Compiler Design - Code-Optimierung
Bei der Optimierung handelt es sich um eine Programmtransformationstechnik, mit der versucht wird, den Code zu verbessern, indem weniger Ressourcen (z. B. CPU, Speicher) verbraucht werden und eine hohe Geschwindigkeit bereitgestellt wird.
Bei der Optimierung werden allgemeine Programmierkonstrukte auf hoher Ebene durch sehr effiziente Programmiercodes auf niedriger Ebene ersetzt. Ein Codeoptimierungsprozess muss den folgenden drei Regeln folgen:
Der Ausgabecode darf die Bedeutung des Programms in keiner Weise ändern.
Die Optimierung sollte die Geschwindigkeit des Programms erhöhen und wenn möglich, sollte das Programm weniger Ressourcen erfordern.
Die Optimierung sollte selbst schnell sein und den gesamten Kompilierungsprozess nicht verzögern.
Auf verschiedenen Ebenen der Kompilierung des Prozesses können Anstrengungen für einen optimierten Code unternommen werden.
Zu Beginn können Benutzer den Code ändern / neu anordnen oder bessere Algorithmen zum Schreiben des Codes verwenden.
Nach dem Generieren des Zwischencodes kann der Compiler den Zwischencode durch Adressberechnungen und Verbessern von Schleifen ändern.
Während der Erstellung des Zielmaschinencodes kann der Compiler Speicherhierarchie und CPU-Register verwenden.
Die Optimierung kann grob in zwei Typen eingeteilt werden: maschinenunabhängig und maschinenabhängig.
Maschinenunabhängige Optimierung
Bei dieser Optimierung nimmt der Compiler den Zwischencode auf und transformiert einen Teil des Codes, der keine CPU-Register und / oder absoluten Speicherplätze enthält. Zum Beispiel:
do
{
item = 10;
value = value + item;
} while(value<100);Dieser Code beinhaltet die wiederholte Zuweisung des Identifizierungselements. Wenn wir dies so ausdrücken:
Item = 10;
do
{
value = value + item;
} while(value<100);sollte nicht nur die CPU-Zyklen speichern, sondern kann auf jedem Prozessor verwendet werden.
Maschinenabhängige Optimierung
Die maschinenabhängige Optimierung erfolgt nach der Generierung des Zielcodes und nach der Transformation des Codes gemäß der Zielmaschinenarchitektur. Es handelt sich um CPU-Register und kann eher absolute als relative Referenzen haben. Maschinenabhängige Optimierer bemühen sich, die Speicherhierarchie optimal zu nutzen.
Grundblöcke
Quellcodes enthalten im Allgemeinen eine Reihe von Anweisungen, die immer nacheinander ausgeführt werden und als Grundblöcke des Codes betrachtet werden. Diese Basisblöcke enthalten keine Sprunganweisungen, dh wenn der erste Befehl ausgeführt wird, werden alle Befehle im selben Basisblock in ihrer Reihenfolge ausgeführt, ohne dass die Ablaufsteuerung des Programms verloren geht.
Ein Programm kann verschiedene Konstrukte als Basisblöcke haben, wie z. B. bedingte Anweisungen IF-THEN-ELSE, SWITCH-CASE und Schleifen wie DO-WHILE, FOR und REPEAT-UNTIL usw.
Grundlegende Blockidentifikation
Wir können den folgenden Algorithmus verwenden, um die Grundblöcke in einem Programm zu finden:
Durchsuchen Sie die Header-Anweisungen aller Basisblöcke, von denen aus ein Basisblock beginnt:
- Erste Aussage eines Programms.
- Anweisungen, die Ziel eines Zweigs sind (bedingt / bedingungslos).
- Anweisungen, die auf eine Verzweigungsanweisung folgen.
Header-Anweisungen und die darauf folgenden Anweisungen bilden einen Basisblock.
Ein Basisblock enthält keine Header-Anweisung eines anderen Basisblocks.
Grundblöcke sind wichtige Konzepte sowohl aus Sicht der Codegenerierung als auch der Optimierung.
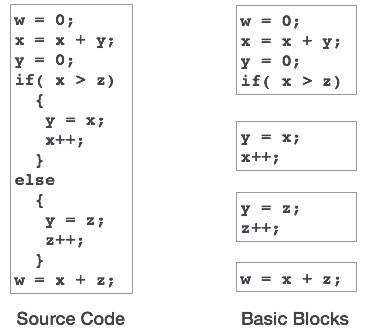
Basisblöcke spielen eine wichtige Rolle bei der Identifizierung von Variablen, die in einem einzelnen Basisblock mehrmals verwendet werden. Wenn eine Variable mehrmals verwendet wird, muss der dieser Variablen zugewiesene Registerspeicher erst geleert werden, wenn der Block die Ausführung beendet hat.
Kontrollflussdiagramm
Grundbausteine in einem Programm können mit Hilfe von Kontrollflussdiagrammen dargestellt werden. Ein Steuerungsflussdiagramm zeigt, wie die Programmsteuerung zwischen den Blöcken übergeben wird. Es ist ein nützliches Tool, das bei der Optimierung hilft, indem es unerwünschte Schleifen im Programm findet.
Schleifenoptimierung
Die meisten Programme werden als Schleife im System ausgeführt. Die Schleifen müssen optimiert werden, um CPU-Zyklen und Speicher zu sparen. Schleifen können durch die folgenden Techniken optimiert werden:
Invariant code: Ein Codefragment, das sich in der Schleife befindet und bei jeder Iteration denselben Wert berechnet, wird als schleifeninvarianter Code bezeichnet. Dieser Code kann aus der Schleife verschoben werden, indem er gespeichert wird, damit er nur einmal und nicht bei jeder Iteration berechnet wird.
Induction analysis : Eine Variable wird als Induktionsvariable bezeichnet, wenn ihr Wert innerhalb der Schleife durch einen schleifeninvarianten Wert geändert wird.
Strength reduction: Es gibt Ausdrücke, die mehr CPU-Zyklen, Zeit und Speicher verbrauchen. Diese Ausdrücke sollten durch billigere Ausdrücke ersetzt werden, ohne die Ausgabe des Ausdrucks zu beeinträchtigen. Beispielsweise ist die Multiplikation (x * 2) in Bezug auf die CPU-Zyklen teurer als (x << 1) und liefert das gleiche Ergebnis.
Dead-Code-Eliminierung
Toter Code ist eine oder mehrere Code-Anweisungen, die:
- Entweder nie ausgeführt oder nicht erreichbar,
- Oder wenn sie ausgeführt werden, wird ihre Ausgabe niemals verwendet.
Somit spielt toter Code bei keiner Programmoperation eine Rolle und kann daher einfach beseitigt werden.
Teilweise toter Code
Es gibt einige Code-Anweisungen, deren berechnete Werte nur unter bestimmten Umständen verwendet werden, dh manchmal werden die Werte verwendet und manchmal nicht. Solche Codes werden als teilweise toter Code bezeichnet.
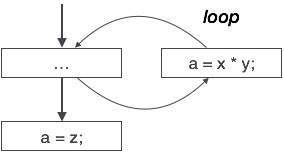
Das obige Kontrollflussdiagramm zeigt einen Programmabschnitt, in dem die Variable 'a' verwendet wird, um die Ausgabe des Ausdrucks 'x * y' zuzuweisen. Nehmen wir an, dass der Wert, der 'a' zugewiesen ist, niemals innerhalb der Schleife verwendet wird. Unmittelbar nachdem das Steuerelement die Schleife verlassen hat, wird 'a' der Wert der Variablen 'z' zugewiesen, der später im Programm verwendet wird. Wir schließen hier, dass der Zuweisungscode von 'a' nirgendwo verwendet wird und daher entfernt werden kann.
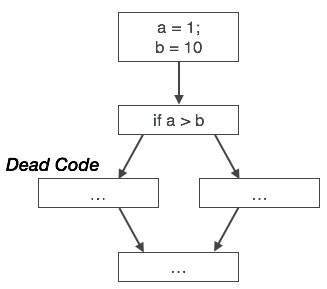
Ebenso zeigt das obige Bild, dass die bedingte Anweisung immer falsch ist, was bedeutet, dass der im wahren Fall geschriebene Code niemals ausgeführt wird und daher entfernt werden kann.
Teilredundanz
Redundante Ausdrücke werden mehr als einmal im parallelen Pfad ohne Änderung der Operanden berechnet. Teilredundante Ausdrücke werden mehr als einmal im Pfad ohne Änderung der Operanden berechnet. Zum Beispiel,
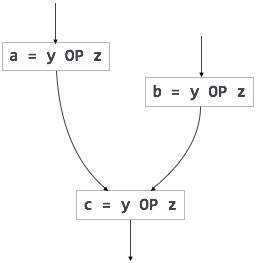
[redundanter Ausdruck] |
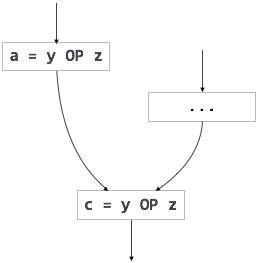
[teilweise redundanter Ausdruck] |
Schleifeninvarianter Code ist teilweise redundant und kann mithilfe einer Code-Motion-Technik eliminiert werden.
Ein weiteres Beispiel für einen teilweise redundanten Code kann sein:
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;Wir nehmen an, dass die Werte von Operanden (y und z) werden von der Zuweisung der Variablen nicht geändert a zu variabel c. Wenn hier die Bedingungsanweisung wahr ist, wird y OP z zweimal berechnet, andernfalls einmal. Code-Bewegung kann verwendet werden, um diese Redundanz zu beseitigen, wie unten gezeigt:
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;Hier, ob die Bedingung wahr oder falsch ist; y OP z sollte nur einmal berechnet werden.