Betriebssystem - Kurzanleitung
Ein Betriebssystem (OS) ist eine Schnittstelle zwischen einem Computerbenutzer und Computerhardware. Ein Betriebssystem ist eine Software, die alle grundlegenden Aufgaben wie Dateiverwaltung, Speicherverwaltung, Prozessverwaltung, Verarbeitung von Ein- und Ausgaben sowie Steuerung von Peripheriegeräten wie Festplatten und Druckern ausführt.
Einige beliebte Betriebssysteme umfassen Linux-Betriebssysteme, Windows-Betriebssysteme, VMS, OS / 400, AIX, z / OS usw.
Definition
Ein Betriebssystem ist ein Programm, das als Schnittstelle zwischen dem Benutzer und der Computerhardware fungiert und die Ausführung aller Arten von Programmen steuert.
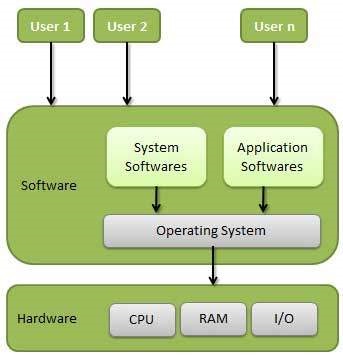
Im Folgenden sind einige wichtige Funktionen eines Betriebssystems aufgeführt.
- Speicherverwaltung
- Prozessorverwaltung
- Geräteverwaltung
- Dokumentenverwaltung
- Security
- Kontrolle über die Systemleistung
- Jobbuchhaltung
- Fehlererkennungshilfen
- Koordination zwischen anderer Software und Benutzern
Speicherverwaltung
Speicherverwaltung bezieht sich auf die Verwaltung des Primärspeichers oder des Hauptspeichers. Der Hauptspeicher besteht aus einer großen Anzahl von Wörtern oder Bytes, wobei jedes Wort oder Byte eine eigene Adresse hat.
Der Hauptspeicher bietet einen schnellen Speicher, auf den die CPU direkt zugreifen kann. Damit ein Programm ausgeführt werden kann, muss es sich im Hauptspeicher befinden. Ein Betriebssystem führt die folgenden Aktivitäten zur Speicherverwaltung aus:
Verfolgt den primären Speicher, dh welcher Teil davon wird von wem verwendet, welcher Teil wird nicht verwendet.
Bei der Multiprogrammierung entscheidet das Betriebssystem, welcher Prozess wann und wie viel Speicher erhält.
Weist den Speicher zu, wenn ein Prozess dies anfordert.
Hebt die Zuordnung des Speichers auf, wenn ein Prozess ihn nicht mehr benötigt oder beendet wurde.
Prozessorverwaltung
In einer Multiprogramming-Umgebung entscheidet das Betriebssystem, welcher Prozess den Prozessor wann und für wie viel Zeit erhält. Diese Funktion wird aufgerufenprocess scheduling. Ein Betriebssystem führt die folgenden Aktivitäten für die Prozessorverwaltung aus:
Verfolgt den Prozessor und den Status des Prozesses. Das für diese Aufgabe verantwortliche Programm ist bekannt alstraffic controller.
Ordnet den Prozessor (CPU) einem Prozess zu.
Hebt die Zuordnung des Prozessors auf, wenn ein Prozess nicht mehr benötigt wird.
Geräteverwaltung
Ein Betriebssystem verwaltet die Gerätekommunikation über die jeweiligen Treiber. Es führt die folgenden Aktivitäten für die Geräteverwaltung aus:
Verfolgt alle Geräte. Das für diese Aufgabe verantwortliche Programm wird als bezeichnetI/O controller.
Legt fest, welcher Prozess das Gerät wann und für wie viel Zeit erhält.
Ordnet das Gerät effizient zu.
Hebt die Zuordnung von Geräten auf.
Dokumentenverwaltung
Ein Dateisystem ist normalerweise in Verzeichnissen organisiert, um die Navigation und Verwendung zu vereinfachen. Diese Verzeichnisse können Dateien und andere Anweisungen enthalten.
Ein Betriebssystem führt die folgenden Aktivitäten für die Dateiverwaltung aus:
Verfolgt Informationen, Standort, Nutzung, Status usw. Die kollektiven Einrichtungen werden häufig als bezeichnet file system.
Entscheidet, wer die Ressourcen erhält.
Weist die Ressourcen zu.
Hebt die Zuordnung der Ressourcen auf.
Andere wichtige Aktivitäten
Im Folgenden sind einige wichtige Aktivitäten aufgeführt, die ein Betriebssystem ausführt:
Security - Durch Passwort und ähnliche andere Techniken wird der unbefugte Zugriff auf Programme und Daten verhindert.
Control over system performance - Aufzeichnen von Verzögerungen zwischen der Anforderung eines Dienstes und der Antwort vom System.
Job accounting - Verfolgen Sie die Zeit und Ressourcen, die von verschiedenen Jobs und Benutzern verwendet werden.
Error detecting aids - Erstellung von Dumps, Traces, Fehlermeldungen und anderen Debugging- und Fehlererkennungshilfen.
Coordination between other softwares and users - Koordination und Zuordnung von Compilern, Dolmetschern, Assemblern und anderer Software zu den verschiedenen Benutzern der Computersysteme.
Betriebssysteme gibt es von der ersten Computergeneration an und sie entwickeln sich mit der Zeit weiter. In diesem Kapitel werden einige der wichtigsten Arten von Betriebssystemen erläutert, die am häufigsten verwendet werden.
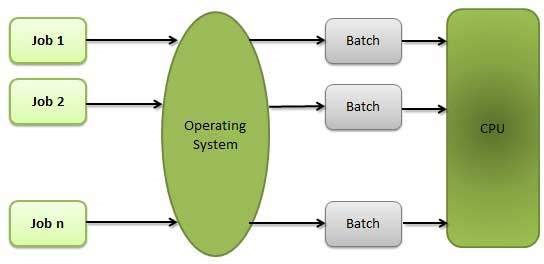
Batch-Betriebssystem
Die Benutzer eines Batch-Betriebssystems interagieren nicht direkt mit dem Computer. Jeder Benutzer bereitet seine Arbeit auf einem Offline-Gerät wie Lochkarten vor und sendet sie an den Computerbetreiber. Um die Verarbeitung zu beschleunigen, werden Jobs mit ähnlichen Anforderungen zusammengefasst und als Gruppe ausgeführt. Die Programmierer überlassen ihre Programme dem Bediener, und der Bediener sortiert dann die Programme mit ähnlichen Anforderungen in Stapel.
Die Probleme mit Batch-Systemen sind wie folgt:
- Fehlende Interaktion zwischen Benutzer und Job.
- Die CPU ist häufig im Leerlauf, da die Geschwindigkeit der mechanischen E / A-Geräte langsamer ist als die der CPU.
- Es ist schwierig, die gewünschte Priorität bereitzustellen.
Time-Sharing-Betriebssysteme
Time-Sharing ist eine Technik, mit der viele Personen an verschiedenen Terminals gleichzeitig ein bestimmtes Computersystem verwenden können. Time-Sharing oder Multitasking ist eine logische Erweiterung der Multiprogrammierung. Die Zeit des Prozessors, die von mehreren Benutzern gleichzeitig geteilt wird, wird als Time-Sharing bezeichnet.
Der Hauptunterschied zwischen Multiprogramm-Batch-Systemen und Time-Sharing-Systemen besteht darin, dass bei Multiprogramm-Batch-Systemen die Prozessorauslastung maximiert werden soll, während bei Time-Sharing-Systemen das Ziel darin besteht, die Antwortzeit zu minimieren.
Mehrere Jobs werden von der CPU durch Umschalten zwischen ihnen ausgeführt, aber die Umschaltungen treten so häufig auf. Somit kann der Benutzer eine sofortige Antwort erhalten. Beispielsweise führt der Prozessor bei einer Transaktionsverarbeitung jedes Benutzerprogramm in einem kurzen Burst oder einem Rechenquantum aus. Das heißt, wennnBenutzer sind anwesend, dann kann jeder Benutzer ein Zeitquantum erhalten. Wenn der Benutzer den Befehl sendet, beträgt die Antwortzeit höchstens einige Sekunden.
Das Betriebssystem verwendet CPU-Scheduling und Multiprogramming, um jedem Benutzer einen kleinen Teil seiner Zeit zur Verfügung zu stellen. Computersysteme, die hauptsächlich als Batch-Systeme konzipiert wurden, wurden auf Time-Sharing-Systeme umgestellt.
Die Vorteile von Timesharing-Betriebssystemen sind folgende:
- Bietet den Vorteil einer schnellen Reaktion.
- Vermeidet doppelte Software.
- Reduziert die CPU-Leerlaufzeit.
Die Nachteile von Time-Sharing-Betriebssystemen sind folgende:
- Problem der Zuverlässigkeit.
- Frage der Sicherheit und Integrität von Benutzerprogrammen und Daten.
- Problem der Datenkommunikation.
Verteiltes Betriebssystem
Verteilte Systeme verwenden mehrere Zentralprozessoren, um mehrere Echtzeitanwendungen und mehrere Benutzer zu bedienen. Datenverarbeitungsjobs werden entsprechend auf die Prozessoren verteilt.
Die Prozessoren kommunizieren über verschiedene Kommunikationsleitungen (wie Hochgeschwindigkeitsbusse oder Telefonleitungen) miteinander. Diese werden als bezeichnetloosely coupled systemsoder verteilte Systeme. Prozessoren in einem verteilten System können in Größe und Funktion variieren. Diese Prozessoren werden als Sites, Knoten, Computer usw. bezeichnet.
Die Vorteile verteilter Systeme sind folgende:
- Mit der Funktion zur gemeinsamen Nutzung von Ressourcen kann ein Benutzer an einem Standort möglicherweise die an einem anderen Standort verfügbaren Ressourcen verwenden.
- Beschleunigen Sie den Datenaustausch untereinander per E-Mail.
- Wenn ein Standort in einem verteilten System ausfällt, können die verbleibenden Standorte möglicherweise weiter betrieben werden.
- Besserer Service für die Kunden.
- Reduzierung der Belastung des Host-Computers.
- Reduzierung von Verzögerungen bei der Datenverarbeitung.
Netzwerkbetriebssystem
Ein Netzwerkbetriebssystem wird auf einem Server ausgeführt und bietet dem Server die Möglichkeit, Daten, Benutzer, Gruppen, Sicherheit, Anwendungen und andere Netzwerkfunktionen zu verwalten. Der Hauptzweck des Netzwerkbetriebssystems besteht darin, mehreren Computern in einem Netzwerk, normalerweise einem lokalen Netzwerk (LAN), einem privaten Netzwerk oder anderen Netzwerken, den Zugriff auf gemeinsam genutzte Dateien und Drucker zu ermöglichen.
Beispiele für Netzwerkbetriebssysteme sind Microsoft Windows Server 2003, Microsoft Windows Server 2008, UNIX, Linux, Mac OS X, Novell NetWare und BSD.
Die Vorteile von Netzwerkbetriebssystemen sind folgende:
- Zentralisierte Server sind sehr stabil.
- Sicherheit wird vom Server verwaltet.
- Upgrades auf neue Technologien und Hardware können problemlos in das System integriert werden.
- Der Fernzugriff auf Server ist von verschiedenen Standorten und Systemtypen aus möglich.
Die Nachteile von Netzwerkbetriebssystemen sind folgende:
- Hohe Kosten für den Kauf und Betrieb eines Servers.
- Abhängigkeit von einem zentralen Ort für die meisten Operationen.
- Regelmäßige Wartung und Updates sind erforderlich.
Echtzeit-Betriebssystem
Ein Echtzeitsystem ist definiert als ein Datenverarbeitungssystem, in dem das Zeitintervall, das zum Verarbeiten und Reagieren auf Eingaben erforderlich ist, so klein ist, dass es die Umgebung steuert. Die Zeit, die das System benötigt, um auf eine Eingabe und Anzeige der erforderlichen aktualisierten Informationen zu reagieren, wird als bezeichnetresponse time. Bei dieser Methode ist die Antwortzeit im Vergleich zur Online-Verarbeitung sehr viel kürzer.
Echtzeitsysteme werden verwendet, wenn strenge Zeitanforderungen für den Betrieb eines Prozessors oder den Datenfluss bestehen und Echtzeitsysteme als Steuergerät in einer dedizierten Anwendung verwendet werden können. Ein Echtzeitbetriebssystem muss genau definierte Zeitbeschränkungen haben, sonst fällt das System aus. Zum Beispiel wissenschaftliche Experimente, medizinische Bildgebungssysteme, industrielle Steuerungssysteme, Waffensysteme, Roboter, Flugsicherungssysteme usw.
Es gibt zwei Arten von Echtzeitbetriebssystemen.
Harte Echtzeitsysteme
Harte Echtzeitsysteme garantieren, dass kritische Aufgaben pünktlich erledigt werden. In harten Echtzeitsystemen ist der Sekundärspeicher begrenzt oder fehlt und die Daten werden im ROM gespeichert. In diesen Systemen wird virtueller Speicher fast nie gefunden.
Weiche Echtzeitsysteme
Weiche Echtzeitsysteme sind weniger restriktiv. Eine kritische Echtzeitaufgabe hat Vorrang vor anderen Aufgaben und behält die Priorität, bis sie abgeschlossen ist. Weiche Echtzeitsysteme sind nur begrenzt nützlich als harte Echtzeitsysteme. Zum Beispiel Multimedia, virtuelle Realität, fortgeschrittene wissenschaftliche Projekte wie Unterwassererkundung und Planetenrover usw.
Ein Betriebssystem bietet Dienste sowohl für die Benutzer als auch für die Programme.
- Es bietet Programmen eine Umgebung zur Ausführung.
- Es bietet Benutzern die Dienste, um die Programme auf bequeme Weise auszuführen.
Im Folgenden finden Sie einige allgemeine Dienste, die von einem Betriebssystem bereitgestellt werden:
- Programmausführung
- E / A-Operationen
- Manipulation des Dateisystems
- Communication
- Fehlererkennung
- Ressourcenzuweisung
- Protection
Programmausführung
Betriebssysteme verarbeiten viele Arten von Aktivitäten, von Benutzerprogrammen bis hin zu Systemprogrammen wie Druckerspooler, Nameserver, Dateiserver usw. Jede dieser Aktivitäten ist als Prozess gekapselt.
Ein Prozess umfasst den vollständigen Ausführungskontext (auszuführender Code, zu manipulierende Daten, Register, verwendete Betriebssystemressourcen). Im Folgenden sind die Hauptaktivitäten eines Betriebssystems in Bezug auf die Programmverwaltung aufgeführt:
- Lädt ein Programm in den Speicher.
- Führt das Programm aus.
- Behandelt die Programmausführung.
- Bietet einen Mechanismus für die Prozesssynchronisation.
- Bietet einen Mechanismus für die Prozesskommunikation.
- Bietet einen Mechanismus für die Behandlung von Deadlocks.
E / A-Betrieb
Ein E / A-Subsystem besteht aus E / A-Geräten und ihrer entsprechenden Treibersoftware. Treiber verbergen die Besonderheiten bestimmter Hardwaregeräte vor den Benutzern.
Ein Betriebssystem verwaltet die Kommunikation zwischen Benutzer- und Gerätetreibern.
- E / A-Vorgang bedeutet Lese- oder Schreibvorgang mit einer beliebigen Datei oder einem bestimmten E / A-Gerät.
- Das Betriebssystem bietet bei Bedarf den Zugriff auf das erforderliche E / A-Gerät.
Manipulation des Dateisystems
Eine Datei repräsentiert eine Sammlung verwandter Informationen. Computer können Dateien auf der Festplatte (Sekundärspeicher) für Langzeitspeicherzwecke speichern. Beispiele für Speichermedien umfassen Magnetbänder, Magnetplatten und optische Laufwerke wie CD, DVD. Jedes dieser Medien hat seine eigenen Eigenschaften wie Geschwindigkeit, Kapazität, Datenübertragungsrate und Datenzugriffsmethoden.
Ein Dateisystem ist normalerweise in Verzeichnissen organisiert, um die Navigation und Verwendung zu vereinfachen. Diese Verzeichnisse können Dateien und andere Anweisungen enthalten. Im Folgenden sind die Hauptaktivitäten eines Betriebssystems in Bezug auf die Dateiverwaltung aufgeführt:
- Das Programm muss eine Datei lesen oder schreiben.
- Das Betriebssystem erteilt dem Programm die Berechtigung zum Betrieb in der Datei.
- Die Berechtigung variiert von schreibgeschützt, schreibgeschützt, verweigert usw.
- Das Betriebssystem bietet dem Benutzer eine Schnittstelle zum Erstellen / Löschen von Dateien.
- Das Betriebssystem bietet dem Benutzer eine Schnittstelle zum Erstellen / Löschen von Verzeichnissen.
- Das Betriebssystem bietet eine Schnittstelle zum Erstellen der Sicherung des Dateisystems.
Kommunikation
Bei verteilten Systemen, bei denen es sich um eine Sammlung von Prozessoren handelt, die keinen Speicher, keine Peripheriegeräte oder keine Uhr gemeinsam nutzen, verwaltet das Betriebssystem die Kommunikation zwischen allen Prozessen. Mehrere Prozesse kommunizieren über Kommunikationsleitungen im Netzwerk miteinander.
Das Betriebssystem behandelt Routing- und Verbindungsstrategien sowie die Probleme von Konflikten und Sicherheit. Im Folgenden sind die Hauptaktivitäten eines Betriebssystems in Bezug auf die Kommunikation aufgeführt:
- Bei zwei Prozessen müssen häufig Daten zwischen ihnen übertragen werden
- Beide Prozesse können sich auf einem Computer oder auf verschiedenen Computern befinden, sind jedoch über ein Computernetzwerk verbunden.
- Die Kommunikation kann auf zwei Arten implementiert werden, entweder durch Shared Memory oder durch Message Passing.
Fehlerbehandlung
Fehler können jederzeit und überall auftreten. Ein Fehler kann in der CPU, in E / A-Geräten oder in der Speicherhardware auftreten. Im Folgenden sind die Hauptaktivitäten eines Betriebssystems in Bezug auf die Fehlerbehandlung aufgeführt:
- Das Betriebssystem prüft ständig auf mögliche Fehler.
- Das Betriebssystem ergreift geeignete Maßnahmen, um eine korrekte und konsistente Datenverarbeitung sicherzustellen.
Resourcenmanagement
In einer Mehrbenutzer- oder Multitasking-Umgebung sind jedem Benutzer oder Auftrag Ressourcen wie Hauptspeicher, CPU-Zyklen und Dateispeicher zuzuweisen. Im Folgenden sind die Hauptaktivitäten eines Betriebssystems in Bezug auf das Ressourcenmanagement aufgeführt:
- Das Betriebssystem verwaltet alle Arten von Ressourcen mithilfe von Schedulern.
- CPU-Planungsalgorithmen werden zur besseren Auslastung der CPU verwendet.
Schutz
In Anbetracht eines Computersystems mit mehreren Benutzern und gleichzeitiger Ausführung mehrerer Prozesse müssen die verschiedenen Prozesse vor den Aktivitäten des jeweils anderen geschützt werden.
Schutz bezieht sich auf einen Mechanismus oder eine Möglichkeit, den Zugriff von Programmen, Prozessen oder Benutzern auf die von einem Computersystem definierten Ressourcen zu steuern. Im Folgenden sind die wichtigsten Aktivitäten eines Betriebssystems in Bezug auf den Schutz aufgeführt:
- Das Betriebssystem stellt sicher, dass der gesamte Zugriff auf Systemressourcen kontrolliert wird.
- Das Betriebssystem stellt sicher, dass externe E / A-Geräte vor ungültigen Zugriffsversuchen geschützt sind.
- Das Betriebssystem bietet Authentifizierungsfunktionen für jeden Benutzer mithilfe von Kennwörtern.
Stapelverarbeitung
Die Stapelverarbeitung ist eine Technik, bei der ein Betriebssystem die Programme und Daten zusammen in einem Stapel sammelt, bevor die Verarbeitung beginnt. Ein Betriebssystem führt die folgenden Aktivitäten im Zusammenhang mit der Stapelverarbeitung aus:
Das Betriebssystem definiert einen Job mit einer vordefinierten Folge von Befehlen, Programmen und Daten als eine Einheit.
Das Betriebssystem speichert eine Anzahl von Jobs im Speicher und führt sie ohne manuelle Informationen aus.
Jobs werden in der Reihenfolge ihrer Einreichung bearbeitet, dh wer zuerst kommt, mahlt zuerst.
Wenn ein Job seine Ausführung abgeschlossen hat, wird sein Speicher freigegeben und die Ausgabe für den Job wird zum späteren Drucken oder Verarbeiten in eine Ausgabespool kopiert.
Vorteile
Die Stapelverarbeitung übernimmt einen Großteil der Arbeit des Bedieners für den Computer.
Erhöhte Leistung, wenn ein neuer Job gestartet wird, sobald der vorherige Job beendet ist, ohne manuelle Eingriffe.
Nachteile
- Schwer zu debuggendes Programm.
- Ein Job könnte in eine Endlosschleife eintreten.
- Aufgrund des fehlenden Schutzschemas kann ein Stapeljob ausstehende Jobs betreffen.
Multitasking
Multitasking ist, wenn mehrere Jobs gleichzeitig von der CPU ausgeführt werden, indem zwischen ihnen gewechselt wird. Wechsel treten so häufig auf, dass die Benutzer mit jedem Programm interagieren können, während es ausgeführt wird. Ein Betriebssystem führt die folgenden Aktivitäten im Zusammenhang mit Multitasking aus:
Der Benutzer gibt Anweisungen an das Betriebssystem oder an ein Programm direkt und erhält sofort eine Antwort.
Das Betriebssystem behandelt Multitasking so, dass es mehrere Vorgänge ausführen / mehrere Programme gleichzeitig ausführen kann.
Multitasking-Betriebssysteme werden auch als Time-Sharing-Systeme bezeichnet.
Diese Betriebssysteme wurden entwickelt, um die interaktive Nutzung eines Computersystems zu angemessenen Kosten zu ermöglichen.
Ein zeitlich geteiltes Betriebssystem verwendet das Konzept der CPU-Planung und Multiprogrammierung, um jedem Benutzer einen kleinen Teil einer zeitlich geteilten CPU bereitzustellen.
Jeder Benutzer hat mindestens ein separates Programm im Speicher.
Ein Programm, das in den Speicher geladen wird und ausgeführt wird, wird üblicherweise als bezeichnet process.
Wenn ein Prozess ausgeführt wird, wird er normalerweise nur für eine sehr kurze Zeit ausgeführt, bevor er entweder abgeschlossen ist oder E / A ausführen muss.
Da interaktive E / A normalerweise langsamer ausgeführt werden, kann der Abschluss lange dauern. Während dieser Zeit kann eine CPU von einem anderen Prozess verwendet werden.
Das Betriebssystem ermöglicht es den Benutzern, den Computer gleichzeitig freizugeben. Da jede Aktion oder jeder Befehl in einem zeitlich geteilten System in der Regel kurz ist, wird für jeden Benutzer nur wenig CPU-Zeit benötigt.
Da das System die CPU schnell von einem Benutzer / Programm zum nächsten wechselt, hat jeder Benutzer den Eindruck, dass er über eine eigene CPU verfügt, während tatsächlich eine CPU von vielen Benutzern gemeinsam genutzt wird.
Multiprogrammierung
Die gemeinsame Nutzung des Prozessors, wenn sich zwei oder mehr Programme gleichzeitig im Speicher befinden, wird als bezeichnet multiprogramming. Bei der Multiprogrammierung wird ein einzelner gemeinsam genutzter Prozessor vorausgesetzt. Multiprogramming erhöht die CPU-Auslastung, indem Jobs so organisiert werden, dass die CPU immer einen ausführen muss.
Die folgende Abbildung zeigt das Speicherlayout für ein Multiprogrammiersystem.
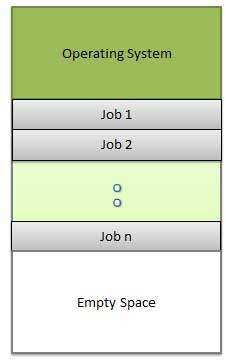
Ein Betriebssystem führt die folgenden Aktivitäten im Zusammenhang mit Multiprogramming aus.
Das Betriebssystem speichert mehrere Jobs gleichzeitig.
Diese Gruppe von Jobs ist eine Teilmenge der Jobs, die im Jobpool gespeichert sind.
Das Betriebssystem wählt einen der Jobs im Speicher aus und beginnt mit der Ausführung.
Multiprogramming-Betriebssysteme überwachen den Status aller aktiven Programme und Systemressourcen mithilfe von Speicherverwaltungsprogrammen, um sicherzustellen, dass die CPU niemals inaktiv ist, es sei denn, es sind keine Jobs zu verarbeiten.
Vorteile
- Hohe und effiziente CPU-Auslastung.
- Der Benutzer ist der Ansicht, dass vielen Programmen fast gleichzeitig CPU zugewiesen wird.
Nachteile
- CPU-Planung ist erforderlich.
- Um viele Jobs im Speicher unterzubringen, ist eine Speicherverwaltung erforderlich.
Interaktivität
Interaktivität bezieht sich auf die Fähigkeit von Benutzern, mit einem Computersystem zu interagieren. Ein Betriebssystem führt die folgenden Aktivitäten im Zusammenhang mit Interaktivität aus:
- Bietet dem Benutzer eine Schnittstelle zur Interaktion mit dem System.
- Verwaltet Eingabegeräte, um Eingaben vom Benutzer zu übernehmen. Zum Beispiel Tastatur.
- Verwaltet Ausgabegeräte, um dem Benutzer Ausgaben anzuzeigen. Zum Beispiel Monitor.
Die Antwortzeit des Betriebssystems muss kurz sein, da der Benutzer das Ergebnis übermittelt und darauf wartet.
Echtzeitsystem
Echtzeitsysteme sind normalerweise dedizierte, eingebettete Systeme. Ein Betriebssystem führt die folgenden Aktivitäten im Zusammenhang mit Echtzeit-Systemaktivitäten aus.
- In solchen Systemen lesen Betriebssysteme normalerweise aus Sensordaten und reagieren darauf.
- Das Betriebssystem muss die Reaktion auf Ereignisse innerhalb festgelegter Zeiträume gewährleisten, um die korrekte Leistung sicherzustellen.
Verteilte Umgebung
Eine verteilte Umgebung bezieht sich auf mehrere unabhängige CPUs oder Prozessoren in einem Computersystem. Ein Betriebssystem führt die folgenden Aktivitäten in Bezug auf verteilte Umgebungen aus:
Das Betriebssystem verteilt die Berechnungslogik auf mehrere physische Prozessoren.
Die Prozessoren teilen sich weder Speicher noch Uhr. Stattdessen hat jeder Prozessor seinen eigenen lokalen Speicher.
Das Betriebssystem verwaltet die Kommunikation zwischen den Prozessoren. Sie kommunizieren über verschiedene Kommunikationsleitungen miteinander.
Spulen
Spooling ist eine Abkürzung für gleichzeitige Online-Peripherieoperationen. Spooling bezieht sich auf das Speichern von Daten verschiedener E / A-Jobs in einem Puffer. Dieser Puffer ist ein spezieller Bereich im Speicher oder auf der Festplatte, auf den E / A-Geräte zugreifen können.
Ein Betriebssystem führt die folgenden Aktivitäten in Bezug auf verteilte Umgebungen aus:
Behandelt das Spoolen von E / A-Gerätedaten, da Geräte unterschiedliche Datenzugriffsraten haben.
Verwaltet den Spooling-Puffer, der eine Wartestation bereitstellt, an der Daten ruhen können, während das langsamere Gerät aufholt.
Behält die parallele Berechnung aufgrund des Spooling-Prozesses bei, da ein Computer E / A parallel ausführen kann. Es wird möglich, dass der Computer Daten von einem Band liest, Daten auf die Festplatte schreibt und auf einen Banddrucker schreibt, während er seine Computeraufgabe ausführt.

Vorteile
- Der Spooling-Vorgang verwendet eine Festplatte als sehr großen Puffer.
- Das Spoolen kann E / A-Operationen für einen Job mit Prozessoroperationen für einen anderen Job überlappen.
Prozess
Ein Prozess ist im Grunde ein Programm in Ausführung. Die Ausführung eines Prozesses muss sequentiell erfolgen.
Ein Prozess ist als eine Entität definiert, die die grundlegende Arbeitseinheit darstellt, die im System implementiert werden soll.
Einfach ausgedrückt schreiben wir unsere Computerprogramme in eine Textdatei. Wenn wir dieses Programm ausführen, wird es zu einem Prozess, der alle im Programm genannten Aufgaben ausführt.
Wenn ein Programm in den Speicher geladen wird und zu einem Prozess wird, kann es in vier Abschnitte unterteilt werden: Stapel, Heap, Text und Daten. Das folgende Bild zeigt ein vereinfachtes Layout eines Prozesses im Hauptspeicher -
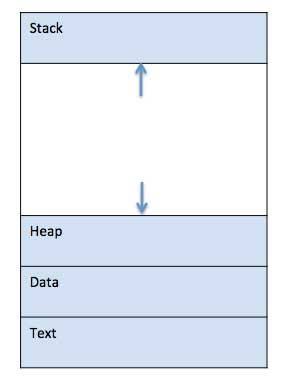
| SN | Komponentenbeschreibung |
|---|---|
| 1 | Stack Der Prozessstapel enthält die temporären Daten wie Methoden- / Funktionsparameter, Rücksprungadresse und lokale Variablen. |
| 2 | Heap Dies wird einem Prozess während seiner Laufzeit dynamisch Speicher zugewiesen. |
| 3 | Text Dies schließt die aktuelle Aktivität ein, die durch den Wert des Programmzählers und den Inhalt der Register des Prozessors dargestellt wird. |
| 4 | Data Dieser Abschnitt enthält die globalen und statischen Variablen. |
Programm
Ein Programm ist ein Code, der aus einer einzelnen Zeile oder Millionen von Zeilen bestehen kann. Ein Computerprogramm wird normalerweise von einem Computerprogrammierer in einer Programmiersprache geschrieben. Hier ist zum Beispiel ein einfaches Programm, das in der Programmiersprache C geschrieben ist -
#include <stdio.h>
int main() {
printf("Hello, World! \n");
return 0;
}Ein Computerprogramm ist eine Sammlung von Anweisungen, die eine bestimmte Aufgabe ausführen, wenn sie von einem Computer ausgeführt werden. Wenn wir ein Programm mit einem Prozess vergleichen, können wir schließen, dass ein Prozess eine dynamische Instanz eines Computerprogramms ist.
Ein Teil eines Computerprogramms, das eine genau definierte Aufgabe ausführt, wird als bezeichnet algorithm. Eine Sammlung von Computerprogrammen, Bibliotheken und verwandten Daten wird als bezeichnetsoftware.
Prozesslebenszyklus
Wenn ein Prozess ausgeführt wird, durchläuft er verschiedene Zustände. Diese Phasen können in verschiedenen Betriebssystemen unterschiedlich sein, und die Namen dieser Zustände sind ebenfalls nicht standardisiert.
Im Allgemeinen kann ein Prozess jeweils einen der folgenden fünf Zustände haben.
| SN | Zustand & Beschreibung |
|---|---|
| 1 | Start Dies ist der Ausgangszustand, wenn ein Prozess zum ersten Mal gestartet / erstellt wird. |
| 2 | Ready Der Prozess wartet darauf, einem Prozessor zugewiesen zu werden. Bereit-Prozesse warten darauf, dass ihnen der Prozessor vom Betriebssystem zugewiesen wird, damit sie ausgeführt werden können. Prozess kann nach in diesen Zustand kommenStart Status oder während der Ausführung durch, aber unterbrochen vom Scheduler, um die CPU einem anderen Prozess zuzuweisen. |
| 3 | Running Sobald der Prozess vom OS-Scheduler einem Prozessor zugewiesen wurde, wird der Prozessstatus auf "Ausführen" gesetzt und der Prozessor führt seine Anweisungen aus. |
| 4 | Waiting Der Prozess wird in den Wartezustand versetzt, wenn auf eine Ressource gewartet werden muss, z. B. auf Benutzereingaben oder auf die Verfügbarkeit einer Datei. |
| 5 | Terminated or Exit Sobald der Prozess seine Ausführung beendet hat oder vom Betriebssystem beendet wird, wird er in den abgeschlossenen Zustand versetzt, in dem er darauf wartet, aus dem Hauptspeicher entfernt zu werden. |

Prozesssteuerungsblock (PCB)
Ein Prozesssteuerungsblock ist eine Datenstruktur, die vom Betriebssystem für jeden Prozess verwaltet wird. Die Leiterplatte wird durch eine ganzzahlige Prozess-ID (PID) identifiziert. Eine Leiterplatte enthält alle Informationen, die zur Verfolgung eines Prozesses erforderlich sind, wie unten in der Tabelle aufgeführt.
| SN | Informationen & Beschreibung |
|---|---|
| 1 | Process State Der aktuelle Status des Prozesses, dh ob er bereit ist, ausgeführt wird, wartet oder was auch immer. |
| 2 | Process privileges Dies ist erforderlich, um den Zugriff auf Systemressourcen zuzulassen / zu verbieten. |
| 3 | Process ID Eindeutige Identifikation für jeden Prozess im Betriebssystem. |
| 4 | Pointer Ein Zeiger auf den übergeordneten Prozess. |
| 5 | Program Counter Der Programmzähler ist ein Zeiger auf die Adresse des nächsten Befehls, der für diesen Prozess ausgeführt werden soll. |
| 6 | CPU registers Verschiedene CPU-Register, in denen der Prozess zur Ausführung für den laufenden Zustand gespeichert werden muss. |
| 7 | CPU Scheduling Information Prozesspriorität und andere Planungsinformationen, die zum Planen des Prozesses erforderlich sind. |
| 8 | Memory management information Dies beinhaltet die Informationen der Seitentabelle, der Speichergrenzen und der Segmenttabelle in Abhängigkeit vom vom Betriebssystem verwendeten Speicher. |
| 9 | Accounting information Dies beinhaltet die Menge an CPU, die für die Prozessausführung verwendet wird, Zeitlimits, Ausführungs-ID usw. |
| 10 | IO status information Dies umfasst eine Liste der dem Prozess zugewiesenen E / A-Geräte. |
Die Architektur einer Leiterplatte ist vollständig vom Betriebssystem abhängig und kann in verschiedenen Betriebssystemen unterschiedliche Informationen enthalten. Hier ist ein vereinfachtes Diagramm einer Leiterplatte -

Die Leiterplatte wird während ihrer gesamten Lebensdauer für einen Prozess gewartet und nach Beendigung des Prozesses gelöscht.
Definition
Die Prozessplanung ist die Aktivität des Prozessmanagers, die das Entfernen des laufenden Prozesses aus der CPU und die Auswahl eines anderen Prozesses auf der Grundlage einer bestimmten Strategie übernimmt.
Die Prozessplanung ist ein wesentlicher Bestandteil eines Multiprogramming-Betriebssystems. Mit solchen Betriebssystemen kann mehr als ein Prozess gleichzeitig in den ausführbaren Speicher geladen werden, und der geladene Prozess teilt die CPU mithilfe von Zeitmultiplex.
Prozessplanungswarteschlangen verarbeiten
Das Betriebssystem verwaltet alle Leiterplatten in Prozessplanungswarteschlangen. Das Betriebssystem unterhält für jeden Prozessstatus eine separate Warteschlange, und die Leiterplatten aller Prozesse im selben Ausführungsstatus werden in dieselbe Warteschlange gestellt. Wenn der Status eines Prozesses geändert wird, wird die Leiterplatte von der aktuellen Warteschlange getrennt und in die neue Statuswarteschlange verschoben.
Das Betriebssystem verwaltet die folgenden wichtigen Prozessplanungswarteschlangen:
Job queue - Diese Warteschlange hält alle Prozesse im System.
Ready queue- Diese Warteschlange hält eine Reihe aller Prozesse im Hauptspeicher bereit und wartet auf ihre Ausführung. In diese Warteschlange wird immer ein neuer Prozess gestellt.
Device queues - Diese Warteschlange bilden die Prozesse, die aufgrund der Nichtverfügbarkeit eines E / A-Geräts blockiert sind.

Das Betriebssystem kann verschiedene Richtlinien zum Verwalten jeder Warteschlange verwenden (FIFO, Round Robin, Priorität usw.). Der OS-Scheduler bestimmt, wie Prozesse zwischen den Bereitschafts- und Ausführungswarteschlangen verschoben werden, die nur einen Eintrag pro Prozessorkern im System haben können. Im obigen Diagramm wurde es mit der CPU zusammengeführt.
Zwei-Zustands-Prozessmodell
Das Zwei-Zustands-Prozessmodell bezieht sich auf laufende und nicht laufende Zustände, die nachfolgend beschrieben werden -
| SN | Zustand & Beschreibung |
|---|---|
| 1 | Running Wenn ein neuer Prozess erstellt wird, tritt er wie im laufenden Zustand in das System ein. |
| 2 | Not Running Prozesse, die nicht ausgeführt werden, werden in der Warteschlange gehalten und warten auf ihre Ausführung. Jeder Eintrag in der Warteschlange ist ein Zeiger auf einen bestimmten Prozess. Die Warteschlange wird mithilfe einer verknüpften Liste implementiert. Die Verwendung des Dispatchers ist wie folgt. Wenn ein Prozess unterbrochen wird, wird dieser Prozess in die Warteschlange übertragen. Wenn der Prozess abgeschlossen oder abgebrochen wurde, wird der Prozess verworfen. In beiden Fällen wählt der Dispatcher dann einen Prozess aus der Warteschlange aus, der ausgeführt werden soll. |
Scheduler
Scheduler sind spezielle Systemsoftware, die die Prozessplanung auf verschiedene Arten handhabt. Ihre Hauptaufgabe besteht darin, die Jobs auszuwählen, die an das System gesendet werden sollen, und zu entscheiden, welcher Prozess ausgeführt werden soll. Es gibt drei Arten von Schedulern:
- Langzeitplaner
- Kurzzeitplaner
- Mittelfristiger Planer
Langzeitplaner
Es wird auch a genannt job scheduler. Ein Langzeitplaner bestimmt, welche Programme zur Verarbeitung in das System zugelassen werden. Es wählt Prozesse aus der Warteschlange aus und lädt sie zur Ausführung in den Speicher. Prozess wird für die CPU-Planung in den Speicher geladen.
Das Hauptziel des Job Schedulers besteht darin, eine ausgewogene Mischung von Jobs bereitzustellen, z. B. E / A-gebunden und prozessorgebunden. Es steuert auch den Grad der Mehrfachprogrammierung. Wenn der Grad der Mehrfachprogrammierung stabil ist, muss die durchschnittliche Rate der Prozesserstellung gleich der durchschnittlichen Abgangsrate der Prozesse sein, die das System verlassen.
Auf einigen Systemen ist der Langzeitplaner möglicherweise nicht verfügbar oder minimal. Time-Sharing-Betriebssysteme haben keinen Langzeitplaner. Wenn ein Prozess den Status von neu auf bereit ändert, wird ein Langzeitplaner verwendet.
Kurzzeitplaner
Es wird auch als bezeichnet CPU scheduler. Hauptziel ist die Steigerung der Systemleistung gemäß den gewählten Kriterien. Dies ist die Änderung des Bereitschaftszustands in den Betriebszustand des Prozesses. Der CPU-Scheduler wählt einen Prozess unter den Prozessen aus, die zur Ausführung bereit sind, und weist einem von ihnen die CPU zu.
Kurzzeitplaner, auch Dispatcher genannt, entscheiden, welcher Prozess als nächstes ausgeführt werden soll. Kurzzeitplaner sind schneller als Langzeitplaner.
Mittelfristiger Planer
Die mittelfristige Planung ist ein Teil von swapping. Es entfernt die Prozesse aus dem Speicher. Es reduziert den Grad der Mehrfachprogrammierung. Der mittelfristige Scheduler ist für die Abwicklung der ausgelagerten Out-Prozesse verantwortlich.
Ein laufender Prozess kann angehalten werden, wenn eine E / A-Anforderung gestellt wird. Ein angehaltener Prozess kann keine Fortschritte auf dem Weg zum Abschluss machen. In diesem Zustand wird der angehaltene Prozess in den sekundären Speicher verschoben, um den Prozess aus dem Speicher zu entfernen und Platz für andere Prozesse zu schaffen. Dieser Vorgang wird aufgerufenswappingund der Prozess soll ausgetauscht oder ausgerollt werden. Möglicherweise ist ein Austausch erforderlich, um den Prozessmix zu verbessern.
Vergleich zwischen Scheduler
| SN | Langzeitplaner | Kurzzeitplaner | Mittelfristiger Planer |
|---|---|---|---|
| 1 | Es ist ein Job Scheduler | Es ist ein CPU-Scheduler | Es ist ein Prozessaustausch-Scheduler. |
| 2 | Die Geschwindigkeit ist geringer als bei einem Kurzzeitplaner | Geschwindigkeit ist unter anderen beiden am schnellsten | Die Geschwindigkeit liegt zwischen Kurz- und Langzeitplaner. |
| 3 | Es steuert den Grad der Mehrfachprogrammierung | Es bietet eine geringere Kontrolle über den Grad der Mehrfachprogrammierung | Es reduziert den Grad der Mehrfachprogrammierung. |
| 4 | Es ist im Time-Sharing-System fast nicht vorhanden oder minimal | Es ist auch im Time-Sharing-System minimal | Es ist Teil von Time-Sharing-Systemen. |
| 5 | Es wählt Prozesse aus dem Pool aus und lädt sie zur Ausführung in den Speicher | Es wählt diejenigen Prozesse aus, die zur Ausführung bereit sind | Es kann den Prozess wieder in den Speicher einführen und die Ausführung kann fortgesetzt werden. |
Kontextwechsel
Ein Kontextwechsel ist der Mechanismus zum Speichern und Wiederherstellen des Status oder Kontexts einer CPU im Prozesssteuerungsblock, sodass eine Prozessausführung zu einem späteren Zeitpunkt an derselben Stelle fortgesetzt werden kann. Mit dieser Technik können mit einem Kontextumschalter mehrere Prozesse eine einzige CPU gemeinsam nutzen. Die Kontextumschaltung ist ein wesentlicher Bestandteil der Funktionen eines Multitasking-Betriebssystems.
Wenn der Scheduler die CPU von der Ausführung eines Prozesses zur Ausführung eines anderen umschaltet, wird der Status des aktuell ausgeführten Prozesses im Prozesssteuerblock gespeichert. Danach wird der Status für den nächsten Prozess von seiner eigenen Platine geladen und zum Einstellen des PCs, der Register usw. verwendet. An diesem Punkt kann der zweite Prozess mit der Ausführung beginnen.
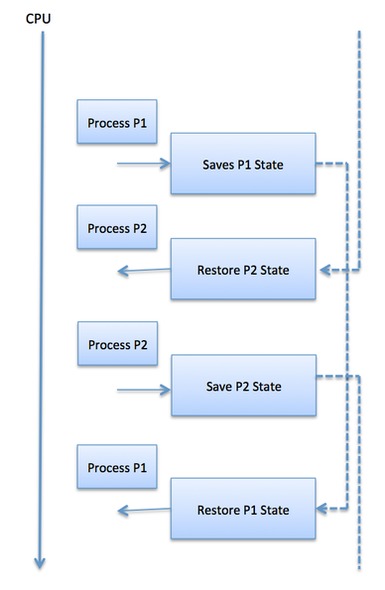
Kontextwechsel sind rechenintensiv, da Register und Speicherstatus gespeichert und wiederhergestellt werden müssen. Um die Zeit für die Kontextumschaltung zu vermeiden, verwenden einige Hardwaresysteme zwei oder mehr Sätze von Prozessorregistern. Wenn der Prozess umgeschaltet wird, werden die folgenden Informationen zur späteren Verwendung gespeichert.
- Programm zähler
- Planungsinformationen
- Basis- und Grenzregisterwert
- Derzeit verwendetes Register
- Geänderter Zustand
- Informationen zum E / A-Status
- Buchhaltungsinformationen
Ein Prozessplaner plant verschiedene Prozesse, die der CPU basierend auf bestimmten Planungsalgorithmen zugewiesen werden sollen. Es gibt sechs gängige Prozessplanungsalgorithmen, die wir in diesem Kapitel behandeln werden -
- FCFS-Planung (First-Come, First-Served)
- SJN-Planung (Shortest-Job-Next)
- Prioritätsplanung
- Kürzeste verbleibende Zeit
- Round Robin (RR) -Planung
- Planung von Warteschlangen auf mehreren Ebenen
Diese Algorithmen sind entweder non-preemptive or preemptive. Nicht präemptive Algorithmen sind so konzipiert, dass ein Prozess, sobald er in den laufenden Zustand übergeht, erst nach Ablauf seiner zugewiesenen Zeit vorbelegt werden kann, während die präemptive Planung auf der Priorität basiert, bei der ein Scheduler einen laufenden Prozess mit niedriger Priorität jederzeit mit hoher Priorität verhindern kann Prozess tritt in einen Bereitschaftszustand ein.
Wer zuerst kommt, mahlt zuerst (FCFS)
- Jobs werden nach dem Prinzip "Wer zuerst kommt, mahlt zuerst" ausgeführt.
- Es ist ein nicht präventiver, präventiver Planungsalgorithmus.
- Einfach zu verstehen und umzusetzen.
- Die Implementierung basiert auf der FIFO-Warteschlange.
- Schlechte Leistung, da die durchschnittliche Wartezeit hoch ist.
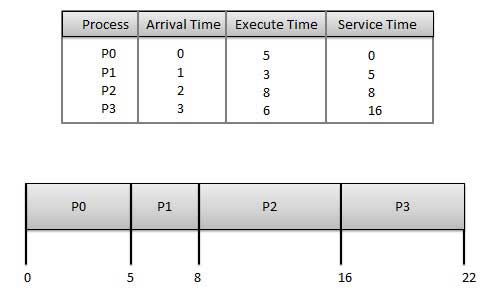
Wait time von jedem Prozess ist wie folgt -
| Prozess | Wartezeit: Servicezeit - Ankunftszeit |
|---|---|
| P0 | 0 - 0 = 0 |
| P1 | 5 - 1 = 4 |
| P2 | 8 - 2 = 6 |
| P3 | 16 - 3 = 13 |
Durchschnittliche Wartezeit: (0 + 4 + 6 + 13) / 4 = 5,75
Kürzester Job als nächstes (SJN)
Dies ist auch bekannt als shortest job firstoder SJF
Dies ist ein nicht präemptiver, präventiver Planungsalgorithmus.
Bester Ansatz zur Minimierung der Wartezeit.
Einfache Implementierung in Batch-Systemen, bei denen die erforderliche CPU-Zeit im Voraus bekannt ist.
In interaktiven Systemen, in denen die erforderliche CPU-Zeit nicht bekannt ist, ist keine Implementierung möglich.
Der Verarbeiter sollte im Voraus wissen, wie viel Zeit der Vorgang in Anspruch nehmen wird.
Gegeben: Tabelle der Prozesse und deren Ankunftszeit, Ausführungszeit
| Prozess | Ankunftszeit | Ausführungszeit | Servicezeit |
|---|---|---|---|
| P0 | 0 | 5 | 0 |
| P1 | 1 | 3 | 5 |
| P2 | 2 | 8 | 14 |
| P3 | 3 | 6 | 8 |

Waiting time von jedem Prozess ist wie folgt -
| Prozess | Wartezeit |
|---|---|
| P0 | 0 - 0 = 0 |
| P1 | 5 - 1 = 4 |
| P2 | 14 - 2 = 12 |
| P3 | 8 - 3 = 5 |
Durchschnittliche Wartezeit: (0 + 4 + 12 + 5) / 4 = 21/4 = 5,25
Prioritätsbasierte Planung
Die Prioritätsplanung ist ein nicht präemptiver Algorithmus und einer der häufigsten Planungsalgorithmen in Batch-Systemen.
Jedem Prozess wird eine Priorität zugewiesen. Der Prozess mit der höchsten Priorität muss zuerst ausgeführt werden und so weiter.
Prozesse mit derselben Priorität werden nach dem Prinzip "Wer zuerst kommt, mahlt zuerst" ausgeführt.
Die Priorität kann basierend auf Speicheranforderungen, Zeitanforderungen oder anderen Ressourcenanforderungen festgelegt werden.
Gegeben: Tabelle der Prozesse und deren Ankunftszeit, Ausführungszeit und Priorität. Hier betrachten wir 1 als die niedrigste Priorität.
| Prozess | Ankunftszeit | Ausführungszeit | Priorität | Servicezeit |
|---|---|---|---|---|
| P0 | 0 | 5 | 1 | 0 |
| P1 | 1 | 3 | 2 | 11 |
| P2 | 2 | 8 | 1 | 14 |
| P3 | 3 | 6 | 3 | 5 |

Waiting time von jedem Prozess ist wie folgt -
| Prozess | Wartezeit |
|---|---|
| P0 | 0 - 0 = 0 |
| P1 | 11-1 = 10 |
| P2 | 14 - 2 = 12 |
| P3 | 5 - 3 = 2 |
Durchschnittliche Wartezeit: (0 + 10 + 12 + 2) / 4 = 24/4 = 6
Kürzeste verbleibende Zeit
Die kürzeste verbleibende Zeit (SRT) ist die präemptive Version des SJN-Algorithmus.
Der Prozessor wird dem Auftrag zugewiesen, der der Fertigstellung am nächsten kommt. Er kann jedoch durch einen neueren Bereitschaftsjob mit kürzerer Zeit bis zur Fertigstellung verhindert werden.
In interaktiven Systemen, in denen die erforderliche CPU-Zeit nicht bekannt ist, ist keine Implementierung möglich.
Es wird häufig in Batch-Umgebungen verwendet, in denen kurze Jobs bevorzugt werden müssen.
Round Robin Scheduling
Round Robin ist der präventive Prozessplanungsalgorithmus.
Jedem Prozess wird eine feste Ausführungszeit zur Verfügung gestellt, die als a bezeichnet wird quantum.
Sobald ein Prozess für einen bestimmten Zeitraum ausgeführt wurde, wird er vorab ausgeführt und ein anderer Prozess wird für einen bestimmten Zeitraum ausgeführt.
Die Kontextumschaltung wird verwendet, um Zustände von vorab freigegebenen Prozessen zu speichern.
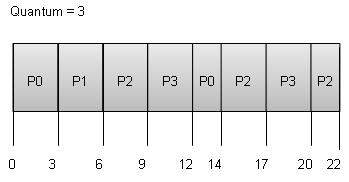
Wait time von jedem Prozess ist wie folgt -
| Prozess | Wartezeit: Servicezeit - Ankunftszeit |
|---|---|
| P0 | (0 - 0) + (12 - 3) = 9 |
| P1 | (3 - 1) = 2 |
| P2 | (6 - 2) + (14 - 9) + (20 - 17) = 12 |
| P3 | (9 - 3) + (17 - 12) = 11 |
Durchschnittliche Wartezeit: (9 + 2 + 12 + 11) / 4 = 8,5
Planung von Warteschlangen auf mehreren Ebenen
Warteschlangen mit mehreren Ebenen sind kein unabhängiger Planungsalgorithmus. Sie verwenden andere vorhandene Algorithmen, um Jobs mit gemeinsamen Merkmalen zu gruppieren und zu planen.
- Für Prozesse mit gemeinsamen Merkmalen werden mehrere Warteschlangen verwaltet.
- Jede Warteschlange kann ihre eigenen Planungsalgorithmen haben.
- Jeder Warteschlange werden Prioritäten zugewiesen.
Beispielsweise können CPU-gebundene Jobs in einer Warteschlange und alle E / A-gebundenen Jobs in einer anderen Warteschlange geplant werden. Der Prozessplaner wählt dann abwechselnd Jobs aus jeder Warteschlange aus und weist sie der CPU basierend auf dem der Warteschlange zugewiesenen Algorithmus zu.
Was ist Thread?
Ein Thread ist ein Ausführungsfluss durch den Prozesscode mit einem eigenen Programmzähler, der verfolgt, welcher Befehl als nächstes ausgeführt werden soll, Systemregistern, die seine aktuellen Arbeitsvariablen enthalten, und einem Stapel, der den Ausführungsverlauf enthält.
Ein Thread teilt mit seinen Peer-Threads nur wenige Informationen wie Codesegment, Datensegment und geöffnete Dateien. Wenn ein Thread ein Codesegment-Speicherelement ändert, sehen dies alle anderen Threads.
Ein Thread wird auch als bezeichnet lightweight process. Threads bieten eine Möglichkeit, die Anwendungsleistung durch Parallelität zu verbessern. Threads stellen einen Softwareansatz zur Verbesserung der Leistung des Betriebssystems dar, indem der Overhead-Thread reduziert wird. Dies entspricht einem klassischen Prozess.
Jeder Thread gehört zu genau einem Prozess und es kann kein Thread außerhalb eines Prozesses existieren. Jeder Thread repräsentiert einen separaten Kontrollfluss. Threads wurden erfolgreich bei der Implementierung von Netzwerkservern und Webservern verwendet. Sie bieten auch eine geeignete Grundlage für die parallele Ausführung von Anwendungen auf Multiprozessoren mit gemeinsamem Speicher. Die folgende Abbildung zeigt die Funktionsweise eines Single-Threaded- und eines Multithread-Prozesses.
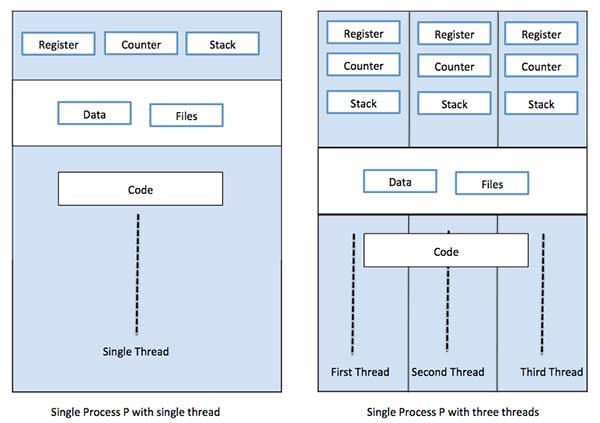
Unterschied zwischen Prozess und Thread
| SN | Prozess | Faden |
|---|---|---|
| 1 | Der Prozess ist schwer oder ressourcenintensiv. | Der Faden ist leicht und benötigt weniger Ressourcen als ein Prozess. |
| 2 | Prozessumschaltung erfordert Interaktion mit dem Betriebssystem. | Thread-Switching muss nicht mit dem Betriebssystem interagieren. |
| 3 | In mehreren Verarbeitungsumgebungen führt jeder Prozess denselben Code aus, verfügt jedoch über eigene Speicher- und Dateiressourcen. | Alle Threads können denselben Satz offener Dateien und untergeordneter Prozesse gemeinsam nutzen. |
| 4 | Wenn ein Prozess blockiert ist, kann kein anderer Prozess ausgeführt werden, bis der erste Prozess entsperrt ist. | Während ein Thread blockiert ist und wartet, kann ein zweiter Thread in derselben Task ausgeführt werden. |
| 5 | Mehrere Prozesse ohne Verwendung von Threads verbrauchen mehr Ressourcen. | Prozesse mit mehreren Threads verbrauchen weniger Ressourcen. |
| 6 | In mehreren Prozessen arbeitet jeder Prozess unabhängig von den anderen. | Ein Thread kann die Daten eines anderen Threads lesen, schreiben oder ändern. |
Vorteile von Thread
- Threads minimieren die Kontextwechselzeit.
- Die Verwendung von Threads bietet Parallelität innerhalb eines Prozesses.
- Effiziente Kommunikation.
- Das Erstellen und Kontextwechseln von Threads ist wirtschaftlicher.
- Threads ermöglichen die Verwendung von Multiprozessor-Architekturen in größerem Maßstab und mit größerer Effizienz.
Arten von Thread
Threads werden auf zwei Arten implementiert:
User Level Threads - Benutzerverwaltete Threads.
Kernel Level Threads - Vom Betriebssystem verwaltete Threads, die auf den Kernel, einen Betriebssystemkern, wirken.
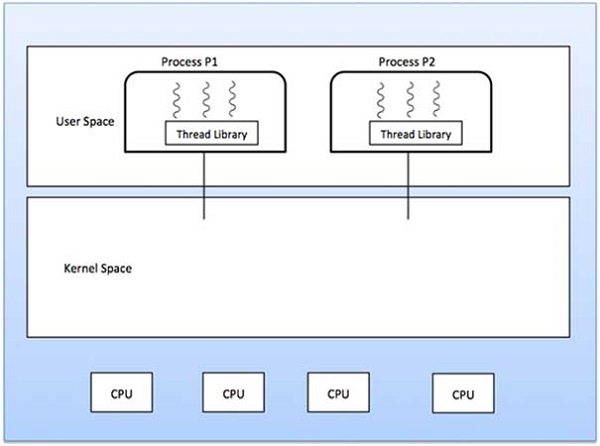
Threads auf Benutzerebene
In diesem Fall ist dem Thread-Verwaltungskern die Existenz von Threads nicht bekannt. Die Thread-Bibliothek enthält Code zum Erstellen und Zerstören von Threads, zum Weiterleiten von Nachrichten und Daten zwischen Threads, zum Planen der Thread-Ausführung sowie zum Speichern und Wiederherstellen von Thread-Kontexten. Die Anwendung beginnt mit einem einzelnen Thread.
Vorteile
- Für das Thread-Switching sind keine Berechtigungen für den Kernel-Modus erforderlich.
- Thread auf Benutzerebene kann auf jedem Betriebssystem ausgeführt werden.
- Die Planung kann im Thread auf Benutzerebene anwendungsspezifisch sein.
- Threads auf Benutzerebene lassen sich schnell erstellen und verwalten.
Nachteile
- In einem typischen Betriebssystem werden die meisten Systemaufrufe blockiert.
- Multithread-Anwendungen können Multiprocessing nicht nutzen.
Threads auf Kernebene
In diesem Fall erfolgt die Thread-Verwaltung über den Kernel. Im Anwendungsbereich befindet sich kein Thread-Verwaltungscode. Kernel-Threads werden direkt vom Betriebssystem unterstützt. Jede Anwendung kann für Multithreading programmiert werden. Alle Threads in einer Anwendung werden in einem einzigen Prozess unterstützt.
Der Kernel verwaltet Kontextinformationen für den gesamten Prozess und für einzelne Threads innerhalb des Prozesses. Die Planung durch den Kernel erfolgt auf Thread-Basis. Der Kernel führt die Erstellung, Planung und Verwaltung von Threads im Kernelbereich durch. Kernel-Threads sind im Allgemeinen langsamer zu erstellen und zu verwalten als die Benutzer-Threads.
Vorteile
- Der Kernel kann gleichzeitig mehrere Threads desselben Prozesses für mehrere Prozesse planen.
- Wenn ein Thread in einem Prozess blockiert ist, kann der Kernel einen anderen Thread desselben Prozesses planen.
- Kernel-Routinen selbst können Multithread-fähig sein.
Nachteile
- Kernel-Threads sind im Allgemeinen langsamer zu erstellen und zu verwalten als die Benutzer-Threads.
- Die Übertragung der Kontrolle von einem Thread auf einen anderen innerhalb desselben Prozesses erfordert einen Moduswechsel zum Kernel.
Multithreading-Modelle
Einige Betriebssysteme bieten eine kombinierte Thread-Funktion auf Benutzerebene und auf Kernel-Ebene. Solaris ist ein gutes Beispiel für diesen kombinierten Ansatz. In einem kombinierten System können mehrere Threads innerhalb derselben Anwendung auf mehreren Prozessoren parallel ausgeführt werden, und ein blockierender Systemaufruf muss nicht den gesamten Prozess blockieren. Es gibt drei Arten von Multithreading-Modellen
- Viele zu viele Beziehungen.
- Viele zu einer Beziehung.
- Eins zu eins Beziehung.
Viele zu viele Modelle
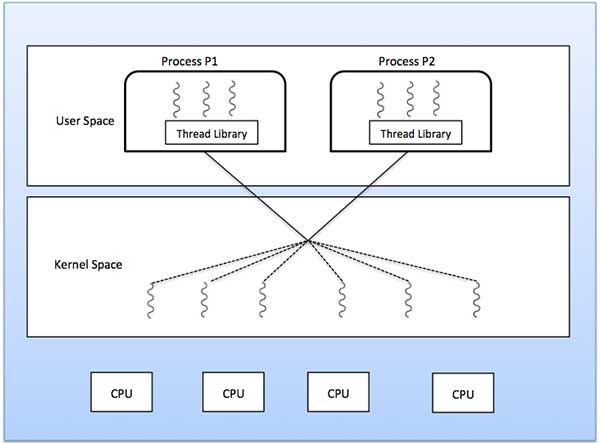
Das Viele-zu-Viele-Modell multiplext eine beliebige Anzahl von Benutzer-Threads auf eine gleiche oder kleinere Anzahl von Kernel-Threads.
Das folgende Diagramm zeigt das Viele-zu-Viele-Threading-Modell, bei dem 6 Threads auf Benutzerebene mit 6 Threads auf Kernelebene multiplexen. In diesem Modell können Entwickler so viele Benutzer-Threads wie nötig erstellen und die entsprechenden Kernel-Threads können parallel auf einem Multiprozessor-Computer ausgeführt werden. Dieses Modell bietet die beste Genauigkeit bei der Parallelität. Wenn ein Thread einen blockierenden Systemaufruf ausführt, kann der Kernel einen anderen Thread für die Ausführung planen.
Viele zu einem Modell
Das Many-to-One-Modell ordnet viele Threads auf Benutzerebene einem Thread auf Kernel-Ebene zu. Die Thread-Verwaltung erfolgt im Benutzerbereich durch die Thread-Bibliothek. Wenn der Thread einen blockierenden Systemaufruf ausführt, wird der gesamte Prozess blockiert. Es kann jeweils nur ein Thread auf den Kernel zugreifen, sodass mehrere Threads auf Multiprozessoren nicht parallel ausgeführt werden können.
Wenn die Thread-Bibliotheken auf Benutzerebene im Betriebssystem so implementiert sind, dass das System sie nicht unterstützt, verwenden die Kernel-Threads die Viele-zu-Eins-Beziehungsmodi.
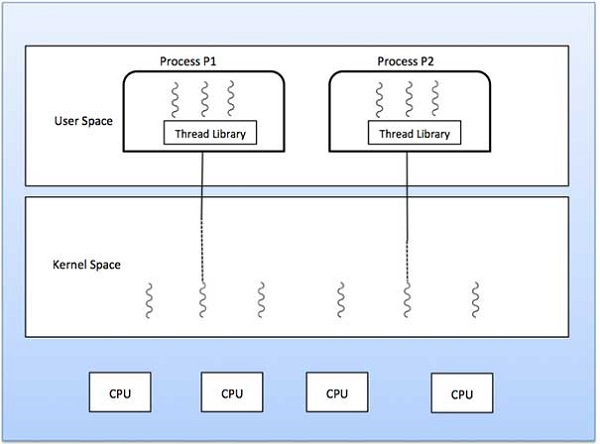
Eins zu Eins Modell
Es gibt eine Eins-zu-Eins-Beziehung zwischen Thread auf Benutzerebene und Thread auf Kernelebene. Dieses Modell bietet mehr Parallelität als das Viele-zu-Eins-Modell. Außerdem kann ein anderer Thread ausgeführt werden, wenn ein Thread einen blockierenden Systemaufruf ausführt. Es unterstützt mehrere Threads, die parallel auf Mikroprozessoren ausgeführt werden.
Nachteil dieses Modells ist, dass zum Erstellen eines Benutzer-Threads der entsprechende Kernel-Thread erforderlich ist. OS / 2, Windows NT und Windows 2000 verwenden ein Eins-zu-Eins-Beziehungsmodell.
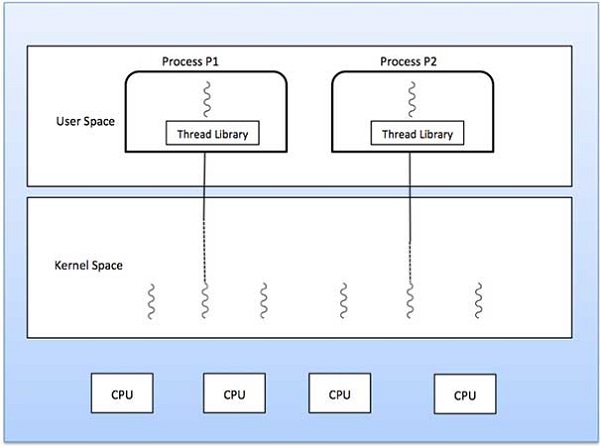
Unterschied zwischen Thread auf Benutzerebene und Kernel-Ebene
| SN | Threads auf Benutzerebene | Thread auf Kernebene |
|---|---|---|
| 1 | Threads auf Benutzerebene lassen sich schneller erstellen und verwalten. | Threads auf Kernel-Ebene lassen sich langsamer erstellen und verwalten. |
| 2 | Die Implementierung erfolgt durch eine Thread-Bibliothek auf Benutzerebene. | Das Betriebssystem unterstützt die Erstellung von Kernel-Threads. |
| 3 | Thread auf Benutzerebene ist generisch und kann auf jedem Betriebssystem ausgeführt werden. | Thread auf Kernel-Ebene ist spezifisch für das Betriebssystem. |
| 4 | Multithread-Anwendungen können Multiprocessing nicht nutzen. | Kernel-Routinen selbst können Multithread-fähig sein. |
Speicherverwaltung ist die Funktionalität eines Betriebssystems, das den Primärspeicher verwaltet oder verwaltet und Prozesse während der Ausführung zwischen Hauptspeicher und Festplatte hin und her bewegt. Die Speicherverwaltung verfolgt jeden Speicherort, unabhängig davon, ob er einem Prozess zugeordnet ist oder kostenlos ist. Es wird geprüft, wie viel Speicher Prozessen zugewiesen werden soll. Es entscheidet, welcher Prozess zu welcher Zeit Speicher erhält. Es verfolgt, wann immer Speicher freigegeben oder nicht zugewiesen wird, und aktualisiert entsprechend den Status.
In diesem Tutorial lernen Sie grundlegende Konzepte zur Speicherverwaltung kennen.
Adressraum verarbeiten
Der Prozessadressraum ist der Satz logischer Adressen, auf die ein Prozess in seinem Code verweist. Wenn beispielsweise eine 32-Bit-Adressierung verwendet wird, können die Adressen zwischen 0 und 0x7fffffff liegen. das sind 2 ^ 31 mögliche Zahlen für eine theoretische Gesamtgröße von 2 Gigabyte.
Das Betriebssystem kümmert sich um die Zuordnung der logischen Adressen zu physischen Adressen zum Zeitpunkt der Speicherzuweisung an das Programm. Es gibt drei Arten von Adressen, die in einem Programm vor und nach der Speicherzuweisung verwendet werden:
| SN | Speicheradressen & Beschreibung |
|---|---|
| 1 | Symbolic addresses Die in einem Quellcode verwendeten Adressen. Die Variablennamen, Konstanten und Anweisungsbezeichnungen sind die Grundelemente des symbolischen Adressraums. |
| 2 | Relative addresses Zum Zeitpunkt der Kompilierung konvertiert ein Compiler symbolische Adressen in relative Adressen. |
| 3 | Physical addresses Der Loader generiert diese Adressen zu dem Zeitpunkt, an dem ein Programm in den Hauptspeicher geladen wird. |
Virtuelle und physische Adressen sind in Adressbindungsschemata zur Kompilierungs- und Ladezeit identisch. Virtuelle und physische Adressen unterscheiden sich im Adressbindungsschema zur Ausführungszeit.
Die Menge aller von einem Programm generierten logischen Adressen wird als bezeichnet logical address space. Die Menge aller diesen logischen Adressen entsprechenden physischen Adressen wird als bezeichnetphysical address space.
Die Laufzeitzuordnung von der virtuellen zur physischen Adresse erfolgt durch die Speicherverwaltungseinheit (MMU), bei der es sich um ein Hardwaregerät handelt. Die MMU verwendet den folgenden Mechanismus, um die virtuelle Adresse in eine physische Adresse umzuwandeln.
Der Wert im Basisregister wird zu jeder von einem Benutzerprozess generierten Adresse addiert, die zum Zeitpunkt des Sendens an den Speicher als Offset behandelt wird. Wenn der Basisregisterwert beispielsweise 10000 ist, wird ein Versuch des Benutzers, den Adressort 100 zu verwenden, dynamisch dem Ort 10100 neu zugewiesen.
Das Anwenderprogramm befasst sich mit virtuellen Adressen; es sieht nie die realen physischen Adressen.
Statisches vs dynamisches Laden
Die Wahl zwischen statischem oder dynamischem Laden muss zum Zeitpunkt der Entwicklung des Computerprogramms getroffen werden. Wenn Sie Ihr Programm statisch laden müssen, werden zum Zeitpunkt der Kompilierung die vollständigen Programme kompiliert und verknüpft, ohne dass eine externe Programm- oder Modulabhängigkeit verbleibt. Der Linker kombiniert das Objektprogramm mit anderen notwendigen Objektmodulen zu einem absoluten Programm, das auch logische Adressen enthält.
Wenn Sie ein dynamisch geladenes Programm schreiben, kompiliert Ihr Compiler das Programm. Für alle Module, die Sie dynamisch einschließen möchten, werden nur Referenzen bereitgestellt und der Rest der Arbeit wird zum Zeitpunkt der Ausführung ausgeführt.
Zum Zeitpunkt des Ladens mit static loadingwird das absolute Programm (und die Daten) in den Speicher geladen, damit die Ausführung beginnen kann.
Wenn Sie verwenden dynamic loadingDynamische Routinen der Bibliothek werden in verschiebbarer Form auf einer Festplatte gespeichert und nur dann in den Speicher geladen, wenn sie vom Programm benötigt werden.
Statische und dynamische Verknüpfung
Wie oben erläutert, kombiniert der Linker bei Verwendung der statischen Verknüpfung alle anderen Module, die von einem Programm benötigt werden, zu einem einzigen ausführbaren Programm, um Laufzeitabhängigkeiten zu vermeiden.
Wenn die dynamische Verknüpfung verwendet wird, muss das eigentliche Modul oder die Bibliothek nicht mit dem Programm verknüpft werden. Zum Zeitpunkt der Kompilierung und Verknüpfung wird lediglich ein Verweis auf das dynamische Modul bereitgestellt. Dynamic Link Libraries (DLL) in Windows und Shared Objects in Unix sind gute Beispiele für dynamische Bibliotheken.
Tauschen
Das Auslagern ist ein Mechanismus, bei dem ein Prozess vorübergehend aus dem Hauptspeicher (oder dem Verschieben) in den Sekundärspeicher (Festplatte) ausgelagert werden kann und diesen Speicher anderen Prozessen zur Verfügung stellt. Zu einem späteren Zeitpunkt tauscht das System den Prozess vom sekundären Speicher in den Hauptspeicher zurück.
Die Leistung wird normalerweise durch den Austauschprozess beeinträchtigt, hilft jedoch dabei, mehrere und große Prozesse parallel auszuführen, und das ist der Grund Swapping is also known as a technique for memory compaction.

Die Gesamtzeit, die der Austauschprozess benötigt, umfasst die Zeit, die benötigt wird, um den gesamten Prozess auf eine sekundäre Festplatte zu verschieben und den Prozess dann wieder in den Speicher zu kopieren, sowie die Zeit, die der Prozess benötigt, um den Hauptspeicher wiederzugewinnen.
Nehmen wir an, dass der Benutzerprozess eine Größe von 2048 KB hat und auf einer Standardfestplatte, auf der der Austausch stattfindet, eine Datenübertragungsrate von etwa 1 MB pro Sekunde aufweist. Die eigentliche Übertragung des 1000K-Prozesses in oder aus dem Speicher dauert
2048KB / 1024KB per second
= 2 seconds
= 2000 millisecondsWenn man nun die Ein- und Aus-Zeit berücksichtigt, dauert es komplette 4000 Millisekunden plus anderen Overhead, wenn der Prozess um die Wiederherstellung des Hauptspeichers konkurriert.
Speicherzuweisung
Der Hauptspeicher besteht normalerweise aus zwei Partitionen -
Low Memory - Das Betriebssystem befindet sich in diesem Speicher.
High Memory - Benutzerprozesse werden in einem hohen Speicher gehalten.
Das Betriebssystem verwendet den folgenden Speicherzuweisungsmechanismus.
| SN | Speicherzuordnung & Beschreibung |
|---|---|
| 1 | Single-partition allocation Bei dieser Art der Zuordnung wird das Verschiebungsregisterschema verwendet, um Benutzerprozesse voreinander und vor dem Ändern von Betriebssystemcode und -daten zu schützen. Das Verschiebungsregister enthält den Wert der kleinsten physischen Adresse, während das Grenzregister den Bereich der logischen Adressen enthält. Jede logische Adresse muss kleiner als das Grenzregister sein. |
| 2 | Multiple-partition allocation Bei dieser Art der Zuordnung ist der Hauptspeicher in mehrere Partitionen fester Größe unterteilt, wobei jede Partition nur einen Prozess enthalten sollte. Wenn eine Partition frei ist, wird ein Prozess aus der Eingabewarteschlange ausgewählt und in die freie Partition geladen. Wenn der Prozess beendet wird, wird die Partition für einen anderen Prozess verfügbar. |
Zersplitterung
Wenn Prozesse geladen und aus dem Speicher entfernt werden, wird der freie Speicherplatz in kleine Teile zerlegt. Es kommt manchmal vor, dass Prozesse aufgrund ihrer geringen Größe nicht Speicherblöcken zugeordnet werden können und Speicherblöcke nicht verwendet werden. Dieses Problem wird als Fragmentierung bezeichnet.
Es gibt zwei Arten der Fragmentierung:
| SN | Fragmentierung & Beschreibung |
|---|---|
| 1 | External fragmentation Der gesamte Speicherplatz reicht aus, um eine Anforderung zu erfüllen oder einen Prozess darin zu speichern. Er ist jedoch nicht zusammenhängend und kann daher nicht verwendet werden. |
| 2 | Internal fragmentation Der dem Prozess zugewiesene Speicherblock ist größer. Ein Teil des Speichers bleibt ungenutzt, da er nicht von einem anderen Prozess verwendet werden kann. |
Das folgende Diagramm zeigt, wie Fragmentierung zu Speicherverschwendung führen kann, und eine Komprimierungstechnik kann verwendet werden, um aus fragmentiertem Speicher mehr freien Speicher zu erstellen.
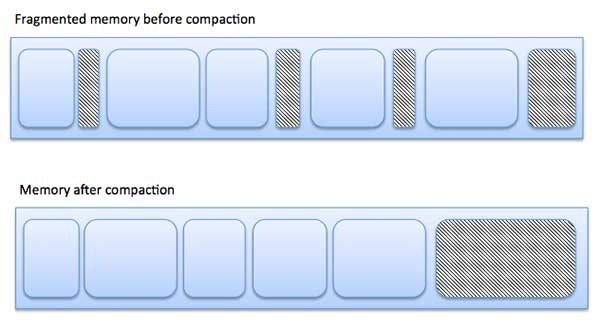
Die externe Fragmentierung kann durch Komprimieren oder Mischen von Speicherinhalten reduziert werden, um den gesamten freien Speicher in einem großen Block zusammenzufassen. Um eine Verdichtung zu ermöglichen, sollte die Verlagerung dynamisch sein.
Die interne Fragmentierung kann reduziert werden, indem die kleinste Partition effektiv zugewiesen wird, die jedoch groß genug für den Prozess ist.
Paging
Ein Computer kann mehr Speicher adressieren als physisch auf dem System installiert ist. Dieser zusätzliche Speicher wird eigentlich als virtueller Speicher bezeichnet und ist ein Teil eines Hard, der so eingerichtet ist, dass er den RAM des Computers emuliert. Die Paging-Technik spielt eine wichtige Rolle bei der Implementierung des virtuellen Speichers.
Paging ist eine Speicherverwaltungstechnik, bei der der Prozessadressraum in Blöcke derselben Größe unterteilt wird pages(Größe ist Potenz von 2, zwischen 512 Bytes und 8192 Bytes). Die Größe des Prozesses wird in der Anzahl der Seiten gemessen.
In ähnlicher Weise ist der Hauptspeicher in kleine (physische) Speicherblöcke fester Größe unterteilt, die aufgerufen werden frames und die Größe eines Rahmens wird gleich der einer Seite gehalten, um den Hauptspeicher optimal zu nutzen und eine externe Fragmentierung zu vermeiden.

Adressübersetzung
Seitenadresse wird aufgerufen logical address und vertreten durch page number und die offset.
Logical Address = Page number + page offsetFrame-Adresse wird aufgerufen physical address und vertreten durch a frame number und die offset.
Physical Address = Frame number + page offsetEine Datenstruktur namens page map table wird verwendet, um die Beziehung zwischen einer Seite eines Prozesses und einem Frame im physischen Speicher zu verfolgen.

Wenn das System einer Seite einen Frame zuweist, übersetzt es diese logische Adresse in eine physische Adresse und erstellt einen Eintrag in die Seitentabelle, der während der Ausführung des Programms verwendet wird.
Wenn ein Prozess ausgeführt werden soll, werden die entsprechenden Seiten in alle verfügbaren Speicherrahmen geladen. Angenommen, Sie haben ein Programm von 8 KB, aber Ihr Speicher kann zu einem bestimmten Zeitpunkt nur 5 KB aufnehmen, dann wird das Paging-Konzept ins Bild gesetzt. Wenn einem Computer der Arbeitsspeicher ausgeht, verschiebt das Betriebssystem (OS) inaktive oder unerwünschte Speicherseiten in den Sekundärspeicher, um RAM für andere Prozesse freizugeben, und bringt sie zurück, wenn dies vom Programm benötigt wird.
Dieser Vorgang wird während der gesamten Programmausführung fortgesetzt, wobei das Betriebssystem immer wieder inaktive Seiten aus dem Hauptspeicher entfernt, in den Sekundärspeicher schreibt und bei Bedarf vom Programm zurückbringt.
Vor- und Nachteile von Paging
Hier ist eine Liste der Vor- und Nachteile von Paging -
Paging reduziert die externe Fragmentierung, leidet jedoch immer noch unter interner Fragmentierung.
Paging ist einfach zu implementieren und wird als effiziente Speicherverwaltungstechnik angenommen.
Aufgrund der gleichen Größe der Seiten und Rahmen wird das Austauschen sehr einfach.
Die Seitentabelle benötigt zusätzlichen Speicherplatz und ist daher möglicherweise nicht für ein System mit kleinem RAM geeignet.
Segmentierung
Die Segmentierung ist eine Speicherverwaltungstechnik, bei der jeder Job in mehrere Segmente unterschiedlicher Größe unterteilt wird, eines für jedes Modul, das Teile enthält, die verwandte Funktionen ausführen. Jedes Segment ist tatsächlich ein anderer logischer Adressraum des Programms.
Wenn ein Prozess ausgeführt werden soll, wird seine entsprechende Segmentierung in einen nicht zusammenhängenden Speicher geladen, obwohl jedes Segment in einen zusammenhängenden Block des verfügbaren Speichers geladen wird.
Die Segmentierungsspeicherverwaltung funktioniert sehr ähnlich wie Paging, aber hier haben Segmente eine variable Länge, während Seiten wie bei Paging eine feste Größe haben.
Ein Programmsegment enthält die Hauptfunktion des Programms, Dienstprogrammfunktionen, Datenstrukturen usw. Das Betriebssystem verwaltet asegment map tablefür jeden Prozess und eine Liste der freien Speicherblöcke zusammen mit den Segmentnummern, ihrer Größe und den entsprechenden Speicherplätzen im Hauptspeicher. In der Tabelle werden für jedes Segment die Startadresse des Segments und die Länge des Segments gespeichert. Ein Verweis auf einen Speicherort enthält einen Wert, der ein Segment und einen Versatz identifiziert.

Ein Computer kann mehr Speicher adressieren als physisch auf dem System installiert ist. Dieser zusätzliche Speicher wird tatsächlich aufgerufenvirtual memory und es ist ein Abschnitt einer Festplatte, der so eingerichtet ist, dass er den RAM des Computers emuliert.
Der sichtbare Hauptvorteil dieses Schemas besteht darin, dass Programme größer als der physische Speicher sein können. Der virtuelle Speicher dient zwei Zwecken. Erstens können wir die Verwendung des physischen Speichers mithilfe der Festplatte erweitern. Zweitens können wir Speicherschutz haben, da jede virtuelle Adresse in eine physische Adresse übersetzt wird.
Es folgen die Situationen, in denen nicht das gesamte Programm vollständig in den Hauptspeicher geladen werden muss.
Vom Benutzer geschriebene Fehlerbehandlungsroutinen werden nur verwendet, wenn ein Fehler in den Daten oder in der Berechnung aufgetreten ist.
Bestimmte Optionen und Funktionen eines Programms werden möglicherweise nur selten verwendet.
Vielen Tabellen wird ein fester Adressraum zugewiesen, obwohl nur ein kleiner Teil der Tabelle tatsächlich verwendet wird.
Die Fähigkeit, ein Programm auszuführen, das sich nur teilweise im Speicher befindet, würde vielen Vorteilen entgegenwirken.
Zum Laden oder Austauschen jedes Benutzerprogramms in den Speicher wäre weniger E / A erforderlich.
Ein Programm würde nicht länger durch die Menge des verfügbaren physischen Speichers eingeschränkt.
Jedes Benutzerprogramm könnte weniger physischen Speicher beanspruchen, mehr Programme könnten gleichzeitig ausgeführt werden, mit einer entsprechenden Erhöhung der CPU-Auslastung und des Durchsatzes.
In die Hardware sind moderne Mikroprozessoren eingebaut, die für den allgemeinen Gebrauch bestimmt sind, eine Speicherverwaltungseinheit oder MMU. Die Aufgabe der MMU besteht darin, virtuelle Adressen in physische Adressen zu übersetzen. Ein grundlegendes Beispiel ist unten angegeben -
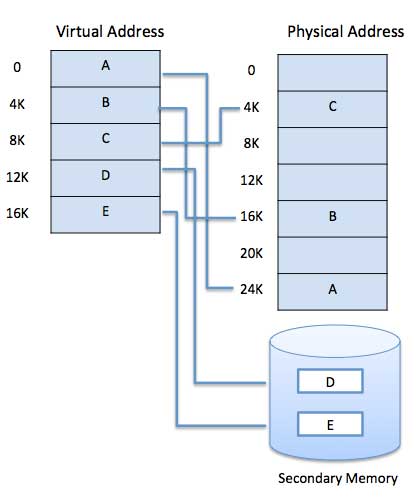
Virtueller Speicher wird üblicherweise durch Demand Paging implementiert. Es kann auch in einem Segmentierungssystem implementiert werden. Die Anforderungssegmentierung kann auch zur Bereitstellung von virtuellem Speicher verwendet werden.
Paging anfordern
Ein Demand-Paging-System ähnelt einem Paging-System mit Swapping, bei dem sich Prozesse im Sekundärspeicher befinden und Seiten nur bei Bedarf und nicht im Voraus geladen werden. Wenn ein Kontextwechsel auftritt, kopiert das Betriebssystem keine der Seiten des alten Programms auf die Festplatte oder eine der Seiten des neuen Programms in den Hauptspeicher. Stattdessen beginnt es erst nach dem Laden der ersten Seite mit der Ausführung des neuen Programms und ruft diese ab Programm-Seiten, wie sie referenziert werden.
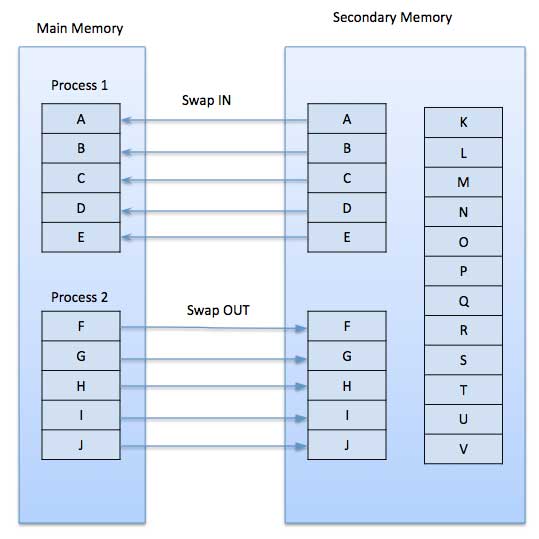
Wenn das Programm beim Ausführen eines Programms auf eine Seite verweist, die nicht im Hauptspeicher verfügbar ist, weil sie vor einiger Zeit ausgetauscht wurde, behandelt der Prozessor diese ungültige Speicherreferenz als page fault und überträgt die Steuerung vom Programm auf das Betriebssystem, um die Seite zurück in den Speicher zu fordern.
Vorteile
Im Folgenden sind die Vorteile von Demand Paging aufgeführt:
- Großer virtueller Speicher.
- Effizientere Speichernutzung.
- Der Grad der Mehrfachprogrammierung ist unbegrenzt.
Nachteile
Die Anzahl der Tabellen und der Prozessoraufwand für die Behandlung von Seiteninterrupts sind größer als bei den einfachen Seitenverwaltungstechniken.
Algorithmus zum Ersetzen von Seiten
Seitenersetzungsalgorithmen sind die Techniken, mit denen ein Betriebssystem entscheidet, welche Speicherseiten ausgetauscht werden sollen, und auf die Festplatte geschrieben werden soll, wenn eine Speicherseite zugewiesen werden muss. Paging tritt immer dann auf, wenn ein Seitenfehler auftritt und eine freie Seite nicht für Zuordnungszwecke verwendet werden kann, da Seiten nicht verfügbar sind oder die Anzahl der freien Seiten geringer als die erforderlichen Seiten ist.
Wenn die Seite, die zum Ersetzen ausgewählt und ausgelagert wurde, erneut referenziert wird, muss sie von der Festplatte eingelesen werden. Dies erfordert den Abschluss der E / A. Dieser Prozess bestimmt die Qualität des Seitenersetzungsalgorithmus: Je weniger Zeit auf Seiteneinträge gewartet wird, desto besser ist der Algorithmus.
Ein Seitenersetzungsalgorithmus untersucht die begrenzten Informationen zum Zugriff auf die von der Hardware bereitgestellten Seiten und versucht auszuwählen, welche Seiten ersetzt werden sollen, um die Gesamtzahl der Seitenfehler zu minimieren, während er mit den Kosten für Primärspeicher und Prozessorzeit des Algorithmus in Einklang gebracht wird selbst. Es gibt viele verschiedene Algorithmen zum Ersetzen von Seiten. Wir bewerten einen Algorithmus, indem wir ihn auf einer bestimmten Zeichenfolge von Speicherreferenzen ausführen und die Anzahl der Seitenfehler berechnen.
Referenzzeichenfolge
Die Zeichenfolge der Speicherreferenzen wird als Referenzzeichenfolge bezeichnet. Referenzzeichenfolgen werden künstlich oder durch Verfolgen eines bestimmten Systems und Aufzeichnen der Adresse jeder Speicherreferenz erzeugt. Die letztere Wahl erzeugt eine große Anzahl von Daten, wobei wir zwei Dinge beachten.
Für eine bestimmte Seitengröße müssen wir nur die Seitenzahl berücksichtigen, nicht die gesamte Adresse.
Wenn wir einen Verweis auf eine Seite haben p, dann alle unmittelbar folgenden Verweise auf Seite pwird niemals einen Seitenfehler verursachen. Seite p wird nach der ersten Referenz gespeichert; Die unmittelbar folgenden Referenzen sind nicht fehlerhaft.
Betrachten Sie beispielsweise die folgende Folge von Adressen: 123,215,600,1234,76,96
Wenn die Seitengröße 100 beträgt, lautet die Referenzzeichenfolge 1,2,6,12,0,0
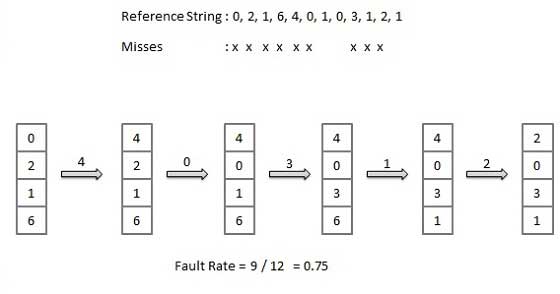
FIFO-Algorithmus (First In First Out)
Die älteste Seite im Hauptspeicher ist diejenige, die zum Ersetzen ausgewählt wird.
Einfach zu implementieren, eine Liste zu führen, Seiten vom Ende zu ersetzen und neue Seiten am Kopf hinzuzufügen.
Optimaler Seitenalgorithmus
Ein optimaler Algorithmus zum Ersetzen von Seiten weist die niedrigste Seitenfehlerrate aller Algorithmen auf. Es gibt einen optimalen Algorithmus zum Ersetzen von Seiten, der als OPT oder MIN bezeichnet wurde.
Ersetzen Sie die Seite, die am längsten nicht verwendet wird. Verwenden Sie die Zeit, zu der eine Seite verwendet werden soll.

LRU-Algorithmus (Least Recent Used)
Die Seite, die am längsten nicht im Hauptspeicher verwendet wurde, wird zum Ersetzen ausgewählt.
Einfach zu implementieren, eine Liste zu führen, Seiten zu ersetzen, indem Sie in die Zeit zurückblicken.

Seitenpufferungsalgorithmus
- Halten Sie einen Pool freier Frames bereit, damit ein Prozess schnell startet.
- Wählen Sie bei einem Seitenfehler eine Seite aus, die ersetzt werden soll.
- Schreiben Sie die neue Seite in den Rahmen des freien Pools, markieren Sie die Seitentabelle und starten Sie den Prozess neu.
- Schreiben Sie nun die schmutzige Seite von der Festplatte und legen Sie den Rahmen mit der ersetzten Seite in den freien Pool.
Am wenigsten häufig verwendeter (LFU) Algorithmus
Die Seite mit der geringsten Anzahl wird zum Ersetzen ausgewählt.
Dieser Algorithmus leidet unter der Situation, dass eine Seite in der Anfangsphase eines Prozesses häufig verwendet wird, dann aber nie wieder verwendet wird.
Am häufigsten verwendeter (MFU) Algorithmus
Dieser Algorithmus basiert auf dem Argument, dass die Seite mit der geringsten Anzahl wahrscheinlich gerade erst eingefügt wurde und noch verwendet werden muss.
Eine der wichtigsten Aufgaben eines Betriebssystems ist die Verwaltung verschiedener E / A-Geräte, einschließlich Maus, Tastaturen, Touchpad, Festplatten, Anzeigeadapter, USB-Geräte, Bitmap-Bildschirm, LED, Analog-Digital-Wandler, Ein / Aus-Schalter, Netzwerkverbindungen, Audio-E / A, Drucker usw.
Ein E / A-System ist erforderlich, um eine Anwendungs-E / A-Anforderung entgegenzunehmen und an das physische Gerät zu senden. Nehmen Sie dann die vom Gerät zurückgegebene Antwort entgegen und senden Sie sie an die Anwendung. E / A-Geräte können in zwei Kategorien unterteilt werden:
Block devices- Ein Blockgerät ist eines, mit dem der Treiber kommuniziert, indem er ganze Datenblöcke sendet. Zum Beispiel Festplatten, USB-Kameras, Disk-On-Key usw.
Character devices- Ein Zeichengerät ist ein Gerät, mit dem der Treiber durch Senden und Empfangen einzelner Zeichen (Bytes, Oktette) kommuniziert. Zum Beispiel serielle Ports, parallele Ports, Soundkarten usw.
Gerätesteuerungen
Gerätetreiber sind Softwaremodule, die an ein Betriebssystem angeschlossen werden können, um ein bestimmtes Gerät zu handhaben. Das Betriebssystem hilft den Gerätetreibern bei der Handhabung aller E / A-Geräte.
Der Gerätecontroller funktioniert wie eine Schnittstelle zwischen einem Gerät und einem Gerätetreiber. E / A-Einheiten (Tastatur, Maus, Drucker usw.) bestehen normalerweise aus einer mechanischen Komponente und einer elektronischen Komponente, wobei die elektronische Komponente als Gerätesteuerung bezeichnet wird.
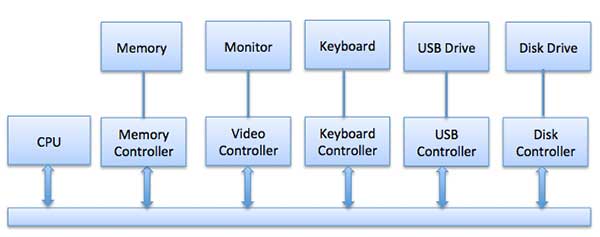
Für jedes Gerät gibt es immer einen Gerätecontroller und einen Gerätetreiber für die Kommunikation mit den Betriebssystemen. Ein Gerätecontroller kann möglicherweise mehrere Geräte verarbeiten. Als Schnittstelle besteht die Hauptaufgabe darin, den seriellen Bitstrom in einen Byteblock umzuwandeln und bei Bedarf eine Fehlerkorrektur durchzuführen.
Jedes an den Computer angeschlossene Gerät ist über einen Stecker und eine Buchse verbunden, und die Buchse ist mit einer Gerätesteuerung verbunden. Im Folgenden finden Sie ein Modell zum Anschließen von CPU, Speicher, Controllern und E / A-Geräten, bei dem CPU und Gerätesteuerungen einen gemeinsamen Bus für die Kommunikation verwenden.
Synchrone vs asynchrone E / A.
Synchronous I/O - In diesem Schema wartet die CPU-Ausführung, während die E / A fortgesetzt wird
Asynchronous I/O - Die E / A wird gleichzeitig mit der CPU-Ausführung fortgesetzt
Kommunikation mit E / A-Geräten
Die CPU muss über eine Möglichkeit verfügen, Informationen an und von einem E / A-Gerät weiterzuleiten. Für die Kommunikation mit der CPU und dem Gerät stehen drei Ansätze zur Verfügung.
- Spezielle Anweisung I / O.
- Speicherzugeordnete E / A.
- Direkter Speicherzugriff (DMA)
Spezielle Anweisung I / O.
Hierbei werden CPU-Anweisungen verwendet, die speziell für die Steuerung von E / A-Geräten erstellt wurden. Mit diesen Anweisungen können normalerweise Daten an ein E / A-Gerät gesendet oder von einem E / A-Gerät gelesen werden.
Speicherzugeordnete E / A.
Bei Verwendung von speicherabgebildeten E / A wird der gleiche Adressraum von Speicher- und E / A-Geräten gemeinsam genutzt. Das Gerät ist direkt mit bestimmten Hauptspeicherplätzen verbunden, sodass das E / A-Gerät Datenblöcke zum / vom Speicher übertragen kann, ohne die CPU zu durchlaufen.
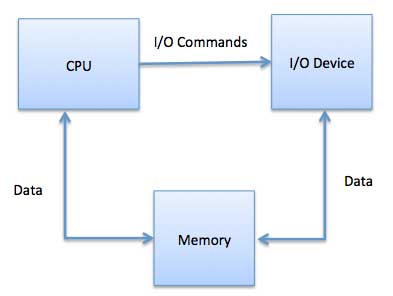
Während der Verwendung von speicherabgebildeten E / A weist das Betriebssystem Puffer im Speicher zu und weist das E / A-Gerät an, diesen Puffer zum Senden von Daten an die CPU zu verwenden. Das E / A-Gerät arbeitet asynchron mit der CPU und unterbricht die CPU, wenn es fertig ist.
Der Vorteil dieser Methode besteht darin, dass jeder Befehl, der auf den Speicher zugreifen kann, zum Manipulieren eines E / A-Geräts verwendet werden kann. Speicherzugeordnete E / A werden für die meisten Hochgeschwindigkeits-E / A-Geräte wie Festplatten und Kommunikationsschnittstellen verwendet.
Direkter Speicherzugriff (DMA)
Langsame Geräte wie Tastaturen erzeugen nach der Übertragung jedes Bytes einen Interrupt zur Haupt-CPU. Wenn ein schnelles Gerät wie eine Festplatte für jedes Byte einen Interrupt generiert, verbringt das Betriebssystem die meiste Zeit damit, diese Interrupts zu verarbeiten. Ein typischer Computer verwendet daher DMA-Hardware (Direct Memory Access), um diesen Overhead zu reduzieren.
Direkter Speicherzugriff (DMA) bedeutet, dass die CPU dem E / A-Modul die Berechtigung erteilt, ohne Beteiligung aus dem Speicher zu lesen oder in diesen zu schreiben. Das DMA-Modul selbst steuert den Datenaustausch zwischen dem Hauptspeicher und dem E / A-Gerät. Die CPU ist nur zu Beginn und am Ende der Übertragung beteiligt und wird erst unterbrochen, nachdem der gesamte Block übertragen wurde.
Der direkte Speicherzugriff erfordert eine spezielle Hardware namens DMA-Controller (DMAC), die die Datenübertragungen verwaltet und den Zugriff auf den Systembus vermittelt. Die Steuerungen sind mit Quell- und Zielzeigern (wo die Daten gelesen / geschrieben werden sollen), Zählern zum Verfolgen der Anzahl der übertragenen Bytes und Einstellungen programmiert, die E / A- und Speichertypen, Interrupts und Zustände für die CPU-Zyklen umfassen.
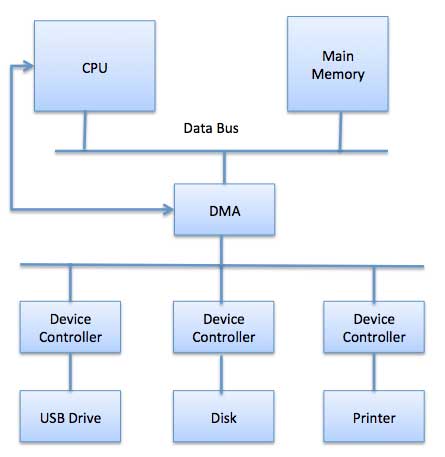
Das Betriebssystem verwendet die DMA-Hardware wie folgt:
| Schritt | Beschreibung |
|---|---|
| 1 | Der Gerätetreiber wird angewiesen, Datenträgerdaten an eine Pufferadresse X zu übertragen. |
| 2 | Der Gerätetreiber weist den Festplattencontroller an, Daten in den Puffer zu übertragen. |
| 3 | Der Festplattencontroller startet die DMA-Übertragung. |
| 4 | Der Festplattencontroller sendet jedes Byte an den DMA-Controller. |
| 5 | Der DMA-Controller überträgt Bytes in den Puffer, erhöht die Speicheradresse und verringert den Zähler C, bis C Null wird. |
| 6 | Wenn C Null wird, unterbricht DMA die CPU, um den Abschluss der Übertragung zu signalisieren. |
Polling vs Interrupts I / O.
Ein Computer muss in der Lage sein, das Eintreffen jeglicher Art von Eingabe zu erkennen. Dies kann auf zwei Arten geschehen:polling und interrupts. Beide Techniken ermöglichen es dem Prozessor, Ereignisse zu verarbeiten, die jederzeit auftreten können und die nicht mit dem aktuell ausgeführten Prozess zusammenhängen.
Polling I / O.
Polling ist die einfachste Möglichkeit für ein E / A-Gerät, mit dem Prozessor zu kommunizieren. Der Vorgang der regelmäßigen Überprüfung des Status des Geräts, um festzustellen, ob es Zeit für den nächsten E / A-Vorgang ist, wird als Abfrage bezeichnet. Das E / A-Gerät legt die Informationen einfach in einem Statusregister ab, und der Prozessor muss kommen und die Informationen abrufen.
In den meisten Fällen benötigen Geräte keine Aufmerksamkeit, und wenn dies der Fall ist, muss gewartet werden, bis sie das nächste Mal vom Abrufprogramm abgefragt werden. Dies ist eine ineffiziente Methode, und ein Großteil der Prozessorzeit wird für unnötige Abfragen verschwendet.
Vergleichen Sie diese Methode mit einem Lehrer, der jeden Schüler einer Klasse nacheinander fragt, ob er Hilfe benötigt. Offensichtlich wäre die effizientere Methode für einen Schüler, den Lehrer zu informieren, wann immer er Hilfe benötigt.
Unterbricht die E / A.
Ein alternatives Schema für den Umgang mit E / A ist die Interrupt-gesteuerte Methode. Ein Interrupt ist ein Signal an den Mikroprozessor von einem Gerät, das Aufmerksamkeit erfordert.
Eine Gerätesteuerung legt ein Interrupt-Signal auf den Bus, wenn sie die Aufmerksamkeit der CPU benötigt, wenn die CPU einen Interrupt empfängt. Sie speichert ihren aktuellen Status und ruft den entsprechenden Interrupt-Handler unter Verwendung des Interrupt-Vektors auf (Adressen von Betriebssystemroutinen zur Behandlung verschiedener Ereignisse). Wenn das unterbrechende Gerät behandelt wurde, setzt die CPU ihre ursprüngliche Aufgabe fort, als wäre sie nie unterbrochen worden.
E / A-Software ist häufig in den folgenden Ebenen organisiert:
User Level Libraries- Dies bietet eine einfache Schnittstelle zum Anwenderprogramm zur Durchführung von Ein- und Ausgaben. Zum Beispiel,stdio ist eine Bibliothek, die von den Programmiersprachen C und C ++ bereitgestellt wird.
Kernel Level Modules - Dadurch können Gerätetreiber mit dem Gerätesteuerer und geräteunabhängigen E / A-Modulen interagieren, die von den Gerätetreibern verwendet werden.
Hardware - Diese Schicht enthält die eigentliche Hardware und den Hardware-Controller, die mit den Gerätetreibern interagieren und die Hardware lebendig machen.
Ein Schlüsselkonzept beim Entwurf von E / A-Software besteht darin, dass sie geräteunabhängig sein sollte, wenn es möglich sein sollte, Programme zu schreiben, die auf jedes E / A-Gerät zugreifen können, ohne das Gerät im Voraus angeben zu müssen. Beispielsweise sollte ein Programm, das eine Datei als Eingabe liest, eine Datei auf einer Diskette, einer Festplatte oder einer CD-ROM lesen können, ohne das Programm für jedes Gerät ändern zu müssen.
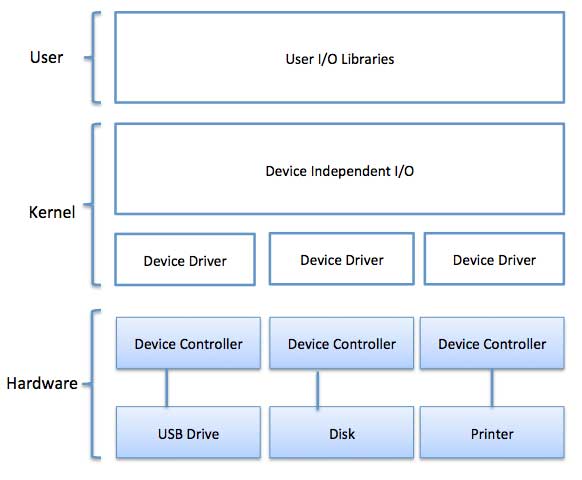
Gerätetreiber
Gerätetreiber sind Softwaremodule, die an ein Betriebssystem angeschlossen werden können, um ein bestimmtes Gerät zu handhaben. Das Betriebssystem hilft den Gerätetreibern bei der Handhabung aller E / A-Geräte. Gerätetreiber kapseln geräteabhängigen Code und implementieren eine Standardschnittstelle so, dass Code gerätespezifische Registerlese- / Schreibvorgänge enthält. Der Gerätetreiber wird in der Regel vom Gerätehersteller geschrieben und zusammen mit dem Gerät auf einer CD-ROM geliefert.
Ein Gerätetreiber führt die folgenden Jobs aus:
- Um Anfragen von der oben genannten geräteunabhängigen Software zu akzeptieren.
- Interagieren Sie mit der Gerätesteuerung, um E / A zu erfassen und zu geben und die erforderliche Fehlerbehandlung durchzuführen
- Stellen Sie sicher, dass die Anforderung erfolgreich ausgeführt wird
Ein Gerätetreiber verarbeitet eine Anforderung wie folgt: Angenommen, eine Anforderung kommt zum Lesen eines Blocks N. Wenn der Treiber zum Zeitpunkt des Eingangs einer Anforderung inaktiv ist, beginnt er sofort mit der Ausführung der Anforderung. Wenn der Treiber bereits mit einer anderen Anforderung beschäftigt ist, wird die neue Anforderung in die Warteschlange ausstehender Anforderungen gestellt.
Handler unterbrechen
Ein Interrupt-Handler, auch als Interrupt-Serviceroutine oder ISR bekannt, ist eine Software oder genauer gesagt eine Rückruffunktion in einem Betriebssystem oder insbesondere in einem Gerätetreiber, dessen Ausführung durch den Empfang eines Interrupts ausgelöst wird.
Wenn der Interrupt auftritt, unternimmt die Interrupt-Prozedur alles, um den Interrupt zu behandeln, aktualisiert Datenstrukturen und aktiviert den Prozess, der auf einen Interrupt gewartet hat.
Der Interrupt-Mechanismus akzeptiert eine Adresse ─ eine Nummer, die eine bestimmte Interrupt-Behandlungsroutine / -funktion aus einem kleinen Satz auswählt. In den meisten Architekturen ist diese Adresse ein Offset, der in einer Tabelle gespeichert ist, die als Interrupt-Vektortabelle bezeichnet wird. Dieser Vektor enthält die Speicheradressen spezialisierter Interrupt-Handler.
Geräteunabhängige E / A-Software
Die Grundfunktion der geräteunabhängigen Software besteht darin, die allen Geräten gemeinsamen E / A-Funktionen auszuführen und eine einheitliche Schnittstelle zur Software auf Benutzerebene bereitzustellen. Es ist zwar schwierig, vollständig geräteunabhängige Software zu schreiben, aber wir können einige Module schreiben, die allen Geräten gemeinsam sind. Es folgt eine Liste der Funktionen der geräteunabhängigen E / A-Software -
- Einheitliche Schnittstelle für Gerätetreiber
- Gerätenamen - Mnemonische Namen, die den Haupt- und Nebengerätenummern zugeordnet sind
- Geräteschutz
- Bereitstellung einer geräteunabhängigen Blockgröße
- Pufferung, da Daten, die von einem Gerät kommen, nicht am endgültigen Ziel gespeichert werden können.
- Speicherzuordnung auf Blockgeräten
- Zuweisung und Freigabe dedizierter Geräte
- Fehler melden
User-Space-E / A-Software
Dies sind die Bibliotheken, die eine umfangreichere und vereinfachte Schnittstelle bieten, um auf die Funktionalität des Kernels zuzugreifen oder letztendlich mit den Gerätetreibern interaktiv zu sein. Der größte Teil der E / A-Software auf Benutzerebene besteht aus Bibliotheksprozeduren mit einigen Ausnahmen wie dem Spooling-System, mit dem dedizierte E / A-Geräte in einem Multiprogrammiersystem behandelt werden können.
E / A-Bibliotheken (z. B. stdio) befinden sich im Benutzerbereich, um eine Schnittstelle zur betriebsunabhängigen E / A-Software des Betriebssystems bereitzustellen. Zum Beispiel sind putchar (), getchar (), printf () und scanf () Beispiele für das in der C-Programmierung verfügbare E / A-Bibliotheks-Standard auf Benutzerebene.
Kernel-E / A-Subsystem
Das Kernel-E / A-Subsystem ist dafür verantwortlich, viele Dienste im Zusammenhang mit E / A bereitzustellen. Im Folgenden sind einige der angebotenen Dienstleistungen aufgeführt.
Scheduling- Der Kernel plant eine Reihe von E / A-Anforderungen, um eine gute Reihenfolge für die Ausführung festzulegen. Wenn eine Anwendung einen blockierenden E / A-Systemaufruf ausgibt, wird die Anforderung in die Warteschlange für dieses Gerät gestellt. Der Kernel-E / A-Scheduler ordnet die Reihenfolge der Warteschlange neu, um die Gesamtsystemeffizienz und die durchschnittliche Antwortzeit der Anwendungen zu verbessern.
Buffering - Das Kernel-E / A-Subsystem verwaltet einen Speicherbereich, der als bekannt ist bufferHier werden Daten gespeichert, während sie zwischen zwei Geräten oder zwischen einem Gerät mit einer Anwendungsoperation übertragen werden. Das Puffern wird durchgeführt, um eine Geschwindigkeitsinkongruenz zwischen dem Hersteller und dem Verbraucher eines Datenstroms zu bewältigen oder um sich zwischen Geräten anzupassen, die unterschiedliche Datenübertragungsgrößen haben.
Caching- Der Kernel verwaltet den Cache-Speicher, einen Bereich des schnellen Speichers, in dem Kopien von Daten gespeichert sind. Der Zugriff auf die zwischengespeicherte Kopie ist effizienter als der Zugriff auf das Original.
Spooling and Device Reservation- Ein Spool ist ein Puffer, der die Ausgabe für ein Gerät wie einen Drucker enthält, das keine verschachtelten Datenströme akzeptieren kann. Das Spooling-System kopiert die in die Warteschlange gestellten Spooldateien einzeln auf den Drucker. In einigen Betriebssystemen wird das Spoolen von einem Systemdämonprozess verwaltet. In anderen Betriebssystemen wird es von einem In-Kernel-Thread verarbeitet.
Error Handling - Ein Betriebssystem, das geschützten Speicher verwendet, kann sich vor vielen Arten von Hardware- und Anwendungsfehlern schützen.
Datei
Eine Datei ist eine benannte Sammlung verwandter Informationen, die auf einem Sekundärspeicher wie Magnetplatten, Magnetbändern und optischen Platten aufgezeichnet werden. Im Allgemeinen ist eine Datei eine Folge von Bits, Bytes, Zeilen oder Datensätzen, deren Bedeutung vom Ersteller und Benutzer der Datei definiert wird.
Dateistruktur
Eine Dateistruktur sollte einem erforderlichen Format entsprechen, das das Betriebssystem verstehen kann.
Eine Datei hat je nach Typ eine bestimmte definierte Struktur.
Eine Textdatei ist eine Folge von Zeichen, die in Zeilen angeordnet sind.
Eine Quelldatei ist eine Folge von Prozeduren und Funktionen.
Eine Objektdatei ist eine Folge von Bytes, die in Blöcken organisiert sind, die für die Maschine verständlich sind.
Wenn das Betriebssystem unterschiedliche Dateistrukturen definiert, enthält es auch den Code zur Unterstützung dieser Dateistruktur. Unix, MS-DOS unterstützt die Mindestanzahl an Dateistrukturen.
Dateityp
Der Dateityp bezieht sich auf die Fähigkeit des Betriebssystems, verschiedene Dateitypen wie Textdateien, Quelldateien und Binärdateien usw. zu unterscheiden. Viele Betriebssysteme unterstützen viele Dateitypen. Betriebssysteme wie MS-DOS und UNIX verfügen über die folgenden Dateitypen:
Gewöhnliche Dateien
- Dies sind die Dateien, die Benutzerinformationen enthalten.
- Diese können Text, Datenbanken oder ausführbare Programme enthalten.
- Der Benutzer kann verschiedene Vorgänge auf solche Dateien anwenden, z. B. das Hinzufügen, Ändern, Löschen oder sogar Entfernen der gesamten Datei.
Verzeichnisdateien
- Diese Dateien enthalten eine Liste der Dateinamen und andere Informationen zu diesen Dateien.
Spezielle Dateien
- Diese Dateien werden auch als Gerätedateien bezeichnet.
- Diese Dateien repräsentieren physische Geräte wie Festplatten, Terminals, Drucker, Netzwerke, Bandlaufwerke usw.
Es gibt zwei Arten von Dateien:
Character special files - Daten werden wie bei Terminals oder Druckern zeichenweise behandelt.
Block special files - Daten werden wie bei Festplatten und Bändern in Blöcken behandelt.
Dateizugriffsmechanismen
Der Dateizugriffsmechanismus bezieht sich auf die Art und Weise, wie auf die Datensätze einer Datei zugegriffen werden kann. Es gibt verschiedene Möglichkeiten, auf Dateien zuzugreifen -
- Sequentieller Zugriff
- Direkter / wahlfreier Zugriff
- Indizierter sequentieller Zugriff
Sequentieller Zugriff
Ein sequentieller Zugriff ist derjenige, bei dem auf die Datensätze in einer bestimmten Reihenfolge zugegriffen wird, dh die Informationen in der Datei werden der Reihe nach ein Datensatz nach dem anderen verarbeitet. Diese Zugriffsmethode ist die primitivste. Beispiel: Compiler greifen normalerweise auf diese Weise auf Dateien zu.
Direkter / wahlfreier Zugriff
Die Organisation von Dateien mit wahlfreiem Zugriff bietet direkten Zugriff auf die Datensätze.
Jeder Datensatz hat eine eigene Adresse in der Datei, mit deren Hilfe direkt auf ihn zum Lesen oder Schreiben zugegriffen werden kann.
Die Datensätze müssen sich nicht in einer beliebigen Reihenfolge innerhalb der Datei befinden und dürfen sich nicht an benachbarten Stellen auf dem Speichermedium befinden.
Indizierter sequentieller Zugriff
- Dieser Mechanismus basiert auf sequentiellem Zugriff.
- Für jede Datei wird ein Index erstellt, der Zeiger auf verschiedene Blöcke enthält.
- Der Index wird nacheinander durchsucht und sein Zeiger wird verwendet, um direkt auf die Datei zuzugreifen.
Platzzuweisung
Dateien werden vom Betriebssystem Speicherplätze zugewiesen. Betriebssysteme werden auf drei Hauptmethoden bereitgestellt, um Dateien Speicherplatz zuzuweisen.
- Aneinandergrenzende Zuordnung
- Verknüpfte Zuordnung
- Indizierte Zuordnung
Aneinandergrenzende Zuordnung
- Jede Datei belegt einen zusammenhängenden Adressraum auf der Festplatte.
- Die zugewiesene Plattenadresse ist in linearer Reihenfolge.
- Einfach zu implementieren.
- Die externe Fragmentierung ist ein Hauptproblem bei dieser Art der Zuordnungstechnik.
Verknüpfte Zuordnung
- Jede Datei enthält eine Liste von Links zu Plattenblöcken.
- Das Verzeichnis enthält einen Link / Zeiger auf den ersten Block einer Datei.
- Keine externe Fragmentierung
- Wird effektiv in Dateien mit sequenziellem Zugriff verwendet.
- Ineffizient bei Direktzugriffsdatei.
Indizierte Zuordnung
- Bietet Lösungen für Probleme der zusammenhängenden und verknüpften Zuordnung.
- Es wird ein Indexblock mit allen Zeigern auf Dateien erstellt.
- Jede Datei verfügt über einen eigenen Indexblock, in dem die Adressen des von der Datei belegten Speicherplatzes gespeichert sind.
- Das Verzeichnis enthält die Adressen der Indexblöcke von Dateien.
Sicherheit bezieht sich auf die Bereitstellung eines Schutzsystems für Computersystemressourcen wie CPU, Speicher, Festplatte, Softwareprogramme und vor allem Daten / Informationen, die im Computersystem gespeichert sind. Wenn ein Computerprogramm von einem nicht autorisierten Benutzer ausgeführt wird, kann dieser den Computer oder die darin gespeicherten Daten schwer beschädigen. Ein Computersystem muss daher vor unbefugtem Zugriff, böswilligem Zugriff auf Systemspeicher, Viren, Würmern usw. geschützt werden. In diesem Kapitel werden die folgenden Themen behandelt.
- Authentication
- Einmalpasswörter
- Programmbedrohungen
- Systembedrohungen
- Computersicherheitsklassifikationen
Authentifizierung
Die Authentifizierung bezieht sich auf die Identifizierung jedes Benutzers des Systems und die Zuordnung der ausgeführten Programme zu diesen Benutzern. Es liegt in der Verantwortung des Betriebssystems, ein Schutzsystem zu erstellen, das sicherstellt, dass ein Benutzer, der ein bestimmtes Programm ausführt, authentisch ist. Betriebssysteme identifizieren / authentifizieren Benutzer im Allgemeinen auf drei Arten:
Username / Password - Der Benutzer muss einen registrierten Benutzernamen und ein Passwort beim Betriebssystem eingeben, um sich beim System anzumelden.
User card/key - Der Benutzer muss die Karte in den Kartensteckplatz lochen oder den vom Schlüsselgenerator generierten Schlüssel in die vom Betriebssystem bereitgestellte Option eingeben, um sich beim System anzumelden.
User attribute - fingerprint/ eye retina pattern/ signature - Der Benutzer muss sein Attribut über ein bestimmtes Betriebssystem übergeben, das vom Betriebssystem verwendet wird, um sich beim System anzumelden.
Einmalpasswörter
Einmalkennwörter bieten neben der normalen Authentifizierung zusätzliche Sicherheit. Im Einmalkennwortsystem ist jedes Mal, wenn der Benutzer versucht, sich beim System anzumelden, ein eindeutiges Kennwort erforderlich. Sobald ein Einmalkennwort verwendet wurde, kann es nicht mehr verwendet werden. Einmalpasswörter werden auf verschiedene Arten implementiert.
Random numbers- Den Benutzern werden Karten mit Nummern und entsprechenden Alphabeten zur Verfügung gestellt. Das System fragt nach Zahlen, die wenigen zufällig ausgewählten Alphabeten entsprechen.
Secret key- Dem Benutzer wird ein Hardwaregerät zur Verfügung gestellt, mit dem eine geheime ID erstellt werden kann, die der Benutzer-ID zugeordnet ist. Das System fragt nach einer solchen geheimen ID, die jedes Mal vor der Anmeldung generiert werden soll.
Network password - Einige kommerzielle Anwendungen senden dem Benutzer einmalige Passwörter auf einem registrierten Handy / einer registrierten E-Mail, die vor der Anmeldung eingegeben werden müssen.
Programmbedrohungen
Die Prozesse und der Kernel des Betriebssystems führen die angegebene Aufgabe wie angewiesen aus. Wenn ein Benutzerprogramm diesen Prozess dazu veranlasst hat, böswillige Aufgaben auszuführen, wird dies als bezeichnetProgram Threats. Eines der häufigsten Beispiele für Programmbedrohungen ist ein auf einem Computer installiertes Programm, das Benutzeranmeldeinformationen speichern und über das Netzwerk an einen Hacker senden kann. Im Folgenden finden Sie eine Liste einiger bekannter Programmbedrohungen.
Trojan Horse - Ein solches Programm fängt Benutzeranmeldeinformationen ab und speichert sie, um sie an böswillige Benutzer zu senden, die sich später am Computer anmelden und auf Systemressourcen zugreifen können.
Trap Door - Wenn ein Programm, das so konzipiert ist, dass es nach Bedarf funktioniert, eine Sicherheitslücke im Code aufweist und ohne Wissen des Benutzers illegale Aktionen ausführt, wird eine Falltür aufgerufen.
Logic Bomb- Eine Logikbombe ist eine Situation, in der sich ein Programm nur dann schlecht verhält, wenn bestimmte Bedingungen erfüllt sind, andernfalls funktioniert es als echtes Programm. Es ist schwerer zu erkennen.
Virus- Viren können sich, wie der Name schon sagt, auf dem Computersystem replizieren. Sie sind sehr gefährlich und können Benutzerdateien und Absturzsysteme ändern / löschen. Ein Virus ist im Allgemeinen ein kleiner Code, der in ein Programm eingebettet ist. Wenn der Benutzer auf das Programm zugreift, wird der Virus in andere Dateien / Programme eingebettet und kann das System für den Benutzer unbrauchbar machen
Systembedrohungen
Systembedrohungen beziehen sich auf den Missbrauch von Systemdiensten und Netzwerkverbindungen, um Benutzer in Schwierigkeiten zu bringen. Systembedrohungen können verwendet werden, um Programmbedrohungen in einem vollständigen Netzwerk zu starten, das als Programmangriff bezeichnet wird. Systembedrohungen schaffen eine solche Umgebung, dass Betriebssystemressourcen / Benutzerdateien missbraucht werden. Im Folgenden finden Sie eine Liste einiger bekannter Systembedrohungen.
Worm- Wurm ist ein Prozess, der die Systemleistung beeinträchtigen kann, indem Systemressourcen auf ein extremes Niveau gebracht werden. Ein Worm-Prozess generiert mehrere Kopien, wobei jede Kopie Systemressourcen verwendet, und verhindert, dass alle anderen Prozesse die erforderlichen Ressourcen erhalten. Worms-Prozesse können sogar ein gesamtes Netzwerk herunterfahren.
Port Scanning - Port-Scanning ist ein Mechanismus oder ein Mittel, mit dem ein Hacker Systemschwachstellen erkennen kann, um einen Angriff auf das System auszuführen.
Denial of Service- Denial-of-Service-Angriffe verhindern normalerweise, dass Benutzer das System legitim nutzen. Beispielsweise kann ein Benutzer das Internet möglicherweise nicht verwenden, wenn der Denial-of-Service die Inhaltseinstellungen des Browsers angreift.
Computersicherheitsklassifikationen
Gemäß den Bewertungskriterien des US-Verteidigungsministeriums für vertrauenswürdige Computersysteme gibt es vier Sicherheitsklassifizierungen in Computersystemen: A, B, C und D. Dies sind weit verbreitete Spezifikationen zur Bestimmung und Modellierung der Sicherheit von Systemen und Sicherheitslösungen. Es folgt die kurze Beschreibung jeder Klassifizierung.
| SN | Klassifizierungstyp & Beschreibung |
|---|---|
| 1 | Type A Höchstes Level. Verwendet formale Designspezifikationen und Verifikationstechniken. Gewährleistet ein hohes Maß an Prozesssicherheit. |
| 2 | Type B Bietet obligatorisches Schutzsystem. Haben Sie alle Eigenschaften eines Systems der Klasse C2. Fügt jedem Objekt ein Empfindlichkeitsetikett hinzu. Es gibt drei Arten.
|
| 3 | Type C Bietet Schutz und Rechenschaftspflicht der Benutzer mithilfe von Überwachungsfunktionen. Es gibt zwei Arten.
|
| 4 | Type D Niedrigstes Level. Minimaler Schutz. MS-DOS, Windows 3.1 fallen in diese Kategorie. |
Linux ist eine der beliebtesten Versionen des UNIX-Betriebssystems. Es ist Open Source, da sein Quellcode frei verfügbar ist. Es ist kostenlos zu benutzen. Linux wurde unter Berücksichtigung der UNIX-Kompatibilität entwickelt. Die Funktionsliste ist der von UNIX sehr ähnlich.
Komponenten des Linux-Systems
Das Linux-Betriebssystem besteht hauptsächlich aus drei Komponenten
Kernel- Kernel ist der Kern von Linux. Es ist für alle wichtigen Aktivitäten dieses Betriebssystems verantwortlich. Es besteht aus verschiedenen Modulen und interagiert direkt mit der zugrunde liegenden Hardware. Der Kernel bietet die erforderliche Abstraktion, um Hardware-Details auf niedriger Ebene für System- oder Anwendungsprogramme auszublenden.
System Library- Systembibliotheken sind spezielle Funktionen oder Programme, mit denen Anwendungsprogramme oder Systemdienstprogramme auf die Kernel-Funktionen zugreifen. Diese Bibliotheken implementieren die meisten Funktionen des Betriebssystems und erfordern keine Codezugriffsrechte des Kernelmoduls.
System Utility - System Utility-Programme sind für spezielle Aufgaben auf individueller Ebene verantwortlich.

Kernel-Modus vs Benutzermodus
Der Kernel-Komponentencode wird in einem speziellen privilegierten Modus ausgeführt, der aufgerufen wird kernel modemit vollem Zugriff auf alle Ressourcen des Computers. Dieser Code stellt einen einzelnen Prozess dar, wird in einem einzelnen Adressraum ausgeführt und erfordert keinen Kontextwechsel und ist daher sehr effizient und schnell. Der Kernel führt jeden Prozess aus und stellt Systemdienste für Prozesse bereit, bietet geschützten Zugriff auf Hardware für Prozesse.
Support-Code, der für die Ausführung im Kernel-Modus nicht erforderlich ist, befindet sich in der Systembibliothek. Benutzerprogramme und andere Systemprogramme funktionieren inUser Modedie keinen Zugriff auf Systemhardware und Kernel-Code hat. Benutzerprogramme / Dienstprogramme verwenden Systembibliotheken, um auf Kernelfunktionen zuzugreifen und die Aufgaben des Systems auf niedriger Ebene abzurufen.
Grundfunktionen
Im Folgenden sind einige wichtige Funktionen des Linux-Betriebssystems aufgeführt.
Portable- Portabilität bedeutet, dass Software auf verschiedene Arten von Hardware auf dieselbe Weise funktionieren kann. Linux-Kernel- und Anwendungsprogramme unterstützen deren Installation auf jeder Art von Hardwareplattform.
Open Source- Linux-Quellcode ist frei verfügbar und ein Community-basiertes Entwicklungsprojekt. Mehrere Teams arbeiten zusammen, um die Leistungsfähigkeit des Linux-Betriebssystems zu verbessern, und es wird ständig weiterentwickelt.
Multi-User - Linux ist ein Mehrbenutzersystem, dh mehrere Benutzer können gleichzeitig auf Systemressourcen wie Speicher / RAM / Anwendungsprogramme zugreifen.
Multiprogramming - Linux ist ein Multiprogrammiersystem, bei dem mehrere Anwendungen gleichzeitig ausgeführt werden können.
Hierarchical File System - Linux bietet eine Standarddateistruktur, in der Systemdateien / Benutzerdateien angeordnet sind.
Shell- Linux bietet ein spezielles Interpreter-Programm, mit dem Befehle des Betriebssystems ausgeführt werden können. Es kann verwendet werden, um verschiedene Arten von Vorgängen auszuführen und Anwendungsprogramme aufzurufen. usw.
Security - Linux bietet Benutzersicherheit mithilfe von Authentifizierungsfunktionen wie Kennwortschutz / kontrollierter Zugriff auf bestimmte Dateien / Verschlüsselung von Daten.
Die Architektur
Die folgende Abbildung zeigt die Architektur eines Linux-Systems -

Die Architektur eines Linux-Systems besteht aus den folgenden Ebenen:
Hardware layer - Hardware besteht aus allen Peripheriegeräten (RAM / HDD / CPU usw.).
Kernel - Es ist die Kernkomponente des Betriebssystems, interagiert direkt mit der Hardware und bietet Low-Level-Services für Komponenten der oberen Schicht.
Shell- Eine Schnittstelle zum Kernel, die die Komplexität der Kernelfunktionen vor den Benutzern verbirgt. Die Shell nimmt Befehle vom Benutzer entgegen und führt die Kernelfunktionen aus.
Utilities - Hilfsprogramme, die dem Benutzer die meisten Funktionen eines Betriebssystems bieten.