Marionette - Kurzanleitung
Puppet ist ein Konfigurationsmanagement-Tool, das von Puppet Labs entwickelt wurde, um das Infrastrukturmanagement und die Konfiguration zu automatisieren. Puppet ist ein sehr leistungsfähiges Werkzeug, das beim Konzept der Infrastruktur als Code hilft. Dieses Tool ist in der Ruby DSL-Sprache geschrieben und hilft bei der Konvertierung einer vollständigen Infrastruktur im Codeformat, die einfach verwaltet und konfiguriert werden kann.
Puppet folgt dem Client-Server-Modell, bei dem ein Computer in einem Cluster als Server fungiert, der als Puppet Master bezeichnet wird, und der andere als Client, der als Slave auf Knoten bezeichnet wird. Puppet kann jedes System von der ersten Konfiguration bis zum Ende der Lebensdauer einer bestimmten Maschine von Grund auf neu verwalten.
Eigenschaften des Puppensystems
Im Folgenden sind die wichtigsten Funktionen von Puppet aufgeführt.
Idempotenz
Puppet unterstützt Idempotenz, was es einzigartig macht. Ähnlich wie bei Chef kann in Puppet dieselbe Konfiguration sicher mehrere Male auf demselben Computer ausgeführt werden. In diesem Ablauf prüft Puppet den aktuellen Status des Zielcomputers und nimmt nur dann Änderungen vor, wenn sich die Konfiguration spezifisch ändert.
Idempotenz hilft bei der Verwaltung einer bestimmten Maschine während ihres gesamten Lebenszyklus, angefangen von der Erstellung der Maschine über Konfigurationsänderungen in der Maschine bis hin zum Ende der Lebensdauer. Die Puppet Idempotency-Funktion ist sehr hilfreich, um die Maschine jahrelang auf dem neuesten Stand zu halten, anstatt sie bei Konfigurationsänderungen mehrmals neu zu erstellen.
Plattformübergreifend
In Puppet kann mithilfe von Resource Abstraction Layer (RAL), das Puppet-Ressourcen verwendet, auf die angegebene Systemkonfiguration abgezielt werden, ohne sich um die Implementierungsdetails und die Funktionsweise des Konfigurationsbefehls im System zu kümmern, die in der zugrunde liegenden Konfiguration definiert sind Datei.
Marionette - Workflow
Puppet verwendet den folgenden Workflow, um die Konfiguration auf das System anzuwenden.
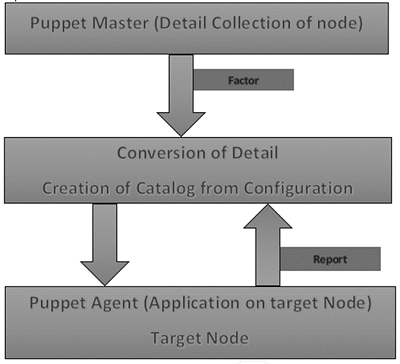
In Puppet sammelt der Puppet-Meister zunächst die Details der Zielmaschine. Unter Verwendung des Faktors, der auf allen Puppet-Knoten vorhanden ist (ähnlich wie bei Ohai in Chef), werden alle Konfigurationsdetails auf Maschinenebene abgerufen. Diese Daten werden gesammelt und an den Puppenmeister zurückgesendet.
Anschließend vergleicht der Puppet Master die abgerufene Konfiguration mit definierten Konfigurationsdetails. Mit der definierten Konfiguration erstellt er einen Katalog und sendet ihn an die Ziel-Puppet-Agenten.
Der Puppet-Agent wendet dann diese Konfigurationen an, um das System in einen gewünschten Zustand zu bringen.
Sobald sich der Zielknoten in einem gewünschten Zustand befindet, sendet er einen Bericht an den Puppet-Master zurück, der dem Puppet-Master hilft, zu verstehen, wo sich der aktuelle Status des Systems befindet, wie im Katalog definiert.
Marionette - Schlüsselkomponenten
Im Folgenden sind die Schlüsselkomponenten von Puppet aufgeführt.
Marionettenressourcen
Marionettenressourcen sind die Schlüsselkomponenten für die Modellierung einer bestimmten Maschine. Diese Ressourcen haben ein eigenes Implementierungsmodell. Puppet verwendet dasselbe Modell, um eine bestimmte Ressource in den gewünschten Zustand zu versetzen.
Anbieter
Anbieter sind im Grunde genommen Erfüllungsgehilfen einer bestimmten Ressource, die in Puppet verwendet wird. Beispielsweise sind die Pakettypen 'apt-get' und 'yum' für die Paketverwaltung gültig. Manchmal ist auf einer bestimmten Plattform mehr als ein Anbieter verfügbar. Obwohl jede Plattform immer einen Standardanbieter hat.
Manifest
Manifest ist eine Sammlung von Ressourcen, die innerhalb der Funktion oder Klassen gekoppelt sind, um ein beliebiges Zielsystem zu konfigurieren. Sie enthalten eine Reihe von Ruby-Code, um ein System zu konfigurieren.
Module
Das Modul ist der Schlüsselbaustein von Puppet, der als Sammlung von Ressourcen, Dateien, Vorlagen usw. definiert werden kann. Sie können problemlos auf verschiedene Arten von Betriebssystemen verteilt werden, die so definiert sind, dass sie denselben Geschmack haben. Da sie leicht verteilt werden können, kann ein Modul mit derselben Konfiguration mehrfach verwendet werden.
Vorlagen
Vorlagen verwenden Ruby-Ausdrücke, um den benutzerdefinierten Inhalt und die variable Eingabe zu definieren. Sie werden verwendet, um benutzerdefinierte Inhalte zu entwickeln. Vorlagen werden in Manifesten definiert und an einen Ort im System kopiert. Wenn Sie beispielsweise httpd mit einem anpassbaren Port definieren möchten, können Sie den folgenden Ausdruck verwenden.
Listen <% = @httpd_port %>Die Variable httpd_port wird in diesem Fall im Manifest definiert, das auf diese Vorlage verweist.
Statische Dateien
Statische Dateien können als allgemeine Dateien definiert werden, die manchmal zur Ausführung bestimmter Aufgaben erforderlich sind. Sie können einfach mit Puppet von einem Ort an einen anderen kopiert werden. Alle statischen Dateien befinden sich im Dateiverzeichnis eines Moduls. Jede Manipulation der Datei in einem Manifest erfolgt über die Dateiressource.
Es folgt die schematische Darstellung der Puppenarchitektur.
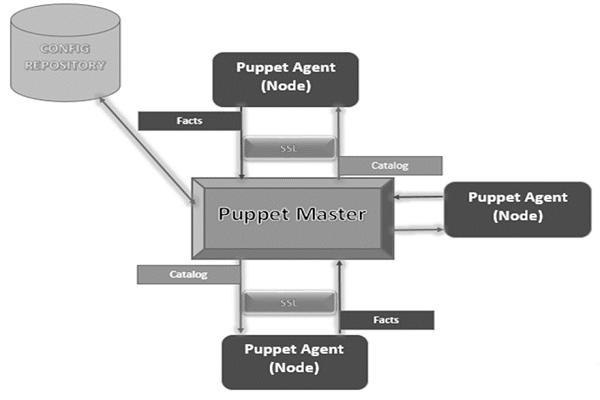
Puppenspieler
Puppet Master ist der Schlüsselmechanismus, der alle konfigurationsbezogenen Dinge erledigt. Die Konfiguration wird mithilfe des Puppet-Agenten auf Knoten angewendet.
Marionettenagent
Puppet Agents sind die eigentlichen Arbeitsmaschinen, die vom Puppet Master verwaltet werden. In ihnen ist der Puppet Agent Daemon-Dienst ausgeführt.
Konfigurations-Repository
Dies ist das Repo, in dem alle Knoten und serverbezogenen Konfigurationen gespeichert und bei Bedarf abgerufen werden.
Fakten
Factssind die Details, die sich auf den Knoten oder die Master-Maschine beziehen und die im Wesentlichen zur Analyse des aktuellen Status eines Knotens verwendet werden. Aufgrund von Fakten werden Änderungen auf jedem Zielcomputer vorgenommen. Es gibt vordefinierte und benutzerdefinierte Fakten in Puppet.
Katalog
Alle Manifestdateien oder Konfigurationen, die in Puppet geschrieben sind, werden zuerst in ein kompiliertes Format namens Katalog konvertiert, und später werden diese Kataloge auf den Zielcomputer angewendet.
Puppet arbeitet mit der Client-Server-Architektur, wobei wir den Server als Puppet-Master und den Client als Puppet-Knoten bezeichnen. Dieses Setup wird erreicht, indem Puppet sowohl auf dem Client als auch auf allen Servercomputern installiert wird.
Für die meisten Plattformen kann Puppet über den Paketmanager Ihrer Wahl installiert werden. Für einige Plattformen kann dies jedoch durch Installation destarball oder RubyGems.
Voraussetzungen
Faktor ist die einzige Voraussetzung, die nicht mitkommt Ohai das ist in Chef vorhanden.
Standard OS Library
Wir benötigen einen Standardbibliothekssatz für jedes zugrunde liegende Betriebssystem. Das verbleibende System wird mit Ruby 1.8.2 + -Versionen geliefert. Im Folgenden finden Sie eine Liste der Bibliothekselemente, aus denen ein Betriebssystem bestehen sollte.
- base64
- cgi
- digest/md5
- etc
- fileutils
- ipaddr
- openssl
- strscan
- syslog
- uri
- webrick
- webrick/https
- xmlrpc
Facter Installation
Wie bereits erwähnt, ist die facterkommt nicht mit der Standard Edition von Ruby. Um den Facter in das Zielsystem zu bekommen, muss er manuell von der Quelle installiert werden, da die Facter-Bibliothek eine Voraussetzung für Puppet ist.
Dieses Paket ist für mehrere Plattformen verfügbar, um jedoch sicherer zu sein, dass es mit installiert werden kann tarball, was hilft, die neueste Version zu bekommen.
Laden Sie zunächst die tarball von der offiziellen Seite von Puppet mit dem wget Nützlichkeit.
$ wget http://puppetlabs.com/downloads/facter/facter-latest.tgz ------: 1Entfernen Sie als Nächstes die Tar-Datei. Gehen Sie mit dem CD-Befehl in das nicht geteerte Verzeichnis. Zum Schluss installieren Sie den Facter mitinstall.rb Datei in der facter Verzeichnis.
$ gzip -d -c facter-latest.tgz | tar xf - -----: 2
$ cd facter-* ------: 3 $ sudo ruby install.rb # or become root and run install.rb -----:4Puppet von der Quelle installieren
Installieren Sie zuerst den Puppet-Tarball von der Puppet-Site mit wget. Extrahieren Sie dann den Tarball an einen Zielort. Bewegen Sie sich mit dem in das erstellte VerzeichnisCDBefehl. Verwenden voninstall.rb Datei, installieren Sie Puppet auf dem zugrunde liegenden Server.
# get the latest tarball
$ wget http://puppetlabs.com/downloads/puppet/puppet-latest.tgz -----: 1 # untar and install it $ gzip -d -c puppet-latest.tgz | tar xf - ----: 2
$ cd puppet-* ------: 3 $ sudo ruby install.rb # or become root and run install.rb -------: 4Puppet und Facter mit Ruby Gem installieren
# Installing Facter
$ wget http://puppetlabs.com/downloads/gems/facter-1.5.7.gem $ sudo gem install facter-1.5.7.gem
# Installing Puppet
$ wget http://puppetlabs.com/downloads/gems/puppet-0.25.1.gem $ sudo gem install puppet-0.25.1.gemSobald Puppet auf dem System installiert ist, müssen Sie es im nächsten Schritt so konfigurieren, dass bestimmte anfängliche Vorgänge ausgeführt werden.
Öffnen Sie Firewall-Ports auf Computern
Damit der Puppet-Server den Client-Server zentral verwaltet, muss auf allen Computern ein bestimmter Port geöffnet werden, d. H. 8140kann verwendet werden, wenn es auf keinem der Computer verwendet wird, die wir konfigurieren möchten. Wir müssen sowohl die TCP- als auch die UDP-Kommunikation auf allen Computern aktivieren.
Konfigurationsdatei
Die Hauptkonfigurationsdatei für Puppet ist etc/puppet/puppet.conf. Alle Konfigurationsdateien werden in einer paketbasierten Konfiguration von Puppet erstellt. Der größte Teil der Konfiguration, die zum Konfigurieren von Puppet erforderlich ist, wird in diesen Dateien gespeichert. Sobald der Puppet-Lauf stattfindet, werden diese Konfigurationen automatisch übernommen. Für bestimmte Aufgaben wie das Konfigurieren eines Webservers oder einer externen Zertifizierungsstelle verfügt Puppet jedoch über eine separate Konfiguration für Dateien und Einstellungen.
Serverkonfigurationsdateien befinden sich in conf.dVerzeichnis, das auch als Puppet Master bekannt ist. Diese Dateien befinden sich standardmäßig unter/etc/puppetlabs/puppetserver/conf.dPfad. Diese Konfigurationsdateien sind im HOCON-Format, das die Grundstruktur von JSON beibehält, aber besser lesbar ist. Wenn der Puppet-Start stattfindet, werden alle .cong-Dateien aus dem Verzeichnis conf.d abgerufen und für Konfigurationsänderungen verwendet. Änderungen an diesen Dateien finden nur statt, wenn der Server neu gestartet wird.
Listendatei und Einstellungsdatei
- global.conf
- webserver.conf
- web-routes.conf
- puppetserver.conf
- auth.conf
- master.conf (veraltet)
- ca.conf (veraltet)
In Puppet gibt es verschiedene Konfigurationsdateien, die für jede Komponente in Puppet spezifisch sind.
Puppet.conf
Die Datei Puppet.conf ist die Hauptkonfigurationsdatei von Puppet. Puppet verwendet dieselbe Konfigurationsdatei, um alle erforderlichen Puppet-Befehle und -Dienste zu konfigurieren. In dieser Datei werden alle Puppet-bezogenen Einstellungen wie die Definition von Puppet Master, Puppet Agent, Puppet Apply und Zertifikate definiert. Puppet kann sie gemäß Anforderung beziehen.
Die Konfigurationsdatei ähnelt einer Standard-INI-Datei, in der die Einstellungen in den spezifischen Anwendungsabschnitt des Hauptabschnitts übernommen werden können.
Hauptkonfigurationsabschnitt
[main]
certname = Test1.vipin.com
server = TestingSrv
environment = production
runinterval = 1hPuppet Master Konfigurationsdatei
[main]
certname = puppetmaster.vipin.com
server = MasterSrv
environment = production
runinterval = 1h
strict_variables = true
[master]
dns_alt_names = MasterSrv,brcleprod01.vipin.com,puppet,puppet.test.com
reports = puppetdb
storeconfigs_backend = puppetdb
storeconfigs = true
environment_timeout = unlimitedDetailübersicht
In der Puppet-Konfiguration enthält die Datei, die verwendet werden soll, mehrere Konfigurationsabschnitte, wobei jeder Abschnitt unterschiedliche Arten von mehreren Anzahlen von Einstellungen aufweist.
Konfigurationsabschnitt
Die Puppet-Konfigurationsdatei besteht hauptsächlich aus den folgenden Konfigurationsabschnitten.
Main- Dies ist als globaler Abschnitt bekannt, der von allen Befehlen und Diensten in Puppet verwendet wird. Man definiert die Standardwerte im Hauptabschnitt, die von jedem Abschnitt in der Datei puppet.conf überschrieben werden können.
Master - Auf diesen Abschnitt wird vom Puppet Master Service und vom Puppet Cert-Befehl verwiesen.
Agent - Dieser Abschnitt wird vom Puppet Agent Service verwiesen.
User - Es wird hauptsächlich von Puppet Apply-Befehlen sowie vielen weniger gebräuchlichen Befehlen verwendet.
[main]
certname = PuppetTestmaster1.example.comSchlüsselkomponenten der Konfigurationsdatei
Im Folgenden sind die wichtigsten Komponenten der Konfigurationsdatei aufgeführt.
Kommentarzeilen
In Puppet beginnt jede Kommentarzeile mit (#) Zeichen. Dies kann mit beliebig viel Platz beabsichtigt sein. Wir können auch einen Teilkommentar innerhalb derselben Zeile haben.
# This is a comment.
Testing = true #this is also a comment in same lineEinstellungszeilen
Die Einstellungszeile muss bestehen aus -
- Beliebige Menge an führendem Platz (optional)
- Name der Einstellungen
- Ein Gleichheitszeichen =, das von einer beliebigen Anzahl von Leerzeichen umgeben sein kann
- Ein Wert für die Einstellung
Variablen einstellen
In den meisten Fällen ist der Wert der Einstellungen ein einzelnes Wort, in einigen Sonderfällen gibt es jedoch nur wenige Sonderwerte.
Wege
Erstellen Sie in den Einstellungen der Konfigurationsdatei eine Liste der Verzeichnisse. Bei der Definition dieser Verzeichnisse sollte beachtet werden, dass sie durch das Systempfad-Trennzeichen (:) in * nix-Plattformen und Semikolons (;) unter Windows getrennt werden sollten.
# *nix version:
environmentpath = $codedir/special_environments:$codedir/environments
# Windows version:
environmentpath = $codedir/environments;C:\ProgramData\PuppetLabs\code\environmentIn der Definition wird das zuerst aufgeführte Dateiverzeichnis gescannt und später in das andere Verzeichnis in der Liste verschoben, falls es keines findet.
Dateien und Verzeichnisse
Alle Einstellungen, die eine einzelne Datei oder ein einzelnes Verzeichnis benötigen, können einen optionalen Hash von Berechtigungen akzeptieren. Wenn der Server gestartet wird, erzwingt Puppet diese Dateien oder Verzeichnisse in der Liste.
ssldir = $vardir/ssl {owner = service, mode = 0771}Im obigen Code sind die zulässigen Hashs Eigentümer, Gruppe und Modus. Es gibt nur zwei gültige Werte für den Eigentümer- und den Gruppenschlüssel.
In Puppet haben alle Umgebungen die environment.confDatei. Diese Datei kann mehrere Standardeinstellungen überschreiben, wenn der Master einen der Knoten oder alle dieser bestimmten Umgebung zugewiesenen Knoten bedient.
Ort
In Puppet befindet sich die Datei environment.conf für alle definierten Umgebungen auf der obersten Ebene ihrer Heimumgebung direkt neben den Direktoren für Manifest und Module. Betrachten Sie ein Beispiel, wenn sich Ihre Umgebung in Standardverzeichnissen befindet(Vipin/testing/environment)Dann befindet sich die Konfigurationsdatei der Testumgebung unter Vipin/testing/environments/test/environment.conf.
Beispiel
# /etc/testingdir/code/environments/test/environment.conf
# Puppet Enterprise requires $basemodulepath; see note below under modulepath". modulepath = site:dist:modules:$basemodulepath
# Use our custom script to get a git commit for the current state of the code:
config_version = get_environment_commit.shFormat
Alle Konfigurationsdateien in Puppet verwenden auf dieselbe Weise dasselbe INI-ähnliche Format. environment.confDie Datei hat dasselbe INI-ähnliche Format wie andere die Datei puppet.conf. Der einzige Unterschied zwischen environment.conf undpuppet.confDie Datei environment.conf darf den Abschnitt [main] nicht enthalten. Alle Einstellungen in der Datei environment.conf müssen sich außerhalb eines Konfigurationsabschnitts befinden.
Relativer Pfad in Werten
Die meisten zulässigen Einstellungen akzeptieren den Dateipfad oder die Pfadliste als Wert. Wenn einer der Pfade ein relevanter Pfad ist, beginnen sie ohne einen führenden Schrägstrich oder einen Laufwerksbuchstaben. Sie werden meistens relativ zum Hauptverzeichnis dieser Umgebung aufgelöst.
Interpolation in Werten
Die Einstellungsdatei Environment.conf kann Werte anderer Einstellungen als Variable verwenden. Es gibt mehrere nützliche Variablen, die in die Datei environment.conf interpoliert werden können. Hier ist eine Liste einiger wichtiger Variablen -
$basemodulepath- Nützlich, um Verzeichnisse in die Modulpfadeinstellungen aufzunehmen. Puppet Enterprise-Benutzer sollten normalerweise diesen Wert von angebenmodulepath da die Puppet Engine Modul in der verwendet basemodulepath.
$environment- Nützlich als Befehlszeilenargument für Ihr config_version-Skript. Sie können diese Variable nur in der Einstellung config_version interpolieren.
$codedir - Nützlich zum Auffinden von Dateien.
Zulässige Einstellungen
Standardmäßig darf die Datei Puppet environment.conf nur vier Einstellungen in der Konfiguration überschreiben, wie aufgeführt.
- Modulepath
- Manifest
- Config_version
- Environment_timeout
Modulepath
Dies ist eine der Schlüsseleinstellungen in der Datei environment.conf. Alle in modulepath definierten Direktoren werden standardmäßig von Puppet geladen. Dies ist der Pfad, von dem aus Puppet seine Module lädt. Man muss dies explizit einrichten. Wenn diese obige Einstellung nicht festgelegt ist, lautet der Standard-Modulpfad einer Umgebung in Puppet -
<MODULES DIRECTORY FROM ENVIRONMENT>:$basemodulepathManifest
Dies wird verwendet, um die Hauptmanifestdatei zu definieren, die Puppet Master beim Starten und Kompilieren des Katalogs aus dem definierten Manifest verwendet, das zum Konfigurieren der Umgebung verwendet werden soll. Hier können wir eine einzelne Datei, eine Liste von Dateien oder sogar ein Verzeichnis definieren, das aus mehreren Manifestdateien besteht, die in einer definierten alphabetischen Reihenfolge ausgewertet und kompiliert werden müssen.
Diese Einstellung muss explizit in der Datei environment.conf definiert werden. Wenn nicht, verwendet Puppet das Standardmanifestverzeichnis der Umgebung als Hauptmanifest.
Config_version
Config_version kann als bestimmte Version definiert werden, mit der Kataloge und Ereignisse identifiziert werden. Wenn Puppet standardmäßig eine Manifestdatei kompiliert, fügt es den generierten Katalogen sowie den Berichten eine Konfigurationsversion hinzu, die generiert wird, wenn der Puppet-Master einen definierten Katalog auf Puppet-Knoten anwendet. Puppet führt ein Skript aus, um alle oben genannten Schritte auszuführen, und verwendet die gesamte generierte Ausgabe als Config_version.
Umgebungs-Timeout
Es wird verwendet, um Details über die Zeit abzurufen, die Puppet zum Laden von Daten für eine bestimmte Umgebung verwenden sollte. Wenn der Wert in der Datei puppet.conf definiert ist, überschreiben diese Werte den Standardwert für das Zeitlimit.
Beispieldatei environment.conf
[master]
manifest = $confdir/environments/$environment/manifests/site.pp
modulepath = $confdir/environments/$environment/modulesIm obigen Code $confdir ist der Pfad des Verzeichnisses, in dem sich Umgebungskonfigurationsdateien befinden. $environment ist der Name der Umgebung, für die die Konfiguration durchgeführt wird.
Produktionsbereite Umgebungskonfigurationsdatei
# The environment configuration file
# The main manifest directory or file where Puppet starts to evaluate code
# This is the default value. Works with just a site.pp file or any other
manifest = manifests/
# The directories added to the module path, looked in first match first used order:
# modules - Directory for external modules, populated by r10k based on Puppetfile
# $basemodulepath - As from: puppet config print basemodulepath modulepath = site:modules:$basemodulepath
# Set the cache timeout for this environment.
# This overrides what is set directly in puppet.conf for the whole Puppet server
# environment_timeout = unlimited
# With caching you need to flush the cache whenever new Puppet code is deployed
# This can also be done manually running: bin/puppet_flush_environment_cache.sh
# To disable catalog caching:
environment_timeout = 0
# Here we pass to one in the control repo the Puppet environment (and git branch)
# to get title and essential info of the last git commit
config_version = 'bin/config_script.sh $environment'In Puppet wird die Client-Server-Architektur des Puppet-Masters als Kontrollautorität des gesamten Setups betrachtet. Puppet Master fungiert als Server im Setup und steuert alle Aktivitäten auf allen Knoten.
Für jeden Server, der als Puppet-Master fungieren muss, sollte die Puppet-Serversoftware ausgeführt werden. Diese Serversoftware ist die Schlüsselkomponente zur Steuerung aller Aktivitäten auf Knoten. In diesem Setup ist es wichtig, einen Superuser-Zugriff auf alle Computer zu haben, die im Setup verwendet werden sollen. Im Folgenden finden Sie die Schritte zum Einrichten des Puppet Masters.
Voraussetzungen
Private Network DNS- Vorwärts und Rückwärts sollten konfiguriert sein, wobei jeder Server einen eindeutigen Hostnamen haben sollte. Wenn der DNS nicht konfiguriert ist, kann ein privates Netzwerk für die Kommunikation mit der Infrastruktur verwendet werden.
Firewall Open Port- Puppet Master sollte an einem bestimmten Port geöffnet sein, damit er die eingehenden Anforderungen an einem bestimmten Port abhören kann. Wir können jeden Port verwenden, der in der Firewall geöffnet ist.
Puppet Master Server erstellen
Der von uns erstellte Puppet Master wird auf einem CentOS 7 × 64-Computer mit Puppet als Hostnamen ausgeführt. Die minimale Systemkonfiguration für die Erstellung des Puppet-Masters beträgt zwei CPU-Kerne und 1 GB Speicher. Die Konfiguration kann auch größer sein, abhängig von der Anzahl der Knoten, die wir mit diesem Master verwalten werden. In der Infrastruktur ist größer als es mit 2 GB RAM konfiguriert ist.
| Hostname | Rolle | Privater FQDN |
|---|---|---|
| Brcleprod001 | Puppenspieler | bnrcleprod001.brcl.com |
Als nächstes muss ein Puppet-Master-SSL-Zertifikat generiert werden, und der Name des Master-Computers wird in die Konfigurationsdatei aller Knoten kopiert.
NTP installieren
Da der Puppet-Master die zentrale Autorität für Agentenknoten in einem bestimmten Setup ist, liegt es in der Hauptverantwortung des Puppet-Masters, die genaue Systemzeit einzuhalten, um mögliche Konfigurationsprobleme zu vermeiden, die auftreten können, wenn Agentenzertifikate an Knoten ausgestellt werden.
Wenn das Problem mit dem Zeitkonflikt auftritt, können Zertifikate als abgelaufen erscheinen, wenn zwischen dem Master und dem Knoten zeitliche Abweichungen bestehen. Das Netzwerkzeitprotokoll ist einer der Schlüsselmechanismen, um solche Probleme zu vermeiden.
Auflistung der verfügbaren Zeitzonen
$ timedatectl list-timezonesDer obige Befehl enthält eine vollständige Liste der verfügbaren Zeitzonen. Regionen erhalten Zeitzonenverfügbarkeit.
Mit dem folgenden Befehl können Sie die erforderliche Zeitzone auf der Maschine einstellen.
$ sudo timedatectl set-timezone India/DelhiInstallieren Sie NTP mit dem Dienstprogramm yum des CentOS-Computers auf dem Puppet-Server.
$ sudo yum -y install ntpSynchronisieren Sie NTP mit der Systemzeit, die wir in den obigen Befehlen festgelegt haben.
$ sudo ntpdate pool.ntp.orgIn der Regel wird die NTP-Konfiguration aktualisiert, um allgemeine Pools zu verwenden, die näher an den Rechenzentren des Computers verfügbar sind. Dazu müssen wir die Datei ntp.conf unter bearbeiten/etc.
$ sudo vi /etc/ntp.confFügen Sie den Zeitserver aus den verfügbaren Zeitzonen des NTP-Pools hinzu. Im Folgenden sehen Sie, wie die Datei ntp.conf aussieht.
brcleprod001.brcl.pool.ntp.org
brcleprod002.brcl.pool.ntp.org
brcleprod003.brcl.pool.ntp.org
brcleprod004.brcl.pool.ntp.orgSpeichern Sie die Konfiguration. Starten Sie den Server und aktivieren Sie den Daemon.
$ sudo systemctl restart ntpd $ sudo systemctl enable ntpdPuppet Server Software einrichten
Puppet Server Software ist eine Software, die auf dem Puppet Master-Computer ausgeführt wird. Es ist der Computer, der Konfigurationen auf andere Computer überträgt, auf denen die Puppet Agent-Software ausgeführt wird.
Aktivieren Sie das offizielle Puppet Labs-Sammlungsrepository mit dem folgenden Befehl.
$ sudo rpm -ivh https://yum.puppetlabs.com/puppetlabs-release-pc1-el7.noarch.rpmInstallieren Sie das Puppetserver-Paket.
$ sudo yum -y install puppetserverKonfigurieren Sie die Speicherzuordnung auf dem Puppet Server
Wie bereits erwähnt, wird der Puppet-Server standardmäßig auf einem 2-GB-RAM-Computer konfiguriert. Das Setup kann entsprechend dem auf dem Computer verfügbaren freien Speicher und der Anzahl der vom Server verwalteten Knoten angepasst werden.
Bearbeiten Sie die Puppet Server-Konfiguration im vi-Modus
$ sudo vi /etc/sysconfig/puppetserver
Find the JAVA_ARGS and use the –Xms and –Xms options to set the memory allocation.
We will allocate 3GB of space
JAVA_ARGS="-Xms3g -Xmx3g"Speichern Sie den Bearbeitungsmodus und beenden Sie ihn.
Nachdem alle oben genannten Einstellungen abgeschlossen sind, können Sie den Puppet-Server auf dem Master-Computer mit dem folgenden Befehl starten.
$ sudo systemctl start puppetserverAls nächstes werden wir das Setup so durchführen, dass der Puppet-Server immer dann startet, wenn der Master-Server startet.
$ sudo systemctl enable puppetserverPuppet.conf Master Section
[master]
autosign = $confdir/autosign.conf { mode = 664 }
reports = foreman
external_nodes = /etc/puppet/node.rb
node_terminus = exec
ca = true
ssldir = /var/lib/puppet/ssl
certname = sat6.example.com
strict_variables = false
manifest =
/etc/puppet/environments/$environment/manifests/site.pp modulepath = /etc/puppet/environments/$environment/modules
config_version =Puppet Agent ist eine Softwareanwendung, die von Puppet Labs bereitgestellt wird und auf jedem Knoten im Puppet-Cluster ausgeführt wird. Wenn Sie einen Server mit dem Puppet-Master verwalten möchten, muss die Puppet-Agentensoftware auf diesem bestimmten Server installiert sein. Im Allgemeinen wird der Puppet-Agent auf allen Computern mit Ausnahme des Puppet-Master-Computers in einer bestimmten Infrastruktur installiert. Puppet Agent-Software kann auf den meisten Linux-, UNIX- und Windows-Computern ausgeführt werden. In den folgenden Beispielen verwenden wir die Puppet Agent-Software für die CentOS-Maschineninstallation.
Step 1 - Aktivieren Sie das offizielle Puppet Labs-Sammlungsrepository mit dem folgenden Befehl.
$ sudo rpm -ivh https://yum.puppetlabs.com/puppetlabs-release-pc1-el7.noarch.rpmStep 2 - Installieren Sie das Puppet Agent-Paket.
$ sudo yum -y install puppet-agentStep 3 - Sobald der Puppet Agent installiert ist, aktivieren Sie ihn mit dem folgenden Befehl.
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable = trueEin wichtiges Merkmal des Puppet-Agenten ist, dass der Puppet-Agent zum ersten Mal, wenn er ausgeführt wird, ein SSL-Zertifikat generiert und an den Puppet-Master sendet, der es zur Unterzeichnung und Genehmigung verwaltet. Sobald der Puppet-Master die Zertifikatsignaturanforderung des Agenten genehmigt hat, kann er den Agentenknoten kommunizieren und verwalten.
Note - Die obigen Schritte müssen auf allen Knoten wiederholt werden, die für einen bestimmten Puppet-Master konfiguriert und verwaltet werden müssen.
Wenn die Puppet Agent-Software zum ersten Mal auf einem Puppet-Knoten ausgeführt wird, generiert sie ein Zertifikat und sendet die Zertifikatsignierungsanforderung an den Puppet-Master. Bevor der Puppet-Server die Agentenknoten kommunizieren und steuern kann, muss er das Zertifikat dieses bestimmten Agentenknotens signieren. In den folgenden Abschnitten wird beschrieben, wie Sie die Signaturanforderung signieren und überprüfen.
Aktuelle Zertifikatanforderungen auflisten
Führen Sie auf dem Puppet-Master den folgenden Befehl aus, um alle nicht signierten Zertifikatanforderungen anzuzeigen.
$ sudo /opt/puppetlabs/bin/puppet cert listDa wir gerade einen neuen Agentenknoten eingerichtet haben, wird eine Genehmigungsanforderung angezeigt. Es folgt dieoutput.
"Brcleprod004.brcl.com" (SHA259)
15:90:C2:FB:ED:69:A4:F7:B1:87:0B:BF:F7:ll:
B5:1C:33:F7:76:67:F3:F6:45:AE:07:4B:F 6:E3:ss:04:11:8dEs enthält am Anfang kein + (Vorzeichen), was darauf hinweist, dass das Zertifikat noch nicht signiert ist.
Unterschreiben Sie eine Anfrage
Um die neue Zertifikatanforderung zu signieren, die beim Ausführen des Puppet-Agentenlaufs auf dem neuen Knoten generiert wurde, wird der Befehl Puppet cert sign verwendet, mit dem Hostnamen des Zertifikats, das von dem neu konfigurierten Knoten generiert wurde, der benötigt wird unterschrieben werden. Da wir das Zertifikat von Brcleprod004.brcl.com haben, verwenden wir den folgenden Befehl.
$ sudo /opt/puppetlabs/bin/puppet cert sign Brcleprod004.brcl.comEs folgt die output.
Notice: Signed certificate request for Brcle004.brcl.com
Notice: Removing file Puppet::SSL::CertificateRequest Brcle004.brcl.com at
'/etc/puppetlabs/puppet/ssl/ca/requests/Brcle004.brcl.com.pem'Der Puppenspieler kann nun mit dem Knoten kommunizieren, zu dem das Zeichenzertifikat gehört.
$ sudo /opt/puppetlabs/bin/puppet cert sign --allWiderrufen des Hosts aus dem Puppet-Setup
Es gibt Bedingungen für die Konfiguration der Kernel-Neuerstellung, wenn der Host aus dem Setup entfernt und erneut hinzugefügt werden muss. Dies sind die Bedingungen, die von der Puppe selbst nicht verwaltet werden können. Dies kann mit dem folgenden Befehl erfolgen.
$ sudo /opt/puppetlabs/bin/puppet cert clean hostnameAlle signierten Anfragen anzeigen
Der folgende Befehl generiert eine Liste signierter Zertifikate mit + (Vorzeichen), die angibt, dass die Anforderung genehmigt wurde.
$ sudo /opt/puppetlabs/bin/puppet cert list --allEs folgt sein output.
+ "puppet" (SHA256) 5A:71:E6:06:D8:0F:44:4D:70:F0:
BE:51:72:15:97:68:D9:67:16:41:B0:38:9A:F2:B2:6C:B
B:33:7E:0F:D4:53 (alt names: "DNS:puppet", "DNS:Brcle004.nyc3.example.com")
+ "Brcle004.brcl.com" (SHA259) F5:DC:68:24:63:E6:F1:9E:C5:FE:F5:
1A:90:93:DF:19:F2:28:8B:D7:BD:D2:6A:83:07:BA:F E:24:11:24:54:6A
+ " Brcle004.brcl.com" (SHA259) CB:CB:CA:48:E0:DF:06:6A:7D:75:E6:CB:22:BE:35:5A:9A:B3Sobald dies erledigt ist, haben wir unsere Infrastruktur bereit, in der der Puppet-Master jetzt neu hinzugefügte Knoten verwalten kann.
In Puppet haben wir ein Code-Management-Tool namens r10k, das bei der Verwaltung von Umgebungskonfigurationen hilft, die sich auf verschiedene Arten von Umgebungen beziehen, die wir in Puppet konfigurieren können, z. B. Entwicklung, Test und Produktion. Dies hilft beim Speichern der umgebungsbezogenen Konfiguration im Quellcode-Repository. Mithilfe der Repo-Zweige der Quellcodeverwaltung erstellt r10k Umgebungen auf Puppet Master-Maschineninstallationen und aktualisiert die Umgebung mithilfe der im Repo vorhandenen Module.
Die Gem-Datei kann verwendet werden, um r10k auf jedem Computer zu installieren, jedoch aus Gründen der Modularität. Um die neueste Version zu erhalten, verwenden wir den Paketmanager rpm und rpm. Das Folgende ist ein Beispiel dafür.
$ urlgrabber -o /etc/yum.repos.d/timhughes-r10k-epel-6.repo
https://copr.fedoraproject.org/coprs/timhughes/yum -y install rubygem-r10kKonfigurieren Sie die Umgebung in /etc/puppet/puppet.conf
[main]
environmentpath = $confdir/environmentsErstellen Sie eine Konfigurationsdatei für r10k Config
cat <<EOF >/etc/r10k.yaml
# The location to use for storing cached Git repos
:cachedir: '/var/cache/r10k'
# A list of git repositories to create
:sources:
# This will clone the git repository and instantiate an environment per
# branch in /etc/puppet/environments
:opstree:
#remote: 'https://github.com/fullstack-puppet/fullstackpuppet-environment.git'
remote: '/var/lib/git/fullstackpuppet-environment.git'
basedir: '/etc/puppet/environments'
EOFPuppet Manifest und Modul installieren
r10k deploy environment -pvDa wir die Umgebung alle 15 Minuten weiter aktualisieren müssen, erstellen wir dafür einen Cron-Job.
cat << EOF > /etc/cron.d/r10k.conf
SHELL = /bin/bash
PATH = /sbin:/bin:/usr/sbin:/usr/bin
H/15 * * * * root r10k deploy environment -p
EOFInstallation testen
Um zu testen, ob alles wie akzeptiert funktioniert, muss das Puppet-Manifest für das Puppet-Modul kompiliert werden. Führen Sie den folgenden Befehl aus und erhalten Sie als Ergebnis eine YAML-Ausgabe.
curl --cert /etc/puppet/ssl/certs/puppet.corp.guest.pem \
--key /etc/puppet/ssl/private_keys/puppet.corp.guest.pem \
--cacert /etc/puppet/ssl/ca/ca_crt.pem \
-H 'Accept: yaml' \
https://puppet.corp.guest:8140/production/catalog/puppet.corp.guestIn Puppet kann das Setup lokal getestet werden. Sobald wir Puppet Master und Node eingerichtet haben, ist es Zeit, das Setup lokal zu validieren. Vagrant und Vagrant Box müssen lokal installiert sein, was beim lokalen Testen des Setups hilft.
Einrichten der virtuellen Maschine
Da wir das Setup lokal testen, benötigen wir keinen laufenden Puppet Master. Dies bedeutet, dass wir Puppet einfach verwenden können, um den Befehl für die Validierung des Puppet-Setups anzuwenden, ohne den Puppet-Master tatsächlich auf dem Server auszuführen. Der Befehl Puppet Apply übernimmt Änderungen vonlocal/etc/puppet abhängig vom Hostnamen der virtuellen Maschine in der Konfigurationsdatei.
Der erste Schritt, den wir ausführen müssen, um das Setup zu testen, besteht darin, Folgendes zu erstellen Vagrantfile und starten Sie eine Maschine und montieren Sie die /etc/puppetOrdner an Ort und Stelle. Alle erforderlichen Dateien werden mit der folgenden Struktur im Versionskontrollsystem abgelegt.
Verzeichnisaufbau
- manifests
\- site.pp
- modules
\- your modules
- test
\- update-puppet.sh
\- Vagrantfile
- puppet.confVagrant-Datei
# -*- mode: ruby -*-
# vi: set ft = ruby :
Vagrant.configure("2") do |config|
config.vm.box = "precise32"
config.vm.box_url = "http://files.vagrantup.com/precise64.box"
config.vm.provider :virtualbox do |vb|
vb.customize ["modifyvm", :id, "--memory", 1028, "--cpus", 2]
end
# Mount our repo onto /etc/puppet
config.vm.synced_folder "../", "/etc/puppet"
# Run our Puppet shell script
config.vm.provision "shell" do |s|
s.path = "update-puppet.sh"
end
config.vm.hostname = "localdev.example.com"
endIm obigen Code haben wir den Shell-Provisioner verwendet, in dem wir versuchen, ein Shell-Skript mit dem Namen auszuführen update-puppet.sh. Das Skript befindet sich in demselben Verzeichnis, in dem sich die Vagrant-Datei befindet, und der Inhalt des Skripts ist unten aufgeführt.
!/bin/bash
echo "Puppet version is $(puppet --version)" if [ $( puppet --version) != "3.4.1" ]; then
echo "Updating puppet"
apt-get install --yes lsb-release
DISTRIB_CODENAME = $(lsb_release --codename --short) DEB = "puppetlabs-release-${DISTRIB_CODENAME}.deb"
DEB_PROVIDES="/etc/apt/sources.list.d/puppetlabs.list"
if [ ! -e $DEB_PROVIDES ] then wget -q http://apt.puppetlabs.com/$DEB
sudo dpkg -i $DEB
fi
sudo apt-get update
sudo apt-get install -o Dpkg::Options:: = "--force-confold"
--force-yes -y puppet
else
echo "Puppet is up to date!"
fiBei der weiteren Verarbeitung muss der Benutzer eine Manifestdatei im Manifests-Verzeichnis mit dem Namen erstellen site.pp Dadurch wird Software auf der VM installiert.
node 'brclelocal03.brcl.com' {
package { ['vim','git'] :
ensure => latest
}
}
echo "Running puppet"
sudo puppet apply /etc/puppet/manifests/site.ppSobald der Benutzer das obige Skript mit der erforderlichen Vagrant-Dateikonfiguration bereit hat, kann er in das Testverzeichnis cd und das ausführen vagrant up command. Dadurch wird eine neue VM gestartet. Später wird Puppet installiert und anschließend mit dem Shell-Skript ausgeführt.
Es folgt die Ausgabe.
Notice: Compiled catalog for localdev.example.com in environment production in 0.09 seconds
Notice: /Stage[main]/Main/Node[brclelocal03.brcl.com]/Package[git]/ensure: created
Notice: /Stage[main]/Main/Node[brcllocal03.brcl.com]/Package[vim]/ensure: ensure changed 'purged' to 'latest'Überprüfen der Konfiguration mehrerer Maschinen
Wenn Sie die Konfiguration mehrerer Computer lokal testen müssen, können Sie dies einfach durch Ändern der Vagrant-Konfigurationsdatei tun.
Neue konfigurierte Vagrant-Datei
config.vm.define "brclelocal003" do |brclelocal003|
brclelocal03.vm.hostname = "brclelocal003.brcl.com"
end
config.vm.define "production" do |production|
production.vm.hostname = "brcleprod004.brcl.com"
endNehmen wir an, wir haben einen neuen Produktionsserver, auf dem das SSL-Dienstprogramm installiert sein muss. Wir müssen nur das alte Manifest mit der folgenden Konfiguration erweitern.
node 'brcleprod004.brcl.com' inherits 'brcleloacl003.brcl.com' {
package { ['SSL'] :
ensure => latest
}
}Nachdem wir Konfigurationsänderungen in der Manifestdatei vorgenommen haben, müssen wir nur in das Testverzeichnis wechseln und den grundlegenden Befehl vagrant up ausführen, der beide aufruft brclelocal003.brcl.com und brcleprod004.brcl.comMaschine. In unserem Fall versuchen wir, eine Produktionsmaschine aufzurufen, die durch Ausführen dervagrant up production command. Dadurch wird ein neuer Computer mit dem Namen Produktion erstellt, wie in der Vagrant-Datei definiert, und es wird ein SSL-Paket installiert.
In Puppet definiert der Codierungsstil alle Standards, denen Sie folgen müssen, wenn Sie versuchen, die Infrastruktur in der Maschinenkonfiguration in einen Code umzuwandeln. Puppet arbeitet und führt alle definierten Aufgaben mit Ressourcen aus.
Die Sprachdefinition von Puppet hilft bei der strukturierten Angabe aller Ressourcen, die für die Verwaltung aller zu verwaltenden Zielcomputer erforderlich sind. Puppet verwendet Ruby als Codierungssprache, die über mehrere integrierte Funktionen verfügt, die es sehr einfach machen, Dinge mit einer einfachen Konfiguration auf der Codeseite zu erledigen.
Grundeinheiten
Puppet verwendet mehrere grundlegende Codierungsstile, die leicht zu verstehen und zu verwalten sind. Es folgt eine Liste von wenigen.
Ressourcen
In Puppet werden Ressourcen als grundlegende Modellierungseinheit bezeichnet, mit der jedes Zielsystem verwaltet oder geändert wird. Die Ressourcen decken alle Aspekte eines Systems ab, z. B. Datei, Dienst und Paket. Puppet verfügt über eine integrierte Funktion, mit der Benutzer oder Entwickler benutzerdefinierte Ressourcen entwickeln können, die bei der Verwaltung einer bestimmten Einheit einer Maschine hilfreich sind
In Puppet werden alle Ressourcen entweder mithilfe von zusammengefasst “define” oder “classes”. Diese Aggregationsfunktionen helfen bei der Organisation eines Moduls. Im Folgenden finden Sie eine Beispielressource, die aus mehreren Typen, einem Titel und einer Liste von Attributen besteht, mit denen Puppet mehrere Attribute unterstützen kann. Jede Ressource in Puppet hat einen eigenen Standardwert, der bei Bedarf überschrieben werden kann.
Beispiel für eine Puppenressource für eine Datei
Im folgenden Befehl versuchen wir, eine Berechtigung für eine bestimmte Datei anzugeben.
file {
'/etc/passwd':
owner => superuser,
group => superuser,
mode => 644,
}Immer wenn der obige Befehl auf einem Computer ausgeführt wird, wird überprüft, ob die passwd-Datei im System wie beschrieben konfiguriert ist. Die Datei vor: Doppelpunkt ist der Titel der Ressource, die in anderen Teilen der Puppet-Konfiguration als Ressource bezeichnet werden kann.
Angabe des lokalen Namens zusätzlich zum Titel
file { 'sshdconfig':
name => $operaSystem ? {
solaris => '/usr/local/etc/ssh/sshd_config',
default => '/etc/ssh/sshd_config',
},
owner => superuser,
group => superuser,
mode => 644,
}Durch die Verwendung des Titels, der immer derselbe ist, ist es sehr einfach, Dateiressourcen in der Konfiguration zu referenzieren, ohne die betriebssystembezogene Logik wiederholen zu müssen.
Ein anderes Beispiel könnte die Verwendung eines Dienstes sein, der von einer Datei abhängt.
service { 'sshd':
subscribe => File[sshdconfig],
}Mit dieser Abhängigkeit kann die sshd Der Dienst wird immer neu gestartet, sobald der sshdconfigDateiänderungen. Der Punkt, an den man sich hier erinnern sollte, istFile[sshdconfig] ist eine Deklaration als Datei wie in Kleinbuchstaben, aber wenn wir sie ändern FILE[sshdconfig] dann wäre es eine Referenz gewesen.
Ein grundlegender Punkt, den Sie beim Deklarieren einer Ressource berücksichtigen müssen, ist, dass sie nur einmal pro Konfigurationsdatei deklariert werden kann. Das mehrmalige Wiederholen der Deklaration derselben Ressource führt zu einem Fehler. Durch dieses grundlegende Konzept stellt Puppet sicher, dass die Konfiguration gut modelliert ist.
Wir haben sogar die Möglichkeit, die Ressourcenabhängigkeit zu verwalten, was bei der Verwaltung mehrerer Beziehungen hilfreich ist.
service { 'sshd':
require => File['sshdconfig', 'sshconfig', 'authorized_keys']
}Metaparameter
Metaparameter werden in Puppet als globale Parameter bezeichnet. Eines der Hauptmerkmale von Metaparameter ist, dass es mit jeder Art von Ressource in Puppet funktioniert.
Ressourcenstandard
Wenn ein Standardwert für Ressourcenattribute definiert werden muss, stellt Puppet eine Reihe von Syntax zur Archivierung bereit, wobei eine großgeschriebene Ressourcenspezifikation ohne Titel verwendet wird.
Wenn Sie beispielsweise den Standardpfad aller ausführbaren Dateien festlegen möchten, können Sie dies mit dem folgenden Befehl tun.
Exec { path => '/usr/bin:/bin:/usr/sbin:/sbin' }
exec { 'echo Testing mataparamaters.': }Im obigen Befehl legt die erste Anweisung Exec den Standardwert für die Exec-Ressource fest. Für die Exec-Ressource ist ein vollständig qualifizierter Pfad oder ein Pfad erforderlich, der wie eine ausführbare Datei aussieht. Damit kann ein einzelner Standardpfad für die gesamte Konfiguration definiert werden. Die Standardeinstellungen funktionieren mit jedem Ressourcentyp in Puppet.
Standardwerte sind keine globalen Werte, sie wirken sich jedoch nur auf den Bereich aus, in dem sie definiert sind, oder auf die nächste Variable. Wenn man definieren willdefault Für eine vollständige Konfiguration definieren wir dann die default und die Klasse im nächsten Abschnitt.
Ressourcensammlungen
Aggregation ist eine Methode, um Dinge zusammen zu sammeln. Puppet unterstützt ein sehr leistungsfähiges Konzept der Aggregation. In Puppet wird die Aggregation zum Gruppieren von Ressourcen verwendet, die die grundlegende Einheit von Puppet bilden. Dieses Konzept der Aggregation in Puppet wird durch die Verwendung von zwei leistungsstarken Methoden erreicht, die als bekannt sindclasses und definition.
Klassen und Definition
Klassen sind für die Modellierung der grundlegenden Aspekte des Knotens verantwortlich. Sie können sagen, dass der Knoten ein Webserver ist und dieser bestimmte Knoten einer von ihnen. In Puppet sind Programmierklassen Singleton-Klassen und können einmal pro Knoten ausgewertet werden.
Die Definition hingegen kann auf einem einzelnen Knoten mehrfach verwendet werden. Sie funktionieren ähnlich, da man mit der Sprache seinen eigenen Puppentyp erstellt hat. Sie sind so erstellt, dass sie mehrmals mit unterschiedlichen Eingaben verwendet werden können. Dies bedeutet, dass man variable Werte an die Definition übergeben kann.
Unterschied zwischen Klasse und Definition
Der einzige wesentliche Unterschied zwischen einer Klasse und einer Definition besteht darin, dass beim Definieren der Gebäudestruktur und beim Zuweisen von Ressourcen die Klasse nur einmal pro Knoten ausgewertet wird, wobei andererseits eine Definition auf demselben einzelnen Knoten mehrmals verwendet wird.
Klassen
Klassen in Puppet werden mit dem Schlüsselwort class eingeführt, und der Inhalt dieser bestimmten Klasse wird in geschweifte Klammern eingeschlossen, wie im folgenden Beispiel gezeigt.
class unix {
file {
'/etc/passwd':
owner => 'superuser',
group => 'superuser',
mode => 644;
'/etc/shadow':
owner => 'vipin',
group => 'vipin',
mode => 440;
}
}Im folgenden Beispiel haben wir eine kurze Hand verwendet, die der obigen ähnlich ist.
class unix {
file {
'/etc/passwd':
owner => 'superuser',
group => 'superuser',
mode => 644;
}
file {'/etc/shadow':
owner => 'vipin',
group => 'vipin',
mode => 440;
}
}Vererbung in Puppenklassen
In Puppet wird standardmäßig das OOP-Konzept der Vererbung unterstützt, bei dem Klassen die Funktionalität der vorherigen Klasse erweitern können, ohne das vollständige Codebit in der neu erstellten Klasse erneut zu kopieren und einzufügen. Durch Vererbung kann die Unterklasse die in der übergeordneten Klasse definierten Ressourceneinstellungen überschreiben. Eine wichtige Sache, die Sie bei der Verwendung der Vererbung beachten sollten, ist, dass eine Klasse nur Features von nur einer übergeordneten Klasse erben kann, nicht mehr als einer.
class superclass inherits testsubclass {
File['/etc/passwd'] { group => wheel }
File['/etc/shadow'] { group => wheel }
}Wenn eine in einer übergeordneten Klasse angegebene Logik rückgängig gemacht werden muss, können wir sie verwenden undef command.
class superclass inherits testsubcalss {
File['/etc/passwd'] { group => undef }
}Alternative Art der Vererbung
class tomcat {
service { 'tomcat': require => Package['httpd'] }
}
class open-ssl inherits tomcat {
Service[tomcat] { require +> File['tomcat.pem'] }
}Verschachtelte Klasse in Puppet
Puppet unterstützt das Konzept der Verschachtelung von Klassen, bei denen verschachtelte Klassen verwendet werden können, dh eine Klasse in der anderen. Dies hilft bei der Erreichung von Modularität und Umfang.
class testclass {
class nested {
file {
'/etc/passwd':
owner => 'superuser',
group => 'superuser',
mode => 644;
}
}
}
class anotherclass {
include myclass::nested
}Parametrisierte Klassen
In Puppet können Klassen ihre Funktionalität erweitern, um die Übergabe von Parametern an eine Klasse zu ermöglichen.
Um einen Parameter in einer Klasse zu übergeben, kann das folgende Konstrukt verwendet werden:
class tomcat($version) {
... class contents ...
}Ein wichtiger Punkt, den Sie in Puppet beachten sollten, ist, dass Klassen mit Parametern nicht mit der Include-Funktion hinzugefügt werden, sondern dass die resultierende Klasse als Definition hinzugefügt werden kann.
node webserver {
class { tomcat: version => "1.2.12" }
}Standardwerte als Parameter in der Klasse
class tomcat($version = "1.2.12",$home = "/var/www") {
... class contents ...
}Stages ausführen
Puppet unterstützt das Konzept der Ausführungsstufe, dh der Benutzer kann je nach Anforderung mehrere Stufen hinzufügen, um eine bestimmte Ressource oder mehrere Ressourcen zu verwalten. Diese Funktion ist sehr hilfreich, wenn der Benutzer einen komplexen Katalog entwickeln möchte. In einem komplexen Katalog verfügt man über eine große Anzahl von Ressourcen, die kompiliert werden müssen, wobei zu berücksichtigen ist, dass die Abhängigkeiten zwischen den definierten Ressourcen nicht beeinträchtigt werden sollten.
Run Stage ist sehr hilfreich beim Verwalten von Ressourcenabhängigkeiten. Dies kann durch Hinzufügen von Klassen in definierten Phasen erfolgen, in denen eine bestimmte Klasse eine Sammlung von Ressourcen enthält. Mit der Ausführungsphase garantiert Puppet, dass die definierten Phasen jedes Mal in einer bestimmten vorhersehbaren Reihenfolge ausgeführt werden, wenn der Katalog ausgeführt wird und auf einen beliebigen Puppet-Knoten angewendet wird.
Um dies zu verwenden, müssen zusätzliche Stufen über die bereits vorhandenen Stufen hinaus deklariert werden. Anschließend kann Puppet so konfiguriert werden, dass jede Stufe in einer bestimmten Reihenfolge mit derselben Syntax für Ressourcenbeziehungen verwaltet wird, bevor dies erforderlich ist “->” und “+>”. Die Beziehung garantiert dann die Reihenfolge der Klassen, die jeder Stufe zugeordnet sind.
Deklarieren zusätzlicher Stufen mit deklarativer Marionettensyntax
stage { "first": before => Stage[main] }
stage { "last": require => Stage[main] }Sobald die Stufen deklariert wurden, kann eine Klasse der anderen Stufe als der Hauptstufe zugeordnet werden, die die Stufe verwendet.
class {
"apt-keys": stage => first;
"sendmail": stage => main;
"apache": stage => last;
}Alle mit der Klasse apt-key verknüpften Ressourcen werden zuerst ausgeführt. Alle Ressourcen in Sendmail sind die Hauptklasse und die mit Apache verknüpften Ressourcen sind die letzte Stufe.
Definitionen
In Puppet erfolgt das Sammeln von Ressourcen in einer beliebigen Manifestdatei entweder nach Klassen oder nach Definitionen. Definitionen sind einer Klasse in Puppet sehr ähnlich, werden jedoch mit a eingeführtdefine keyword (not class)und sie unterstützen Argumente, nicht Vererbung. Sie können mehrmals mit unterschiedlichen Parametern auf demselben System ausgeführt werden.
Wenn Sie beispielsweise eine Definition erstellen möchten, die die Quellcode-Repositorys steuert, bei denen versucht wird, mehrere Repositorys auf demselben System zu erstellen, können Sie die Definition nicht als Klasse verwenden.
define perforce_repo($path) {
exec {
"/usr/bin/svnadmin create $path/$title":
unless => "/bin/test -d $path",
}
}
svn_repo { puppet_repo: path => '/var/svn_puppet' }
svn_repo { other_repo: path => '/var/svn_other' }Der wichtigste Punkt, der hier zu beachten ist, ist, wie eine Variable mit einer Definition verwendet werden kann. Wir gebrauchen ($) Dollarzeichenvariable. Oben haben wir verwendet$title. Definitions can have both a $Titel und $name with which the name and the title can be represented. By default, $Titel und $name are set to the same value, but one can set a title attribute and pass different name as a parameter. $title und $ name funktionieren nur in der Definition, nicht in Klassen oder anderen Ressourcen.
Module
Ein Modul kann als Sammlung aller Konfigurationen definiert werden, die vom Puppet-Master verwendet werden, um Konfigurationsänderungen auf einen bestimmten Puppet-Knoten (Agenten) anzuwenden. Sie werden auch als tragbare Sammlung verschiedener Arten von Konfigurationen bezeichnet, die zur Ausführung einer bestimmten Aufgabe erforderlich sind. Ein Modul kann beispielsweise alle Ressourcen enthalten, die zum Konfigurieren von Postfix und Apache erforderlich sind.
Knoten
Knoten sind ein sehr einfacher verbleibender Schritt. So passen wir das, was wir definiert haben („so sieht ein Webserver aus“), an die Maschinen an, die ausgewählt wurden, um diese Anweisungen zu erfüllen.
Die Knotendefinition sieht genau wie Klassen aus, einschließlich der unterstützenden Vererbung. Sie sind jedoch speziell, sodass der Name eines Knotens (eines verwalteten Computers, auf dem ein Puppet-Client ausgeführt wird) mit dem Puppet-Master-Daemon in der definierten Liste der Knoten angezeigt wird. Die definierten Informationen werden für den Knoten ausgewertet, und dann sendet der Knoten diese Konfiguration.
Der Knotenname kann ein kurzer Hostname oder der vollqualifizierte Domänenname (FQDN) sein.
node 'www.vipin.com' {
include common
include apache, squid
}Die obige Definition erstellt einen Knoten namens www.vipin.com und enthält die Klassen common, Apache und Squid
Wir können dieselbe Konfiguration an verschiedene Knoten senden, indem wir sie jeweils durch Komma trennen.
node 'www.testing.com', 'www.testing2.com', 'www3.testing.com' {
include testing
include tomcat, squid
}Regulärer Ausdruck für übereinstimmende Knoten
node /^www\d+$/ {
include testing
}Knotenvererbung
Der Knoten unterstützt ein begrenztes Vererbungsmodell. Wie Klassen können Knoten nur von einem anderen Knoten erben.
node 'www.testing2.com' inherits 'www.testing.com' {
include loadbalancer
}Im obigen Code erbt www.testing2.com zusätzlich zu einer zusätzlichen Loadbalancer-Klasse alle Funktionen von www.testing.com.
Erweiterte unterstützte Funktionen
Quoting- In den meisten Fällen müssen wir in Puppet keine Zeichenfolge zitieren. Jede alphanumerische Zeichenfolge, die mit einem Buchstaben beginnt, darf ohne Anführungszeichen bleiben. Es wird jedoch immer empfohlen, eine Zeichenfolge für nicht negative Werte anzugeben.
Variable Interpolation mit Anführungszeichen
Bisher haben wir Variablen in Bezug auf die Definition erwähnt. Wenn Sie diese Variablen mit einer Zeichenfolge verwenden müssen, verwenden Sie doppelte Anführungszeichen, keine einfachen Anführungszeichen. Eine einfache Anführungszeichenfolge führt keine Variableninterpolation durch, eine doppelte Anführungszeichenfolge. Die Variable kann in Klammern gesetzt werden{} das macht sie einfacher zusammen zu verwenden und leichter zu verstehen.
$value = "${one}${two}"Als bewährte Methode sollten für alle Zeichenfolgen, für die keine Zeichenfolgeninterpolation erforderlich ist, einfache Anführungszeichen verwendet werden.
Kapitalisierung
Die Großschreibung ist ein Prozess, der zum Referenzieren, Vererben und Festlegen von Standardattributen einer bestimmten Ressource verwendet wird. Grundsätzlich gibt es zwei grundlegende Verwendungsmöglichkeiten.
Referencing- Auf diese Weise wird auf eine bereits erstellte Ressource verwiesen. Es wird hauptsächlich für Abhängigkeitszwecke verwendet, man muss den Namen der Ressource groß schreiben. Beispiel, erfordern => Datei [sshdconfig]
Inheritance- Wenn Sie die Einstellung für die übergeordnete Klasse aus der Unterklasse überschreiben, verwenden Sie die Großbuchstabenversion des Ressourcennamens. Die Verwendung der Kleinbuchstabenversion führt zu einem Fehler.
Setting Default Attribute Value - Wenn Sie die großgeschriebene Ressource ohne Titel verwenden, wird der Standardwert der Ressource festgelegt.
Arrays
Puppet ermöglicht die Verwendung von Arrays in mehreren Bereichen [Eins, zwei, drei].
Mehrere Typmitglieder, z. B. Alias in der Hostdefinition, akzeptieren Arrays in ihren Werten. Eine Host-Ressource mit mehreren Aliasen sieht folgendermaßen aus.
host { 'one.vipin.com':
alias => [ 'satu', 'dua', 'tiga' ],
ip => '192.168.100.1',
ensure => present,
}Der obige Code fügt einen Host hinzu ‘one.brcletest.com’ zur Hostliste mit drei Aliasen ‘satu’ ‘dua’ ‘tiga’. Wenn Sie einer Ressource mehrere Ressourcen hinzufügen möchten, können Sie dies wie im folgenden Beispiel gezeigt tun.
resource { 'baz':
require => [ Package['rpm'], File['testfile'] ],
}Variablen
Puppet unterstützt wie die meisten anderen Programmiersprachen mehrere Variablen. Marionettenvariablen werden mit bezeichnet$.
$content = 'some content\n' file { '/tmp/testing': content => $content }Wie bereits erwähnt, ist Puppet eine deklarative Sprache, was bedeutet, dass sich Umfang und Zuweisungsregeln von der imperativen Sprache unterscheiden. Der Hauptunterschied besteht darin, dass die Variable nicht innerhalb eines einzelnen Bereichs geändert werden kann, da sie sich auf die Reihenfolge in der Datei stützen, um den Wert einer Variablen zu bestimmen. Die Reihenfolge spielt in der deklarativen Sprache keine Rolle.
$user = root file { '/etc/passwd': owner => $user,
}
$user = bin file { '/bin': owner => $user,
recurse => true,
}Variabler Umfang
Der Variablenbereich definiert, ob alle definierten Variablen gültig sind. Wie bei den neuesten Funktionen ist Puppet derzeit dynamisch ausgerichtet, was in Puppet-Begriffen bedeutet, dass alle definierten Variablen nach ihrem Umfang und nicht nach dem Ort bewertet werden, an dem sie definiert sind.
$test = 'top' class Testclass { exec { "/bin/echo $test": logoutput => true }
}
class Secondtestclass {
$test = 'other'
include myclass
}
include SecondtestclassQualifizierte Variable
Puppet unterstützt die Verwendung qualifizierter Variablen innerhalb einer Klasse oder Definition. Dies ist sehr hilfreich, wenn der Benutzer dieselbe Variable in anderen Klassen verwenden möchte, die er definiert hat oder definieren wird.
class testclass {
$test = 'content'
}
class secondtestclass {
$other = $myclass::test
}Im obigen Code wertet der Wert der Variablen $ other den Inhalt aus.
Bedingungen
Bedingungen sind Situationen, in denen der Benutzer eine Reihe von Anweisungen oder Codes ausführen möchte, wenn die definierte Bedingung oder die erforderliche Bedingung erfüllt ist. Puppet unterstützt zwei Arten von Bedingungen.
Die Auswahlbedingung, die nur innerhalb der definierten Ressourcen verwendet werden kann, um den korrekten Wert der Maschine auszuwählen.
Anweisungsbedingungen sind häufig verwendete Bedingungen im Manifest, die dazu beitragen, zusätzliche Klassen aufzunehmen, die der Benutzer in dieselbe Manifestdatei aufnehmen möchte. Definieren Sie einen bestimmten Satz von Ressourcen innerhalb einer Klasse oder treffen Sie andere strukturelle Entscheidungen.
Selektoren
Selektoren sind nützlich, wenn der Benutzer ein Ressourcenattribut und Variablen angeben möchte, die sich von den Standardwerten aufgrund der Fakten oder anderer Variablen unterscheiden. In Puppet funktioniert der Selektorindex wie ein mehrwertiger Drei-Wege-Operator. Selektoren können auch die benutzerdefinierten Standardwerte ohne Werte definieren, die im Manifest definiert sind und der Bedingung entsprechen.
$owner = $Sysoperenv ? {
sunos => 'adm',
redhat => 'bin',
default => undef,
}In späteren Versionen von Puppet 0.25.0 können Selektoren als reguläre Ausdrücke verwendet werden.
$owner = $Sysoperenv ? {
/(Linux|Ubuntu)/ => 'bin',
default => undef,
}Im obigen Beispiel der Selektor $Sysoperenv Der Wert entspricht entweder Linux oder Ubuntu. Dann ist der Bin das ausgewählte Ergebnis. Andernfalls wird der Benutzer als undefiniert festgelegt.
Anweisungsbedingung
Die Anweisungsbedingung ist eine andere Art der bedingten Anweisung in Puppet, die der Switch-Case-Bedingung im Shell-Skript sehr ähnlich ist. Hierbei werden mehrere case-Anweisungen definiert und die angegebenen Eingabewerte mit jeder Bedingung abgeglichen.
Die case-Anweisung, die der angegebenen Eingabebedingung entspricht, wird ausgeführt. Diese case-Anweisungsbedingung hat keinen Rückgabewert. In Puppet wird in einem sehr häufigen Anwendungsfall für Bedingungsanweisungen eine Reihe von Codebits ausgeführt, die auf dem zugrunde liegenden Betriebssystem basieren.
case $ Sysoperenv {
sunos: { include solaris }
redhat: { include redhat }
default: { include generic}
}Case Statement kann auch mehrere Bedingungen angeben, indem sie durch ein Komma getrennt werden.
case $Sysoperenv {
development,testing: { include development } testing,production: { include production }
default: { include generic }
}If-Else-Anweisung
Puppet unterstützt das Konzept des zustandsbasierten Betriebs. Um dies zu erreichen, bietet die If / else-Anweisung Verzweigungsoptionen basierend auf dem Rückgabewert der Bedingung. Wie im folgenden Beispiel gezeigt -
if $Filename {
file { '/some/file': ensure => present }
} else {
file { '/some/other/file': ensure => present }
}Die neueste Version von Puppet unterstützt Variablenausdrücke, bei denen die if-Anweisung auch basierend auf dem Wert eines Ausdrucks verzweigen kann.
if $machine == 'production' {
include ssl
} else {
include nginx
}Um mehr Vielfalt im Code zu erreichen und komplexe bedingte Operationen auszuführen, unterstützt Puppet verschachtelte if / else-Anweisungen, wie im folgenden Code gezeigt.
if $ machine == 'production' { include ssl } elsif $ machine == 'testing' {
include nginx
} else {
include openssl
}Virtuelle Ressource
Virtuelle Ressourcen sind solche, die erst dann an den Client gesendet werden, wenn sie realisiert wurden.
Im Folgenden finden Sie die Syntax für die Verwendung virtueller Ressourcen in Puppet.
@user { vipin: ensure => present }Im obigen Beispiel wird das Benutzer-Vipin virtuell definiert, um die Definition zu realisieren, die in der Sammlung verwendet werden kann.
User <| title == vipin |>Bemerkungen
Kommentare werden in jedem Codebit verwendet, um einen zusätzlichen Knoten über eine Reihe von Codezeilen und deren Funktionalität zu erstellen. In Puppet gibt es derzeit zwei Arten von unterstützten Kommentaren.
- Kommentare im Unix-Shell-Stil. Sie können in ihrer eigenen Zeile oder in der nächsten Zeile stehen.
- Mehrzeilige Kommentare im C-Stil.
Das Folgende ist ein Beispiel für einen Kommentar im Shell-Stil.
# this is a commentDas Folgende ist ein Beispiel für einen mehrzeiligen Kommentar.
/*
This is a comment
*/Vorrang des Bedieners
Die Priorität des Puppet-Operators entspricht der Standard-Priorität in den meisten Systemen, vom höchsten zum niedrigsten.
Es folgt die Liste der Ausdrücke
- ! = nicht
- / = mal und teile
- - + = minus, plus
- << >> = Links- und Rechtsverschiebung
- ==! = = nicht gleich, gleich
- > = <=> <= größer gleich, kleiner oder gleich, größer als, kleiner als
Vergleichsausdruck
Vergleichsausdrücke werden verwendet, wenn der Benutzer eine Reihe von Anweisungen ausführen möchte, wenn die angegebene Bedingung erfüllt ist. Vergleichsausdrücke umfassen Tests auf Gleichheit unter Verwendung des Ausdrucks ==.
if $environment == 'development' {
include openssl
} else {
include ssl
}Nicht gleiches Beispiel
if $environment != 'development' {
$otherenvironment = 'testing' } else { $otherenvironment = 'production'
}Arithmetischer Ausdruck
$one = 1 $one_thirty = 1.30
$two = 2.034e-2 $result = ((( $two + 2) / $one_thirty) + 4 * 5.45) -
(6 << ($two + 4)) + (0×800 + -9)Boolescher Ausdruck
Boolesche Ausdrücke sind mit oder und & nicht möglich.
$one = 1
$two = 2 $var = ( $one < $two ) and ( $one + 1 == $two )Regulären Ausdruck
Puppet unterstützt den Abgleich regulärer Ausdrücke mit = ~ (Übereinstimmung) und! ~ (Nichtübereinstimmung).
if $website =~ /^www(\d+)\./ { notice('Welcome web server #$1')
}Wie bei der Übereinstimmung von Groß- und Kleinschreibung und Selektor wird für jede Regex eine begrenzte Bereichsvariable erstellt.
exec { "Test":
command => "/bin/echo now we don’t have openssl installed on machine > /tmp/test.txt",
unless => "/bin/which php"
}In ähnlicher Weise können wir verwenden, es sei denn, der Befehl wird nicht ständig ausgeführt, mit Ausnahme des Befehls unter, sofern er nicht erfolgreich beendet wird.
exec { "Test":
command => "/bin/echo now we don’t have openssl installed on machine > /tmp/test.txt",
unless => "/bin/which php"
}Arbeiten mit Vorlagen
Vorlagen werden verwendet, wenn eine vordefinierte Struktur gewünscht wird, die über mehrere Module in Puppet verwendet wird, und diese Module auf mehrere Computer verteilt werden. Der erste Schritt zur Verwendung der Vorlage besteht darin, eine zu erstellen, die den Vorlageninhalt mit Vorlagenmethoden rendert.
file { "/etc/tomcat/sites-available/default.conf":
ensure => "present",
content => template("tomcat/vhost.erb")
}Puppet macht beim Umgang mit lokalen Dateien nur wenige Annahmen, um Organisation und Modularität durchzusetzen. Puppet sucht nach der Vorlage vhost.erb im Ordner apache / templates im Modulverzeichnis.
Dienste definieren und auslösen
In Puppet verfügt es über eine Ressource namens "Dienst", mit der der Lebenszyklus aller Dienste verwaltet werden kann, die auf einem bestimmten Computer oder einer bestimmten Umgebung ausgeführt werden. Serviceressourcen werden verwendet, um sicherzustellen, dass Services initialisiert und aktiviert werden. Sie werden auch für den Neustart des Dienstes verwendet.
Zum Beispiel in der vorherigen Vorlage von Tomcat, in der wir den virtuellen Apache-Host festgelegt haben. Wenn Sie sicherstellen möchten, dass Apache nach einem virtuellen Hostwechsel neu gestartet wird, müssen Sie mit dem folgenden Befehl eine Serviceressource für den Apache-Service erstellen.
service { 'tomcat':
ensure => running,
enable => true
}Bei der Definition der Ressourcen müssen wir die Benachrichtigungsoption einschließen, um den Neustart auszulösen.
file { "/etc/tomcat/sites-available/default.conf":
ensure => "present",
content => template("vhost.erb"),
notify => Service['tomcat']
}In Puppet alle Programme, die mit der Programmiersprache Ruby geschrieben und mit einer Erweiterung von gespeichert wurden .pp werden genannt manifests. Im Allgemeinen werden alle Puppet-Programme, die mit dem Ziel erstellt wurden, einen Zielhostcomputer zu erstellen oder zu verwalten, als Manifest bezeichnet. Alle in Puppet geschriebenen Programme folgen dem Puppet-Codierungsstil.
Der Kern von Puppet ist die Art und Weise, wie Ressourcen deklariert werden und wie diese Ressourcen ihren Zustand darstellen. In jedem Manifest kann der Benutzer über eine Sammlung verschiedener Arten von Ressourcen verfügen, die mithilfe von Klasse und Definition zusammengefasst werden.
In einigen Fällen kann das Puppenmanifest sogar eine bedingte Anweisung enthalten, um einen gewünschten Zustand zu erreichen. Letztendlich kommt es jedoch darauf an, sicherzustellen, dass alle Ressourcen richtig definiert und verwendet werden und dass das definierte Manifest, wenn es nach der Konvertierung in einen Katalog angewendet wird, die Aufgabe ausführen kann, für die es entworfen wurde.
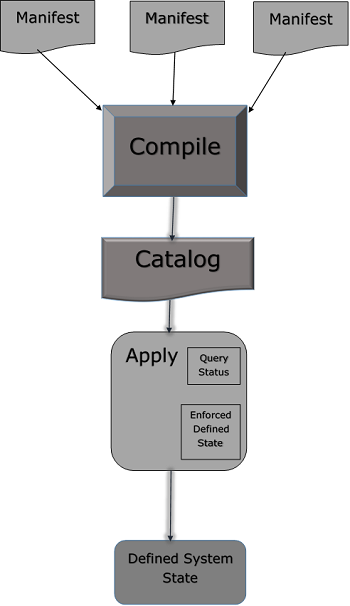
Manifest File Workflow
Das Puppenmanifest besteht aus folgenden Komponenten:
Files (Dies sind einfache Dateien, mit denen Puppet nichts zu tun hat, nur um sie aufzunehmen und am Zielort zu platzieren.)
Resources
Templates (Diese können verwendet werden, um Konfigurationsdateien auf dem Knoten zu erstellen).
Nodes (Alle Definitionen, die sich auf einen Clientknoten beziehen, werden hier definiert.)
Classes
Zu beachtende Punkte
In Puppet verwenden alle Manifestdateien Ruby als Codierungssprache und werden mit gespeichert .pp Erweiterung.
Die "Import" -Anweisung in vielen Manifesten wird zum Laden von Dateien verwendet, wenn Puppet gestartet wird.
Um alle in einem Verzeichnis enthaltenen Dateien zu importieren, können Sie die import-Anweisung auf andere Weise verwenden, z. B. durch Importieren von 'clients / *'. Dies wird alle importieren.pp Dateien in diesem Verzeichnis.
Manifeste schreiben
Arbeiten mit Variablen
Während des Schreibens eines Manifests kann der Benutzer an jedem Punkt eines Manifests eine neue Variable definieren oder eine vorhandene Variable verwenden. Puppet unterstützt verschiedene Arten von Variablen, von denen jedoch nur wenige häufig verwendet werden, z. B. Zeichenfolgen und Zeichenfolgenarrays. Neben ihnen werden auch andere Formate unterstützt.
Beispiel für eine Zeichenfolgenvariable
$package = "vim" package { $package:
ensure => "installed"
}Verwenden von Schleifen
Schleifen werden verwendet, wenn mehrere Iterationen mit demselben Codesatz durchlaufen werden sollen, bis eine definierte Bedingung erfüllt ist. Sie werden auch verwendet, um sich wiederholende Aufgaben mit unterschiedlichen Werten auszuführen. Erstellen von 10 Aufgaben für 10 verschiedene Dinge. Man kann eine einzelne Aufgabe erstellen und eine Schleife verwenden, um die Aufgabe mit verschiedenen Paketen zu wiederholen, die man installieren möchte.
Am häufigsten wird ein Array verwendet, um einen Test mit unterschiedlichen Werten zu wiederholen.
$packages = ['vim', 'git', 'curl'] package { $packages:
ensure => "installed"
}Bedingungen verwenden
Puppet unterstützt den größten Teil der bedingten Struktur, die in traditionellen Programmiersprachen zu finden ist. Die Bedingung kann verwendet werden, um dynamisch zu definieren, ob eine bestimmte Aufgabe ausgeführt werden soll oder ob ein Satz von Code ausgeführt werden soll. Wie if / else und case Anweisungen. Darüber hinaus unterstützen Bedingungen wie "Ausführen" auch Attribute, die wie eine Bedingung funktionieren, jedoch nur eine Befehlsausgabe als Bedingung akzeptieren.
if $OperatingSystem != 'Linux' {
warning('This manifest is not supported on this other OS apart from linux.')
} else {
notify { 'the OS is Linux. We are good to go!': }
}In Puppet kann ein Modul als Sammlung von Ressourcen, Klassen, Dateien, Definitionen und Vorlagen definiert werden. Puppet unterstützt die einfache Neuverteilung von Modulen, was für die Modularität des Codes sehr hilfreich ist, da ein bestimmtes generisches Modul geschrieben und mit sehr wenigen einfachen Codeänderungen mehrmals verwendet werden kann. Dies aktiviert beispielsweise die Standard-Site-Konfiguration unter / etc / puppet mit Modulen, die von Puppet in / etc / share / puppet geliefert werden.
Modulkonfiguration
In jedem Puppet-Modul gibt es zwei Partitionen, die bei der Definition der Codestruktur und der Steuerung der Nennwerte helfen.
Der Suchpfad von Modulen wird mithilfe einer durch Doppelpunkte getrennten Liste von Verzeichnissen in der konfiguriert puppetmasterd oder masterd, der spätere Abschnitt der Puppet-Hauptkonfigurationsdatei mit dem modulepath Parameter.
[puppetmasterd]
...
modulepath = /var/lib/puppet/modules:/data/puppet/modulesZugriffssteuerungseinstellungen für die Dateiservermodule in der Datei fileserver.conf. Die Pfadkonfiguration für dieses Modul wird immer ignoriert. Wenn Sie einen Pfad angeben, wird eine Warnung ausgegeben.
Der Suchpfad kann zur Laufzeit hinzugefügt werden, indem die Umgebungsvariable PUPPETLAB festgelegt wird, die auch eine durch Doppelpunkte getrennte Liste von Variablen sein muss.
Modulquelle
Puppet unterstützt einen anderen Speicherort für Module. Jedes Modul kann in einem anderen Dateisystem eines bestimmten Computers gespeichert werden. Alle Pfade, in denen Module gespeichert sind, müssen jedoch in der Konfigurationsvariablen angegeben werden, die als bekannt istmodulepath Dies ist im Allgemeinen eine Pfadvariable, bei der Puppet nach allen Modulverzeichnissen sucht und diese beim Booten lädt.
Ein angemessener Standardpfad kann wie folgt konfiguriert werden:
/etc/puppet/modules:/usr/share/puppet:/var/lib/modules.Alternativ könnte das Verzeichnis / etc / puppet als spezielles anonymes Modul eingerichtet werden, das immer zuerst durchsucht wird.
Modulbenennung
Puppet folgt den gleichen Namensstandards eines bestimmten Moduls, wobei der Modulname normale Wörter sein muss, die mit [- \\ w +] (Buchstabe, Wort, Zahl, Unterstrich und Bindestriche) übereinstimmen und nicht das Namespace-Trennzeichen enthalten :: oder /. Während dies in Bezug auf Modulhierarchien zulässig sein kann, kann es für neue Module nicht verschachtelt werden.
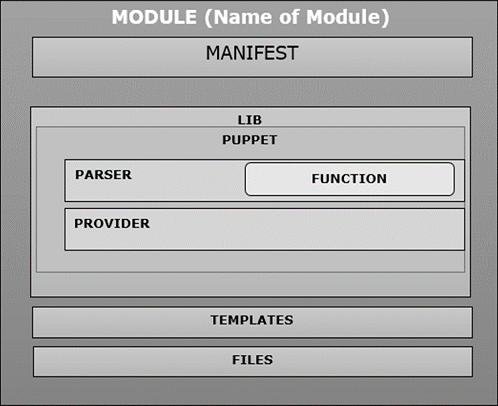
Modul Interne Organisation
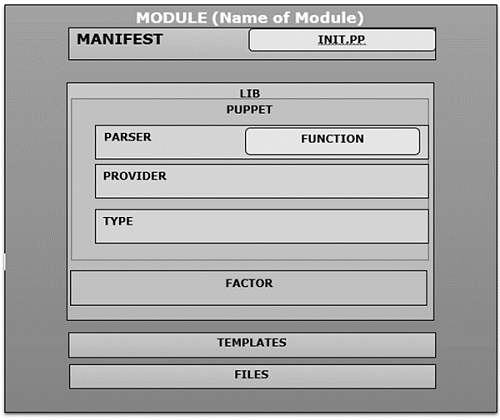
Wenn der Benutzer ein neues Modul in Puppet erstellt, folgt es derselben Struktur und enthält Manifest, verteilte Dateien, Plugins und Vorlagen, die in einer bestimmten Verzeichnisstruktur angeordnet sind, wie im folgenden Code gezeigt.
MODULE_PATH/
downcased_module_name/
files/
manifests/
init.pp
lib/
puppet/
parser/
functions
provider/
type/
facter/
templates/
READMEWann immer ein Modul erstellt wird, enthält es init.ppManifestdatei am angegebenen Fixspeicherort im Manifestverzeichnis. Diese Manifestdatei ist eine Standarddatei, die zuerst in einem bestimmten Modul ausgeführt wird und eine Sammlung aller Klassen enthält, die diesem bestimmten Modul zugeordnet sind. Zusätzlich.ppDatei kann direkt unter dem Manifest-Ordner hinzugefügt werden. Wenn wir zusätzliche PP-Dateien hinzufügen, sollten diese nach der Klasse benannt werden.
Eine der Hauptfunktionen, die durch die Verwendung von Modulen erreicht werden, ist die gemeinsame Nutzung von Code. Ein Modul sollte von Natur aus in sich geschlossen sein, was bedeutet, dass man jedes Modul von überall einschließen und auf den Modulpfad legen kann, der beim Hochfahren von Puppet geladen wird. Mit Hilfe von Modulen erhält man Modularität bei der Codierung der Puppet-Infrastruktur.
Beispiel
Stellen Sie sich ein autofs-Modul vor, das eine feste auto.homes-Zuordnung installiert und den auto.master aus Vorlagen generiert.
class autofs {
package { autofs: ensure => latest }
service { autofs: ensure => running }
file { "/etc/auto.homes":
source => "puppet://$servername/modules/autofs/auto.homes"
}
file { "/etc/auto.master":
content => template("autofs/auto.master.erb")
}
}Das Dateisystem verfügt über die folgenden Dateien.
MODULE_PATH/
autofs/
manifests/
init.pp
files/
auto.homes
templates/
auto.master.erbModul-Suche
Puppet folgt einer vordefinierten Struktur, in der mehrere Verzeichnisse und Unterverzeichnisse in einer definierten Struktur enthalten sind. Diese Verzeichnisse enthalten verschiedene Arten von Dateien, die ein Modul benötigt, um bestimmte Aktionen auszuführen. Ein wenig Magie hinter den Kulissen stellt sicher, dass die richtige Datei dem richtigen Kontext zugeordnet ist. Alle Modulsuchen befinden sich im Modulpfad, einer durch Doppelpunkte getrennten Liste von Verzeichnissen.
Für Dateiverweise auf dem Dateiserver wird ein ähnlicher Verweis verwendet, sodass ein Verweis auf Puppet: //$servername/modules/autofs/auto.homes in die Datei autofs / files / auto.homes im Pfad des Moduls aufgelöst wird.
Um ein Modul sowohl mit dem Befehlszeilenclient als auch mit einem Puppet-Master verwendbar zu machen, kann eine URL des from-Puppet: /// -Pfads verwendet werden. dh eine URL ohne expliziten Servernamen. Eine solche URL wird von etwas anders behandeltPuppet und puppetd. Puppet sucht im lokalen Dateisystem nach einer serverlosen URL.
Vorlagendateien werden auf ähnliche Weise wie Manifest und Dateien durchsucht: Durch Erwähnung der Vorlage („autofs / auto.master.erb“) sucht der Puppenspieler zuerst nach einer Datei in $templatedir/autofs/auto.master.erb und dann autofs/templates/auto.master.erbauf dem Modulpfad. Mit Puppet-Versionen von allem unter der Puppet steht es zur Verfügung. Dies wird als automatisches Laden des Moduls bezeichnet. Puppet versucht, Klassen und Definitionen automatisch aus dem Modul zu laden.
Puppet folgt dem Konzept von Client und Server, bei dem ein Computer in einem Setup als Server mit Puppet-Serversoftware und der verbleibende als Client mit Puppet-Agentensoftware fungiert. Diese Funktion des Dateiservers hilft beim Kopieren der Dateien auf mehrere Computer. Diese Funktion der Dateiserving-Funktion in Puppet ist Teil des zentralen Puppet-Daemons. Puppetmasterd und die Client-Funktion spielen eine Schlüsselrolle bei der Beschaffung von Dateiattributen als Dateiobjekt.
class { 'java':
package => 'jdk-8u25-linux-x64',
java_alternative => 'jdk1.8.0_25',
java_alternative_path => '/usr/java/jdk1.8.0_25/jre/bin/java'
}Wie im obigen Codefragment abstrahieren die Dateiservingfunktionen von Puppet die lokale Dateisystemtopologie, indem sie das Dateiservicemodul unterstützen. Wir werden das Dateiservingemodul auf folgende Weise spezifizieren.
“puppet://server/modules/module_name/sudoers”Datei Format
In der Puppet-Verzeichnisstruktur befindet sich standardmäßig die Dateiserverkonfiguration unter /etc/puppet/fileserver.config Verzeichnis, wenn der Benutzer diesen Standardpfad der Konfigurationsdatei ändern möchte, kann dies mit dem neuen Konfigurationsflag auf erfolgen puppetmasterd. Die Konfigurationsdatei ähnelt INI-Dateien, ist jedoch nicht genau gleich.
[module]
path /path/to/files
allow *.domain.com
deny *.wireless.domain.comWie im obigen Codeausschnitt gezeigt, werden alle drei Optionen in der Konfigurationsdatei dargestellt. Der Modulname steht etwas in Klammern. Der Pfad ist die einzige erforderliche Option. Die Standardsicherheitsoption besteht darin, den gesamten Zugriff zu verweigern. Wenn also keine Zulassungsleitungen angegeben sind, steht das zu konfigurierende Modul jedem zur Verfügung.
Der Pfad kann einige oder alle% d,% h und% H enthalten, die dynamisch durch den Domänennamen, den Hostnamen und den vollständig qualifizierten Hostnamen ersetzt werden. Alle werden dem SSL-Zertifikat des Clients entnommen (seien Sie also vorsichtig, wenn Hostname und Zertifikatsname nicht übereinstimmen). Dies ist nützlich, um Module zu erstellen, in denen die Dateien jedes Clients vollständig separat aufbewahrt werden. Beispiel für private Hostschlüssel.
[private]
path /data/private/%h
allow *Im obigen Codefragment versucht der Code, vom Client aus nach der Datei /private/file.txt zu suchen client1.vipin.com. Es wird in /data/private/client1/file.txt danach suchen, während dieselbe Anforderung für client2.vipin.com versucht, die Datei /data/private/client2/file.txt auf dem Dateiserver abzurufen.
Sicherheit
Puppet unterstützt die beiden Grundkonzepte zum Sichern von Dateien auf dem Puppet-Dateiserver. Dies wird erreicht, indem der Zugriff auf bestimmte Dateien ermöglicht und der Zugriff auf diejenigen Dateien verweigert wird, die nicht erforderlich sind. Standardmäßig erlaubt Puppet keinen Zugriff auf eine der Dateien. Es muss explizit definiert werden. Das Format, das in den Dateien verwendet werden kann, um den Zugriff zuzulassen oder zu verweigern, ist die Verwendung von IP-Adresse, Name oder globaler Erlaubnis.
Wenn der Client nicht direkt mit dem Puppet-Dateiserver verbunden ist, z. B. über einen Reverse-Proxy und Mongrel, sieht der Dateiserver, dass alle Verbindungen vom Proxyserver und nicht vom Puppet-Client stammen. In den oben genannten Fällen empfiehlt es sich, den Hostnamen auf der Basis des Hostnamens einzuschränken.
Ein wichtiger Punkt beim Definieren der Dateistruktur ist, dass alle Verweigerungsanweisungen vor der allow-Anweisung analysiert werden. Wenn also eine Verweigerungsanweisung mit einem Host übereinstimmt, wird dieser Host abgelehnt, und wenn in den kommenden Dateien keine Erlaubnisanweisung geschrieben ist, wird der Host abgelehnt. Diese Funktion hilft beim Festlegen der Priorität einer bestimmten Site.
Hostname
In jeder Dateiserverkonfiguration kann der Datei-Hostname auf zwei Arten angegeben werden, entweder unter Verwendung eines vollständigen Hostnamens oder durch Angabe eines gesamten Domänennamens mithilfe des Platzhalters *, wie im folgenden Beispiel gezeigt.
[export]
path /usr
allow brcleprod001.brcl.com
allow *.brcl.com
deny brcleprod002.brcl.comIP Adresse
In jeder Dateiserverkonfiguration kann die Dateianschrift ähnlich wie die Hostnamen angegeben werden, wobei entweder die vollständige IP-Adresse oder die Platzhalteradresse verwendet wird. Man kann auch die CIDR-Systemnotation verwenden.
[export]
path /usr
allow 127.0.0.1
allow 172.223.30.*
allow 172.223.30.0/24Globales Zulassen
Die globale Erlaubnis wird verwendet, wenn der Benutzer möchte, dass jeder auf ein bestimmtes Modul zugreifen kann. Zu diesem Zweck hilft ein einziger Platzhalter dabei, dass jeder auf das Modul zugreifen kann.
[export]
path /export
allow *Puppet unterstützt das Halten mehrerer Werte als Umgebungsvariable. Diese Funktion wird in Puppet mithilfe von unterstütztfacter. In Puppet ist facter ein eigenständiges Tool, das die Umgebungsvariable enthält. In kann als ähnlich der env-Variablen von Bash oder Linux angesehen werden. Manchmal kann es zu einer Überlappung zwischen den in Fakten gespeicherten Informationen und der Umgebungsvariablen der Maschine kommen. In Puppet wird das Schlüssel-Wert-Paar als "Tatsache" bezeichnet. Jede Ressource hat ihre eigenen Fakten und in Puppet kann der Benutzer seine eigenen benutzerdefinierten Fakten erstellen.
# facterFacter commandkann verwendet werden, um alle verschiedenen Umgebungsvariablen und die zugehörigen Werte aufzulisten. Diese Sammlung von Fakten wird sofort mit Facter geliefert und als Kernfakten bezeichnet. Man kann der Sammlung benutzerdefinierte Fakten hinzufügen.
Wenn man nur eine Variable anzeigen möchte. Dies kann mit dem folgenden Befehl erfolgen.
# facter {Variable Name}
Example
[root@puppetmaster ~]# facter virtual
virtualboxDer Grund, warum Facter für Puppet wichtig ist, ist, dass Facter und Fakten im gesamten Puppet-Code als verfügbar sind “global variable”Dies bedeutet, dass es jederzeit ohne weitere Referenz im Code verwendet werden kann.
Beispiel zum Testen
[root@puppetmaster modules]# tree brcle_account
brcle_account
└── manifests └── init.pp [root@puppetmaster modules]# cat brcle_account/manifests/init.pp
class brcle_account {
user { 'G01063908':
ensure => 'present',
uid => '121',
shell => '/bin/bash',
home => '/home/G01063908',
}
file {'/tmp/userfile.txt':
ensure => file,
content => "the value for the 'OperatingSystem' fact is: $OperatingSystem \n",
}
}Testen
[root@puppetmaster modules]# puppet agent --test
Notice: /Stage[main]/Activemq::Service/Service[activemq]/ensure:
ensure changed 'stopped' to 'running'
Info: /Stage[main]/Activemq::Service/Service[activemq]:
Unscheduling refresh on Service[activemq]
Notice: Finished catalog run in 4.09 seconds
[root@puppetmaster modules]# cat /tmp/testfile.txt
the value for the 'OperatingSystem' fact is: Linux
[root@puppetmaster modules]# facter OperatingSystem
LinuxWie wir im obigen Code-Snippet sehen können, haben wir das nicht definiert OperatingSystem. Wir haben gerade den Wert durch einen weich codierten Wert ersetzt$OperatingSystem als normale Variable.
In Puppet gibt es drei Arten von Fakten, die verwendet und definiert werden können:
- Kern Fakten
- Benutzerdefinierte Fakten
- Externe Fakten
Kernfakten werden auf der obersten Ebene definiert und sind an jedem Punkt des Codes für alle zugänglich.
Marionetten Fakten
Kurz bevor ein Agent einen Katalog vom Master anfordert, erstellt der Agent zunächst eine vollständige Liste der in sich verfügbaren Informationen in Form eines Schlüsselwertpaars. Die Informationen über den Agenten werden von einem Tool namens Facter gesammelt, und jedes Schlüssel-Wert-Paar wird als Fakt bezeichnet. Im Folgenden finden Sie eine allgemeine Ausgabe von Fakten zu einem Agenten.
[root@puppetagent1 ~]# facter
architecture => x86_64
augeasversion => 1.0.0
bios_release_date => 13/09/2012
bios_vendor => innotek GmbH
bios_version => VirtualBox
blockdevice_sda_model => VBOX HARDDISK
blockdevice_sda_size => 22020587520
blockdevice_sda_vendor => ATA
blockdevice_sr0_model => CD-ROM
blockdevice_sr0_size => 1073741312
blockdevice_sr0_vendor => VBOX
blockdevices => sda,sr0
boardmanufacturer => Oracle Corporation
boardproductname => VirtualBox
boardserialnumber => 0
domain => codingbee.dyndns.org
facterversion => 2.1.0
filesystems => ext4,iso9660
fqdn => puppetagent1.codingbee.dyndns.org
hardwareisa => x86_64
hardwaremodel => x86_64
hostname => puppetagent1
id => root
interfaces => eth0,lo
ipaddress => 172.228.24.01
ipaddress_eth0 => 172.228.24.01
ipaddress_lo => 127.0.0.1
is_virtual => true
kernel => Linux
kernelmajversion => 2.6
kernelrelease => 2.6.32-431.23.3.el6.x86_64
kernelversion => 2.6.32
lsbdistcodename => Final
lsbdistdescription => CentOS release 6.5 (Final)
lsbdistid => CentOS
lsbdistrelease => 6.5
lsbmajdistrelease => 6
lsbrelease => :base-4.0-amd64:base-4.0-noarch:core-4.0-amd64:core-4.0noarch:graphics-4.0-amd64:
graphics-4.0-noarch:printing-4.0-amd64:printing-4.0noarch
macaddress => 05:00:22:47:H9:77
macaddress_eth0 => 05:00:22:47:H9:77
manufacturer => innotek GmbH
memoryfree => 125.86 GB
memoryfree_mb => 805.86
memorysize => 500 GB
memorysize_mb => 996.14
mtu_eth0 => 1500
mtu_lo => 16436
netmask => 255.255.255.0
netmask_eth0 => 255.255.255.0
network_lo => 127.0.0.0
operatingsystem => CentOS
operatingsystemmajrelease => 6
operatingsystemrelease => 6.5
osfamily => RedHat
partitions => {"sda1"=>{
"uuid"=>"d74a4fa8-0883-4873-8db0-b09d91e2ee8d", "size" =>"1024000",
"mount" => "/boot", "filesystem" => "ext4"}, "sda2"=>{"size" => "41981952",
"filesystem" => "LVM2_member"}
}
path => /usr/lib64/qt3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
physicalprocessorcount => 1
processor0 => Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz
processor1 => Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz
processor2 => Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz
processorcount => 3
productname => VirtualBox
ps => ps -ef
puppetversion => 3.6.2
rubysitedir => /usr/lib/ruby/site_ruby/1.8
rubyversion => 1.8.7
selinux => true
selinux_config_mode => enforcing
selinux_config_policy => targeted
selinux_current_mode => enforcing
selinux_enforced => true
selinux_policyversion => 24
serialnumber => 0
sshdsakey => AAAAB3NzaC1kc3MAAACBAK5fYwRM3UtOs8zBCtRTjuHLw56p94X/E0UZBZwFR3q7
WH0x5+MNsjfmdCxKvpY/WlIIUcFJzvlfjXm4qDaTYalbzSZJMT266njNbw5WwLJcJ74KdW92ds76pjgm
CsjAh+R9YnyKCEE35GsYjGH7whw0gl/rZVrjvWYKQDOmJA2dAAAAFQCoYABgjpv3EkTWgjLIMnxA0Gfud
QAAAIBM4U6/nerfn6Qvt43FC2iybvwVo8ufixJl5YSEhs92uzsW6jiw68aaZ32q095/gEqYzeF7a2knr
OpASgO9xXqStYKg8ExWQVaVGFTR1NwqhZvz0oRSbrN3h3tHgknoKETRAg/imZQ2P6tppAoQZ8wpuLrXU
CyhgJGZ04Phv8hinAAAAIBN4xaycuK0mdH/YdcgcLiSn8cjgtiETVzDYa+jF
swapfree => 3.55 GB
swapfree_mb => 2015.99
swapsize => 3.55 GB
swapsize_mb => 2015.99
timezone => GMT
type => Other
uniqueid => a8c0af01
uptime => 45:012 hours
uptime_days => 0
uptime_hours => 6
uptime_seconds => 21865
uuid => BD8B9D85-1BFD-4015-A633-BF71D9A6A741
virtual => virtualboxIm obigen Code können wir sehen, dass sich einige Daten mit einigen der in der Bash-Variablen "env" verfügbaren Informationen überschneiden. Puppet verwendet die Daten direkt nicht, sondern verwendet Facter-Daten. Facter-Daten werden als globale Variable behandelt.
Die Fakten sind dann als Variable der obersten Ebene verfügbar und der Puppet-Master kann sie verwenden, um den Puppet-Katalog für den anfordernden Agenten zu kompilieren. Faktoren werden im Manifest als normale Variable mit dem Präfix $ aufgerufen.
Beispiel
if ($OperatingSystem == "Linux") {
$message = "This machine OS is of the type $OperatingSystem \n"
} else {
$message = "This machine is unknown \n" } file { "/tmp/machineOperatingSystem.txt": ensure => file, content => "$message"
}Die obige Manifestdatei stört nur eine einzelne aufgerufene Datei machineOperatingSystem.txt, wo der Inhalt dieser Datei durch die aufgerufene Tatsache abgezogen wird OperatingSystem.
[root@puppetagent1 /]# facter OperatingSystem
Linux
[root@puppetagent1 /]# puppet apply /tmp/ostype.pp
Notice: Compiled catalog for puppetagent1.codingbee.dyndns.org
in environment production in 0.07 seconds
Notice: /Stage[main]/Main/File[/tmp/machineOperatingSystem.txt]/ensure:
defined content as '{md5}f59dc5797d5402b1122c28c6da54d073'
Notice: Finished catalog run in 0.04 seconds
[root@puppetagent1 /]# cat /tmp/machinetype.txt
This machine OS is of the type LinuxBenutzerdefinierte Fakten
Alle oben genannten Fakten, die wir gesehen haben, sind die Kernfakten der Maschine. Sie können diese benutzerdefinierten Fakten auf folgende Weise zum Knoten hinzufügen:
- Verwenden der "Export FACTER ... Syntax"
- Verwenden der $ LOAD_PATH-Einstellungen
- FACTERLIB
- Pluginsync
Verwenden der Syntax „export FACTER“
Man kann die Fakten manuell mit der Exportsyntax FACTER_ {Name der Fakten} hinzufügen.
Beispiel
[root@puppetagent1 facter]# export FACTER_tallest_mountain="Everest"
[root@puppetagent1 facter]# facter tallest_mountain EverestVerwenden der $ LOAD_PATH-Einstellungen
In Ruby, $LOAD_PATH is equivalent to Bash special parameter. Although it is similar to bash $PATH-Variable, in realen Fakten $ LOAD_PATH ist keine Umgebungsvariable, sondern eine vordefinierte Variable.
$ LOAD_PATH hat ein Synonym "$:". Diese Variable ist ein Array zum Suchen und Laden der Werte.
[root@puppetagent1 ~]# ruby -e 'puts $LOAD_PATH'
# note you have to use single quotes.
/usr/lib/ruby/site_ruby/1.6
/usr/lib64/ruby/site_ruby/1.6
/usr/lib64/ruby/site_ruby/1.6/x86_64-linux
/usr/lib/ruby/site_ruby
/usr/lib64/ruby/site_ruby
/usr/lib64/site_ruby/1.6
/usr/lib64/site_ruby/1.6/x86_64-linux
/usr/lib64/site_ruby
/usr/lib/ruby/1.6
/usr/lib64/ruby/1.6
/usr/lib64/ruby/1.6/x86_64-linuxNehmen wir ein Beispiel für das Erstellen eines Verzeichnisfaktors und das Hinzufügen eines .pp Datei und Anhängen eines Inhalts daran.
[root@puppetagent1 ~]# cd /usr/lib/ruby/site_ruby/
[root@puppetagent1 site_ruby]# mkdir facter
[root@puppetagent1 site_ruby]# cd facter/
[root@puppetagent1 facter]# ls
[root@puppetagent1 facter]# touch newadded_facts.rbFügen Sie der Datei custom_facts.rb den folgenden Inhalt hinzu.
[root@puppetagent1 facter]# cat newadded_facts.rb
Facter.add('tallest_mountain') do
setcode "echo Everest"
endFacter scannt alle in $ LOAD_PATH aufgelisteten Ordner und sucht nach einem Director namens facter. Sobald dieser bestimmte Ordner gefunden wurde, werden sie an einer beliebigen Stelle in der Ordnerstruktur geladen. Wenn dieser Ordner gefunden wird, sucht er nach einer Ruby-Datei in diesem Facter-Ordner und lädt alle definierten Fakten zu einer bestimmten Konfiguration in den Speicher.
Verwenden von FACTERLIB
In Puppet funktioniert FACTERLIB sehr ähnlich wie $ LOAD_PATH, jedoch mit nur einem wesentlichen Unterschied, dass es sich eher um einen Umgebungsparameter auf Betriebssystemebene als um eine spezielle Ruby-Variable handelt. Standardmäßig ist die Umgebungsvariable möglicherweise nicht festgelegt.
[root@puppetagent1 facter]# env | grep "FACTERLIB"
[root@puppetagent1 facter]#Um FACTERLIB zu testen, müssen wir die folgenden Schritte ausführen.
Erstellen Sie einen Ordner mit dem Namen test_facts in der folgenden Struktur.
[root@puppetagent1 tmp]# tree /tmp/test_facts/
/tmp/some_facts/
├── vipin
│ └── longest_river.rb
└── testing
└── longest_wall.rbFügen Sie den .rb-Dateien den folgenden Inhalt hinzu.
[root@puppetagent1 vipin]# cat longest_river.rb
Facter.add('longest_river') do
setcode "echo Nile"
end
[root@puppetagent1 testing]# cat longest_wall.rb
Facter.add('longest_wall') do
setcode "echo 'China Wall'"
endVerwenden Sie die Exportanweisung.
[root@puppetagent1 /]# export
FACTERLIB = "/tmp/some_facts/river:/tmp/some_facts/wall"
[root@puppetagent1 /]# env | grep "FACTERLIB"
FACTERLIB = /tmp/some_facts/river:/tmp/some_facts/wallTesten Sie den neuen Facter.
[root@puppetagent1 /]# facter longest_river
Nile
[root@puppetagent1 /]# facter longest_wall
China WallExterne Fakten
Externe Fakten sind sehr nützlich, wenn der Benutzer einige neue Fakten anwenden möchte, die zum Zeitpunkt der Bereitstellung erstellt wurden. Externe Fakten sind eine der wichtigsten Methoden zum Anwenden von Metadaten auf eine VM in der Bereitstellungsphase (z. B. mithilfe von vSphere, OpenStack, AWS usw.).
Alle erstellten Metadaten und Details können von Puppet verwendet werden, um zu bestimmen, welche Details im Katalog enthalten sein sollen, der angewendet werden soll.
Externe Fakten erstellen
Auf dem Agentencomputer müssen wir ein Verzeichnis wie unten beschrieben erstellen.
$ mkdir -p /etc/facter/facts.dErstellen Sie ein Shell-Skript im Verzeichnis mit dem folgenden Inhalt.
$ ls -l /etc/facter/facts.d
total 4
-rwxrwxrwx. 1 root root 65 Sep 18 13:11 external-factstest.sh
$ cat /etc/facter/facts.d/external-factstest.sh
#!/bin/bash
echo "hostgroup = dev"
echo "environment = development"Ändern Sie die Berechtigung der Skriptdatei.
$ chmod u+x /etc/facter/facts.d/external-facts.shSobald dies erledigt ist, können wir nun die Variable sehen, die mit dem Schlüssel / Wert-Paar vorhanden ist.
$ facter hostgroup dev $ facter environment
developmentMan kann benutzerdefinierte Fakten in Puppet schreiben. Verwenden Sie als Referenz den folgenden Link von der Puppet-Site.
https://docs.puppet.com/facter/latest/fact_overview.html#writing-structured-facts
Ressourcen sind eine der wichtigsten Grundeinheiten von Puppet, mit denen eine bestimmte Infrastruktur oder Maschine entworfen und gebaut wird. Sie werden hauptsächlich zur Modellierung und Pflege von Systemkonfigurationen verwendet. Puppet verfügt über mehrere Arten von Ressourcen, mit denen die Systemarchitektur definiert werden kann, oder der Benutzer kann eine neue Ressource erstellen und definieren.
Der Block des Marionettencodes in der Manifestdatei oder einer anderen Datei wird als Ressourcendeklaration bezeichnet. Der Codeblock ist in einer Sprache namens Declarative Modeling Language (DML) geschrieben. Das Folgende ist ein Beispiel dafür, wie es aussieht.
user { 'vipin':
ensure => present,
uid => '552',
shell => '/bin/bash',
home => '/home/vipin',
}In Puppet erfolgt die Ressourcendeklaration für einen bestimmten Ressourcentyp im Codeblock. Im folgenden Beispiel besteht der Benutzer hauptsächlich aus vier vordefinierten Parametern.
Resource Type - Im obigen Code-Snippet ist es der Benutzer.
Resource Parameter - Im obigen Code-Snippet ist es Vipin.
Attributes - Im obigen Code-Snippet ist sichergestellt, UID, Shell, Home.
Values - Dies sind die Werte, die jeder Eigenschaft entsprechen.
Jeder Ressourcentyp hat seine eigene Art, Definitionen und Parameter zu definieren, und der Benutzer hat das Recht, auszuwählen, wie seine Ressource aussehen soll.
Ressourcentyp
In Puppet stehen verschiedene Arten von Ressourcen zur Verfügung, die ihre eigene Funktionalität haben. Diese Ressourcentypen können mit dem Befehl "beschreiben" zusammen mit der Option "-list" angezeigt werden.
[root@puppetmaster ~]# puppet describe --list
These are the types known to puppet:
augeas - Apply a change or an array of changes to the ...
computer - Computer object management using DirectorySer ...
cron - Installs and manages cron jobs
exec - Executes external commands
file - Manages files, including their content, owner ...
filebucket - A repository for storing and retrieving file ...
group - Manage groups
host - Installs and manages host entries
interface - This represents a router or switch interface
k5login - Manage the ‘.k5login’ file for a user
macauthorization - Manage the Mac OS X authorization database
mailalias - .. no documentation ..
maillist - Manage email lists
mcx - MCX object management using DirectoryService ...
mount - Manages mounted filesystems, including puttin ...
nagios_command - The Nagios type command
nagios_contact - The Nagios type contact
nagios_contactgroup - The Nagios type contactgroup
nagios_host - The Nagios type host
nagios_hostdependency - The Nagios type hostdependency
nagios_hostescalation - The Nagios type hostescalation
nagios_hostextinfo - The Nagios type hostextinfo
nagios_hostgroup - The Nagios type hostgroup
nagios_service - The Nagios type service
nagios_servicedependency - The Nagios type servicedependency
nagios_serviceescalation - The Nagios type serviceescalation
nagios_serviceextinfo - The Nagios type serviceextinfo
nagios_servicegroup - The Nagios type servicegroup
nagios_timeperiod - The Nagios type timeperiod
notify - .. no documentation ..
package - Manage packages
resources - This is a metatype that can manage other reso ...
router - .. no documentation ..
schedule - Define schedules for Puppet
scheduled_task - Installs and manages Windows Scheduled Tasks
selboolean - Manages SELinux booleans on systems with SELi ...
service - Manage running services
ssh_authorized_key - Manages SSH authorized keys
sshkey - Installs and manages ssh host keys
stage - A resource type for creating new run stages
tidy - Remove unwanted files based on specific crite ...
user - Manage users
vlan - .. no documentation ..
whit - Whits are internal artifacts of Puppet's curr ...
yumrepo - The client-side description of a yum reposito ...
zfs - Manage zfs
zone - Manages Solaris zones
zpool - Manage zpoolsRessourcentitel
Im obigen Code-Snippet haben wir den Ressourcentitel als Vipin, der für jede Ressource eindeutig ist, die in derselben Datei des Codes verwendet wird. Dies ist ein eindeutiger Titel für diesen Benutzerressourcentyp. Wir können keine Ressource mit demselben Namen haben, da dies zu Konflikten führen kann.
Mit dem Befehl "Ressource" können Sie die Liste aller Ressourcen mit dem Typ "Benutzer" anzeigen.
[root@puppetmaster ~]# puppet resource user
user { 'abrt':
ensure => 'present',
gid => '173',
home => '/etc/abrt',
password => '!!',
password_max_age => '-1',
password_min_age => '-1',
shell => '/sbin/nologin',
uid => '173',
}
user { 'admin':
ensure => 'present',
comment => 'admin',
gid => '444',
groups => ['sys', 'admin'],
home => '/var/admin',
password => '*',
password_max_age => '99999',
password_min_age => '0',
shell => '/sbin/nologin',
uid => '55',
}
user { 'tomcat':
ensure => 'present',
comment => 'tomcat',
gid => '100',
home => '/var/www',
password => '!!',
password_max_age => '-1',
password_min_age => '-1',
shell => '/sbin/nologin',
uid => '100',
}Auflisten der Ressourcen eines bestimmten Benutzers
[root@puppetmaster ~]# puppet resource user tomcat
user { 'apache':
ensure => 'present',
comment => 'tomcat',
gid => '100',
home => '/var/www',
password => '!!',
password_max_age => '-1',
password_min_age => '-1',
shell => '/sbin/nologin',
uid => '100’,
}Attribute & Werte
Der Hauptteil einer Ressource besteht aus einer Sammlung von Attribut-Wert-Paaren. Hier kann man die Werte für die Eigenschaft einer bestimmten Ressource angeben. Jeder Ressourcentyp verfügt über einen eigenen Satz von Attributen, die mit den Schlüssel-Wert-Paaren konfiguriert werden können.
Beschreiben Sie den Unterbefehl, mit dem Sie weitere Details zu einem bestimmten Ressourcenattribut abrufen können. Im folgenden Beispiel finden Sie die Details zur Benutzerressource sowie alle konfigurierbaren Attribute.
[root@puppetmaster ~]# puppet describe user
user
====
Manage users. This type is mostly built to manage system users,
so it is lacking some features useful for managing normal users.
This resource type uses the prescribed native tools for creating groups
and generally uses POSIX APIs for retrieving information about them.
It does not directly modify ‘/etc/passwd’ or anything.
**Autorequires:** If Puppet is managing the user's primary group
(as provided in the ‘gid’ attribute),
the user resource will autorequire that group.
If Puppet is managing any role accounts corresponding to the user's roles,
the user resource will autorequire those role accounts.
Parameters
----------
- **allowdupe**
Whether to allow duplicate UIDs. Defaults to ‘false’.
Valid values are ‘true’, ‘false’, ‘yes’, ‘no’.
- **attribute_membership**
Whether specified attribute value pairs should be treated as the
**complete list** (‘inclusive’) or the **minimum list** (‘minimum’) of
attribute/value pairs for the user. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **auths**
The auths the user has. Multiple auths should be
specified as an array.
Requires features manages_solaris_rbac.
- **comment**
A description of the user. Generally the user's full name.
- **ensure**
The basic state that the object should be in.
Valid values are ‘present’, ‘absent’, ‘role’.
- **expiry**
The expiry date for this user. Must be provided in
a zero-padded YYYY-MM-DD format --- e.g. 2010-02-19.
If you want to make sure the user account does never
expire, you can pass the special value ‘absent’.
Valid values are ‘absent’. Values can match ‘/^\d{4}-\d{2}-\d{2}$/’. Requires features manages_expiry. - **forcelocal** Forces the mangement of local accounts when accounts are also being managed by some other NSS - **gid** The user's primary group. Can be specified numerically or by name. This attribute is not supported on Windows systems; use the ‘groups’ attribute instead. (On Windows, designating a primary group is only meaningful for domain accounts, which Puppet does not currently manage.) - **groups** The groups to which the user belongs. The primary group should not be listed, and groups should be identified by name rather than by GID. Multiple groups should be specified as an array. - **home** The home directory of the user. The directory must be created separately and is not currently checked for existence. - **ia_load_module** The name of the I&A module to use to manage this user. Requires features manages_aix_lam. - **iterations** This is the number of iterations of a chained computation of the password hash (http://en.wikipedia.org/wiki/PBKDF2). This parameter is used in OS X. This field is required for managing passwords on OS X >= 10.8. Requires features manages_password_salt. - **key_membership** - **managehome** Whether to manage the home directory when managing the user. This will create the home directory when ‘ensure => present’, and delete the home directory when ‘ensure => absent’. Defaults to ‘false’. Valid values are ‘true’, ‘false’, ‘yes’, ‘no’. - **membership** Whether specified groups should be considered the **complete list** (‘inclusive’) or the **minimum list** (‘minimum’) of groups to which the user belongs. Defaults to ‘minimum’. Valid values are ‘inclusive’, ‘minimum’. - **name** The user name. While naming limitations vary by operating system, it is advisable to restrict names to the lowest common denominator, which is a maximum of 8 characters beginning with a letter. Note that Puppet considers user names to be case-sensitive, regardless of the platform's own rules; be sure to always use the same case when referring to a given user. - **password** The user's password, in whatever encrypted format the local system requires. * Most modern Unix-like systems use salted SHA1 password hashes. You can use Puppet's built-in ‘sha1’ function to generate a hash from a password. * Mac OS X 10.5 and 10.6 also use salted SHA1 hashes. Windows API for setting the password hash. [stdlib]: https://github.com/puppetlabs/puppetlabs-stdlib/ Be sure to enclose any value that includes a dollar sign ($) in single
quotes (') to avoid accidental variable interpolation.
Requires features manages_passwords.
- **password_max_age**
The maximum number of days a password may be used before it must be changed.
Requires features manages_password_age.
- **password_min_age**
The minimum number of days a password must be used before it may be changed.
Requires features manages_password_age.
- **profile_membership**
Whether specified roles should be treated as the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of roles
of which the user is a member. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **profiles**
The profiles the user has. Multiple profiles should be
specified as an array.
Requires features manages_solaris_rbac.
- **project**
The name of the project associated with a user.
Requires features manages_solaris_rbac.
- **uid**
The user ID; must be specified numerically. If no user ID is
specified when creating a new user, then one will be chosen
automatically. This will likely result in the same user having
different UIDs on different systems, which is not recommended. This is
especially noteworthy when managing the same user on both Darwin and
other platforms, since Puppet does UID generation on Darwin, but
the underlying tools do so on other platforms.
On Windows, this property is read-only and will return the user's
security identifier (SID).In Puppet kann die Resource Abstraction Layer (RAL) als das konzeptionelle Kernmodell betrachtet werden, auf dem die gesamte Infrastruktur und das Puppet-Setup funktionieren. In RAL hat jedes Alphabet seine eigene signifikante Bedeutung, die wie folgt definiert ist.
Ressource [R]
Eine Ressource kann als alle Ressourcen betrachtet werden, die zum Modellieren einer Konfiguration in Puppet verwendet werden. Es handelt sich im Grunde genommen um eingebaute Ressourcen, die standardmäßig in Puppet vorhanden sind. Sie können als eine Reihe von Ressourcen betrachtet werden, die zu einem vordefinierten Ressourcentyp gehören. Sie ähneln dem OOP-Konzept in jeder anderen Programmiersprache, in der das Objekt eine Klasseninstanz ist. In Puppet ist seine Ressource eine Instanz eines Ressourcentyps.
Abstraktion [A]
Die Abstraktion kann als Schlüsselmerkmal betrachtet werden, bei dem die Ressourcen unabhängig vom Zielbetriebssystem definiert werden. Mit anderen Worten, beim Schreiben einer Manifestdatei muss sich der Benutzer keine Gedanken über den Zielcomputer oder das Betriebssystem machen, das auf diesem bestimmten Computer vorhanden ist. In der Abstraktion geben Ressourcen genügend Informationen darüber, was auf dem Puppet-Agenten vorhanden sein muss.
Puppet kümmert sich um alle Funktionen oder Magie, die sich hinter den Kulissen abspielen. Unabhängig von den Ressourcen und dem Betriebssystem kümmert sich Puppet um die Implementierung der Konfiguration auf dem Zielcomputer, wobei sich der Benutzer keine Sorgen machen muss, wie sich Puppet hinter den Kulissen verhält.
In der Abstraktion trennt Puppet die Ressourcen von seiner Implementierung. Diese plattformspezifische Konfiguration existiert von Anbietern. Wir können mehrere Unterbefehle zusammen mit ihren Anbietern verwenden.
Schicht [L]
Es ist möglich, dass man eine gesamte Maschinenkonfiguration und -konfiguration in Bezug auf die Sammlung von Ressourcen definiert und diese über die CLI-Schnittstelle von Puppet anzeigen und verwalten kann.
Beispiel für den Benutzerressourcentyp
[root@puppetmaster ~]# puppet describe user --providers
user
====
Manage users.
This type is mostly built to manage systemusers,
so it is lacking some features useful for managing normalusers.
This resource type uses the prescribed native tools for
creating groups and generally uses POSIX APIs for retrieving informationabout them.
It does not directly modify '/etc/passwd' or anything.
- **comment**
A description of the user. Generally the user's full name.
- **ensure**
The basic state that the object should be in.
Valid values are 'present', 'absent', 'role'.
- **expiry**
The expiry date for this user.
Must be provided in a zero-padded YYYY-MM-DD format --- e.g. 2010-02-19.
If you want to make sure the user account does never expire,
you can pass the special value 'absent'.
Valid values are 'absent'.
Values can match '/^\d{4}-\d{2}-\d{2}$/'. Requires features manages_expiry. - **forcelocal** Forces the management of local accounts when accounts are also being managed by some other NSS Valid values are 'true', 'false', 'yes', 'no'. Requires features libuser. - **gid** The user's primary group. Can be specified numerically or by name. This attribute is not supported on Windows systems; use the ‘groups’ attribute instead. (On Windows, designating a primary group is only meaningful for domain accounts, which Puppet does not currently manage.) - **groups** The groups to which the user belongs. The primary group should not be listed, and groups should be identified by name rather than by GID. Multiple groups should be specified as an array. - **home** The home directory of the user. The directory must be created separately and is not currently checked for existence. - **ia_load_module** The name of the I&A module to use to manage this user. Requires features manages_aix_lam. - **iterations** This is the number of iterations of a chained computation of the password hash (http://en.wikipedia.org/wiki/PBKDF2). This parameter is used in OS X. This field is required for managing passwords on OS X >= 10.8. - **key_membership** Whether specified key/value pairs should be considered the **complete list** ('inclusive') or the **minimum list** ('minimum') of the user's attributes. Defaults to 'minimum'. Valid values are 'inclusive', 'minimum'. - **keys** Specify user attributes in an array of key = value pairs. Requires features manages_solaris_rbac. - **managehome** Whether to manage the home directory when managing the user. This will create the home directory when 'ensure => present', and delete the home directory when ‘ensure => absent’. Defaults to ‘false’. Valid values are ‘true’, ‘false’, ‘yes’, ‘no’. - **membership** Whether specified groups should be considered the **complete list** (‘inclusive’) or the **minimum list** (‘minimum’) of groups to which the user belongs. Defaults to ‘minimum’. Valid values are ‘inclusive’, ‘minimum’. - **name** The user name. While naming limitations vary by operating system, it is advisable to restrict names to the lowest common denominator. - **password** The user's password, in whatever encrypted format the local system requires. * Most modern Unix-like systems use salted SHA1 password hashes. You can use Puppet's built-in ‘sha1’ function to generate a hash from a password. * Mac OS X 10.5 and 10.6 also use salted SHA1 hashes. * Mac OS X 10.7 (Lion) uses salted SHA512 hashes. The Puppet Labs [stdlib][] module contains a ‘str2saltedsha512’ function which can generate password hashes for Lion. * Mac OS X 10.8 and higher use salted SHA512 PBKDF2 hashes. When managing passwords on these systems the salt and iterations properties need to be specified as well as the password. [stdlib]: https://github.com/puppetlabs/puppetlabs-stdlib/ Be sure to enclose any value that includes a dollar sign ($) in single
quotes (') to avoid accidental variable interpolation.
Requires features manages_passwords.
- **password_max_age**
The maximum number of days a password may be used before it must be changed.
Requires features manages_password_age.
- **password_min_age**
The minimum number of days a password must be used before it may be changed.
Requires features manages_password_age.
- **profile_membership**
Whether specified roles should be treated as the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of roles
of which the user is a member. Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **profiles**
The profiles the user has. Multiple profiles should be
specified as an array.
Requires features manages_solaris_rbac.
- **project**
The name of the project associated with a user.
Requires features manages_solaris_rbac.
- **purge_ssh_keys**
Purge ssh keys authorized for the user
if they are not managed via ssh_authorized_keys.
When true, looks for keys in .ssh/authorized_keys in the user's home directory.
Possible values are true, false, or an array of
paths to file to search for authorized keys.
If a path starts with ~ or %h, this token is replaced with the user's home directory.
Valid values are ‘true’, ‘false’.
- **role_membership**
Whether specified roles should be considered the **complete list**
(‘inclusive’) or the **minimum list** (‘minimum’) of roles the user has.
Defaults to ‘minimum’.
Valid values are ‘inclusive’, ‘minimum’.
- **roles**
The roles the user has. Multiple roles should be
specified as an array.
Requires features manages_solaris_rbac.
- **salt**
This is the 32 byte salt used to generate the PBKDF2 password used in
OS X. This field is required for managing passwords on OS X >= 10.8.
Requires features manages_password_salt.
- **shell**
The user's login shell. The shell must exist and be
executable.
This attribute cannot be managed on Windows systems.
Requires features manages_shell.
- **system**
Whether the user is a system user, according to the OS's criteria;
on most platforms, a UID less than or equal to 500 indicates a system
user. Defaults to ‘false’.
Valid values are ‘true’, ‘false’, ‘yes’, ‘no’.
- **uid**
The user ID; must be specified numerically. If no user ID is
specified when creating a new user, then one will be chosen
automatically. This will likely result in the same user having
different UIDs on different systems, which is not recommended.
This is especially noteworthy when managing the same user on both Darwin and
other platforms, since Puppet does UID generation on Darwin, but
the underlying tools do so on other platforms.
On Windows, this property is read-only and will return the user's
security identifier (SID).
Providers
---------
- **aix**
User management for AIX.
* Required binaries: '/bin/chpasswd', '/usr/bin/chuser',
'/usr/bin/mkuser', '/usr/sbin/lsgroup', '/usr/sbin/lsuser',
'/usr/sbin/rmuser'.
* Default for ‘operatingsystem’ == ‘aix’.
* Supported features: ‘manages_aix_lam’, ‘manages_expiry’,
‘manages_homedir’, ‘manages_password_age’, ‘manages_passwords’,
‘manages_shell’.
- **directoryservice**
User management on OS X.
* Required binaries: ‘/usr/bin/dscacheutil’, ‘/usr/bin/dscl’,
‘/usr/bin/dsimport’, ‘/usr/bin/plutil’, ‘/usr/bin/uuidgen’.
* Default for ‘operatingsystem’ == ‘darwin’.
* Supported features: ‘manages_password_salt’, ‘manages_passwords’,
‘manages_shell’.
- **hpuxuseradd**
User management for HP-UX. This provider uses the undocumented ‘-F’
switch to HP-UX's special ‘usermod’ binary to work around the fact that
its standard ‘usermod’ cannot make changes while the user is logged in.
* Required binaries: ‘/usr/sam/lbin/useradd.sam’,
‘/usr/sam/lbin/userdel.sam’, ‘/usr/sam/lbin/usermod.sam’.
* Default for ‘operatingsystem’ == ‘hp-ux’.
* Supported features: ‘allows_duplicates’, ‘manages_homedir’,
‘manages_passwords’.
- **ldap**
User management via LDAP.
This provider requires that you have valid values for all of the
LDAP-related settings in ‘puppet.conf’, including ‘ldapbase’.
You will almost definitely need settings for ‘ldapuser’ and ‘ldappassword’ in order
for your clients to write to LDAP.
* Supported features: ‘manages_passwords’, ‘manages_shell’.
- **pw**
User management via ‘pw’ on FreeBSD and DragonFly BSD.
* Required binaries: ‘pw’.
* Default for ‘operatingsystem’ == ‘freebsd, dragonfly’.
* Supported features: ‘allows_duplicates’, ‘manages_expiry’,
‘manages_homedir’, ‘manages_passwords’, ‘manages_shell’.
- **user_role_add**
User and role management on Solaris, via ‘useradd’ and ‘roleadd’.
* Required binaries: ‘passwd’, ‘roleadd’, ‘roledel’, ‘rolemod’,
‘useradd’, ‘userdel’, ‘usermod’.
* Default for ‘osfamily’ == ‘solaris’.
* Supported features: ‘allows_duplicates’, ‘manages_homedir’,
‘manages_password_age’, ‘manages_passwords’, ‘manages_solaris_rbac’.
- **useradd**
User management via ‘useradd’ and its ilk. Note that you will need to
install Ruby's shadow password library (often known as ‘ruby-libshadow’)
if you wish to manage user passwords.
* Required binaries: ‘chage’, ‘luseradd’, ‘useradd’, ‘userdel’, ‘usermod’.
* Supported features: ‘allows_duplicates’, ‘libuser’, ‘manages_expiry’,
‘manages_homedir’, ‘manages_password_age’, ‘manages_passwords’,
‘manages_shell’, ‘system_users’.
- **windows_adsi**
Local user management for Windows.
* Default for 'operatingsystem' == 'windows'.
* Supported features: 'manages_homedir', 'manages_passwords'.Ressource testen
In Puppet zeigt das direkte Testen einer Ressource an, dass zuerst Ressourcen angewendet werden müssen, die zum Konfigurieren eines Zielknotens verwendet werden sollen, damit sich der Status der Maschine entsprechend ändert.
Zum Testen werden wir die Ressource lokal anwenden. Da haben wir eine oben mit vordefinierte Ressourceuser = vipin. Eine Möglichkeit zum Anwenden einer Ressource ist die CLI. Dies kann erreicht werden, indem die gesamte Ressource in einen einzelnen Befehl neu geschrieben und dann an einen Ressourcenunterbefehl übergeben wird.
puppet resource user vipin ensure = present uid = '505'
shell = '/bin/bash' home = '/home/vipin'Testen Sie die angewendete Ressource.
[root@puppetmaster ~]# cat /etc/passwd | grep "vipin"
vipin:x:505:501::/home/vipin:/bin/bashDie obige Ausgabe zeigt, dass die Ressource auf das System angewendet wird und wir einen neuen Benutzer mit dem Namen Vipin erstellt haben. Es ist ratsam, dies selbst zu testen, da alle oben genannten Codes getestet werden und Arbeitscodes sind.
Templatingist eine Methode, um Dinge in einem Standardformat abzurufen, das an mehreren Orten verwendet werden kann. In Puppet werden Vorlagen und Vorlagen mit erb unterstützt, das Teil der Standard-Ruby-Bibliothek ist, die neben Ruby auch für andere Projekte verwendet werden kann, wie in Ruby on Rails-Projekten. Standardmäßig muss man ein grundlegendes Verständnis von Ruby haben. Vorlagen sind sehr hilfreich, wenn der Benutzer versucht, den Inhalt einer Vorlagendatei zu verwalten. Vorlagen spielen eine Schlüsselrolle, wenn Konfigurationen nicht von einem integrierten Puppet-Typ verwaltet werden können.
Vorlagen auswerten
Vorlagen werden mit einfachen Funktionen ausgewertet.
$value = template ("testtemplate.erb")Man kann den vollständigen Pfad einer Vorlage angeben oder alle Vorlagen in Puppets Templatedir abrufen, das sich normalerweise unter / var / puppet / templates befindet. Sie können den Speicherort des Verzeichnisses finden, indem Sie das Marionetten-Konfigurationsdruck-Template-Verzeichnis ausführen.
Vorlagen werden immer vom Parser und nicht vom Client ausgewertet. Wenn Sie also puppetmasterd verwenden, muss sich die Vorlage nur auf dem Server befinden und niemals auf den Client herunterladen. Es gibt keinen Unterschied, wie der Client zwischen der Verwendung einer Vorlage und der Angabe des gesamten Inhalts einer Datei als Zeichenfolge sieht. Dies zeigt deutlich, dass clientspezifische Variablen zuerst von Puppetmaster während der Puppet-Startphase gelernt werden.
Vorlagen verwenden
Im Folgenden finden Sie ein Beispiel für das Generieren der Tomcat-Konfiguration zum Testen von Standorten.
define testingsite($cgidir, $tracdir) { file { "testing-$name":
path => "/etc/tomcat/testing/$name.conf", owner => superuser, group => superuser, mode => 644, require => File[tomcatconf], content => template("testsite.erb"), notify => Service[tomcat] } symlink { "testsym-$name":
path => "$cgidir/$name.cgi",
ensure => "/usr/share/test/cgi-bin/test.cgi"
}
}Es folgt die Vorlagendefinition.
<Location "/cgi-bin/ <%= name %>.cgi">
SetEnv TEST_ENV "/export/svn/test/<%= name %>"
</Location>
# You need something like this to authenticate users
<Location "/cgi-bin/<%= name %>.cgi/login">
AuthType Basic
AuthName "Test"
AuthUserFile /etc/tomcat/auth/svn
Require valid-user
</Location>Dadurch wird jede Vorlagendatei in eine separate Datei verschoben, und Apache muss lediglich angewiesen werden, diese Konfigurationsdateien zu laden.
Include /etc/apache2/trac/[^.#]*Vorlagen kombinieren
Mit dem folgenden Befehl können zwei Vorlagen einfach kombiniert werden.
template('/path/to/template1','/path/to/template2')Iteration in Vorlagen
Die Puppet-Vorlage unterstützt auch die Array-Iteration. Wenn die Variable, auf die zugegriffen wird, ein Array ist, kann man darüber iterieren.
$values = [val1, val2, otherval]Wir können Vorlagen wie die folgenden haben.
<% values.each do |val| -%>
Some stuff with <%= val %>
<% end -%>Der obige Befehl führt zu folgendem Ergebnis.
Some stuff with val1
Some stuff with val2
Some stuff with othervalBedingungen in Vorlagen
Das erbVorlagen unterstützen Bedingungen. Das folgende Konstrukt ist eine schnelle und einfache Möglichkeit, einen Inhalt bedingt in eine Datei einzufügen.
<% if broadcast != "NONE" %> broadcast <%= broadcast %> <% end %>Vorlagen und Variablen
Man kann Vorlagen verwenden, um Variablen zusätzlich zum Ausfüllen des Dateiinhalts auszufüllen.
testvariable = template('/var/puppet/template/testvar')Undefinierte Variable
Wenn Sie überprüfen müssen, ob die Variable definiert ist, bevor Sie sie verwenden, funktioniert der folgende Befehl.
<% if has_variable?("myvar") then %>
myvar has <%= myvar %> value
<% end %>Variable außerhalb des Gültigkeitsbereichs
Mit der Funktion lookupvar kann explizit nach Variablen außerhalb des Gültigkeitsbereichs gesucht werden.
<%= scope.lookupvar('apache::user') %>Beispielprojektvorlage
<#Autogenerated by puppet. Do not edit.
[default]
#Default priority (lower value means higher priority)
priority = <%= @priority %>
#Different types of backup. Will be done in the same order as specified here.
#Valid options: rdiff-backup, mysql, command
backups = <% if @backup_rdiff %>rdiff-backup,
<% end %><% if @backup_mysql %>mysql,
<% end %><% if @backup_command %>command<% end %>
<% if @backup_rdiff -%>
[rdiff-backup]
<% if @rdiff_global_exclude_file -%>
global-exclude-file = <%= @rdiff_global_exclude_file %>
<% end -%>
<% if @rdiff_user -%>
user = <%= @rdiff_user %>
<% end -%>
<% if @rdiff_path -%>
path = <%= @rdiff_path %>
<% end -%>
#Optional extra parameters for rdiff-backup
extra-parameters = <%= @rdiff_extra_parameters %>
#How long backups are going to be kept
keep = <%= @rdiff_keep %>
<% end -%>
<% if @backup_mysql -%>%= scope.lookupvar('apache::user') %>
[mysql]
#ssh user to connect for running the backup
sshuser = <%= @mysql_sshuser %>
#ssh private key to be used
sshkey = <%= @backup_home %>/<%= @mysql_sshkey %>
<% end -%>
<% if @backup_command -%>
[command]
#Run a specific command on the backup server after the backup has finished
command = <%= @command_to_execute %>
<% end -%>Marionettenklassen werden als eine Sammlung von Ressourcen definiert, die zusammen gruppiert werden, um einen Zielknoten oder eine Zielmaschine in einen gewünschten Zustand zu versetzen. Diese Klassen werden in Puppet-Manifestdateien definiert, die sich in Puppet-Modulen befinden. Der Hauptzweck der Verwendung einer Klasse besteht darin, die gleiche Codewiederholung in jeder Manifestdatei oder jedem anderen Puppet-Code zu reduzieren.
Das Folgende ist ein Beispiel für eine Puppenklasse.
[root@puppetmaster manifests]# cat site.pp
class f3backup (
$backup_home = '/backup',
$backup_server = 'default', $myname = $::fqdn, $ensure = 'directory',
) {
include '::f3backup::common'
if ( $myname == '' or $myname == undef ) {
fail('myname must not be empty')
}
@@file { "${backup_home}/f3backup/${myname}":
# To support 'absent', though force will be needed
ensure => $ensure, owner => 'backup', group => 'backup', mode => '0644', tag => "f3backup-${backup_server}",
}
}Im obigen Beispiel haben wir zwei Clients, auf denen der Benutzer vorhanden sein muss. Wie zu bemerken ist, haben wir dieselbe Ressource zweimal wiederholt. Eine Möglichkeit, nicht dieselbe Aufgabe beim Kombinieren der beiden Knoten auszuführen.
[root@puppetmaster manifests]# cat site.pp
node 'Brcleprod001','Brcleprod002' {
user { 'vipin':
ensure => present,
uid => '101',
shell => '/bin/bash',
home => '/home/homer',
}
}Das Zusammenführen von Knoten auf diese Weise zur Durchführung der Konfiguration ist keine gute Vorgehensweise. Dies kann einfach erreicht werden, indem eine Klasse erstellt und die erstellte Klasse in Knoten eingeschlossen wird, was wie folgt dargestellt wird.
class vipin_g01063908 {
user { 'g01063908':
ensure => present,
uid => '101',
shell => '/bin/bash',
home => '/home/g01063908',
}
}
node 'Brcleprod001' {
class {vipin_g01063908:}
}
node 'Brcleprod002' {
class {vipin_g01063908:}
}Zu beachten ist, wie die Klassenstruktur aussieht und wie wir mit dem Schlüsselwort class eine neue Ressource hinzugefügt haben. Jede Syntax in Puppet hat ihre eigene Funktion. Daher hängt die Syntax, die man wählt, von den Bedingungen ab.
Parametrisierte Klasse
Wie im obigen Beispiel haben wir gesehen, wie eine Klasse erstellt und in einen Knoten aufgenommen wird. Jetzt gibt es Situationen, in denen auf jedem Knoten unterschiedliche Konfigurationen erforderlich sind, z. B. wenn auf jedem Knoten unterschiedliche Benutzer mit derselben Klasse erforderlich sind. Diese Funktion wird in Puppet mithilfe einer parametrisierten Klasse bereitgestellt. Die Konfiguration für eine neue Klasse sieht wie im folgenden Beispiel aus.
[root@puppetmaster ~]# cat /etc/puppet/manifests/site.pp
class user_account ($username){ user { $username:
ensure => present,
uid => '101',
shell => '/bin/bash',
home => "/home/$username",
}
}
node 'Brcleprod002' {
class { user_account:
username => "G01063908",
}
}
node 'Brcleprod002' {
class {user_account:
username => "G01063909",
}
}Wenn wir das obige site.pp-Manifest auf Knoten anwenden, sieht die Ausgabe für jeden Knoten wie folgt aus.
Brcleprod001
[root@puppetagent1 ~]# puppet agent --test
Info: Retrieving pluginfacts
Info: Retrieving plugin
Info: Caching catalog for puppetagent1.testing.dyndns.org
Info: Applying configuration version '1419452655'
Notice: /Stage[main]/User_account/User[homer]/ensure: created
Notice: Finished catalog run in 0.15 seconds
[root@brcleprod001 ~]# cat /etc/passwd | grep "vipin"
G01063908:x:101:501::/home/G01063909:/bin/bashBrcleprod002
[root@Brcleprod002 ~]# puppet agent --test
Info: Retrieving pluginfacts
Info: Retrieving plugin
Info: Caching catalog for puppetagent2.testing.dyndns.org
Info: Applying configuration version '1419452725'
Notice: /Stage[main]/User_account/User[bart]/ensure: created
Notice: Finished catalog run in 0.19 seconds
[root@puppetagent2 ~]# cat /etc/passwd | grep "varsha"
G01063909:x:101:501::/home/G01063909:/bin/bashSie können auch den Standardwert eines Klassenparameters festlegen, wie im folgenden Code gezeigt.
[root@puppetmaster ~]# cat /etc/puppet/manifests/site.pp
class user_account ($username = ‘g01063908'){
user { $username: ensure => present, uid => '101', shell => '/bin/bash', home => "/home/$username",
}
}
node 'Brcleprod001' {
class {user_account:}
}
node 'Brcleprod002' {
class {user_account:
username => "g01063909",
}
}Puppet unterstützt Funktionen wie jede andere Programmiersprache, da die Basisentwicklungssprache von Puppet Ruby ist. Es unterstützt zwei Arten von Funktionen, die unter dem Namen bekannt sindstatement und rvalue Funktionen.
Statementsstehen für sich und haben keinen Rückgabetyp. Sie werden zum Ausführen eigenständiger Aufgaben wie dem Importieren anderer Puppet-Module in die neue Manifestdatei verwendet.
Rvalue Gibt Werte zurück und kann nur verwendet werden, wenn für die Anweisung ein Wert erforderlich ist, z. B. eine Zuweisung oder eine case-Anweisung.
Der Schlüssel hinter der Ausführung der Funktion in Puppet ist, dass sie nur auf dem Puppet-Master ausgeführt wird und nicht auf dem Client oder dem Puppet-Agenten. Daher haben sie nur Zugriff auf die Befehle und Daten, die auf dem Puppet Master verfügbar sind. Es gibt verschiedene Arten von Funktionen, die bereits vorhanden sind, und sogar der Benutzer hat das Recht, benutzerdefinierte Funktionen gemäß den Anforderungen zu erstellen. Einige eingebaute Funktionen sind unten aufgeführt.
Dateifunktion
Die Dateifunktion der Dateiressource besteht darin, ein Modul in Puppet zu laden und die gewünschte Ausgabe in Form einer Zeichenfolge zurückzugeben. Die Argumente, nach denen gesucht wird, sind die Referenz <Modulname> / <Datei>, die beim Laden des Moduls aus dem Dateiverzeichnis des Puppet-Moduls hilft.
Wie script lädt / tesingscript.sh die Dateien aus <Modulname> /script/files/testingscript.sh. Die Funktion kann einen absoluten Pfad lesen und akzeptieren, wodurch die Datei von einer beliebigen Stelle auf der Festplatte geladen werden kann.
Funktion einschließen
In Puppet ist die Include-Funktion der Include-Funktion in jeder anderen Programmiersprache sehr ähnlich. Es wird für die Deklaration einer oder mehrerer Klassen verwendet, wodurch alle in diesen Klassen vorhandenen Ressourcen ausgewertet und schließlich einem Katalog hinzugefügt werden. Die Funktion include akzeptiert einen Klassennamen, eine Liste von Klassen oder eine durch Kommas getrennte Liste von Klassennamen.
Eine Sache, die Sie bei der Verwendung von a beachten sollten includeAussage ist, es kann mehrfach in einer Klasse verwendet werden, hat aber die Einschränkung, eine einzelne Klasse nur einmal einzuschließen. Wenn die eingeschlossene Klasse einen Parameter akzeptiert, sucht die Include-Funktion automatisch nach Werten, wobei <Klassenname> :: <Parametername> als Suchschlüssel verwendet wird.
Die Include-Funktion bewirkt nicht, dass eine Klasse in der Klasse enthalten ist, wenn sie deklariert wird. Dazu müssen wir eine enthaltene Funktion verwenden. Es wird sogar keine Abhängigkeit in der deklarierten Klasse und den sie umgebenden Klassen erstellt.
In der Include-Funktion ist nur der vollständige Name einer Klasse zulässig, relative Namen sind nicht zulässig.
Definierte Funktion
In Puppet hilft die definierte Funktion beim Bestimmen, wo eine bestimmte Klasse oder ein bestimmter Ressourcentyp definiert ist, und gibt einen Booleschen Wert zurück oder nicht. Mit define können Sie auch bestimmen, ob eine bestimmte Ressource definiert ist oder ob die definierte Variable einen Wert hat. Bei der Verwendung der definierten Funktion ist zu beachten, dass diese Funktion mindestens ein Zeichenfolgenargument verwendet. Dies kann ein Klassenname, ein Typname, eine Ressourcenreferenz oder eine Variablenreferenz der Form „$ name“ sein.
Definieren Sie Funktionsprüfungen sowohl für native als auch für definierte Funktionstypen, einschließlich der von Modulen bereitgestellten Typen. Typ und Klasse stimmen mit ihren Namen überein. Die Funktion entspricht der Ressourcenverzögerung unter Verwendung der Ressourcenreferenz.
Funktionsübereinstimmungen definieren
# Matching resource types
defined("file")
defined("customtype")
# Matching defines and classes
defined("testing")
defined("testing::java")
# Matching variables
defined('$name')
# Matching declared resources
defined(File['/tmp/file'])Wie im vorherigen Kapitel beschrieben, bietet die Funktion dem Benutzer die Berechtigung, benutzerdefinierte Funktionen zu entwickeln. Puppet kann seine Interpretationskraft durch benutzerdefinierte Funktionen erweitern. Die benutzerdefinierte Funktion hilft beim Erhöhen und Erweitern der Leistung von Puppet-Modulen und Manifestdateien.
Benutzerdefinierte Funktion schreiben
Es gibt einige Dinge, die man beachten muss, bevor man eine Funktion schreibt.
In Puppet werden Funktionen von Compilern ausgeführt, was bedeutet, dass alle Funktionen auf dem Puppet-Master ausgeführt werden und sie sich nicht mit einem der Puppet-Clients befassen müssen. Funktionen können nur mit Agenten interagieren, sofern die Informationen in Form von Fakten vorliegen.
Der Puppet Master fängt benutzerdefinierte Funktionen ab, was bedeutet, dass man den Puppet Master neu starten muss, wenn man einige Änderungen an der Puppet-Funktion vornimmt.
Die Funktion wird auf dem Server ausgeführt, was bedeutet, dass jede Datei, die die Funktion benötigt, auf dem Server vorhanden sein sollte, und man kann nichts tun, wenn die Funktion direkten Zugriff auf den Client-Computer erfordert.
Es stehen zwei völlig unterschiedliche Arten von Funktionen zur Verfügung: die Rvalue-Funktion, die den Wert zurückgibt, und die Anweisungsfunktion, die nichts zurückgibt.
Der Name der Datei, die die Funktion enthält, sollte mit dem Namen der Funktion in der Datei übereinstimmen. Andernfalls wird es nicht automatisch geladen.
Speicherort für die benutzerdefinierte Funktion
Alle benutzerdefinierten Funktionen werden separat implementiert .rbDateien und werden auf Module verteilt. Man muss benutzerdefinierte Funktionen in lib / puppet / parser / function einfügen. Funktionen können von geladen werden.rb Datei von den folgenden Speicherorten.
- $libdir/puppet/parser/functions
- Unterverzeichnisse puppet / parser / functions in Ihrem Ruby $ LOAD_PATH
Neue Funktion erstellen
Neue Funktionen werden mit dem erstellt oder definiert newfunction Methode innerhalb der puppet::parser::FunctionsModul. Man muss den Funktionsnamen als Symbol an übergebennewfunctionMethode und der Code, der als Block ausgeführt werden soll. Das folgende Beispiel ist eine Funktion, mit der eine Zeichenfolge in die Datei im Verzeichnis / user geschrieben wird.
module Puppet::Parser::Functions
newfunction(:write_line_to_file) do |args|
filename = args[0]
str = args[1]
File.open(filename, 'a') {|fd| fd.puts str }
end
endSobald der Benutzer die Funktion deklariert hat, kann sie wie unten gezeigt in der Manifestdatei verwendet werden.
write_line_to_file('/user/vipin.txt, "Hello vipin!")Im Softwareentwicklungs- und Bereitstellungsmodell gibt es verschiedene Arten von Testumgebungen, die zum Testen eines bestimmten Produkts oder einer bestimmten Dienstleistung verwendet werden. Standardmäßig gibt es hauptsächlich drei Arten von Umgebungen wie Entwicklung, Test und Produktion, in denen jede ihre eigene Set-Konfiguration hat.
Puppet unterstützt die Verwaltung mehrerer Umgebungen in derselben Richtung wie Ruby on Rails. Der Schlüsselfaktor für die Erstellung dieser Umgebungen ist die Bereitstellung eines einfachen Mechanismus für die Verwaltung auf verschiedenen Ebenen der SLA-Vereinbarung. In einigen Fällen muss die Maschine immer ohne Toleranz und Verwendung alter Software betriebsbereit sein. Wobei andere Umgebungen aktuell sind und zu Testzwecken verwendet werden. Sie werden für Upgrades für wichtigere Maschinen verwendet.
Puppet empfiehlt, sich an die Standardkonfiguration für Produktions-, Test- und Entwicklungsumgebungen zu halten. Hier bietet es dem Benutzer jedoch sogar die Möglichkeit, benutzerdefinierte Umgebungen gemäß den Anforderungen zu erstellen.
Umweltziel
Das Hauptziel des durch eine Umgebung aufgeteilten Setups besteht darin, dass Puppet unterschiedliche Quellen für Module und Manifeste haben kann. Anschließend können die Konfigurationsänderungen in der Testumgebung getestet werden, ohne dass dies Auswirkungen auf die Produktionsknoten hat. Diese Umgebungen können auch zum Bereitstellen der Infrastruktur in verschiedenen Netzwerkquellen verwendet werden.
Verwenden der Umgebung auf Puppet Master
In einer Umgebung muss getestet werden, welches Manifest, Modul und welche Vorlage der Datei an den Client gesendet werden muss. Daher muss Puppet so konfiguriert werden, dass es eine umgebungsspezifische Quelle für diese Informationen bereitstellt.
Puppet-Umgebungen werden einfach implementiert, indem die Abschnitte vor der Umgebung zur Puppet.conf des Servers hinzugefügt werden und für jede Umgebung eine andere Konfigurationsquelle ausgewählt wird. Diese Vorumgebungsabschnitte werden dann dem Hauptabschnitt vorgezogen.
[main]
manifest = /usr/testing/puppet/site.pp
modulepath = /usr/testing/puppet/modules
[development]
manifest = /usr/testing/puppet/development/site.pp
modulepath = /usr/testing/puppet/development/modulesIm obigen Code verwendet jeder Client in der Entwicklungsumgebung die Manifestdatei site.pp, die sich im Verzeichnis befindet /usr/share/puppet/development und Puppet sucht nach einem beliebigen Modul in /usr/share/puppet/development/modules directory.
Wenn Sie Puppet mit oder ohne Umgebung ausführen, wird standardmäßig die Datei site.pp und das Verzeichnis verwendet, das in den Werten für Manifest und Modulpfad im Hauptkonfigurationsabschnitt angegeben ist.
Es gibt nur wenige Konfigurationen, deren Konfiguration in der Vorumgebung tatsächlich sinnvoll ist. Bei all diesen Parametern geht es darum, anzugeben, welche Dateien zum Kompilieren der Clientkonfiguration verwendet werden sollen.
Es folgen die Parameter.
Modulepath- In Puppet ist es als Standardstandardmodus am besten, ein Standardmodulverzeichnis zu haben, das alle Umgebungen gemeinsam nutzen, und dann ein Vorumgebungsverzeichnis, in dem das benutzerdefinierte Modul gespeichert werden kann. Der Modulpfad ist der Speicherort, an dem Puppet nach allen umgebungsbezogenen Konfigurationsdateien sucht.
Templatedir- Das Vorlagenverzeichnis ist der Speicherort, an dem alle Versionen der zugehörigen Vorlagen gespeichert werden. Das Modul sollte diesen Einstellungen vorgezogen werden, es ermöglicht jedoch, in jeder Umgebung unterschiedliche Versionen einer bestimmten Vorlage zu haben.
Manifest - Hiermit wird festgelegt, welche Konfiguration als Einstiegspunktskript verwendet werden soll.
Mit mehreren Modulen helfen Puppen dabei, die Modularität für Konfigurationen zu erhalten. In Puppet kann man mehrere Umgebungen verwenden, was viel besser funktioniert, wenn man sich weitgehend auf Module verlässt. Es ist einfacher, Änderungen in Umgebungen zu migrieren, indem Änderungen im Modul gekapselt werden. Der Dateiserver verwendet einen umgebungsspezifischen Modulpfad. Wenn eine Datei aus Modulen bereitgestellt wird, kann diese Umgebung anstelle von separat bereitgestellten Verzeichnissen umgebungsspezifische Dateien abrufen, und schließlich ist die aktuelle Umgebung auch in der Umgebungsvariablen $ in der Manifestdatei verfügbar.
Festlegen der Client-Umgebung
Alle Konfigurationen im Zusammenhang mit der Umgebungskonfiguration werden in der Datei puppet.conf vorgenommen. Um anzugeben, welche Umgebung der Puppet-Client verwenden soll, kann in der Datei puppet.conf des Clients ein Wert für die Umgebungskonfigurationsvariable angegeben werden.
[puppetd]
environment = TestingDie obige Definition in der Konfigurationsdatei definiert, in welcher Umgebung sich die Konfigurationsdatei in unserem Fall befindet.
Sie können dies auch in der Befehlszeile mit - angeben
#puppetd -–environment = testingAlternativ unterstützt Puppet auch die Verwendung dynamischer Werte in der Umgebungskonfiguration. Anstatt die statischen Werte zu definieren, kann der Entwickler benutzerdefinierte Fakten erstellen, die eine Clientumgebung basierend auf einigen anderen Clientattributen oder einer externen Datenquelle erstellen. Die bevorzugte Methode ist die Verwendung eines benutzerdefinierten Tools. Diese Tools können die Umgebung eines Knotens angeben und sind im Allgemeinen viel besser in der Angabe von Knoteninformationen.
Puppensuchpfad
Puppet verwendet einen einfachen Suchpfad, um zu bestimmen, welche Konfiguration auf dem Zielcomputer angewendet werden muss. Ebenso ist der Suchpfad in Puppet sehr nützlich, wenn versucht wird, geeignete Werte zu ermitteln, die angewendet werden müssen. Wie unten aufgeführt, gibt es mehrere Stellen, an denen Puppet nach den Werten sucht, die angewendet werden müssen.
- In der Befehlszeile angegebener Wert
- In einem umgebungsspezifischen Abschnitt angegebene Werte
- In einem ausführbaren Abschnitt angegebene Werte
- Im Hauptabschnitt angegebene Werte
Puppentypen werden für das individuelle Konfigurationsmanagement verwendet. Puppet hat verschiedene Typen wie einen Diensttyp, einen Pakettyp, einen Anbietertyp usw. Wobei jeder Typ Anbieter hat. Der Anbieter übernimmt die Konfiguration auf verschiedenen Plattformen oder Tools. Beispielsweise hat der Pakettyp Eignungs-, Yum-, U / min- und DGM-Anbieter. Es gibt viele Typen und Puppet deckt ein gutes Element zur Verwaltung der Spektrumkonfiguration ab, das verwaltet werden muss.
Puppet verwendet Ruby als Basissprache. Alle vorhandenen Puppentypen und Anbieter sind in Ruby-Sprache geschrieben. Da es dem Standardcodierungsformat folgt, kann man sie einfach erstellen, wie im Beispiel für Repo gezeigt, das Repositorys verwaltet. Hier erstellen wir Type Repo und Provider's SVN und Git. Der erste Teil des Repo-Typs ist der Typ selbst. Die Typen werden normalerweise in lib / puppet / type gespeichert. Dazu erstellen wir eine Datei namensrepo.rb.
$ touch repo.rbFügen Sie der Datei den folgenden Inhalt hinzu.
Puppet::Type.newtype(:repo) do
@doc = "Manage repos"
Ensurable
newparam(:source) do
desc "The repo source"
validate do |value|
if value =~ /^git/
resource[:provider] = :git
else
resource[:provider] = :svn
end
end
isnamevar
end
newparam(:path) do
desc "Destination path"
validate do |value|
unless value =~ /^\/[a-z0-9]+/
raise ArgumentError , "%s is not a valid file path" % value
end
end
end
endIm obigen Skript haben wir einen Block erstellt "Puppet::Type.newtype(:repo) do", das einen neuen Typ mit dem Namen repo erstellt. Dann haben wir @doc, das beim Hinzufügen der gewünschten Detailebene hilft. Die nächste Anweisung lautet" Sicherstellbar ". Es wird eine grundlegende Eigenschaft" Sicherstellen "erstellt ensure Eigenschaft, um den Status des Konfigurationselements zu bestimmen.
Beispiel
service { "sshd":
ensure => present,
}Die Sicherstellungsanweisung weist Puppet an, drei Methoden auszuschließen: Erstellen, Zerstören und Vorhandensein im Anbieter. Diese Methoden bieten die folgenden Funktionen:
- Ein Befehl zum Erstellen einer Ressource
- Ein Befehl zum Löschen einer Ressource
- Ein Befehl zum Überprüfen der Existenz einer Ressource
Dann müssen wir nur noch diese Methoden und ihren Inhalt angeben. Puppet erstellt die unterstützende Infrastruktur um sie herum.
Als nächstes definieren wir einen neuen Parameter namens source.
newparam(:source) do
desc "The repo source"
validate do |value|
if value =~ /^git/
resource[:provider] = :git
else
resource[:provider] = :svn
end
end
isnamevar
endDie Quelle teilt dem Repo-Typ mit, wo das Quell-Repository abgerufen / geklont / ausgecheckt werden soll. In diesem Fall verwenden wir auch einen Hook namens validate. Im Provider-Bereich haben wir git und svn definiert, die die Gültigkeit des von uns definierten Repositorys prüfen.
Schließlich haben wir im Code einen weiteren Parameter namens path definiert.
newparam(:path) do
desc "Destination path"
validate do |value|
unless value =~ /^\/[a-z0-9]+/
raise ArgumentError , "%s is not a valid file path" % value
endDies ist der Werttyp, der angibt, wo der neu abgerufene Code abgelegt werden soll. Verwenden Sie auch hier erneut den Validierungs-Hook, um einen Block zu erstellen, der den Wert der Angemessenheit überprüft.
Anwendungsfall des Subversion-Anbieters
Beginnen wir mit dem Subversion-Anbieter, der den oben erstellten Typ verwendet.
require 'fileutils'
Puppet::Type.type(:repo).provide(:svn) do
desc "SVN Support"
commands :svncmd => "svn"
commands :svnadmin => "svnadmin"
def create
svncmd "checkout", resource[:name], resource[:path]
end
def destroy
FileUtils.rm_rf resource[:path]
end
def exists?
File.directory? resource[:path]
end
endIm obigen Code haben wir im Voraus definiert, dass wir brauchen fileutils Bibliothek benötigen 'fileutils' von denen wir Methode verwenden werden.
Als nächstes haben wir den Provider als Block Puppet :: Type.type (: repo) .provide (: svn) do definiert, der Puppet mitteilt, dass dies der Provider für den Typ repo ist.
Dann haben wir hinzugefügt descDadurch kann dem Anbieter eine Dokumentation hinzugefügt werden. Wir haben auch den Befehl definiert, den dieser Anbieter verwenden wird. In der nächsten Zeile überprüfen wir die Funktionen von Ressourcen wie Erstellen, Löschen und Vorhandensein.
Eine Ressource erstellen
Sobald alle oben genannten Schritte ausgeführt sind, erstellen wir eine Ressource, die in unseren Klassen und Manifestdateien verwendet wird, wie im folgenden Code gezeigt.
repo { "wp":
source => "http://g01063908.git.brcl.org/trunk/",
path => "/var/www/wp",
ensure => present,
}Puppet verwendet RESTful-APIs als Kommunikationskanal zwischen Puppet-Master und Puppet-Agenten. Im Folgenden finden Sie die grundlegende URL für den Zugriff auf diese RESTful-API.
https://brcleprod001:8140/{environment}/{resource}/{key}
https://brcleprod001:8139/{environment}/{resource}/{key}REST-API-Sicherheit
Puppet kümmert sich normalerweise um die Sicherheit und die Verwaltung der SSL-Zertifikate. Wenn Sie jedoch die RESTful-API außerhalb des Clusters verwenden möchten, müssen Sie das Zertifikat selbst verwalten, wenn Sie versuchen, eine Verbindung zu einem Computer herzustellen. Die Sicherheitsrichtlinie für Puppet kann über die restliche authconfig-Datei konfiguriert werden.
Testen der REST-API
Das Curl-Dienstprogramm kann als Basisdienstprogramm verwendet werden, um die RESTful-API-Konnektivität wiederherzustellen. Im Folgenden finden Sie ein Beispiel dafür, wie Sie den Knotenkatalog mit dem Befehl REST API curl abrufen können.
curl --cert /etc/puppet/ssl/certs/brcleprod001.pem --key
/etc/puppet/ssl/private_keys/brcleprod001.pemIn den folgenden Befehlen legen wir nur das SSL-Zertifikat fest, das je nach Standort des SSL-Verzeichnisses und dem Namen des verwendeten Knotens unterschiedlich ist. Schauen wir uns zum Beispiel den folgenden Befehl an.
curl --insecure -H 'Accept: yaml'
https://brcleprod002:8140/production/catalog/brcleprod001Im obigen Befehl senden wir einfach einen Header, der das Format oder die Formate angibt, die wir zurückhaben möchten, und eine RESTful-URL zum Generieren eines Katalogs von brcleprod001 In der Produktionsumgebung wird die folgende Ausgabe generiert.
--- &id001 !ruby/object:Puppet::Resource::Catalog
aliases: {}
applying: false
classes: []
...Nehmen wir ein anderes Beispiel an, in dem wir das CA-Zertifikat vom Puppet-Master zurückerhalten möchten. Es muss nicht mit einem eigenen signierten SSL-Zertifikat authentifiziert werden, da dies vor der Authentifizierung erforderlich ist.
curl --insecure -H 'Accept: s' https://brcleprod001:8140/production/certificate/ca
-----BEGIN CERTIFICATE-----
MIICHTCCAYagAwIBAgIBATANBgkqhkiG9w0BAQUFADAXMRUwEwYDVQQDDAxwdXBwGemeinsame API-Referenz für Puppet Master und Agent
GET /certificate/{ca, other}
curl -k -H "Accept: s" https://brcelprod001:8140/production/certificate/ca
curl -k -H "Accept: s" https://brcleprod002:8139/production/certificate/brcleprod002Puppet Master API-Referenz
Authentifizierte Ressourcen (Gültiges, signiertes Zertifikat erforderlich).
Kataloge
GET /{environment}/catalog/{node certificate name}
curl -k -H "Accept: pson" https://brcelprod001:8140/production/catalog/myclientSperrliste für Zertifikate
GET /certificate_revocation_list/ca
curl -k -H "Accept: s" https://brcleprod001:8140/production/certificate/caZertifikatsanforderung
GET /{environment}/certificate_requests/{anything} GET
/{environment}/certificate_request/{node certificate name}
curl -k -H "Accept: yaml" https://brcelprod001:8140/production/certificate_requests/all
curl -k -H "Accept: yaml" https://brcleprod001:8140/production/certificate_request/puppetclientBerichte Senden Sie einen Bericht
PUT /{environment}/report/{node certificate name}
curl -k -X PUT -H "Content-Type: text/yaml" -d "{key:value}" https://brcleprod002:8139/productionKnoten - Fakten zu einem bestimmten Knoten
GET /{environment}/node/{node certificate name}
curl -k -H "Accept: yaml" https://brcleprod002:8140/production/node/puppetclientStatus - Wird zum Testen verwendet
GET /{environment}/status/{anything}
curl -k -H "Accept: pson" https://brcleprod002:8140/production/certificate_request/puppetclientPuppet Agent API-Referenz
Wenn auf einem Computer ein neuer Agent eingerichtet wird, hört der Puppet-Agent standardmäßig nicht auf HTTP-Anforderungen. Es muss in Puppet aktiviert werden, indem in der Datei puppet.conf "listen = true" hinzugefügt wird. Dadurch können Puppet-Agenten die HTTP-Anforderung abhören, wenn der Puppet-Agent gestartet wird.
Fakten
GET /{environment}/facts/{anything}
curl -k -H "Accept: yaml" https://brcelprod002:8139/production/facts/{anything}Run - Bewirkt, dass der Client wie Puppetturn oder Puppet Kick aktualisiert wird.
PUT /{environment}/run/{node certificate name}
curl -k -X PUT -H "Content-Type: text/pson" -d "{}"
https://brcleprod002:8139/production/run/{anything}Um die Live-Tests zum Anwenden von Konfigurationen und Manifesten auf dem Puppet-Knoten durchzuführen, verwenden wir eine Live-Arbeitsdemo. Dies kann direkt kopiert und eingefügt werden, um die Funktionsweise der Konfiguration zu testen. Wenn der Benutzer denselben Codesatz verwenden möchte, muss er dieselbe Namenskonvention haben, wie in den folgenden Codeausschnitten gezeigt.
Beginnen wir mit der Erstellung eines neuen Moduls.
Neues Modul erstellen
Der erste Schritt beim Testen und Anwenden der httpd-Konfiguration besteht darin, ein Modul zu erstellen. Dazu muss der Benutzer sein Arbeitsverzeichnis in das Puppet-Modulverzeichnis ändern und eine grundlegende Modulstruktur erstellen. Die Strukturerstellung kann manuell oder mithilfe von Puppet erfolgen, um eine Boilerplate für das Modul zu erstellen.
# cd /etc/puppet/modules
# puppet module generate Live-moduleNote - Der Befehl zum Generieren des Puppet-Moduls erfordert, dass der Modulname das Format [Benutzername] - [Modul] hat, um den Puppet-Schmiedespezifikationen zu entsprechen.
Das neue Modul enthält einige grundlegende Dateien, einschließlich eines Manifestverzeichnisses. Das Verzeichnis enthält bereits ein Manifest mit dem Namen init.pp, bei dem es sich um die Hauptmanifestdatei des Moduls handelt. Dies ist eine leere Klassendeklaration für das Modul.
class live-module {
}Das Modul enthält auch ein Testverzeichnis mit einem Manifest namens init.pp. Dieses Testmanifest enthält einen Verweis auf die Live-Modulklasse in manifest / init.pp:
include live-modulePuppet verwendet dieses Testmodul, um das Manifest zu testen. Jetzt können wir die Konfiguration zum Modul hinzufügen.
Installieren eines HTTP-Servers
Das Puppet-Modul installiert die erforderlichen Pakete, um den http-Server auszuführen. Dies erfordert eine Ressourcendefinition, die die Konfiguration von httpd-Paketen definiert.
Erstellen Sie im Manifestverzeichnis des Moduls eine neue Manifestdatei mit dem Namen httpd.pp.
# touch test-module/manifests/httpd.ppDieses Manifest enthält die gesamte HTTP-Konfiguration für unser Modul. Zu Trennungszwecken wird die Datei httpd.pp von der Manifestdatei init.pp getrennt
Wir müssen den folgenden Code in die Manifestdatei httpd.pp einfügen.
class test-module::httpd {
package { 'httpd':
ensure => installed,
}
}Dieser Code definiert eine Unterklasse des Testmoduls mit dem Namen httpd und definiert dann eine Paketressourcendeklaration für das httpd-Paket. Das Attribut Sicherstellen => Installiert prüft, ob das erforderliche Paket installiert ist. Wenn nicht installiert, verwendet Puppet das Dienstprogramm yum, um es zu installieren. Als nächstes soll diese Unterklasse in unsere Hauptmanifestdatei aufgenommen werden. Wir müssen das Manifest init.pp bearbeiten.
class test-module {
include test-module::httpd
}Jetzt ist es an der Zeit, das Modul zu testen. Dies kann wie folgt erfolgen
# puppet apply test-module/tests/init.pp --noopDer Puppet Apply-Befehl wendet die Konfiguration an, die in der Manifestdatei auf dem Zielsystem vorhanden ist. Hier verwenden wir test init.pp, der sich auf main init.pp bezieht. Der –noop führt den Trockenlauf der Konfiguration durch, der nur die Ausgabe anzeigt, aber tatsächlich nichts tut.
Es folgt die Ausgabe.
Notice: Compiled catalog for puppet.example.com in environment
production in 0.59 seconds
Notice: /Stage[main]/test-module::Httpd/Package[httpd]/ensure:
current_value absent, should be present (noop)
Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 1
events
Notice: Stage[main]: Would have triggered 'refresh' from 1 events
Notice: Finished catalog run in 0.67 secondsDie Markierungszeile ist das Ergebnis des Attributs sure => install. Der aktuelle_Wert fehlt, dass Puppet erkannt hat, dass das httpd-Paket installiert ist. Ohne die Option –noop installiert Puppet das httpd-Paket.
Ausführen des httpd-Servers
Nach der Installation der httpd-Server müssen wir den Dienst mit einer anderen Ressourcenverzögerung starten: Dienst
Wir müssen die Manifestdatei httpd.pp bearbeiten und den folgenden Inhalt bearbeiten.
class test-module::httpd {
package { 'httpd':
ensure => installed,
}
service { 'httpd':
ensure => running,
enable => true,
require => Package["httpd"],
}
}Im Folgenden finden Sie eine Liste der Ziele, die wir mit dem obigen Code erreicht haben.
Das ensure => Der Ausführungsstatus prüft, ob der Dienst ausgeführt wird. Wenn nicht, wird er aktiviert.
Das enable => Das Attribut true legt fest, dass der Dienst ausgeführt wird, wenn das System hochfährt.
Das require => Package["httpd"]Das Attribut definiert eine Ordnungsbeziehung zwischen einer Ressourcenverzögerung und einer anderen. Im obigen Fall wird sichergestellt, dass der httpd-Dienst nach der Installation des http-Pakets gestartet wird. Dies schafft eine Abhängigkeit zwischen dem Dienst und dem jeweiligen Paket.
Führen Sie den Puppet Apply-Befehl aus, um die Änderungen erneut zu testen.
# puppet apply test-module/tests/init.pp --noop
Notice: Compiled catalog for puppet.example.com in environment
production in 0.56 seconds
Notice: /Stage[main]/test-module::Httpd/Package[httpd]/ensure:
current_value absent, should be present (noop)
Notice: /Stage[main]/test-module::Httpd/Service[httpd]/ensure:
current_value stopped, should be running (noop)
Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 2
events
Notice: Stage[main]: Would have triggered 'refresh' from 1 events
Notice: Finished catalog run in 0.41 secondsHTTP-Server konfigurieren
Sobald die obigen Schritte abgeschlossen sind, wird der HTTP-Server installiert und aktiviert. Der nächste Schritt besteht darin, dem Server eine Konfiguration bereitzustellen. Standardmäßig bietet httpd einige Standardkonfigurationen in /etc/httpd/conf/httpd.conf, die einen Webhost-Port 80 bereitstellen. Wir werden einen zusätzlichen Host hinzufügen, um dem Webhost einige benutzerspezifische Funktionen bereitzustellen.
Eine Vorlage wird verwendet, um einen zusätzlichen Port bereitzustellen, da eine variable Eingabe erforderlich ist. Wir werden ein Verzeichnis namens template erstellen und eine Datei mit dem Namen test-server.config.erb im neuen Director hinzufügen und den folgenden Inhalt hinzufügen.
Listen <%= @httpd_port %>
NameVirtualHost *:<% = @httpd_port %>
<VirtualHost *:<% = @httpd_port %>>
DocumentRoot /var/www/testserver/
ServerName <% = @fqdn %>
<Directory "/var/www/testserver/">
Options All Indexes FollowSymLinks
Order allow,deny
Allow from all
</Directory>
</VirtualHost>Die obige Vorlage folgt dem Standardkonfigurationsformat für Apache-Tomcat-Server. Der einzige Unterschied besteht in der Verwendung des Ruby-Escape-Zeichens zum Einfügen von Variablen aus dem Modul. Wir haben einen vollqualifizierten Domänennamen, in dem der vollständig qualifizierte Domänenname des Systems gespeichert ist. Dies ist als die bekanntsystem fact.
Systemfakten werden von jedem System gesammelt, bevor der Marionettenkatalog des jeweiligen Systems erstellt wird. Puppet verwendet den Befehl facter, um diese Informationen abzurufen, und man kann facter verwenden, um andere Details zum System abzurufen. Wir müssen die Markierungszeilen in der Manifestdatei httpd.pp hinzufügen.
class test-module::httpd {
package { 'httpd':
ensure => installed,
}
service { 'httpd':
ensure => running,
enable => true,
require => Package["httpd"],
}
file {'/etc/httpd/conf.d/testserver.conf':
notify => Service["httpd"],
ensure => file,
require => Package["httpd"],
content => template("test-module/testserver.conf.erb"),
}
file { "/var/www/myserver":
ensure => "directory",
}
}Dies hilft dabei, die folgenden Dinge zu erreichen:
Dadurch wird eine Dateiressourcendeklaration für die Serverkonfigurationsdatei (/etc/httpd/conf.d/test-server.conf) hinzugefügt. Der Inhalt dieser Datei ist die zuvor erstellte Vorlage test-serverconf.erb. Wir überprüfen auch das installierte httpd-Paket, bevor wir diese Datei hinzufügen.
Dies fügt die zweite Dateiressourcendeklaration hinzu, die ein Verzeichnis (/ var / www / test-server) für den Webserver erstellt.
Als Nächstes fügen wir die Beziehung zwischen der Konfigurationsdatei und dem https-Dienst mithilfe von hinzu notify => Service["httpd"]attribute. Dadurch wird überprüft, ob Änderungen an der Konfigurationsdatei vorgenommen wurden. Wenn dies der Fall ist, startet Puppet den Dienst neu.
Als nächstes wird der httpd_port in die Hauptmanifestdatei aufgenommen. Dazu müssen wir die Hauptmanifestdatei init.pp beenden und den folgenden Inhalt einschließen.
class test-module (
$http_port = 80
) {
include test-module::httpd
}Dadurch wird der httpd-Port auf den Standardwert 80 festgelegt. Als Nächstes führen Sie den Befehl Puppet apply aus.
Es folgt die Ausgabe.
# puppet apply test-module/tests/init.pp --noop
Warning: Config file /etc/puppet/hiera.yaml not found, using Hiera
defaults
Notice: Compiled catalog for puppet.example.com in environment
production in 0.84 seconds
Notice: /Stage[main]/test-module::Httpd/File[/var/www/myserver]/ensure:
current_value absent, should be directory (noop)
Notice: /Stage[main]/test-module::Httpd/Package[httpd]/ensure:
current_value absent, should be present (noop)
Notice:
/Stage[main]/test-module::Httpd/File[/etc/httpd/conf.d/myserver.conf]/ensure:
current_value absent, should be file (noop)
Notice: /Stage[main]/test-module::Httpd/Service[httpd]/ensure:
current_value stopped, should be running (noop)
Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 4
events
Notice: Stage[main]: Would have triggered 'refresh' from 1 events
Notice: Finished catalog run in 0.51 secondsFirewall konfigurieren
Um mit dem Server zu kommunizieren, benötigt man einen offenen Port. Das Problem hierbei ist, dass verschiedene Betriebssysteme unterschiedliche Methoden zur Steuerung der Firewall verwenden. Unter Linux verwenden Versionen unter 6 iptables und Version 7 firewalld.
Diese Entscheidung, einen geeigneten Dienst zu verwenden, wird von Puppet unter Verwendung der Systemfakten und ihrer Logik in gewisser Weise getroffen. Dazu müssen wir zuerst das Betriebssystem überprüfen und dann den entsprechenden Firewall-Befehl ausführen.
Um dies zu erreichen, müssen wir das folgende Code-Snippet in der Klasse testmodule :: http hinzufügen.
if $operatingsystemmajrelease <= 6 {
exec { 'iptables':
command => "iptables -I INPUT 1 -p tcp -m multiport --ports
${httpd_port} -m comment --comment 'Custom HTTP Web Host' -j ACCEPT && iptables-save > /etc/sysconfig/iptables", path => "/sbin", refreshonly => true, subscribe => Package['httpd'], } service { 'iptables': ensure => running, enable => true, hasrestart => true, subscribe => Exec['iptables'], } } elsif $operatingsystemmajrelease == 7 {
exec { 'firewall-cmd':
command => "firewall-cmd --zone=public --addport = $ {
httpd_port}/tcp --permanent",
path => "/usr/bin/",
refreshonly => true,
subscribe => Package['httpd'],
}
service { 'firewalld':
ensure => running,
enable => true,
hasrestart => true,
subscribe => Exec['firewall-cmd'],
}
}Der obige Code führt Folgendes aus:
Verwendung der operatingsystemmajrelease bestimmt, ob das verwendete Betriebssystem Version 6 oder 7 ist.
Wenn die Version 6 ist, werden alle erforderlichen Konfigurationsbefehle zum Konfigurieren der Linux 6-Version ausgeführt.
Wenn die Betriebssystemversion 7 ist, werden alle erforderlichen Befehle ausgeführt, die zum Konfigurieren der Firewall erforderlich sind.
Das Code-Snippet für beide Betriebssysteme enthält eine Logik, die sicherstellt, dass die Konfiguration erst nach der Installation des http-Pakets ausgeführt wird.
Führen Sie abschließend den Befehl Puppet Apply aus.
# puppet apply test-module/tests/init.pp --noop
Warning: Config file /etc/puppet/hiera.yaml not found, using Hiera
defaults
Notice: Compiled catalog for puppet.example.com in environment
production in 0.82 seconds
Notice: /Stage[main]/test-module::Httpd/Exec[iptables]/returns:
current_value notrun, should be 0 (noop)
Notice: /Stage[main]/test-module::Httpd/Service[iptables]: Would have
triggered 'refresh' from 1 eventsSELinux konfigurieren
Da wir an einem Linux-Computer mit Version 7 und höher arbeiten, müssen wir ihn für eine http-Kommunikation konfigurieren. SELinux beschränkt standardmäßig den nicht standardmäßigen Zugriff auf den HTTP-Server. Wenn wir einen benutzerdefinierten Port definieren, müssen wir SELinux konfigurieren, um den Zugriff auf diesen Port zu ermöglichen.
Puppet enthält einen Ressourcentyp zum Verwalten von SELinux-Funktionen, z. B. Boolesche Werte und Module. Hier müssen wir den Befehl semanage ausführen, um die Porteinstellungen zu verwalten. Dieses Tool ist Teil des Policycoreutils-Python-Pakets, das standardmäßig nicht auf Red-Hat-Servern installiert ist. Um dies zu erreichen, müssen wir den folgenden Code in die Klasse test-module :: http einfügen.
exec { 'semanage-port':
command => "semanage port -a -t http_port_t -p tcp ${httpd_port}",
path => "/usr/sbin",
require => Package['policycoreutils-python'],
before => Service ['httpd'],
subscribe => Package['httpd'],
refreshonly => true,
}
package { 'policycoreutils-python':
ensure => installed,
}Der obige Code führt Folgendes aus:
Das require => Package ['policycoreutils-python'] stellt sicher, dass das erforderliche Python-Modul installiert ist.
Puppet verwendet Semanage, um den Port mit dem httpd_port als verifizierbar zu öffnen.
Der Dienst before => stellt sicher, dass dieser Befehl ausgeführt wird, bevor der httpd-Dienst gestartet wird. Wenn HTTPD vor dem SELinux-Befehl gestartet wird, schlägt SELinux die Dienstanforderung und die Dienstanforderung fehl.
Führen Sie abschließend den Befehl Puppet Apply aus
# puppet apply test-module/tests/init.pp --noop
...
Notice: /Stage[main]/test-module::Httpd/Package[policycoreutilspython]/
ensure: current_value absent, should be present (noop)
...
Notice: /Stage[main]/test-module::Httpd/Exec[semanage-port]/returns:
current_value notrun, should be 0 (noop)
...
Notice: /Stage[main]/test-module::Httpd/Service[httpd]/ensure:
current_value stopped, should be running (noop)Puppet installiert zuerst das Python-Modul, konfiguriert dann den Portzugriff und startet schließlich den httpd-Dienst.
Kopieren von HTML-Dateien im Webhost
Mit den obigen Schritten haben wir die http-Serverkonfiguration abgeschlossen. Jetzt haben wir eine Plattform bereit, um eine webbasierte Anwendung zu installieren, die Puppet auch konfigurieren kann. Zum Testen kopieren wir einige Beispiel-HTML-Index-Webseiten auf den Server.
Erstellen Sie eine index.html-Datei im Dateiverzeichnis.
<html>
<head>
<title>Congratulations</title>
<head>
<body>
<h1>Congratulations</h1>
<p>Your puppet module has correctly applied your configuration.</p>
</body>
</html>Erstellen Sie eine Manifest-App.pp im Manifest-Verzeichnis und fügen Sie den folgenden Inhalt hinzu.
class test-module::app {
file { "/var/www/test-server/index.html":
ensure => file,
mode => 755,
owner => root,
group => root,
source => "puppet:///modules/test-module/index.html",
require => Class["test-module::httpd"],
}
}Diese neue Klasse enthält eine einzelne Ressourcenverzögerung. Dadurch wird eine Datei aus dem Dateiverzeichnis des Moduls auf den Webserver kopiert und die Berechtigungen festgelegt. Das erforderliche Attribut stellt sicher, dass die Klasse test-module :: http die Konfiguration erfolgreich abschließt, bevor test-module :: app angewendet wird.
Schließlich müssen wir ein neues Manifest in unser Hauptmanifest init.pp aufnehmen.
class test-module (
$http_port = 80
) {
include test-module::httpd
include test-module::app
}Führen Sie nun den Befehl apply aus, um tatsächlich zu testen, was gerade passiert. Es folgt die Ausgabe.
# puppet apply test-module/tests/init.pp --noop
Warning: Config file /etc/puppet/hiera.yaml not found, using Hiera
defaults
Notice: Compiled catalog for brcelprod001.brcle.com in environment
production in 0.66 seconds
Notice: /Stage[main]/Test-module::Httpd/Exec[iptables]/returns:
current_value notrun, should be 0 (noop)
Notice: /Stage[main]/Test-module::Httpd/Package[policycoreutilspython]/
ensure: current_value absent, should be present (noop)
Notice: /Stage[main]/Test-module::Httpd/Service[iptables]: Would have
triggered 'refresh' from 1 events
Notice: /Stage[main]/Test-module::Httpd/File[/var/www/myserver]/ensure:
current_value absent, should be directory (noop)
Notice: /Stage[main]/Test-module::Httpd/Package[httpd]/ensure:
current_value absent, should be present (noop)
Notice:
/Stage[main]/Test-module::Httpd/File[/etc/httpd/conf.d/myserver.conf]/ensur
e: current_value absent, should be file (noop)
Notice: /Stage[main]/Test-module::Httpd/Exec[semanage-port]/returns:
current_value notrun, should be 0 (noop)
Notice: /Stage[main]/Test-module::Httpd/Service[httpd]/ensure:
current_value stopped, should be running (noop)
Notice: Class[test-module::Httpd]: Would have triggered 'refresh' from 8
Notice:
/Stage[main]/test-module::App/File[/var/www/myserver/index.html]/ensur:
current_value absent, should be file (noop)
Notice: Class[test-module::App]: Would have triggered 'refresh' from 1
Notice: Stage[main]: Would have triggered 'refresh' from 2 events Notice:
Finished catalog run in 0.74 secondsDie hervorgehobene Zeile zeigt das Ergebnis der Datei index.html, die auf den Webhost kopiert wurde.
Abschluss des Moduls
Mit all den oben genannten Schritten ist unser neues Modul, das wir erstellt haben, einsatzbereit. Wenn Sie ein Archiv des Moduls erstellen möchten, können Sie dies mit dem folgenden Befehl tun.
# puppet module build test-module