Kubernetes - Kurzanleitung
Kubernetes in einem Open Source Container Management Tool, das von der Cloud Native Computing Foundation (CNCF) gehostet wird. Dies wird auch als erweiterte Version von Borg bezeichnet, die bei Google entwickelt wurde, um sowohl lang laufende Prozesse als auch Batch-Jobs zu verwalten, die zuvor von separaten Systemen verarbeitet wurden.
Kubernetes bietet die Möglichkeit, die Bereitstellung, Skalierung von Anwendungen und den Betrieb von Anwendungscontainern über Cluster hinweg zu automatisieren. Es ist in der Lage, eine containerzentrierte Infrastruktur zu erstellen.
Eigenschaften von Kubernetes
Im Folgenden sind einige wichtige Funktionen von Kubernetes aufgeführt.
Setzt Entwicklung, Integration und Bereitstellung fort
Containerisierte Infrastruktur
Anwendungsorientiertes Management
Automatisch skalierbare Infrastruktur
Umgebungskonsistenz bei Entwicklungstests und Produktion
Locker gekoppelte Infrastruktur, bei der jede Komponente als separate Einheit fungieren kann
Höhere Dichte der Ressourcennutzung
Vorhersehbare Infrastruktur, die erstellt werden soll
Eine der Schlüsselkomponenten von Kubernetes ist, dass es Anwendungen auf Clustern der Infrastruktur physischer und virtueller Maschinen ausführen kann. Es kann auch Anwendungen in der Cloud ausführen.It helps in moving from host-centric infrastructure to container-centric infrastructure.
In diesem Kapitel werden wir die grundlegende Architektur von Kubernetes diskutieren.
Kubernetes - Cluster-Architektur
Wie im folgenden Diagramm dargestellt, folgt Kubernetes der Client-Server-Architektur. Dabei haben wir Master auf einem Computer und den Knoten auf separaten Linux-Computern installiert.
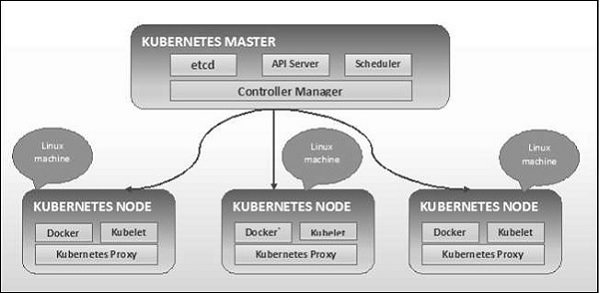
Die Schlüsselkomponenten von Master und Knoten werden im folgenden Abschnitt definiert.
Kubernetes - Master Machine Components
Im Folgenden sind die Komponenten von Kubernetes Master Machine aufgeführt.
etcd
Es speichert die Konfigurationsinformationen, die von jedem der Knoten im Cluster verwendet werden können. Es handelt sich um einen Schlüsselwertspeicher mit hoher Verfügbarkeit, der auf mehrere Knoten verteilt werden kann. Auf ihn kann nur der Kubernetes-API-Server zugreifen, da er möglicherweise vertrauliche Informationen enthält. Es ist ein verteilter Schlüsselwertspeicher, auf den alle zugreifen können.
API-Server
Kubernetes ist ein API-Server, der alle Operationen im Cluster mithilfe der API bereitstellt. Der API-Server implementiert eine Schnittstelle, sodass verschiedene Tools und Bibliotheken problemlos mit ihm kommunizieren können.Kubeconfigist ein Paket zusammen mit den serverseitigen Tools, die für die Kommunikation verwendet werden können. Es macht die Kubernetes-API verfügbar.
Controller Manager
Diese Komponente ist für die meisten Kollektoren verantwortlich, die den Status des Clusters regeln und eine Aufgabe ausführen. Im Allgemeinen kann es als Daemon betrachtet werden, der in einer nicht abschließenden Schleife ausgeführt wird und für das Sammeln und Senden von Informationen an den API-Server verantwortlich ist. Es arbeitet daran, den freigegebenen Status des Clusters abzurufen und dann Änderungen vorzunehmen, um den aktuellen Status des Servers in den gewünschten Status zu versetzen. Die Schlüsselcontroller sind Replikationscontroller, Endpunktcontroller, Namespacecontroller und Dienstkontocontroller. Der Controller-Manager führt verschiedene Arten von Controllern aus, um Knoten, Endpunkte usw. zu verwalten.
Planer
Dies ist eine der Schlüsselkomponenten von Kubernetes Master. Es ist ein Dienst im Master, der für die Verteilung der Arbeitslast verantwortlich ist. Es ist dafür verantwortlich, die Auslastung der Arbeitslast auf Clusterknoten zu verfolgen und dann die Arbeitslast zu platzieren, auf der Ressourcen verfügbar sind, und die Arbeitslast zu akzeptieren. Mit anderen Worten, dies ist der Mechanismus, der für die Zuweisung von Pods zu verfügbaren Knoten verantwortlich ist. Der Scheduler ist für die Auslastung der Workloads und die Zuweisung des Pods zu einem neuen Knoten verantwortlich.
Kubernetes - Knotenkomponenten
Im Folgenden sind die Schlüsselkomponenten des Knotenservers aufgeführt, die für die Kommunikation mit dem Kubernetes-Master erforderlich sind.
Docker
Die erste Anforderung für jeden Knoten ist Docker, mit dessen Hilfe die gekapselten Anwendungscontainer in einer relativ isolierten, aber leichtgewichtigen Betriebsumgebung ausgeführt werden können.
Kubelet Service
Dies ist ein kleiner Dienst in jedem Knoten, der für die Weiterleitung von Informationen zum und vom Steuerebenendienst verantwortlich ist. Es interagiert mitetcdSpeichern, um Konfigurationsdetails und Wright-Werte zu lesen. Dies kommuniziert mit der Master-Komponente, um Befehle zu empfangen und zu arbeiten. DaskubeletDer Prozess übernimmt dann die Verantwortung für die Aufrechterhaltung des Arbeitsstatus und des Knotenservers. Es verwaltet Netzwerkregeln, Portweiterleitung usw.
Kubernetes Proxy Service
Dies ist ein Proxy-Dienst, der auf jedem Knoten ausgeführt wird und dabei hilft, Dienste für den externen Host verfügbar zu machen. Es hilft bei der Weiterleitung der Anforderung an korrekte Container und kann einen primitiven Lastausgleich durchführen. Es stellt sicher, dass die Netzwerkumgebung vorhersehbar und zugänglich ist und gleichzeitig isoliert ist. Es verwaltet Pods auf Knoten, Volumes, Geheimnissen, erstellt die Integritätsprüfung neuer Container usw.
Kubernetes - Master- und Knotenstruktur
Die folgenden Abbildungen zeigen die Struktur von Kubernetes Master und Node.
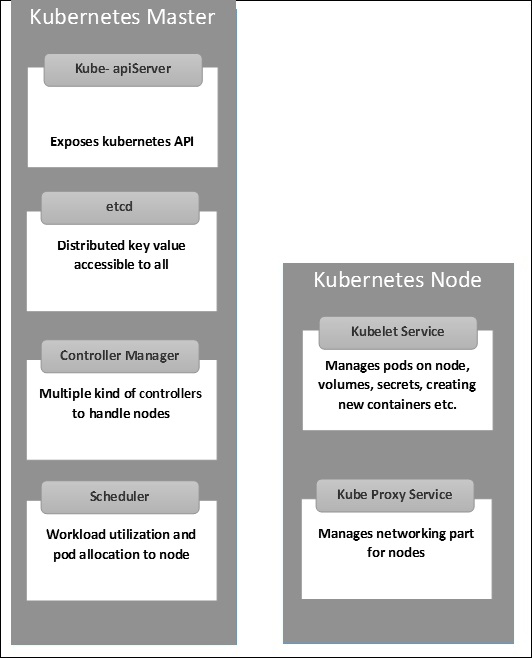
Es ist wichtig, das Virtual Datacenter (vDC) einzurichten, bevor Sie Kubernetes einrichten. Dies kann als eine Reihe von Maschinen betrachtet werden, auf denen sie über das Netzwerk miteinander kommunizieren können. Für den praktischen Ansatz können Sie vDC aktivierenPROFITBRICKS Wenn Sie keine physische oder Cloud-Infrastruktur eingerichtet haben.
Sobald das IaaS-Setup in einer Cloud abgeschlossen ist, müssen Sie das konfigurieren Master und die Node.
Note- Das Setup wird für Ubuntu-Maschinen angezeigt. Das gleiche kann auch auf anderen Linux-Rechnern eingerichtet werden.
Voraussetzungen
Installing Docker- Docker ist für alle Instanzen von Kubernetes erforderlich. Im Folgenden finden Sie die Schritte zum Installieren des Dockers.
Step 1 - Melden Sie sich mit dem Root-Benutzerkonto am Computer an.
Step 2- Aktualisieren Sie die Paketinformationen. Stellen Sie sicher, dass das apt-Paket funktioniert.
Step 3 - Führen Sie die folgenden Befehle aus.
$ sudo apt-get update $ sudo apt-get install apt-transport-https ca-certificatesStep 4 - Fügen Sie den neuen GPG-Schlüssel hinzu.
$ sudo apt-key adv \ --keyserver hkp://ha.pool.sks-keyservers.net:80 \ --recv-keys 58118E89F3A912897C070ADBF76221572C52609D $ echo "deb https://apt.dockerproject.org/repo ubuntu-trusty main" | sudo tee
/etc/apt/sources.list.d/docker.listStep 5 - Aktualisieren Sie das API-Paket-Image.
$ sudo apt-get updateSobald alle oben genannten Aufgaben abgeschlossen sind, können Sie mit der eigentlichen Installation der Docker-Engine beginnen. Zuvor müssen Sie jedoch überprüfen, ob die von Ihnen verwendete Kernelversion korrekt ist.
Installieren Sie Docker Engine
Führen Sie die folgenden Befehle aus, um die Docker-Engine zu installieren.
Step 1 - Melden Sie sich am Computer an.
Step 2 - Aktualisieren Sie den Paketindex.
$ sudo apt-get updateStep 3 - Installieren Sie die Docker Engine mit dem folgenden Befehl.
$ sudo apt-get install docker-engineStep 4 - Starten Sie den Docker-Daemon.
$ sudo apt-get install docker-engineStep 5 - Wenn der Docker installiert ist, verwenden Sie den folgenden Befehl.
$ sudo docker run hello-worldInstallieren Sie etcd 2.0
Dies muss auf der Kubernetes Master Machine installiert werden. Führen Sie die folgenden Befehle aus, um es zu installieren.
$ curl -L https://github.com/coreos/etcd/releases/download/v2.0.0/etcd
-v2.0.0-linux-amd64.tar.gz -o etcd-v2.0.0-linux-amd64.tar.gz ->1
$ tar xzvf etcd-v2.0.0-linux-amd64.tar.gz ------>2 $ cd etcd-v2.0.0-linux-amd64 ------------>3
$ mkdir /opt/bin ------------->4 $ cp etcd* /opt/bin ----------->5Im obigen Befehlssatz -
- Zuerst laden wir die etcd. Speichern Sie dies unter dem angegebenen Namen.
- Dann müssen wir das Teerpaket entfernen.
- Wir machen ein dir. im / opt namens bin.
- Kopieren Sie die extrahierte Datei an den Zielspeicherort.
Jetzt sind wir bereit, Kubernetes zu bauen. Wir müssen Kubernetes auf allen Computern im Cluster installieren.
$ git clone https://github.com/GoogleCloudPlatform/kubernetes.git $ cd kubernetes
$ make releaseDer obige Befehl erstellt eine _outputdir im Stammverzeichnis des Kubernetes-Ordners. Als nächstes können wir das Verzeichnis in ein beliebiges Verzeichnis unserer Wahl / opt / bin usw. extrahieren.
Als nächstes kommt der Netzwerkteil, in dem wir tatsächlich mit der Einrichtung von Kubernetes Master und Node beginnen müssen. Zu diesem Zweck erstellen wir einen Eintrag in der Hostdatei, der auf dem Knotencomputer ausgeführt werden kann.
$ echo "<IP address of master machine> kube-master
< IP address of Node Machine>" >> /etc/hostsEs folgt die Ausgabe des obigen Befehls.
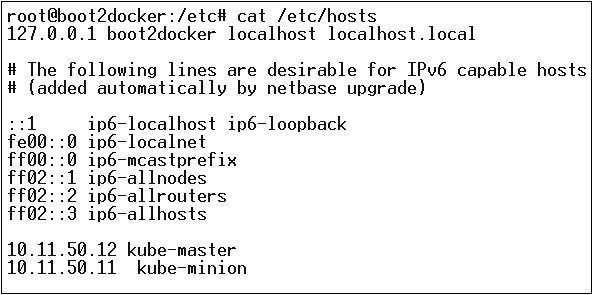
Nun beginnen wir mit der eigentlichen Konfiguration auf Kubernetes Master.
Zuerst kopieren wir alle Konfigurationsdateien an den richtigen Speicherort.
$ cp <Current dir. location>/kube-apiserver /opt/bin/ $ cp <Current dir. location>/kube-controller-manager /opt/bin/
$ cp <Current dir. location>/kube-kube-scheduler /opt/bin/ $ cp <Current dir. location>/kubecfg /opt/bin/
$ cp <Current dir. location>/kubectl /opt/bin/ $ cp <Current dir. location>/kubernetes /opt/bin/Mit dem obigen Befehl werden alle Konfigurationsdateien an den gewünschten Speicherort kopiert. Jetzt kehren wir zu demselben Verzeichnis zurück, in dem wir den Kubernetes-Ordner erstellt haben.
$ cp kubernetes/cluster/ubuntu/init_conf/kube-apiserver.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-controller-manager.conf /etc/init/
$ cp kubernetes/cluster/ubuntu/init_conf/kube-kube-scheduler.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-apiserver /etc/init.d/
$ cp kubernetes/cluster/ubuntu/initd_scripts/kube-controller-manager /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-kube-scheduler /etc/init.d/
$ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/
$ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/Der nächste Schritt ist das Aktualisieren der kopierten Konfigurationsdatei unter / etc. dir.
Konfigurieren Sie etcd auf dem Master mit dem folgenden Befehl.
$ ETCD_OPTS = "-listen-client-urls = http://kube-master:4001"Konfigurieren Sie kube-apiserver
Dazu müssen wir auf dem Master die bearbeiten /etc/default/kube-apiserver Datei, die wir zuvor kopiert haben.
$ KUBE_APISERVER_OPTS = "--address = 0.0.0.0 \
--port = 8080 \
--etcd_servers = <The path that is configured in ETCD_OPTS> \
--portal_net = 11.1.1.0/24 \
--allow_privileged = false \
--kubelet_port = < Port you want to configure> \
--v = 0"Konfigurieren Sie den kube Controller Manager
Wir müssen den folgenden Inhalt hinzufügen /etc/default/kube-controller-manager.
$ KUBE_CONTROLLER_MANAGER_OPTS = "--address = 0.0.0.0 \
--master = 127.0.0.1:8080 \
--machines = kube-minion \ -----> #this is the kubernatics node
--v = 0Konfigurieren Sie als Nächstes den Kube-Scheduler in der entsprechenden Datei.
$ KUBE_SCHEDULER_OPTS = "--address = 0.0.0.0 \
--master = 127.0.0.1:8080 \
--v = 0"Sobald alle oben genannten Aufgaben erledigt sind, können Sie den Kubernetes Master aufrufen. Dazu starten wir den Docker neu.
$ service docker restartKubernetes-Knotenkonfiguration
Der Kubernetes-Knoten führt zwei Dienste aus kubelet and the kube-proxy. Bevor wir fortfahren, müssen wir die heruntergeladenen Binärdateien in die erforderlichen Ordner kopieren, in denen wir den Kubernetes-Knoten konfigurieren möchten.
Verwenden Sie zum Kopieren der Dateien dieselbe Methode wie für kubernetes master. Da nur das Kubelet und der Kube-Proxy ausgeführt werden, werden sie konfiguriert.
$ cp <Path of the extracted file>/kubelet /opt/bin/ $ cp <Path of the extracted file>/kube-proxy /opt/bin/
$ cp <Path of the extracted file>/kubecfg /opt/bin/ $ cp <Path of the extracted file>/kubectl /opt/bin/
$ cp <Path of the extracted file>/kubernetes /opt/bin/Jetzt kopieren wir den Inhalt in das entsprechende Verzeichnis.
$ cp kubernetes/cluster/ubuntu/init_conf/kubelet.conf /etc/init/
$ cp kubernetes/cluster/ubuntu/init_conf/kube-proxy.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kubelet /etc/init.d/
$ cp kubernetes/cluster/ubuntu/initd_scripts/kube-proxy /etc/init.d/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/
$ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/Wir werden das konfigurieren kubelet und kube-proxy conf Dateien.
Wir werden das konfigurieren /etc/init/kubelet.conf.
$ KUBELET_OPTS = "--address = 0.0.0.0 \
--port = 10250 \
--hostname_override = kube-minion \
--etcd_servers = http://kube-master:4001 \
--enable_server = true
--v = 0"
/Für kube-proxy konfigurieren wir mit dem folgenden Befehl.
$ KUBE_PROXY_OPTS = "--etcd_servers = http://kube-master:4001 \
--v = 0"
/etc/init/kube-proxy.confSchließlich werden wir den Docker-Dienst neu starten.
$ service docker restartJetzt sind wir mit der Konfiguration fertig. Sie können dies überprüfen, indem Sie die folgenden Befehle ausführen.
$ /opt/bin/kubectl get minionsKubernetes (Docker) -Bilder sind die Schlüsselbausteine der Containerized Infrastructure. Ab sofort unterstützen wir nur Kubernetes, um Docker-Images zu unterstützen. In jedem Container in einem Pod befindet sich ein Docker-Image.
Wenn wir einen Pod konfigurieren, hat die Image-Eigenschaft in der Konfigurationsdatei dieselbe Syntax wie der Docker-Befehl. Die Konfigurationsdatei enthält ein Feld zum Definieren des Bildnamens, den wir aus der Registrierung abrufen möchten.
Im Folgenden finden Sie die allgemeine Konfigurationsstruktur, mit der das Image aus der Docker-Registrierung abgerufen und im Kubernetes-Container bereitgestellt wird.
apiVersion: v1
kind: pod
metadata:
name: Tesing_for_Image_pull -----------> 1
spec:
containers:
- name: neo4j-server ------------------------> 2
image: <Name of the Docker image>----------> 3
imagePullPolicy: Always ------------->4
command: ["echo", "SUCCESS"] ------------------->Im obigen Code haben wir definiert -
name: Tesing_for_Image_pull - Dieser Name wird angegeben, um den Namen des Containers zu identifizieren und zu überprüfen, der nach dem Abrufen der Bilder aus der Docker-Registrierung erstellt wird.
name: neo4j-server- Dies ist der Name des Containers, den wir erstellen möchten. Wie wir neo4j-Server gegeben haben.
image: <Name of the Docker image>- Dies ist der Name des Bildes, das wir aus dem Docker oder der internen Registrierung von Bildern abrufen möchten. Wir müssen einen vollständigen Registrierungspfad zusammen mit dem Bildnamen definieren, den wir abrufen möchten.
imagePullPolicy - Immer - Diese Image-Pull-Richtlinie definiert, dass bei jeder Ausführung dieser Datei zum Erstellen des Containers derselbe Name erneut abgerufen wird.
command: [“echo”, “SUCCESS”] - Wenn wir den Container erstellen und alles in Ordnung ist, wird eine Meldung angezeigt, wenn wir auf den Container zugreifen.
Um das Bild abzurufen und einen Container zu erstellen, führen wir den folgenden Befehl aus.
$ kubectl create –f Tesing_for_Image_pullSobald wir das Protokoll abgerufen haben, erhalten wir die Ausgabe als erfolgreich.
$ kubectl log Tesing_for_Image_pullDer obige Befehl erzeugt eine Ausgabe von Erfolg oder wir erhalten eine Ausgabe als Fehler.
Note - Es wird empfohlen, alle Befehle selbst auszuprobieren.
Die Hauptfunktion eines Jobs besteht darin, einen oder mehrere Pods zu erstellen und den Erfolg von Pods zu verfolgen. Sie stellen sicher, dass die angegebene Anzahl von Pods erfolgreich abgeschlossen wird. Wenn eine bestimmte Anzahl erfolgreicher Pod-Läufe abgeschlossen ist, wird der Job als abgeschlossen betrachtet.
Einen Job erstellen
Verwenden Sie den folgenden Befehl, um einen Job zu erstellen:
apiVersion: v1
kind: Job ------------------------> 1
metadata:
name: py
spec:
template:
metadata
name: py -------> 2
spec:
containers:
- name: py ------------------------> 3
image: python----------> 4
command: ["python", "SUCCESS"]
restartPocliy: Never --------> 5Im obigen Code haben wir definiert -
kind: Job → Wir haben die Art als Job definiert, die es zeigen wird kubectl dass die yaml Die verwendete Datei dient zum Erstellen eines Pods vom Typ Job.
Name:py → Dies ist der Name der Vorlage, die wir verwenden, und die Spezifikation definiert die Vorlage.
name: py → wir haben einen Namen gegeben als py unter Containerspezifikation, die hilft, den Pod zu identifizieren, der daraus erstellt werden soll.
Image: python → Das Bild, das wir ziehen werden, um den Container zu erstellen, der im Pod ausgeführt wird.
restartPolicy: Never →Diese Bedingung für den Neustart des Images wird als nie angegeben. Dies bedeutet, dass der Container nicht neu gestartet wird, wenn er beendet wird oder wenn er falsch ist.
Wir erstellen den Job mit dem folgenden Befehl mit yaml, der unter dem Namen gespeichert wird py.yaml.
$ kubectl create –f py.yamlDer obige Befehl erstellt einen Job. Wenn Sie den Status eines Jobs überprüfen möchten, verwenden Sie den folgenden Befehl.
$ kubectl describe jobs/pyDer obige Befehl erstellt einen Job. Wenn Sie den Status eines Jobs überprüfen möchten, verwenden Sie den folgenden Befehl.
Geplanter Job
Geplanter Job in Kubernetes verwendet Cronetes, der den Kubernetes-Job übernimmt und sie im Kubernetes-Cluster startet.
- Wenn Sie einen Job planen, wird ein Pod zu einem bestimmten Zeitpunkt ausgeführt.
- Dafür wird ein parodistischer Job erstellt, der sich automatisch aufruft.
Note - Die Funktion eines geplanten Jobs wird von Version 1.4 unterstützt und die betch / v2alpha 1-API wird durch Übergeben von aktiviert –runtime-config=batch/v2alpha1 beim Aufrufen des API-Servers.
Wir werden dasselbe Yaml verwenden, mit dem wir den Job erstellt und zu einem geplanten Job gemacht haben.
apiVersion: v1
kind: Job
metadata:
name: py
spec:
schedule: h/30 * * * * ? -------------------> 1
template:
metadata
name: py
spec:
containers:
- name: py
image: python
args:
/bin/sh -------> 2
-c
ps –eaf ------------> 3
restartPocliy: OnFailureIm obigen Code haben wir definiert -
schedule: h/30 * * * * ? → So planen Sie die Ausführung des Jobs alle 30 Minuten.
/bin/sh: Dies wird mit / bin / sh in den Container eingegeben
ps –eaf → Führt den Befehl ps -eaf auf dem Computer aus und listet den gesamten laufenden Prozess in einem Container auf.
Dieses geplante Jobkonzept ist nützlich, wenn wir versuchen, eine Reihe von Aufgaben zu einem bestimmten Zeitpunkt zu erstellen und auszuführen und dann den Prozess abzuschließen.
Etiketten
Beschriftungen sind Schlüssel-Wert-Paare, die an Pods, Replikationscontroller und Dienste angehängt sind. Sie werden als Identifikationsattribute für Objekte wie Pods und Replikationscontroller verwendet. Sie können zur Erstellungszeit einem Objekt hinzugefügt und zur Laufzeit hinzugefügt oder geändert werden.
Selektoren
Etiketten bieten keine Eindeutigkeit. Im Allgemeinen können wir sagen, dass viele Objekte dieselben Beschriftungen tragen können. Der Labels Selector ist in Kubernetes ein primitives Kerngruppierungselement. Sie werden von den Benutzern verwendet, um eine Reihe von Objekten auszuwählen.
Die Kubernetes-API unterstützt derzeit zwei Arten von Selektoren:
- Gleichstellungsbasierte Selektoren
- Set-basierte Selektoren
Gleichstellungsbasierte Selektoren
Sie ermöglichen das Filtern nach Schlüssel und Wert. Übereinstimmende Objekte sollten alle angegebenen Beschriftungen erfüllen.
Set-basierte Selektoren
Set-basierte Selektoren ermöglichen das Filtern von Schlüsseln nach einer Reihe von Werten.
apiVersion: v1
kind: Service
metadata:
name: sp-neo4j-standalone
spec:
ports:
- port: 7474
name: neo4j
type: NodePort
selector:
app: salesplatform ---------> 1
component: neo4j -----------> 2Im obigen Code verwenden wir den Label-Selektor als app: salesplatform und Komponente als component: neo4j.
Sobald wir die Datei mit dem ausführen kubectl Befehl wird ein Dienst mit dem Namen erstellt sp-neo4j-standalone die auf Port 7474 kommunizieren wird. Das ype ist NodePort mit dem neuen Etikettenwähler als app: salesplatform und component: neo4j.
Der Namespace bietet eine zusätzliche Qualifikation für einen Ressourcennamen. Dies ist hilfreich, wenn mehrere Teams denselben Cluster verwenden und die Gefahr einer Namenskollision besteht. Es kann sich um eine virtuelle Wand zwischen mehreren Clustern handeln.
Funktionalität des Namespace
Im Folgenden finden Sie einige wichtige Funktionen eines Namespace in Kubernetes:
Namespaces unterstützen die Kommunikation von Pod zu Pod mit demselben Namespace.
Namespaces sind virtuelle Cluster, die sich auf demselben physischen Cluster befinden können.
Sie bieten eine logische Trennung zwischen den Teams und ihren Umgebungen.
Erstellen Sie einen Namespace
Der folgende Befehl wird verwendet, um einen Namespace zu erstellen.
apiVersion: v1
kind: Namespce
metadata
name: elkSteuern Sie den Namespace
Der folgende Befehl wird verwendet, um den Namespace zu steuern.
$ kubectl create –f namespace.yml ---------> 1
$ kubectl get namespace -----------------> 2 $ kubectl get namespace <Namespace name> ------->3
$ kubectl describe namespace <Namespace name> ---->4 $ kubectl delete namespace <Namespace name>Im obigen Code
- Wir verwenden den Befehl, um einen Namespace zu erstellen.
- Dadurch werden alle verfügbaren Namespace aufgelistet.
- Dadurch wird ein bestimmter Namespace abgerufen, dessen Name im Befehl angegeben ist.
- Hier werden die vollständigen Details des Dienstes beschrieben.
- Dadurch wird ein bestimmter im Cluster vorhandener Namespace gelöscht.
Verwenden des Namespace im Dienst - Beispiel
Im Folgenden finden Sie ein Beispiel für eine Beispieldatei zur Verwendung des Namespace im Dienst.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCPIm obigen Code verwenden wir denselben Namespace unter Service-Metadaten mit dem Namen elk.
Ein Knoten ist eine funktionierende Maschine im Kubernetes-Cluster, der auch als Minion bezeichnet wird. Es handelt sich um Arbeitseinheiten, die physisch, VM oder eine Cloud-Instanz sein können.
Jeder Knoten verfügt über alle erforderlichen Konfigurationen, um einen Pod auf ihm auszuführen, z. B. den Proxy-Dienst und den Kubelet-Dienst, zusammen mit dem Docker, mit dem die Docker-Container auf dem auf dem Knoten erstellten Pod ausgeführt werden.
Sie werden nicht von Kubernetes erstellt, sondern extern entweder vom Cloud-Dienstanbieter oder vom Kubernetes-Cluster-Manager auf physischen oder VM-Computern.
Die Schlüsselkomponente von Kubernetes für die Verarbeitung mehrerer Knoten ist der Controller-Manager, der mehrere Arten von Controllern zur Verwaltung von Knoten ausführt. Um Knoten zu verwalten, erstellt Kubernetes ein Objekt vom Typ Knoten, das überprüft, ob das erstellte Objekt ein gültiger Knoten ist.
Service mit Selector
apiVersion: v1
kind: node
metadata:
name: < ip address of the node>
labels:
name: <lable name>Im JSON-Format wird das eigentliche Objekt erstellt, das wie folgt aussieht:
{
Kind: node
apiVersion: v1
"metadata":
{
"name": "10.01.1.10",
"labels"
{
"name": "cluster 1 node"
}
}
}Knoten-Controller
Sie sind die Sammlung von Diensten, die im Kubernetes-Master ausgeführt werden und den Knoten im Cluster auf der Grundlage von metadata.name kontinuierlich überwachen. Wenn alle erforderlichen Dienste ausgeführt werden, wird der Knoten validiert und diesem Knoten wird vom Controller ein neu erstellter Pod zugewiesen. Wenn es nicht gültig ist, weist der Master ihm keinen Pod zu und wartet, bis er gültig wird.
Kubernetes Master registriert den Knoten automatisch, wenn –register-node Flagge ist wahr.
–register-node = trueWenn der Clusteradministrator es jedoch manuell verwalten möchte, kann dies durch Drehen der Ebene von - erfolgen.
–register-node = falseEin Dienst kann als logischer Satz von Pods definiert werden. Es kann als Abstraktion oben im Pod definiert werden, die eine einzelne IP-Adresse und einen DNS-Namen enthält, über die auf Pods zugegriffen werden kann. Mit Service ist es sehr einfach, die Lastausgleichskonfiguration zu verwalten. Es hilft Pods sehr einfach zu skalieren.
Ein Service ist ein REST-Objekt in Kubernetes, dessen Definition an Kubernetes apiServer auf dem Kubernetes-Master gesendet werden kann, um eine neue Instanz zu erstellen.
Service ohne Selektor
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
ports:
- port: 8080
targetPort: 31999Mit der obigen Konfiguration wird ein Dienst mit dem Namen Tutorial_point_service erstellt.
Service-Konfigurationsdatei mit Selector
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: "My Application" -------------------> (Selector)
ports:
- port: 8080
targetPort: 31999In diesem Beispiel haben wir einen Selektor. Um Datenverkehr zu übertragen, müssen wir einen Endpunkt manuell erstellen.
apiVersion: v1
kind: Endpoints
metadata:
name: Tutorial_point_service
subnets:
address:
"ip": "192.168.168.40" -------------------> (Selector)
ports:
- port: 8080Im obigen Code haben wir einen Endpunkt erstellt, der den Datenverkehr an den als "192.168.168.40:8080" definierten Endpunkt weiterleitet.
Erstellung von Multi-Port-Diensten
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: “My Application” -------------------> (Selector)
ClusterIP: 10.3.0.12
ports:
-name: http
protocol: TCP
port: 80
targetPort: 31999
-name:https
Protocol: TCP
Port: 443
targetPort: 31998Arten von Dienstleistungen
ClusterIP- Dies hilft bei der Einschränkung des Dienstes innerhalb des Clusters. Es macht den Dienst innerhalb des definierten Kubernetes-Clusters verfügbar.
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: NodeportServiceNodePort- Der Dienst wird an einem statischen Port auf dem bereitgestellten Knoten verfügbar gemacht. EINClusterIP Service, zu dem NodePortService wird weitergeleitet, wird automatisch erstellt. Auf den Dienst kann von außerhalb des Clusters mit dem zugegriffen werdenNodeIP:nodePort.
spec:
ports:
- port: 8080
nodePort: 31999
name: NodeportService
clusterIP: 10.20.30.40Load Balancer - Es verwendet den Load Balancer von Cloud-Anbietern. NodePort und ClusterIP Es werden automatisch Dienste erstellt, an die der externe Load Balancer weitergeleitet wird.
Ein Full-Service yamlDatei mit dem Diensttyp als Knotenport. Versuchen Sie, selbst eine zu erstellen.
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: env_nameEin Pod ist eine Sammlung von Containern und deren Speicherung in einem Knoten eines Kubernetes-Clusters. Es ist möglich, einen Pod mit mehreren Containern zu erstellen. Beispiel: Halten Sie einen Datenbankcontainer und einen Datencontainer im selben Pod.
Arten von Pod
Es gibt zwei Arten von Pods -
- Einzelcontainer-Kapsel
- Multi Container Pod
Einzelcontainer-Pod
Sie können einfach mit dem Befehl kubctl run erstellt werden, wobei Sie ein definiertes Image in der Docker-Registrierung haben, das wir beim Erstellen eines Pods abrufen.
$ kubectl run <name of pod> --image=<name of the image from registry>Example - Wir erstellen einen Pod mit einem Tomcat-Image, der auf dem Docker-Hub verfügbar ist.
$ kubectl run tomcat --image = tomcat:8.0Dies kann auch durch Erstellen der yaml Datei und dann ausführen die kubectl create Befehl.
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: AlwaysEinmal oben yaml Datei erstellt wird, speichern wir die Datei mit dem Namen tomcat.yml und führen Sie den Befehl create aus, um das Dokument auszuführen.
$ kubectl create –f tomcat.ymlEs wird ein Pod mit dem Namen Tomcat erstellt. Wir können den Befehl description zusammen mit verwendenkubectl um die Kapsel zu beschreiben.
Multi Container Pod
Multi-Container-Pods werden mit erstellt yaml mail mit der Definition der Container.
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: Always
-name: Database
Image: mongoDB
Ports:
containerPort: 7501
imagePullPolicy: AlwaysIm obigen Code haben wir einen Pod mit zwei Containern erstellt, einen für Tomcat und einen für MongoDB.
Replication Controller ist eine der Hauptfunktionen von Kubernetes, das für die Verwaltung des Pod-Lebenszyklus verantwortlich ist. Es ist dafür verantwortlich, dass die angegebene Anzahl von Pod-Replikaten zu jedem Zeitpunkt ausgeführt wird. Es wird in der Zeit verwendet, in der sichergestellt werden soll, dass die angegebene Anzahl von Pods oder mindestens ein Pod ausgeführt wird. Es hat die Fähigkeit, die angegebene Anzahl von Pods nach oben oder unten zu bringen.
Es wird empfohlen, den Replikationscontroller zum Verwalten des Pod-Lebenszyklus zu verwenden, anstatt immer wieder einen Pod zu erstellen.
apiVersion: v1
kind: ReplicationController --------------------------> 1
metadata:
name: Tomcat-ReplicationController --------------------------> 2
spec:
replicas: 3 ------------------------> 3
template:
metadata:
name: Tomcat-ReplicationController
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat- -----------------------> 4
image: tomcat: 8.0
ports:
- containerPort: 7474 ------------------------> 5Setup-Details
Kind: ReplicationController → Im obigen Code haben wir die Art als Replikationscontroller definiert, der die kubectl dass die yaml Die Datei wird zum Erstellen des Replikationscontrollers verwendet.
name: Tomcat-ReplicationController→ Dies hilft bei der Identifizierung des Namens, mit dem der Replikationscontroller erstellt wird. Wenn wir den Kubctl ausführen, holen Sie sichrc < Tomcat-ReplicationController > Es werden die Details des Replikationscontrollers angezeigt.
replicas: 3 → Dies hilft dem Replikationscontroller zu verstehen, dass er zu jedem Zeitpunkt im Pod-Lebenszyklus drei Replikate eines Pods verwalten muss.
name: Tomcat → Im Spezifikationsabschnitt haben wir den Namen als Tomcat definiert, der dem Replikationscontroller mitteilt, dass der in den Pods vorhandene Container Tomcat ist.
containerPort: 7474 → Es hilft sicherzustellen, dass alle Knoten in dem Cluster, auf dem der Pod ausgeführt wird, den Container im Pod auf demselben Port 7474 verfügbar machen.

Hier arbeitet der Kubernetes-Dienst als Load Balancer für drei Tomcat-Replikate.
Das Replikatset stellt sicher, wie viele Replikate des Pods ausgeführt werden sollen. Es kann als Ersatz für den Replikationscontroller betrachtet werden. Der Hauptunterschied zwischen dem Replikatsatz und dem Replikationscontroller besteht darin, dass der Replikationscontroller nur einen auf Gleichheit basierenden Selektor unterstützt, während der Replikatsatz einen auf Sätzen basierenden Selektor unterstützt.
apiVersion: extensions/v1beta1 --------------------->1
kind: ReplicaSet --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
selector:
matchLables:
tier: Backend ------------------> 3
matchExpression:
{ key: tier, operation: In, values: [Backend]} --------------> 4
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
- containerPort: 7474Setup-Details
apiVersion: extensions/v1beta1 → Im obigen Code ist die API-Version die erweiterte Beta-Version von Kubernetes, die das Konzept des Replikatsatzes unterstützt.
kind: ReplicaSet → Wir haben die Art als Replikatsatz definiert, der kubectl hilft zu verstehen, dass die Datei zum Erstellen eines Replikatsatzes verwendet wird.
tier: Backend → Wir haben die Label-Ebene als Backend definiert, das einen passenden Selektor erstellt.
{key: tier, operation: In, values: [Backend]} → Das wird helfen matchExpression um die Übereinstimmungsbedingung zu verstehen, die wir definiert haben, und in der Operation, die von verwendet wird matchlabel um Details zu finden.
Führen Sie die obige Datei mit aus kubectl und erstellen Sie das Backend-Replikatset mit der angegebenen Definition in der yaml Datei.

Bereitstellungen werden aktualisiert und eine höhere Version des Replikationscontrollers. Sie verwalten die Bereitstellung von Replikatsätzen, bei denen es sich auch um eine aktualisierte Version des Replikationscontrollers handelt. Sie können den Replikatsatz aktualisieren und auf die vorherige Version zurücksetzen.
Sie bieten viele aktualisierte Funktionen von matchLabels und selectors. Wir haben einen neuen Controller im Kubernetes-Master, den Deployment-Controller, der dies ermöglicht. Es kann die Bereitstellung auf halbem Weg ändern.
Ändern der Bereitstellung
Updating- Der Benutzer kann die laufende Bereitstellung aktualisieren, bevor sie abgeschlossen ist. In diesem Fall wird die vorhandene Bereitstellung abgerechnet und eine neue Bereitstellung erstellt.
Deleting- Der Benutzer kann die Bereitstellung anhalten / abbrechen, indem er sie löscht, bevor sie abgeschlossen ist. Wenn Sie dieselbe Bereitstellung neu erstellen, wird sie fortgesetzt.
Rollback- Wir können die Bereitstellung oder die laufende Bereitstellung zurücksetzen. Der Benutzer kann die Bereitstellung mithilfe von erstellen oder aktualisierenDeploymentSpec.PodTemplateSpec = oldRC.PodTemplateSpec.
Bereitstellungsstrategien
Bereitstellungsstrategien helfen bei der Definition, wie der neue RC den vorhandenen RC ersetzen soll.
Recreate- Diese Funktion beendet alle vorhandenen RC und ruft dann die neuen auf. Dies führt zu einer schnellen Bereitstellung, führt jedoch zu Ausfallzeiten, wenn die alten Pods ausgefallen sind und die neuen Pods nicht hochgefahren sind.
Rolling Update- Mit dieser Funktion wird der alte RC schrittweise heruntergefahren und der neue hochgefahren. Dies führt zu einer langsamen Bereitstellung, es erfolgt jedoch keine Bereitstellung. In diesem Prozess sind immer nur wenige alte und wenige neue Pods verfügbar.
Die Konfigurationsdatei von Deployment sieht folgendermaßen aus.
apiVersion: extensions/v1beta1 --------------------->1
kind: Deployment --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
spec:
containers:
- name: Tomcatimage:
tomcat: 8.0
ports:
- containerPort: 7474Im obigen Code unterscheidet sich das einzige, was sich vom Replikatsatz unterscheidet, darin, dass wir die Art als Bereitstellung definiert haben.
Bereitstellung erstellen
$ kubectl create –f Deployment.yaml -–record
deployment "Deployment" created Successfully.Rufen Sie die Bereitstellung ab
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVILABLE AGE
Deployment 3 3 3 3 20sÜberprüfen Sie den Bereitstellungsstatus
$ kubectl rollout status deployment/DeploymentAktualisieren der Bereitstellung
$ kubectl set image deployment/Deployment tomcat=tomcat:6.0Zurücksetzen auf die vorherige Bereitstellung
$ kubectl rollout undo deployment/Deployment –to-revision=2In Kubernetes kann ein Volume als ein Verzeichnis betrachtet werden, auf das die Container in einem Pod zugreifen können. Wir haben verschiedene Arten von Volumes in Kubernetes und der Typ definiert, wie das Volume erstellt wird und welchen Inhalt es hat.
Das Konzept des Volumens war beim Docker vorhanden, das einzige Problem war jedoch, dass das Volumen sehr stark auf einen bestimmten Pod beschränkt war. Sobald das Leben eines Pods endete, ging auch die Lautstärke verloren.
Andererseits sind die Volumes, die über Kubernetes erstellt werden, nicht auf einen Container beschränkt. Es unterstützt einen oder alle Container, die im Pod von Kubernetes bereitgestellt werden. Ein wesentlicher Vorteil des Kubernetes-Volumes besteht darin, dass es verschiedene Arten von Speicher unterstützt, wobei der Pod mehrere davon gleichzeitig verwenden kann.
Arten von Kubernetes Volume
Hier ist eine Liste einiger beliebter Kubernetes-Bände -
emptyDir- Dies ist eine Art von Volume, das erstellt wird, wenn ein Pod zum ersten Mal einem Knoten zugewiesen wird. Es bleibt aktiv, solange der Pod auf diesem Knoten ausgeführt wird. Das Volume ist anfangs leer und die Container im Pod können die Dateien auf dem emptyDir-Volume lesen und schreiben. Sobald der Pod vom Knoten entfernt wurde, werden die Daten im emptyDir gelöscht.
hostPath - Diese Art von Volume stellt eine Datei oder ein Verzeichnis aus dem Dateisystem des Hostknotens in Ihrem Pod bereit.
gcePersistentDisk- Bei dieser Art von Volume wird eine persistente Google Compute Engine (GCE) -Diskette in Ihrem Pod bereitgestellt. Die Daten in agcePersistentDisk bleibt intakt, wenn der Pod vom Knoten entfernt wird.
awsElasticBlockStore- Bei dieser Art von Volume wird ein Elastic Block Store von Amazon Web Services (AWS) in Ihrem Pod bereitgestellt. So wiegcePersistentDisk, die Daten in einem awsElasticBlockStore bleibt intakt, wenn der Pod vom Knoten entfernt wird.
nfs - Ein nfsMit Volume können Sie ein vorhandenes NFS (Network File System) in Ihren Pod einbinden. Die Daten in einemnfsDie Lautstärke wird nicht gelöscht, wenn der Pod vom Knoten entfernt wird. Das Volume ist nur nicht gemountet.
iscsi - Ein iscsi Mit Volume können Sie ein vorhandenes iSCSI-Volume (SCSI over IP) in Ihren Pod einbinden.
flocker- Es handelt sich um einen Open-Source-Cluster-Container-Datenvolumen-Manager. Es wird zum Verwalten von Datenmengen verwendet. EINflockerMit Volume kann ein Flocker-Dataset in einen Pod eingebunden werden. Wenn das Dataset in Flocker nicht vorhanden ist, müssen Sie es zuerst mithilfe der Flocker-API erstellen.
glusterfs- Glusterfs ist ein Open-Source-Netzwerkdateisystem. Mit einem glusterfs-Volume kann ein glusterfs-Volume in Ihren Pod eingebunden werden.
rbd- RBD steht für Rados Block Device. EinrbdMit Volume können Sie ein Rados Block Device-Volume in Ihren Pod einbinden. Die Daten bleiben erhalten, nachdem der Pod vom Knoten entfernt wurde.
cephfs - A. cephfsMit Volume können Sie ein vorhandenes CephFS-Volume in Ihren Pod einbinden. Die Daten bleiben erhalten, nachdem der Pod vom Knoten entfernt wurde.
gitRepo - A. gitRepo Volume stellt ein leeres Verzeichnis bereit und klont a git Repository darin für Ihren Pod zu verwenden.
secret - A. secret Das Volume wird verwendet, um vertrauliche Informationen wie Kennwörter an Pods zu übergeben.
persistentVolumeClaim - A. persistentVolumeClaimMit Volume wird ein PersistentVolume in einen Pod eingebunden. Mit PersistentVolumes können Benutzer dauerhaften Speicher (z. B. eine GCE PersistentDisk oder ein iSCSI-Volume) "beanspruchen", ohne die Details der jeweiligen Cloud-Umgebung zu kennen.
downwardAPI - A. downwardAPIVolume wird verwendet, um abwärts gerichtete API-Daten für Anwendungen verfügbar zu machen. Es stellt ein Verzeichnis bereit und schreibt die angeforderten Daten in Klartextdateien.
azureDiskVolume - Ein AzureDiskVolume wird verwendet, um eine Microsoft Azure-Datendiskette in einen Pod einzubinden.
Persistent Volume und Persistent Volume Claim
Persistent Volume (PV)- Es handelt sich um einen Netzwerkspeicher, der vom Administrator bereitgestellt wurde. Es ist eine Ressource im Cluster, die unabhängig von jedem einzelnen Pod ist, der die PV verwendet.
Persistent Volume Claim (PVC)- Der von Kubernetes für seine Pods angeforderte Speicher wird als PVC bezeichnet. Der Benutzer muss die zugrunde liegende Bereitstellung nicht kennen. Die Ansprüche müssen in demselben Namespace erstellt werden, in dem der Pod erstellt wird.
Persistentes Volume erstellen
kind: PersistentVolume ---------> 1
apiVersion: v1
metadata:
name: pv0001 ------------------> 2
labels:
type: local
spec:
capacity: -----------------------> 3
storage: 10Gi ----------------------> 4
accessModes:
- ReadWriteOnce -------------------> 5
hostPath:
path: "/tmp/data01" --------------------------> 6Im obigen Code haben wir definiert -
kind: PersistentVolume → Wir haben die Art als PersistentVolume definiert, die Kubernetes mitteilt, dass die verwendete Yaml-Datei zum Erstellen des persistenten Volumes verwendet wird.
name: pv0001 → Name des von uns erstellten PersistentVolume.
capacity: → Diese Spezifikation definiert die Kapazität der PV, die wir erstellen möchten.
storage: 10Gi → Dies teilt der zugrunde liegenden Infrastruktur mit, dass wir versuchen, 10Gi-Speicherplatz auf dem definierten Pfad zu beanspruchen.
ReadWriteOnce → Hier werden die Zugriffsrechte des von uns erstellten Volumes angegeben.
path: "/tmp/data01" → Diese Definition teilt dem Computer mit, dass wir versuchen, unter diesem Pfad ein Volume in der zugrunde liegenden Infrastruktur zu erstellen.
PV erstellen
$ kubectl create –f local-01.yaml
persistentvolume "pv0001" createdPV prüfen
$ kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv0001 10Gi RWO Available 14sPV beschreiben
$ kubectl describe pv pv0001Persistenten Volumenanspruch erstellen
kind: PersistentVolumeClaim --------------> 1
apiVersion: v1
metadata:
name: myclaim-1 --------------------> 2
spec:
accessModes:
- ReadWriteOnce ------------------------> 3
resources:
requests:
storage: 3Gi ---------------------> 4Im obigen Code haben wir definiert -
kind: PersistentVolumeClaim → Es weist die zugrunde liegende Infrastruktur an, dass wir versuchen, eine bestimmte Menge an Speicherplatz zu beanspruchen.
name: myclaim-1 → Name des Anspruchs, den wir erstellen möchten.
ReadWriteOnce → Dies gibt den Modus des Anspruchs an, den wir erstellen möchten.
storage: 3Gi → Dadurch erfahren die Kubernetes, wie viel Speicherplatz wir beanspruchen möchten.
PVC erstellen
$ kubectl create –f myclaim-1
persistentvolumeclaim "myclaim-1" createdDetails zu PVC abrufen
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
myclaim-1 Bound pv0001 10Gi RWO 7sBeschreiben Sie PVC
$ kubectl describe pv pv0001Verwendung von PV und PVC mit POD
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
name: frontendhttp
spec:
containers:
- name: myfrontend
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts: ----------------------------> 1
- mountPath: "/usr/share/tomcat/html"
name: mypd
volumes: -----------------------> 2
- name: mypd
persistentVolumeClaim: ------------------------->3
claimName: myclaim-1Im obigen Code haben wir definiert -
volumeMounts: → Dies ist der Pfad im Container, auf dem die Montage erfolgen soll.
Volume: → Diese Definition definiert die Volumendefinition, die wir beanspruchen werden.
persistentVolumeClaim: → Darunter definieren wir den Datenträgernamen, den wir im definierten Pod verwenden werden.
Geheimnisse können als Kubernetes-Objekte definiert werden, mit denen vertrauliche Daten wie Benutzername und Kennwörter verschlüsselt gespeichert werden.
Es gibt mehrere Möglichkeiten, Geheimnisse in Kubernetes zu erstellen.
- Erstellen aus txt-Dateien.
- Erstellen aus Yaml-Datei.
Erstellen aus Textdatei
Um Geheimnisse aus einer Textdatei wie Benutzername und Passwort zu erstellen, müssen wir sie zuerst in einer txt-Datei speichern und den folgenden Befehl verwenden.
$ kubectl create secret generic tomcat-passwd –-from-file = ./username.txt –fromfile = ./.
password.txtErstellen aus Yaml-Datei
apiVersion: v1
kind: Secret
metadata:
name: tomcat-pass
type: Opaque
data:
password: <User Password>
username: <User Name>Das Geheimnis schaffen
$ kubectl create –f Secret.yaml
secrets/tomcat-passGeheimnisse benutzen
Sobald wir die Geheimnisse erstellt haben, können sie in einem Pod oder im Replikationscontroller als - verwendet werden.
- Umgebungsvariable
- Volume
Als Umgebungsvariable
Um das Geheimnis als Umgebungsvariable zu verwenden, werden wir verwenden env unter dem Spezifikationsabschnitt der pod yaml-Datei.
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: tomcat-passAls Lautstärke
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat:7.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"Geheime Konfiguration als Umgebungsvariable
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
spec:
nodeSelector:
resource-group:
containers:
- name: appname
image:
imagePullPolicy: Always
ports:
- containerPort: 3000
env: -----------------------------> 1
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: tomcat-secretsIm obigen Code unter dem env Definition verwenden wir Geheimnisse als Umgebungsvariable im Replikationscontroller.
Geheimnisse als Volume Mount
apiVersion: v1
kind: pod
metadata:
name: appname
spec:
metadata:
name: appname
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat: 8.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"Die Netzwerkrichtlinie definiert, wie die Pods im selben Namespace miteinander und mit dem Netzwerkendpunkt kommunizieren. Es benötigtextensions/v1beta1/networkpoliciesin der Laufzeitkonfiguration auf dem API-Server aktiviert werden. Die Ressourcen verwenden Beschriftungen, um die Pods auszuwählen und Regeln zu definieren, um den Datenverkehr zu einem bestimmten Pod zuzulassen, der zusätzlich im Namespace definiert ist.
Zuerst müssen wir die Namespace-Isolationsrichtlinie konfigurieren. Grundsätzlich sind diese Netzwerkrichtlinien für die Load Balancer erforderlich.
kind: Namespace
apiVersion: v1
metadata:
annotations:
net.beta.kubernetes.io/network-policy: |
{
"ingress":
{
"isolation": "DefaultDeny"
}
}$ kubectl annotate ns <namespace> "net.beta.kubernetes.io/network-policy =
{\"ingress\": {\"isolation\": \"DefaultDeny\"}}"Sobald der Namespace erstellt ist, müssen wir die Netzwerkrichtlinie erstellen.
Netzwerkrichtlinie Yaml
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: allow-frontend
namespace: myns
spec:
podSelector:
matchLabels:
role: backend
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379Die Kubernetes-API dient als Grundlage für das deklarative Konfigurationsschema für das System. KubectlDas Befehlszeilentool kann zum Erstellen, Aktualisieren, Löschen und Abrufen von API-Objekten verwendet werden. Die Kubernetes-API fungiert als Kommunikator zwischen verschiedenen Komponenten von Kubernetes.
Hinzufügen von API zu Kubernetes
Durch Hinzufügen einer neuen API zu Kubernetes werden Kubernetes neue Funktionen hinzugefügt, die die Funktionalität von Kubernetes erhöhen. Daneben werden jedoch auch die Kosten und die Wartbarkeit des Systems erhöht. Um ein Gleichgewicht zwischen Kosten und Komplexität herzustellen, sind einige Sätze dafür definiert.
Die API, die hinzugefügt wird, sollte für mehr als 50% der Benutzer nützlich sein. Es gibt keine andere Möglichkeit, die Funktionalität in Kubernetes zu implementieren. Außergewöhnliche Umstände werden im Community-Meeting von Kubernetes besprochen, und dann wird die API hinzugefügt.
API-Änderungen
Um die Leistungsfähigkeit von Kubernetes zu erhöhen, werden kontinuierlich Änderungen am System vorgenommen. Es wird vom Kubernetes-Team durchgeführt, um die Funktionalität zu Kubernetes hinzuzufügen, ohne die vorhandene Funktionalität des Systems zu entfernen oder zu beeinträchtigen.
Um den allgemeinen Prozess zu demonstrieren, hier ein (hypothetisches) Beispiel -
Ein Benutzer sendet ein Pod-Objekt an /api/v7beta1/...
Der JSON wird nicht in a v7beta1.Pod Struktur
Standardwerte werden auf die angewendet v7beta1.Pod
Das v7beta1.Pod wird in ein konvertiert api.Pod Struktur
Das api.Pod wird validiert und alle Fehler werden an den Benutzer zurückgegeben
Das api.Pod wird in einen v6.Pod konvertiert (da v6 die neueste stabile Version ist)
Das v6.Pod wird in JSON gemarshallt und an geschrieben etcd
Nachdem wir das Pod-Objekt gespeichert haben, kann ein Benutzer dieses Objekt in jeder unterstützten API-Version abrufen. Zum Beispiel -
Ein Benutzer erhält den Pod von /api/v5/...
Der JSON wird aus gelesen etcd und unmarshalled in ein v6.Pod Struktur
Standardwerte werden auf die angewendet v6.Pod
Das v6.Pod wird in eine api.Pod-Struktur konvertiert
Das api.Pod wird in a umgewandelt v5.Pod Struktur
Das v5.Pod wird in JSON gemarshallt und an den Benutzer gesendet
Dieser Prozess impliziert, dass API-Änderungen sorgfältig und abwärtskompatibel durchgeführt werden müssen.
API-Versionierung
Um die Unterstützung mehrerer Strukturen zu vereinfachen, unterstützt Kubernetes mehrere API-Versionen mit jeweils unterschiedlichen API-Pfaden, z /api/v1 oder /apsi/extensions/v1beta1
Versionsstandards bei Kubernetes werden in mehreren Standards definiert.
Alpha Level
Diese Version enthält Alpha (zB v1alpha1)
Diese Version ist möglicherweise fehlerhaft. Die aktivierte Version weist möglicherweise Fehler auf
Die Unterstützung für Fehler kann jederzeit eingestellt werden.
Empfohlen, nur für Kurzzeittests verwendet zu werden, da der Support möglicherweise nicht immer vorhanden ist.
Beta-Level
Der Versionsname enthält Beta (zB v2beta3)
Der Code ist vollständig getestet und die aktivierte Version soll stabil sein.
Die Unterstützung der Funktion wird nicht eingestellt. Es kann einige kleine Änderungen geben.
Empfohlen nur für nicht geschäftskritische Zwecke, da in nachfolgenden Versionen möglicherweise nicht kompatible Änderungen vorgenommen werden können.
Stabiles Niveau
Der Versionsname lautet vX wo X ist eine ganze Zahl.
In der freigegebenen Software werden für viele nachfolgende Versionen stabile Versionen von Funktionen angezeigt.
Kubectl ist das Befehlszeilenprogramm für die Interaktion mit der Kubernetes-API. Es ist eine Schnittstelle, über die Pods im Kubernetes-Cluster kommuniziert und verwaltet werden.
Man muss kubectl auf local einrichten, um mit dem Kubernetes-Cluster zu interagieren.
Kubectl einstellen
Laden Sie die ausführbare Datei mit dem Befehl curl auf die lokale Workstation herunter.
Unter Linux
$ curl -O https://storage.googleapis.com/kubernetesrelease/
release/v1.5.2/bin/linux/amd64/kubectlAuf der OS X-Workstation
$ curl -O https://storage.googleapis.com/kubernetesrelease/
release/v1.5.2/bin/darwin/amd64/kubectlVerschieben Sie nach Abschluss des Downloads die Binärdateien in den Pfad des Systems.
$ chmod +x kubectl
$ mv kubectl /usr/local/bin/kubectlKubectl konfigurieren
Im Folgenden finden Sie die Schritte zum Ausführen des Konfigurationsvorgangs.
$ kubectl config set-cluster default-cluster --server = https://${MASTER_HOST} -- certificate-authority = ${CA_CERT}
$ kubectl config set-credentials default-admin --certificateauthority = ${
CA_CERT} --client-key = ${ADMIN_KEY} --clientcertificate = ${
ADMIN_CERT}
$ kubectl config set-context default-system --cluster = default-cluster -- user = default-admin $ kubectl config use-context default-systemErsetzen ${MASTER_HOST} mit der Adresse oder dem Namen des Hauptknotens, die in den vorherigen Schritten verwendet wurden.
Ersetzen ${CA_CERT} mit dem absoluten Weg zum ca.pem in den vorherigen Schritten erstellt.
Ersetzen ${ADMIN_KEY} mit dem absoluten Weg zum admin-key.pem in den vorherigen Schritten erstellt.
Ersetzen ${ADMIN_CERT} mit dem absoluten Weg zum admin.pem in den vorherigen Schritten erstellt.
Überprüfen des Setups
Um zu überprüfen, ob die kubectl funktioniert einwandfrei oder nicht, überprüfen Sie, ob der Kubernetes-Client korrekt eingerichtet ist.
$ kubectl get nodes
NAME LABELS STATUS
Vipin.com Kubernetes.io/hostname = vipin.mishra.com ReadyKubectlsteuert den Kubernetes-Cluster. Es ist eine der Schlüsselkomponenten von Kubernetes, die nach Abschluss des Setups auf jedem Computer auf der Workstation ausgeführt wird. Es kann die Knoten im Cluster verwalten.
KubectlBefehle werden verwendet, um Kubernetes-Objekte und den Cluster zu interagieren und zu verwalten. In diesem Kapitel werden einige Befehle erläutert, die in Kubernetes über kubectl verwendet werden.
kubectl annotate - Es aktualisiert die Anmerkung zu einer Ressource.
$kubectl annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ...
KEY_N = VAL_N [--resource-version = version]Zum Beispiel,
kubectl annotate pods tomcat description = 'my frontend'kubectl api-versions - Es werden die unterstützten API-Versionen im Cluster gedruckt.
$ kubectl api-version;kubectl apply - Es kann eine Ressource per Datei oder Standard konfigurieren.
$ kubectl apply –f <filename>kubectl attach - Dadurch werden Dinge an den laufenden Container angehängt.
$ kubectl attach <pod> –c <container> $ kubectl attach 123456-7890 -c tomcat-conatinerkubectl autoscale - Dies wird verwendet, um Pods automatisch zu skalieren, die wie Bereitstellung, Replikatsatz, Replikationscontroller definiert sind.
$ kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min = MINPODS] -- max = MAXPODS [--cpu-percent = CPU] [flags] $ kubectl autoscale deployment foo --min = 2 --max = 10kubectl cluster-info - Es zeigt die Cluster-Informationen an.
$ kubectl cluster-infokubectl cluster-info dump - Es werden relevante Informationen zum Cluster für das Debuggen und die Diagnose ausgegeben.
$ kubectl cluster-info dump
$ kubectl cluster-info dump --output-directory = /path/to/cluster-statekubectl config - Ändert die kubeconfig-Datei.
$ kubectl config <SUBCOMMAD>
$ kubectl config –-kubeconfig <String of File name>kubectl config current-context - Es zeigt den aktuellen Kontext an.
$ kubectl config current-context
#deploys the current contextkubectl config delete-cluster - Löscht den angegebenen Cluster aus kubeconfig.
$ kubectl config delete-cluster <Cluster Name>kubectl config delete-context - Löscht einen angegebenen Kontext aus kubeconfig.
$ kubectl config delete-context <Context Name>kubectl config get-clusters - Zeigt den in der Kubeconfig definierten Cluster an.
$ kubectl config get-cluster $ kubectl config get-cluster <Cluser Name>kubectl config get-contexts - Beschreibt einen oder mehrere Kontexte.
$ kubectl config get-context <Context Name>kubectl config set-cluster - Legt den Clustereintrag in Kubernetes fest.
$ kubectl config set-cluster NAME [--server = server] [--certificateauthority =
path/to/certificate/authority] [--insecure-skip-tls-verify = true]kubectl config set-context - Legt einen Kontexteintrag im kubernetes-Einstiegspunkt fest.
$ kubectl config set-context NAME [--cluster = cluster_nickname] [-- user = user_nickname] [--namespace = namespace] $ kubectl config set-context prod –user = vipin-mishrakubectl config set-credentials - Legt einen Benutzereintrag in kubeconfig fest.
$ kubectl config set-credentials cluster-admin --username = vipin --
password = uXFGweU9l35qcifkubectl config set - Legt einen individuellen Wert in der kubeconfig-Datei fest.
$ kubectl config set PROPERTY_NAME PROPERTY_VALUEkubectl config unset - Es setzt eine bestimmte Komponente in kubectl.
$ kubectl config unset PROPERTY_NAME PROPERTY_VALUEkubectl config use-context - Legt den aktuellen Kontext in der Kubectl-Datei fest.
$ kubectl config use-context <Context Name>kubectl config view
$ kubectl config view $ kubectl config view –o jsonpath='{.users[?(@.name == "e2e")].user.password}'kubectl cp - Kopieren Sie Dateien und Verzeichnisse in und aus Containern.
$ kubectl cp <Files from source> <Files to Destinatiion> $ kubectl cp /tmp/foo <some-pod>:/tmp/bar -c <specific-container>kubectl create- Um eine Ressource nach Dateiname oder Standard zu erstellen. Dazu werden JSON- oder YAML-Formate akzeptiert.
$ kubectl create –f <File Name> $ cat <file name> | kubectl create –f -Auf die gleiche Weise können wir mehrere Dinge erstellen, wie sie mit aufgelistet sind create Befehl zusammen mit kubectl.
- deployment
- namespace
- quota
- geheime Docker-Registrierung
- secret
- geheimes Generikum
- geheime tls
- serviceaccount
- Service-Clusterip
- Service Loadbalancer
- Service Nodeport
kubectl delete - Löscht Ressourcen nach Dateiname, Standard, Ressource und Namen.
$ kubectl delete –f ([-f FILENAME] | TYPE [(NAME | -l label | --all)])kubectl describe- Beschreibt eine bestimmte Ressource in Kubernetes. Zeigt Details der Ressource oder einer Gruppe von Ressourcen an.
$ kubectl describe <type> <type name>
$ kubectl describe pod tomcatkubectl drain- Dies wird verwendet, um einen Knoten zu Wartungszwecken zu entleeren. Es bereitet den Knoten für die Wartung vor. Dadurch wird der Knoten als nicht verfügbar markiert, sodass ihm kein neuer Container zugewiesen werden sollte, der erstellt wird.
$ kubectl drain tomcat –forcekubectl edit- Es wird verwendet, um die Ressourcen auf dem Server zu beenden. Dies ermöglicht das direkte Bearbeiten einer Ressource, die über das Befehlszeilentool empfangen werden kann.
$ kubectl edit <Resource/Name | File Name) Ex. $ kubectl edit rc/tomcatkubectl exec - Dies hilft, einen Befehl im Container auszuführen.
$ kubectl exec POD <-c CONTAINER > -- COMMAND < args...> $ kubectl exec tomcat 123-5-456 datekubectl expose- Hiermit werden die Kubernetes-Objekte wie Pod, Replikationscontroller und Dienst als neuer Kubernetes-Dienst verfügbar gemacht. Dies hat die Fähigkeit, es über einen laufenden Container oder von einem aus freizulegenyaml Datei.
$ kubectl expose (-f FILENAME | TYPE NAME) [--port=port] [--protocol = TCP|UDP] [--target-port = number-or-name] [--name = name] [--external-ip = external-ip-ofservice] [--type = type] $ kubectl expose rc tomcat –-port=80 –target-port = 30000
$ kubectl expose –f tomcat.yaml –port = 80 –target-port =kubectl get - Dieser Befehl kann Daten über die Kubernetes-Ressourcen im Cluster abrufen.
$ kubectl get [(-o|--output=)json|yaml|wide|custom-columns=...|custom-columnsfile=...|
go-template=...|go-template-file=...|jsonpath=...|jsonpath-file=...]
(TYPE [NAME | -l label] | TYPE/NAME ...) [flags]Zum Beispiel,
$ kubectl get pod <pod name> $ kubectl get service <Service name>kubectl logs- Sie werden verwendet, um die Protokolle des Containers in eine Kapsel zu bekommen. Durch das Drucken der Protokolle kann der Containername im Pod definiert werden. Wenn der POD nur einen Container hat, muss sein Name nicht definiert werden.
$ kubectl logs [-f] [-p] POD [-c CONTAINER] Example $ kubectl logs tomcat.
$ kubectl logs –p –c tomcat.8kubectl port-forward - Sie werden verwendet, um einen oder mehrere lokale Ports an Pods weiterzuleiten.
$ kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT
[...[LOCAL_PORT_N:]REMOTE_PORT_N]
$ kubectl port-forward tomcat 3000 4000 $ kubectl port-forward tomcat 3000:5000kubectl replace - Kann eine Ressource durch den Dateinamen oder ersetzen stdin.
$ kubectl replace -f FILENAME $ kubectl replace –f tomcat.yml
$ cat tomcat.yml | kubectl replace –f -kubectl rolling-update- Führt ein fortlaufendes Update auf einem Replikationscontroller durch. Ersetzt den angegebenen Replikationscontroller durch einen neuen Replikationscontroller, indem jeweils ein POD aktualisiert wird.
$ kubectl rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] --
image = NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC)
$ kubectl rolling-update frontend-v1 –f freontend-v2.yamlkubectl rollout - Es ist in der Lage, den Rollout der Bereitstellung zu verwalten.
$ Kubectl rollout <Sub Command>
$ kubectl rollout undo deployment/tomcatAbgesehen von den oben genannten Funktionen können wir mithilfe des Rollouts mehrere Aufgaben ausführen, z.
- Rollout-Verlauf
- Rollout-Pause
- Rollout-Lebenslauf
- Rollout-Status
- Rollout rückgängig machen
kubectl run - Der Befehl Ausführen kann ein Image auf dem Kubernetes-Cluster ausführen.
$ kubectl run NAME --image = image [--env = "key = value"] [--port = port] [--
replicas = replicas] [--dry-run = bool] [--overrides = inline-json] [--command] --
[COMMAND] [args...]
$ kubectl run tomcat --image = tomcat:7.0 $ kubectl run tomcat –-image = tomcat:7.0 –port = 5000kubectl scale - Die Größe von Kubernetes-Bereitstellungen, ReplicaSet, Replication Controller oder Job wird skaliert.
$ kubectl scale [--resource-version = version] [--current-replicas = count] -- replicas = COUNT (-f FILENAME | TYPE NAME ) $ kubectl scale –-replica = 3 rs/tomcat
$ kubectl scale –replica = 3 tomcat.yamlkubectl set image - Es aktualisiert das Bild einer Pod-Vorlage.
$ kubectl set image (-f FILENAME | TYPE NAME)
CONTAINER_NAME_1 = CONTAINER_IMAGE_1 ... CONTAINER_NAME_N = CONTAINER_IMAGE_N
$ kubectl set image deployment/tomcat busybox = busybox ngnix = ngnix:1.9.1 $ kubectl set image deployments, rc tomcat = tomcat6.0 --allkubectl set resources- Hiermit wird der Inhalt der Ressource festgelegt. Es aktualisiert die Ressourcen / Grenzen des Objekts mit der Pod-Vorlage.
$ kubectl set resources (-f FILENAME | TYPE NAME) ([--limits = LIMITS & -- requests = REQUESTS] $ kubectl set resources deployment tomcat -c = tomcat --
limits = cpu = 200m,memory = 512Mikubectl top node- Es zeigt die CPU- / Speicher- / Speichernutzung an. Mit dem Befehl top können Sie den Ressourcenverbrauch für Knoten anzeigen.
$ kubectl top node [node Name]Der gleiche Befehl kann auch mit einem Pod verwendet werden.
Um eine Anwendung für die Kubernetes-Bereitstellung zu erstellen, müssen Sie zuerst die Anwendung auf dem Docker erstellen. Dies kann auf zwei Arten erfolgen:
- Durch Herunterladen
- Aus der Docker-Datei
Durch Herunterladen
Das vorhandene Image kann vom Docker-Hub heruntergeladen und in der lokalen Docker-Registrierung gespeichert werden.
Führen Sie dazu den Docker aus pull Befehl.
$ docker pull --help
Usage: docker pull [OPTIONS] NAME[:TAG|@DIGEST]
Pull an image or a repository from the registry
-a, --all-tags = false Download all tagged images in the repository
--help = false Print usageEs folgt die Ausgabe des obigen Codes.

Der obige Screenshot zeigt eine Reihe von Bildern, die in unserer lokalen Docker-Registrierung gespeichert sind.
Wenn wir aus dem Image einen Container erstellen möchten, der aus einer zu testenden Anwendung besteht, können wir dies mit dem Docker-Befehl run ausführen.
$ docker run –i –t unbunt /bin/bashAus der Docker-Datei
Um eine Anwendung aus der Docker-Datei zu erstellen, müssen Sie zuerst eine Docker-Datei erstellen.
Es folgt ein Beispiel für eine Jenkins Docker-Datei.
FROM ubuntu:14.04
MAINTAINER [email protected]
ENV REFRESHED_AT 2017-01-15
RUN apt-get update -qq && apt-get install -qqy curl
RUN curl https://get.docker.io/gpg | apt-key add -
RUN echo deb http://get.docker.io/ubuntu docker main > /etc/apt/↩
sources.list.d/docker.list
RUN apt-get update -qq && apt-get install -qqy iptables ca-↩
certificates lxc openjdk-6-jdk git-core lxc-docker
ENV JENKINS_HOME /opt/jenkins/data
ENV JENKINS_MIRROR http://mirrors.jenkins-ci.org
RUN mkdir -p $JENKINS_HOME/plugins
RUN curl -sf -o /opt/jenkins/jenkins.war -L $JENKINS_MIRROR/war-↩ stable/latest/jenkins.war RUN for plugin in chucknorris greenballs scm-api git-client git ↩ ws-cleanup ;\ do curl -sf -o $JENKINS_HOME/plugins/${plugin}.hpi \ -L $JENKINS_MIRROR/plugins/${plugin}/latest/${plugin}.hpi ↩
; done
ADD ./dockerjenkins.sh /usr/local/bin/dockerjenkins.sh
RUN chmod +x /usr/local/bin/dockerjenkins.sh
VOLUME /var/lib/docker
EXPOSE 8080
ENTRYPOINT [ "/usr/local/bin/dockerjenkins.sh" ]Sobald die obige Datei erstellt wurde, speichern Sie sie unter dem Namen Dockerfile und cd im Dateipfad. Führen Sie dann den folgenden Befehl aus.

$ sudo docker build -t jamtur01/Jenkins .Sobald das Bild erstellt ist, können wir testen, ob das Bild einwandfrei funktioniert und in einen Container konvertiert werden kann.
$ docker run –i –t jamtur01/Jenkins /bin/bashDie Bereitstellung ist eine Methode zum Konvertieren von Bildern in Container und zum anschließenden Zuweisen dieser Bilder zu Pods im Kubernetes-Cluster. Dies hilft auch beim Einrichten des Anwendungsclusters, der die Bereitstellung von Service, Pod, Replikationscontroller und Replikatsatz umfasst. Der Cluster kann so eingerichtet werden, dass die auf dem Pod bereitgestellten Anwendungen miteinander kommunizieren können.
In diesem Setup können wir eine Load Balancer-Einstellung über einer Anwendung haben, die den Datenverkehr auf eine Reihe von Pods umleitet und später mit Backend-Pods kommuniziert. Die Kommunikation zwischen Pods erfolgt über das in Kubernetes erstellte Serviceobjekt.
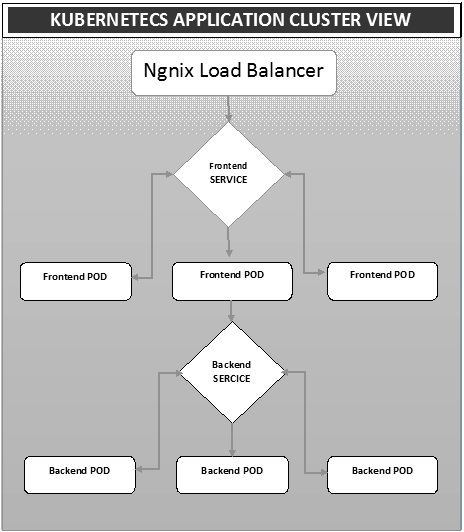
Ngnix Load Balancer Yaml-Datei
apiVersion: v1
kind: Service
metadata:
name: oppv-dev-nginx
labels:
k8s-app: omni-ppv-api
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: devNgnix Replication Controller Yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
labels:
k8s-app: appname
component: nginx
env: env_name
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 8080
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: BACKEND_HOST
value: oppv-env_name-node:3000Frontend Service Yaml-Datei
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- name: http
port: 3000
protocol: TCP
targetPort: 3000
selector:
k8s-app: appname
component: nodejs
env: devFrontend Replication Controller Yaml-Datei
apiVersion: v1
kind: ReplicationController
metadata:
name: Frontend
spec:
replicas: 3
template:
metadata:
name: frontend
labels:
k8s-app: Frontend
component: nodejs
env: Dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 3000
resources:
requests:
memory: "request_mem"
cpu: "limit_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: config-envBackend-Service Yaml-Datei
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
k8s-app: backend
spec:
type: NodePort
ports:
- name: http
port: 9010
protocol: TCP
targetPort: 9000
selector:
k8s-app: appname
component: play
env: devUnterstützte Replication Controller Yaml-Datei
apiVersion: v1
kind: ReplicationController
metadata:
name: backend
spec:
replicas: 3
template:
metadata:
name: backend
labels:
k8s-app: beckend
component: play
env: dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 9000
command: [ "./docker-entrypoint.sh" ]
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
volumeMounts:
- name: config-volume
mountPath: /app/vipin/play/conf
volumes:
- name: config-volume
configMap:
name: appnameAutoscalingist eine der Hauptfunktionen im Kubernetes-Cluster. Es ist eine Funktion, bei der der Cluster in der Lage ist, die Anzahl der Knoten zu erhöhen, wenn die Nachfrage nach Dienstantworten zunimmt, und die Anzahl der Knoten zu verringern, wenn die Anforderung abnimmt. Diese Funktion der automatischen Skalierung wird derzeit in Google Cloud Engine (GCE) und Google Container Engine (GKE) unterstützt und wird in Kürze mit AWS beginnen.
Um eine skalierbare Infrastruktur in GCE einzurichten, muss zunächst ein aktives GCE-Projekt mit Funktionen wie Google Cloud Monitoring, Google Cloud Logging und Stackdriver aktiviert sein.
Zunächst richten wir den Cluster mit wenigen Knoten ein, die darin ausgeführt werden. Sobald dies erledigt ist, müssen wir die folgende Umgebungsvariable einrichten.
Umgebungsvariable
export NUM_NODES = 2
export KUBE_AUTOSCALER_MIN_NODES = 2
export KUBE_AUTOSCALER_MAX_NODES = 5
export KUBE_ENABLE_CLUSTER_AUTOSCALER = trueSobald dies erledigt ist, starten wir den Cluster durch Ausführen kube-up.sh. Dadurch wird ein Cluster zusammen mit dem automatisch skalaren Cluster-Add-On erstellt.
./cluster/kube-up.shBei der Erstellung des Clusters können wir unseren Cluster mit dem folgenden Befehl kubectl überprüfen.
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 10m
kubernetes-minion-group-de5q Ready 10m
kubernetes-minion-group-yhdx Ready 8mJetzt können wir eine Anwendung im Cluster bereitstellen und dann den horizontalen Pod-Autoscaler aktivieren. Dies kann mit dem folgenden Befehl erfolgen.
$ kubectl autoscale deployment <Application Name> --cpu-percent = 50 --min = 1 --
max = 10Der obige Befehl zeigt, dass wir mindestens eine und maximal 10 Replikate des POD beibehalten, wenn die Belastung der Anwendung zunimmt.
Wir können den Status des Autoscalers überprüfen, indem wir das ausführen $kubclt get hpaBefehl. Wir werden die Belastung der Pods mit dem folgenden Befehl erhöhen.
$ kubectl run -i --tty load-generator --image = busybox /bin/sh
$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; doneWir können das überprüfen hpa durch Laufen $ kubectl get hpa Befehl.
$ kubectl get hpa NAME REFERENCE TARGET CURRENT php-apache Deployment/php-apache/scale 50% 310% MINPODS MAXPODS AGE 1 20 2m $ kubectl get deployment php-apache
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 7 7 7 3 4mWir können die Anzahl der laufenden Pods mit dem folgenden Befehl überprüfen.
jsz@jsz-desk2:~/k8s-src$ kubectl get pods
php-apache-2046965998-3ewo6 0/1 Pending 0 1m
php-apache-2046965998-8m03k 1/1 Running 0 1m
php-apache-2046965998-ddpgp 1/1 Running 0 5m
php-apache-2046965998-lrik6 1/1 Running 0 1m
php-apache-2046965998-nj465 0/1 Pending 0 1m
php-apache-2046965998-tmwg1 1/1 Running 0 1m
php-apache-2046965998-xkbw1 0/1 Pending 0 1mUnd schließlich können wir den Knotenstatus erhalten.
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 9m
kubernetes-minion-group-6z5i Ready 43s
kubernetes-minion-group-de5q Ready 9m
kubernetes-minion-group-yhdx Ready 9mDas Einrichten des Kubernetes-Dashboards umfasst mehrere Schritte mit einer Reihe von Tools, die als Voraussetzungen für die Einrichtung erforderlich sind.
- Docker (1.3+)
- go (1.5+)
- nodejs (4.2.2+)
- npm (1,3+)
- Java (7+)
- schlucken (3,9+)
- Kubernetes (1.1.2+)
Einrichten des Dashboards
$ sudo apt-get update && sudo apt-get upgrade Installing Python $ sudo apt-get install python
$ sudo apt-get install python3 Installing GCC $ sudo apt-get install gcc-4.8 g++-4.8
Installing make
$ sudo apt-get install make Installing Java $ sudo apt-get install openjdk-7-jdk
Installing Node.js
$ wget https://nodejs.org/dist/v4.2.2/node-v4.2.2.tar.gz $ tar -xzf node-v4.2.2.tar.gz
$ cd node-v4.2.2 $ ./configure
$ make $ sudo make install
Installing gulp
$ npm install -g gulp $ npm install gulpVersionen überprüfen
Java Version
$ java –version java version "1.7.0_91" OpenJDK Runtime Environment (IcedTea 2.6.3) (7u91-2.6.3-1~deb8u1+rpi1) OpenJDK Zero VM (build 24.91-b01, mixed mode) $ node –v
V4.2.2
$ npn -v 2.14.7 $ gulp -v
[09:51:28] CLI version 3.9.0
$ sudo gcc --version
gcc (Raspbian 4.8.4-1) 4.8.4
Copyright (C) 2013 Free Software Foundation, Inc. This is free software;
see the source for copying conditions. There is NO warranty; not even for
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.GO installieren
$ git clone https://go.googlesource.com/go
$ cd go $ git checkout go1.4.3
$ cd src Building GO $ ./all.bash
$ vi /root/.bashrc In the .bashrc export GOROOT = $HOME/go
export PATH = $PATH:$GOROOT/bin
$ go version
go version go1.4.3 linux/armKubernetes Dashboard installieren
$ git clone https://github.com/kubernetes/dashboard.git
$ cd dashboard $ npm install -g bowerAusführen des Dashboards
$ git clone https://github.com/kubernetes/dashboard.git $ cd dashboard
$ npm install -g bower $ gulp serve
[11:19:12] Requiring external module babel-core/register
[11:20:50] Using gulpfile ~/dashboard/gulpfile.babel.js
[11:20:50] Starting 'package-backend-source'...
[11:20:50] Starting 'kill-backend'...
[11:20:50] Finished 'kill-backend' after 1.39 ms
[11:20:50] Starting 'scripts'...
[11:20:53] Starting 'styles'...
[11:21:41] Finished 'scripts' after 50 s
[11:21:42] Finished 'package-backend-source' after 52 s
[11:21:42] Starting 'backend'...
[11:21:43] Finished 'styles' after 49 s
[11:21:43] Starting 'index'...
[11:21:44] Finished 'index' after 1.43 s
[11:21:44] Starting 'watch'...
[11:21:45] Finished 'watch' after 1.41 s
[11:23:27] Finished 'backend' after 1.73 min
[11:23:27] Starting 'spawn-backend'...
[11:23:27] Finished 'spawn-backend' after 88 ms
[11:23:27] Starting 'serve'...
2016/02/01 11:23:27 Starting HTTP server on port 9091
2016/02/01 11:23:27 Creating API client for
2016/02/01 11:23:27 Creating Heapster REST client for http://localhost:8082
[11:23:27] Finished 'serve' after 312 ms
[BS] [BrowserSync SPA] Running...
[BS] Access URLs:
--------------------------------------
Local: http://localhost:9090/
External: http://192.168.1.21:9090/
--------------------------------------
UI: http://localhost:3001
UI External: http://192.168.1.21:3001
--------------------------------------
[BS] Serving files from: /root/dashboard/.tmp/serve
[BS] Serving files from: /root/dashboard/src/app/frontend
[BS] Serving files from: /root/dashboard/src/appDas Kubernetes Dashboard
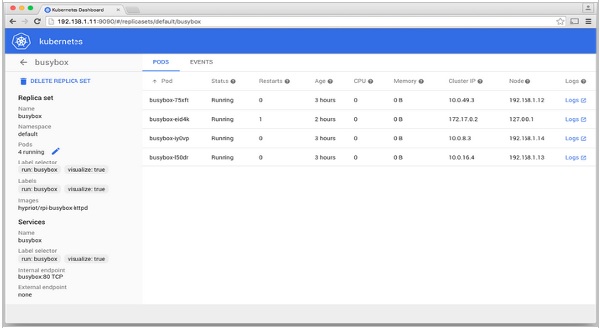
Die Überwachung ist eine der Schlüsselkomponenten für die Verwaltung großer Cluster. Dafür haben wir eine Reihe von Werkzeugen.
Überwachung mit Prometheus
Es ist ein Überwachungs- und Warnsystem. Es wurde bei SoundCloud gebaut und war 2012 Open Source. Es verarbeitet die mehrdimensionalen Daten sehr gut.
Prometheus hat mehrere Komponenten, um an der Überwachung teilzunehmen -
Prometheus - Es ist die Kernkomponente, die Daten verschrottet und speichert.
Prometheus node explore - Ruft die Matrizen auf Hostebene ab und setzt sie Prometheus aus.
Ranch-eye - ist ein haproxy und belichtet cAdvisor Statistiken zu Prometheus.
Grafana - Visualisierung von Daten.
InfuxDB - Zeitreihendatenbank, die speziell zum Speichern von Daten vom Rancher verwendet wird.
Prom-ranch-exporter - Es handelt sich um eine einfache Anwendung node.js, mit deren Hilfe der Rancher-Server nach dem Status des Dienststapels abgefragt werden kann.
Sematext Docker Agent
Es ist ein moderner Docker-fähiger Metrik-, Ereignis- und Protokollsammlungsagent. Es wird als winziger Container auf jedem Docker-Host ausgeführt und sammelt Protokolle, Metriken und Ereignisse für alle Clusterknoten und Container. Es erkennt alle Container (ein Pod kann mehrere Container enthalten), einschließlich Container für Kubernetes-Kerndienste, wenn die Kerndienste in Docker-Containern bereitgestellt werden. Nach der Bereitstellung sind alle Protokolle und Metriken sofort verfügbar.
Bereitstellen von Agenten auf Knoten
Kubernetes bietet DeamonSets an, mit denen sichergestellt wird, dass dem Cluster Pods hinzugefügt werden.
Konfigurieren des SemaText Docker-Agenten
Es wird über Umgebungsvariablen konfiguriert.
Eröffnen Sie ein kostenloses Konto unter apps.sematext.com , falls Sie noch keines haben.
Erstellen Sie eine SPM-App vom Typ „Docker“, um das SPM-App-Token zu erhalten. Die SPM-App speichert Ihre Kubernetes-Leistungsmetriken und -Ereignisse.
Erstellen Sie eine Logsene-App, um das Logsene-App-Token zu erhalten. Die Logsene App speichert Ihre Kubernetes-Protokolle.
Bearbeiten Sie die Werte von LOGSENE_TOKEN und SPM_TOKEN in der DaemonSet-Definition wie unten gezeigt.
Holen Sie sich die neueste Vorlage für sematext-agent-daemonset.yml (roher Klartext) (siehe auch unten).
Speichern Sie es irgendwo auf der Festplatte.
Ersetzen Sie die Platzhalter SPM_TOKEN und LOGSENE_TOKEN durch Ihre SPM- und Logsene-App-Token.
Erstellen Sie ein DaemonSet-Objekt
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: sematext-agent
spec:
template:
metadata:
labels:
app: sematext-agent
spec:
selector: {}
dnsPolicy: "ClusterFirst"
restartPolicy: "Always"
containers:
- name: sematext-agent
image: sematext/sematext-agent-docker:latest
imagePullPolicy: "Always"
env:
- name: SPM_TOKEN
value: "REPLACE THIS WITH YOUR SPM TOKEN"
- name: LOGSENE_TOKEN
value: "REPLACE THIS WITH YOUR LOGSENE TOKEN"
- name: KUBERNETES
value: "1"
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
- mountPath: /etc/localtime
name: localtime
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
- name: localtime
hostPath:
path: /etc/localtimeAusführen des Sematext Agent Docker mit kubectl
$ kubectl create -f sematext-agent-daemonset.yml
daemonset "sematext-agent-daemonset" createdKubernetes Log
Die Protokolle der Kubernetes-Container unterscheiden sich nicht wesentlich von den Docker-Containerprotokollen. Kubernetes-Benutzer müssen jedoch Protokolle für die bereitgestellten Pods anzeigen. Daher ist es sehr nützlich, Kubernetes-spezifische Informationen für die Protokollsuche verfügbar zu haben, z.
- Kubernetes-Namespace
- Kubernetes Pod Name
- Kubernetes Containername
- Name des Docker-Bildes
- Kubernetes UID
Verwenden von ELK Stack und LogSpout
Der ELK-Stack enthält Elasticsearch, Logstash und Kibana. Um die Protokolle zu sammeln und an die Protokollierungsplattform weiterzuleiten, verwenden wir LogSpout (obwohl es andere Optionen wie FluentD gibt).
Der folgende Code zeigt, wie Sie einen ELK-Cluster auf Kubernetes einrichten und einen Dienst für ElasticSearch erstellen.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCPReplikationscontroller erstellen
apiVersion: v1
kind: ReplicationController
metadata:
name: es
namespace: elk
labels:
component: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
spec:
serviceAccount: elasticsearch
containers:
- name: es
securityContext:
capabilities:
add:
- IPC_LOCK
image: quay.io/pires/docker-elasticsearch-kubernetes:1.7.1-4
env:
- name: KUBERNETES_CA_CERTIFICATE_FILE
value: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "CLUSTER_NAME"
value: "myesdb"
- name: "DISCOVERY_SERVICE"
value: "elasticsearch"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "true"
- name: HTTP_ENABLE
value: "true"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
volumeMounts:
- mountPath: /data
name: storage
volumes:
- name: storage
emptyDir: {}Kibana URL
Für Kibana stellen wir die Elasticsearch-URL als Umgebungsvariable bereit.
- name: KIBANA_ES_URL
value: "http://elasticsearch.elk.svc.cluster.local:9200"
- name: KUBERNETES_TRUST_CERT
value: "true"Die Kibana-Benutzeroberfläche ist über den Containerport 5601 und die entsprechende Kombination aus Host und Knotenport erreichbar. Wenn Sie beginnen, werden in Kibana keine Daten vorhanden sein (was erwartet wird, da Sie keine Daten übertragen haben).