Abfrageoptimierung in zentralisierten Systemen
Sobald die alternativen Zugriffspfade zur Berechnung eines relationalen Algebraausdrucks abgeleitet sind, wird der optimale Zugriffspfad bestimmt. In diesem Kapitel werden wir uns mit der Abfrageoptimierung in einem zentralisierten System befassen, während wir im nächsten Kapitel die Abfrageoptimierung in einem verteilten System untersuchen werden.
In einem zentralisierten System erfolgt die Abfrageverarbeitung mit dem folgenden Ziel:
Minimierung der Antwortzeit der Abfrage (Zeit, die benötigt wird, um die Ergebnisse für die Benutzerabfrage zu erstellen).
Maximieren Sie den Systemdurchsatz (die Anzahl der Anforderungen, die in einem bestimmten Zeitraum verarbeitet werden).
Reduzieren Sie den für die Verarbeitung erforderlichen Speicherplatz.
Erhöhen Sie die Parallelität.
Analyse und Übersetzung von Abfragen
Zunächst wird die SQL-Abfrage gescannt. Anschließend wird analysiert, ob syntaktische Fehler und die Richtigkeit der Datentypen vorliegen. Wenn die Abfrage diesen Schritt besteht, wird die Abfrage in kleinere Abfrageblöcke zerlegt. Jeder Block wird dann in einen äquivalenten Ausdruck der relationalen Algebra übersetzt.
Schritte zur Abfrageoptimierung
Die Abfrageoptimierung umfasst drei Schritte: Abfragebaumgenerierung, Plangenerierung und Abfrageplancodegenerierung.
Step 1 − Query Tree Generation
Ein Abfragebaum ist eine Baumdatenstruktur, die einen relationalen Algebraausdruck darstellt. Die Tabellen der Abfrage werden als Blattknoten dargestellt. Die relationalen Algebraoperationen werden als interne Knoten dargestellt. Die Wurzel repräsentiert die Abfrage als Ganzes.
Während der Ausführung wird ein interner Knoten ausgeführt, wenn seine Operandentabellen verfügbar sind. Der Knoten wird dann durch die Ergebnistabelle ersetzt. Dieser Prozess wird für alle internen Knoten fortgesetzt, bis der Stammknoten ausgeführt und durch die Ergebnistabelle ersetzt wird.
Betrachten wir zum Beispiel die folgenden Schemata:
MITARBEITER
| EmpID | EName | Gehalt | DeptNo | Beitrittsdatum |
ABTEILUNG
| DNo | DName | Ort |
Beispiel 1
Betrachten wir die Abfrage wie folgt.
$$ \ pi_ {EmpID} (\ sigma_ {EName = \ small "ArunKumar"} {(MITARBEITER)}) $$
Der entsprechende Abfragebaum lautet -
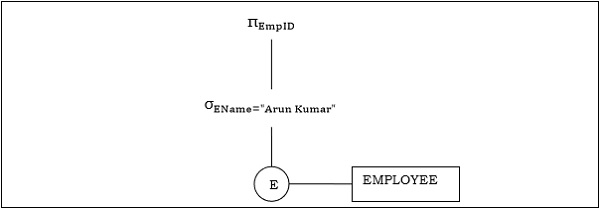
Beispiel 2
Betrachten wir eine weitere Abfrage mit einem Join.
$ \ pi_ {EName, Gehalt} (\ sigma_ {DName = \ small "Marketing"} {(ABTEILUNG)}) \ bowtie_ {DNo = DeptNo} {(MITARBEITER)} $
Es folgt der Abfragebaum für die obige Abfrage.

Step 2 − Query Plan Generation
Nachdem der Abfragebaum generiert wurde, wird ein Abfrageplan erstellt. Ein Abfrageplan ist ein erweiterter Abfragebaum, der Zugriffspfade für alle Vorgänge im Abfragebaum enthält. Zugriffspfade geben an, wie die relationalen Operationen in der Baumstruktur ausgeführt werden sollen. Beispielsweise kann eine Auswahloperation einen Zugriffspfad haben, der Details zur Verwendung des B + -Baumindex für die Auswahl enthält.
Außerdem gibt ein Abfrageplan auch an, wie die Zwischentabellen von einem Operator zum nächsten übergeben werden sollen, wie temporäre Tabellen verwendet werden sollen und wie Operationen per Pipeline verbunden / kombiniert werden sollen.
Step 3− Code Generation
Die Codegenerierung ist der letzte Schritt bei der Abfrageoptimierung. Dies ist die ausführbare Form der Abfrage, deren Form vom Typ des zugrunde liegenden Betriebssystems abhängt. Sobald der Abfragecode generiert wurde, führt ihn der Ausführungsmanager aus und erstellt die Ergebnisse.
Ansätze zur Abfrageoptimierung
Unter den Ansätzen zur Abfrageoptimierung werden hauptsächlich umfassende Such- und heuristikbasierte Algorithmen verwendet.
Umfassende Suchoptimierung
Bei diesen Techniken werden für eine Abfrage zunächst alle möglichen Abfragepläne generiert und dann der beste Plan ausgewählt. Obwohl diese Techniken die beste Lösung bieten, weist sie aufgrund des großen Lösungsraums eine exponentielle zeitliche und räumliche Komplexität auf. Zum Beispiel dynamische Programmiertechnik.
Heuristische Optimierung
Die heuristische Optimierung verwendet regelbasierte Optimierungsansätze für die Abfrageoptimierung. Diese Algorithmen weisen eine polynomielle zeitliche und räumliche Komplexität auf, die geringer ist als die exponentielle Komplexität erschöpfender suchbasierter Algorithmen. Diese Algorithmen erzeugen jedoch nicht unbedingt den besten Abfrageplan.
Einige der gängigen heuristischen Regeln sind:
Führen Sie Auswahl- und Projektvorgänge aus, bevor Sie Verknüpfungsvorgänge ausführen. Dies erfolgt durch Verschieben der Auswahl- und Projektoperationen im Abfragebaum. Dies reduziert die Anzahl der Tupel, die zum Verbinden verfügbar sind.
Führen Sie zuerst die restriktivsten Auswahl- / Projektvorgänge vor den anderen Vorgängen aus.
Vermeiden Sie produktübergreifende Operationen, da diese zu sehr großen Zwischentabellen führen.