DBMS - Kurzanleitung
Database ist eine Sammlung verwandter Daten und Daten sind eine Sammlung von Fakten und Zahlen, die zu Informationen verarbeitet werden können.
Meist handelt es sich bei den Daten um aufzeichnbare Fakten. Daten helfen bei der Erstellung von Informationen, die auf Fakten basieren. Wenn wir beispielsweise Daten über Noten haben, die von allen Schülern erhalten wurden, können wir auf Topper und Durchschnittsnoten schließen.
EIN database management system speichert Daten so, dass das Abrufen, Bearbeiten und Produzieren von Informationen einfacher wird.
Eigenschaften
Traditionell wurden Daten in Dateiformaten organisiert. DBMS war damals ein neues Konzept, und alle Untersuchungen wurden durchgeführt, um die Mängel im traditionellen Stil des Datenmanagements zu überwinden. Ein modernes DBMS hat folgende Eigenschaften:
Real-world entity- Ein modernes DBMS ist realistischer und verwendet reale Entitäten, um seine Architektur zu entwerfen. Es verwendet auch das Verhalten und die Attribute. Beispielsweise kann eine Schuldatenbank Schüler als Entität und ihr Alter als Attribut verwenden.
Relation-based tables- Mit DBMS können Entitäten und Beziehungen zwischen ihnen Tabellen bilden. Ein Benutzer kann die Architektur einer Datenbank nur anhand der Tabellennamen verstehen.
Isolation of data and application- Ein Datenbanksystem unterscheidet sich grundlegend von seinen Daten. Eine Datenbank ist eine aktive Entität, während Daten als passiv bezeichnet werden, auf denen die Datenbank arbeitet und organisiert. DBMS speichert auch Metadaten, bei denen es sich um Daten zu Daten handelt, um den eigenen Prozess zu vereinfachen.
Less redundancy- DBMS folgt den Normalisierungsregeln, die eine Beziehung aufteilen, wenn eines ihrer Attribute redundant in Werten ist. Normalisierung ist ein mathematisch reicher und wissenschaftlicher Prozess, der die Datenredundanz reduziert.
Consistency- Konsistenz ist ein Zustand, in dem jede Beziehung in einer Datenbank konsistent bleibt. Es gibt Methoden und Techniken, die den Versuch erkennen können, die Datenbank in einem inkonsistenten Zustand zu belassen. Ein DBMS kann im Vergleich zu früheren Formen von Datenspeicheranwendungen wie Dateiverarbeitungssystemen eine größere Konsistenz bieten.
Query Language- DBMS ist mit einer Abfragesprache ausgestattet, die das Abrufen und Bearbeiten von Daten effizienter macht. Ein Benutzer kann so viele und so unterschiedliche Filteroptionen anwenden, wie zum Abrufen eines Datensatzes erforderlich sind. Traditionell war es nicht möglich, wo ein Dateiverarbeitungssystem verwendet wurde.
ACID Properties - DBMS folgt den Konzepten von ATomizität, CBeständigkeit, ISolation und DUrabilität (normalerweise als ACID verkürzt). Diese Konzepte werden auf Transaktionen angewendet, die Daten in einer Datenbank bearbeiten. Mit den ACID-Eigenschaften bleibt die Datenbank in Umgebungen mit mehreren Transaktionen und im Fehlerfall funktionsfähig.
Multiuser and Concurrent Access- DBMS unterstützt Mehrbenutzerumgebungen und ermöglicht den parallelen Zugriff auf und die Bearbeitung von Daten. Es gibt zwar Einschränkungen für Transaktionen, wenn Benutzer versuchen, dasselbe Datenelement zu verarbeiten, aber Benutzer sind sich ihrer immer nicht bewusst.
Multiple views- DBMS bietet mehrere Ansichten für verschiedene Benutzer. Ein Benutzer in der Verkaufsabteilung hat eine andere Ansicht der Datenbank als eine Person in der Produktionsabteilung. Diese Funktion ermöglicht es den Benutzern, eine konzentrierte Ansicht der Datenbank entsprechend ihren Anforderungen zu erhalten.
Security- Funktionen wie mehrere Ansichten bieten in gewissem Maße Sicherheit, wenn Benutzer nicht auf Daten anderer Benutzer und Abteilungen zugreifen können. DBMS bietet Methoden zum Auferlegen von Einschränkungen, während Daten in die Datenbank eingegeben und zu einem späteren Zeitpunkt abgerufen werden. DBMS bietet viele verschiedene Sicherheitsstufen, sodass mehrere Benutzer unterschiedliche Ansichten mit unterschiedlichen Funktionen haben können. Beispielsweise kann ein Benutzer in der Verkaufsabteilung die Daten, die zur Einkaufsabteilung gehören, nicht sehen. Darüber hinaus kann verwaltet werden, wie viele Daten der Verkaufsabteilung dem Benutzer angezeigt werden sollen. Da ein DBMS nicht wie herkömmliche Dateisysteme auf der Festplatte gespeichert wird, ist es für Schurken sehr schwierig, den Code zu brechen.
Benutzer
Ein typisches DBMS verfügt über Benutzer mit unterschiedlichen Rechten und Berechtigungen, die es für unterschiedliche Zwecke verwenden. Einige Benutzer rufen Daten ab und andere sichern sie. Die Benutzer eines DBMS können grob wie folgt eingeteilt werden:
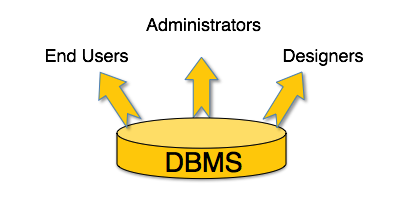
Administrators- Administratoren verwalten das DBMS und sind für die Verwaltung der Datenbank verantwortlich. Sie sind dafür verantwortlich, für die Verwendung zu sorgen und von wem es verwendet werden soll. Sie erstellen Zugriffsprofile für Benutzer und wenden Einschränkungen an, um die Isolation aufrechtzuerhalten und die Sicherheit zu erzwingen. Administratoren kümmern sich auch um DBMS-Ressourcen wie Systemlizenzen, erforderliche Tools und andere Software- und Hardware-bezogene Wartungsarbeiten.
Designers- Designer sind die Gruppe von Personen, die tatsächlich am Entwurfsteil der Datenbank arbeiten. Sie beobachten genau, welche Daten in welchem Format aufbewahrt werden sollen. Sie identifizieren und gestalten den gesamten Satz von Entitäten, Beziehungen, Einschränkungen und Ansichten.
End Users- Endbenutzer sind diejenigen, die tatsächlich die Vorteile eines DBMS nutzen. Endbenutzer können von einfachen Zuschauern, die auf die Protokolle oder Marktpreise achten, bis zu anspruchsvollen Benutzern wie Geschäftsanalysten reichen.
Das Design eines DBMS hängt von seiner Architektur ab. Es kann zentral oder dezentral oder hierarchisch sein. Die Architektur eines DBMS kann entweder als ein- oder mehrschichtig angesehen werden. Eine n-Tier-Architektur unterteilt das gesamte System in verwandte, aber unabhängige Systemen Module, die unabhängig voneinander modifiziert, geändert, geändert oder ersetzt werden können.
In einer einstufigen Architektur ist das DBMS die einzige Entität, in der der Benutzer direkt auf dem DBMS sitzt und es verwendet. Alle hier vorgenommenen Änderungen werden direkt im DBMS selbst vorgenommen. Es bietet keine praktischen Tools für Endbenutzer. Datenbankdesigner und Programmierer bevorzugen normalerweise die Verwendung einer einstufigen Architektur.
Wenn die Architektur von DBMS zweistufig ist, muss eine Anwendung vorhanden sein, über die auf das DBMS zugegriffen werden kann. Programmierer verwenden eine zweistufige Architektur, bei der sie über eine Anwendung auf das DBMS zugreifen. Hier ist die Anwendungsebene in Bezug auf Betrieb, Design und Programmierung völlig unabhängig von der Datenbank.
3-stufige Architektur
Eine dreistufige Architektur trennt ihre Ebenen voneinander, basierend auf der Komplexität der Benutzer und der Art und Weise, wie sie die in der Datenbank vorhandenen Daten verwenden. Es ist die am weitesten verbreitete Architektur zum Entwerfen eines DBMS.
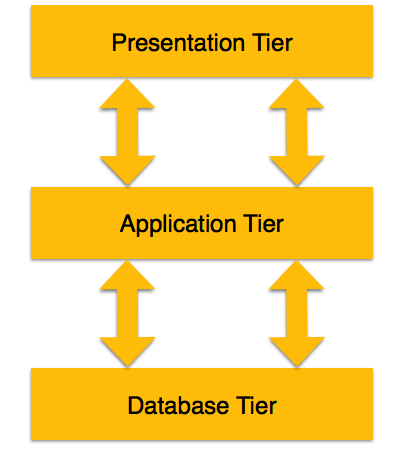
Database (Data) Tier- Auf dieser Ebene befindet sich die Datenbank zusammen mit ihren Abfrageverarbeitungssprachen. Wir haben auch die Beziehungen, die die Daten und ihre Einschränkungen auf dieser Ebene definieren.
Application (Middle) Tier- Auf dieser Ebene befinden sich der Anwendungsserver und die Programme, die auf die Datenbank zugreifen. Für einen Benutzer bietet diese Anwendungsebene eine abstrahierte Ansicht der Datenbank. Endbenutzer wissen nicht, dass die Datenbank außerhalb der Anwendung vorhanden ist. Am anderen Ende kennt die Datenbankebene keinen anderen Benutzer außerhalb der Anwendungsebene. Daher befindet sich die Anwendungsschicht in der Mitte und fungiert als Vermittler zwischen dem Endbenutzer und der Datenbank.
User (Presentation) Tier- Endbenutzer arbeiten auf dieser Ebene und wissen nichts über die Existenz der Datenbank außerhalb dieser Ebene. Auf dieser Ebene kann die Anwendung mehrere Ansichten der Datenbank bereitstellen. Alle Ansichten werden von Anwendungen generiert, die sich in der Anwendungsebene befinden.
Die mehrschichtige Datenbankarchitektur ist stark modifizierbar, da fast alle Komponenten unabhängig sind und unabhängig voneinander geändert werden können.
Datenmodelle definieren, wie die logische Struktur einer Datenbank modelliert wird. Datenmodelle sind grundlegende Einheiten zur Einführung der Abstraktion in ein DBMS. Datenmodelle definieren, wie Daten miteinander verbunden sind und wie sie im System verarbeitet und gespeichert werden.
Das allererste Datenmodell könnten flache Datenmodelle sein, bei denen alle verwendeten Daten in derselben Ebene gehalten werden sollen. Frühere Datenmodelle waren nicht so wissenschaftlich, daher neigten sie dazu, viele Duplikate einzuführen und Anomalien zu aktualisieren.
Entity-Relationship-Modell
Das Entity-Relationship (ER) -Modell basiert auf der Vorstellung von realen Entitäten und Beziehungen zwischen ihnen. Während der Formulierung eines realen Szenarios in das Datenbankmodell erstellt das ER-Modell einen Entitätssatz, einen Beziehungssatz, allgemeine Attribute und Einschränkungen.
Das ER-Modell eignet sich am besten für die Konzeption einer Datenbank.
ER-Modell basiert auf -
Entitiesund ihre Attribute.
Relationships unter Entitäten.
Diese Konzepte werden nachfolgend erläutert.
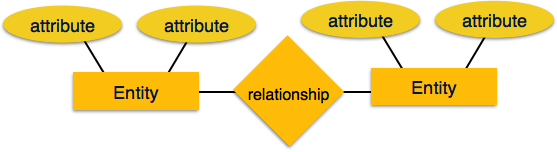
Entity - Eine Entität in einem ER-Modell ist eine reale Entität mit Eigenschaften, die aufgerufen werden attributes. Jederattribute wird durch die aufgerufene Wertemenge definiert domain. In einer Schuldatenbank wird beispielsweise ein Schüler als eine Einheit betrachtet. Der Schüler hat verschiedene Attribute wie Name, Alter, Klasse usw.
Relationship - Die logische Zuordnung zwischen Entitäten wird aufgerufen relationship. Beziehungen zu Entitäten werden auf verschiedene Arten zugeordnet. Mapping-Kardinalitäten definieren die Anzahl der Assoziationen zwischen zwei Entitäten.
Kardinalitäten abbilden -
- eins zu eins
- eins zu viele
- viele zu eins
- viel zu viel
Relationales Modell
Das beliebteste Datenmodell in DBMS ist das relationale Modell. Es ist ein wissenschaftlicheres Modell als andere. Dieses Modell basiert auf Prädikatenlogik erster Ordnung und definiert eine Tabelle alsn-ary relation.
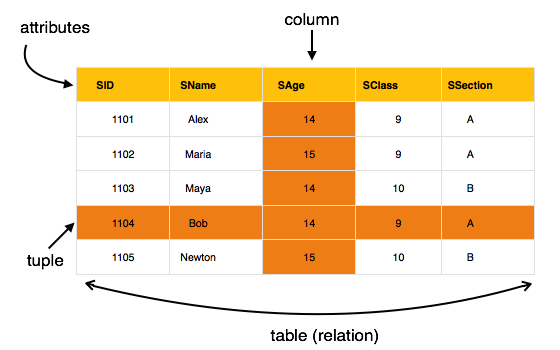
Die wichtigsten Highlights dieses Modells sind -
- Daten werden in aufgerufenen Tabellen gespeichert relations.
- Beziehungen können normalisiert werden.
- In normalisierten Beziehungen sind gespeicherte Werte Atomwerte.
- Jede Zeile in einer Beziehung enthält einen eindeutigen Wert.
- Jede Spalte in einer Beziehung enthält Werte aus derselben Domäne.
Datenbankschema
Ein Datenbankschema ist die Grundstruktur, die die logische Ansicht der gesamten Datenbank darstellt. Es definiert, wie die Daten organisiert sind und wie die Beziehungen zwischen ihnen verknüpft sind. Es formuliert alle Einschränkungen, die auf die Daten angewendet werden sollen.
Ein Datenbankschema definiert seine Entitäten und die Beziehung zwischen ihnen. Es enthält ein beschreibendes Detail der Datenbank, das anhand von Schemadiagrammen dargestellt werden kann. Es sind die Datenbankdesigner, die das Schema entwerfen, um Programmierern zu helfen, die Datenbank zu verstehen und nützlich zu machen.
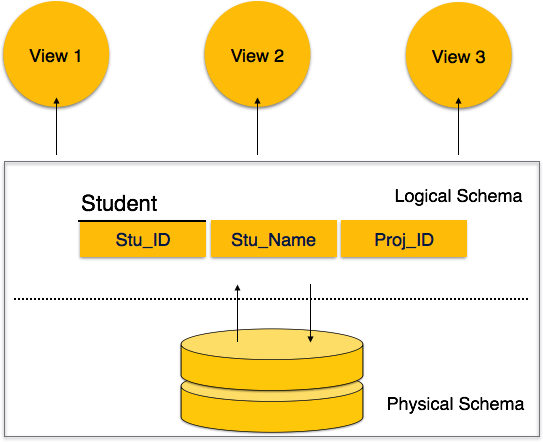
Ein Datenbankschema kann grob in zwei Kategorien unterteilt werden:
Physical Database Schema - Dieses Schema bezieht sich auf die tatsächliche Speicherung von Daten und deren Speicherform wie Dateien, Indizes usw. Es definiert, wie die Daten in einem Sekundärspeicher gespeichert werden.
Logical Database Schema- Dieses Schema definiert alle logischen Einschränkungen, die auf die gespeicherten Daten angewendet werden müssen. Es definiert Tabellen, Ansichten und Integritätsbeschränkungen.
Datenbankinstanz
Es ist wichtig, dass wir diese beiden Begriffe einzeln unterscheiden. Das Datenbankschema ist das Grundgerüst der Datenbank. Es wurde entwickelt, wenn die Datenbank überhaupt nicht vorhanden ist. Sobald die Datenbank betriebsbereit ist, ist es sehr schwierig, Änderungen daran vorzunehmen. Ein Datenbankschema enthält keine Daten oder Informationen.
Eine Datenbankinstanz ist eine betriebsbereite Datenbank mit Daten zu einem bestimmten Zeitpunkt. Es enthält eine Momentaufnahme der Datenbank. Datenbankinstanzen ändern sich tendenziell mit der Zeit. Ein DBMS stellt sicher, dass sich jede Instanz (jeder Status) in einem gültigen Status befindet, indem alle von den Datenbankdesignern auferlegten Validierungen, Einschränkungen und Bedingungen sorgfältig befolgt werden.
Wenn ein Datenbanksystem nicht mehrschichtig ist, ist es schwierig, Änderungen am Datenbanksystem vorzunehmen. Wie wir bereits erfahren haben, sind Datenbanksysteme mehrschichtig aufgebaut.
Datenunabhängigkeit
Ein Datenbanksystem enthält normalerweise zusätzlich zu den Benutzerdaten viele Daten. Beispielsweise werden Daten zu Daten gespeichert, die als Metadaten bezeichnet werden, um Daten leicht zu finden und abzurufen. Es ist ziemlich schwierig, einen Satz von Metadaten zu ändern oder zu aktualisieren, sobald sie in der Datenbank gespeichert sind. Wenn ein DBMS jedoch erweitert wird, muss es sich im Laufe der Zeit ändern, um die Anforderungen der Benutzer zu erfüllen. Wenn die gesamten Daten abhängig sind, wird dies zu einer mühsamen und hochkomplexen Aufgabe.
Metadaten selbst folgen einer geschichteten Architektur, sodass sich das Ändern von Daten auf einer Ebene nicht auf die Daten auf einer anderen Ebene auswirkt. Diese Daten sind unabhängig, aber einander zugeordnet.
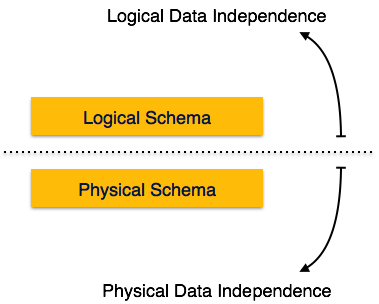
Unabhängigkeit logischer Daten
Logische Daten sind Daten zur Datenbank, dh sie speichern Informationen darüber, wie Daten in der Datenbank verwaltet werden. Beispiel: Eine in der Datenbank gespeicherte Tabelle (Relation) und alle ihre Einschränkungen, die auf diese Relation angewendet werden.
Die Unabhängigkeit von logischen Daten ist eine Art Mechanismus, der sich von den auf der Festplatte gespeicherten tatsächlichen Daten befreit. Wenn wir einige Änderungen am Tabellenformat vornehmen, sollten die auf der Festplatte befindlichen Daten nicht geändert werden.
Unabhängigkeit von physischen Daten
Alle Schemata sind logisch und die tatsächlichen Daten werden im Bitformat auf der Festplatte gespeichert. Die Unabhängigkeit von physischen Daten ist die Fähigkeit, die physischen Daten zu ändern, ohne das Schema oder die logischen Daten zu beeinflussen.
Wenn wir beispielsweise das Speichersystem selbst ändern oder aktualisieren möchten - nehmen wir an, wir möchten Festplatten durch SSD ersetzen -, sollte dies keine Auswirkungen auf die logischen Daten oder Schemata haben.
Das ER-Modell definiert die konzeptionelle Ansicht einer Datenbank. Es funktioniert um reale Entitäten und die Assoziationen zwischen ihnen. Auf Ansichtsebene wird das ER-Modell als gute Option zum Entwerfen von Datenbanken angesehen.
Entität
Eine Entität kann ein reales Objekt sein, entweder animiert oder unbelebt, das leicht zu identifizieren ist. Beispielsweise können in einer Schuldatenbank Schüler, Lehrer, Klassen und angebotene Kurse als Einheiten betrachtet werden. Alle diese Entitäten haben einige Attribute oder Eigenschaften, die ihnen ihre Identität geben.
Ein Entitätssatz ist eine Sammlung ähnlicher Entitätstypen. Ein Entitätssatz kann Entitäten mit Attributen enthalten, die ähnliche Werte teilen. Beispielsweise kann ein Schülerset alle Schüler einer Schule enthalten. Ebenso kann ein Lehrerset alle Lehrer einer Schule aus allen Fakultäten enthalten. Entitätssätze müssen nicht disjunkt sein.
Attribute
Entitäten werden durch ihre Eigenschaften dargestellt, die als bezeichnet werden attributes. Alle Attribute haben Werte. Beispielsweise kann eine Schülerentität Name, Klasse und Alter als Attribute haben.
Es gibt eine Domäne oder einen Wertebereich, die Attributen zugewiesen werden können. Beispielsweise kann der Name eines Schülers kein numerischer Wert sein. Es muss alphabetisch sein. Das Alter eines Schülers kann nicht negativ sein usw.
Arten von Attributen
Simple attribute- Einfache Attribute sind Atomwerte, die nicht weiter unterteilt werden können. Die Telefonnummer eines Schülers ist beispielsweise ein Atomwert mit 10 Ziffern.
Composite attribute- Zusammengesetzte Attribute bestehen aus mehr als einem einfachen Attribut. Beispielsweise kann der vollständige Name eines Schülers Vorname und Nachname haben.
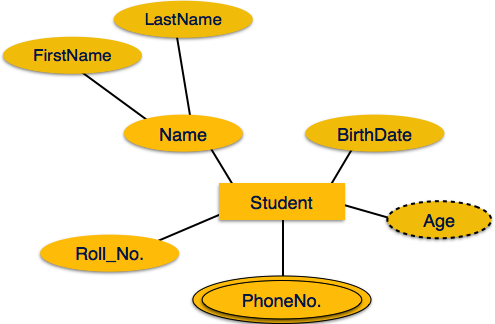
Derived attribute- Abgeleitete Attribute sind Attribute, die in der physischen Datenbank nicht vorhanden sind, deren Werte jedoch von anderen in der Datenbank vorhandenen Attributen abgeleitet werden. Beispielsweise sollte durchschnittliches Gehalt in einer Abteilung nicht direkt in der Datenbank gespeichert werden, sondern kann abgeleitet werden. Für ein anderes Beispiel kann das Alter aus data_of_birth abgeleitet werden.
Single-value attribute- Einzelwertattribute enthalten Einzelwertattribute. Zum Beispiel - Social_Security_Number.
Multi-value attribute- Mehrwertattribute können mehr als einen Wert enthalten. Beispielsweise kann eine Person mehr als eine Telefonnummer, E-Mail-Adresse usw. haben.
Diese Attributtypen können auf folgende Weise zusammenkommen:
- einfache einwertige Attribute
- einfache mehrwertige Attribute
- zusammengesetzte einwertige Attribute
- zusammengesetzte mehrwertige Attribute
Entity-Set und Schlüssel
Schlüssel ist ein Attribut oder eine Sammlung von Attributen, die eine Entität innerhalb des Entitätssatzes eindeutig identifizieren.
Zum Beispiel macht die Rollennummer eines Schülers ihn unter den Schülern identifizierbar.
Super Key - Eine Reihe von Attributen (eines oder mehrere), die eine Entität in einer Entitätsmenge gemeinsam identifizieren.
Candidate Key- Ein minimaler Superschlüssel wird als Kandidatenschlüssel bezeichnet. Ein Entitätssatz kann mehr als einen Kandidatenschlüssel haben.
Primary Key - Ein Primärschlüssel ist einer der Kandidatenschlüssel, die vom Datenbankdesigner ausgewählt wurden, um den Entitätssatz eindeutig zu identifizieren.
Beziehung
Die Zuordnung zwischen Entitäten wird als Beziehung bezeichnet. Zum Beispiel ein Mitarbeiterworks_at eine Abteilung, ein Student enrollsin einem Kurs. Hier werden Works_at und Enrolls als Beziehungen bezeichnet.
Beziehungsset
Eine Menge von Beziehungen ähnlichen Typs wird als Beziehungsmenge bezeichnet. Wie Entitäten kann auch eine Beziehung Attribute haben. Diese Attribute werden aufgerufendescriptive attributes.
Grad der Beziehung
Die Anzahl der an einer Beziehung beteiligten Entitäten definiert den Grad der Beziehung.
- Binär = Grad 2
- Ternär = Grad 3
- n-ary = Grad
Kardinalitäten abbilden
Cardinality Definiert die Anzahl der Entitäten in einem Entitätssatz, die über den Beziehungssatz der Anzahl der Entitäten eines anderen Satzes zugeordnet werden können.
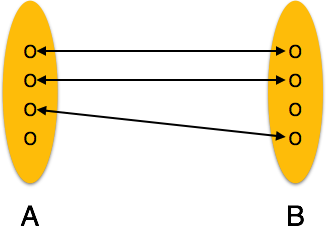
One-to-one - Eine Entität aus Entitätssatz A kann höchstens einer Entität aus Entitätssatz B zugeordnet werden und umgekehrt.
One-to-many - Eine Entität aus Entitätssatz A kann mehr als einer Entität aus Entitätssatz B zugeordnet werden. Eine Entität aus Entitätssatz B kann jedoch höchstens einer Entität zugeordnet werden.
Many-to-one - Mehr als eine Entität aus Entitätssatz A kann höchstens einer Entität aus Entitätssatz B zugeordnet werden. Eine Entität aus Entitätssatz B kann jedoch mehr als einer Entität aus Entitätssatz A zugeordnet werden.
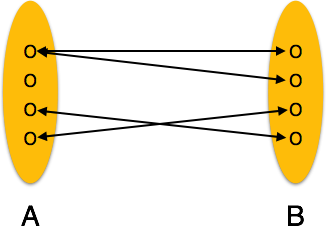
Many-to-many - Eine Entität von A kann mehr als einer Entität von B zugeordnet werden und umgekehrt.
Lassen Sie uns nun lernen, wie das ER-Modell anhand eines ER-Diagramms dargestellt wird. Jedes Objekt, z. B. Entitäten, Attribute einer Entität, Beziehungssätze und Attribute von Beziehungssätzen, kann mithilfe eines ER-Diagramms dargestellt werden.
Entität
Entitäten werden durch Rechtecke dargestellt. Rechtecke werden mit dem Entitätssatz benannt, den sie darstellen.

Attribute
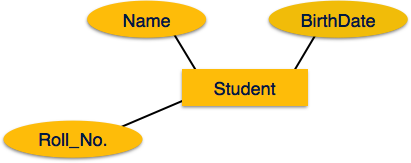
Attribute sind die Eigenschaften von Entitäten. Attribute werden durch Ellipsen dargestellt. Jede Ellipse repräsentiert ein Attribut und ist direkt mit ihrer Entität (Rechteck) verbunden.
Wenn die Attribute sind compositesind sie weiter in eine baumartige Struktur unterteilt. Jeder Knoten ist dann mit seinem Attribut verbunden. Das heißt, zusammengesetzte Attribute werden durch Ellipsen dargestellt, die mit einer Ellipse verbunden sind.
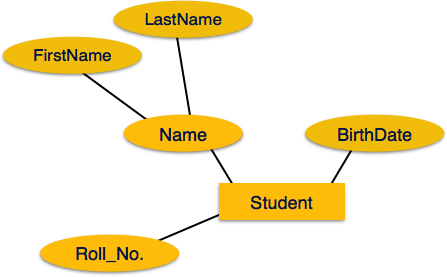
Multivalued Attribute werden durch Doppelellipse dargestellt.
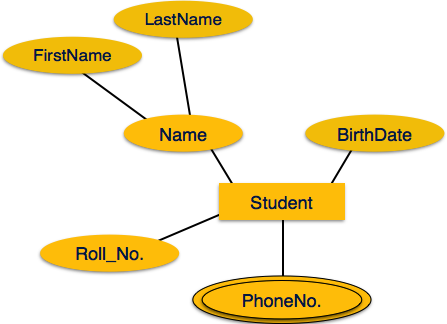
Derived Attribute werden durch eine gestrichelte Ellipse dargestellt.
Beziehung
Beziehungen werden durch eine rautenförmige Box dargestellt. Der Name der Beziehung steht in der Diamantbox. Alle an einer Beziehung beteiligten Entitäten (Rechtecke) sind durch eine Linie mit ihr verbunden.
Binäre Beziehung und Kardinalität
Eine Beziehung, an der zwei Entitäten teilnehmen, wird als a bezeichnet binary relationship. Kardinalität ist die Anzahl der Instanzen einer Entität aus einer Beziehung, die der Beziehung zugeordnet werden kann.
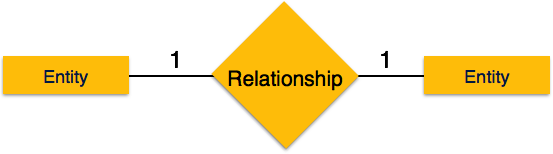
One-to-one- Wenn der Beziehung nur eine Instanz einer Entität zugeordnet ist, wird sie als "1: 1" markiert. Das folgende Bild zeigt, dass der Beziehung nur eine Instanz jeder Entität zugeordnet werden sollte. Es zeigt eine Eins-zu-Eins-Beziehung.
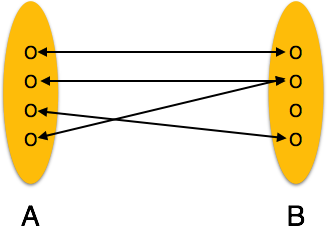
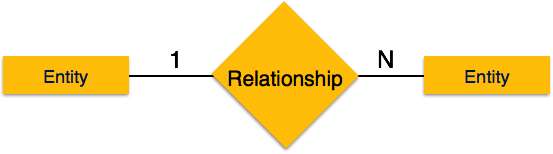
One-to-many- Wenn einer Beziehung mehr als eine Instanz einer Entität zugeordnet ist, wird sie als '1: N' markiert. Das folgende Bild zeigt, dass der Beziehung nur eine Instanz einer Entität links und mehr als eine Instanz einer Entität rechts zugeordnet werden kann. Es zeigt eine Eins-zu-Viele-Beziehung.
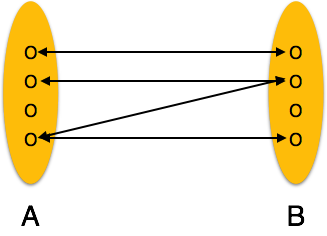
Many-to-one- Wenn der Beziehung mehr als eine Instanz einer Entität zugeordnet ist, wird sie als 'N: 1' markiert. Das folgende Bild zeigt, dass der Beziehung mehr als eine Instanz einer Entität links und nur eine Instanz einer Entität rechts zugeordnet werden kann. Es zeigt eine Eins-zu-Eins-Beziehung.
Many-to-many- Das folgende Bild zeigt, dass der Beziehung mehr als eine Instanz einer Entität links und mehr als eine Instanz einer Entität rechts zugeordnet werden kann. Es zeigt eine Viele-zu-Viele-Beziehung.
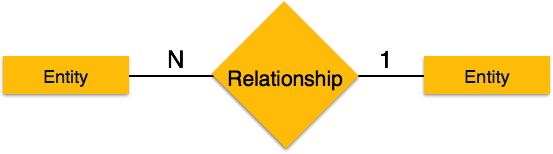
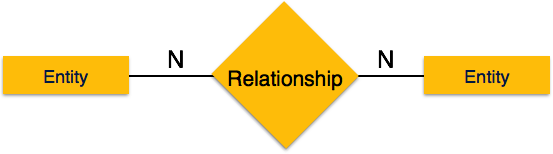
Teilnahmebedingungen
Total Participation- Jede Entität ist an der Beziehung beteiligt. Die Gesamtbeteiligung wird durch doppelte Linien dargestellt.
Partial participation- Nicht alle Entitäten sind an der Beziehung beteiligt. Teilbeteiligung wird durch einzelne Zeilen dargestellt.
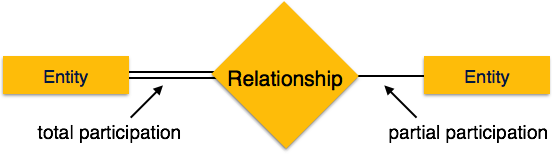
Lassen Sie uns nun lernen, wie das ER-Modell anhand eines ER-Diagramms dargestellt wird. Jedes Objekt, z. B. Entitäten, Attribute einer Entität, Beziehungssätze und Attribute von Beziehungssätzen, kann mithilfe eines ER-Diagramms dargestellt werden.
Entität
Entitäten werden durch Rechtecke dargestellt. Rechtecke werden mit dem Entitätssatz benannt, den sie darstellen.
Attribute
Attribute sind die Eigenschaften von Entitäten. Attribute werden durch Ellipsen dargestellt. Jede Ellipse repräsentiert ein Attribut und ist direkt mit ihrer Entität (Rechteck) verbunden.
Wenn die Attribute sind compositesind sie weiter in eine baumartige Struktur unterteilt. Jeder Knoten ist dann mit seinem Attribut verbunden. Das heißt, zusammengesetzte Attribute werden durch Ellipsen dargestellt, die mit einer Ellipse verbunden sind.
Multivalued Attribute werden durch Doppelellipse dargestellt.
Derived Attribute werden durch eine gestrichelte Ellipse dargestellt.
Beziehung
Beziehungen werden durch eine rautenförmige Box dargestellt. Der Name der Beziehung steht in der Diamantbox. Alle an einer Beziehung beteiligten Entitäten (Rechtecke) sind durch eine Linie mit ihr verbunden.
Binäre Beziehung und Kardinalität
Eine Beziehung, an der zwei Entitäten teilnehmen, wird als a bezeichnet binary relationship. Kardinalität ist die Anzahl der Instanzen einer Entität aus einer Beziehung, die der Beziehung zugeordnet werden kann.
One-to-one- Wenn der Beziehung nur eine Instanz einer Entität zugeordnet ist, wird sie als "1: 1" markiert. Das folgende Bild zeigt, dass der Beziehung nur eine Instanz jeder Entität zugeordnet werden sollte. Es zeigt eine Eins-zu-Eins-Beziehung.
One-to-many- Wenn einer Beziehung mehr als eine Instanz einer Entität zugeordnet ist, wird sie als '1: N' markiert. Das folgende Bild zeigt, dass der Beziehung nur eine Instanz einer Entität links und mehr als eine Instanz einer Entität rechts zugeordnet werden kann. Es zeigt eine Eins-zu-Viele-Beziehung.
Many-to-one- Wenn der Beziehung mehr als eine Instanz einer Entität zugeordnet ist, wird sie als 'N: 1' markiert. Das folgende Bild zeigt, dass der Beziehung mehr als eine Instanz einer Entität links und nur eine Instanz einer Entität rechts zugeordnet werden kann. Es zeigt eine Eins-zu-Eins-Beziehung.
Many-to-many- Das folgende Bild zeigt, dass der Beziehung mehr als eine Instanz einer Entität links und mehr als eine Instanz einer Entität rechts zugeordnet werden kann. Es zeigt eine Viele-zu-Viele-Beziehung.
Teilnahmebedingungen
Total Participation- Jede Entität ist an der Beziehung beteiligt. Die Gesamtbeteiligung wird durch doppelte Linien dargestellt.
Partial participation- Nicht alle Entitäten sind an der Beziehung beteiligt. Teilbeteiligung wird durch einzelne Zeilen dargestellt.
Das ER-Modell kann Datenbankentitäten konzeptionell hierarchisch ausdrücken. Wenn die Hierarchie nach oben geht, wird die Ansicht von Entitäten verallgemeinert, und wenn wir tief in die Hierarchie eintauchen, erhalten wir die Details aller enthaltenen Entitäten.
In diese Struktur aufzusteigen heißt generalization, wo Entitäten zusammengelegt werden, um eine allgemeinere Ansicht darzustellen. Beispielsweise kann ein bestimmter Schüler namens Mira zusammen mit allen Schülern verallgemeinert werden. Die Entität soll ein Student sein, und ferner ist der Student eine Person. Das Gegenteil heißtspecialization wo eine Person ein Student ist und dieser Student Mira ist.
Verallgemeinerung
Wie oben erwähnt, wird der Prozess der Generalisierung von Entitäten, bei dem die generalisierten Entitäten die Eigenschaften aller generalisierten Entitäten enthalten, als Generalisierung bezeichnet. Bei der Verallgemeinerung werden mehrere Entitäten aufgrund ihrer ähnlichen Merkmale zu einer verallgemeinerten Entität zusammengefasst. Zum Beispiel können Taube, Haussperling, Krähe und Taube als Vögel verallgemeinert werden.

Spezialisierung
Spezialisierung ist das Gegenteil von Generalisierung. Bei der Spezialisierung wird eine Gruppe von Entitäten anhand ihrer Merkmale in Untergruppen unterteilt. Nehmen Sie zum Beispiel eine Gruppe 'Person'. Eine Person hat Name, Geburtsdatum, Geschlecht usw. Diese Eigenschaften sind allen Personen, Menschen, gemeinsam. In einem Unternehmen können Personen jedoch als Mitarbeiter, Arbeitgeber, Kunde oder Verkäufer identifiziert werden, je nachdem, welche Rolle sie im Unternehmen spielen.
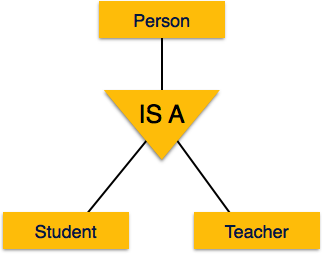
In ähnlicher Weise können Personen in einer Schuldatenbank als Lehrer, Schüler oder Mitarbeiter spezialisiert werden, je nachdem, welche Rolle sie als Einheiten in der Schule spielen.
Erbe
Wir verwenden alle oben genannten Funktionen von ER-Model, um Klassen von Objekten in der objektorientierten Programmierung zu erstellen. Die Details von Entitäten sind dem Benutzer im Allgemeinen verborgen. Dieser Prozess ist bekannt alsabstraction.
Vererbung ist ein wichtiges Merkmal der Generalisierung und Spezialisierung. Entitäten auf niedrigerer Ebene können die Attribute von Entitäten auf höherer Ebene erben.
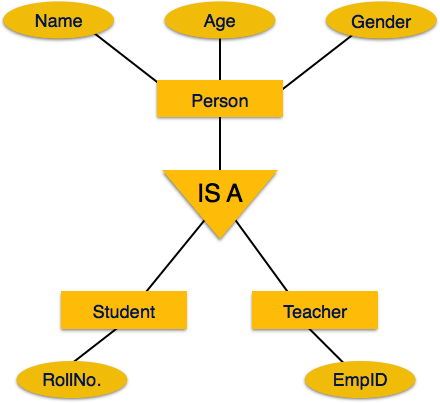
Beispielsweise können die Attribute einer Personenklasse wie Name, Alter und Geschlecht von untergeordneten Entitäten wie Schüler oder Lehrer geerbt werden.
Dr. Edgar F. Codd hat nach seinen umfangreichen Forschungen zum relationalen Modell von Datenbanksystemen zwölf eigene Regeln aufgestellt, denen eine Datenbank seiner Meinung nach gehorchen muss, um als echte relationale Datenbank angesehen zu werden.
Diese Regeln können auf jedes Datenbanksystem angewendet werden, das gespeicherte Daten nur mit seinen relationalen Funktionen verwaltet. Dies ist eine Grundregel, die als Grundlage für alle anderen Regeln dient.
Regel 1: Informationsregel
Die in einer Datenbank gespeicherten Daten, möglicherweise Benutzerdaten oder Metadaten, müssen ein Wert einer Tabellenzelle sein. Alles in einer Datenbank muss in einem Tabellenformat gespeichert werden.
Regel 2: Garantierte Zugriffsregel
Es ist garantiert, dass auf jedes einzelne Datenelement (Wert) mit einer Kombination aus Tabellenname, Primärschlüssel (Zeilenwert) und Attributname (Spaltenwert) logisch zugegriffen werden kann. Für den Zugriff auf Daten können keine anderen Mittel wie Zeiger verwendet werden.
Regel 3: Systematische Behandlung von NULL-Werten
Die NULL-Werte in einer Datenbank müssen systematisch und einheitlich behandelt werden. Dies ist eine sehr wichtige Regel, da ein NULL wie folgt interpretiert werden kann: Daten fehlen, Daten sind nicht bekannt oder Daten sind nicht anwendbar.
Regel 4: Aktiver Online-Katalog
Die Strukturbeschreibung der gesamten Datenbank muss in einem Online-Katalog gespeichert werden, der als bezeichnet wird data dictionary, auf die autorisierte Benutzer zugreifen können. Benutzer können dieselbe Abfragesprache verwenden, um auf den Katalog zuzugreifen, mit dem sie auf die Datenbank selbst zugreifen.
Regel 5: Umfassende Daten-Subsprache-Regel
Auf eine Datenbank kann nur mit einer Sprache mit linearer Syntax zugegriffen werden, die Datendefinitions-, Datenmanipulations- und Transaktionsverwaltungsvorgänge unterstützt. Diese Sprache kann direkt oder mittels einer Anwendung verwendet werden. Wenn die Datenbank den Zugriff auf Daten ohne Hilfe dieser Sprache ermöglicht, wird dies als Verstoß angesehen.
Regel 6: Aktualisierungsregel anzeigen
Alle Ansichten einer Datenbank, die theoretisch aktualisiert werden können, müssen auch vom System aktualisiert werden können.
Regel 7: Übergeordnete Regel zum Einfügen, Aktualisieren und Löschen
Eine Datenbank muss das Einfügen, Aktualisieren und Löschen auf hoher Ebene unterstützen. Dies darf nicht auf eine einzelne Zeile beschränkt sein, dh es müssen auch Vereinigungs-, Schnitt- und Minusoperationen unterstützt werden, um Datensätze zu erhalten.
Regel 8: Unabhängigkeit von physischen Daten
Die in einer Datenbank gespeicherten Daten müssen unabhängig von den Anwendungen sein, die auf die Datenbank zugreifen. Änderungen in der physischen Struktur einer Datenbank dürfen keine Auswirkungen darauf haben, wie externe Anwendungen auf die Daten zugreifen.
Regel 9: Unabhängigkeit von logischen Daten
Die logischen Daten in einer Datenbank müssen unabhängig von der Ansicht des Benutzers (Anwendung) sein. Änderungen an logischen Daten dürfen sich nicht auf die Anwendungen auswirken, die sie verwenden. Wenn beispielsweise zwei Tabellen zusammengeführt oder eine in zwei verschiedene Tabellen aufgeteilt wird, sollte dies keine Auswirkungen oder Änderungen auf die Benutzeranwendung haben. Dies ist eine der am schwierigsten anzuwendenden Regeln.
Regel 10: Integrität Unabhängigkeit
Eine Datenbank muss unabhängig von der Anwendung sein, die sie verwendet. Alle Integritätsbeschränkungen können unabhängig voneinander geändert werden, ohne dass Änderungen an der Anwendung erforderlich sind. Diese Regel macht eine Datenbank unabhängig von der Front-End-Anwendung und ihrer Schnittstelle.
Regel 11: Vertriebsunabhängigkeit
Der Endbenutzer darf nicht sehen können, dass die Daten auf verschiedene Standorte verteilt sind. Benutzer sollten immer den Eindruck haben, dass sich die Daten nur an einem Standort befinden. Diese Regel wurde als Grundlage verteilter Datenbanksysteme angesehen.
Regel 12: Nicht-Subversion-Regel
Wenn ein System über eine Schnittstelle verfügt, die Zugriff auf Datensätze auf niedriger Ebene bietet, darf die Schnittstelle das System nicht untergraben und Sicherheits- und Integritätsbeschränkungen umgehen können.
Das relationale Datenmodell ist das primäre Datenmodell, das weltweit zur Speicherung und Verarbeitung von Daten verwendet wird. Dieses Modell ist einfach und verfügt über alle Eigenschaften und Funktionen, die für die Verarbeitung von Daten mit Speichereffizienz erforderlich sind.
Konzepte
Tables- Im relationalen Datenmodell werden Beziehungen im Format Tabellen gespeichert. Dieses Format speichert die Beziehung zwischen Entitäten. Eine Tabelle enthält Zeilen und Spalten, wobei Zeilen Datensätze und Spalten die Attribute darstellen.
Tuple - Eine einzelne Zeile einer Tabelle, die einen einzelnen Datensatz für diese Beziehung enthält, wird als Tupel bezeichnet.
Relation instance- Eine endliche Menge von Tupeln im relationalen Datenbanksystem repräsentiert die Beziehungsinstanz. Beziehungsinstanzen haben keine doppelten Tupel.
Relation schema - Ein Beziehungsschema beschreibt den Beziehungsnamen (Tabellennamen), Attribute und deren Namen.
Relation key - Jede Zeile verfügt über ein oder mehrere Attribute, die als Beziehungsschlüssel bezeichnet werden und die Zeile in der Beziehung (Tabelle) eindeutig identifizieren können.
Attribute domain - Jedes Attribut verfügt über einen vordefinierten Wertebereich, der als Attributdomäne bezeichnet wird.
Einschränkungen
Jede Beziehung hat einige Bedingungen, die gelten müssen, damit sie eine gültige Beziehung ist. Diese Bedingungen werden aufgerufenRelational Integrity Constraints. Es gibt drei Hauptintegritätsbeschränkungen:
- Wichtige Einschränkungen
- Domäneneinschränkungen
- Einschränkungen der referenziellen Integrität
Wichtige Einschränkungen
Die Beziehung muss mindestens eine minimale Teilmenge von Attributen enthalten, mit denen ein Tupel eindeutig identifiziert werden kann. Diese minimale Teilmenge von Attributen wird aufgerufenkeyfür diese Beziehung. Wenn es mehr als eine solche minimale Teilmenge gibt, werden diese aufgerufencandidate keys.
Wichtige Einschränkungen erzwingen, dass -
In einer Beziehung mit einem Schlüsselattribut können keine zwei Tupel identische Werte für Schlüsselattribute haben.
Ein Schlüsselattribut darf keine NULL-Werte haben.
Wichtige Einschränkungen werden auch als Entitätsbeschränkungen bezeichnet.
Domain-Einschränkungen
Attribute haben im realen Szenario bestimmte Werte. Zum Beispiel kann das Alter nur eine positive ganze Zahl sein. Es wurde versucht, die gleichen Einschränkungen für die Attribute einer Beziehung anzuwenden. Jedes Attribut muss einen bestimmten Wertebereich haben. Beispielsweise darf das Alter nicht unter Null liegen und Telefonnummern dürfen keine Ziffer außerhalb von 0-9 enthalten.
Einschränkungen der referenziellen Integrität
Einschränkungen der referenziellen Integrität wirken sich auf das Konzept der Fremdschlüssel aus. Ein Fremdschlüssel ist ein Schlüsselattribut einer Beziehung, auf die in einer anderen Beziehung verwiesen werden kann.
Die Einschränkung der referenziellen Integrität besagt, dass dieses Schlüsselelement vorhanden sein muss, wenn sich eine Beziehung auf ein Schlüsselattribut einer anderen oder derselben Beziehung bezieht.
Von relationalen Datenbanksystemen wird erwartet, dass sie mit einer Abfragesprache ausgestattet sind, die den Benutzern beim Abfragen der Datenbankinstanzen helfen kann. Es gibt zwei Arten von Abfragesprachen - relationale Algebra und relationale Berechnung.
Relationale Algebra
Relationale Algebra ist eine prozedurale Abfragesprache, die Instanzen von Beziehungen als Eingabe verwendet und Instanzen von Beziehungen als Ausgabe liefert. Es verwendet Operatoren, um Abfragen durchzuführen. Ein Operator kann entweder seinunary oder binary. Sie akzeptieren Beziehungen als ihre Eingabe und ergeben Beziehungen als ihre Ausgabe. Die relationale Algebra wird rekursiv für eine Beziehung durchgeführt, und Zwischenergebnisse werden ebenfalls als Beziehungen betrachtet.
Die grundlegenden Operationen der relationalen Algebra sind wie folgt:
- Select
- Project
- Union
- Anders einstellen
- kartesisches Produkt
- Rename
Wir werden alle diese Operationen in den folgenden Abschnitten diskutieren.
Wählen Sie Operation (σ)
Es wählt Tupel aus einer Beziehung aus, die das angegebene Prädikat erfüllen.
Notation- σ p (r)
Wo σ steht für Auswahlprädikat und rsteht für Beziehung. p ist eine Präpositionallogikformel, die Konnektoren wie verwenden kannand, or, und not. Diese Begriffe können relationale Operatoren wie - =, ≠, ≥, <,>, ≤ verwenden.
For example - -
σsubject="database"(Books)
Output - Wählt Tupel aus Büchern aus, deren Thema "Datenbank" ist.
σsubject="database" and price="450"(Books)
Output - Wählt Tupel aus Büchern aus, bei denen das Thema "Datenbank" und "Preis" 450 ist.
σsubject="database" and price < "450" or year > "2010"(Books)
Output - Wählt Tupel aus Büchern aus, deren Thema "Datenbank" und "Preis" 450 ist, oder aus Büchern, die nach 2010 veröffentlicht wurden.
Projektbetrieb (∏)
Es werden Spalten projiziert, die ein bestimmtes Prädikat erfüllen.
Notation - 1 A 1 , A 2 , A n (r)
Wobei A 1 , A 2 , A n Attributnamen der Beziehung sindr.
Doppelte Zeilen werden automatisch entfernt, da die Beziehung eine Menge ist.
For example - -
∏subject, author (Books)
Wählt und projiziert Spalten, die als Betreff und Autor benannt sind, aus der Beziehung Bücher.
Gewerkschaftsbetrieb (∪)
Es führt eine binäre Vereinigung zwischen zwei gegebenen Beziehungen durch und ist definiert als -
r ∪ s = { t | t ∈ r or t ∈ s}
Notation - r U s
Wo r und s sind entweder Datenbankbeziehungen oder Beziehungsergebnismenge (temporäre Beziehung).
Damit eine Gewerkschaftsoperation gültig ist, müssen die folgenden Bedingungen erfüllt sein:
- r, und s muss die gleiche Anzahl von Attributen haben.
- Attributdomänen müssen kompatibel sein.
- Doppelte Tupel werden automatisch entfernt.
∏ author (Books) ∪ ∏ author (Articles)
Output - Projiziert die Namen der Autoren, die entweder ein Buch oder einen Artikel oder beides geschrieben haben.
Differenz einstellen (-)
Das Ergebnis der eingestellten Differenzoperation sind Tupel, die in einer Beziehung vorhanden sind, aber nicht in der zweiten Beziehung.
Notation - - r - - s
Findet alle Tupel, die in vorhanden sind r aber nicht in s.
∏ author (Books) − ∏ author (Articles)
Output - Gibt den Namen der Autoren an, die Bücher, aber keine Artikel geschrieben haben.
Kartesisches Produkt (Χ)
Kombiniert Informationen aus zwei verschiedenen Beziehungen zu einer.
Notation - r Χ s
Wo r und s sind Beziehungen und ihre Ausgabe wird definiert als -
r Χ s = {qt | q ∈ r und t ∈ s}
∏ author = 'tutorialspoint'(Books Χ Articles)
Output - Ergibt eine Beziehung, die alle Bücher und Artikel zeigt, die von tutorialspoint geschrieben wurden.
Operation umbenennen (ρ)
Die Ergebnisse der relationalen Algebra sind ebenfalls Beziehungen, jedoch ohne Namen. Mit der Umbenennungsoperation können wir die Ausgabebeziehung umbenennen. Die Operation 'Umbenennen' wird mit einem kleinen griechischen Buchstaben bezeichnetrho ρ .
Notation- ρ x (E)
Wo das Ergebnis des Ausdrucks E wird mit dem Namen von gespeichert x.
Zusätzliche Operationen sind -
- Schnittpunkt einstellen
- Assignment
- Natürliche Verbindung
Beziehungsrechnung
Im Gegensatz zur relationalen Algebra ist der relationale Kalkül eine nicht prozedurale Abfragesprache, dh er sagt, was zu tun ist, erklärt jedoch nie, wie es zu tun ist.
Beziehungsrechnung existiert in zwei Formen -
Tupel-Beziehungsrechnung (TRC)
Das Filtern von Variablenbereichen über Tupel
Notation- {T | Bedingung}
Gibt alle Tupel T zurück, die eine Bedingung erfüllen.
For example - -
{ T.name | Author(T) AND T.article = 'database' }Output - Gibt Tupel mit 'Name' vom Autor zurück, der einen Artikel über 'Datenbank' geschrieben hat.
TRC kann quantifiziert werden. Wir können existentielle (∃) und universelle Quantifizierer (∀) verwenden.
For example - -
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}Output - Die obige Abfrage liefert das gleiche Ergebnis wie die vorherige.
Domain Relational Calculus (DRC)
In DRC verwendet die Filtervariable die Domäne der Attribute anstelle ganzer Tupelwerte (wie in TRC, wie oben erwähnt).
Notation - -
{a 1 , a 2 , a 3 , ..., a n | P (a 1 , a 2 , a 3 , ..., a n )}
Wobei a1, a2 Attribute sind und P steht für Formeln, die durch innere Attribute aufgebaut sind.
For example - -
{< article, page, subject > |
∈ TutorialsPoint ∧ subject = 'database'}
Output - Ergibt Artikel, Seite und Betreff aus der Beziehung TutorialsPoint, wobei Betreff eine Datenbank ist.
Genau wie TRC kann DRC auch mit existenziellen und universellen Quantifizierern geschrieben werden. In der Demokratischen Republik Kongo sind auch Vergleichsoperatoren beteiligt.
Die Ausdruckskraft von Tupel-Beziehungsrechnung und Domänen-Beziehungsrechnung entspricht der relationalen Algebra.
Wenn das ER-Modell in Diagrammen konzipiert ist, bietet es einen guten Überblick über die Entitätsbeziehung, der leichter zu verstehen ist. ER-Diagramme können einem relationalen Schema zugeordnet werden, dh es ist möglich, ein relationales Schema mithilfe eines ER-Diagramms zu erstellen. Wir können nicht alle ER-Einschränkungen in das relationale Modell importieren, aber es kann ein ungefähres Schema generiert werden.
Es stehen verschiedene Prozesse und Algorithmen zur Verfügung, um ER-Diagramme in ein relationales Schema zu konvertieren. Einige von ihnen sind automatisiert und einige sind manuell. Wir können uns hier auf den Inhalt des Mapping-Diagramms auf relationale Grundlagen konzentrieren.
ER-Diagramme bestehen hauptsächlich aus -
- Entität und ihre Attribute
- Beziehung, die Assoziation zwischen Entitäten ist.
Mapping-Entität
Eine Entität ist ein reales Objekt mit einigen Attributen.
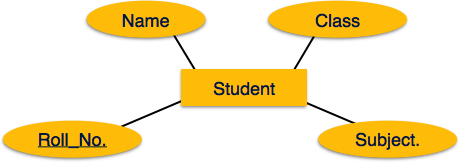
Mapping-Prozess (Algorithmus)
- Erstellen Sie eine Tabelle für jede Entität.
- Die Attribute der Entität sollten zu Tabellenfeldern mit ihren jeweiligen Datentypen werden.
- Primärschlüssel deklarieren.
Beziehung zuordnen
Eine Beziehung ist eine Assoziation zwischen Entitäten.
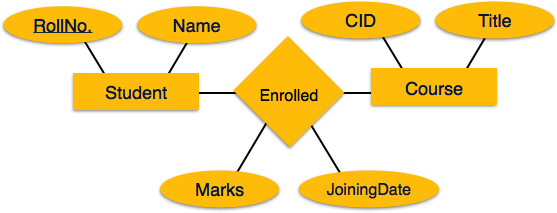
Zuordnungsprozess
- Erstellen Sie eine Tabelle für eine Beziehung.
- Fügen Sie die Primärschlüssel aller teilnehmenden Entitäten als Tabellenfelder mit ihren jeweiligen Datentypen hinzu.
- Wenn die Beziehung ein Attribut hat, fügen Sie jedes Attribut als Tabellenfeld hinzu.
- Deklarieren Sie einen Primärschlüssel, der alle Primärschlüssel der teilnehmenden Entitäten enthält.
- Deklarieren Sie alle Fremdschlüsseleinschränkungen.
Zuordnen schwacher Entitätssätze
Ein schwacher Entitätssatz ist einer, dem kein Primärschlüssel zugeordnet ist.
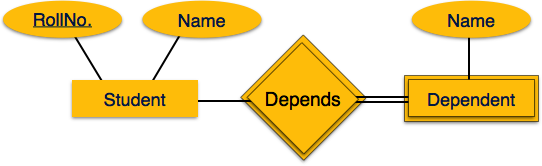
Zuordnungsprozess
- Erstellen Sie eine Tabelle für einen schwachen Entitätssatz.
- Fügen Sie alle Attribute der Tabelle als Feld hinzu.
- Fügen Sie den Primärschlüssel zur Identifizierung des Entitätssatzes hinzu.
- Deklarieren Sie alle Fremdschlüsseleinschränkungen.
Zuordnen hierarchischer Entitäten
Die ER-Spezialisierung oder Generalisierung erfolgt in Form von hierarchischen Entitätssätzen.
Zuordnungsprozess
Erstellen Sie Tabellen für alle übergeordneten Entitäten.
Erstellen Sie Tabellen für untergeordnete Entitäten.
Fügen Sie Primärschlüssel von Entitäten höherer Ebene in die Tabelle der Entitäten niedrigerer Ebene ein.
Fügen Sie in Tabellen niedrigerer Ebene alle anderen Attribute von Entitäten niedrigerer Ebene hinzu.
Deklarieren Sie den Primärschlüssel der übergeordneten Tabelle und den Primärschlüssel für die untergeordnete Tabelle.
Deklarieren Sie Fremdschlüsseleinschränkungen.
SQL ist eine Programmiersprache für relationale Datenbanken. Es basiert auf relationaler Algebra und Tupel-Beziehungsrechnung. SQL wird als Paket mit allen wichtigen Distributionen von RDBMS geliefert.
SQL umfasst sowohl Datendefinitions- als auch Datenmanipulationssprachen. Mithilfe der Datendefinitionseigenschaften von SQL kann ein Datenbankschema entworfen und geändert werden, während die Datenbearbeitungseigenschaften es SQL ermöglichen, Daten aus der Datenbank zu speichern und abzurufen.
Datendefinitionssprache
SQL verwendet die folgenden Befehle, um das Datenbankschema zu definieren:
ERSTELLEN
Erstellt neue Datenbanken, Tabellen und Ansichten aus RDBMS.
For example - -
Create database tutorialspoint;
Create table article;
Create view for_students;FALLEN
Löscht Befehle, Ansichten, Tabellen und Datenbanken aus RDBMS.
For example- -
Drop object_type object_name;
Drop database tutorialspoint;
Drop table article;
Drop view for_students;ÄNDERN
Ändert das Datenbankschema.
Alter object_type object_name parameters;For example- -
Alter table article add subject varchar;Dieser Befehl fügt der Beziehung ein Attribut hinzu article mit dem Namen subject vom String-Typ.
Datenmanipulierungssprache
SQL ist mit einer Datenmanipulationssprache (DML) ausgestattet. DML ändert die Datenbankinstanz durch Einfügen, Aktualisieren und Löschen ihrer Daten. DML ist für alle Formulardatenänderungen in einer Datenbank verantwortlich. SQL enthält die folgenden Befehle in seinem DML-Abschnitt:
- SELECT/FROM/WHERE
- INSERT IN / VALUES
- UPDATE/SET/WHERE
- LÖSCHEN VON / WO
Mit diesen grundlegenden Konstrukten können Datenbankprogrammierer und Benutzer Daten und Informationen in die Datenbank eingeben und mithilfe einer Reihe von Filteroptionen effizient abrufen.
SELECT / FROM / WHERE
SELECT- Dies ist einer der grundlegenden Abfragebefehle von SQL. Es ähnelt der Projektionsoperation der relationalen Algebra. Es wählt die Attribute basierend auf der durch die WHERE-Klausel beschriebenen Bedingung aus.
FROM- Diese Klausel verwendet einen Beziehungsnamen als Argument, aus dem Attribute ausgewählt / projiziert werden sollen. Wenn mehr als ein Beziehungsname angegeben wird, entspricht diese Klausel dem kartesischen Produkt.
WHERE - Diese Klausel definiert Prädikate oder Bedingungen, die übereinstimmen müssen, um die zu projizierenden Attribute zu qualifizieren.
For example - -
Select author_name
From book_author
Where age > 50;Dieser Befehl liefert die Namen der Autoren aus der Beziehung book_author deren Alter größer als 50 ist.
INSERT IN / VALUES
Dieser Befehl wird zum Einfügen von Werten in die Zeilen einer Tabelle (Relation) verwendet.
Syntax- -
INSERT INTO table (column1 [, column2, column3 ... ]) VALUES (value1 [, value2, value3 ... ])Oder
INSERT INTO table VALUES (value1, [value2, ... ])For example - -
INSERT INTO tutorialspoint (Author, Subject) VALUES ("anonymous", "computers");UPDATE / SET / WHERE
Dieser Befehl wird zum Aktualisieren oder Ändern der Werte von Spalten in einer Tabelle (Relation) verwendet.
Syntax - -
UPDATE table_name SET column_name = value [, column_name = value ...] [WHERE condition]For example - -
UPDATE tutorialspoint SET Author="webmaster" WHERE Author="anonymous";LÖSCHEN / VON / WO
Dieser Befehl wird zum Entfernen einer oder mehrerer Zeilen aus einer Tabelle (Beziehung) verwendet.
Syntax - -
DELETE FROM table_name [WHERE condition];For example - -
DELETE FROM tutorialspoints
WHERE Author="unknown";Funktionale Abhängigkeit
Die funktionale Abhängigkeit (FD) ist eine Reihe von Einschränkungen zwischen zwei Attributen in einer Beziehung. Die funktionale Abhängigkeit besagt, dass, wenn zwei Tupel dieselben Werte für die Attribute A1, A2, ..., An haben, diese beiden Tupel dieselben Werte für die Attribute B1, B2, ..., Bn haben müssen.
Die funktionale Abhängigkeit wird durch ein Pfeilzeichen (→) dargestellt, dh X → Y, wobei X Y funktional bestimmt. Die Attribute auf der linken Seite bestimmen die Werte der Attribute auf der rechten Seite.
Armstrongs Axiome
Wenn F eine Menge von funktionalen Abhängigkeiten ist, dann ist der Abschluss von F, der als F + bezeichnet wird, die Menge aller funktionalen Abhängigkeiten, die logisch durch F impliziert werden. Armstrongs Axiome sind eine Reihe von Regeln, die bei wiederholter Anwendung einen Abschluss von funktionalen Abhängigkeiten erzeugen .
Reflexive rule - Wenn Alpha eine Menge von Attributen ist und Beta_subset_of Alpha ist, dann hält Alpha Beta.
Augmentation rule- Wenn a → b gilt und y Attribut gesetzt ist, gilt auch ay → by. Das Hinzufügen von Attributen in Abhängigkeiten ändert nichts an den grundlegenden Abhängigkeiten.
Transitivity rule- Wie bei der transitiven Regel in der Algebra gilt auch a → c, wenn a → b und b → c gilt. a → b wird als eine Funktion aufgerufen, die b bestimmt.
Triviale funktionale Abhängigkeit
Trivial- Wenn eine funktionale Abhängigkeit (FD) X → Y gilt, wobei Y eine Teilmenge von X ist, wird dies als triviale FD bezeichnet. Triviale FDs halten immer.
Non-trivial - Wenn ein FD X → Y gilt, wobei Y keine Teilmenge von X ist, wird es als nicht triviales FD bezeichnet.
Completely non-trivial - Wenn ein FD X → Y gilt, wobei x Y = Φ schneidet, spricht man von einem völlig nicht trivialen FD.
Normalisierung
Wenn ein Datenbankdesign nicht perfekt ist, kann es Anomalien enthalten, die für jeden Datenbankadministrator wie ein böser Traum sind. Das Verwalten einer Datenbank mit Anomalien ist nahezu unmöglich.
Update anomalies- Wenn Datenelemente verstreut und nicht richtig miteinander verknüpft sind, kann dies zu seltsamen Situationen führen. Wenn wir beispielsweise versuchen, ein Datenelement zu aktualisieren, dessen Kopien über mehrere Stellen verteilt sind, werden einige Instanzen ordnungsgemäß aktualisiert, während einige andere mit alten Werten belassen werden. Solche Instanzen verlassen die Datenbank in einem inkonsistenten Zustand.
Deletion anomalies - Wir haben versucht, einen Datensatz zu löschen, aber Teile davon wurden aufgrund von Unwissenheit nicht gelöscht. Die Daten werden auch an einer anderen Stelle gespeichert.
Insert anomalies - Wir haben versucht, Daten in einen Datensatz einzufügen, der überhaupt nicht vorhanden ist.
Die Normalisierung ist eine Methode, um alle diese Anomalien zu entfernen und die Datenbank in einen konsistenten Zustand zu versetzen.
Erste Normalform
Die erste Normalform wird in der Definition der Beziehungen (Tabellen) selbst definiert. Diese Regel definiert, dass alle Attribute in einer Beziehung atomare Domänen haben müssen. Die Werte in einer Atomdomäne sind unteilbare Einheiten.

Wir ordnen die Beziehung (Tabelle) wie folgt neu an, um sie in die erste Normalform umzuwandeln.
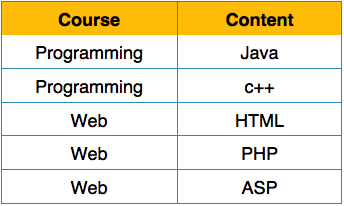
Jedes Attribut darf nur einen einzigen Wert aus seiner vordefinierten Domäne enthalten.
Zweite Normalform
Bevor wir etwas über die zweite Normalform lernen, müssen wir Folgendes verstehen:
Prime attribute - Ein Attribut, das Teil des Kandidatenschlüssels ist, wird als Hauptattribut bezeichnet.
Non-prime attribute - Ein Attribut, das nicht Teil des Primschlüssels ist, wird als Nicht-Primat-Attribut bezeichnet.
Wenn wir der zweiten Normalform folgen, sollte jedes Nicht-Prim-Attribut vollständig funktional vom Prim-Schlüssel-Attribut abhängig sein. Das heißt, wenn X → A gilt, sollte es keine richtige Teilmenge Y von X geben, für die auch Y → A gilt.

Wir sehen hier in der Student_Project-Beziehung, dass die Hauptschlüsselattribute Stu_ID und Proj_ID sind. Gemäß der Regel müssen Nichtschlüsselattribute, dh Stu_Name und Proj_Name, von beiden und nicht von einem der Hauptschlüsselattribute einzeln abhängig sein. Wir stellen jedoch fest, dass Stu_Name durch Stu_ID identifiziert werden kann und Proj_Name unabhängig von Proj_ID identifiziert werden kann. Das nennt manpartial dependency, was in der zweiten Normalform nicht erlaubt ist.
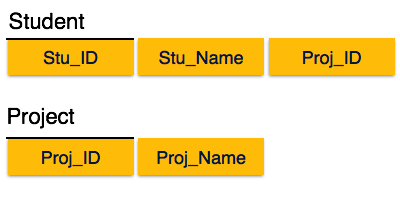
Wir haben die Beziehung in zwei Teile geteilt, wie im obigen Bild dargestellt. Es besteht also keine teilweise Abhängigkeit.
Dritte Normalform
Damit eine Beziehung in der dritten Normalform vorliegt, muss sie in der zweiten Normalform vorliegen und Folgendes muss erfüllt sein:
- Kein Nicht-Prim-Attribut ist transitiv vom Prim-Schlüssel-Attribut abhängig.
- Für jede nicht triviale funktionale Abhängigkeit gilt X → A, dann entweder -
-
X ist ein Superkey oder,
- A ist das Hauptattribut.

Wir finden, dass in der obigen Student_detail-Beziehung Stu_ID der Schlüssel und das einzige Hauptschlüsselattribut ist. Wir finden, dass City sowohl durch Stu_ID als auch durch Zip selbst identifiziert werden kann. Weder ist Zip ein Superkey noch City ein Hauptattribut. Zusätzlich ist Stu_ID → Zip → City vorhandentransitive dependency.
Um diese Beziehung in die dritte Normalform zu bringen, teilen wir die Beziehung wie folgt in zwei Beziehungen auf:
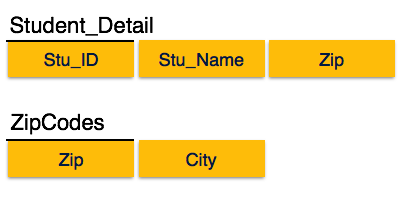
Boyce-Codd Normalform
Die Boyce-Codd-Normalform (BCNF) ist eine Erweiterung der dritten Normalform unter strengen Bedingungen. BCNF erklärt, dass -
- Für jede nicht triviale funktionale Abhängigkeit muss X → A, X ein Superschlüssel sein.
Im obigen Bild ist Stu_ID der Superschlüssel in der Beziehung Student_Detail und Zip ist der Superschlüssel in der Beziehung Postleitzahlen. Damit,
Stu_ID → Stu_Name, Zip
und
Postleitzahl → Stadt
Was bestätigt, dass beide Beziehungen in BCNF sind.
Wir verstehen die Vorteile eines kartesischen Produkts aus zwei Beziehungen, das uns alle möglichen Tupel gibt, die miteinander gepaart sind. In bestimmten Fällen ist es jedoch möglicherweise nicht möglich, ein kartesisches Produkt zu verwenden, bei dem wir auf große Beziehungen zu Tausenden von Tupeln mit einer beträchtlichen Anzahl von Attributen stoßen.
Joinist eine Kombination aus einem kartesischen Produkt, gefolgt von einem Auswahlverfahren. Eine Join-Operation koppelt genau dann zwei Tupel aus verschiedenen Beziehungen, wenn eine bestimmte Join-Bedingung erfüllt ist.
In den folgenden Abschnitten werden verschiedene Join-Typen kurz beschrieben.
Theta (θ) Join
Die Theta-Verknüpfung kombiniert Tupel aus verschiedenen Beziehungen, sofern sie die Theta-Bedingung erfüllen. Die Verknüpfungsbedingung wird durch das Symbol gekennzeichnetθ.
Notation
R1 ⋈θ R2R1 und R2 sind Beziehungen mit Attributen (A1, A2, .., An) und (B1, B2, .., Bn), so dass die Attribute nichts gemeinsam haben, dh R1 ∩ R2 = Φ.
Theta Join kann alle Arten von Vergleichsoperatoren verwenden.
Student SID Name Std 101 Alex 10 102 Maria 11 Themen Klasse Gegenstand 10 Mathematik 10 Englisch 11 Musik 11 Sport Student_Detail =
STUDENT ⋈Student.Std = Subject.Class SUBJECTStudent_detail SID Name Std Klasse Gegenstand 101 Alex 10 10 Mathematik 101 Alex 10 10 Englisch 102 Maria 11 11 Musik 102 Maria 11 11 Sport Equijoin
Wenn Theta Join nur verwendet equalityVergleichsoperator soll es Equijoin sein. Das obige Beispiel entspricht Equijoin.
Natürliche Verbindung ( ⋈ )
Natural Join verwendet keinen Vergleichsoperator. Es verkettet nicht wie ein kartesisches Produkt. Wir können einen natürlichen Join nur durchführen, wenn zwischen zwei Beziehungen mindestens ein gemeinsames Attribut besteht. Darüber hinaus müssen die Attribute denselben Namen und dieselbe Domäne haben.
Natural Join wirkt sich auf die übereinstimmenden Attribute aus, bei denen die Werte der Attribute in beiden Beziehungen gleich sind.
Kurse CID Kurs Abteilung CS01 Datenbank CS ME01 Mechanik MICH EE01 Elektronik EE HoD Abteilung Kopf CS Alex MICH Maya EE Mira Kurse ⋈ HoD Abteilung CID Kurs Kopf CS CS01 Datenbank Alex MICH ME01 Mechanik Maya EE EE01 Elektronik Mira Äußere Verbindungen
Theta Join, Equijoin und Natural Join werden als innere Joins bezeichnet. Ein innerer Join enthält nur die Tupel mit übereinstimmenden Attributen, und der Rest wird in der resultierenden Beziehung verworfen. Daher müssen wir äußere Verknüpfungen verwenden, um alle Tupel aus den beteiligten Beziehungen in die resultierende Beziehung aufzunehmen. Es gibt drei Arten von äußeren Verknüpfungen: linke äußere Verknüpfung, rechte äußere Verknüpfung und vollständige äußere Verknüpfung.
Linke äußere Verbindung (R
S)
Alle Tupel aus der linken Beziehung R sind in der resultierenden Beziehung enthalten. Wenn es in R Tupel ohne übereinstimmendes Tupel in der rechten Beziehung S gibt, werden die S-Attribute der resultierenden Beziehung auf NULL gesetzt.
Links EIN B. 100 Datenbank 101 Mechanik 102 Elektronik Recht EIN B. 100 Alex 102 Maya 104 Mira Kurse HoD
EIN B. C. D. 100 Datenbank 100 Alex 101 Mechanik --- ---. --- ---. 102 Elektronik 102 Maya Rechte äußere Verbindung: (R
S)
Alle Tupel aus der rechten Beziehung S sind in der resultierenden Beziehung enthalten. Wenn es in S Tupel ohne übereinstimmendes Tupel in R gibt, werden die R-Attribute der resultierenden Beziehung auf NULL gesetzt.
Kurse HoD
EIN B. C. D. 100 Datenbank 100 Alex 102 Elektronik 102 Maya --- ---. --- ---. 104 Mira Vollständige äußere Verbindung: (R
S)
Alle Tupel aus beiden teilnehmenden Beziehungen sind in der resultierenden Beziehung enthalten. Wenn für beide Relationen keine übereinstimmenden Tupel vorhanden sind, werden ihre jeweiligen nicht übereinstimmenden Attribute auf NULL gesetzt.
Kurse HoD
EIN B. C. D. 100 Datenbank 100 Alex 101 Mechanik --- ---. --- ---. 102 Elektronik 102 Maya --- ---. --- ---. 104 Mira Datenbanken werden in Dateiformaten gespeichert, die Datensätze enthalten. Auf physikalischer Ebene werden die tatsächlichen Daten auf einigen Geräten im elektromagnetischen Format gespeichert. Diese Speichergeräte können grob in drei Typen eingeteilt werden:

Primary Storage- Der Speicher, auf den die CPU direkt zugreifen kann, fällt unter diese Kategorie. Der interne Speicher (Register), der schnelle Speicher (Cache) und der Hauptspeicher (RAM) der CPU sind für die CPU direkt zugänglich, da sie sich alle auf dem Motherboard oder dem CPU-Chipsatz befinden. Dieser Speicher ist normalerweise sehr klein, ultraschnell und flüchtig. Der Primärspeicher benötigt eine kontinuierliche Stromversorgung, um seinen Zustand aufrechtzuerhalten. Bei einem Stromausfall gehen alle Daten verloren.
Secondary Storage- Sekundärspeichergeräte werden zum Speichern von Daten für die zukünftige Verwendung oder als Backup verwendet. Der Sekundärspeicher umfasst Speichergeräte, die nicht Teil des CPU-Chipsatzes oder der Hauptplatine sind, z. B. Magnetplatten, optische Platten (DVD, CD usw.), Festplatten, Flash-Laufwerke und Magnetbänder.
Tertiary Storage- Im Tertiärspeicher werden große Datenmengen gespeichert. Da sich solche Speichergeräte außerhalb des Computersystems befinden, sind sie am langsamsten. Diese Speichergeräte werden hauptsächlich zur Sicherung eines gesamten Systems verwendet. Optische Platten und Magnetbänder werden häufig als Tertiärspeicher verwendet.
Speicherhierarchie
Ein Computersystem hat eine genau definierte Speicherhierarchie. Eine CPU hat direkten Zugriff auf den Hauptspeicher sowie die eingebauten Register. Die Zugriffszeit des Hauptspeichers ist offensichtlich geringer als die CPU-Geschwindigkeit. Um diese Geschwindigkeitsinkongruenz zu minimieren, wird ein Cache-Speicher eingeführt. Der Cache-Speicher bietet die schnellste Zugriffszeit und enthält Daten, auf die die CPU am häufigsten zugreift.
Der Speicher mit dem schnellsten Zugriff ist der teuerste. Größere Speichergeräte bieten eine langsame Geschwindigkeit und sind kostengünstiger. Sie können jedoch im Vergleich zu CPU-Registern oder Cache-Speicher große Datenmengen speichern.
Magnetplatten
Festplattenlaufwerke sind die gebräuchlichsten sekundären Speichergeräte in gegenwärtigen Computersystemen. Diese werden als Magnetplatten bezeichnet, da sie das Konzept der Magnetisierung zum Speichern von Informationen verwenden. Festplatten bestehen aus Metallscheiben, die mit magnetisierbarem Material beschichtet sind. Diese Scheiben sind vertikal auf einer Spindel angeordnet. Ein Lese- / Schreibkopf bewegt sich zwischen den Platten und wird verwendet, um den Punkt darunter zu magnetisieren oder zu entmagnetisieren. Ein magnetisierter Punkt kann als 0 (Null) oder 1 (Eins) erkannt werden.
Festplatten werden in einer genau definierten Reihenfolge formatiert, um Daten effizient zu speichern. Auf einer Festplattenplatte befinden sich viele konzentrische Kreisetracks. Jeder Track ist weiter unterteilt insectors. Ein Sektor auf einer Festplatte speichert normalerweise 512 Datenbytes.
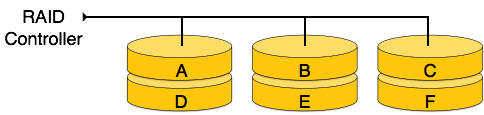
RAID
RAID steht für Redundant Array von Iunabhängig Disks, eine Technologie, mit der mehrere sekundäre Speichergeräte verbunden und als einzelnes Speichermedium verwendet werden können.
RAID besteht aus einer Reihe von Festplatten, auf denen mehrere Festplatten miteinander verbunden sind, um unterschiedliche Ziele zu erreichen. RAID-Level definieren die Verwendung von Festplatten-Arrays.
RAID 0- In dieser Ebene ist ein gestreiftes Festplattenarray implementiert. Die Daten werden in Blöcke zerlegt und die Blöcke auf die Festplatten verteilt. Jede Platte empfängt einen Datenblock zum parallelen Schreiben / Lesen. Es verbessert die Geschwindigkeit und Leistung des Speichergeräts. In Level 0 gibt es keine Parität und Sicherung.
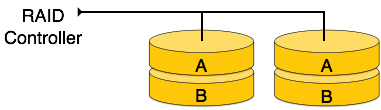
RAID 1- RAID 1 verwendet Spiegelungstechniken. Wenn Daten an einen RAID-Controller gesendet werden, sendet er eine Kopie der Daten an alle Festplatten im Array. RAID Level 1 wird auch aufgerufenmirroring und bietet 100% Redundanz im Falle eines Fehlers.
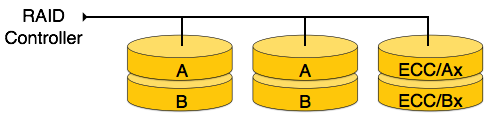
RAID 2- RAID 2 zeichnet den Fehlerkorrekturcode unter Verwendung der Hamming-Entfernung für seine Daten auf, die auf verschiedenen Festplatten gestreift sind. Wie bei Stufe 0 wird jedes Datenbit in einem Wort auf einer separaten Platte aufgezeichnet, und die ECC-Codes der Datenwörter werden auf einer anderen gesetzten Platte gespeichert. Aufgrund seiner komplexen Struktur und hohen Kosten ist RAID 2 nicht im Handel erhältlich.
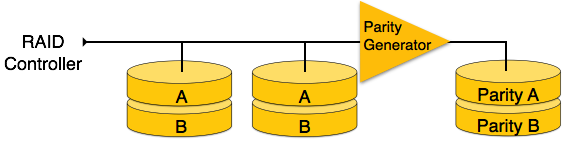
RAID 3- RAID 3 streift die Daten auf mehrere Festplatten. Das für das Datenwort erzeugte Paritätsbit wird auf einer anderen Platte gespeichert. Mit dieser Technik können einzelne Festplattenfehler behoben werden.
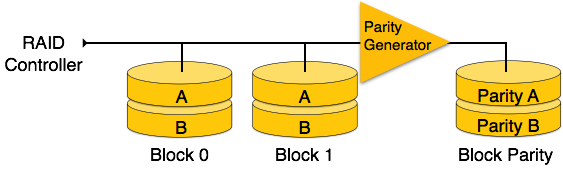
RAID 4- In dieser Ebene wird ein ganzer Datenblock auf Datenplatten geschrieben, und dann wird die Parität generiert und auf einer anderen Platte gespeichert. Beachten Sie, dass Ebene 3 Striping auf Byte-Ebene verwendet, während Level 4 Striping auf Blockebene verwendet. Sowohl Level 3 als auch Level 4 erfordern mindestens drei Festplatten, um RAID zu implementieren.
RAID 5 - RAID 5 schreibt ganze Datenblöcke auf verschiedene Festplatten, aber die für den Datenblockstreifen generierten Paritätsbits werden auf alle Datenfestplatten verteilt, anstatt sie auf einer anderen dedizierten Festplatte zu speichern.
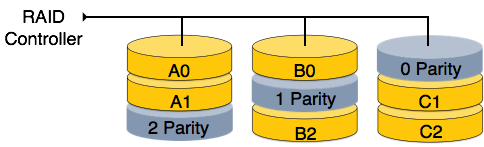
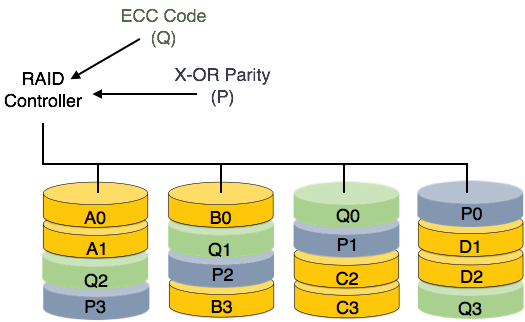
RAID 6- RAID 6 ist eine Erweiterung von Level 5. In diesem Level werden zwei unabhängige Paritäten generiert und auf mehrere Festplatten verteilt gespeichert. Zwei Paritäten bieten zusätzliche Fehlertoleranz. Diese Stufe erfordert mindestens vier Festplattenlaufwerke, um RAID zu implementieren.
Relative Daten und Informationen werden gemeinsam in Dateiformaten gespeichert. Eine Datei ist eine Folge von Datensätzen, die im Binärformat gespeichert sind. Ein Festplattenlaufwerk ist in mehrere Blöcke formatiert, in denen Datensätze gespeichert werden können. Dateidatensätze werden auf diese Plattenblöcke abgebildet.
Dateiorganisation
Die Dateiorganisation definiert, wie Dateidatensätze auf Plattenblöcken abgebildet werden. Wir haben vier Arten der Dateiorganisation, um Dateidatensätze zu organisieren:
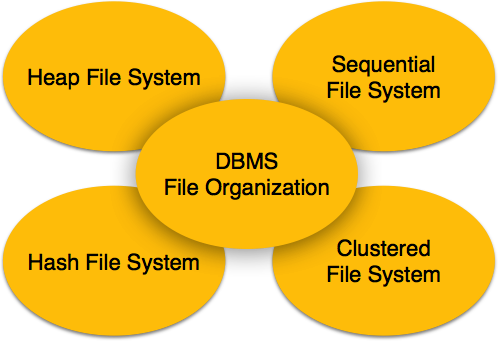
Organisation der Heap-Datei
Wenn eine Datei mit Heap File Organization erstellt wird, weist das Betriebssystem dieser Datei ohne weitere Abrechnungsdetails Speicherbereich zu. Dateidatensätze können an einer beliebigen Stelle in diesem Speicherbereich abgelegt werden. Es liegt in der Verantwortung der Software, die Aufzeichnungen zu verwalten. Heap File unterstützt keine eigene Bestellung, Sequenzierung oder Indizierung.
Sequentielle Dateiorganisation
Jeder Dateidatensatz enthält ein Datenfeld (Attribut), um diesen Datensatz eindeutig zu identifizieren. Bei der sequentiellen Dateiorganisation werden Datensätze in einer sequentiellen Reihenfolge basierend auf dem eindeutigen Schlüsselfeld oder Suchschlüssel in die Datei eingefügt. In der Praxis ist es nicht möglich, alle Datensätze nacheinander in physischer Form zu speichern.
Hash-Datei-Organisation
Die Hash-Dateiorganisation verwendet die Berechnung der Hash-Funktion für einige Felder der Datensätze. Die Ausgabe der Hash-Funktion bestimmt den Ort des Plattenblocks, an dem die Datensätze abgelegt werden sollen.
Clustered File Organization
Die Organisation von Clusterdateien wird für große Datenbanken nicht als gut angesehen. Bei diesem Mechanismus werden verwandte Datensätze aus einer oder mehreren Beziehungen im selben Plattenblock gespeichert, dh die Reihenfolge der Datensätze basiert nicht auf dem Primärschlüssel oder dem Suchschlüssel.
Dateivorgänge
Operationen an Datenbankdateien können grob in zwei Kategorien eingeteilt werden:
Update Operations
Retrieval Operations
Aktualisierungsvorgänge ändern die Datenwerte durch Einfügen, Löschen oder Aktualisieren. Abrufvorgänge hingegen ändern die Daten nicht, sondern rufen sie nach optionaler bedingter Filterung ab. Bei beiden Arten von Operationen spielt die Auswahl eine wichtige Rolle. Abgesehen vom Erstellen und Löschen einer Datei können verschiedene Vorgänge für Dateien ausgeführt werden.
Open - Eine Datei kann in einem der beiden Modi geöffnet werden: read mode oder write mode. Im Lesemodus erlaubt das Betriebssystem niemandem, Daten zu ändern. Mit anderen Worten, Daten sind schreibgeschützt. Im Lesemodus geöffnete Dateien können von mehreren Entitäten gemeinsam genutzt werden. Der Schreibmodus ermöglicht die Änderung von Daten. Im Schreibmodus geöffnete Dateien können gelesen, aber nicht freigegeben werden.
Locate- Jede Datei verfügt über einen Dateizeiger, der die aktuelle Position angibt, an der die Daten gelesen oder geschrieben werden sollen. Dieser Zeiger kann entsprechend angepasst werden. Mit der Suchoperation kann sie vorwärts oder rückwärts verschoben werden.
Read- Wenn Dateien im Lesemodus geöffnet werden, zeigt der Dateizeiger standardmäßig auf den Anfang der Datei. Es gibt Optionen, mit denen der Benutzer dem Betriebssystem mitteilen kann, wo sich der Dateizeiger zum Zeitpunkt des Öffnens einer Datei befindet. Die nächsten Daten zum Dateizeiger werden gelesen.
Write- Der Benutzer kann auswählen, ob eine Datei im Schreibmodus geöffnet werden soll, um den Inhalt zu bearbeiten. Dies kann das Löschen, Einfügen oder Ändern sein. Der Dateizeiger kann sich zum Zeitpunkt des Öffnens befinden oder dynamisch geändert werden, wenn das Betriebssystem dies zulässt.
Close- Dies ist aus Sicht des Betriebssystems die wichtigste Operation. Wenn eine Anforderung zum Schließen einer Datei generiert wird, wird das Betriebssystem
- entfernt alle Sperren (wenn im freigegebenen Modus),
- speichert die Daten (falls geändert) auf dem sekundären Speichermedium und
- Gibt alle Puffer und Dateihandler frei, die der Datei zugeordnet sind.
Die Organisation von Daten innerhalb einer Datei spielt hier eine große Rolle. Der Prozess zum Suchen des Dateizeigers auf einen gewünschten Datensatz in einer Datei hängt davon ab, ob die Datensätze nacheinander oder in Clustern angeordnet sind.
Wir wissen, dass Daten in Form von Aufzeichnungen gespeichert werden. Jeder Datensatz verfügt über ein Schlüsselfeld, mit dessen Hilfe er eindeutig erkannt werden kann.
Die Indizierung ist eine Datenstrukturtechnik zum effizienten Abrufen von Datensätzen aus den Datenbankdateien basierend auf einigen Attributen, für die die Indizierung durchgeführt wurde. Die Indizierung in Datenbanksystemen ähnelt der in Büchern.
Die Indizierung wird basierend auf ihren Indizierungsattributen definiert. Es gibt folgende Arten der Indizierung:
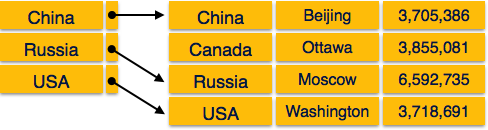
Primary Index- Der Primärindex wird für eine geordnete Datendatei definiert. Die Datendatei wird auf einem bestelltkey field. Das Schlüsselfeld ist im Allgemeinen der Primärschlüssel der Beziehung.
Secondary Index - Der Sekundärindex kann aus einem Feld generiert werden, das ein Kandidatenschlüssel ist und in jedem Datensatz einen eindeutigen Wert hat, oder aus einem Nichtschlüssel mit doppelten Werten.
Clustering Index- Der Clustering-Index wird für eine geordnete Datendatei definiert. Die Datendatei wird in einem Nicht-Schlüsselfeld angeordnet.
Es gibt zwei Arten der geordneten Indizierung:
- Dichter Index
- Sparse Index
Dichter Index
Im dichten Index gibt es einen Indexdatensatz für jeden Suchschlüsselwert in der Datenbank. Dies beschleunigt die Suche, erfordert jedoch mehr Speicherplatz zum Speichern von Indexdatensätzen. Indexdatensätze enthalten einen Suchschlüsselwert und einen Zeiger auf den tatsächlichen Datensatz auf der Festplatte.
Sparse Index
Im Sparse-Index werden nicht für jeden Suchschlüssel Indexdatensätze erstellt. Ein Indexdatensatz enthält hier einen Suchschlüssel und einen tatsächlichen Zeiger auf die Daten auf der Festplatte. Um einen Datensatz zu durchsuchen, gehen wir zunächst nach Indexdatensatz vor und erreichen den tatsächlichen Speicherort der Daten. Wenn die gesuchten Daten nicht dort sind, wo wir sie direkt erreichen, indem wir dem Index folgen, startet das System die sequentielle Suche, bis die gewünschten Daten gefunden sind.
Mehrstufiger Index
Indexdatensätze umfassen Suchschlüsselwerte und Datenzeiger. Der mehrstufige Index wird zusammen mit den tatsächlichen Datenbankdateien auf der Festplatte gespeichert. Mit zunehmender Größe der Datenbank wächst auch die Größe der Indizes. Es ist immens notwendig, die Indexdatensätze im Hauptspeicher zu halten, um die Suchvorgänge zu beschleunigen. Wenn ein einstufiger Index verwendet wird, kann ein großer Index nicht im Speicher gespeichert werden, was zu mehreren Festplattenzugriffen führt.
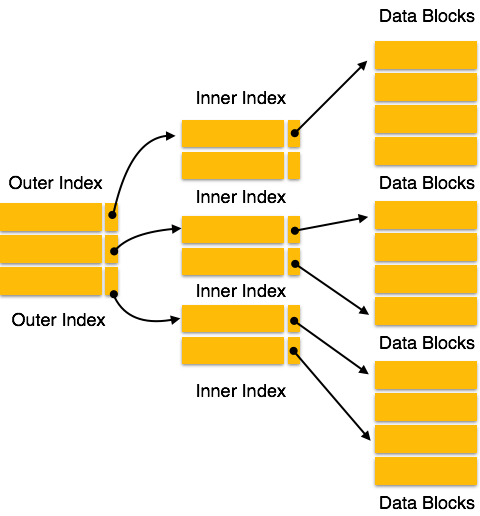
Der mehrstufige Index hilft bei der Aufteilung des Index in mehrere kleinere Indizes, um die äußerste Ebene so klein zu machen, dass sie in einem einzelnen Plattenblock gespeichert werden kann, der problemlos überall im Hauptspeicher untergebracht werden kann.
B + Baum
AB + Baum ist ein ausgeglichener binärer Suchbaum, der einem mehrstufigen Indexformat folgt. Die Blattknoten eines B + -Baums bezeichnen tatsächliche Datenzeiger. Der B + -Baum sorgt dafür, dass alle Blattknoten auf der gleichen Höhe bleiben und somit ausgeglichen sind. Zusätzlich werden die Blattknoten über eine Verknüpfungsliste verknüpft. Daher kann ein B + -Baum sowohl Direktzugriff als auch sequentiellen Zugriff unterstützen.
Struktur von B + Tree
Jeder Blattknoten befindet sich in gleichem Abstand vom Wurzelknoten. AB + Baum ist in der Reihenfolgen wo nist für jeden B + -Baum festgelegt.
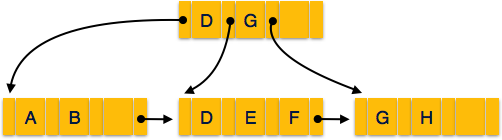
Internal nodes - -
- Interne (Nicht-Blatt-) Knoten enthalten mit Ausnahme des Wurzelknotens mindestens ⌈n / 2⌉ Zeiger.
- Ein interner Knoten kann höchstens enthalten n Zeiger.
Leaf nodes - -
- Blattknoten enthalten mindestens ⌈n / 2⌉ Datensatzzeiger und ⌈n / 2⌉ Schlüsselwerte.
- Ein Blattknoten kann höchstens enthalten n Zeiger aufzeichnen und n Schlüsselwerte.
- Jeder Blattknoten enthält einen Blockzeiger P um auf den nächsten Blattknoten zu zeigen und eine verknüpfte Liste zu bilden.
B + Baumeinfügung
B + -Bäume werden von unten gefüllt und jede Eingabe erfolgt am Blattknoten.
- Wenn ein Blattknoten überläuft -
Teilen Sie den Knoten in zwei Teile.
Partition bei i = ⌊(m+1)/2⌋.
Zuerst i Einträge werden in einem Knoten gespeichert.
Die restlichen Einträge (ab i + 1) werden auf einen neuen Knoten verschoben.
ith Der Schlüssel wird am übergeordneten Blatt dupliziert.
Wenn ein Nicht-Blattknoten überläuft -
Teilen Sie den Knoten in zwei Teile.
Partitionieren Sie den Knoten unter i = ⌈(m+1)/2⌉.
Einträge bis zu i werden in einem Knoten gehalten.
Die restlichen Einträge werden auf einen neuen Knoten verschoben.
B + Baumlöschung
B + -Baumeinträge werden an den Blattknoten gelöscht.
Der Zieleintrag wird gesucht und gelöscht.
Wenn es sich um einen internen Knoten handelt, löschen Sie ihn und ersetzen Sie ihn durch den Eintrag von der linken Position.
Nach dem Löschen wird der Unterlauf getestet.
Wenn ein Unterlauf auftritt, verteilen Sie die Einträge von den verbleibenden Knoten.
Wenn eine Verteilung von links nicht möglich ist, dann
Verteilen Sie von den Knoten direkt darauf.
Wenn eine Verteilung von links oder von rechts nicht möglich ist, dann
Führen Sie den Knoten mit links und rechts zusammen.
Bei einer riesigen Datenbankstruktur kann es nahezu unmöglich sein, alle Indexwerte auf allen Ebenen zu durchsuchen und dann den Zieldatenblock zu erreichen, um die gewünschten Daten abzurufen. Hashing ist eine effektive Technik, um den direkten Speicherort eines Datensatzes auf der Festplatte ohne Verwendung der Indexstruktur zu berechnen.
Hashing verwendet Hash-Funktionen mit Suchschlüsseln als Parameter, um die Adresse eines Datensatzes zu generieren.
Hash-Organisation
Bucket- Eine Hash-Datei speichert Daten im Bucket-Format. Der Eimer wird als Speichereinheit betrachtet. In einem Bucket wird normalerweise ein vollständiger Plattenblock gespeichert, in dem wiederum ein oder mehrere Datensätze gespeichert werden können.
Hash Function - Eine Hash-Funktion, h, ist eine Zuordnungsfunktion, die alle Suchschlüssel abbildet Kan die Adresse, an der die tatsächlichen Datensätze abgelegt werden. Es ist eine Funktion von Suchschlüsseln bis zu Bucket-Adressen.
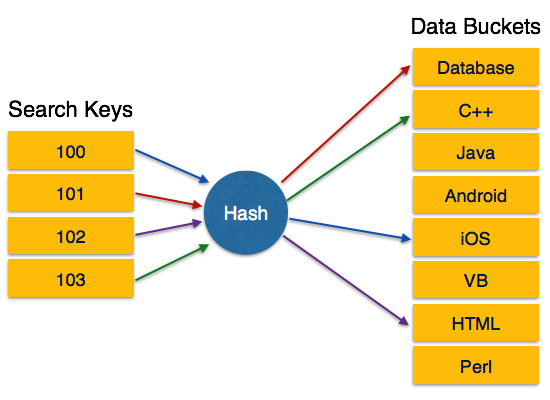
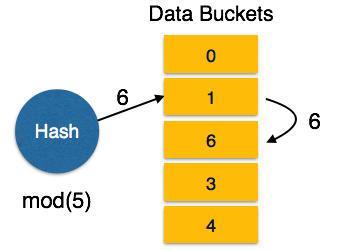
Statisches Hashing
Wenn beim statischen Hashing ein Suchschlüsselwert angegeben wird, berechnet die Hash-Funktion immer dieselbe Adresse. Wenn beispielsweise die Mod-4-Hash-Funktion verwendet wird, werden nur 5 Werte generiert. Die Ausgangsadresse muss für diese Funktion immer gleich sein. Die Anzahl der bereitgestellten Eimer bleibt jederzeit unverändert.
Betrieb
Insertion - Wenn ein Datensatz mit statischem Hash eingegeben werden muss, wird die Hash-Funktion verwendet h berechnet die Bucket-Adresse für den Suchschlüssel K, wo der Datensatz gespeichert wird.
Bucket-Adresse = h (K)
Search - Wenn ein Datensatz abgerufen werden muss, kann dieselbe Hash-Funktion verwendet werden, um die Adresse des Buckets abzurufen, in dem die Daten gespeichert sind.
Delete - Dies ist einfach eine Suche, gefolgt von einem Löschvorgang.
Schaufelüberlauf
Der Zustand des Schaufelüberlaufs ist bekannt als collision. Dies ist ein schwerwiegender Zustand für jede statische Hash-Funktion. In diesem Fall kann eine Überlaufverkettung verwendet werden.
Overflow Chaining- Wenn die Buckets voll sind, wird ein neuer Bucket für dasselbe Hash-Ergebnis zugewiesen und nach dem vorherigen verknüpft. Dieser Mechanismus wird aufgerufenClosed Hashing.
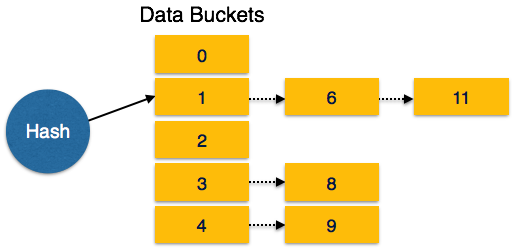
Linear Probing- Wenn eine Hash-Funktion eine Adresse generiert, an der bereits Daten gespeichert sind, wird ihr der nächste freie Bucket zugewiesen. Dieser Mechanismus wird aufgerufenOpen Hashing.
Dynamisches Hashing
Das Problem beim statischen Hashing besteht darin, dass es nicht dynamisch erweitert oder verkleinert wird, wenn die Größe der Datenbank zunimmt oder abnimmt. Dynamisches Hashing bietet einen Mechanismus, mit dem Daten-Buckets dynamisch und bei Bedarf hinzugefügt und entfernt werden. Dynamisches Hashing wird auch als bezeichnetextended hashing.
Die Hash-Funktion beim dynamischen Hashing erzeugt eine große Anzahl von Werten, und anfangs werden nur wenige verwendet.
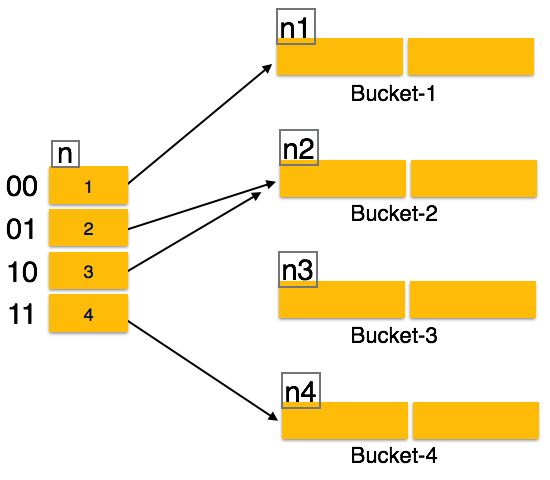
Organisation
Das Präfix eines gesamten Hashwerts wird als Hashindex verwendet. Nur ein Teil des Hashwerts wird zum Berechnen von Bucket-Adressen verwendet. Jeder Hash-Index hat einen Tiefenwert, der angibt, wie viele Bits zur Berechnung einer Hash-Funktion verwendet werden. Diese Bits können 2n Buckets adressieren. Wenn alle diese Bits verbraucht sind, dh wenn alle Eimer voll sind, wird der Tiefenwert linear erhöht und das Doppelte der Eimer zugewiesen.
Betrieb
Querying - Sehen Sie sich den Tiefenwert des Hash-Index an und verwenden Sie diese Bits, um die Bucket-Adresse zu berechnen.
Update - Führen Sie eine Abfrage wie oben durch und aktualisieren Sie die Daten.
Deletion - Führen Sie eine Abfrage durch, um die gewünschten Daten zu finden und diese zu löschen.
Insertion - Berechnen Sie die Adresse des Eimers
- Wenn der Eimer schon voll ist.
- Fügen Sie weitere Eimer hinzu.
- Fügen Sie dem Hash-Wert zusätzliche Bits hinzu.
- Berechnen Sie die Hash-Funktion neu.
- Sonst
- Daten zum Bucket hinzufügen,
- Wenn alle Eimer voll sind, führen Sie die Abhilfemaßnahmen für statisches Hashing durch.
- Wenn der Eimer schon voll ist.
Hashing ist nicht günstig, wenn die Daten in einer bestimmten Reihenfolge angeordnet sind und die Abfragen eine Reihe von Daten erfordern. Wenn Daten diskret und zufällig sind, bietet Hash die beste Leistung.
Hashing-Algorithmen sind komplexer als die Indizierung. Alle Hash-Operationen werden in konstanter Zeit ausgeführt.
Eine Transaktion kann als eine Gruppe von Aufgaben definiert werden. Eine einzelne Aufgabe ist die minimale Verarbeitungseinheit, die nicht weiter unterteilt werden kann.
Nehmen wir ein Beispiel für eine einfache Transaktion. Angenommen, ein Bankangestellter überweist Rs 500 vom Konto von A auf das Konto von B. Diese sehr einfache und kleine Transaktion beinhaltet mehrere Aufgaben auf niedriger Ebene.
A’s Account
Open_Account(A) Old_Balance = A.balance New_Balance = Old_Balance - 500 A.balance = New_Balance Close_Account(A)B’s Account
Open_Account(B) Old_Balance = B.balance New_Balance = Old_Balance + 500 B.balance = New_Balance Close_Account(B)ACID-Eigenschaften
Eine Transaktion ist eine sehr kleine Einheit eines Programms und kann mehrere Aufgaben auf niedriger Ebene enthalten. Eine Transaktion in einem Datenbanksystem muss verwaltet werdenATomizität, CBeständigkeit, ISolation und DUrabilität - allgemein bekannt als ACID-Eigenschaften - um Genauigkeit, Vollständigkeit und Datenintegrität sicherzustellen.
Atomicity- Diese Eigenschaft besagt, dass eine Transaktion als atomare Einheit behandelt werden muss, dh entweder alle ihre Operationen werden ausgeführt oder keine. Es darf keinen Status in einer Datenbank geben, in dem eine Transaktion teilweise abgeschlossen bleibt. Zustände sollten entweder vor der Ausführung der Transaktion oder nach der Ausführung / Abbruch / Fehlschlag der Transaktion definiert werden.
Consistency- Die Datenbank muss nach jeder Transaktion in einem konsistenten Zustand bleiben. Keine Transaktion sollte sich nachteilig auf die Daten in der Datenbank auswirken. Wenn sich die Datenbank vor der Ausführung einer Transaktion in einem konsistenten Zustand befand, muss sie auch nach der Ausführung der Transaktion konsistent bleiben.
Durability- Die Datenbank sollte langlebig genug sein, um alle neuesten Updates zu speichern, selbst wenn das System ausfällt oder neu startet. Wenn eine Transaktion einen Datenblock in einer Datenbank aktualisiert und festschreibt, enthält die Datenbank die geänderten Daten. Wenn eine Transaktion festgeschrieben wird, das System jedoch fehlschlägt, bevor die Daten auf die Festplatte geschrieben werden konnten, werden diese Daten aktualisiert, sobald das System wieder aktiv wird.
Isolation- In einem Datenbanksystem, in dem mehr als eine Transaktion gleichzeitig und parallel ausgeführt wird, besagt die Eigenschaft der Isolation, dass alle Transaktionen so ausgeführt und ausgeführt werden, als wäre es die einzige Transaktion im System. Keine Transaktion hat Auswirkungen auf die Existenz einer anderen Transaktion.
Serialisierbarkeit
Wenn mehrere Transaktionen vom Betriebssystem in einer Multiprogrammierumgebung ausgeführt werden, besteht die Möglichkeit, dass Anweisungen einer Transaktion mit einer anderen Transaktion verschachtelt werden.
Schedule- Eine chronologische Ausführungssequenz einer Transaktion wird als Zeitplan bezeichnet. Ein Zeitplan kann viele Transaktionen enthalten, die jeweils eine Reihe von Anweisungen / Aufgaben umfassen.
Serial Schedule- Es ist ein Zeitplan, in dem Transaktionen so ausgerichtet werden, dass eine Transaktion zuerst ausgeführt wird. Wenn die erste Transaktion ihren Zyklus abgeschlossen hat, wird die nächste Transaktion ausgeführt. Transaktionen werden nacheinander bestellt. Diese Art von Zeitplan wird als serieller Zeitplan bezeichnet, da Transaktionen seriell ausgeführt werden.
In einer Umgebung mit mehreren Transaktionen werden serielle Zeitpläne als Benchmark betrachtet. Die Ausführungssequenz eines Befehls in einer Transaktion kann nicht geändert werden, aber bei zwei Transaktionen können die Befehle zufällig ausgeführt werden. Diese Ausführung schadet nicht, wenn zwei Transaktionen voneinander unabhängig sind und an unterschiedlichen Datensegmenten arbeiten. Wenn diese beiden Transaktionen jedoch mit denselben Daten arbeiten, können die Ergebnisse variieren. Dieses sich ständig ändernde Ergebnis kann die Datenbank in einen inkonsistenten Zustand versetzen.
Um dieses Problem zu beheben, erlauben wir die parallele Ausführung eines Transaktionsplans, wenn seine Transaktionen entweder serialisierbar sind oder eine Äquivalenzbeziehung zwischen ihnen aufweisen.
Äquivalenzpläne
Es gibt folgende Arten von Äquivalenzplänen:
Ergebnisäquivalenz
Wenn zwei Zeitpläne nach der Ausführung dasselbe Ergebnis liefern, werden sie als ergebnisäquivalent bezeichnet. Sie können für einen bestimmten Wert das gleiche Ergebnis und für einen anderen Wertesatz unterschiedliche Ergebnisse liefern. Deshalb wird diese Äquivalenz im Allgemeinen nicht als signifikant angesehen.
Äquivalenz anzeigen
Zwei Zeitpläne wären Ansichtsäquivalenz, wenn die Transaktionen in beiden Zeitplänen ähnliche Aktionen auf ähnliche Weise ausführen.
Zum Beispiel -
Wenn T die Anfangsdaten in S1 liest, liest es auch die Anfangsdaten in S2.
Wenn T den von J in S1 geschriebenen Wert liest, liest es auch den von J in S2 geschriebenen Wert.
Wenn T den endgültigen Schreibvorgang für den Datenwert in S1 ausführt, führt es auch den endgültigen Schreibvorgang für den Datenwert in S2 durch.
Konfliktäquivalenz
Zwei Zeitpläne stehen in Konflikt, wenn sie die folgenden Eigenschaften haben:
- Beide gehören zu getrennten Transaktionen.
- Beide greifen auf dasselbe Datenelement zu.
- Mindestens eine davon ist die "Schreib" -Operation.
Zwei Zeitpläne mit mehreren Transaktionen mit widersprüchlichen Vorgängen gelten genau dann als konfliktäquivalent, wenn -
- Beide Zeitpläne enthalten denselben Satz von Transaktionen.
- Die Reihenfolge der widersprüchlichen Operationspaare wird in beiden Zeitplänen beibehalten.
Note- Äquivalente Zeitpläne anzeigen sind serialisierbar und konfliktäquivalente Zeitpläne sind konfliktserialisierbar. Alle konfliktserialisierbaren Zeitpläne können auch serialisierbar angezeigt werden.
Transaktionszustände
Eine Transaktion in einer Datenbank kann sich in einem der folgenden Zustände befinden:
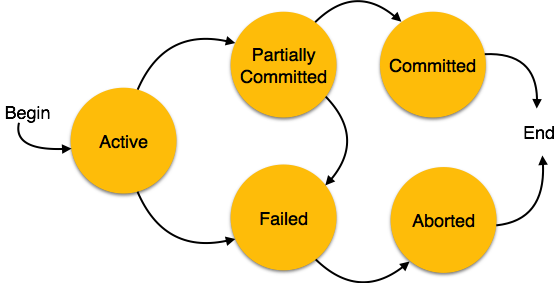
Active- In diesem Zustand wird die Transaktion ausgeführt. Dies ist der Ausgangszustand jeder Transaktion.
Partially Committed - Wenn eine Transaktion ihre letzte Operation ausführt, befindet sie sich in einem teilweise festgeschriebenen Zustand.
Failed- Eine Transaktion befindet sich in einem fehlgeschlagenen Zustand, wenn eine der vom Datenbankwiederherstellungssystem durchgeführten Überprüfungen fehlschlägt. Eine fehlgeschlagene Transaktion kann nicht mehr fortgesetzt werden.
Aborted- Wenn eine der Prüfungen fehlschlägt und die Transaktion einen fehlgeschlagenen Status erreicht hat, setzt der Wiederherstellungsmanager alle Schreibvorgänge in der Datenbank zurück, um die Datenbank wieder in den ursprünglichen Zustand zu versetzen, in dem sie sich vor der Ausführung der Transaktion befand. Transaktionen in diesem Zustand werden als abgebrochen bezeichnet. Das Datenbankwiederherstellungsmodul kann eine der beiden Operationen auswählen, nachdem eine Transaktion abgebrochen wurde.
- Starten Sie die Transaktion erneut
- Beenden Sie die Transaktion
Committed- Wenn eine Transaktion alle ihre Operationen erfolgreich ausführt, wird sie als festgeschrieben bezeichnet. Alle seine Auswirkungen sind jetzt dauerhaft auf dem Datenbanksystem festgelegt.
In einer Multiprogrammierumgebung, in der mehrere Transaktionen gleichzeitig ausgeführt werden können, ist es äußerst wichtig, die Parallelität von Transaktionen zu steuern. Wir verfügen über Protokolle zur Parallelitätskontrolle, um die Atomizität, Isolation und Serialisierbarkeit gleichzeitiger Transaktionen sicherzustellen. Parallelitätskontrollprotokolle können grob in zwei Kategorien unterteilt werden -
- Sperrbasierte Protokolle
- Zeitstempel-basierte Protokolle
Sperrenbasierte Protokolle
Datenbanksysteme, die mit sperrbasierten Protokollen ausgestattet sind, verwenden einen Mechanismus, mit dem jede Transaktion keine Daten lesen oder schreiben kann, bis sie eine entsprechende Sperre dafür erhält. Es gibt zwei Arten von Schlössern:
Binary Locks- Eine Sperre für ein Datenelement kann sich in zwei Zuständen befinden. es ist entweder gesperrt oder entsperrt.
Shared/exclusive- Diese Art von Verriegelungsmechanismus unterscheidet die Schlösser nach ihrer Verwendung. Wenn eine Sperre für ein Datenelement erworben wird, um eine Schreiboperation auszuführen, handelt es sich um eine exklusive Sperre. Wenn mehr als eine Transaktion auf dasselbe Datenelement schreiben kann, wird die Datenbank in einen inkonsistenten Zustand versetzt. Lesesperren werden gemeinsam genutzt, da kein Datenwert geändert wird.
Es stehen vier Arten von Sperrprotokollen zur Verfügung:
Simplistic Lock Protocol
Durch vereinfachte sperrenbasierte Protokolle können Transaktionen für jedes Objekt eine Sperre erhalten, bevor eine Schreiboperation ausgeführt wird. Transaktionen können das Datenelement nach Abschluss des Schreibvorgangs entsperren.
Sperrprotokoll vorab beanspruchen
Protokolle, die vorab beansprucht werden, bewerten ihre Vorgänge und erstellen eine Liste von Datenelementen, für die sie Sperren benötigen. Vor dem Einleiten einer Ausführung fordert die Transaktion das System vorab nach allen erforderlichen Sperren auf. Wenn alle Sperren gewährt wurden, führt die Transaktion alle Sperren aus und gibt sie frei, wenn alle Vorgänge abgeschlossen sind. Wenn nicht alle Sperren gewährt werden, wird die Transaktion zurückgesetzt und gewartet, bis alle Sperren gewährt wurden.
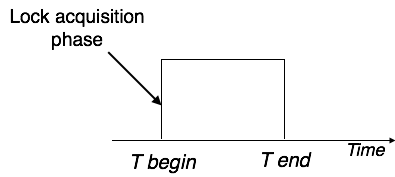
Zweiphasenverriegelung 2PL
Dieses Sperrprotokoll unterteilt die Ausführungsphase einer Transaktion in drei Teile. Wenn die Transaktion im ersten Teil ausgeführt wird, bittet sie um Erlaubnis für die erforderlichen Sperren. Im zweiten Teil erwirbt die Transaktion alle Sperren. Sobald die Transaktion ihre erste Sperre aufhebt, beginnt die dritte Phase. In dieser Phase kann die Transaktion keine neuen Sperren verlangen. Es werden nur die erworbenen Sperren freigegeben.

Zweiphasenverriegelung hat zwei Phasen, eine ist growing, wo alle Sperren durch die Transaktion erworben werden; und die zweite Phase schrumpft, in der die von der Transaktion gehaltenen Sperren freigegeben werden.
Um eine exklusive (Schreib-) Sperre zu beanspruchen, muss eine Transaktion zuerst eine gemeinsam genutzte (Lese-) Sperre erwerben und diese dann auf eine exklusive Sperre aktualisieren.
Strikte Zweiphasenverriegelung
Die erste Phase von Strict-2PL ist dieselbe wie 2PL. Nach dem Erwerb aller Sperren in der ersten Phase wird die Transaktion normal weiter ausgeführt. Im Gegensatz zu 2PL gibt Strict-2PL nach der Verwendung keine Sperre frei. Strict-2PL hält alle Sperren bis zum Festschreibungspunkt und gibt alle Sperren gleichzeitig frei.
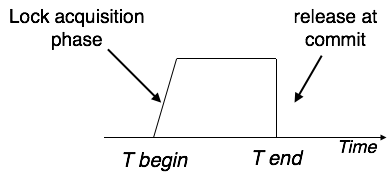
Strict-2PL hat keinen kaskadierenden Abbruch wie 2PL.
Zeitstempel-basierte Protokolle
Das am häufigsten verwendete Parallelitätsprotokoll ist das auf Zeitstempeln basierende Protokoll. Dieses Protokoll verwendet entweder die Systemzeit oder den logischen Zähler als Zeitstempel.
Sperrenbasierte Protokolle verwalten die Reihenfolge zwischen den Konfliktpaaren zwischen Transaktionen zum Zeitpunkt der Ausführung, während zeitstempelbasierte Protokolle funktionieren, sobald eine Transaktion erstellt wird.
Jeder Transaktion ist ein Zeitstempel zugeordnet, und die Bestellung wird durch das Alter der Transaktion bestimmt. Eine Transaktion, die zur Uhrzeit 0002 erstellt wurde, ist älter als alle anderen darauf folgenden Transaktionen. Zum Beispiel ist jede Transaktion 'y', die bei 0004 in das System eingeht, zwei Sekunden jünger und die Priorität würde der älteren gegeben.
Zusätzlich erhält jedes Datenelement den neuesten Lese- und Schreibzeitstempel. Dadurch wird dem System mitgeteilt, wann der letzte Lese- und Schreibvorgang für das Datenelement ausgeführt wurde.
Bestellprotokoll für Zeitstempel
Das Zeitstempel-Bestellprotokoll stellt die Serialisierbarkeit zwischen Transaktionen in ihren widersprüchlichen Lese- und Schreibvorgängen sicher. Es liegt in der Verantwortung des Protokollsystems, dass das in Konflikt stehende Aufgabenpaar gemäß den Zeitstempelwerten der Transaktionen ausgeführt wird.
- Der Zeitstempel der Transaktion T i wird als TS (T i ) bezeichnet.
- Der Lesezeitstempel des Datenelements X wird mit dem R-Zeitstempel (X) bezeichnet.
- Der Schreibzeitstempel des Datenelements X wird mit dem W-Zeitstempel (X) bezeichnet.
Das Bestellprotokoll für den Zeitstempel funktioniert wie folgt:
If a transaction Ti issues a read(X) operation −
- Wenn TS (Ti) <W-Zeitstempel (X)
- Operation abgelehnt.
- Wenn TS (Ti)> = W-Zeitstempel (X)
- Operation ausgeführt.
- Alle Zeitstempel der Datenelemente wurden aktualisiert.
If a transaction Ti issues a write(X) operation −
- Wenn TS (Ti) <R-Zeitstempel (X)
- Operation abgelehnt.
- Wenn TS (Ti) <W-Zeitstempel (X)
- Operation abgelehnt und Ti zurückgerollt.
- Andernfalls wird die Operation ausgeführt.
Thomas 'Schreibregel
Diese Regel besagt, wenn TS (Ti) <W-Zeitstempel (X) ist, wird die Operation zurückgewiesen und T i wird zurückgesetzt.
Die Bestellregeln für Zeitstempel können geändert werden, um die Zeitplanansicht serialisierbar zu machen.
Anstatt T i zurückzusetzen, wird die 'Schreib'-Operation selbst ignoriert.
In einem Multiprozesssystem ist Deadlock eine unerwünschte Situation, die in einer Umgebung mit gemeinsam genutzten Ressourcen auftritt, in der ein Prozess auf unbestimmte Zeit auf eine Ressource wartet, die von einem anderen Prozess gehalten wird.
Nehmen Sie beispielsweise eine Reihe von Transaktionen an {T 0 , T 1 , T 2 , ..., T n }. T 0 benötigt eine Ressource X, um ihre Aufgabe abzuschließen. Die Ressource X wird von T 1 gehalten , und T 1 wartet auf eine Ressource Y, die von T 2 gehalten wird . T 2 wartet auf die Ressource Z, die von T 0 gehalten wird . Daher warten alle Prozesse aufeinander, um Ressourcen freizugeben. In dieser Situation kann keiner der Prozesse seine Aufgabe beenden. Diese Situation wird als Deadlock bezeichnet.
Deadlocks sind für ein System nicht gesund. Wenn ein System in einem Deadlock steckt, werden die an dem Deadlock beteiligten Transaktionen entweder zurückgesetzt oder neu gestartet.
Deadlock-Prävention
Um eine Deadlock-Situation im System zu vermeiden, überprüft das DBMS aggressiv alle Vorgänge, bei denen Transaktionen ausgeführt werden sollen. Das DBMS überprüft die Vorgänge und analysiert, ob sie zu einer Deadlock-Situation führen können. Wenn sich herausstellt, dass eine Deadlock-Situation auftreten kann, darf diese Transaktion niemals ausgeführt werden.
Es gibt Deadlock-Verhinderungsschemata, die den Zeitstempel-Ordnungsmechanismus von Transaktionen verwenden, um eine Deadlock-Situation vorab zu bestimmen.
Wait-Die-Schema
Wenn in diesem Schema eine Transaktion das Sperren einer Ressource (Datenelement) anfordert, die bereits von einer anderen Transaktion mit einer widersprüchlichen Sperre gehalten wird, kann eine der beiden Möglichkeiten auftreten:
Wenn TS (T i ) <TS (T j ) - das heißt T i , das eine widersprüchliche Sperre anfordert, älter als T j ist -, darf T i warten, bis das Datenelement verfügbar ist.
Wenn TS (T i )> TS (t j ) - das heißt T i ist jünger als T j - dann stirbt T i . T i wird später mit einer zufälligen Verzögerung, aber mit demselben Zeitstempel neu gestartet.
Dieses Schema ermöglicht es der älteren Transaktion zu warten, tötet jedoch die jüngere.
Wundwarte-Schema
In diesem Schema kann eine der beiden Möglichkeiten auftreten, wenn eine Transaktion das Sperren einer Ressource (Datenelement) anfordert, die bereits von einer anderen Transaktion mit widersprüchlicher Sperre gehalten wird.
Wenn TS (T i ) <TS (T j ), dann T i zwingt T j zurück gerollt werden - die T i Wunden T j . T j wird später mit einer zufälligen Verzögerung, aber mit demselben Zeitstempel neu gestartet.
Wenn TS (T i )> TS (T j ) ist, muss T i warten, bis die Ressource verfügbar ist.
Dieses Schema ermöglicht es der jüngeren Transaktion zu warten; Wenn jedoch eine ältere Transaktion einen Artikel anfordert, der von einem jüngeren gehalten wird, zwingt die ältere Transaktion den jüngeren, den Artikel abzubrechen und freizugeben.
In beiden Fällen wird die Transaktion, die zu einem späteren Zeitpunkt in das System eingeht, abgebrochen.
Deadlock-Vermeidung
Das Abbrechen einer Transaktion ist nicht immer ein praktischer Ansatz. Stattdessen können Deadlock-Vermeidungsmechanismen verwendet werden, um jede Deadlock-Situation im Voraus zu erkennen. Methoden wie "Wait-for-Graph" sind verfügbar, eignen sich jedoch nur für Systeme, bei denen Transaktionen mit weniger Ressourceninstanzen leichtgewichtig sind. In einem sperrigen System können Deadlock-Verhinderungstechniken gut funktionieren.
Warten auf Grafik
Dies ist eine einfache Methode, um zu verfolgen, ob eine Deadlock-Situation auftreten kann. Für jede in das System eingehende Transaktion wird ein Knoten erstellt. Wenn eine Transaktion T i eine Sperre für ein Element anfordert, beispielsweise X, das von einer anderen Transaktion T j gehalten wird , wird eine gerichtete Kante von T i bis T j erzeugt . Wenn T j Element X freigibt, wird die Kante zwischen ihnen entfernt und T i sperrt das Datenelement.
Das System verwaltet dieses Wartediagramm für jede Transaktion, die auf einige Datenelemente wartet, die von anderen gehalten werden. Das System prüft ständig, ob das Diagramm einen Zyklus enthält.
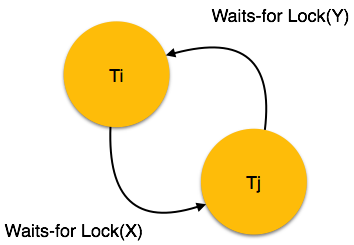
Hier können wir einen der beiden folgenden Ansätze verwenden:
Lassen Sie zunächst keine Anforderung für einen Artikel zu, der bereits durch eine andere Transaktion gesperrt ist. Dies ist nicht immer möglich und kann zu Hunger führen, wenn eine Transaktion auf unbestimmte Zeit auf ein Datenelement wartet und es niemals erfassen kann.
Die zweite Möglichkeit besteht darin, eine der Transaktionen zurückzusetzen. Es ist nicht immer möglich, die jüngere Transaktion zurückzusetzen, da dies möglicherweise wichtiger ist als die ältere. Mit Hilfe eines relativen Algorithmus wird eine Transaktion ausgewählt, die abgebrochen werden soll. Diese Transaktion wird als bezeichnetvictim und der Prozess ist bekannt als victim selection.
Verlust flüchtiger Speicher
Ein flüchtiger Speicher wie RAM speichert alle aktiven Protokolle, Festplattenpuffer und zugehörigen Daten. Außerdem werden alle Transaktionen gespeichert, die gerade ausgeführt werden. Was passiert, wenn solch ein flüchtiger Speicher abrupt abstürzt? Es würde offensichtlich alle Protokolle und aktiven Kopien der Datenbank entfernen. Dies macht eine Wiederherstellung fast unmöglich, da alles, was zur Wiederherstellung der Daten erforderlich ist, verloren geht.
Bei Verlust der flüchtigen Speicherung können folgende Techniken angewendet werden:
Wir können haben checkpoints in mehreren Phasen, um den Inhalt der Datenbank regelmäßig zu speichern.
Ein Status der aktiven Datenbank im flüchtigen Speicher kann periodisch sein dumped auf einen stabilen Speicher, der auch Protokolle und aktive Transaktionen und Pufferblöcke enthalten kann.
<Dump> kann in einer Protokolldatei markiert werden, wenn der Datenbankinhalt von einem nichtflüchtigen Speicher in einen stabilen Speicher verschoben wird.
Wiederherstellung
Wenn sich das System von einem Fehler erholt, kann es den neuesten Speicherauszug wiederherstellen.
Es kann eine Redo-Liste und eine Undo-Liste als Checkpoints verwalten.
Es kann das System wiederherstellen, indem es Rückgängig-Listen konsultiert, um den Status aller Transaktionen bis zum letzten Prüfpunkt wiederherzustellen.
Datenbanksicherung und -wiederherstellung nach einem katastrophalen Fehler
Ein katastrophaler Fehler ist ein Fehler, bei dem ein stabiles sekundäres Speichergerät beschädigt wird. Mit dem Speichergerät gehen alle wertvollen Daten verloren, die darin gespeichert sind. Wir haben zwei verschiedene Strategien, um Daten von einem solchen katastrophalen Fehler wiederherzustellen -
Remote Backup & minu; Hier wird eine Sicherungskopie der Datenbank an einem entfernten Ort gespeichert, von wo aus sie im Katastrophenfall wiederhergestellt werden kann.
Alternativ können Datenbanksicherungen auf Magnetbändern erstellt und an einem sichereren Ort gespeichert werden. Diese Sicherung kann später in eine frisch installierte Datenbank übertragen werden, um sie an den Sicherungspunkt zu bringen.
Erwachsene Datenbanken sind zu umfangreich, um häufig gesichert zu werden. In solchen Fällen haben wir Techniken, mit denen wir eine Datenbank wiederherstellen können, indem wir nur ihre Protokolle betrachten. Alles, was wir hier tun müssen, ist, in regelmäßigen Abständen eine Sicherungskopie aller Protokolle zu erstellen. Die Datenbank kann einmal pro Woche gesichert werden, und die sehr kleinen Protokolle können jeden Tag oder so oft wie möglich gesichert werden.
Remote Backup
Remote-Backup bietet ein Gefühl der Sicherheit für den Fall, dass der primäre Speicherort der Datenbank zerstört wird. Remote-Backup kann offline oder in Echtzeit oder online sein. Falls es offline ist, wird es manuell gepflegt.
Online-Backup-Systeme sind mehr Echtzeit- und Lebensretter für Datenbankadministratoren und Investoren. Ein Online-Backup-System ist ein Mechanismus, bei dem jedes Bit der Echtzeitdaten gleichzeitig an zwei entfernten Orten gesichert wird. Einer von ihnen ist direkt mit dem System verbunden und der andere wird als Backup an einem entfernten Ort aufbewahrt.
Sobald der primäre Datenbankspeicher ausfällt, erkennt das Sicherungssystem den Fehler und schaltet das Benutzersystem auf den Remotespeicher um. Manchmal ist dies so augenblicklich, dass die Benutzer nicht einmal einen Fehler erkennen können.
Crash Recovery
DBMS ist ein hochkomplexes System, bei dem jede Sekunde Hunderte von Transaktionen ausgeführt werden. Die Haltbarkeit und Robustheit eines DBMS hängt von seiner komplexen Architektur und der zugrunde liegenden Hardware und Systemsoftware ab. Wenn es bei Transaktionen fehlschlägt oder abstürzt, wird erwartet, dass das System einem Algorithmus oder einer Technik zur Wiederherstellung verlorener Daten folgt.
Fehlerklassifizierung
Um zu sehen, wo das Problem aufgetreten ist, verallgemeinern wir einen Fehler wie folgt in verschiedene Kategorien:
Transaktionsfehler
Eine Transaktion muss abgebrochen werden, wenn sie nicht ausgeführt werden kann oder wenn sie einen Punkt erreicht, von dem aus sie nicht weiter gehen kann. Dies wird als Transaktionsfehler bezeichnet, bei dem nur wenige Transaktionen oder Prozesse verletzt werden.
Gründe für einen Transaktionsfehler könnten sein:
Logical errors - Wenn eine Transaktion nicht abgeschlossen werden kann, weil ein Codefehler oder eine interne Fehlerbedingung vorliegt.
System errors- Wenn das Datenbanksystem selbst eine aktive Transaktion beendet, weil das DBMS sie nicht ausführen kann oder aufgrund einer Systembedingung anhalten muss. Beispielsweise bricht das System im Falle eines Deadlocks oder der Nichtverfügbarkeit von Ressourcen eine aktive Transaktion ab.
System Absturz
Es gibt Probleme - außerhalb des Systems -, die dazu führen können, dass das System abrupt stoppt und das System abstürzt. Beispielsweise können Unterbrechungen der Stromversorgung zum Ausfall des zugrunde liegenden Hardware- oder Softwarefehlers führen.
Beispiele können Betriebssystemfehler sein.
Festplattenfehler
In den frühen Tagen der technologischen Entwicklung war es ein häufiges Problem, bei dem Festplatten oder Speicherlaufwerke häufig ausfielen.
Zu den Festplattenfehlern gehören die Bildung fehlerhafter Sektoren, die Nichterreichbarkeit der Festplatte, ein Absturz des Festplattenkopfs oder ein anderer Fehler, der den gesamten oder einen Teil des Festplattenspeichers zerstört.
Speicherstruktur
Wir haben das Speichersystem bereits beschrieben. Kurz gesagt, die Speicherstruktur kann in zwei Kategorien unterteilt werden -
Volatile storage- Wie der Name schon sagt, kann ein flüchtiger Speicher Systemabstürze nicht überstehen. Flüchtige Speichergeräte befinden sich sehr nahe an der CPU. Normalerweise sind sie in den Chipsatz selbst eingebettet. Beispielsweise sind Hauptspeicher und Cache-Speicher Beispiele für flüchtigen Speicher. Sie sind schnell, können aber nur eine kleine Menge an Informationen speichern.
Non-volatile storage- Diese Erinnerungen sind gemacht, um Systemabstürze zu überleben. Ihre Datenspeicherkapazität ist enorm, die Zugänglichkeit jedoch langsamer. Beispiele können Festplatten, Magnetbänder, Flash-Speicher und nichtflüchtiger (batteriegepufferter) RAM sein.
Erholung und Atomizität
Wenn ein System abstürzt, werden möglicherweise mehrere Transaktionen ausgeführt und verschiedene Dateien geöffnet, um die Datenelemente zu ändern. Transaktionen bestehen aus verschiedenen Operationen, die atomarer Natur sind. Gemäß den ACID-Eigenschaften von DBMS muss jedoch die Atomizität der Transaktionen als Ganzes beibehalten werden, dh, entweder werden alle Operationen ausgeführt oder keine.
Wenn sich ein DBMS nach einem Absturz erholt, sollte Folgendes beibehalten werden:
Es sollte den Status aller Transaktionen überprüfen, die ausgeführt wurden.
Eine Transaktion befindet sich möglicherweise mitten in einer Operation. Das DBMS muss in diesem Fall die Atomizität der Transaktion sicherstellen.
Es sollte geprüft werden, ob die Transaktion jetzt abgeschlossen werden kann oder zurückgesetzt werden muss.
Keine Transaktionen dürfen das DBMS in einem inkonsistenten Zustand belassen.
Es gibt zwei Arten von Techniken, die einem DBMS bei der Wiederherstellung und Aufrechterhaltung der Atomizität einer Transaktion helfen können:
Verwalten Sie die Protokolle jeder Transaktion und schreiben Sie sie in einen stabilen Speicher, bevor Sie die Datenbank tatsächlich ändern.
Beibehalten von Shadow Paging, bei dem die Änderungen in einem flüchtigen Speicher vorgenommen werden, und später wird die tatsächliche Datenbank aktualisiert.
Protokollbasierte Wiederherstellung
Protokoll ist eine Folge von Datensätzen, die die Aufzeichnungen der von einer Transaktion ausgeführten Aktionen verwaltet. Es ist wichtig, dass die Protokolle vor der eigentlichen Änderung geschrieben und auf einem stabilen Speichermedium gespeichert werden, was ausfallsicher ist.
Die protokollbasierte Wiederherstellung funktioniert wie folgt:
Die Protokolldatei wird auf einem stabilen Speichermedium gespeichert.
Wenn eine Transaktion in das System eingeht und mit der Ausführung beginnt, schreibt sie ein Protokoll darüber.
<Tn, Start>Wenn die Transaktion ein Element X ändert, schreibt sie Protokolle wie folgt:
<Tn, X, V1, V2>Es wird gelesen, dass T n den Wert von X von V 1 auf V 2 geändert hat .
- Wenn die Transaktion abgeschlossen ist, wird protokolliert -
<Tn, commit>Die Datenbank kann mit zwei Ansätzen geändert werden:
Deferred database modification - Alle Protokolle werden in den stabilen Speicher geschrieben und die Datenbank wird aktualisiert, wenn eine Transaktion festgeschrieben wird.
Immediate database modification- Jedes Protokoll folgt einer tatsächlichen Datenbankänderung. Das heißt, die Datenbank wird unmittelbar nach jeder Operation geändert.
Wiederherstellung bei gleichzeitigen Transaktionen
Wenn mehr als eine Transaktion parallel ausgeführt wird, werden die Protokolle verschachtelt. Zum Zeitpunkt der Wiederherstellung würde es für das Wiederherstellungssystem schwierig werden, alle Protokolle zurückzuverfolgen und dann mit der Wiederherstellung zu beginnen. Um diese Situation zu vereinfachen, verwenden die meisten modernen DBMS das Konzept der "Checkpoints".
Kontrollpunkt
Das Speichern und Verwalten von Protokollen in Echtzeit und in einer realen Umgebung kann den gesamten im System verfügbaren Speicherplatz ausfüllen. Mit der Zeit wird die Protokolldatei möglicherweise zu groß, um überhaupt verarbeitet zu werden. Checkpoint ist ein Mechanismus, bei dem alle vorherigen Protokolle aus dem System entfernt und dauerhaft auf einer Speicherplatte gespeichert werden. Checkpoint deklariert einen Punkt, vor dem sich das DBMS im konsistenten Zustand befand und alle Transaktionen festgeschrieben wurden.
Wiederherstellung
Wenn ein System mit gleichzeitigen Transaktionen abstürzt und wiederhergestellt wird, verhält es sich wie folgt:

Das Wiederherstellungssystem liest die Protokolle vom Ende bis zum letzten Prüfpunkt rückwärts.
Es werden zwei Listen verwaltet, eine Rückgängig-Liste und eine Wiederherstellungsliste.
Wenn das Wiederherstellungssystem ein Protokoll mit <T n , Start> und <T n , Commit> oder nur <T n , Commit> sieht , wird die Transaktion in die Redo-Liste aufgenommen.
Wenn das Wiederherstellungssystem ein Protokoll mit <T n , Start> sieht , aber kein Festschreibungs- oder Abbruchprotokoll gefunden wurde, wird die Transaktion in die Rückgängig-Liste aufgenommen.
Alle Transaktionen in der Rückgängig-Liste werden dann rückgängig gemacht und ihre Protokolle werden entfernt. Alle Transaktionen in der Redo-Liste und ihre vorherigen Protokolle werden entfernt und vor dem Speichern ihrer Protokolle erneut ausgeführt.