OpenNLP - Kurzanleitung
NLP ist eine Reihe von Tools, mit denen aussagekräftige und nützliche Informationen aus Quellen in natürlicher Sprache wie Webseiten und Textdokumenten abgeleitet werden können.
Was ist Open NLP?
Apache OpenNLPist eine Open-Source-Java-Bibliothek, mit der Text in natürlicher Sprache verarbeitet wird. Mit dieser Bibliothek können Sie einen effizienten Textverarbeitungsdienst erstellen.
OpenNLP bietet Dienste wie Tokenisierung, Satzsegmentierung, Tag-of-Speech-Tagging, Extraktion benannter Entitäten, Chunking, Parsing und Co-Referenz-Auflösung usw. an.
Funktionen von OpenNLP
Im Folgenden sind die bemerkenswerten Funktionen von OpenNLP aufgeführt:
Named Entity Recognition (NER) - Open NLP unterstützt NER, mit dem Sie Namen von Orten, Personen und Dingen auch während der Verarbeitung von Abfragen extrahieren können.
Summarize - Verwenden der summarize Mit dieser Funktion können Sie Absätze, Artikel, Dokumente oder deren Sammlung in NLP zusammenfassen.
Searching - In OpenNLP können eine bestimmte Suchzeichenfolge oder ihre Synonyme in einem bestimmten Text identifiziert werden, obwohl das angegebene Wort geändert oder falsch geschrieben wurde.
Tagging (POS) - Das Markieren in NLP wird verwendet, um den Text zur weiteren Analyse in verschiedene grammatikalische Elemente zu unterteilen.
Translation - In NLP hilft die Übersetzung beim Übersetzen einer Sprache in eine andere.
Information grouping - Diese Option in NLP gruppiert die Textinformationen im Inhalt des Dokuments, genau wie Wortarten.
Natural Language Generation - Es wird zum Generieren von Informationen aus einer Datenbank und zum Automatisieren von Informationsberichten wie Wetteranalysen oder medizinischen Berichten verwendet.
Feedback Analysis - Wie der Name schon sagt, sammelt NLP verschiedene Arten von Rückmeldungen von Personen zu den Produkten, um zu analysieren, wie gut das Produkt erfolgreich sein Herz erobert.
Speech recognition - Obwohl es schwierig ist, die menschliche Sprache zu analysieren, verfügt NLP über einige integrierte Funktionen für diese Anforderung.
Öffnen Sie die NLP-API
Die Apache OpenNLP-Bibliothek bietet Klassen und Schnittstellen, mit denen verschiedene Aufgaben der Verarbeitung natürlicher Sprache ausgeführt werden können, z. B. Satzerkennung, Tokenisierung, Suchen eines Namens, Markieren der Wortteile, Aufteilen eines Satzes, Parsen, Auflösung von Co-Referenzen und Kategorisieren von Dokumenten.
Zusätzlich zu diesen Aufgaben können wir auch unsere eigenen Modelle für jede dieser Aufgaben trainieren und bewerten.
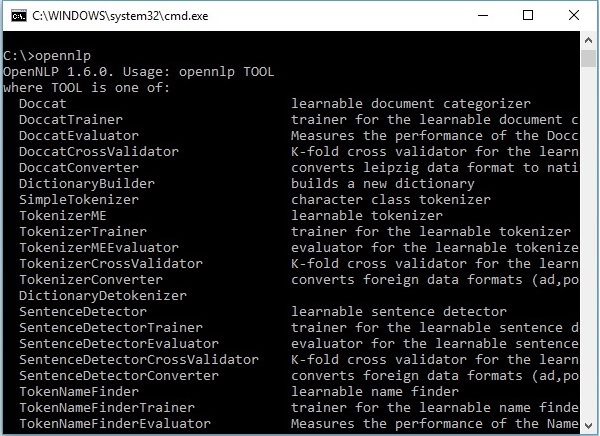
OpenNLP CLI
Neben der Bibliothek bietet OpenNLP auch eine Befehlszeilenschnittstelle (Command Line Interface, CLI), über die wir Modelle trainieren und bewerten können. Wir werden dieses Thema im letzten Kapitel dieses Tutorials ausführlich behandeln.
Öffnen Sie NLP-Modelle
Um verschiedene NLP-Aufgaben auszuführen, bietet OpenNLP eine Reihe vordefinierter Modelle. Dieses Set enthält Modelle für verschiedene Sprachen.
Modelle herunterladen
Sie können die folgenden Schritte ausführen, um die von OpenNLP bereitgestellten vordefinierten Modelle herunterzuladen.
Step 1 - Öffnen Sie die Indexseite von OpenNLP-Modellen, indem Sie auf den folgenden Link klicken - http://opennlp.sourceforge.net/models-1.5/.

Step 2- Wenn Sie den angegebenen Link besuchen, sehen Sie eine Liste der Komponenten verschiedener Sprachen und die Links zum Herunterladen. Hier erhalten Sie eine Liste aller von OpenNLP bereitgestellten vordefinierten Modelle.
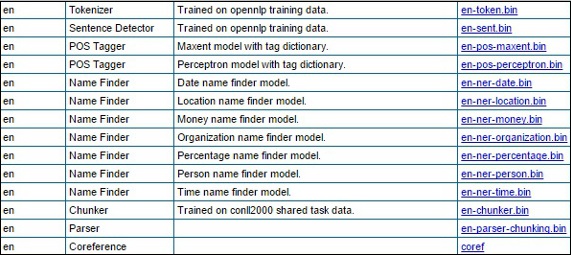
Laden Sie alle diese Modelle in den Ordner herunter C:/OpenNLP_models/>, indem Sie auf die entsprechenden Links klicken. Alle diese Modelle sind sprachabhängig. Während Sie diese verwenden, müssen Sie sicherstellen, dass die Modellsprache mit der Sprache des Eingabetextes übereinstimmt.
Geschichte von OpenNLP
Im Jahr 2010 trat OpenNLP in die Apache-Inkubation ein.
Im Jahr 2011 wurde Apache OpenNLP 1.5.2 Incubating veröffentlicht und im selben Jahr als Apache-Projekt der obersten Ebene abgeschlossen.
Im Jahr 2015 wurde OpenNLP 1.6.0 veröffentlicht.
In diesem Kapitel wird erläutert, wie Sie die OpenNLP-Umgebung in Ihrem System einrichten können. Beginnen wir mit dem Installationsprozess.
OpenNLP installieren
Im Folgenden finden Sie die Schritte zum Herunterladen Apache OpenNLP library in Ihrem System.
Step 1 - Öffnen Sie die Homepage von Apache OpenNLP durch Klicken auf den folgenden Link - https://opennlp.apache.org/.
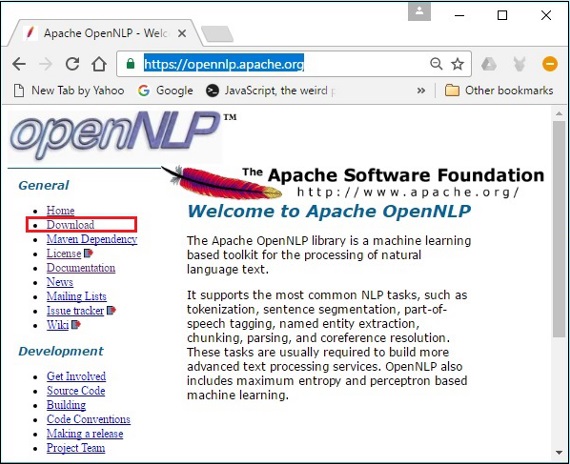
Step 2 - Klicken Sie nun auf DownloadsVerknüpfung. Wenn Sie auf klicken, werden Sie zu einer Seite weitergeleitet, auf der Sie verschiedene Spiegel finden, die Sie zum Verteilungsverzeichnis der Apache Software Foundation weiterleiten.
Step 3- Auf dieser Seite finden Sie Links zum Herunterladen verschiedener Apache-Distributionen. Durchsuchen Sie sie, suchen Sie die OpenNLP-Distribution und klicken Sie darauf.
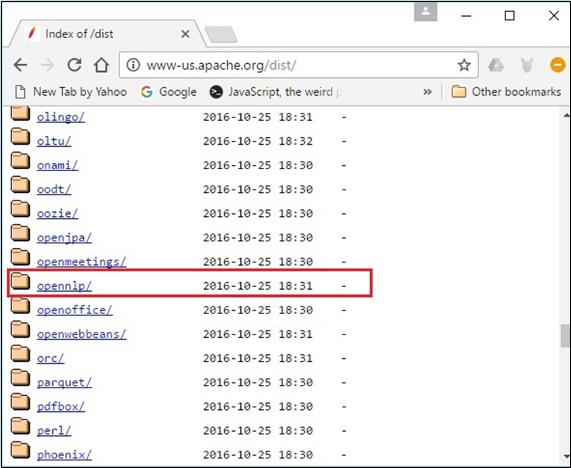
Step 4 - Wenn Sie auf klicken, werden Sie zu dem Verzeichnis weitergeleitet, in dem Sie den Index der OpenNLP-Distribution sehen können, wie unten gezeigt.
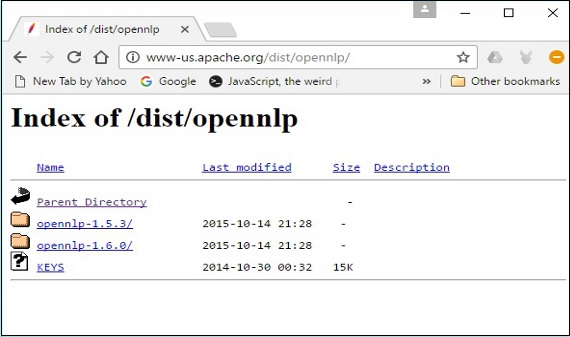
Klicken Sie auf die neueste Version der verfügbaren Distributionen.
Step 5- Jede Distribution bietet Quell- und Binärdateien der OpenNLP-Bibliothek in verschiedenen Formaten. Laden Sie die Quell- und Binärdateien herunter.apache-opennlp-1.6.0-bin.zip und apache-opennlp1.6.0-src.zip (für Windows).

Klassenpfad einstellen
Nach dem Herunterladen der OpenNLP-Bibliothek müssen Sie den Pfad zum festlegen binVerzeichnis. Angenommen, Sie haben die OpenNLP-Bibliothek auf das E-Laufwerk Ihres Systems heruntergeladen.
Befolgen Sie nun die unten angegebenen Schritte -
Step 1 - Klicken Sie mit der rechten Maustaste auf "Arbeitsplatz" und wählen Sie "Eigenschaften".
Step 2 - Klicken Sie auf der Registerkarte "Erweitert" auf die Schaltfläche "Umgebungsvariablen".
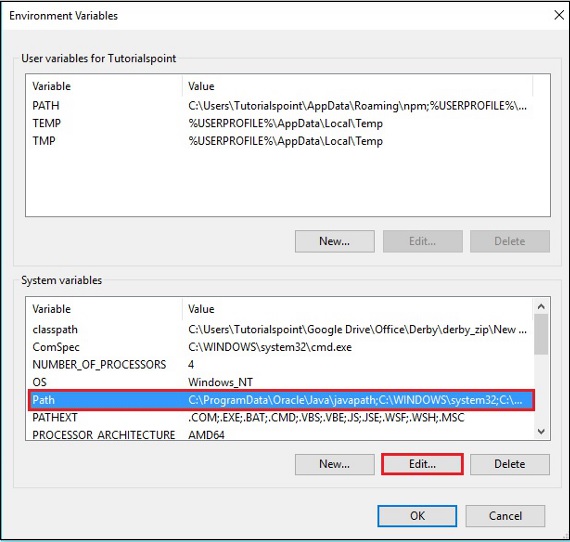
Step 3 - Wählen Sie die path Variable und klicken Sie auf die Edit Schaltfläche, wie im folgenden Screenshot gezeigt.
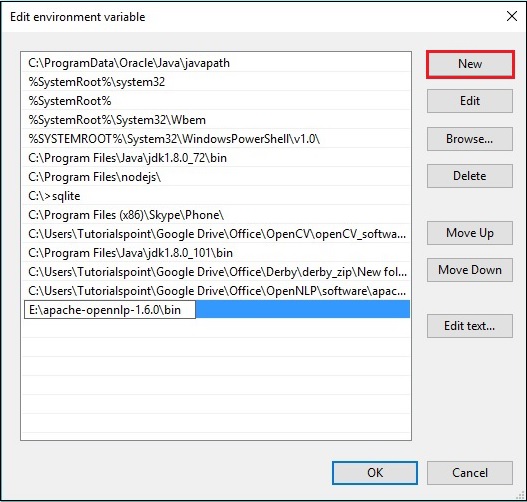
Step 4 - Klicken Sie im Fenster Umgebungsvariable bearbeiten auf New Klicken Sie auf die Schaltfläche und fügen Sie den Pfad für das OpenNLP-Verzeichnis hinzu E:\apache-opennlp-1.6.0\bin und klicken Sie auf OK Schaltfläche, wie im folgenden Screenshot gezeigt.
Eclipse-Installation
Sie können die Eclipse-Umgebung für die OpenNLP-Bibliothek festlegen, indem Sie entweder die Build path zu den JAR-Dateien oder mit pom.xml.
Festlegen des Erstellungspfads zu den JAR-Dateien
Führen Sie die folgenden Schritte aus, um OpenNLP in Eclipse zu installieren -
Step 1 - Stellen Sie sicher, dass auf Ihrem System die Eclipse-Umgebung installiert ist.
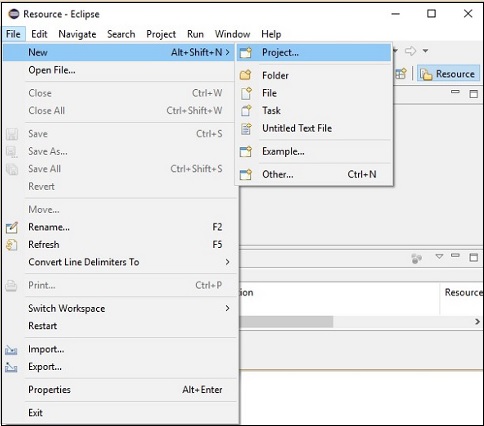
Step 2- Öffnen Sie Eclipse. Klicken Sie auf Datei → Neu → Öffnen Sie ein neues Projekt, wie unten gezeigt.
Step 3 - Du wirst das bekommen New ProjectMagier. Wählen Sie in diesem Assistenten Java-Projekt aus und klicken Sie aufNext Taste.
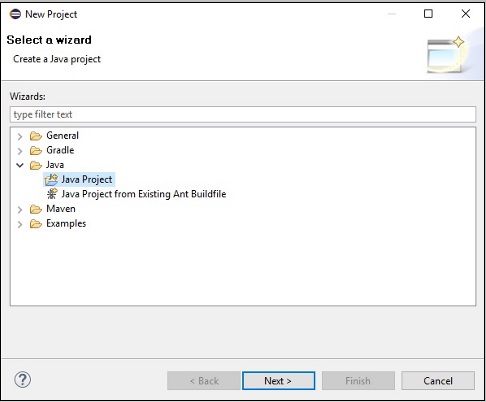
Step 4 - Als nächstes erhalten Sie die New Java Project wizard. Hier müssen Sie ein neues Projekt erstellen und auf klickenNext Schaltfläche, wie unten gezeigt.
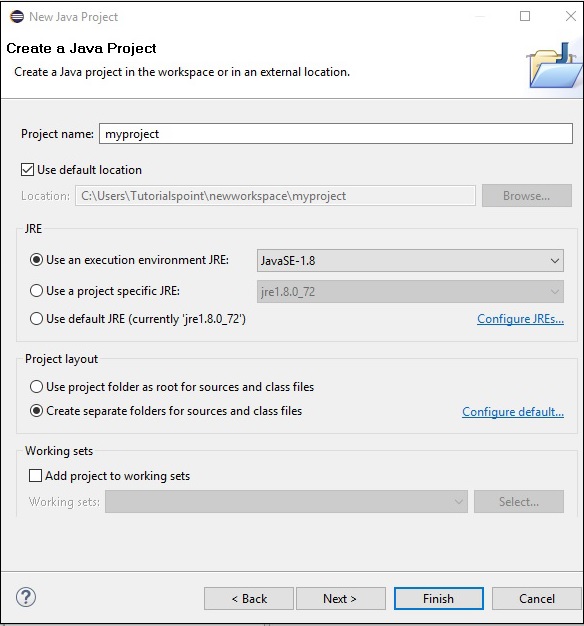
Step 5 - Nachdem Sie ein neues Projekt erstellt haben, klicken Sie mit der rechten Maustaste darauf und wählen Sie Build Path und klicken Sie auf Configure Build Path.
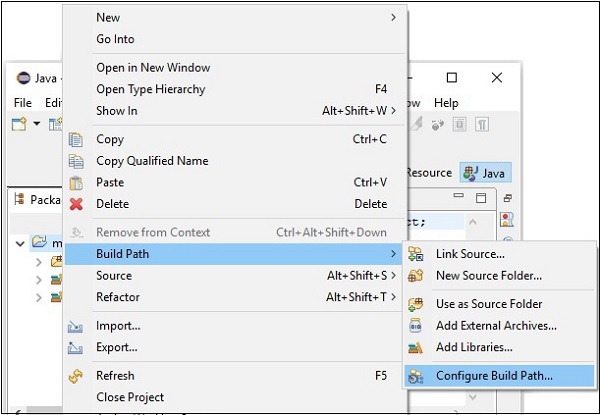
Step 6 - Als nächstes erhalten Sie die Java Build PathMagier. Klicken Sie hier aufAdd External JARs Schaltfläche, wie unten gezeigt.
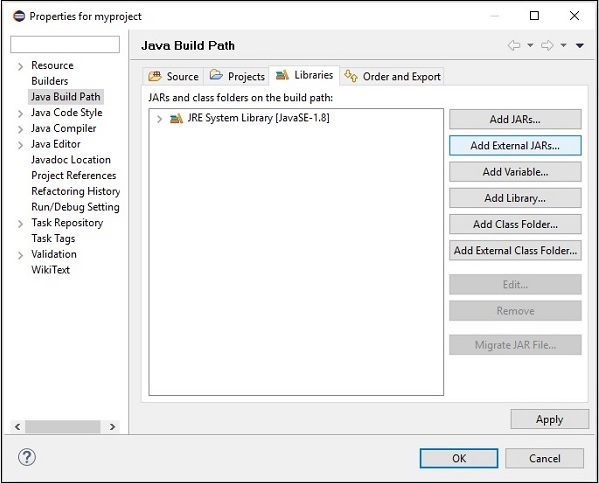
Step 7 - Wählen Sie die JAR-Dateien aus opennlp-tools-1.6.0.jar und opennlp-uima-1.6.0.jar liegt in den lib Ordner von apache-opennlp-1.6.0 folder.
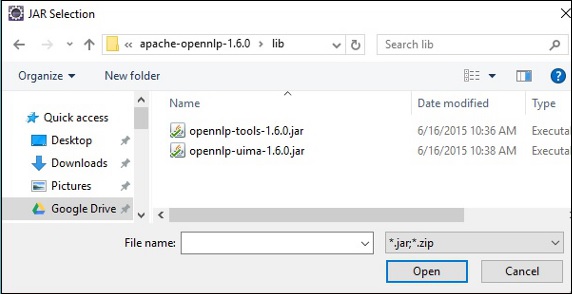
Beim Klicken auf die Open Klicken Sie im obigen Bildschirm auf die Schaltfläche. Die ausgewählten Dateien werden Ihrer Bibliothek hinzugefügt.
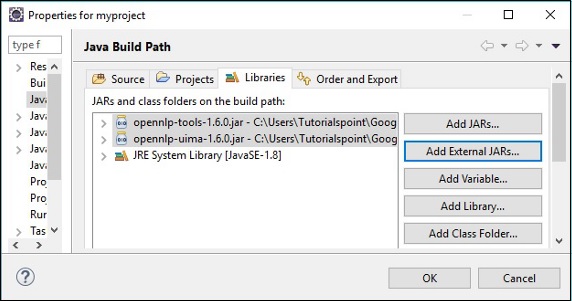
Beim Klicken OKWenn Sie die erforderlichen JAR-Dateien erfolgreich zum aktuellen Projekt hinzufügen, können Sie diese hinzugefügten Bibliotheken überprüfen, indem Sie die referenzierten Bibliotheken wie unten gezeigt erweitern.

Verwenden von pom.xml
Konvertieren Sie das Projekt in ein Maven-Projekt und fügen Sie den folgenden Code hinzu pom.xml.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>In diesem Kapitel werden wir die Klassen und Methoden diskutieren, die wir in den folgenden Kapiteln dieses Tutorials verwenden werden.
Satzerkennung
Satzmodellklasse
Diese Klasse stellt das vordefinierte Modell dar, mit dem die Sätze im angegebenen Rohtext erkannt werden. Diese Klasse gehört zum Paketopennlp.tools.sentdetect.
Der Konstruktor dieser Klasse akzeptiert eine InputStream Objekt der Satzdetektor-Modelldatei (en-sent.bin).
SatzDetectorME-Klasse
Diese Klasse gehört zum Paket opennlp.tools.sentdetectund es enthält Methoden, um den Rohtext in Sätze aufzuteilen. Diese Klasse verwendet ein Maximum-Entropie-Modell, um Zeichen am Ende des Satzes in einer Zeichenfolge auszuwerten und festzustellen, ob sie das Ende eines Satzes bedeuten.
Im Folgenden sind die wichtigen Methoden dieser Klasse aufgeführt.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | sentDetect() Diese Methode wird verwendet, um die Sätze im übergebenen Rohtext zu erkennen. Es akzeptiert eine String-Variable als Parameter und gibt ein String-Array zurück, das die Sätze aus dem angegebenen Rohtext enthält. |
| 2 | sentPosDetect() Diese Methode wird verwendet, um die Positionen der Sätze im angegebenen Text zu ermitteln. Diese Methode akzeptiert eine Zeichenfolgenvariable, die den Satz darstellt, und gibt ein Array von Objekten des Typs zurückSpan. Die benannte Klasse Span des opennlp.tools.util Paket wird verwendet, um die Start- und End-Ganzzahl von Mengen zu speichern. |
| 3 | getSentenceProbabilities() Diese Methode gibt die Wahrscheinlichkeiten zurück, die den letzten Aufrufen von zugeordnet sind sentDetect() Methode. |
Tokenisierung
TokenizerModel-Klasse
Diese Klasse stellt das vordefinierte Modell dar, mit dem der angegebene Satz tokenisiert wird. Diese Klasse gehört zum Paketopennlp.tools.tokenizer.
Der Konstruktor dieser Klasse akzeptiert a InputStream Objekt der Tokenizer-Modelldatei (entoken.bin).
Klassen
Zur Durchführung der Tokenisierung bietet die OpenNLP-Bibliothek drei Hauptklassen. Alle drei Klassen implementieren die aufgerufene SchnittstelleTokenizer.
| S.No. | Klassen und Beschreibung |
|---|---|
| 1 | SimpleTokenizer Diese Klasse markiert den angegebenen Rohtext mithilfe von Zeichenklassen. |
| 2 | WhitespaceTokenizer Diese Klasse verwendet Leerzeichen, um den angegebenen Text zu tokenisieren. |
| 3 | TokenizerME Diese Klasse konvertiert Rohtext in separate Token. Es verwendet Maximum Entropy, um seine Entscheidungen zu treffen. |
Diese Klassen enthalten die folgenden Methoden.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | tokenize() Diese Methode wird verwendet, um den Rohtext zu tokenisieren. Diese Methode akzeptiert eine String-Variable als Parameter und gibt ein Array von Strings (Token) zurück. |
| 2 | sentPosDetect() Diese Methode wird verwendet, um die Positionen oder Bereiche der Token abzurufen. Es akzeptiert den Satz (oder) den Rohtext in Form der Zeichenfolge und gibt ein Array von Objekten des Typs zurückSpan. |
Zusätzlich zu den beiden oben genannten Methoden kann die TokenizerME Klasse hat die getTokenProbabilities() Methode.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | getTokenProbabilities() Diese Methode wird verwendet, um die Wahrscheinlichkeiten abzurufen, die mit den letzten Aufrufen von verbunden sind tokenizePos() Methode. |
NameEntityRecognition
TokenNameFinderModel-Klasse
Diese Klasse stellt das vordefinierte Modell dar, mit dem die benannten Entitäten im angegebenen Satz gefunden werden. Diese Klasse gehört zum Paketopennlp.tools.namefind.
Der Konstruktor dieser Klasse akzeptiert a InputStream Objekt der Namensfinder-Modelldatei (enner-person.bin).
NameFinderME-Klasse
Die Klasse gehört zum Paket opennlp.tools.namefindund es enthält Methoden zum Ausführen der NER-Aufgaben. Diese Klasse verwendet ein maximales Entropiemodell, um die benannten Entitäten im angegebenen Rohtext zu finden.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | find() Diese Methode wird verwendet, um die Namen im Rohtext zu erkennen. Es akzeptiert eine String-Variable, die den Rohtext als Parameter darstellt, und gibt ein Array von Objekten vom Typ Span zurück. |
| 2 | probs() Diese Methode wird verwendet, um die Wahrscheinlichkeiten der zuletzt decodierten Sequenz zu erhalten. |
Die Wortarten finden
POSModel-Klasse
Diese Klasse stellt das vordefinierte Modell dar, mit dem die Wortarten des angegebenen Satzes markiert werden. Diese Klasse gehört zum Paketopennlp.tools.postag.
Der Konstruktor dieser Klasse akzeptiert a InputStream Objekt der pos-tagger-Modelldatei (enpos-maxent.bin).
POSTaggerME-Klasse
Diese Klasse gehört zum Paket opennlp.tools.postagund es wird verwendet, um die Wortarten des gegebenen Rohtextes vorherzusagen. Es verwendet Maximum Entropy, um seine Entscheidungen zu treffen.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | tag() Diese Methode wird verwendet, um den Satz von Token-POS-Tags zuzuweisen. Diese Methode akzeptiert ein Array von Token (String) als Parameter und gibt ein Tag (Array) zurück. |
| 2 | getSentenceProbabilities() Diese Methode wird verwendet, um die Wahrscheinlichkeiten für jedes Tag des kürzlich markierten Satzes abzurufen. |
Parsen des Satzes
ParserModel-Klasse
Diese Klasse stellt das vordefinierte Modell dar, mit dem der angegebene Satz analysiert wird. Diese Klasse gehört zum Paketopennlp.tools.parser.
Der Konstruktor dieser Klasse akzeptiert a InputStream Objekt der Parser-Modelldatei (en-parserchunking.bin).
Parser Factory Klasse
Diese Klasse gehört zum Paket opennlp.tools.parser und es wird verwendet, um Parser zu erstellen.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | create() Dies ist eine statische Methode, mit der ein Parserobjekt erstellt wird. Diese Methode akzeptiert das Filestream-Objekt der Parser-Modelldatei. |
ParserTool-Klasse
Diese Klasse gehört zur opennlp.tools.cmdline.parser Paket und wird verwendet, um den Inhalt zu analysieren.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | parseLine() Diese Methode der ParserToolKlasse wird verwendet, um den Rohtext in OpenNLP zu analysieren. Diese Methode akzeptiert -
|
Chunking
ChunkerModel-Klasse
Diese Klasse stellt das vordefinierte Modell dar, mit dem ein Satz in kleinere Teile unterteilt wird. Diese Klasse gehört zum Paketopennlp.tools.chunker.
Der Konstruktor dieser Klasse akzeptiert a InputStream Gegenstand der chunker Modelldatei (enchunker.bin).
ChunkerME-Klasse
Diese Klasse gehört zum genannten Paket opennlp.tools.chunker und es wird verwendet, um den gegebenen Satz in kleinere Stücke zu teilen.
| S.No. | Methoden und Beschreibung |
|---|---|
| 1 | chunk() Diese Methode wird verwendet, um den angegebenen Satz in kleinere Teile aufzuteilen. Es akzeptiert Token eines Satzes undPKunst Of SPeech-Tags als Parameter. |
| 2 | probs() Diese Methode gibt die Wahrscheinlichkeiten der zuletzt decodierten Sequenz zurück. |
Bei der Verarbeitung einer natürlichen Sprache ist die Entscheidung über Anfang und Ende der Sätze eines der zu behandelnden Probleme. Dieser Vorgang ist bekannt alsSEntenz Boundary DIsambiguierung (SBD) oder einfach Satzbruch.
Die Techniken, mit denen wir die Sätze im angegebenen Text erkennen, hängen von der Sprache des Textes ab.
Satzerkennung mit Java
Wir können die Sätze im angegebenen Text in Java mithilfe von regulären Ausdrücken und einer Reihe einfacher Regeln erkennen.
Nehmen wir zum Beispiel an, ein Punkt, ein Fragezeichen oder ein Ausrufezeichen beenden einen Satz im angegebenen Text, dann können wir den Satz mit dem split() Methode der StringKlasse. Hier müssen wir einen regulären Ausdruck im String-Format übergeben.
Das folgende Programm ermittelt die Sätze in einem bestimmten Text mithilfe von regulären Java-Ausdrücken (split method). Speichern Sie dieses Programm in einer Datei mit dem NamenSentenceDetection_RE.java.
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie mit den folgenden Befehlen an der Eingabeaufforderung aus.
javac SentenceDetection_RE.java
java SentenceDetection_REBei der Ausführung erstellt das obige Programm ein PDF-Dokument mit der folgenden Meldung.
Hi
How are you
Welcome to Tutorialspoint
We provide free tutorials on various technologiesSatzerkennung mit OpenNLP
Um Sätze zu erkennen, verwendet OpenNLP ein vordefiniertes Modell, eine Datei mit dem Namen en-sent.bin. Dieses vordefinierte Modell ist darauf trainiert, Sätze in einem bestimmten Rohtext zu erkennen.
Das opennlp.tools.sentdetect Das Paket enthält die Klassen und Schnittstellen, die zur Ausführung der Satzerkennungsaufgabe verwendet werden.
Um einen Satz mithilfe der OpenNLP-Bibliothek zu erkennen, müssen Sie -
Laden Sie die en-sent.bin Modell mit dem SentenceModel Klasse
Instanziieren Sie die SentenceDetectorME Klasse.
Erkennen Sie die Sätze mit dem sentDetect() Methode dieser Klasse.
Im Folgenden sind die Schritte aufgeführt, die zum Schreiben eines Programms ausgeführt werden müssen, das die Sätze aus dem angegebenen Rohtext erkennt.
Schritt 1: Laden des Modells
Das Modell zur Satzerkennung wird durch die genannte Klasse dargestellt SentenceModel, die zum Paket gehört opennlp.tools.sentdetect.
So laden Sie ein Satzerkennungsmodell:
Erstelle ein InputStream Objekt des Modells (Instanziieren Sie den FileInputStream und übergeben Sie den Pfad des Modells im String-Format an seinen Konstruktor).
Instanziieren Sie die SentenceModel Klasse und bestehen die InputStream (Objekt) des Modells als Parameter für seinen Konstruktor, wie im folgenden Codeblock gezeigt -
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);Schritt 2: Instanziieren der SentenceDetectorME-Klasse
Das SentenceDetectorME Klasse des Pakets opennlp.tools.sentdetectenthält Methoden zum Aufteilen des Rohtextes in Sätze. Diese Klasse verwendet das Maximum-Entropy-Modell, um Satzende-Zeichen in einer Zeichenfolge auszuwerten und festzustellen, ob sie das Ende eines Satzes bedeuten.
Instanziieren Sie diese Klasse und übergeben Sie das im vorherigen Schritt erstellte Modellobjekt, wie unten gezeigt.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);Schritt 3: Erkennen des Satzes
Das sentDetect() Methode der SentenceDetectorMEKlasse wird verwendet, um die Sätze im übergebenen Rohtext zu erkennen. Diese Methode akzeptiert eine String-Variable als Parameter.
Rufen Sie diese Methode auf, indem Sie das String-Format des Satzes an diese Methode übergeben.
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);Example
Es folgt das Programm, das die Sätze in einem bestimmten Rohtext erkennt. Speichern Sie dieses Programm in einer Datei mit dem NamenSentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac SentenceDetectorME.java
java SentenceDetectorMEBei der Ausführung liest das obige Programm den angegebenen String und erkennt die darin enthaltenen Sätze und zeigt die folgende Ausgabe an.
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesErkennen der Positionen der Sätze
Wir können die Positionen der Sätze auch mit der sentPosDetect () -Methode von ermitteln SentenceDetectorME class.
Im Folgenden sind die Schritte aufgeführt, die zum Schreiben eines Programms ausgeführt werden müssen, das die Positionen der Sätze aus dem angegebenen Rohtext erkennt.
Schritt 1: Laden des Modells
Das Modell zur Satzerkennung wird durch die genannte Klasse dargestellt SentenceModel, die zum Paket gehört opennlp.tools.sentdetect.
So laden Sie ein Satzerkennungsmodell:
Erstelle ein InputStream Objekt des Modells (Instanziieren Sie den FileInputStream und übergeben Sie den Pfad des Modells im String-Format an seinen Konstruktor).
Instanziieren Sie die SentenceModel Klasse und bestehen die InputStream (Objekt) des Modells als Parameter für seinen Konstruktor, wie im folgenden Codeblock gezeigt.
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);Schritt 2: Instanziieren der SentenceDetectorME-Klasse
Das SentenceDetectorME Klasse des Pakets opennlp.tools.sentdetectenthält Methoden zum Aufteilen des Rohtextes in Sätze. Diese Klasse verwendet das Maximum-Entropy-Modell, um Satzende-Zeichen in einer Zeichenfolge auszuwerten und festzustellen, ob sie das Ende eines Satzes bedeuten.
Instanziieren Sie diese Klasse und übergeben Sie das im vorherigen Schritt erstellte Modellobjekt.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);Schritt 3: Ermitteln der Position des Satzes
Das sentPosDetect() Methode der SentenceDetectorMEDie Klasse wird verwendet, um die Positionen der Sätze im übergebenen Rohtext zu ermitteln. Diese Methode akzeptiert eine String-Variable als Parameter.
Rufen Sie diese Methode auf, indem Sie das String-Format des Satzes als Parameter an diese Methode übergeben.
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sentence);Schritt 4: Drucken der Sätze
Das sentPosDetect() Methode der SentenceDetectorME Klasse gibt ein Array von Objekten des Typs zurück Span. Die Klasse namens Span of theopennlp.tools.util Paket wird verwendet, um die Start- und End-Ganzzahl von Mengen zu speichern.
Sie können die vom sentPosDetect() Methode im Span-Array und drucken Sie sie aus, wie im folgenden Codeblock gezeigt.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);Example
Es folgt das Programm, das die Sätze im angegebenen Rohtext erkennt. Speichern Sie dieses Programm in einer Datei mit dem NamenSentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac SentencePosDetection.java
java SentencePosDetectionBei der Ausführung liest das obige Programm den angegebenen String und erkennt die darin enthaltenen Sätze und zeigt die folgende Ausgabe an.
[0..16)
[17..43)
[44..93)Sätze zusammen mit ihren Positionen
Das substring() Methode der String-Klasse akzeptiert die begin und die end offsetsund gibt die entsprechende Zeichenfolge zurück. Mit dieser Methode können wir die Sätze und ihre Bereiche (Positionen) zusammen drucken, wie im folgenden Codeblock gezeigt.
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);Das folgende Programm erkennt die Sätze aus dem angegebenen Rohtext und zeigt sie zusammen mit ihren Positionen an. Speichern Sie dieses Programm in einer Datei mit NamenSentencesAndPosDetection.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac SentencesAndPosDetection.java
java SentencesAndPosDetectionBei der Ausführung liest das obige Programm den angegebenen String und erkennt die Sätze zusammen mit ihren Positionen und zeigt die folgende Ausgabe an.
Hi. How are you? [0..16)
Welcome to Tutorialspoint. [17..43)
We provide free tutorials on various technologies [44..93)Satzwahrscheinlichkeitserkennung
Das getSentenceProbabilities() Methode der SentenceDetectorME Klasse gibt die Wahrscheinlichkeiten zurück, die den letzten Aufrufen der sentDetect () -Methode zugeordnet sind.
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();Im Folgenden finden Sie das Programm zum Drucken der Wahrscheinlichkeiten, die mit den Aufrufen der sentDetect () -Methode verbunden sind. Speichern Sie dieses Programm in einer Datei mit dem NamenSentenceDetectionMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac SentenceDetectionMEProbs.java
java SentenceDetectionMEProbsBei der Ausführung liest das obige Programm den angegebenen String, erkennt die Sätze und druckt sie aus. Darüber hinaus werden auch die Wahrscheinlichkeiten zurückgegeben, die den letzten Aufrufen der sentDetect () -Methode zugeordnet sind (siehe unten).
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies
0.9240246995179983
0.9957680129995953
1.0Der Vorgang des Zerlegens des angegebenen Satzes in kleinere Teile (Token) ist bekannt als tokenization. Im Allgemeinen wird der angegebene Rohtext basierend auf einer Reihe von Trennzeichen (meistens Leerzeichen) tokenisiert.
Die Tokenisierung wird für Aufgaben wie Rechtschreibprüfung, Suchverarbeitung, Identifizierung von Wortarten, Satzerkennung, Dokumentklassifizierung von Dokumenten usw. verwendet.
Tokenisierung mit OpenNLP
Das opennlp.tools.tokenize Das Paket enthält die Klassen und Schnittstellen, die zur Durchführung der Tokenisierung verwendet werden.
Um die angegebenen Sätze in einfachere Fragmente zu unterteilen, bietet die OpenNLP-Bibliothek drei verschiedene Klassen:
SimpleTokenizer - Diese Klasse markiert den angegebenen Rohtext mithilfe von Zeichenklassen.
WhitespaceTokenizer - Diese Klasse verwendet Leerzeichen, um den angegebenen Text zu tokenisieren.
TokenizerME- Diese Klasse konvertiert Rohtext in separate Token. Es verwendet Maximum Entropy, um seine Entscheidungen zu treffen.
SimpleTokenizer
Um einen Satz mit dem zu tokenisieren SimpleTokenizer Klasse, müssen Sie -
Erstellen Sie ein Objekt der jeweiligen Klasse.
Tokenisieren Sie den Satz mit dem tokenize() Methode.
Drucken Sie die Token.
Im Folgenden finden Sie die Schritte zum Schreiben eines Programms, das den angegebenen Rohtext tokenisiert.
Step 1 - Instanziieren der jeweiligen Klasse
In beiden Klassen sind keine Konstruktoren verfügbar, um sie zu instanziieren. Daher müssen wir Objekte dieser Klassen mit der statischen Variablen erstellenINSTANCE.
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;Step 2 - Tokenisieren Sie die Sätze
Beide Klassen enthalten eine aufgerufene Methode tokenize(). Diese Methode akzeptiert einen Rohtext im String-Format. Beim Aufrufen wird der angegebene String mit einem Token versehen und ein Array von Strings (Token) zurückgegeben.
Tokenisieren Sie den Satz mit dem tokenizer() Methode wie unten gezeigt.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - Drucken Sie die Token
Nach dem Tokenisieren des Satzes können Sie die Token mit drucken for loop, Wie nachfolgend dargestellt.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Das folgende Programm markiert den angegebenen Satz mithilfe der SimpleTokenizer-Klasse. Speichern Sie dieses Programm in einer Datei mit dem NamenSimpleTokenizerExample.java.
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac SimpleTokenizerExample.java
java SimpleTokenizerExampleBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), markiert ihn mit einem Token und zeigt die folgende Ausgabe an:
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologiesWhitespaceTokenizer
Um einen Satz mit dem zu tokenisieren WhitespaceTokenizer Klasse, müssen Sie -
Erstellen Sie ein Objekt der jeweiligen Klasse.
Tokenisieren Sie den Satz mit dem tokenize() Methode.
Drucken Sie die Token.
Im Folgenden finden Sie die Schritte zum Schreiben eines Programms, das den angegebenen Rohtext tokenisiert.
Step 1 - Instanziieren der jeweiligen Klasse
In beiden Klassen sind keine Konstruktoren verfügbar, um sie zu instanziieren. Daher müssen wir Objekte dieser Klassen mit der statischen Variablen erstellenINSTANCE.
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;Step 2 - Tokenisieren Sie die Sätze
Beide Klassen enthalten eine aufgerufene Methode tokenize(). Diese Methode akzeptiert einen Rohtext im String-Format. Beim Aufrufen wird der angegebene String mit einem Token versehen und ein Array von Strings (Token) zurückgegeben.
Tokenisieren Sie den Satz mit dem tokenizer() Methode wie unten gezeigt.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - Drucken Sie die Token
Nach dem Tokenisieren des Satzes können Sie die Token mit drucken for loop, Wie nachfolgend dargestellt.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Es folgt das Programm, das den angegebenen Satz mit dem Token markiert WhitespaceTokenizerKlasse. Speichern Sie dieses Programm in einer Datei mit dem NamenWhitespaceTokenizerExample.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac WhitespaceTokenizerExample.java
java WhitespaceTokenizerExampleBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), markiert ihn mit einem Token und zeigt die folgende Ausgabe an.
Hi.
How
are
you?
Welcome
to
Tutorialspoint.
We
provide
free
tutorials
on
various
technologiesTokenizerME-Klasse
OpenNLP verwendet auch ein vordefiniertes Modell, eine Datei mit dem Namen de-token.bin, um die Sätze zu tokenisieren. Es wird trainiert, um die Sätze in einem bestimmten Rohtext zu tokenisieren.
Das TokenizerME Klasse der opennlp.tools.tokenizerDas Paket wird verwendet, um dieses Modell zu laden und den angegebenen Rohtext mithilfe der OpenNLP-Bibliothek zu tokenisieren. Dazu müssen Sie -
Laden Sie die en-token.bin Modell mit dem TokenizerModel Klasse.
Instanziieren Sie die TokenizerME Klasse.
Tokenisieren Sie die Sätze mit dem tokenize() Methode dieser Klasse.
Im Folgenden sind die Schritte aufgeführt, die zum Schreiben eines Programms ausgeführt werden müssen, das die Sätze aus dem angegebenen Rohtext mithilfe von tokenisiert TokenizerME Klasse.
Step 1 - Laden des Modells
Das Modell für die Tokenisierung wird durch die genannte Klasse dargestellt TokenizerModel, die zum Paket gehört opennlp.tools.tokenize.
So laden Sie ein Tokenizer-Modell:
Erstelle ein InputStream Objekt des Modells (Instanziieren Sie den FileInputStream und übergeben Sie den Pfad des Modells im String-Format an seinen Konstruktor).
Instanziieren Sie die TokenizerModel Klasse und bestehen die InputStream (Objekt) des Modells als Parameter für seinen Konstruktor, wie im folgenden Codeblock gezeigt.
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);Step 2 - Instanziieren der TokenizerME-Klasse
Das TokenizerME Klasse des Pakets opennlp.tools.tokenizeenthält Methoden, um den Rohtext in kleinere Teile (Token) zu zerlegen. Es verwendet Maximum Entropy, um seine Entscheidungen zu treffen.
Instanziieren Sie diese Klasse und übergeben Sie das im vorherigen Schritt erstellte Modellobjekt wie unten gezeigt.
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);Step 3 - Tokenisierung des Satzes
Das tokenize() Methode der TokenizerMEKlasse wird verwendet, um den an sie übergebenen Rohtext zu tokenisieren. Diese Methode akzeptiert eine String-Variable als Parameter und gibt ein Array von Strings (Token) zurück.
Rufen Sie diese Methode auf, indem Sie das String-Format des Satzes wie folgt an diese Methode übergeben.
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(paragraph);Example
Es folgt das Programm, das den angegebenen Rohtext tokenisiert. Speichern Sie dieses Programm in einer Datei mit dem NamenTokenizerMEExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac TokenizerMEExample.java
java TokenizerMEExampleBei der Ausführung liest das obige Programm den angegebenen String und erkennt die darin enthaltenen Sätze und zeigt die folgende Ausgabe an:
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologieAbrufen der Positionen der Token
Wir können auch die Positionen bekommen oder spans der Token mit dem tokenizePos()Methode. Dies ist die Methode der Tokenizer-Schnittstelle des Paketsopennlp.tools.tokenize. Da alle (drei) Tokenizer-Klassen diese Schnittstelle implementieren, finden Sie diese Methode in allen.
Diese Methode akzeptiert den Satz oder Rohtext in Form einer Zeichenfolge und gibt ein Array von Objekten des Typs zurück Span.
Sie können die Positionen der Token mit dem abrufen tokenizePos() Methode wie folgt -
//Retrieving the tokens
tokenizer.tokenizePos(sentence);Drucken der Positionen (Bereiche)
Die benannte Klasse Span des opennlp.tools.util Paket wird verwendet, um die Start- und End-Ganzzahl von Mengen zu speichern.
Sie können die vom tokenizePos() Methode im Span-Array und drucken Sie sie aus, wie im folgenden Codeblock gezeigt.
//Retrieving the tokens
Span[] tokens = tokenizer.tokenizePos(sentence);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token);Token und ihre Positionen zusammen drucken
Das substring() Methode der String-Klasse akzeptiert die begin und die endversetzt und gibt die entsprechende Zeichenfolge zurück. Mit dieser Methode können wir die Token und ihre Bereiche (Positionen) zusammen drucken, wie im folgenden Codeblock gezeigt.
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));Example(SimpleTokenizer)
Es folgt das Programm, das die Token-Bereiche des Rohtextes mit dem abruft SimpleTokenizerKlasse. Außerdem werden die Token zusammen mit ihren Positionen gedruckt. Speichern Sie dieses Programm in einer Datei mit dem NamenSimpleTokenizerSpans.java.
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac SimpleTokenizerSpans.java
java SimpleTokenizerSpansBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), markiert ihn mit einem Token und zeigt die folgende Ausgabe an:
[0..2) Hi
[2..3) .
[4..7) How
[8..11) are
[12..15) you
[15..16) ?
[17..24) Welcome
[25..27) to
[28..42) Tutorialspoint
[42..43) .
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (WhitespaceTokenizer)
Es folgt das Programm, das die Token-Bereiche des Rohtextes mit dem abruft WhitespaceTokenizerKlasse. Außerdem werden die Token zusammen mit ihren Positionen gedruckt. Speichern Sie dieses Programm in einer Datei mit dem NamenWhitespaceTokenizerSpans.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie mit den folgenden Befehlen an der Eingabeaufforderung aus
javac WhitespaceTokenizerSpans.java
java WhitespaceTokenizerSpansBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), markiert ihn mit einem Token und zeigt die folgende Ausgabe an.
[0..3) Hi.
[4..7) How
[8..11) are
[12..16) you?
[17..24) Welcome
[25..27) to
[28..43) Tutorialspoint.
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (TokenizerME)
Es folgt das Programm, das die Token-Bereiche des Rohtextes mit dem abruft TokenizerMEKlasse. Außerdem werden die Token zusammen mit ihren Positionen gedruckt. Speichern Sie dieses Programm in einer Datei mit dem NamenTokenizerMESpans.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac TokenizerMESpans.java
java TokenizerMESpansBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), markiert ihn mit einem Token und zeigt die folgende Ausgabe an:
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) TutorialspointTokenizer-Wahrscheinlichkeit
Die Methode getTokenProbabilities () der TokenizerME-Klasse wird verwendet, um die Wahrscheinlichkeiten abzurufen, die den letzten Aufrufen der tokenizePos () -Methode zugeordnet sind.
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Im Folgenden finden Sie das Programm zum Drucken der Wahrscheinlichkeiten, die mit den Aufrufen der tokenizePos () -Methode verbunden sind. Speichern Sie dieses Programm in einer Datei mit dem NamenTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac TokenizerMEProbs.java
java TokenizerMEProbsBei der Ausführung liest das obige Programm den angegebenen String, markiert die Sätze und druckt sie aus. Darüber hinaus werden auch die Wahrscheinlichkeiten zurückgegeben, die mit den letzten Aufrufen der tokenizerPos () -Methode verknüpft sind.
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0Das Finden von Namen, Personen, Orten und anderen Entitäten aus einem bestimmten Text ist bekannt als Named Entität RErkenntnis (NER). In diesem Kapitel werden wir diskutieren, wie NER über ein Java-Programm unter Verwendung der OpenNLP-Bibliothek ausgeführt wird.
Named Entity Recognition mit offenem NLP
Um verschiedene NER-Aufgaben auszuführen, verwendet OpenNLP verschiedene vordefinierte Modelle, nämlich en-nerdate.bn, en-ner-location.bin, en-ner-organisation.bin, en-ner-person.bin und en-ner-time. Behälter. Alle diese Dateien sind vordefinierte Modelle, die darauf trainiert sind, die jeweiligen Entitäten in einem bestimmten Rohtext zu erkennen.
Das opennlp.tools.namefindDas Paket enthält die Klassen und Schnittstellen, die zur Ausführung der NER-Aufgabe verwendet werden. Um eine NER-Aufgabe mit der OpenNLP-Bibliothek auszuführen, müssen Sie -
Laden Sie das entsprechende Modell mit dem TokenNameFinderModel Klasse.
Instanziieren Sie die NameFinder Klasse.
Finde die Namen und drucke sie aus.
Im Folgenden finden Sie die Schritte zum Schreiben eines Programms, das die Namensentitäten aus einem bestimmten Rohtext erkennt.
Schritt 1: Laden des Modells
Das Modell zur Satzerkennung wird durch die genannte Klasse dargestellt TokenNameFinderModel, die zum Paket gehört opennlp.tools.namefind.
So laden Sie ein NER-Modell:
Erstelle ein InputStream Objekt des Modells (Instanziieren Sie den FileInputStream und übergeben Sie den Pfad des entsprechenden NER-Modells im String-Format an seinen Konstruktor).
Instanziieren Sie die TokenNameFinderModel Klasse und bestehen die InputStream (Objekt) des Modells als Parameter für seinen Konstruktor, wie im folgenden Codeblock gezeigt.
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);Schritt 2: Instanziieren der NameFinderME-Klasse
Das NameFinderME Klasse des Pakets opennlp.tools.namefindenthält Methoden zum Ausführen der NER-Aufgaben. Diese Klasse verwendet das Maximum-Entropy-Modell, um die benannten Entitäten im angegebenen Rohtext zu finden.
Instanziieren Sie diese Klasse und übergeben Sie das im vorherigen Schritt erstellte Modellobjekt wie unten gezeigt -
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);Schritt 3: Finden der Namen im Satz
Das find() Methode der NameFinderMEKlasse wird verwendet, um die Namen in dem an sie übergebenen Rohtext zu erkennen. Diese Methode akzeptiert eine String-Variable als Parameter.
Rufen Sie diese Methode auf, indem Sie das String-Format des Satzes an diese Methode übergeben.
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);Schritt 4: Drucken der Spannweiten der Namen im Satz
Das find() Methode der NameFinderMEKlasse gibt ein Array von Objekten vom Typ Span zurück. Die Klasse namens Span of theopennlp.tools.util Paket wird verwendet, um die zu speichern start und end Ganzzahl von Mengen.
Sie können die vom find() Methode im Span-Array und drucken Sie sie aus, wie im folgenden Codeblock gezeigt.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);NER Example
Es folgt das Programm, das den angegebenen Satz liest und die Spannweiten der Namen der darin enthaltenen Personen erkennt. Speichern Sie dieses Programm in einer Datei mit dem NamenNameFinderME_Example.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac NameFinderME_Example.java
java NameFinderME_ExampleBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), erkennt die Namen der Personen darin und zeigt ihre Positionen (Bereiche) an, wie unten gezeigt.
[0..1) person
[2..3) personNamen zusammen mit ihren Positionen
Das substring() Methode der String-Klasse akzeptiert die begin und die end offsetsund gibt die entsprechende Zeichenfolge zurück. Mit dieser Methode können wir die Namen und ihre Bereiche (Positionen) zusammen drucken, wie im folgenden Codeblock gezeigt.
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);Das folgende Programm erkennt die Namen aus dem angegebenen Rohtext und zeigt sie zusammen mit ihren Positionen an. Speichern Sie dieses Programm in einer Datei mit dem NamenNameFinderSentences.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac NameFinderSentences.java
java NameFinderSentencesBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), erkennt die Namen der Personen darin und zeigt ihre Positionen (Bereiche) wie unten gezeigt an.
[0..1) person MikeSuchen der Namen des Standorts
Durch Laden verschiedener Modelle können Sie verschiedene benannte Entitäten erkennen. Es folgt ein Java-Programm, das das lädten-ner-location.binmodelliert und erkennt die Ortsnamen im angegebenen Satz. Speichern Sie dieses Programm in einer Datei mit dem NamenLocationFinder.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac LocationFinder.java
java LocationFinderBei der Ausführung liest das obige Programm den angegebenen String (Rohtext), erkennt die Namen der Personen darin und zeigt ihre Positionen (Bereiche) an, wie unten gezeigt.
[4..5) location HyderabadNameFinder Wahrscheinlichkeit
Das probs()Methode der NameFinderME Klasse wird verwendet, um die Wahrscheinlichkeiten der zuletzt decodierten Sequenz zu erhalten.
double[] probs = nameFinder.probs();Es folgt das Programm zum Drucken der Wahrscheinlichkeiten. Speichern Sie dieses Programm in einer Datei mit dem NamenTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac TokenizerMEProbs.java
java TokenizerMEProbsBei der Ausführung liest das obige Programm den angegebenen String, markiert die Sätze und druckt sie aus. Außerdem werden die Wahrscheinlichkeiten der zuletzt decodierten Sequenz zurückgegeben, wie unten gezeigt.
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0Mit OpenNLP können Sie auch die Wortarten eines bestimmten Satzes erkennen und ausdrucken. Anstelle des vollständigen Namens der Wortteile verwendet OpenNLP Kurzformen der einzelnen Wortarten. Die folgende Tabelle zeigt die verschiedenen Teile von Reden, die von OpenNLP erkannt wurden, und ihre Bedeutung.
| Teile der Rede | Bedeutung von Wortarten |
|---|---|
| NN | Substantiv, Singular oder Masse |
| DT | Bestimmer |
| VB | Verb, Grundform |
| VBD | Verb, Vergangenheitsform |
| VBZ | Verb, dritte Person Singular anwesend |
| IM | Präposition oder untergeordnete Konjunktion |
| NNP | Eigenname, Singular |
| ZU | zu |
| JJ | Adjektiv |
Markieren der Wortarten
Um die Wortarten eines Satzes zu kennzeichnen, verwendet OpenNLP ein Modell, eine Datei mit dem Namen en-posmaxent.bin. Dies ist ein vordefiniertes Modell, das darauf trainiert ist, die Wortarten des angegebenen Rohtextes zu kennzeichnen.
Das POSTaggerME Klasse der opennlp.tools.postagDas Paket wird verwendet, um dieses Modell zu laden und die Wortarten des angegebenen Rohtextes mithilfe der OpenNLP-Bibliothek zu markieren. Dazu müssen Sie -
Laden Sie die en-pos-maxent.bin Modell mit dem POSModel Klasse.
Instanziieren Sie die POSTaggerME Klasse.
Tokenisieren Sie den Satz.
Generieren Sie die Tags mit tag() Methode.
Drucken Sie die Token und Tags mit POSSample Klasse.
Im Folgenden sind die Schritte aufgeführt, die zum Schreiben eines Programms ausgeführt werden müssen, das die Teile der Sprache im angegebenen Rohtext mit dem Tag markiert POSTaggerME Klasse.
Schritt 1: Laden Sie das Modell
Das Modell für die POS-Kennzeichnung wird durch die genannte Klasse dargestellt POSModel, die zum Paket gehört opennlp.tools.postag.
So laden Sie ein Tokenizer-Modell:
Erstelle ein InputStream Objekt des Modells (Instanziieren Sie den FileInputStream und übergeben Sie den Pfad des Modells im String-Format an seinen Konstruktor).
Instanziieren Sie die POSModel Klasse und bestehen die InputStream (Objekt) des Modells als Parameter für seinen Konstruktor, wie im folgenden Codeblock gezeigt -
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);Schritt 2: Instanziieren der POSTaggerME-Klasse
Das POSTaggerME Klasse des Pakets opennlp.tools.postagwird verwendet, um die Wortarten des gegebenen Rohtextes vorherzusagen. Es verwendet Maximum Entropy, um seine Entscheidungen zu treffen.
Instanziieren Sie diese Klasse und übergeben Sie das im vorherigen Schritt erstellte Modellobjekt wie unten gezeigt -
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);Schritt 3: Tokenisieren des Satzes
Das tokenize() Methode der whitespaceTokenizerKlasse wird verwendet, um den an sie übergebenen Rohtext zu tokenisieren. Diese Methode akzeptiert eine String-Variable als Parameter und gibt ein Array von Strings (Token) zurück.
Instanziieren Sie die whitespaceTokenizer Klasse und rufen Sie diese Methode auf, indem Sie das String-Format des Satzes an diese Methode übergeben.
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);Schritt 4: Generieren der Tags
Das tag() Methode der whitespaceTokenizerKlasse weist dem Satz von Token POS-Tags zu. Diese Methode akzeptiert ein Array von Token (String) als Parameter und gibt ein Tag (Array) zurück.
Rufen Sie die tag() Methode, indem die im vorherigen Schritt generierten Token an sie übergeben werden.
//Generating tags
String[] tags = tagger.tag(tokens);Schritt 5: Drucken der Token und Tags
Das POSSampleKlasse repräsentiert den POS-markierten Satz. Um diese Klasse zu instanziieren, benötigen wir ein Array von Token (des Textes) und ein Array von Tags.
Das toString()Die Methode dieser Klasse gibt den markierten Satz zurück. Instanziieren Sie diese Klasse, indem Sie das Token und die in den vorherigen Schritten erstellten Tag-Arrays übergeben und ihre aufrufentoString() Methode, wie im folgenden Codeblock gezeigt.
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());Example
Es folgt das Programm, das die Wortarten in einem bestimmten Rohtext markiert. Speichern Sie dieses Programm in einer Datei mit dem NamenPosTaggerExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac PosTaggerExample.java
java PosTaggerExampleBei der Ausführung liest das obige Programm den angegebenen Text und erkennt die Wortarten dieser Sätze und zeigt sie an, wie unten gezeigt.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VBPOS-Tagger-Leistung
Es folgt das Programm, das die Wortarten eines bestimmten Rohtextes markiert. Es überwacht auch die Leistung und zeigt die Leistung des Taggers an. Speichern Sie dieses Programm in einer Datei mit dem NamenPosTagger_Performance.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac PosTaggerExample.java
java PosTaggerExampleBei der Ausführung liest das obige Programm den angegebenen Text und markiert die Wortarten dieser Sätze und zeigt sie an. Darüber hinaus wird die Leistung des POS-Taggers überwacht und angezeigt.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
Average: 0.0 sent/s
Total: 1 sent
Runtime: 0.0sPOS-Tagger-Wahrscheinlichkeit
Das probs() Methode der POSTaggerME Klasse wird verwendet, um die Wahrscheinlichkeiten für jedes Tag des kürzlich markierten Satzes zu finden.
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Das folgende Programm zeigt die Wahrscheinlichkeiten für jedes Tag des letzten markierten Satzes an. Speichern Sie dieses Programm in einer Datei mit dem NamenPosTaggerProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac TokenizerMEProbs.java
java TokenizerMEProbsBei der Ausführung liest das obige Programm den angegebenen Rohtext, markiert die Wortarten jedes darin enthaltenen Tokens und zeigt sie an. Darüber hinaus werden die Wahrscheinlichkeiten für jeden Wortteil im angegebenen Satz angezeigt, wie unten gezeigt.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
0.6416834779738033
0.42983612874819177
0.8584513635863117
0.4394784478206072Mit der OpenNLP-API können Sie die angegebenen Sätze analysieren. In diesem Kapitel wird erläutert, wie Rohtext mithilfe der OpenNLP-API analysiert wird.
Analysieren von Rohtext mithilfe der OpenNLP-Bibliothek
Um die Sätze zu erkennen, verwendet OpenNLP ein vordefiniertes Modell, eine Datei mit dem Namen en-parserchunking.bin. Dies ist ein vordefiniertes Modell, das darauf trainiert ist, den angegebenen Rohtext zu analysieren.
Das Parser Klasse der opennlp.tools.Parser Paket wird verwendet, um die Analysebestandteile und die zu enthalten ParserTool Klasse der opennlp.tools.cmdline.parser Paket wird verwendet, um den Inhalt zu analysieren.
Im Folgenden finden Sie die Schritte zum Schreiben eines Programms, das den angegebenen Rohtext mithilfe von analysiert ParserTool Klasse.
Schritt 1: Laden des Modells
Das Modell zum Parsen von Text wird durch die genannte Klasse dargestellt ParserModel, die zum Paket gehört opennlp.tools.parser.
So laden Sie ein Tokenizer-Modell:
Erstelle ein InputStream Objekt des Modells (Instanziieren Sie den FileInputStream und übergeben Sie den Pfad des Modells im String-Format an seinen Konstruktor).
Instanziieren Sie die ParserModel Klasse und bestehen die InputStream (Objekt) des Modells als Parameter für seinen Konstruktor, wie im folgenden Codeblock gezeigt.
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);Schritt 2: Erstellen eines Objekts der Parser-Klasse
Das Parser Klasse des Pakets opennlp.tools.parserstellt eine Datenstruktur zum Halten von Analysebestandteilen dar. Sie können ein Objekt dieser Klasse mit der Statik erstellencreate() Methode der ParserFactory Klasse.
Rufen Sie die create() Methode der ParserFactory indem Sie das im vorherigen Schritt erstellte Modellobjekt übergeben, wie unten gezeigt -
//Creating a parser Parser parser = ParserFactory.create(model);Schritt 3: Analysieren des Satzes
Das parseLine() Methode der ParserToolKlasse wird verwendet, um den Rohtext in OpenNLP zu analysieren. Diese Methode akzeptiert -
Eine String-Variable, die den zu analysierenden Text darstellt.
ein Parser-Objekt.
eine Ganzzahl, die die Anzahl der auszuführenden Parses darstellt.
Rufen Sie diese Methode auf, indem Sie dem Satz die folgenden Parameter übergeben: das in den vorherigen Schritten erstellte Analyseobjekt und eine Ganzzahl, die die erforderliche Anzahl der auszuführenden Analysen darstellt.
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);Example
Es folgt das Programm, das den angegebenen Rohtext analysiert. Speichern Sie dieses Programm in einer Datei mit dem NamenParserExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac ParserExample.java
java ParserExampleBei der Ausführung liest das obige Programm den angegebenen Rohtext, analysiert ihn und zeigt die folgende Ausgabe an:
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN
tutorial) (NN library.)))))Das Aufteilen eines Satzes bezieht sich auf das Brechen / Teilen eines Satzes in Wortteile wie Wortgruppen und Verbgruppen.
Chunking eines Satzes mit OpenNLP
Um die Sätze zu erkennen, verwendet OpenNLP ein Modell, eine Datei mit dem Namen en-chunker.bin. Dies ist ein vordefiniertes Modell, das darauf trainiert ist, die Sätze im angegebenen Rohtext zu zerlegen.
Das opennlp.tools.chunker Das Paket enthält die Klassen und Schnittstellen, die zum Auffinden nicht rekursiver syntaktischer Annotationen wie Substantivphrasenblöcken verwendet werden.
Mit der Methode können Sie einen Satz aufteilen chunk() des ChunkerMEKlasse. Diese Methode akzeptiert Token eines Satzes und POS-Tags als Parameter. Bevor Sie mit dem Chunking beginnen, müssen Sie daher zunächst den Satz tokenisieren und die Teile-POS-Tags daraus generieren.
Um einen Satz mit der OpenNLP-Bibliothek zu zerlegen, müssen Sie -
Tokenisieren Sie den Satz.
Generieren Sie dafür POS-Tags.
Laden Sie die en-chunker.bin Modell mit dem ChunkerModel Klasse
Instanziieren Sie die ChunkerME Klasse.
Chunk die Sätze mit dem chunk() Methode dieser Klasse.
Im Folgenden sind die Schritte aufgeführt, die ausgeführt werden müssen, um ein Programm zu schreiben, das Sätze aus dem angegebenen Rohtext aufteilt.
Schritt 1: Tokenisieren des Satzes
Tokenisieren Sie die Sätze mit dem tokenize() Methode der whitespaceTokenizer Klasse, wie im folgenden Codeblock gezeigt.
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);Schritt 2: Generieren der POS-Tags
Generieren Sie die POS-Tags des Satzes mit dem tag() Methode der POSTaggerME Klasse, wie im folgenden Codeblock gezeigt.
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);Schritt 3: Laden des Modells
Das Modell zum Aufteilen eines Satzes wird durch die genannte Klasse dargestellt ChunkerModel, die zum Paket gehört opennlp.tools.chunker.
So laden Sie ein Satzerkennungsmodell:
Erstelle ein InputStream Objekt des Modells (Instanziieren Sie den FileInputStream und übergeben Sie den Pfad des Modells im String-Format an seinen Konstruktor).
Instanziieren Sie die ChunkerModel Klasse und bestehen die InputStream (Objekt) des Modells als Parameter für seinen Konstruktor, wie im folgenden Codeblock gezeigt -
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);Schritt 4: Instanziieren der chunkerME-Klasse
Das chunkerME Klasse des Pakets opennlp.tools.chunkerenthält Methoden zum Aufteilen der Sätze. Dies ist ein Chunker auf der Basis maximaler Entropie.
Instanziieren Sie diese Klasse und übergeben Sie das im vorherigen Schritt erstellte Modellobjekt.
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);Schritt 5: Den Satz aufteilen
Das chunk() Methode der ChunkerMEKlasse wird verwendet, um die Sätze in dem an sie übergebenen Rohtext zu zerlegen. Diese Methode akzeptiert zwei String-Arrays, die Token und Tags darstellen, als Parameter.
Rufen Sie diese Methode auf, indem Sie das in den vorherigen Schritten erstellte Token-Array und Tag-Array als Parameter übergeben.
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);Example
Es folgt das Programm zum Aufteilen der Sätze in den angegebenen Rohtext. Speichern Sie dieses Programm in einer Datei mit dem NamenChunkerExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit dem folgenden Befehl aus:
javac ChunkerExample.java
java ChunkerExampleBei der Ausführung liest das obige Programm den angegebenen String, zerlegt die darin enthaltenen Sätze und zeigt sie wie unten gezeigt an.
Loading POS Tagger model ... done (1.040s)
B-NP
I-NP
B-VP
I-VPErkennen der Positionen der Token
Wir können auch die Positionen oder Spannweiten der Chunks mithilfe von erkennen chunkAsSpans() Methode der ChunkerMEKlasse. Diese Methode gibt ein Array von Objekten vom Typ Span zurück. Die Klasse namens Span of theopennlp.tools.util Paket wird verwendet, um die zu speichern start und end Ganzzahl von Mengen.
Sie können die vom chunkAsSpans() Methode im Span-Array und drucken Sie sie aus, wie im folgenden Codeblock gezeigt.
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());Example
Es folgt das Programm, das die Sätze im angegebenen Rohtext erkennt. Speichern Sie dieses Programm in einer Datei mit dem NamenChunkerSpansEample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac ChunkerSpansEample.java
java ChunkerSpansEampleBei der Ausführung liest das obige Programm den angegebenen String und die angegebenen Bereiche der darin enthaltenen Chunks und zeigt die folgende Ausgabe an:
Loading POS Tagger model ... done (1.059s)
[0..2) NP
[2..4) VPChunker-Wahrscheinlichkeitserkennung
Das probs() Methode der ChunkerME Klasse gibt die Wahrscheinlichkeiten der zuletzt dekodierten Sequenz zurück.
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();Es folgt das Programm zum Drucken der Wahrscheinlichkeiten der zuletzt decodierten Sequenz durch die chunker. Speichern Sie dieses Programm in einer Datei mit dem NamenChunkerProbsExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kompilieren Sie die gespeicherte Java-Datei und führen Sie sie an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac ChunkerProbsExample.java
java ChunkerProbsExampleBei der Ausführung liest das obige Programm den angegebenen String, zerlegt ihn und gibt die Wahrscheinlichkeiten der zuletzt decodierten Sequenz aus.
0.9592746040797778
0.6883933131241501
0.8830563473996004
0.8951150529746051OpenNLP bietet eine Befehlszeilenschnittstelle (Command Line Interface, CLI), mit der verschiedene Vorgänge über die Befehlszeile ausgeführt werden können. In diesem Kapitel zeigen wir anhand einiger Beispiele, wie wir die OpenNLP-Befehlszeilenschnittstelle verwenden können.
Tokenisierung
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSyntax
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..Befehl
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txtAusgabe
Loading Tokenizer model ... done (0.207s)
Average: 214.3 sent/s
Total: 3 sent
Runtime: 0.014soutput.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologiesSatzerkennung
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSyntax
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..Befehl
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txtAusgabe
Loading Sentence Detector model ... done (0.067s)
Average: 750.0 sent/s
Total: 3 sent
Runtime: 0.004sOutput_sendet.txt
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesNamed Entity Recognition
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at TutorialspointSyntax
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..Befehl
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txtAusgabe
Loading Token Name Finder model ... done (0.730s)
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspoint
Average: 55.6 sent/s
Total: 1 sent
Runtime: 0.018sTeile der Sprachkennzeichnung
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSyntax
> opennlp POSTagger path_for_models../en-token.bin <inputfile..Befehl
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txtAusgabe
Loading POS Tagger model ... done (1.315s)
Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP
provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS
Average: 66.7 sent/s
Total: 1 sent
Runtime: 0.015s