DocumentDB SQL - Kurzanleitung
DocumentDB ist die neueste NoSQL-Dokumentendatenbankplattform von Microsoft, die unter Azure ausgeführt wird. In diesem Tutorial erfahren Sie alles über das Abfragen von Dokumenten mit der von DocumentDB unterstützten speziellen SQL-Version.
NoSQL-Dokumentendatenbank
DocumentDB ist die neueste NoSQL-Dokumentendatenbank von Microsoft. Wenn wir jedoch NoSQL-Dokumentendatenbank sagen, was genau meinen wir mit NoSQL und Dokumentendatenbank?
SQL bedeutet strukturierte Abfragesprache, eine traditionelle Abfragesprache relationaler Datenbanken. SQL wird häufig mit relationalen Datenbanken gleichgesetzt.
Es ist wirklich hilfreicher, sich eine NoSQL-Datenbank als eine nicht relationale Datenbank vorzustellen, daher bedeutet NoSQL wirklich nicht relational.
Es gibt verschiedene Arten von NoSQL-Datenbanken, die Schlüsselwertspeicher enthalten, wie z.
- Azure-Tabellenspeicher
- Spaltenbasierte Geschäfte wie Cassandra
- Grafikdatenbanken wie NEO4
- Dokumentdatenbanken wie MongoDB und Azure DocumentDB
Warum SQL-Syntax?
Das mag zunächst seltsam klingen, aber in DocumentDB, einer NoSQL-Datenbank, fragen wir mit SQL ab. Wie oben erwähnt, ist dies eine spezielle Version von SQL, die auf JSON- und JavaScript-Semantik basiert.
SQL ist nur eine Sprache, aber es ist auch eine sehr beliebte Sprache, die reich und ausdrucksstark ist. Daher scheint es auf jeden Fall eine gute Idee zu sein, einen SQL-Dialekt zu verwenden, anstatt eine völlig neue Methode zum Ausdrücken von Abfragen zu entwickeln, die wir lernen müssten, wenn Sie Dokumente aus Ihrer Datenbank herausholen möchten.
SQL wurde für relationale Datenbanken entwickelt, und DocumentDB ist eine nicht relationale Dokumentendatenbank. Das DocumentDB-Team hat die SQL-Syntax tatsächlich für die nicht relationale Welt der Dokumentendatenbanken angepasst. Dies ist das Rooten von SQL in JSON und JavaScript.
Die Sprache liest sich immer noch als vertrautes SQL, aber die Semantik basiert alle auf schemafreien JSON-Dokumenten und nicht auf relationalen Tabellen. In DocumentDB werden wir eher mit JavaScript-Datentypen als mit SQL-Datentypen arbeiten. Wir werden mit SELECT, FROM, WHERE usw. vertraut sein, aber mit JavaScript-Typen, die auf Zahlen und Zeichenfolgen beschränkt sind, sind Objekte, Arrays, Boolean und Null weitaus weniger als die zahlreichen SQL-Datentypen.
In ähnlicher Weise werden Ausdrücke eher als JavaScript-Ausdrücke als als irgendeine Form von T-SQL ausgewertet. In einer Welt denormalisierter Daten handelt es sich beispielsweise nicht um Zeilen und Spalten, sondern um schemafreie Dokumente mit hierarchischen Strukturen, die verschachtelte Arrays und Objekte enthalten.
Wie funktioniert SQL?
Das DocumentDB-Team hat diese Frage auf verschiedene innovative Arten beantwortet. Nur wenige von ihnen sind wie folgt aufgeführt:
Angenommen, Sie haben das Standardverhalten nicht geändert, um automatisch jede Eigenschaft in einem Dokument zu indizieren, können Sie in Ihren Abfragen die gepunktete Notation verwenden, um einen Pfad zu einer Eigenschaft zu navigieren, unabhängig davon, wie tief sie im Dokument verschachtelt ist.
Sie können auch einen dokumentinternen Join ausführen, bei dem verschachtelte Array-Elemente mit ihrem übergeordneten Element innerhalb eines Dokuments auf eine Weise verknüpft werden, die der Art und Weise sehr ähnlich ist, wie ein Join zwischen zwei Tabellen in der relationalen Welt ausgeführt wird.
Ihre Abfragen können Dokumente aus der Datenbank so wie sie sind zurückgeben oder Sie können jede gewünschte benutzerdefinierte JSON-Form basierend auf so viel oder so wenig der gewünschten Dokumentdaten projizieren.
SQL in DocumentDB unterstützt viele der gängigen Operatoren, darunter -
Arithmetische und bitweise Operationen
UND- und ODER-Logik
Gleichheits- und Bereichsvergleiche
String-Verkettung
Die Abfragesprache unterstützt auch eine Vielzahl integrierter Funktionen.
Das Azure-Portal verfügt über einen Abfrage-Explorer, mit dem wir jede SQL-Abfrage für unsere DocumentDB-Datenbank ausführen können. Wir werden den Abfrage-Explorer verwenden, um die vielen verschiedenen Funktionen und Merkmale der Abfragesprache zu demonstrieren, beginnend mit der einfachsten möglichen Abfrage.
Step 1 - Öffnen Sie das Azure-Portal und klicken Sie im Datenbank-Blade auf das Blade des Abfrage-Explorers.
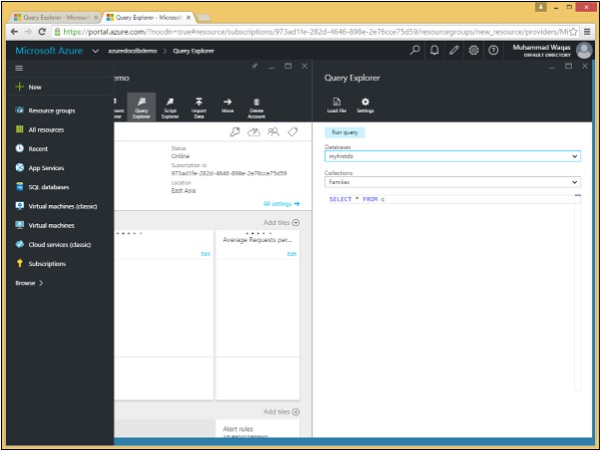
Denken Sie daran, dass Abfragen im Bereich einer Sammlung ausgeführt werden. Daher können wir im Abfrage-Explorer die Sammlung in dieser Dropdown-Liste auswählen. Wir werden es unserer Familiensammlung überlassen, die die drei Dokumente enthält. Betrachten wir diese drei Dokumente in diesem Beispiel.
Es folgt die AndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
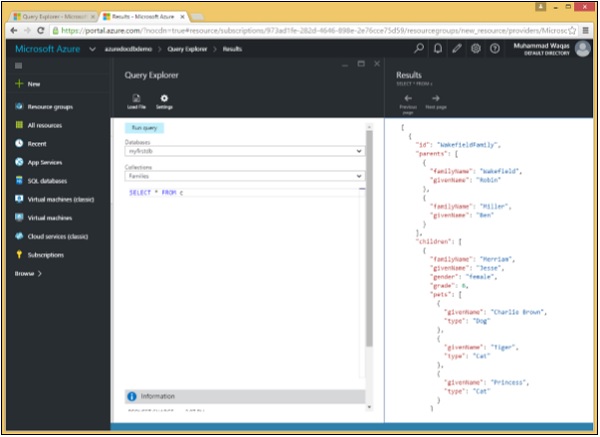
}Der Abfrage-Explorer wird mit dieser einfachen Abfrage SELECT * FROM c geöffnet, mit der einfach alle Dokumente aus der Sammlung abgerufen werden. Obwohl es einfach ist, unterscheidet es sich immer noch erheblich von der entsprechenden Abfrage in einer relationalen Datenbank.
Step 2- In relationalen Datenbanken bedeutet SELECT *, dass alle Spalten in DocumentDB zurückgegeben werden. Dies bedeutet, dass jedes Dokument in Ihrem Ergebnis genau so zurückgegeben werden soll, wie es in der Datenbank gespeichert ist.
Wenn Sie jedoch bestimmte Eigenschaften und Ausdrücke auswählen, anstatt einfach ein SELECT * auszugeben, projizieren Sie für jedes Dokument im Ergebnis eine neue Form, die Sie möchten.
Step 3 - Klicken Sie auf "Ausführen", um die Abfrage auszuführen und das Ergebnisblatt zu öffnen.

Wie zu sehen ist, werden die WakefieldFamily, die SmithFamily und die AndersonFamily abgerufen.
Es folgen die drei Dokumente, die als Ergebnis der abgerufen werden SELECT * FROM c Abfrage.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
"givenName": "Fluffy",
"type": "Rabbit"
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Zu diesen Ergebnissen gehören jedoch auch die vom System generierten Eigenschaften, denen alle der Unterstrich vorangestellt ist.
In diesem Kapitel werden wir die FROM-Klausel behandeln, die in regulärem SQL nicht wie eine Standard-FROM-Klausel funktioniert.
Abfragen werden immer im Kontext einer bestimmten Sammlung ausgeführt und können nicht über Dokumente innerhalb der Sammlung hinweg verknüpft werden. Daher fragen wir uns, warum wir eine FROM-Klausel benötigen. Tatsächlich tun wir das nicht, aber wenn wir es nicht aufnehmen, werden wir keine Dokumente in der Sammlung abfragen.
Der Zweck dieser Klausel besteht darin, die Datenquelle anzugeben, mit der die Abfrage ausgeführt werden muss. Im Allgemeinen ist die gesamte Sammlung die Quelle, aber man kann stattdessen eine Teilmenge der Sammlung angeben. Die FROM <from_specification> -Klausel ist optional, es sei denn, die Quelle wird später in der Abfrage gefiltert oder projiziert.
Schauen wir uns noch einmal dasselbe Beispiel an. Es folgt dieAndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
In der obigen AbfrageSELECT * FROM c”Gibt an, dass die gesamte Families-Sammlung die Quelle für die Aufzählung ist.
Unterdokumente
Die Quelle kann auch auf eine kleinere Teilmenge reduziert werden. Wenn wir in jedem Dokument nur einen Teilbaum abrufen möchten, kann der Teilstamm zur Quelle werden, wie im folgenden Beispiel gezeigt.
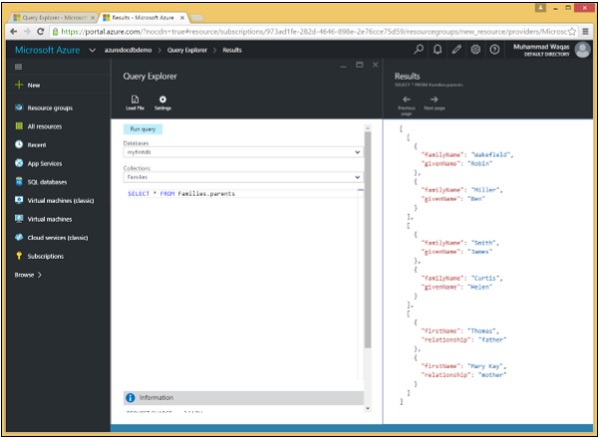
Wenn wir die folgende Abfrage ausführen -
SELECT * FROM Families.parentsDie folgenden Unterdokumente werden abgerufen.
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]Als Ergebnis dieser Abfrage können wir sehen, dass nur die übergeordneten Unterdokumente abgerufen werden.
In diesem Kapitel werden wir die WHERE-Klausel behandeln, die ebenso wie die FROM-Klausel optional ist. Es wird verwendet, um eine Bedingung anzugeben, während die Daten in Form von JSON-Dokumenten abgerufen werden, die von der Quelle bereitgestellt werden. Jedes JSON-Dokument muss die angegebenen Bedingungen als "wahr" bewerten, um für das Ergebnis berücksichtigt zu werden. Wenn die angegebene Bedingung erfüllt ist, werden nur dann bestimmte Daten in Form von JSON-Dokumenten zurückgegeben. Wir können die WHERE-Klausel verwenden, um die Datensätze zu filtern und nur die erforderlichen Datensätze abzurufen.
In diesem Beispiel werden dieselben drei Dokumente betrachtet. Es folgt dieAndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein einfaches Beispiel an, in dem die WHERE-Klausel verwendet wird.
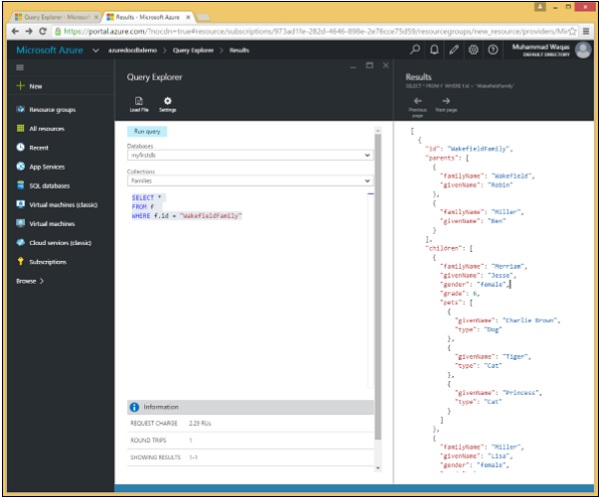
In dieser Abfrage wird in der WHERE-Klausel die Bedingung (WHERE f.id = "WakefieldFamily") angegeben.
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"Wenn die obige Abfrage ausgeführt wird, wird das vollständige JSON-Dokument für WakefieldFamily zurückgegeben, wie in der folgenden Ausgabe gezeigt.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]Ein Operator ist ein reserviertes Wort oder ein Zeichen, das hauptsächlich in einer SQL WHERE-Klausel verwendet wird, um Operationen auszuführen, z. B. Vergleiche und arithmetische Operationen. DocumentDB SQL unterstützt auch eine Vielzahl von skalaren Ausdrücken. Die am häufigsten verwendeten sindbinary and unary expressions.
Die folgenden SQL-Operatoren werden derzeit unterstützt und können in Abfragen verwendet werden.
SQL-Vergleichsoperatoren
Im Folgenden finden Sie eine Liste aller in der DocumentDB SQL-Grammatik verfügbaren Vergleichsoperatoren.
| S.No. | Operatoren & Beschreibung |
|---|---|
| 1 | = Überprüft, ob die Werte von zwei Operanden gleich sind oder nicht. Wenn ja, wird die Bedingung wahr. |
| 2 | != Überprüft, ob die Werte von zwei Operanden gleich sind oder nicht. Wenn die Werte nicht gleich sind, wird die Bedingung wahr. |
| 3 | <> Überprüft, ob die Werte von zwei Operanden gleich sind oder nicht. Wenn die Werte nicht gleich sind, wird die Bedingung wahr. |
| 4 | > Überprüft, ob der Wert des linken Operanden größer als der Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. |
| 5 | < Überprüft, ob der Wert des linken Operanden kleiner als der Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. |
| 6 | >= Überprüft, ob der Wert des linken Operanden größer oder gleich dem Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. |
| 7 | <= Überprüft, ob der Wert des linken Operanden kleiner oder gleich dem Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. |
Logische SQL-Operatoren
Im Folgenden finden Sie eine Liste aller logischen Operatoren, die in der DocumentDB SQL-Grammatik verfügbar sind.
| S.No. | Operatoren & Beschreibung |
|---|---|
| 1 | AND Der AND-Operator ermöglicht das Vorhandensein mehrerer Bedingungen in der WHERE-Klausel einer SQL-Anweisung. |
| 2 | BETWEEN Der Operator BETWEEN wird verwendet, um nach Werten zu suchen, die innerhalb eines Satzes von Werten liegen, wobei der Minimalwert und der Maximalwert angegeben werden. |
| 3 | IN Der IN-Operator wird verwendet, um einen Wert mit einer Liste der angegebenen Literalwerte zu vergleichen. |
| 4 | OR Der OR-Operator wird verwendet, um mehrere Bedingungen in der WHERE-Klausel einer SQL-Anweisung zu kombinieren. |
| 5 | NOT Der NOT-Operator kehrt die Bedeutung des logischen Operators um, mit dem er verwendet wird. Zum Beispiel NICHT EXISTIERT, NICHT ZWISCHEN, NICHT IN usw. Dies ist ein negativer Operator. |
SQL-Arithmetikoperatoren
Im Folgenden finden Sie eine Liste aller in der DocumentDB SQL-Grammatik verfügbaren arithmetischen Operatoren.
| S.No. | Operatoren & Beschreibung |
|---|---|
| 1 | + Addition - Fügt Werte auf beiden Seiten des Operators hinzu. |
| 2 | - Subtraction - Subtrahiert den rechten Operanden vom linken Operanden. |
| 3 | * Multiplication - Multipliziert Werte auf beiden Seiten des Operators. |
| 4 | / Division - Teilt den linken Operanden durch den rechten Operanden. |
| 5 | % Modulus - Dividiert den linken Operanden durch den rechten Operanden und gibt den Rest zurück. |
Wir werden die gleichen Dokumente auch in diesem Beispiel betrachten. Es folgt dieAndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein einfaches Beispiel an, in dem ein Vergleichsoperator in der WHERE-Klausel verwendet wird.
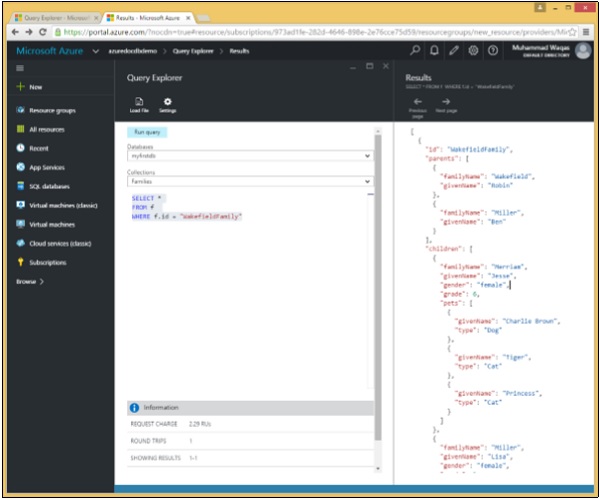
In dieser Abfrage wird in der WHERE-Klausel die Bedingung (WHERE f.id = "WakefieldFamily") angegeben, und das Dokument wird abgerufen, dessen ID WakefieldFamily entspricht.
SELECT *
FROM f
WHERE f.id = "WakefieldFamily"Wenn die obige Abfrage ausgeführt wird, wird das vollständige JSON-Dokument für WakefieldFamily zurückgegeben, wie in der folgenden Ausgabe gezeigt.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]Schauen wir uns ein anderes Beispiel an, in dem die Abfrage die untergeordneten Daten abruft, deren Note größer als 5 ist.
SELECT *
FROM Families.children[0] c
WHERE (c.grade > 5)Wenn die obige Abfrage ausgeführt wird, wird das folgende Unterdokument abgerufen, wie in der Ausgabe gezeigt.
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]Das Schlüsselwort BETWEEN wird verwendet, um Abfragen für Wertebereiche wie in SQL auszudrücken. ZWISCHEN kann gegen Zeichenfolgen oder Zahlen verwendet werden. Der Hauptunterschied zwischen der Verwendung von BETWEEN in DocumentDB und ANSI SQL besteht darin, dass Sie Bereichsabfragen für Eigenschaften gemischter Typen ausdrücken können.
In einigen Dokumenten ist es beispielsweise möglich, dass Sie als Note "Note" haben, und in anderen Dokumenten sind es möglicherweise Zeichenfolgen. In diesen Fällen ist ein Vergleich zwischen zwei verschiedenen Ergebnistypen "undefiniert", und das Dokument wird übersprungen.
Betrachten wir die drei Dokumente aus dem vorherigen Beispiel. Es folgt dieAndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Following is the SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Following is the WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Let’s take a look at an example, where the query returns all family documents in which the first child's grade is between 1-5 (both inclusive).
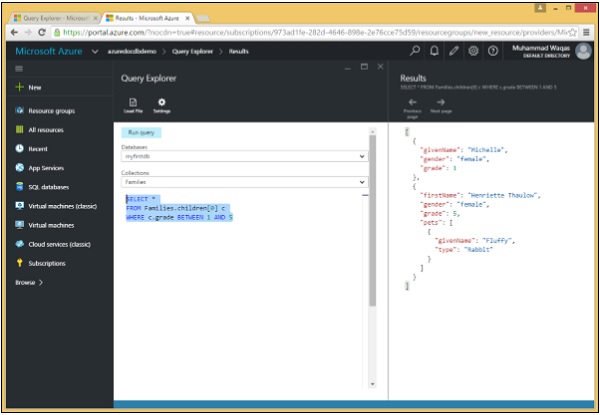
Following is the query in which BETWEEN keyword is used and then AND logical operator.
SELECT *
FROM Families.children[0] c
WHERE c.grade BETWEEN 1 AND 5When the above query is executed, it produces the following output.
[
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
]To display the grades outside the range of the previous example, use NOT BETWEEN as shown in the following query.
SELECT *
FROM Families.children[0] c
WHERE c.grade NOT BETWEEN 1 AND 5When this query is executed. It produces the following output.
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]The IN keyword can be used to check whether a specified value matches any value in a list. The IN operator allows you to specify multiple values in a WHERE clause. IN is equivalent to chaining multiple OR clauses.
The similar three documents are considered as done in earlier examples. Following is the AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Following is the SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Following is the WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Let’s take a look at a simple example.
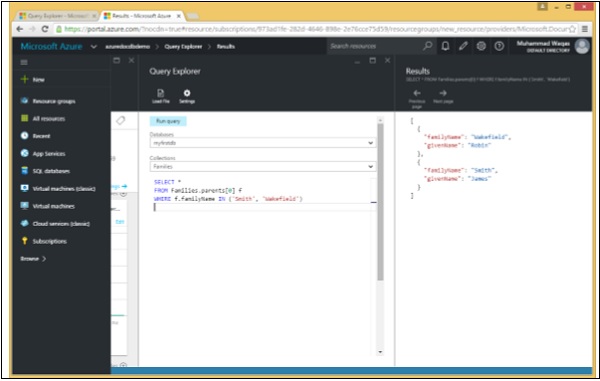
Following is the query which will retrieve the data whose familyName is either “Smith” or Wakefield.
SELECT *
FROM Families.parents[0] f
WHERE f.familyName IN ('Smith', 'Wakefield')When the above query is executed, it produces the following output.
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Smith",
"givenName": "James"
}
]Let’s consider another simple example in which all family documents will be retrieved where the id is one of "SmithFamily" or "AndersenFamily". Following is the query.
SELECT *
FROM Families
WHERE Families.id IN ('SmithFamily', 'AndersenFamily')When the above query is executed, it produces the following output.
[
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]When you know you're only returning a single value, then the VALUE keyword can help produce a leaner result set by avoiding the overhead of creating a full-blown object. The VALUE keyword provides a way to return JSON value.
Let’s take a look at a simple example.
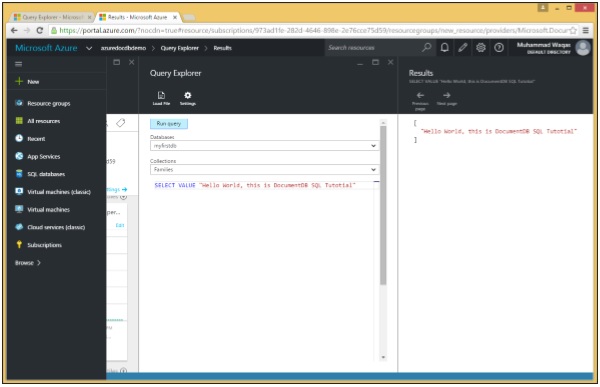
Following is the query with VALUE keyword.
SELECT VALUE "Hello World, this is DocumentDB SQL Tutorial"When this query is executed, it returns the scalar "Hello World, this is DocumentDB SQL Tutorial".
[
"Hello World, this is DocumentDB SQL Tutorial"
]In another example, let’s consider the three documents from the previous examples.
Following is the AndersenFamily document.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Following is the SmithFamily document.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Following is the WakefieldFamily document.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Following is the query.
SELECT VALUE f.location
FROM Families fWhen this query is executed, it return the returns the address without the location label.
[
{
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
{
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
{
"state": "WA",
"county": "King",
"city": "Seattle"
}
]If we now specify the same query without VALUE Keyword, then it will return the address with location label. Following is the query.
SELECT f.location
FROM Families fWhen this query is executed, it produces the following output.
[
{
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
}
},
{
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
},
{
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
}
}
]Microsoft Azure DocumentDB unterstützt das Abfragen von Dokumenten mithilfe von SQL über JSON-Dokumente. Sie können Dokumente in der Sammlung nach Zahlen und Zeichenfolgen sortieren, indem Sie in Ihrer Abfrage eine ORDER BY-Klausel verwenden. Die Klausel kann ein optionales ASC / DESC-Argument enthalten, um die Reihenfolge anzugeben, in der die Ergebnisse abgerufen werden müssen.
Wir werden die gleichen Dokumente wie in den vorherigen Beispielen betrachten.
Es folgt die AndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein einfaches Beispiel an.
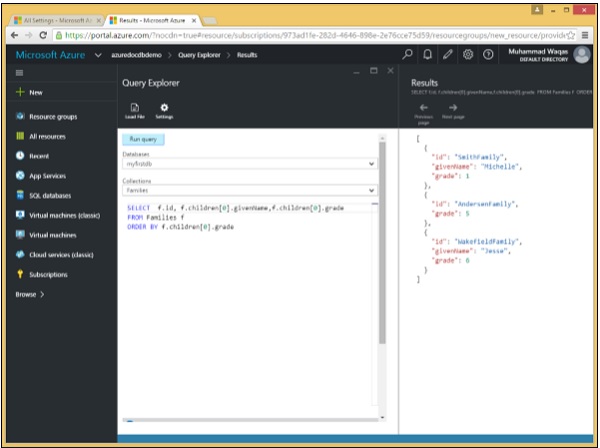
Es folgt die Abfrage, die das Schlüsselwort ORDER BY enthält.
SELECT f.id, f.children[0].givenName,f.children[0].grade
FROM Families f
ORDER BY f.children[0].gradeWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"id": "SmithFamily",
"givenName": "Michelle",
"grade": 1
},
{
"id": "AndersenFamily",
"grade": 5
},
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]Betrachten wir ein weiteres einfaches Beispiel.
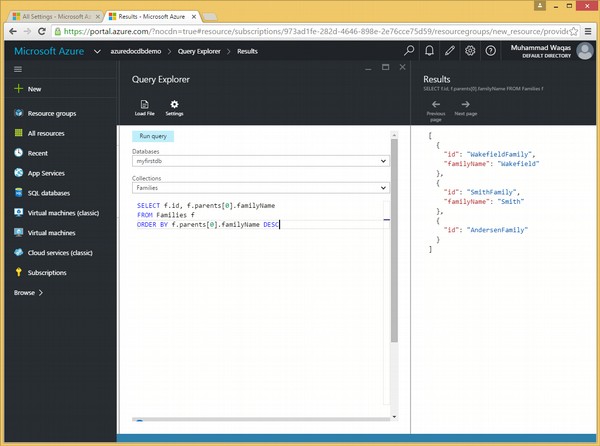
Es folgt die Abfrage, die das Schlüsselwort ORDER BY und das optionale Schlüsselwort DESC enthält.
SELECT f.id, f.parents[0].familyName
FROM Families f
ORDER BY f.parents[0].familyName DESCWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"id": "WakefieldFamily",
"familyName": "Wakefield"
},
{
"id": "SmithFamily",
"familyName": "Smith"
},
{
"id": "AndersenFamily"
}
]In DocumentDB SQL hat Microsoft ein neues Konstrukt hinzugefügt, das mit dem Schlüsselwort IN verwendet werden kann, um die Iteration über JSON-Arrays zu unterstützen. Die Unterstützung für die Iteration wird in der FROM-Klausel bereitgestellt.
Wir werden ähnliche drei Dokumente aus den vorherigen Beispielen noch einmal betrachten.
Es folgt die AndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein einfaches Beispiel ohne IN-Schlüsselwort in der FROM-Klausel an.
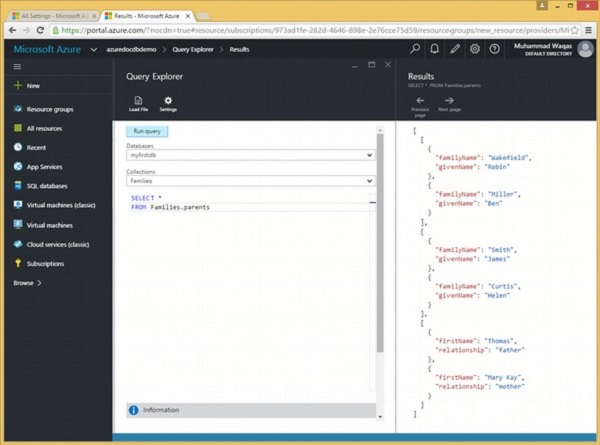
Im Folgenden finden Sie die Abfrage, mit der alle Eltern aus der Families-Sammlung zurückgegeben werden.
SELECT *
FROM Families.parentsWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]Wie in der obigen Ausgabe zu sehen ist, werden die Eltern jeder Familie in einem separaten JSON-Array angezeigt.
Schauen wir uns dasselbe Beispiel an, aber dieses Mal verwenden wir das Schlüsselwort IN in der FROM-Klausel.
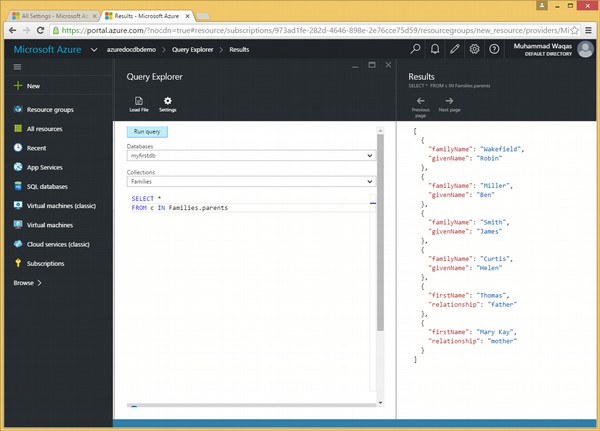
Es folgt die Abfrage, die das Schlüsselwort IN enthält.
SELECT *
FROM c IN Families.parentsWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
},
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
},
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]Im obigen Beispiel ist zu sehen, dass bei der Iteration die Abfrage, die die Iteration über die übergeordneten Elemente in der Sammlung ausführt, ein anderes Ausgabearray aufweist. Daher werden alle Eltern aus jeder Familie zu einem einzigen Array hinzugefügt.
In relationalen Datenbanken wird die Joins-Klausel verwendet, um Datensätze aus zwei oder mehr Tabellen in einer Datenbank zu kombinieren. Die Notwendigkeit, tabellenübergreifende Verknüpfungen herzustellen, ist beim Entwerfen normalisierter Schemas sehr wichtig. Da sich DocumentDB mit dem denormalisierten Datenmodell von schemafreien Dokumenten befasst, ist JOIN in DocumentDB SQL das logische Äquivalent eines "Selfjoin".
Betrachten wir die drei Dokumente wie in den vorherigen Beispielen.
Es folgt die AndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein Beispiel an, um zu verstehen, wie die JOIN-Klausel funktioniert.
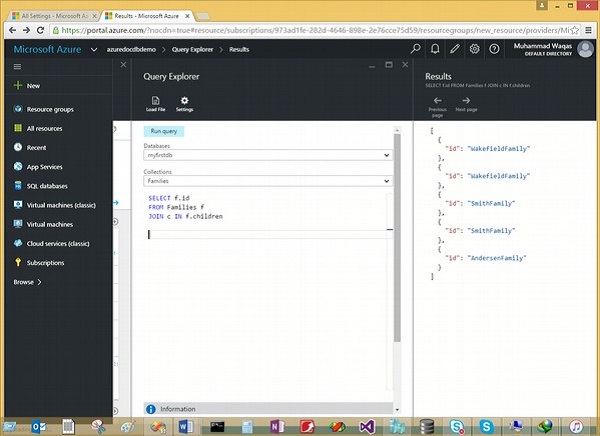
Im Folgenden finden Sie die Abfrage, die das Unterdokument "root to children" verknüpft.
SELECT f.id
FROM Families f
JOIN c IN f.childrenWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"id": "WakefieldFamily"
},
{
"id": "WakefieldFamily"
},
{
"id": "SmithFamily"
},
{
"id": "SmithFamily"
},
{
"id": "AndersenFamily"
}
]Im obigen Beispiel befindet sich der Join zwischen dem Dokumentstamm und dem untergeordneten Unterstamm, wodurch ein Kreuzprodukt zwischen zwei JSON-Objekten entsteht. Im Folgenden sind einige Punkte zu beachten -
In der FROM-Klausel ist die JOIN-Klausel ein Iterator.
Die ersten beiden Dokumente WakefieldFamily und SmithFamily enthalten zwei untergeordnete Dokumente. Daher enthält die Ergebnismenge auch das Kreuzprodukt, das für jedes untergeordnete Objekt ein eigenes Objekt erzeugt.
Das dritte Dokument AndersenFamily enthält nur ein Kind, daher gibt es nur ein einziges Objekt, das diesem Dokument entspricht.
Schauen wir uns dasselbe Beispiel an, aber dieses Mal rufen wir auch den untergeordneten Namen ab, um die JOIN-Klausel besser zu verstehen.
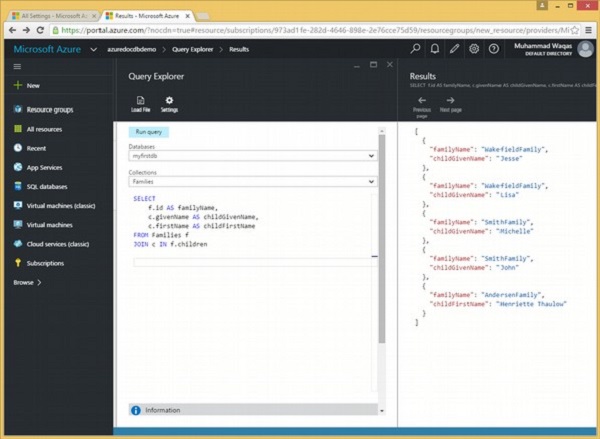
Im Folgenden finden Sie die Abfrage, die das Unterdokument "root to children" verknüpft.
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]In relationalen Datenbanken werden SQL-Aliase verwendet, um eine Tabelle oder eine Spaltenüberschrift vorübergehend umzubenennen. In ähnlicher Weise werden in DocumentDB Aliase verwendet, um ein JSON-Dokument, ein Unterdokument, ein Objekt oder ein beliebiges Feld vorübergehend umzubenennen.
Die Umbenennung ist eine vorübergehende Änderung und das tatsächliche Dokument ändert sich nicht. Grundsätzlich werden Aliase erstellt, um die Lesbarkeit von Feld- / Dokumentnamen zu verbessern. Für das Aliasing wird das optionale Schlüsselwort AS verwendet.
Betrachten wir drei ähnliche Dokumente aus den in den vorherigen Beispielen verwendeten.
Es folgt die AndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein Beispiel an, um die Aliase zu diskutieren.
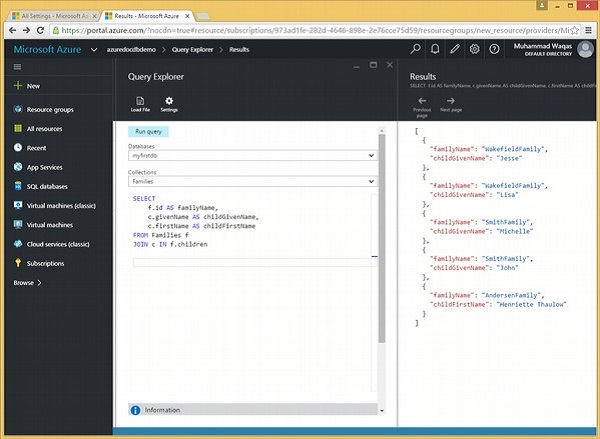
Im Folgenden finden Sie die Abfrage, die das Unterdokument "root to children" verknüpft. Wir haben Aliase wie f.id AS familyName, c.givenName AS childGivenName und c.firstName AS childFirstName.
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.childrenWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]Die obige Ausgabe zeigt, dass die abgelegten Namen geändert werden, es sich jedoch um eine vorübergehende Änderung handelt und die Originaldokumente nicht geändert werden.
In DocumentDB SQL hat Microsoft eine Schlüsselfunktion hinzugefügt, mit deren Hilfe wir auf einfache Weise ein Array erstellen können. Wenn wir eine Abfrage ausführen, wird als Ergebnis der Abfrage ein Sammlungsarray erstellt, das dem JSON-Objekt ähnelt.
Betrachten wir die gleichen Dokumente wie in den vorherigen Beispielen.
Es folgt die AndersenFamily Dokument.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}Es folgt die SmithFamily Dokument.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}Es folgt die WakefieldFamily Dokument.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein Beispiel an.
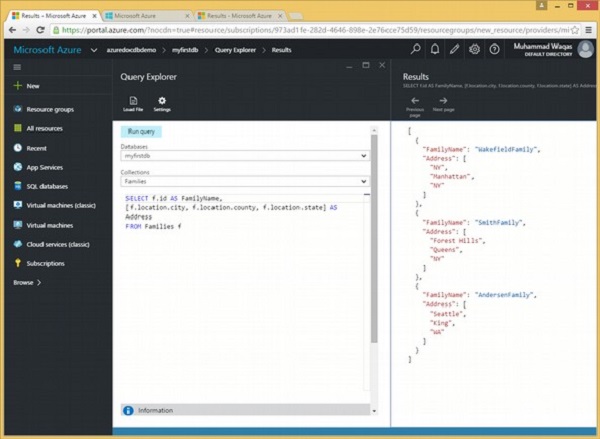
Es folgt die Abfrage, die den Familiennamen und die Adresse jeder Familie zurückgibt.
SELECT f.id AS FamilyName,
[f.location.city, f.location.county, f.location.state] AS Address
FROM Families fWie zu sehen ist, sind die Felder Stadt, Landkreis und Bundesland in eckigen Klammern eingeschlossen, wodurch ein Array erstellt wird und dieses Array den Namen Adresse trägt. Wenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"FamilyName": "WakefieldFamily",
"Address": [
"NY",
"Manhattan",
"NY"
]
},
{
"FamilyName": "SmithFamily",
"Address": [
"Forest Hills",
"Queens",
"NY"
]
},
{
"FamilyName": "AndersenFamily",
"Address": [
"Seattle",
"King",
"WA"
]
}
]Die Informationen zu Stadt, Landkreis und Bundesland werden in der obigen Ausgabe im Adressarray hinzugefügt.
In DocumentDB SQL unterstützt die SELECT-Klausel auch skalare Ausdrücke wie Konstanten, arithmetische Ausdrücke, logische Ausdrücke usw. Normalerweise werden skalare Abfragen selten verwendet, da sie keine Dokumente in der Auflistung abfragen, sondern nur Ausdrücke auswerten. Es ist jedoch weiterhin hilfreich, skalare Ausdrucksabfragen zu verwenden, um die Grundlagen, die Verwendung von Ausdrücken und die Formgebung von JSON in einer Abfrage zu erlernen. Diese Konzepte gelten direkt für die tatsächlichen Abfragen, die Sie für Dokumente in einer Sammlung ausführen.
Schauen wir uns ein Beispiel an, das mehrere skalare Abfragen enthält.
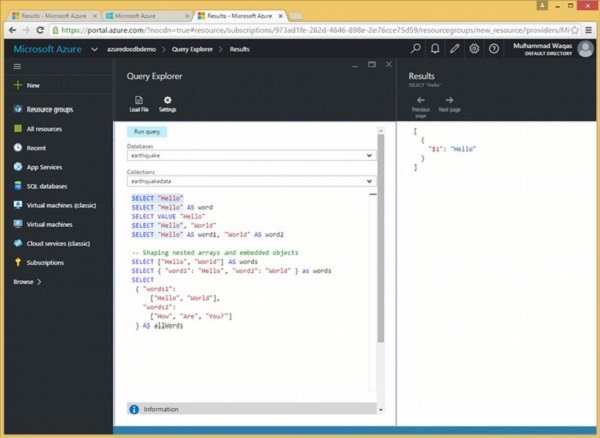
Wählen Sie im Abfrage-Explorer nur den auszuführenden Text aus und klicken Sie auf "Ausführen". Lassen Sie uns diesen ersten ausführen.
SELECT "Hello"Wenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"$1": "Hello"
}
]Diese Ausgabe sieht möglicherweise etwas verwirrend aus. Lassen Sie uns sie also aufschlüsseln.
Erstens sind Abfrageergebnisse, wie wir in der letzten Demo gesehen haben, immer in eckigen Klammern enthalten, da sie als JSON-Array zurückgegeben werden, selbst wenn sie aus Abfragen mit skalaren Ausdrücken wie dieser resultieren, die nur ein einziges Dokument zurückgeben.
Wir haben ein Array mit einem Dokument darin, und dieses Dokument enthält eine einzelne Eigenschaft für den einzelnen Ausdruck in der SELECT-Anweisung.
Die SELECT-Anweisung gibt keinen Namen für diese Eigenschaft an, daher generiert DocumentDB automatisch einen mit $ 1.
Dies ist normalerweise nicht das, was wir wollen. Aus diesem Grund können wir AS verwenden, um den Ausdruck in der Abfrage zu aliasisieren. Dadurch wird der Eigenschaftsname im generierten Dokument so festgelegt, wie Sie es in diesem Beispiel möchten, Wort.
SELECT "Hello" AS wordWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"word": "Hello"
}
]In ähnlicher Weise folgt eine weitere einfache Abfrage.
SELECT ((2 + 11 % 7)-2)/3Die Abfrage ruft die folgende Ausgabe ab.
[
{
"$1": 1.3333333333333333
}
]Schauen wir uns ein weiteres Beispiel für die Gestaltung verschachtelter Arrays und eingebetteter Objekte an.
SELECT
{
"words1":
["Hello", "World"],
"words2":
["How", "Are", "You?"]
} AS allWordsWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"allWords": {
"words1": [
"Hello",
"World"
],
"words2": [
"How",
"Are",
"You?"
]
}
}
]In relationalen Datenbanken ist eine parametrisierte Abfrage eine Abfrage, bei der Platzhalter für Parameter verwendet werden und die Parameterwerte zur Ausführungszeit angegeben werden. DocumentDB unterstützt auch parametrisierte Abfragen, und Parameter in parametrisierten Abfragen können mit der bekannten @ -Notation ausgedrückt werden. Der wichtigste Grund für die Verwendung parametrisierter Abfragen ist die Vermeidung von SQL-Injection-Angriffen. Es kann auch eine robuste Handhabung und das Entkommen von Benutzereingaben ermöglichen.
Schauen wir uns ein Beispiel an, in dem wir das .Net SDK verwenden werden. Es folgt der Code, mit dem die Sammlung gelöscht wird.
private async static Task DeleteCollection(DocumentClient client, string collectionId) {
Console.WriteLine();
Console.WriteLine(">>> Delete Collection {0} in {1} <<<",
collectionId, _database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
DocumentCollection collection = client.CreateDocumentCollectionQuery(database.SelfLink,
query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}",
collectionId, _database.Id);
}Der Aufbau einer parametrisierten Abfrage ist wie folgt.
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};Wir haben die collectionId nicht fest codiert, sodass mit dieser Methode jede Sammlung gelöscht werden kann. Wir können das Symbol '@' verwenden, um Parameternamen ähnlich wie bei SQL Server voranzustellen.
Im obigen Beispiel fragen wir nach einer bestimmten Auflistung nach ID ab, wobei der Id-Parameter in dieser SqlParameterCollection definiert ist, die der Eigenschaft des Parameters dieser SqlQuerySpec zugewiesen ist. Das SDK erstellt dann die endgültige Abfragezeichenfolge für DocumentDB mit der darin eingebetteten collectionId. Wir führen die Abfrage aus und löschen dann mit ihrem SelfLink die Sammlung.
Im Folgenden finden Sie die Implementierung der CreateDocumentClient-Task.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM
c WHERE c.id = 'earthquake'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "MyCollection1");
await DeleteCollection(client, "MyCollection2");
}
}Wenn der Code ausgeführt wird, wird die folgende Ausgabe erzeugt.
**** Delete Collection MyCollection1 in mydb ****
Deleted collection MyCollection1 from database myfirstdb
**** Delete Collection MyCollection2 in mydb ****
Deleted collection MyCollection2 from database myfirstdbSchauen wir uns ein anderes Beispiel an. Wir können eine Abfrage schreiben, die Nachname und Adressstatus als Parameter verwendet und diese dann für verschiedene Werte von Nachname und Standort.Status basierend auf der Benutzereingabe ausführt.
SELECT *
FROM Families f
WHERE f.lastName = @lastName AND f.location.state = @addressStateDiese Anforderung kann dann als parametrisierte JSON-Abfrage an DocumentDB gesendet werden, wie im folgenden Code gezeigt.
{
"query": "SELECT * FROM Families f WHERE f.lastName = @lastName AND
f.location.state = @addressState",
"parameters": [
{"name": "@lastName", "value": "Wakefield"},
{"name": "@addressState", "value": "NY"},
]
}DocumentDB unterstützt eine Vielzahl integrierter Funktionen für allgemeine Vorgänge, die in Abfragen verwendet werden können. Es gibt eine Reihe von Funktionen zum Ausführen mathematischer Berechnungen sowie Funktionen zur Typprüfung, die bei der Arbeit mit unterschiedlichen Schemata äußerst nützlich sind. Diese Funktionen können testen, ob eine bestimmte Eigenschaft vorhanden ist und ob es sich um eine Zahl oder eine Zeichenfolge, einen Booleschen Wert oder ein Objekt handelt.
Wir erhalten auch diese praktischen Funktionen zum Parsen und Bearbeiten von Zeichenfolgen sowie verschiedene Funktionen zum Arbeiten mit Arrays, mit denen Sie beispielsweise Arrays verketten und testen können, ob ein Array ein bestimmtes Element enthält.
Im Folgenden sind die verschiedenen Arten von integrierten Funktionen aufgeführt:
| S.No. | Eingebaute Funktionen & Beschreibung |
|---|---|
| 1 | Mathematische Funktionen Die mathematischen Funktionen führen eine Berechnung durch, die normalerweise auf Eingabewerten basiert, die als Argumente bereitgestellt werden, und geben einen numerischen Wert zurück. |
| 2 | Typprüfungsfunktionen Mit den Typprüfungsfunktionen können Sie den Typ eines Ausdrucks in SQL-Abfragen überprüfen. |
| 3 | String-Funktionen Die Zeichenfolgenfunktionen führen eine Operation für einen Zeichenfolgeneingabewert aus und geben eine Zeichenfolge, einen numerischen oder einen booleschen Wert zurück. |
| 4 | Array-Funktionen Die Array-Funktionen führen eine Operation für einen Array-Eingabewert aus und geben sie in Form eines numerischen, booleschen oder Array-Werts zurück. |
| 5 | Raumfunktionen DocumentDB unterstützt auch die integrierten Funktionen des Open Geospatial Consortium (OGC) für die Geodatenabfrage. |
In DocumentDB verwenden wir tatsächlich SQL, um Dokumente abzufragen. Wenn wir eine .NET-Entwicklung durchführen, gibt es auch einen LINQ-Anbieter, der verwendet werden kann und der aus einer LINQ-Abfrage geeignetes SQL generieren kann.
Unterstützte Datentypen
In DocumentDB werden alle primitiven JSON-Typen im LINQ-Anbieter unterstützt, der im DocumentDB .NET SDK enthalten ist.
- Numeric
- Boolean
- String
- Null
Unterstützter Ausdruck
Die folgenden skalaren Ausdrücke werden vom LINQ-Anbieter unterstützt, der im DocumentDB .NET SDK enthalten ist.
Constant Values - Enthält konstante Werte der primitiven Datentypen.
Property/Array Index Expressions - Ausdrücke beziehen sich auf die Eigenschaft eines Objekts oder eines Array-Elements.
Arithmetic Expressions - Enthält allgemeine arithmetische Ausdrücke für numerische und boolesche Werte.
String Comparison Expression - Beinhaltet den Vergleich eines Zeichenfolgenwerts mit einem konstanten Zeichenfolgenwert.
Object/Array Creation Expression- Gibt ein Objekt vom Typ zusammengesetzter Wert oder anonymer Typ oder ein Array solcher Objekte zurück. Diese Werte können verschachtelt werden.
Unterstützte LINQ-Operatoren
Hier finden Sie eine Liste der unterstützten LINQ-Operatoren im LINQ-Anbieter, die im DocumentDB .NET SDK enthalten sind.
Select - Projektionen werden in SQL SELECT einschließlich Objektkonstruktion übersetzt.
Where- Filter werden in SQL WHERE übersetzt und unterstützen die Übersetzung zwischen &&, || und ! zu den SQL-Operatoren.
SelectMany- Ermöglicht das Abwickeln von Arrays in die SQL JOIN-Klausel. Kann zum Verketten / Verschachteln von Ausdrücken zum Filtern von Array-Elementen verwendet werden.
OrderBy and OrderByDescending - Übersetzt in ORDER BY aufsteigend / absteigend.
CompareTo- Übersetzt in Bereichsvergleiche. Wird häufig für Zeichenfolgen verwendet, da sie in .NET nicht vergleichbar sind.
Take - Wird in SQL TOP übersetzt, um die Ergebnisse einer Abfrage einzuschränken.
Math Functions - Unterstützt die Übersetzung von .NETs Abs, Acos, Asin, Atan, Ceiling, Cos, Exp, Floor, Log, Log10, Pow, Round, Sign, Sin, Sqrt, Tan und Truncate in die entsprechenden integrierten SQL-Funktionen.
String Functions - Unterstützt die Übersetzung von .NETs Concat, Contains, EndsWith, IndexOf, Count, ToLower, TrimStart, Replace, Reverse, TrimEnd, StartsWith, SubString und ToUpper in die entsprechenden integrierten SQL-Funktionen.
Array Functions - Unterstützt die Übersetzung von .NETs Concat, Contains und Count in die entsprechenden integrierten SQL-Funktionen.
Geospatial Extension Functions - Unterstützt die Übersetzung von Stub-Methoden Distance, Within, IsValid und IsValidDetailed in die entsprechenden integrierten SQL-Funktionen.
User-Defined Extension Function - Unterstützt die Übersetzung von der Stub-Methode UserDefinedFunctionProvider.Invoke in die entsprechende benutzerdefinierte Funktion.
Miscellaneous- Unterstützt die Übersetzung von Koaleszenz- und bedingten Operatoren. Kann je nach Kontext Contains in String CONTAINS, ARRAY_CONTAINS oder SQL IN übersetzen.
Schauen wir uns ein Beispiel an, in dem wir das .Net SDK verwenden werden. Im Folgenden sind die drei Dokumente aufgeführt, die wir für dieses Beispiel betrachten werden.
Neukunde 1
{
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}Neukunde 2
{
"name": "New Customer 2",
"address": {
"addressType": "Main Office",
"addressLine1": "678 Main Street",
"location": {
"city": "London",
"stateProvinceName": " London "
},
"postalCode": "11229",
"countryRegionName": "United Kingdom"
},
}Neukunde 3
{
"name": "New Customer 3",
"address": {
"addressType": "Main Office",
"addressLine1": "12 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}Es folgt der Code, in dem wir mit LINQ abfragen. Wir haben eine LINQ-Abfrage in definiertq, aber es wird nicht ausgeführt, bis wir .ToList darauf ausführen.
private static void QueryDocumentsWithLinq(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (LINQ) ****");
Console.WriteLine();
Console.WriteLine("Quering for US customers (LINQ)");
var q =
from d in client.CreateDocumentQuery<Customer>(collection.DocumentsLink)
where d.Address.CountryRegionName == "United States"
select new {
Id = d.Id,
Name = d.Name,
City = d.Address.Location.City
};
var documents = q.ToList();
Console.WriteLine("Found {0} US customers", documents.Count);
foreach (var document in documents) {
var d = document as dynamic;
Console.WriteLine(" Id: {0}; Name: {1}; City: {2}", d.Id, d.Name, d.City);
}
Console.WriteLine();
}Das SDK konvertiert unsere LINQ-Abfrage in die SQL-Syntax für DocumentDB und generiert eine SELECT- und WHERE-Klausel basierend auf unserer LINQ-Syntax.
Rufen wir die obigen Abfragen aus der CreateDocumentClient-Task auf.
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
QueryDocumentsWithLinq(client);
}
}Wenn der obige Code ausgeführt wird, wird die folgende Ausgabe erzeugt.
**** Query Documents (LINQ) ****
Quering for US customers (LINQ)
Found 2 US customers
Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1; City: Brooklyn
Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1; City: BrooklynHeutzutage ist JavaScript überall und nicht nur in Browsern. DocumentDB verwendet JavaScript als eine Art modernes T-SQL und unterstützt die transaktionale Ausführung der JavaScript-Logik nativ direkt innerhalb der Datenbank-Engine. DocumentDB bietet ein Programmiermodell zum Ausführen von JavaScript-basierter Anwendungslogik direkt in den Sammlungen in Bezug auf gespeicherte Prozeduren und Trigger.
Schauen wir uns ein Beispiel an, in dem wir eine einfache Speicherprozedur erstellen. Es folgen die Schritte -
Step 1 - Erstellen Sie eine neue Konsolenanwendung.
Step 2- Fügen Sie das .NET SDK von NuGet hinzu. Wir verwenden hier das .NET SDK. Dies bedeutet, dass wir C # -Code schreiben, um unsere gespeicherte Prozedur zu erstellen, auszuführen und dann zu löschen. Die gespeicherte Prozedur selbst wird jedoch in JavaScript geschrieben.
Step 3 - Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt.
Step 4 - Fügen Sie eine neue JavaScript-Datei für die gespeicherte Prozedur hinzu und nennen Sie sie HelloWorldStoreProce.js
Jede gespeicherte Prozedur ist nur eine JavaScript-Funktion, daher erstellen wir eine neue Funktion und benennen diese Funktion natürlich auch HelloWorldStoreProce. Es spielt keine Rolle, ob wir der Funktion überhaupt einen Namen geben. DocumentDB verweist auf diese gespeicherte Prozedur nur mit der ID, die wir beim Erstellen angeben.
function HelloWorldStoreProce() {
var context = getContext();
var response = context.getResponse();
response.setBody('Hello, and welcome to DocumentDB!');
}Die gespeicherte Prozedur ruft lediglich das Antwortobjekt aus dem Kontext ab und ruft dessen auf setBodyMethode zum Zurückgeben einer Zeichenfolge an den Aufrufer. In C # -Code erstellen wir die gespeicherte Prozedur, führen sie aus und löschen sie dann.
Gespeicherte Prozeduren sind pro Sammlung gültig, daher benötigen wir den SelfLink der Sammlung, um die gespeicherte Prozedur zu erstellen.
Step 5 - Erste Abfrage für die myfirstdb Datenbank und dann für die MyCollection Sammlung.
Das Erstellen einer gespeicherten Prozedur entspricht dem Erstellen einer anderen Ressource in DocumentDB.
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink, "SELECT * FROM
c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client.
CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client.ExecuteStoredProcedureAsync
(sproc.SelfLink); Console.WriteLine("Executed stored procedure; response = {0}", result.Response); // Delete stored procedure await client.DeleteStoredProcedureAsync(sproc.SelfLink); Console.WriteLine("Deleted stored procedure {0} ({1})", sproc.Id, sproc.ResourceId); } }
Step 6 - Erstellen Sie zuerst ein Definitionsobjekt mit der ID für die neue Ressource und rufen Sie dann eine der Create-Methoden auf der auf DocumentClientObjekt. Bei einer gespeicherten Prozedur enthält die Definition die ID und den tatsächlichen JavaScript-Code, den Sie an den Server senden möchten.
Step 7 - Rufen Sie an File.ReadAllText um den gespeicherten Prozedurcode aus der JS-Datei zu extrahieren.
Step 8 - Weisen Sie den Code der gespeicherten Prozedur der Eigenschaft body des Definitionsobjekts zu.
In Bezug auf DocumentDB ist die ID, die wir hier in der Definition angeben, der Name der gespeicherten Prozedur, unabhängig davon, wie wir die JavaScript-Funktion tatsächlich benennen.
Beim Erstellen gespeicherter Prozeduren und anderer serverseitiger Objekte wird jedoch empfohlen, JavaScript-Funktionen zu benennen und diese Funktionsnamen mit der ID übereinzustimmen, die wir in der Definition für DocumentDB festgelegt haben.
Step 9 - Rufen Sie an CreateStoredProcedureAsync, vorbei in der SelfLink für die MyCollectionSammlung und die Definition der gespeicherten Prozedur. Dies erstellt die gespeicherte Prozedur undResourceId die ihm zugewiesene DocumentDB.
Step 10 - Rufen Sie die gespeicherte Prozedur auf. ExecuteStoredProcedureAsyncNimmt einen Typparameter, den Sie auf den erwarteten Datentyp des von der gespeicherten Prozedur zurückgegebenen Werts festlegen, den Sie einfach als Objekt angeben können, wenn ein dynamisches Objekt zurückgegeben werden soll. Dies ist ein Objekt, dessen Eigenschaften zur Laufzeit gebunden werden.
In diesem Beispiel wissen wir, dass unsere gespeicherte Prozedur nur eine Zeichenfolge zurückgibt, und rufen daher auf ExecuteStoredProcedureAsync<string>.
Im Folgenden finden Sie die vollständige Implementierung der Datei Program.cs.
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocumentDBStoreProce {
class Program {
private static void Main(string[] args) {
Task.Run(async () => {
await SimpleStoredProcDemo();
}).Wait();
}
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client
.CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})", sproc
.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client
.ExecuteStoredProcedureAsync<string>(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}",
result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
}
}Wenn der obige Code ausgeführt wird, wird die folgende Ausgabe erzeugt.
Created stored procedure HelloWorldStoreProce (Ic8LAMEUVgACAAAAAAAAgA==)
Executed stored procedure; response = Hello, and welcome to DocumentDB!Wie in der obigen Ausgabe zu sehen ist, hat die Antwort-Eigenschaft "Hallo und willkommen bei DocumentDB!" von unserer gespeicherten Prozedur zurückgegeben.
DocumentDB SQL bietet Unterstützung für benutzerdefinierte Funktionen (User Defined Functions, UDFs). UDFs sind nur eine andere Art von JavaScript-Funktionen, die Sie schreiben können, und diese funktionieren so ziemlich wie erwartet. Sie können UDFs erstellen, um die Abfragesprache mit benutzerdefinierter Geschäftslogik zu erweitern, auf die Sie in Ihren Abfragen verweisen können.
Die DocumentDB SQL-Syntax wird erweitert, um benutzerdefinierte Anwendungslogik mit diesen UDFs zu unterstützen. UDFs können bei DocumentDB registriert und dann als Teil einer SQL-Abfrage referenziert werden.
Betrachten wir die folgenden drei Dokumente für dieses Beispiel.
AndersenFamily Dokument ist wie folgt.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily Dokument ist wie folgt.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily Dokument ist wie folgt.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein Beispiel an, in dem wir einige einfache UDFs erstellen.
Es folgt die Implementierung von CreateUserDefinedFunctions.
private async static Task CreateUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create User Defined Functions ****");
Console.WriteLine();
await CreateUserDefinedFunction(client, "udfRegEx");
}Wir haben eine udfRegEx und in CreateUserDefinedFunction erhalten wir den JavaScript-Code aus unserer lokalen Datei. Wir erstellen das Definitionsobjekt für die neue UDF und rufen CreateUserDefinedFunctionAsync mit dem SelfLink der Sammlung und dem udfDefinition-Objekt auf, wie im folgenden Code gezeigt.
private async static Task<UserDefinedFunction>
CreateUserDefinedFunction(DocumentClient client, string udfId) {
var udfBody = File.ReadAllText(@"..\..\Server\" + udfId + ".js");
var udfDefinition = new UserDefinedFunction {
Id = udfId,
Body = udfBody
};
var result = await client
.CreateUserDefinedFunctionAsync(_collection.SelfLink, udfDefinition);
var udf = result.Resource;
Console.WriteLine("Created user defined function {0}; RID: {1}",
udf.Id, udf.ResourceId);
return udf;
}Wir erhalten die neue UDF von der Ressourceneigenschaft des Ergebnisses zurück und geben sie an den Aufrufer zurück. Um die vorhandene UDF anzuzeigen, folgt die Implementierung vonViewUserDefinedFunctions. Wir nennenCreateUserDefinedFunctionQuery und durchlaufen sie wie gewohnt.
private static void ViewUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** View UDFs ****");
Console.WriteLine();
var udfs = client
.CreateUserDefinedFunctionQuery(_collection.UserDefinedFunctionsLink)
.ToList();
foreach (var udf in udfs) {
Console.WriteLine("User defined function {0}; RID: {1}", udf.Id, udf.ResourceId);
}
}DocumentDB SQL bietet keine integrierten Funktionen zum Suchen nach Teilzeichenfolgen oder regulären Ausdrücken. Daher füllt der folgende kleine Einzeiler diese Lücke, die eine JavaScript-Funktion ist.
function udfRegEx(input, regex) {
return input.match(regex);
}Verwenden Sie angesichts der Eingabezeichenfolge im ersten Parameter die in JavaScript integrierte Unterstützung für reguläre Ausdrücke, indem Sie die Mustervergleichszeichenfolge im zweiten Parameter an übergeben.match. Wir können eine Teilstring-Abfrage ausführen, um alle Geschäfte mit dem Wort Andersen zu findenlastName Eigentum.
private static void Execute_udfRegEx(DocumentClient client) {
var sql = "SELECT c.name FROM c WHERE udf.udfRegEx(c.lastName, 'Andersen') != null";
Console.WriteLine();
Console.WriteLine("Querying for Andersen");
var documents = client.CreateDocumentQuery(_collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} Andersen:", documents.Count);
foreach (var document in documents) {
Console.WriteLine("Id: {0}, Name: {1}", document.id, document.lastName);
}
}Beachten Sie, dass wir jede UDF-Referenz mit dem Präfix qualifizieren müssen udf. Wir haben gerade die SQL an weitergegebenCreateDocumentQuerywie jede gewöhnliche Abfrage. Rufen wir abschließend die obigen Abfragen aus dem aufCreateDocumentClient Aufgabe
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)){
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE
c.id = 'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'Families'").AsEnumerable().First();
await CreateUserDefinedFunctions(client);
ViewUserDefinedFunctions(client);
Execute_udfRegEx(client);
}
}Wenn der obige Code ausgeführt wird, wird die folgende Ausgabe erzeugt.
**** Create User Defined Functions ****
Created user defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
**** View UDFs ****
User defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA==
Querying for Andersen
Found 1 Andersen:
Id: AndersenFamily, Name: AndersenComposite QueryMit dieser Option können Sie Daten aus vorhandenen Abfragen kombinieren und anschließend Filter, Aggregate usw. anwenden, bevor Sie die Berichtsergebnisse anzeigen, die den kombinierten Datensatz anzeigen. Composite Query ruft mehrere Ebenen verwandter Informationen zu vorhandenen Abfragen ab und präsentiert die kombinierten Daten als einzelnes und abgeflachtes Abfrageergebnis.
Mit Composite Query haben Sie auch die Möglichkeit:
Wählen Sie die Option SQL-Bereinigung aus, um Tabellen und Felder zu entfernen, die aufgrund der Attributauswahl der Benutzer nicht benötigt werden.
Setzen Sie die Klauseln ORDER BY und GROUP BY.
Legen Sie die WHERE-Klausel als Filter für die Ergebnismenge einer zusammengesetzten Abfrage fest.
Die obigen Operatoren können zusammengesetzt werden, um leistungsfähigere Abfragen zu bilden. Da DocumentDB verschachtelte Sammlungen unterstützt, kann die Komposition entweder verkettet oder verschachtelt werden.
Betrachten wir die folgenden Dokumente für dieses Beispiel.
AndersenFamily Dokument ist wie folgt.
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}SmithFamily Dokument ist wie folgt.
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}WakefieldFamily Dokument ist wie folgt.
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}Schauen wir uns ein Beispiel für eine verkettete Abfrage an.
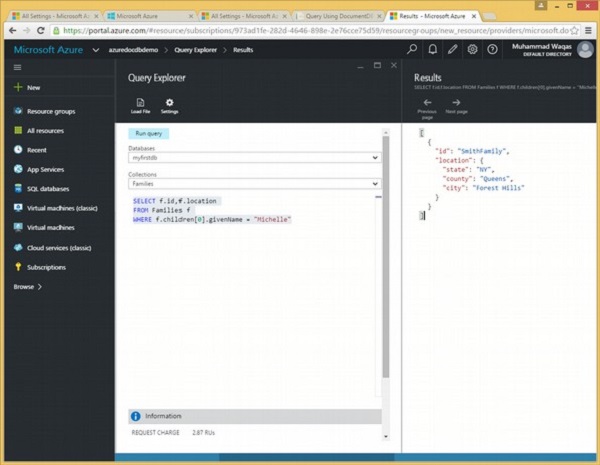
Es folgt die Abfrage, mit der die ID und der Standort der Familie abgerufen werden, in der sich das erste Kind befindet givenName ist Michelle.
SELECT f.id,f.location
FROM Families f
WHERE f.children[0].givenName = "Michelle"Wenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"id": "SmithFamily",
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
}
]Betrachten wir ein weiteres Beispiel für eine verkettete Abfrage.
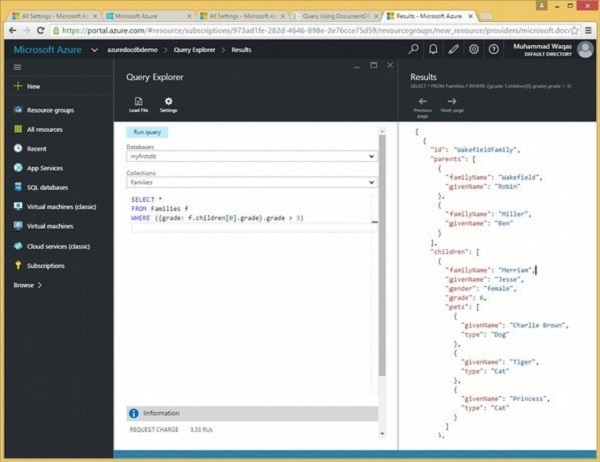
Es folgt die Abfrage, die alle Dokumente zurückgibt, bei denen die erste untergeordnete Klasse größer als 3 ist.
SELECT *
FROM Families f
WHERE ({grade: f.children[0].grade}.grade > 3)Wenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]Werfen wir einen Blick auf eine example von verschachtelten Abfragen.
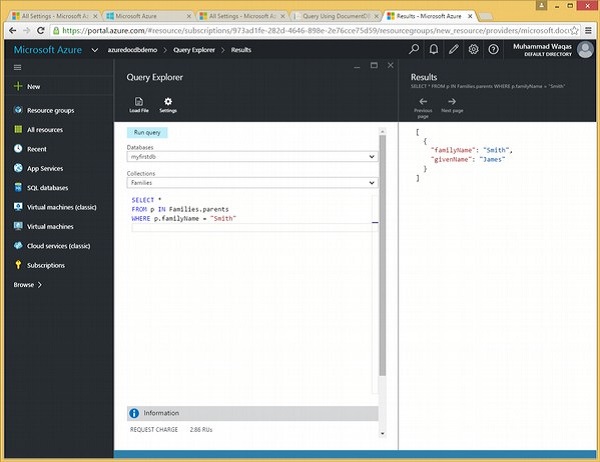
Im Folgenden finden Sie die Abfrage, die alle übergeordneten Elemente wiederholt und das Dokument an den folgenden Ort zurückgibt familyName ist Smith.
SELECT *
FROM p IN Families.parents
WHERE p.familyName = "Smith"Wenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
{
"familyName": "Smith",
"givenName": "James"
}
]Lassen Sie uns überlegen another example der verschachtelten Abfrage.
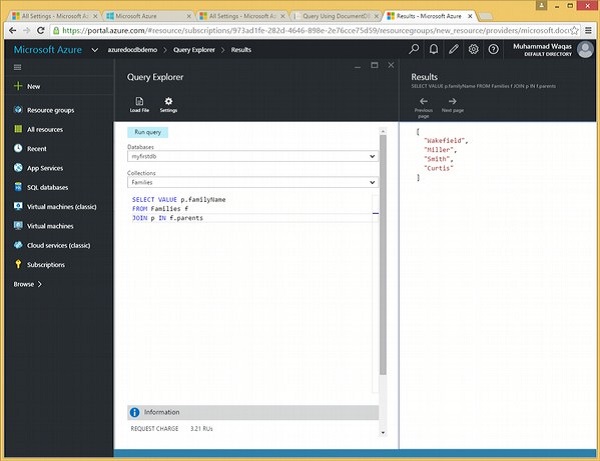
Es folgt die Abfrage, die alle zurückgibt familyName.
SELECT VALUE p.familyName
FROM Families f
JOIN p IN f.parentsWenn die obige Abfrage ausgeführt wird, wird die folgende Ausgabe erzeugt.
[
"Wakefield",
"Miller",
"Smith",
"Curtis"
]