Python Web Scraping - Kurzanleitung
Web Scraping ist ein automatischer Prozess zum Extrahieren von Informationen aus dem Web. In diesem Kapitel erhalten Sie eine detaillierte Vorstellung vom Web-Scraping, dem Vergleich mit dem Web-Crawlen und warum Sie sich für das Web-Scraping entscheiden sollten. Sie lernen auch die Komponenten und die Funktionsweise eines Web Scraper kennen.
Was ist Web Scraping?
Die Wörterbuchbedeutung des Wortes "Verschrotten" impliziert, dass etwas aus dem Web abgerufen wird. Hier stellen sich zwei Fragen: Was können wir aus dem Internet bekommen und wie bekommen wir das?
Die Antwort auf die erste Frage lautet ‘data’. Daten sind für jeden Programmierer unverzichtbar und die Grundvoraussetzung für jedes Programmierprojekt ist die große Menge nützlicher Daten.
Die Antwort auf die zweite Frage ist etwas schwierig, da es viele Möglichkeiten gibt, Daten abzurufen. Im Allgemeinen erhalten wir möglicherweise Daten aus einer Datenbank oder Datendatei und anderen Quellen. Aber was ist, wenn wir eine große Datenmenge benötigen, die online verfügbar ist? Eine Möglichkeit, solche Daten abzurufen, besteht darin, die erforderlichen Daten manuell zu suchen (in einem Webbrowser wegzuklicken) und zu speichern (in eine Tabelle oder Datei kopieren). Diese Methode ist ziemlich langwierig und zeitaufwändig. Eine andere Möglichkeit, solche Daten abzurufen, ist die Verwendungweb scraping.
Web scraping, auch genannt web data mining oder web harvestingist der Prozess der Erstellung eines Agenten, der nützliche Informationen aus dem Web automatisch extrahieren, analysieren, herunterladen und organisieren kann. Mit anderen Worten, wir können sagen, dass die Web-Scraping-Software die Daten von Websites nicht manuell speichert, sondern automatisch Daten von mehreren Websites gemäß unseren Anforderungen lädt und extrahiert.
Ursprung des Web Scraping
Der Ursprung des Web-Scrapings ist das Screen-Scrapping, mit dem nicht webbasierte Anwendungen oder native Windows-Anwendungen integriert wurden. Ursprünglich wurde Screen Scraping vor der weit verbreiteten Nutzung des World Wide Web (WWW) verwendet, konnte jedoch das erweiterte WWW nicht vergrößern. Dies machte es notwendig, den Ansatz des Screen Scraping und die aufgerufene Technik zu automatisieren‘Web Scraping’ entstanden.
Web Crawling v / s Web Scraping
Die Begriffe Web Crawling und Scraping werden häufig synonym verwendet, da das Grundkonzept darin besteht, Daten zu extrahieren. Sie unterscheiden sich jedoch voneinander. Wir können den grundlegenden Unterschied zu ihren Definitionen verstehen.
Webcrawling wird im Wesentlichen verwendet, um die Informationen auf der Seite mithilfe von Bots, auch bekannt als Crawler, zu indizieren. Es wird auch genanntindexing. Auf der anderen Seite ist Web Scraping eine automatisierte Methode zum Extrahieren der Informationen mithilfe von Bots, auch bekannt als Scraper. Es wird auch genanntdata extraction.
Um den Unterschied zwischen diesen beiden Begriffen zu verstehen, schauen wir uns die nachstehende Vergleichstabelle an -
| Web-Crawling | Web Scraping |
|---|---|
| Bezieht sich auf das Herunterladen und Speichern des Inhalts einer großen Anzahl von Websites. | Bezieht sich auf das Extrahieren einzelner Datenelemente aus der Website mithilfe einer ortsspezifischen Struktur. |
| Meistens in großem Maßstab. | Kann in jeder Größenordnung implementiert werden. |
| Ergibt allgemeine Informationen. | Ergibt spezifische Informationen. |
| Wird von großen Suchmaschinen wie Google, Bing, Yahoo verwendet. Googlebot ist ein Beispiel für einen Webcrawler. | Die mithilfe von Web Scraping extrahierten Informationen können zur Replikation auf einer anderen Website oder zur Durchführung von Datenanalysen verwendet werden. Zum Beispiel können die Datenelemente Namen, Adresse, Preis usw. sein. |
Verwendung von Web Scraping
Die Verwendungsmöglichkeiten und Gründe für die Verwendung von Web Scraping sind so endlos wie die Verwendungszwecke des World Wide Web. Web-Scraper können alles tun, wie Online-Lebensmittel bestellen, Online-Shopping-Websites für Sie scannen und Tickets für ein Match kaufen, sobald sie verfügbar sind usw., genau wie es ein Mensch tun kann. Einige der wichtigen Anwendungen des Web Scraping werden hier diskutiert -
E-commerce Websites - Web-Scraper können die Daten, die sich speziell auf den Preis eines bestimmten Produkts beziehen, von verschiedenen E-Commerce-Websites zum Vergleich sammeln.
Content Aggregators - Web-Scraping wird häufig von Inhaltsaggregatoren wie Nachrichtenaggregatoren und Jobaggregatoren verwendet, um ihren Benutzern aktualisierte Daten bereitzustellen.
Marketing and Sales Campaigns - Web-Scraper können verwendet werden, um Daten wie E-Mails, Telefonnummern usw. für Verkaufs- und Marketingkampagnen abzurufen.
Search Engine Optimization (SEO) - Web-Scraping wird häufig von SEO-Tools wie SEMRush, Majestic usw. verwendet, um Unternehmen mitzuteilen, wie sie für Suchbegriffe rangieren, die für sie wichtig sind.
Data for Machine Learning Projects - Das Abrufen von Daten für Projekte zum maschinellen Lernen hängt vom Web-Scraping ab.
Data for Research - Forscher können nützliche Daten für ihre Forschungsarbeit sammeln, indem sie durch diesen automatisierten Prozess Zeit sparen.
Komponenten eines Web Scraper
Ein Web Scraper besteht aus folgenden Komponenten:
Web Crawler-Modul
Eine sehr notwendige Komponente des Web Scraper, das Webcrawler-Modul, wird zum Navigieren auf der Zielwebsite verwendet, indem eine HTTP- oder HTTPS-Anforderung an die URLs gesendet wird. Der Crawler lädt die unstrukturierten Daten (HTML-Inhalte) herunter und übergibt sie an den Extraktor, das nächste Modul.
Extraktor
Der Extraktor verarbeitet den abgerufenen HTML-Inhalt und extrahiert die Daten in ein semistrukturiertes Format. Dies wird auch als Parser-Modul bezeichnet und verwendet verschiedene Parsing-Techniken wie regulärer Ausdruck, HTML-Parsing, DOM-Parsing oder künstliche Intelligenz für seine Funktion.
Modul zur Datenumwandlung und -bereinigung
Die oben extrahierten Daten sind nicht für die sofortige Verwendung geeignet. Es muss ein Reinigungsmodul durchlaufen, damit wir es verwenden können. Zu diesem Zweck können Methoden wie String-Manipulation oder regulärer Ausdruck verwendet werden. Beachten Sie, dass Extraktion und Transformation auch in einem einzigen Schritt durchgeführt werden können.
Speichermodul
Nach dem Extrahieren der Daten müssen wir sie gemäß unserer Anforderung speichern. Das Speichermodul gibt die Daten in einem Standardformat aus, das in einer Datenbank oder einem JSON- oder CSV-Format gespeichert werden kann.
Arbeiten mit einem Web Scraper
Web Scraper kann als Software oder Skript definiert werden, mit der der Inhalt mehrerer Webseiten heruntergeladen und Daten daraus extrahiert werden.
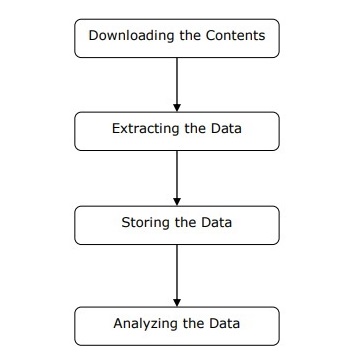
Wir können die Funktionsweise eines Web-Scrapers in einfachen Schritten verstehen, wie in der obigen Abbildung gezeigt.
Schritt 1: Herunterladen von Inhalten von Webseiten
In diesem Schritt lädt ein Web-Scraper die angeforderten Inhalte von mehreren Webseiten herunter.
Schritt 2: Daten extrahieren
Die Daten auf Websites sind HTML und meist unstrukturiert. Daher analysiert und extrahiert Web Scraper in diesem Schritt strukturierte Daten aus den heruntergeladenen Inhalten.
Schritt 3: Speichern der Daten
Hier speichert und speichert ein Web-Scraper die extrahierten Daten in einem beliebigen Format wie CSV, JSON oder in einer Datenbank.
Schritt 4: Analysieren der Daten
Nachdem alle diese Schritte erfolgreich ausgeführt wurden, analysiert der Web Scraper die so erhaltenen Daten.
Im ersten Kapitel haben wir gelernt, worum es beim Web Scraping geht. In diesem Kapitel erfahren Sie, wie Sie Web Scraping mit Python implementieren.
Warum Python für Web Scraping?
Python ist ein beliebtes Tool zum Implementieren von Web Scraping. Die Programmiersprache Python wird auch für andere nützliche Projekte im Zusammenhang mit Cybersicherheit, Penetrationstests sowie digitalen forensischen Anwendungen verwendet. Mit der Basisprogrammierung von Python kann Web Scraping ohne Verwendung eines anderen Tools von Drittanbietern durchgeführt werden.
Die Programmiersprache Python wird immer beliebter und die Gründe, warum Python für Web-Scraping-Projekte gut geeignet ist, sind folgende:
Syntax Einfachheit
Python hat im Vergleich zu anderen Programmiersprachen die einfachste Struktur. Diese Funktion von Python erleichtert das Testen und ein Entwickler kann sich mehr auf die Programmierung konzentrieren.
Eingebaute Module
Ein weiterer Grund für die Verwendung von Python für das Web-Scraping sind die eingebauten und externen nützlichen Bibliotheken. Wir können viele Implementierungen im Zusammenhang mit Web Scraping durchführen, indem wir Python als Basis für die Programmierung verwenden.
Open Source Programmiersprache
Python hat große Unterstützung von der Community, da es eine Open-Source-Programmiersprache ist.
Breites Anwendungsspektrum
Python kann für verschiedene Programmieraufgaben verwendet werden, die von kleinen Shell-Skripten bis hin zu Webanwendungen für Unternehmen reichen.
Installation von Python
Die Python-Distribution ist für Plattformen wie Windows, MAC und Unix / Linux verfügbar. Wir müssen nur den Binärcode herunterladen, der für unsere Plattform zur Installation von Python gilt. Falls der Binärcode für unsere Plattform jedoch nicht verfügbar ist, benötigen wir einen C-Compiler, damit der Quellcode manuell kompiliert werden kann.
Wir können Python wie folgt auf verschiedenen Plattformen installieren:
Python unter Unix und Linux installieren
Sie müssen die folgenden Schritte ausführen, um Python auf Unix / Linux-Computern zu installieren.
Step 1 - Gehen Sie zum Link https://www.python.org/downloads/
Step 2 - Laden Sie den für Unix / Linux verfügbaren komprimierten Quellcode über den obigen Link herunter.
Step 3 - Extrahieren Sie die Dateien auf Ihren Computer.
Step 4 - Verwenden Sie die folgenden Befehle, um die Installation abzuschließen. -
run ./configure script
make
make installSie finden installiertes Python am Standardspeicherort /usr/local/bin und seine Bibliotheken bei /usr/local/lib/pythonXX, wobei XX die Version von Python ist.
Python unter Windows installieren
Sie müssen die folgenden Schritte ausführen, um Python auf Windows-Computern zu installieren:
Step 1 - Gehen Sie zum Link https://www.python.org/downloads/
Step 2 - Laden Sie das Windows-Installationsprogramm herunter python-XYZ.msi Datei, wobei XYZ die Version ist, die wir installieren müssen.
Step 3 - Speichern Sie nun die Installationsdatei auf Ihrem lokalen Computer und führen Sie die MSI-Datei aus.
Step 4 - Führen Sie zuletzt die heruntergeladene Datei aus, um den Python-Installationsassistenten aufzurufen.
Python auf Macintosh installieren
Wir müssen verwenden Homebrew für die Installation von Python 3 unter Mac OS X. Homebrew ist einfach zu installieren und ein großartiges Paketinstallationsprogramm.
Homebrew kann auch mit dem folgenden Befehl installiert werden:
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"Zum Aktualisieren des Paketmanagers können wir den folgenden Befehl verwenden:
$ brew updateMit Hilfe des folgenden Befehls können wir Python3 auf unserem MAC-Computer installieren -
$ brew install python3Einrichten des Pfads
Mit den folgenden Anweisungen können Sie den Pfad in verschiedenen Umgebungen einrichten:
Einrichten des Pfads unter Unix / Linux
Verwenden Sie die folgenden Befehle, um Pfade mit verschiedenen Befehlsshells einzurichten:
Für csh Shell
setenv PATH "$PATH:/usr/local/bin/python".Für Bash Shell (Linux)
ATH="$PATH:/usr/local/bin/python".Für sh oder ksh Shell
PATH="$PATH:/usr/local/bin/python".Einrichten des Pfads unter Windows
Zum Festlegen des Pfads unter Windows können wir den Pfad verwenden %path%;C:\Python an der Eingabeaufforderung und drücken Sie die Eingabetaste.
Python ausführen
Wir können Python auf eine der folgenden drei Arten starten:
Interaktiver Dolmetscher
Zum Starten von Python kann ein Betriebssystem wie UNIX und DOS verwendet werden, das einen Befehlszeileninterpreter oder eine Shell bereitstellt.
Wir können mit der Codierung im interaktiven Interpreter wie folgt beginnen:
Step 1 - Geben Sie ein python an der Kommandozeile.
Step 2 - Dann können wir sofort mit dem Codieren im interaktiven Interpreter beginnen.
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOSSkript über die Befehlszeile
Wir können ein Python-Skript in der Befehlszeile ausführen, indem wir den Interpreter aufrufen. Es kann wie folgt verstanden werden:
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOSIntegrierte Entwicklungsumgebung
Wir können Python auch in einer GUI-Umgebung ausführen, wenn das System über eine GUI-Anwendung verfügt, die Python unterstützt. Einige IDEs, die Python auf verschiedenen Plattformen unterstützen, sind unten aufgeführt:
IDE for UNIX - UNIX für Python hat IDLE IDE.
IDE for Windows - Windows hat PythonWin IDE, die auch GUI hat.
IDE for Macintosh - Macintosh verfügt über eine IDLE-IDE, die entweder als MacBinary- oder BinHex-Datei von der Hauptwebsite heruntergeladen werden kann.
In diesem Kapitel lernen wir verschiedene Python-Module kennen, die wir für das Web-Scraping verwenden können.
Python-Entwicklungsumgebungen mit virtualenv
Virtualenv ist ein Tool zum Erstellen isolierter Python-Umgebungen. Mithilfe von virtualenv können wir einen Ordner erstellen, der alle erforderlichen ausführbaren Dateien enthält, um die für unser Python-Projekt erforderlichen Pakete zu verwenden. Außerdem können wir Python-Module hinzufügen und ändern, ohne Zugriff auf die globale Installation zu haben.
Sie können den folgenden Befehl zur Installation verwenden virtualenv - -
(base) D:\ProgramData>pip install virtualenv
Collecting virtualenv
Downloading
https://files.pythonhosted.org/packages/b6/30/96a02b2287098b23b875bc8c2f58071c3
5d2efe84f747b64d523721dc2b5/virtualenv-16.0.0-py2.py3-none-any.whl
(1.9MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.9MB 86kB/s
Installing collected packages: virtualenv
Successfully installed virtualenv-16.0.0Jetzt müssen wir ein Verzeichnis erstellen, das das Projekt mit Hilfe des folgenden Befehls darstellt:
(base) D:\ProgramData>mkdir webscrapGeben Sie nun mit Hilfe des folgenden Befehls in dieses Verzeichnis ein:
(base) D:\ProgramData>cd webscrapJetzt müssen wir den Ordner der virtuellen Umgebung unserer Wahl wie folgt initialisieren:
(base) D:\ProgramData\webscrap>virtualenv websc
Using base prefix 'd:\\programdata'
New python executable in D:\ProgramData\webscrap\websc\Scripts\python.exe
Installing setuptools, pip, wheel...done.Aktivieren Sie nun die virtuelle Umgebung mit dem folgenden Befehl. Nach erfolgreicher Aktivierung sehen Sie den Namen auf der linken Seite in Klammern.
(base) D:\ProgramData\webscrap>websc\scripts\activateWir können jedes Modul in dieser Umgebung wie folgt installieren:
(websc) (base) D:\ProgramData\webscrap>pip install requests
Collecting requests
Downloading
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (9
1kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 148kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading
https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca
55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133
kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 369kB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading
https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee6364
4d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl
(147kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 153kB 527kB/s
Collecting urllib3<1.24,>=1.21.1 (from requests)
Downloading
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133k
B)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 517kB/s
Collecting idna<2.8,>=2.5 (from requests)
Downloading
https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746
a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 61kB 339kB/s
Installing collected packages: chardet, certifi, urllib3, idna, requests
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1
urllib3-1.23Zum Deaktivieren der virtuellen Umgebung können wir den folgenden Befehl verwenden:
(websc) (base) D:\ProgramData\webscrap>deactivate
(base) D:\ProgramData\webscrap>Sie können sehen, dass (websc) deaktiviert wurde.
Python-Module für Web Scraping
Beim Web-Scraping wird ein Agent erstellt, der nützliche Informationen aus dem Web automatisch extrahieren, analysieren, herunterladen und organisieren kann. Mit anderen Worten, anstatt die Daten von Websites manuell zu speichern, lädt und extrahiert die Web-Scraping-Software automatisch Daten von mehreren Websites gemäß unserer Anforderung.
In diesem Abschnitt werden nützliche Python-Bibliotheken für das Web-Scraping erläutert.
Anfragen
Es ist eine einfache Python-Web-Scraping-Bibliothek. Es ist eine effiziente HTTP-Bibliothek, die für den Zugriff auf Webseiten verwendet wird. Mit der Hilfe vonRequestskönnen wir den rohen HTML-Code von Webseiten abrufen, der dann zum Abrufen der Daten analysiert werden kann. Vor GebrauchrequestsLassen Sie uns die Installation verstehen.
Anfragen installieren
Wir können es entweder in unserer virtuellen Umgebung oder in der globalen Installation installieren. Mit der Hilfe vonpip Befehl können wir es einfach wie folgt installieren -
(base) D:\ProgramData> pip install requests
Collecting requests
Using cached
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl
Requirement already satisfied: idna<2.8,>=2.5 in d:\programdata\lib\sitepackages
(from requests) (2.6)
Requirement already satisfied: urllib3<1.24,>=1.21.1 in
d:\programdata\lib\site-packages (from requests) (1.22)
Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\lib\sitepackages
(from requests) (2018.1.18)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in
d:\programdata\lib\site-packages (from requests) (3.0.4)
Installing collected packages: requests
Successfully installed requests-2.19.1Beispiel
In diesem Beispiel stellen wir eine GET-HTTP-Anforderung für eine Webseite. Dazu müssen wir zuerst die Anforderungsbibliothek wie folgt importieren:
In [1]: import requestsIn dieser folgenden Codezeile verwenden wir Anforderungen, um GET-HTTP-Anforderungen für die URL zu erstellen: https://authoraditiagarwal.com/ durch eine GET-Anfrage.
In [2]: r = requests.get('https://authoraditiagarwal.com/')Jetzt können wir den Inhalt mit abrufen .text Eigenschaft wie folgt -
In [5]: r.text[:200]Beachten Sie, dass wir in der folgenden Ausgabe die ersten 200 Zeichen erhalten haben.
Out[5]: '<!DOCTYPE html>\n<html lang="en-US"\n\titemscope
\n\titemtype="http://schema.org/WebSite" \n\tprefix="og: http://ogp.me/ns#"
>\n<head>\n\t<meta charset
="UTF-8" />\n\t<meta http-equiv="X-UA-Compatible" content="IE'Urllib3
Es ist eine weitere Python-Bibliothek, die zum Abrufen von Daten von URLs ähnlich der verwendet werden kann requestsBibliothek. Weitere Informationen hierzu finden Sie in der technischen Dokumentation unterhttps://urllib3.readthedocs.io/en/latest/.
Urllib3 installieren
Verwendung der pip Befehl können wir installieren urllib3 entweder in unserer virtuellen Umgebung oder in einer globalen Installation.
(base) D:\ProgramData>pip install urllib3
Collecting urllib3
Using cached
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl
Installing collected packages: urllib3
Successfully installed urllib3-1.23Beispiel: Scraping mit Urllib3 und BeautifulSoup
Im folgenden Beispiel wird die Webseite mithilfe von abgekratzt Urllib3 und BeautifulSoup. Wir benutzenUrllib3an der Stelle der Anforderungsbibliothek zum Abrufen der Rohdaten (HTML) von der Webseite. Dann verwenden wirBeautifulSoup zum Parsen dieser HTML-Daten.
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://authoraditiagarwal.com')
soup = BeautifulSoup(r.data, 'lxml')
print (soup.title)
print (soup.title.text)Dies ist die Ausgabe, die Sie beobachten werden, wenn Sie diesen Code ausführen -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalSelen
Es handelt sich um eine automatisierte Open Source-Testsuite für Webanwendungen in verschiedenen Browsern und Plattformen. Es ist kein einzelnes Tool, sondern eine Suite von Software. Wir haben Selenbindungen für Python, Java, C #, Ruby und JavaScript. Hier werden wir Web Scraping unter Verwendung von Selen und seinen Python-Bindungen durchführen. Weitere Informationen zu Selenium mit Java finden Sie unter dem Link Selenium .
Selenium Python-Bindungen bieten eine praktische API für den Zugriff auf Selenium WebDrivers wie Firefox, IE, Chrome, Remote usw. Die derzeit unterstützten Python-Versionen sind 2.7, 3.5 und höher.
Selen installieren
Verwendung der pip Befehl können wir installieren urllib3 entweder in unserer virtuellen Umgebung oder in einer globalen Installation.
pip install seleniumDa für Selen ein Treiber erforderlich ist, um mit dem ausgewählten Browser zu kommunizieren, müssen wir ihn herunterladen. Die folgende Tabelle zeigt verschiedene Browser und deren Links zum Herunterladen derselben.
Chrome |
https://sites.google.com/a/chromium.org/ |
Edge |
https://developer.microsoft.com/ |
Firefox |
https://github.com/ |
Safari |
https://webkit.org/ |
Beispiel
Dieses Beispiel zeigt das Web-Scraping mit Selen. Es kann auch zum Testen verwendet werden, was als Selentest bezeichnet wird.
Nachdem wir den bestimmten Treiber für die angegebene Browserversion heruntergeladen haben, müssen wir in Python programmieren.
Zuerst muss importiert werden webdriver aus Selen wie folgt -
from selenium import webdriverGeben Sie nun den Pfad des Webtreibers an, den wir gemäß unserer Anforderung heruntergeladen haben.
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)Geben Sie nun die URL an, die wir in diesem Webbrowser öffnen möchten, der jetzt von unserem Python-Skript gesteuert wird.
browser.get('https://authoraditiagarwal.com/leadershipmanagement')Wir können ein bestimmtes Element auch kratzen, indem wir den in lxml angegebenen xpath angeben.
browser.find_element_by_xpath('/html/body').click()Sie können den vom Python-Skript gesteuerten Browser auf Ausgabe überprüfen.
Scrapy
Scrapy ist ein schnelles, in Python geschriebenes Open-Source-Webcrawling-Framework, mit dem die Daten mithilfe von auf XPath basierenden Selektoren von der Webseite extrahiert werden. Scrapy wurde erstmals am 26. Juni 2008 unter BSD-Lizenz veröffentlicht. Der Meilenstein 1.0 wurde im Juni 2015 veröffentlicht. Es bietet uns alle Tools, die wir zum Extrahieren, Verarbeiten und Strukturieren der Daten von Websites benötigen.
Scrapy installieren
Verwendung der pip Befehl können wir installieren urllib3 entweder in unserer virtuellen Umgebung oder in einer globalen Installation.
pip install scrapyWeitere Informationen zu Scrapy finden Sie unter dem Link Scrapy
Mit Python können wir jede Website oder bestimmte Elemente einer Webseite kratzen. Haben Sie jedoch eine Vorstellung davon, ob diese legal ist oder nicht? Vor dem Scraping einer Website müssen wir die Rechtmäßigkeit des Web-Scrapings kennen. In diesem Kapitel werden die Konzepte zur Legalität von Web Scraping erläutert.
Einführung
Wenn Sie die gescrapten Daten für den persönlichen Gebrauch verwenden, liegt im Allgemeinen möglicherweise kein Problem vor. Wenn Sie diese Daten jedoch erneut veröffentlichen möchten, sollten Sie, bevor Sie dasselbe tun, eine Download-Anfrage an den Eigentümer richten oder Hintergrundinformationen zu Richtlinien sowie zu den Daten, die Sie kratzen möchten, durchführen.
Vor dem Schaben erforderliche Forschung
Wenn Sie auf eine Website abzielen, um Daten daraus zu entfernen, müssen wir deren Umfang und Struktur verstehen. Im Folgenden finden Sie einige der Dateien, die wir analysieren müssen, bevor Sie mit dem Web-Scraping beginnen.
Analyse von robots.txt
Tatsächlich erlauben die meisten Publisher Programmierern, ihre Websites in gewissem Umfang zu crawlen. In einem anderen Sinne möchten Publisher, dass bestimmte Teile der Websites gecrawlt werden. Um dies zu definieren, müssen Websites einige Regeln festlegen, um anzugeben, welche Teile gecrawlt werden können und welche nicht. Solche Regeln werden in einer aufgerufenen Datei definiertrobots.txt.
robots.txtist eine lesbare Datei, die verwendet wird, um die Teile der Website zu identifizieren, die Crawler dürfen und nicht kratzen dürfen. Es gibt kein Standardformat für die robots.txt-Datei und die Herausgeber der Website können Änderungen gemäß ihren Anforderungen vornehmen. Wir können die robots.txt-Datei für eine bestimmte Website überprüfen, indem wir einen Schrägstrich und robots.txt nach der URL dieser Website angeben. Wenn wir beispielsweise nach Google.com suchen möchten, müssen wir Folgendes eingebenhttps://www.google.com/robots.txt und wir werden etwas wie folgt bekommen -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..Einige der häufigsten Regeln, die in der robots.txt-Datei einer Website definiert sind, lauten wie folgt:
User-agent: BadCrawler
Disallow: /Die obige Regel bedeutet, dass die robots.txt-Datei einen Crawler mit fragt BadCrawler Benutzeragent, um ihre Website nicht zu crawlen.
User-agent: *
Crawl-delay: 5
Disallow: /trapDie obige Regel bedeutet, dass die robots.txt-Datei einen Crawler zwischen den Download-Anforderungen für alle Benutzeragenten um 5 Sekunden verzögert, um eine Überlastung des Servers zu vermeiden. Das/traplink versucht, böswillige Crawler zu blockieren, die nicht zugelassenen Links folgen. Es gibt viele weitere Regeln, die vom Herausgeber der Website gemäß seinen Anforderungen definiert werden können. Einige von ihnen werden hier diskutiert -
Sitemap-Dateien analysieren
Was sollten Sie tun, wenn Sie eine Website nach aktualisierten Informationen durchsuchen möchten? Sie werden jede Webseite crawlen, um diese aktualisierten Informationen zu erhalten. Dies erhöht jedoch den Serververkehr dieser bestimmten Website. Aus diesem Grund bieten Websites Sitemap-Dateien, mit denen die Crawler aktualisierte Inhalte leichter finden können, ohne jede Webseite crawlen zu müssen. Der Sitemap-Standard ist definiert unterhttp://www.sitemaps.org/protocol.html.
Inhalt der Sitemap-Datei
Das Folgende ist der Inhalt der Sitemap-Datei von https://www.microsoft.com/robots.txt das wird in der Datei robot.txt entdeckt -
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xmlDer obige Inhalt zeigt, dass die Sitemap die URLs auf der Website auflistet und es einem Webmaster außerdem ermöglicht, einige zusätzliche Informationen wie das Datum der letzten Aktualisierung, die Änderung des Inhalts, die Wichtigkeit der URL im Verhältnis zu anderen usw. zu jeder URL anzugeben.
Wie groß ist die Website?
Beeinflusst die Größe einer Website, dh die Anzahl der Webseiten einer Website, die Art und Weise, wie wir crawlen? Sicherlich ja. Denn wenn weniger Webseiten gecrawlt werden müssen, ist die Effizienz kein ernstes Problem. Wenn unsere Website jedoch über Millionen von Webseiten verfügt, z. B. Microsoft.com, dauert das Herunterladen jeder Webseite nacheinander mehrere Monate dann wäre Effizienz ein ernstes Problem.
Überprüfen der Größe der Website
Durch Überprüfen der Ergebnisgröße des Google-Crawlers können wir eine Schätzung der Größe einer Website erhalten. Unser Ergebnis kann mithilfe des Schlüsselworts gefiltert werdensitewährend der Google-Suche. Zum Beispiel das Schätzen der Größe vonhttps://authoraditiagarwal.com/ ist unten angegeben -
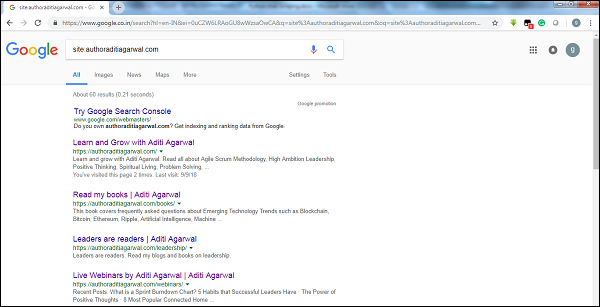
Sie können sehen, dass es ungefähr 60 Ergebnisse gibt, was bedeutet, dass es sich nicht um eine große Website handelt und das Crawlen nicht zu Effizienzproblemen führen würde.
Welche Technologie wird von der Website verwendet?
Eine weitere wichtige Frage ist, ob die von der Website verwendete Technologie die Art und Weise beeinflusst, wie wir crawlen. Ja, es betrifft. Aber wie können wir die von einer Website verwendete Technologie überprüfen? Es gibt eine Python-Bibliothek mit dem Namenbuiltwith mit deren Hilfe wir uns über die von einer Website verwendete Technologie informieren können.
Beispiel
In diesem Beispiel werden wir die von der Website verwendete Technologie überprüfen https://authoraditiagarwal.com mit Hilfe der Python-Bibliothek builtwith. Bevor wir diese Bibliothek verwenden können, müssen wir sie wie folgt installieren:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3Mithilfe der folgenden einfachen Codezeile können wir nun die von einer bestimmten Website verwendete Technologie überprüfen.
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}Wer ist der Eigentümer der Website?
Der Eigentümer der Website ist auch wichtig, denn wenn der Eigentümer dafür bekannt ist, die Crawler zu blockieren, müssen die Crawler vorsichtig sein, wenn sie die Daten von der Website entfernen. Es gibt ein Protokoll mit dem NamenWhois mit deren Hilfe wir uns über den Inhaber der Website informieren können.
Beispiel
In diesem Beispiel überprüfen wir den Eigentümer der Website, beispielsweise microsoft.com, mithilfe von Whois. Bevor wir diese Bibliothek verwenden können, müssen wir sie wie folgt installieren:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0Mithilfe der folgenden einfachen Codezeile können wir nun die von einer bestimmten Website verwendete Technologie überprüfen.
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
],
}Das Analysieren einer Webseite bedeutet, ihre Struktur zu verstehen. Nun stellt sich die Frage, warum es für das Web-Scraping wichtig ist. Lassen Sie uns dies in diesem Kapitel im Detail verstehen.
Webseitenanalyse
Die Analyse von Webseiten ist wichtig, da wir ohne Analyse nicht wissen können, in welcher Form wir die Daten von dieser Webseite (strukturiert oder unstrukturiert) nach der Extraktion erhalten werden. Wir können Webseitenanalysen auf folgende Arten durchführen:
Anzeigen der Seitenquelle
Auf diese Weise können Sie verstehen, wie eine Webseite strukturiert ist, indem Sie den Quellcode untersuchen. Um dies zu implementieren, müssen wir mit der rechten Maustaste auf die Seite klicken und dann die auswählenView page sourceMöglichkeit. Dann erhalten wir die Daten unseres Interesses von dieser Webseite in Form von HTML. Das Hauptanliegen sind jedoch Leerzeichen und Formatierungen, die für uns schwer zu formatieren sind.
Überprüfen der Seitenquelle durch Klicken auf Option Element überprüfen
Dies ist eine weitere Möglichkeit, Webseiten zu analysieren. Der Unterschied besteht jedoch darin, dass das Problem der Formatierung und Leerzeichen im Quellcode der Webseite behoben wird. Sie können dies implementieren, indem Sie mit der rechten Maustaste klicken und dann die auswählenInspect oder Inspect elementOption aus dem Menü. Es enthält Informationen zu bestimmten Bereichen oder Elementen dieser Webseite.
Verschiedene Möglichkeiten zum Extrahieren von Daten von Webseiten
Die folgenden Methoden werden hauptsächlich zum Extrahieren von Daten von einer Webseite verwendet:
Regulären Ausdruck
Sie sind eine hochspezialisierte Programmiersprache, die in Python eingebettet ist. Wir können es durch nutzenreModul von Python. Es wird auch als RE oder Regexes oder Regex-Muster bezeichnet. Mithilfe regulärer Ausdrücke können wir einige Regeln für den möglichen Satz von Zeichenfolgen angeben, die aus den Daten übereinstimmen sollen.
Wenn Sie mehr über reguläre Ausdrücke im Allgemeinen erfahren möchten, gehen Sie zum Link https://www.tutorialspoint.com/automata_theory/regular_expressions.htmWenn Sie mehr über das Modul oder den regulären Ausdruck in Python erfahren möchten, folgen Sie dem Link https://www.tutorialspoint.com/python/python_reg_expressions.htm .
Beispiel
Im folgenden Beispiel werden wir Daten über Indien aus kratzen http://example.webscraping.com nach dem Abgleichen des Inhalts von <td> mit Hilfe des regulären Ausdrucks.
import re
import urllib.request
response =
urllib.request.urlopen('http://example.webscraping.com/places/default/view/India-102')
html = response.read()
text = html.decode()
re.findall('<td class="w2p_fw">(.*?)</td>',text)Ausgabe
Die entsprechende Ausgabe wird wie hier gezeigt sein -
[
'<img src="/places/static/images/flags/in.png" />',
'3,287,590 square kilometres',
'1,173,108,018',
'IN',
'India',
'New Delhi',
'<a href="/places/default/continent/AS">AS</a>',
'.in',
'INR',
'Rupee',
'91',
'######',
'^(\\d{6})$',
'enIN,hi,bn,te,mr,ta,ur,gu,kn,ml,or,pa,as,bh,sat,ks,ne,sd,kok,doi,mni,sit,sa,fr,lus,inc',
'<div>
<a href="/places/default/iso/CN">CN </a>
<a href="/places/default/iso/NP">NP </a>
<a href="/places/default/iso/MM">MM </a>
<a href="/places/default/iso/BT">BT </a>
<a href="/places/default/iso/PK">PK </a>
<a href="/places/default/iso/BD">BD </a>
</div>'
]Beachten Sie, dass Sie in der obigen Ausgabe die Details zum Land Indien mit regulären Ausdrücken sehen können.
Schöne Suppe
Angenommen, wir möchten alle Hyperlinks von einer Webseite sammeln, dann können wir einen Parser namens BeautifulSoup verwenden, der unter näher bekannt ist https://www.crummy.com/software/BeautifulSoup/bs4/doc/.Mit einfachen Worten, BeautifulSoup ist eine Python-Bibliothek zum Abrufen von Daten aus HTML- und XML-Dateien. Es kann mit Anforderungen verwendet werden, da es eine Eingabe (Dokument oder URL) benötigt, um ein Suppenobjekt zu erstellen, da es keine Webseite selbst abrufen kann. Sie können das folgende Python-Skript verwenden, um den Titel der Webseite und der Hyperlinks zu erfassen.
Schöne Suppe installieren
Verwendung der pip Befehl können wir installieren beautifulsoup entweder in unserer virtuellen Umgebung oder in einer globalen Installation.
(base) D:\ProgramData>pip install bs4
Collecting bs4
Downloading
https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89
a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz
Requirement already satisfied: beautifulsoup4 in d:\programdata\lib\sitepackages
(from bs4) (4.6.0)
Building wheels for collected packages: bs4
Running setup.py bdist_wheel for bs4 ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\a0\b0\b2\4f80b9456b87abedbc0bf2d
52235414c3467d8889be38dd472
Successfully built bs4
Installing collected packages: bs4
Successfully installed bs4-0.0.1Beispiel
Beachten Sie, dass wir in diesem Beispiel das obige Beispiel erweitern, das mit dem Anforderungs-Python-Modul implementiert wurde. wir benutzenr.text zum Erstellen eines Suppenobjekts, das weiterhin zum Abrufen von Details wie dem Titel der Webseite verwendet wird.
Zuerst müssen wir die notwendigen Python-Module importieren -
import requests
from bs4 import BeautifulSoupIn dieser folgenden Codezeile verwenden wir Anforderungen, um GET-HTTP-Anforderungen für die URL zu erstellen: https://authoraditiagarwal.com/ durch eine GET-Anfrage.
r = requests.get('https://authoraditiagarwal.com/')Jetzt müssen wir ein Soup-Objekt wie folgt erstellen:
soup = BeautifulSoup(r.text, 'lxml')
print (soup.title)
print (soup.title.text)Ausgabe
Die entsprechende Ausgabe wird wie hier gezeigt sein -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalLxml
Eine weitere Python-Bibliothek, die wir für das Web-Scraping diskutieren werden, ist lxml. Es ist eine leistungsstarke HTML- und XML-Parsing-Bibliothek. Es ist vergleichsweise schnell und unkompliziert. Sie können mehr darüber lesenhttps://lxml.de/.
Lxml installieren
Mit dem Befehl pip können wir installieren lxml entweder in unserer virtuellen Umgebung oder in einer globalen Installation.
(base) D:\ProgramData>pip install lxml
Collecting lxml
Downloading
https://files.pythonhosted.org/packages/b9/55/bcc78c70e8ba30f51b5495eb0e
3e949aa06e4a2de55b3de53dc9fa9653fa/lxml-4.2.5-cp36-cp36m-win_amd64.whl
(3.
6MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 3.6MB 64kB/s
Installing collected packages: lxml
Successfully installed lxml-4.2.5Beispiel: Datenextraktion mit lxml und Anfragen
Im folgenden Beispiel wird ein bestimmtes Element der Webseite entfernt authoraditiagarwal.com mit lxml und Anfragen -
Zuerst müssen wir die Anforderungen und HTML aus der lxml-Bibliothek wie folgt importieren:
import requests
from lxml import htmlJetzt müssen wir die URL der Webseite angeben, die verschrottet werden soll
url = 'https://authoraditiagarwal.com/leadershipmanagement/'Jetzt müssen wir den Weg bereitstellen (Xpath) zu einem bestimmten Element dieser Webseite -
path = '//*[@id="panel-836-0-0-1"]/div/div/p[1]'
response = requests.get(url)
byte_string = response.content
source_code = html.fromstring(byte_string)
tree = source_code.xpath(path)
print(tree[0].text_content())Ausgabe
Die entsprechende Ausgabe wird wie hier gezeigt sein -
The Sprint Burndown or the Iteration Burndown chart is a powerful tool to communicate
daily progress to the stakeholders. It tracks the completion of work for a given sprint
or an iteration. The horizontal axis represents the days within a Sprint. The vertical
axis represents the hours remaining to complete the committed work.In früheren Kapiteln haben wir gelernt, wie Sie Daten von Webseiten extrahieren oder mit verschiedenen Python-Modulen Web-Scraping durchführen können. Lassen Sie uns in diesem Kapitel verschiedene Techniken untersuchen, um die Daten zu verarbeiten, die abgekratzt wurden.
Einführung
Um die Daten zu verarbeiten, die gelöscht wurden, müssen wir die Daten auf unserem lokalen Computer in einem bestimmten Format wie Spreadsheet (CSV), JSON oder manchmal in Datenbanken wie MySQL speichern.
CSV- und JSON-Datenverarbeitung
Zuerst schreiben wir die Informationen nach dem Abrufen von der Webseite in eine CSV-Datei oder eine Tabelle. Lassen Sie uns zunächst anhand eines einfachen Beispiels verstehen, in dem wir die Informationen zunächst anhand von erfassenBeautifulSoup Modul, wie zuvor, und dann mit dem Python CSV-Modul werden wir diese Textinformationen in die CSV-Datei schreiben.
Zuerst müssen wir die erforderlichen Python-Bibliotheken wie folgt importieren:
import requests
from bs4 import BeautifulSoup
import csvIn dieser folgenden Codezeile verwenden wir Anforderungen, um GET-HTTP-Anforderungen für die URL zu erstellen: https://authoraditiagarwal.com/ durch eine GET-Anfrage.
r = requests.get('https://authoraditiagarwal.com/')Jetzt müssen wir ein Suppenobjekt wie folgt erstellen:
soup = BeautifulSoup(r.text, 'lxml')Mit Hilfe der nächsten Codezeilen schreiben wir nun die erfassten Daten in eine CSV-Datei mit dem Namen dataprocessing.csv.
f = csv.writer(open(' dataprocessing.csv ','w'))
f.writerow(['Title'])
f.writerow([soup.title.text])Nach dem Ausführen dieses Skripts werden die Textinformationen oder der Titel der Webseite in der oben genannten CSV-Datei auf Ihrem lokalen Computer gespeichert.
Ebenso können wir die gesammelten Informationen in einer JSON-Datei speichern. Das Folgende ist ein leicht verständliches Python-Skript, mit dem wir dieselben Informationen wie im letzten Python-Skript abrufen. Diesmal werden die erfassten Informationen jedoch mithilfe des JSON-Python-Moduls in JSONfile.txt gespeichert.
import requests
from bs4 import BeautifulSoup
import csv
import json
r = requests.get('https://authoraditiagarwal.com/')
soup = BeautifulSoup(r.text, 'lxml')
y = json.dumps(soup.title.text)
with open('JSONFile.txt', 'wt') as outfile:
json.dump(y, outfile)Nach dem Ausführen dieses Skripts werden die erfassten Informationen, dh der Titel der Webseite, in der oben genannten Textdatei auf Ihrem lokalen Computer gespeichert.
Datenverarbeitung mit AWS S3
Manchmal möchten wir möglicherweise kratzende Daten zu Archivierungszwecken in unserem lokalen Speicher speichern. Aber was ist, wenn wir diese Daten in großem Umfang speichern und analysieren müssen? Die Antwort lautet Cloud-Speicherdienst mit dem Namen Amazon S3 oder AWS S3 (Simple Storage Service). Grundsätzlich ist AWS S3 ein Objektspeicher, mit dem beliebige Datenmengen von überall gespeichert und abgerufen werden können.
Wir können die folgenden Schritte zum Speichern von Daten in AWS S3 ausführen:
Step 1- Zuerst benötigen wir ein AWS-Konto, das uns die geheimen Schlüssel zur Verwendung in unserem Python-Skript beim Speichern der Daten zur Verfügung stellt. Es wird ein S3-Bucket erstellt, in dem wir unsere Daten speichern können.
Step 2 - Als nächstes müssen wir installieren boto3Python-Bibliothek für den Zugriff auf den S3-Bucket. Es kann mit Hilfe des folgenden Befehls installiert werden -
pip install boto3Step 3 - Als Nächstes können wir das folgende Python-Skript verwenden, um Daten von der Webseite zu kratzen und im AWS S3-Bucket zu speichern.
Zuerst müssen wir Python-Bibliotheken zum Scraping importieren, hier arbeiten wir requests, und boto3 Speichern von Daten im S3-Bucket.
import requests
import boto3Jetzt können wir die Daten von unserer URL kratzen.
data = requests.get("Enter the URL").textUm nun Daten im S3-Bucket zu speichern, müssen wir den S3-Client wie folgt erstellen:
s3 = boto3.client('s3')
bucket_name = "our-content"In der nächsten Codezeile wird der S3-Bucket wie folgt erstellt:
s3.create_bucket(Bucket = bucket_name, ACL = 'public-read')
s3.put_object(Bucket = bucket_name, Key = '', Body = data, ACL = "public-read")Jetzt können Sie den Bucket mit dem Namen our-content in Ihrem AWS-Konto überprüfen.
Datenverarbeitung mit MySQL
Lassen Sie uns lernen, wie Daten mit MySQL verarbeitet werden. Wenn Sie mehr über MySQL erfahren möchten, können Sie dem Link folgenhttps://www.tutorialspoint.com/mysql/.
Mit Hilfe der folgenden Schritte können wir Daten in die MySQL-Tabelle kratzen und verarbeiten -
Step 1- Zuerst müssen wir mit MySQL eine Datenbank und eine Tabelle erstellen, in der wir unsere Scraped-Daten speichern möchten. Zum Beispiel erstellen wir die Tabelle mit der folgenden Abfrage:
CREATE TABLE Scrap_pages (id BIGINT(7) NOT NULL AUTO_INCREMENT,
title VARCHAR(200), content VARCHAR(10000),PRIMARY KEY(id));Step 2- Als nächstes müssen wir uns mit Unicode befassen. Beachten Sie, dass MySQL standardmäßig keinen Unicode verarbeitet. Wir müssen diese Funktion mithilfe der folgenden Befehle aktivieren, mit denen der Standardzeichensatz für die Datenbank, die Tabelle und beide Spalten geändert wird.
ALTER DATABASE scrap CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CONVERT TO CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;Step 3- Integrieren Sie jetzt MySQL in Python. Dazu benötigen wir PyMySQL, das mit Hilfe des folgenden Befehls installiert werden kann
pip install PyMySQLStep 4- Jetzt kann unsere zuvor erstellte Datenbank mit dem Namen Scrap die Daten nach dem Scraping aus dem Web in einer Tabelle mit dem Namen Scrap_pages speichern. Hier in unserem Beispiel werden wir Daten aus Wikipedia kratzen und sie werden in unserer Datenbank gespeichert.
Zuerst müssen wir die erforderlichen Python-Module importieren.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import pymysql
import reStellen Sie nun eine Verbindung her, die in Python integriert ist.
conn = pymysql.connect(host='127.0.0.1',user='root', passwd = None, db = 'mysql',
charset = 'utf8')
cur = conn.cursor()
cur.execute("USE scrap")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute('INSERT INTO scrap_pages (title, content) VALUES ''("%s","%s")', (title, content))
cur.connection.commit()Verbinden Sie sich jetzt mit Wikipedia und erhalten Sie Daten von Wikipedia.
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org'+articleUrl)
bs = BeautifulSoup(html, 'html.parser')
title = bs.find('h1').get_text()
content = bs.find('div', {'id':'mw-content-text'}).find('p').get_text()
store(title, content)
return bs.find('div', {'id':'bodyContent'}).findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
links = getLinks('/wiki/Kevin_Bacon')
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)Zuletzt müssen wir sowohl den Cursor als auch die Verbindung schließen.
finally:
cur.close()
conn.close()Dadurch werden die von Wikipedia gesammelten Daten in einer Tabelle mit dem Namenrap_pages gespeichert. Wenn Sie mit MySQL und Web Scraping vertraut sind, ist der obige Code nicht schwer zu verstehen.
Datenverarbeitung mit PostgreSQL
PostgreSQL wurde von einem weltweiten Team von Freiwilligen entwickelt und ist ein relationales Open-Source-Datenbankmanagementsystem (RDMS). Der Prozess der Verarbeitung der Scraped-Daten mit PostgreSQL ähnelt dem von MySQL. Es würde zwei Änderungen geben: Erstens würden sich die Befehle von MySQL unterscheiden, und zweitens werden wir hier verwendenpsycopg2 Python-Bibliothek, um die Integration mit Python durchzuführen.
Wenn Sie mit PostgreSQL nicht vertraut sind, können Sie es unter lernen https://www.tutorialspoint.com/postgresql/. Und mit Hilfe des folgenden Befehls können wir die Python-Bibliothek psycopg2 installieren -
pip install psycopg2Beim Web-Scraping werden normalerweise die Webmedieninhalte heruntergeladen, gespeichert und verarbeitet. Lassen Sie uns in diesem Kapitel verstehen, wie der aus dem Web heruntergeladene Inhalt verarbeitet wird.
Einführung
Die Webmedieninhalte, die wir beim Scraping erhalten, können Bilder, Audio- und Videodateien in Form von Nicht-Webseiten sowie Datendateien sein. Aber können wir den heruntergeladenen Daten vertrauen, insbesondere bei der Erweiterung der Daten, die wir herunterladen und in unserem Computerspeicher speichern werden? Daher ist es wichtig zu wissen, welche Art von Daten wir lokal speichern werden.
Abrufen von Medieninhalten von der Webseite
In diesem Abschnitt erfahren Sie, wie Sie Medieninhalte herunterladen können, die den Medientyp basierend auf den Informationen vom Webserver korrekt darstellen. Wir können es mit Hilfe von Python tunrequests Modul wie im vorherigen Kapitel.
Zuerst müssen wir die erforderlichen Python-Module wie folgt importieren:
import requestsGeben Sie nun die URL des Medieninhalts an, den wir herunterladen und lokal speichern möchten.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"Verwenden Sie den folgenden Code, um ein HTTP-Antwortobjekt zu erstellen.
r = requests.get(url)Mit Hilfe der folgenden Codezeile können wir den empfangenen Inhalt als PNG-Datei speichern.
with open("ThinkBig.png",'wb') as f:
f.write(r.content)Nach dem Ausführen des obigen Python-Skripts erhalten wir eine Datei mit dem Namen ThinkBig.png, die das heruntergeladene Bild enthält.
Dateinamen aus URL extrahieren
Nach dem Herunterladen des Inhalts von der Website möchten wir ihn auch in einer Datei speichern, deren Dateiname in der URL enthalten ist. Wir können aber auch überprüfen, ob in der URL auch eine Anzahl zusätzlicher Fragmente vorhanden ist. Dazu müssen wir den tatsächlichen Dateinamen aus der URL ermitteln.
Mit Hilfe des folgenden Python-Skripts verwenden Sie urlparsekönnen wir den Dateinamen aus der URL extrahieren -
import urllib3
import os
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
a = urlparse(url)
a.pathSie können die Ausgabe wie unten gezeigt beobachten -
'/wp-content/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg'
os.path.basename(a.path)Sie können die Ausgabe wie unten gezeigt beobachten -
'MetaSlider_ThinkBig-1080x180.jpg'Sobald Sie das obige Skript ausführen, erhalten wir den Dateinamen von der URL.
Informationen zum Inhaltstyp über die URL
Beim Extrahieren des Inhalts vom Webserver können wir auf GET-Anfrage auch die vom Webserver bereitgestellten Informationen überprüfen. Mit Hilfe des folgenden Python-Skripts können wir bestimmen, was Webserver mit dem Typ des Inhalts bedeutet -
Zuerst müssen wir die erforderlichen Python-Module wie folgt importieren:
import requestsJetzt müssen wir die URL des Medieninhalts angeben, den wir herunterladen und lokal speichern möchten.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"Die folgende Codezeile erstellt ein HTTP-Antwortobjekt.
r = requests.get(url, allow_redirects=True)Jetzt können wir abrufen, welche Art von Informationen über Inhalte vom Webserver bereitgestellt werden können.
for headers in r.headers: print(headers)Sie können die Ausgabe wie unten gezeigt beobachten -
Date
Server
Upgrade
Connection
Last-Modified
Accept-Ranges
Content-Length
Keep-Alive
Content-TypeMit Hilfe der folgenden Codezeile können wir die speziellen Informationen über den Inhaltstyp erhalten, z. B. Inhaltstyp -
print (r.headers.get('content-type'))Sie können die Ausgabe wie unten gezeigt beobachten -
image/jpegMithilfe der folgenden Codezeile können wir die speziellen Informationen zum Inhaltstyp abrufen, z. B. EType -
print (r.headers.get('ETag'))Sie können die Ausgabe wie unten gezeigt beobachten -
NoneBeachten Sie den folgenden Befehl:
print (r.headers.get('content-length'))Sie können die Ausgabe wie unten gezeigt beobachten -
12636Mithilfe der folgenden Codezeile können wir die speziellen Informationen zum Inhaltstyp abrufen, z. B. Server -
print (r.headers.get('Server'))Sie können die Ausgabe wie unten gezeigt beobachten -
ApacheThumbnail für Bilder generieren
Thumbnail ist eine sehr kleine Beschreibung oder Darstellung. Ein Benutzer möchte möglicherweise nur die Miniaturansicht eines großen Bildes oder sowohl das Bild als auch die Miniaturansicht speichern. In diesem Abschnitt erstellen wir eine Miniaturansicht des genannten BildesThinkBig.png im vorherigen Abschnitt „Abrufen von Medieninhalten von der Webseite“ heruntergeladen.
Für dieses Python-Skript müssen wir die Python-Bibliothek Pillow installieren, eine Abzweigung der Python-Bildbibliothek mit nützlichen Funktionen zum Bearbeiten von Bildern. Es kann mit Hilfe des folgenden Befehls installiert werden:
pip install pillowDas folgende Python-Skript erstellt eine Miniaturansicht des Bildes und speichert es im aktuellen Verzeichnis, indem der Miniaturbilddatei ein Präfix vorangestellt wird Th_
import glob
from PIL import Image
for infile in glob.glob("ThinkBig.png"):
img = Image.open(infile)
img.thumbnail((128, 128), Image.ANTIALIAS)
if infile[0:2] != "Th_":
img.save("Th_" + infile, "png")Der obige Code ist sehr einfach zu verstehen und Sie können im aktuellen Verzeichnis nach der Miniaturbilddatei suchen.
Screenshot von der Website
Beim Web-Scraping besteht eine sehr häufige Aufgabe darin, einen Screenshot einer Website zu erstellen. Um dies zu implementieren, werden wir Selen und Webdriver verwenden. Das folgende Python-Skript nimmt den Screenshot von der Website auf und speichert ihn im aktuellen Verzeichnis.
From selenium import webdriver
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)
browser.get('https://tutorialspoint.com/')
screenshot = browser.save_screenshot('screenshot.png')
browser.quitSie können die Ausgabe wie unten gezeigt beobachten -
DevTools listening on ws://127.0.0.1:1456/devtools/browser/488ed704-9f1b-44f0-
a571-892dc4c90eb7
<bound method WebDriver.quit of <selenium.webdriver.chrome.webdriver.WebDriver
(session="37e8e440e2f7807ef41ca7aa20ce7c97")>>Nach dem Ausführen des Skripts können Sie Ihr aktuelles Verzeichnis auf überprüfen screenshot.png Datei.
Miniaturansicht für Video
Angenommen, wir haben Videos von der Website heruntergeladen und wollten Miniaturansichten für sie erstellen, damit auf ein bestimmtes Video basierend auf dessen Miniaturansicht geklickt werden kann. Zum Generieren von Miniaturansichten für Videos benötigen wir ein einfaches Tool namensffmpeg welches von heruntergeladen werden kann www.ffmpeg.org. Nach dem Herunterladen müssen wir es gemäß den Spezifikationen unseres Betriebssystems installieren.
Das folgende Python-Skript generiert eine Miniaturansicht des Videos und speichert es in unserem lokalen Verzeichnis.
import subprocess
video_MP4_file = “C:\Users\gaurav\desktop\solar.mp4
thumbnail_image_file = 'thumbnail_solar_video.jpg'
subprocess.call(['ffmpeg', '-i', video_MP4_file, '-ss', '00:00:20.000', '-
vframes', '1', thumbnail_image_file, "-y"])Nach dem Ausführen des obigen Skripts erhalten wir das Miniaturbild mit dem Namen thumbnail_solar_video.jpg in unserem lokalen Verzeichnis gespeichert.
Rippen eines MP4-Videos in einen MP3
Angenommen, Sie haben eine Videodatei von einer Website heruntergeladen, benötigen jedoch nur Audio aus dieser Datei, um Ihren Zweck zu erfüllen. Dies kann dann in Python mithilfe der aufgerufenen Python-Bibliothek erfolgen moviepy die mit Hilfe des folgenden Befehls installiert werden kann -
pip install moviepyNach der erfolgreichen Installation von moviepy mit Hilfe des folgenden Skripts können wir nun MP4 in MP3 konvertieren.
import moviepy.editor as mp
clip = mp.VideoFileClip(r"C:\Users\gaurav\Desktop\1234.mp4")
clip.audio.write_audiofile("movie_audio.mp3")Sie können die Ausgabe wie unten gezeigt beobachten -
[MoviePy] Writing audio in movie_audio.mp3
100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦
¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 674/674 [00:01<00:00,
476.30it/s]
[MoviePy] Done.Das obige Skript speichert die Audio-MP3-Datei im lokalen Verzeichnis.
Im vorherigen Kapitel haben wir gesehen, wie wir mit Videos und Bildern umgehen, die wir als Teil von Web-Scraping-Inhalten erhalten. In diesem Kapitel werden wir uns mit der Textanalyse unter Verwendung der Python-Bibliothek befassen und dies im Detail erfahren.
Einführung
Sie können eine Textanalyse mithilfe der Python-Bibliothek namens Natural Language Tool Kit (NLTK) durchführen. Bevor wir uns mit den Konzepten von NLTK befassen, wollen wir die Beziehung zwischen Textanalyse und Web Scraping verstehen.
Die Analyse der Wörter im Text kann dazu führen, dass wir wissen, welche Wörter wichtig sind, welche Wörter ungewöhnlich sind und wie Wörter gruppiert werden. Diese Analyse erleichtert das Web-Scraping.
Erste Schritte mit NLTK
Das Natural Language Toolkit (NLTK) ist eine Sammlung von Python-Bibliotheken, die speziell zum Identifizieren und Kennzeichnen von Wortarten entwickelt wurden, die im Text natürlicher Sprache wie Englisch enthalten sind.
NLTK installieren
Mit dem folgenden Befehl können Sie NLTK in Python installieren:
pip install nltkWenn Sie Anaconda verwenden, kann mit dem folgenden Befehl ein Conda-Paket für NLTK erstellt werden:
conda install -c anaconda nltkHerunterladen der NLTK-Daten
Nach der Installation von NLTK müssen wir voreingestellte Textrepositorys herunterladen. Bevor wir jedoch voreingestellte Text-Repositorys herunterladen können, müssen wir NLTK mithilfe von importierenimport Befehl wie folgt -
mport nltkJetzt können mit Hilfe des folgenden Befehls NLTK-Daten heruntergeladen werden -
nltk.download()Die Installation aller verfügbaren NLTK-Pakete dauert einige Zeit, es wird jedoch immer empfohlen, alle Pakete zu installieren.
Installieren anderer erforderlicher Pakete
Wir brauchen auch einige andere Python-Pakete wie gensim und pattern für die Durchführung von Textanalysen sowie für die Erstellung von Anwendungen zur Verarbeitung natürlicher Sprache mithilfe von NLTK.
gensim- Eine robuste semantische Modellierungsbibliothek, die für viele Anwendungen nützlich ist. Es kann mit dem folgenden Befehl installiert werden:
pip install gensimpattern - Wird verwendet, um zu machen gensimPaket funktioniert richtig. Es kann mit dem folgenden Befehl installiert werden:
pip install patternTokenisierung
Der Vorgang des Aufteilens des angegebenen Textes in kleinere Einheiten, die als Token bezeichnet werden, wird als Tokenisierung bezeichnet. Diese Token können Wörter, Zahlen oder Satzzeichen sein. Es wird auch genanntword segmentation.
Beispiel

Das NLTK-Modul bietet verschiedene Pakete für die Tokenisierung. Wir können diese Pakete gemäß unserer Anforderung verwenden. Einige der Pakete werden hier beschrieben -
sent_tokenize package- Dieses Paket unterteilt den eingegebenen Text in Sätze. Mit dem folgenden Befehl können Sie dieses Paket importieren:
from nltk.tokenize import sent_tokenizeword_tokenize package- Dieses Paket teilt den eingegebenen Text in Wörter. Mit dem folgenden Befehl können Sie dieses Paket importieren:
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Dieses Paket unterteilt den eingegebenen Text sowie die Satzzeichen in Wörter. Mit dem folgenden Befehl können Sie dieses Paket importieren:
from nltk.tokenize import WordPuncttokenizerStemming
In jeder Sprache gibt es verschiedene Formen von Wörtern. Eine Sprache enthält aus grammatikalischen Gründen viele Variationen. Betrachten Sie zum Beispiel die Wörterdemocracy, democratic, und democratization. Für maschinelles Lernen sowie für Web-Scraping-Projekte ist es wichtig, dass Maschinen verstehen, dass diese verschiedenen Wörter dieselbe Grundform haben. Daher können wir sagen, dass es nützlich sein kann, die Grundformen der Wörter während der Analyse des Textes zu extrahieren.
Dies kann durch Stemming erreicht werden, das als heuristischer Prozess des Extrahierens der Grundformen der Wörter durch Abhacken der Wortenden definiert werden kann.
Das NLTK-Modul bietet verschiedene Pakete für das Stemming. Wir können diese Pakete gemäß unserer Anforderung verwenden. Einige dieser Pakete werden hier beschrieben -
PorterStemmer package- Der Porter-Algorithmus wird von diesem Python-Stemming-Paket verwendet, um das Basisformular zu extrahieren. Mit dem folgenden Befehl können Sie dieses Paket importieren:
from nltk.stem.porter import PorterStemmerZum Beispiel nach dem Wort ‘writing’ Als Eingabe für diesen Stemmer wäre die Ausgabe das Wort ‘write’ nach dem Stemming.
LancasterStemmer package- Der Lancaster-Algorithmus wird von diesem Python-Stemming-Paket verwendet, um das Basisformular zu extrahieren. Mit dem folgenden Befehl können Sie dieses Paket importieren:
from nltk.stem.lancaster import LancasterStemmerZum Beispiel nach dem Wort ‘writing’ Als Eingabe für diesen Stemmer wäre die Ausgabe das Wort ‘writ’ nach dem Stemming.
SnowballStemmer package- Der Algorithmus von Snowball wird von diesem Python-Stemming-Paket verwendet, um die Basisform zu extrahieren. Mit dem folgenden Befehl können Sie dieses Paket importieren:
from nltk.stem.snowball import SnowballStemmerWenn Sie beispielsweise das Wort "Schreiben" als Eingabe für diesen Stemmer angegeben haben, ist die Ausgabe das Wort "Schreiben" nach dem Stemming.
Lemmatisierung
Eine andere Möglichkeit, die Grundform von Wörtern zu extrahieren, ist die Lemmatisierung, die normalerweise darauf abzielt, Flexionsenden mithilfe von Vokabeln und morphologischen Analysen zu entfernen. Die Grundform eines Wortes nach der Lemmatisierung heißt Lemma.
Das NLTK-Modul bietet folgende Pakete für die Lemmatisierung:
WordNetLemmatizer package- Es wird die Grundform des Wortes extrahiert, je nachdem, ob es als Substantiv als Verb verwendet wird. Mit dem folgenden Befehl können Sie dieses Paket importieren:
from nltk.stem import WordNetLemmatizerChunking
Chunking, dh das Aufteilen der Daten in kleine Chunks, ist einer der wichtigen Prozesse bei der Verarbeitung natürlicher Sprache, um die Teile der Sprache und kurze Phrasen wie Nominalphrasen zu identifizieren. Beim Chunking werden Token beschriftet. Wir können die Struktur des Satzes mit Hilfe des Chunking-Prozesses erhalten.
Beispiel
In diesem Beispiel implementieren wir das Nunk-Phrase-Chunking mithilfe des NLTK-Python-Moduls. NP-Chunking ist eine Kategorie von Chunking, bei der die Nominalphrasen-Chunks im Satz gefunden werden.
Schritte zum Implementieren von Nominalphrasen-Chunking
Wir müssen die folgenden Schritte ausführen, um das Chunking von Nominalphrasen zu implementieren -
Schritt 1 - Chunk-Grammatikdefinition
Im ersten Schritt definieren wir die Grammatik für das Chunking. Es würde aus den Regeln bestehen, denen wir folgen müssen.
Schritt 2 - Chunk-Parser-Erstellung
Jetzt erstellen wir einen Chunk-Parser. Es würde die Grammatik analysieren und die Ausgabe geben.
Schritt 3 - Die Ausgabe
In diesem letzten Schritt würde die Ausgabe in einem Baumformat erzeugt.
Zuerst müssen wir das NLTK-Paket wie folgt importieren:
import nltkAls nächstes müssen wir den Satz definieren. Hier DT: die Determinante, VBP: das Verb, JJ: das Adjektiv, IN: die Präposition und NN: das Substantiv.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Als nächstes geben wir die Grammatik in Form eines regulären Ausdrucks.
grammar = "NP:{<DT>?<JJ>*<NN>}"In der nächsten Codezeile wird nun ein Parser zum Parsen der Grammatik definiert.
parser_chunking = nltk.RegexpParser(grammar)Jetzt analysiert der Parser den Satz.
parser_chunking.parse(sentence)Als nächstes geben wir unsere Ausgabe in der Variablen an.
Output = parser_chunking.parse(sentence)Mit Hilfe des folgenden Codes können wir unsere Ausgabe in Form eines Baums zeichnen, wie unten gezeigt.
output.draw()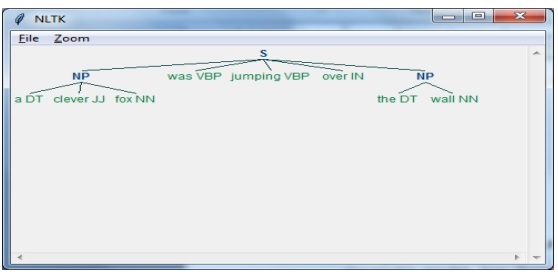
Bag of Word (BoW) -Modell Extrahieren und Konvertieren des Textes in eine numerische Form
Bag of Word (BoW), ein nützliches Modell für die Verarbeitung natürlicher Sprache, wird im Wesentlichen zum Extrahieren der Funktionen aus Text verwendet. Nach dem Extrahieren der Features aus dem Text kann es bei der Modellierung in Algorithmen für maschinelles Lernen verwendet werden, da Rohdaten in ML-Anwendungen nicht verwendet werden können.
Arbeitsweise des BoW-Modells
Zunächst extrahiert model ein Vokabular aus allen Wörtern im Dokument. Später würde unter Verwendung einer Dokumenttermmatrix ein Modell erstellt. Auf diese Weise stellt das BoW-Modell das Dokument nur als Wortbeutel dar und die Reihenfolge oder Struktur wird verworfen.
Beispiel
Angenommen, wir haben die folgenden zwei Sätze -
Sentence1 - Dies ist ein Beispiel für das Bag of Words-Modell.
Sentence2 - Wir können Features mithilfe des Bag of Words-Modells extrahieren.
Wenn wir nun diese beiden Sätze betrachten, haben wir die folgenden 14 verschiedenen Wörter -
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Erstellen eines Bag of Words-Modells in NLTK
Schauen wir uns das folgende Python-Skript an, mit dem ein BoW-Modell in NLTK erstellt wird.
Importieren Sie zunächst das folgende Paket:
from sklearn.feature_extraction.text import CountVectorizerAls nächstes definieren Sie die Menge der Sätze -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Ausgabe
Es zeigt, dass wir in den beiden obigen Sätzen 14 verschiedene Wörter haben -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Themenmodellierung: Identifizieren von Mustern in Textdaten
Im Allgemeinen werden Dokumente in Themen gruppiert, und die Themenmodellierung ist eine Technik zum Identifizieren der Muster in einem Text, der einem bestimmten Thema entspricht. Mit anderen Worten, die Themenmodellierung wird verwendet, um abstrakte Themen oder verborgene Strukturen in einem bestimmten Satz von Dokumenten aufzudecken.
Sie können die Themenmodellierung in folgenden Szenarien verwenden:
Textklassifizierung
Die Klassifizierung kann durch Themenmodellierung verbessert werden, da ähnliche Wörter zusammengefasst werden, anstatt jedes Wort einzeln als Feature zu verwenden.
Empfehlungssysteme
Wir können Empfehlungssysteme mithilfe von Ähnlichkeitsmaßen erstellen.
Themenmodellierungsalgorithmen
Wir können die Themenmodellierung mithilfe der folgenden Algorithmen implementieren:
Latent Dirichlet Allocation(LDA) - Es ist einer der beliebtesten Algorithmen, der die probabilistischen grafischen Modelle zur Implementierung der Themenmodellierung verwendet.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - Es basiert auf der linearen Algebra und verwendet das Konzept der SVD (Singular Value Decomposition) für die Dokumenttermmatrix.
Non-Negative Matrix Factorization (NMF) - Es basiert auch auf linearer Algebra wie LDA.
Die oben genannten Algorithmen hätten die folgenden Elemente:
- Anzahl der Themen: Parameter
- Dokument-Wort-Matrix: Eingabe
- WTM (Word Topic Matrix) und TDM (Topic Document Matrix): Ausgabe
Einführung
Web Scraping ist eine komplexe Aufgabe und die Komplexität vervielfacht sich, wenn die Website dynamisch ist. Laut dem Global Audit of Web Accessibility der Vereinten Nationen sind mehr als 70% der Websites dynamischer Natur und verlassen sich für ihre Funktionen auf JavaScript.
Beispiel für eine dynamische Website
Schauen wir uns ein Beispiel für eine dynamische Website an und wissen, warum es schwierig ist, zu kratzen. Hier nehmen wir ein Beispiel für die Suche von einer Website mit dem Namenhttp://example.webscraping.com/places/default/search.Aber wie können wir sagen, dass diese Website dynamischer Natur ist? Es kann anhand der Ausgabe des folgenden Python-Skripts beurteilt werden, das versucht, Daten von der oben genannten Webseite zu kratzen -
import re
import urllib.request
response = urllib.request.urlopen('http://example.webscraping.com/places/default/search')
html = response.read()
text = html.decode()
re.findall('(.*?)',text)Ausgabe
[ ]Die obige Ausgabe zeigt, dass der Beispiel-Scraper keine Informationen extrahieren konnte, weil das <div> -Element, das wir suchen, leer ist.
Ansätze zum Scraping von Daten von dynamischen Websites
Wir haben gesehen, dass der Scraper die Informationen von einer dynamischen Website nicht kratzen kann, da die Daten dynamisch mit JavaScript geladen werden. In solchen Fällen können wir die folgenden zwei Techniken zum Scrapen von Daten von dynamischen JavaScript-abhängigen Websites verwenden:
- Reverse Engineering JavaScript
- JavaScript rendern
Reverse Engineering JavaScript
Der als Reverse Engineering bezeichnete Prozess wäre nützlich und lässt uns verstehen, wie Daten dynamisch von Webseiten geladen werden.
Dazu müssen wir auf das klicken inspect elementRegisterkarte für eine angegebene URL. Als nächstes werden wir klickenNETWORK Registerkarte, um alle für diese Webseite gestellten Anforderungen einschließlich search.json mit dem Pfad von zu finden /ajax. Anstatt über den Browser oder über die Registerkarte NETWORK auf AJAX-Daten zuzugreifen, können wir dies auch mithilfe des folgenden Python-Skripts tun -
import requests
url=requests.get('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')
url.json()Beispiel
Mit dem obigen Skript können wir mithilfe der Python-json-Methode auf die JSON-Antwort zugreifen. In ähnlicher Weise können wir die Antwort auf die Rohzeichenfolge herunterladen und mithilfe der json.loads-Methode von Python auch laden. Wir tun dies mit Hilfe des folgenden Python-Skripts. Grundsätzlich werden alle Länder abgekratzt, indem der Buchstabe des Alphabets 'a' durchsucht und dann die resultierenden Seiten der JSON-Antworten iteriert werden.
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))Nach dem Ausführen des obigen Skripts erhalten wir die folgende Ausgabe und die Datensätze werden in der Datei mit dem Namen country.txt gespeichert.
Ausgabe
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...JavaScript rendern
Im vorherigen Abschnitt haben wir auf der Webseite ein Reverse Engineering durchgeführt, in dem erläutert wurde, wie die API funktioniert und wie wir sie verwenden können, um die Ergebnisse in einer einzelnen Anforderung abzurufen. Beim Reverse Engineering können wir jedoch auf folgende Schwierigkeiten stoßen:
Manchmal können Websites sehr schwierig sein. Wenn die Website beispielsweise mit einem erweiterten Browser-Tool wie Google Web Toolkit (GWT) erstellt wird, wird der resultierende JS-Code maschinell generiert und ist schwer zu verstehen und zurückzuentwickeln.
Einige übergeordnete Frameworks mögen React.js kann das Reverse Engineering erschweren, indem bereits komplexe JavaScript-Logik abstrahiert wird.
Die Lösung für die oben genannten Schwierigkeiten besteht darin, eine Browser-Rendering-Engine zu verwenden, die HTML analysiert, die CSS-Formatierung anwendet und JavaScript zum Anzeigen einer Webseite ausführt.
Beispiel
In diesem Beispiel verwenden wir zum Rendern von Java Script ein bekanntes Python-Modul Selenium. Der folgende Python-Code rendert eine Webseite mit Hilfe von Selenium -
Zuerst müssen wir den Webdriver wie folgt aus Selen importieren:
from selenium import webdriverGeben Sie nun den Pfad des Webtreibers an, den wir gemäß unserer Anforderung heruntergeladen haben.
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)Geben Sie nun die URL an, die wir in diesem Webbrowser öffnen möchten, der jetzt von unserem Python-Skript gesteuert wird.
driver.get('http://example.webscraping.com/search')Jetzt können wir die ID der Such-Toolbox verwenden, um das auszuwählende Element festzulegen.
driver.find_element_by_id('search_term').send_keys('.')Als nächstes können wir das Java-Skript verwenden, um den Inhalt des Auswahlfelds wie folgt festzulegen:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)Die folgende Codezeile zeigt, dass die Suche auf der Webseite angeklickt werden kann -
driver.find_element_by_id('search').click()Die nächste Codezeile zeigt, dass 45 Sekunden gewartet wird, bis die AJAX-Anforderung abgeschlossen ist.
driver.implicitly_wait(45)Für die Auswahl von Länderlinks können wir nun den CSS-Selektor wie folgt verwenden:
links = driver.find_elements_by_css_selector('#results a')Jetzt kann der Text jedes Links extrahiert werden, um die Liste der Länder zu erstellen -
countries = [link.text for link in links]
print(countries)
driver.close()Im vorherigen Kapitel haben wir das Scrapen dynamischer Websites gesehen. Lassen Sie uns in diesem Kapitel das Scraping von Websites verstehen, die mit benutzerbasierten Eingaben arbeiten, dh formularbasierten Websites.
Einführung
In diesen Tagen bewegt sich das WWW (World Wide Web) in Richtung sozialer Medien sowie benutzergenerierter Inhalte. Es stellt sich also die Frage, wie wir auf solche Informationen zugreifen können, die über den Anmeldebildschirm hinausgehen. Dazu müssen wir uns mit Formularen und Logins befassen.
In den vorherigen Kapiteln haben wir mit der HTTP-GET-Methode gearbeitet, um Informationen anzufordern. In diesem Kapitel werden wir jedoch mit der HTTP-POST-Methode arbeiten, mit der Informationen zur Speicherung und Analyse an einen Webserver übertragen werden.
Interaktion mit Anmeldeformularen
Während Sie im Internet arbeiten, müssen Sie viele Male mit Anmeldeformularen interagiert haben. Sie können sehr einfach sein, z. B. nur wenige HTML-Felder, eine Schaltfläche zum Senden und eine Aktionsseite, oder sie können kompliziert sein und einige zusätzliche Felder wie E-Mail enthalten. Hinterlassen Sie aus Sicherheitsgründen eine Nachricht zusammen mit Captcha.
In diesem Abschnitt werden wir uns mit einem einfachen Übermittlungsformular mit Hilfe der Python-Anforderungsbibliothek befassen.
Zuerst müssen wir die Anforderungsbibliothek wie folgt importieren:
import requestsJetzt müssen wir die Informationen für die Felder des Anmeldeformulars bereitstellen.
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}In der nächsten Codezeile müssen wir die URL angeben, unter der die Aktion des Formulars stattfinden würde.
r = requests.post(“enter the URL”, data = parameters)
print(r.text)Nach dem Ausführen des Skripts wird der Inhalt der Seite zurückgegeben, auf der die Aktion ausgeführt wurde.
Angenommen, Sie möchten ein Bild mit dem Formular senden, dann ist es mit request.post () sehr einfach. Sie können es mit Hilfe des folgenden Python-Skripts verstehen -
import requests
file = {‘Uploadfile’: open(’C:\Usres\desktop\123.png’,‘rb’)}
r = requests.post(“enter the URL”, files = file)
print(r.text)Laden von Cookies vom Webserver
Ein Cookie, manchmal auch als Web-Cookie oder Internet-Cookie bezeichnet, ist ein kleines Datenelement, das von einer Website gesendet wird und von unserem Computer in einer Datei in unserem Webbrowser gespeichert wird.
Im Zusammenhang mit dem Umgang mit Anmeldeformularen kann es zwei Arten von Cookies geben. Zum einen haben wir uns im vorherigen Abschnitt mit der Übermittlung von Informationen an eine Website befasst und zum anderen können wir während unseres gesamten Besuchs auf der Website in einem permanenten „angemeldeten“ Zustand bleiben. Bei der zweiten Art von Formularen verwenden Websites Cookies, um zu verfolgen, wer angemeldet ist und wer nicht.
Was machen Cookies?
Heutzutage verwenden die meisten Websites Cookies zur Verfolgung. Wir können die Funktionsweise von Cookies anhand der folgenden Schritte verstehen:
Step 1- Zunächst authentifiziert die Site unsere Anmeldeinformationen und speichert sie im Cookie unseres Browsers. Dieses Cookie enthält im Allgemeinen vom Server generierte Token-, Timeout- und Tracking-Informationen.
Step 2- Als Nächstes verwendet die Website das Cookie als Authentifizierungsnachweis. Diese Authentifizierung wird immer angezeigt, wenn wir die Website besuchen.
Cookies sind für Web-Scraper sehr problematisch, da das übermittelte Formular zurückgesendet wird, wenn Web-Scraper die Cookies nicht verfolgen. Auf der nächsten Seite scheint es, dass sie sich nie angemeldet haben. Es ist sehr einfach, die Cookies mithilfe von zu verfolgen Python requests Bibliothek, wie unten gezeigt -
import requests
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = requests.post(“enter the URL”, data = parameters)In der obigen Codezeile ist die URL die Seite, die als Prozessor für das Anmeldeformular fungiert.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)Nach dem Ausführen des obigen Skripts werden die Cookies aus dem Ergebnis der letzten Anforderung abgerufen.
Es gibt ein weiteres Problem mit Cookies, bei dem Websites Cookies manchmal häufig ohne Vorwarnung ändern. Eine solche Situation kann behandelt werdenrequests.Session() wie folgt -
import requests
session = requests.Session()
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = session.post(“enter the URL”, data = parameters)In der obigen Codezeile ist die URL die Seite, die als Prozessor für das Anmeldeformular fungiert.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)Beachten Sie, dass Sie den Unterschied zwischen Skript mit und ohne Sitzung leicht verstehen können.
Formulare mit Python automatisieren
In diesem Abschnitt beschäftigen wir uns mit einem Python-Modul namens Mechanize, das unsere Arbeit reduziert und das Ausfüllen von Formularen automatisiert.
Modul mechanisieren
Das Mechanize-Modul bietet uns eine übergeordnete Schnittstelle für die Interaktion mit Formularen. Bevor wir es verwenden können, müssen wir es mit dem folgenden Befehl installieren:
pip install mechanizeBeachten Sie, dass dies nur in Python 2.x funktioniert.
Beispiel
In diesem Beispiel automatisieren wir das Ausfüllen eines Anmeldeformulars mit zwei Feldern, nämlich E-Mail und Passwort.
import mechanize
brwsr = mechanize.Browser()
brwsr.open(Enter the URL of login)
brwsr.select_form(nr = 0)
brwsr['email'] = ‘Enter email’
brwsr['password'] = ‘Enter password’
response = brwsr.submit()
brwsr.submit()Der obige Code ist sehr einfach zu verstehen. Zuerst haben wir das Mechanisierungsmodul importiert. Anschließend wurde ein Mechanize-Browserobjekt erstellt. Dann haben wir zur Anmelde-URL navigiert und das Formular ausgewählt. Danach werden Namen und Werte direkt an das Browserobjekt übergeben.
Lassen Sie uns in diesem Kapitel verstehen, wie das Web-Scraping und die Verarbeitung von CAPTCHA durchgeführt werden, das zum Testen eines Benutzers auf Mensch oder Roboter verwendet wird.
Was ist CAPTCHA?
Die vollständige Form von CAPTCHA ist Completely Automated Public Turing test to tell Computers and Humans ApartDies deutet eindeutig darauf hin, dass es sich um einen Test handelt, um festzustellen, ob der Benutzer ein Mensch ist oder nicht.
Ein CAPTCHA ist ein verzerrtes Bild, das normalerweise mit einem Computerprogramm nicht leicht zu erkennen ist, aber ein Mensch kann es irgendwie schaffen, es zu verstehen. Die meisten Websites verwenden CAPTCHA, um die Interaktion von Bots zu verhindern.
Laden von CAPTCHA mit Python
Angenommen, wir möchten uns auf einer Website registrieren und es gibt ein Formular bei CAPTCHA. Bevor wir das CAPTCHA-Bild laden, müssen wir die spezifischen Informationen kennen, die für das Formular erforderlich sind. Mit Hilfe des nächsten Python-Skripts können wir die Formularanforderungen des Registrierungsformulars auf der genannten Website verstehenhttp://example.webscrapping.com.
import lxml.html
import urllib.request as urllib2
import pprint
import http.cookiejar as cookielib
def form_parsing(html):
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
REGISTER_URL = '<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/user/register">http://example.webscraping.com/user/register'</a>
ckj = cookielib.CookieJar()
browser = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckj))
html = browser.open(
'<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/places/default/user/register?_next">
http://example.webscraping.com/places/default/user/register?_next</a> = /places/default/index'
).read()
form = form_parsing(html)
pprint.pprint(form)Im obigen Python-Skript haben wir zuerst eine Funktion definiert, die das Formular mithilfe des lxml-Python-Moduls analysiert und dann die Formularanforderungen wie folgt druckt:
{
'_formkey': '5e306d73-5774-4146-a94e-3541f22c95ab',
'_formname': 'register',
'_next': '/places/default/index',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': '',
'recaptcha_response_field': None
}Sie können anhand der obigen Ausgabe überprüfen, ob alle Informationen außer recpatcha_response_fieldsind verständlich und unkompliziert. Nun stellt sich die Frage, wie wir mit diesen komplexen Informationen umgehen und CAPTCHA herunterladen können. Dies kann mit Hilfe der Pillow Python-Bibliothek wie folgt erfolgen:
Kissen Python-Paket
Pillow ist eine Abzweigung der Python-Bildbibliothek mit nützlichen Funktionen zum Bearbeiten von Bildern. Es kann mit Hilfe des folgenden Befehls installiert werden:
pip install pillowIm nächsten Beispiel werden wir es zum Laden des CAPTCHA verwenden -
from io import BytesIO
import lxml.html
from PIL import Image
def load_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return imgDas obige Python-Skript wird verwendet pillowPython-Paket und Definieren einer Funktion zum Laden des CAPTCHA-Images. Es muss mit der genannten Funktion verwendet werdenform_parser()Dies ist im vorherigen Skript definiert, um Informationen zum Registrierungsformular abzurufen. Dieses Skript speichert das CAPTCHA-Bild in einem nützlichen Format, das weiter als Zeichenfolge extrahiert werden kann.
OCR: Extrahieren von Text aus Bildern mit Python
Nachdem Sie das CAPTCHA in einem nützlichen Format geladen haben, können Sie es mithilfe der optischen Zeichenerkennung (OCR) extrahieren, einem Prozess zum Extrahieren von Text aus den Bildern. Zu diesem Zweck werden wir die Open-Source-OCR-Engine Tesseract verwenden. Es kann mit Hilfe des folgenden Befehls installiert werden:
pip install pytesseractBeispiel
Hier erweitern wir das obige Python-Skript, das das CAPTCHA mithilfe des Pillow Python-Pakets geladen hat, wie folgt:
import pytesseract
img = get_captcha(html)
img.save('captcha_original.png')
gray = img.convert('L')
gray.save('captcha_gray.png')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
bw.save('captcha_thresholded.png')Das obige Python-Skript liest das CAPTCHA im Schwarzweißmodus, der klar und einfach wie folgt an tesseract übergeben werden kann:
pytesseract.image_to_string(bw)Nach dem Ausführen des obigen Skripts erhalten wir das CAPTCHA des Registrierungsformulars als Ausgabe.
In diesem Kapitel wird erläutert, wie Sie Tests mit Web-Scrapern in Python durchführen.
Einführung
In großen Webprojekten werden regelmäßig automatisierte Tests des Backends der Website durchgeführt, die Frontend-Tests werden jedoch häufig übersprungen. Der Hauptgrund dafür ist, dass die Programmierung von Websites wie ein Netz aus verschiedenen Markup- und Programmiersprachen ist. Wir können Unit-Tests für eine Sprache schreiben, aber es wird schwierig, wenn die Interaktion in einer anderen Sprache durchgeführt wird. Aus diesem Grund müssen wir eine Reihe von Tests durchführen, um sicherzustellen, dass unser Code unseren Erwartungen entspricht.
Testen mit Python
Wenn wir über das Testen sprechen, bedeutet dies Unit-Test. Bevor wir uns eingehend mit dem Testen mit Python befassen, müssen wir uns mit Unit-Tests auskennen. Im Folgenden sind einige der Merkmale von Unit-Tests aufgeführt:
In jedem Komponententest würde mindestens ein Aspekt der Funktionalität einer Komponente getestet.
Jeder Komponententest ist unabhängig und kann auch unabhängig ausgeführt werden.
Der Komponententest beeinträchtigt nicht den Erfolg oder Misserfolg eines anderen Tests.
Unit-Tests können in beliebiger Reihenfolge ausgeführt werden und müssen mindestens eine Aussage enthalten.
Unittest - Python-Modul
Das Python-Modul mit dem Namen Unittest für Unit-Tests wird mit der gesamten Standard-Python-Installation geliefert. Wir müssen es nur importieren und ruhen ist die Aufgabe von unittest.TestCase Klasse, die die folgenden Aufgaben erledigt -
SetUp- und TearDown-Funktionen werden von der unittest.TestCase-Klasse bereitgestellt. Diese Funktionen können vor und nach jedem Komponententest ausgeführt werden.
Es enthält auch Assert-Anweisungen, mit denen Tests bestanden oder nicht bestanden werden können.
Es werden alle Funktionen ausgeführt, die mit test_ als Komponententest beginnen.
Beispiel
In diesem Beispiel kombinieren wir Web Scraping mit unittest. Wir werden die Wikipedia-Seite auf die Suche nach der Zeichenfolge 'Python' testen. Grundsätzlich werden zwei Tests durchgeführt: Erstens, ob die Titelseite mit der Suchzeichenfolge identisch ist, dh "Python" oder nicht, und der zweite Test stellt sicher, dass die Seite einen Inhaltsbereich hat.
Zuerst importieren wir die erforderlichen Python-Module. Wir verwenden BeautifulSoup zum Web-Scraping und natürlich nicht zum Testen.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import unittestJetzt müssen wir eine Klasse definieren, die unittest.TestCase erweitert. Das globale Objekt bs wird von allen Tests gemeinsam genutzt. Eine unittest angegebene Funktion setUpClass wird dies ausführen. Hier definieren wir zwei Funktionen, eine zum Testen der Titelseite und eine zum Testen des Seiteninhalts.
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = '<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a>
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()Nach dem Ausführen des obigen Skripts erhalten wir die folgende Ausgabe:
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)Testen mit Selen
Lassen Sie uns diskutieren, wie Python Selenium zum Testen verwendet wird. Es wird auch als Selentest bezeichnet. Beide Pythonunittest und Seleniumhabe nicht viel gemeinsam. Wir wissen, dass Selenium die Standard-Python-Befehle an verschiedene Browser sendet, obwohl das Design des Browsers unterschiedlich ist. Denken Sie daran, dass wir Selenium bereits in früheren Kapiteln installiert und mit ihm gearbeitet haben. Hier erstellen wir Testskripte in Selenium und verwenden sie zur Automatisierung.
Beispiel
Mit Hilfe des nächsten Python-Skripts erstellen wir ein Testskript für die Automatisierung der Facebook-Anmeldeseite. Sie können das Beispiel für die Automatisierung anderer Formulare und Anmeldungen Ihrer Wahl ändern, das Konzept ist jedoch dasselbe.
Zuerst für die Verbindung zum Webbrowser importieren wir den Webdriver aus dem Selenium-Modul -
from selenium import webdriverJetzt müssen wir Schlüssel aus dem Selenmodul importieren.
from selenium.webdriver.common.keys import KeysAls nächstes müssen wir den Benutzernamen und das Passwort für die Anmeldung in unserem Facebook-Konto angeben
user = "[email protected]"
pwd = ""Geben Sie als Nächstes den Pfad zum Webtreiber für Chrome an.
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("http://www.facebook.com")Jetzt werden wir die Bedingungen mit dem Schlüsselwort assert überprüfen.
assert "Facebook" in driver.titleMit Hilfe der folgenden Codezeile senden wir Werte an den E-Mail-Bereich. Hier suchen wir es nach seiner ID, aber wir können es tun, indem wir es nach Namen als suchendriver.find_element_by_name("email").
element = driver.find_element_by_id("email")
element.send_keys(user)Mit Hilfe der folgenden Codezeile senden wir Werte an den Passwortbereich. Hier suchen wir es nach seiner ID, aber wir können es tun, indem wir es nach Namen als suchendriver.find_element_by_name("pass").
element = driver.find_element_by_id("pass")
element.send_keys(pwd)In der nächsten Codezeile drücken Sie die Eingabetaste, nachdem Sie die Werte in das Feld E-Mail und Passwort eingegeben haben.
element.send_keys(Keys.RETURN)Jetzt schließen wir den Browser.
driver.close()Nach dem Ausführen des obigen Skripts wird der Chrome-Webbrowser geöffnet und Sie können sehen, dass E-Mail und Passwort eingefügt und auf die Anmeldeschaltfläche geklickt werden.
Vergleich: unittest oder Selen
Der Vergleich von Unittest und Selen ist schwierig, da bei der Arbeit mit großen Testsuiten die syntaktische Steifigkeit von Units erforderlich ist. Wenn Sie jedoch die Flexibilität der Website testen möchten, ist der Selentest unsere erste Wahl. Aber was ist, wenn wir beide kombinieren können? Wir können Selen unittest in Python importieren und das Beste aus beiden herausholen. Selen kann verwendet werden, um Informationen über eine Website zu erhalten, und unittest kann bewerten, ob diese Informationen die Kriterien für das Bestehen des Tests erfüllen oder nicht.
Zum Beispiel schreiben wir das obige Python-Skript zur Automatisierung der Facebook-Anmeldung neu, indem wir beide wie folgt kombinieren:
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "[email protected]"
pwd = ""
pageUrl = "http://www.facebook.com"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()