Parallelität in Python - Kurzanleitung
In diesem Kapitel werden wir das Konzept der Parallelität in Python verstehen und die verschiedenen Threads und Prozesse kennenlernen.
Was ist Parallelität?
Mit einfachen Worten, Parallelität ist das gleichzeitige Auftreten von zwei oder mehr Ereignissen. Parallelität ist ein natürliches Phänomen, da viele Ereignisse gleichzeitig auftreten.
Parallelität ist in Bezug auf die Programmierung, wenn sich zwei Aufgaben bei der Ausführung überschneiden. Durch die gleichzeitige Programmierung kann die Leistung unserer Anwendungen und Softwaresysteme verbessert werden, da wir die Anforderungen gleichzeitig bearbeiten können, anstatt darauf zu warten, dass eine vorherige abgeschlossen wird.
Historischer Rückblick auf die Parallelität
Die folgenden Punkte geben uns einen kurzen historischen Überblick über die Parallelität -
Aus dem Konzept der Eisenbahnen
Parallelität ist eng mit dem Konzept der Eisenbahnen verbunden. Bei den Eisenbahnen mussten mehrere Züge im selben Eisenbahnsystem so umgeschlagen werden, dass jeder Zug sicher ans Ziel kam.
Concurrent Computing im akademischen Bereich
Das Interesse an Parallelität in der Informatik begann mit dem 1965 von Edsger W. Dijkstra veröffentlichten Forschungsbericht. In diesem Artikel identifizierte und löste er das Problem des gegenseitigen Ausschlusses, die Eigenschaft der Parallelitätskontrolle.
Parallelitätsprimitive auf hoher Ebene
In jüngster Zeit erhalten Programmierer aufgrund der Einführung von Parallelitätsprimitiven auf hoher Ebene verbesserte gleichzeitige Lösungen.
Verbesserte Parallelität mit Programmiersprachen
Programmiersprachen wie Golang, Rust und Python von Google haben unglaubliche Entwicklungen in Bereichen gemacht, die uns helfen, bessere gleichzeitige Lösungen zu erhalten.
Was ist Thread & Multithreading?
Threadist die kleinste Ausführungseinheit, die in einem Betriebssystem ausgeführt werden kann. Es ist selbst kein Programm, sondern läuft innerhalb eines Programms. Mit anderen Worten, Threads sind nicht unabhängig voneinander. Jeder Thread teilt den Codeabschnitt, den Datenabschnitt usw. mit anderen Threads. Sie werden auch als Leichtbauprozesse bezeichnet.
Ein Thread besteht aus folgenden Komponenten:
Programmzähler, der aus der Adresse des nächsten ausführbaren Befehls besteht
Stack
Registersatz
Eine eindeutige ID
MultithreadingAuf der anderen Seite ist die Fähigkeit einer CPU, die Verwendung des Betriebssystems durch gleichzeitiges Ausführen mehrerer Threads zu verwalten. Die Hauptidee von Multithreading besteht darin, Parallelität zu erreichen, indem ein Prozess in mehrere Threads aufgeteilt wird. Das Konzept des Multithreading kann anhand des folgenden Beispiels verstanden werden.
Beispiel
Angenommen, wir führen einen bestimmten Prozess aus, bei dem wir MS Word öffnen, um Inhalte einzugeben. Ein Thread wird zum Öffnen von MS Word zugewiesen, und ein anderer Thread wird zum Eingeben von Inhalten benötigt. Und jetzt, wenn wir das vorhandene bearbeiten möchten, wird ein anderer Thread benötigt, um die Bearbeitungsaufgabe zu erledigen und so weiter.
Was ist Prozess & Multiprocessing?
EINprocessist definiert als eine Entität, die die grundlegende Arbeitseinheit darstellt, die im System implementiert werden soll. Einfach ausgedrückt, schreiben wir unsere Computerprogramme in eine Textdatei. Wenn wir dieses Programm ausführen, wird es zu einem Prozess, der alle im Programm genannten Aufgaben ausführt. Während des Prozesslebenszyklus durchläuft es verschiedene Phasen - Start, Bereit, Ausführen, Warten und Beenden.
Das folgende Diagramm zeigt die verschiedenen Phasen eines Prozesses -
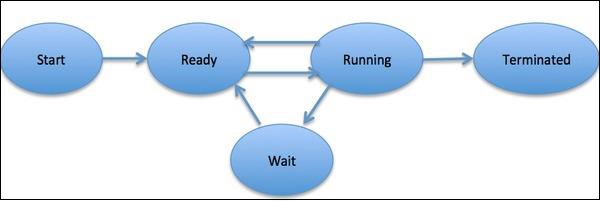
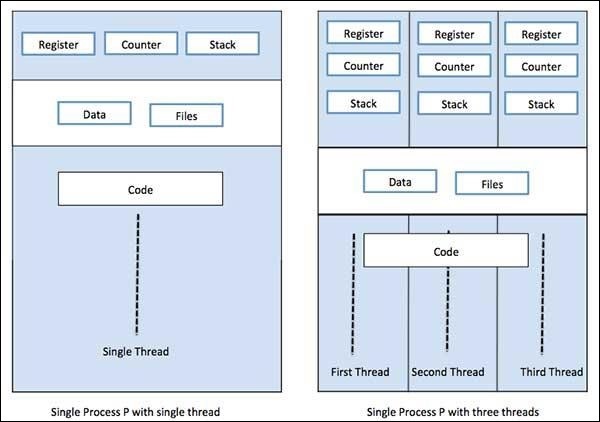
Ein Prozess kann nur einen Thread haben, der als primärer Thread bezeichnet wird, oder mehrere Threads mit einem eigenen Satz von Registern, Programmzählern und Stapeln. Das folgende Diagramm zeigt uns den Unterschied -
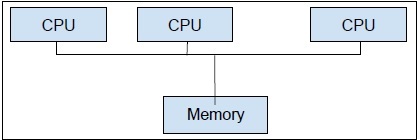
Multiprocessing,Zum anderen werden zwei oder mehr CPU-Einheiten in einem einzigen Computersystem verwendet. Unser primäres Ziel ist es, das volle Potenzial unserer Hardware auszuschöpfen. Um dies zu erreichen, müssen wir die gesamte Anzahl der in unserem Computersystem verfügbaren CPU-Kerne verwenden. Multiprocessing ist der beste Ansatz dafür.
Python ist eine der beliebtesten Programmiersprachen. Im Folgenden sind einige Gründe aufgeführt, die es für gleichzeitige Anwendungen geeignet machen:
Syntethischer Zucker
Syntaktischer Zucker ist eine Syntax innerhalb einer Programmiersprache, die das Lesen oder Ausdrücken erleichtern soll. Es macht die Sprache für den menschlichen Gebrauch „süßer“: Dinge können klarer, präziser oder in einem alternativen Stil ausgedrückt werden, der auf Präferenzen basiert. Python wird mit Magic-Methoden geliefert, die so definiert werden können, dass sie auf Objekte wirken. Diese Magic-Methoden werden als syntaktischer Zucker verwendet und sind an leichter verständliche Schlüsselwörter gebunden.
Große Gemeinschaft
Die Python-Sprache hat eine massive Akzeptanzrate bei Datenwissenschaftlern und Mathematikern erlebt, die auf den Gebieten KI, maschinelles Lernen, tiefes Lernen und quantitative Analyse tätig sind.
Nützliche APIs für die gleichzeitige Programmierung
Python 2 und 3 verfügen über eine große Anzahl von APIs, die für die parallele / gleichzeitige Programmierung vorgesehen sind. Am beliebtesten sind siethreading, concurrent.features, multiprocessing, asyncio, gevent and greenlets, usw.
Einschränkungen von Python bei der Implementierung gleichzeitiger Anwendungen
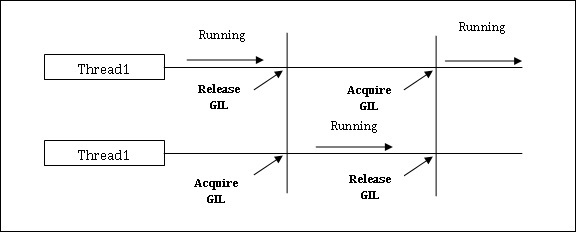
Python hat eine Einschränkung für gleichzeitige Anwendungen. Diese Einschränkung wird aufgerufenGIL (Global Interpreter Lock)ist in Python vorhanden. GIL erlaubt uns niemals, mehrere CPU-Kerne zu verwenden, und daher können wir sagen, dass es in Python keine echten Threads gibt. Wir können das Konzept von GIL wie folgt verstehen:
GIL (Global Interpreter Lock)
Es ist eines der umstrittensten Themen in der Python-Welt. In CPython ist GIL der Mutex - die gegenseitige Ausschlusssperre, die die Thread-Sicherheit erhöht. Mit anderen Worten, wir können sagen, dass GIL verhindert, dass mehrere Threads Python-Code parallel ausführen. Die Sperre kann jeweils nur von einem Thread gehalten werden. Wenn wir einen Thread ausführen möchten, muss er zuerst die Sperre erhalten. Das folgende Diagramm hilft Ihnen, die Funktionsweise von GIL zu verstehen.
Es gibt jedoch einige Bibliotheken und Implementierungen in Python, wie z Numpy, Jpython und IronPytbhon. Diese Bibliotheken funktionieren ohne Interaktion mit GIL.
Sowohl Parallelität als auch Parallelität werden in Bezug auf Multithread-Programme verwendet, aber es gibt viel Verwirrung über die Ähnlichkeit und den Unterschied zwischen ihnen. Die große Frage in dieser Hinsicht: Ist Parallelität Parallelität oder nicht? Obwohl beide Begriffe ziemlich ähnlich erscheinen, aber die Antwort auf die obige Frage NEIN lautet, sind Parallelität und Parallelität nicht gleich. Wenn sie nicht gleich sind, was ist dann der grundlegende Unterschied zwischen ihnen?
In einfachen Worten, bei der Parallelität wird der Zugriff auf den gemeinsam genutzten Status von verschiedenen Threads aus verwaltet, und bei der Parallelität werden mehrere CPUs oder deren Kerne verwendet, um die Leistung der Hardware zu verbessern.
Parallelität im Detail
Parallelität ist, wenn sich zwei Aufgaben bei der Ausführung überschneiden. Es kann vorkommen, dass eine Anwendung mehrere Aufgaben gleichzeitig bearbeitet. Wir können es schematisch verstehen; Mehrere Aufgaben machen gleichzeitig Fortschritte:
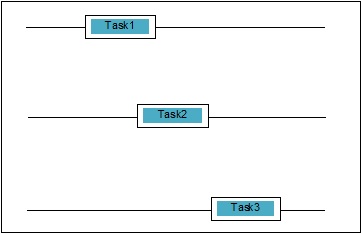
Parallelitätsstufen
In diesem Abschnitt werden wir die drei wichtigen Ebenen der Parallelität in Bezug auf die Programmierung diskutieren -
Low-Level-Parallelität
In dieser Ebene der Parallelität werden atomare Operationen explizit verwendet. Wir können eine solche Parallelität nicht für die Anwendungserstellung verwenden, da sie sehr fehleranfällig und schwer zu debuggen ist. Selbst Python unterstützt eine solche Parallelität nicht.
Mittlere Parallelität
In dieser Parallelität werden keine expliziten atomaren Operationen verwendet. Es werden die expliziten Sperren verwendet. Python und andere Programmiersprachen unterstützen eine solche Parallelität. Meistens verwenden Anwendungsprogrammierer diese Parallelität.
Parallelität auf hoher Ebene
In dieser Parallelität werden weder explizite atomare Operationen noch explizite Sperren verwendet. Python hatconcurrent.futures Modul zur Unterstützung dieser Art von Parallelität.
Eigenschaften gleichzeitiger Systeme
Damit ein Programm oder ein gleichzeitiges System korrekt ist, müssen einige Eigenschaften erfüllt sein. Eigenschaften im Zusammenhang mit der Beendigung des Systems sind wie folgt:
Korrektheitseigenschaft
Die Korrektheitseigenschaft bedeutet, dass das Programm oder das System die gewünschte richtige Antwort liefern muss. Um es einfach zu halten, können wir sagen, dass das System den Startprogrammstatus korrekt dem Endstatus zuordnen muss.
Sicherheitseigenschaft
Die Sicherheitseigenschaft bedeutet, dass das Programm oder das System in a bleiben muss “good” oder “safe” Zustand und tut nie etwas “bad”.
Lebendigkeitseigenschaft
Diese Eigenschaft bedeutet, dass ein Programm oder System muss “make progress” und es würde einen wünschenswerten Zustand erreichen.
Akteure gleichzeitiger Systeme
Dies ist eine gemeinsame Eigenschaft eines gleichzeitigen Systems, in dem mehrere Prozesse und Threads gleichzeitig ausgeführt werden können, um Fortschritte bei ihren eigenen Aufgaben zu erzielen. Diese Prozesse und Threads werden als Akteure des gleichzeitigen Systems bezeichnet.
Ressourcen gleichzeitiger Systeme
Die Akteure müssen die Ressourcen wie Speicher, Festplatte, Drucker usw. nutzen, um ihre Aufgaben auszuführen.
Bestimmte Regeln
Jedes gleichzeitige System muss über eine Reihe von Regeln verfügen, um die Art der von den Akteuren auszuführenden Aufgaben und den Zeitpunkt für jede Aufgabe zu definieren. Die Aufgaben könnten das Erfassen von Sperren, die gemeinsame Nutzung von Speicher, das Ändern des Status usw. sein.
Barrieren gleichzeitiger Systeme
Weitergabe von Daten
Ein wichtiges Problem bei der Implementierung der gleichzeitigen Systeme ist die gemeinsame Nutzung von Daten zwischen mehreren Threads oder Prozessen. Tatsächlich muss der Programmierer sicherstellen, dass Sperren die gemeinsam genutzten Daten schützen, damit alle Zugriffe darauf serialisiert werden und jeweils nur ein Thread oder Prozess auf die gemeinsam genutzten Daten zugreifen kann. Wenn mehrere Threads oder Prozesse versuchen, auf dieselben gemeinsam genutzten Daten zuzugreifen, werden nicht alle bis auf mindestens einen blockiert und bleiben inaktiv. Mit anderen Worten, wir können sagen, dass wir jeweils nur einen Prozess oder Thread verwenden können, wenn die Sperre in Kraft ist. Es kann einige einfache Lösungen geben, um die oben genannten Hindernisse zu beseitigen -
Einschränkung des Datenaustauschs
Die einfachste Lösung besteht darin, keine veränderlichen Daten gemeinsam zu nutzen. In diesem Fall müssen wir keine explizite Sperrung verwenden, und die Barriere der Parallelität aufgrund gegenseitiger Daten wäre gelöst.
Unterstützung bei der Datenstruktur
Oft müssen die gleichzeitigen Prozesse gleichzeitig auf dieselben Daten zugreifen. Eine andere Lösung als die Verwendung expliziter Sperren besteht darin, eine Datenstruktur zu verwenden, die den gleichzeitigen Zugriff unterstützt. Zum Beispiel können wir die verwendenqueueModul, das thread-sichere Warteschlangen bereitstellt. Wir können auch verwendenmultiprocessing.JoinableQueue Klassen für Multiprozessor-basierte Parallelität.
Unveränderliche Datenübertragung
Manchmal ist die von uns verwendete Datenstruktur, beispielsweise die Parallelitätswarteschlange, nicht geeignet. Dann können wir die unveränderlichen Daten übergeben, ohne sie zu sperren.
Veränderliche Datenübertragung
Nehmen wir in Fortsetzung der obigen Lösung an, wenn nur veränderbare Daten anstatt unveränderlicher Daten übergeben werden müssen, können wir veränderbare Daten übergeben, die schreibgeschützt sind.
Gemeinsame Nutzung von E / A-Ressourcen
Ein weiteres wichtiges Problem bei der Implementierung gleichzeitiger Systeme ist die Verwendung von E / A-Ressourcen durch Threads oder Prozesse. Das Problem tritt auf, wenn ein Thread oder Prozess die E / A so lange verwendet und der andere im Leerlauf sitzt. Wir können eine solche Barriere sehen, wenn wir mit einer E / A-schweren Anwendung arbeiten. Es kann anhand eines Beispiels verstanden werden, wie Seiten vom Webbrowser angefordert werden. Es ist eine schwere Anwendung. Wenn die Rate, mit der die Daten angefordert werden, langsamer ist als die Rate, mit der sie verbraucht werden, haben wir hier eine E / A-Barriere in unserem gleichzeitigen System.
Das folgende Python-Skript dient zum Anfordern einer Webseite und zum Abrufen der Zeit, die unser Netzwerk benötigt hat, um die angeforderte Seite abzurufen.
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('http://www.tutorialspoint.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))Nach dem Ausführen des obigen Skripts können wir die Zeit zum Abrufen der Seite wie unten gezeigt abrufen.
Ausgabe
Page Fetching Time: 1.0991398811340332 SecondsWir können sehen, dass die Zeit zum Abrufen der Seite mehr als eine Sekunde beträgt. Was ist nun, wenn wir Tausende verschiedener Webseiten abrufen möchten? Sie können verstehen, wie viel Zeit unser Netzwerk in Anspruch nehmen würde.
Was ist Parallelität?
Parallelität kann als die Kunst definiert werden, die Aufgaben in Unteraufgaben aufzuteilen, die gleichzeitig verarbeitet werden können. Es ist entgegengesetzt zu der oben diskutierten Parallelität, bei der zwei oder mehr Ereignisse gleichzeitig stattfinden. Wir können es schematisch verstehen; Eine Aufgabe ist in mehrere Unteraufgaben unterteilt, die wie folgt parallel verarbeitet werden können:
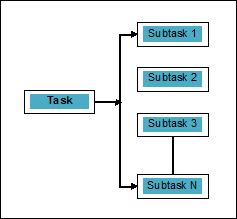
Beachten Sie die folgenden Punkte, um mehr über die Unterscheidung zwischen Parallelität und Parallelität zu erfahren:
Gleichzeitig aber nicht parallel
Eine Anwendung kann gleichzeitig, aber nicht parallel sein. Dies bedeutet, dass sie mehrere Aufgaben gleichzeitig verarbeitet, die Aufgaben jedoch nicht in Unteraufgaben unterteilt sind.
Parallel aber nicht gleichzeitig
Eine Anwendung kann parallel, aber nicht gleichzeitig sein. Dies bedeutet, dass sie jeweils nur für eine Aufgabe ausgeführt wird und die in Unteraufgaben aufgeschlüsselten Aufgaben parallel verarbeitet werden können.
Weder parallel noch gleichzeitig
Eine Anwendung kann weder parallel noch gleichzeitig sein. Dies bedeutet, dass jeweils nur eine Aufgabe bearbeitet wird und die Aufgabe niemals in Unteraufgaben unterteilt wird.
Sowohl parallel als auch gleichzeitig
Eine Anwendung kann sowohl parallel als auch gleichzeitig ausgeführt werden. Dies bedeutet, dass beide Aufgaben gleichzeitig ausgeführt werden und die Aufgabe in Unteraufgaben unterteilt ist, um sie parallel auszuführen.
Notwendigkeit der Parallelität
Wir können Parallelität erreichen, indem wir die Unteraufgaben auf verschiedene Kerne einer einzelnen CPU oder auf mehrere Computer verteilen, die innerhalb eines Netzwerks verbunden sind.
Berücksichtigen Sie die folgenden wichtigen Punkte, um zu verstehen, warum Parallelität erforderlich ist:
Effiziente Codeausführung
Mit Hilfe der Parallelität können wir unseren Code effizient ausführen. Dies spart Zeit, da derselbe Code in Teilen parallel ausgeführt wird.
Schneller als sequentielles Rechnen
Sequentielles Rechnen wird durch physikalische und praktische Faktoren eingeschränkt, aufgrund derer es nicht möglich ist, schnellere Rechenergebnisse zu erzielen. Auf der anderen Seite wird dieses Problem durch paralleles Rechnen gelöst und liefert schnellere Rechenergebnisse als sequentielles Rechnen.
Weniger Ausführungszeit
Die parallele Verarbeitung reduziert die Ausführungszeit des Programmcodes.
Wenn wir über ein reales Beispiel für Parallelität sprechen, ist die Grafikkarte unseres Computers das Beispiel, das die wahre Leistungsfähigkeit der Parallelverarbeitung hervorhebt, da sie Hunderte einzelner Verarbeitungskerne aufweist, die unabhängig voneinander arbeiten und gleichzeitig die Ausführung durchführen können. Aus diesem Grund können wir auch High-End-Anwendungen und Spiele ausführen.
Verständnis der Prozessoren für die Implementierung
Wir kennen Parallelität, Parallelität und den Unterschied zwischen ihnen, aber was ist mit dem System, auf dem es implementiert werden soll? Es ist sehr wichtig, das System zu verstehen, auf dem wir implementieren werden, da es uns den Vorteil gibt, beim Entwerfen der Software fundierte Entscheidungen zu treffen. Wir haben die folgenden zwei Arten von Prozessoren -
Single-Core-Prozessoren
Single-Core-Prozessoren können jeweils einen Thread ausführen. Diese Prozessoren verwendencontext switchingum alle erforderlichen Informationen für einen Thread zu einem bestimmten Zeitpunkt zu speichern und die Informationen später wiederherzustellen. Der Kontextwechselmechanismus hilft uns, innerhalb einer bestimmten Sekunde Fortschritte bei einer Reihe von Threads zu erzielen, und es sieht so aus, als würde das System an mehreren Dingen arbeiten.
Single-Core-Prozessoren bieten viele Vorteile. Diese Prozessoren benötigen weniger Strom und es gibt kein komplexes Kommunikationsprotokoll zwischen mehreren Kernen. Andererseits ist die Geschwindigkeit von Single-Core-Prozessoren begrenzt und für größere Anwendungen nicht geeignet.
Multi-Core-Prozessoren
Mehrkernprozessoren haben mehrere unabhängige Prozessoreinheiten, die auch als solche bezeichnet werden cores.
Solche Prozessoren benötigen keinen Kontextumschaltmechanismus, da jeder Kern alles enthält, was zum Ausführen einer Folge gespeicherter Anweisungen erforderlich ist.
Fetch-Decode-Execute-Zyklus
Die Kerne von Mehrkernprozessoren folgen einem Ausführungszyklus. Dieser Zyklus wird als bezeichnetFetch-Decode-ExecuteZyklus. Es umfasst die folgenden Schritte:
Holen
Dies ist der erste Schritt des Zyklus, bei dem Anweisungen aus dem Programmspeicher abgerufen werden.
Dekodieren
Kürzlich abgerufene Anweisungen würden in eine Reihe von Signalen umgewandelt, die andere Teile der CPU auslösen.
Ausführen
Dies ist der letzte Schritt, in dem die abgerufenen und die decodierten Anweisungen ausgeführt werden. Das Ergebnis der Ausführung wird in einem CPU-Register gespeichert.
Ein Vorteil hierbei ist, dass die Ausführung in Multi-Core-Prozessoren schneller ist als die von Single-Core-Prozessoren. Es ist für größere Anwendungen geeignet. Andererseits ist ein komplexes Kommunikationsprotokoll zwischen mehreren Kernen ein Problem. Mehrere Kerne benötigen mehr Strom als Single-Core-Prozessoren.
Es gibt verschiedene System- und Speicherarchitekturstile, die beim Entwerfen des Programms oder des gleichzeitigen Systems berücksichtigt werden müssen. Dies ist sehr wichtig, da ein System- und Speicherstil für eine Aufgabe geeignet sein kann, für andere Aufgaben jedoch fehleranfällig sein kann.
Computersystemarchitekturen, die Parallelität unterstützen
Michael Flynn gab 1972 Taxonomie für die Kategorisierung verschiedener Stile der Computersystemarchitektur. Diese Taxonomie definiert vier verschiedene Stile wie folgt:
- Einzelbefehlsstrom, Einzeldatenstrom (SISD)
- Einzelbefehlsstrom, Mehrfachdatenstrom (SIMD)
- Mehrfachbefehlsstrom, Einzeldatenstrom (MISD)
- Mehrfachbefehlsstrom, Mehrfachdatenstrom (MIMD).
Einzelbefehlsstrom, Einzeldatenstrom (SISD)
Wie der Name schon sagt, würden solche Systeme einen sequentiellen eingehenden Datenstrom und eine einzelne Verarbeitungseinheit haben, um den Datenstrom auszuführen. Sie sind wie Einprozessorsysteme mit paralleler Computerarchitektur. Es folgt die Architektur von SISD -
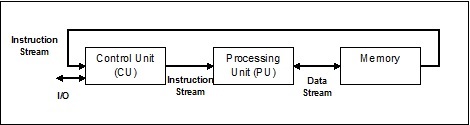
Vorteile von SISD
Die Vorteile der SISD-Architektur sind folgende:
- Es benötigt weniger Strom.
- Es gibt kein Problem mit komplexen Kommunikationsprotokollen zwischen mehreren Kernen.
Nachteile von SISD
Die Nachteile der SISD-Architektur sind folgende:
- Die Geschwindigkeit der SISD-Architektur ist genau wie bei Single-Core-Prozessoren begrenzt.
- Es ist nicht für größere Anwendungen geeignet.
Einzelbefehlsstrom, Mehrfachdatenstrom (SIMD)
Wie der Name schon sagt, würden solche Systeme mehrere eingehende Datenströme und eine Anzahl von Verarbeitungseinheiten haben, die zu einem bestimmten Zeitpunkt auf einen einzelnen Befehl einwirken können. Sie sind wie Multiprozessorsysteme mit paralleler Computerarchitektur. Es folgt die Architektur von SIMD -
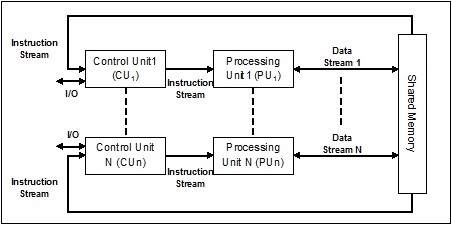
Das beste Beispiel für SIMD sind die Grafikkarten. Diese Karten haben Hunderte von einzelnen Verarbeitungseinheiten. Wenn wir über den Rechenunterschied zwischen SISD und SIMD sprechen, dann für das Hinzufügen von Arrays[5, 15, 20] und [15, 25, 10],Die SISD-Architektur müsste drei verschiedene Addiervorgänge ausführen. Andererseits können wir mit der SIMD-Architektur dann in einem einzigen Addiervorgang hinzufügen.
Vorteile von SIMD
Die Vorteile der SIMD-Architektur sind folgende:
Dieselbe Operation an mehreren Elementen kann nur mit einer Anweisung ausgeführt werden.
Der Durchsatz des Systems kann durch Erhöhen der Anzahl der Kerne des Prozessors erhöht werden.
Die Verarbeitungsgeschwindigkeit ist höher als bei der SISD-Architektur.
Nachteile von SIMD
Die Nachteile der SIMD-Architektur sind folgende:
- Es gibt eine komplexe Kommunikation zwischen der Anzahl der Prozessorkerne.
- Die Kosten sind höher als bei der SISD-Architektur.
MISD-Stream (Multiple Instruction Single Data)
Systeme mit MISD-Stream haben eine Anzahl von Verarbeitungseinheiten, die unterschiedliche Operationen ausführen, indem sie unterschiedliche Anweisungen für denselben Datensatz ausführen. Es folgt die Architektur von MISD -
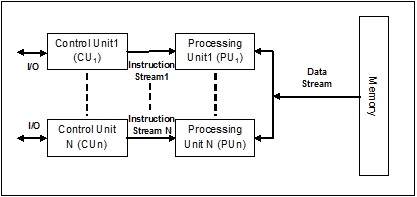
Die Vertreter der MISD-Architektur existieren kommerziell noch nicht.
MIMD-Stream (Multiple Instruction Multiple Data)
In dem System, das eine MIMD-Architektur verwendet, kann jeder Prozessor in einem Multiprozessorsystem verschiedene Befehlssätze unabhängig voneinander auf dem unterschiedlichen Datensatz parallel ausführen. Dies steht im Gegensatz zur SIMD-Architektur, bei der eine einzelne Operation für mehrere Datensätze ausgeführt wird. Es folgt die Architektur von MIMD -
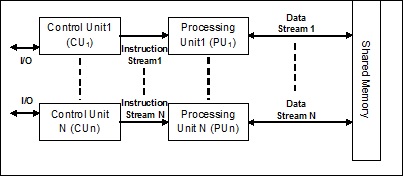
Ein normaler Multiprozessor verwendet die MIMD-Architektur. Diese Architekturen werden grundsätzlich in einer Reihe von Anwendungsbereichen verwendet, wie z. B. computergestütztes Design / computergestützte Fertigung, Simulation, Modellierung, Kommunikationsschalter usw.
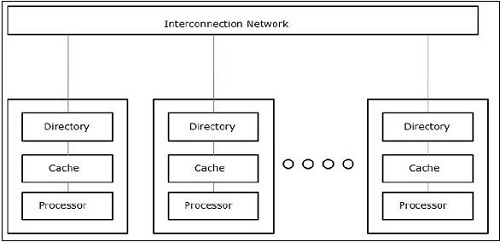
Speicherarchitekturen, die Parallelität unterstützen
Bei der Arbeit mit Konzepten wie Parallelität und Parallelität müssen die Programme immer beschleunigt werden. Eine von Computerdesignern gefundene Lösung besteht darin, Mehrfachcomputer mit gemeinsamem Speicher zu erstellen, dh Computer mit einem einzigen physischen Adressraum, auf den alle Kerne eines Prozessors zugreifen. In diesem Szenario kann es verschiedene Architekturstile geben. Im Folgenden sind die drei wichtigen Architekturstile aufgeführt:
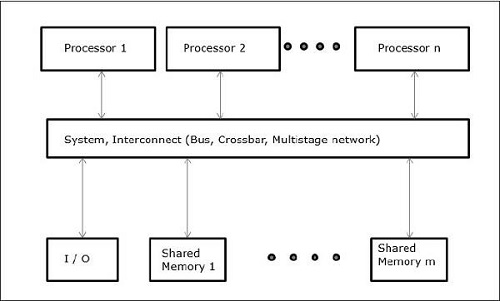
UMA (Uniform Memory Access)
In diesem Modell teilen sich alle Prozessoren den physischen Speicher einheitlich. Alle Prozessoren haben die gleiche Zugriffszeit auf alle Speicherwörter. Jeder Prozessor kann einen privaten Cache-Speicher haben. Die Peripheriegeräte folgen einer Reihe von Regeln.
Wenn alle Prozessoren gleichen Zugriff auf alle Peripheriegeräte haben, wird das System als a bezeichnet symmetric multiprocessor. Wenn nur ein oder wenige Prozessoren auf die Peripheriegeräte zugreifen können, wird das System als bezeichnetasymmetric multiprocessor.
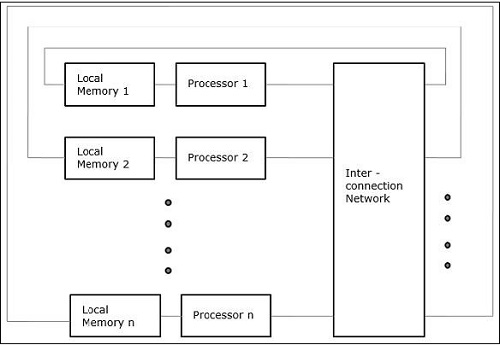
Ungleichmäßiger Speicherzugriff (NUMA)
Im NUMA-Multiprozessormodell variiert die Zugriffszeit mit dem Ort des Speicherworts. Hier wird der gemeinsam genutzte Speicher physisch auf alle Prozessoren verteilt, die als lokale Speicher bezeichnet werden. Die Sammlung aller lokalen Speicher bildet einen globalen Adressraum, auf den alle Prozessoren zugreifen können.
Nur Cache-Speicherarchitektur (COMA)
Das COMA-Modell ist eine spezielle Version des NUMA-Modells. Hier werden alle verteilten Hauptspeicher in Cache-Speicher konvertiert.
Wie wir wissen, ist der Faden im Allgemeinen eine sehr dünne, gedrehte Schnur, die normalerweise aus Baumwoll- oder Seidenstoff besteht und zum Nähen von Kleidung und dergleichen verwendet wird. Der gleiche Begriff Thread wird auch in der Welt der Computerprogrammierung verwendet. Wie hängen wir nun den zum Nähen von Kleidung verwendeten Faden und den für die Computerprogrammierung verwendeten Faden zusammen? Die Rollen der beiden Threads sind hier ähnlich. In der Kleidung halten Sie das Tuch zusammen und auf der anderen Seite halten Sie bei der Computerprogrammierung das Computerprogramm in einem Faden und lassen das Programm aufeinanderfolgende Aktionen oder viele Aktionen gleichzeitig ausführen.
Threadist die kleinste Ausführungseinheit in einem Betriebssystem. Es ist an sich kein Programm, sondern läuft innerhalb eines Programms. Mit anderen Worten, Threads sind nicht unabhängig voneinander und teilen Codeabschnitt, Datenabschnitt usw. mit anderen Threads. Diese Fäden werden auch als leichte Prozesse bezeichnet.
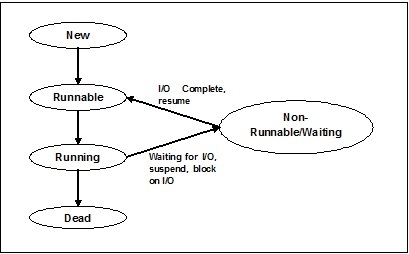
Fadenzustände
Um die Funktionalität von Threads im Detail zu verstehen, müssen wir den Lebenszyklus der Threads oder die verschiedenen Thread-Zustände kennenlernen. Normalerweise kann ein Thread in fünf verschiedenen Zuständen existieren. Die verschiedenen Zustände sind unten gezeigt -
Neues Thema
Ein neuer Thread beginnt seinen Lebenszyklus im neuen Zustand. Zu diesem Zeitpunkt wurde es jedoch noch nicht gestartet und es wurden keine Ressourcen zugewiesen. Wir können sagen, dass es nur eine Instanz eines Objekts ist.
Runnable
Wenn der neugeborene Thread gestartet wird, kann der Thread ausgeführt werden, dh er wartet darauf, ausgeführt zu werden. In diesem Status verfügt es über alle Ressourcen, aber der Taskplaner hat die Ausführung noch nicht geplant.
Laufen
In diesem Zustand macht der Thread Fortschritte und führt die Aufgabe aus, die vom Aufgabenplaner zur Ausführung ausgewählt wurde. Jetzt kann der Thread entweder in den toten Zustand oder in den nicht ausführbaren / wartenden Zustand wechseln.
Nicht laufen / warten
In diesem Zustand wird der Thread angehalten, weil er entweder auf die Antwort einer E / A-Anforderung wartet oder auf den Abschluss der Ausführung eines anderen Threads.
tot
Ein ausführbarer Thread wechselt in den Status "Beendet", wenn er seine Aufgabe abgeschlossen oder auf andere Weise beendet hat.
Das folgende Diagramm zeigt den gesamten Lebenszyklus eines Threads -
Arten von Thread
In diesem Abschnitt sehen wir die verschiedenen Arten von Threads. Die Typen werden unten beschrieben -
Threads auf Benutzerebene
Dies sind vom Benutzer verwaltete Threads.
In diesem Fall ist dem Thread-Verwaltungskern die Existenz von Threads nicht bekannt. Die Thread-Bibliothek enthält Code zum Erstellen und Zerstören von Threads, zum Weiterleiten von Nachrichten und Daten zwischen Threads, zum Planen der Thread-Ausführung sowie zum Speichern und Wiederherstellen von Thread-Kontexten. Die Anwendung beginnt mit einem einzelnen Thread.
Die Beispiele für Threads auf Benutzerebene sind -
- Java-Threads
- POSIX-Threads
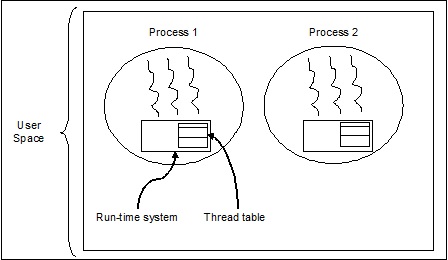
Vorteile von Threads auf Benutzerebene
Im Folgenden sind die verschiedenen Vorteile von Threads auf Benutzerebene aufgeführt:
- Für das Thread-Switching sind keine Berechtigungen für den Kernel-Modus erforderlich.
- Thread auf Benutzerebene kann auf jedem Betriebssystem ausgeführt werden.
- Die Planung kann im Thread auf Benutzerebene anwendungsspezifisch sein.
- Threads auf Benutzerebene lassen sich schnell erstellen und verwalten.
Nachteile von Threads auf Benutzerebene
Im Folgenden sind die verschiedenen Nachteile von Threads auf Benutzerebene aufgeführt:
- In einem typischen Betriebssystem werden die meisten Systemaufrufe blockiert.
- Multithread-Anwendungen können Multiprocessing nicht nutzen.
Threads auf Kernebene
Vom Betriebssystem verwaltete Threads wirken auf den Kernel, der ein Betriebssystemkern ist.
In diesem Fall führt der Kernel die Thread-Verwaltung durch. Im Anwendungsbereich befindet sich kein Thread-Verwaltungscode. Kernel-Threads werden direkt vom Betriebssystem unterstützt. Jede Anwendung kann für Multithreading programmiert werden. Alle Threads in einer Anwendung werden in einem einzigen Prozess unterstützt.
Der Kernel verwaltet Kontextinformationen für den gesamten Prozess und für einzelne Threads innerhalb des Prozesses. Die Planung durch den Kernel erfolgt auf Thread-Basis. Der Kernel führt die Thread-Erstellung, -Planung und -Verwaltung im Kernelbereich durch. Kernel-Threads sind im Allgemeinen langsamer zu erstellen und zu verwalten als die Benutzer-Threads. Beispiele für Threads auf Kernelebene sind Windows und Solaris.
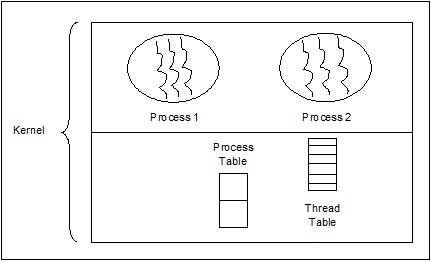
Vorteile von Threads auf Kernel-Ebene
Im Folgenden sind die verschiedenen Vorteile von Threads auf Kernelebene aufgeführt:
Der Kernel kann mehrere Threads aus demselben Prozess gleichzeitig für mehrere Prozesse planen.
Wenn ein Thread in einem Prozess blockiert ist, kann der Kernel einen anderen Thread desselben Prozesses planen.
Kernel-Routinen selbst können Multithread-fähig sein.
Nachteile von Threads auf Kernel-Ebene
Kernel-Threads sind im Allgemeinen langsamer zu erstellen und zu verwalten als die Benutzer-Threads.
Die Übertragung der Kontrolle von einem Thread auf einen anderen innerhalb desselben Prozesses erfordert einen Moduswechsel zum Kernel.
Thread Control Block - TCB
Thread Control Block (TCB) kann als Datenstruktur im Kernel des Betriebssystems definiert werden, die hauptsächlich Informationen zum Thread enthält. In TCB gespeicherte threadspezifische Informationen würden einige wichtige Informationen zu jedem Prozess hervorheben.
Beachten Sie die folgenden Punkte in Bezug auf die in TCB enthaltenen Threads:
Thread identification - Dies ist die eindeutige Thread-ID (tid), die jedem neuen Thread zugewiesen wird.
Thread state - Es enthält Informationen zum Status (Running, Runnable, Non-Running, Dead) des Threads.
Program Counter (PC) - Es zeigt auf die aktuelle Programmanweisung des Threads.
Register set - Es enthält die Registerwerte des Threads, die ihnen für Berechnungen zugewiesen wurden.
Stack Pointer- Es zeigt auf den Stapel des Threads im Prozess. Es enthält die lokalen Variablen im Bereich des Threads.
Pointer to PCB - Es enthält den Zeiger auf den Prozess, der diesen Thread erstellt hat.

Beziehung zwischen Prozess & Thread
Beim Multithreading sind Prozess und Thread zwei sehr eng verwandte Begriffe mit dem gleichen Ziel, dass der Computer mehr als eine Sache gleichzeitig ausführen kann. Ein Prozess kann einen oder mehrere Threads enthalten, im Gegenteil, Thread kann keinen Prozess enthalten. Beide bleiben jedoch die beiden grundlegenden Ausführungseinheiten. Ein Programm, das eine Reihe von Anweisungen ausführt, initiiert sowohl den Prozess als auch den Thread.
Die folgende Tabelle zeigt den Vergleich zwischen Prozess und Thread -
| Prozess | Faden |
|---|---|
| Der Prozess ist schwer oder ressourcenintensiv. | Thread ist leichtgewichtig und benötigt weniger Ressourcen als ein Prozess. |
| Prozessumschaltung erfordert Interaktion mit dem Betriebssystem. | Thread-Switching muss nicht mit dem Betriebssystem interagieren. |
| In mehreren Verarbeitungsumgebungen führt jeder Prozess denselben Code aus, verfügt jedoch über eigene Speicher- und Dateiressourcen. | Alle Threads können denselben Satz offener Dateien und untergeordneter Prozesse gemeinsam nutzen. |
| Wenn ein Prozess blockiert ist, kann kein anderer Prozess ausgeführt werden, bis der erste Prozess entsperrt ist. | Während ein Thread blockiert ist und wartet, kann ein zweiter Thread in derselben Task ausgeführt werden. |
| Mehrere Prozesse ohne Verwendung von Threads verbrauchen mehr Ressourcen. | Prozesse mit mehreren Threads verbrauchen weniger Ressourcen. |
| In mehreren Prozessen arbeitet jeder Prozess unabhängig von den anderen. | Ein Thread kann die Daten eines anderen Threads lesen, schreiben oder ändern. |
| Wenn sich der übergeordnete Prozess ändert, hat dies keine Auswirkungen auf die untergeordneten Prozesse. | Wenn sich im Hauptthread etwas ändert, kann dies das Verhalten anderer Threads dieses Prozesses beeinflussen. |
| Um mit Geschwisterprozessen zu kommunizieren, müssen Prozesse prozessübergreifende Kommunikation verwenden. | Threads können direkt mit anderen Threads dieses Prozesses kommunizieren. |
Konzept des Multithreading
Wie bereits erwähnt, ist Multithreading die Fähigkeit einer CPU, die Verwendung des Betriebssystems durch gleichzeitiges Ausführen mehrerer Threads zu verwalten. Die Hauptidee von Multithreading besteht darin, Parallelität zu erreichen, indem ein Prozess in mehrere Threads aufgeteilt wird. Einfacher ausgedrückt können wir sagen, dass Multithreading der Weg ist, um Multitasking mithilfe des Thread-Konzepts zu erreichen.
Das Konzept des Multithreading kann anhand des folgenden Beispiels verstanden werden.
Beispiel
Angenommen, wir führen einen Prozess aus. Der Prozess könnte darin bestehen, MS Word zum Schreiben von etwas zu öffnen. In einem solchen Prozess wird ein Thread zum Öffnen von MS Word zugewiesen und ein anderer Thread wird zum Schreiben benötigt. Angenommen, wir möchten etwas bearbeiten, dann ist ein anderer Thread erforderlich, um die Bearbeitungsaufgabe usw. auszuführen.
Das folgende Diagramm hilft uns zu verstehen, wie mehrere Threads im Speicher vorhanden sind -
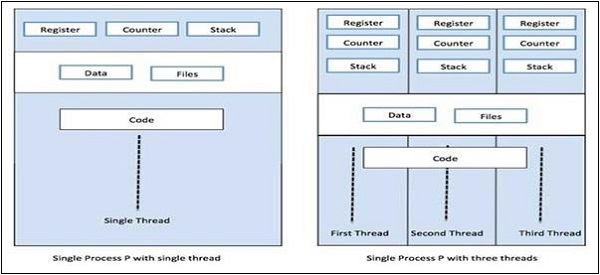
Wir können im obigen Diagramm sehen, dass mehr als ein Thread innerhalb eines Prozesses existieren kann, wobei jeder Thread seinen eigenen Registersatz und lokale Variablen enthält. Ansonsten teilen sich alle Threads in einem Prozess globale Variablen.
Vorteile des Multithreading
Lassen Sie uns nun einige Vorteile des Multithreading sehen. Die Vorteile sind wie folgt:
Speed of communication - Multithreading verbessert die Rechengeschwindigkeit, da jeder Kern oder Prozessor gleichzeitig separate Threads verarbeitet.
Program remains responsive - Ein Programm kann so reagieren, dass ein Thread auf die Eingabe wartet und ein anderer gleichzeitig eine GUI ausführt.
Access to global variables - Beim Multithreading können alle Threads eines bestimmten Prozesses auf die globalen Variablen zugreifen. Wenn sich die globale Variable ändert, ist sie auch für andere Threads sichtbar.
Utilization of resources - Das Ausführen mehrerer Threads in jedem Programm nutzt die CPU besser aus und die Leerlaufzeit der CPU wird kürzer.
Sharing of data - Es ist kein zusätzlicher Speicherplatz für jeden Thread erforderlich, da Threads innerhalb eines Programms dieselben Daten gemeinsam nutzen können.
Nachteile von Multithreading
Lassen Sie uns nun einige Nachteile des Multithreading sehen. Die Nachteile sind wie folgt:
Not suitable for single processor system - Beim Multithreading ist es schwierig, eine Leistung in Bezug auf die Rechengeschwindigkeit auf einem Einzelprozessorsystem im Vergleich zur Leistung auf einem Multiprozessorsystem zu erzielen.
Issue of security - Da wir wissen, dass alle Threads in einem Programm dieselben Daten gemeinsam haben, besteht immer ein Sicherheitsproblem, da jeder unbekannte Thread die Daten ändern kann.
Increase in complexity - Multithreading kann die Komplexität des Programms erhöhen und das Debuggen wird schwierig.
Lead to deadlock state - Multithreading kann das Programm zu einem potenziellen Risiko führen, den Deadlock-Status zu erreichen.
Synchronization required- Eine Synchronisierung ist erforderlich, um einen gegenseitigen Ausschluss zu vermeiden. Dies führt zu mehr Speicher- und CPU-Auslastung.
In diesem Kapitel erfahren Sie, wie Sie Threads in Python implementieren.
Python-Modul für die Thread-Implementierung
Python-Threads werden manchmal als einfache Prozesse bezeichnet, da Threads viel weniger Speicher belegen als Prozesse. Mit Threads können mehrere Aufgaben gleichzeitig ausgeführt werden. In Python haben wir die folgenden zwei Module, die Threads in einem Programm implementieren:
<_thread>module
<threading>module
Der Hauptunterschied zwischen diesen beiden Modulen besteht darin, dass <_thread> Modul behandelt einen Thread als Funktion, während das <threading>Das Modul behandelt jeden Thread als Objekt und implementiert ihn objektorientiert. Darüber hinaus ist die<_thread>Modul ist effektiv in Low-Level-Threading und hat weniger Funktionen als das <threading> Modul.
Modul <_Thread>
In der früheren Version von Python hatten wir die <thread>Modul, aber es wurde für eine ziemlich lange Zeit als "veraltet" angesehen. Benutzer wurden aufgefordert, die zu verwenden<threading>Modul stattdessen. Daher ist in Python 3 das Modul "Thread" nicht mehr verfügbar. Es wurde umbenannt in "<_thread>"für Abwärtsinkompatibilitäten in Python3.
Um einen neuen Thread mit Hilfe des zu generieren <_thread> Modul müssen wir das aufrufen start_new_threadMethode davon. Die Funktionsweise dieser Methode kann mit Hilfe der folgenden Syntax verstanden werden:
_thread.start_new_thread ( function, args[, kwargs] )Hier -
args ist ein Tupel von Argumenten
kwargs ist ein optionales Wörterbuch mit Schlüsselwortargumenten
Wenn wir die Funktion aufrufen möchten, ohne ein Argument zu übergeben, müssen wir ein leeres Tupel von Argumenten in verwenden args.
Dieser Methodenaufruf wird sofort zurückgegeben, der untergeordnete Thread wird gestartet und die Funktion mit der übergebenen Liste von Argumenten (falls vorhanden) aufgerufen. Der Thread wird beendet, sobald die Funktion zurückgegeben wird.
Beispiel
Im Folgenden finden Sie ein Beispiel zum Generieren eines neuen Threads mithilfe von <_thread>Modul. Wir verwenden hier die Methode start_new_thread ().
import _thread
import time
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
passAusgabe
Die folgende Ausgabe hilft uns, die Erzeugung neuer Threads mithilfe von zu verstehen <_thread> Modul.
Thread-1: Mon Apr 23 10:03:33 2018
Thread-2: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:37 2018
Thread-2: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:41 2018
Thread-2: Mon Apr 23 10:03:43 2018
Thread-2: Mon Apr 23 10:03:47 2018
Thread-2: Mon Apr 23 10:03:51 2018<Threading> -Modul
Das <threading>Das Modul wird objektorientiert implementiert und behandelt jeden Thread als Objekt. Daher bietet es eine viel leistungsfähigere Unterstützung für Threads auf hoher Ebene als das Modul <_thread>. Dieses Modul ist in Python 2.4 enthalten.
Zusätzliche Methoden im Modul <threading>
Das <threading> Modul umfasst alle Methoden der <_thread>Modul, bietet aber auch zusätzliche Methoden. Die zusätzlichen Methoden sind wie folgt:
threading.activeCount() - Diese Methode gibt die Anzahl der aktiven Thread-Objekte zurück
threading.currentThread() - Diese Methode gibt die Anzahl der Thread-Objekte im Thread-Steuerelement des Aufrufers zurück.
threading.enumerate() - Diese Methode gibt eine Liste aller aktuell aktiven Thread-Objekte zurück.
run() - Die run () -Methode ist der Einstiegspunkt für einen Thread.
start() - Die Methode start () startet einen Thread durch Aufrufen der Methode run.
join([time]) - Join () wartet auf das Beenden von Threads.
isAlive() - Die Methode isAlive () prüft, ob noch ein Thread ausgeführt wird.
getName() - Die Methode getName () gibt den Namen eines Threads zurück.
setName() - Die Methode setName () legt den Namen eines Threads fest.
Für die Implementierung von Threading wird die <threading> Modul hat die Thread Klasse, die die folgenden Methoden bereitstellt -
Wie erstelle ich Threads mit dem Modul <threading>?
In diesem Abschnitt erfahren Sie, wie Sie mithilfe von Threads erstellen <threading>Modul. Führen Sie die folgenden Schritte aus, um mit dem Modul <threading> einen neuen Thread zu erstellen.
Step 1 - In diesem Schritt müssen wir eine neue Unterklasse der definieren Thread Klasse.
Step 2 - Um zusätzliche Argumente hinzuzufügen, müssen wir das überschreiben __init__(self [,args]) Methode.
Step 3 - In diesem Schritt müssen wir die Methode run (self [, args]) überschreiben, um zu implementieren, was der Thread beim Starten tun soll.
Jetzt nach dem Erstellen der neuen Thread Unterklasse können wir eine Instanz davon erstellen und dann einen neuen Thread starten, indem wir die aufrufen start(), was wiederum die nennt run() Methode.
Beispiel
In diesem Beispiel erfahren Sie, wie Sie mithilfe von einen neuen Thread generieren <threading> Modul.
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")
Starting Thread-1
Starting Thread-2Ausgabe
Betrachten Sie nun die folgende Ausgabe:
Thread-1: Mon Apr 23 10:52:09 2018
Thread-1: Mon Apr 23 10:52:10 2018
Thread-2: Mon Apr 23 10:52:10 2018
Thread-1: Mon Apr 23 10:52:11 2018
Thread-1: Mon Apr 23 10:52:12 2018
Thread-2: Mon Apr 23 10:52:12 2018
Thread-1: Mon Apr 23 10:52:13 2018
Exiting Thread-1
Thread-2: Mon Apr 23 10:52:14 2018
Thread-2: Mon Apr 23 10:52:16 2018
Thread-2: Mon Apr 23 10:52:18 2018
Exiting Thread-2
Exiting Main ThreadPython-Programm für verschiedene Thread-Zustände
Es gibt fünf Thread-Zustände - neu, lauffähig, laufend, wartend und tot. Unter diesen fünf werden wir uns hauptsächlich auf drei Staaten konzentrieren - Laufen, Warten und Tot. Ein Thread erhält seine Ressourcen im laufenden Zustand und wartet auf die Ressourcen im wartenden Zustand. Die endgültige Freigabe der Ressource befindet sich, wenn sie ausgeführt und erworben wurde, im toten Zustand.
Das folgende Python-Programm zeigt mit Hilfe der Methoden start (), sleep () und join (), wie ein Thread im laufenden, wartenden und toten Zustand eingegeben wurde.
Step 1 - Importieren Sie die erforderlichen Module <Threading> und <Zeit>
import threading
import timeStep 2 - Definieren Sie eine Funktion, die beim Erstellen eines Threads aufgerufen wird.
def thread_states():
print("Thread entered in running state")Step 3 - Wir verwenden das Modul sleep () des Zeitmoduls, um unseren Thread etwa 2 Sekunden warten zu lassen.
time.sleep(2)Step 4 - Jetzt erstellen wir einen Thread mit dem Namen T1, der das Argument der oben definierten Funktion übernimmt.
T1 = threading.Thread(target=thread_states)Step 5- Jetzt können wir mit Hilfe der Funktion start () unseren Thread starten. Es wird die Nachricht erzeugt, die von uns bei der Definition der Funktion festgelegt wurde.
T1.start()
Thread entered in running stateStep 6 - Jetzt können wir den Thread endlich mit der join () -Methode beenden, nachdem er seine Ausführung abgeschlossen hat.
T1.join()Starten eines Threads in Python
In Python können wir einen neuen Thread auf verschiedene Arten starten. Am einfachsten ist es jedoch, ihn als einzelne Funktion zu definieren. Nachdem wir die Funktion definiert haben, können wir diese als Ziel für eine neue übergebenthreading.ThreadObjekt und so weiter. Führen Sie den folgenden Python-Code aus, um zu verstehen, wie die Funktion funktioniert:
import threading
import time
import random
def Thread_execution(i):
print("Execution of Thread {} started\n".format(i))
sleepTime = random.randint(1,4)
time.sleep(sleepTime)
print("Execution of Thread {} finished".format(i))
for i in range(4):
thread = threading.Thread(target=Thread_execution, args=(i,))
thread.start()
print("Active Threads:" , threading.enumerate())Ausgabe
Execution of Thread 0 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>]
Execution of Thread 1 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>]
Execution of Thread 2 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>]
Execution of Thread 3 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>,
<Thread(Thread-3579, started 4520)>]
Execution of Thread 0 finished
Execution of Thread 1 finished
Execution of Thread 2 finished
Execution of Thread 3 finishedDaemon-Threads in Python
Bevor Sie die Daemon-Threads in Python implementieren, müssen Sie sich mit Daemon-Threads und ihrer Verwendung vertraut machen. In Bezug auf die Datenverarbeitung ist Daemon ein Hintergrundprozess, der die Anforderungen für verschiedene Dienste wie Datenübertragung, Dateiübertragung usw. verarbeitet. Es wäre ruhend, wenn es nicht mehr benötigt wird. Dieselbe Aufgabe kann auch mit Hilfe von Nicht-Daemon-Threads ausgeführt werden. In diesem Fall muss der Hauptthread die Nicht-Daemon-Threads jedoch manuell verfolgen. Wenn wir dagegen Daemon-Threads verwenden, kann der Haupt-Thread dies vollständig vergessen und wird beendet, wenn der Haupt-Thread beendet wird. Ein weiterer wichtiger Punkt bei Daemon-Threads ist, dass wir sie nur für nicht wesentliche Aufgaben verwenden können, die uns nicht betreffen würden, wenn sie nicht abgeschlossen werden oder dazwischen beendet werden. Es folgt die Implementierung von Daemon-Threads in Python -
import threading
import time
def nondaemonThread():
print("starting my thread")
time.sleep(8)
print("ending my thread")
def daemonThread():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonThread = threading.Thread(target = nondaemonThread)
daemonThread = threading.Thread(target = daemonThread)
daemonThread.setDaemon(True)
daemonThread.start()
nondaemonThread.start()Im obigen Code gibt es nämlich zwei Funktionen >nondaemonThread() und >daemonThread(). Die erste Funktion druckt ihren Status und schläft nach 8 Sekunden, während die Funktion deamonThread () alle 2 Sekunden auf unbestimmte Zeit Hallo druckt. Wir können den Unterschied zwischen Nondaemon- und Daemon-Threads anhand der folgenden Ausgabe verstehen:
Hello
starting my thread
Hello
Hello
Hello
Hello
ending my thread
Hello
Hello
Hello
Hello
HelloDie Thread-Synchronisation kann als eine Methode definiert werden, mit deren Hilfe sichergestellt werden kann, dass zwei oder mehr gleichzeitige Threads nicht gleichzeitig auf das als kritischer Abschnitt bekannte Programmsegment zugreifen. Andererseits ist, wie wir wissen, dieser kritische Abschnitt der Teil des Programms, auf den auf die gemeinsam genutzte Ressource zugegriffen wird. Daher können wir sagen, dass bei der Synchronisierung sichergestellt wird, dass zwei oder mehr Threads nicht miteinander verbunden sind, indem gleichzeitig auf die Ressourcen zugegriffen wird. Das folgende Diagramm zeigt, dass vier Threads gleichzeitig versuchen, auf den kritischen Abschnitt eines Programms zuzugreifen.
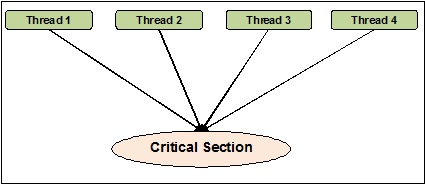
Nehmen wir zur Verdeutlichung an, dass zwei oder mehr Threads gleichzeitig versuchen, das Objekt zur Liste hinzuzufügen. Dieser Vorgang kann nicht zu einem erfolgreichen Ende führen, da entweder ein oder alle Objekte gelöscht werden oder der Status der Liste vollständig beschädigt wird. Hier besteht die Rolle der Synchronisation darin, dass jeweils nur ein Thread auf die Liste zugreifen kann.
Probleme bei der Thread-Synchronisation
Beim Implementieren der gleichzeitigen Programmierung oder beim Anwenden synchronisierender Grundelemente können Probleme auftreten. In diesem Abschnitt werden wir zwei Hauptthemen diskutieren. Die Probleme sind -
- Deadlock
- Rennbedingung
Rennbedingung
Dies ist eines der Hauptprobleme bei der gleichzeitigen Programmierung. Der gleichzeitige Zugriff auf gemeinsam genutzte Ressourcen kann zu Rennbedingungen führen. Eine Race-Bedingung kann als das Auftreten einer Bedingung definiert werden, wenn zwei oder mehr Threads auf gemeinsam genutzte Daten zugreifen und dann versuchen können, ihren Wert gleichzeitig zu ändern. Aus diesem Grund können die Werte von Variablen unvorhersehbar sein und abhängig von den Zeitpunkten der Kontextwechsel der Prozesse variieren.
Beispiel
Betrachten Sie dieses Beispiel, um das Konzept der Rennbedingungen zu verstehen -
Step 1 - In diesem Schritt müssen wir das Threading-Modul importieren -
import threadingStep 2 - Definieren Sie nun eine globale Variable, z. B. x, zusammen mit ihrem Wert als 0 -
x = 0Step 3 - Jetzt müssen wir das definieren increment_global() Funktion, die in dieser globalen Funktion das Inkrement um 1 ausführt x -
def increment_global():
global x
x += 1Step 4 - In diesem Schritt definieren wir die taskofThread()Funktion, die die Funktion increment_global () für eine bestimmte Anzahl von Malen aufruft; für unser Beispiel ist es 50000 mal -
def taskofThread():
for _ in range(50000):
increment_global()Step 5- Definieren Sie nun die main () - Funktion, in der die Threads t1 und t2 erstellt werden. Beide werden mit Hilfe der Funktion start () gestartet und warten, bis sie ihre Arbeit mit Hilfe der Funktion join () beendet haben.
def main():
global x
x = 0
t1 = threading.Thread(target= taskofThread)
t2 = threading.Thread(target= taskofThread)
t1.start()
t2.start()
t1.join()
t2.join()Step 6- Nun müssen wir den Bereich angeben, in dem angegeben wird, wie viele Iterationen wir die main () - Funktion aufrufen möchten. Hier rufen wir es 5 mal an.
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))In der unten gezeigten Ausgabe können wir den Effekt der Rennbedingung als den Wert von x sehen, nachdem jede Iteration 100000 erwartet wird. Es gibt jedoch viele Variationen im Wert. Dies ist auf den gleichzeitigen Zugriff von Threads auf die gemeinsam genutzte globale Variable x zurückzuführen.
Ausgabe
x = 100000 after Iteration 0
x = 54034 after Iteration 1
x = 80230 after Iteration 2
x = 93602 after Iteration 3
x = 93289 after Iteration 4Umgang mit Rennbedingungen mit Schlössern
Da wir die Auswirkung der Race-Bedingung im obigen Programm gesehen haben, benötigen wir ein Synchronisationstool, das die Race-Bedingung zwischen mehreren Threads verarbeiten kann. In Python ist die<threading>Das Modul bietet eine Lock-Klasse für den Umgang mit Rennbedingungen. Weiterhin ist dieLockDie Klasse bietet verschiedene Methoden, mit deren Hilfe wir die Race-Bedingungen zwischen mehreren Threads behandeln können. Die Methoden werden nachfolgend beschrieben -
erwerben () Methode
Diese Methode wird verwendet, um eine Sperre zu erfassen, dh zu blockieren. Eine Sperre kann blockierend oder nicht blockierend sein, abhängig vom folgenden wahren oder falschen Wert -
With value set to True - Wenn die Methode purchase () mit True aufgerufen wird, was das Standardargument ist, wird die Thread-Ausführung blockiert, bis die Sperre aufgehoben wird.
With value set to False - Wenn die Methode purchase () mit False aufgerufen wird, was nicht das Standardargument ist, wird die Thread-Ausführung erst blockiert, wenn sie auf true gesetzt ist, dh bis sie gesperrt ist.
release () Methode
Diese Methode wird verwendet, um eine Sperre aufzuheben. Im Folgenden sind einige wichtige Aufgaben im Zusammenhang mit dieser Methode aufgeführt:
Wenn ein Schloss gesperrt ist, wird das release()Methode würde es entsperren. Seine Aufgabe ist es, genau einem Thread zu erlauben, fortzufahren, wenn mehr als ein Thread blockiert ist und darauf wartet, dass die Sperre entsperrt wird.
Es wird ein erhöhen ThreadError wenn die Sperre bereits entsperrt ist.
Jetzt können wir das obige Programm mit der Lock-Klasse und ihren Methoden umschreiben, um die Race-Bedingung zu vermeiden. Wir müssen die taskofThread () -Methode mit dem Argument lock definieren und dann die Methoden purchase () und release () zum Blockieren und Nichtblockieren von Sperren verwenden, um Race-Bedingungen zu vermeiden.
Beispiel
Das folgende Beispiel zeigt ein Python-Programm, um das Konzept von Sperren für den Umgang mit Race-Bedingungen zu verstehen:
import threading
x = 0
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target = taskofThread, args = (lock,))
t2 = threading.Thread(target = taskofThread, args = (lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))Die folgende Ausgabe zeigt, dass der Effekt der Rennbedingung vernachlässigt wird. Der Wert von x beträgt nach jeder Iteration jetzt 100000, was den Erwartungen dieses Programms entspricht.
Ausgabe
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4Deadlocks - Das Problem der Dining Philosophen
Deadlock ist ein problematisches Problem beim Entwerfen der gleichzeitigen Systeme. Wir können dieses Problem mit Hilfe des Essensphilosophenproblems wie folgt veranschaulichen:
Edsger Dijkstra führte ursprünglich das Problem des Speisephilosophen ein, eines der bekanntesten Beispiele für eines der größten Probleme des gleichzeitigen Systems namens Deadlock.
In diesem Problem sitzen fünf berühmte Philosophen an einem runden Tisch und essen etwas aus ihren Schalen. Es gibt fünf Gabeln, mit denen die fünf Philosophen ihr Essen essen können. Die Philosophen beschließen jedoch, zwei Gabeln gleichzeitig zu verwenden, um ihr Essen zu essen.
Nun gibt es zwei Hauptbedingungen für die Philosophen. Erstens kann jeder der Philosophen entweder essen oder denken, und zweitens müssen sie zuerst beide Gabeln erhalten, dh links und rechts. Das Problem tritt auf, wenn jeder der fünf Philosophen gleichzeitig die linke Gabel auswählt. Jetzt warten alle darauf, dass die richtige Gabel frei ist, aber sie werden ihre Gabel niemals abgeben, bis sie ihr Essen gegessen haben und die richtige Gabel niemals verfügbar sein würde. Daher würde es am Esstisch einen Deadlock-Zustand geben.
Deadlock im gleichzeitigen System
Wenn wir jetzt sehen, kann das gleiche Problem auch in unseren gleichzeitigen Systemen auftreten. Die Gabeln im obigen Beispiel wären die Systemressourcen, und jeder Philosoph kann den Prozess darstellen, der im Wettbewerb um die Ressourcen steht.
Lösung mit Python-Programm
Die Lösung dieses Problems kann gefunden werden, indem die Philosophen in zwei Typen aufgeteilt werden - greedy philosophers und generous philosophers. Hauptsächlich wird ein gieriger Philosoph versuchen, die linke Gabel aufzunehmen und zu warten, bis sie da ist. Er wird dann warten, bis die richtige Gabel da ist, sie aufheben, essen und dann ablegen. Auf der anderen Seite wird ein großzügiger Philosoph versuchen, die linke Gabel aufzuheben, und wenn sie nicht da ist, wird er warten und es nach einiger Zeit erneut versuchen. Wenn sie die linke Gabel bekommen, werden sie versuchen, die richtige zu bekommen. Wenn sie auch die richtige Gabel bekommen, essen sie beide Gabeln und lassen sie los. Wenn sie jedoch nicht die richtige Gabel bekommen, lassen sie die linke Gabel los.
Beispiel
Das folgende Python-Programm hilft uns, eine Lösung für das Problem des Essensphilosophen zu finden:
import threading
import random
import time
class DiningPhilosopher(threading.Thread):
running = True
def __init__(self, xname, Leftfork, Rightfork):
threading.Thread.__init__(self)
self.name = xname
self.Leftfork = Leftfork
self.Rightfork = Rightfork
def run(self):
while(self.running):
time.sleep( random.uniform(3,13))
print ('%s is hungry.' % self.name)
self.dine()
def dine(self):
fork1, fork2 = self.Leftfork, self.Rightfork
while self.running:
fork1.acquire(True)
locked = fork2.acquire(False)
if locked: break
fork1.release()
print ('%s swaps forks' % self.name)
fork1, fork2 = fork2, fork1
else:
return
self.dining()
fork2.release()
fork1.release()
def dining(self):
print ('%s starts eating '% self.name)
time.sleep(random.uniform(1,10))
print ('%s finishes eating and now thinking.' % self.name)
def Dining_Philosophers():
forks = [threading.Lock() for n in range(5)]
philosopherNames = ('1st','2nd','3rd','4th', '5th')
philosophers= [DiningPhilosopher(philosopherNames[i], forks[i%5], forks[(i+1)%5]) \
for i in range(5)]
random.seed()
DiningPhilosopher.running = True
for p in philosophers: p.start()
time.sleep(30)
DiningPhilosopher.running = False
print (" It is finishing.")
Dining_Philosophers()Das obige Programm verwendet das Konzept gieriger und großzügiger Philosophen. Das Programm hat auch die verwendetacquire() und release() Methoden der Lock Klasse der <threading>Modul. Wir können die Lösung in der folgenden Ausgabe sehen -
Ausgabe
4th is hungry.
4th starts eating
1st is hungry.
1st starts eating
2nd is hungry.
5th is hungry.
3rd is hungry.
1st finishes eating and now thinking.3rd swaps forks
2nd starts eating
4th finishes eating and now thinking.
3rd swaps forks5th starts eating
5th finishes eating and now thinking.
4th is hungry.
4th starts eating
2nd finishes eating and now thinking.
3rd swaps forks
1st is hungry.
1st starts eating
4th finishes eating and now thinking.
3rd starts eating
5th is hungry.
5th swaps forks
1st finishes eating and now thinking.
5th starts eating
2nd is hungry.
2nd swaps forks
4th is hungry.
5th finishes eating and now thinking.
3rd finishes eating and now thinking.
2nd starts eating 4th starts eating
It is finishing.Wenn im wirklichen Leben ein Team von Menschen an einer gemeinsamen Aufgabe arbeitet, sollte zwischen ihnen eine Kommunikation bestehen, um die Aufgabe ordnungsgemäß zu erledigen. Die gleiche Analogie gilt auch für Threads. Um die ideale Zeit des Prozessors zu verkürzen, erstellen wir bei der Programmierung mehrere Threads und weisen jedem Thread unterschiedliche Unteraufgaben zu. Daher muss eine Kommunikationseinrichtung vorhanden sein, und sie sollten miteinander interagieren, um den Auftrag synchron zu beenden.
Berücksichtigen Sie die folgenden wichtigen Punkte im Zusammenhang mit der Thread-Interkommunikation:
No performance gain - Wenn wir keine ordnungsgemäße Kommunikation zwischen Threads und Prozessen erreichen können, sind die Leistungsgewinne durch Parallelität und Parallelität nutzlos.
Accomplish task properly - Ohne einen ordnungsgemäßen Interkommunikationsmechanismus zwischen Threads kann die zugewiesene Aufgabe nicht ordnungsgemäß ausgeführt werden.
More efficient than inter-process communication - Die Kommunikation zwischen Threads ist effizienter und benutzerfreundlicher als die Kommunikation zwischen Prozessen, da alle Threads innerhalb eines Prozesses denselben Adressraum verwenden und keinen gemeinsamen Speicher verwenden müssen.
Python-Datenstrukturen für die thread-sichere Kommunikation
Multithread-Code hat das Problem, Informationen von einem Thread an einen anderen Thread zu übergeben. Die Standard-Kommunikationsprimitive lösen dieses Problem nicht. Daher müssen wir unser eigenes zusammengesetztes Objekt implementieren, um Objekte zwischen Threads zu teilen, um die Kommunikation threadsicher zu machen. Im Folgenden finden Sie einige Datenstrukturen, die nach einigen Änderungen eine thread-sichere Kommunikation ermöglichen.
Sets
Um die Set-Datenstruktur threadsicher zu verwenden, müssen wir die Set-Klasse erweitern, um unseren eigenen Sperrmechanismus zu implementieren.
Beispiel
Hier ist ein Python-Beispiel für die Erweiterung der Klasse -
class extend_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(extend_class, self).__init__(*args, **kwargs)
def add(self, elem):
self._lock.acquire()
try:
super(extend_class, self).add(elem)
finally:
self._lock.release()
def delete(self, elem):
self._lock.acquire()
try:
super(extend_class, self).delete(elem)
finally:
self._lock.release()Im obigen Beispiel wurde ein Klassenobjekt benannt extend_class wurde definiert, die weiter von Python geerbt wird set class. Im Konstruktor dieser Klasse wird ein Sperrobjekt erstellt. Nun gibt es zwei Funktionen -add() und delete(). Diese Funktionen sind definiert und threadsicher. Sie verlassen sich beide auf diesuper Klassenfunktionalität mit einer Schlüsselausnahme.
Dekorateur
Dies ist eine weitere wichtige Methode für die thread-sichere Kommunikation, bei der Dekoratoren verwendet werden.
Beispiel
Betrachten Sie ein Python-Beispiel, das zeigt, wie Dekorateure verwendet werden & mminus;
def lock_decorator(method):
def new_deco_method(self, *args, **kwargs):
with self._lock:
return method(self, *args, **kwargs)
return new_deco_method
class Decorator_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(Decorator_class, self).__init__(*args, **kwargs)
@lock_decorator
def add(self, *args, **kwargs):
return super(Decorator_class, self).add(elem)
@lock_decorator
def delete(self, *args, **kwargs):
return super(Decorator_class, self).delete(elem)Im obigen Beispiel wurde eine Dekorationsmethode mit dem Namen lock_decorator definiert, die weiter von der Python-Methodenklasse geerbt wird. Anschließend wird im Konstruktor dieser Klasse ein Sperrobjekt erstellt. Jetzt gibt es zwei Funktionen - add () und delete (). Diese Funktionen sind definiert und threadsicher. Beide sind mit einer Ausnahme auf erstklassige Funktionen angewiesen.
Listen
Die Listendatenstruktur ist threadsicher, schnell und einfach für die temporäre Speicherung im Speicher. In Cpython schützt die GIL vor gleichzeitigem Zugriff auf sie. Als wir erfuhren, dass Listen threadsicher sind, aber was ist mit den darin enthaltenen Daten? Tatsächlich sind die Daten der Liste nicht geschützt. Zum Beispiel,L.append(x)Es kann nicht garantiert werden, dass das erwartete Ergebnis zurückgegeben wird, wenn ein anderer Thread versucht, dasselbe zu tun. Dies liegt jedoch daranappend() ist eine atomare Operation und threadsicher, aber der andere Thread versucht, die Daten der Liste gleichzeitig zu ändern, sodass wir die Nebenwirkungen der Race-Bedingungen auf die Ausgabe sehen können.
Um diese Art von Problem zu beheben und die Daten sicher zu ändern, müssen wir einen geeigneten Sperrmechanismus implementieren, der ferner sicherstellt, dass mehrere Threads möglicherweise nicht unter Rennbedingungen laufen können. Um einen ordnungsgemäßen Sperrmechanismus zu implementieren, können wir die Klasse wie in den vorherigen Beispielen erweitern.
Einige andere atomare Operationen auf Listen sind wie folgt:
L.append(x)
L1.extend(L2)
x = L[i]
x = L.pop()
L1[i:j] = L2
L.sort()
x = y
x.field = y
D[x] = y
D1.update(D2)
D.keys()Hier -
- L, L1, L2 sind alle Listen
- D, D1, D2 sind Diktate
- x, y sind Objekte
- Ich, ich bin Ints
Warteschlangen
Wenn die Daten der Liste nicht geschützt sind, müssen wir uns möglicherweise den Konsequenzen stellen. Wir können falsche Daten der Rennbedingungen erhalten oder löschen. Aus diesem Grund wird empfohlen, die Warteschlangendatenstruktur zu verwenden. Ein reales Beispiel für eine Warteschlange kann eine einspurige Einbahnstraße sein, bei der das Fahrzeug zuerst ein- und zuerst ausfährt. Weitere Beispiele aus der Praxis sind die Warteschlangen an den Fahrkartenschaltern und Bushaltestellen.
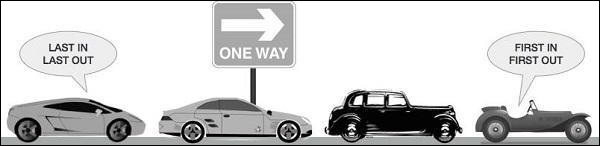
Warteschlangen sind standardmäßig threadsichere Datenstrukturen, und wir müssen uns nicht um die Implementierung komplexer Sperrmechanismen kümmern. Python bietet uns die
Arten von Warteschlangen
In diesem Abschnitt werden wir uns mit den verschiedenen Arten von Warteschlangen befassen. Python bietet drei Optionen für Warteschlangen, die aus dem verwendet werden können<queue> Modul -
- Normale Warteschlangen (FIFO, First in First out)
- LIFO, Last in First Out
- Priority
In den folgenden Abschnitten erfahren Sie mehr über die verschiedenen Warteschlangen.
Normale Warteschlangen (FIFO, First in First out)
Es sind die am häufigsten verwendeten Warteschlangenimplementierungen, die von Python angeboten werden. In diesem Warteschlangenmechanismus erhält jeder, der zuerst kommt, zuerst den Dienst. FIFO wird auch als normale Warteschlange bezeichnet. FIFO-Warteschlangen können wie folgt dargestellt werden:

Python-Implementierung der FIFO-Warteschlange
In Python kann die FIFO-Warteschlange sowohl mit einem Thread als auch mit Multithreads implementiert werden.
FIFO-Warteschlange mit einem Thread
Für die Implementierung der FIFO-Warteschlange mit einem einzelnen Thread wird die QueueDie Klasse implementiert einen einfachen First-In- und First-Out-Container. Elemente werden an einem „Ende“ der Sequenz mit hinzugefügtput()und vom anderen Ende mit entfernt get().
Beispiel
Es folgt ein Python-Programm zur Implementierung der FIFO-Warteschlange mit einem einzelnen Thread -
import queue
q = queue.Queue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end = " ")Ausgabe
item-0 item-1 item-2 item-3 item-4 item-5 item-6 item-7Die Ausgabe zeigt, dass das obige Programm einen einzelnen Thread verwendet, um zu veranschaulichen, dass die Elemente in derselben Reihenfolge aus der Warteschlange entfernt werden, in der sie eingefügt wurden.
FIFO-Warteschlange mit mehreren Threads
Um FIFO mit mehreren Threads zu implementieren, müssen wir die Funktion myqueue () definieren, die vom Warteschlangenmodul erweitert wird. Die Funktionsweise der Methoden get () und put () ist dieselbe wie oben beschrieben, während die FIFO-Warteschlange mit einem einzelnen Thread implementiert wird. Um es dann multithreaded zu machen, müssen wir die Threads deklarieren und instanziieren. Diese Threads belegen die Warteschlange auf FIFO-Weise.
Beispiel
Es folgt ein Python-Programm zur Implementierung einer FIFO-Warteschlange mit mehreren Threads
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.Queue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Ausgabe
<Thread(Thread-3654, started 5044)> removed 0 from the queue
<Thread(Thread-3655, started 3144)> removed 1 from the queue
<Thread(Thread-3656, started 6996)> removed 2 from the queue
<Thread(Thread-3657, started 2672)> removed 3 from the queue
<Thread(Thread-3654, started 5044)> removed 4 from the queueLIFO, Last in First Out-Warteschlange
Diese Warteschlange verwendet eine völlig entgegengesetzte Analogie zu FIFO-Warteschlangen (First in First Out). In diesem Warteschlangenmechanismus erhält derjenige, der zuletzt kommt, zuerst den Dienst. Dies ähnelt der Implementierung einer Stapeldatenstruktur. LIFO-Warteschlangen erweisen sich als nützlich bei der Implementierung der Tiefensuche wie Algorithmen der künstlichen Intelligenz.
Python-Implementierung der LIFO-Warteschlange
In Python kann die LIFO-Warteschlange sowohl mit einem Thread als auch mit Multithreads implementiert werden.
LIFO-Warteschlange mit einem Thread
Für die Implementierung der LIFO-Warteschlange mit einem einzelnen Thread wird die Queue Die Klasse implementiert mithilfe der Struktur einen grundlegenden Last-In- und First-Out-Container Queue.LifoQueue. Nun zum Anrufput()werden die Elemente im Kopf des Behälters hinzugefügt und auch bei Verwendung aus dem Kopf entfernt get().
Beispiel
Es folgt ein Python-Programm zur Implementierung der LIFO-Warteschlange mit einem einzelnen Thread -
import queue
q = queue.LifoQueue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end=" ")
Output:
item-7 item-6 item-5 item-4 item-3 item-2 item-1 item-0Die Ausgabe zeigt, dass das obige Programm einen einzelnen Thread verwendet, um zu veranschaulichen, dass Elemente in der entgegengesetzten Reihenfolge aus der Warteschlange entfernt werden, in der sie eingefügt werden.
LIFO-Warteschlange mit mehreren Threads
Die Implementierung ist ähnlich wie bei der Implementierung von FIFO-Warteschlangen mit mehreren Threads. Der einzige Unterschied ist, dass wir die verwenden müssenQueue Klasse, die mithilfe der Struktur einen grundlegenden Last-In- und First-Out-Container implementiert Queue.LifoQueue.
Beispiel
Es folgt ein Python-Programm zur Implementierung einer LIFO-Warteschlange mit mehreren Threads -
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.LifoQueue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Ausgabe
<Thread(Thread-3882, started 4928)> removed 4 from the queue
<Thread(Thread-3883, started 4364)> removed 3 from the queue
<Thread(Thread-3884, started 6908)> removed 2 from the queue
<Thread(Thread-3885, started 3584)> removed 1 from the queue
<Thread(Thread-3882, started 4928)> removed 0 from the queuePrioritätswarteschlange
In FIFO- und LIFO-Warteschlangen hängt die Reihenfolge der Elemente mit der Reihenfolge des Einfügens zusammen. Es gibt jedoch viele Fälle, in denen die Priorität wichtiger ist als die Reihenfolge des Einfügens. Betrachten wir ein Beispiel aus der Praxis. Angenommen, die Sicherheit am Flughafen überprüft Personen verschiedener Kategorien. Personen der VVIP, Mitarbeiter der Fluggesellschaft, Zollbeamte und Kategorien können vorrangig überprüft werden, anstatt wie bei den Bürgern auf der Grundlage der Ankunft überprüft zu werden.
Ein weiterer wichtiger Aspekt, der für die Prioritätswarteschlange berücksichtigt werden muss, ist die Entwicklung eines Taskplaners. Ein gängiges Design besteht darin, die meisten Agentenaufgaben vorrangig in der Warteschlange zu erledigen. Diese Datenstruktur kann verwendet werden, um die Elemente basierend auf ihrem Prioritätswert aus der Warteschlange aufzunehmen.
Python-Implementierung der Prioritätswarteschlange
In Python kann die Prioritätswarteschlange sowohl mit einem Thread als auch mit Multithreads implementiert werden.
Prioritätswarteschlange mit einem Thread
Für die Implementierung der Prioritätswarteschlange mit einem einzelnen Thread wird die Queue Die Klasse implementiert eine Aufgabe für den Prioritätscontainer mithilfe der Struktur Queue.Prioritätswarteschlange. Nun zum Anrufput()werden die Elemente mit einem Wert hinzugefügt, bei dem der niedrigste Wert die höchste Priorität hat, und daher zuerst mithilfe von abgerufen werden get().
Beispiel
Betrachten Sie das folgende Python-Programm zur Implementierung der Prioritätswarteschlange mit einem einzelnen Thread:
import queue as Q
p_queue = Q.PriorityQueue()
p_queue.put((2, 'Urgent'))
p_queue.put((1, 'Most Urgent'))
p_queue.put((10, 'Nothing important'))
prio_queue.put((5, 'Important'))
while not p_queue.empty():
item = p_queue.get()
print('%s - %s' % item)Ausgabe
1 – Most Urgent
2 - Urgent
5 - Important
10 – Nothing importantIn der obigen Ausgabe können wir sehen, dass die Warteschlange die Elemente basierend auf der Priorität gespeichert hat - weniger Wert hat hohe Priorität.
Prioritätswarteschlange mit mehreren Threads
Die Implementierung ähnelt der Implementierung von FIFO- und LIFO-Warteschlangen mit mehreren Threads. Der einzige Unterschied ist, dass wir die verwenden müssenQueue Klasse zum Initialisieren der Priorität mithilfe der Struktur Queue.PriorityQueue. Ein weiterer Unterschied besteht in der Art und Weise, wie die Warteschlange generiert wird. Im folgenden Beispiel wird es mit zwei identischen Datensätzen generiert.
Beispiel
Das folgende Python-Programm hilft bei der Implementierung der Prioritätswarteschlange mit mehreren Threads:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(1)
q = queue.PriorityQueue()
for i in range(5):
q.put(i,1)
for i in range(5):
q.put(i,1)
threads = []
for i in range(2):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Ausgabe
<Thread(Thread-4939, started 2420)> removed 0 from the queue
<Thread(Thread-4940, started 3284)> removed 0 from the queue
<Thread(Thread-4939, started 2420)> removed 1 from the queue
<Thread(Thread-4940, started 3284)> removed 1 from the queue
<Thread(Thread-4939, started 2420)> removed 2 from the queue
<Thread(Thread-4940, started 3284)> removed 2 from the queue
<Thread(Thread-4939, started 2420)> removed 3 from the queue
<Thread(Thread-4940, started 3284)> removed 3 from the queue
<Thread(Thread-4939, started 2420)> removed 4 from the queue
<Thread(Thread-4940, started 3284)> removed 4 from the queueIn diesem Kapitel erfahren Sie, wie Sie Thread-Anwendungen testen. Wir werden auch lernen, wie wichtig das Testen ist.
Warum testen?
Bevor wir uns mit der Bedeutung des Testens befassen, müssen wir wissen, was Testen ist. Im Allgemeinen ist das Testen eine Technik, um herauszufinden, wie gut etwas funktioniert. Wenn wir jedoch speziell über Computerprogramme oder Software sprechen, ist Testen die Technik, um auf die Funktionalität eines Softwareprogramms zuzugreifen.
In diesem Abschnitt werden wir die Bedeutung von Softwaretests diskutieren. Bei der Softwareentwicklung muss vor der Freigabe der Software an den Client eine doppelte Überprüfung durchgeführt werden. Aus diesem Grund ist es sehr wichtig, die Software von einem erfahrenen Testteam zu testen. Berücksichtigen Sie die folgenden Punkte, um die Bedeutung von Softwaretests zu verstehen:
Verbesserung der Softwarequalität
Sicherlich möchte kein Unternehmen Software von geringer Qualität liefern und kein Kunde möchte Software von geringer Qualität kaufen. Das Testen verbessert die Qualität der Software, indem die darin enthaltenen Fehler gefunden und behoben werden.
Kundenzufriedenheit
Der wichtigste Teil eines Unternehmens ist die Zufriedenheit seiner Kunden. Durch die Bereitstellung fehlerfreier und qualitativ hochwertiger Software können die Unternehmen Kundenzufriedenheit erreichen.
Verringern Sie die Auswirkungen neuer Funktionen
Angenommen, wir haben ein Softwaresystem mit 10000 Zeilen erstellt und müssen eine neue Funktion hinzufügen, dann hätte das Entwicklungsteam Bedenken hinsichtlich der Auswirkungen dieser neuen Funktion auf die gesamte Software. Auch hier spielt das Testen eine wichtige Rolle, denn wenn das Testteam eine gute Reihe von Tests durchgeführt hat, kann es uns vor möglichen katastrophalen Unterbrechungen bewahren.
Benutzererfahrung
Ein weiterer wichtiger Teil eines Unternehmens ist die Erfahrung der Benutzer dieses Produkts. Nur durch Tests kann sichergestellt werden, dass der Endbenutzer die Verwendung des Produkts einfach und unkompliziert findet.
Kosten senken
Durch Testen können die Gesamtkosten von Software gesenkt werden, indem die Fehler in der Testphase ihrer Entwicklung gefunden und behoben werden, anstatt sie nach der Auslieferung zu beheben. Wenn nach der Lieferung der Software ein schwerwiegender Fehler auftritt, erhöht dies die materiellen Kosten, beispielsweise in Bezug auf die Kosten, und die immateriellen Kosten, beispielsweise in Bezug auf die Unzufriedenheit der Kunden, den negativen Ruf des Unternehmens usw.
Was zu testen?
Es wird immer empfohlen, über ausreichende Kenntnisse darüber zu verfügen, was getestet werden soll. In diesem Abschnitt werden wir zunächst verstehen, was das Hauptmotiv des Testers beim Testen einer Software ist. Codeabdeckung, dh wie viele Codezeilen unsere Testsuite beim Testen trifft, sollte vermieden werden. Dies liegt daran, dass beim Testen die Konzentration auf die Anzahl der Codezeilen unserem System keinen wirklichen Wert verleiht. Möglicherweise bleiben einige Fehler bestehen, die sich auch nach der Bereitstellung zu einem späteren Zeitpunkt widerspiegeln.
Berücksichtigen Sie die folgenden wichtigen Punkte in Bezug auf das zu testende Element:
Wir müssen uns darauf konzentrieren, die Funktionalität des Codes zu testen und nicht die Codeabdeckung.
Wir müssen zuerst die wichtigsten Teile des Codes testen und uns dann den weniger wichtigen Teilen des Codes zuwenden. Das spart definitiv Zeit.
Der Tester muss über eine Vielzahl verschiedener Tests verfügen, die die Software an ihre Grenzen bringen können.
Ansätze zum Testen gleichzeitiger Softwareprogramme
Aufgrund der Fähigkeit, die wahre Fähigkeit einer Mehrkernarchitektur zu nutzen, ersetzen gleichzeitige Softwaresysteme sequentielle Systeme. In jüngster Zeit werden gleichzeitige Systemprogramme in allen Bereichen verwendet, von Mobiltelefonen bis zu Waschmaschinen, von Autos bis zu Flugzeugen usw. Wir müssen beim Testen der gleichzeitigen Softwareprogramme vorsichtiger sein, da wir einer einzelnen Thread-Anwendung mehrere Threads hinzugefügt haben schon ein Fehler, dann würden wir am Ende mehrere Fehler haben.
Testtechniken für gleichzeitige Softwareprogramme konzentrieren sich weitgehend auf die Auswahl von Verschachtelungen, die potenziell schädliche Muster wie Rennbedingungen, Deadlocks und Verstöße gegen die Atomizität aufdecken. Es folgen zwei Ansätze zum Testen gleichzeitiger Softwareprogramme:
Systematische Erforschung
Dieser Ansatz zielt darauf ab, den Raum der Verschachtelungen so weit wie möglich zu untersuchen. Solche Ansätze können eine Brute-Force-Technik anwenden, und andere verwenden eine Technik zur Reduzierung der Teilordnung oder eine heuristische Technik, um den Raum der Verschachtelungen zu erkunden.
Immobiliengetrieben
Eigenschaftsgesteuerte Ansätze beruhen auf der Beobachtung, dass Parallelitätsfehler eher bei Verschachtelungen auftreten, die bestimmte Eigenschaften wie verdächtiges Speicherzugriffsmuster offenlegen. Unterschiedliche eigenschaftsgesteuerte Ansätze zielen auf unterschiedliche Fehler wie Rennbedingungen, Deadlocks und Verletzung der Atomizität ab, was ferner von der einen oder anderen spezifischen Eigenschaft abhängt.
Teststrategien
Die Teststrategie wird auch als Testansatz bezeichnet. Die Strategie definiert, wie Tests durchgeführt werden sollen. Testansatz hat zwei Techniken -
Proaktiv
Ein Ansatz, bei dem der Testentwurfsprozess so früh wie möglich eingeleitet wird, um die Fehler zu finden und zu beheben, bevor der Build erstellt wird.
Reaktiv
Ein Ansatz, bei dem das Testen erst nach Abschluss des Entwicklungsprozesses beginnt.
Bevor wir eine Teststrategie oder einen Testansatz auf ein Python-Programm anwenden, müssen wir eine grundlegende Vorstellung von der Art der Fehler haben, die ein Softwareprogramm haben kann. Die Fehler sind wie folgt:
Syntaktische Fehler
Während der Programmentwicklung können viele kleine Fehler auftreten. Die Fehler sind hauptsächlich auf Tippfehler zurückzuführen. Zum Beispiel fehlender Doppelpunkt oder falsche Schreibweise eines Schlüsselworts usw. Solche Fehler sind auf Fehler in der Programmsyntax und nicht in der Logik zurückzuführen. Daher werden diese Fehler als syntaktische Fehler bezeichnet.
Semantische Fehler
Die semantischen Fehler werden auch als logische Fehler bezeichnet. Wenn im Softwareprogramm ein logischer oder semantischer Fehler vorliegt, wird die Anweisung kompiliert und korrekt ausgeführt, es wird jedoch nicht die gewünschte Ausgabe ausgegeben, da die Logik nicht korrekt ist.
Unit Testing
Dies ist eine der am häufigsten verwendeten Teststrategien zum Testen von Python-Programmen. Diese Strategie wird zum Testen von Einheiten oder Komponenten des Codes verwendet. Mit Einheiten oder Komponenten meinen wir Klassen oder Funktionen des Codes. Unit-Tests vereinfachen das Testen großer Programmiersysteme, indem „kleine“ Einheiten getestet werden. Mit Hilfe des obigen Konzepts kann das Testen von Einheiten als ein Verfahren definiert werden, bei dem einzelne Einheiten des Quellcodes getestet werden, um festzustellen, ob sie die gewünschte Ausgabe zurückgeben.
In unseren folgenden Abschnitten lernen wir die verschiedenen Python-Module für Unit-Tests kennen.
unittest Modul
Das allererste Modul für Unit-Tests ist das unittest-Modul. Es ist von JUnit inspiriert und standardmäßig in Python3.6 enthalten. Es unterstützt die Testautomatisierung, die gemeinsame Nutzung von Setup- und Shutdown-Code für Tests, die Zusammenfassung von Tests zu Sammlungen und die Unabhängigkeit der Tests vom Berichtsframework.
Im Folgenden finden Sie einige wichtige Konzepte, die vom unittest-Modul unterstützt werden
Textvorrichtung
Es wird verwendet, um einen Test so einzurichten, dass er vor Beginn des Tests ausgeführt und nach Beendigung des Tests abgerissen werden kann. Möglicherweise müssen temporäre Datenbanken, Verzeichnisse usw. erstellt werden, die vor Beginn des Tests erforderlich sind.
Testfall
Der Testfall prüft, ob eine erforderliche Antwort von einem bestimmten Satz von Eingaben kommt oder nicht. Das unittest-Modul enthält eine Basisklasse namens TestCase, mit der neue Testfälle erstellt werden können. Es enthält standardmäßig zwei Methoden:
setUp()- eine Hakenmethode zum Aufstellen der Prüfvorrichtung vor dem Training. Dies wird aufgerufen, bevor die implementierten Testmethoden aufgerufen werden.
tearDown( - Eine Hook-Methode zum Dekonstruieren des Klassen-Fixtures, nachdem alle Tests in der Klasse ausgeführt wurden.
Testsuite
Es ist eine Sammlung von Testsuiten, Testfällen oder beidem.
Testläufer
Es steuert den Ablauf der Testfälle oder Anzüge und liefert dem Benutzer das Ergebnis. Es kann eine grafische Benutzeroberfläche oder eine einfache Textschnittstelle verwenden, um das Ergebnis bereitzustellen.
Example
Das folgende Python-Programm verwendet das unittest-Modul, um ein Modul mit dem Namen zu testen Fibonacci. Das Programm hilft bei der Berechnung der Fibonacci-Reihe einer Zahl. In diesem Beispiel haben wir eine Klasse namens Fibo_test erstellt, um die Testfälle mithilfe verschiedener Methoden zu definieren. Diese Methoden werden von unittest.TestCase geerbt. Wir verwenden standardmäßig zwei Methoden - setUp () und tearDown (). Wir definieren auch die Testfibokalmethode. Der Name des Tests muss mit dem Buchstabentest begonnen werden. Im letzten Block bietet unittest.main () eine Befehlszeilenschnittstelle zum Testskript.
import unittest
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
class Fibo_Test(unittest.TestCase):
def setUp(self):
print("This is run before our tests would be executed")
def tearDown(self):
print("This is run after the completion of execution of our tests")
def testfibocal(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
self.assertEqual(fib(5), 5)
self.assertEqual(fib(10), 55)
self.assertEqual(fib(20), 6765)
if __name__ == "__main__":
unittest.main()Wenn das obige Skript über die Befehlszeile ausgeführt wird, wird eine Ausgabe erstellt, die folgendermaßen aussieht:
Ausgabe
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
.
----------------------------------------------------------------------
Ran 1 test in 0.006s
OKUm es klarer zu machen, ändern wir jetzt unseren Code, der bei der Definition des Fibonacci-Moduls geholfen hat.
Betrachten Sie den folgenden Codeblock als Beispiel:
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aEinige Änderungen am Codeblock werden wie unten gezeigt vorgenommen -
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aNachdem Sie das Skript mit dem geänderten Code ausgeführt haben, erhalten wir die folgende Ausgabe:
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
F
======================================================================
FAIL: testCalculation (__main__.Fibo_Test)
----------------------------------------------------------------------
Traceback (most recent call last):
File "unitg.py", line 15, in testCalculation
self.assertEqual(fib(0), 0)
AssertionError: 1 != 0
----------------------------------------------------------------------
Ran 1 test in 0.007s
FAILED (failures = 1)Die obige Ausgabe zeigt, dass das Modul die gewünschte Ausgabe nicht liefern konnte.
Docktest-Modul
Das Docktest-Modul hilft auch beim Testen von Einheiten. Es kommt auch mit Python vorverpackt. Es ist einfacher zu bedienen als das unittest Modul. Das unittest-Modul eignet sich besser für komplexe Tests. Um das doctest-Modul verwenden zu können, müssen wir es importieren. Die Dokumentzeichenfolge der entsprechenden Funktion muss zusammen mit ihren Ausgaben über eine interaktive Python-Sitzung verfügen.
Wenn in unserem Code alles in Ordnung ist, wird vom Docktest-Modul keine Ausgabe ausgegeben. Andernfalls wird die Ausgabe bereitgestellt.
Beispiel
Im folgenden Python-Beispiel wird das Docktest-Modul verwendet, um ein Modul mit dem Namen Fibonacci zu testen, mit dessen Hilfe die Fibonacci-Reihe einer Zahl berechnet werden kann.
import doctest
def fibonacci(n):
"""
Calculates the Fibonacci number
>>> fibonacci(0)
0
>>> fibonacci(1)
1
>>> fibonacci(10)
55
>>> fibonacci(20)
6765
>>>
"""
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
doctest.testmod()Wir können sehen, dass die Dokumentzeichenfolge der entsprechenden Funktion namens fib zusammen mit den Ausgaben eine interaktive Python-Sitzung hatte. Wenn unser Code in Ordnung ist, wird vom doctest-Modul keine Ausgabe ausgegeben. Um zu sehen, wie es funktioniert, können wir es mit der Option –v ausführen.
(base) D:\ProgramData>python dock_test.py -v
Trying:
fibonacci(0)
Expecting:
0
ok
Trying:
fibonacci(1)
Expecting:
1
ok
Trying:
fibonacci(10)
Expecting:
55
ok
Trying:
fibonacci(20)
Expecting:
6765
ok
1 items had no tests:
__main__
1 items passed all tests:
4 tests in __main__.fibonacci
4 tests in 2 items.
4 passed and 0 failed.
Test passed.Jetzt werden wir den Code ändern, der bei der Definition des Fibonacci-Moduls geholfen hat
Betrachten Sie den folgenden Codeblock als Beispiel:
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aDer folgende Codeblock hilft bei den Änderungen -
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aNachdem Sie das Skript auch ohne die Option –v mit dem geänderten Code ausgeführt haben, erhalten Sie die Ausgabe wie unten gezeigt.
Ausgabe
(base) D:\ProgramData>python dock_test.py
**********************************************************************
File "unitg.py", line 6, in __main__.fibonacci
Failed example:
fibonacci(0)
Expected:
0
Got:
1
**********************************************************************
File "unitg.py", line 10, in __main__.fibonacci
Failed example:
fibonacci(10)
Expected:
55
Got:
89
**********************************************************************
File "unitg.py", line 12, in __main__.fibonacci
Failed example:
fibonacci(20)
Expected:
6765
Got:
10946
**********************************************************************
1 items had failures:
3 of 4 in __main__.fibonacci
***Test Failed*** 3 failures.Wir können in der obigen Ausgabe sehen, dass drei Tests fehlgeschlagen sind.
In diesem Kapitel erfahren Sie, wie Sie Thread-Anwendungen debuggen. Wir werden auch lernen, wie wichtig das Debuggen ist.
Was ist Debugging?
In der Computerprogrammierung ist das Debuggen der Prozess des Findens und Entfernens von Fehlern, Fehlern und Anomalien aus dem Computerprogramm. Dieser Prozess beginnt, sobald der Code geschrieben wurde, und wird in aufeinanderfolgenden Schritten fortgesetzt, da der Code mit anderen Programmiereinheiten kombiniert wird, um ein Softwareprodukt zu bilden. Das Debuggen ist Teil des Software-Testprozesses und ein wesentlicher Bestandteil des gesamten Lebenszyklus der Softwareentwicklung.
Python-Debugger
Der Python-Debugger oder der pdbist Teil der Python-Standardbibliothek. Es ist ein gutes Fallback-Tool zum Aufspüren schwer zu findender Fehler und ermöglicht es uns, fehlerhaften Code schnell und zuverlässig zu beheben. Folgendes sind die beiden wichtigsten Aufgaben derpdp Debugger -
- Damit können wir die Werte von Variablen zur Laufzeit überprüfen.
- Wir können den Code schrittweise durchlaufen und auch Haltepunkte setzen.
Wir können auf folgende zwei Arten mit pdb arbeiten:
- Über die Kommandozeile; Dies wird auch als Postmortem-Debugging bezeichnet.
- Durch interaktives Ausführen von pdb.
Arbeiten mit pdb
Für die Arbeit mit dem Python-Debugger müssen wir den folgenden Code an der Stelle verwenden, an der wir in den Debugger einbrechen möchten:
import pdb;
pdb.set_trace()Beachten Sie die folgenden Befehle, um mit pdb über die Befehlszeile zu arbeiten.
- h(help)
- d(down)
- u(up)
- b(break)
- cl(clear)
- l(list))
- n(next))
- c(continue)
- s(step)
- r(return))
- b(break)
Es folgt eine Demo des Befehls h (Hilfe) des Python-Debuggers -
import pdb
pdb.set_trace()
--Call--
>d:\programdata\lib\site-packages\ipython\core\displayhook.py(247)__call__()
-> def __call__(self, result = None):
(Pdb) h
Documented commands (type help <topic>):
========================================
EOF c d h list q rv undisplay
a cl debug help ll quit s unt
alias clear disable ignore longlist r source until
args commands display interact n restart step up
b condition down j next return tbreak w
break cont enable jump p retval u whatis
bt continue exit l pp run unalias where
Miscellaneous help topics:
==========================
exec pdbBeispiel
Während der Arbeit mit dem Python-Debugger können wir den Haltepunkt an einer beliebigen Stelle im Skript mithilfe der folgenden Zeilen festlegen:
import pdb;
pdb.set_trace()Nach dem Festlegen des Haltepunkts können wir das Skript normal ausführen. Das Skript wird bis zu einem bestimmten Punkt ausgeführt. bis wo eine Linie gesetzt wurde. Betrachten Sie das folgende Beispiel, in dem wir das Skript mithilfe der oben genannten Zeilen an verschiedenen Stellen im Skript ausführen.
import pdb;
a = "aaa"
pdb.set_trace()
b = "bbb"
c = "ccc"
final = a + b + c
print (final)Wenn das obige Skript ausgeführt wird, wird das Programm ausgeführt, bis a = "aaa". Dies können wir in der folgenden Ausgabe überprüfen.
Ausgabe
--Return--
> <ipython-input-7-8a7d1b5cc854>(3)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
*** NameError: name 'b' is not defined
(Pdb) p c
*** NameError: name 'c' is not definedNach Verwendung des Befehls 'p (print)' in pdb druckt dieses Skript nur 'aaa'. Darauf folgt ein Fehler, da wir den Haltepunkt auf a = "aaa" gesetzt haben.
Ebenso können wir das Skript ausführen, indem wir die Haltepunkte ändern und den Unterschied in der Ausgabe sehen -
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
pdb.set_trace()
final = a + b + c
print (final)Ausgabe
--Return--
> <ipython-input-9-a59ef5caf723>(5)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
*** NameError: name 'final' is not defined
(Pdb) exitIm folgenden Skript setzen wir den Haltepunkt in der letzten Zeile des Programms -
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
final = a + b + c
pdb.set_trace()
print (final)Die Ausgabe ist wie folgt -
--Return--
> <ipython-input-11-8019b029997d>(6)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
'aaabbbccc'
(Pdb)In diesem Kapitel erfahren Sie, wie Benchmarking und Profiling bei der Behebung von Leistungsproblemen helfen.
Angenommen, wir haben einen Code geschrieben, der auch das gewünschte Ergebnis liefert. Was ist, wenn wir diesen Code etwas schneller ausführen möchten, weil sich die Anforderungen geändert haben? In diesem Fall müssen wir herausfinden, welche Teile unseres Codes das gesamte Programm verlangsamen. In diesem Fall kann Benchmarking und Profiling hilfreich sein.
Was ist Benchmarking?
Benchmarking zielt darauf ab, etwas durch Vergleich mit einem Standard zu bewerten. Hier stellt sich jedoch die Frage, was das Benchmarking wäre und warum wir es bei der Softwareprogrammierung benötigen. Das Benchmarking des Codes bedeutet, wie schnell der Code ausgeführt wird und wo der Engpass liegt. Ein Hauptgrund für das Benchmarking ist die Optimierung des Codes.
Wie funktioniert Benchmarking?
Wenn wir über die Funktionsweise des Benchmarking sprechen, müssen wir zunächst das gesamte Programm als einen aktuellen Status bewerten, dann können wir Mikro-Benchmarks kombinieren und dann ein Programm in kleinere Programme zerlegen. Um die Engpässe in unserem Programm zu finden und zu optimieren. Mit anderen Worten, wir können es so verstehen, dass das große und schwierige Problem in eine Reihe kleinerer und etwas einfacherer Probleme unterteilt wird, um sie zu optimieren.
Python-Modul für das Benchmarking
In Python haben wir ein Standardmodul für das Benchmarking, das aufgerufen wird timeit. Mit Hilfe dertimeit Modul können wir die Leistung eines kleinen Teils des Python-Codes in unserem Hauptprogramm messen.
Beispiel
Im folgenden Python-Skript importieren wir das timeit Modul, das die Zeit misst, die benötigt wird, um zwei Funktionen auszuführen - functionA und functionB - -
import timeit
import time
def functionA():
print("Function A starts the execution:")
print("Function A completes the execution:")
def functionB():
print("Function B starts the execution")
print("Function B completes the execution")
start_time = timeit.default_timer()
functionA()
print(timeit.default_timer() - start_time)
start_time = timeit.default_timer()
functionB()
print(timeit.default_timer() - start_time)Nach dem Ausführen des obigen Skripts erhalten wir die Ausführungszeit beider Funktionen wie unten gezeigt.
Ausgabe
Function A starts the execution:
Function A completes the execution:
0.0014599495514175942
Function B starts the execution
Function B completes the execution
0.0017024724827479076Schreiben Sie unseren eigenen Timer mit der Dekorationsfunktion
In Python können wir unseren eigenen Timer erstellen, der genau wie der funktioniert timeitModul. Dies kann mit Hilfe derdecoratorFunktion. Es folgt ein Beispiel für den benutzerdefinierten Timer -
import random
import time
def timer_func(func):
def function_timer(*args, **kwargs):
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "{func} took {time} seconds to complete its execution."
print(msg.format(func = func.__name__,time = runtime))
return value
return function_timer
@timer_func
def Myfunction():
for x in range(5):
sleep_time = random.choice(range(1,3))
time.sleep(sleep_time)
if __name__ == '__main__':
Myfunction()Das obige Python-Skript hilft beim Importieren von zufälligen Zeitmodulen. Wir haben die Dekorationsfunktion timer_func () erstellt. Darin befindet sich die Funktion function_timer (). Jetzt erfasst die verschachtelte Funktion die Zeit, bevor die übergebene Funktion aufgerufen wird. Dann wartet es auf die Rückkehr der Funktion und erfasst die Endzeit. Auf diese Weise können wir endlich die Ausführungszeit für das Python-Skript drucken lassen. Das Skript generiert die Ausgabe wie unten gezeigt.
Ausgabe
Myfunction took 8.000457763671875 seconds to complete its execution.Was ist Profiling?
Manchmal möchte der Programmierer einige Attribute wie die Verwendung des Speichers, die Zeitkomplexität oder die Verwendung bestimmter Anweisungen zu den Programmen messen, um die tatsächliche Leistungsfähigkeit dieses Programms zu messen. Eine solche Art der Programmmessung wird als Profiling bezeichnet. Die Profilerstellung verwendet eine dynamische Programmanalyse, um solche Messungen durchzuführen.
In den folgenden Abschnitten lernen wir die verschiedenen Python-Module für die Profilerstellung kennen.
cProfile - das eingebaute Modul
cProfileist ein in Python integriertes Modul zur Profilerstellung. Das Modul ist eine C-Erweiterung mit angemessenem Overhead, die es für die Profilerstellung von Programmen mit langer Laufzeit geeignet macht. Nach dem Ausführen werden alle Funktionen und Ausführungszeiten protokolliert. Es ist sehr mächtig, aber manchmal etwas schwierig zu interpretieren und zu handeln. Im folgenden Beispiel verwenden wir cProfile für den folgenden Code:
Beispiel
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target=taskofThread, args=(lock,))
t2 = threading.Thread(target= taskofThread, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))Der obige Code wird im gespeichert thread_increment.pyDatei. Führen Sie nun den Code mit cProfile in der Befehlszeile wie folgt aus:
(base) D:\ProgramData>python -m cProfile thread_increment.py
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4
3577 function calls (3522 primitive calls) in 1.688 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:103(release)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:147(__enter__)
… … … …Aus der obigen Ausgabe geht hervor, dass cProfile alle aufgerufenen 3577-Funktionen mit der jeweils aufgewendeten Zeit und der Häufigkeit ihres Aufrufs ausgibt. Es folgen die Spalten, die wir in der Ausgabe erhalten haben -
ncalls - Dies ist die Anzahl der getätigten Anrufe.
tottime - Dies ist die Gesamtzeit, die für die angegebene Funktion aufgewendet wurde.
percall - Es bezieht sich auf den Quotienten der Totzeit geteilt durch ncalls.
cumtime- Dies ist die kumulierte Zeit, die für diese und alle Unterfunktionen aufgewendet wird. Es ist sogar für rekursive Funktionen genau.
percall - Es ist der Quotient der Cumtime geteilt durch primitive Aufrufe.
filename:lineno(function) - Es liefert grundsätzlich die jeweiligen Daten jeder Funktion.
Angenommen, wir müssten eine große Anzahl von Threads für unsere Multithread-Aufgaben erstellen. Dies wäre rechenintensiv, da aufgrund zu vieler Threads viele Leistungsprobleme auftreten können. Ein Hauptproblem könnte darin bestehen, dass der Durchsatz begrenzt wird. Wir können dieses Problem lösen, indem wir einen Pool von Threads erstellen. Ein Thread-Pool kann als die Gruppe von vorinstanziierten und inaktiven Threads definiert werden, die bereit sind, Arbeit zu leisten. Das Erstellen eines Thread-Pools wird dem Instanziieren neuer Threads für jede Aufgabe vorgezogen, wenn eine große Anzahl von Aufgaben ausgeführt werden muss. Ein Thread-Pool kann die gleichzeitige Ausführung einer großen Anzahl von Threads wie folgt verwalten:
Wenn ein Thread in einem Thread-Pool seine Ausführung abgeschlossen hat, kann dieser Thread wiederverwendet werden.
Wenn ein Thread beendet wird, wird ein anderer Thread erstellt, um diesen Thread zu ersetzen.
Python-Modul - Concurrent.futures
Die Python-Standardbibliothek enthält die concurrent.futuresModul. Dieses Modul wurde in Python 3.2 hinzugefügt, um den Entwicklern eine allgemeine Benutzeroberfläche zum Starten asynchroner Aufgaben bereitzustellen. Es ist eine Abstraktionsschicht über den Threading- und Multiprocessing-Modulen von Python, um die Schnittstelle zum Ausführen der Aufgaben mithilfe eines Pools von Threads oder Prozessen bereitzustellen.
In unseren folgenden Abschnitten lernen wir die verschiedenen Klassen des Moduls concurrent.futures kennen.
Executor-Klasse
Executorist eine abstrakte Klasse der concurrent.futuresPython-Modul. Es kann nicht direkt verwendet werden und wir müssen eine der folgenden konkreten Unterklassen verwenden -
- ThreadPoolExecutor
- ProcessPoolExecutor
ThreadPoolExecutor - Eine konkrete Unterklasse
Es ist eine der konkreten Unterklassen der Executor-Klasse. Die Unterklasse verwendet Multithreading und wir erhalten einen Thread-Pool zum Senden der Aufgaben. Dieser Pool weist den verfügbaren Threads Aufgaben zu und plant deren Ausführung.
Wie erstelle ich einen ThreadPoolExecutor?
Mit der Hilfe von concurrent.futures Modul und seine konkrete Unterklasse Executorkönnen wir leicht einen Pool von Threads erstellen. Dazu müssen wir a konstruierenThreadPoolExecutormit der Anzahl der Threads, die wir im Pool haben wollen. Standardmäßig ist die Nummer 5. Dann können wir eine Aufgabe an den Thread-Pool senden. Wenn wirsubmit() eine Aufgabe, wir bekommen zurück a Future. Das Future-Objekt hat eine Methode namensdone(), was zeigt, ob sich die Zukunft aufgelöst hat. Damit wurde ein Wert für das jeweilige zukünftige Objekt festgelegt. Wenn eine Aufgabe abgeschlossen ist, setzt der Thread-Pool-Executor den Wert auf das zukünftige Objekt.
Beispiel
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ThreadPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Ausgabe
False
True
CompletedIm obigen Beispiel a ThreadPoolExecutorwurde mit 5 Fäden konstruiert. Anschließend wird eine Aufgabe, die 2 Sekunden wartet, bevor die Nachricht gesendet wird, an den Thread-Pool-Executor gesendet. Wie aus der Ausgabe ersichtlich, wird die Aufgabe erst nach 2 Sekunden abgeschlossen, also der erste Aufruf vondone()wird False zurückgeben. Nach 2 Sekunden ist die Aufgabe erledigt und wir erhalten das Ergebnis der Zukunft, indem wir das aufrufenresult() Methode darauf.
Instanziieren von ThreadPoolExecutor - Context Manager
Ein anderer Weg, um zu instanziieren ThreadPoolExecutorist mit Hilfe des Kontextmanagers. Es funktioniert ähnlich wie im obigen Beispiel. Der Hauptvorteil der Verwendung von Kontextmanager besteht darin, dass er syntaktisch gut aussieht. Die Instanziierung kann mit Hilfe des folgenden Codes erfolgen:
with ThreadPoolExecutor(max_workers = 5) as executorBeispiel
Das folgende Beispiel stammt aus den Python-Dokumenten. In diesem Beispiel zunächst dieconcurrent.futuresModul muss importiert werden. Dann eine Funktion namensload_url()wird erstellt, wodurch die angeforderte URL geladen wird. Die Funktion erstellt dannThreadPoolExecutormit den 5 Threads im Pool. DasThreadPoolExecutorwurde als Kontextmanager verwendet. Wir können das Ergebnis der Zukunft erhalten, indem wir die anrufenresult() Methode darauf.
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor(max_workers = 5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))Ausgabe
Es folgt die Ausgabe des obigen Python-Skripts -
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229313 bytes
'http://www.cnn.com/' page is 168933 bytes
'http://www.bbc.co.uk/' page is 283893 bytes
'http://europe.wsj.com/' page is 938109 bytesVerwendung der Funktion Executor.map ()
Der Python map()Funktion ist in einer Reihe von Aufgaben weit verbreitet. Eine solche Aufgabe besteht darin, auf jedes Element in iterables eine bestimmte Funktion anzuwenden. Ebenso können wir alle Elemente eines Iterators einer Funktion zuordnen und diese als unabhängige Jobs an out sendenThreadPoolExecutor. Betrachten Sie das folgende Beispiel eines Python-Skripts, um zu verstehen, wie die Funktion funktioniert.
Beispiel
In diesem Beispiel unten wird die Kartenfunktion verwendet, um das anzuwenden square() Funktion für jeden Wert im Werte-Array.
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ThreadPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Ausgabe
Das obige Python-Skript generiert die folgende Ausgabe:
4
9
16
25Der Prozesspool kann auf dieselbe Weise erstellt und verwendet werden, wie wir den Thread-Pool erstellt und verwendet haben. Der Prozesspool kann als die Gruppe von vorinstanziierten und inaktiven Prozessen definiert werden, die bereit sind, Arbeit zu leisten. Das Erstellen eines Prozesspools wird dem Instanziieren neuer Prozesse für jede Aufgabe vorgezogen, wenn eine große Anzahl von Aufgaben ausgeführt werden muss.
Python-Modul - Concurrent.futures
Die Python-Standardbibliothek verfügt über ein Modul namens concurrent.futures. Dieses Modul wurde in Python 3.2 hinzugefügt, um den Entwicklern eine allgemeine Benutzeroberfläche zum Starten asynchroner Aufgaben bereitzustellen. Es ist eine Abstraktionsschicht über den Threading- und Multiprocessing-Modulen von Python, um die Schnittstelle zum Ausführen der Aufgaben mithilfe eines Pools von Threads oder Prozessen bereitzustellen.
In unseren folgenden Abschnitten werden wir uns die verschiedenen Unterklassen des Moduls concurrent.futures ansehen.
Executor-Klasse
Executor ist eine abstrakte Klasse der concurrent.futuresPython-Modul. Es kann nicht direkt verwendet werden und wir müssen eine der folgenden konkreten Unterklassen verwenden -
- ThreadPoolExecutor
- ProcessPoolExecutor
ProcessPoolExecutor - Eine konkrete Unterklasse
Es ist eine der konkreten Unterklassen der Executor-Klasse. Es verwendet Multi-Processing und wir erhalten einen Pool von Prozessen zum Einreichen der Aufgaben. Dieser Pool weist den verfügbaren Prozessen Aufgaben zu und plant deren Ausführung.
Wie erstelle ich einen ProcessPoolExecutor?
Mit Hilfe der concurrent.futures Modul und seine konkrete Unterklasse Executorkönnen wir leicht einen Prozesspool erstellen. Dazu müssen wir a konstruierenProcessPoolExecutormit der Anzahl der Prozesse, die wir im Pool haben wollen. Standardmäßig ist die Nummer 5. Anschließend wird eine Aufgabe an den Prozesspool gesendet.
Beispiel
Wir werden nun dasselbe Beispiel betrachten, das wir beim Erstellen des Thread-Pools verwendet haben. Der einzige Unterschied besteht darin, dass wir es jetzt verwenden werden ProcessPoolExecutor Anstatt von ThreadPoolExecutor .
from concurrent.futures import ProcessPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ProcessPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Ausgabe
False
False
CompletedIm obigen Beispiel ein ProzessPoolExecutorwurde mit 5 Fäden konstruiert. Anschließend wird eine Aufgabe, die 2 Sekunden wartet, bevor die Nachricht gesendet wird, an den Prozesspool-Executor gesendet. Wie aus der Ausgabe ersichtlich, wird die Aufgabe erst nach 2 Sekunden abgeschlossen, also der erste Aufruf vondone()wird False zurückgeben. Nach 2 Sekunden ist die Aufgabe erledigt und wir erhalten das Ergebnis der Zukunft, indem wir das aufrufenresult() Methode darauf.
Instanziieren von ProcessPoolExecutor - Kontextmanager
Eine andere Möglichkeit, ProcessPoolExecutor zu instanziieren, ist die Verwendung des Kontextmanagers. Es funktioniert ähnlich wie im obigen Beispiel. Der Hauptvorteil der Verwendung von Kontextmanager besteht darin, dass er syntaktisch gut aussieht. Die Instanziierung kann mit Hilfe des folgenden Codes erfolgen:
with ProcessPoolExecutor(max_workers = 5) as executorBeispiel
Zum besseren Verständnis verwenden wir dasselbe Beispiel wie beim Erstellen des Thread-Pools. In diesem Beispiel müssen wir zunächst das importierenconcurrent.futuresModul. Dann eine Funktion namensload_url()wird erstellt, wodurch die angeforderte URL geladen wird. DasProcessPoolExecutorwird dann mit der 5 Anzahl von Threads im Pool erstellt. Der ProzessPoolExecutorwurde als Kontextmanager verwendet. Wir können das Ergebnis der Zukunft erhalten, indem wir die anrufenresult() Methode darauf.
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
def main():
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
if __name__ == '__main__':
main()Ausgabe
Das obige Python-Skript generiert die folgende Ausgabe:
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229476 bytes
'http://www.cnn.com/' page is 165323 bytes
'http://www.bbc.co.uk/' page is 284981 bytes
'http://europe.wsj.com/' page is 967575 bytesVerwendung der Funktion Executor.map ()
Der Python map()Funktion wird häufig verwendet, um eine Reihe von Aufgaben auszuführen. Eine solche Aufgabe besteht darin, auf jedes Element in iterables eine bestimmte Funktion anzuwenden. Ebenso können wir alle Elemente eines Iterators einer Funktion zuordnen und diese als unabhängige Jobs an die sendenProcessPoolExecutor. Betrachten Sie das folgende Beispiel eines Python-Skripts, um dies zu verstehen.
Beispiel
Wir werden das gleiche Beispiel betrachten, das wir beim Erstellen des Thread-Pools mit dem verwendet haben Executor.map()Funktion. In dem unten angegebenen Beispiel wird die Kartenfunktion zum Anwenden verwendetsquare() Funktion für jeden Wert im Werte-Array.
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ProcessPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Ausgabe
Das obige Python-Skript generiert die folgende Ausgabe
4
9
16
25Wann sollten ProcessPoolExecutor und ThreadPoolExecutor verwendet werden?
Nachdem wir uns nun mit den beiden Executor-Klassen ThreadPoolExecutor und ProcessPoolExecutor befasst haben, müssen wir wissen, wann welcher Executor verwendet werden soll. Bei CPU-gebundenen Workloads müssen wir ProcessPoolExecutor und bei E / A-gebundenen Workloads ThreadPoolExecutor auswählen.
Wenn wir verwenden ProcessPoolExecutorDann brauchen wir uns keine Sorgen um GIL zu machen, da es Multiprocessing verwendet. Darüber hinaus ist die Ausführungszeit im Vergleich zu kürzerThreadPoolExecution. Betrachten Sie das folgende Python-Skriptbeispiel, um dies zu verstehen.
Beispiel
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Ausgabe
Start: 8000000 Time taken: 1.5509998798370361
Start: 7000000 Time taken: 1.3259999752044678
Total time taken: 2.0840001106262207
Example- Python script with ThreadPoolExecutor:
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Ausgabe
Start: 8000000 Time taken: 3.8420000076293945
Start: 7000000 Time taken: 3.6010000705718994
Total time taken: 3.8480000495910645An den Ausgaben der beiden oben genannten Programme können wir den Unterschied der Ausführungszeit während der Verwendung erkennen ProcessPoolExecutor und ThreadPoolExecutor.
In diesem Kapitel konzentrieren wir uns mehr auf den Vergleich zwischen Multiprocessing und Multithreading.
Mehrfachverarbeitung
Hierbei werden zwei oder mehr CPU-Einheiten in einem einzigen Computersystem verwendet. Dies ist der beste Ansatz, um das volle Potenzial unserer Hardware auszuschöpfen, indem Sie die gesamte Anzahl der in unserem Computersystem verfügbaren CPU-Kerne nutzen.
Multithreading
Es ist die Fähigkeit einer CPU, die Verwendung des Betriebssystems zu verwalten, indem mehrere Threads gleichzeitig ausgeführt werden. Die Hauptidee von Multithreading besteht darin, Parallelität zu erreichen, indem ein Prozess in mehrere Threads aufgeteilt wird.
Die folgende Tabelle zeigt einige der wichtigen Unterschiede zwischen ihnen -
| Mehrfachverarbeitung | Multiprogrammierung |
|---|---|
| Multiprocessing bezieht sich auf die Verarbeitung mehrerer Prozesse gleichzeitig durch mehrere CPUs. | Durch die Multiprogrammierung werden mehrere Programme gleichzeitig im Hauptspeicher gespeichert und gleichzeitig mit einer einzigen CPU ausgeführt. |
| Es werden mehrere CPUs verwendet. | Es verwendet eine einzelne CPU. |
| Es ermöglicht eine parallele Verarbeitung. | Es findet eine Kontextumschaltung statt. |
| Weniger Zeit für die Bearbeitung der Aufträge. | Mehr Zeit für die Bearbeitung der Aufträge. |
| Es erleichtert eine sehr effiziente Nutzung von Geräten des Computersystems. | Weniger effizient als Multiprocessing. |
| Normalerweise teurer. | Solche Systeme sind kostengünstiger. |
Beseitigung der Auswirkungen der globalen Dolmetschersperre (GIL)
Bei der Arbeit mit gleichzeitigen Anwendungen gibt es in Python eine Einschränkung namens GIL (Global Interpreter Lock). GIL erlaubt uns niemals, mehrere CPU-Kerne zu verwenden, und daher können wir sagen, dass es in Python keine echten Threads gibt. GIL ist die Mutex-Sperre für gegenseitigen Ausschluss, die die Sicherheit von Threads erhöht. Mit anderen Worten, wir können sagen, dass GIL verhindert, dass mehrere Threads Python-Code parallel ausführen. Die Sperre kann jeweils nur von einem Thread gehalten werden. Wenn wir einen Thread ausführen möchten, muss er zuerst die Sperre erhalten.
Mit der Verwendung von Multiprocessing können wir die durch GIL verursachte Einschränkung effektiv umgehen -
Durch die Verwendung von Multiprocessing nutzen wir die Fähigkeit mehrerer Prozesse und daher mehrere Instanzen der GIL.
Aus diesem Grund gibt es keine Einschränkung, den Bytecode eines Threads innerhalb unserer Programme gleichzeitig auszuführen.
Prozesse in Python starten
Die folgenden drei Methoden können verwendet werden, um einen Prozess in Python innerhalb des Multiprocessing-Moduls zu starten:
- Fork
- Spawn
- Forkserver
Erstellen eines Prozesses mit Fork
Der Fork-Befehl ist ein Standardbefehl unter UNIX. Es wird verwendet, um neue Prozesse zu erstellen, die als untergeordnete Prozesse bezeichnet werden. Dieser untergeordnete Prozess wird gleichzeitig mit dem als übergeordneter Prozess bezeichneten Prozess ausgeführt. Diese untergeordneten Prozesse sind auch mit ihren übergeordneten Prozessen identisch und erben alle Ressourcen, die dem übergeordneten Prozess zur Verfügung stehen. Die folgenden Systemaufrufe werden beim Erstellen eines Prozesses mit Fork verwendet:
fork()- Es handelt sich um einen Systemaufruf, der im Allgemeinen im Kernel implementiert ist. Es wird verwendet, um eine Kopie des Prozesses zu erstellen
getpid() - Dieser Systemaufruf gibt die Prozess-ID (PID) des aufrufenden Prozesses zurück.
Beispiel
Das folgende Python-Skriptbeispiel hilft Ihnen zu verstehen, wie Sie einen neuen untergeordneten Prozess erstellen und die PIDs von untergeordneten und übergeordneten Prozessen abrufen.
import os
def child():
n = os.fork()
if n > 0:
print("PID of Parent process is : ", os.getpid())
else:
print("PID of Child process is : ", os.getpid())
child()Ausgabe
PID of Parent process is : 25989
PID of Child process is : 25990Erstellen eines Prozesses mit Spawn
Spawn bedeutet, etwas Neues zu beginnen. Das Laichen eines Prozesses bedeutet daher das Erstellen eines neuen Prozesses durch einen übergeordneten Prozess. Der übergeordnete Prozess setzt seine Ausführung asynchron fort oder wartet, bis der untergeordnete Prozess seine Ausführung beendet. Befolgen Sie diese Schritte, um einen Prozess zu erzeugen -
Multiprozessor-Modul importieren.
Objektprozess erstellen.
Starten der Prozessaktivität durch Aufrufen start() Methode.
Warten Sie, bis der Prozess seine Arbeit beendet hat, und beenden Sie ihn durch einen Anruf join() Methode.
Beispiel
Das folgende Beispiel eines Python-Skripts hilft beim Erstellen von drei Prozessen
import multiprocessing
def spawn_process(i):
print ('This is process: %s' %i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(3):
p = multiprocessing.Process(target = spawn_process, args = (i,))
Process_jobs.append(p)
p.start()
p.join()Ausgabe
This is process: 0
This is process: 1
This is process: 2Erstellen eines Prozesses mit Forkserver
Der Forkserver-Mechanismus ist nur auf den ausgewählten UNIX-Plattformen verfügbar, die die Übergabe der Dateideskriptoren über Unix Pipes unterstützen. Berücksichtigen Sie die folgenden Punkte, um die Funktionsweise des Forkserver-Mechanismus zu verstehen:
Ein Server wird instanziiert, wenn der Forkserver-Mechanismus zum Starten eines neuen Prozesses verwendet wird.
Der Server empfängt dann den Befehl und verarbeitet alle Anforderungen zum Erstellen neuer Prozesse.
Um einen neuen Prozess zu erstellen, sendet unser Python-Programm eine Anfrage an Forkserver und erstellt einen Prozess für uns.
Endlich können wir diesen neu erstellten Prozess in unseren Programmen verwenden.
Daemon-Prozesse in Python
Python multiprocessingModul ermöglicht es uns, Daemon-Prozesse durch seine Daemonic-Option zu haben. Daemon-Prozesse oder die Prozesse, die im Hintergrund ausgeführt werden, folgen einem ähnlichen Konzept wie die Daemon-Threads. Um den Prozess im Hintergrund auszuführen, müssen wir das Daemonic-Flag auf true setzen. Der Daemon-Prozess wird so lange ausgeführt, wie der Hauptprozess ausgeführt wird, und er wird beendet, nachdem die Ausführung abgeschlossen wurde oder wenn das Hauptprogramm beendet wird.
Beispiel
Hier verwenden wir dasselbe Beispiel wie in den Daemon-Threads. Der einzige Unterschied ist der Wechsel des Moduls vonmultithreading zu multiprocessingund Setzen des dämonischen Flags auf true. Es würde jedoch eine Änderung der Ausgabe geben, wie unten gezeigt -
import multiprocessing
import time
def nondaemonProcess():
print("starting my Process")
time.sleep(8)
print("ending my Process")
def daemonProcess():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonProcess = multiprocessing.Process(target = nondaemonProcess)
daemonProcess = multiprocessing.Process(target = daemonProcess)
daemonProcess.daemon = True
nondaemonProcess.daemon = False
daemonProcess.start()
nondaemonProcess.start()Ausgabe
starting my Process
ending my ProcessDie Ausgabe unterscheidet sich von der von Daemon-Threads generierten, da der Prozess in keinem Daemon-Modus eine Ausgabe hat. Daher endet der dämonische Prozess automatisch nach dem Ende der Hauptprogramme, um das Fortbestehen laufender Prozesse zu vermeiden.
Prozesse in Python beenden
Wir können einen Prozess sofort beenden oder beenden, indem wir das verwenden terminate()Methode. Wir werden diese Methode verwenden, um den mit Hilfe der Funktion erstellten untergeordneten Prozess unmittelbar vor Abschluss seiner Ausführung zu beenden.
Beispiel
import multiprocessing
import time
def Child_process():
print ('Starting function')
time.sleep(5)
print ('Finished function')
P = multiprocessing.Process(target = Child_process)
P.start()
print("My Process has terminated, terminating main thread")
print("Terminating Child Process")
P.terminate()
print("Child Process successfully terminated")Ausgabe
My Process has terminated, terminating main thread
Terminating Child Process
Child Process successfully terminatedDie Ausgabe zeigt, dass das Programm vor der Ausführung des untergeordneten Prozesses beendet wird, der mit Hilfe der Funktion Child_process () erstellt wurde. Dies bedeutet, dass der untergeordnete Prozess erfolgreich beendet wurde.
Identifizieren des aktuellen Prozesses in Python
Jeder Prozess im Betriebssystem hat eine Prozessidentität, die als PID bezeichnet wird. In Python können wir die PID des aktuellen Prozesses mithilfe des folgenden Befehls ermitteln:
import multiprocessing
print(multiprocessing.current_process().pid)Beispiel
Das folgende Beispiel eines Python-Skripts hilft dabei, die PID des Hauptprozesses sowie die PID des untergeordneten Prozesses herauszufinden.
import multiprocessing
import time
def Child_process():
print("PID of Child Process is: {}".format(multiprocessing.current_process().pid))
print("PID of Main process is: {}".format(multiprocessing.current_process().pid))
P = multiprocessing.Process(target=Child_process)
P.start()
P.join()Ausgabe
PID of Main process is: 9401
PID of Child Process is: 9402Verwenden eines Prozesses in der Unterklasse
Wir können Threads erstellen, indem wir das unterordnen threading.ThreadKlasse. Darüber hinaus können wir auch Prozesse erstellen, indem wir die unterklassifizierenmultiprocessing.ProcessKlasse. Um einen Prozess in einer Unterklasse zu verwenden, müssen wir die folgenden Punkte berücksichtigen:
Wir müssen eine neue Unterklasse der definieren Process Klasse.
Wir müssen das außer Kraft setzen _init_(self [,args] ) Klasse.
Wir müssen das von außer Kraft setzen run(self [,args] ) Methode, um was zu implementieren Process
Wir müssen den Prozess durch Aufrufen von startenstart() Methode.
Beispiel
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' %self.name)
return
if __name__ == '__main__':
jobs = []
for i in range(5):
P = MyProcess()
jobs.append(P)
P.start()
P.join()Ausgabe
called run method in process: MyProcess-1
called run method in process: MyProcess-2
called run method in process: MyProcess-3
called run method in process: MyProcess-4
called run method in process: MyProcess-5Python-Multiprocessing-Modul - Pool-Klasse
Wenn wir über einfache Parallele sprechen processingAufgaben in unseren Python-Anwendungen und dann das Multiprocessing-Modul stellen uns die Pool-Klasse zur Verfügung. Die folgenden Methoden vonPool class kann verwendet werden, um die Anzahl der untergeordneten Prozesse in unserem Hauptprogramm zu erhöhen
apply () -Methode
Diese Methode ähnelt der.submit()Methode von .ThreadPoolExecutor.Es wird blockiert, bis das Ergebnis fertig ist.
apply_async () -Methode
Wenn wir unsere Aufgaben parallel ausführen müssen, müssen wir die verwendenapply_async()Methode zum Senden von Aufgaben an den Pool. Es ist eine asynchrone Operation, die den Hauptthread erst sperrt, wenn alle untergeordneten Prozesse ausgeführt wurden.
map () Methode
Genau wie die apply()Methode blockiert es auch, bis das Ergebnis fertig ist. Es entspricht dem eingebautenmap() Funktion, die die iterierbaren Daten in mehrere Blöcke aufteilt und als separate Aufgaben an den Prozesspool übermittelt.
map_async () -Methode
Es ist eine Variante des map() Methode als apply_async() ist zum apply()Methode. Es gibt ein Ergebnisobjekt zurück. Wenn das Ergebnis fertig ist, wird ein Callable darauf angewendet. Der Anruf muss sofort abgeschlossen sein; Andernfalls wird der Thread, der die Ergebnisse verarbeitet, blockiert.
Beispiel
Das folgende Beispiel hilft Ihnen bei der Implementierung eines Prozesspools für die parallele Ausführung. Eine einfache Berechnung des Quadrats der Zahl wurde durchgeführt, indem das angewendet wurdesquare() Funktion durch die multiprocessing.PoolMethode. Dannpool.map() wurde verwendet, um die 5 zu senden, da die Eingabe eine Liste von Ganzzahlen von 0 bis 4 ist. Das Ergebnis würde in gespeichert p_outputs und es wird gedruckt.
def square(n):
result = n*n
return result
if __name__ == '__main__':
inputs = list(range(5))
p = multiprocessing.Pool(processes = 4)
p_outputs = pool.map(function_square, inputs)
p.close()
p.join()
print ('Pool :', p_outputs)Ausgabe
Pool : [0, 1, 4, 9, 16]Prozesskommunikation bedeutet den Datenaustausch zwischen Prozessen. Es ist notwendig, die Daten zwischen Prozessen auszutauschen, um eine parallele Anwendung zu entwickeln. Das folgende Diagramm zeigt die verschiedenen Kommunikationsmechanismen für die Synchronisation zwischen mehreren Unterprozessen -

Verschiedene Kommunikationsmechanismen
In diesem Abschnitt lernen wir die verschiedenen Kommunikationsmechanismen kennen. Die Mechanismen werden unten beschrieben -
Warteschlangen
Warteschlangen können mit Multiprozessprogrammen verwendet werden. Die Warteschlangenklasse vonmultiprocessing Modul ähnelt dem Queue.QueueKlasse. Daher kann dieselbe API verwendet werden.Multiprocessing.Queue bietet uns einen thread- und prozesssicheren FIFO-Mechanismus (First-In-First-Out) für die Kommunikation zwischen Prozessen.
Beispiel
Im Folgenden finden Sie ein einfaches Beispiel aus den offiziellen Python-Dokumenten zur Mehrfachverarbeitung, um das Konzept der Queue-Klasse der Mehrfachverarbeitung zu verstehen.
from multiprocessing import Process, Queue
import queue
import random
def f(q):
q.put([42, None, 'hello'])
def main():
q = Queue()
p = Process(target = f, args = (q,))
p.start()
print (q.get())
if __name__ == '__main__':
main()Ausgabe
[42, None, 'hello']Rohre
Es ist eine Datenstruktur, die zur Kommunikation zwischen Prozessen in Mehrprozessprogrammen verwendet wird. Die Funktion Pipe () gibt ein Paar von Verbindungsobjekten zurück, die durch eine Pipe verbunden sind, die standardmäßig Duplex (bidirektional) ist. Es funktioniert folgendermaßen:
Es gibt ein Paar Verbindungsobjekte zurück, die die beiden Rohrenden darstellen.
Jedes Objekt hat zwei Methoden - send() und recv(), um zwischen Prozessen zu kommunizieren.
Beispiel
Im Folgenden finden Sie ein einfaches Beispiel aus den offiziellen Python-Dokumenten zur Mehrfachverarbeitung, um das Konzept von zu verstehen Pipe() Funktion der Mehrfachverarbeitung.
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target = f, args = (child_conn,))
p.start()
print (parent_conn.recv())
p.join()Ausgabe
[42, None, 'hello']Manager
Manager ist eine Klasse von Multiprozessor-Modulen, mit denen gemeinsame Informationen zwischen allen Benutzern koordiniert werden können. Ein Managerobjekt steuert einen Serverprozess, der freigegebene Objekte verwaltet und es anderen Prozessen ermöglicht, diese zu bearbeiten. Mit anderen Worten, Manager bieten eine Möglichkeit, Daten zu erstellen, die von verschiedenen Prozessen gemeinsam genutzt werden können. Im Folgenden sind die verschiedenen Eigenschaften des Managerobjekts aufgeführt:
Die Haupteigenschaft von Manager ist die Steuerung eines Serverprozesses, der die freigegebenen Objekte verwaltet.
Eine weitere wichtige Eigenschaft besteht darin, alle freigegebenen Objekte zu aktualisieren, wenn ein Prozess sie ändert.
Beispiel
Im Folgenden finden Sie ein Beispiel, in dem das Managerobjekt zum Erstellen eines Listendatensatzes im Serverprozess und zum Hinzufügen eines neuen Datensatzes zu dieser Liste verwendet wird.
import multiprocessing
def print_records(records):
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
records.append(record)
print("A New record is added\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
records = manager.list([('Computers', 1), ('Histoty', 5), ('Hindi',9)])
new_record = ('English', 3)
p1 = multiprocessing.Process(target = insert_record, args = (new_record, records))
p2 = multiprocessing.Process(target = print_records, args = (records,))
p1.start()
p1.join()
p2.start()
p2.join()Ausgabe
A New record is added
Name: Computers
Score: 1
Name: Histoty
Score: 5
Name: Hindi
Score: 9
Name: English
Score: 3Konzept der Namespaces im Manager
Manager Class wird mit dem Konzept von Namespaces geliefert, einer schnellen Methode zum Teilen mehrerer Attribute über mehrere Prozesse hinweg. Namespaces verfügen über keine öffentliche Methode, die aufgerufen werden kann, sie verfügen jedoch über beschreibbare Attribute.
Beispiel
Das folgende Python-Skriptbeispiel hilft uns, Namespaces für die gemeinsame Nutzung von Daten zwischen Hauptprozess und untergeordnetem Prozess zu verwenden.
import multiprocessing
def Mng_NaSp(using_ns):
using_ns.x +=5
using_ns.y *= 10
if __name__ == '__main__':
manager = multiprocessing.Manager()
using_ns = manager.Namespace()
using_ns.x = 1
using_ns.y = 1
print ('before', using_ns)
p = multiprocessing.Process(target = Mng_NaSp, args = (using_ns,))
p.start()
p.join()
print ('after', using_ns)Ausgabe
before Namespace(x = 1, y = 1)
after Namespace(x = 6, y = 10)Ctypes-Array und Wert
Das Multiprocessing-Modul bietet Array- und Value-Objekte zum Speichern der Daten in einer gemeinsam genutzten Speicherzuordnung. Array ist ein ctypes-Array, das aus dem gemeinsam genutzten Speicher und zugewiesen wird Value ist ein ctypes-Objekt, das aus dem gemeinsam genutzten Speicher zugewiesen wird.
Importieren Sie dazu Process, Value, Array aus Multiprocessing.
Beispiel
Das folgende Python-Skript ist ein Beispiel aus Python-Dokumenten, in dem Ctypes Array und Value zum Teilen einiger Daten zwischen Prozessen verwendet werden.
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target = f, args = (num, arr))
p.start()
p.join()
print (num.value)
print (arr[:])Ausgabe
3.1415927
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]Sequentielle Prozesse kommunizieren (CSP)
CSP wird verwendet, um die Interaktion von Systemen mit anderen Systemen mit gleichzeitigen Modellen zu veranschaulichen. CSP ist ein Framework zum gleichzeitigen Schreiben von Programmen oder Programmen über das Weiterleiten von Nachrichten und daher zur Beschreibung der Parallelität wirksam.
Python-Bibliothek - PyCSP
Für die Implementierung von Kernprimitiven in CSP verfügt Python über eine Bibliothek namens PyCSP. Es hält die Implementierung sehr kurz und lesbar, so dass es sehr leicht zu verstehen ist. Es folgt das grundlegende Prozessnetzwerk von PyCSP -
Im obigen PyCSP-Prozessnetzwerk gibt es zwei Prozesse - Prozess1 und Prozess 2. Diese Prozesse kommunizieren, indem sie Nachrichten über zwei Kanäle weiterleiten - Kanal 1 und Kanal 2.
PyCSP installieren
Mit Hilfe des folgenden Befehls können wir die Python-Bibliothek PyCSP installieren -
pip install PyCSPBeispiel
Das folgende Python-Skript ist ein einfaches Beispiel für die parallele Ausführung von zwei Prozessen. Dies geschieht mit Hilfe der PyCSP Python Libabary -
from pycsp.parallel import *
import time
@process
def P1():
time.sleep(1)
print('P1 exiting')
@process
def P2():
time.sleep(1)
print('P2 exiting')
def main():
Parallel(P1(), P2())
print('Terminating')
if __name__ == '__main__':
main()Im obigen Skript gibt es nämlich zwei Funktionen P1 und P2 wurden erstellt und dann mit dekoriert @process um sie in Prozesse umzuwandeln.
Ausgabe
P2 exiting
P1 exiting
TerminatingDie ereignisgesteuerte Programmierung konzentriert sich auf Ereignisse. Schließlich hängt der Programmfluss von Ereignissen ab. Bisher beschäftigten wir uns entweder mit sequentiellen oder parallelen Ausführungsmodellen, aber das Modell mit dem Konzept der ereignisgesteuerten Programmierung wird als asynchrones Modell bezeichnet. Die ereignisgesteuerte Programmierung hängt von einer Ereignisschleife ab, die immer auf die neuen eingehenden Ereignisse wartet. Die Funktionsweise der ereignisgesteuerten Programmierung hängt von Ereignissen ab. Sobald sich ein Ereignis wiederholt, entscheiden die Ereignisse, was und in welcher Reihenfolge ausgeführt werden soll. Das folgende Flussdiagramm hilft Ihnen zu verstehen, wie dies funktioniert -
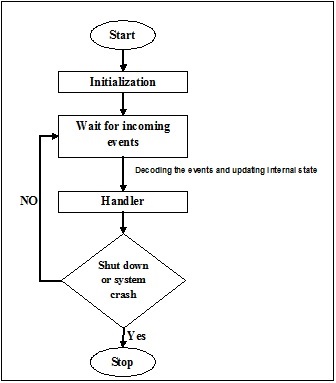
Python-Modul - Asyncio
Das Asyncio-Modul wurde in Python 3.4 hinzugefügt und bietet eine Infrastruktur zum Schreiben von Single-Threaded-Concurrent-Code mithilfe von Co-Routinen. Im Folgenden sind die verschiedenen Konzepte aufgeführt, die vom Asyncio-Modul verwendet werden:
Die Ereignisschleife
Die Ereignisschleife ist eine Funktion zum Behandeln aller Ereignisse in einem Rechencode. Es agiert während der Ausführung des gesamten Programms und verfolgt den Eingang und die Ausführung von Ereignissen. Das Asyncio-Modul ermöglicht eine einzelne Ereignisschleife pro Prozess. Im Folgenden sind einige Methoden aufgeführt, die vom Asyncio-Modul zum Verwalten einer Ereignisschleife bereitgestellt werden:
loop = get_event_loop() - Diese Methode stellt die Ereignisschleife für den aktuellen Kontext bereit.
loop.call_later(time_delay,callback,argument) - Diese Methode sorgt für den Rückruf, der nach den angegebenen time_delay Sekunden aufgerufen werden soll.
loop.call_soon(callback,argument)- Diese Methode sorgt für einen Rückruf, der so schnell wie möglich aufgerufen werden soll. Der Rückruf wird aufgerufen, nachdem call_soon () zurückgegeben wurde und wenn das Steuerelement zur Ereignisschleife zurückkehrt.
loop.time() - Diese Methode wird verwendet, um die aktuelle Zeit gemäß der internen Uhr der Ereignisschleife zurückzugeben.
asyncio.set_event_loop() - Diese Methode setzt die Ereignisschleife für den aktuellen Kontext auf die Schleife.
asyncio.new_event_loop() - Diese Methode erstellt ein neues Ereignisschleifenobjekt und gibt es zurück.
loop.run_forever() - Diese Methode wird ausgeführt, bis die Methode stop () aufgerufen wird.
Beispiel
Das folgende Beispiel für eine Ereignisschleife hilft beim Drucken hello worldmit der Methode get_event_loop (). Dieses Beispiel stammt aus den offiziellen Python-Dokumenten.
import asyncio
def hello_world(loop):
print('Hello World')
loop.stop()
loop = asyncio.get_event_loop()
loop.call_soon(hello_world, loop)
loop.run_forever()
loop.close()Ausgabe
Hello WorldFutures
Dies ist kompatibel mit der Klasse concurrent.futures.Future, die eine Berechnung darstellt, die noch nicht durchgeführt wurde. Es gibt folgende Unterschiede zwischen asyncio.futures.Future und concurrent.futures.Future -
Die Methoden result () und exception () verwenden kein Timeout-Argument und lösen eine Ausnahme aus, wenn die Zukunft noch nicht abgeschlossen ist.
Mit add_done_callback () registrierte Rückrufe werden immer über call_soon () der Ereignisschleife aufgerufen.
Die Klasse asyncio.futures.Future ist nicht mit den Funktionen wait () und as_completed () im Paket concurrent.futures kompatibel.
Beispiel
Das folgende Beispiel hilft Ihnen beim Verständnis der Verwendung der Klasse asyncio.futures.future.
import asyncio
async def Myoperation(future):
await asyncio.sleep(2)
future.set_result('Future Completed')
loop = asyncio.get_event_loop()
future = asyncio.Future()
asyncio.ensure_future(Myoperation(future))
try:
loop.run_until_complete(future)
print(future.result())
finally:
loop.close()Ausgabe
Future CompletedCoroutinen
Das Konzept der Coroutinen in Asyncio ähnelt dem Konzept des Standard-Thread-Objekts unter dem Threading-Modul. Dies ist die Verallgemeinerung des Unterprogrammkonzepts. Eine Coroutine kann während der Ausführung angehalten werden, so dass sie auf die externe Verarbeitung wartet und von dem Punkt zurückkehrt, an dem sie zum Zeitpunkt der externen Verarbeitung gestoppt wurde. Die folgenden zwei Möglichkeiten helfen uns bei der Implementierung von Coroutinen:
asynchrone def Funktion ()
Dies ist eine Methode zur Implementierung von Coroutinen unter dem Asyncio-Modul. Es folgt ein Python-Skript für dasselbe -
import asyncio
async def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Ausgabe
First Coroutine@ asyncio.coroutine Dekorateur
Eine andere Methode zur Implementierung von Coroutinen besteht darin, Generatoren mit dem Dekorator @ asyncio.coroutine zu verwenden. Es folgt ein Python-Skript für dasselbe -
import asyncio
@asyncio.coroutine
def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Ausgabe
First CoroutineAufgaben
Diese Unterklasse des Asyncio-Moduls ist für die parallele Ausführung von Coroutinen innerhalb einer Ereignisschleife verantwortlich. Das folgende Python-Skript ist ein Beispiel für die parallele Verarbeitung einiger Aufgaben.
import asyncio
import time
async def Task_ex(n):
time.sleep(1)
print("Processing {}".format(n))
async def Generator_task():
for i in range(10):
asyncio.ensure_future(Task_ex(i))
int("Tasks Completed")
asyncio.sleep(2)
loop = asyncio.get_event_loop()
loop.run_until_complete(Generator_task())
loop.close()Ausgabe
Tasks Completed
Processing 0
Processing 1
Processing 2
Processing 3
Processing 4
Processing 5
Processing 6
Processing 7
Processing 8
Processing 9Transporte
Das Asyncio-Modul bietet Transportklassen für die Implementierung verschiedener Kommunikationsarten. Diese Klassen sind nicht threadsicher und werden nach dem Einrichten des Kommunikationskanals immer mit einer Protokollinstanz gepaart.
Im Folgenden sind verschiedene Arten von Transporten aufgeführt, die vom BaseTransport geerbt wurden:
ReadTransport - Dies ist eine Schnittstelle für schreibgeschützte Transporte.
WriteTransport - Dies ist eine Schnittstelle für Nur-Schreib-Transporte.
DatagramTransport - Dies ist eine Schnittstelle zum Senden der Daten.
BaseSubprocessTransport - Ähnlich der BaseTransport-Klasse.
Es folgen fünf verschiedene Methoden der BaseTransport-Klasse, die anschließend über die vier Transporttypen hinweg vorübergehend sind:
close() - Es schließt den Transport.
is_closing() - Diese Methode gibt true zurück, wenn der Transport geschlossen wird oder bereits geschlossen ist.
get_extra_info(name, default = none) - Dies gibt uns einige zusätzliche Informationen über den Transport.
get_protocol() - Diese Methode gibt das aktuelle Protokoll zurück.
Protokolle
Das Asyncio-Modul bietet Basisklassen, die Sie zur Implementierung Ihrer Netzwerkprotokolle in Unterklassen unterteilen können. Diese Klassen werden in Verbindung mit Transporten verwendet. Das Protokoll analysiert eingehende Daten und fordert das Schreiben ausgehender Daten an, während der Transport für die eigentliche E / A und Pufferung verantwortlich ist. Es folgen drei Protokollklassen:
Protocol - Dies ist die Basisklasse für die Implementierung von Streaming-Protokollen zur Verwendung mit TCP- und SSL-Transporten.
DatagramProtocol - Dies ist die Basisklasse zum Implementieren von Datagrammprotokollen zur Verwendung mit UDP-Transporten.
SubprocessProtocol - Dies ist die Basisklasse für die Implementierung von Protokollen, die mit untergeordneten Prozessen über eine Reihe von unidirektionalen Pipes kommunizieren.
Reaktive Programmierung ist ein Programmierparadigma, das sich mit Datenflüssen und der Ausbreitung von Veränderungen befasst. Dies bedeutet, dass, wenn ein Datenfluss von einer Komponente ausgegeben wird, die Änderung durch eine reaktive Programmierbibliothek auf andere Komponenten übertragen wird. Die Weitergabe der Änderung wird fortgesetzt, bis sie den endgültigen Empfänger erreicht. Der Unterschied zwischen ereignisgesteuerter und reaktiver Programmierung besteht darin, dass sich ereignisgesteuerte Programmierung um Ereignisse und reaktive Programmierung um Daten dreht.
ReactiveX oder RX für die reaktive Programmierung
ReactiveX oder Raective Extension ist die bekannteste Implementierung der reaktiven Programmierung. Die Arbeitsweise von ReactiveX hängt von den folgenden zwei Klassen ab:
Beobachtbare Klasse
Diese Klasse ist die Quelle für Datenströme oder Ereignisse und packt die eingehenden Daten, damit die Daten von einem Thread an einen anderen übergeben werden können. Es werden keine Daten angegeben, bis ein Beobachter sie abonniert hat.
Beobachterklasse
Diese Klasse verwendet den von ausgegebenen Datenstrom observable. Es können mehrere Beobachter mit Observable vorhanden sein, und jeder Beobachter erhält jedes Datenelement, das ausgegeben wird. Der Beobachter kann drei Arten von Ereignissen empfangen, indem er Observable abonniert -
on_next() event - Dies bedeutet, dass der Datenstrom ein Element enthält.
on_completed() event - Es bedeutet das Ende der Emission und es kommen keine weiteren Artikel.
on_error() event - Dies bedeutet auch ein Ende der Emission, jedoch für den Fall, dass ein Fehler auftritt observable.
RxPY - Python-Modul für reaktive Programmierung
RxPY ist ein Python-Modul, das für die reaktive Programmierung verwendet werden kann. Wir müssen sicherstellen, dass das Modul installiert ist. Mit dem folgenden Befehl können Sie das RxPY-Modul installieren:
pip install RxPYBeispiel
Es folgt ein Python-Skript, das verwendet RxPY Modul und seine Klassen Observable und Observe forreaktive Programmierung. Grundsätzlich gibt es zwei Klassen -
get_strings() - um die Saiten vom Beobachter zu bekommen.
PrintObserver()- zum Drucken der Zeichenfolgen vom Beobachter. Es werden alle drei Ereignisse der Beobachterklasse verwendet. Es wird auch die Klasse subscribe () verwendet.
from rx import Observable, Observer
def get_strings(observer):
observer.on_next("Ram")
observer.on_next("Mohan")
observer.on_next("Shyam")
observer.on_completed()
class PrintObserver(Observer):
def on_next(self, value):
print("Received {0}".format(value))
def on_completed(self):
print("Finished")
def on_error(self, error):
print("Error: {0}".format(error))
source = Observable.create(get_strings)
source.subscribe(PrintObserver())Ausgabe
Received Ram
Received Mohan
Received Shyam
FinishedPyFunctional Bibliothek zur reaktiven Programmierung
PyFunctionalist eine weitere Python-Bibliothek, die für die reaktive Programmierung verwendet werden kann. Es ermöglicht uns, funktionale Programme mit der Programmiersprache Python zu erstellen. Dies ist nützlich, da wir damit Datenpipelines mithilfe verketteter Funktionsoperatoren erstellen können.
Unterschied zwischen RxPY und PyFunctional
Beide Bibliotheken werden für die reaktive Programmierung verwendet und behandeln den Stream auf ähnliche Weise, aber der Hauptunterschied zwischen beiden hängt vom Umgang mit Daten ab. RxPY behandelt Daten und Ereignisse im System während PyFunctional konzentriert sich auf die Transformation von Daten unter Verwendung funktionaler Programmierparadigmen.
PyFunctional Module installieren
Wir müssen dieses Modul installieren, bevor wir es verwenden können. Es kann mit Hilfe des Befehls pip wie folgt installiert werden:
pip install pyfunctionalBeispiel
Das folgende Beispiel verwendet the PyFunctional Modul und seine seqKlasse, die als Stream-Objekt fungiert, mit dem wir iterieren und manipulieren können. In diesem Programm wird die Sequenz mithilfe der Lamda-Funktion abgebildet, die jeden Wert verdoppelt. Anschließend wird der Wert gefiltert, bei dem x größer als 4 ist, und schließlich wird die Sequenz in eine Summe aller verbleibenden Werte reduziert.
from functional import seq
result = seq(1,2,3).map(lambda x: x*2).filter(lambda x: x > 4).reduce(lambda x, y: x + y)
print ("Result: {}".format(result))Ausgabe
Result: 6