H2O - Ausführen einer Beispielanwendung
Klicken Sie in der Liste der Beispiele auf den Link Airlines Delay Flow (siehe Abbildung unten).
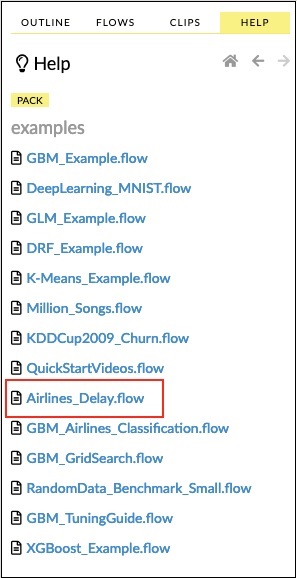
Nach der Bestätigung wird das neue Notebook geladen.
Alle Ausgaben löschen
Bevor wir die Code-Anweisungen im Notizbuch erläutern, lassen Sie uns alle Ausgaben löschen und das Notizbuch dann schrittweise ausführen. Um alle Ausgänge zu löschen, wählen Sie die folgende Menüoption:
Flow / Clear All Cell ContentsDies wird im folgenden Screenshot gezeigt -
Sobald alle Ausgaben gelöscht sind, werden wir jede Zelle im Notizbuch einzeln ausführen und ihre Ausgabe untersuchen.
Erste Zelle ausführen
Klicken Sie auf die erste Zelle. Links erscheint eine rote Flagge, die anzeigt, dass die Zelle ausgewählt ist. Dies ist wie im folgenden Screenshot gezeigt -

Der Inhalt dieser Zelle ist nur der in MarkDown (MD) geschriebene Programmkommentar. Der Inhalt beschreibt, was die geladene Anwendung tut. Um die Zelle auszuführen, klicken Sie auf das Symbol Ausführen (siehe Abbildung unten).

Unter der Zelle wird keine Ausgabe angezeigt, da die aktuelle Zelle keinen ausführbaren Code enthält. Der Cursor bewegt sich nun automatisch zur nächsten Zelle, die zur Ausführung bereit ist.
Daten importieren
Die nächste Zelle enthält die folgende Python-Anweisung:
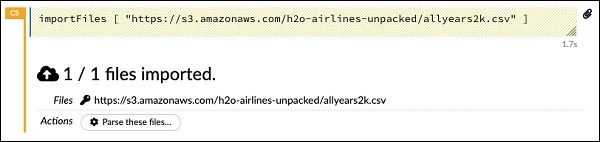
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]Die Anweisung importiert die Datei allyears2k.csv von Amazon AWS in das System. Wenn Sie die Zelle ausführen, wird die Datei importiert und Sie erhalten die folgende Ausgabe.
Einrichten des Datenparsers
Jetzt müssen wir die Daten analysieren und für unseren ML-Algorithmus geeignet machen. Dies erfolgt mit dem folgenden Befehl:
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]Nach Ausführung der obigen Anweisung wird ein Setup-Konfigurationsdialog angezeigt. Im Dialogfeld können Sie verschiedene Einstellungen zum Parsen der Datei vornehmen. Dies ist wie im folgenden Screenshot gezeigt -
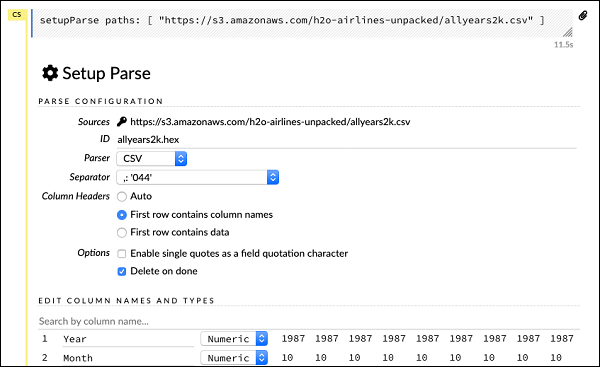
In diesem Dialogfeld können Sie den gewünschten Parser aus der angegebenen Dropdown-Liste auswählen und andere Parameter wie das Feldtrennzeichen usw. festlegen.
Daten analysieren
Die nächste Anweisung, die die Datendatei mithilfe der obigen Konfiguration analysiert, ist lang und wie hier gezeigt -
parseFiles
paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
destination_frame: "allyears2k.hex"
parse_type: "CSV"
separator: 44
number_columns: 31
single_quotes: false
column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime",
"ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode",
"Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed","IsDepDelayed"]
column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric"
,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric",
"Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum",
"Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"]
delete_on_done: true
check_header: 1
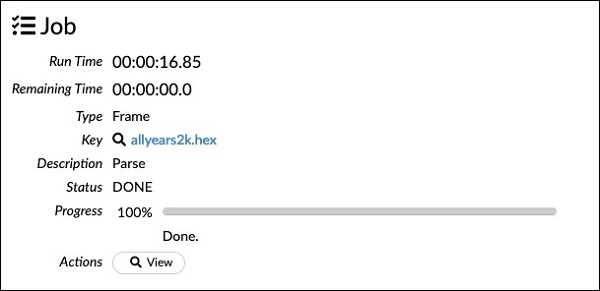
chunk_size: 4194304Beachten Sie, dass die Parameter, die Sie im Konfigurationsfeld eingerichtet haben, im obigen Code aufgeführt sind. Führen Sie nun diese Zelle aus. Nach einer Weile ist die Analyse abgeschlossen und Sie sehen die folgende Ausgabe:
Untersuchen des Datenrahmens
Nach der Verarbeitung wird ein Datenrahmen generiert, der mit der folgenden Anweisung überprüft werden kann:
getFrameSummary "allyears2k.hex"Nach Ausführung der obigen Anweisung wird die folgende Ausgabe angezeigt:
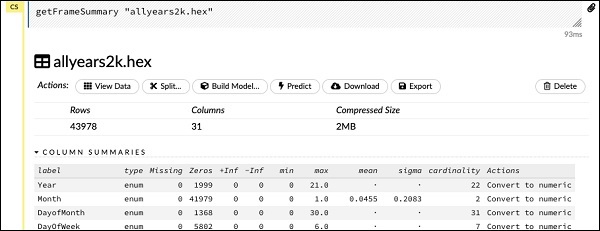
Jetzt können Ihre Daten in einen Algorithmus für maschinelles Lernen eingespeist werden.
Die nächste Anweisung ist ein Programmkommentar, der besagt, dass wir das Regressionsmodell verwenden und die voreingestellte Regularisierung und die Lambda-Werte angeben.
Modell erstellen
Als nächstes kommt die wichtigste Aussage, die das Modell selbst erstellt. Dies wird in der folgenden Anweisung angegeben -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}Wir verwenden glm, eine Suite für verallgemeinerte lineare Modelle, deren Familientyp auf Binomial eingestellt ist. Sie können diese in der obigen Anweisung hervorgehoben sehen. In unserem Fall ist die erwartete Ausgabe binär und deshalb verwenden wir den Binomialtyp. Sie können die anderen Parameter selbst untersuchen. Schauen Sie sich zum Beispiel Alpha und Lambda an, die wir zuvor angegeben hatten. In der Dokumentation zum GLM-Modell finden Sie Erläuterungen zu allen Parametern.
Führen Sie nun diese Anweisung aus. Bei der Ausführung wird die folgende Ausgabe generiert:

Natürlich würde die Ausführungszeit auf Ihrem Computer unterschiedlich sein. Nun kommt der interessanteste Teil dieses Beispielcodes.
Ausgabe untersuchen
Wir geben einfach das Modell aus, das wir mit der folgenden Anweisung erstellt haben:
getModel "glm_model"Beachten Sie, dass glm_model die Modell-ID ist, die wir beim Erstellen des Modells in der vorherigen Anweisung als model_id-Parameter angegeben haben. Dies gibt uns eine riesige Ausgabe, die die Ergebnisse mit verschiedenen Parametern detailliert. Eine Teilausgabe des Berichts ist im folgenden Screenshot dargestellt -
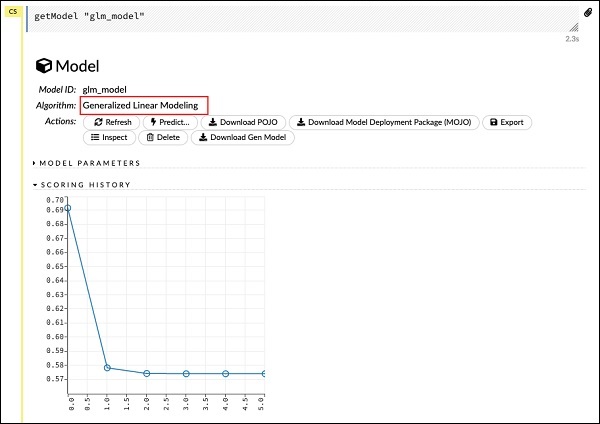
Wie Sie in der Ausgabe sehen können, ist dies das Ergebnis der Ausführung des Algorithmus für die verallgemeinerte lineare Modellierung in Ihrem Dataset.
Direkt über der SCORING HISTORY sehen Sie das MODEL PARAMETERS-Tag, erweitern es und sehen die Liste aller Parameter, die beim Erstellen des Modells verwendet werden. Dies ist im folgenden Screenshot dargestellt.
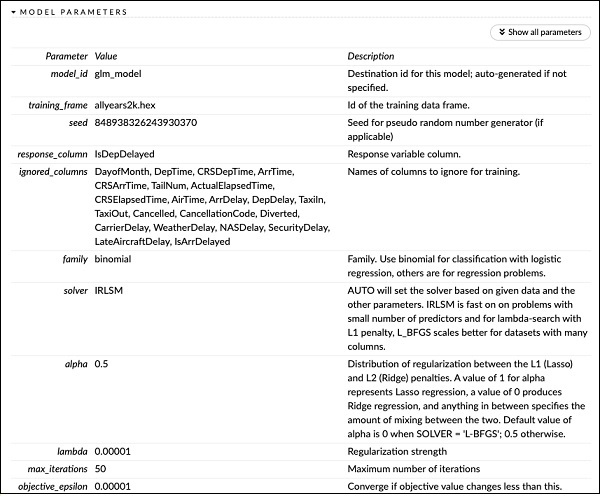
Ebenso bietet jedes Tag eine detaillierte Ausgabe eines bestimmten Typs. Erweitern Sie die verschiedenen Tags selbst, um die Ergebnisse verschiedener Arten zu untersuchen.
Ein anderes Modell bauen
Als nächstes werden wir ein Deep Learning-Modell auf unserem Datenrahmen erstellen. Die nächste Anweisung im Beispielcode ist nur ein Programmkommentar. Die folgende Anweisung ist eigentlich ein Modellbildungsbefehl. Es ist wie hier gezeigt -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}Wie Sie im obigen Code sehen können, geben wir Deeplearning zum Erstellen des Modells mit mehreren Parametern an, die auf die entsprechenden Werte eingestellt sind, wie in der Dokumentation des Deeplearning-Modells angegeben. Wenn Sie diese Anweisung ausführen, dauert es länger als beim Erstellen des GLM-Modells. Sie sehen die folgende Ausgabe, wenn der Modellbau abgeschlossen ist, wenn auch mit unterschiedlichen Zeitpunkten.

Untersuchen der Ausgabe des Deep Learning-Modells
Dies erzeugt die Art der Ausgabe, die wie im vorherigen Fall mit der folgenden Anweisung untersucht werden kann.
getModel "deeplearning_model"Wir werden die ROC-Kurvenausgabe wie unten gezeigt als Kurzreferenz betrachten.
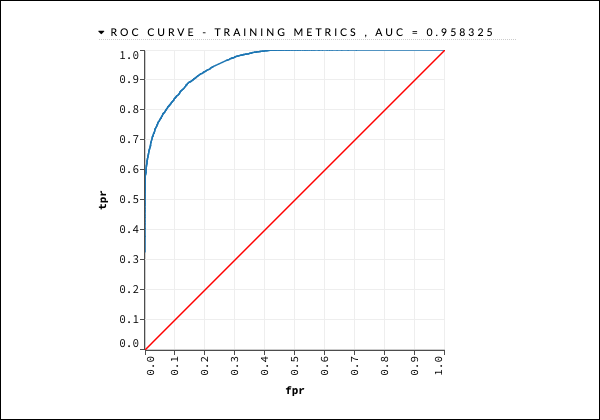
Erweitern Sie wie im vorherigen Fall die verschiedenen Registerkarten und untersuchen Sie die verschiedenen Ausgaben.
Modell speichern
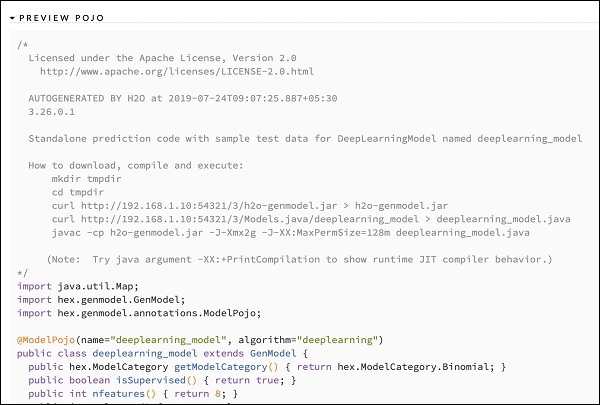
Nachdem Sie die Ausgabe verschiedener Modelle untersucht haben, entscheiden Sie sich für eines dieser Modelle in Ihrer Produktionsumgebung. Mit H20 können Sie dieses Modell als POJO (Plain Old Java Object) speichern.
Erweitern Sie das letzte Tag PREVIEW POJO in der Ausgabe, und Sie sehen den Java-Code für Ihr fein abgestimmtes Modell. Verwenden Sie dies in Ihrer Produktionsumgebung.
Als nächstes lernen wir eine sehr aufregende Funktion von H2O kennen. Wir werden lernen, wie man AutoML verwendet, um verschiedene Algorithmen basierend auf ihrer Leistung zu testen und zu bewerten.