Mahout - Maschinelles Lernen
Apache Mahout ist eine hoch skalierbare Bibliothek für maschinelles Lernen, mit der Entwickler optimierte Algorithmen verwenden können. Mahout implementiert gängige Techniken des maschinellen Lernens wie Empfehlung, Klassifizierung und Clustering. Daher ist es ratsam, einen kurzen Abschnitt über maschinelles Lernen zu lesen, bevor wir fortfahren.
Was ist maschinelles Lernen?
Maschinelles Lernen ist ein Wissenschaftszweig, der sich mit der Programmierung der Systeme so befasst, dass sie automatisch lernen und sich mit der Erfahrung verbessern. Lernen bedeutet hier, die Eingabedaten zu erkennen und zu verstehen und auf der Grundlage der bereitgestellten Daten kluge Entscheidungen zu treffen.
Es ist sehr schwierig, alle Entscheidungen auf der Grundlage aller möglichen Eingaben zu treffen. Um dieses Problem anzugehen, werden Algorithmen entwickelt. Diese Algorithmen bauen Wissen aus spezifischen Daten und früheren Erfahrungen mit den Prinzipien der Statistik, Wahrscheinlichkeitstheorie, Logik, kombinatorischen Optimierung, Suche, Verstärkungslernen und Steuerungstheorie auf.
Die entwickelten Algorithmen bilden die Grundlage für verschiedene Anwendungen wie:
- Bildverarbeitung
- Sprachverarbeitung
- Prognose (z. B. Börsentrends)
- Mustererkennung
- Games
- Data Mining
- Expertensysteme
- Robotics
Maschinelles Lernen ist ein weites Feld und es geht weit über den Rahmen dieses Tutorials hinaus, alle seine Funktionen abzudecken. Es gibt verschiedene Möglichkeiten, maschinelle Lerntechniken zu implementieren. Die am häufigsten verwendeten sind jedochsupervised und unsupervised learning.
Überwachtes Lernen
Betreutes Lernen befasst sich mit dem Lernen einer Funktion aus verfügbaren Trainingsdaten. Ein überwachter Lernalgorithmus analysiert die Trainingsdaten und erzeugt eine abgeleitete Funktion, die zur Abbildung neuer Beispiele verwendet werden kann. Häufige Beispiele für überwachtes Lernen sind:
- E-Mails als Spam klassifizieren,
- Beschriften von Webseiten anhand ihres Inhalts und
- Spracherkennung.
Es gibt viele überwachte Lernalgorithmen wie neuronale Netze, Support Vector Machines (SVMs) und Naive Bayes-Klassifikatoren. Mahout implementiert den Naive Bayes-Klassifikator.
Unbeaufsichtigtes Lernen
Unbeaufsichtigtes Lernen macht Sinn für unbeschriftete Daten, ohne dass ein vordefinierter Datensatz für das Training vorhanden ist. Unbeaufsichtigtes Lernen ist ein äußerst leistungsfähiges Werkzeug, um verfügbare Daten zu analysieren und nach Mustern und Trends zu suchen. Es wird am häufigsten zum Clustering ähnlicher Eingaben in logische Gruppen verwendet. Zu den gängigen Ansätzen für unbeaufsichtigtes Lernen gehören:
- k-means
- selbstorganisierende Karten und
- hierarchisches Clustering
Empfehlung
Empfehlung ist eine beliebte Technik, die auf der Grundlage von Benutzerinformationen wie früheren Einkäufen, Klicks und Bewertungen genaue Empfehlungen liefert.
Amazon verwendet diese Technik, um eine Liste empfohlener Elemente anzuzeigen, an denen Sie interessiert sein könnten, und um Informationen aus Ihren früheren Aktionen zu zeichnen. Es gibt Empfehlungs-Engines, die hinter Amazon arbeiten, um das Benutzerverhalten zu erfassen und ausgewählte Elemente basierend auf Ihren früheren Aktionen zu empfehlen.
Facebook verwendet die Empfehlungstechnik, um die Liste der Personen zu identifizieren und zu empfehlen, die Sie möglicherweise kennen.

Einstufung
Klassifizierung, auch bekannt als categorizationist eine maschinelle Lerntechnik, bei der anhand bekannter Daten festgelegt wird, wie die neuen Daten in eine Reihe vorhandener Kategorien eingeteilt werden sollen. Die Klassifizierung ist eine Form des überwachten Lernens.
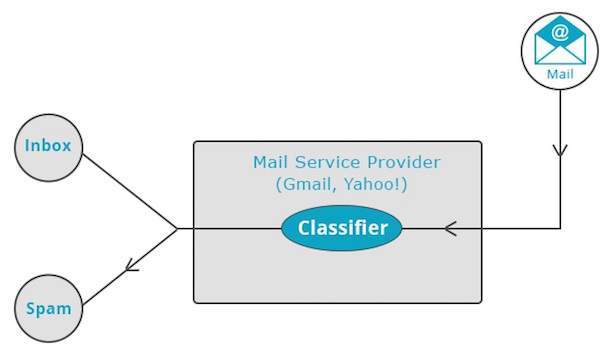
Mail-Dienstleister wie Yahoo! und Google Mail verwenden diese Technik, um zu entscheiden, ob eine neue E-Mail als Spam eingestuft werden soll. Der Kategorisierungsalgorithmus trainiert sich selbst, indem er die Benutzergewohnheiten analysiert, bestimmte E-Mails als Spam zu markieren. Auf dieser Grundlage entscheidet der Klassifizierer, ob eine zukünftige E-Mail in Ihrem Posteingang oder im Spam-Ordner abgelegt werden soll.
Die iTunes-Anwendung verwendet die Klassifizierung, um Wiedergabelisten vorzubereiten.
Clustering
Clustering wird verwendet, um Gruppen oder Cluster ähnlicher Daten basierend auf gemeinsamen Merkmalen zu bilden. Clustering ist eine Form des unbeaufsichtigten Lernens.
Suchmaschinen wie Google und Yahoo! Verwenden Sie Clustering-Techniken, um Daten mit ähnlichen Merkmalen zu gruppieren.
Newsgroups verwenden Clustering-Techniken, um verschiedene Artikel basierend auf verwandten Themen zu gruppieren.
Die Clustering-Engine durchläuft die Eingabedaten vollständig und entscheidet anhand der Dateneigenschaften, unter welchem Cluster sie gruppiert werden soll. Schauen Sie sich das folgende Beispiel an.
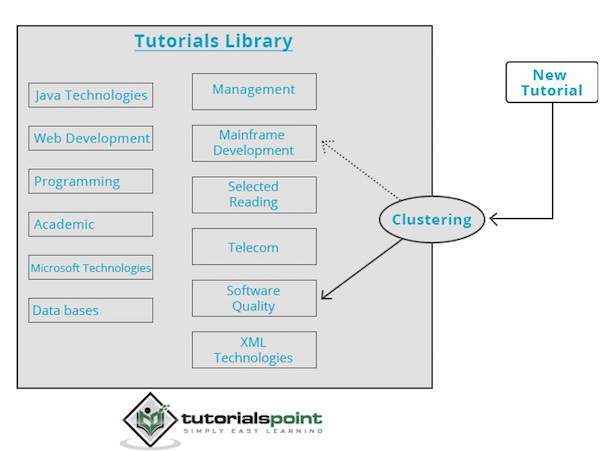
Unsere Bibliothek mit Tutorials enthält Themen zu verschiedenen Themen. Wenn wir bei TutorialsPoint ein neues Tutorial erhalten, wird es von einer Clustering-Engine verarbeitet, die anhand ihres Inhalts entscheidet, wo es gruppiert werden soll.