HBase - Kurzanleitung
Seit 1970 ist RDBMS die Lösung für Probleme bei der Datenspeicherung und -wartung. Nach dem Aufkommen von Big Data erkannten Unternehmen den Vorteil der Verarbeitung von Big Data und entschieden sich für Lösungen wie Hadoop.
Hadoop verwendet ein verteiltes Dateisystem zum Speichern von Big Data und MapReduce zum Verarbeiten. Hadoop zeichnet sich durch die Speicherung und Verarbeitung großer Datenmengen in verschiedenen Formaten aus, z. B. beliebig, halb- oder sogar unstrukturiert.
Einschränkungen von Hadoop
Hadoop kann nur Stapelverarbeitung durchführen, und auf Daten wird nur nacheinander zugegriffen. Das heißt, man muss den gesamten Datensatz auch nach den einfachsten Jobs durchsuchen.
Ein großer Datensatz führt bei der Verarbeitung zu einem weiteren großen Datensatz, der ebenfalls nacheinander verarbeitet werden sollte. Zu diesem Zeitpunkt ist eine neue Lösung erforderlich, um auf jeden Datenpunkt in einer einzigen Zeiteinheit zuzugreifen (Direktzugriff).
Hadoop-Direktzugriffsdatenbanken
Anwendungen wie HBase, Cassandra, couchDB, Dynamo und MongoDB sind einige der Datenbanken, die große Datenmengen speichern und auf zufällige Weise auf die Daten zugreifen.
Was ist HBase?
HBase ist eine verteilte spaltenorientierte Datenbank, die auf dem Hadoop-Dateisystem basiert. Es ist ein Open-Source-Projekt und horizontal skalierbar.
HBase ist ein Datenmodell, das der großen Tabelle von Google ähnelt und einen schnellen Direktzugriff auf große Mengen strukturierter Daten ermöglicht. Es nutzt die Fehlertoleranz des Hadoop File System (HDFS).
Es ist Teil des Hadoop-Ökosystems, das zufälligen Lese- / Schreibzugriff in Echtzeit auf Daten im Hadoop-Dateisystem bietet.
Man kann die Daten entweder direkt oder über HBase in HDFS speichern. Der Datenkonsument liest / greift mit HBase zufällig auf die Daten in HDFS zu. HBase befindet sich auf dem Hadoop-Dateisystem und bietet Lese- und Schreibzugriff.

HBase und HDFS
| HDFS | HBase |
|---|---|
| HDFS ist ein verteiltes Dateisystem, das zum Speichern großer Dateien geeignet ist. | HBase ist eine Datenbank, die auf dem HDFS basiert. |
| HDFS unterstützt keine schnelle Suche nach einzelnen Datensätzen. | HBase bietet schnelle Suchvorgänge für größere Tabellen. |
| Es bietet eine Stapelverarbeitung mit hoher Latenz; Kein Konzept der Stapelverarbeitung. | Es bietet Zugriff auf einzelne Zeilen mit geringer Latenz aus Milliarden von Datensätzen (Direktzugriff). |
| Es bietet nur sequentiellen Zugriff auf Daten. | HBase verwendet intern Hash-Tabellen und bietet Direktzugriff. Die Daten werden in indizierten HDFS-Dateien gespeichert, um eine schnellere Suche zu ermöglichen. |
Speichermechanismus in HBase
HBase ist a column-oriented databaseund die darin enthaltenen Tabellen sind nach Zeilen sortiert. Das Tabellenschema definiert nur Spaltenfamilien, bei denen es sich um die Schlüsselwertpaare handelt. Eine Tabelle hat mehrere Spaltenfamilien und jede Spaltenfamilie kann eine beliebige Anzahl von Spalten haben. Nachfolgende Spaltenwerte werden zusammenhängend auf der Festplatte gespeichert. Jeder Zellenwert der Tabelle hat einen Zeitstempel. Kurz gesagt, in einer HBase:
- Tabelle ist eine Sammlung von Zeilen.
- Zeile ist eine Sammlung von Spaltenfamilien.
- Die Spaltenfamilie ist eine Sammlung von Spalten.
- Die Spalte ist eine Sammlung von Schlüsselwertpaaren.
Im Folgenden finden Sie ein Beispielschema für eine Tabelle in HBase.
| Rowid | Spaltenfamilie | Spaltenfamilie | Spaltenfamilie | Spaltenfamilie | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
Spaltenorientiert und zeilenorientiert
Spaltenorientierte Datenbanken sind solche, in denen Datentabellen als Abschnitte von Datenspalten und nicht als Datenzeilen gespeichert werden. In Kürze werden sie Spaltenfamilien haben.
| Zeilenorientierte Datenbank | Spaltenorientierte Datenbank |
|---|---|
| Es ist für den Online-Transaktionsprozess (OLTP) geeignet. | Es ist für die Online Analytical Processing (OLAP) geeignet. |
| Solche Datenbanken sind für eine kleine Anzahl von Zeilen und Spalten ausgelegt. | Spaltenorientierte Datenbanken sind für große Tabellen konzipiert. |
Das folgende Bild zeigt Spaltenfamilien in einer spaltenorientierten Datenbank:
HBase und RDBMS
| HBase | RDBMS |
|---|---|
| HBase ist schemalos und hat nicht das Konzept eines festen Spaltenschemas. definiert nur Spaltenfamilien. | Ein RDBMS wird von seinem Schema gesteuert, das die gesamte Struktur von Tabellen beschreibt. |
| Es ist für breite Tische gebaut. HBase ist horizontal skalierbar. | Es ist dünn und für kleine Tische gebaut. Schwer zu skalieren. |
| In HBase sind keine Transaktionen vorhanden. | RDBMS ist eine Transaktion. |
| Es hat de-normalisierte Daten. | Es werden normalisierte Daten vorliegen. |
| Es ist sowohl für halbstrukturierte als auch für strukturierte Daten geeignet. | Es ist gut für strukturierte Daten. |
Eigenschaften von HBase
- HBase ist linear skalierbar.
- Es verfügt über eine automatische Fehlerunterstützung.
- Es bietet konsistentes Lesen und Schreiben.
- Es lässt sich sowohl als Quelle als auch als Ziel in Hadoop integrieren.
- Es hat einfache Java-API für Client.
- Es bietet Datenreplikation über Cluster hinweg.
Verwendung von HBase
Apache HBase wird verwendet, um zufälligen Lese- / Schreibzugriff in Echtzeit auf Big Data zu haben.
Es hostet sehr große Tabellen auf Clustern von Standardhardware.
Apache HBase ist eine nicht relationale Datenbank, die dem Bigtable von Google nachempfunden ist. Bigtable funktioniert im Google File System, ebenso wie Apache HBase auf Hadoop und HDFS.
Anwendungen von HBase
- Es wird immer dann verwendet, wenn schwere Anwendungen geschrieben werden müssen.
- HBase wird immer dann verwendet, wenn ein schneller Direktzugriff auf verfügbare Daten erforderlich ist.
- Unternehmen wie Facebook, Twitter, Yahoo und Adobe verwenden HBase intern.
HBase-Geschichte
| Jahr | Veranstaltung |
|---|---|
| November 2006 | Google hat das Papier auf BigTable veröffentlicht. |
| Februar 2007 | Der erste HBase-Prototyp wurde als Hadoop-Beitrag erstellt. |
| Okt 2007 | Die erste verwendbare HBase zusammen mit Hadoop 0.15.0 wurde veröffentlicht. |
| Jan 2008 | HBase wurde das Teilprojekt von Hadoop. |
| Okt 2008 | HBase 0.18.1 wurde freigesetzt. |
| Jan 2009 | HBase 0.19.0 wurde veröffentlicht. |
| September 2009 | HBase 0.20.0 wurde veröffentlicht. |
| Mai 2010 | HBase wurde zum Apache-Top-Level-Projekt. |
In HBase werden Tabellen in Regionen aufgeteilt und von den Regionsservern bereitgestellt. Regionen werden vertikal durch Spaltenfamilien in "Stores" unterteilt. Speicher werden als Dateien in HDFS gespeichert. Unten ist die Architektur von HBase dargestellt.
Note: Der Begriff "Speicher" wird für Regionen verwendet, um die Speicherstruktur zu erklären.
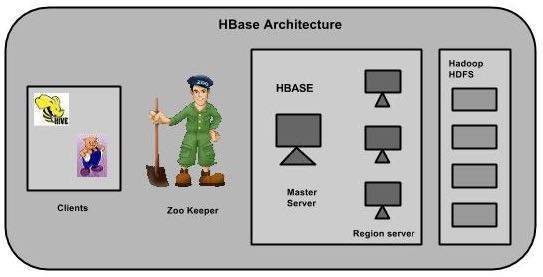
HBase besteht aus drei Hauptkomponenten: der Clientbibliothek, einem Master-Server und Regionsservern. Regionsserver können je nach Anforderung hinzugefügt oder entfernt werden.
MasterServer
Der Master-Server -
Weist den Regionsservern Regionen zu und verwendet für diese Aufgabe die Hilfe von Apache ZooKeeper.
Behandelt den Lastausgleich der Regionen über Regionsserver hinweg. Es entlädt die ausgelasteten Server und verschiebt die Regionen auf weniger belegte Server.
Behält den Status des Clusters bei, indem der Lastausgleich ausgehandelt wird.
Ist verantwortlich für Schemaänderungen und andere Metadatenoperationen wie das Erstellen von Tabellen und Spaltenfamilien.
Regionen
Regionen sind nichts anderes als Tabellen, die auf die Regionsserver verteilt sind.
Regionsserver
Die Regionsserver haben Regionen, die -
- Kommunizieren Sie mit dem Client und erledigen Sie datenbezogene Vorgänge.
- Verarbeiten Sie Lese- und Schreibanforderungen für alle Regionen darunter.
- Bestimmen Sie die Größe der Region, indem Sie die Schwellenwerte für die Regionsgröße befolgen.
Wenn wir uns den Regionsserver genauer ansehen, enthält er Regionen und Speicher wie folgt:
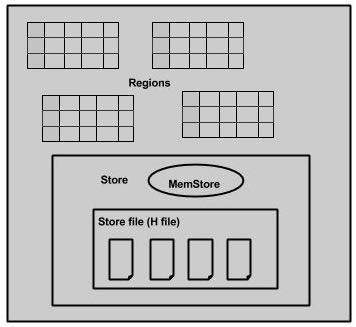
Der Speicher enthält Speicher und HFiles. Memstore ist wie ein Cache-Speicher. Alles, was in die HBase eingegeben wird, wird hier zunächst gespeichert. Später werden die Daten übertragen und als Blöcke in Hfiles gespeichert und der Memstore wird geleert.
Tierpfleger
Zookeeper ist ein Open-Source-Projekt, das Dienste wie das Verwalten von Konfigurationsinformationen, das Benennen, das Bereitstellen einer verteilten Synchronisierung usw. bereitstellt.
Zookeeper verfügt über kurzlebige Knoten, die verschiedene Regionsserver darstellen. Master-Server verwenden diese Knoten, um verfügbare Server zu ermitteln.
Zusätzlich zur Verfügbarkeit werden die Knoten auch zum Verfolgen von Serverfehlern oder Netzwerkpartitionen verwendet.
Clients kommunizieren über Zookeeper mit Regionsservern.
Im Pseudo- und Standalone-Modus kümmert sich HBase selbst um den Tierpfleger.
In diesem Kapitel wird erläutert, wie HBase installiert und zunächst konfiguriert wird. Java und Hadoop sind erforderlich, um mit HBase fortzufahren. Daher müssen Sie Java und Hadoop herunterladen und auf Ihrem System installieren.
Setup vor der Installation
Bevor wir Hadoop in einer Linux-Umgebung installieren, müssen wir Linux mit einrichten ssh(Sichere Shell). Führen Sie die folgenden Schritte aus, um die Linux-Umgebung einzurichten.
Benutzer erstellen
Zunächst wird empfohlen, einen separaten Benutzer für Hadoop zu erstellen, um das Hadoop-Dateisystem vom Unix-Dateisystem zu isolieren. Führen Sie die folgenden Schritte aus, um einen Benutzer zu erstellen.
- Öffnen Sie den Stamm mit dem Befehl "su".
- Erstellen Sie einen Benutzer aus dem Root-Konto mit dem Befehl "useradd username".
- Jetzt können Sie mit dem Befehl "su username" ein bestehendes Benutzerkonto eröffnen.
Öffnen Sie das Linux-Terminal und geben Sie die folgenden Befehle ein, um einen Benutzer zu erstellen.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdSSH-Setup und Schlüsselgenerierung
Das SSH-Setup ist erforderlich, um verschiedene Vorgänge im Cluster auszuführen, z. B. Start-, Stopp- und verteilte Daemon-Shell-Vorgänge. Um verschiedene Benutzer von Hadoop zu authentifizieren, muss ein öffentliches / privates Schlüsselpaar für einen Hadoop-Benutzer bereitgestellt und für verschiedene Benutzer freigegeben werden.
Die folgenden Befehle werden verwendet, um mit SSH ein Schlüsselwertpaar zu generieren. Kopieren Sie die öffentlichen Schlüssel aus id_rsa.pub in autorisierte Schlüssel und geben Sie Eigentümer-, Lese- und Schreibberechtigungen für die Datei "autorisierte Schlüssel" an.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keysÜberprüfen Sie ssh
ssh localhostJava installieren
Java ist die Hauptvoraussetzung für Hadoop und HBase. Zunächst sollten Sie die Existenz von Java in Ihrem System mithilfe von "Java-Version" überprüfen. Die Syntax des Java-Versionsbefehls ist unten angegeben.
$ java -versionWenn alles gut funktioniert, erhalten Sie die folgende Ausgabe.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Wenn Java nicht auf Ihrem System installiert ist, führen Sie die folgenden Schritte aus, um Java zu installieren.
Schritt 1
Laden Sie Java (JDK <neueste Version> - X64.tar.gz) über den folgenden Link Oracle Java herunter .
Dann jdk-7u71-linux-x64.tar.gz wird in Ihr System heruntergeladen.
Schritt 2
Im Allgemeinen finden Sie die heruntergeladene Java-Datei im Ordner Downloads. Überprüfen Sie es und extrahieren Sie diejdk-7u71-linux-x64.gz Datei mit den folgenden Befehlen.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzSchritt 3
Um Java allen Benutzern zur Verfügung zu stellen, müssen Sie es an den Speicherort „/ usr / local /“ verschieben. Öffnen Sie root und geben Sie die folgenden Befehle ein.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitSchritt 4
Zum Einrichten PATH und JAVA_HOME Variablen, fügen Sie die folgenden Befehle hinzu ~/.bashrc Datei.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binÜbernehmen Sie nun alle Änderungen in das aktuell laufende System.
$ source ~/.bashrcSchritt 5
Verwenden Sie die folgenden Befehle, um Java-Alternativen zu konfigurieren:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarÜberprüfen Sie nun die java -version Befehl vom Terminal wie oben erläutert.
Hadoop herunterladen
Nach der Installation von Java müssen Sie Hadoop installieren. Überprüfen Sie zunächst die Existenz von Hadoop mit dem Befehl „Hadoop-Version“ (siehe unten).
hadoop versionWenn alles gut funktioniert, erhalten Sie die folgende Ausgabe.
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using
/home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarWenn Ihr System Hadoop nicht finden kann, laden Sie Hadoop in Ihr System herunter. Befolgen Sie dazu die unten angegebenen Befehle.
Laden Sie hadoop-2.6.0 mit den folgenden Befehlen von Apache Software Foundation herunter und extrahieren Sie es .
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitHadoop installieren
Installieren Sie Hadoop in einem der erforderlichen Modi. Hier demonstrieren wir HBase-Funktionen im pseudoverteilten Modus. Installieren Sie daher Hadoop im pseudoverteilten Modus.
Die folgenden Schritte werden zur Installation verwendet Hadoop 2.4.1.
Schritt 1 - Hadoop einrichten
Sie können Hadoop-Umgebungsvariablen festlegen, indem Sie die folgenden Befehle an anhängen ~/.bashrc Datei.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEÜbernehmen Sie nun alle Änderungen in das aktuell laufende System.
$ source ~/.bashrcSchritt 2 - Hadoop-Konfiguration
Sie finden alle Hadoop-Konfigurationsdateien unter dem Speicherort "$ HADOOP_HOME / etc / hadoop". Sie müssen Änderungen an diesen Konfigurationsdateien entsprechend Ihrer Hadoop-Infrastruktur vornehmen.
$ cd $HADOOP_HOME/etc/hadoopUm Hadoop-Programme in Java zu entwickeln, müssen Sie die Java-Umgebungsvariable in zurücksetzen hadoop-env.sh Datei durch Ersetzen JAVA_HOME Wert mit dem Speicherort von Java in Ihrem System.
export JAVA_HOME=/usr/local/jdk1.7.0_71Sie müssen die folgenden Dateien bearbeiten, um Hadoop zu konfigurieren.
core-site.xml
Das core-site.xml Die Datei enthält Informationen wie die für die Hadoop-Instanz verwendete Portnummer, den für das Dateisystem zugewiesenen Speicher, das Speicherlimit zum Speichern von Daten und die Größe der Lese- / Schreibpuffer.
Öffnen Sie core-site.xml und fügen Sie die folgenden Eigenschaften zwischen den Tags <configuration> und </ configuration> hinzu.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Das hdfs-site.xml Die Datei enthält Informationen wie den Wert der Replikationsdaten, den Namensknotenpfad und den Datenknotenpfad Ihrer lokalen Dateisysteme, in denen Sie die Hadoop-Infrastruktur speichern möchten.
Nehmen wir die folgenden Daten an.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeÖffnen Sie diese Datei und fügen Sie die folgenden Eigenschaften zwischen den Tags <configuration>, </ configuration> hinzu.
<configuration>
<property>
<name>dfs.replication</name >
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note: In der obigen Datei sind alle Eigenschaftswerte benutzerdefiniert und Sie können Änderungen entsprechend Ihrer Hadoop-Infrastruktur vornehmen.
yarn-site.xml
Diese Datei wird verwendet, um Garn in Hadoop zu konfigurieren. Öffnen Sie die Datei yarn-site.xml und fügen Sie die folgende Eigenschaft zwischen <configuration $ gt;, </ configuration $ gt; Tags in dieser Datei.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Diese Datei wird verwendet, um anzugeben, welches MapReduce-Framework wir verwenden. Standardmäßig enthält Hadoop eine Vorlage von yarn-site.xml. Zunächst muss die Datei von kopiert werdenmapred-site.xml.template zu mapred-site.xml Datei mit dem folgenden Befehl.
$ cp mapred-site.xml.template mapred-site.xmlÖffnen mapred-site.xml Datei und fügen Sie die folgenden Eigenschaften zwischen den Tags <configuration> und </ configuration> hinzu.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Überprüfen der Hadoop-Installation
Die folgenden Schritte werden verwendet, um die Hadoop-Installation zu überprüfen.
Schritt 1 - Einrichtung des Namensknotens
Richten Sie den Namensknoten mit dem Befehl "hdfs namenode -format" wie folgt ein.
$ cd ~ $ hdfs namenode -formatDas erwartete Ergebnis ist wie folgt.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Schritt 2 - Überprüfen von Hadoop dfs
Der folgende Befehl wird verwendet, um dfs zu starten. Durch Ausführen dieses Befehls wird Ihr Hadoop-Dateisystem gestartet.
$ start-dfs.shDie erwartete Ausgabe ist wie folgt.
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Schritt 3 - Überprüfen des Garnskripts
Der folgende Befehl wird verwendet, um das Garnskript zu starten. Wenn Sie diesen Befehl ausführen, werden Ihre Garn-Dämonen gestartet.
$ start-yarn.shDie erwartete Ausgabe ist wie folgt.
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outSchritt 4 - Zugriff auf Hadoop über den Browser
Die Standardportnummer für den Zugriff auf Hadoop ist 50070. Verwenden Sie die folgende URL, um Hadoop-Dienste in Ihrem Browser abzurufen.
http://localhost:50070
Schritt 5 - Überprüfen Sie alle Anwendungen des Clusters
Die Standardportnummer für den Zugriff auf alle Clusteranwendungen lautet 8088. Verwenden Sie die folgende URL, um diesen Dienst aufzurufen.
http://localhost:8088/
HBase installieren
Wir können HBase in jedem der drei Modi installieren: Standalone-Modus, Pseudo Distributed-Modus und Fully Distributed-Modus.
HBase im Standalone-Modus installieren
Laden Sie die neueste stabile Version des HBase-Formulars herunter http://www.interior-dsgn.com/apache/hbase/stable/Verwenden Sie den Befehl „wget“ und extrahieren Sie ihn mit dem Befehl tar „zxvf“. Siehe den folgenden Befehl.
$cd usr/local/ $wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gzWechseln Sie in den Superuser-Modus und verschieben Sie den HBase-Ordner wie unten gezeigt nach / usr / local.
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/HBase im Standalone-Modus konfigurieren
Bevor Sie mit HBase fortfahren können, müssen Sie die folgenden Dateien bearbeiten und HBase konfigurieren.
hbase-env.sh
Stellen Sie das Java-Home für HBase ein und öffnen Sie es hbase-env.shDatei aus dem Ordner conf. Bearbeiten Sie die Umgebungsvariable JAVA_HOME und ändern Sie den vorhandenen Pfad zu Ihrer aktuellen Variablen JAVA_HOME wie unten gezeigt.
cd /usr/local/Hbase/conf
gedit hbase-env.shDadurch wird die Datei env.sh von HBase geöffnet. Ersetzen Sie nun die vorhandenenJAVA_HOME Wert mit Ihrem aktuellen Wert wie unten gezeigt.
export JAVA_HOME=/usr/lib/jvm/java-1.7.0hbase-site.xml
Dies ist die Hauptkonfigurationsdatei von HBase. Stellen Sie das Datenverzeichnis auf einen geeigneten Speicherort ein, indem Sie den HBase-Basisordner in / usr / local / HBase öffnen. Im conf-Ordner finden Sie mehrere Dateien, öffnen Sie diehbase-site.xml Datei wie unten gezeigt.
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xmlIn der hbase-site.xmlDatei finden Sie die Tags <configuration> und </ configuration>. Legen Sie in ihnen das HBase-Verzeichnis unter dem Eigenschaftsschlüssel mit dem Namen "hbase.rootdir" fest, wie unten gezeigt.
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>Damit ist der HBase-Installations- und Konfigurationsteil erfolgreich abgeschlossen. Wir können HBase mit verwendenstart-hbase.shSkript im Ordner bin von HBase. Öffnen Sie dazu den HBase-Home-Ordner und führen Sie das HBase-Startskript wie unten gezeigt aus.
$cd /usr/local/HBase/bin
$./start-hbase.shWenn beim Versuch, das HBase-Startskript auszuführen, alles gut läuft, wird eine Meldung angezeigt, dass HBase gestartet wurde.
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.outInstallieren von HBase im pseudoverteilten Modus
Lassen Sie uns nun überprüfen, wie HBase im pseudoverteilten Modus installiert ist.
HBase konfigurieren
Bevor Sie mit HBase fortfahren, konfigurieren Sie Hadoop und HDFS auf Ihrem lokalen System oder auf einem Remote-System und stellen Sie sicher, dass sie ausgeführt werden. Stoppen Sie HBase, wenn es ausgeführt wird.
hbase-site.xml
Bearbeiten Sie die Datei hbase-site.xml, um die folgenden Eigenschaften hinzuzufügen.
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>Es wird erwähnt, in welchem Modus HBase ausgeführt werden soll. Ändern Sie in derselben Datei aus dem lokalen Dateisystem die Datei hbase.rootdir, Ihre HDFS-Instanzadresse, mithilfe der URI-Syntax hdfs: ////. Wir führen HDFS auf dem lokalen Host an Port 8030 aus.
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8030/hbase</value>
</property>HBase starten
Navigieren Sie nach Abschluss der Konfiguration zum HBase-Ausgangsordner und starten Sie HBase mit dem folgenden Befehl.
$cd /usr/local/HBase
$bin/start-hbase.shNote: Stellen Sie vor dem Starten von HBase sicher, dass Hadoop ausgeführt wird.
Überprüfen des HBase-Verzeichnisses in HDFS
HBase erstellt sein Verzeichnis in HDFS. Navigieren Sie zum Anzeigen des erstellten Verzeichnisses zu Hadoop bin und geben Sie den folgenden Befehl ein.
$ ./bin/hadoop fs -ls /hbaseWenn alles gut geht, erhalten Sie die folgende Ausgabe.
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALsStarten und Stoppen eines Masters
Mit der Datei "local-master-backup.sh" können Sie bis zu 10 Server starten. Öffnen Sie den Home-Ordner von HBase, master und führen Sie den folgenden Befehl aus, um ihn zu starten.
$ ./bin/local-master-backup.sh 2 4Um einen Sicherungsmaster zu beenden, benötigen Sie seine Prozess-ID, die in einer Datei mit dem Namen gespeichert wird “/tmp/hbase-USER-X-master.pid.” Sie können den Sicherungsmaster mit dem folgenden Befehl beenden.
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9RegionServer starten und stoppen
Mit dem folgenden Befehl können Sie mehrere Regionsserver von einem einzigen System aus ausführen.
$ .bin/local-regionservers.sh start 2 3Verwenden Sie den folgenden Befehl, um einen Regionsserver zu stoppen.
$ .bin/local-regionservers.sh stop 3
Starten von HBaseShell
Nach erfolgreicher Installation von HBase können Sie HBase Shell starten. Nachfolgend finden Sie die Abfolge der Schritte, die zum Starten der HBase-Shell ausgeführt werden müssen. Öffnen Sie das Terminal und melden Sie sich als Superuser an.
Starten Sie das Hadoop-Dateisystem
Durchsuchen Sie den Hadoop-Home-Ordner sbin und starten Sie das Hadoop-Dateisystem wie unten gezeigt.
$cd $HADOOP_HOME/sbin
$start-all.shStarten Sie HBase
Durchsuchen Sie den Ordner bin im HBase-Stammverzeichnis und starten Sie HBase.
$cd /usr/local/HBase
$./bin/start-hbase.shStarten Sie HBase Master Server
Dies ist das gleiche Verzeichnis. Starten Sie es wie unten gezeigt.
$./bin/local-master-backup.sh start 2 (number signifies specific
server.)Region starten
Starten Sie den Regionsserver wie unten gezeigt.
$./bin/./local-regionservers.sh start 3Starten Sie die HBase-Shell
Sie können die HBase-Shell mit dem folgenden Befehl starten.
$cd bin
$./hbase shellDadurch erhalten Sie die unten gezeigte HBase Shell-Eingabeaufforderung.
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18:26:29 PST 2014
hbase(main):001:0>HBase-Webschnittstelle
Geben Sie die folgende URL in den Browser ein, um auf die Weboberfläche von HBase zuzugreifen.
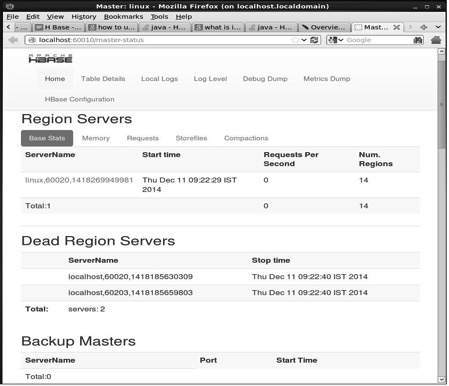
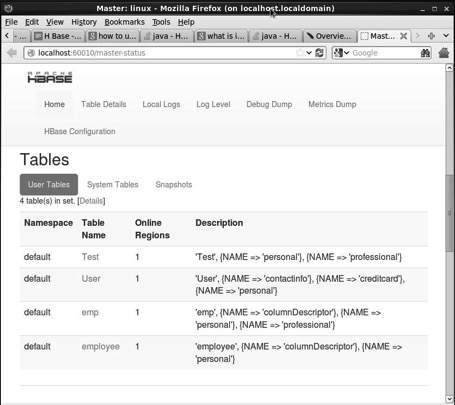
http://localhost:60010Diese Schnittstelle listet Ihre aktuell ausgeführten Region-Server, Backup-Master und HBase-Tabellen auf.
HBase Region Server und Backup Master
HBase-Tabellen
Java-Umgebung einstellen
Wir können auch über Java-Bibliotheken mit HBase kommunizieren. Bevor Sie jedoch über die Java-API auf HBase zugreifen, müssen Sie den Klassenpfad für diese Bibliotheken festlegen.
Klassenpfad einstellen
Bevor Sie mit der Programmierung fortfahren, setzen Sie den Klassenpfad auf HBase-Bibliotheken in .bashrcDatei. Öffnen.bashrc in einem der Editoren wie unten gezeigt.
$ gedit ~/.bashrcLegen Sie den Klassenpfad für HBase-Bibliotheken (lib-Ordner in HBase) wie unten gezeigt fest.
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*Dies soll verhindern, dass beim Zugriff auf die HBase über die Java-API die Ausnahme "Klasse nicht gefunden" auftritt.
In diesem Kapitel wird erläutert, wie Sie die mit HBase gelieferte interaktive HBase-Shell starten.
HBase Shell
HBase enthält eine Shell, mit der Sie mit HBase kommunizieren können. HBase verwendet das Hadoop-Dateisystem zum Speichern seiner Daten. Es wird einen Master-Server und Regionsserver haben. Die Datenspeicherung erfolgt in Form von Regionen (Tabellen). Diese Regionen werden aufgeteilt und auf Regionsservern gespeichert.
Der Master-Server verwaltet diese Regionsserver und alle diese Aufgaben werden in HDFS ausgeführt. Im Folgenden sind einige der von HBase Shell unterstützten Befehle aufgeführt.
Allgemeine Befehle
status - Gibt den Status von HBase an, z. B. die Anzahl der Server.
version - Stellt die verwendete Version von HBase bereit.
table_help - Bietet Hilfe für Tabellenreferenzbefehle.
whoami - Bietet Informationen über den Benutzer.
Datendefinitionssprache
Dies sind die Befehle, die für die Tabellen in HBase ausgeführt werden.
create - Erstellt eine Tabelle.
list - Listet alle Tabellen in HBase auf.
disable - Deaktiviert eine Tabelle.
is_disabled - Überprüft, ob eine Tabelle deaktiviert ist.
enable - Aktiviert eine Tabelle.
is_enabled - Überprüft, ob eine Tabelle aktiviert ist.
describe - Bietet die Beschreibung einer Tabelle.
alter - Ändert einen Tisch.
exists - Überprüft, ob eine Tabelle vorhanden ist.
drop - Löscht eine Tabelle aus HBase.
drop_all - Löscht die Tabellen, die dem im Befehl angegebenen 'regulären Ausdruck' entsprechen.
Java Admin API- Vor allen oben genannten Befehlen bietet Java eine Admin-API, um DDL-Funktionen durch Programmierung zu erreichen. Unterorg.apache.hadoop.hbase.client Paket, HBaseAdmin und HTableDescriptor sind die beiden wichtigen Klassen in diesem Paket, die DDL-Funktionen bereitstellen.
Datenmanipulierungssprache
put - Setzt einen Zellenwert an eine bestimmte Spalte in einer bestimmten Zeile in einer bestimmten Tabelle.
get - Ruft den Inhalt einer Zeile oder einer Zelle ab.
delete - Löscht einen Zellenwert in einer Tabelle.
deleteall - Löscht alle Zellen in einer bestimmten Zeile.
scan - Scannt die Tabellendaten und gibt sie zurück.
count - Zählt und gibt die Anzahl der Zeilen in einer Tabelle zurück.
truncate - Deaktiviert, löscht und erstellt eine angegebene Tabelle neu.
Java client API - Vor allen oben genannten Befehlen bietet Java eine Client-API zum Erreichen von DML-Funktionen. CRUD (Create Retrieve Update Delete) -Operationen und mehr durch Programmierung unter dem Paket org.apache.hadoop.hbase.client. HTable Put und Get sind die wichtigen Klassen in diesem Paket.
Starten der HBase Shell
Um auf die HBase-Shell zuzugreifen, müssen Sie zum HBase-Ausgangsordner navigieren.
cd /usr/localhost/
cd HbaseSie können die interaktive HBase-Shell mit starten “hbase shell” Befehl wie unten gezeigt.
./bin/hbase shellWenn Sie HBase erfolgreich in Ihrem System installiert haben, wird die unten gezeigte HBase-Shell-Eingabeaufforderung angezeigt.
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.23, rf42302b28aceaab773b15f234aa8718fff7eea3c, Wed Aug 27
00:54:09 UTC 2014
hbase(main):001:0>Um den interaktiven Shell-Befehl jederzeit zu beenden, geben Sie exit ein oder verwenden Sie <Strg + c>. Überprüfen Sie die Funktion der Shell, bevor Sie fortfahren. Verwenden Sie dielist Befehl zu diesem Zweck. Listist ein Befehl, mit dem die Liste aller Tabellen in HBase abgerufen wird. Überprüfen Sie zunächst die Installation und Konfiguration von HBase in Ihrem System mit diesem Befehl, wie unten gezeigt.
hbase(main):001:0> listWenn Sie diesen Befehl eingeben, erhalten Sie die folgende Ausgabe.
hbase(main):001:0> list
TABLEDie allgemeinen Befehle in HBase sind status, version, table_help und whoami. In diesem Kapitel werden diese Befehle erläutert.
Status
Dieser Befehl gibt den Status des Systems einschließlich der Details der auf dem System ausgeführten Server zurück. Die Syntax lautet wie folgt:
hbase(main):009:0> statusWenn Sie diesen Befehl ausführen, wird die folgende Ausgabe zurückgegeben.
hbase(main):009:0> status
3 servers, 0 dead, 1.3333 average loadAusführung
Dieser Befehl gibt die in Ihrem System verwendete HBase-Version zurück. Die Syntax lautet wie folgt:
hbase(main):010:0> versionWenn Sie diesen Befehl ausführen, wird die folgende Ausgabe zurückgegeben.
hbase(main):009:0> version
0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14
18:26:29 PST 2014table_help
Dieser Befehl zeigt Ihnen, was und wie tabellenbezogene Befehle verwendet werden. Im Folgenden wird die Syntax zur Verwendung dieses Befehls angegeben.
hbase(main):02:0> table_helpWenn Sie diesen Befehl verwenden, werden Hilfethemen für tabellenbezogene Befehle angezeigt. Unten ist die Teilausgabe dieses Befehls angegeben.
hbase(main):002:0> table_help
Help for table-reference commands.
You can either create a table via 'create' and then manipulate the table
via commands like 'put', 'get', etc.
See the standard help information for how to use each of these commands.
However, as of 0.96, you can also get a reference to a table, on which
you can invoke commands.
For instance, you can get create a table and keep around a reference to
it via:
hbase> t = create 't', 'cf'…...Wer bin ich
Dieser Befehl gibt die Benutzerdetails von HBase zurück. Wenn Sie diesen Befehl ausführen, wird der aktuelle HBase-Benutzer wie unten gezeigt zurückgegeben.
hbase(main):008:0> whoami
hadoop (auth:SIMPLE)
groups: hadoopHBase ist in Java geschrieben und bietet daher eine Java-API für die Kommunikation mit HBase. Die Java-API ist der schnellste Weg, um mit HBase zu kommunizieren. Im Folgenden wird die referenzierte Java-Admin-API angegeben, die die Aufgaben zum Verwalten von Tabellen abdeckt.
Klasse HBaseAdmin
HBaseAdminist eine Klasse, die den Administrator darstellt. Diese Klasse gehört zurorg.apache.hadoop.hbase.clientPaket. Mit dieser Klasse können Sie die Aufgaben eines Administrators ausführen. Sie können die Instanz von Admin mit abrufenConnection.getAdmin() Methode.
Methoden und Beschreibung
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | void createTable(HTableDescriptor desc) Erstellt eine neue Tabelle. |
| 2 | void createTable(HTableDescriptor desc, byte[][] splitKeys) Erstellt eine neue Tabelle mit einem anfänglichen Satz leerer Bereiche, die durch die angegebenen geteilten Schlüssel definiert sind. |
| 3 | void deleteColumn(byte[] tableName, String columnName) Löscht eine Spalte aus einer Tabelle. |
| 4 | void deleteColumn(String tableName, String columnName) Löschen Sie eine Spalte aus einer Tabelle. |
| 5 | void deleteTable(String tableName) Löscht eine Tabelle. |
Klassendeskriptor
Diese Klasse enthält die Details zu einer HBase-Tabelle wie:
- die Deskriptoren aller Spaltenfamilien,
- Wenn die Tabelle eine Katalogtabelle ist,
- Wenn die Tabelle schreibgeschützt ist,
- die maximale Größe des Mem-Speichers,
- wenn die Regionsaufteilung erfolgen soll,
- damit verbundene Co-Prozessoren usw.
Konstruktoren
| S.No. | Konstruktor und Zusammenfassung |
|---|---|
| 1 | HTableDescriptor(TableName name) Erstellt einen Tabellendeskriptor, der ein TableName-Objekt angibt. |
Methoden und Beschreibung
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | HTableDescriptor addFamily(HColumnDescriptor family) Fügt dem angegebenen Deskriptor eine Spaltenfamilie hinzu |
Erstellen einer Tabelle mit HBase Shell
Sie können eine Tabelle mit dem erstellen createBefehl, hier müssen Sie den Tabellennamen und den Namen der Spaltenfamilie angeben. Dassyntax Das Erstellen einer Tabelle in der HBase-Shell wird unten gezeigt.
create ‘<table name>’,’<column family>’Beispiel
Im Folgenden finden Sie ein Beispielschema einer Tabelle mit dem Namen emp. Es gibt zwei Spaltenfamilien: "personenbezogene Daten" und "berufliche Daten".
| Zeilenschlüssel | persönliche Daten | professionelle Daten |
|---|---|---|
Sie können diese Tabelle in der HBase-Shell wie unten gezeigt erstellen.
hbase(main):002:0> create 'emp', 'personal data', 'professional data'Und es gibt Ihnen die folgende Ausgabe.
0 row(s) in 1.1300 seconds
=> Hbase::Table - empÜberprüfung
Sie können überprüfen, ob die Tabelle mit dem erstellt wurde listBefehl wie unten gezeigt. Hier können Sie die erstellte emp-Tabelle beobachten.
hbase(main):002:0> list
TABLE
emp
2 row(s) in 0.0340 secondsErstellen einer Tabelle mit der Java-API
Sie können eine Tabelle in HBase mit dem erstellen createTable() Methode von HBaseAdminKlasse. Diese Klasse gehört zurorg.apache.hadoop.hbase.clientPaket. Im Folgenden werden die Schritte zum Erstellen einer Tabelle in HBase mithilfe der Java-API aufgeführt.
Schritt 1: HBaseAdmin instanziieren
Diese Klasse benötigt das Konfigurationsobjekt als Parameter. Instanziieren Sie daher zunächst die Konfigurationsklasse und übergeben Sie diese Instanz an HBaseAdmin.
Configuration conf = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2: Erstellen Sie TableDescriptor
HTableDescriptor ist eine Klasse, die zur gehört org.apache.hadoop.hbaseKlasse. Diese Klasse ist wie ein Container mit Tabellennamen und Spaltenfamilien.
//creating table descriptor
HTableDescriptor table = new HTableDescriptor(toBytes("Table name"));
//creating column family descriptor
HColumnDescriptor family = new HColumnDescriptor(toBytes("column family"));
//adding coloumn family to HTable
table.addFamily(family);Schritt 3: Durch Admin ausführen
Verwendung der createTable() Methode von HBaseAdmin Klasse können Sie die erstellte Tabelle im Admin-Modus ausführen.
admin.createTable(table);Im Folgenden finden Sie das vollständige Programm zum Erstellen einer Tabelle über den Administrator.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.conf.Configuration;
public class CreateTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration con = HBaseConfiguration.create();
// Instantiating HbaseAdmin class
HBaseAdmin admin = new HBaseAdmin(con);
// Instantiating table descriptor class
HTableDescriptor tableDescriptor = new
HTableDescriptor(TableName.valueOf("emp"));
// Adding column families to table descriptor
tableDescriptor.addFamily(new HColumnDescriptor("personal"));
tableDescriptor.addFamily(new HColumnDescriptor("professional"));
// Execute the table through admin
admin.createTable(tableDescriptor);
System.out.println(" Table created ");
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac CreateTable.java
$java CreateTableFolgendes sollte die Ausgabe sein:
Table createdAuflisten einer Tabelle mit HBase Shell
list ist der Befehl, mit dem alle Tabellen in HBase aufgelistet werden. Unten ist die Syntax des Befehls list angegeben.
hbase(main):001:0 > listWenn Sie diesen Befehl eingeben und in der HBase-Eingabeaufforderung ausführen, wird die Liste aller Tabellen in HBase angezeigt (siehe unten).
hbase(main):001:0> list
TABLE
empHier können Sie eine Tabelle mit dem Namen emp beobachten.
Auflisten von Tabellen mit der Java-API
Führen Sie die folgenden Schritte aus, um die Liste der Tabellen von HBase mithilfe der Java-API abzurufen.
Schritt 1
Sie haben eine Methode namens listTables() in der Klasse HBaseAdminum die Liste aller Tabellen in HBase zu erhalten. Diese Methode gibt ein Array von zurückHTableDescriptor Objekte.
//creating a configuration object
Configuration conf = HBaseConfiguration.create();
//Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);
//Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();Schritt 2
Sie können die Länge der erhalten HTableDescriptor[] Array mit der Längenvariablen des HTableDescriptorKlasse. Rufen Sie den Namen der Tabellen von diesem Objekt mit abgetNameAsString()Methode. Führen Sie die 'for'-Schleife mit diesen aus und rufen Sie die Liste der Tabellen in HBase ab.
Im Folgenden finden Sie das Programm zum Auflisten aller Tabellen in HBase mithilfe der Java-API.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ListTables {
public static void main(String args[])throws MasterNotRunningException, IOException{
// Instantiating a configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();
// printing all the table names.
for (int i=0; i<tableDescriptor.length;i++ ){
System.out.println(tableDescriptor[i].getNameAsString());
}
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac ListTables.java
$java ListTablesFolgendes sollte die Ausgabe sein:
User
empDeaktivieren einer Tabelle mit HBase Shell
Um eine Tabelle zu löschen oder ihre Einstellungen zu ändern, müssen Sie sie zuerst mit dem Befehl disable deaktivieren. Sie können es mit dem Befehl enable wieder aktivieren.
Im Folgenden wird die Syntax zum Deaktivieren einer Tabelle angegeben:
disable ‘emp’Beispiel
Im Folgenden finden Sie ein Beispiel, das zeigt, wie eine Tabelle deaktiviert wird.
hbase(main):025:0> disable 'emp'
0 row(s) in 1.2760 secondsÜberprüfung
Nachdem Sie die Tabelle deaktiviert haben, können Sie ihre Existenz weiterhin erkennen list und existsBefehle. Sie können es nicht scannen. Es wird Ihnen der folgende Fehler angezeigt.
hbase(main):028:0> scan 'emp'
ROW COLUMN + CELL
ERROR: emp is disabled.ist behindert
Mit diesem Befehl wird ermittelt, ob eine Tabelle deaktiviert ist. Die Syntax lautet wie folgt.
hbase> is_disabled 'table name'Das folgende Beispiel überprüft, ob die Tabelle mit dem Namen emp deaktiviert ist. Wenn es deaktiviert ist, wird true zurückgegeben, und wenn nicht, wird false zurückgegeben.
hbase(main):031:0> is_disabled 'emp'
true
0 row(s) in 0.0440 secondsAlle deaktivieren
Dieser Befehl wird verwendet, um alle Tabellen zu deaktivieren, die dem angegebenen regulären Ausdruck entsprechen. Die Syntax fürdisable_all Befehl ist unten angegeben.
hbase> disable_all 'r.*'Angenommen, es gibt 5 Tabellen in HBase, nämlich Raja, Rajani, Rajendra, Rajesh und Raju. Der folgende Code deaktiviert alle Tabellen, die mit beginnenraj.
hbase(main):002:07> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledDeaktivieren Sie eine Tabelle mithilfe der Java-API
Um zu überprüfen, ob eine Tabelle deaktiviert ist, isTableDisabled() Methode verwendet wird und um eine Tabelle zu deaktivieren, disableTable()Methode wird verwendet. Diese Methoden gehören zu denHBaseAdminKlasse. Führen Sie die folgenden Schritte aus, um eine Tabelle zu deaktivieren.
Schritt 1
Instanziieren HBaseAdmin Klasse wie unten gezeigt.
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2
Überprüfen Sie, ob die Tabelle mit deaktiviert ist isTableDisabled() Methode wie unten gezeigt.
Boolean b = admin.isTableDisabled("emp");Schritt 3
Wenn die Tabelle nicht deaktiviert ist, deaktivieren Sie sie wie unten gezeigt.
if(!b){
admin.disableTable("emp");
System.out.println("Table disabled");
}Im Folgenden finden Sie das vollständige Programm zum Überprüfen, ob die Tabelle deaktiviert ist. Wenn nicht, wie man es deaktiviert.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DisableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying weather the table is disabled
Boolean bool = admin.isTableDisabled("emp");
System.out.println(bool);
// Disabling the table using HBaseAdmin object
if(!bool){
admin.disableTable("emp");
System.out.println("Table disabled");
}
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac DisableTable.java
$java DsiableTableFolgendes sollte die Ausgabe sein:
false
Table disabledAktivieren einer Tabelle mit HBase Shell
Syntax zum Aktivieren einer Tabelle:
enable ‘emp’Beispiel
Im Folgenden finden Sie ein Beispiel zum Aktivieren einer Tabelle.
hbase(main):005:0> enable 'emp'
0 row(s) in 0.4580 secondsÜberprüfung
Nachdem Sie die Tabelle aktiviert haben, scannen Sie sie. Wenn Sie das Schema sehen können, wurde Ihre Tabelle erfolgreich aktiviert.
hbase(main):006:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417516501, value = hyderabad
1 column = personal data:name, timestamp = 1417525058, value = ramu
1 column = professional data:designation, timestamp = 1417532601, value = manager
1 column = professional data:salary, timestamp = 1417524244109, value = 50000
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 14175292204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 14175246987, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000
3 row(s) in 0.0400 secondsaktiviert
Mit diesem Befehl wird ermittelt, ob eine Tabelle aktiviert ist. Die Syntax lautet wie folgt:
hbase> is_enabled 'table name'Der folgende Code überprüft, ob die Tabelle benannt ist empaktiviert. Wenn es aktiviert ist, wird true zurückgegeben, und wenn nicht, wird false zurückgegeben.
hbase(main):031:0> is_enabled 'emp'
true
0 row(s) in 0.0440 secondsAktivieren Sie eine Tabelle mithilfe der Java-API
Um zu überprüfen, ob eine Tabelle aktiviert ist, isTableEnabled()Methode wird verwendet; und um eine Tabelle zu aktivieren,enableTable()Methode wird verwendet. Diese Methoden gehören zuHBaseAdminKlasse. Führen Sie die folgenden Schritte aus, um eine Tabelle zu aktivieren.
Schritt 1
Instanziieren HBaseAdmin Klasse wie unten gezeigt.
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2
Überprüfen Sie, ob die Tabelle mit aktiviert ist isTableEnabled() Methode wie unten gezeigt.
Boolean bool = admin.isTableEnabled("emp");Schritt 3
Wenn die Tabelle nicht deaktiviert ist, deaktivieren Sie sie wie unten gezeigt.
if(!bool){
admin.enableTable("emp");
System.out.println("Table enabled");
}Im Folgenden finden Sie das vollständige Programm, mit dem überprüft werden kann, ob die Tabelle aktiviert ist, und wenn dies nicht der Fall ist, wie sie aktiviert wird.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class EnableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying whether the table is disabled
Boolean bool = admin.isTableEnabled("emp");
System.out.println(bool);
// Enabling the table using HBaseAdmin object
if(!bool){
admin.enableTable("emp");
System.out.println("Table Enabled");
}
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac EnableTable.java
$java EnableTableFolgendes sollte die Ausgabe sein:
false
Table Enabledbeschreiben
Dieser Befehl gibt die Beschreibung der Tabelle zurück. Die Syntax lautet wie folgt:
hbase> describe 'table name'Unten ist die Ausgabe des Befehls description auf dem emp Tabelle.
hbase(main):006:0> describe 'emp'
DESCRIPTION
ENABLED
'emp', {NAME ⇒ 'READONLY', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER
⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒ 'NONE', VERSIONS ⇒
'1', TTL true
⇒ 'FOREVER', MIN_VERSIONS ⇒ '0', KEEP_DELETED_CELLS ⇒ 'false',
BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME
⇒ 'personal
data', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW',
REPLICATION_SCOPE ⇒ '0', VERSIONS ⇒ '5', COMPRESSION ⇒ 'NONE',
MIN_VERSIONS ⇒ '0', TTL
⇒ 'FOREVER', KEEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536',
IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'professional
data', DATA_BLO
CK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0',
VERSIONS ⇒ '1', COMPRESSION ⇒ 'NONE', MIN_VERSIONS ⇒ '0', TTL ⇒
'FOREVER', K
EEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒
'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'table_att_unset',
DATA_BLOCK_ENCODING ⇒ 'NO
NE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒
'NONE', VERSIONS ⇒ '1', TTL ⇒ 'FOREVER', MIN_VERSIONS ⇒ '0',
KEEP_DELETED_CELLS
⇒ 'false', BLOCKSIZE ⇒ '6ändern
Ändern ist der Befehl, mit dem Änderungen an einer vorhandenen Tabelle vorgenommen werden. Mit diesem Befehl können Sie die maximale Anzahl von Zellen einer Spaltenfamilie ändern, Tabellenbereichsoperatoren festlegen und löschen sowie eine Spaltenfamilie aus einer Tabelle löschen.
Ändern der maximalen Anzahl von Zellen einer Spaltenfamilie
Im Folgenden wird die Syntax zum Ändern der maximalen Anzahl von Zellen einer Spaltenfamilie angegeben.
hbase> alter 't1', NAME ⇒ 'f1', VERSIONS ⇒ 5Im folgenden Beispiel wird die maximale Anzahl von Zellen auf 5 festgelegt.
hbase(main):003:0> alter 'emp', NAME ⇒ 'personal data', VERSIONS ⇒ 5
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.3050 secondsTabellenbereichsoperatoren
Mit alter können Sie Tabellenbereichsoperatoren wie MAX_FILESIZE, READONLY, MEMSTORE_FLUSHSIZE, DEFERRED_LOG_FLUSH usw. festlegen und entfernen.
Schreibgeschützt einstellen
Nachstehend ist die Syntax angegeben, mit der eine Tabelle schreibgeschützt wird.
hbase>alter 't1', READONLY(option)Im folgenden Beispiel haben wir die gemacht emp Tabelle schreibgeschützt.
hbase(main):006:0> alter 'emp', READONLY
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2140 secondsEntfernen von Tabellenbereichsoperatoren
Wir können auch die Tabellenbereichsoperatoren entfernen. Im Folgenden wird die Syntax zum Entfernen von 'MAX_FILESIZE' aus der emp-Tabelle angegeben.
hbase> alter 't1', METHOD ⇒ 'table_att_unset', NAME ⇒ 'MAX_FILESIZE'Löschen einer Spaltenfamilie
Mit alter können Sie auch eine Spaltenfamilie löschen. Im Folgenden wird die Syntax zum Löschen einer Spaltenfamilie mit alter angegeben.
hbase> alter ‘ table name ’, ‘delete’ ⇒ ‘ column family ’Im Folgenden finden Sie ein Beispiel zum Löschen einer Spaltenfamilie aus der Tabelle 'emp'.
Angenommen, in HBase gibt es eine Tabelle mit dem Namen employee. Es enthält folgende Daten:
hbase(main):006:0> scan 'employee'
ROW COLUMN+CELL
row1 column = personal:city, timestamp = 1418193767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
row1 column = professional:designation, timestamp = 1418193767, value = manager
row1 column = professional:salary, timestamp = 1418193806767, value = 50000
1 row(s) in 0.0160 secondsLöschen wir nun die benannte Spaltenfamilie professional mit dem Befehl alter.
hbase(main):007:0> alter 'employee','delete'⇒'professional'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2380 secondsÜberprüfen Sie nun die Daten in der Tabelle nach der Änderung. Beachten Sie, dass die Spaltenfamilie 'professional' nicht mehr ist, da wir sie gelöscht haben.
hbase(main):003:0> scan 'employee'
ROW COLUMN + CELL
row1 column = personal:city, timestamp = 14181936767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
1 row(s) in 0.0830 secondsHinzufügen einer Spaltenfamilie mithilfe der Java-API
Mit der Methode können Sie einer Tabelle eine Spaltenfamilie hinzufügen addColumn() von HBAseAdminKlasse. Führen Sie die folgenden Schritte aus, um einer Tabelle eine Spaltenfamilie hinzuzufügen.
Schritt 1
Instanziieren Sie die HBaseAdmin Klasse.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2
Das addColumn() Methode erfordert einen Tabellennamen und ein Objekt von HColumnDescriptorKlasse. Instanziieren Sie daher dieHColumnDescriptorKlasse. Der Konstruktor vonHColumnDescriptorerfordert wiederum einen Spaltenfamiliennamen, der hinzugefügt werden soll. Hier fügen wir der vorhandenen Tabelle "Mitarbeiter" eine Spaltenfamilie mit dem Namen "contactDetails" hinzu.
// Instantiating columnDescriptor object
HColumnDescriptor columnDescriptor = new
HColumnDescriptor("contactDetails");Schritt 3
Fügen Sie die Spaltenfamilie mit hinzu addColumnMethode. Übergeben Sie den Tabellennamen und dieHColumnDescriptor Klassenobjekt als Parameter für diese Methode.
// Adding column family
admin.addColumn("employee", new HColumnDescriptor("columnDescriptor"));Im Folgenden finden Sie das vollständige Programm zum Hinzufügen einer Spaltenfamilie zu einer vorhandenen Tabelle.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class AddColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Instantiating columnDescriptor class
HColumnDescriptor columnDescriptor = new HColumnDescriptor("contactDetails");
// Adding column family
admin.addColumn("employee", columnDescriptor);
System.out.println("coloumn added");
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac AddColumn.java
$java AddColumnDie obige Kompilierung funktioniert nur, wenn Sie den Klassenpfad in „ .bashrc”. Wenn nicht, befolgen Sie die unten angegebenen Schritte, um Ihre Java-Datei zu kompilieren.
//if "/home/home/hadoop/hbase " is your Hbase home folder then.
$javac -cp /home/hadoop/hbase/lib/*: Demo.javaWenn alles gut geht, wird die folgende Ausgabe erzeugt:
column addedLöschen einer Spaltenfamilie mithilfe der Java-API
Mit der Methode können Sie eine Spaltenfamilie aus einer Tabelle löschen deleteColumn() von HBAseAdminKlasse. Führen Sie die folgenden Schritte aus, um einer Tabelle eine Spaltenfamilie hinzuzufügen.
Schritt 1
Instanziieren Sie die HBaseAdmin Klasse.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2
Fügen Sie die Spaltenfamilie mit hinzu deleteColumn()Methode. Übergeben Sie den Tabellennamen und den Spaltenfamiliennamen als Parameter an diese Methode.
// Deleting column family
admin.deleteColumn("employee", "contactDetails");Im Folgenden finden Sie das vollständige Programm zum Löschen einer Spaltenfamilie aus einer vorhandenen Tabelle.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Deleting a column family
admin.deleteColumn("employee","contactDetails");
System.out.println("coloumn deleted");
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac DeleteColumn.java $java DeleteColumnFolgendes sollte die Ausgabe sein:
column deletedVorhandensein einer Tabelle unter Verwendung der HBase-Shell
Sie können die Existenz einer Tabelle mit der überprüfen existsBefehl. Das folgende Beispiel zeigt, wie dieser Befehl verwendet wird.
hbase(main):024:0> exists 'emp'
Table emp does exist
0 row(s) in 0.0750 seconds
==================================================================
hbase(main):015:0> exists 'student'
Table student does not exist
0 row(s) in 0.0480 secondsÜberprüfen der Existenz einer Tabelle mithilfe der Java-API
Sie können das Vorhandensein einer Tabelle in HBase mithilfe von überprüfen tableExists() Methode der HBaseAdmin Klasse. Führen Sie die folgenden Schritte aus, um das Vorhandensein einer Tabelle in HBase zu überprüfen.
Schritt 1
Instantiate the HBaseAdimn class
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2
Überprüfen Sie die Existenz der Tabelle mit der tableExists( ) Methode.
Im Folgenden finden Sie das Java-Programm zum Testen der Existenz einer Tabelle in HBase mithilfe der Java-API.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class TableExists{
public static void main(String args[])throws IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying the existance of the table
boolean bool = admin.tableExists("emp");
System.out.println( bool);
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac TableExists.java $java TableExistsFolgendes sollte die Ausgabe sein:
trueLöschen einer Tabelle mit HBase Shell
Verwendung der dropBefehl können Sie eine Tabelle löschen. Bevor Sie eine Tabelle löschen, müssen Sie sie deaktivieren.
hbase(main):018:0> disable 'emp'
0 row(s) in 1.4580 seconds
hbase(main):019:0> drop 'emp'
0 row(s) in 0.3060 secondsÜberprüfen Sie mit dem Befehl exist, ob die Tabelle gelöscht wurde.
hbase(main):020:07gt; exists 'emp'
Table emp does not exist
0 row(s) in 0.0730 secondsdrop_all
Dieser Befehl wird verwendet, um die Tabellen zu löschen, die dem im Befehl angegebenen "regulären Ausdruck" entsprechen. Die Syntax lautet wie folgt:
hbase> drop_all ‘t.*’Note: Bevor Sie eine Tabelle löschen, müssen Sie sie deaktivieren.
Beispiel
Angenommen, es gibt Tabellen mit den Namen Raja, Rajani, Rajendra, Rajesh und Raju.
hbase(main):017:0> list
TABLE
raja
rajani
rajendra
rajesh
raju
9 row(s) in 0.0270 secondsAlle diese Tabellen beginnen mit den Buchstaben raj. Lassen Sie uns zunächst alle diese Tabellen mit dem deaktivierendisable_all Befehl wie unten gezeigt.
hbase(main):002:0> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledJetzt können Sie alle mit dem löschen drop_all Befehl wie unten angegeben.
hbase(main):018:0> drop_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Drop the above 5 tables (y/n)?
y
5 tables successfully droppedLöschen einer Tabelle mit der Java-API
Sie können eine Tabelle mit dem löschen deleteTable() Methode in der HBaseAdminKlasse. Führen Sie die folgenden Schritte aus, um eine Tabelle mithilfe der Java-API zu löschen.
Schritt 1
Instanziieren Sie die HBaseAdmin-Klasse.
// creating a configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2
Deaktivieren Sie die Tabelle mit disableTable() Methode der HBaseAdmin Klasse.
admin.disableTable("emp1");Schritt 3
Löschen Sie nun die Tabelle mit dem deleteTable() Methode der HBaseAdmin Klasse.
admin.deleteTable("emp12");Im Folgenden finden Sie das vollständige Java-Programm zum Löschen einer Tabelle in HBase.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// disabling table named emp
admin.disableTable("emp12");
// Deleting emp
admin.deleteTable("emp12");
System.out.println("Table deleted");
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac DeleteTable.java $java DeleteTableFolgendes sollte die Ausgabe sein:
Table deletedAusfahrt
Sie verlassen die Shell, indem Sie das eingeben exit Befehl.
hbase(main):021:0> exitHBase stoppen
Um HBase zu stoppen, navigieren Sie zum HBase-Basisordner und geben Sie den folgenden Befehl ein.
./bin/stop-hbase.shBeenden von HBase mithilfe der Java-API
Sie können die HBase mit dem herunterfahren shutdown() Methode der HBaseAdminKlasse. Führen Sie die folgenden Schritte aus, um HBase herunterzufahren:
Schritt 1
Instanziieren Sie die HbaseAdmin-Klasse.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);Schritt 2
Fahren Sie die HBase mit dem herunter shutdown() Methode der HBaseAdmin Klasse.
admin.shutdown();Im Folgenden finden Sie das Programm zum Stoppen der HBase.
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ShutDownHbase{
public static void main(String args[])throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Shutting down HBase
System.out.println("Shutting down hbase");
admin.shutdown();
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac ShutDownHbase.java $java ShutDownHbaseFolgendes sollte die Ausgabe sein:
Shutting down hbaseIn diesem Kapitel wird die Java-Client-API für HBase beschrieben, die für die Ausführung verwendet wird CRUDOperationen an HBase-Tabellen. HBase ist in Java geschrieben und verfügt über eine Java Native API. Daher bietet es programmgesteuerten Zugriff auf Data Manipulation Language (DML).
Klassen-HBase-Konfiguration
Fügt einer Konfiguration HBase-Konfigurationsdateien hinzu. Diese Klasse gehört zurorg.apache.hadoop.hbase Paket.
Methoden und Beschreibung
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | static org.apache.hadoop.conf.Configuration create() Diese Methode erstellt eine Konfiguration mit HBase-Ressourcen. |
Klasse HTable
HTable ist eine interne HBase-Klasse, die eine HBase-Tabelle darstellt. Es ist eine Implementierung einer Tabelle, die zur Kommunikation mit einer einzelnen HBase-Tabelle verwendet wird. Diese Klasse gehört zurorg.apache.hadoop.hbase.client Klasse.
Konstruktoren
| S.No. | Konstruktoren und Beschreibung |
|---|---|
| 1 | HTable() |
| 2 | HTable(TableName tableName, ClusterConnection connection, ExecutorService pool) Mit diesem Konstruktor können Sie ein Objekt erstellen, um auf eine HBase-Tabelle zuzugreifen. |
Methoden und Beschreibung
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | void close() Gibt alle Ressourcen der HTable frei. |
| 2 | void delete(Delete delete) Löscht die angegebenen Zellen / Zeilen. |
| 3 | boolean exists(Get get) Mit dieser Methode können Sie die Existenz von Spalten in der Tabelle testen, wie von Get angegeben. |
| 4 | Result get(Get get) Ruft bestimmte Zellen aus einer bestimmten Zeile ab. |
| 5 | org.apache.hadoop.conf.Configuration getConfiguration() Gibt das von dieser Instanz verwendete Konfigurationsobjekt zurück. |
| 6 | TableName getName() Gibt die Tabellennameninstanz dieser Tabelle zurück. |
| 7 | HTableDescriptor getTableDescriptor() Gibt den Tabellendeskriptor für diese Tabelle zurück. |
| 8 | byte[] getTableName() Gibt den Namen dieser Tabelle zurück. |
| 9 | void put(Put put) Mit dieser Methode können Sie Daten in die Tabelle einfügen. |
Klasse Put
Diese Klasse wird verwendet, um Put-Operationen für eine einzelne Zeile auszuführen. Es gehört zu denorg.apache.hadoop.hbase.client Paket.
Konstruktoren
| S.No. | Konstruktoren und Beschreibung |
|---|---|
| 1 | Put(byte[] row) Mit diesem Konstruktor können Sie eine Put-Operation für die angegebene Zeile erstellen. |
| 2 | Put(byte[] rowArray, int rowOffset, int rowLength) Mit diesem Konstruktor können Sie eine Kopie des übergebenen Zeilenschlüssels erstellen, um lokal zu bleiben. |
| 3 | Put(byte[] rowArray, int rowOffset, int rowLength, long ts) Mit diesem Konstruktor können Sie eine Kopie des übergebenen Zeilenschlüssels erstellen, um lokal zu bleiben. |
| 4 | Put(byte[] row, long ts) Mit diesem Konstruktor können wir eine Put-Operation für die angegebene Zeile unter Verwendung eines bestimmten Zeitstempels erstellen. |
Methoden
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | Put add(byte[] family, byte[] qualifier, byte[] value) Fügt der Put-Operation die angegebene Spalte und den angegebenen Wert hinzu. |
| 2 | Put add(byte[] family, byte[] qualifier, long ts, byte[] value) Fügt die angegebene Spalte und den angegebenen Wert mit dem angegebenen Zeitstempel als Version zu dieser Put-Operation hinzu. |
| 3 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) Fügt die angegebene Spalte und den angegebenen Wert mit dem angegebenen Zeitstempel als Version zu dieser Put-Operation hinzu. |
| 4 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) Fügt die angegebene Spalte und den angegebenen Wert mit dem angegebenen Zeitstempel als Version zu dieser Put-Operation hinzu. |
Klasse Get
Diese Klasse wird verwendet, um Get-Operationen für eine einzelne Zeile auszuführen. Diese Klasse gehört zurorg.apache.hadoop.hbase.client Paket.
Konstrukteur
| S.No. | Konstruktor und Beschreibung |
|---|---|
| 1 | Get(byte[] row) Mit diesem Konstruktor können Sie eine Get-Operation für die angegebene Zeile erstellen. |
| 2 | Get(Get get) |
Methoden
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | Get addColumn(byte[] family, byte[] qualifier) Ruft die Spalte aus der bestimmten Familie mit dem angegebenen Qualifikationsmerkmal ab. |
| 2 | Get addFamily(byte[] family) Ruft alle Spalten aus der angegebenen Familie ab. |
Klasse löschen
Diese Klasse wird verwendet, um Löschvorgänge für eine einzelne Zeile auszuführen. Um eine ganze Zeile zu löschen, instanziieren Sie ein Löschobjekt mit der zu löschenden Zeile. Diese Klasse gehört zurorg.apache.hadoop.hbase.client Paket.
Konstrukteur
| S.No. | Konstruktor und Beschreibung |
|---|---|
| 1 | Delete(byte[] row) Erstellt einen Löschvorgang für die angegebene Zeile. |
| 2 | Delete(byte[] rowArray, int rowOffset, int rowLength) Erstellt einen Löschvorgang für die angegebene Zeile und den angegebenen Zeitstempel. |
| 3 | Delete(byte[] rowArray, int rowOffset, int rowLength, long ts) Erstellt einen Löschvorgang für die angegebene Zeile und den angegebenen Zeitstempel. |
| 4 | Delete(byte[] row, long timestamp) Erstellt einen Löschvorgang für die angegebene Zeile und den angegebenen Zeitstempel. |
Methoden
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | Delete addColumn(byte[] family, byte[] qualifier) Löscht die neueste Version der angegebenen Spalte. |
| 2 | Delete addColumns(byte[] family, byte[] qualifier, long timestamp) Löscht alle Versionen der angegebenen Spalte mit einem Zeitstempel, der kleiner oder gleich dem angegebenen Zeitstempel ist. |
| 3 | Delete addFamily(byte[] family) Löscht alle Versionen aller Spalten der angegebenen Familie. |
| 4 | Delete addFamily(byte[] family, long timestamp) Löscht alle Spalten der angegebenen Familie mit einem Zeitstempel, der kleiner oder gleich dem angegebenen Zeitstempel ist. |
Klassenergebnis
Diese Klasse wird verwendet, um ein einzelnes Zeilenergebnis einer Get- oder Scan-Abfrage abzurufen.
Konstruktoren
| S.No. | Konstruktoren |
|---|---|
| 1 | Result() Mit diesem Konstruktor können Sie ein leeres Ergebnis ohne KeyValue-Nutzdaten erstellen. Gibt null zurück, wenn Sie raw Cells () aufrufen. |
Methoden
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | byte[] getValue(byte[] family, byte[] qualifier) Diese Methode wird verwendet, um die neueste Version der angegebenen Spalte abzurufen. |
| 2 | byte[] getRow() Diese Methode wird verwendet, um den Zeilenschlüssel abzurufen, der der Zeile entspricht, aus der dieses Ergebnis erstellt wurde. |
Einfügen von Daten mit HBase Shell
Dieses Kapitel zeigt, wie Sie Daten in einer HBase-Tabelle erstellen. Zum Erstellen von Daten in einer HBase-Tabelle werden die folgenden Befehle und Methoden verwendet:
put Befehl,
add() Methode von Put Klasse und
put() Methode von HTable Klasse.
Als Beispiel erstellen wir die folgende Tabelle in HBase.
Verwenden von putBefehl können Sie Zeilen in eine Tabelle einfügen. Die Syntax lautet wie folgt:
put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’Einfügen der ersten Zeile
Fügen wir die Werte der ersten Zeile wie unten gezeigt in die Tabelle emp ein.
hbase(main):005:0> put 'emp','1','personal data:name','raju'
0 row(s) in 0.6600 seconds
hbase(main):006:0> put 'emp','1','personal data:city','hyderabad'
0 row(s) in 0.0410 seconds
hbase(main):007:0> put 'emp','1','professional
data:designation','manager'
0 row(s) in 0.0240 seconds
hbase(main):007:0> put 'emp','1','professional data:salary','50000'
0 row(s) in 0.0240 secondsFügen Sie die verbleibenden Zeilen mit dem Befehl put auf die gleiche Weise ein. Wenn Sie die gesamte Tabelle einfügen, erhalten Sie die folgende Ausgabe.
hbase(main):022:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1417524216501, value=hyderabad
1 column=personal data:name, timestamp=1417524185058, value=ramu
1 column=professional data:designation, timestamp=1417524232601,
value=manager
1 column=professional data:salary, timestamp=1417524244109, value=50000
2 column=personal data:city, timestamp=1417524574905, value=chennai
2 column=personal data:name, timestamp=1417524556125, value=ravi
2 column=professional data:designation, timestamp=1417524592204,
value=sr:engg
2 column=professional data:salary, timestamp=1417524604221, value=30000
3 column=personal data:city, timestamp=1417524681780, value=delhi
3 column=personal data:name, timestamp=1417524672067, value=rajesh
3 column=professional data:designation, timestamp=1417524693187,
value=jr:engg
3 column=professional data:salary, timestamp=1417524702514,
value=25000Einfügen von Daten mithilfe der Java-API
Sie können Daten mit dem in Hbase einfügen add() Methode der PutKlasse. Sie können es mit dem speichernput() Methode der HTableKlasse. Diese Klassen gehören zu denorg.apache.hadoop.hbase.clientPaket. Nachfolgend sind die Schritte zum Erstellen von Daten in einer HBase-Tabelle aufgeführt.
Schritt 1: Instanziieren Sie die Konfigurationsklasse
Das ConfigurationKlasse fügt ihrem Objekt HBase-Konfigurationsdateien hinzu. Sie können ein Konfigurationsobjekt mit dem erstellencreate() Methode der HbaseConfiguration Klasse wie unten gezeigt.
Configuration conf = HbaseConfiguration.create();Schritt 2: Instanziieren Sie die HTable-Klasse
Sie haben eine Klasse namens HTable, eine Implementierung von Table in HBase. Diese Klasse wird zur Kommunikation mit einer einzelnen HBase-Tabelle verwendet. Während der Instanziierung dieser Klasse werden Konfigurationsobjekt und Tabellenname als Parameter akzeptiert. Sie können die HTable-Klasse wie unten gezeigt instanziieren.
HTable hTable = new HTable(conf, tableName);Schritt 3: Instanziieren Sie die PutClass
Um Daten in eine HBase-Tabelle einzufügen, muss die add()Methode und ihre Varianten werden verwendet. Diese Methode gehört zuPutInstanziieren Sie daher die Put-Klasse. Diese Klasse benötigt den Zeilennamen, in den Sie die Daten einfügen möchten, im Zeichenfolgenformat. Sie können das instanziierenPut Klasse wie unten gezeigt.
Put p = new Put(Bytes.toBytes("row1"));Schritt 4: InsertData
Das add() Methode von PutKlasse wird zum Einfügen von Daten verwendet. Es sind 3-Byte-Arrays erforderlich, die die Spaltenfamilie, das Spaltenqualifikationsmerkmal (Spaltenname) und den einzufügenden Wert darstellen. Fügen Sie Daten mit der add () -Methode wie unten gezeigt in die HBase-Tabelle ein.
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));Schritt 5: Speichern Sie die Daten in der Tabelle
Speichern Sie nach dem Einfügen der erforderlichen Zeilen die Änderungen, indem Sie die put-Instanz zum hinzufügen put() Methode der HTable-Klasse wie unten gezeigt.
hTable.put(p);Schritt 6: Schließen Sie die HTable-Instanz
Schließen Sie nach dem Erstellen von Daten in der HBase-Tabelle die HTable Instanz mit dem close() Methode wie unten gezeigt.
hTable.close();Im Folgenden finden Sie das vollständige Programm zum Erstellen von Daten in der HBase-Tabelle.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
// accepts a row name.
Put p = new Put(Bytes.toBytes("row1"));
// adding values using add() method
// accepts column family name, qualifier/row name ,value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("name"),Bytes.toBytes("raju"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("hyderabad"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("designation"),
Bytes.toBytes("manager"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("salary"),
Bytes.toBytes("50000"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data inserted");
// closing HTable
hTable.close();
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac InsertData.java $java InsertDataFolgendes sollte die Ausgabe sein:
data insertedAktualisieren von Daten mit HBase Shell
Sie können einen vorhandenen Zellenwert mithilfe von aktualisieren putBefehl. Befolgen Sie dazu einfach dieselbe Syntax und geben Sie Ihren neuen Wert wie unten gezeigt an.
put ‘table name’,’row ’,'Column family:column name',’new value’Der neu angegebene Wert ersetzt den vorhandenen Wert und aktualisiert die Zeile.
Beispiel
Angenommen, in HBase gibt es eine Tabelle mit dem Namen emp mit den folgenden Daten.
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418051555, value = raju
row1 column = personal:city, timestamp = 1418275907, value = Hyderabad
row1 column = professional:designation, timestamp = 14180555,value = manager
row1 column = professional:salary, timestamp = 1418035791555,value = 50000
1 row(s) in 0.0100 secondsMit dem folgenden Befehl wird der Stadtwert des Mitarbeiters mit dem Namen "Raju" in Delhi aktualisiert.
hbase(main):002:0> put 'emp','row1','personal:city','Delhi'
0 row(s) in 0.0400 secondsDie aktualisierte Tabelle sieht wie folgt aus: Sie können beobachten, dass die Stadt Raju in "Delhi" geändert wurde.
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418035791555, value = raju
row1 column = personal:city, timestamp = 1418274645907, value = Delhi
row1 column = professional:designation, timestamp = 141857555,value = manager
row1 column = professional:salary, timestamp = 1418039555, value = 50000
1 row(s) in 0.0100 secondsAktualisieren von Daten mithilfe der Java-API
Sie können die Daten in einer bestimmten Zelle mithilfe von aktualisieren put()Methode. Führen Sie die folgenden Schritte aus, um einen vorhandenen Zellenwert einer Tabelle zu aktualisieren.
Schritt 1: Instanziieren Sie die Konfigurationsklasse
ConfigurationKlasse fügt ihrem Objekt HBase-Konfigurationsdateien hinzu. Sie können ein Konfigurationsobjekt mit dem erstellencreate() Methode der HbaseConfiguration Klasse wie unten gezeigt.
Configuration conf = HbaseConfiguration.create();Schritt 2: Instanziieren Sie die HTable-Klasse
Sie haben eine Klasse namens HTable, eine Implementierung von Table in HBase. Diese Klasse wird zur Kommunikation mit einer einzelnen HBase-Tabelle verwendet. Beim Instanziieren dieser Klasse werden das Konfigurationsobjekt und der Tabellenname als Parameter akzeptiert. Sie können die HTable-Klasse wie unten gezeigt instanziieren.
HTable hTable = new HTable(conf, tableName);Schritt 3: Instanziieren Sie die Put-Klasse
Um Daten in die HBase-Tabelle einzufügen, muss die add()Methode und ihre Varianten werden verwendet. Diese Methode gehört zuPut, instanziieren Sie daher die putKlasse. Diese Klasse benötigt den Zeilennamen, in den Sie die Daten einfügen möchten, im Zeichenfolgenformat. Sie können das instanziierenPut Klasse wie unten gezeigt.
Put p = new Put(Bytes.toBytes("row1"));Schritt 4: Aktualisieren Sie eine vorhandene Zelle
Das add() Methode von PutKlasse wird zum Einfügen von Daten verwendet. Es sind 3-Byte-Arrays erforderlich, die die Spaltenfamilie, das Spaltenqualifikationsmerkmal (Spaltenname) und den einzufügenden Wert darstellen. Fügen Sie Daten mit der in die HBase-Tabelle einadd() Methode wie unten gezeigt.
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));Schritt 5: Speichern Sie die Daten in der Tabelle
Speichern Sie nach dem Einfügen der erforderlichen Zeilen die Änderungen, indem Sie die put-Instanz zum hinzufügen put() Methode der HTable-Klasse wie unten gezeigt.
hTable.put(p);Schritt 6: Schließen Sie die HTable-Instanz
Schließen Sie nach dem Erstellen von Daten in der HBase-Tabelle die HTable Instanz mit der Methode close () wie unten gezeigt.
hTable.close();Im Folgenden finden Sie das vollständige Programm zum Aktualisieren von Daten in einer bestimmten Tabelle.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class UpdateData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
//accepts a row name
Put p = new Put(Bytes.toBytes("row1"));
// Updating a cell value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data Updated");
// closing HTable
hTable.close();
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac UpdateData.java $java UpdateDataFolgendes sollte die Ausgabe sein:
data UpdatedDaten mit HBase Shell lesen
Das get Befehl und die get() Methode von HTableKlasse werden verwendet, um Daten aus einer Tabelle in HBase zu lesen. Verwenden vongetBefehl können Sie jeweils eine einzelne Datenzeile abrufen. Die Syntax lautet wie folgt:
get ’<table name>’,’row1’Beispiel
Das folgende Beispiel zeigt, wie der Befehl get verwendet wird. Scannen wir die erste Reihe desemp Tabelle.
hbase(main):012:0> get 'emp', '1'
COLUMN CELL
personal : city timestamp = 1417521848375, value = hyderabad
personal : name timestamp = 1417521785385, value = ramu
professional: designation timestamp = 1417521885277, value = manager
professional: salary timestamp = 1417521903862, value = 50000
4 row(s) in 0.0270 secondsLesen einer bestimmten Spalte
Im Folgenden wird die Syntax zum Lesen einer bestimmten Spalte mit dem angegeben get Methode.
hbase> get 'table name', ‘rowid’, {COLUMN ⇒ ‘column family:column name ’}Beispiel
Im Folgenden finden Sie ein Beispiel zum Lesen einer bestimmten Spalte in der HBase-Tabelle.
hbase(main):015:0> get 'emp', 'row1', {COLUMN ⇒ 'personal:name'}
COLUMN CELL
personal:name timestamp = 1418035791555, value = raju
1 row(s) in 0.0080 secondsLesen von Daten mit der Java-API
Verwenden Sie die, um Daten aus einer HBase-Tabelle zu lesen get()Methode der HTable-Klasse. Diese Methode erfordert eine Instanz vonGetKlasse. Führen Sie die folgenden Schritte aus, um Daten aus der HBase-Tabelle abzurufen.
Schritt 1: Instanziieren Sie die Konfigurationsklasse
ConfigurationKlasse fügt ihrem Objekt HBase-Konfigurationsdateien hinzu. Sie können ein Konfigurationsobjekt mit dem erstellencreate() Methode der HbaseConfiguration Klasse wie unten gezeigt.
Configuration conf = HbaseConfiguration.create();Schritt 2: Instanziieren Sie die HTable-Klasse
Sie haben eine Klasse namens HTable, eine Implementierung von Table in HBase. Diese Klasse wird zur Kommunikation mit einer einzelnen HBase-Tabelle verwendet. Beim Instanziieren dieser Klasse werden das Konfigurationsobjekt und der Tabellenname als Parameter akzeptiert. Sie können die HTable-Klasse wie unten gezeigt instanziieren.
HTable hTable = new HTable(conf, tableName);Schritt 3: Instanziieren Sie die Get-Klasse
Sie können Daten aus der HBase-Tabelle mit dem abrufen get() Methode der HTableKlasse. Diese Methode extrahiert eine Zelle aus einer bestimmten Zeile. Es erfordert eineGetKlassenobjekt als Parameter. Erstellen Sie es wie unten gezeigt.
Get get = new Get(toBytes("row1"));Schritt 4: Lesen Sie die Daten
Beim Abrufen von Daten können Sie eine einzelne Zeile nach ID oder eine Reihe von Zeilen nach einer Reihe von Zeilen-IDs abrufen oder eine gesamte Tabelle oder eine Teilmenge von Zeilen scannen.
Sie können HBase-Tabellendaten mit den Methodenvarianten hinzufügen in abrufen Get Klasse.
Verwenden Sie die folgende Methode, um eine bestimmte Spalte aus einer bestimmten Spaltenfamilie abzurufen.
get.addFamily(personal)Verwenden Sie die folgende Methode, um alle Spalten aus einer bestimmten Spaltenfamilie abzurufen.
get.addColumn(personal, name)Schritt 5: Holen Sie sich das Ergebnis
Holen Sie sich das Ergebnis, indem Sie Ihre übergeben Get Klasseninstanz zur get-Methode der HTableKlasse. Diese Methode gibt die zurückResultKlassenobjekt, das das angeforderte Ergebnis enthält. Unten ist die Verwendung von angegebenget() Methode.
Result result = table.get(g);Schritt 6: Lesen von Werten aus der Ergebnisinstanz
Das Result Klasse bietet die getValue()Methode zum Lesen der Werte aus seiner Instanz. Verwenden Sie es wie unten gezeigt, um die Werte aus dem zu lesenResult Beispiel.
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));Im Folgenden finden Sie das vollständige Programm zum Lesen von Werten aus einer HBase-Tabelle.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class RetriveData{
public static void main(String[] args) throws IOException, Exception{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating Get class
Get g = new Get(Bytes.toBytes("row1"));
// Reading the data
Result result = table.get(g);
// Reading values from Result class object
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
// Printing the values
String name = Bytes.toString(value);
String city = Bytes.toString(value1);
System.out.println("name: " + name + " city: " + city);
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac RetriveData.java $java RetriveDataFolgendes sollte die Ausgabe sein:
name: Raju city: DelhiLöschen einer bestimmten Zelle in einer Tabelle
Verwendung der deleteBefehl können Sie eine bestimmte Zelle in einer Tabelle löschen. Die Syntax vondelete Befehl ist wie folgt:
delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’Beispiel
Hier ist ein Beispiel zum Löschen einer bestimmten Zelle. Hier löschen wir das Gehalt.
hbase(main):006:0> delete 'emp', '1', 'personal data:city',
1417521848375
0 row(s) in 0.0060 secondsLöschen aller Zellen in einer Tabelle
Mit dem Befehl "deleteall" können Sie alle Zellen in einer Reihe löschen. Im Folgenden ist die Syntax des Befehls deleteall angegeben.
deleteall ‘<table name>’, ‘<row>’,Beispiel
Hier ist ein Beispiel für den Befehl "deleteall", bei dem alle Zellen von Zeile 1 der Tabelle emp gelöscht werden.
hbase(main):007:0> deleteall 'emp','1'
0 row(s) in 0.0240 secondsÜberprüfen Sie die Tabelle mit dem scanBefehl. Eine Momentaufnahme der Tabelle nach dem Löschen der Tabelle ist unten angegeben.
hbase(main):022:0> scan 'emp'
ROW COLUMN + CELL
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 1417524204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 1417523187, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000Daten mit Java API löschen
Sie können Daten aus einer HBase-Tabelle mit dem löschen delete() Methode der HTableKlasse. Führen Sie die folgenden Schritte aus, um Daten aus einer Tabelle zu löschen.
Schritt 1: Instanziieren Sie die Konfigurationsklasse
ConfigurationKlasse fügt ihrem Objekt HBase-Konfigurationsdateien hinzu. Sie können ein Konfigurationsobjekt mit dem erstellencreate() Methode der HbaseConfiguration Klasse wie unten gezeigt.
Configuration conf = HbaseConfiguration.create();Schritt 2: Instanziieren Sie die HTable-Klasse
Sie haben eine Klasse namens HTable, eine Implementierung von Table in HBase. Diese Klasse wird zur Kommunikation mit einer einzelnen HBase-Tabelle verwendet. Beim Instanziieren dieser Klasse werden das Konfigurationsobjekt und der Tabellenname als Parameter akzeptiert. Sie können die HTable-Klasse wie unten gezeigt instanziieren.
HTable hTable = new HTable(conf, tableName);Schritt 3: Instanziieren Sie die Löschklasse
Instanziieren Sie die DeleteKlasse durch Übergeben der Zeilen-ID der zu löschenden Zeile im Byte-Array-Format. Sie können diesem Konstruktor auch Zeitstempel und Rowlock übergeben.
Delete delete = new Delete(toBytes("row1"));Schritt 4: Wählen Sie die zu löschenden Daten aus
Sie können die Daten mit den Löschmethoden von löschen DeleteKlasse. Diese Klasse verfügt über verschiedene Löschmethoden. Wählen Sie die Spalten oder Spaltenfamilien aus, die mit diesen Methoden gelöscht werden sollen. Schauen Sie sich die folgenden Beispiele an, die die Verwendung von Delete-Klassenmethoden zeigen.
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));Schritt 5: Löschen Sie die Daten
Löschen Sie die ausgewählten Daten, indem Sie die übergeben delete Instanz zum delete() Methode der HTable Klasse wie unten gezeigt.
table.delete(delete);Schritt 6: Schließen Sie die HTableInstance
Schließen Sie nach dem Löschen der Daten die HTable Beispiel.
table.close();Im Folgenden finden Sie das vollständige Programm zum Löschen von Daten aus der HBase-Tabelle.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class DeleteData {
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(conf, "employee");
// Instantiating Delete class
Delete delete = new Delete(Bytes.toBytes("row1"));
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
// deleting the data
table.delete(delete);
// closing the HTable object
table.close();
System.out.println("data deleted.....");
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac Deletedata.java $java DeleteDataFolgendes sollte die Ausgabe sein:
data deletedScannen mit HBase Shell
Das scanBefehl wird verwendet, um die Daten in HTable anzuzeigen. Mit dem Scan-Befehl können Sie die Tabellendaten abrufen. Die Syntax lautet wie folgt:
scan ‘<table name>’Beispiel
Das folgende Beispiel zeigt, wie Sie mit dem Befehl scan Daten aus einer Tabelle lesen. Hier lesen wir dieemp Tabelle.
hbase(main):010:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417521848375, value = hyderabad
1 column = personal data:name, timestamp = 1417521785385, value = ramu
1 column = professional data:designation, timestamp = 1417585277,value = manager
1 column = professional data:salary, timestamp = 1417521903862, value = 50000
1 row(s) in 0.0370 secondsScannen mit Java API
Das vollständige Programm zum Scannen der gesamten Tabellendaten mithilfe der Java-API lautet wie folgt.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating the Scan class
Scan scan = new Scan();
// Scanning the required columns
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("city"));
// Getting the scan result
ResultScanner scanner = table.getScanner(scan);
// Reading values from scan result
for (Result result = scanner.next(); result != null; result = Scanner.next())
System.out.println("Found row : " + result);
//closing the scanner
scanner.close();
}
}Kompilieren Sie das obige Programm und führen Sie es wie unten gezeigt aus.
$javac ScanTable.java $java ScanTableFolgendes sollte die Ausgabe sein:
Found row :
keyvalues={row1/personal:city/1418275612888/Put/vlen=5/mvcc=0,
row1/personal:name/1418035791555/Put/vlen=4/mvcc=0}Anzahl
Sie können die Anzahl der Zeilen einer Tabelle mit dem zählen countBefehl. Die Syntax lautet wie folgt:
count ‘<table name>’Nach dem Löschen der ersten Zeile enthält die Tabelle emp zwei Zeilen. Überprüfen Sie es wie unten gezeigt.
hbase(main):023:0> count 'emp'
2 row(s) in 0.090 seconds
⇒ 2kürzen
Dieser Befehl deaktiviert das Löschen und erstellt eine Tabelle neu. Die Syntax vontruncate ist wie folgt:
hbase> truncate 'table name'Beispiel
Im Folgenden finden Sie ein Beispiel für einen Befehl zum Abschneiden. Hier haben wir das abgeschnittenemp Tabelle.
hbase(main):011:0> truncate 'emp'
Truncating 'one' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 1.5950 secondsVerwenden Sie nach dem Abschneiden der Tabelle den Scan-Befehl, um dies zu überprüfen. Sie erhalten eine Tabelle mit null Zeilen.
hbase(main):017:0> scan ‘emp’
ROW COLUMN + CELL
0 row(s) in 0.3110 secondsWir können Benutzern in HBase Berechtigungen erteilen und widerrufen. Aus Sicherheitsgründen gibt es drei Befehle: Erteilen, Widerrufen und Benutzerberechtigung.
gewähren
Das grantDer Befehl gewährt einem bestimmten Benutzer bestimmte Rechte wie Lesen, Schreiben, Ausführen und Verwalten einer Tabelle. Die Syntax des Befehls grant lautet wie folgt:
hbase> grant <user> <permissions> [<table> [<column family> [<column; qualifier>]]Wir können einem Benutzer null oder mehr Berechtigungen aus dem Satz von RWXCA gewähren, wobei
- R - steht für Leseberechtigung.
- W - steht für Schreibberechtigung.
- X - steht für das Ausführungsrecht.
- C - steht für das Erstellungsrecht.
- A - steht für Administratorrechte.
Im Folgenden finden Sie ein Beispiel, das einem Benutzer mit dem Namen "Tutorialspoint" alle Berechtigungen gewährt.
hbase(main):018:0> grant 'Tutorialspoint', 'RWXCA'widerrufen
Das revokeMit diesem Befehl werden die Zugriffsrechte eines Benutzers für eine Tabelle widerrufen. Die Syntax lautet wie folgt:
hbase> revoke <user>Der folgende Code widerruft alle Berechtigungen des Benutzers 'Tutorialspoint'.
hbase(main):006:0> revoke 'Tutorialspoint'user_permission
Mit diesem Befehl werden alle Berechtigungen für eine bestimmte Tabelle aufgelistet. Die Syntax vonuser_permission ist wie folgt:
hbase>user_permission ‘tablename’Der folgende Code listet alle Benutzerberechtigungen der Tabelle 'emp' auf.
hbase(main):013:0> user_permission 'emp'