Lucene - Suchoperation
Der Suchprozess ist eine der Kernfunktionen von Lucene. Das folgende Diagramm zeigt den Prozess und seine Verwendung. IndexSearcher ist eine der Kernkomponenten des Suchprozesses.
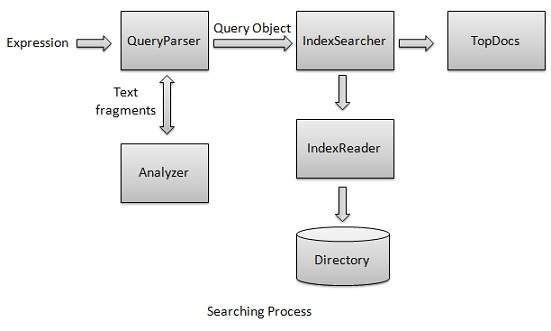
Wir erstellen zuerst Verzeichnisse mit Indizes und übergeben sie dann an IndexSearcher, der das Verzeichnis mit IndexReader öffnet . Anschließend erstellen wir eine Abfrage mit einem Begriff und führen eine Suche mit IndexSearcher durch, indem wir die Abfrage an den Sucher übergeben. IndexSearcher gibt ein TopDocs- Objekt zurück, das die Suchdetails zusammen mit den Dokument-IDs des Dokuments enthält, die das Ergebnis des Suchvorgangs sind .
Wir zeigen Ihnen nun einen schrittweisen Ansatz und helfen Ihnen anhand eines einfachen Beispiels, den Indizierungsprozess zu verstehen.
Erstellen Sie einen QueryParser
Die QueryParser-Klasse analysiert die vom Benutzer eingegebenen Eingaben in die Lucene-Abfrage im verständlichen Format. Führen Sie die folgenden Schritte aus, um einen QueryParser zu erstellen.
Step 1 - Objekt von QueryParser erstellen.
Step 2 - Initialisieren Sie das QueryParser-Objekt, das mit einem Standardanalysator mit Versionsinformationen und Indexnamen erstellt wurde, auf dem diese Abfrage ausgeführt werden soll.
QueryParser queryParser;
public Searcher(String indexDirectoryPath) throws IOException {
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}Erstellen Sie einen IndexSearcher
Die IndexSearcher-Klasse fungiert als Kernkomponente, mit der Suchindizes während des Indizierungsprozesses erstellt werden. Führen Sie die folgenden Schritte aus, um einen IndexSearcher zu erstellen.
Step 1 - Objekt von IndexSearcher erstellen.
Step 2 - Erstellen Sie ein Lucene-Verzeichnis, das auf den Speicherort der Indizes verweisen soll.
Step 3 - Initialisieren Sie das mit dem Indexverzeichnis erstellte IndexSearcher-Objekt.
IndexSearcher indexSearcher;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
}Suche machen
Befolgen Sie diese Schritte, um die Suche durchzuführen -
Step 1 - Erstellen Sie ein Abfrageobjekt, indem Sie den Suchausdruck über QueryParser analysieren.
Step 2 - Führen Sie die Suche durch, indem Sie die Methode IndexSearcher.search () aufrufen.
Query query;
public TopDocs search( String searchQuery) throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}Holen Sie sich das Dokument
Das folgende Programm zeigt, wie Sie das Dokument erhalten.
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}Schließen Sie IndexSearcher
Das folgende Programm zeigt, wie Sie den IndexSearcher schließen.
public void close() throws IOException {
indexSearcher.close();
}Beispielanwendung
Lassen Sie uns eine Test-Lucene-Anwendung erstellen, um den Suchprozess zu testen.
| Schritt | Beschreibung |
|---|---|
| 1 | Erstellen Sie ein Projekt mit dem Namen LuceneFirstApplication unter einem Paket com.tutorialspoint.lucene, wie im Kapitel Lucene - Erste Anwendung erläutert . Sie können auch das im Kapitel Lucene - Erste Anwendung erstellte Projekt als solches für dieses Kapitel verwenden, um den Suchprozess zu verstehen. |
| 2 | Erstellen Sie LuceneConstants.java, TextFileFilter.java und Searcher.java, wie im Kapitel Lucene - Erste Anwendung erläutert . Lassen Sie den Rest der Dateien unverändert. |
| 3 | Erstellen Sie LuceneTester.java wie unten beschrieben. |
| 4 | Bereinigen und erstellen Sie die Anwendung, um sicherzustellen, dass die Geschäftslogik gemäß den Anforderungen funktioniert. |
LuceneConstants.java
Diese Klasse wird verwendet, um verschiedene Konstanten bereitzustellen, die in der Beispielanwendung verwendet werden können.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
Diese Klasse wird als verwendet .txt Dateifilter.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Searcher.java
Diese Klasse wird verwendet, um die für Rohdaten erstellten Indizes zu lesen und Daten mithilfe der Lucene-Bibliothek zu durchsuchen.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath) throws IOException {
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException {
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException {
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException {
indexSearcher.close();
}
}LuceneTester.java
Diese Klasse wird verwendet, um die Suchfunktion der Lucene-Bibliothek zu testen.
package com.tutorialspoint.lucene;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void search(String searchQuery) throws IOException, ParseException {
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime) +" ms");
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}Erstellung von Daten- und Indexverzeichnissen
Wir haben 10 Textdateien mit dem Namen record1.txt für record10.txt verwendet, die Namen und andere Details der Schüler enthalten, und sie in das Verzeichnis E: \ Lucene \ Data gestellt. Testdaten . Ein Indexverzeichnispfad sollte als E: \ Lucene \ Index erstellt werden. Nach dem Ausführen des Indexierungsprogramms im KapitelLucene - Indexing Processkönnen Sie die Liste der in diesem Ordner erstellten Indexdateien anzeigen.
Ausführen des Programms
Sobald Sie mit der Erstellung der Quelle, der Rohdaten, des Datenverzeichnisses, des Indexverzeichnisses und der Indizes fertig sind, können Sie Ihr Programm kompilieren und ausführen. Um dies zu tun, behalten SieLuceneTester.Java Registerkarte "Datei" aktiv und verwenden Sie entweder die in der Eclipse-IDE verfügbare Option "Ausführen" oder "Verwenden" Ctrl + F11 um Ihre zu kompilieren und auszuführen LuceneTesterapplication. Wenn Ihre Anwendung erfolgreich ausgeführt wird, wird die folgende Meldung in der Konsole von Eclipse IDE gedruckt:
1 documents found. Time :29 ms
File: E:\Lucene\Data\record4.txt