MS SQL Server - Kurzanleitung
In diesem Kapitel wird SQL Server vorgestellt und seine Verwendung, Vorteile, Versionen und Komponenten erläutert.
Was ist SQL Server?
Es ist eine von Microsoft entwickelte Software, die aus der Spezifikation von RDBMS implementiert wird.
Es ist auch ein ORDBMS.
Es ist plattformabhängig.
Es ist sowohl GUI als auch befehlsbasierte Software.
Es unterstützt die SQL-Sprache (SEQUEL), bei der es sich um ein IBM Produkt, eine nicht prozedurale, gemeinsame Datenbank und eine Sprache handelt, bei der die Groß- und Kleinschreibung nicht berücksichtigt wird.
Verwendung von SQL Server
- So erstellen Sie Datenbanken.
- Datenbanken pflegen.
- So analysieren Sie die Daten über SQL Server Analysis Services (SSAS).
- So generieren Sie Berichte über SQL Server Reporting Services (SSRS).
- So führen Sie ETL-Vorgänge über SQL Server Integration Services (SSIS) aus
Versionen von SQL Server
| Ausführung | Jahr | Code Name |
|---|---|---|
| 6.0 | 1995 | SQL95 |
| 6.5 | 1996 | Hydra |
| 7.0 | 1998 | Sphinx |
| 8,0 (2000) | 2000 | Shiloh |
| 9,0 (2005) | 2005 | Yukon |
| 10,0 (2008) | 2008 | Katmai |
| 10,5 (2008 R2) | 2010 | Kilimanjaro |
| 11,0 (2012) | 2012 | Denali |
| 12 (2014) | 2014 | Hekaton (anfangs), SQL 14 (aktuell) |
SQL Server-Komponenten
SQL Server arbeitet in einer Client-Server-Architektur und unterstützt daher zwei Arten von Komponenten: (a) Workstation und (b) Server.
Workstation componentssind auf jedem Computer des Geräts / SQL Server-Bedieners installiert. Dies sind nur Schnittstellen für die Interaktion mit Serverkomponenten. Beispiel: SSMS, SSCM, Profiler, BIDS, SQLEM usw.
Server componentssind auf einem zentralen Server installiert. Dies sind Dienstleistungen. Beispiel: SQL Server, SQL Server-Agent, SSIS, SSAS, SSRS, SQL-Browser, SQL Server-Volltextsuche usw.
Instanz von SQL Server
- Eine Instanz ist eine Installation von SQL Server.
- Eine Instanz ist eine exakte Kopie derselben Software.
- Wenn wir 'n' mal installieren, werden 'n' Instanzen erstellt.
- Es gibt zwei Arten von Instanzen in SQL Server: a) Standard b) Benannt.
- Auf einem Server wird nur eine Standardinstanz unterstützt.
- Auf einem Server werden mehrere benannte Instanzen unterstützt.
- Die Standardinstanz verwendet den Servernamen als Instanznamen.
- Der Standardname des Instanzdienstes lautet MSSQLSERVER.
- In der Version 2000 werden 16 Instanzen unterstützt.
- 50 Instanzen werden ab 2005 unterstützt.
Vorteile von Instanzen
- So installieren Sie verschiedene Versionen auf einem Computer.
- Kosten senken.
- Produktions-, Entwicklungs- und Testumgebungen separat warten.
- Um temporäre Datenbankprobleme zu reduzieren.
- So trennen Sie Sicherheitsrechte.
- Standby-Server warten.
SQL Server ist in verschiedenen Editionen verfügbar. In diesem Kapitel werden die verschiedenen Editionen mit ihren Funktionen aufgeführt.
Enterprise - Dies ist die Top-End-Edition mit allen Funktionen.
Standard - Dies hat weniger Funktionen als Enterprise, wenn keine erweiterten Funktionen erforderlich sind.
Workgroup - Dies ist für Remote-Büros eines größeren Unternehmens geeignet.
Web - Dies ist für Webanwendungen konzipiert.
Developer- Dies ähnelt Enterprise, ist jedoch nur für die Entwicklung, das Testen und die Demo an einen Benutzer lizenziert. Es kann ohne Neuinstallation problemlos auf Enterprise aktualisiert werden.
Express- Dies ist eine kostenlose Einstiegsdatenbank. Es kann nur 1 CPU und 1 GB Speicher verwenden, die maximale Größe der Datenbank beträgt 10 GB.
Compact- Dies ist eine kostenlose eingebettete Datenbank für die Entwicklung mobiler Anwendungen. Die maximale Größe der Datenbank beträgt 4 GB.
Datacenter- Die wichtigste Änderung in neuem SQL Server 2008 R2 ist Datacenter Edition. Die Datacenter Edition hat keine Speicherbeschränkung und bietet Unterstützung für mehr als 25 Instanzen.
Business Intelligence - Business Intelligence Edition ist eine neue Einführung in SQL Server 2012. Diese Edition enthält alle Funktionen der Standard Edition und Unterstützung für erweiterte BI-Funktionen wie Power View und PowerPivot, jedoch keine Unterstützung für erweiterte Verfügbarkeitsfunktionen wie AlwaysOn Availability Groups und andere Online-Betrieb.
Enterprise Evaluation- Die SQL Server Evaluation Edition ist eine hervorragende Möglichkeit, eine voll funktionsfähige und kostenlose Instanz von SQL Server zum Lernen und Entwickeln von Lösungen zu erhalten. Diese Edition hat einen integrierten Ablauf von 6 Monaten ab dem Zeitpunkt der Installation.
| 2005 | 2008 | 2008 R2 | 2012 | 2014 |
|---|---|---|---|---|
| Unternehmen | Ja | Ja | Ja | Ja |
| Standard | Ja | Ja | Ja | Ja |
| Entwickler | Ja | Ja | Ja | Ja |
| Arbeitsgruppe | Ja | Ja | Nein | Nein |
| Win Compact Edition - Mobil | Ja | Ja | Ja | Ja |
| Unternehmensbewertung | Ja | Ja | Ja | Ja |
| ausdrücken | Ja | Ja | Ja | Ja |
| Netz | Ja | Ja | Ja | |
| Rechenzentrum | Nein | Nein | ||
| Business Intelligence | Ja |
SQL Server unterstützt zwei Arten der Installation:
- Standalone
- Clusterbasiert
Schecks
- Überprüfen Sie den RDP-Zugriff für den Server.
- Überprüfen Sie das Betriebssystembit, die IP und die Domäne des Servers.
- Überprüfen Sie, ob sich Ihr Konto in der Administratorgruppe befindet, um die Datei setup.exe auszuführen.
- Software-Standort.
Bedarf
- Welche Version, Edition, SP und Hotfix, falls vorhanden.
- Dienstkonten für Datenbankmodul, Agent, SSAS, SSIS, SSRS, falls vorhanden.
- Benannter Instanzname, falls vorhanden.
- Speicherort für Binärdateien, Systemdatenbanken und Benutzerdatenbanken.
- Authentifizierungsmodus.
- Sortiereinstellung.
- Liste der Funktionen.
Voraussetzungen für 2005
- Support-Dateien einrichten.
- .net Framework 2.0.
- Native SQL Server-Client.
Voraussetzungen für 2008 & 2008R2
- Support-Dateien einrichten.
- .net Framework 3.5 SP1.
- Native SQL Server-Client.
- Windows Installer 4.5 / höher Version.
Voraussetzungen für 2012 & 2014
- Support-Dateien einrichten.
- .net Framework 4.0.
- Native SQL Server-Client.
- Windows Installer 4.5 / höher Version.
- Windows PowerShell 2.0.
Installationsschritte
Step 1 - Laden Sie die Evaluation Edition von herunter http://www.microsoft.com/download/en/details.aspx?id=29066
Sobald die Software heruntergeladen wurde, sind die folgenden Dateien basierend auf Ihrer Download-Option (32 oder 64 Bit) verfügbar.
ENU \ x86 \ SQLFULL_x86_ENU_Core.box
ENU \ x86 \ SQLFULL_x86_ENU_Install.exe
ENU \ x86 \ SQLFULL_x86_ENU_Lang.box
OR
ENU \ x86 \ SQLFULL_x64_ENU_Core.box
ENU \ x86 \ SQLFULL_x64_ENU_Install.exe
ENU \ x86 \ SQLFULL_x64_ENU_Lang.box
Note - X86 (32 Bit) und X64 (64 Bit)
Step 2 - Doppelklicken Sie auf "SQLFULL_x86_ENU_Install.exe" oder "SQLFULL_x64_ENU_Install.exe". Die für die Installation erforderlichen Dateien werden im Ordner "SQLFULL_x86_ENU" bzw. "SQLFULL_x86_ENU" extrahiert.
Step 3 - Klicken Sie auf den Ordner "SQLFULL_x86_ENU" oder "SQLFULL_x64_ENU_Install.exe" und doppelklicken Sie auf die Anwendung "SETUP".
Zum Verständnis haben wir hier die Software SQLFULL_x64_ENU_Install.exe verwendet.
Step 4 - Sobald wir auf "Setup" -Anwendung klicken, wird der folgende Bildschirm geöffnet.

Step 5 - Klicken Sie auf Installation auf der linken Seite des obigen Bildschirms.

Step 6- Klicken Sie auf die erste Option auf der rechten Seite, die auf dem obigen Bildschirm angezeigt wird. Der folgende Bildschirm wird geöffnet.

Step 7 - Klicken Sie auf OK und der folgende Bildschirm wird angezeigt.
Step 8 - Klicken Sie auf Weiter, um den folgenden Bildschirm aufzurufen.

Step 9 - Überprüfen Sie unbedingt die Auswahl der Produktschlüssel und klicken Sie auf Weiter.

Step 10 - Aktivieren Sie das Kontrollkästchen, um die Lizenzoption zu akzeptieren, und klicken Sie auf Weiter.

Step 11 - Wählen Sie die Installationsoption für die SQL Server-Funktion und klicken Sie auf Weiter.

Step 12 - Aktivieren Sie das Kontrollkästchen Datenbankmoduldienste und klicken Sie auf Weiter.
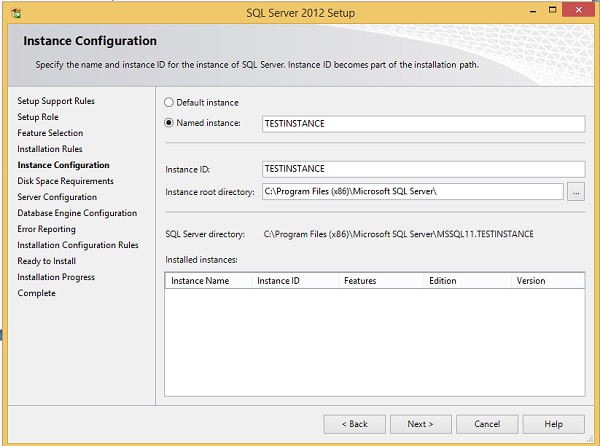
Step 13 - Geben Sie die benannte Instanz ein (hier habe ich TestInstance verwendet) und klicken Sie auf Weiter.

Step 14 - Klicken Sie im obigen Bildschirm auf Weiter. Der folgende Bildschirm wird angezeigt.

Step 15 - Wählen Sie Dienstkontonamen und Starttypen für die oben aufgeführten Dienste aus und klicken Sie auf Sortierung.

Step 16 - Stellen Sie sicher, dass die richtige Sortierauswahl aktiviert ist, und klicken Sie auf Weiter.

Step 17 - Stellen Sie sicher, dass die Auswahl des Authentifizierungsmodus und die Administratoren aktiviert sind, und klicken Sie auf Datenverzeichnisse.
Step 18- Stellen Sie sicher, dass Sie die oben genannten Verzeichnispositionen auswählen und klicken Sie auf Weiter. Der folgende Bildschirm wird angezeigt.

Step 19 - Klicken Sie im obigen Bildschirm auf Weiter.

Step 20 - Klicken Sie im obigen Bildschirm auf Weiter, um den folgenden Bildschirm aufzurufen.

Step 21 - Überprüfen Sie die obige Auswahl korrekt und klicken Sie auf Installieren.
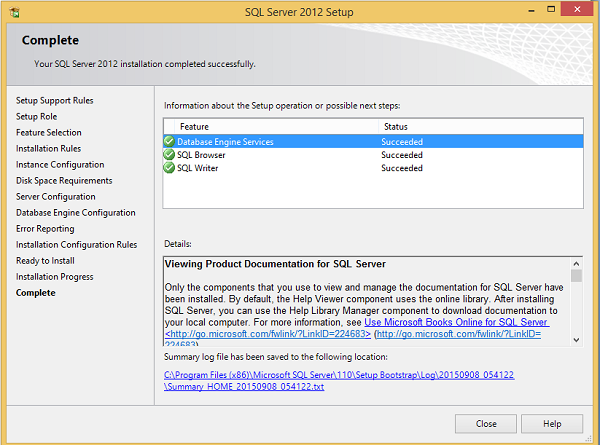
Die Installation ist erfolgreich, wie im obigen Bildschirm gezeigt. Klicken Sie zum Schließen auf Schließen.
Wir haben die Architektur von SQL Server zum besseren Verständnis in die folgenden Teile unterteilt:
- Allgemeine Architektur
- Speicherarchitektur
- Datendatei-Architektur
- Protokolldatei-Architektur
Allgemeine Architektur
Client - Wo die Anfrage initiiert wurde.
Query - SQL-Abfrage, die Hochsprache ist.
Logical Units - Schlüsselwörter, Ausdrücke und Operatoren usw.
N/W Packets - Netzwerkbezogener Code.
Protocols - In SQL Server haben wir 4 Protokolle.
Gemeinsamer Speicher (für lokale Verbindungen und zur Fehlerbehebung).
Named Pipes (für Verbindungen mit LAN-Konnektivität).
TCP / IP (für Verbindungen mit WAN-Konnektivität).
VIA-Virtual Interface Adapter (erfordert spezielle Hardware, die vom Hersteller eingerichtet werden muss und auch von der SQL 2012-Version veraltet ist).
Server - Wo SQL Services installiert wurden und sich Datenbanken befinden.
Relational Engine- Hier erfolgt die eigentliche Ausführung. Es enthält Query Parser, Query Optimizer und Query Executor.
Query Parser (Command Parser) and Compiler (Translator) - Dadurch wird die Syntax der Abfrage überprüft und die Abfrage in die Maschinensprache konvertiert.
Query Optimizer - Der Ausführungsplan wird als Ausgabe vorbereitet, indem Abfrage, Statistik und Algebrizer-Baum als Eingabe verwendet werden.
Execution Plan - Es ist wie eine Roadmap, die die Reihenfolge aller Schritte enthält, die im Rahmen der Abfrageausführung ausgeführt werden sollen.
Query Executor - Hier wird die Abfrage mit Hilfe des Ausführungsplans Schritt für Schritt ausgeführt und auch die Speicher-Engine kontaktiert.
Storage Engine - Es ist verantwortlich für das Speichern und Abrufen von Daten auf dem Speichersystem (Festplatte, SAN usw.), die Datenmanipulation, das Sperren und die Verwaltung von Transaktionen.
SQL OS- Dies liegt zwischen dem Host-Computer (Windows-Betriebssystem) und SQL Server. Alle im Datenbankmodul ausgeführten Aktivitäten werden von SQL OS ausgeführt. SQL OS bietet verschiedene Betriebssystemdienste, z. B. Speicherverwaltung für Pufferpool, Protokollpuffer und Deadlock-Erkennung mithilfe der Blockierungs- und Sperrstruktur.
Checkpoint Process- Checkpoint ist ein interner Prozess, der alle fehlerhaften Seiten (geänderten Seiten) vom Puffercache auf die physische Festplatte schreibt. Abgesehen davon schreibt es auch die Protokolldatensätze aus dem Protokollpuffer in die physische Datei. Das Schreiben schmutziger Seiten aus dem Puffercache in eine Datendatei wird auch als Härten schmutziger Seiten bezeichnet.
Es ist ein dedizierter Prozess und wird in bestimmten Intervallen automatisch von SQL Server ausgeführt. SQL Server führt den Prüfpunktprozess für jede Datenbank einzeln aus. Checkpoint hilft, die Wiederherstellungszeit für SQL Server im Falle eines unerwarteten Herunterfahrens oder eines Systemabsturzes \ Failure zu verkürzen.
Prüfpunkte in SQL Server
In SQL Server 2012 gibt es vier Arten von checkpoints - -
Automatic - Dies ist der häufigste Prüfpunkt, der als Prozess im Hintergrund ausgeführt wird, um sicherzustellen, dass die SQL Server-Datenbank innerhalb des durch das Wiederherstellungsintervall - Serverkonfigurationsoption festgelegten Zeitlimits wiederhergestellt werden kann.
Indirect- Dies ist neu in SQL Server 2012. Dies wird auch im Hintergrund ausgeführt, jedoch um eine benutzerdefinierte Zielwiederherstellungszeit für die spezifische Datenbank einzuhalten, für die die Option konfiguriert wurde. Sobald die Target_Recovery_Time für eine bestimmte Datenbank ausgewählt wurde, überschreibt dies das für den Server angegebene Wiederherstellungsintervall und vermeidet den automatischen Prüfpunkt in einer solchen Datenbank.
Manual- Diese Anweisung wird wie jede andere T-SQL-Anweisung ausgeführt. Sobald Sie den Befehl checkpoint ausgeben, wird sie vollständig ausgeführt. Der manuelle Prüfpunkt wird nur für Ihre aktuelle Datenbank ausgeführt. Sie können auch die optionale Checkpoint_Duration angeben. Diese Dauer gibt die Zeit an, in der Ihr Checkpoint abgeschlossen werden soll.
Internal- Als Benutzer können Sie den internen Prüfpunkt nicht steuern. Ausgestellt für bestimmte Operationen wie
Durch das Herunterfahren wird eine Prüfpunktoperation für alle Datenbanken gestartet, außer wenn das Herunterfahren nicht sauber ist (Herunterfahren mit nowait).
Wenn das Wiederherstellungsmodell von "Vollständig \ Massenprotokolliert" in "Einfach" geändert wird.
Während der Sicherung der Datenbank.
Wenn sich Ihre Datenbank in einem einfachen Wiederherstellungsmodell befindet, wird der Prüfpunktprozess automatisch ausgeführt, entweder wenn das Protokoll zu 70% voll ist, oder basierend auf dem Wiederherstellungsintervall der Serveroption.
Durch Ändern des Datenbankbefehls zum Hinzufügen oder Entfernen einer Daten- / Protokolldatei wird auch ein Prüfpunkt initiiert.
Der Prüfpunkt findet auch statt, wenn das Wiederherstellungsmodell der Datenbank massenprotokolliert ist und eine minimal protokollierte Operation ausgeführt wird.
DB-Snapshot-Erstellung.
Lazy Writer Process- Lazy Writer überträgt schmutzige Seiten aus einem ganz anderen Grund auf die Festplatte, da Speicher im Pufferpool freigegeben werden muss. Dies geschieht, wenn der SQL Server unter Speicherdruck gerät. Soweit mir bekannt ist, wird dies durch einen internen Prozess gesteuert und es gibt keine Einstellung dafür.
SQL Server überwacht ständig die Speichernutzung, um den Ressourcenkonflikt (oder die Verfügbarkeit) zu bewerten. Seine Aufgabe ist es, sicherzustellen, dass jederzeit eine bestimmte Menge an freiem Speicherplatz verfügbar ist. Als Teil dieses Prozesses löst Lazy Writer, wenn er einen solchen Ressourcenkonflikt bemerkt, einige Seiten im Speicher frei, indem er schmutzige Seiten auf die Festplatte schreibt. Es verwendet den LRU-Algorithmus (Least Recent Used), um zu entscheiden, welche Seiten auf die Festplatte geleert werden sollen.
Wenn Lazy Writer immer aktiv ist, kann dies auf einen Speicherengpass hinweisen.
Speicherarchitektur
Im Folgenden sind einige der wichtigsten Merkmale der Speicherarchitektur aufgeführt.
Eines der Hauptentwurfsziele aller Datenbanksoftware ist die Minimierung der Festplatten-E / A, da das Lesen und Schreiben von Festplatten zu den ressourcenintensivsten Vorgängen gehört.
Der Speicher in Windows kann mit dem virtuellen Adressraum aufgerufen werden, der vom Kernelmodus (Betriebssystemmodus) und vom Benutzermodus (Anwendung wie SQL Server) gemeinsam genutzt wird.
SQL Server "Benutzeradressraum" ist in zwei Regionen unterteilt: MemToLeave und Buffer Pool.
Die Größe von MemToLeave (MTL) und Buffer Pool (BPool) wird beim Start von SQL Server festgelegt.
Buffer managementist eine Schlüsselkomponente für die Erzielung einer hohen E / A-Effizienz. Die Pufferverwaltungskomponente besteht aus zwei Mechanismen: dem Puffermanager für den Zugriff auf und die Aktualisierung von Datenbankseiten und dem Pufferpool für die Reduzierung der E / A-Datenbanken.
Der Pufferpool ist weiter in mehrere Abschnitte unterteilt. Die wichtigsten sind der Puffercache (auch als Datencache bezeichnet) und der Prozedurcache.Buffer cacheHält die Datenseiten im Speicher, sodass Daten, auf die häufig zugegriffen wird, aus dem Cache abgerufen werden können. Die Alternative wäre das Lesen von Datenseiten von der Festplatte. Das Lesen von Datenseiten aus dem Cache optimiert die Leistung, indem die Anzahl der erforderlichen E / A-Vorgänge minimiert wird, die von Natur aus langsamer sind als das Abrufen von Daten aus dem Speicher.
Procedure cacheBehält die gespeicherten Prozedur- und Abfrageausführungspläne bei, um die Häufigkeit zu minimieren, mit der Abfragepläne generiert werden müssen. Informationen zur Größe und Aktivität im Prozedurcache finden Sie mit der Anweisung DBCC PROCCACHE.
Andere Teile des Pufferpools umfassen -
System level data structures - Enthält Daten auf SQL Server-Instanzebene zu Datenbanken und Sperren.
Log cache - Reserviert zum Lesen und Schreiben von Transaktionsprotokollseiten.
Connection context- Jede Verbindung zur Instanz verfügt über einen kleinen Speicherbereich, in dem der aktuelle Status der Verbindung aufgezeichnet wird. Diese Informationen umfassen gespeicherte Prozeduren und benutzerdefinierte Funktionsparameter, Cursorpositionen und mehr.
Stack space - Windows weist jedem von SQL Server gestarteten Thread Stapelspeicherplatz zu.
Datendatei-Architektur
Die Datendatei-Architektur besteht aus folgenden Komponenten:
Dateigruppen
Datenbankdateien können zu Zuordnungs- und Verwaltungszwecken in Dateigruppen zusammengefasst werden. Keine Datei kann Mitglied mehrerer Dateigruppen sein. Protokolldateien sind niemals Teil einer Dateigruppe. Der Protokollbereich wird getrennt vom Datenbereich verwaltet.
In SQL Server gibt es zwei Arten von Dateigruppen: Primär und Benutzerdefiniert. Die primäre Dateigruppe enthält die primäre Datendatei und alle anderen Dateien, die nicht speziell einer anderen Dateigruppe zugeordnet sind. Alle Seiten für die Systemtabellen werden in der primären Dateigruppe zugeordnet. Benutzerdefinierte Dateigruppen sind alle Dateigruppen, die mit dem Schlüsselwort Dateigruppe in Datenbank erstellen oder Datenbankanweisung ändern angegeben werden.
Eine Dateigruppe in jeder Datenbank fungiert als Standarddateigruppe. Wenn SQL Server einer Seite oder einem Index eine Seite zuweist, für die beim Erstellen keine Dateigruppe angegeben wurde, werden die Seiten aus der Standarddateigruppe zugewiesen. Um die Standarddateigruppe von einer Dateigruppe in eine andere Dateigruppe zu wechseln, sollte die Datenbankrolle db_owner festgelegt sein.
Standardmäßig ist die primäre Dateigruppe die Standarddateigruppe. Der Benutzer sollte über eine feste Datenbankrolle für db_owner verfügen, um Dateien und Dateigruppen einzeln sichern zu können.
Dateien
Datenbanken haben drei Arten von Dateien: Primärdatendatei, Sekundärdatendatei und Protokolldatei. Die primäre Datendatei ist der Startpunkt der Datenbank und zeigt auf die anderen Dateien in der Datenbank.
Jede Datenbank verfügt über eine Primärdatendatei. Wir können eine beliebige Erweiterung für die primäre Datendatei angeben, die empfohlene Erweiterung lautet jedoch.mdf. Die sekundäre Datendatei ist eine andere Datei als die primäre Datendatei in dieser Datenbank. Einige Datenbanken können mehrere sekundäre Datendateien enthalten. Einige Datenbanken verfügen möglicherweise nicht über eine einzige sekundäre Datendatei. Empfohlene Erweiterung für sekundäre Datendatei ist.ndf.
Protokolldateien enthalten alle Protokollinformationen, die zum Wiederherstellen der Datenbank verwendet werden. Die Datenbank muss mindestens eine Protokolldatei enthalten. Wir können mehrere Protokolldateien für eine Datenbank haben. Die empfohlene Erweiterung für die Protokolldatei lautet.ldf.
Der Speicherort aller Dateien in einer Datenbank wird sowohl in der Masterdatenbank als auch in der Primärdatei für die Datenbank aufgezeichnet. In den meisten Fällen verwendet das Datenbankmodul den Speicherort der Datei aus der Masterdatenbank.
Dateien haben zwei Namen - Logisch und Physisch. Der logische Name wird verwendet, um in allen T-SQL-Anweisungen auf die Datei zu verweisen. Der physische Name ist der OS-Dateiname. Er muss den Regeln des Betriebssystems entsprechen. Daten- und Protokolldateien können entweder auf FAT- oder NTFS-Dateisystemen abgelegt werden, jedoch nicht auf komprimierten Dateisystemen. Eine Datenbank kann bis zu 32.767 Dateien enthalten.
Ausmaße
Extents sind Grundeinheiten, in denen Tabellen und Indizes Speicherplatz zugewiesen wird. Ein Umfang beträgt 8 zusammenhängende Seiten oder 64 KB. SQL Server verfügt über zwei Arten von Extents: Uniform und Mixed. Einheitliche Ausmaße bestehen nur aus einem einzigen Objekt. Gemischte Ausmaße werden von bis zu acht Objekten gemeinsam genutzt.
Seiten
Es ist die grundlegende Einheit der Datenspeicherung in MS SQL Server. Die Größe der Seite beträgt 8 KB. Der Anfang jeder Seite ist ein 96-Byte-Header, in dem Systeminformationen wie Seitentyp, freier Speicherplatz auf der Seite und Objekt-ID des Objekts gespeichert werden, dem die Seite gehört. In SQL Server gibt es 9 Arten von Datenseiten.
Data - Datenzeilen mit allen Daten außer Text-, Text- und Bilddaten.
Index - Indexeinträge.
Text\Image - Text-, Bild- und Textdaten.
GAM - Informationen zu zugewiesenen Ausdehnungen.
SGAM - Informationen zu zugewiesenen Extents auf Systemebene.
Page Free Space (PFS) - Informationen zum freien Speicherplatz auf den Seiten.
Index Allocation Map (IAM) - Informationen zu den von einer Tabelle oder einem Index verwendeten Extents.
Bulk Changed Map (BCM) - Informationen zu Extents, die durch Massenvorgänge seit der letzten Sicherungsprotokollanweisung geändert wurden.
Differential Changed Map (DCM) - Informationen zu Extents, die sich seit der letzten Sicherungsdatenbankanweisung geändert haben.
Protokolldatei-Architektur
Das SQL Server-Transaktionsprotokoll arbeitet logisch so, als wäre das Transaktionsprotokoll eine Zeichenfolge von Protokolldatensätzen. Jeder Protokolldatensatz wird durch die Protokollsequenznummer (LSN) identifiziert. Jeder Protokolldatensatz enthält die ID der Transaktion, zu der er gehört.
Protokolldatensätze für Datenänderungen zeichnen entweder die durchgeführte logische Operation auf oder sie zeichnen die Vorher- und Nachher-Bilder der geänderten Daten auf. Das Vorher-Bild ist eine Kopie der Daten, bevor die Operation ausgeführt wird. Das Nachbild ist eine Kopie der Daten, nachdem der Vorgang ausgeführt wurde.
Die Schritte zum Wiederherstellen eines Vorgangs hängen von der Art des Protokolldatensatzes ab.
- Logischer Vorgang protokolliert.
- Um die logische Operation vorwärts zu rollen, wird die Operation erneut ausgeführt.
- Um die logische Operation zurückzusetzen, wird die umgekehrte logische Operation ausgeführt.
- Vor und nach dem Bild protokolliert.
- Um den Vorgang vorwärts zu rollen, wird das Nachbild angewendet.
- Um den Vorgang zurückzusetzen, wird das vorherige Bild angewendet.
Verschiedene Arten von Vorgängen werden im Transaktionsprotokoll aufgezeichnet. Diese Operationen umfassen -
Beginn und Ende jeder Transaktion.
Jede Datenänderung (Einfügen, Aktualisieren oder Löschen). Dies umfasst Änderungen durch gespeicherte Systemprozeduren oder DDL-Anweisungen (Data Definition Language) an einer Tabelle, einschließlich Systemtabellen.
Jeder Umfang und jede Seitenzuweisung oder Zuweisung.
Erstellen oder Löschen einer Tabelle oder eines Index.
Rollback-Vorgänge werden ebenfalls protokolliert. Jede Transaktion reserviert Speicherplatz im Transaktionsprotokoll, um sicherzustellen, dass genügend Protokollspeicherplatz vorhanden ist, um ein Rollback zu unterstützen, das entweder durch eine explizite Rollback-Anweisung oder durch Auftreten eines Fehlers verursacht wird. Dieser reservierte Speicherplatz wird freigegeben, wenn die Transaktion abgeschlossen ist.
Der Abschnitt der Protokolldatei vom ersten Protokolldatensatz, der für ein erfolgreiches datenbankweites Rollback zum zuletzt geschriebenen Protokolldatensatz vorhanden sein muss, wird als aktiver Teil des Protokolls oder aktives Protokoll bezeichnet. Dies ist der Abschnitt des Protokolls, der für eine vollständige Wiederherstellung der Datenbank erforderlich ist. Kein Teil des aktiven Protokolls kann jemals abgeschnitten werden. Die LSN dieses ersten Protokolldatensatzes wird als minimale Wiederherstellungs-LSN (Min. LSN) bezeichnet.
Das SQL Server-Datenbankmodul unterteilt jede physische Protokolldatei intern in mehrere virtuelle Protokolldateien. Virtuelle Protokolldateien haben keine feste Größe und es gibt keine feste Anzahl virtueller Protokolldateien für eine physische Protokolldatei.
Das Datenbankmodul wählt die Größe der virtuellen Protokolldateien dynamisch aus, während Protokolldateien erstellt oder erweitert werden. Das Datenbankmodul versucht, eine kleine Anzahl virtueller Dateien zu verwalten. Die Größe oder Anzahl der virtuellen Protokolldateien kann von Administratoren nicht konfiguriert oder festgelegt werden. Virtuelle Protokolldateien wirken sich nur dann auf die Systemleistung aus, wenn die physischen Protokolldateien durch kleine Werte und Werte für das Wachstumsinkrement definiert sind.
Der Größenwert ist die Anfangsgröße für die Protokolldatei und der Wert für grow_increment ist der Speicherplatz, der der Datei jedes Mal hinzugefügt wird, wenn neuer Speicherplatz benötigt wird. Wenn die Protokolldateien aufgrund vieler kleiner Schritte zu einer großen Größe werden, verfügen sie über viele virtuelle Protokolldateien. Dies kann den Datenbankstart verlangsamen und auch Sicherungs- und Wiederherstellungsvorgänge protokollieren.
Wir empfehlen, dass Sie Protokolldateien einen Größenwert zuweisen, der nahe an der erforderlichen Endgröße liegt, und einen relativ großen Wert für das Wachstum inkrementieren. SQL Server verwendet ein Write-Ahead-Protokoll (WAL), das garantiert, dass keine Datenänderungen auf die Festplatte geschrieben werden, bevor der zugehörige Protokolldatensatz auf die Festplatte geschrieben wird. Dadurch werden die ACID-Eigenschaften für eine Transaktion beibehalten.
SQL Server Management Studio ist ein Workstation Component \ Client-Tool, das installiert wird, wenn wir in den Installationsschritten die Workstation-Komponente auswählen. Auf diese Weise können Sie über eine grafische Oberfläche eine Verbindung zu Ihrem SQL Server herstellen und diesen verwalten, anstatt die Befehlszeile verwenden zu müssen.
Um eine Verbindung zu einer Remote-Instanz eines SQL Servers herzustellen, benötigen Sie diese oder eine ähnliche Software. Es wird von Administratoren, Entwicklern, Testern usw. verwendet.
Die folgenden Methoden werden zum Öffnen von SQL Server Management Studio verwendet.
Erste Methode
Start → Alle Programme → MS SQL Server 2012 → SQL Server Management Studio
Zweite Methode
Gehen Sie zu Ausführen und geben Sie SQLWB (For 2005 Version) SSMS (For 2008 und spätere Versionen) ein. Klicken Sie dann auf Enter.
SQL Server Management Studio wird wie im folgenden Snapshot gezeigt in einer der oben genannten Methoden geöffnet.

Ein Login ist ein einfacher Berechtigungsnachweis für den Zugriff auf SQL Server. Beispielsweise geben Sie Ihren Benutzernamen und Ihr Kennwort an, wenn Sie sich bei Windows oder sogar bei Ihrem E-Mail-Konto anmelden. Dieser Benutzername und dieses Passwort bilden die Anmeldeinformationen. Anmeldeinformationen sind daher einfach ein Benutzername und ein Passwort.
SQL Server erlaubt vier Arten von Anmeldungen:
- Eine Anmeldung basierend auf Windows-Anmeldeinformationen.
- Eine für SQL Server spezifische Anmeldung.
- Ein Login, das einem Zertifikat zugeordnet ist.
- Ein Login, das einem asymmetrischen Schlüssel zugeordnet ist.
In diesem Lernprogramm interessieren uns Anmeldungen, die auf Windows-Anmeldeinformationen basieren, und Anmeldungen, die für SQL Server spezifisch sind.
Mit Anmeldungen basierend auf Windows-Anmeldeinformationen können Sie sich mit einem Windows-Benutzernamen und -Kennwort bei SQL Server anmelden. Wenn Sie Ihre eigenen Anmeldeinformationen (Benutzername und Kennwort) erstellen müssen, können Sie eine Anmeldung speziell für SQL Server erstellen.
Um eine SQL Server-Anmeldung zu erstellen, zu ändern oder zu entfernen, haben Sie zwei Möglichkeiten:
- Verwenden von SQL Server Management Studio.
- Verwenden von T-SQL-Anweisungen.
Die folgenden Methoden werden zum Erstellen der Anmeldung verwendet:
Erste Methode - Verwenden von SQL Server Management Studio
Step 1 - Erweitern Sie nach dem Herstellen einer Verbindung mit der SQL Server-Instanz den Anmeldeordner wie im folgenden Snapshot gezeigt.

Step 2 - Klicken Sie mit der rechten Maustaste auf Anmeldungen und dann auf Neue Anmeldung. Der folgende Bildschirm wird geöffnet.

Step 3 - Füllen Sie die Spalten Anmeldename, Kennwort und Kennwort bestätigen wie oben gezeigt aus und klicken Sie dann auf OK.
Die Anmeldung wird wie im folgenden Bild gezeigt erstellt.

Zweite Methode - Verwenden von T-SQL Script
Create login yourloginname with password='yourpassword'Um einen Anmeldenamen mit TestLogin und dem Kennwort 'P @ ssword' zu erstellen, führen Sie die folgende Abfrage aus.
Create login TestLogin with password='P@ssword'Die Datenbank ist eine Sammlung von Objekten wie Tabelle, Ansicht, gespeicherte Prozedur, Funktion, Trigger usw.
In MS SQL Server stehen zwei Arten von Datenbanken zur Verfügung.
- Systemdatenbanken
- Benutzerdatenbanken
Systemdatenbanken
Systemdatenbanken werden automatisch erstellt, wenn wir MS SQL Server installieren. Es folgt eine Liste der Systemdatenbanken -
- Master
- Model
- MSDB
- Tempdb
- Ressource (Eingeführt in der Version 2005)
- Verteilung (nur für die Replikationsfunktion)
Benutzerdatenbanken
Benutzerdatenbanken werden von Benutzern erstellt (Administratoren, Entwickler und Tester, die Zugriff zum Erstellen von Datenbanken haben).
Die folgenden Methoden werden zum Erstellen einer Benutzerdatenbank verwendet.
Methode 1 - Verwenden von T-SQL-Skript oder Datenbank wiederherstellen
Im Folgenden finden Sie die grundlegende Syntax zum Erstellen einer Datenbank in MS SQL Server.
Create database <yourdatabasename>ODER
Restore Database <Your database name> from disk = '<Backup file location + file name>Beispiel
Führen Sie die folgende Abfrage aus, um eine Datenbank mit dem Namen 'Testdb' zu erstellen.
Create database TestdbODER
Restore database Testdb from disk = 'D:\Backup\Testdb_full_backup.bak'Note - D: \ backup ist der Speicherort der Sicherungsdatei und Testdb_full_backup.bak ist der Name der Sicherungsdatei
Methode 2 - Verwenden von SQL Server Management Studio
Stellen Sie eine Verbindung zur SQL Server-Instanz her und klicken Sie mit der rechten Maustaste auf den Datenbankordner. Klicken Sie auf Neue Datenbank und der folgende Bildschirm wird angezeigt.

Geben Sie das Feld Datenbankname mit Ihrem Datenbanknamen ein (Beispiel: Datenbank mit dem Namen 'Testdb' erstellen) und klicken Sie auf OK. Die Testdb-Datenbank wird wie im folgenden Snapshot gezeigt erstellt.
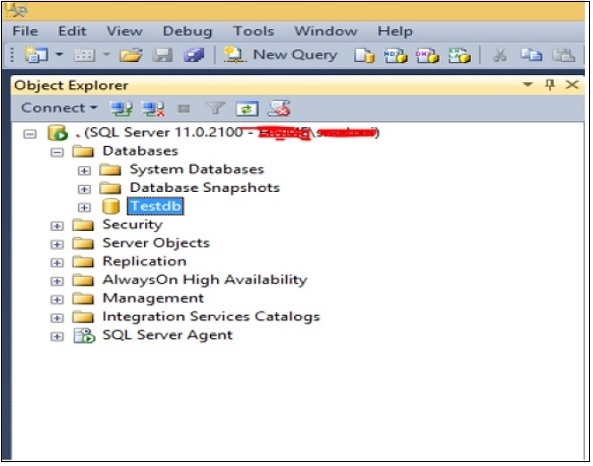
Wählen Sie Ihre Datenbank basierend auf Ihrer Aktion aus, bevor Sie mit einer der folgenden Methoden fortfahren.
Methode 1 - Verwenden von SQL Server Management Studio
Beispiel
Um eine Abfrage zur Auswahl des Sicherungsverlaufs in der Datenbank 'msdb' auszuführen, wählen Sie die msdb-Datenbank aus, wie im folgenden Snapshot gezeigt.
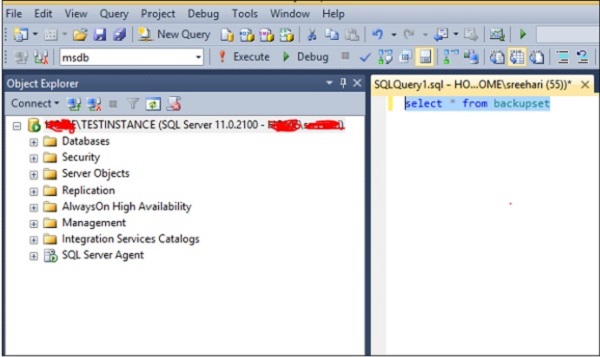
Methode 2 - Verwenden von T-SQL Script
Use <your database name>Beispiel
Um Ihre Abfrage zur Auswahl des Sicherungsverlaufs in der Datenbank 'msdb' auszuführen, wählen Sie die msdb-Datenbank aus, indem Sie die folgende Abfrage ausführen.
Exec use msdbDie Abfrage öffnet die msdb-Datenbank. Sie können die folgende Abfrage ausführen, um den Sicherungsverlauf auszuwählen.
Select * from backupsetVerwenden Sie den Befehl drop database, um Ihre Datenbank aus MS SQL Server zu entfernen. Zu diesem Zweck können die folgenden zwei Methoden verwendet werden.
Methode 1 - Verwenden von T-SQL Script
Im Folgenden finden Sie die grundlegende Syntax zum Entfernen der Datenbank aus MS SQL Server.
Drop database <your database name>Beispiel
Führen Sie die folgende Abfrage aus, um den Datenbanknamen 'Testdb' zu entfernen.
Drop database TestdbMethode 2 - Verwenden von MS SQL Server Management Studio
Stellen Sie eine Verbindung zu SQL Server her und klicken Sie mit der rechten Maustaste auf die Datenbank, die Sie entfernen möchten. Klicken Sie auf den Befehl Löschen. Der folgende Bildschirm wird angezeigt.

Klicken Sie auf OK, um die Datenbank (in diesem Beispiel lautet der Name Testdb, wie im obigen Bildschirm gezeigt) aus MS SQL Server zu entfernen.
Backupist eine Kopie von Daten / Datenbanken usw. Das Sichern der MS SQL Server-Datenbank ist für den Schutz von Daten unerlässlich. Es gibt hauptsächlich drei Arten von MS SQL Server-Sicherungen: Vollständig oder Datenbank, Differential oder Inkrementell und Transaktionsprotokoll oder -protokoll.
Die Sicherungsdatenbank kann mit einer der beiden folgenden Methoden erstellt werden.
Methode 1 - Verwenden von T-SQL
Vollständiger Typ
Backup database <Your database name> to disk = '<Backup file location + file name>'Differentialtyp
Backup database <Your database name> to
disk = '<Backup file location + file name>' with differentialProtokolltyp
Backup log <Your database name> to disk = '<Backup file location + file name>'Beispiel
Der folgende Befehl wird für die vollständige Sicherungsdatenbank 'TestDB' an den Speicherort 'D: \' mit dem Namen der Sicherungsdatei 'TestDB_Full.bak' verwendet.
Backup database TestDB to disk = 'D:\TestDB_Full.bak'Der folgende Befehl wird für die differenzielle Sicherungsdatenbank 'TestDB' an den Speicherort 'D: \' mit dem Namen der Sicherungsdatei 'TestDB_diff.bak' verwendet.
Backup database TestDB to disk = 'D:\TestDB_diff.bak' with differentialDer folgende Befehl wird für die Protokollsicherungsdatenbank 'TestDB' an den Speicherort 'D: \' mit dem Namen der Sicherungsdatei 'TestDB_log.trn' verwendet.
Backup log TestDB to disk = 'D:\TestDB_log.trn'Methode 2 - Verwenden von SSMS (SQL SERVER Management Studio)
Step 1 - Stellen Sie eine Verbindung zur Datenbankinstanz 'TESTINSTANCE' her und erweitern Sie den Datenbankordner wie im folgenden Snapshot gezeigt.

Step 2- Klicken Sie mit der rechten Maustaste auf die Datenbank 'TestDB' und wählen Sie Aufgaben aus. Klicken Sie auf Sichern. Der folgende Bildschirm wird angezeigt.

Step 3- Wählen Sie den Sicherungstyp (Full \ diff \ log) und überprüfen Sie den Zielpfad, in dem die Sicherungsdatei erstellt wird. Wählen Sie oben links Optionen aus, um den folgenden Bildschirm anzuzeigen.

Step 4 - Klicken Sie auf OK, um eine vollständige Sicherung der 'TestDB'-Datenbank zu erstellen, wie im folgenden Schnappschuss gezeigt.


Restoringist der Vorgang des Kopierens von Daten aus einer Sicherung und des Anwendens protokollierter Transaktionen auf die Daten. Wiederherstellen ist das, was Sie mit Backups machen. Nehmen Sie die Sicherungsdatei und verwandeln Sie sie wieder in eine Datenbank.
Die Option Datenbank wiederherstellen kann mit einer der beiden folgenden Methoden durchgeführt werden.
Methode 1 - T-SQL
Syntax
Restore database <Your database name> from disk = '<Backup file location + file name>'Beispiel
Der folgende Befehl wird verwendet, um die Datenbank 'TestDB' mit dem Namen der Sicherungsdatei 'TestDB_Full.bak' wiederherzustellen, die unter 'D: \' verfügbar ist, wenn Sie die vorhandene Datenbank überschreiben.
Restore database TestDB from disk = ' D:\TestDB_Full.bak' with replaceWenn Sie mit diesem Wiederherstellungsbefehl eine neue Datenbank erstellen und es keinen ähnlichen Datenpfad gibt, protokollieren Sie Dateien auf dem Zielserver und verwenden Sie die Verschiebungsoption wie den folgenden Befehl.
Stellen Sie sicher, dass der Pfad D: \ Data vorhanden ist, wie er im folgenden Befehl für Daten- und Protokolldateien verwendet wird.
RESTORE DATABASE TestDB FROM DISK = 'D:\ TestDB_Full.bak' WITH MOVE 'TestDB' TO
'D:\Data\TestDB.mdf', MOVE 'TestDB_Log' TO 'D:\Data\TestDB_Log.ldf'Methode 2 - SSMS (SQL SERVER Management Studio)
Step 1- Stellen Sie eine Verbindung zur Datenbankinstanz 'TESTINSTANCE' her und klicken Sie mit der rechten Maustaste auf den Datenbankordner. Klicken Sie auf Datenbank wiederherstellen, wie im folgenden Snapshot gezeigt.

Step 2 - Aktivieren Sie das Optionsfeld Gerät und klicken Sie auf Ellipse, um die Sicherungsdatei auszuwählen, wie im folgenden Schnappschuss gezeigt.
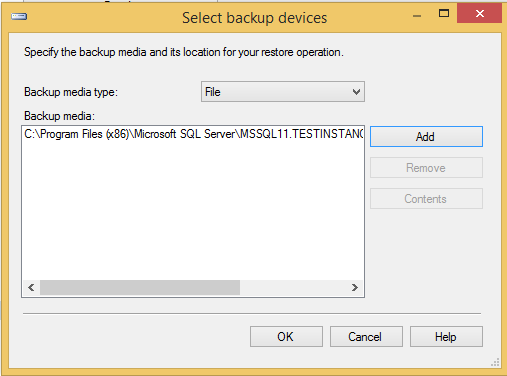
Step 3 - Klicken Sie auf OK und der folgende Bildschirm wird angezeigt.

Step 4 - Wählen Sie die Option Dateien in der oberen linken Ecke, wie im folgenden Schnappschuss gezeigt.

Step 5 - Wählen Sie Optionen in der oberen linken Ecke und klicken Sie auf OK, um die 'TestDB'-Datenbank wiederherzustellen, wie im folgenden Schnappschuss gezeigt.

Benutzer bezieht sich auf ein Konto in der MS SQL Server-Datenbank, mit dem auf die Datenbank zugegriffen wird.
Benutzer können mit einer der beiden folgenden Methoden erstellt werden.
Methode 1 - Verwenden von T-SQL
Syntax
Create user <username> for login <loginname>Beispiel
Führen Sie die folgende Abfrage aus, um den Benutzernamen 'TestUser' mit der Zuordnung zum Anmeldenamen 'TestLogin' in der TestDB-Datenbank zu erstellen.
create user TestUser for login TestLoginWobei 'TestLogin' der Anmeldename ist, der im Rahmen der Anmeldeerstellung erstellt wurde
Methode 2 - Verwenden von SSMS (SQL Server Management Studio)
Note - Zuerst müssen wir ein Login mit einem beliebigen Namen erstellen, bevor wir ein Benutzerkonto erstellen.
Verwenden wir den Anmeldenamen 'TestLogin'.
Step 1- Verbinden Sie SQL Server und erweitern Sie den Datenbankordner. Erweitern Sie dann die Datenbank 'TestDB', in der wir das Benutzerkonto erstellen und den Sicherheitsordner erweitern. Klicken Sie mit der rechten Maustaste auf Benutzer und klicken Sie auf den neuen Benutzer, um den folgenden Bildschirm anzuzeigen.

Step 2 - Geben Sie 'TestUser' in das Feld Benutzername ein und klicken Sie auf Ellipse, um den Anmeldenamen 'TestLogin' auszuwählen, wie im folgenden Schnappschuss gezeigt.

Step 3- Klicken Sie auf OK, um den Anmeldenamen anzuzeigen. Klicken Sie erneut auf OK, um den Benutzer 'TestUser' zu erstellen, wie im folgenden Snapshot gezeigt.

PermissionsWeitere Informationen finden Sie in den Regeln für die Zugriffsebenen, die Principals auf Securables haben. Sie können Berechtigungen in MS SQL Server erteilen, widerrufen und verweigern.
Zum Zuweisen von Berechtigungen kann eine der beiden folgenden Methoden verwendet werden.
Methode 1 - Verwenden von T-SQL
Syntax
Use <database name>
Grant <permission name> on <object name> to <username\principle>Beispiel
Führen Sie die folgende Abfrage aus, um einem Benutzer mit dem Namen 'TestUser' für das Objekt 'TestTable' in der Datenbank 'TestDB' eine Auswahlberechtigung zuzuweisen.
USE TestDB
GO
Grant select on TestTable to TestUserMethode 2 - Verwenden von SSMS (SQL Server Management Studio)
Step 1 - Stellen Sie eine Verbindung zur Instanz her und erweitern Sie die Ordner wie im folgenden Schnappschuss gezeigt.

Step 2- Klicken Sie mit der rechten Maustaste auf TestUser und klicken Sie auf Eigenschaften. Der folgende Bildschirm wird angezeigt.
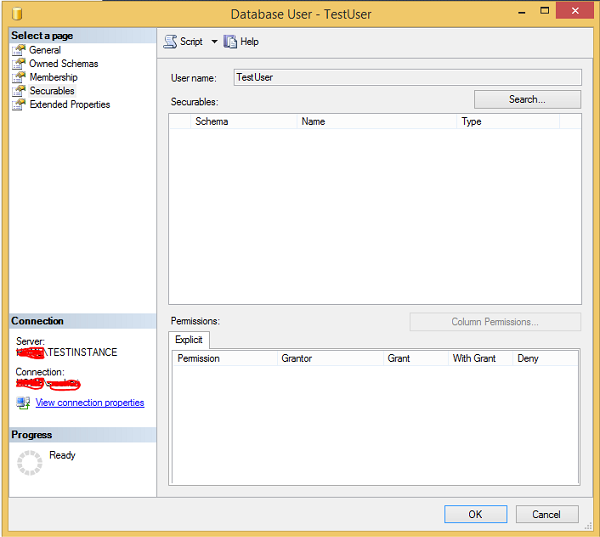
Step 3Klicken Sie auf Suchen und wählen Sie bestimmte Optionen aus. Klicken Sie auf Objekttypen, wählen Sie Tabellen aus und klicken Sie auf Durchsuchen. Wählen Sie 'TestTable' und klicken Sie auf OK. Der folgende Bildschirm wird angezeigt.

Step 4 Aktivieren Sie das Kontrollkästchen für die Spalte Gewähren unter Berechtigung auswählen und klicken Sie auf OK, wie im obigen Schnappschuss gezeigt.

Step 5Wählen Sie die Berechtigung für 'TestTable' der TestDB-Datenbank aus, die 'TestUser' erteilt wurde. OK klicken.
Die Überwachung bezieht sich auf die Überprüfung des Datenbankstatus, der Einstellungen, die der Name des Besitzers, Dateinamen, Dateigrößen, Sicherungszeitpläne usw. sein können.
SQL Server-Datenbanken können hauptsächlich über SQL Server Management Studio oder T-SQL überwacht werden. Sie können auch über verschiedene Methoden wie das Erstellen von Agentenjobs und das Konfigurieren von Datenbankmail, Tools von Drittanbietern usw. überwacht werden.
Der Datenbankstatus kann überprüft werden, ob er online oder in einem anderen Status ist, wie im folgenden Schnappschuss gezeigt.

Gemäß dem obigen Bildschirm befinden sich alle Datenbanken im Status "Online". Befindet sich eine Datenbank in einem anderen Status, wird dieser Status wie im folgenden Snapshot angezeigt.

MS SQL Server bietet die folgenden zwei Dienste, die für die Erstellung und Wartung von Datenbanken obligatorisch sind. Andere für verschiedene Zwecke verfügbare Zusatzdienste sind ebenfalls aufgeführt.
- SQL Server
- SQL Server Agent
Andere Dienstleistungen
- SQL Server Browser
- SQL Server-Volltextsuche
- SQL Server Integration Services
- SQL Server Reporting Services
- SQL Server Analysis Services
Die oben genannten Dienste können mit der folgenden Methode in Anspruch genommen werden.
Starten Sie Dienste
Zum Starten eines der Dienste kann eine der beiden folgenden Methoden verwendet werden.
Methode 1 - Services.msc
Step 1- Gehen Sie zu Ausführen, geben Sie services.msc ein und klicken Sie auf OK. Der folgende Bildschirm wird angezeigt.

Step 2- Um den Dienst zu starten, klicken Sie mit der rechten Maustaste auf Dienst und klicken Sie auf die Schaltfläche Start. Die Dienste werden wie im folgenden Schnappschuss gezeigt gestartet.

Methode 2 - SQL Server Configuration Manager
Step 1 - Öffnen Sie den Konfigurationsmanager wie folgt.
Start → Alle Programme → MS SQL Server 2012 → Konfigurationstools → SQL Server-Konfigurationsmanager.

Step 2- Wählen Sie den Dienstnamen aus, klicken Sie mit der rechten Maustaste und klicken Sie auf Startoption. Die Dienste werden wie im folgenden Schnappschuss gezeigt gestartet.

Dienste stoppen
Um einen der Dienste zu stoppen, kann eine der folgenden drei Methoden verwendet werden.
Methode 1 - Services.msc
Step 1- Gehen Sie zu Ausführen, geben Sie services.msc ein und klicken Sie auf OK. Der folgende Bildschirm wird angezeigt.

Step 2- Um Dienste zu beenden, klicken Sie mit der rechten Maustaste auf Dienst und klicken Sie auf Beenden. Der ausgewählte Dienst wird wie im folgenden Schnappschuss gezeigt gestoppt.

Methode 2 - SQL Server Configuration Manager
Step 1 - Öffnen Sie den Konfigurationsmanager wie folgt.
Start → Alle Programme → MS SQL Server 2012 → Konfigurationstools → SQL Server-Konfigurationsmanager.

Step 2- Wählen Sie den Dienstnamen aus, klicken Sie mit der rechten Maustaste und klicken Sie auf die Option Stopp. Der ausgewählte Dienst wird wie im folgenden Schnappschuss gezeigt gestoppt.

Methode 3 - SSMS (SQL Server Management Studio)
Step 1 - Stellen Sie eine Verbindung zur Instanz her, wie im folgenden Snapshot gezeigt.

Step 2- Klicken Sie mit der rechten Maustaste auf den Instanznamen und klicken Sie auf die Option Stopp. Der folgende Bildschirm wird angezeigt.

Step 3 - Klicken Sie auf die Schaltfläche Ja. Der folgende Bildschirm wird geöffnet.

Step 4- Klicken Sie im obigen Bildschirm auf die Option Ja, um den SQL Server-Agentendienst zu beenden. Die Dienste werden wie im folgenden Screenshot gezeigt gestoppt.

Hinweis
Wir können die SQL Server Management Studio-Methode nicht verwenden, um die Dienste zu starten, da aufgrund des bereits gestoppten Status der Dienste keine Verbindung hergestellt werden kann.
Wir können das Beenden des SQL Service-Agentendienstes beim Beenden des SQL Server-Dienstes nicht ausschließen, da der SQL Server-Agentendienst ein abhängiger Dienst ist.
Hochverfügbarkeit (HA) ist die Lösung \ Prozess \ Technologie, um die Anwendung \ Datenbank bei geplanten oder ungeplanten Ausfällen rund um die Uhr verfügbar zu machen.
In MS SQL Server gibt es hauptsächlich fünf Optionen, um eine Hochverfügbarkeitslösung für die Datenbanken einzurichten.
Reproduzieren
Die Quelldaten werden über Replikationsagenten (Jobs) zum Ziel kopiert. Technologie auf Objektebene.
Terminologie
- Herausgeber ist Quellserver.
- Der Verteiler ist optional und speichert replizierte Daten für den Abonnenten.
- Teilnehmer ist der Zielserver.
Protokollversand
Die Quelldaten werden über Transaktionsprotokoll-Sicherungsjobs zum Ziel kopiert. Technologie auf Datenbankebene.
Terminologie
- Primärserver ist Quellserver.
- Der sekundäre Server ist der Zielserver.
- Der Überwachungsserver ist optional und wird anhand des Protokollversandstatus überwacht.
Spiegeln
Die Primärdaten werden mithilfe der Spiegelung des Endpunkts und der Portnummer über die Netzwerktransaktion auf die Sekundärdaten kopiert. Technologie auf Datenbankebene.
Terminologie
- Der Hauptserver ist der Quellserver.
- Der Spiegelserver ist der Zielserver.
- Der Zeugenserver ist optional und wird für das automatische Failover verwendet.
Clustering
Die Daten werden an einem gemeinsam genutzten Ort gespeichert, der je nach Verfügbarkeit des Servers sowohl vom primären als auch vom sekundären Server verwendet wird. Technologie auf Instanzebene. Das Windows-Clustering-Setup ist für gemeinsam genutzten Speicher erforderlich.
Terminologie
- Auf dem aktiven Knoten werden SQL Services ausgeführt.
- Auf dem passiven Knoten werden SQL Services nicht ausgeführt.
AlwaysON-Verfügbarkeitsgruppen
Die Primärdaten werden über Netzwerktransaktionsbasis in die Sekundärdaten kopiert. Gruppe von Technologie auf Datenbankebene. Das Windows-Clustering-Setup ist ohne gemeinsam genutzten Speicher erforderlich.
Terminologie
- Das primäre Replikat ist der Quellserver.
- Das sekundäre Replikat ist der Zielserver.
Im Folgenden werden die Schritte zum Konfigurieren der HA-Technologie (Spiegelung und Protokollversand) mit Ausnahme von Clustering, AlwaysON-Verfügbarkeitsgruppen und Replikation beschrieben.
Step 1 - Erstellen Sie eine vollständige und eine T-Log-Sicherung der Quellendatenbank.
Beispiel
Um die Spiegelung \ Protokollversand für die Datenbank 'TestDB' in 'TESTINSTANCE' als primären und 'DEVINSTANCE' als sekundären SQL Server zu konfigurieren, schreiben Sie die folgende Abfrage, um vollständige und T-Log-Sicherungen auf dem Quellserver (TESTINSTANCE) durchzuführen.
Stellen Sie eine Verbindung zu 'TESTINSTANCE' SQL Server her, öffnen Sie eine neue Abfrage, schreiben Sie den folgenden Code und führen Sie ihn wie im folgenden Screenshot gezeigt aus.
Backup database TestDB to disk = 'D:\testdb_full.bak'
GO
Backup log TestDB to disk = 'D:\testdb_log.trn'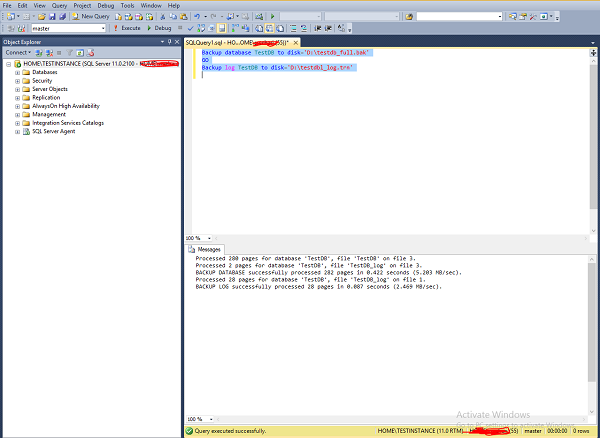
Step 2 - Kopieren Sie die Sicherungsdateien auf den Zielserver.
In diesem Fall sind nur ein physischer Server und zwei SQL Server-Instanzen installiert. Daher ist kein Kopieren erforderlich. Wenn sich jedoch zwei SQL Server-Instanzen auf einem anderen physischen Server befinden, müssen die folgenden beiden Dateien an einen beliebigen Speicherort des kopiert werden Sekundärserver, auf dem die Instanz 'DEVINSTANCE' installiert ist.

Step 3 - Stellen Sie die Datenbank mit Sicherungsdateien auf dem Zielserver mit der Option 'norecovery' wieder her.
Beispiel
Stellen Sie eine Verbindung zu 'DEVINSTANCE' SQL Server her und öffnen Sie New Query. Schreiben Sie den folgenden Code, um die Datenbank mit dem Namen 'TestDB' wiederherzustellen, der der Name der Primärdatenbank ('TestDB') für die Datenbankspiegelung entspricht. Wir können jedoch einen anderen Namen für die Protokollversandkonfiguration angeben. In diesem Fall verwenden wir den Datenbanknamen 'TestDB'. Verwenden Sie die Option 'norecovery' für zwei Wiederherstellungen (vollständige und T-Log-Sicherungsdateien).
Restore database TestDB from disk = 'D:\TestDB_full.bak'
with move 'TestDB' to 'D:\DATA\TestDB_DR.mdf',
move 'TestDB_log' to 'D:\DATA\TestDB_log_DR.ldf',
norecovery
GO
Restore database TestDB from disk = 'D:\TestDB_log.trn' with norecovery
Aktualisieren Sie den Datenbankordner auf dem Server 'DEVINSTANCE', um die wiederhergestellte Datenbank 'TestDB' mit dem Wiederherstellungsstatus anzuzeigen, wie im folgenden Snapshot gezeigt.
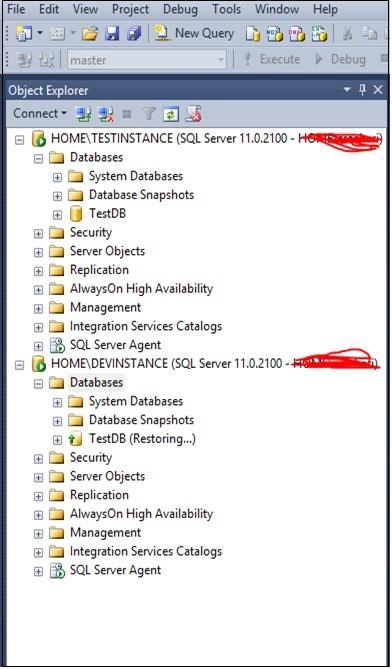
Step 4 - Konfigurieren Sie die HA (Protokollversand, Spiegelung) gemäß Ihren Anforderungen, wie im folgenden Schnappschuss gezeigt.
Beispiel
Klicken Sie mit der rechten Maustaste auf die 'TestDB'-Datenbank von' TESTINSTANCE 'SQL Server, die primär ist, und klicken Sie auf Eigenschaften. Der folgende Bildschirm wird angezeigt.

Step 5 - Wählen Sie die Option "Spiegeln" oder "Versand des Transaktionsprotokolls" aus, die je nach Anforderung im roten Farbfeld angezeigt wird (siehe Abbildung oben), und befolgen Sie die vom System selbst geleiteten Assistentenschritte, um die Konfiguration abzuschließen.
Report ist eine anzeigbare Komponente.
Verwendung
Der Bericht wird grundsätzlich für zwei Zwecke verwendet - firmeninterne Operationen und firmenexterne Operationen.
Reporting Services
Dies ist ein Dienst, mit dem verschiedene Arten von Berichten erstellt und veröffentlicht werden.
Im Folgenden sind die drei Anforderungen aufgeführt, die für die Erstellung eines Berichts erforderlich sind.
- Geschäftsprozess
- Layout
- Query\Procedure\View
Die BIDS (Business Intelligence Studio bis 2008 R2) und SSDT (SQL Server Data Tools von 2012) sind Umgebungen zum Erstellen von Berichten.
Im Folgenden finden Sie die Schritte zum Öffnen der BIDS \ SSDT-Umgebung zum Erstellen von Berichten.
Step 1- Öffnen Sie entweder BIDS \ SSDT basierend auf der Version aus der Microsoft SQL Server-Programmgruppe. Der folgende Bildschirm wird angezeigt. In diesem Fall wurde SSDT geöffnet.
Step 2- Gehen Sie zur Datei in der oberen linken Ecke des obigen Screenshots. Klicken Sie auf Neu und wählen Sie Projekt aus. Der folgende Bildschirm wird geöffnet.

Step 3 - Wählen Sie im obigen Bildschirm unter Business Intelligence in der oberen linken Ecke Berichtsdienste aus, wie im folgenden Screenshot gezeigt.

Step 4 - Wählen Sie im obigen Bildschirm entweder den Berichtsserver-Projektassistenten (der Sie Schritt für Schritt durch die Assistenten führt) oder den Berichtsserver-Projekt (der zur Auswahl benutzerdefinierter Einstellungen verwendet wird) aus, je nachdem, wie Sie den Bericht erstellen müssen.
Der Ausführungsplan wird vom Abfrageoptimierer mithilfe von Statistiken und dem Algebrizer \ Prozessorbaum erstellt. Es ist das Ergebnis des Abfrageoptimierers und zeigt an, wie Sie Ihre Arbeit ausführen.
Es gibt zwei verschiedene Ausführungspläne - Geschätzt und Ist.
Estimated execution plan zeigt die Optimierungsansicht an.
Actual execution plan Gibt an, was die Abfrage ausgeführt hat und wie sie durchgeführt wurde.
Ausführungspläne werden im Speicher gespeichert, der als Plan-Cache bezeichnet wird, und können daher wiederverwendet werden. Jeder Plan wird einmal gespeichert, es sei denn, der Optimierer entscheidet über die Parallelität für die Ausführung der Abfrage.
In SQL Server stehen drei verschiedene Formate von Ausführungsplänen zur Verfügung: Grafische Pläne, Textpläne und XML-Pläne.
SHOWPLAN ist die Berechtigung, die für den Benutzer erforderlich ist, der den Ausführungsplan anzeigen möchte.
Beispiel 1
Im Folgenden wird beschrieben, wie Sie den geschätzten Ausführungsplan anzeigen.
Step 1- Stellen Sie eine Verbindung zur SQL Server-Instanz her. In diesem Fall ist 'TESTINSTANCE' der Instanzname, wie im folgenden Snapshot gezeigt.

Step 2- Klicken Sie im obigen Bildschirm auf die Option Neue Abfrage und schreiben Sie die folgende Abfrage. Wählen Sie vor dem Schreiben der Abfrage den Datenbanknamen aus. In diesem Fall ist 'TestDB' der Datenbankname.
Select * from StudentTable
Step 3 - Klicken Sie auf das Symbol, das auf dem obigen Bildschirm im roten Farbfeld hervorgehoben ist, um den geschätzten Ausführungsplan anzuzeigen, wie im folgenden Screenshot gezeigt.

Step 4- Platzieren Sie die Maus auf dem Tabellenscan, dem zweiten Symbol über dem roten Farbfeld im obigen Bildschirm, um den geschätzten Ausführungsplan im Detail anzuzeigen. Der folgende Screenshot wird angezeigt.

Beispiel 2
Im Folgenden wird beschrieben, wie Sie den tatsächlichen Ausführungsplan anzeigen.
Step 1Stellen Sie eine Verbindung zur SQL Server-Instanz her. In diesem Fall ist 'TESTINSTANCE' der Instanzname.

Step 2- Klicken Sie auf die oben auf dem Bildschirm angezeigte Option Neue Abfrage und schreiben Sie die folgende Abfrage. Wählen Sie vor dem Schreiben der Abfrage den Datenbanknamen aus. In diesem Fall ist 'TestDB' der Datenbankname.
Select * from StudentTable
Step 3 - Klicken Sie auf das Symbol, das auf dem obigen Bildschirm im roten Farbfeld hervorgehoben ist, und führen Sie dann die Abfrage aus, um den tatsächlichen Ausführungsplan zusammen mit dem Abfrageergebnis anzuzeigen, wie im folgenden Screenshot gezeigt.

Step 4- Platzieren Sie die Maus auf dem Tabellenscan, dem zweiten Symbol über dem roten Farbfeld auf dem Bildschirm, um den tatsächlichen Ausführungsplan im Detail anzuzeigen. Der folgende Screenshot wird angezeigt.

Step 5 - Klicken Sie auf Ergebnisse in der linken oberen Ecke des obigen Bildschirms, um den folgenden Bildschirm aufzurufen.

Dieser Dienst wird zum Ausführen von ETL- (Extrahieren, Transformieren und Laden von Daten) und Verwaltungsvorgängen verwendet. BIDS (Business Intelligence Studio bis 2008 R2) und SSDT (SQL Server Data Tools von 2012) sind die Umgebungen für die Entwicklung von Paketen.
SSIS-Basisarchitektur
Lösung (Sammlung von Projekten) ---> Projekt (Sammlung von Paketen) ---> Paket (Sammlung von Aufgaben für ETL- und Administratoroperationen)
Unter Paket stehen folgende Komponenten zur Verfügung:
- Kontrollfluss (Container und Aufgaben)
- Datenfluss (Quelle, Transformationen, Ziele)
- Ereignishandler (Senden von Nachrichten, E-Mails)
- Paket-Explorer (Eine einzelne Ansicht für alle im Paket)
- Parameter (Benutzerinteraktion)
Im Folgenden finden Sie die Schritte zum Öffnen von BIDS \ SSDT.
Step 1- Öffnen Sie entweder BIDS \ SSDT basierend auf der Version aus der Microsoft SQL Server-Programmgruppe. Der folgende Bildschirm wird angezeigt.
Step 2- Der obige Bildschirm zeigt, dass SSDT geöffnet wurde. Gehen Sie zur Datei in der oberen linken Ecke des obigen Bildes und klicken Sie auf Neu. Projekt auswählen und der folgende Bildschirm wird geöffnet.

Step 3 - Wählen Sie im obigen Bildschirm unter Business Intelligence in der oberen linken Ecke Integration Services aus, um den folgenden Bildschirm aufzurufen.

Step 4 - Wählen Sie im obigen Bildschirm entweder Integration Services Project oder Integration Services Import Project Wizard aus, je nachdem, ob Sie das Paket entwickeln oder erstellen möchten.
Dieser Service wird verwendet, um große Datenmengen zu analysieren und auf Geschäftsentscheidungen anzuwenden. Es wird auch verwendet, um zwei- oder mehrdimensionale Geschäftsmodelle zu erstellen.
In der SQL Server 2000-Version heißt es MSAS (Microsoft Analysis Services).
Ab SQL Server 2005 heißt es SSAS (SQL Server Analysis Services).
Modi
Es gibt zwei Modi: den einheitlichen Modus (SQL Server-Modus) und den Share Point-Modus.
Modelle
Es gibt zwei Modelle: Tabellenmodell (für Team- und Personalanalyse) und Mehrdimensionsmodell (für Unternehmensanalyse).
Die BIDS (Business Intelligence Studio bis 2008 R2) und SSDT (SQL Server Data Tools von 2012) sind Umgebungen für die Arbeit mit SSAS.
Step 1- Öffnen Sie entweder BIDS \ SSDT basierend auf der Version aus der Microsoft SQL Server-Programmgruppe. Der folgende Bildschirm wird angezeigt.

Step 2- Der obige Bildschirm zeigt, dass SSDT geöffnet wurde. Gehen Sie zur Datei in der oberen linken Ecke des obigen Bildes und klicken Sie auf Neu. Projekt auswählen und der folgende Bildschirm wird geöffnet.

Step 3- Wählen Sie im obigen Bildschirm unter Business Intelligence die Option Analysis Services aus (siehe oben links). Der folgende Bildschirm wird angezeigt.
Step 4 - Wählen Sie im obigen Bildschirm eine der fünf Optionen aus, die auf Ihren Anforderungen für die Arbeit mit Analysis Services basieren.