Cassandra - Datenmodell
Das Datenmodell von Cassandra unterscheidet sich erheblich von dem, was wir normalerweise in einem RDBMS sehen. Dieses Kapitel bietet einen Überblick darüber, wie Cassandra seine Daten speichert.
Cluster
Die Cassandra-Datenbank ist auf mehrere Computer verteilt, die zusammenarbeiten. Der äußerste Container wird als Cluster bezeichnet. Für die Fehlerbehandlung enthält jeder Knoten ein Replikat, und im Falle eines Fehlers übernimmt das Replikat die Verantwortung. Cassandra ordnet die Knoten in einem Cluster in einem Ringformat an und weist ihnen Daten zu.
Schlüsselraum
Keyspace ist der äußerste Container für Daten in Cassandra. Die grundlegenden Attribute eines Keyspace in Cassandra sind -
Replication factor - Dies ist die Anzahl der Computer im Cluster, die Kopien derselben Daten empfangen.
Replica placement strategy- Es ist nichts anderes als die Strategie, Repliken in den Ring zu legen. Wir haben Strategien wiesimple strategy (Rack-Aware-Strategie), old network topology strategy (Rack-Aware-Strategie) und network topology strategy (Strategie für gemeinsam genutzte Rechenzentren).
Column families- Keyspace ist ein Container für eine Liste einer oder mehrerer Spaltenfamilien. Eine Spaltenfamilie ist wiederum ein Container einer Sammlung von Zeilen. Jede Zeile enthält geordnete Spalten. Spaltenfamilien repräsentieren die Struktur Ihrer Daten. Jeder Schlüsselbereich hat mindestens eine und häufig viele Spaltenfamilien.
Die Syntax zum Erstellen eines Schlüsselraums lautet wie folgt:
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};Die folgende Abbildung zeigt eine schematische Ansicht eines Schlüsselraums.
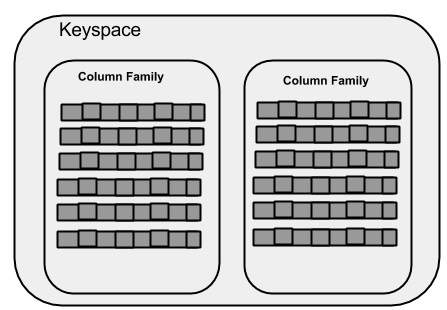
Spaltenfamilie
Eine Spaltenfamilie ist ein Container für eine geordnete Sammlung von Zeilen. Jede Zeile ist wiederum eine geordnete Sammlung von Spalten. In der folgenden Tabelle sind die Punkte aufgeführt, die eine Spaltenfamilie von einer Tabelle relationaler Datenbanken unterscheiden.
| Relationale Tabelle | Cassandra-Säulenfamilie |
|---|---|
| Ein Schema in einem relationalen Modell ist festgelegt. Sobald wir beim Einfügen von Daten bestimmte Spalten für eine Tabelle definiert haben, müssen in jeder Zeile alle Spalten mindestens mit einem Nullwert gefüllt sein. | In Cassandra sind die Spaltenfamilien zwar definiert, die Spalten jedoch nicht. Sie können jede Spalte jederzeit frei zu jeder Spaltenfamilie hinzufügen. |
| Relationale Tabellen definieren nur Spalten und der Benutzer füllt die Tabelle mit Werten aus. | In Cassandra enthält eine Tabelle Spalten oder kann als Superspaltenfamilie definiert werden. |
Eine Cassandra-Spaltenfamilie weist die folgenden Attribute auf:
keys_cached - Es gibt die Anzahl der Speicherorte an, die pro SSTable zwischengespeichert werden sollen.
rows_cached - Es gibt die Anzahl der Zeilen an, deren gesamter Inhalt im Speicher zwischengespeichert wird.
preload_row_cache - Gibt an, ob Sie den Zeilencache vorab füllen möchten.
Note − Im Gegensatz zu relationalen Tabellen, in denen das Schema einer Spaltenfamilie nicht festgelegt ist, erzwingt Cassandra nicht, dass einzelne Zeilen alle Spalten enthalten.
Die folgende Abbildung zeigt ein Beispiel einer Cassandra-Spaltenfamilie.
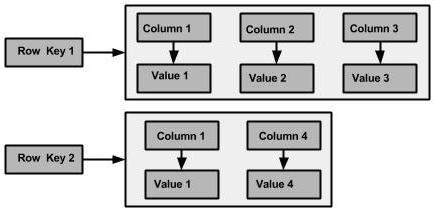
Säule
Eine Spalte ist die grundlegende Datenstruktur von Cassandra mit drei Werten, nämlich Schlüssel- oder Spaltenname, Wert und Zeitstempel. Unten ist die Struktur einer Spalte angegeben.

SuperColumn
Eine Superspalte ist eine spezielle Spalte, daher ist sie auch ein Schlüssel-Wert-Paar. In einer Superspalte wird jedoch eine Karte mit Unterspalten gespeichert.
Im Allgemeinen werden Spaltenfamilien in einzelnen Dateien auf der Festplatte gespeichert. Um die Leistung zu optimieren, ist es daher wichtig, Spalten, die Sie wahrscheinlich zusammen abfragen, in derselben Spaltenfamilie zu belassen. Eine Superspalte kann hier hilfreich sein. Im Folgenden wird die Struktur einer Superspalte angegeben.

Datenmodelle von Cassandra und RDBMS
In der folgenden Tabelle sind die Punkte aufgeführt, die das Datenmodell von Cassandra von dem eines RDBMS unterscheiden.
| RDBMS | Kassandra |
|---|---|
| RDBMS befasst sich mit strukturierten Daten. | Cassandra befasst sich mit unstrukturierten Daten. |
| Es hat ein festes Schema. | Cassandra hat ein flexibles Schema. |
| In RDBMS ist eine Tabelle ein Array von Arrays. (REIHE x SPALTE) | In Cassandra ist eine Tabelle eine Liste von "verschachtelten Schlüssel-Wert-Paaren". (ROW x COLUMN-Taste x COLUMN-Wert) |
| Datenbank ist der äußerste Container, der Daten enthält, die einer Anwendung entsprechen. | Der Schlüsselbereich ist der äußerste Container, der Daten enthält, die einer Anwendung entsprechen. |
| Tabellen sind die Entitäten einer Datenbank. | Tabellen oder Spaltenfamilien sind die Entität eines Schlüsselbereichs. |
| Zeile ist ein einzelner Datensatz in RDBMS. | Row ist eine Replikationseinheit in Cassandra. |
| Die Spalte repräsentiert die Attribute einer Beziehung. | Die Säule ist eine Speichereinheit in Cassandra. |
| RDBMS unterstützt die Konzepte von Fremdschlüsseln und Joins. | Beziehungen werden mithilfe von Sammlungen dargestellt. |