diese Richtlinie ermöglicht auch eine Neudefinition und unterscheidet zwischen Groß- und Kleinschreibung.
Die INC-Anweisung
Der INC-Befehl wird zum Inkrementieren eines Operanden um eins verwendet. Es funktioniert mit einem einzelnen Operanden, der sich entweder in einem Register oder im Speicher befinden kann.
Syntax
Der INC-Befehl hat die folgende Syntax:
INC destinationDer Operand Ziel könnte einen 8-Bit, 16-Bit oder 32-Bit - Operanden sein.
Beispiel
INC EBX ; Increments 32-bit register
INC DL ; Increments 8-bit register
INC [count] ; Increments the count variableDie DEC-Anweisung
Der DEC-Befehl wird zum Dekrementieren eines Operanden um eins verwendet. Es funktioniert mit einem einzelnen Operanden, der sich entweder in einem Register oder im Speicher befinden kann.
Syntax
Der DEC-Befehl hat die folgende Syntax:
DEC destinationDer Operand Ziel könnte einen 8-Bit, 16-Bit oder 32-Bit - Operanden sein.
Beispiel
segment .data
count dw 0
value db 15
segment .text
inc [count]
dec [value]
mov ebx, count
inc word [ebx]
mov esi, value
dec byte [esi]Die ADD- und SUB-Anweisungen
Die ADD- und SUB-Anweisungen werden zum Durchführen einer einfachen Addition / Subtraktion von Binärdaten in Byte-, Wort- und Doppelwortgröße verwendet, dh zum Addieren oder Subtrahieren von 8-Bit-, 16-Bit- bzw. 32-Bit-Operanden.
Syntax
Die Anweisungen ADD und SUB haben die folgende Syntax:
ADD/SUB destination, sourceDer ADD / SUB-Befehl kann zwischen - erfolgen.
- Registrieren, um sich zu registrieren
- Speicher zum Registrieren
- Im Speicher registrieren
- Registrieren Sie sich zu konstanten Daten
- Speicher für konstante Daten
Wie bei anderen Anweisungen sind jedoch Speicher-zu-Speicher-Operationen mit ADD / SUB-Anweisungen nicht möglich. Eine ADD- oder SUB-Operation setzt oder löscht den Überlauf und überträgt Flags.
Beispiel
Im folgenden Beispiel werden zwei Ziffern vom Benutzer angefordert, die Ziffern im EAX- bzw. EBX-Register gespeichert, die Werte hinzugefügt, das Ergebnis an einem Speicherort ' res ' gespeichert und schließlich das Ergebnis angezeigt.
SYS_EXIT equ 1
SYS_READ equ 3
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
segment .data
msg1 db "Enter a digit ", 0xA,0xD
len1 equ $- msg1 msg2 db "Please enter a second digit", 0xA,0xD len2 equ $- msg2
msg3 db "The sum is: "
len3 equ $- msg3
segment .bss
num1 resb 2
num2 resb 2
res resb 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num1
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num2
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
; moving the first number to eax register and second number to ebx
; and subtracting ascii '0' to convert it into a decimal number
mov eax, [num1]
sub eax, '0'
mov ebx, [num2]
sub ebx, '0'
; add eax and ebx
add eax, ebx
; add '0' to to convert the sum from decimal to ASCII
add eax, '0'
; storing the sum in memory location res
mov [res], eax
; print the sum
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, res
mov edx, 1
int 0x80
exit:
mov eax, SYS_EXIT
xor ebx, ebx
int 0x80Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Enter a digit:
3
Please enter a second digit:
4
The sum is:
7The program with hardcoded variables −
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The sum is:
7Die MUL / IMUL-Anweisung
Es gibt zwei Anweisungen zum Multiplizieren von Binärdaten. Der MUL-Befehl (Multiply) verarbeitet vorzeichenlose Daten und der IMUL-Befehl (Integer Multiply) verarbeitet vorzeichenbehaftete Daten. Beide Anweisungen wirken sich auf das Carry- und Overflow-Flag aus.
Syntax
Die Syntax für die MUL / IMUL-Anweisungen lautet wie folgt:
MUL/IMUL multiplierDer Multiplikand befindet sich in beiden Fällen in einem Akkumulator, abhängig von der Größe des Multiplikanden und des Multiplikators, und das erzeugte Produkt wird abhängig von der Größe der Operanden auch in zwei Registern gespeichert. Im folgenden Abschnitt werden die MUL-Anweisungen in drei verschiedenen Fällen erläutert:
| Sr.Nr. | Szenarien |
|---|---|
| 1 | When two bytes are multiplied − Der Multiplikand befindet sich im AL-Register, und der Multiplikator ist ein Byte im Speicher oder in einem anderen Register. Das Produkt ist in AX. Hochwertige 8 Bits des Produkts werden in AH und die niederwertigen 8 Bits in AL gespeichert.

|
| 2 | When two one-word values are multiplied − Der Multiplikand sollte sich im AX-Register befinden, und der Multiplikator ist ein Wort im Speicher oder ein anderes Register. Für eine Anweisung wie MUL DX müssen Sie beispielsweise den Multiplikator in DX und den Multiplikanden in AX speichern. Das resultierende Produkt ist ein Doppelwort, das zwei Register benötigt. Der Teil höherer Ordnung (ganz links) wird in DX und der Teil niedrigerer Ordnung (ganz rechts) in AX gespeichert.

|
| 3 | When two doubleword values are multiplied − Wenn zwei Doppelwortwerte multipliziert werden, sollte sich der Multiplikand in EAX befinden und der Multiplikator ist ein Doppelwortwert, der im Speicher oder in einem anderen Register gespeichert ist. Das erzeugte Produkt wird in den EDX: EAX-Registern gespeichert, dh die 32 Bits höherer Ordnung werden im EDX-Register gespeichert und die 32 Bits niedriger Ordnung werden im EAX-Register gespeichert.

|
Beispiel
MOV AL, 10
MOV DL, 25
MUL DL
...
MOV DL, 0FFH ; DL= -1
MOV AL, 0BEH ; AL = -66
IMUL DLBeispiel
Das folgende Beispiel multipliziert 3 mit 2 und zeigt das Ergebnis an -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al,'3'
sub al, '0'
mov bl, '2'
sub bl, '0'
mul bl
add al, '0'
mov [res], al
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The result is:
6Die DIV / IDIV-Anweisungen
Die Divisionsoperation erzeugt zwei Elemente - a quotient und ein remainder. Im Falle einer Multiplikation tritt kein Überlauf auf, da Register mit doppelter Länge verwendet werden, um das Produkt zu halten. Im Falle einer Teilung kann jedoch ein Überlauf auftreten. Der Prozessor erzeugt einen Interrupt, wenn ein Überlauf auftritt.
Der Befehl DIV (Divide) wird für vorzeichenlose Daten und der Befehl IDIV (Integer Divide) für vorzeichenbehaftete Daten verwendet.
Syntax
Das Format für die DIV / IDIV-Anweisung -
DIV/IDIV divisorDie Dividende befindet sich in einem Akkumulator. Beide Anweisungen können mit 8-Bit-, 16-Bit- oder 32-Bit-Operanden arbeiten. Die Operation wirkt sich auf alle sechs Statusflags aus. Im folgenden Abschnitt werden drei Fälle von Division mit unterschiedlicher Operandengröße erläutert:
| Sr.Nr. | Szenarien |
|---|---|
| 1 | When the divisor is 1 byte − Es wird angenommen, dass sich die Dividende im AX-Register befindet (16 Bit). Nach der Division geht der Quotient in das AL-Register und der Rest in das AH-Register.

|
| 2 | When the divisor is 1 word − Die Dividende wird mit 32 Bit Länge und in den DX: AX-Registern angenommen. Die 16 Bits höherer Ordnung befinden sich in DX und die 16 Bits niedriger Ordnung befinden sich in AX. Nach der Division geht der 16-Bit-Quotient in das AX-Register und der 16-Bit-Rest in das DX-Register.
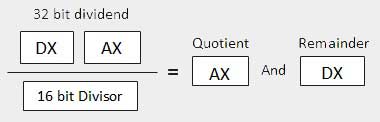
|
| 3 | When the divisor is doubleword − Die Dividende wird als 64 Bit lang und in den EDX: EAX-Registern angenommen. Die höherwertigen 32 Bit befinden sich in EDX und die niederwertigen 32 Bit in EAX. Nach der Division geht der 32-Bit-Quotient in das EAX-Register und der 32-Bit-Rest in das EDX-Register.
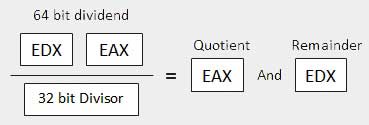
|
Beispiel
Das folgende Beispiel teilt 8 durch 2. Die dividend 8 ist in der gespeichert 16-bit AX register und die divisor 2 ist in der gespeichert 8-bit BL register.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax,'8'
sub ax, '0'
mov bl, '2'
sub bl, '0'
div bl
add ax, '0'
mov [res], ax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The result is:
4Der Prozessorbefehlssatz enthält die Befehle AND, OR, XOR, TEST und NOT Boolean Logic, die die Bits entsprechend den Anforderungen des Programms testen, setzen und löschen.
Das Format für diese Anleitung -
| Sr.Nr. | Anweisung | Format |
|---|---|---|
| 1 | UND | UND Operand1, Operand2 |
| 2 | ODER | ODER Operand1, Operand2 |
| 3 | XOR | XOR-Operand1, Operand2 |
| 4 | PRÜFUNG | TEST operand1, operand2 |
| 5 | NICHT | NICHT operand1 |
Der erste Operand kann sich in allen Fällen entweder im Register oder im Speicher befinden. Der zweite Operand kann sich entweder im Register / Speicher oder in einem unmittelbaren (konstanten) Wert befinden. Speicher-zu-Speicher-Operationen sind jedoch nicht möglich. Diese Anweisungen vergleichen oder stimmen Bits der Operanden ab und setzen die Flags CF, OF, PF, SF und ZF.
Die AND-Anweisung
Der AND-Befehl wird zur Unterstützung logischer Ausdrücke verwendet, indem eine bitweise AND-Operation ausgeführt wird. Die bitweise AND-Operation gibt 1 zurück, wenn die übereinstimmenden Bits von beiden Operanden 1 sind, andernfalls gibt sie 0 zurück. Zum Beispiel -
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001Die UND-Operation kann zum Löschen eines oder mehrerer Bits verwendet werden. Angenommen, das BL-Register enthält 0011 1010. Wenn Sie die höherwertigen Bits auf Null löschen müssen, UND-Verknüpfung mit 0FH.
AND BL, 0FH ; This sets BL to 0000 1010Nehmen wir ein anderes Beispiel. Wenn Sie überprüfen möchten, ob eine bestimmte Zahl ungerade oder gerade ist, besteht ein einfacher Test darin, das niedrigstwertige Bit der Zahl zu überprüfen. Wenn dies 1 ist, ist die Zahl ungerade, andernfalls ist die Zahl gerade.
Angenommen, die Nummer befindet sich im AL-Register, können wir schreiben -
AND AL, 01H ; ANDing with 0000 0001
JZ EVEN_NUMBERDas folgende Programm veranschaulicht dies -
Beispiel
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax, 8h ;getting 8 in the ax
and ax, 1 ;and ax with 1
jz evnn
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, odd_msg ;message to write
mov edx, len2 ;length of message
int 0x80 ;call kernel
jmp outprog
evnn:
mov ah, 09h
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, even_msg ;message to write
mov edx, len1 ;length of message
int 0x80 ;call kernel
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
even_msg db 'Even Number!' ;message showing even number
len1 equ $ - even_msg odd_msg db 'Odd Number!' ;message showing odd number len2 equ $ - odd_msgWenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Even Number!Ändern Sie den Wert im Axtregister mit einer ungeraden Ziffer wie -
mov ax, 9h ; getting 9 in the axDas Programm würde Folgendes anzeigen:
Odd Number!Ebenso können Sie das gesamte Register mit 00H UND löschen.
Die OP-Anweisung
Der OR-Befehl wird zur Unterstützung des logischen Ausdrucks durch Ausführen einer bitweisen OR-Operation verwendet. Der bitweise ODER-Operator gibt 1 zurück, wenn die übereinstimmenden Bits von einem oder beiden Operanden eins sind. Es gibt 0 zurück, wenn beide Bits Null sind.
Zum Beispiel,
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111Die ODER-Verknüpfung kann zum Setzen eines oder mehrerer Bits verwendet werden. Nehmen wir zum Beispiel an, das AL-Register enthält 0011 1010, Sie müssen die vier niederwertigen Bits setzen, Sie können es ODER mit einem Wert 0000 1111, dh FH, ODER.
OR BL, 0FH ; This sets BL to 0011 1111Beispiel
Das folgende Beispiel zeigt die ODER-Anweisung. Speichern wir den Wert 5 und 3 in den Registern AL und BL, dann den Befehl,
OR AL, BLsollte 7 im AL-Register speichern -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
7Die XOR-Anweisung
Der XOR-Befehl implementiert die bitweise XOR-Operation. Die XOR-Operation setzt das resultierende Bit genau dann auf 1, wenn sich die Bits von den Operanden unterscheiden. Wenn die Bits von den Operanden gleich sind (beide 0 oder beide 1), wird das resultierende Bit auf 0 gelöscht.
Zum Beispiel,
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110XORing Ein Operand mit sich selbst ändert den Operanden in 0. Dies wird verwendet, um ein Register zu löschen.
XOR EAX, EAXDie TEST-Anweisung
Der TEST-Befehl funktioniert genauso wie die AND-Operation, ändert jedoch im Gegensatz zum AND-Befehl nicht den ersten Operanden. Wenn wir also prüfen müssen, ob eine Zahl in einem Register gerade oder ungerade ist, können wir dies auch mit der Anweisung TEST tun, ohne die ursprüngliche Zahl zu ändern.
TEST AL, 01H
JZ EVEN_NUMBERDie NOT-Anweisung
Der NOT-Befehl implementiert die bitweise NOT-Operation. Die Operation NOT kehrt die Bits in einem Operanden um. Der Operand kann sich entweder in einem Register oder im Speicher befinden.
Zum Beispiel,
Operand1: 0101 0011
After NOT -> Operand1: 1010 1100Die bedingte Ausführung in Assemblersprache wird durch mehrere Schleifen- und Verzweigungsanweisungen erreicht. Diese Anweisungen können den Steuerungsfluss in einem Programm ändern. Die bedingte Ausführung wird in zwei Szenarien beobachtet:
| Sr.Nr. | Bedingte Anweisungen |
|---|---|
| 1 | Unconditional jump Dies wird durch die JMP-Anweisung ausgeführt. Die bedingte Ausführung beinhaltet häufig eine Übertragung der Steuerung an die Adresse eines Befehls, der nicht dem aktuell ausgeführten Befehl folgt. Die Übertragung der Steuerung kann vorwärts erfolgen, um einen neuen Befehlssatz auszuführen, oder rückwärts, um dieselben Schritte erneut auszuführen. |
| 2 | Conditional jump Dies wird durch einen Satz von Sprungbefehlen j <Bedingung> abhängig von der Bedingung ausgeführt. Die bedingten Anweisungen übertragen die Steuerung, indem sie den sequentiellen Fluss unterbrechen, und sie tun dies, indem sie den Versatzwert in IP ändern. |
Lassen Sie uns die CMP-Anweisung besprechen, bevor wir die bedingten Anweisungen besprechen.
CMP-Anweisung
Der CMP-Befehl vergleicht zwei Operanden. Es wird im Allgemeinen bei der bedingten Ausführung verwendet. Diese Anweisung subtrahiert grundsätzlich einen Operanden vom anderen, um zu vergleichen, ob die Operanden gleich sind oder nicht. Die Ziel- oder Quelloperanden werden nicht gestört. Es wird zusammen mit der bedingten Sprunganweisung zur Entscheidungsfindung verwendet.
Syntax
CMP destination, sourceCMP vergleicht zwei numerische Datenfelder. Der Zieloperand kann sich entweder im Register oder im Speicher befinden. Der Quelloperand kann ein konstantes (unmittelbares) Daten-, Register- oder Speicherelement sein.
Beispiel
CMP DX, 00 ; Compare the DX value with zero
JE L7 ; If yes, then jump to label L7
.
.
L7: ...CMP wird häufig verwendet, um zu vergleichen, ob ein Zählerwert die Häufigkeit erreicht hat, mit der eine Schleife ausgeführt werden muss. Betrachten Sie den folgenden typischen Zustand:
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1Bedingungsloser Sprung
Wie bereits erwähnt, wird dies von der JMP-Anweisung ausgeführt. Die bedingte Ausführung beinhaltet häufig eine Übertragung der Steuerung an die Adresse eines Befehls, der nicht dem aktuell ausgeführten Befehl folgt. Die Übertragung der Steuerung kann vorwärts erfolgen, um einen neuen Befehlssatz auszuführen, oder rückwärts, um dieselben Schritte erneut auszuführen.
Syntax
Der JMP-Befehl enthält einen Labelnamen, bei dem der Kontrollfluss sofort übertragen wird. Die Syntax der JMP-Anweisung lautet -
JMP labelBeispiel
Das folgende Codeausschnitt veranschaulicht die JMP-Anweisung -
MOV AX, 00 ; Initializing AX to 0
MOV BX, 00 ; Initializing BX to 0
MOV CX, 01 ; Initializing CX to 1
L20:
ADD AX, 01 ; Increment AX
ADD BX, AX ; Add AX to BX
SHL CX, 1 ; shift left CX, this in turn doubles the CX value
JMP L20 ; repeats the statementsBedingter Sprung
Wenn eine bestimmte Bedingung im bedingten Sprung erfüllt ist, wird der Steuerfluss an einen Zielbefehl übertragen. Abhängig von der Bedingung und den Daten gibt es zahlreiche Anweisungen für bedingte Sprünge.
Im Folgenden sind die Anweisungen für bedingte Sprünge aufgeführt, die für vorzeichenbehaftete Daten verwendet werden, die für arithmetische Operationen verwendet werden.
| Anweisung | Beschreibung | Flaggen getestet |
|---|---|---|
| JE / JZ | Jump Equal oder Jump Zero | ZF |
| JNE / JNZ | Springe nicht gleich oder springe nicht Null | ZF |
| JG / JNLE | Springe größer oder springe nicht weniger / gleich | OF, SF, ZF |
| JGE / JNL | Springe größer / gleich oder springe nicht weniger | OF, SF |
| JL / JNGE | Weniger springen oder nicht größer / gleich springen | OF, SF |
| JLE / JNG | Weniger / gleich springen oder nicht größer springen | OF, SF, ZF |
Im Folgenden sind die Anweisungen für bedingte Sprünge aufgeführt, die für vorzeichenlose Daten verwendet werden, die für logische Operationen verwendet werden.
| Anweisung | Beschreibung | Flaggen getestet |
|---|---|---|
| JE / JZ | Jump Equal oder Jump Zero | ZF |
| JNE / JNZ | Springe nicht gleich oder springe nicht Null | ZF |
| JA / JNBE | Über oder über nicht unter / gleich springen | CF, ZF |
| JAE / JNB | Springe über / gleich oder springe nicht unter | CF. |
| JB / JNAE | Springe nach unten oder springe nicht nach oben / gleich | CF. |
| JBE / JNA | Springe unter / gleich oder springe nicht über | AF, CF. |
Die folgenden Anweisungen für bedingte Sprünge haben spezielle Verwendungszwecke und überprüfen den Wert von Flags -
| Anweisung | Beschreibung | Flaggen getestet |
|---|---|---|
| JXCZ | Springe, wenn CX Null ist | keiner |
| JC | Springen, wenn tragen | CF. |
| JNC | Springen, wenn kein Tragen | CF. |
| JO | Bei Überlauf springen | VON |
| JNO | Springen, wenn kein Überlauf vorliegt | VON |
| JP / JPE | Jump Parity oder Jump Parity Even | PF |
| JNP / JPO | Jump No Parity oder Jump Parity Odd | PF |
| JS | Sprungzeichen (negativer Wert) | SF |
| JNS | Kein Vorzeichen springen (positiver Wert) | SF |
Die Syntax für den Befehlssatz J <Bedingung> -
Beispiel,
CMP AL, BL
JE EQUAL
CMP AL, BH
JE EQUAL
CMP AL, CL
JE EQUAL
NON_EQUAL: ...
EQUAL: ...Beispiel
Das folgende Programm zeigt die größte von drei Variablen an. Die Variablen sind zweistellige Variablen. Die drei Variablen num1, num2 und num3 haben die Werte 47, 22 bzw. 31 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The largest digit is:
47Der JMP-Befehl kann zum Implementieren von Schleifen verwendet werden. Beispielsweise kann das folgende Codeausschnitt zum zehnmaligen Ausführen des Schleifenkörpers verwendet werden.
MOV CL, 10
L1:
<LOOP-BODY>
DEC CL
JNZ L1Der Prozessorbefehlssatz enthält jedoch eine Gruppe von Schleifenbefehlen zum Implementieren der Iteration. Der grundlegende LOOP-Befehl hat die folgende Syntax:
LOOP labelDabei ist label das Zieletikett, das die Zielanweisung wie in den Sprunganweisungen identifiziert. Der LOOP-Befehl geht davon aus, dass dieECX register contains the loop count. Wenn der Schleifenbefehl ausgeführt wird, wird das ECX-Register dekrementiert und die Steuerung springt zum Zieletikett, bis der ECX-Registerwert, dh der Zähler, den Wert Null erreicht.
Das obige Code-Snippet könnte geschrieben werden als -
mov ECX,10
l1:
<loop body>
loop l1Beispiel
Das folgende Programm druckt die Nummern 1 bis 9 auf dem Bildschirm -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,10
mov eax, '1'
l1:
mov [num], eax
mov eax, 4
mov ebx, 1
push ecx
mov ecx, num
mov edx, 1
int 0x80
mov eax, [num]
sub eax, '0'
inc eax
add eax, '0'
pop ecx
loop l1
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
num resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
123456789:Numerische Daten werden im Allgemeinen im Binärsystem dargestellt. Arithmetische Anweisungen arbeiten mit Binärdaten. Wenn Zahlen auf dem Bildschirm angezeigt oder über die Tastatur eingegeben werden, liegen sie in ASCII-Form vor.
Bisher haben wir diese Eingabedaten für arithmetische Berechnungen in ASCII-Form in Binär konvertiert und das Ergebnis wieder in Binär konvertiert. Der folgende Code zeigt dies -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The sum is:
7Solche Konvertierungen sind jedoch mit einem Overhead verbunden, und die Assembler-Programmierung ermöglicht eine effizientere Verarbeitung von Zahlen in binärer Form. Dezimalzahlen können in zwei Formen dargestellt werden -
- ASCII-Formular
- BCD oder binär codierte Dezimalform
ASCII-Darstellung
In der ASCII-Darstellung werden Dezimalzahlen als Zeichenfolge von ASCII-Zeichen gespeichert. Beispielsweise wird der Dezimalwert 1234 als - gespeichert
31 32 33 34HDabei ist 31H der ASCII-Wert für 1, 32H der ASCII-Wert für 2 und so weiter. Es gibt vier Anweisungen zum Verarbeiten von Nummern in der ASCII-Darstellung:
AAA - ASCII-Anpassung nach Zugabe
AAS - ASCII-Anpassung nach Subtraktion
AAM - ASCII-Anpassung nach Multiplikation
AAD - ASCII-Anpassung vor Division
Diese Anweisungen nehmen keine Operanden an und setzen voraus, dass sich der erforderliche Operand im AL-Register befindet.
Das folgende Beispiel verwendet die AAS-Anweisung, um das Konzept zu demonstrieren -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
sub ah, ah
mov al, '9'
sub al, '3'
aas
or al, 30h
mov [res], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,res ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Result is:',0xa
len equ $ - msg
section .bss
res resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The Result is:
6BCD-Vertretung
Es gibt zwei Arten der BCD-Darstellung:
- Entpackte BCD-Darstellung
- Gepackte BCD-Darstellung
In der entpackten BCD-Darstellung speichert jedes Byte das binäre Äquivalent einer Dezimalstelle. Beispielsweise wird die Nummer 1234 als - gespeichert
01 02 03 04HEs gibt zwei Anweisungen zum Verarbeiten dieser Nummern -
AAM - ASCII-Anpassung nach Multiplikation
AAD - ASCII-Anpassung vor Division
Die vier ASCII-Anpassungsanweisungen AAA, AAS, AAM und AAD können auch mit entpackter BCD-Darstellung verwendet werden. In der gepackten BCD-Darstellung wird jede Ziffer mit vier Bits gespeichert. Zwei Dezimalstellen werden in ein Byte gepackt. Beispielsweise wird die Nummer 1234 als - gespeichert
12 34HEs gibt zwei Anweisungen zum Verarbeiten dieser Nummern -
DAA - Dezimalanpassung nach Addition
DAS - Dezimalanpassung nach Subtraktion
Es gibt keine Unterstützung für Multiplikation und Division in der gepackten BCD-Darstellung.
Beispiel
Das folgende Programm addiert zwei 5-stellige Dezimalzahlen und zeigt die Summe an. Es verwendet die oben genannten Konzepte -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov esi, 4 ;pointing to the rightmost digit
mov ecx, 5 ;num of digits
clc
add_loop:
mov al, [num1 + esi]
adc al, [num2 + esi]
aaa
pushf
or al, 30h
popf
mov [sum + esi], al
dec esi
loop add_loop
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,5 ;message length
mov ecx,sum ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Sum is:',0xa
len equ $ - msg
num1 db '12345'
num2 db '23456'
sum db ' 'Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The Sum is:
35801In unseren vorherigen Beispielen haben wir bereits Zeichenfolgen mit variabler Länge verwendet. Die Zeichenfolgen variabler Länge können beliebig viele Zeichen enthalten. Im Allgemeinen geben wir die Länge der Zeichenfolge auf eine der beiden Arten an:
- Zeichenfolgenlänge explizit speichern
- Verwenden eines Sentinel-Zeichens
Wir können die Zeichenfolgenlänge explizit speichern, indem wir das Symbol $ location counter verwenden, das den aktuellen Wert des Standortzählers darstellt. Im folgenden Beispiel -
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string$ zeigt auf das Byte nach dem letzten Zeichen der Zeichenfolgenvariablen msg . Deshalb,$-msggibt die Länge der Zeichenfolge an. Wir können auch schreiben
msg db 'Hello, world!',0xa ;our dear string
len equ 13 ;length of our dear stringAlternativ können Sie Zeichenfolgen mit einem nachgestellten Sentinel-Zeichen speichern, um eine Zeichenfolge abzugrenzen, anstatt die Zeichenfolgenlänge explizit zu speichern. Das Sentinel-Zeichen sollte ein Sonderzeichen sein, das nicht in einer Zeichenfolge enthalten ist.
Zum Beispiel -
message DB 'I am loving it!', 0String-Anweisungen
Jeder Zeichenfolgenbefehl kann einen Quelloperanden, einen Zieloperanden oder beides erfordern. Bei 32-Bit-Segmenten verwenden Zeichenfolgenbefehle ESI- und EDI-Register, um auf die Quell- bzw. Zieloperanden zu verweisen.
Für 16-Bit-Segmente werden jedoch die SI- und DI-Register verwendet, um auf die Quelle bzw. das Ziel zu zeigen.
Es gibt fünf grundlegende Anweisungen zum Verarbeiten von Zeichenfolgen. Sie sind -
MOVS - Diese Anweisung verschiebt 1 Byte, Word oder Doubleword von Daten vom Speicherort zu einem anderen.
LODS- Diese Anweisung wird aus dem Speicher geladen. Wenn der Operand ein Byte hat, wird er in das AL-Register geladen, wenn der Operand ein Wort ist, wird er in das AX-Register geladen und ein Doppelwort wird in das EAX-Register geladen.
STOS - Dieser Befehl speichert Daten aus dem Register (AL, AX oder EAX) im Speicher.
CMPS- Diese Anweisung vergleicht zwei Datenelemente im Speicher. Daten können eine Bytegröße, ein Wort oder ein Doppelwort haben.
SCAS - Diese Anweisung vergleicht den Inhalt eines Registers (AL, AX oder EAX) mit dem Inhalt eines Elements im Speicher.
Jeder der obigen Befehle hat eine Byte-, Wort- und Doppelwortversion, und Zeichenfolgenbefehle können unter Verwendung eines Wiederholungspräfixes wiederholt werden.
Diese Anweisungen verwenden das Registerpaar ES: DI und DS: SI, wobei DI- und SI-Register gültige Versatzadressen enthalten, die sich auf im Speicher gespeicherte Bytes beziehen. SI ist normalerweise mit DS (Datensegment) verbunden und DI ist immer mit ES (zusätzliches Segment) verbunden.
Die Register DS: SI (oder ESI) und ES: DI (oder EDI) zeigen auf die Quell- bzw. Zieloperanden. Es wird angenommen, dass sich der Quelloperand bei DS: SI (oder ESI) und der Zieloperand bei ES: DI (oder EDI) im Speicher befindet.
Für 16-Bit-Adressen werden die SI- und DI-Register verwendet, und für 32-Bit-Adressen werden die ESI- und EDI-Register verwendet.
Die folgende Tabelle enthält verschiedene Versionen von Zeichenfolgenanweisungen und den angenommenen Platz der Operanden.
| Grundlegende Anweisung | Operanden bei | Byte-Betrieb | Wortoperation | Doppelwortoperation |
|---|---|---|---|---|
| MOVS | ES: DI, DS: SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS: SI | LODSB | LODSW | LODSD |
| STOS | ES: DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS: SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES: DI, AX | SCASB | SCASW | SCASD |
Wiederholungspräfixe
Wenn das REP-Präfix vor einem Zeichenfolgenbefehl gesetzt wird, z. B. REP MOVSB, wird der Befehl basierend auf einem im CX-Register platzierten Zähler wiederholt. REP führt den Befehl aus, verringert CX um 1 und prüft, ob CX Null ist. Es wiederholt die Befehlsverarbeitung, bis CX Null ist.
Das Richtungsflag (DF) bestimmt die Richtung der Operation.
- Verwenden Sie CLD (Clear Direction Flag, DF = 0), um die Operation von links nach rechts durchzuführen.
- Verwenden Sie STD (Set Direction Flag, DF = 1), um die Operation von rechts nach links durchzuführen.
Das REP-Präfix weist auch die folgenden Variationen auf:
REP: Es ist die bedingungslose Wiederholung. Der Vorgang wird wiederholt, bis CX Null ist.
REPE oder REPZ: Dies ist eine bedingte Wiederholung. Es wiederholt den Vorgang, während das Null-Flag gleich / Null anzeigt. Es stoppt, wenn der ZF ungleich / Null anzeigt oder wenn CX Null ist.
REPNE oder REPNZ: Dies ist auch eine bedingte Wiederholung. Es wiederholt die Operation, während das Null-Flag ungleich / Null anzeigt. Es stoppt, wenn der ZF gleich / Null anzeigt oder wenn CX auf Null dekrementiert wird.
Wir haben bereits diskutiert, dass die Datendefinitionsanweisungen an den Assembler zum Zuweisen von Speicher für Variablen verwendet werden. Die Variable könnte auch mit einem bestimmten Wert initialisiert werden. Der initialisierte Wert kann in hexadezimaler, dezimaler oder binärer Form angegeben werden.
Zum Beispiel können wir eine Wortvariable 'Monate' auf eine der folgenden Arten definieren:
MONTHS DW 12
MONTHS DW 0CH
MONTHS DW 0110BDie Datendefinitionsanweisungen können auch zum Definieren eines eindimensionalen Arrays verwendet werden. Definieren wir ein eindimensionales Array von Zahlen.
NUMBERS DW 34, 45, 56, 67, 75, 89Die obige Definition deklariert ein Array von sechs Wörtern, die jeweils mit den Nummern 34, 45, 56, 67, 75, 89 initialisiert sind. Dies weist 2x6 = 12 Bytes aufeinanderfolgenden Speicherplatzes zu. Die symbolische Adresse der ersten Nummer lautet NUMBERS und die der zweiten Nummer lautet NUMBERS + 2 usw.
Nehmen wir ein anderes Beispiel. Sie können ein Array mit dem Namen Inventar der Größe 8 definieren und alle Werte mit Null initialisieren, als -
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0Was abgekürzt werden kann als -
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0Die TIMES-Direktive kann auch für mehrere Initialisierungen mit demselben Wert verwendet werden. Mit TIMES kann das INVENTORY-Array wie folgt definiert werden:
INVENTORY TIMES 8 DW 0Beispiel
Das folgende Beispiel demonstriert die obigen Konzepte durch Definieren eines 3-Element-Arrays x, in dem drei Werte gespeichert sind: 2, 3 und 4. Es fügt die Werte im Array hinzu und zeigt die Summe 9 - an.
section .text
global _start ;must be declared for linker (ld)
_start:
mov eax,3 ;number bytes to be summed
mov ebx,0 ;EBX will store the sum
mov ecx, x ;ECX will point to the current element to be summed
top: add ebx, [ecx]
add ecx,1 ;move pointer to next element
dec eax ;decrement counter
jnz top ;if counter not 0, then loop again
done:
add ebx, '0'
mov [sum], ebx ;done, store result in "sum"
display:
mov edx,1 ;message length
mov ecx, sum ;message to write
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
global x
x:
db 2
db 4
db 3
sum:
db 0Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
9Prozeduren oder Unterprogramme sind in der Assemblersprache sehr wichtig, da die Assemblersprachenprogramme in der Regel groß sind. Prozeduren sind durch einen Namen gekennzeichnet. Nach diesem Namen wird der Hauptteil der Prozedur beschrieben, die eine genau definierte Aufgabe ausführt. Das Ende des Vorgangs wird durch eine return-Anweisung angezeigt.
Syntax
Es folgt die Syntax zum Definieren einer Prozedur:
proc_name:
procedure body
...
retDie Prozedur wird von einer anderen Funktion mit der Anweisung CALL aufgerufen. Die CALL-Anweisung sollte den Namen der aufgerufenen Prozedur als Argument haben, wie unten gezeigt -
CALL proc_nameDie aufgerufene Prozedur gibt die Steuerung unter Verwendung der RET-Anweisung an die aufrufende Prozedur zurück.
Beispiel
Schreiben wir eine sehr einfache Prozedur namens sum , die die im ECX- und EDX-Register gespeicherten Variablen addiert und die Summe im EAX-Register zurückgibt.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,'4'
sub ecx, '0'
mov edx, '5'
sub edx, '0'
call sum ;call sum procedure
mov [res], eax
mov ecx, msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx, res
mov edx, 1
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
sum:
mov eax, ecx
add eax, edx
add eax, '0'
ret
section .data
msg db "The sum is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
The sum is:
9Stapelt Datenstruktur
Ein Stapel ist eine Array-ähnliche Datenstruktur im Speicher, in der Daten gespeichert und von einem Ort entfernt werden können, der als "Oberseite" des Stapels bezeichnet wird. Die Daten, die gespeichert werden müssen, werden in den Stapel "geschoben" und die abzurufenden Daten werden aus dem Stapel "herausgeschleudert". Der Stapel ist eine LIFO-Datenstruktur, dh die zuerst gespeicherten Daten werden zuletzt abgerufen.
Die Assemblersprache enthält zwei Anweisungen für Stapeloperationen: PUSH und POP. Diese Anweisungen haben Syntaxen wie -
PUSH operand
POP address/registerDer im Stapelsegment reservierte Speicherplatz wird zum Implementieren des Stapels verwendet. Die Register SS und ESP (oder SP) werden zur Implementierung des Stapels verwendet. Auf die Oberseite des Stapels, die auf das letzte in den Stapel eingefügte Datenelement zeigt, zeigt das SS: ESP-Register, wobei das SS-Register auf den Anfang des Stapelsegments zeigt und der SP (oder ESP) den Versatz in angibt das Stapelsegment.
Die Stapelimplementierung weist die folgenden Merkmale auf:
Nur words oder doublewords könnte im Stapel gespeichert werden, kein Byte.
Der Stapel wächst in umgekehrter Richtung, dh in Richtung der unteren Speicheradresse
Die Oberseite des Stapels zeigt auf das zuletzt in den Stapel eingefügte Element. es zeigt auf das untere Byte des zuletzt eingefügten Wortes.
Wie wir über das Speichern der Werte der Register im Stapel besprochen haben, bevor sie für eine bestimmte Verwendung verwendet wurden; es kann folgendermaßen geschehen:
; Save the AX and BX registers in the stack
PUSH AX
PUSH BX
; Use the registers for other purpose
MOV AX, VALUE1
MOV BX, VALUE2
...
MOV VALUE1, AX
MOV VALUE2, BX
; Restore the original values
POP BX
POP AXBeispiel
Das folgende Programm zeigt den gesamten ASCII-Zeichensatz an. Das Hauptprogramm ruft eine Prozedur namens display auf , die den ASCII-Zeichensatz anzeigt.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
call display
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
display:
mov ecx, 256
next:
push ecx
mov eax, 4
mov ebx, 1
mov ecx, achar
mov edx, 1
int 80h
pop ecx
mov dx, [achar]
cmp byte [achar], 0dh
inc byte [achar]
loop next
ret
section .data
achar db '0'Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...Eine rekursive Prozedur ruft sich selbst auf. Es gibt zwei Arten von Rekursionen: direkte und indirekte. Bei der direkten Rekursion ruft sich die Prozedur selbst auf, und bei der indirekten Rekursion ruft die erste Prozedur eine zweite Prozedur auf, die wiederum die erste Prozedur aufruft.
Rekursion konnte in zahlreichen mathematischen Algorithmen beobachtet werden. Betrachten Sie beispielsweise den Fall der Berechnung der Fakultät einer Zahl. Faktor einer Zahl ist gegeben durch die Gleichung -
Fact (n) = n * fact (n-1) for n > 0Beispiel: Fakultät von 5 ist 1 x 2 x 3 x 4 x 5 = 5 x Fakultät von 4, und dies kann ein gutes Beispiel für die Darstellung einer rekursiven Prozedur sein. Jeder rekursive Algorithmus muss eine Endbedingung haben, dh der rekursive Aufruf des Programms sollte gestoppt werden, wenn eine Bedingung erfüllt ist. Im Fall eines faktoriellen Algorithmus ist die Endbedingung erreicht, wenn n 0 ist.
Das folgende Programm zeigt, wie Fakultät n in Assemblersprache implementiert ist. Um das Programm einfach zu halten, berechnen wir Fakultät 3.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Factorial 3 is:
6Das Schreiben eines Makros ist eine weitere Möglichkeit, die modulare Programmierung in Assemblersprache sicherzustellen.
Ein Makro ist eine Folge von Anweisungen, die durch einen Namen zugewiesen werden und an einer beliebigen Stelle im Programm verwendet werden können.
In NASM werden Makros mit definiert %macro und %endmacro Richtlinien.
Das Makro beginnt mit der% -Makro-Direktive und endet mit der% endmacro-Direktive.
Die Syntax für die Makrodefinition -
%macro macro_name number_of_params
<macro body>
%endmacroWobei number_of_params die Nummernparameter angibt, macro_name den Namen des Makros angibt.
Das Makro wird aufgerufen, indem der Makroname zusammen mit den erforderlichen Parametern verwendet wird. Wenn Sie eine Folge von Anweisungen in einem Programm mehrmals verwenden müssen, können Sie diese Anweisungen in ein Makro einfügen und verwenden, anstatt die Anweisungen ständig zu schreiben.
Beispielsweise besteht ein sehr häufiger Bedarf an Programmen darin, eine Zeichenfolge auf dem Bildschirm zu schreiben. Zum Anzeigen einer Zeichenfolge benötigen Sie die folgende Folge von Anweisungen:
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernelIm obigen Beispiel für die Anzeige einer Zeichenfolge wurden die Register EAX, EBX, ECX und EDX vom Funktionsaufruf INT 80H verwendet. Jedes Mal, wenn Sie auf dem Bildschirm anzeigen müssen, müssen Sie diese Register auf dem Stapel speichern, INT 80H aufrufen und dann den ursprünglichen Wert der Register aus dem Stapel wiederherstellen. Daher kann es nützlich sein, zwei Makros zum Speichern und Wiederherstellen von Daten zu schreiben.
Wir haben festgestellt, dass einige Anweisungen wie IMUL, IDIV, INT usw. einige der Informationen benötigen, um in bestimmten Registern gespeichert zu werden, und sogar Werte in bestimmten Registern zurückgeben müssen. Wenn das Programm diese Register bereits zum Speichern wichtiger Daten verwendet hat, sollten die vorhandenen Daten aus diesen Registern im Stapel gespeichert und nach Ausführung des Befehls wiederhergestellt werden.
Beispiel
Das folgende Beispiel zeigt das Definieren und Verwenden von Makros -
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1 msg2 db 'Welcome to the world of,', 0xA,0xD len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Hello, programmers!
Welcome to the world of,
Linux assembly programming!Das System betrachtet alle Eingabe- oder Ausgabedaten als Bytestrom. Es gibt drei Standarddateistreams -
- Standardeingabe (stdin),
- Standardausgabe (stdout) und
- Standardfehler (stderr).
Dateideskriptor
EIN file descriptorist eine 16-Bit-Ganzzahl, die einer Datei als Datei-ID zugewiesen ist. Wenn eine neue Datei erstellt oder eine vorhandene Datei geöffnet wird, wird der Dateideskriptor für den Zugriff auf die Datei verwendet.
Dateideskriptor der Standarddateistreams - stdin, stdout und stderr sind 0, 1 bzw. 2.
Dateizeiger
EIN file pointerGibt den Speicherort für eine nachfolgende Lese- / Schreiboperation in der Datei in Bytes an. Jede Datei wird als Folge von Bytes betrachtet. Jede geöffnete Datei ist einem Dateizeiger zugeordnet, der einen Versatz in Byte relativ zum Dateianfang angibt. Wenn eine Datei geöffnet wird, wird der Dateizeiger auf Null gesetzt.
Systemaufrufe für die Dateiverwaltung
In der folgenden Tabelle werden die Systemaufrufe im Zusammenhang mit der Dateiverwaltung kurz beschrieben.
| % eax | Name | % ebx | % ecx | % edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - - | - - |
| 3 | sys_read | unsigned int | char * | size_t |
| 4 | sys_write | unsigned int | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | unsigned int | - - | - - |
| 8 | sys_creat | const char * | int | - - |
| 19 | sys_lseek | unsigned int | off_t | unsigned int |
Die für die Verwendung der Systemaufrufe erforderlichen Schritte sind dieselben, wie wir zuvor erläutert haben -
- Tragen Sie die Systemrufnummer in das EAX-Register ein.
- Speichern Sie die Argumente für den Systemaufruf in den Registern EBX, ECX usw.
- Rufen Sie den entsprechenden Interrupt an (80h).
- Das Ergebnis wird normalerweise im EAX-Register zurückgegeben.
Erstellen und Öffnen einer Datei
Führen Sie zum Erstellen und Öffnen einer Datei die folgenden Aufgaben aus:
- Fügen Sie den Systemaufruf sys_creat () Nummer 8 in das EAX-Register ein.
- Tragen Sie den Dateinamen in das EBX-Register ein.
- Fügen Sie die Dateiberechtigungen in das ECX-Register ein.
Der Systemaufruf gibt den Dateideskriptor der erstellten Datei im EAX-Register zurück. Im Fehlerfall befindet sich der Fehlercode im EAX-Register.
Vorhandene Datei öffnen
Führen Sie zum Öffnen einer vorhandenen Datei die folgenden Aufgaben aus:
- Tragen Sie den Systemaufruf sys_open () Nummer 5 in das EAX-Register ein.
- Tragen Sie den Dateinamen in das EBX-Register ein.
- Stellen Sie den Dateizugriffsmodus in das ECX-Register.
- Fügen Sie die Dateiberechtigungen in das EDX-Register ein.
Der Systemaufruf gibt den Dateideskriptor der erstellten Datei im EAX-Register zurück. Im Fehlerfall befindet sich der Fehlercode im EAX-Register.
Unter den Dateizugriffsmodi werden am häufigsten Folgendes verwendet: schreibgeschützt (0), schreibgeschützt (1) und schreibgeschützt (2).
Lesen aus einer Datei
Führen Sie zum Lesen aus einer Datei die folgenden Aufgaben aus:
Fügen Sie den Systemaufruf sys_read () Nummer 3 in das EAX-Register ein.
Legen Sie den Dateideskriptor in das EBX-Register.
Setzen Sie den Zeiger auf den Eingangspuffer im ECX-Register.
Tragen Sie die Puffergröße, dh die Anzahl der zu lesenden Bytes, in das EDX-Register ein.
Der Systemaufruf gibt die Anzahl der im EAX-Register gelesenen Bytes zurück. Im Fehlerfall befindet sich der Fehlercode im EAX-Register.
In eine Datei schreiben
Führen Sie zum Schreiben in eine Datei die folgenden Aufgaben aus:
Fügen Sie den Systemaufruf sys_write () Nummer 4 in das EAX-Register ein.
Legen Sie den Dateideskriptor in das EBX-Register.
Setzen Sie den Zeiger auf den Ausgabepuffer im ECX-Register.
Tragen Sie die Puffergröße, dh die Anzahl der zu schreibenden Bytes, in das EDX-Register ein.
Der Systemaufruf gibt die tatsächliche Anzahl der in das EAX-Register geschriebenen Bytes zurück. Im Fehlerfall befindet sich der Fehlercode im EAX-Register.
Eine Datei schließen
Führen Sie zum Schließen einer Datei die folgenden Aufgaben aus:
- Fügen Sie den Systemaufruf sys_close () Nummer 6 in das EAX-Register ein.
- Legen Sie den Dateideskriptor in das EBX-Register.
Der Systemaufruf gibt im Fehlerfall den Fehlercode im EAX-Register zurück.
Aktualisieren einer Datei
Führen Sie zum Aktualisieren einer Datei die folgenden Aufgaben aus:
- Tragen Sie den Systemaufruf sys_lseek () Nummer 19 in das EAX-Register ein.
- Legen Sie den Dateideskriptor in das EBX-Register.
- Tragen Sie den Offset-Wert in das ECX-Register ein.
- Tragen Sie die Referenzposition für den Offset in das EDX-Register ein.
Die Referenzposition könnte sein:
- Dateianfang - Wert 0
- Aktuelle Position - Wert 1
- Dateiende - Wert 2
Der Systemaufruf gibt im Fehlerfall den Fehlercode im EAX-Register zurück.
Beispiel
Das folgende Programm erstellt und öffnet eine Datei mit dem Namen myfile.txt und schreibt einen Text 'Welcome to Tutorials Point' in diese Datei. Als nächstes liest das Programm aus der Datei und speichert die Daten in einem Puffer namens info . Zuletzt wird der in info gespeicherte Text angezeigt .
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to Tutorials Point'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26Wenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Written to file
Welcome to Tutorials PointDas sys_brk()Der Systemaufruf wird vom Kernel bereitgestellt, um Speicher zuzuweisen, ohne ihn später verschieben zu müssen. Dieser Aufruf weist Speicher direkt hinter dem Anwendungsabbild im Speicher zu. Mit dieser Systemfunktion können Sie die höchste verfügbare Adresse im Datenbereich einstellen.
Dieser Systemaufruf verwendet einen Parameter, der die höchste Speicheradresse ist, die eingestellt werden muss. Dieser Wert wird im EBX-Register gespeichert.
Im Fehlerfall gibt sys_brk () -1 oder den negativen Fehlercode selbst zurück. Das folgende Beispiel zeigt die dynamische Speicherzuordnung.
Beispiel
Das folgende Programm reserviert 16 KB Speicher mithilfe des Systemaufrufs sys_brk () -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, 45 ;sys_brk
xor ebx, ebx
int 80h
add eax, 16384 ;number of bytes to be reserved
mov ebx, eax
mov eax, 45 ;sys_brk
int 80h
cmp eax, 0
jl exit ;exit, if error
mov edi, eax ;EDI = highest available address
sub edi, 4 ;pointing to the last DWORD
mov ecx, 4096 ;number of DWORDs allocated
xor eax, eax ;clear eax
std ;backward
rep stosd ;repete for entire allocated area
cld ;put DF flag to normal state
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, len
int 80h ;print a message
exit:
mov eax, 1
xor ebx, ebx
int 80h
section .data
msg db "Allocated 16 kb of memory!", 10
len equ $ - msgWenn der obige Code kompiliert und ausgeführt wird, ergibt sich das folgende Ergebnis:
Allocated 16 kb of memory!