MapReduce - Einführung
MapReduce ist ein Programmiermodell zum Schreiben von Anwendungen, die Big Data auf mehreren Knoten parallel verarbeiten können. MapReduce bietet Analysefunktionen für die Analyse großer Mengen komplexer Daten.
Was ist Big Data?
Big Data ist eine Sammlung großer Datenmengen, die mit herkömmlichen Computertechniken nicht verarbeitet werden können. Beispielsweise kann das Datenvolumen, das Facebook oder Youtube täglich sammeln und verwalten muss, unter die Kategorie Big Data fallen. Bei Big Data geht es jedoch nicht nur um Skalierung und Volumen, sondern auch um einen oder mehrere der folgenden Aspekte: Geschwindigkeit, Vielfalt, Volumen und Komplexität.
Warum MapReduce?
Herkömmliche Unternehmenssysteme verfügen normalerweise über einen zentralen Server zum Speichern und Verarbeiten von Daten. Die folgende Abbildung zeigt eine schematische Ansicht eines herkömmlichen Unternehmenssystems. Das herkömmliche Modell ist sicherlich nicht für die Verarbeitung großer Mengen skalierbarer Daten geeignet und kann von Standard-Datenbankservern nicht berücksichtigt werden. Darüber hinaus verursacht das zentralisierte System einen zu großen Engpass, während mehrere Dateien gleichzeitig verarbeitet werden.

Google hat dieses Engpassproblem mithilfe eines Algorithmus namens MapReduce behoben. MapReduce unterteilt eine Aufgabe in kleine Teile und weist sie vielen Computern zu. Später werden die Ergebnisse an einem Ort gesammelt und in den Ergebnisdatensatz integriert.

Wie funktioniert MapReduce?
Der MapReduce-Algorithmus enthält zwei wichtige Aufgaben, nämlich Map und Reduce.
Die Map-Aufgabe nimmt einen Datensatz und konvertiert ihn in einen anderen Datensatz, wobei einzelne Elemente in Tupel (Schlüssel-Wert-Paare) zerlegt werden.
Die Aufgabe "Reduzieren" verwendet die Ausgabe von der Karte als Eingabe und kombiniert diese Datentupel (Schlüssel-Wert-Paare) zu einem kleineren Satz von Tupeln.
Die Reduzierungsaufgabe wird immer nach dem Kartenjob ausgeführt.
Schauen wir uns nun die einzelnen Phasen genauer an und versuchen, ihre Bedeutung zu verstehen.
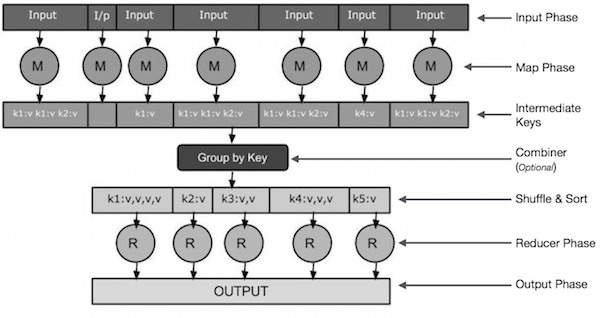
Input Phase - Hier haben wir einen Datensatzleser, der jeden Datensatz in eine Eingabedatei übersetzt und die analysierten Daten in Form von Schlüssel-Wert-Paaren an den Mapper sendet.
Map - Map ist eine benutzerdefinierte Funktion, die eine Reihe von Schlüssel-Wert-Paaren verwendet und jedes einzelne verarbeitet, um null oder mehr Schlüssel-Wert-Paare zu generieren.
Intermediate Keys - Die vom Mapper generierten Schlüssel-Wert-Paare werden als Zwischenschlüssel bezeichnet.
Combiner- Ein Kombinierer ist eine Art lokaler Reduzierer, der ähnliche Daten aus der Kartenphase in identifizierbare Mengen gruppiert. Es nimmt die Zwischenschlüssel aus dem Mapper als Eingabe und wendet einen benutzerdefinierten Code an, um die Werte in einem kleinen Bereich eines Mappers zu aggregieren. Es ist nicht Teil des Hauptalgorithmus von MapReduce. es ist optional.
Shuffle and Sort- Die Reduzierungsaufgabe beginnt mit dem Schritt Mischen und Sortieren. Es lädt die gruppierten Schlüssel-Wert-Paare auf den lokalen Computer herunter, auf dem der Reducer ausgeführt wird. Die einzelnen Schlüssel-Wert-Paare werden nach Schlüssel in eine größere Datenliste sortiert. In der Datenliste werden die entsprechenden Schlüssel zusammengefasst, sodass ihre Werte in der Reduzierungsaufgabe problemlos wiederholt werden können.
Reducer- Der Reduzierer verwendet die gruppierten Schlüssel-Wert-gepaarten Daten als Eingabe und führt für jeden eine Reduziererfunktion aus. Hier können die Daten auf verschiedene Weise aggregiert, gefiltert und kombiniert werden, und es ist ein breites Verarbeitungsspektrum erforderlich. Sobald die Ausführung beendet ist, werden für den letzten Schritt null oder mehr Schlüssel-Wert-Paare angegeben.
Output Phase - In der Ausgabephase haben wir einen Ausgabeformatierer, der die endgültigen Schlüssel-Wert-Paare aus der Reducer-Funktion übersetzt und sie mit einem Record Writer in eine Datei schreibt.
Versuchen wir, die beiden Aufgaben Map & f Reduce mit Hilfe eines kleinen Diagramms zu verstehen -

MapReduce-Beispiel
Nehmen wir ein Beispiel aus der Praxis, um die Leistungsfähigkeit von MapReduce zu verstehen. Twitter empfängt täglich rund 500 Millionen Tweets, was fast 3000 Tweets pro Sekunde entspricht. Die folgende Abbildung zeigt, wie Tweeter seine Tweets mithilfe von MapReduce verwaltet.
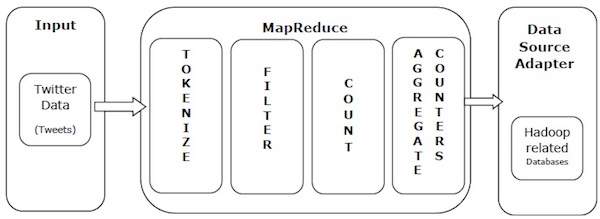
Wie in der Abbildung gezeigt, führt der MapReduce-Algorithmus die folgenden Aktionen aus:
Tokenize - Tokenisiert die Tweets in Karten von Token und schreibt sie als Schlüssel-Wert-Paare.
Filter - Filtert unerwünschte Wörter aus den Karten von Token und schreibt die gefilterten Karten als Schlüssel-Wert-Paare.
Count - Erzeugt einen Token-Zähler pro Wort.
Aggregate Counters - Bereitet ein Aggregat ähnlicher Zählerwerte in kleinen überschaubaren Einheiten vor.