Ruby - Kurzanleitung
Ruby ist eine reine objektorientierte Programmiersprache. Es wurde 1993 von Yukihiro Matsumoto aus Japan erstellt.
Sie finden den Namen Yukihiro Matsumoto auf der Ruby-Mailingliste unter www.ruby-lang.org . Matsumoto ist in der Ruby-Community auch als Matz bekannt.
Ruby is "A Programmer's Best Friend".
Ruby verfügt über ähnliche Funktionen wie Smalltalk, Perl und Python. Perl, Python und Smalltalk sind Skriptsprachen. Smalltalk ist eine echte objektorientierte Sprache. Ruby ist wie Smalltalk eine perfekte objektorientierte Sprache. Die Verwendung der Ruby-Syntax ist viel einfacher als die Verwendung der Smalltalk-Syntax.
Eigenschaften von Ruby
Ruby ist Open Source und im Web frei verfügbar, unterliegt jedoch einer Lizenz.
Ruby ist eine universell interpretierte Programmiersprache.
Ruby ist eine echte objektorientierte Programmiersprache.
Ruby ist eine serverseitige Skriptsprache, die Python und PERL ähnelt.
Ruby kann zum Schreiben von CGI-Skripten (Common Gateway Interface) verwendet werden.
Ruby kann in Hypertext Markup Language (HTML) eingebettet werden.
Ruby hat eine saubere und einfache Syntax, mit der ein neuer Entwickler sehr schnell und einfach lernen kann.
Ruby hat eine ähnliche Syntax wie viele andere Programmiersprachen wie C ++ und Perl.
Ruby ist sehr skalierbar und große Programme, die in Ruby geschrieben wurden, sind leicht zu warten.
Ruby kann zur Entwicklung von Internet- und Intranetanwendungen verwendet werden.
Ruby kann in Windows- und POSIX-Umgebungen installiert werden.
Ruby unterstützt viele GUI-Tools wie Tcl / Tk, GTK und OpenGL.
Ruby kann problemlos mit DB2, MySQL, Oracle und Sybase verbunden werden.
Ruby verfügt über zahlreiche integrierte Funktionen, die direkt in Ruby-Skripten verwendet werden können.
Werkzeuge, die Sie benötigen
Für die Durchführung der in diesem Lernprogramm beschriebenen Beispiele benötigen Sie einen neuesten Computer wie Intel Core i3 oder i5 mit mindestens 2 GB RAM (4 GB RAM empfohlen). Sie benötigen außerdem die folgende Software:
Linux oder Windows 95/98/2000 / NT oder Windows 7 Betriebssystem.
Apache 1.3.19-5 Webserver.
Internet Explorer 5.0 oder höher Webbrowser.
Ruby 1.8.5
Dieses Tutorial vermittelt die erforderlichen Kenntnisse zum Erstellen von GUI-, Netzwerk- und Webanwendungen mit Ruby. Es wird auch über das Erweitern und Einbetten von Ruby-Anwendungen gesprochen.
Was kommt als nächstes?
Das nächste Kapitel führt Sie dahin, wo Sie Ruby und seine Dokumentation erhalten können. Schließlich erfahren Sie, wie Sie Ruby installieren und eine Umgebung für die Entwicklung von Ruby-Anwendungen vorbereiten.
Einrichtung der lokalen Umgebung
Wenn Sie immer noch bereit sind, Ihre Umgebung für die Programmiersprache Ruby einzurichten, fahren wir fort. In diesem Tutorial lernen Sie alle wichtigen Themen im Zusammenhang mit der Einrichtung der Umgebung kennen. Wir empfehlen Ihnen, zuerst die folgenden Themen durchzugehen und dann weiterzumachen -
Ruby-Installation unter Linux / Unix - Wenn Sie planen, Ihre Entwicklungsumgebung unter Linux / Unix zu installieren, lesen Sie dieses Kapitel.
Ruby-Installation unter Windows - Wenn Sie planen, Ihre Entwicklungsumgebung auf Windows-Computern zu installieren, lesen Sie dieses Kapitel.
Ruby-Befehlszeilenoptionen - In diesem Kapitel werden alle Befehlszeilenoptionen aufgelistet, die Sie zusammen mit dem Ruby-Interpreter verwenden können.
Ruby-Umgebungsvariablen - Dieses Kapitel enthält eine Liste aller wichtigen Umgebungsvariablen, die festgelegt werden müssen, damit Ruby Interpreter funktioniert.
Beliebte Ruby-Editoren
Um Ihre Ruby-Programme zu schreiben, benötigen Sie einen Editor -
Wenn Sie auf einem Windows-Computer arbeiten, können Sie einen einfachen Texteditor wie Notepad oder Edit Plus verwenden.
VIM (Vi IMproved) ist ein sehr einfacher Texteditor. Dies ist auf fast allen Unix-Computern und jetzt auch auf Windows verfügbar. Andernfalls können Sie Ihren bevorzugten vi-Editor verwenden, um Ruby-Programme zu schreiben.
RubyWin ist eine Ruby Integrated Development Environment (IDE) für Windows.
Ruby Development Environment (RDE) ist auch eine sehr gute IDE für Windows-Benutzer.
Interaktiver Rubin (IRb)
Interactive Ruby (IRb) bietet eine Shell zum Experimentieren. Innerhalb der IRb-Shell können Sie die Ausdrucksergebnisse sofort Zeile für Zeile anzeigen.
Dieses Tool wird zusammen mit der Ruby-Installation geliefert, sodass Sie nichts extra tun müssen, damit IRb funktioniert.
Schreib einfach irb an Ihrer Eingabeaufforderung und eine interaktive Ruby-Sitzung wird wie unten angegeben gestartet -
$irb
irb 0.6.1(99/09/16)
irb(main):001:0> def hello
irb(main):002:1> out = "Hello World"
irb(main):003:1> puts out
irb(main):004:1> end
nil
irb(main):005:0> hello
Hello World
nil
irb(main):006:0>Mach dir keine Sorgen darüber, was wir hier gemacht haben. Sie werden alle diese Schritte in den folgenden Kapiteln lernen.
Was kommt als nächstes?
Wir gehen davon aus, dass Sie jetzt eine funktionierende Ruby-Umgebung haben und bereit sind, das erste Ruby-Programm zu schreiben. Im nächsten Kapitel erfahren Sie, wie Sie Ruby-Programme schreiben.
Schreiben wir ein einfaches Programm in Ruby. Alle Ruby-Dateien haben die Erweiterung.rb. Fügen Sie also den folgenden Quellcode in eine test.rb-Datei ein.
#!/usr/bin/ruby -w
puts "Hello, Ruby!";Hier haben wir angenommen, dass Sie den Ruby-Interpreter im Verzeichnis / usr / bin verfügbar haben. Versuchen Sie nun, dieses Programm wie folgt auszuführen:
$ ruby test.rbDies führt zu folgendem Ergebnis:
Hello, Ruby!Sie haben ein einfaches Ruby-Programm gesehen. Lassen Sie uns nun einige grundlegende Konzepte zur Ruby-Syntax sehen.
Leerzeichen im Ruby-Programm
Leerzeichen wie Leerzeichen und Tabulatoren werden im Ruby-Code im Allgemeinen ignoriert, außer wenn sie in Zeichenfolgen angezeigt werden. Manchmal werden sie jedoch verwendet, um mehrdeutige Aussagen zu interpretieren. Interpretationen dieser Art erzeugen Warnungen, wenn die Option -w aktiviert ist.
Beispiel
a + b is interpreted as a+b ( Here a is a local variable)
a +b is interpreted as a(+b) ( Here a is a method call)Zeilenenden im Ruby-Programm
Ruby interpretiert Semikolons und Zeilenumbrüche als Ende einer Anweisung. Wenn Ruby jedoch auf Operatoren wie +, - oder Backslash am Ende einer Zeile stößt, geben sie die Fortsetzung einer Anweisung an.
Ruby-Kennungen
Bezeichner sind Namen von Variablen, Konstanten und Methoden. Ruby-IDs unterscheiden zwischen Groß- und Kleinschreibung. Dies bedeutet, dass Ram und RAM in Ruby zwei verschiedene Bezeichner sind.
Ruby-Bezeichnernamen können aus alphanumerischen Zeichen und dem Unterstrich (_) bestehen.
Reservierte Wörter
Die folgende Liste zeigt die reservierten Wörter in Ruby. Diese reservierten Wörter dürfen nicht als Konstanten- oder Variablennamen verwendet werden. Sie können jedoch als Methodennamen verwendet werden.
| START | tun | Nächster | dann |
| ENDE | sonst | Null | wahr |
| alias | elsif | nicht | undef |
| und | Ende | oder | es sei denn |
| Start | dafür sorgen | wiederholen | bis um |
| Unterbrechung | falsch | Rettung | wann |
| Fall | zum | wiederholen | während |
| Klasse | wenn | Rückkehr | während |
| def | im | selbst | __DATEI__ |
| definiert? | Modul | Super | __LINIE__ |
Hier Dokument in Ruby
"Here Document" bezieht sich auf das Erstellen von Zeichenfolgen aus mehreren Zeilen. Nach einem << können Sie eine Zeichenfolge oder einen Bezeichner angeben, um das Zeichenfolgenliteral zu beenden. Alle Zeilen, die der aktuellen Zeile bis zum Abschluss folgen, sind der Wert der Zeichenfolge.
Wenn der Terminator in Anführungszeichen gesetzt ist, bestimmt die Art der Anführungszeichen den Typ des zeilenorientierten Zeichenfolgenliteral. Beachten Sie, dass zwischen << und dem Abschlusszeichen kein Leerzeichen stehen darf.
Hier sind verschiedene Beispiele -
#!/usr/bin/ruby -w
print <<EOF
This is the first way of creating
here document ie. multiple line string.
EOF
print <<"EOF"; # same as above
This is the second way of creating
here document ie. multiple line string.
EOF
print <<`EOC` # execute commands
echo hi there
echo lo there
EOC
print <<"foo", <<"bar" # you can stack them
I said foo.
foo
I said bar.
barDies führt zu folgendem Ergebnis:
This is the first way of creating
her document ie. multiple line string.
This is the second way of creating
her document ie. multiple line string.
hi there
lo there
I said foo.
I said bar.Ruby BEGIN-Anweisung
Syntax
BEGIN {
code
}Gibt an, dass Code aufgerufen werden soll, bevor das Programm ausgeführt wird.
Beispiel
#!/usr/bin/ruby
puts "This is main Ruby Program"
BEGIN {
puts "Initializing Ruby Program"
}Dies führt zu folgendem Ergebnis:
Initializing Ruby Program
This is main Ruby ProgramRuby END-Anweisung
Syntax
END {
code
}Deklariert den Code , der am Ende des Programms aufgerufen werden soll.
Beispiel
#!/usr/bin/ruby
puts "This is main Ruby Program"
END {
puts "Terminating Ruby Program"
}
BEGIN {
puts "Initializing Ruby Program"
}Dies führt zu folgendem Ergebnis:
Initializing Ruby Program
This is main Ruby Program
Terminating Ruby ProgramRuby Kommentare
Ein Kommentar verbirgt eine Zeile, einen Teil einer Zeile oder mehrere Zeilen vor dem Ruby-Interpreter. Sie können das Hash-Zeichen (#) am Anfang einer Zeile verwenden -
# I am a comment. Just ignore me.Oder ein Kommentar kann sich nach einer Anweisung oder einem Ausdruck in derselben Zeile befinden.
name = "Madisetti" # This is again commentSie können mehrere Zeilen wie folgt kommentieren:
# This is a comment.
# This is a comment, too.
# This is a comment, too.
# I said that already.Hier ist eine andere Form. Dieser Blockkommentar verbirgt mehrere Zeilen vor dem Interpreter mit = begin / = end -
=begin
This is a comment.
This is a comment, too.
This is a comment, too.
I said that already.
=endRuby ist eine perfekte objektorientierte Programmiersprache. Zu den Merkmalen der objektorientierten Programmiersprache gehören -
- Datenverkapselung
- Datenabstraktion
- Polymorphism
- Inheritance
Diese Funktionen wurden im Kapitel Objektorientiertes Ruby erläutert .
Ein objektorientiertes Programm umfasst Klassen und Objekte. Eine Klasse ist die Blaupause, aus der einzelne Objekte erstellt werden. In objektorientierten Begriffen sagen wir, dass Ihr Fahrrad eine Instanz der Klasse von Objekten ist, die als Fahrräder bekannt sind.
Nehmen Sie das Beispiel eines Fahrzeugs. Es umfasst Räder, Leistung und Kraftstoff- oder Gastankkapazität. Diese Merkmale bilden die Datenelemente der Klasse Fahrzeug. Anhand dieser Eigenschaften können Sie ein Fahrzeug vom anderen unterscheiden.
Ein Fahrzeug kann auch bestimmte Funktionen haben, wie z. B. Anhalten, Fahren und Beschleunigen. Auch diese Funktionen bilden die Datenelemente der Klasse Fahrzeug. Sie können daher eine Klasse als eine Kombination von Merkmalen und Funktionen definieren.
Eine Klasse Fahrzeug kann definiert werden als -
Class Vehicle {
Number no_of_wheels
Number horsepower
Characters type_of_tank
Number Capacity
Function speeding {
}
Function driving {
}
Function halting {
}
}Durch Zuweisen unterschiedlicher Werte zu diesen Datenelementen können Sie mehrere Instanzen der Klasse Fahrzeug bilden. Zum Beispiel hat ein Flugzeug drei Räder, eine Leistung von 1.000 PS, Kraftstoff als Tanktyp und ein Fassungsvermögen von 100 Litern. Ebenso hat ein Auto vier Räder, eine Leistung von 200 PS, Benzin als Tanktyp und ein Fassungsvermögen von 25 Litern.
Eine Klasse in Ruby definieren
Um die objektorientierte Programmierung mit Ruby zu implementieren, müssen Sie zunächst lernen, wie Sie Objekte und Klassen in Ruby erstellen.
Eine Klasse in Ruby beginnt immer mit der Schlüsselwortklasse , gefolgt vom Namen der Klasse. Der Name sollte immer in Großbuchstaben stehen. Die Klasse Kunde kann angezeigt werden als -
class Customer
endSie beenden eine Klasse mit dem Schlüsselwort end . Alle Datenelemente in der Klasse befinden sich zwischen der Klassendefinition und dem Schlüsselwort end .
Variablen in einer Ruby-Klasse
Ruby bietet vier Arten von Variablen:
Local Variables- Lokale Variablen sind die Variablen, die in einer Methode definiert sind. Lokale Variablen sind außerhalb der Methode nicht verfügbar. Weitere Details zur Methode finden Sie im folgenden Kapitel. Lokale Variablen beginnen mit einem Kleinbuchstaben oder _.
Instance Variables- Instanzvariablen sind methodenübergreifend für eine bestimmte Instanz oder ein bestimmtes Objekt verfügbar. Das bedeutet, dass sich Instanzvariablen von Objekt zu Objekt ändern. Instanzvariablen wird das at-Zeichen (@) gefolgt vom Variablennamen vorangestellt.
Class Variables- Klassenvariablen sind für verschiedene Objekte verfügbar. Eine Klassenvariable gehört zur Klasse und ist ein Merkmal einer Klasse. Vor ihnen steht das Zeichen @@ und der Variablenname.
Global Variables- Klassenvariablen sind nicht klassenübergreifend verfügbar. Wenn Sie eine einzelne Variable haben möchten, die klassenübergreifend verfügbar ist, müssen Sie eine globale Variable definieren. Vor den globalen Variablen steht immer das Dollarzeichen ($).
Beispiel
Mit der Klassenvariablen @@ no_of_customers können Sie die Anzahl der Objekte bestimmen, die erstellt werden. Dies ermöglicht die Ableitung der Anzahl der Kunden.
class Customer
@@no_of_customers = 0
endErstellen von Objekten in Ruby mit einer neuen Methode
Objekte sind Instanzen der Klasse. Sie lernen nun, wie Sie Objekte einer Klasse in Ruby erstellen. Sie können Objekte in Ruby mithilfe der neuen Methode der Klasse erstellen .
Die Methode new ist ein eindeutiger Methodentyp, der in der Ruby-Bibliothek vordefiniert ist. Die neue Methode gehört zu den Klassenmethoden .
Hier ist das Beispiel zum Erstellen von zwei Objekten cust1 und cust2 der Klasse Customer -
cust1 = Customer. new
cust2 = Customer. newHier sind cust1 und cust2 die Namen zweier Objekte. Sie schreiben den Objektnamen gefolgt vom Gleichheitszeichen (=), worauf der Klassenname folgt. Dann folgen der Punktoperator und das Schlüsselwort new .
Benutzerdefinierte Methode zum Erstellen von Ruby-Objekten
Sie können Parameter an die Methode new übergeben und diese Parameter können zum Initialisieren von Klassenvariablen verwendet werden.
Wenn Sie die neue Methode mit Parametern deklarieren möchten, müssen Sie die Initialisierung der Methode zum Zeitpunkt der Klassenerstellung deklarieren .
Die Initialisierungsmethode ist ein spezieller Methodentyp, der ausgeführt wird, wenn die neue Methode der Klasse mit Parametern aufgerufen wird.
Hier ist das Beispiel zum Erstellen einer Initialisierungsmethode:
class Customer
@@no_of_customers = 0
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
endIn diesem Beispiel deklarieren Sie die Initialisierungsmethode mitid, name, und addrals lokale Variablen. Hier def und Ende verwendet , um eine Methode zu definieren Rubin initialize . Weitere Informationen zu Methoden finden Sie in den folgenden Kapiteln.
Bei der Initialisierungsmethode übergeben Sie die Werte dieser lokalen Variablen an die Instanzvariablen @cust_id, @cust_name und @cust_addr. Hier enthalten lokale Variablen die Werte, die zusammen mit der neuen Methode übergeben werden.
Jetzt können Sie Objekte wie folgt erstellen:
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")Mitgliedsfunktionen in der Ruby-Klasse
In Ruby werden Funktionen als Methoden bezeichnet. Jede Methode in einer Klasse beginnt mit dem Schlüsselwort def, gefolgt vom Methodennamen.
Der Methodenname wird in immer bevorzugt lowercase letters. Sie beenden eine Methode in Ruby mit dem Schlüsselwort end .
Hier ist das Beispiel zum Definieren einer Ruby-Methode:
class Sample
def function
statement 1
statement 2
end
endHier Anweisung 1 und Anweisung 2 sind ein Teil des Körpers des Verfahrens Funktion innerhalb der Klasse Probe. Diese Aussagen können jede gültige Ruby-Anweisung sein. Zum Beispiel können wir eine Methode setzen , um Hello Ruby wie folgt zu drucken :
class Sample
def hello
puts "Hello Ruby!"
end
endErstellen Sie nun im folgenden Beispiel ein Objekt der Sample-Klasse, rufen Sie die Hello- Methode auf und sehen Sie das Ergebnis:
#!/usr/bin/ruby
class Sample
def hello
puts "Hello Ruby!"
end
end
# Now using above class to create objects
object = Sample. new
object.helloDies führt zu folgendem Ergebnis:
Hello Ruby!Einfache Fallstudie
Hier ist eine Fallstudie, wenn Sie mehr mit Klasse und Objekten üben möchten.
Ruby Class Fallstudie
Variablen sind die Speicherorte, die alle Daten enthalten, die von einem Programm verwendet werden sollen.
Es gibt fünf Arten von Variablen, die von Ruby unterstützt werden. Sie haben bereits im vorherigen Kapitel eine kleine Beschreibung dieser Variablen durchgearbeitet. Diese fünf Arten von Variablen werden in diesem Kapitel erläutert.
Ruby Global Variables
Globale Variablen beginnen mit $. Nicht initialisierte globale Variablen haben den Wert nil und erzeugen mit der Option -w Warnungen.
Die Zuweisung zu globalen Variablen ändert den globalen Status. Es wird nicht empfohlen, globale Variablen zu verwenden. Sie machen Programme kryptisch.
Hier ist ein Beispiel, das die Verwendung globaler Variablen zeigt.
#!/usr/bin/ruby
$global_variable = 10 class Class1 def print_global puts "Global variable in Class1 is #$global_variable"
end
end
class Class2
def print_global
puts "Global variable in Class2 is #$global_variable"
end
end
class1obj = Class1.new
class1obj.print_global
class2obj = Class2.new
class2obj.print_globalHier ist $ global_variable eine globale Variable. Dies führt zu folgendem Ergebnis:
NOTE - In Ruby können Sie auf den Wert einer Variablen oder Konstante zugreifen, indem Sie ein Hash-Zeichen (#) direkt vor diese Variable oder Konstante setzen.
Global variable in Class1 is 10
Global variable in Class2 is 10Ruby-Instanzvariablen
Instanzvariablen beginnen mit @. Nicht initialisierte Instanzvariablen haben den Wert nil und erzeugen mit der Option -w Warnungen.
Hier ist ein Beispiel, das die Verwendung von Instanzvariablen zeigt.
#!/usr/bin/ruby
class Customer
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
def display_details()
puts "Customer id #@cust_id"
puts "Customer name #@cust_name"
puts "Customer address #@cust_addr"
end
end
# Create Objects
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")
# Call Methods
cust1.display_details()
cust2.display_details()Hier sind @cust_id, @cust_name und @cust_addr Instanzvariablen. Dies führt zu folgendem Ergebnis:
Customer id 1
Customer name John
Customer address Wisdom Apartments, Ludhiya
Customer id 2
Customer name Poul
Customer address New Empire road, KhandalaRuby-Klassenvariablen
Klassenvariablen beginnen mit @@ und müssen initialisiert werden, bevor sie in Methodendefinitionen verwendet werden können.
Das Verweisen auf eine nicht initialisierte Klassenvariable führt zu einem Fehler. Klassenvariablen werden von Nachkommen der Klasse oder des Moduls geteilt, in dem die Klassenvariablen definiert sind.
Überschreibende Klassenvariablen erzeugen Warnungen mit der Option -w.
Hier ist ein Beispiel, das die Verwendung der Klassenvariablen zeigt -
#!/usr/bin/ruby
class Customer
@@no_of_customers = 0
def initialize(id, name, addr)
@cust_id = id
@cust_name = name
@cust_addr = addr
end
def display_details()
puts "Customer id #@cust_id"
puts "Customer name #@cust_name"
puts "Customer address #@cust_addr"
end
def total_no_of_customers()
@@no_of_customers += 1
puts "Total number of customers: #@@no_of_customers"
end
end
# Create Objects
cust1 = Customer.new("1", "John", "Wisdom Apartments, Ludhiya")
cust2 = Customer.new("2", "Poul", "New Empire road, Khandala")
# Call Methods
cust1.total_no_of_customers()
cust2.total_no_of_customers()Hier ist @@ no_of_customers eine Klassenvariable. Dies führt zu folgendem Ergebnis:
Total number of customers: 1
Total number of customers: 2Lokale Ruby-Variablen
Lokale Variablen beginnen mit einem Kleinbuchstaben oder _. Der Umfang einer lokalen Variablen reicht von Klasse, Modul, Def oder Do bis zum entsprechenden Ende oder von der öffnenden Klammer eines Blocks bis zu seiner geschlossenen Klammer {}.
Wenn auf eine nicht initialisierte lokale Variable verwiesen wird, wird dies als Aufruf einer Methode ohne Argumente interpretiert.
Die Zuordnung zu nicht initialisierten lokalen Variablen dient auch als Variablendeklaration. Die Variablen beginnen zu existieren, bis das Ende des aktuellen Bereichs erreicht ist. Die Lebensdauer lokaler Variablen wird bestimmt, wenn Ruby das Programm analysiert.
Im obigen Beispiel sind die lokalen Variablen id, name und addr.
Rubinkonstanten
Konstanten beginnen mit einem Großbuchstaben. Auf Konstanten, die innerhalb einer Klasse oder eines Moduls definiert sind, kann innerhalb dieser Klasse oder dieses Moduls zugegriffen werden, und auf Konstanten, die außerhalb einer Klasse oder eines Moduls definiert sind, kann global zugegriffen werden.
Konstanten dürfen nicht innerhalb von Methoden definiert werden. Das Verweisen auf eine nicht initialisierte Konstante führt zu einem Fehler. Wenn Sie einer bereits initialisierten Konstante eine Zuweisung vornehmen, wird eine Warnung ausgegeben.
#!/usr/bin/ruby
class Example
VAR1 = 100
VAR2 = 200
def show
puts "Value of first Constant is #{VAR1}"
puts "Value of second Constant is #{VAR2}"
end
end
# Create Objects
object = Example.new()
object.showHier sind VAR1 und VAR2 Konstanten. Dies führt zu folgendem Ergebnis:
Value of first Constant is 100
Value of second Constant is 200Ruby Pseudo-Variablen
Es handelt sich um spezielle Variablen, die wie lokale Variablen aussehen, sich jedoch wie Konstanten verhalten. Sie können diesen Variablen keinen Wert zuweisen.
self - Das Empfängerobjekt der aktuellen Methode.
true - Wert, der wahr darstellt.
false - Wert, der false darstellt.
nil - Wert für undefiniert.
__FILE__ - Der Name der aktuellen Quelldatei.
__LINE__ - Die aktuelle Zeilennummer in der Quelldatei.
Ruby Basic Literals
Die Regeln, die Ruby für Literale verwendet, sind einfach und intuitiv. In diesem Abschnitt werden alle grundlegenden Ruby-Literale erläutert.
Ganzzahlige Zahlen
Ruby unterstützt Ganzzahlen. Eine Ganzzahl kann zwischen -2 30 und 2 30-1 oder -2 62 bis 2 62-1 liegen . Ganzzahlen innerhalb dieses Bereichs sind Objekte der Klasse Fixnum, und Ganzzahlen außerhalb dieses Bereichs werden in Objekten der Klasse Bignum gespeichert .
Sie schreiben Ganzzahlen mit einem optionalen Vorzeichen, einem optionalen Basisindikator (0 für Oktal, 0x für Hex oder 0b für Binär), gefolgt von einer Ziffernfolge in der entsprechenden Basis. Unterstriche werden in der Ziffernfolge ignoriert.
Sie können auch den ganzzahligen Wert abrufen, der einem ASCII-Zeichen entspricht, oder die Sequenz umgehen, indem Sie ihm ein Fragezeichen voranstellen.
Beispiel
123 # Fixnum decimal
1_234 # Fixnum decimal with underline
-500 # Negative Fixnum
0377 # octal
0xff # hexadecimal
0b1011 # binary
?a # character code for 'a'
?\n # code for a newline (0x0a)
12345678901234567890 # BignumNOTE - Klasse und Objekte werden in einem separaten Kapitel dieses Tutorials erläutert.
Floating Numbers
Ruby unterstützt schwebende Zahlen. Sie sind auch Zahlen, aber mit Dezimalstellen. Gleitkommazahlen sind Objekte der Klasse Float und können eine der folgenden sein:
Beispiel
123.4 # floating point value
1.0e6 # scientific notation
4E20 # dot not required
4e+20 # sign before exponentialString-Literale
Ruby-Strings sind einfach Sequenzen von 8-Bit-Bytes und Objekte der Klasse String. Zeichenfolgen in doppelten Anführungszeichen ermöglichen Substitution und Backslash-Notation, Zeichenfolgen in einfachen Anführungszeichen ermöglichen jedoch keine Substitution und Backslash-Notation nur für \\ und \ '
Beispiel
#!/usr/bin/ruby -w
puts 'escape using "\\"';
puts 'That\'s right';Dies führt zu folgendem Ergebnis:
escape using "\"
That's rightSie können den Wert eines beliebigen Ruby-Ausdrucks mithilfe der Sequenz in eine Zeichenfolge einsetzen #{ expr }. Hier könnte expr ein beliebiger rubinroter Ausdruck sein.
#!/usr/bin/ruby -w
puts "Multiplication Value : #{24*60*60}";Dies führt zu folgendem Ergebnis:
Multiplication Value : 86400Backslash-Notationen
Im Folgenden finden Sie eine Liste der von Ruby unterstützten Backslash-Notationen:
| Notation | Zeichen dargestellt |
|---|---|
| \ n | Newline (0x0a) |
| \ r | Wagenrücklauf (0x0d) |
| \ f | Formfeed (0x0c) |
| \ b | Rücktaste (0x08) |
| \ein | Bell (0x07) |
| \ e | Flucht (0x1b) |
| \ s | Leerzeichen (0x20) |
| \ nnn | Oktalschreibweise (n ist 0-7) |
| \ xnn | Hexadezimale Notation (n ist 0-9, af oder AF) |
| \ cx, \ Cx | Control-x |
| \ Mx | Meta-x (c | 0x80) |
| \ M- \ Cx | Meta-Control-x |
| \ x | Zeichen x |
Weitere Informationen zu Ruby Strings finden Sie unter Ruby Strings .
Ruby Arrays
Literale von Ruby Array werden erstellt, indem eine durch Kommas getrennte Reihe von Objektreferenzen zwischen die eckigen Klammern gesetzt wird. Ein nachfolgendes Komma wird ignoriert.
Beispiel
#!/usr/bin/ruby
ary = [ "fred", 10, 3.14, "This is a string", "last element", ]
ary.each do |i|
puts i
endDies führt zu folgendem Ergebnis:
fred
10
3.14
This is a string
last elementWeitere Informationen zu Ruby-Arrays finden Sie in Ruby-Arrays .
Ruby Hashes
Ein wörtlicher Ruby Hash wird erstellt, indem eine Liste von Schlüssel / Wert-Paaren zwischen geschweiften Klammern mit einem Komma oder der Sequenz => zwischen dem Schlüssel und dem Wert platziert wird. Ein nachfolgendes Komma wird ignoriert.
Beispiel
#!/usr/bin/ruby
hsh = colors = { "red" => 0xf00, "green" => 0x0f0, "blue" => 0x00f }
hsh.each do |key, value|
print key, " is ", value, "\n"
endDies führt zu folgendem Ergebnis:
red is 3840
green is 240
blue is 15Weitere Informationen zu Ruby Hashes finden Sie unter Ruby Hashes .
Ruby Ranges
Ein Bereich stellt ein Intervall dar, bei dem es sich um eine Reihe von Werten mit einem Anfang und einem Ende handelt. Bereiche können mit den Literalen s..e und s ... e oder mit Range.new erstellt werden.
Bereiche, die mit .. erstellt wurden, verlaufen vom Anfang bis zum Ende einschließlich. Diejenigen, die mit ... erstellt wurden, schließen den Endwert aus. Bei Verwendung als Iterator geben Bereiche jeden Wert in der Sequenz zurück.
Ein Bereich (1..5) bedeutet, dass er 1, 2, 3, 4, 5 Werte enthält, und ein Bereich (1 ... 5) bedeutet, dass er 1, 2, 3, 4 Werte enthält.
Beispiel
#!/usr/bin/ruby
(10..15).each do |n|
print n, ' '
endDies führt zu folgendem Ergebnis:
10 11 12 13 14 15Weitere Informationen zu Ruby Ranges finden Sie unter Ruby Ranges .
Ruby unterstützt eine Vielzahl von Operatoren, wie Sie es von einer modernen Sprache erwarten würden. Die meisten Operatoren sind tatsächlich Methodenaufrufe. Zum Beispiel wird a + b als a. + (B) interpretiert, wobei die + -Methode in dem Objekt, auf das die Variable a verweist, mit b als Argument aufgerufen wird .
Für jeden Operator (+ - * /% ** & | ^ << >> && ||) gibt es eine entsprechende Form eines abgekürzten Zuweisungsoperators (+ = - = usw.).
Ruby-Arithmetikoperatoren
Angenommen, Variable a hält 10 und Variable b hält 20, dann -
| Operator | Beschreibung | Beispiel |
|---|---|---|
| + | Addition - Fügt Werte auf beiden Seiten des Operators hinzu. | a + b ergibt 30 |
| - - | Subtraktion - Subtrahiert den rechten Operanden vom linken Operanden. | a - b ergibt -10 |
| * * | Multiplikation - Multipliziert Werte auf beiden Seiten des Operators. | a * b ergibt 200 |
| /. | Division - Teilt den linken Operanden durch den rechten Operanden. | b / a ergibt 2 |
| %. | Modul - Teilt den linken Operanden durch den rechten Operanden und gibt den Rest zurück. | b% a ergibt 0 |
| ** **. | Exponent - Führt eine Exponentialberechnung (Leistungsberechnung) für Operatoren durch. | a ** b gibt 10 zur Potenz 20 |
Ruby-Vergleichsoperatoren
Angenommen, Variable a hält 10 und Variable b hält 20, dann -
| Operator | Beschreibung | Beispiel |
|---|---|---|
| == | Überprüft, ob der Wert von zwei Operanden gleich ist oder nicht. Wenn ja, wird die Bedingung wahr. | (a == b) ist nicht wahr. |
| ! = | Überprüft, ob der Wert von zwei Operanden gleich ist oder nicht. Wenn die Werte nicht gleich sind, wird die Bedingung wahr. | (a! = b) ist wahr. |
| > | Überprüft, ob der Wert des linken Operanden größer als der Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (a> b) ist nicht wahr. |
| < | Überprüft, ob der Wert des linken Operanden kleiner als der Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (a <b) ist wahr. |
| > = | Überprüft, ob der Wert des linken Operanden größer oder gleich dem Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (a> = b) ist nicht wahr. |
| <= | Überprüft, ob der Wert des linken Operanden kleiner oder gleich dem Wert des rechten Operanden ist. Wenn ja, wird die Bedingung wahr. | (a <= b) ist wahr. |
| <=> | Kombinierter Vergleichsoperator. Gibt 0 zurück, wenn der erste Operand gleich dem zweiten ist, 1, wenn der erste Operand größer als der zweite ist, und -1, wenn der erste Operand kleiner als der zweite ist. | (a <=> b) gibt -1 zurück. |
| === | Wird verwendet, um die Gleichheit innerhalb einer when-Klausel einer case- Anweisung zu testen . | (1 ... 10) === 5 gibt true zurück. |
| .eql? | True, wenn Empfänger und Argument denselben Typ und dieselben Werte haben. | 1 == 1.0 gibt true zurück, aber 1.eql? (1.0) ist false. |
| gleich? | True, wenn Empfänger und Argument dieselbe Objekt-ID haben. | Wenn aObj ein Duplikat von bObj ist, dann ist aObj == bObj wahr, a.equal? bObj ist falsch, aber a.equal? aObj ist wahr. |
Ruby-Zuweisungsoperatoren
Angenommen, Variable a hält 10 und Variable b hält 20, dann -
| Operator | Beschreibung | Beispiel |
|---|---|---|
| = | Einfacher Zuweisungsoperator, weist dem linken Operanden Werte von Operanden auf der rechten Seite zu. | c = a + b weist c den Wert von a + b zu |
| + = | Fügen Sie den AND-Zuweisungsoperator hinzu, fügen Sie dem linken Operanden den rechten Operanden hinzu und weisen Sie das Ergebnis dem linken Operanden zu. | c + = a entspricht c = c + a |
| - = | Subtrahieren Sie den UND-Zuweisungsoperator, subtrahieren Sie den rechten Operanden vom linken Operanden und weisen Sie das Ergebnis dem linken Operanden zu. | c - = a entspricht c = c - a |
| * = | Multiplizieren Sie den UND-Zuweisungsoperator, multiplizieren Sie den rechten Operanden mit dem linken Operanden und weisen Sie das Ergebnis dem linken Operanden zu. | c * = a entspricht c = c * a |
| / = | Teilen Sie den UND-Zuweisungsoperator, teilen Sie den linken Operanden mit dem rechten Operanden und weisen Sie das Ergebnis dem linken Operanden zu. | c / = a entspricht c = c / a |
| % = | Modul UND Zuweisungsoperator, nimmt den Modul mit zwei Operanden und weist das Ergebnis dem linken Operanden zu. | c% = a entspricht c = c% a |
| ** = | Exponent AND Zuweisungsoperator, führt Exponentialberechnung (Potenzberechnung) für Operatoren durch und weist dem linken Operanden einen Wert zu. | c ** = a entspricht c = c ** a |
Ruby Parallel Assignment
Ruby unterstützt auch die parallele Zuweisung von Variablen. Dadurch können mehrere Variablen mit einer einzigen Zeile Ruby-Code initialisiert werden. Zum Beispiel -
a = 10
b = 20
c = 30Dies kann durch parallele Zuweisung schneller deklariert werden -
a, b, c = 10, 20, 30Die parallele Zuweisung ist auch nützlich, um die in zwei Variablen enthaltenen Werte auszutauschen.
a, b = b, cRuby Bitwise Operatoren
Der bitweise Operator arbeitet mit Bits und führt eine bitweise Operation durch.
Angenommen, a = 60; und b = 13; jetzt im Binärformat werden sie wie folgt sein -
a = 0011 1100
b = 0000 1101
------------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011Die folgenden bitweisen Operatoren werden von der Ruby-Sprache unterstützt.
| Operator | Beschreibung | Beispiel |
|---|---|---|
| & | Der binäre UND-Operator kopiert ein Bit in das Ergebnis, wenn es in beiden Operanden vorhanden ist. | (a & b) ergibt 12, was 0000 1100 ist |
| | | Der binäre ODER-Operator kopiert ein Bit, wenn es in einem der Operanden vorhanden ist. | (a | b) ergibt 61, was 0011 1101 ist |
| ^ | Der binäre XOR-Operator kopiert das Bit, wenn es in einem Operanden gesetzt ist, aber nicht in beiden. | (a ^ b) ergibt 49, was 0011 0001 ist |
| ~ | Der Komplementoperator für binäre Einsen ist unär und bewirkt das Umdrehen von Bits. | (~ a) ergibt -61, was aufgrund einer vorzeichenbehafteten Binärzahl 1100 0011 in 2er-Komplementform ist. |
| << | Binärer Linksschaltoperator. Der Wert der linken Operanden wird um die Anzahl der vom rechten Operanden angegebenen Bits nach links verschoben. | a << 2 ergibt 240, was 1111 0000 ist |
| >> | Binärer Rechtsschieber. Der Wert der linken Operanden wird um die Anzahl der vom rechten Operanden angegebenen Bits nach rechts verschoben. | Eine >> 2 ergibt 15, was 0000 1111 ist |
Ruby Logical Operators
Die folgenden logischen Operatoren werden von der Ruby-Sprache unterstützt
Angenommen, Variable a hält 10 und Variable b hält 20, dann -
| Operator | Beschreibung | Beispiel |
|---|---|---|
| und | Wird als logischer UND-Operator bezeichnet. Wenn beide Operanden wahr sind, wird die Bedingung wahr. | (a und b) ist wahr. |
| oder | Wird als logischer ODER-Operator bezeichnet. Wenn einer der beiden Operanden nicht Null ist, wird die Bedingung wahr. | (a oder b) ist wahr. |
| && | Wird als logischer UND-Operator bezeichnet. Wenn beide Operanden nicht Null sind, wird die Bedingung wahr. | (a && b) ist wahr. |
| || | Wird als logischer ODER-Operator bezeichnet. Wenn einer der beiden Operanden nicht Null ist, wird die Bedingung wahr. | (a || b) ist wahr. |
| ! | Wird als logischer NICHT-Operator bezeichnet. Verwenden Sie diese Option, um den logischen Status des Operanden umzukehren. Wenn eine Bedingung wahr ist, macht der Operator Logical NOT false. | ! (a && b) ist falsch. |
| nicht | Wird als logischer NICHT-Operator bezeichnet. Verwenden Sie diese Option, um den logischen Status des Operanden umzukehren. Wenn eine Bedingung wahr ist, macht der Operator Logical NOT false. | nicht (a && b) ist falsch. |
Ruby Ternary Operator
Es gibt noch einen Operator namens Ternary Operator. Es wertet zuerst einen Ausdruck für einen wahren oder falschen Wert aus und führt dann abhängig vom Ergebnis der Bewertung eine der beiden angegebenen Anweisungen aus. Der bedingte Operator hat diese Syntax -
| Operator | Beschreibung | Beispiel |
|---|---|---|
| ? :: | Bedingter Ausdruck | Wenn Bedingung wahr ist? Dann Wert X: Andernfalls Wert Y. |
Ruby Range Operatoren
Sequenzbereiche in Ruby werden verwendet, um einen Bereich aufeinanderfolgender Werte zu erstellen - bestehend aus einem Startwert, einem Endwert und einem Wertebereich dazwischen.
In Ruby werden diese Sequenzen mit den Bereichsoperatoren ".." und "..." erstellt. Das Zwei-Punkt-Formular erstellt einen Inklusivbereich, während das Drei-Punkt-Formular einen Bereich erstellt, der den angegebenen hohen Wert ausschließt.
| Operator | Beschreibung | Beispiel |
|---|---|---|
| .. | Erstellt einen Bereich vom Startpunkt bis einschließlich Endpunkt. | 1..10 Erstellt einen Bereich von 1 bis einschließlich 10. |
| ... | Erstellt einen exklusiven Bereich vom Startpunkt bis zum Endpunkt. | 1 ... 10 Erstellt einen Bereich von 1 bis 9. |
Ruby definiert? Betreiber
definiert? ist ein spezieller Operator, der die Form eines Methodenaufrufs hat, um zu bestimmen, ob der übergebene Ausdruck definiert ist oder nicht. Es gibt eine Beschreibungszeichenfolge des Ausdrucks zurück oder nil, wenn der Ausdruck nicht definiert ist.
Es gibt verschiedene Verwendungszwecke von definiert? Operator
Verwendungszweck 1
defined? variable # True if variable is initializedFor Example
foo = 42
defined? foo # => "local-variable"
defined? $_ # => "global-variable"
defined? bar # => nil (undefined)Verwendung 2
defined? method_call # True if a method is definedFor Example
defined? puts # => "method"
defined? puts(bar) # => nil (bar is not defined here)
defined? unpack # => nil (not defined here)Verwendung 3
# True if a method exists that can be called with super user
defined? superFor Example
defined? super # => "super" (if it can be called)
defined? super # => nil (if it cannot be)Verwendung 4
defined? yield # True if a code block has been passedFor Example
defined? yield # => "yield" (if there is a block passed)
defined? yield # => nil (if there is no block)Ruby Dot "." und Double Colon "::" Operatoren
Sie rufen eine Modulmethode auf, indem Sie ihrem Namen den Namen des Moduls und einen Punkt voranstellen und eine Konstante mit dem Modulnamen und zwei Doppelpunkten referenzieren.
Das :: ist ein unärer Operator, mit dem auf Konstanten, Instanzmethoden und Klassenmethoden, die in einer Klasse oder einem Modul definiert sind, von überall außerhalb der Klasse oder des Moduls zugegriffen werden kann.
Remember In Ruby können Klassen und Methoden auch als Konstanten betrachtet werden.
Sie müssen nur das Präfix :: Const_name mit einem Ausdruck, der das entsprechende Klassen- oder Modulobjekt zurückgibt.
Wenn kein Präfixausdruck verwendet wird, wird standardmäßig die Hauptobjektklasse verwendet.
Hier sind zwei Beispiele -
MR_COUNT = 0 # constant defined on main Object class
module Foo
MR_COUNT = 0
::MR_COUNT = 1 # set global count to 1
MR_COUNT = 2 # set local count to 2
end
puts MR_COUNT # this is the global constant
puts Foo::MR_COUNT # this is the local "Foo" constantSecond Example
CONST = ' out there'
class Inside_one
CONST = proc {' in there'}
def where_is_my_CONST
::CONST + ' inside one'
end
end
class Inside_two
CONST = ' inside two'
def where_is_my_CONST
CONST
end
end
puts Inside_one.new.where_is_my_CONST
puts Inside_two.new.where_is_my_CONST
puts Object::CONST + Inside_two::CONST
puts Inside_two::CONST + CONST
puts Inside_one::CONST
puts Inside_one::CONST.call + Inside_two::CONSTVorrang der Ruby-Operatoren
In der folgenden Tabelle sind alle Operatoren von der höchsten bis zur niedrigsten Priorität aufgeführt.
| Methode | Operator | Beschreibung |
|---|---|---|
| Ja | :: :: | Operator mit konstanter Auflösung |
| Ja | [] [] = | Elementreferenz, Elementsatz |
| Ja | ** **. | Potenzierung (zur Macht erheben) |
| Ja | ! ~ + - | Nicht, Komplement, unäres Plus und Minus (Methodennamen für die letzten beiden sind + @ und - @) |
| Ja | * /% | Multiplizieren, dividieren und modulo |
| Ja | + - | Addition und Subtraktion |
| Ja | >> << | Bitweise Verschiebung nach rechts und links |
| Ja | & | Bitweises 'UND' |
| Ja | ^ | | Bitweises exklusives ODER und reguläres ODER |
| Ja | <= <>> = | Vergleichsoperatoren |
| Ja | <=> == ===! = = ~! ~ | Gleichheits- und Musterübereinstimmungsoperatoren (! = Und! ~ Können möglicherweise nicht als Methoden definiert werden) |
| && | Logisches 'UND' | |
| || | Logisches 'ODER' | |
| .. ... | Reichweite (inklusive und exklusiv) | |
| ? :: | Ternäres Wenn-Dann-Sonst | |
| =% = {/ = - = + = | = & = >> = << = * = && = || = ** = | Zuordnung | |
| definiert? | Überprüfen Sie, ob das angegebene Symbol definiert ist | |
| nicht | Logische Negation | |
| oder und | Logische Komposition |
NOTE- Operatoren mit einem Ja in der Methodenspalte sind tatsächlich Methoden und können als solche überschrieben werden.
Kommentare sind Anmerkungszeilen in Ruby-Code, die zur Laufzeit ignoriert werden. Ein einzeiliger Kommentar beginnt mit dem Zeichen # und erstreckt sich wie folgt vom # bis zum Ende der Zeile:
#!/usr/bin/ruby -w
# This is a single line comment.
puts "Hello, Ruby!"Bei Ausführung führt das obige Programm das folgende Ergebnis aus:
Hello, Ruby!Ruby Multiline Kommentare
Sie können mehrere Zeilen mit kommentieren =begin und =end Syntax wie folgt -
#!/usr/bin/ruby -w
puts "Hello, Ruby!"
=begin
This is a multiline comment and con spwan as many lines as you
like. But =begin and =end should come in the first line only.
=endBei Ausführung führt das obige Programm das folgende Ergebnis aus:
Hello, Ruby!Stellen Sie sicher, dass nachfolgende Kommentare weit genug vom Code entfernt sind und leicht unterschieden werden können. Wenn in einem Block mehr als ein nachfolgender Kommentar vorhanden ist, richten Sie diese aus. Zum Beispiel -
@counter # keeps track times page has been hit
@siteCounter # keeps track of times all pages have been hitRuby bietet bedingte Strukturen, die in modernen Sprachen häufig vorkommen. Hier werden alle in Ruby verfügbaren bedingten Anweisungen und Modifikatoren erläutert.
Ruby if ... else Statement
Syntax
if conditional [then]
code...
[elsif conditional [then]
code...]...
[else
code...]
endwenn Ausdrücke für die bedingte Ausführung verwendet werden. Die Werte false und nil sind false und alles andere ist true. Beachten Sie, dass Ruby elsif verwendet, weder if noch elif.
Führt Code aus, wenn die Bedingung wahr ist. Wenn die Bedingung nicht wahr ist, wird der in der else-Klausel angegebene Code ausgeführt.
Am wenn Ausdruck bedingter von Code durch das reservierte Wort getrennt dann , eine neue Zeile oder ein Semikolon.
Beispiel
#!/usr/bin/ruby
x = 1
if x > 2
puts "x is greater than 2"
elsif x <= 2 and x!=0
puts "x is 1"
else
puts "I can't guess the number"
endx is 1Ruby wenn Modifikator
Syntax
code if conditionFührt Code aus, wenn die Bedingung wahr ist.
Example
#!/usr/bin/ruby
$debug = 1
print "debug\n" if $debugThis will produce the following result −
debugRuby unless Statement
Syntax
unless conditional [then]
code
[else
code ]
endExecutes code if conditional is false. If the conditional is true, code specified in the else clause is executed.
Example
#!/usr/bin/ruby
x = 1
unless x>=2
puts "x is less than 2"
else
puts "x is greater than 2"
endThis will produce the following result −
x is less than 2Ruby unless modifier
Syntax
code unless conditionalExecutes code if conditional is false.
Example
#!/usr/bin/ruby
$var = 1
print "1 -- Value is set\n" if $var print "2 -- Value is set\n" unless $var
$var = false print "3 -- Value is set\n" unless $varThis will produce the following result −
1 -- Value is set
3 -- Value is setRuby case Statement
Syntax
case expression
[when expression [, expression ...] [then]
code ]...
[else
code ]
endCompares the expression specified by case and that specified by when using the === operator and executes the code of the when clause that matches.
The expression specified by the when clause is evaluated as the left operand. If no when clauses match, case executes the code of the else clause.
A when statement's expression is separated from code by the reserved word then, a newline, or a semicolon. Thus −
case expr0
when expr1, expr2
stmt1
when expr3, expr4
stmt2
else
stmt3
endis basically similar to the following −
_tmp = expr0
if expr1 === _tmp || expr2 === _tmp
stmt1
elsif expr3 === _tmp || expr4 === _tmp
stmt2
else
stmt3
endBeispiel
#!/usr/bin/ruby
$age = 5 case $age
when 0 .. 2
puts "baby"
when 3 .. 6
puts "little child"
when 7 .. 12
puts "child"
when 13 .. 18
puts "youth"
else
puts "adult"
endDies führt zu folgendem Ergebnis:
little childSchleifen in Ruby werden verwendet, um denselben Codeblock eine bestimmte Anzahl von Malen auszuführen. In diesem Kapitel werden alle von Ruby unterstützten Schleifenanweisungen beschrieben.
Ruby while-Anweisung
Syntax
while conditional [do]
code
endFührt Code aus, solange die Bedingung wahr ist. Die Bedingung einer while- Schleife wird durch das reservierte Wort do, einen Zeilenumbruch, einen umgekehrten Schrägstrich oder ein Semikolon vom Code getrennt .
Beispiel
#!/usr/bin/ruby
$i = 0
$num = 5
while $i < $num do
puts("Inside the loop i = #$i" )
$i +=1
endDies führt zu folgendem Ergebnis:
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4Ruby während Modifikator
Syntax
code while condition
OR
begin
code
end while conditionalFührt Code aus, solange die Bedingung wahr ist.
Wenn ein while- Modifikator einer begin- Anweisung ohne Rettungs- oder Sicherstellungsklauseln folgt , wird der Code einmal ausgeführt, bevor die Bedingung ausgewertet wird.
Beispiel
#!/usr/bin/ruby
$i = 0
$num = 5
begin
puts("Inside the loop i = #$i" )
$i +=1
end while $i < $numDies führt zu folgendem Ergebnis:
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4Ruby bis Anweisung
until conditional [do]
code
endFührt Code aus, während die Bedingung falsch ist. AN bis bedingte Aussage wird von getrennt Code durch das reservierte Wort zu tun , eine neue Zeile oder ein Semikolon.
Beispiel
#!/usr/bin/ruby
$i = 0
$num = 5
until $i > $num do
puts("Inside the loop i = #$i" )
$i +=1;
endDies führt zu folgendem Ergebnis:
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4
Inside the loop i = 5Ruby bis Modifikator
Syntax
code until conditional
OR
begin
code
end until conditionalFührt Code aus, während die Bedingung falsch ist.
Wenn ein bis- Modifikator einer begin- Anweisung ohne Rettungs- oder Sicherstellungsklauseln folgt , wird der Code einmal ausgeführt, bevor die Bedingung ausgewertet wird.
Beispiel
#!/usr/bin/ruby
$i = 0
$num = 5
begin
puts("Inside the loop i = #$i" )
$i +=1;
end until $i > $numDies führt zu folgendem Ergebnis:
Inside the loop i = 0
Inside the loop i = 1
Inside the loop i = 2
Inside the loop i = 3
Inside the loop i = 4
Inside the loop i = 5Ruby for Statement
Syntax
for variable [, variable ...] in expression [do]
code
endFührt Code für jedes Element im Ausdruck einmal aus .
Beispiel
#!/usr/bin/ruby
for i in 0..5
puts "Value of local variable is #{i}"
endHier haben wir den Bereich 0..5 definiert. Die Anweisung für i in 0..5 ermöglicht es i , Werte im Bereich von 0 bis 5 (einschließlich 5) anzunehmen . Dies führt zu folgendem Ergebnis:
Value of local variable is 0
Value of local variable is 1
Value of local variable is 2
Value of local variable is 3
Value of local variable is 4
Value of local variable is 5Eine for ... in Schleife entspricht fast genau der folgenden -
(expression).each do |variable[, variable...]| code endmit der Ausnahme, dass eine for- Schleife keinen neuen Bereich für lokale Variablen erstellt. Der Ausdruck einer for- Schleife wird durch das reservierte Wort do, eine neue Zeile oder ein Semikolon vom Code getrennt .
Beispiel
#!/usr/bin/ruby
(0..5).each do |i|
puts "Value of local variable is #{i}"
endDies führt zu folgendem Ergebnis:
Value of local variable is 0
Value of local variable is 1
Value of local variable is 2
Value of local variable is 3
Value of local variable is 4
Value of local variable is 5Ruby break Statement
Syntax
breakBeendet die interneste Schleife. Beendet eine Methode mit einem zugeordneten Block, wenn sie innerhalb des Blocks aufgerufen wird (wobei die Methode nil zurückgibt).
Beispiel
#!/usr/bin/ruby
for i in 0..5
if i > 2 then
break
end
puts "Value of local variable is #{i}"
endDies führt zu folgendem Ergebnis:
Value of local variable is 0
Value of local variable is 1
Value of local variable is 2Ruby nächste Aussage
Syntax
nextSpringt zur nächsten Iteration der internesten Schleife. Beendet die Ausführung eines Blocks, wenn er innerhalb eines Blocks aufgerufen wird (wobei Yield oder Call Null zurückgeben).
Beispiel
#!/usr/bin/ruby
for i in 0..5
if i < 2 then
next
end
puts "Value of local variable is #{i}"
endDies führt zu folgendem Ergebnis:
Value of local variable is 2
Value of local variable is 3
Value of local variable is 4
Value of local variable is 5Ruby Redo Statement
Syntax
redoStartet diese Iteration der internesten Schleife neu, ohne den Schleifenzustand zu überprüfen. Startet Yield oder Call neu, wenn es innerhalb eines Blocks aufgerufen wird.
Beispiel
#!/usr/bin/ruby
for i in 0..5
if i < 2 then
puts "Value of local variable is #{i}"
redo
end
endDies führt zu folgendem Ergebnis und geht in eine Endlosschleife -
Value of local variable is 0
Value of local variable is 0
............................Ruby-Wiederholungsanweisung
Syntax
retryWenn in der Rettungsklausel des Ausdrucks begin ein erneuter Versuch angezeigt wird, starten Sie ihn am Anfang des Startkörpers neu.
begin
do_something # exception raised
rescue
# handles error
retry # restart from beginning
endWenn im Iterator ein erneuter Versuch angezeigt wird , startet der Block oder der Hauptteil des for- Ausdrucks den Aufruf des Iteratoraufrufs neu. Argumente für den Iterator werden neu bewertet.
for i in 1..5
retry if some_condition # restart from i == 1
endBeispiel
#!/usr/bin/ruby
for i in 0..5
retry if i > 2
puts "Value of local variable is #{i}"
endDies führt zu folgendem Ergebnis und geht in eine Endlosschleife -
Value of local variable is 1
Value of local variable is 2
Value of local variable is 1
Value of local variable is 2
Value of local variable is 1
Value of local variable is 2
............................Ruby-Methoden sind Funktionen in jeder anderen Programmiersprache sehr ähnlich. Ruby-Methoden werden verwendet, um eine oder mehrere wiederholbare Anweisungen in einer einzigen Einheit zu bündeln.
Methodennamen sollten mit einem Kleinbuchstaben beginnen. Wenn Sie einen Methodennamen mit einem Großbuchstaben beginnen, könnte Ruby denken, dass es sich um eine Konstante handelt, und daher den Aufruf falsch analysieren.
Methoden sollten vor dem Aufruf definiert werden, andernfalls löst Ruby eine Ausnahme für den Aufruf undefinierter Methoden aus.
Syntax
def method_name [( [arg [= default]]...[, * arg [, &expr ]])]
expr..
endSie können also eine einfache Methode wie folgt definieren:
def method_name
expr..
endSie können eine Methode darstellen, die folgende Parameter akzeptiert:
def method_name (var1, var2)
expr..
endSie können Standardwerte für die Parameter festlegen, die verwendet werden, wenn die Methode aufgerufen wird, ohne die erforderlichen Parameter zu übergeben.
def method_name (var1 = value1, var2 = value2)
expr..
endWenn Sie die einfache Methode aufrufen, schreiben Sie nur den Methodennamen wie folgt:
method_nameWenn Sie jedoch eine Methode mit Parametern aufrufen, schreiben Sie den Methodennamen zusammen mit den Parametern, z.
method_name 25, 30Der wichtigste Nachteil bei der Verwendung von Methoden mit Parametern besteht darin, dass Sie sich die Anzahl der Parameter merken müssen, wenn Sie solche Methoden aufrufen. Wenn eine Methode beispielsweise drei Parameter akzeptiert und Sie nur zwei übergeben, zeigt Ruby einen Fehler an.
Beispiel
#!/usr/bin/ruby
def test(a1 = "Ruby", a2 = "Perl")
puts "The programming language is #{a1}"
puts "The programming language is #{a2}"
end
test "C", "C++"
testDies führt zu folgendem Ergebnis:
The programming language is C
The programming language is C++
The programming language is Ruby
The programming language is PerlRückgabewerte von Methoden
Jede Methode in Ruby gibt standardmäßig einen Wert zurück. Dieser zurückgegebene Wert ist der Wert der letzten Anweisung. Zum Beispiel -
def test
i = 100
j = 10
k = 0
endDiese Methode gibt beim Aufruf die zuletzt deklarierte Variable k zurück .
Ruby return Statement
Die return- Anweisung in Ruby wird verwendet, um einen oder mehrere Werte von einer Ruby-Methode zurückzugeben.
Syntax
return [expr[`,' expr...]]Wenn mehr als zwei Ausdrücke angegeben werden, ist das Array, das diese Werte enthält, der Rückgabewert. Wenn kein Ausdruck angegeben wird, ist nil der Rückgabewert.
Beispiel
return
OR
return 12
OR
return 1,2,3Schauen Sie sich dieses Beispiel an -
#!/usr/bin/ruby
def test
i = 100
j = 200
k = 300
return i, j, k
end
var = test
puts varDies führt zu folgendem Ergebnis:
100
200
300Variable Anzahl von Parametern
Angenommen, Sie deklarieren eine Methode, die zwei Parameter akzeptiert. Wenn Sie diese Methode aufrufen, müssen Sie zwei Parameter übergeben.
Mit Ruby können Sie jedoch Methoden deklarieren, die mit einer variablen Anzahl von Parametern arbeiten. Lassen Sie uns ein Beispiel davon untersuchen -
#!/usr/bin/ruby
def sample (*test)
puts "The number of parameters is #{test.length}"
for i in 0...test.length
puts "The parameters are #{test[i]}"
end
end
sample "Zara", "6", "F"
sample "Mac", "36", "M", "MCA"In diesem Code haben Sie ein Methodenbeispiel deklariert, das einen Parametertest akzeptiert. Dieser Parameter ist jedoch ein variabler Parameter. Dies bedeutet, dass dieser Parameter eine beliebige Anzahl von Variablen aufnehmen kann. Der obige Code führt also zu folgendem Ergebnis:
The number of parameters is 3
The parameters are Zara
The parameters are 6
The parameters are F
The number of parameters is 4
The parameters are Mac
The parameters are 36
The parameters are M
The parameters are MCAKlassenmethoden
Wenn eine Methode außerhalb der Klassendefinition definiert wird, wird die Methode standardmäßig als privat markiert . Andererseits sind die in der Klassendefinition definierten Methoden standardmäßig als öffentlich markiert. Die Standardsichtbarkeit und die private Markierung der Methoden können öffentlich oder privat des Moduls geändert werden .
Wenn Sie auf eine Methode einer Klasse zugreifen möchten, müssen Sie zuerst die Klasse instanziieren. Mit dem Objekt können Sie dann auf jedes Mitglied der Klasse zugreifen.
Ruby bietet Ihnen die Möglichkeit, auf eine Methode zuzugreifen, ohne eine Klasse zu instanziieren. Lassen Sie uns sehen, wie eine Klassenmethode deklariert wird und auf sie zugegriffen wird -
class Accounts
def reading_charge
end
def Accounts.return_date
end
endSehen Sie, wie die Methode return_date deklariert wird. Es wird mit dem Klassennamen gefolgt von einem Punkt deklariert, gefolgt vom Namen der Methode. Sie können wie folgt direkt auf diese Klassenmethode zugreifen:
Accounts.return_dateUm auf diese Methode zuzugreifen, müssen Sie keine Objekte der Klasse Accounts erstellen.
Ruby alias Statement
Dies gibt Methoden oder globalen Variablen einen Alias. Aliase können nicht innerhalb des Methodenkörpers definiert werden. Der Alias der Methode behält die aktuelle Definition der Methode bei, auch wenn Methoden überschrieben werden.
Das Erstellen von Aliasnamen für die nummerierten globalen Variablen ($ 1, $ 2, ...) ist verboten. Das Überschreiben der integrierten globalen Variablen kann schwerwiegende Probleme verursachen.
Syntax
alias method-name method-name
alias global-variable-name global-variable-nameBeispiel
alias foo bar
alias $MATCH $&Hier haben wir einen foo-Alias für bar definiert, und $ MATCH ist ein Alias für $ &
Ruby undef Anweisung
Dadurch wird die Methodendefinition abgebrochen. Ein Undef kann nicht im Methodenkörper angezeigt werden.
Durch die Verwendung von undef und alias kann die Schnittstelle der Klasse unabhängig von der Oberklasse geändert werden. Beachten Sie jedoch, dass durch den internen Methodenaufruf an self möglicherweise Programme beschädigt werden .
Syntax
undef method-nameBeispiel
Um die Definition einer Methode namens bar aufzuheben, gehen Sie wie folgt vor:
undef barSie haben gesehen, wie Ruby Methoden definiert, bei denen Sie eine Anzahl von Anweisungen eingeben und diese Methode dann aufrufen können. Ebenso hat Ruby ein Konzept von Block.
Ein Block besteht aus Codestücken.
Sie weisen einem Block einen Namen zu.
Der Code im Block steht immer in geschweiften Klammern ({}).
Ein Block wird immer von einer Funktion aufgerufen, die denselben Namen wie der Block hat. Dies bedeutet , dass , wenn Sie einen Block mit dem Namen Test , dann die Funktion verwenden Test , um diesen Block aufzurufen.
Sie rufen einen Block mit der Yield- Anweisung auf.
Syntax
block_name {
statement1
statement2
..........
}Hier lernen Sie, einen Block mithilfe einer einfachen Yield- Anweisung aufzurufen . Sie werden auch lernen, eine Yield- Anweisung mit Parametern zum Aufrufen eines Blocks zu verwenden. Sie überprüfen den Beispielcode mit beiden Arten von Ertragsanweisungen .
Die Renditeerklärung
Schauen wir uns ein Beispiel für die Renditeerklärung an -
#!/usr/bin/ruby
def test
puts "You are in the method"
yield
puts "You are again back to the method"
yield
end
test {puts "You are in the block"}Dies führt zu folgendem Ergebnis:
You are in the method
You are in the block
You are again back to the method
You are in the blockSie können Parameter auch mit der Yield-Anweisung übergeben. Hier ist ein Beispiel -
#!/usr/bin/ruby
def test
yield 5
puts "You are in the method test"
yield 100
end
test {|i| puts "You are in the block #{i}"}Dies führt zu folgendem Ergebnis:
You are in the block 5
You are in the method test
You are in the block 100Hier wird die Yield- Anweisung geschrieben, gefolgt von Parametern. Sie können sogar mehr als einen Parameter übergeben. Im Block platzieren Sie eine Variable zwischen zwei vertikalen Linien (||), um die Parameter zu akzeptieren. Daher übergibt die Anweisung Yield 5 im vorhergehenden Code den Wert 5 als Parameter an den Testblock.
Schauen Sie sich nun die folgende Aussage an:
test {|i| puts "You are in the block #{i}"}Hier wird der Wert 5 in der Variablen i empfangen . Beachten Sie nun die folgende Puts- Anweisung:
puts "You are in the block #{i}"Die Ausgabe dieser put- Anweisung lautet -
You are in the block 5Wenn Sie mehr als einen Parameter übergeben möchten, lautet die Yield- Anweisung -
yield a, bund der Block ist -
test {|a, b| statement}Die Parameter werden durch Kommas getrennt.
Blöcke und Methoden
Sie haben gesehen, wie ein Block und eine Methode miteinander verknüpft werden können. Normalerweise rufen Sie einen Block auf, indem Sie die Yield-Anweisung einer Methode verwenden, die denselben Namen wie der Block hat. Deshalb schreiben Sie -
#!/usr/bin/ruby
def test
yield
end
test{ puts "Hello world"}Dieses Beispiel ist der einfachste Weg, einen Block zu implementieren. Sie rufen den Testblock mit der Yield- Anweisung auf.
Wenn dem letzten Argument einer Methode jedoch & vorangestellt ist, können Sie dieser Methode einen Block übergeben, und dieser Block wird dem letzten Parameter zugewiesen. Falls sowohl * als auch & in der Argumentliste vorhanden sind, sollte & später kommen.
#!/usr/bin/ruby
def test(&block)
block.call
end
test { puts "Hello World!"}Dies führt zu folgendem Ergebnis:
Hello World!BEGIN- und END-Blöcke
Jede Ruby-Quelldatei kann Codeblöcke deklarieren, die beim Laden der Datei (die BEGIN-Blöcke) und nach Beendigung der Programmausführung (die END-Blöcke) ausgeführt werden sollen.
#!/usr/bin/ruby
BEGIN {
# BEGIN block code
puts "BEGIN code block"
}
END {
# END block code
puts "END code block"
}
# MAIN block code
puts "MAIN code block"Ein Programm kann mehrere BEGIN- und END-Blöcke enthalten. BEGIN-Blöcke werden in der Reihenfolge ausgeführt, in der sie angetroffen werden. END-Blöcke werden in umgekehrter Reihenfolge ausgeführt. Bei Ausführung führt das obige Programm das folgende Ergebnis aus:
BEGIN code block
MAIN code block
END code blockModule sind eine Möglichkeit, Methoden, Klassen und Konstanten zu gruppieren. Module bieten Ihnen zwei Hauptvorteile.
Module bieten einen Namespace und verhindern Namenskonflikte.
Module implementieren die Mixin-Funktion .
Module definieren einen Namespace, eine Sandbox, in der Ihre Methoden und Konstanten abgespielt werden können, ohne sich Sorgen machen zu müssen, dass andere Methoden und Konstanten darauf treten.
Syntax
module Identifier
statement1
statement2
...........
endModulkonstanten werden wie Klassenkonstanten mit einem Anfangsbuchstaben in Großbuchstaben benannt. Auch die Methodendefinitionen sehen ähnlich aus: Modulmethoden werden wie Klassenmethoden definiert.
Wie bei Klassenmethoden rufen Sie eine Modulmethode auf, indem Sie ihrem Namen den Namen des Moduls und einen Punkt voranstellen und eine Konstante mit dem Modulnamen und zwei Doppelpunkten referenzieren.
Beispiel
#!/usr/bin/ruby
# Module defined in trig.rb file
module Trig
PI = 3.141592654
def Trig.sin(x)
# ..
end
def Trig.cos(x)
# ..
end
endWir können ein weiteres Modul mit demselben Funktionsnamen, aber unterschiedlicher Funktionalität definieren -
#!/usr/bin/ruby
# Module defined in moral.rb file
module Moral
VERY_BAD = 0
BAD = 1
def Moral.sin(badness)
# ...
end
endWie bei Klassenmethoden geben Sie bei jeder Definition einer Methode in einem Modul den Modulnamen gefolgt von einem Punkt und anschließend den Methodennamen an.
Ruby erfordert Statement
Die require-Anweisung ähnelt der include-Anweisung von C und C ++ und der import-Anweisung von Java. Wenn ein drittes Programm ein definiertes Modul verwenden möchte, kann es die Moduldateien einfach mit der Ruby require- Anweisung laden.
Syntax
require filenameHier ist es nicht erforderlich zu geben .rb Erweiterung zusammen mit einem Dateinamen.
Beispiel
$LOAD_PATH << '.'
require 'trig.rb'
require 'moral'
y = Trig.sin(Trig::PI/4)
wrongdoing = Moral.sin(Moral::VERY_BAD)Hier verwenden wir $LOAD_PATH << '.'um Ruby darauf aufmerksam zu machen, dass eingeschlossene Dateien im aktuellen Verzeichnis durchsucht werden müssen. Wenn Sie $ LOAD_PATH nicht verwenden möchten, können Sie verwendenrequire_relative um Dateien aus einem relativen Verzeichnis einzuschließen.
IMPORTANT- Hier enthalten beide Dateien den gleichen Funktionsnamen. Dies führt zu einer Mehrdeutigkeit des Codes beim Einbeziehen in das aufrufende Programm, aber Module vermeiden diese Mehrdeutigkeit des Codes und wir können die entsprechende Funktion unter Verwendung des Modulnamens aufrufen.
Ruby include Statement
Sie können ein Modul in eine Klasse einbetten. Um ein Modul in eine Klasse einzubetten, verwenden Sie die include- Anweisung in der Klasse -
Syntax
include modulenameWenn ein Modul in einer separaten Datei definiert ist, muss diese Datei mit der Anweisung require eingeschlossen werden , bevor das Modul in eine Klasse eingebettet wird.
Beispiel
Betrachten Sie das folgende Modul, das in der Datei support.rb geschrieben ist.
module Week
FIRST_DAY = "Sunday"
def Week.weeks_in_month
puts "You have four weeks in a month"
end
def Week.weeks_in_year
puts "You have 52 weeks in a year"
end
endJetzt können Sie dieses Modul wie folgt in eine Klasse aufnehmen:
#!/usr/bin/ruby
$LOAD_PATH << '.'
require "support"
class Decade
include Week
no_of_yrs = 10
def no_of_months
puts Week::FIRST_DAY
number = 10*12
puts number
end
end
d1 = Decade.new
puts Week::FIRST_DAY
Week.weeks_in_month
Week.weeks_in_year
d1.no_of_monthsDies führt zu folgendem Ergebnis:
Sunday
You have four weeks in a month
You have 52 weeks in a year
Sunday
120Mixins in Ruby
Bevor Sie diesen Abschnitt durchgehen, gehen wir davon aus, dass Sie über Kenntnisse in objektorientierten Konzepten verfügen.
Wenn eine Klasse Features von mehr als einer übergeordneten Klasse erben kann, soll die Klasse mehrere Vererbungen aufweisen.
Ruby unterstützt die Mehrfachvererbung nicht direkt, aber Ruby-Module haben eine weitere wunderbare Verwendung. Mit einem Schlag machen sie die Mehrfachvererbung so gut wie überflüssig und bieten eine Einrichtung, die als Mixin bezeichnet wird .
Mixins bieten Ihnen eine wunderbar kontrollierte Möglichkeit, Klassen Funktionen hinzuzufügen. Ihre wahre Kraft kommt jedoch zum Ausdruck, wenn der Code im Mixin mit dem Code in der Klasse interagiert, die ihn verwendet.
Lassen Sie uns den folgenden Beispielcode untersuchen, um das Mixin zu verstehen -
module A
def a1
end
def a2
end
end
module B
def b1
end
def b2
end
end
class Sample
include A
include B
def s1
end
end
samp = Sample.new
samp.a1
samp.a2
samp.b1
samp.b2
samp.s1Modul A besteht aus den Methoden a1 und a2. Modul B besteht aus den Methoden b1 und b2. Das Klassenbeispiel enthält beide Module A und B. Das Klassenbeispiel kann auf alle vier Methoden zugreifen, nämlich a1, a2, b1 und b2. Daher können Sie sehen, dass die Klasse Sample von beiden Modulen erbt. Man kann also sagen, dass die Klasse Sample Mehrfachvererbung oder ein Mixin zeigt .
Ein String-Objekt in Ruby enthält und bearbeitet eine beliebige Folge von einem oder mehreren Bytes, die normalerweise Zeichen darstellen, die die menschliche Sprache darstellen.
Die einfachsten Zeichenfolgenliterale werden in einfache Anführungszeichen gesetzt (das Apostrophzeichen). Der Text innerhalb der Anführungszeichen ist der Wert der Zeichenfolge -
'This is a simple Ruby string literal'Wenn Sie ein Apostroph in ein Zeichenfolgenliteral mit einfachen Anführungszeichen einfügen müssen, stellen Sie ihm einen Backslash voran, damit der Ruby-Interpreter nicht glaubt, dass er die Zeichenfolge beendet.
'Won\'t you read O\'Reilly\'s book?'Der Backslash dient auch dazu, einem anderen Backslash zu entgehen, sodass der zweite Backslash selbst nicht als Escape-Zeichen interpretiert wird.
Im Folgenden sind die Zeichenfolgenfunktionen von Ruby aufgeführt.
Ausdruckssubstitution
Die Ausdruckssubstitution ist ein Mittel zum Einbetten des Werts eines Ruby-Ausdrucks in eine Zeichenfolge mit # {und} -
#!/usr/bin/ruby
x, y, z = 12, 36, 72
puts "The value of x is #{ x }."
puts "The sum of x and y is #{ x + y }."
puts "The average was #{ (x + y + z)/3 }."Dies führt zu folgendem Ergebnis:
The value of x is 12.
The sum of x and y is 48.
The average was 40.General Delimited Strings
Mit allgemein begrenzten Zeichenfolgen können Sie Zeichenfolgen innerhalb eines Paares übereinstimmender, jedoch beliebiger Trennzeichen erstellen, z. B.!, (, {, <Usw., denen ein Prozentzeichen (%) vorangestellt ist. Q, q und x haben spezielle Bedeutungen Allgemein begrenzte Zeichenfolgen können sein -
%{Ruby is fun.} equivalent to "Ruby is fun."
%Q{ Ruby is fun. } equivalent to " Ruby is fun. "
%q[Ruby is fun.] equivalent to a single-quoted string
%x!ls! equivalent to back tick command output `ls`Escape-Charaktere
NOTE- In einer Zeichenfolge in doppelten Anführungszeichen wird ein Escape-Zeichen interpretiert. In einer Zeichenfolge in einfachen Anführungszeichen bleibt ein Escapezeichen erhalten.
| Backslash-Notation | Hexadezimalzeichen | Beschreibung |
|---|---|---|
| \ein | 0x07 | Glocke oder Alarm |
| \ b | 0x08 | Rücktaste |
| \ cx | Control-x | |
| \ Cx | Control-x | |
| \ e | 0x1b | Flucht |
| \ f | 0x0c | Formfeed |
| \ M- \ Cx | Meta-Control-x | |
| \ n | 0x0a | Neue Zeile |
| \ nnn | Oktalschreibweise, wobei n im Bereich von 0,7 liegt | |
| \ r | 0x0d | Wagenrücklauf |
| \ s | 0x20 | Raum |
| \ t | 0x09 | Tab |
| \ v | 0x0b | Vertikale Registerkarte |
| \ x | Zeichen x | |
| \ xnn | Hexadezimale Notation, wobei n im Bereich von 0,9, af oder AF liegt |
Zeichenkodierung
Der Standardzeichensatz für Ruby ist ASCII, dessen Zeichen durch einzelne Bytes dargestellt werden können. Wenn Sie UTF-8 oder einen anderen modernen Zeichensatz verwenden, können Zeichen in ein bis vier Bytes dargestellt werden.
Sie können Ihren Zeichensatz mit $ KCODE zu Beginn Ihres Programms folgendermaßen ändern:
$KCODE = 'u'| Sr.Nr. | Code & Beschreibung |
|---|---|
| 1 | a ASCII (wie keine). Dies ist die Standardeinstellung. |
| 2 | e EUC. |
| 3 | n Keine (wie ASCII). |
| 4 | u UTF-8. |
Integrierte Methoden für Zeichenfolgen
Wir benötigen eine Instanz des String-Objekts, um eine String-Methode aufzurufen. Im Folgenden wird beschrieben, wie Sie eine Instanz des String-Objekts erstellen.
new [String.new(str = "")]Dies gibt ein neues String-Objekt zurück, das eine Kopie von str enthält . Mit dem str- Objekt können wir jetzt alle verfügbaren Instanzmethoden verwenden. Zum Beispiel -
#!/usr/bin/ruby
myStr = String.new("THIS IS TEST")
foo = myStr.downcase
puts "#{foo}"Dies führt zu folgendem Ergebnis:
this is test| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | str % arg Formatiert eine Zeichenfolge mithilfe einer Formatspezifikation. arg muss ein Array sein, wenn es mehr als eine Substitution enthält. Informationen zur Formatspezifikation finden Sie unter sprintf unter "Kernelmodul". |
| 2 | str * integer Gibt eine neue Zeichenfolge zurück, die ganzzahlige Zeiten str enthält. Mit anderen Worten, str wird ganzzahlig wiederholt. |
| 3 | str + other_str Verkettet other_str mit str. |
| 4 | str << obj Verkettet ein Objekt mit str. Wenn das Objekt eine Fixnummer im Bereich von 0,255 ist, wird es in ein Zeichen konvertiert. Vergleichen Sie es mit concat. |
| 5 | str <=> other_str Vergleicht str mit other_str und gibt -1 (kleiner als), 0 (gleich) oder 1 (größer als) zurück. Der Vergleich unterscheidet zwischen Groß- und Kleinschreibung. |
| 6 | str == obj Testet str und obj auf Gleichheit. Wenn obj kein String ist, wird false zurückgegeben. Gibt true zurück, wenn str <=> obj 0 zurückgibt. |
| 7 | str =~ obj Stimmt str mit einem regulären Ausdrucksmuster obj überein. Gibt die Position zurück, an der das Spiel beginnt. sonst falsch. |
| 8 | str.capitalize Großschreibt eine Zeichenfolge. |
| 9 | str.capitalize! Entspricht der Großschreibung, es werden jedoch Änderungen vorgenommen. |
| 10 | str.casecmp Ermöglicht den Vergleich von Zeichenfolgen ohne Berücksichtigung der Groß- und Kleinschreibung. |
| 11 | str.center Zentriert eine Zeichenfolge. |
| 12 | str.chomp Entfernt das Datensatztrennzeichen ($ /), normalerweise \ n, vom Ende einer Zeichenfolge. Wenn kein Datensatztrennzeichen vorhanden ist, wird nichts ausgeführt. |
| 13 | str.chomp! Wie chomp, jedoch werden Änderungen vorgenommen. |
| 14 | str.chop Entfernt das letzte Zeichen in str. |
| 15 | str.chop! Wie hacken, aber Änderungen werden vorgenommen. |
| 16 | str.concat(other_str) Verkettet other_str mit str. |
| 17 | str.count(str, ...) Zählt einen oder mehrere Zeichensätze. Wenn mehr als ein Zeichensatz vorhanden ist, wird der Schnittpunkt dieser Sätze gezählt |
| 18 | str.crypt(other_str) Wendet einen kryptografischen Einweg-Hash auf str an. Das Argument ist die Salzzeichenfolge, die zwei Zeichen lang sein sollte, wobei jedes Zeichen im Bereich az, AZ, 0,9 ,. oder /. |
| 19 | str.delete(other_str, ...) Gibt eine Kopie von str zurück, wobei alle Zeichen im Schnittpunkt der Argumente gelöscht wurden. |
| 20 | str.delete!(other_str, ...) Wie Löschen, jedoch werden Änderungen vorgenommen. |
| 21 | str.downcase Gibt eine Kopie von str zurück, wobei alle Großbuchstaben durch Kleinbuchstaben ersetzt werden. |
| 22 | str.downcase! Wie Fallbuchstaben, jedoch werden Änderungen vorgenommen. |
| 23 | str.dump Gibt eine Version von str zurück, bei der alle nicht druckbaren Zeichen durch die Notation \ nnn ersetzt werden und alle Sonderzeichen maskiert sind. |
| 24 | str.each(separator = $/) { |substr| block } Teilt str mit dem Argument als Datensatztrennzeichen (standardmäßig $ /) und übergibt jeden Teilstring an den angegebenen Block. |
| 25 | str.each_byte { |fixnum| block } Übergibt jedes Byte von str an den Block und gibt jedes Byte als Dezimaldarstellung des Bytes zurück. |
| 26 | str.each_line(separator=$/) { |substr| block } Teilt str mit dem Argument als Datensatztrennzeichen (standardmäßig $ /) und übergibt jeden Teilstring an den angegebenen Block. |
| 27 | str.empty? Gibt true zurück, wenn str leer ist (eine Länge von Null hat). |
| 28 | str.eql?(other) Zwei Zeichenfolgen sind gleich, wenn sie dieselbe Länge und denselben Inhalt haben. |
| 29 | str.gsub(pattern, replacement) [or] str.gsub(pattern) { |match| block } Gibt eine Kopie von str zurück, wobei alle Vorkommen von Mustern entweder durch Ersetzen oder durch den Wert des Blocks ersetzt werden. Das Muster ist normalerweise ein Regexp. Wenn es sich um einen String handelt, werden keine Metazeichen für reguläre Ausdrücke interpretiert (dh / \ d / stimmt mit einer Ziffer überein, aber '\ d' entspricht einem Backslash, gefolgt von einem 'd'). |
| 30 | str[fixnum] [or] str[fixnum,fixnum] [or] str[range] [or] str[regexp] [or] str[regexp, fixnum] [or] str[other_str] Verweist auf str mit den folgenden Argumenten: one Fixnum gibt einen Zeichencode bei fixnum zurück; zwei Fixnums, gibt einen Teilstring zurück, der mit einem Versatz (erstes Fixnum) zur Länge (zweites Fixnum) beginnt; range, gibt einen Teilstring im Bereich zurück; Regexp gibt einen Teil der übereinstimmenden Zeichenfolge zurück. regexp mit fixnum, gibt übereinstimmende Daten bei fixnum zurück; other_str gibt einen Teilstring zurück, der mit other_str übereinstimmt. Ein negatives Fixnum beginnt am Ende der Zeichenfolge mit -1. |
| 31 | str[fixnum] = fixnum [or] str[fixnum] = new_str [or] str[fixnum, fixnum] = new_str [or] str[range] = aString [or] str[regexp] = new_str [or] str[regexp, fixnum] = new_str [or] str[other_str] = new_str ] Ersetzen (zuweisen) Sie einen String ganz oder teilweise. Synonym für Scheibe!. |
| 32 | str.gsub!(pattern, replacement) [or] str.gsub!(pattern) { |match|block } Führt die Ersetzungen von String # gsub an Ort und Stelle durch und gibt str oder nil zurück, wenn keine Ersetzungen durchgeführt wurden. |
| 33 | str.hash Gibt einen Hash zurück, der auf der Länge und dem Inhalt der Zeichenfolge basiert. |
| 34 | str.hex Behandelt führende Zeichen aus str als hexadezimale Ziffernfolge (mit einem optionalen Vorzeichen und einem optionalen 0x) und gibt die entsprechende Zahl zurück. Bei einem Fehler wird Null zurückgegeben. |
| 35 | str.include? other_str [or] str.include? fixnum Gibt true zurück, wenn str die angegebene Zeichenfolge oder das angegebene Zeichen enthält. |
| 36 | str.index(substring [, offset]) [or] str.index(fixnum [, offset]) [or] str.index(regexp [, offset]) Gibt den Index des ersten Auftretens des angegebenen Teilstrings, Zeichens (Fixnum) oder Musters (Regexp) in str zurück. Gibt null zurück, wenn nicht gefunden. Wenn der zweite Parameter vorhanden ist, gibt er die Position in der Zeichenfolge an, an der die Suche gestartet werden soll. |
| 37 | str.insert(index, other_str) Fügt other_str vor dem Zeichen am angegebenen Index ein und ändert str. Negative Indizes zählen ab dem Ende der Zeichenfolge und werden nach dem angegebenen Zeichen eingefügt. Es ist beabsichtigt, eine Zeichenfolge so einzufügen, dass sie am angegebenen Index beginnt. |
| 38 | str.inspect Gibt eine druckbare Version von str zurück, bei der Sonderzeichen maskiert sind. |
| 39 | str.intern [or] str.to_sym Gibt das Symbol zurück, das str entspricht, und erstellt das Symbol, falls es zuvor nicht vorhanden war. |
| 40 | str.length Gibt die Länge von str zurück. Größe vergleichen. |
| 41 | str.ljust(integer, padstr = ' ') Wenn die Ganzzahl größer als die Länge von str ist, wird eine neue Zeichenfolge mit einer Ganzzahl mit str linksbündig und mit padstr aufgefüllt zurückgegeben. Andernfalls wird str zurückgegeben. |
| 42 | str.lstrip Gibt eine Kopie von str zurück, wobei das führende Leerzeichen entfernt wurde. |
| 43 | str.lstrip! Entfernt führende Leerzeichen aus str und gibt null zurück, wenn keine Änderung vorgenommen wurde. |
| 44 | str.match(pattern) Konvertiert das Muster in einen Regexp (falls noch keiner vorhanden ist) und ruft dann die Übereinstimmungsmethode für str auf. |
| 45 | str.oct Behandelt führende Zeichen von str als eine Folge von Oktalziffern (mit einem optionalen Vorzeichen) und gibt die entsprechende Zahl zurück. Gibt 0 zurück, wenn die Konvertierung fehlschlägt. |
| 46 | str.replace(other_str) Ersetzt den Inhalt und die Verschmutzung von str durch die entsprechenden Werte in other_str. |
| 47 | str.reverse Gibt eine neue Zeichenfolge mit den Zeichen von str in umgekehrter Reihenfolge zurück. |
| 48 | str.reverse! Kehrt str an Ort und Stelle um. |
| 49 | str.rindex(substring [, fixnum]) [or] str.rindex(fixnum [, fixnum]) [or] str.rindex(regexp [, fixnum]) Gibt den Index des letzten Auftretens des angegebenen Teilstrings, Zeichens (Fixnum) oder Musters (Regexp) in str zurück. Gibt null zurück, wenn nicht gefunden. Wenn der zweite Parameter vorhanden ist, gibt er die Position in der Zeichenfolge an, an der die Suche beendet werden soll. Zeichen, die über diesen Punkt hinausgehen, werden nicht berücksichtigt. |
| 50. | str.rjust(integer, padstr = ' ') Wenn die Ganzzahl größer als die Länge von str ist, wird ein neuer String mit einer Ganzzahl mit str rechtsbündig und mit padstr aufgefüllt zurückgegeben. Andernfalls wird str zurückgegeben. |
| 51 | str.rstrip Gibt eine Kopie von str mit entferntem Leerzeichen zurück. |
| 52 | str.rstrip! Entfernt nachgestellte Leerzeichen aus str und gibt null zurück, wenn keine Änderung vorgenommen wurde. |
| 53 | str.scan(pattern) [or] str.scan(pattern) { |match, ...| block } Beide Formen durchlaufen str und entsprechen dem Muster (das ein Regexp oder ein String sein kann). Für jede Übereinstimmung wird ein Ergebnis generiert und entweder dem Ergebnisarray hinzugefügt oder an den Block übergeben. Wenn das Muster keine Gruppen enthält, besteht jedes einzelne Ergebnis aus der übereinstimmenden Zeichenfolge $ &. Wenn das Muster Gruppen enthält, ist jedes einzelne Ergebnis selbst ein Array, das einen Eintrag pro Gruppe enthält. |
| 54 | str.slice(fixnum) [or] str.slice(fixnum, fixnum) [or] str.slice(range) [or] str.slice(regexp) [or] str.slice(regexp, fixnum) [or] str.slice(other_str) See str[fixnum], etc. str.slice!(fixnum) [or] str.slice!(fixnum, fixnum) [or] str.slice!(range) [or] str.slice!(regexp) [or] str.slice!(other_str) Löscht den angegebenen Teil aus str und gibt den gelöschten Teil zurück. Die Formulare, die eine Fixnummer annehmen, lösen einen IndexError aus, wenn der Wert außerhalb des Bereichs liegt. Das Range-Formular löst einen RangeError aus, und die Regexp- und String-Formulare ignorieren die Zuweisung stillschweigend. |
| 55 | str.split(pattern = $, [limit]) Teilt str basierend auf einem Trennzeichen in Teilzeichenfolgen und gibt ein Array dieser Teilzeichenfolgen zurück. Wenn pattern ein String ist, wird sein Inhalt als Trennzeichen beim Teilen von str verwendet. Wenn das Muster ein einzelnes Leerzeichen ist, wird str in Leerzeichen aufgeteilt, wobei führende Leerzeichen und Läufe zusammenhängender Leerzeichen ignoriert werden. Wenn das Muster ein Regexp ist, wird str dort geteilt, wo das Muster übereinstimmt. Immer wenn das Muster mit einer Zeichenfolge mit der Länge Null übereinstimmt, wird str in einzelne Zeichen aufgeteilt. Wenn das Muster weggelassen wird, wird der Wert von$; is used. If $;; ist nil (dies ist die Standardeinstellung), str wird auf Leerzeichen aufgeteilt, als ob `` angegeben würde. Wenn der Grenzwertparameter weggelassen wird, werden nachfolgende Nullfelder unterdrückt. Wenn limit eine positive Zahl ist, wird höchstens diese Anzahl von Feldern zurückgegeben (wenn limit 1 ist, wird die gesamte Zeichenfolge als einziger Eintrag in einem Array zurückgegeben). Wenn negativ, gibt es keine Begrenzung für die Anzahl der zurückgegebenen Felder, und nachfolgende Nullfelder werden nicht unterdrückt. |
| 56 | str.squeeze([other_str]*) Erstellt eine Reihe von Zeichen aus den anderen_str-Parametern unter Verwendung der für String # count beschriebenen Prozedur. Gibt eine neue Zeichenfolge zurück, bei der Läufe desselben Zeichens, die in diesem Satz vorkommen, durch ein einzelnes Zeichen ersetzt werden. Wenn keine Argumente angegeben werden, werden alle Läufe identischer Zeichen durch ein einzelnes Zeichen ersetzt. |
| 57 | str.squeeze!([other_str]*) Drückt str an Ort und Stelle und gibt entweder str oder nil zurück, wenn keine Änderungen vorgenommen wurden. |
| 58 | str.strip Gibt eine Kopie von str zurück, wobei führende und nachfolgende Leerzeichen entfernt wurden. |
| 59 | str.strip! Entfernt führende und nachfolgende Leerzeichen aus str. Gibt null zurück, wenn str nicht geändert wurde. |
| 60 | str.sub(pattern, replacement) [or] str.sub(pattern) { |match| block } Gibt eine Kopie von str zurück, wobei das erste Auftreten eines Musters entweder durch Ersetzen oder durch den Wert des Blocks ersetzt wird. Das Muster ist normalerweise ein Regexp. Wenn es sich um einen String handelt, werden keine Metazeichen für reguläre Ausdrücke interpretiert. |
| 61 | str.sub!(pattern, replacement) [or] str.sub!(pattern) { |match| block } Führt die Ersetzungen von String # sub an Ort und Stelle aus und gibt str oder nil zurück, wenn keine Ersetzungen durchgeführt wurden. |
| 62 | str.succ [or] str.next Gibt den Nachfolger von str zurück. |
| 63 | str.succ! [or] str.next! Entspricht String # succ, ändert jedoch den Empfänger an Ort und Stelle. |
| 64 | str.sum(n = 16) Gibt eine grundlegende n-Bit-Prüfsumme der Zeichen in str zurück, wobei n der optionale Fixnum-Parameter ist, der standardmäßig 16 ist. Das Ergebnis ist einfach die Summe des Binärwerts jedes Zeichens in str modulo 2n - 1. Dies ist nicht besonders gute Prüfsumme. |
| 65 | str.swapcase Gibt eine Kopie von str zurück, wobei alphabetische Großbuchstaben in Kleinbuchstaben und Kleinbuchstaben in Großbuchstaben konvertiert werden. |
| 66 | str.swapcase! Entspricht String # swapcase, ändert jedoch den Empfänger an Ort und Stelle und gibt str oder nil zurück, wenn keine Änderungen vorgenommen wurden. |
| 67 | str.to_f > Gibt das Ergebnis der Interpretation führender Zeichen in str als Gleitkommazahl zurück. Fremdzeichen nach dem Ende einer gültigen Nummer werden ignoriert. Wenn zu Beginn von str keine gültige Nummer vorhanden ist, wird 0.0 zurückgegeben. Diese Methode löst niemals eine Ausnahme aus. |
| 68 | str.to_i(base = 10) Gibt das Ergebnis der Interpretation führender Zeichen in str als Ganzzahlbasis zurück (Basis 2, 8, 10 oder 16). Fremdzeichen nach dem Ende einer gültigen Nummer werden ignoriert. Wenn zu Beginn von str keine gültige Nummer vorhanden ist, wird 0 zurückgegeben. Diese Methode löst niemals eine Ausnahme aus. |
| 69 | str.to_s [or] str.to_str Gibt den Empfänger zurück. |
| 70 | str.tr(from_str, to_str) Gibt eine Kopie von str zurück, wobei die Zeichen in from_str durch die entsprechenden Zeichen in to_str ersetzt werden. Wenn to_str kürzer als from_str ist, wird es mit seinem letzten Zeichen aufgefüllt. Beide Zeichenfolgen können die Notation c1.c2 verwenden, um Zeichenbereiche zu kennzeichnen, und from_str kann mit einem ^ beginnen, das alle Zeichen außer den aufgelisteten kennzeichnet. |
| 71 | str.tr!(from_str, to_str) Übersetzt str an Ort und Stelle nach den gleichen Regeln wie String # tr. Gibt str oder nil zurück, wenn keine Änderungen vorgenommen wurden. |
| 72 | str.tr_s(from_str, to_str) Verarbeitet eine Kopie von str wie unter String # tr beschrieben und entfernt dann doppelte Zeichen in Regionen, die von der Übersetzung betroffen waren. |
| 73 | str.tr_s!(from_str, to_str) Führt die Verarbeitung von String # tr_s für str an Ort und Stelle durch und gibt str oder nil zurück, wenn keine Änderungen vorgenommen wurden. |
| 74 | str.unpack(format) > Dekodiert str (das möglicherweise Binärdaten enthält) gemäß der Formatzeichenfolge und gibt ein Array jedes extrahierten Werts zurück. Die Formatzeichenfolge besteht aus einer Folge von Direktiven mit einem Zeichen, die in Tabelle 18 zusammengefasst sind. Auf jede Direktive kann eine Zahl folgen, die angibt, wie oft mit dieser Direktive wiederholt werden soll. Ein Sternchen (*) verbraucht alle verbleibenden Elemente. Auf die Direktiven sSiIlL kann jeweils ein Unterstrich (_) folgen, um die native Größe der zugrunde liegenden Plattform für den angegebenen Typ zu verwenden. Andernfalls wird eine plattformunabhängige konsistente Größe verwendet. Leerzeichen werden in der Formatzeichenfolge ignoriert. |
| 75 | str.upcase Gibt eine Kopie von str zurück, wobei alle Kleinbuchstaben durch ihre Gegenstücke in Großbuchstaben ersetzt werden. Die Operation ist unempfindlich gegenüber dem Gebietsschema. Es sind nur die Zeichen a bis z betroffen. |
| 76 | str.upcase! Ändert den Inhalt von str in Großbuchstaben und gibt null zurück, wenn keine Änderungen vorgenommen werden. |
| 77 | str.upto(other_str) { |s| block } Iteriert durch aufeinanderfolgende Werte, beginnend bei str und endend bei other_str einschließlich, wobei jeder Wert der Reihe nach an den Block übergeben wird. Die String # succ-Methode wird verwendet, um jeden Wert zu generieren. |
Anweisungen zum Entpacken von Zeichenfolgen
| Richtlinie | Kehrt zurück | Beschreibung |
|---|---|---|
| EIN | String | Mit nachgestellten Nullen und Leerzeichen entfernt. |
| ein | String | String. |
| B. | String | Extracts bits from each character (most significant bit first). |
| b | String | Extracts bits from each character (least significant bit first). |
| C | Fixnum | Extracts a character as an unsigned integer. |
| c | Fixnum | Extracts a character as an integer. |
| D, d | Float | Treats sizeof(double) characters as a native double. |
| E | Float | Treats sizeof(double) characters as a double in littleendian byte order. |
| e | Float | Treats sizeof(float) characters as a float in littleendian byte order. |
| F, f | Float | Treats sizeof(float) characters as a native float. |
| G | Float | Treats sizeof(double) characters as a double in network byte order. |
| g | String | Treats sizeof(float) characters as a float in network byte order. |
| H | String | Extracts hex nibbles from each character (most significant bit first) |
| h | String | Extracts hex nibbles from each character (least significant bit first). |
| I | Integer | Treats sizeof(int) (modified by _) successive characters as an unsigned native integer. |
| i | Integer | Treats sizeof(int) (modified by _) successive characters as a signed native integer. |
| L | Integer | Treats four (modified by _) successive characters as an unsigned native long integer. |
| l | Integer | Treats four (modified by _) successive characters as a signed native long integer. |
| M | String | Quoted-printable. |
| m | String | Base64-encoded. |
| N | Integer | Treats four characters as an unsigned long in network byte order. |
| n | Fixnum | Treats two characters as an unsigned short in network byte order. |
| P | String | Treats sizeof(char *) characters as a pointer, and return \emph{len} characters from the referenced location. |
| p | String | Treats sizeof(char *) characters as a pointer to a null-terminated string. |
| Q | Integer | Treats eight characters as an unsigned quad word (64 bits). |
| q | Integer | Treats eight characters as a signed quad word (64 bits). |
| S | Fixnum | Treats two (different if _ used) successive characters as an unsigned short in native byte order. |
| s | Fixnum | Treats two (different if _ used) successive characters as a signed short in native byte order. |
| U | Integer | UTF-8 characters as unsigned integers. |
| u | String | UU-encoded. |
| V | Fixnum | Treats four characters as an unsigned long in little-endian byte order. |
| v | Fixnum | Treats two characters as an unsigned short in little-endian byte order. |
| w | Integer | BER-compressed integer. |
| X | Skips backward one character. | |
| x | Skips forward one character. | |
| Z | String | With trailing nulls removed up to first null with *. |
| @ | Skips to the offset given by the length argument. |
Example
Try the following example to unpack various data.
"abc \0\0abc \0\0".unpack('A6Z6') #=> ["abc", "abc "]
"abc \0\0".unpack('a3a3') #=> ["abc", " \000\000"]
"abc \0abc \0".unpack('Z*Z*') #=> ["abc ", "abc "]
"aa".unpack('b8B8') #=> ["10000110", "01100001"]
"aaa".unpack('h2H2c') #=> ["16", "61", 97]
"\xfe\xff\xfe\xff".unpack('sS') #=> [-2, 65534]
"now = 20is".unpack('M*') #=> ["now is"]
"whole".unpack('xax2aX2aX1aX2a') #=> ["h", "e", "l", "l", "o"]Ruby-Arrays sind geordnete, ganzzahlig indizierte Sammlungen eines beliebigen Objekts. Jedes Element in einem Array ist einem Index zugeordnet und wird von diesem referenziert.
Die Array-Indizierung beginnt wie in C oder Java bei 0. Ein negativer Index wird relativ zum Ende des Arrays angenommen - das heißt, ein Index von -1 gibt das letzte Element des Arrays an, -2 ist das vorletzte Element im Array und so weiter.
Ruby-Arrays können Objekte wie String, Integer, Fixnum, Hash, Symbol und sogar andere Array-Objekte enthalten. Ruby-Arrays sind nicht so starr wie Arrays in anderen Sprachen. Ruby-Arrays wachsen automatisch, während ihnen Elemente hinzugefügt werden.
Arrays erstellen
Es gibt viele Möglichkeiten, ein Array zu erstellen oder zu initialisieren. Eine Möglichkeit ist die neue Klassenmethode -
names = Array.newSie können die Größe eines Arrays zum Zeitpunkt der Erstellung des Arrays festlegen.
names = Array.new(20)Die Array- Namen haben jetzt eine Größe oder Länge von 20 Elementen. Sie können die Größe eines Arrays entweder mit der Größen- oder der Längenmethode zurückgeben.
#!/usr/bin/ruby
names = Array.new(20)
puts names.size # This returns 20
puts names.length # This also returns 20Dies führt zu folgendem Ergebnis:
20
20Sie können jedem Element im Array wie folgt einen Wert zuweisen:
#!/usr/bin/ruby
names = Array.new(4, "mac")
puts "#{names}"Dies führt zu folgendem Ergebnis:
["mac", "mac", "mac", "mac"]Sie können auch einen Block mit new verwenden und jedes Element mit dem füllen, was der Block auswertet -
#!/usr/bin/ruby
nums = Array.new(10) { |e| e = e * 2 }
puts "#{nums}"Dies führt zu folgendem Ergebnis:
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]Es gibt eine andere Methode von Array, []. Es funktioniert so -
nums = Array.[](1, 2, 3, 4,5)Eine weitere Form der Array-Erstellung lautet wie folgt:
nums = Array[1, 2, 3, 4,5]Das in Core Ruby verfügbare Kernel- Modul verfügt über eine Array-Methode, die nur ein einziges Argument akzeptiert. Hier verwendet die Methode einen Bereich als Argument, um ein Array von Ziffern zu erstellen -
#!/usr/bin/ruby
digits = Array(0..9)
puts "#{digits}"Dies führt zu folgendem Ergebnis:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]Integrierte Array-Methoden
Wir benötigen eine Instanz des Array-Objekts, um eine Array-Methode aufzurufen. Wie wir gesehen haben, können Sie im Folgenden eine Instanz des Array-Objekts erstellen:
Array.[](...) [or] Array[...] [or] [...]Dies gibt ein neues Array zurück, das mit den angegebenen Objekten gefüllt ist. Mit dem erstellten Objekt können wir jetzt alle verfügbaren Instanzmethoden aufrufen. Zum Beispiel -
#!/usr/bin/ruby
digits = Array(0..9)
num = digits.at(6)
puts "#{num}"Dies führt zu folgendem Ergebnis:
6| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | array & other_array Gibt ein neues Array zurück, das Elemente enthält, die den beiden Arrays gemeinsam sind, ohne Duplikate. |
| 2 | array * int [or] array * str Gibt ein neues Array zurück, das durch Verketten der int-Kopien von self erstellt wurde. Mit einem String-Argument, das self.join (str) entspricht. |
| 3 | array + other_array Gibt ein neues Array zurück, das durch Verketten der beiden Arrays zu einem dritten Array erstellt wurde. |
| 4 | array - other_array Gibt ein neues Array zurück, das eine Kopie des ursprünglichen Arrays ist, und entfernt alle Elemente, die auch in other_array angezeigt werden. |
| 5 | array <=> other_array Vergleicht str mit other_str und gibt -1 (kleiner als), 0 (gleich) oder 1 (größer als) zurück. Der Vergleich unterscheidet zwischen Groß- und Kleinschreibung. |
| 6 | array | other_array Gibt ein neues Array zurück, indem das Array mit other_array verknüpft und Duplikate entfernt werden. |
| 7 | array << obj Schiebt das angegebene Objekt auf das Ende des Arrays. Dieser Ausdruck gibt das Array selbst zurück, sodass mehrere Anhänge miteinander verkettet werden können. |
| 8 | array <=> other_array Gibt eine Ganzzahl (-1, 0 oder +1) zurück, wenn dieses Array kleiner, gleich oder größer als other_array ist. |
| 9 | array == other_array Zwei Arrays sind gleich, wenn sie die gleiche Anzahl von Elementen enthalten und wenn jedes Element (gemäß Object. ==) dem entsprechenden Element im anderen Array entspricht. |
| 10 | array[index] [or] array[start, length] [or] array[range] [or] array.slice(index) [or] array.slice(start, length) [or] array.slice(range) Gibt das Element an Index , oder gibt einen Sub - Array beim Start Start und Weiterbildung für Länge Elemente oder gibt einen Sub - Array von spezifizierten Bereich . Negative Indizes zählen ab dem Ende des Arrays rückwärts (-1 ist das letzte Element). Gibt null zurück, wenn der Index (oder Startindex) außerhalb des Bereichs liegt. |
| 11 | array[index] = obj [or] array[start, length] = obj or an_array or nil [or] array[range] = obj or an_array or nil Setzt das Element am Index oder ersetzt ein Subarray beim Start Start und Weiterbildung für Länge Elemente oder ersetzt einen Sub - Array von spezifizierten Bereich . Wenn die Indizes größer als die aktuelle Kapazität des Arrays sind, wächst das Array automatisch. Negative Indizes zählen ab dem Ende des Arrays rückwärts. Fügt Elemente ein, wenn die Länge Null ist. Wenn in der zweiten und dritten Form nil verwendet wird, werden Elemente aus self gelöscht . |
| 12 | array.abbrev(pattern = nil) Berechnet die Menge der eindeutigen Abkürzungen für die Zeichenfolgen in self . Wenn ein Muster oder eine Zeichenfolge übergeben wird, werden nur die Zeichenfolgen berücksichtigt, die mit dem Muster übereinstimmen oder mit der Zeichenfolge beginnen. |
| 13 | array.assoc(obj) Durchsucht ein Array, dessen Elemente auch Arrays sind, wobei obj mit dem ersten Element jedes enthaltenen Arrays mit obj. == verglichen wird. Gibt das erste enthaltene Array zurück, das übereinstimmt, oder null, wenn keine Übereinstimmung gefunden wird. |
| 14 | array.at(index) Gibt das Element am Index zurück. Ein negativer Index zählt ab dem Ende des Selbst. Gibt null zurück, wenn der Index außerhalb des Bereichs liegt. |
| 15 | array.clear Entfernt alle Elemente aus dem Array. |
| 16 | array.collect { |item| block } [or] array.map { |item| block } Ruft den Block einmal für jedes Element des Selbst auf . Erstellt ein neues Array mit den vom Block zurückgegebenen Werten. |
| 17 | array.collect! { |item| block } [or] array.map! { |item| block } Ruft den Block einmal für jedes Element von self auf und ersetzt das Element durch den vom Block zurückgegebenen Wert . |
| 18 | array.compact Gibt eine Kopie von self zurück, bei der alle Null- Elemente entfernt wurden. |
| 19 | array.compact! Entfernt keine Elemente aus dem Array. Gibt null zurück, wenn keine Änderungen vorgenommen wurden. |
| 20 | array.concat(other_array) Hängt die Elemente in other_array an self an . |
| 21 | array.delete(obj) [or] array.delete(obj) { block } Löscht Elemente aus self , die gleich obj sind . Wenn der Artikel nicht gefunden wird, wird null zurückgegeben . Wenn der optionale Codeblock angegeben ist, wird das Ergebnis des Blocks zurückgegeben, wenn das Element nicht gefunden wird. |
| 22 | array.delete_at(index) Löscht das Element am angegebenen Index und gibt dieses Element zurück oder null, wenn der Index außerhalb des Bereichs liegt. |
| 23 | array.delete_if { |item| block } Löscht jedes Element von self, für das der Block true ergibt. |
| 24 | array.each { |item| block } Ruft den Block einmal für jedes Element in self auf und übergibt dieses Element als Parameter. |
| 25 | array.each_index { |index| block } Entspricht jeweils Array #, übergibt jedoch den Index des Elements anstelle des Elements selbst. |
| 26 | array.empty? Gibt true zurück, wenn das Self-Array keine Elemente enthält. |
| 27 | array.eql?(other) Gibt true zurück, wenn Array und andere dasselbe Objekt sind oder beide Arrays denselben Inhalt haben. |
| 28 | array.fetch(index) [or] array.fetch(index, default) [or] array.fetch(index) { |index| block } Versucht , das Element an der Position zurückzukehren Index . Wenn der Index außerhalb des Arrays liegt, löst das erste Formular eine IndexError- Ausnahme aus, das zweite Formular gibt den Standard zurück und das dritte Formular gibt den Wert des aufrufenden Blocks zurück , der den Index übergibt . Negative Werte des Index zählen ab dem Ende des Arrays. |
| 29 | array.fill(obj) [or] array.fill(obj, start [, length]) [or] array.fill(obj, range) [or] array.fill { |index| block } [or] array.fill(start [, length] ) { |index| block } [or] array.fill(range) { |index| block } Die ersten drei Formen setzen die ausgewählten Elemente des Selbst auf obj . Ein Start von Null entspricht Null. Eine Länge von Null entspricht der Selbstlänge . Die letzten drei Formulare füllen das Array mit dem Wert des Blocks. Der Block wird mit dem absoluten Index jedes zu füllenden Elements übergeben. |
| 30 | array.first [or] array.first(n) Gibt das erste Element oder die ersten n Elemente des Arrays zurück. Wenn das Array leer ist, gibt das erste Formular null und das zweite Formular ein leeres Array zurück. |
| 31 | array.flatten Gibt ein neues Array zurück, das eine eindimensionale Abflachung dieses Arrays darstellt (rekursiv). |
| 32 | array.flatten! Flacht das Array an Ort und Stelle ab. Gibt null zurück, wenn keine Änderungen vorgenommen wurden. (Array enthält keine Subarrays.) |
| 33 | array.frozen? Gibt true zurück, wenn das Array eingefroren ist (oder während des Sortierens vorübergehend eingefroren wird). |
| 34 | array.hash Berechnet einen Hash-Code für das Array. Zwei Arrays mit demselben Inhalt haben denselben Hashcode. |
| 35 | array.include?(obj) Gibt true zurück, wenn obj in self vorhanden ist , andernfalls false. |
| 36 | array.index(obj) Gibt den Index des ersten Objekts in self zurück , das == to obj ist. Gibt null zurück, wenn keine Übereinstimmung gefunden wird. |
| 37 | array.indexes(i1, i2, ... iN) [or] array.indices(i1, i2, ... iN) Diese Methode ist in der neuesten Version von Ruby veraltet. Verwenden Sie daher bitte Array # values_at. |
| 38 | array.indices(i1, i2, ... iN) [or] array.indexes(i1, i2, ... iN) Diese Methode ist in der neuesten Version von Ruby veraltet. Verwenden Sie daher bitte Array # values_at. |
| 39 | array.insert(index, obj...) Fügt die angegebenen Werte vor dem Element mit dem angegebenen Index ein (der negativ sein kann). |
| 40 | array.inspect Erstellt eine druckbare Version des Arrays. |
| 41 | array.join(sep = $,) Gibt eine Zeichenfolge zurück, die durch Konvertieren jedes Elements des Arrays in eine durch sep getrennte Zeichenfolge erstellt wurde . |
| 42 | array.last [or] array.last(n) Gibt die letzten Elemente von self zurück . Wenn das Array leer ist , gibt das erste Formular null zurück . |
| 43 | array.length Gibt die Anzahl der Elemente in self zurück . Kann Null sein. |
| 44 | array.map { |item| block } [or] array.collect { |item| block } Ruft den Block einmal für jedes Element des Selbst auf . Erstellt ein neues Array mit den vom Block zurückgegebenen Werten. |
| 45 | array.map! { |item| block } [or] array.collect! { |item| block } Ruft den Block einmal für jedes Element des Arrays auf und ersetzt das Element durch den vom Block zurückgegebenen Wert. |
| 46 | array.nitems Gibt die Anzahl der Nicht-Null-Elemente in self zurück . Kann Null sein. |
| 47 | array.pack(aTemplateString) Packt den Inhalt des Arrays gemäß den Anweisungen in einem TemplateString in eine Binärsequenz. Auf die Anweisungen A, a und Z kann eine Zählung folgen, die die Breite des resultierenden Feldes angibt. Die verbleibenden Anweisungen können auch eine Zählung vornehmen, die die Anzahl der zu konvertierenden Array-Elemente angibt. Wenn die Anzahl ein Sternchen (*) ist, werden alle verbleibenden Array-Elemente konvertiert. Auf jede der Anweisungen kann weiterhin ein Unterstrich (_) folgen, um die native Größe der zugrunde liegenden Plattform für den angegebenen Typ zu verwenden. Andernfalls verwenden sie eine plattformunabhängige Größe. Leerzeichen werden in der Vorlagenzeichenfolge ignoriert. |
| 48 | array.pop Entfernt das letzte Element aus dem Array und gibt es zurück oder null, wenn das Array leer ist. |
| 49 | array.push(obj, ...) Schiebt das angegebene Objekt an das Ende dieses Arrays. Dieser Ausdruck gibt das Array selbst zurück, sodass mehrere Anhänge miteinander verkettet werden können. |
| 50 | array.rassoc(key) Durchsucht das Array, dessen Elemente auch Arrays sind. Vergleicht den Schlüssel mit dem zweiten Element jedes enthaltenen Arrays mit ==. Gibt das erste enthaltene Array zurück, das übereinstimmt. |
| 51 | array.reject { |item| block } Gibt ein neues Array mit dem Artikel - Array , für die der Block nicht ist wahr . |
| 52 | array.reject! { |item| block } Löscht Elemente aus dem Array, für die der Block den Wert true hat , gibt jedoch null zurück, wenn keine Änderungen vorgenommen wurden. Entspricht dem Array # delete_if. |
| 53 | array.replace(other_array) Ersetzt den Inhalt des Arrays durch den Inhalt von other_array und schneidet ihn bei Bedarf ab oder erweitert ihn. |
| 54 | array.reverse Gibt ein neues Array zurück, das die Elemente des Arrays in umgekehrter Reihenfolge enthält. |
| 55 | array.reverse! Kehrt das Array um. |
| 56 | array.reverse_each {|item| block } Entspricht jeweils Array #, durchläuft jedoch das Array in umgekehrter Reihenfolge. |
| 57 | array.rindex(obj) Gibt den Index des letzten Objekts in Array == an obj zurück. Gibt null zurück, wenn keine Übereinstimmung gefunden wird. |
| 58 | array.select {|item| block } Ruft den Block auf, der aufeinanderfolgende Elemente aus dem Array übergibt, und gibt ein Array zurück, das die Elemente enthält, für die der Block einen wahren Wert zurückgibt . |
| 59 | array.shift Gibt das erste Element von self zurück und entfernt es (indem alle anderen Elemente um eins nach unten verschoben werden). Gibt null zurück, wenn das Array leer ist. |
| 60 | array.size Gibt die Länge des Arrays (Anzahl der Elemente) zurück. Alias für die Länge. |
| 61 | array.slice(index) [or] array.slice(start, length) [or] array.slice(range) [or] array[index] [or] array[start, length] [or] array[range] Gibt das Element an Index , oder gibt einen Sub - Array beim Start Start und Weiterbildung für Länge Elemente oder gibt einen Sub - Array von spezifizierten Bereich . Negative Indizes zählen ab dem Ende des Arrays rückwärts (-1 ist das letzte Element). Gibt null zurück, wenn der Index (oder der Startindex) außerhalb des Bereichs liegt. |
| 62 | array.slice!(index) [or] array.slice!(start, length) [or] array.slice!(range) Löscht die Elemente, die durch einen Index (optional mit einer Länge) oder durch einen Bereich angegeben werden . Gibt das gelöschte Objekt, Subarray oder Null zurück, wenn der Index außerhalb des Bereichs liegt. |
| 63 | array.sort [or] array.sort { | a,b | block } Gibt ein neues Array zurück, das durch Sortieren von self erstellt wurde. |
| 64 | array.sort! [or] array.sort! { | a,b | block } Sortiert sich selbst. |
| 65 | array.to_a Gibt sich selbst zurück . Wenn es für eine Unterklasse von Array aufgerufen wird , konvertiert es den Empfänger in ein Array-Objekt. |
| 66 | array.to_ary Gibt sich selbst zurück. |
| 67 | array.to_s Gibt self.join zurück. |
| 68 | array.transpose Angenommen, self ist ein Array von Arrays und transponiert die Zeilen und Spalten. |
| 69 | array.uniq Gibt ein neues Array zurück, indem doppelte Werte im Array entfernt werden . |
| 70 | array.uniq! Entfernt doppelte Elemente aus sich selbst . Gibt null zurück, wenn keine Änderungen vorgenommen wurden (dh es wurden keine Duplikate gefunden). |
| 71 | array.unshift(obj, ...) Stellt Objekte vor das Array, andere Elemente nach oben. |
| 72 | array.values_at(selector,...) Gibt ein Array zurück, das die Elemente in self enthält, die dem angegebenen Selektor (einem oder mehreren) entsprechen. Die Selektoren können entweder ganzzahlige Indizes oder Bereiche sein. |
| 73 | array.zip(arg, ...) [or] array.zip(arg, ...){ | arr | block } Konvertiert alle Argumente in Arrays und führt dann Elemente des Arrays mit entsprechenden Elementen aus jedem Argument zusammen. |
Array Pack-Anweisungen
| Sr.Nr. | Richtlinie & Beschreibung |
|---|---|
| 1 | @ Bewegt sich in die absolute Position. |
| 2 | A ASCII-Zeichenfolge (Leerzeichen aufgefüllt, Anzahl ist Breite). |
| 3 | a ASCII-Zeichenfolge (null aufgefüllt, Anzahl ist Breite). |
| 4 | B Zeichenfolge (absteigende Bitreihenfolge). |
| 5 | b Bitfolge (aufsteigende Bitreihenfolge). |
| 6 | C Vorzeichenloses Zeichen. |
| 7 | c Verkohlen. |
| 8 | D, d Float mit doppelter Genauigkeit, natives Format. |
| 9 | E Float mit doppelter Genauigkeit, Little-Endian-Bytereihenfolge. |
| 10 | e Float mit einfacher Genauigkeit, Little-Endian-Bytereihenfolge. |
| 11 | F, f Float mit einfacher Genauigkeit, natives Format. |
| 12 | G Float mit doppelter Genauigkeit, Netzwerk-Bytereihenfolge (Big-Endian). |
| 13 | g Float mit einfacher Genauigkeit, Netzwerk-Bytereihenfolge (Big-Endian). |
| 14 | H Hex-Saite (hohes Knabbern zuerst). |
| 15 | h Hex-String (Low Nibble zuerst). |
| 16 | I Ganzzahl ohne Vorzeichen. |
| 17 | i Ganze Zahl. |
| 18 | L Lange ohne Vorzeichen. |
| 19 | l Lange. |
| 20 | M Zitierte druckbare MIME-Codierung (siehe RFC 2045). |
| 21 | m Base64-codierte Zeichenfolge. |
| 22 | N Lange Netzwerk-Bytereihenfolge (Big-Endian). |
| 23 | n Kurze Netzwerk-Bytereihenfolge (Big-Endian). |
| 24 | P Zeiger auf eine Struktur (Zeichenfolge fester Länge). |
| 25 | p Zeiger auf eine nullterminierte Zeichenfolge. |
| 26 | Q, q 64-Bit-Nummer. |
| 27 | S Kurz ohne Vorzeichen. |
| 28 | s Kurz. |
| 29 | U UTF-8. |
| 30 | u UU-codierte Zeichenfolge. |
| 31 | V Lange Little-Endian-Bytereihenfolge. |
| 32 | v Kurze Little-Endian-Bytereihenfolge. |
| 33 | w BER-komprimierte Ganzzahl \ fnm. |
| 34 | X Sichern Sie ein Byte. |
| 35 | x Null-Byte. |
| 36 | Z Gleich wie a, außer dass null mit * hinzugefügt wird. |
Beispiel
Versuchen Sie das folgende Beispiel, um verschiedene Daten zu packen.
a = [ "a", "b", "c" ]
n = [ 65, 66, 67 ]
puts a.pack("A3A3A3") #=> "a b c "
puts a.pack("a3a3a3") #=> "a\000\000b\000\000c\000\000"
puts n.pack("ccc") #=> "ABC"Dies führt zu folgendem Ergebnis:
a b c
abc
ABCEin Hash ist eine Sammlung von Schlüssel-Wert-Paaren wie folgt: "Mitarbeiter" => "Gehalt". Es ähnelt einem Array, außer dass die Indizierung über beliebige Schlüssel eines beliebigen Objekttyps und nicht über einen ganzzahligen Index erfolgt.
Die Reihenfolge, in der Sie einen Hash nach Schlüssel oder Wert durchlaufen, scheint willkürlich zu sein und liegt im Allgemeinen nicht in der Einfügereihenfolge. Wenn Sie versuchen, mit einem nicht vorhandenen Schlüssel auf einen Hash zuzugreifen, gibt die Methode nil zurück .
Hashes erstellen
Wie bei Arrays gibt es verschiedene Möglichkeiten, Hashes zu erstellen. Sie können mit der neuen Klassenmethode einen leeren Hash erstellen -
months = Hash.newSie können auch verwenden , neu nur sonst ist eine Hash mit einem Standardwert zu schaffen, die Null -
months = Hash.new( "month" )
or
months = Hash.new "month"Wenn Sie auf einen Schlüssel in einem Hash mit einem Standardwert zugreifen und der Schlüssel oder Wert nicht vorhanden ist, wird beim Zugriff auf den Hash der Standardwert zurückgegeben.
#!/usr/bin/ruby
months = Hash.new( "month" )
puts "#{months[0]}"
puts "#{months[72]}"Dies führt zu folgendem Ergebnis:
month
month#!/usr/bin/ruby
H = Hash["a" => 100, "b" => 200]
puts "#{H['a']}"
puts "#{H['b']}"Dies führt zu folgendem Ergebnis:
100
200Sie können jedes Ruby-Objekt als Schlüssel oder Wert verwenden, auch als Array. Das folgende Beispiel ist also gültig -
[1,"jan"] => "January"Integrierte Hash-Methoden
Wir benötigen eine Instanz des Hash-Objekts, um eine Hash-Methode aufzurufen. Wie wir gesehen haben, können Sie im Folgenden eine Instanz des Hash-Objekts erstellen:
Hash[[key =>|, value]* ] or
Hash.new [or] Hash.new(obj) [or]
Hash.new { |hash, key| block }Dies gibt einen neuen Hash zurück, der mit den angegebenen Objekten gefüllt ist. Mit dem erstellten Objekt können wir nun alle verfügbaren Instanzmethoden aufrufen. Zum Beispiel -
#!/usr/bin/ruby
$, = ", "
months = Hash.new( "month" )
months = {"1" => "January", "2" => "February"}
keys = months.keys
puts "#{keys}"Dies führt zu folgendem Ergebnis:
["1", "2"]Im Folgenden sind die öffentlichen Hash-Methoden aufgeführt (vorausgesetzt, Hash ist ein Array-Objekt).
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | hash == other_hash Testet, ob zwei Hashes gleich sind, basierend darauf, ob sie die gleiche Anzahl von Schlüssel-Wert-Paaren haben und ob die Schlüssel-Wert-Paare mit dem entsprechenden Paar in jedem Hash übereinstimmen. |
| 2 | hash.[key] Verweist mit einem Schlüssel auf einen Wert aus dem Hash. Wenn der Schlüssel nicht gefunden wird, wird ein Standardwert zurückgegeben. |
| 3 | hash.[key] = value Ordnet den durch value angegebenen Wert dem durch key angegebenen Schlüssel zu . |
| 4 | hash.clear Entfernt alle Schlüssel-Wert-Paare aus dem Hash. |
| 5 | hash.default(key = nil) Gibt den Standardwert für Hash zurück , nil, wenn nicht standardmäßig = festgelegt. ([] gibt einen Standardwert zurück, wenn der Schlüssel nicht im Hash vorhanden ist .) |
| 6 | hash.default = obj Legt einen Standardwert für Hash fest . |
| 7 | hash.default_proc Gibt einen Block zurück, wenn ein Hash von einem Block erstellt wurde. |
| 8 | hash.delete(key) [or] array.delete(key) { |key| block } Löscht ein Schlüssel-Wert-Paar aus Hash für Schlüssel . Wenn ein Block verwendet wird, wird das Ergebnis eines Blocks zurückgegeben, wenn kein Paar gefunden wird. Vergleiche delete_if . |
| 9 | hash.delete_if { |key,value| block } Löscht ein Schlüssel-Wert-Paar aus dem Hash für jedes Paar, das der Block als wahr auswertet . |
| 10 | hash.each { |key,value| block } Iteriert über Hash , ruft den Block für jeden Schlüssel einmal auf und übergibt den Schlüsselwert als Array mit zwei Elementen. |
| 11 | hash.each_key { |key| block } Iteriert über Hash , ruft den Block einmal für jeden Schlüssel auf und übergibt den Schlüssel als Parameter. |
| 12 | hash.each_key { |key_value_array| block } Iteriert über Hash , ruft den Block für jeden Schlüssel einmal auf und übergibt den Schlüssel und den Wert als Parameter. |
| 13 | hash.each_key { |value| block } Iteriert über Hash , ruft den Block für jeden Schlüssel einmal auf und übergibt den Wert als Parameter. |
| 14 | hash.empty? Testet, ob der Hash leer ist (keine Schlüssel-Wert-Paare enthält) und gibt true oder false zurück . |
| 15 | hash.fetch(key [, default] ) [or] hash.fetch(key) { | key | block } Gibt einen Wert aus dem Hash für den angegebenen Schlüssel zurück . Wenn der Schlüssel nicht gefunden werden kann und keine anderen Argumente vorhanden sind, wird eine IndexError- Ausnahme ausgelöst . Wenn der Standardwert angegeben ist, wird er zurückgegeben. Wenn der optionale Block angegeben wird, wird sein Ergebnis zurückgegeben. |
| 16 | hash.has_key?(key) [or] hash.include?(key) [or] hash.key?(key) [or] hash.member?(key) Testet, ob ein bestimmter Schlüssel im Hash vorhanden ist, und gibt true oder false zurück . |
| 17 | hash.has_value?(value) Testet, ob der Hash den angegebenen Wert enthält . |
| 18 | hash.index(value) Gibt den Schlüssel für den angegebenen Wert in Hash zurück, nil, wenn kein übereinstimmender Wert gefunden wird. |
| 19 | hash.indexes(keys) Gibt ein neues Array zurück, das aus Werten für die angegebenen Schlüssel besteht. Fügt den Standardwert für Schlüssel ein, die nicht gefunden wurden. Diese Methode ist veraltet. Verwenden Sie select. |
| 20 | hash.indices(keys) Gibt ein neues Array zurück, das aus Werten für die angegebenen Schlüssel besteht. Fügt den Standardwert für Schlüssel ein, die nicht gefunden wurden. Diese Methode ist veraltet. Verwenden Sie select. |
| 21 | hash.inspect Gibt eine hübsche Druckzeichenfolgenversion von Hash zurück. |
| 22 | hash.invert Erstellt einen neuen Hash , in dem Schlüssel und Werte aus dem Hash invertiert werden . Das heißt, im neuen Hash werden die Schlüssel aus dem Hash zu Werten und die Werte zu Schlüsseln. |
| 23 | hash.keys Erstellt ein neues Array mit Schlüsseln aus Hash . |
| 24 | hash.length Gibt die Größe oder Länge des Hash als Ganzzahl zurück. |
| 25 | hash.merge(other_hash) [or] hash.merge(other_hash) { |key, oldval, newval| block } Gibt einen neuen Hash zurück, der den Inhalt von Hash und other_hash enthält , wobei Paare in Hash mit doppelten Schlüsseln mit denen von other_hash überschrieben werden . |
| 26 | hash.merge!(other_hash) [or] hash.merge!(other_hash) { |key, oldval, newval| block } Entspricht dem Zusammenführen, jedoch werden Änderungen vorgenommen. |
| 27 | hash.rehash Erstellt einen Hash basierend auf den aktuellen Werten für jeden Schlüssel neu . Wenn sich die Werte seit dem Einfügen geändert haben, indiziert diese Methode den Hash neu . |
| 28 | hash.reject { |key, value| block } Erstellt einen neuen Hash für jedes Paar, das der Block als wahr bewertet |
| 29 | hash.reject! { |key, value| block } Entspricht der Ablehnung , es werden jedoch Änderungen vorgenommen. |
| 30 | hash.replace(other_hash) Ersetzt den Inhalt von Hash durch den Inhalt von other_hash . |
| 31 | hash.select { |key, value| block } Gibt ein neues Array zurück, das aus Schlüssel-Wert-Paaren aus dem Hash besteht, für das der Block true zurückgibt . |
| 32 | hash.shift Entfernt ein Schlüssel-Wert-Paar aus dem Hash und gibt es als Array mit zwei Elementen zurück. |
| 33 | hash.size Gibt die Größe oder Länge des Hash als Ganzzahl zurück. |
| 34 | hash.sort Konvertiert Hash in ein zweidimensionales Array, das Arrays von Schlüssel-Wert-Paaren enthält, und sortiert es dann als Array. |
| 35 | hash.store(key, value) Speichert ein Schlüssel-Wert-Paar in Hash . |
| 36 | hash.to_a Erstellt ein zweidimensionales Array aus Hash. Jedes Schlüssel / Wert-Paar wird in ein Array konvertiert, und alle diese Arrays werden in einem enthaltenden Array gespeichert. |
| 37 | hash.to_hash Gibt Hash (Selbst) zurück. |
| 38 | hash.to_s Konvertiert Hash in ein Array und konvertiert dieses Array dann in eine Zeichenfolge. |
| 39 | hash.update(other_hash) [or] hash.update(other_hash) {|key, oldval, newval| block} Gibt einen neuen Hash zurück, der den Inhalt von Hash und other_hash enthält , wobei Paare in Hash mit doppelten Schlüsseln mit denen von other_hash überschrieben werden . |
| 40 | hash.value?(value) Testet, ob der Hash den angegebenen Wert enthält . |
| 41 | hash.values Gibt ein neues Array zurück, das alle Werte von Hash enthält . |
| 42 | hash.values_at(obj, ...) Gibt ein neues Array zurück, das die Werte aus dem Hash enthält , die dem angegebenen Schlüssel oder den angegebenen Schlüsseln zugeordnet sind. |
Das TimeKlasse repräsentiert Datum und Uhrzeit in Ruby. Es ist eine dünne Schicht über der vom Betriebssystem bereitgestellten Datums- und Uhrzeitfunktionalität des Systems. Diese Klasse kann auf Ihrem System möglicherweise keine Daten vor 1970 oder nach 2038 darstellen.
Dieses Kapitel macht Sie mit den wichtigsten Konzepten von Datum und Uhrzeit vertraut.
Aktuelles Datum und Uhrzeit abrufen
Im Folgenden finden Sie ein einfaches Beispiel, um das aktuelle Datum und die aktuelle Uhrzeit abzurufen.
#!/usr/bin/ruby -w
time1 = Time.new
puts "Current Time : " + time1.inspect
# Time.now is a synonym:
time2 = Time.now
puts "Current Time : " + time2.inspectDies führt zu folgendem Ergebnis:
Current Time : Mon Jun 02 12:02:39 -0700 2008
Current Time : Mon Jun 02 12:02:39 -0700 2008Komponenten eines Datums und einer Uhrzeit abrufen
Wir können das Time- Objekt verwenden, um verschiedene Komponenten von Datum und Uhrzeit abzurufen. Das folgende Beispiel zeigt dasselbe -
#!/usr/bin/ruby -w
time = Time.new
# Components of a Time
puts "Current Time : " + time.inspect
puts time.year # => Year of the date
puts time.month # => Month of the date (1 to 12)
puts time.day # => Day of the date (1 to 31 )
puts time.wday # => 0: Day of week: 0 is Sunday
puts time.yday # => 365: Day of year
puts time.hour # => 23: 24-hour clock
puts time.min # => 59
puts time.sec # => 59
puts time.usec # => 999999: microseconds
puts time.zone # => "UTC": timezone nameDies führt zu folgendem Ergebnis:
Current Time : Mon Jun 02 12:03:08 -0700 2008
2008
6
2
1
154
12
3
8
247476
UTCTime.utc-, Time.gm- und Time.local-Funktionen
Diese beiden Funktionen können verwendet werden, um das Datum in einem Standardformat wie folgt zu formatieren:
# July 8, 2008
Time.local(2008, 7, 8)
# July 8, 2008, 09:10am, local time
Time.local(2008, 7, 8, 9, 10)
# July 8, 2008, 09:10 UTC
Time.utc(2008, 7, 8, 9, 10)
# July 8, 2008, 09:10:11 GMT (same as UTC)
Time.gm(2008, 7, 8, 9, 10, 11)Das folgende Beispiel zeigt, wie alle Komponenten in einem Array im folgenden Format abgerufen werden:
[sec,min,hour,day,month,year,wday,yday,isdst,zone]Versuchen Sie Folgendes:
#!/usr/bin/ruby -w
time = Time.new
values = time.to_a
p valuesDies führt zu folgendem Ergebnis:
[26, 10, 12, 2, 6, 2008, 1, 154, false, "MST"]Dieses Array kann an die Funktionen Time.utc oder Time.local übergeben werden, um ein anderes Datumsformat wie folgt zu erhalten:
#!/usr/bin/ruby -w
time = Time.new
values = time.to_a
puts Time.utc(*values)Dies führt zu folgendem Ergebnis:
Mon Jun 02 12:15:36 UTC 2008Das Folgende ist der Weg, um die Zeit intern als Sekunden seit der (plattformabhängigen) Epoche darzustellen -
# Returns number of seconds since epoch
time = Time.now.to_i
# Convert number of seconds into Time object.
Time.at(time)
# Returns second since epoch which includes microseconds
time = Time.now.to_fZeitzonen und Sommerzeit
Sie können ein Zeitobjekt verwenden , um alle Informationen zu Zeitzonen und Sommerzeit wie folgt abzurufen:
time = Time.new
# Here is the interpretation
time.zone # => "UTC": return the timezone
time.utc_offset # => 0: UTC is 0 seconds offset from UTC
time.zone # => "PST" (or whatever your timezone is)
time.isdst # => false: If UTC does not have DST.
time.utc? # => true: if t is in UTC time zone
time.localtime # Convert to local timezone.
time.gmtime # Convert back to UTC.
time.getlocal # Return a new Time object in local zone
time.getutc # Return a new Time object in UTCFormatierungszeiten und -daten
Es gibt verschiedene Möglichkeiten, Datum und Uhrzeit zu formatieren. Hier ist ein Beispiel, das einige zeigt -
#!/usr/bin/ruby -w
time = Time.new
puts time.to_s
puts time.ctime
puts time.localtime
puts time.strftime("%Y-%m-%d %H:%M:%S")Dies führt zu folgendem Ergebnis:
Mon Jun 02 12:35:19 -0700 2008
Mon Jun 2 12:35:19 2008
Mon Jun 02 12:35:19 -0700 2008
2008-06-02 12:35:19Zeitformatierungsanweisungen
Diese Anweisungen in der folgenden Tabelle werden mit der Methode Time.strftime verwendet .
| Sr.Nr. | Richtlinie & Beschreibung |
|---|---|
| 1 | %a Der abgekürzte Wochentagsname (So). |
| 2 | %A Der vollständige Wochentagsname (Sonntag). |
| 3 | %b Der abgekürzte Monatsname (Jan). |
| 4 | %B Der vollständige Monatsname (Januar). |
| 5 | %c Die bevorzugte lokale Datums- und Uhrzeitdarstellung. |
| 6 | %d Tag des Monats (01 bis 31). |
| 7 | %H Tageszeit, 24-Stunden-Uhr (00 bis 23). |
| 8 | %I Stunde des Tages, 12-Stunden-Uhr (01 bis 12). |
| 9 | %j Tag des Jahres (001 bis 366). |
| 10 | %m Monat des Jahres (01 bis 12). |
| 11 | %M Stunde der Stunde (00 bis 59). |
| 12 | %p Meridiananzeige (AM oder PM). |
| 13 | %S Sekunde der Minute (00 bis 60). |
| 14 | %U Wochennummer des laufenden Jahres, beginnend mit dem ersten Sonntag als erstem Tag der ersten Woche (00 bis 53). |
| 15 | %W Wochennummer des laufenden Jahres, beginnend mit dem ersten Montag als erstem Tag der ersten Woche (00 bis 53). |
| 16 | %w Wochentag (Sonntag ist 0, 0 bis 6). |
| 17 | %x Bevorzugte Darstellung nur für das Datum, keine Zeit. |
| 18 | %X Bevorzugte Darstellung nur für die Zeit, kein Datum. |
| 19 | %y Jahr ohne Jahrhundert (00 bis 99). |
| 20 | %Y Jahr mit Jahrhundert. |
| 21 | %Z Name der Zeitzone. |
| 22 | %% Literal% Zeichen. |
Zeitarithmetik
Sie können einfache Arithmetik mit der Zeit wie folgt ausführen:
now = Time.now # Current time
puts now
past = now - 10 # 10 seconds ago. Time - number => Time
puts past
future = now + 10 # 10 seconds from now Time + number => Time
puts future
diff = future - past # => 10 Time - Time => number of seconds
puts diffDies führt zu folgendem Ergebnis:
Thu Aug 01 20:57:05 -0700 2013
Thu Aug 01 20:56:55 -0700 2013
Thu Aug 01 20:57:15 -0700 2013
20.0Bereiche treten überall auf: Januar bis Dezember, 0 bis 9, Zeilen 50 bis 67 und so weiter. Ruby unterstützt Bereiche und ermöglicht es uns, Bereiche auf verschiedene Arten zu verwenden -
- Bereiche als Sequenzen
- Bereiche als Bedingungen
- Bereiche als Intervalle
Bereiche als Sequenzen
Die erste und vielleicht natürlichste Verwendung von Bereichen besteht darin, eine Sequenz auszudrücken. Sequenzen haben einen Startpunkt, einen Endpunkt und eine Möglichkeit, aufeinanderfolgende Werte in der Sequenz zu erzeugen.
Ruby erstellt diese Sequenzen mit dem ''..'' und ''...''Bereichsoperatoren. Das Zwei-Punkt-Formular erstellt einen Inklusivbereich, während das Drei-Punkt-Formular einen Bereich erstellt, der den angegebenen hohen Wert ausschließt.
(1..5) #==> 1, 2, 3, 4, 5
(1...5) #==> 1, 2, 3, 4
('a'..'d') #==> 'a', 'b', 'c', 'd'Die Sequenz 1..100 wird als Range- Objekt gehalten, das Verweise auf zwei Fixnum- Objekte enthält. Bei Bedarf können Sie einen Bereich mit der Methode to_a in eine Liste konvertieren . Versuchen Sie das folgende Beispiel -
#!/usr/bin/ruby
$, =", " # Array value separator
range1 = (1..10).to_a
range2 = ('bar'..'bat').to_a
puts "#{range1}"
puts "#{range2}"Dies führt zu folgendem Ergebnis:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
["bar", "bas", "bat"]Bereiche implementieren Methoden, mit denen Sie sie durchlaufen und ihren Inhalt auf verschiedene Weise testen können -
#!/usr/bin/ruby
# Assume a range
digits = 0..9
puts digits.include?(5)
ret = digits.min
puts "Min value is #{ret}"
ret = digits.max
puts "Max value is #{ret}"
ret = digits.reject {|i| i < 5 }
puts "Rejected values are #{ret}"
digits.each do |digit|
puts "In Loop #{digit}"
endDies führt zu folgendem Ergebnis:
true
Min value is 0
Max value is 9
Rejected values are 5, 6, 7, 8, 9
In Loop 0
In Loop 1
In Loop 2
In Loop 3
In Loop 4
In Loop 5
In Loop 6
In Loop 7
In Loop 8
In Loop 9Bereiche als Bedingungen
Bereiche können auch als bedingte Ausdrücke verwendet werden. Zum Beispiel Der folgenden Codefragment druckt Sätze von Zeilen von der Standardeingabe, wobei die erste Zeile in jedem Satz , das Wort enthält Start- und die letzte Zeile der Wortende -
while gets
print if /start/../end/
endBereiche können in case-Anweisungen verwendet werden -
#!/usr/bin/ruby
score = 70
result = case score
when 0..40 then "Fail"
when 41..60 then "Pass"
when 61..70 then "Pass with Merit"
when 71..100 then "Pass with Distinction"
else "Invalid Score"
end
puts resultDies führt zu folgendem Ergebnis:
Pass with MeritBereiche als Intervalle
Eine letzte Verwendung des vielseitigen Bereichs ist ein Intervalltest: Überprüfen, ob ein Wert innerhalb des durch den Bereich dargestellten Intervalls liegt. Dies erfolgt mit ===, dem Gleichheitsoperator für Groß- und Kleinschreibung.
#!/usr/bin/ruby
if ((1..10) === 5)
puts "5 lies in (1..10)"
end
if (('a'..'j') === 'c')
puts "c lies in ('a'..'j')"
end
if (('a'..'j') === 'z')
puts "z lies in ('a'..'j')"
endDies führt zu folgendem Ergebnis:
5 lies in (1..10)
c lies in ('a'..'j')Iteratoren sind nichts anderes als Methoden, die von Sammlungen unterstützt werden . Objekte, die eine Gruppe von Datenelementen speichern, werden als Sammlungen bezeichnet. In Ruby können Arrays und Hashes als Sammlungen bezeichnet werden.
Iteratoren geben alle Elemente einer Sammlung nacheinander zurück. Wir werden hier jeweils zwei Iteratoren diskutieren und sammeln . Schauen wir uns diese im Detail an.
Ruby jeden Iterator
Jeder Iterator gibt alle Elemente eines Arrays oder eines Hash zurück.
Syntax
collection.each do |variable|
code
endFührt Code für jedes Element in der Sammlung aus . Hier kann die Sammlung ein Array oder ein Ruby-Hash sein.
Beispiel
#!/usr/bin/ruby
ary = [1,2,3,4,5]
ary.each do |i|
puts i
endDies führt zu folgendem Ergebnis:
1
2
3
4
5Sie ordnen jeden Iterator immer einem Block zu. Es gibt jeden Wert des Arrays einzeln an den Block zurück. Der Wert wird in der Variablen gespeicherti und dann auf dem Bildschirm angezeigt.
Ruby sammelt Iterator
Die collect Iterator gibt alle Elemente einer Sammlung.
Syntax
collection = collection.collectDie Erfassungsmethode muss nicht immer einem Block zugeordnet sein. Die Methode collect gibt die gesamte Sammlung zurück, unabhängig davon, ob es sich um ein Array oder einen Hash handelt.
Beispiel
#!/usr/bin/ruby
a = [1,2,3,4,5]
b = Array.new
b = a.collect
puts bDies führt zu folgendem Ergebnis:
1
2
3
4
5NOTE- Die Collect- Methode ist nicht der richtige Weg, um zwischen Arrays zu kopieren. Es gibt eine andere Methode namens Klon , mit der ein Array in ein anderes Array kopiert werden sollte.
Normalerweise verwenden Sie die Methode collect, wenn Sie mit jedem der Werte etwas tun möchten, um das neue Array abzurufen. Beispielsweise erzeugt dieser Code ein Array b, das das 10-fache jedes Wertes in a enthält .
#!/usr/bin/ruby
a = [1,2,3,4,5]
b = a.collect{|x| 10*x}
puts bDies führt zu folgendem Ergebnis:
10
20
30
40
50Ruby bietet eine ganze Reihe von E / A-bezogenen Methoden, die im Kernel-Modul implementiert sind. Alle E / A-Methoden werden von der Klasse IO abgeleitet.
Die Klasse IO bietet alle grundlegenden Methoden, wie Lesen, Schreiben, bekommt, puts, Readline-, getc, und printf .
Dieses Kapitel behandelt alle grundlegenden E / A-Funktionen, die in Ruby verfügbar sind. Weitere Funktionen finden Sie unter Ruby Class IO .
Die Puts-Anweisung
In den vorherigen Kapiteln haben Sie Variablen Werte zugewiesen und die Ausgabe dann mit der Puts- Anweisung gedruckt .
Die Anweisung putt weist das Programm an, den in der Variablen gespeicherten Wert anzuzeigen. Dadurch wird am Ende jeder geschriebenen Zeile eine neue Zeile hinzugefügt.
Beispiel
#!/usr/bin/ruby
val1 = "This is variable one"
val2 = "This is variable two"
puts val1
puts val2Dies führt zu folgendem Ergebnis:
This is variable one
This is variable twoDas bekommt Statement
Die get- Anweisung kann verwendet werden, um alle Eingaben des Benutzers vom Standardbildschirm STDIN zu übernehmen.
Beispiel
Der folgende Code zeigt Ihnen, wie Sie die Anweisung gets verwenden. Dieser Code fordert den Benutzer auf, einen Wert einzugeben, der in einem variablen Wert gespeichert und schließlich auf STDOUT gedruckt wird.
#!/usr/bin/ruby
puts "Enter a value :"
val = gets
puts valDies führt zu folgendem Ergebnis:
Enter a value :
This is entered value
This is entered valueDie putc Aussage
Im Gegensatz zur put- Anweisung, die die gesamte Zeichenfolge auf dem Bildschirm ausgibt , kann mit der putc- Anweisung jeweils ein Zeichen ausgegeben werden.
Beispiel
Die Ausgabe des folgenden Codes ist nur das Zeichen H -
#!/usr/bin/ruby
str = "Hello Ruby!"
putc strDies führt zu folgendem Ergebnis:
HDie Druckanweisung
Die print- Anweisung ähnelt der put- Anweisung. Der einzige Unterschied besteht darin , dass die Puts Aussage in die nächste Zeile geht nach den Inhalt gedruckt wird , während bei der Druck Anweisung der Cursor auf der gleichen Linie positioniert ist.
Beispiel
#!/usr/bin/ruby
print "Hello World"
print "Good Morning"Dies führt zu folgendem Ergebnis:
Hello WorldGood MorningDateien öffnen und schließen
Bis jetzt haben Sie die Standardeingabe und -ausgabe gelesen und geschrieben. Jetzt werden wir sehen, wie man mit tatsächlichen Datendateien spielt.
Die File.new-Methode
Sie können ein erstellen Datei - Objekt mit File.new zum Lesen, Schreiben oder beides, je nach Betriebsart String - Methode. Schließlich können Sie die File.close- Methode verwenden, um diese Datei zu schließen.
Syntax
aFile = File.new("filename", "mode")
# ... process the file
aFile.closeDie File.open-Methode
Mit der File.open- Methode können Sie ein neues Dateiobjekt erstellen und dieses Dateiobjekt einer Datei zuweisen. Es gibt jedoch einen Unterschied zwischen den Methoden File.open und File.new . Der Unterschied besteht darin, dass die File.open- Methode einem Block zugeordnet werden kann, während Sie dies mit der File.new- Methode nicht tun können .
File.open("filename", "mode") do |aFile|
# ... process the file
end| Sr.Nr. | Modi & Beschreibung |
|---|---|
| 1 | r Schreibgeschützter Modus. Der Dateizeiger befindet sich am Anfang der Datei. Dies ist der Standardmodus. |
| 2 | r+ Lese- / Schreibmodus. Der Dateizeiger befindet sich am Anfang der Datei. |
| 3 | w Nur-Schreib-Modus. Überschreibt die Datei, wenn die Datei vorhanden ist. Wenn die Datei nicht vorhanden ist, wird eine neue Datei zum Schreiben erstellt. |
| 4 | w+ Lese- / Schreibmodus. Überschreibt die vorhandene Datei, wenn die Datei vorhanden ist. Wenn die Datei nicht vorhanden ist, wird eine neue Datei zum Lesen und Schreiben erstellt. |
| 5 | a Nur-Schreib-Modus. Der Dateizeiger befindet sich am Ende der Datei, wenn die Datei vorhanden ist. Das heißt, die Datei befindet sich im Anhänge-Modus. Wenn die Datei nicht vorhanden ist, wird eine neue Datei zum Schreiben erstellt. |
| 6 | a+ Lese- und Schreibmodus. Der Dateizeiger befindet sich am Ende der Datei, wenn die Datei vorhanden ist. Die Datei wird im Anhänge-Modus geöffnet. Wenn die Datei nicht vorhanden ist, wird eine neue Datei zum Lesen und Schreiben erstellt. |
Dateien lesen und schreiben
Die gleichen Methoden, die wir für 'einfache' E / A verwendet haben, sind für alle Dateiobjekte verfügbar. Get liest also eine Zeile aus der Standardeingabe und aFile.gets liest eine Zeile aus dem Dateiobjekt aFile.
E / A-Objekte bieten jedoch zusätzliche Zugriffsmethoden, um unser Leben zu erleichtern.
Die Sysread-Methode
Mit der Methode sysread können Sie den Inhalt einer Datei lesen. Sie können die Datei in jedem der Modi öffnen, wenn Sie die Methode sysread verwenden. Zum Beispiel -
Es folgt die Eingabetextdatei -
This is a simple text file for testing purpose.Versuchen wir nun, diese Datei zu lesen -
#!/usr/bin/ruby
aFile = File.new("input.txt", "r")
if aFile
content = aFile.sysread(20)
puts content
else
puts "Unable to open file!"
endDiese Anweisung gibt die ersten 20 Zeichen der Datei aus. Der Dateizeiger wird nun auf das 21. Zeichen in der Datei gesetzt.
Die Syswrite-Methode
Mit der Methode syswrite können Sie den Inhalt in eine Datei schreiben. Sie müssen die Datei im Schreibmodus öffnen, wenn Sie die Methode syswrite verwenden. Zum Beispiel -
#!/usr/bin/ruby
aFile = File.new("input.txt", "r+")
if aFile
aFile.syswrite("ABCDEF")
else
puts "Unable to open file!"
endDiese Anweisung schreibt "ABCDEF" in die Datei.
Die each_byte-Methode
Diese Methode gehört zur Klasse Datei . Die Methode each_byte ist immer einem Block zugeordnet. Betrachten Sie das folgende Codebeispiel -
#!/usr/bin/ruby
aFile = File.new("input.txt", "r+")
if aFile
aFile.syswrite("ABCDEF")
aFile.each_byte {|ch| putc ch; putc ?. }
else
puts "Unable to open file!"
endZeichen werden einzeln an die Variable ch übergeben und dann wie folgt auf dem Bildschirm angezeigt:
s. .a. .s.i.m.p.l.e. .t.e.x.t. .f.i.l.e. .f.o.r. .t.e.s.t.i.n.g. .p.u.r.p.o.s.e...
.
.Die IO.readlines-Methode
Die Klasse Datei ist eine Unterklasse der Klasse IO. Die Klasse IO verfügt auch über einige Methoden, mit denen Dateien bearbeitet werden können.
Eine der IO-Klassenmethoden ist IO.readlines . Diese Methode gibt den Inhalt der Datei zeilenweise zurück. Der folgende Code zeigt die Verwendung der Methode IO.readlines -
#!/usr/bin/ruby
arr = IO.readlines("input.txt")
puts arr[0]
puts arr[1]In this code, the variable arr is an array. Each line of the file input.txt will be an element in the array arr. Therefore, arr[0] will contain the first line, whereas arr[1] will contain the second line of the file.
The IO.foreach Method
Diese Methode gibt die Ausgabe auch zeilenweise zurück. Der Unterschied zwischen der Methode foreach und den Methoden- Readlines besteht darin, dass die Methode foreach einem Block zugeordnet ist. Im Gegensatz zu den Methoden- Readlines gibt die Methode foreach jedoch kein Array zurück. Zum Beispiel -
#!/usr/bin/ruby
IO.foreach("input.txt"){|block| puts block}Dieser Code wird den Inhalt der Datei passiert Test Zeile für Zeile mit dem variablen Block, und dann wird die Ausgabe auf dem Bildschirm angezeigt werden.
Dateien umbenennen und löschen
Mit den Methoden zum Umbenennen und Löschen können Sie Dateien programmgesteuert mit Ruby umbenennen und löschen .
Es folgt das Beispiel zum Umbenennen einer vorhandenen Datei test1.txt -
#!/usr/bin/ruby
# Rename a file from test1.txt to test2.txt
File.rename( "test1.txt", "test2.txt" )Es folgt das Beispiel zum Löschen einer vorhandenen Datei test2.txt -
#!/usr/bin/ruby
# Delete file test2.txt
File.delete("test2.txt")Dateimodi und Besitz
Verwenden Sie die chmod- Methode mit einer Maske, um den Modus oder die Berechtigungs- / Zugriffsliste einer Datei zu ändern.
Das folgende Beispiel ändert den Modus einer vorhandenen Datei test.txt in einen Maskenwert :
#!/usr/bin/ruby
file = File.new( "test.txt", "w" )
file.chmod( 0755 )| Sr.Nr. | Maske & Beschreibung |
|---|---|
| 1 | 0700 RWX-Maske für Besitzer |
| 2 | 0400 r für Besitzer |
| 3 | 0200 w für Besitzer |
| 4 | 0100 x für Besitzer |
| 5 | 0070 rwx Maske für Gruppe |
| 6 | 0040 r für Gruppe |
| 7 | 0020 w für Gruppe |
| 8 | 0010 x für Gruppe |
| 9 | 0007 RWX-Maske für andere |
| 10 | 0004 r für andere |
| 11 | 0002 w für andere |
| 12 | 0001 x für andere |
| 13 | 4000 Legen Sie die Benutzer-ID bei der Ausführung fest |
| 14 | 2000 Legen Sie die Gruppen-ID bei der Ausführung fest |
| 15 | 1000 Speichern Sie den ausgetauschten Text auch nach der Verwendung |
Dateianfragen
Der folgende Befehl testet vor dem Öffnen, ob eine Datei vorhanden ist:
#!/usr/bin/ruby
File.open("file.rb") if File::exists?( "file.rb" )Der folgende Befehl fragt ab, ob die Datei wirklich eine Datei ist -
#!/usr/bin/ruby
# This returns either true or false
File.file?( "text.txt" )Der folgende Befehl ermittelt, ob der angegebene Dateiname ein Verzeichnis ist -
#!/usr/bin/ruby
# a directory
File::directory?( "/usr/local/bin" ) # => true
# a file
File::directory?( "file.rb" ) # => falseDer folgende Befehl ermittelt, ob die Datei lesbar, beschreibbar oder ausführbar ist.
#!/usr/bin/ruby
File.readable?( "test.txt" ) # => true
File.writable?( "test.txt" ) # => true
File.executable?( "test.txt" ) # => falseDer folgende Befehl ermittelt, ob die Datei die Größe Null hat oder nicht -
#!/usr/bin/ruby
File.zero?( "test.txt" ) # => trueDer folgende Befehl gibt die Größe der Datei zurück -
#!/usr/bin/ruby
File.size?( "text.txt" ) # => 1002Mit dem folgenden Befehl können Sie einen Dateityp ermitteln:
#!/usr/bin/ruby
File::ftype( "test.txt" ) # => fileDie ftype-Methode identifiziert den Dateityp, indem sie eine der folgenden Optionen zurückgibt: Datei, Verzeichnis, CharacterSpecial, BlockSpecial, Fifo, Link, Socket oder Unbekannt.
Mit dem folgenden Befehl können Sie ermitteln, wann eine Datei erstellt, geändert oder zuletzt aufgerufen wurde:
#!/usr/bin/ruby
File::ctime( "test.txt" ) # => Fri May 09 10:06:37 -0700 2008
File::mtime( "text.txt" ) # => Fri May 09 10:44:44 -0700 2008
File::atime( "text.txt" ) # => Fri May 09 10:45:01 -0700 2008Verzeichnisse in Ruby
Alle Dateien sind in verschiedenen Verzeichnissen enthalten, und Ruby hat auch keine Probleme damit. Während die File- Klasse Dateien verarbeitet, werden Verzeichnisse mit der Dir- Klasse behandelt.
Durch Verzeichnisse navigieren
Verwenden Sie Dir.chdir wie folgt, um das Verzeichnis innerhalb eines Ruby-Programms zu ändern . In diesem Beispiel wird das aktuelle Verzeichnis in / usr / bin geändert .
Dir.chdir("/usr/bin")Mit Dir.pwd können Sie herausfinden, wie das aktuelle Verzeichnis lautet -
puts Dir.pwd # This will return something like /usr/binMit Dir.entries - können Sie eine Liste der Dateien und Verzeichnisse in einem bestimmten Verzeichnis abrufen.
puts Dir.entries("/usr/bin").join(' ')Dir.entries gibt ein Array mit allen Einträgen im angegebenen Verzeichnis zurück. Dir.foreach bietet die gleiche Funktion -
Dir.foreach("/usr/bin") do |entry|
puts entry
endEine noch präzisere Methode zum Abrufen von Verzeichnislisten ist die Verwendung der Klassenarray-Methode von Dir -
Dir["/usr/bin/*"]Verzeichnis erstellen
Mit Dir.mkdir können Verzeichnisse erstellt werden -
Dir.mkdir("mynewdir")Sie können mit mkdir - auch Berechtigungen für ein neues Verzeichnis festlegen (das noch nicht vorhanden ist).
NOTE - Die Maske 755 setzt die Berechtigungen Eigentümer, Gruppe, Welt [jedermann] auf rwxr-xr-x, wobei r = Lesen, w = Schreiben und x = Ausführen.
Dir.mkdir( "mynewdir", 755 )Verzeichnis löschen
Mit Dir.delete kann ein Verzeichnis gelöscht werden. Die Dir.unlink und Dir.rmdir führt genau die gleiche Funktion und sind für die Bequemlichkeit zur Verfügung gestellt.
Dir.delete("testdir")Dateien und temporäre Verzeichnisse erstellen
Temporäre Dateien sind solche, die möglicherweise während der Ausführung eines Programms kurz erstellt werden, jedoch kein permanenter Informationsspeicher sind.
Dir.tmpdir stellt den Pfad zum temporären Verzeichnis auf dem aktuellen System bereit, obwohl die Methode standardmäßig nicht verfügbar ist. Um Dir.tmpdir verfügbar zu machen, muss require 'tmpdir' verwendet werden.
Sie können Dir.tmpdir mit File.join verwenden , um eine plattformunabhängige temporäre Datei zu erstellen.
require 'tmpdir'
tempfilename = File.join(Dir.tmpdir, "tingtong")
tempfile = File.new(tempfilename, "w")
tempfile.puts "This is a temporary file"
tempfile.close
File.delete(tempfilename)Dieser Code erstellt eine temporäre Datei, schreibt Daten in sie und löscht sie. Rubys Standardbibliothek enthält auch eine Bibliothek namens Tempfile , mit der temporäre Dateien für Sie erstellt werden können.
require 'tempfile'
f = Tempfile.new('tingtong')
f.puts "Hello"
puts f.path
f.closeEingebaute Funktionen
Hier sind die in Ruby integrierten Funktionen zum Verarbeiten von Dateien und Verzeichnissen:
Dateiklasse und Methoden .
Dir Klasse und Methoden .
Die Ausführung und die Ausnahme gehören immer zusammen. Wenn Sie eine Datei öffnen, die nicht vorhanden ist, und wenn Sie diese Situation nicht richtig behandelt haben, wird Ihr Programm als von schlechter Qualität angesehen.
Das Programm stoppt, wenn eine Ausnahme auftritt. Daher werden Ausnahmen verwendet, um verschiedene Arten von Fehlern zu behandeln, die während einer Programmausführung auftreten können, und um geeignete Maßnahmen zu ergreifen, anstatt das Programm vollständig anzuhalten.
Ruby bietet einen guten Mechanismus, um Ausnahmen zu behandeln. Wir fügen den Code, der eine Ausnahme auslösen könnte, in einen Anfangs- / Endblock ein und verwenden Rettungsklauseln , um Ruby die Arten von Ausnahmen mitzuteilen, die wir behandeln möchten.
Syntax
begin
# -
rescue OneTypeOfException
# -
rescue AnotherTypeOfException
# -
else
# Other exceptions
ensure
# Always will be executed
endAlles von Anfang bis zur Rettung ist geschützt. Wenn während der Ausführung dieses Codeblocks eine Ausnahme auftritt, wird die Steuerung zwischen Rettung und Ende an den Block übergeben .
Für jede Rettungsklausel im beginnen Block vergleicht Ruby den erhöhten Ausnahme gegen jeden der Parameter der Reihe nach . Die Übereinstimmung ist erfolgreich, wenn die in der Rettungsklausel genannte Ausnahme mit dem Typ der aktuell ausgelösten Ausnahme identisch ist oder eine Oberklasse dieser Ausnahme darstellt.
Für den Fall, dass eine Ausnahme keinem der angegebenen Fehlertypen entspricht, dürfen wir nach allen Rettungsklauseln eine else- Klausel verwenden .
Beispiel
#!/usr/bin/ruby
begin
file = open("/unexistant_file")
if file
puts "File opened successfully"
end
rescue
file = STDIN
end
print file, "==", STDIN, "\n"Dies führt zu folgendem Ergebnis. Sie können sehen, dass STDIN die Datei ersetzt, weil das Öffnen fehlgeschlagen ist.
#<IO:0xb7d16f84>==#<IO:0xb7d16f84>Retry-Anweisung verwenden
Sie können eine Ausnahme mit erfassen Rettungsblock und dann Verwendung Retry - Anweisung auszuführen , beginnen Block von Anfang an .
Syntax
begin
# Exceptions raised by this code will
# be caught by the following rescue clause
rescue
# This block will capture all types of exceptions
retry # This will move control to the beginning of begin
endBeispiel
#!/usr/bin/ruby
begin
file = open("/unexistant_file")
if file
puts "File opened successfully"
end
rescue
fname = "existant_file"
retry
endDas Folgende ist der Ablauf des Prozesses -
- Beim Öffnen ist eine Ausnahme aufgetreten.
- Ging zu retten. fname wurde neu zugewiesen.
- Durch einen erneuten Versuch ging es an den Anfang des Anfangs.
- Diese Zeitdatei wird erfolgreich geöffnet.
- Fortsetzung des wesentlichen Prozesses.
NOTE- Beachten Sie, dass dieser Beispielcode unendlich oft wiederholt wird, wenn die Datei mit dem neu ersetzten Namen nicht vorhanden ist. Seien Sie vorsichtig , wenn Sie verwenden Wiederholungs für einen Ausnahmeprozess.
Raise-Anweisung verwenden
Sie können die Anweisung raise verwenden , um eine Ausnahme auszulösen. Die folgende Methode löst bei jedem Aufruf eine Ausnahme aus. Die zweite Nachricht wird gedruckt.
Syntax
raise
OR
raise "Error Message"
OR
raise ExceptionType, "Error Message"
OR
raise ExceptionType, "Error Message" conditionDas erste Formular löst einfach die aktuelle Ausnahme erneut aus (oder einen RuntimeError, wenn keine aktuelle Ausnahme vorliegt). Dies wird in Ausnahmebehandlungsroutinen verwendet, die eine Ausnahme abfangen müssen, bevor sie weitergeleitet werden.
Das zweite Formular erstellt eine neue RuntimeError- Ausnahme und setzt die Nachricht auf die angegebene Zeichenfolge. Diese Ausnahme wird dann im Aufrufstapel ausgelöst.
Das dritte Formular verwendet das erste Argument, um eine Ausnahme zu erstellen, und setzt dann die zugehörige Nachricht auf das zweite Argument.
Das vierte Formular ähnelt dem dritten Formular, Sie können jedoch eine beliebige bedingte Anweisung hinzufügen, es sei denn , Sie möchten eine Ausnahme auslösen.
Beispiel
#!/usr/bin/ruby
begin
puts 'I am before the raise.'
raise 'An error has occurred.'
puts 'I am after the raise.'
rescue
puts 'I am rescued.'
end
puts 'I am after the begin block.'Dies führt zu folgendem Ergebnis:
I am before the raise.
I am rescued.
I am after the begin block.Ein weiteres Beispiel für die Verwendung von Raise -
#!/usr/bin/ruby
begin
raise 'A test exception.'
rescue Exception => e
puts e.message
puts e.backtrace.inspect
endDies führt zu folgendem Ergebnis:
A test exception.
["main.rb:4"]Verwenden Sie sure-Anweisung
Manchmal müssen Sie sicherstellen, dass am Ende eines Codeblocks eine gewisse Verarbeitung erfolgt, unabhängig davon, ob eine Ausnahme ausgelöst wurde. Beispielsweise kann beim Eintritt in den Block eine Datei geöffnet sein, und Sie müssen sicherstellen, dass sie beim Beenden des Blocks geschlossen wird.
Die Sicherungsklausel macht genau das. Stellen Sie sicher, dass die letzte Rettungsklausel verwendet wird und einen Codeabschnitt enthält, der immer ausgeführt wird, wenn der Block beendet wird. Es spielt keine Rolle, ob der Block normal beendet wird, ob er eine Ausnahme auslöst und rettet oder ob er durch eine nicht erfasste Ausnahme beendet wird, der Sicherstellungsblock wird ausgeführt.
Syntax
begin
#.. process
#..raise exception
rescue
#.. handle error
ensure
#.. finally ensure execution
#.. This will always execute.
endBeispiel
begin
raise 'A test exception.'
rescue Exception => e
puts e.message
puts e.backtrace.inspect
ensure
puts "Ensuring execution"
endDies führt zu folgendem Ergebnis:
A test exception.
["main.rb:4"]
Ensuring executionVerwenden der else-Anweisung
Wenn die else- Klausel vorhanden ist, folgt sie den Rettungsklauseln und bevor sie sichergestellt wird .
Der Hauptteil einer else- Klausel wird nur ausgeführt, wenn vom Hauptteil des Codes keine Ausnahmen ausgelöst werden.
Syntax
begin
#.. process
#..raise exception
rescue
# .. handle error
else
#.. executes if there is no exception
ensure
#.. finally ensure execution
#.. This will always execute.
endBeispiel
begin
# raise 'A test exception.'
puts "I'm not raising exception"
rescue Exception => e
puts e.message
puts e.backtrace.inspect
else
puts "Congratulations-- no errors!"
ensure
puts "Ensuring execution"
endDies führt zu folgendem Ergebnis:
I'm not raising exception
Congratulations-- no errors!
Ensuring executionAusgelöste Fehlermeldung kann mit $ erfasst werden! Variable.
Fangen und werfen
Während der Ausnahmemechanismus von Erhöhen und Speichern großartig ist, um die Ausführung abzubrechen, wenn etwas schief geht, ist es manchmal schön, während der normalen Verarbeitung aus einem tief verschachtelten Konstrukt herausspringen zu können. Hier bieten sich Fangen und Werfen an.
Der catch definiert einen Block, der mit dem angegebenen Namen gekennzeichnet ist (dies kann ein Symbol oder eine Zeichenfolge sein). Der Block wird normal ausgeführt, bis ein Wurf auftritt.
Syntax
throw :lablename
#.. this will not be executed
catch :lablename do
#.. matching catch will be executed after a throw is encountered.
end
OR
throw :lablename condition
#.. this will not be executed
catch :lablename do
#.. matching catch will be executed after a throw is encountered.
endBeispiel
Im folgenden Beispiel wird ein Wurf verwendet, um die Interaktion mit dem Benutzer zu beenden, wenn '!' wird als Antwort auf eine Eingabeaufforderung eingegeben.
def promptAndGet(prompt)
print prompt
res = readline.chomp
throw :quitRequested if res == "!"
return res
end
catch :quitRequested do
name = promptAndGet("Name: ")
age = promptAndGet("Age: ")
sex = promptAndGet("Sex: ")
# ..
# process information
end
promptAndGet("Name:")Sie sollten das oben genannte Programm auf Ihrem Computer ausprobieren, da eine manuelle Interaktion erforderlich ist. Dies führt zu folgendem Ergebnis:
Name: Ruby on Rails
Age: 3
Sex: !
Name:Just RubyKlassenausnahme
Rubys Standardklassen und Module lösen Ausnahmen aus. Alle Ausnahmeklassen bilden eine Hierarchie, wobei die Klasse Exception oben steht. Das nächste Level enthält sieben verschiedene Typen -
- Interrupt
- NoMemoryError
- SignalException
- ScriptError
- StandardError
- SystemExit
Es gibt eine weitere Ausnahme auf dieser Ebene: Fatal, aber der Ruby-Interpreter verwendet dies nur intern.
Sowohl ScriptError als auch StandardError haben eine Reihe von Unterklassen, aber wir müssen hier nicht auf die Details eingehen. Wichtig ist, dass beim Erstellen eigener Ausnahmeklassen Unterklassen entweder der Klasse Exception oder einer ihrer Nachkommen sein müssen.
Schauen wir uns ein Beispiel an -
class FileSaveError < StandardError
attr_reader :reason
def initialize(reason)
@reason = reason
end
endSchauen Sie sich nun das folgende Beispiel an, in dem diese Ausnahme verwendet wird:
File.open(path, "w") do |file|
begin
# Write out the data ...
rescue
# Something went wrong!
raise FileSaveError.new($!)
end
endDie wichtige Zeile hier ist das Erhöhen von FileSaveError.new ($!) . Wir rufen Raise auf, um zu signalisieren, dass eine Ausnahme aufgetreten ist, und übergeben ihm eine neue Instanz von FileSaveError. Der Grund dafür ist, dass eine bestimmte Ausnahme das Schreiben der Daten fehlgeschlagen hat.
Ruby ist eine reine objektorientierte Sprache und alles erscheint Ruby als Objekt. Jeder Wert in Ruby ist ein Objekt, selbst die primitivsten Dinge: Zeichenfolgen, Zahlen und sogar wahr und falsch. Selbst eine Klasse selbst ist ein Objekt , das eine Instanz der ist Klasse Klasse. Dieses Kapitel führt Sie durch alle wichtigen Funktionen im Zusammenhang mit objektorientiertem Ruby.
Eine Klasse wird verwendet, um die Form eines Objekts anzugeben. Sie kombiniert Datendarstellung und Methoden zum Bearbeiten dieser Daten in einem übersichtlichen Paket. Die Daten und Methoden innerhalb einer Klasse werden als Mitglieder der Klasse bezeichnet.
Ruby-Klassendefinition
Wenn Sie eine Klasse definieren, definieren Sie einen Entwurf für einen Datentyp. Dies definiert eigentlich keine Daten, aber es definiert, was der Klassenname bedeutet, dh woraus ein Objekt der Klasse besteht und welche Operationen an einem solchen Objekt ausgeführt werden können.
Eine Klassendefinition beginnt mit dem Schlüsselwort class gefolgt von der class name und ist mit einem abgegrenzt end. Zum Beispiel haben wir die Box-Klasse mit der Schlüsselwortklasse wie folgt definiert:
class Box
code
endDer Name muss mit einem Großbuchstaben beginnen. Konventionell werden Namen, die mehr als ein Wort enthalten, zusammen mit jedem großgeschriebenen Wort und ohne Trennzeichen (CamelCase) ausgeführt.
Definieren Sie Ruby-Objekte
Eine Klasse stellt die Blaupausen für Objekte bereit, sodass im Grunde genommen ein Objekt aus einer Klasse erstellt wird. Wir deklarieren Objekte einer Klasse mitnewStichwort. Die folgenden Anweisungen deklarieren zwei Objekte der Klasse Box -
box1 = Box.new
box2 = Box.newDie Initialisierungsmethode
Das initialize method ist eine Standardmethode der Ruby-Klasse und funktioniert fast genauso wie constructorarbeitet in anderen objektorientierten Programmiersprachen. Die Initialisierungsmethode ist nützlich, wenn Sie einige Klassenvariablen zum Zeitpunkt der Objekterstellung initialisieren möchten. Diese Methode kann eine Liste von Parametern enthalten und wird wie jede andere Ruby-Methode vorangestelltdef Schlüsselwort wie unten gezeigt -
class Box
def initialize(w,h)
@width, @height = w, h
end
endDie Instanzvariablen
Das instance variablessind Klassenattribute und werden zu Eigenschaften von Objekten, sobald Objekte mit der Klasse erstellt wurden. Die Attribute jedes Objekts werden einzeln zugewiesen und teilen keinen Wert mit anderen Objekten. Auf sie wird mit dem Operator @ innerhalb der Klasse zugegriffen, um jedoch außerhalb der von uns verwendeten Klasse darauf zuzugreifenpublic Methoden, die aufgerufen werden accessor methods. Wenn wir die oben definierte Klasse nehmenBox dann sind @width und @height Instanzvariablen für die Klassenbox.
class Box
def initialize(w,h)
# assign instance variables
@width, @height = w, h
end
endDie Accessor & Setter-Methoden
Um die Variablen von außerhalb der Klasse verfügbar zu machen, müssen sie innerhalb definiert werden accessor methodsDiese Accessor-Methoden werden auch als Getter-Methoden bezeichnet. Das folgende Beispiel zeigt die Verwendung von Zugriffsmethoden -
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def printWidth
@width
end
def printHeight
@height
end
end
# create an object
box = Box.new(10, 20)
# use accessor methods
x = box.printWidth()
y = box.printHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Width of the box is : 10
Height of the box is : 20Ähnlich wie bei Zugriffsmethoden, mit denen auf den Wert der Variablen zugegriffen wird, bietet Ruby eine Möglichkeit, die Werte dieser Variablen von außerhalb der Klasse mithilfe von festzulegen setter methods, die wie folgt definiert sind -
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def getWidth
@width
end
def getHeight
@height
end
# setter methods
def setWidth=(value)
@width = value
end
def setHeight=(value)
@height = value
end
end
# create an object
box = Box.new(10, 20)
# use setter methods
box.setWidth = 30
box.setHeight = 50
# use accessor methods
x = box.getWidth()
y = box.getHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Width of the box is : 30
Height of the box is : 50Die Instanzmethoden
Das instance methods werden ebenfalls auf die gleiche Weise definiert, wie wir jede andere Methode definieren defSchlüsselwort und sie können nur mit einer Klasseninstanz verwendet werden, wie unten gezeigt. Ihre Funktionalität beschränkt sich nicht nur auf den Zugriff auf die Instanzvariablen, sondern sie können auch viel mehr gemäß Ihren Anforderungen tun.
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Area of the box is : 200Die Klasse Methoden und Variablen
Das class variablesist eine Variable, die von allen Instanzen einer Klasse gemeinsam genutzt wird. Mit anderen Worten, es gibt eine Instanz der Variablen, auf die Objektinstanzen zugreifen. Klassenvariablen werden zwei @ -Zeichen (@@) vorangestellt. Eine Klassenvariable muss innerhalb der Klassendefinition wie unten gezeigt initialisiert werden.
Eine Klassenmethode wird mit definiert def self.methodname(), das mit dem Endbegrenzer endet und mit dem Klassennamen as aufgerufen wird classname.methodname wie im folgenden Beispiel gezeigt -
#!/usr/bin/ruby -w
class Box
# Initialize our class variables
@@count = 0
def initialize(w,h)
# assign instance avriables
@width, @height = w, h
@@count += 1
end
def self.printCount()
puts "Box count is : #@@count"
end
end
# create two object
box1 = Box.new(10, 20)
box2 = Box.new(30, 100)
# call class method to print box count
Box.printCount()Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Box count is : 2Die to_s-Methode
Jede Klasse, die Sie definieren, sollte eine haben to_sInstanzmethode zum Zurückgeben einer Zeichenfolgendarstellung des Objekts. Das folgende Beispiel zeigt ein Box-Objekt in Bezug auf Breite und Höhe:
#!/usr/bin/ruby -w
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# define to_s method
def to_s
"(w:#@width,h:#@height)" # string formatting of the object.
end
end
# create an object
box = Box.new(10, 20)
# to_s method will be called in reference of string automatically.
puts "String representation of box is : #{box}"Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
String representation of box is : (w:10,h:20)Zugangskontrolle
Ruby bietet Ihnen drei Schutzstufen auf der Ebene der Instanzmethoden public, private, or protected. Ruby wendet keine Zugriffssteuerung auf Instanz- und Klassenvariablen an.
Public Methods- Öffentliche Methoden können von jedem aufgerufen werden. Methoden sind standardmäßig öffentlich, mit Ausnahme der Initialisierung, die immer privat ist.
Private Methods- Auf private Methoden kann nicht zugegriffen oder von außerhalb der Klasse angezeigt werden. Nur die Klassenmethoden können auf private Mitglieder zugreifen.
Protected Methods- Eine geschützte Methode kann nur von Objekten der definierenden Klasse und ihrer Unterklassen aufgerufen werden. Der Zugang bleibt innerhalb der Familie.
Das folgende Beispiel zeigt die Syntax aller drei Zugriffsmodifikatoren:
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method by default it is public
def getArea
getWidth() * getHeight
end
# define private accessor methods
def getWidth
@width
end
def getHeight
@height
end
# make them private
private :getWidth, :getHeight
# instance method to print area
def printArea
@area = getWidth() * getHeight
puts "Big box area is : #@area"
end
# make it protected
protected :printArea
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"
# try to call protected or methods
box.printArea()Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt. Hier wird die erste Methode erfolgreich aufgerufen, die zweite Methode ergab jedoch ein Problem.
Area of the box is : 200
test.rb:42: protected method `printArea' called for #
<Box:0xb7f11280 @height = 20, @width = 10> (NoMethodError)Klassenvererbung
Eines der wichtigsten Konzepte in der objektorientierten Programmierung ist das der Vererbung. Durch Vererbung können wir eine Klasse in Bezug auf eine andere Klasse definieren, was das Erstellen und Verwalten einer Anwendung erleichtert.
Die Vererbung bietet auch die Möglichkeit, die Codefunktionalität und die schnelle Implementierungszeit wiederzuverwenden. Leider unterstützt Ruby nicht mehrere Vererbungsebenen, aber Ruby mixins. Ein Mixin ist wie eine spezialisierte Implementierung der Mehrfachvererbung, bei der nur der Schnittstellenteil vererbt wird.
Beim Erstellen einer Klasse kann der Programmierer festlegen, dass die neue Klasse die Mitglieder einer vorhandenen Klasse erben soll, anstatt vollständig neue Datenelemente und Elementfunktionen zu schreiben. Diese vorhandene Klasse heißtbase class or superclassund die neue Klasse wird als die bezeichnet derived class or sub-class.
Ruby unterstützt auch das Konzept der Unterklasse, dh der Vererbung, und das folgende Beispiel erläutert das Konzept. Die Syntax zum Erweitern einer Klasse ist einfach. Fügen Sie Ihrer Klassenanweisung einfach ein <-Zeichen und den Namen der Oberklasse hinzu. Im Folgenden wird beispielsweise eine Klasse BigBox als Unterklasse von Box definiert :
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# define a subclass
class BigBox < Box
# add a new instance method
def printArea
@area = @width * @height
puts "Big box area is : #@area"
end
end
# create an object
box = BigBox.new(10, 20)
# print the area
box.printArea()Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Big box area is : 200Methoden überschreiben
Sie können zwar einer abgeleiteten Klasse neue Funktionen hinzufügen, aber manchmal möchten Sie das Verhalten bereits definierter Methoden in einer übergeordneten Klasse ändern. Sie können dies einfach tun, indem Sie den Methodennamen beibehalten und die Funktionalität der Methode überschreiben, wie im folgenden Beispiel gezeigt.
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# define a subclass
class BigBox < Box
# change existing getArea method as follows
def getArea
@area = @width * @height
puts "Big box area is : #@area"
end
end
# create an object
box = BigBox.new(10, 20)
# print the area using overriden method.
box.getArea()Überlastung des Bedieners
Wir möchten, dass der Operator + die Vektoraddition von zwei Box-Objekten mit + durchführt, der Operator * die Breite und Höhe einer Box mit einem Skalar multipliziert und der Operator unary - die Breite und Höhe der Box negiert. Hier ist eine Version der Box-Klasse mit definierten mathematischen Operatoren -
class Box
def initialize(w,h) # Initialize the width and height
@width,@height = w, h
end
def +(other) # Define + to do vector addition
Box.new(@width + other.width, @height + other.height)
end
def -@ # Define unary minus to negate width and height
Box.new(-@width, -@height)
end
def *(scalar) # To perform scalar multiplication
Box.new(@width*scalar, @height*scalar)
end
endObjekte einfrieren
Manchmal möchten wir verhindern, dass ein Objekt geändert wird. Die Einfriermethode in Object ermöglicht es uns, ein Objekt effektiv in eine Konstante umzuwandeln. Jedes Objekt kann durch Aufrufen eingefroren werdenObject.freeze. Ein eingefrorenes Objekt darf nicht geändert werden: Sie können seine Instanzvariablen nicht ändern.
Sie können überprüfen, ob ein bestimmtes Objekt bereits eingefroren ist oder nicht verwendet wird Object.frozen?Methode, die true zurückgibt, falls das Objekt eingefroren ist, andernfalls wird ein falscher Wert zurückgegeben. Das folgende Beispiel verdeutlicht das Konzept -
#!/usr/bin/ruby -w
# define a class
class Box
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# accessor methods
def getWidth
@width
end
def getHeight
@height
end
# setter methods
def setWidth=(value)
@width = value
end
def setHeight=(value)
@height = value
end
end
# create an object
box = Box.new(10, 20)
# let us freez this object
box.freeze
if( box.frozen? )
puts "Box object is frozen object"
else
puts "Box object is normal object"
end
# now try using setter methods
box.setWidth = 30
box.setHeight = 50
# use accessor methods
x = box.getWidth()
y = box.getHeight()
puts "Width of the box is : #{x}"
puts "Height of the box is : #{y}"Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Box object is frozen object
test.rb:20:in `setWidth=': can't modify frozen object (TypeError)
from test.rb:39Klassenkonstanten
Sie können eine Konstante innerhalb einer Klasse definieren, indem Sie einer Variablen einen direkten numerischen oder Zeichenfolgenwert zuweisen, der ohne Verwendung von @ oder @@ definiert wird. Konventionell behalten wir konstante Namen in Großbuchstaben.
Sobald eine Konstante definiert ist, können Sie ihren Wert nicht mehr ändern, aber Sie können auf eine Konstante direkt innerhalb einer Klasse zugreifen, ähnlich wie auf eine Variable. Wenn Sie jedoch auf eine Konstante außerhalb der Klasse zugreifen möchten, müssen Sie diese verwenden classname::constant wie im folgenden Beispiel gezeigt.
#!/usr/bin/ruby -w
# define a class
class Box
BOX_COMPANY = "TATA Inc"
BOXWEIGHT = 10
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object
box = Box.new(10, 20)
# call instance methods
a = box.getArea()
puts "Area of the box is : #{a}"
puts Box::BOX_COMPANY
puts "Box weight is: #{Box::BOXWEIGHT}"Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Area of the box is : 200
TATA Inc
Box weight is: 10Klassenkonstanten werden vererbt und können wie Instanzmethoden überschrieben werden.
Objekt mit Allocate erstellen
Es kann vorkommen, dass Sie ein Objekt erstellen möchten, ohne dessen Konstruktor aufzurufen initializeWenn Sie also eine neue Methode verwenden, können Sie in diesem Fall allocate aufrufen , wodurch ein nicht initialisiertes Objekt für Sie erstellt wird, wie im folgenden Beispiel:
#!/usr/bin/ruby -w
# define a class
class Box
attr_accessor :width, :height
# constructor method
def initialize(w,h)
@width, @height = w, h
end
# instance method
def getArea
@width * @height
end
end
# create an object using new
box1 = Box.new(10, 20)
# create another object using allocate
box2 = Box.allocate
# call instance method using box1
a = box1.getArea()
puts "Area of the box is : #{a}"
# call instance method using box2
a = box2.getArea()
puts "Area of the box is : #{a}"Wenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Area of the box is : 200
test.rb:14: warning: instance variable @width not initialized
test.rb:14: warning: instance variable @height not initialized
test.rb:14:in `getArea': undefined method `*'
for nil:NilClass (NoMethodError) from test.rb:29Klasseninformationen
Wenn Klassendefinitionen ausführbarer Code sind, bedeutet dies, dass sie im Kontext eines Objekts ausgeführt werden: self muss auf etwas verweisen. Lassen Sie uns herausfinden, was es ist.
#!/usr/bin/ruby -w
class Box
# print class information
puts "Type of self = #{self.type}"
puts "Name of self = #{self.name}"
endWenn der obige Code ausgeführt wird, wird das folgende Ergebnis erzeugt:
Type of self = Class
Name of self = BoxDies bedeutet, dass eine Klassendefinition mit dieser Klasse als aktuellem Objekt ausgeführt wird. Dies bedeutet, dass Methoden in der Metaklasse und ihren Oberklassen während der Ausführung der Methodendefinition verfügbar sind.
Ein regulärer Ausdruck ist eine spezielle Zeichenfolge, mit der Sie andere Zeichenfolgen oder Zeichenfolgen mithilfe einer speziellen Syntax in einem Muster abgleichen oder finden können.
Ein Literal für reguläre Ausdrücke ist ein Muster zwischen Schrägstrichen oder zwischen beliebigen Trennzeichen, gefolgt von% r wie folgt:
Syntax
/pattern/
/pattern/im # option can be specified
%r!/usr/local! # general delimited regular expressionBeispiel
#!/usr/bin/ruby
line1 = "Cats are smarter than dogs";
line2 = "Dogs also like meat";
if ( line1 =~ /Cats(.*)/ )
puts "Line1 contains Cats"
end
if ( line2 =~ /Cats(.*)/ )
puts "Line2 contains Dogs"
endDies führt zu folgendem Ergebnis:
Line1 contains CatsModifikatoren für reguläre Ausdrücke
Literale für reguläre Ausdrücke können einen optionalen Modifikator enthalten, um verschiedene Aspekte des Abgleichs zu steuern. Der Modifikator wird wie zuvor gezeigt nach dem zweiten Schrägstrich angegeben und kann durch eines dieser Zeichen dargestellt werden -
| Sr.Nr. | Modifikator & Beschreibung |
|---|---|
| 1 | i Ignoriert Groß- und Kleinschreibung beim Abgleichen von Text. |
| 2 | o Führt # {} Interpolationen nur einmal durch, wenn das Regexp-Literal zum ersten Mal ausgewertet wird. |
| 3 | x Ignoriert Leerzeichen und erlaubt Kommentare in regulären Ausdrücken. |
| 4 | m Entspricht mehreren Zeilen und erkennt Zeilenumbrüche als normale Zeichen. |
| 5 | u,e,s,n Interpretiert den regulären Ausdruck als Unicode (UTF-8), EUC, SJIS oder ASCII. Wenn keiner dieser Modifikatoren angegeben ist, wird angenommen, dass der reguläre Ausdruck die Quellcodierung verwendet. |
Wie mit% Q begrenzte Zeichenfolgenliterale können Sie mit Ruby Ihre regulären Ausdrücke mit% r beginnen, gefolgt von einem Trennzeichen Ihrer Wahl. Dies ist nützlich, wenn das von Ihnen beschriebene Muster viele Schrägstriche enthält, denen Sie nicht entkommen möchten.
# Following matches a single slash character, no escape required
%r|/|
# Flag characters are allowed with this syntax, too
%r[</(.*)>]iMuster mit regulärem Ausdruck
Mit Ausnahme von Steuerzeichen, (+ ? . * ^ $ ( ) [ ] { } | \)Alle Charaktere stimmen überein. Sie können einem Steuerzeichen entkommen, indem Sie ihm einen Backslash voranstellen.
| Sr.Nr. | Muster & Beschreibung |
|---|---|
| 1 | ^ Entspricht dem Zeilenanfang. |
| 2 | $ Entspricht dem Zeilenende. |
| 3 | . Entspricht einem einzelnen Zeichen außer Zeilenumbruch. Mit der Option m kann auch der Zeilenumbruch abgeglichen werden. |
| 4 | [...] Entspricht einem einzelnen Zeichen in Klammern. |
| 5 | [^...] Entspricht einem einzelnen Zeichen, das nicht in Klammern steht |
| 6 | re* Entspricht 0 oder mehr Vorkommen des vorhergehenden Ausdrucks. |
| 7 | re+ Entspricht 1 oder mehr Vorkommen des vorhergehenden Ausdrucks. |
| 8 | re? Entspricht 0 oder 1 Vorkommen des vorhergehenden Ausdrucks. |
| 9 | re{ n} Entspricht genau n Vorkommen des vorhergehenden Ausdrucks. |
| 10 | re{ n,} Entspricht n oder mehr Vorkommen des vorhergehenden Ausdrucks. |
| 11 | re{ n, m} Entspricht mindestens n und höchstens m Vorkommen des vorhergehenden Ausdrucks. |
| 12 | a| b Entspricht entweder a oder b. |
| 13 | (re) Gruppiert reguläre Ausdrücke und merkt sich übereinstimmenden Text. |
| 14 | (?imx) Schaltet vorübergehend die Optionen i, m oder x innerhalb eines regulären Ausdrucks um. In Klammern ist nur dieser Bereich betroffen. |
| 15 | (?-imx) Schaltet die Optionen i, m oder x innerhalb eines regulären Ausdrucks vorübergehend aus. In Klammern ist nur dieser Bereich betroffen. |
| 16 | (?: re) Gruppiert reguläre Ausdrücke, ohne sich an übereinstimmenden Text zu erinnern. |
| 17 | (?imx: re) Schaltet vorübergehend die Optionen i, m oder x in Klammern um. |
| 18 | (?-imx: re) Schaltet die Optionen i, m oder x vorübergehend in Klammern aus. |
| 19 | (?#...) Kommentar. |
| 20 | (?= re) Gibt die Position anhand eines Musters an. Hat keine Reichweite. |
| 21 | (?! re) Gibt die Position mithilfe der Musterverneinung an. Hat keine Reichweite. |
| 22 | (?> re) Entspricht einem unabhängigen Muster ohne Rückverfolgung. |
| 23 | \w Entspricht Wortzeichen. |
| 24 | \W Entspricht Nichtwortzeichen. |
| 25 | \s Entspricht dem Leerzeichen. Entspricht [\ t \ n \ r \ f]. |
| 26 | \S Entspricht Nicht-Leerzeichen. |
| 27 | \d Entspricht den Ziffern. Entspricht [0-9]. |
| 28 | \D Entspricht nicht-stelligen. |
| 29 | \A Entspricht dem Stringanfang. |
| 30 | \Z Entspricht dem Ende der Zeichenfolge. Wenn eine neue Zeile vorhanden ist, stimmt sie kurz vor der neuen Zeile überein. |
| 31 | \z Entspricht dem Ende der Zeichenfolge. |
| 32 | \G Spielpunkt, an dem das letzte Spiel beendet wurde. |
| 33 | \b Entspricht den Wortgrenzen außerhalb der Klammern. Entspricht der Rücktaste (0x08) in Klammern. |
| 34 | \B Entspricht Nicht-Wortgrenzen. |
| 35 | \n, \t, etc. Entspricht Zeilenumbrüchen, Wagenrückläufen, Tabulatoren usw. |
| 36 | \1...\9 Entspricht dem n-ten gruppierten Unterausdruck. |
| 37 | \10 Entspricht dem n-ten gruppierten Unterausdruck, wenn er bereits übereinstimmt. Ansonsten bezieht sich auf die oktale Darstellung eines Zeichencodes. |
Beispiele für reguläre Ausdrücke
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /ruby/ Entspricht "Rubin". |
| 2 | ¥ Entspricht dem Yen-Zeichen. Multibyte-Zeichen werden in Ruby 1.9 und Ruby 1.8 unterstützt. |
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /[Rr]uby/ Entspricht "Ruby" oder "Ruby". |
| 2 | /rub[ye]/ Entspricht "Rubin" oder "Rube". |
| 3 | /[aeiou]/ Entspricht einem beliebigen Kleinbuchstaben. |
| 4 | /[0-9]/ Entspricht einer beliebigen Ziffer. wie / [0123456789] /. |
| 5 | /[a-z]/ Entspricht einem beliebigen ASCII-Kleinbuchstaben. |
| 6 | /[A-Z]/ Entspricht einem beliebigen ASCII-Großbuchstaben. |
| 7 | /[a-zA-Z0-9]/ Entspricht einem der oben genannten Punkte. |
| 8 | /[^aeiou]/ Entspricht etwas anderem als einem Kleinbuchstaben. |
| 9 | /[^0-9]/ Entspricht etwas anderem als einer Ziffer. |
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /./ Entspricht jedem Zeichen außer Zeilenumbruch. |
| 2 | /./m Entspricht im Mehrzeilenmodus auch der Zeilenumbruch. |
| 3 | /\d/ Entspricht einer Ziffer: / [0-9] /. |
| 4 | /\D/ Entspricht einer nichtstelligen Zahl: / [^ 0-9] /. |
| 5 | /\s/ Entspricht einem Leerzeichen: / [\ t \ r \ n \ f] /. |
| 6 | /\S/ Entspricht Nicht-Leerzeichen: / [^ \ t \ r \ n \ f] /. |
| 7 | /\w/ Entspricht einem einzelnen Wortzeichen: / [A-Za-z0-9 _] /. |
| 8 | /\W/ Entspricht einem Nicht-Wort-Zeichen: / [^ A-Za-z0-9 _] /. |
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /ruby?/ Entspricht "rub" oder "ruby": das y ist optional. |
| 2 | /ruby*/ Entspricht "reiben" plus 0 oder mehr ys. |
| 3 | /ruby+/ Entspricht "reiben" plus 1 oder mehr ys. |
| 4 | /\d{3}/ Entspricht genau 3 Ziffern. |
| 5 | /\d{3,}/ Entspricht 3 oder mehr Ziffern. |
| 6 | /\d{3,5}/ Entspricht 3, 4 oder 5 Ziffern. |
Dies entspricht der geringsten Anzahl von Wiederholungen -
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /<.*>/ Gierige Wiederholung: Entspricht "<ruby> perl>". |
| 2 | /<.*?>/ Nicht gierig: Entspricht "<ruby>" in "<ruby> perl>". |
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /\D\d+/ Keine Gruppe: + wiederholt \ d |
| 2 | /(\D\d)+/ Gruppiert: + wiederholt \ D \ d Paar |
| 3 | /([Rr]uby(, )?)+/ Match "Ruby", "Ruby, Ruby, Ruby" usw. |
Dies entspricht wieder einer zuvor übereinstimmenden Gruppe -
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /([Rr])uby&\1ails/ Passt zu Ruby & Rails oder Ruby & Rails. |
| 2 | /(['"])(?:(?!\1).)*\1/ Einfache oder doppelte Zeichenfolge. \ 1 stimmt mit der 1. Gruppe überein. \ 2 stimmt mit der 2. Gruppe überein usw. |
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /ruby|rube/ Entspricht "Rubin" oder "Rube". |
| 2 | /rub(y|le))/ Entspricht "Rubin" oder "Rubel". |
| 3 | /ruby(!+|\?)/ "rubin" gefolgt von einem oder mehreren! oder einer? |
Es muss die Übereinstimmungsposition angegeben werden.
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /^Ruby/ Entspricht "Ruby" am Anfang einer Zeichenfolge oder einer internen Zeile. |
| 2 | /Ruby$/ Entspricht "Ruby" am Ende einer Zeichenfolge oder Zeile. |
| 3 | /\ARuby/ Entspricht "Ruby" am Anfang einer Zeichenfolge. |
| 4 | /Ruby\Z/ Entspricht "Ruby" am Ende einer Zeichenfolge. |
| 5 | /\bRuby\b/ Entspricht "Ruby" an einer Wortgrenze. |
| 6 | /\brub\B/ \ B ist keine Wortgrenze: Entspricht "rub" in "rube" und "ruby", aber nicht alleine. |
| 7 | /Ruby(?=!)/ Entspricht "Ruby", wenn ein Ausrufezeichen folgt. |
| 8 | /Ruby(?!!)/ Entspricht "Ruby", wenn kein Ausrufezeichen folgt. |
| Sr.Nr. | Beispiel & Beschreibung |
|---|---|
| 1 | /R(?#comment)/ Entspricht "R". Der Rest ist ein Kommentar. |
| 2 | /R(?i)uby/ Groß- und Kleinschreibung wird nicht berücksichtigt, wenn "uby" angezeigt wird. |
| 3 | /R(?i:uby)/ Das gleiche wie oben. |
| 4 | /rub(?:y|le))/ Nur gruppieren, ohne \ 1 Rückreferenz zu erstellen. |
Suchen und ersetzen
Einige der wichtigsten String-Methoden, die reguläre Ausdrücke verwenden, sind sub und gsubund ihre In-Place-Varianten sub! und gsub!.
Alle diese Methoden führen eine Such- und Ersetzungsoperation unter Verwendung eines Regexp-Musters durch. Dassub & sub! ersetzt das erste Auftreten des Musters und gsub & gsub! ersetzt alle Vorkommen.
Das sub und gsub Gibt eine neue Zeichenfolge zurück, wobei das Original unverändert bleibt sub! und gsub! Ändern Sie die Zeichenfolge, für die sie aufgerufen werden.
Es folgt das Beispiel -
#!/usr/bin/ruby
phone = "2004-959-559 #This is Phone Number"
# Delete Ruby-style comments
phone = phone.sub!(/#.*$/, "")
puts "Phone Num : #{phone}"
# Remove anything other than digits
phone = phone.gsub!(/\D/, "")
puts "Phone Num : #{phone}"Dies führt zu folgendem Ergebnis:
Phone Num : 2004-959-559
Phone Num : 2004959559Das Folgende ist ein weiteres Beispiel -
#!/usr/bin/ruby
text = "rails are rails, really good Ruby on Rails"
# Change "rails" to "Rails" throughout
text.gsub!("rails", "Rails")
# Capitalize the word "Rails" throughout
text.gsub!(/\brails\b/, "Rails")
puts "#{text}"Dies führt zu folgendem Ergebnis:
Rails are Rails, really good Ruby on RailsIn diesem Kapitel erfahren Sie, wie Sie mit Ruby auf eine Datenbank zugreifen. Das Ruby DBI- Modul bietet eine datenbankunabhängige Schnittstelle für Ruby-Skripte, die der des Perl DBI-Moduls ähnelt.
DBI steht für Database Independent Interface for Ruby. Dies bedeutet, dass DBI eine Abstraktionsschicht zwischen dem Ruby-Code und der zugrunde liegenden Datenbank bereitstellt, sodass Sie die Datenbankimplementierungen ganz einfach wechseln können. Es definiert eine Reihe von Methoden, Variablen und Konventionen, die unabhängig von der tatsächlich verwendeten Datenbank eine konsistente Datenbankschnittstelle bieten.
DBI kann mit folgenden Schnittstellen arbeiten:
- ADO (ActiveX-Datenobjekte)
- DB2
- Frontbase
- mSQL
- MySQL
- ODBC
- Oracle
- OCI8 (Oracle)
- PostgreSQL
- Proxy/Server
- SQLite
- SQLRelay
Architektur einer DBI-Anwendung
DBI ist unabhängig von jeder im Backend verfügbaren Datenbank. Sie können DBI verwenden, unabhängig davon, ob Sie mit Oracle, MySQL oder Informix usw. arbeiten. Dies geht aus dem folgenden Architekturdiagramm hervor.

Die allgemeine Architektur für Ruby DBI verwendet zwei Ebenen:
Die Datenbankschnittstellenschicht (DBI). Diese Schicht ist datenbankunabhängig und bietet eine Reihe allgemeiner Zugriffsmethoden, die unabhängig vom Typ des Datenbankservers, mit dem Sie kommunizieren, auf dieselbe Weise verwendet werden.
Die DBD-Schicht (Database Driver). Diese Schicht ist datenbankabhängig. Verschiedene Treiber bieten Zugriff auf verschiedene Datenbank-Engines. Es gibt einen Treiber für MySQL, einen anderen für PostgreSQL, einen anderen für InterBase, einen anderen für Oracle und so weiter. Jeder Treiber interpretiert Anforderungen von der DBI-Schicht und ordnet sie Anforderungen zu, die für einen bestimmten Typ von Datenbankserver geeignet sind.
Voraussetzungen
Wenn Sie Ruby-Skripte schreiben möchten, um auf MySQL-Datenbanken zuzugreifen, muss das Ruby MySQL-Modul installiert sein.
Dieses Modul fungiert wie oben erläutert als DBD und kann von heruntergeladen werden https://www.tmtm.org/en/mysql/ruby/
Beziehen und Installieren von Ruby / DBI
Sie können das Ruby DBI-Modul von folgendem Speicherort herunterladen und installieren:
https://imgur.com/NFEuWe4/embed
Stellen Sie vor dem Starten dieser Installation sicher, dass Sie über das Root-Recht verfügen. Befolgen Sie nun die unten angegebenen Schritte -
Schritt 1
$ tar zxf dbi-0.2.0.tar.gzSchritt 2
Gehen Sie in das Verteilungsverzeichnis dbi-0.2.0 und konfigurieren Sie es mit dem Skript setup.rb in diesem Verzeichnis. Der allgemeinste Konfigurationsbefehl sieht folgendermaßen aus, ohne dass dem Konfigurationsargument Argumente folgen. Dieser Befehl konfiguriert die Distribution so, dass standardmäßig alle Treiber installiert werden.
$ ruby setup.rb configUm genauer zu sein, geben Sie die Option --with an, mit der die bestimmten Teile der Distribution aufgelistet werden, die Sie verwenden möchten. Geben Sie beispielsweise den folgenden Befehl aus, um nur das Haupt-DBI-Modul und den MySQL-Treiber auf DBD-Ebene zu konfigurieren:
$ ruby setup.rb config --with = dbi,dbd_mysqlSchritt 3
Der letzte Schritt besteht darin, den Treiber zu erstellen und mit den folgenden Befehlen zu installieren:
$ ruby setup.rb setup $ ruby setup.rb installDatenbankverbindung
Angenommen, wir arbeiten mit der MySQL-Datenbank, bevor Sie eine Verbindung zu einer Datenbank herstellen, stellen Sie Folgendes sicher:
Sie haben eine Datenbank TESTDB erstellt.
Sie haben EMPLOYEE in TESTDB erstellt.
Diese Tabelle enthält die Felder FIRST_NAME, LAST_NAME, AGE, SEX und INCOME.
Die Benutzer-ID "testuser" und das Kennwort "test123" sind für den Zugriff auf TESTDB festgelegt.
Ruby Module DBI ist ordnungsgemäß auf Ihrem Computer installiert.
Sie haben das MySQL-Tutorial durchgearbeitet, um die MySQL-Grundlagen zu verstehen.
Das folgende Beispiel zeigt die Verbindung mit der MySQL-Datenbank "TESTDB".
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
# get server version string and display it
row = dbh.select_one("SELECT VERSION()")
puts "Server version: " + row[0]
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
endWährend dieses Skripts ausgeführt wird, wird auf unserem Linux-Computer das folgende Ergebnis erzielt.
Server version: 5.0.45Wenn eine Verbindung mit der Datenquelle hergestellt wird, wird ein Datenbankhandle zurückgegeben und in gespeichert dbh zur weiteren Verwendung sonst dbhwird auf Null gesetzt und e.err und e :: errstr geben einen Fehlercode bzw. eine Fehlerzeichenfolge zurück.
Stellen Sie schließlich sicher, dass die Datenbankverbindung geschlossen und Ressourcen freigegeben sind, bevor Sie sie veröffentlichen.
INSERT-Betrieb
Die INSERT-Operation ist erforderlich, wenn Sie Ihre Datensätze in einer Datenbanktabelle erstellen möchten.
Sobald eine Datenbankverbindung hergestellt ist, können wir mithilfe von Tabellen oder Datensätzen in die Datenbanktabellen erstellen do Methode oder prepare und execute Methode.
Do-Anweisung verwenden
Anweisungen, die keine Zeilen zurückgeben, können durch Aufrufen von ausgegeben werden doDatenbankhandle-Methode. Diese Methode verwendet ein Anweisungszeichenfolgenargument und gibt die Anzahl der von der Anweisung betroffenen Zeilen zurück.
dbh.do("DROP TABLE IF EXISTS EMPLOYEE")
dbh.do("CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )" );Ebenso können Sie die SQL INSERT- Anweisung ausführen , um einen Datensatz in der EMPLOYEE-Tabelle zu erstellen.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
dbh.do( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)" )
puts "Record has been created"
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endMit vorbereiten und ausführen
Sie können Vorbereitungs- und Ausführungsmethoden der DBI-Klasse verwenden, um die SQL-Anweisung über Ruby-Code auszuführen.
Die Datensatzerstellung umfasst die folgenden Schritte:
SQL-Anweisung mit INSERT-Anweisung vorbereiten. Dies erfolgt mit demprepare Methode.
Ausführen einer SQL-Abfrage, um alle Ergebnisse aus der Datenbank auszuwählen. Dies erfolgt mit demexecute Methode.
Anweisungshandle freigeben. Dies erfolgt mitfinish API
Wenn alles gut geht, dann commit diese Operation können Sie sonst rollback die vollständige Transaktion.
Im Folgenden finden Sie die Syntax zur Verwendung dieser beiden Methoden:
sth = dbh.prepare(statement)
sth.execute
... zero or more SQL operations ...
sth.finishDiese beiden Methoden können zum Bestehen verwendet werden bindWerte zu SQL-Anweisungen. Es kann vorkommen, dass die einzugebenden Werte nicht im Voraus angegeben werden. In diesem Fall werden Bindungswerte verwendet. Ein Fragezeichen (?) wird anstelle der tatsächlichen Werte verwendet und dann werden die tatsächlichen Werte über die API execute () übergeben.
Im Folgenden finden Sie ein Beispiel zum Erstellen von zwei Datensätzen in der Tabelle EMPLOYEE:
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare( "INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES (?, ?, ?, ?, ?)" )
sth.execute('John', 'Poul', 25, 'M', 2300)
sth.execute('Zara', 'Ali', 17, 'F', 1000)
sth.finish
dbh.commit
puts "Record has been created"
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endWenn mehrere INSERTs gleichzeitig vorhanden sind, ist es effizienter, zuerst eine Anweisung vorzubereiten und dann innerhalb einer Schleife mehrmals auszuführen, als jedes Mal durch die Schleife aufzurufen.
LESEN Betrieb
READ Operation für eine beliebige Datenbank bedeutet, einige nützliche Informationen aus der Datenbank abzurufen.
Sobald unsere Datenbankverbindung hergestellt ist, können wir eine Abfrage in diese Datenbank durchführen. Wir können entweder verwendendo Methode oder prepare und execute Methoden zum Abrufen von Werten aus einer Datenbanktabelle.
Das Abrufen von Datensätzen erfolgt in folgenden Schritten:
Vorbereiten der SQL-Abfrage basierend auf den erforderlichen Bedingungen. Dies erfolgt mit demprepare Methode.
Ausführen einer SQL-Abfrage, um alle Ergebnisse aus der Datenbank auszuwählen. Dies erfolgt mit demexecute Methode.
Abrufen aller Ergebnisse nacheinander und Drucken dieser Ergebnisse. Dies erfolgt mit demfetch Methode.
Anweisungshandle freigeben. Dies erfolgt mit demfinish Methode.
Im Folgenden wird beschrieben, wie alle Datensätze aus der EMPLOYEE-Tabelle mit einem Gehalt von mehr als 1000 abgefragt werden.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("SELECT * FROM EMPLOYEE WHERE INCOME > ?")
sth.execute(1000)
sth.fetch do |row|
printf "First Name: %s, Last Name : %s\n", row[0], row[1]
printf "Age: %d, Sex : %s\n", row[2], row[3]
printf "Salary :%d \n\n", row[4]
end
sth.finish
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
# disconnect from server
dbh.disconnect if dbh
endDies führt zu folgendem Ergebnis:
First Name: Mac, Last Name : Mohan
Age: 20, Sex : M
Salary :2000
First Name: John, Last Name : Poul
Age: 25, Sex : M
Salary :2300Es gibt weitere Verknüpfungsmethoden zum Abrufen von Datensätzen aus der Datenbank. Wenn Sie interessiert sind, gehen Sie durch das Abrufen des Ergebnisses, andernfalls fahren Sie mit dem nächsten Abschnitt fort.
Vorgang aktualisieren
UPDATE Operation für eine beliebige Datenbank bedeutet, einen oder mehrere Datensätze zu aktualisieren, die bereits in der Datenbank verfügbar sind. Im Folgenden wird beschrieben, wie Sie alle Datensätze mit SEX als 'M' aktualisieren. Hier werden wir das ALTER aller Männer um ein Jahr erhöhen. Dies dauert drei Schritte -
Vorbereiten der SQL-Abfrage basierend auf den erforderlichen Bedingungen. Dies erfolgt mit demprepare Methode.
Ausführen einer SQL-Abfrage, um alle Ergebnisse aus der Datenbank auszuwählen. Dies erfolgt mit demexecute Methode.
Anweisungshandle freigeben. Dies erfolgt mit demfinish Methode.
Wenn alles gut geht, dann commit diese Operation können Sie sonst rollback die vollständige Transaktion.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = ?")
sth.execute('M')
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endDELETE-Betrieb
Der Vorgang LÖSCHEN ist erforderlich, wenn Sie einige Datensätze aus Ihrer Datenbank löschen möchten. Im Folgenden wird beschrieben, wie Sie alle Datensätze aus EMPLOYEE löschen, wenn das Alter mehr als 20 Jahre beträgt. Dieser Vorgang führt die folgenden Schritte aus.
Vorbereiten der SQL-Abfrage basierend auf den erforderlichen Bedingungen. Dies erfolgt mit demprepare Methode.
Ausführen einer SQL-Abfrage zum Löschen der erforderlichen Datensätze aus der Datenbank. Dies erfolgt mit demexecute Methode.
Anweisungshandle freigeben. Dies erfolgt mit demfinish Methode.
Wenn alles gut geht, dann commit diese Operation können Sie sonst rollback die vollständige Transaktion.
#!/usr/bin/ruby -w
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
sth = dbh.prepare("DELETE FROM EMPLOYEE WHERE AGE > ?")
sth.execute(20)
sth.finish
dbh.commit
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endTransaktionen durchführen
Transaktionen sind ein Mechanismus, der die Datenkonsistenz gewährleistet. Transaktionen sollten die folgenden vier Eigenschaften haben:
Atomicity - Entweder wird eine Transaktion abgeschlossen oder es passiert überhaupt nichts.
Consistency - Eine Transaktion muss in einem konsistenten Zustand beginnen und das System in einem konsistenten Zustand verlassen.
Isolation - Zwischenergebnisse einer Transaktion sind außerhalb der aktuellen Transaktion nicht sichtbar.
Durability - Sobald eine Transaktion festgeschrieben wurde, bleiben die Auswirkungen auch nach einem Systemausfall bestehen.
Das DBI bietet zwei Methoden zum Festschreiben oder Zurücksetzen einer Transaktion. Es gibt eine weitere Methode namens Transaktion, mit der Transaktionen implementiert werden können. Es gibt zwei einfache Ansätze zur Implementierung von Transaktionen:
Ansatz I.
Der erste Ansatz verwendet die Commit- und Rollback- Methoden von DBI, um die Transaktion explizit festzuschreiben oder abzubrechen.
dbh['AutoCommit'] = false # Set auto commit to false.
begin
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
dbh.commit
rescue
puts "transaction failed"
dbh.rollback
end
dbh['AutoCommit'] = trueAnsatz II
Der zweite Ansatz verwendet die Transaktionsmethode . Dies ist einfacher, da ein Codeblock erforderlich ist, der die Anweisungen enthält, aus denen die Transaktion besteht. Die Transaktionsmethode führt den Block aus und ruft dann automatisch ein Commit oder Rollback auf , je nachdem, ob der Block erfolgreich ist oder fehlschlägt.
dbh['AutoCommit'] = false # Set auto commit to false.
dbh.transaction do |dbh|
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'John'")
dbh.do("UPDATE EMPLOYEE SET AGE = AGE+1 WHERE FIRST_NAME = 'Zara'")
end
dbh['AutoCommit'] = trueCOMMIT-Betrieb
Commit ist die Operation, die der Datenbank ein grünes Signal gibt, um die Änderungen abzuschließen. Nach dieser Operation kann keine Änderung zurückgesetzt werden.
Hier ist ein einfaches Beispiel, um das aufzurufen commit Methode.
dbh.commitROLLBACK-Betrieb
Wenn Sie mit einer oder mehreren Änderungen nicht zufrieden sind und diese Änderungen vollständig zurücksetzen möchten, verwenden Sie die rollback Methode.
Hier ist ein einfaches Beispiel, um das aufzurufen rollback Methode.
dbh.rollbackDatenbank trennen
Verwenden Sie zum Trennen der Datenbankverbindung die API zum Trennen der Verbindung.
dbh.disconnectWenn die Verbindung zu einer Datenbank vom Benutzer mit der Trennungsmethode geschlossen wird, werden alle ausstehenden Transaktionen vom DBI zurückgesetzt. Anstatt jedoch von den Implementierungsdetails des DBI abhängig zu sein, ist es besser, wenn Ihre Anwendung das Commit oder Rollback explizit aufruft.
Fehler behandeln
Es gibt viele Fehlerquellen. Einige Beispiele sind ein Syntaxfehler in einer ausgeführten SQL-Anweisung, ein Verbindungsfehler oder das Aufrufen der Abrufmethode für ein bereits abgebrochenes oder abgeschlossenes Anweisungshandle.
Wenn eine DBI-Methode fehlschlägt, löst DBI eine Ausnahme aus. DBI-Methoden können verschiedene Ausnahmetypen auslösen, die beiden wichtigsten Ausnahmeklassen sind jedoch DBI :: InterfaceError und DBI :: DatabaseError .
Ausnahmeobjekte dieser Klassen haben drei Attribute mit den Namen err , errstr und state , die die Fehlernummer, eine beschreibende Fehlerzeichenfolge und einen Standardfehlercode darstellen. Die Attribute werden unten erklärt -
err- Gibt eine ganzzahlige Darstellung des aufgetretenen Fehlers oder Null zurück, wenn dies vom DBD nicht unterstützt wird. Der Oracle-DBD gibt beispielsweise den numerischen Teil einer ORA-XXXX- Fehlermeldung zurück.
errstr - Gibt eine Zeichenfolgendarstellung des aufgetretenen Fehlers zurück.
state- Gibt den SQLSTATE-Code des aufgetretenen Fehlers zurück. Der SQLSTATE ist eine fünf Zeichen lange Zeichenfolge. Die meisten DBDs unterstützen dies nicht und geben stattdessen nil zurück.
In den meisten Beispielen haben Sie den folgenden Code gesehen:
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
dbh.rollback
ensure
# disconnect from server
dbh.disconnect if dbh
endUm Debugging-Informationen darüber zu erhalten, was Ihr Skript während der Ausführung tut, können Sie die Ablaufverfolgung aktivieren. Dazu müssen Sie zuerst das Modul dbi / trace laden und dann die Trace- Methode aufrufen , die den Trace-Modus und das Ausgabeziel steuert.
require "dbi/trace"
..............
trace(mode, destination)Der Moduswert kann 0 (aus), 1, 2 oder 3 sein, und das Ziel sollte ein E / A-Objekt sein. Die Standardwerte sind 2 bzw. STDERR.
Codeblöcke mit Methoden
Es gibt einige Methoden, die Handles erstellen. Diese Methoden können mit einem Codeblock aufgerufen werden. Der Vorteil der Verwendung von Codeblöcken zusammen mit Methoden besteht darin, dass sie das Handle für den Codeblock als Parameter bereitstellen und das Handle automatisch bereinigen, wenn der Block beendet wird. Es gibt nur wenige Beispiele, um das Konzept zu verstehen.
DBI.connect- Diese Methode generiert ein Datenbankhandle. Es wird empfohlen, die Trennung am Ende des Blocks aufzurufen , um die Datenbank zu trennen.
dbh.prepare- Diese Methode generiert ein Anweisungshandle und es wird empfohlen, am Ende des Blocks fertig zu werden. Innerhalb des Blocks müssen Sie die Methode execute aufrufen , um die Anweisung auszuführen.
dbh.execute- Diese Methode ist ähnlich, außer dass wir nicht die Ausführung innerhalb des Blocks aufrufen müssen. Das Anweisungshandle wird automatisch ausgeführt.
Beispiel 1
DBI.connect kann einen Codeblock nehmen, das Datenbankhandle an ihn übergeben und das Handle am Ende des Blocks automatisch wie folgt trennen.
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123") do |dbh|Beispiel 2
dbh.prepare kann einen Codeblock nehmen, übergibt das Anweisungshandle an ihn und ruft am Ende des Blocks automatisch den Abschluss wie folgt auf.
dbh.prepare("SHOW DATABASES") do |sth|
sth.execute
puts "Databases: " + sth.fetch_all.join(", ")
endBeispiel 3
dbh.execute kann einen Codeblock nehmen, das Anweisungshandle an ihn übergeben und am Ende des Blocks automatisch den Abschluss wie folgt aufrufen:
dbh.execute("SHOW DATABASES") do |sth|
puts "Databases: " + sth.fetch_all.join(", ")
endDie DBI- Transaktionsmethode verwendet auch einen Codeblock, der oben beschrieben wurde.
Treiberspezifische Funktionen und Attribute
Mit dem DBI können die Datenbanktreiber zusätzliche datenbankspezifische Funktionen bereitstellen, die vom Benutzer über die func- Methode eines beliebigen Handle-Objekts aufgerufen werden können .
Treiberspezifische Attribute werden unterstützt und können mithilfe von festgelegt oder abgerufen werden []= oder [] Methoden.
| Sr.Nr. | Funktionen & Beschreibung |
|---|---|
| 1 | dbh.func(:createdb, db_name) Erstellt eine neue Datenbank. |
| 2 | dbh.func(:dropdb, db_name) Löscht eine Datenbank. |
| 3 | dbh.func(:reload) Führt einen Neuladevorgang durch. |
| 4 | dbh.func(:shutdown) Fährt den Server herunter. |
| 5 | dbh.func(:insert_id) => Fixnum Gibt den neuesten AUTO_INCREMENT-Wert für eine Verbindung zurück. |
| 6 | dbh.func(:client_info) => String Gibt MySQL-Client-Informationen in Bezug auf die Version zurück. |
| 7 | dbh.func(:client_version) => Fixnum Gibt Clientinformationen in Bezug auf die Version zurück. Es ist ähnlich wie: client_info, gibt jedoch ein Fixnum anstelle von sting zurück. |
| 8 | dbh.func(:host_info) => String Gibt Hostinformationen zurück. |
| 9 | dbh.func(:proto_info) => Fixnum Gibt das Protokoll zurück, das für die Kommunikation verwendet wird. |
| 10 | dbh.func(:server_info) => String Gibt MySQL-Serverinformationen in Bezug auf die Version zurück. |
| 11 | dbh.func(:stat) => String Gibt den aktuellen Status der Datenbank zurück. |
| 12 | dbh.func(:thread_id) => Fixnum Gibt die aktuelle Thread-ID zurück. |
Beispiel
#!/usr/bin/ruby
require "dbi"
begin
# connect to the MySQL server
dbh = DBI.connect("DBI:Mysql:TESTDB:localhost", "testuser", "test123")
puts dbh.func(:client_info)
puts dbh.func(:client_version)
puts dbh.func(:host_info)
puts dbh.func(:proto_info)
puts dbh.func(:server_info)
puts dbh.func(:thread_id)
puts dbh.func(:stat)
rescue DBI::DatabaseError => e
puts "An error occurred"
puts "Error code: #{e.err}"
puts "Error message: #{e.errstr}"
ensure
dbh.disconnect if dbh
endDies führt zu folgendem Ergebnis:
5.0.45
50045
Localhost via UNIX socket
10
5.0.45
150621
Uptime: 384981 Threads: 1 Questions: 1101078 Slow queries: 4 \
Opens: 324 Flush tables: 1 Open tables: 64 \
Queries per second avg: 2.860Ruby ist eine Allzwecksprache. Es kann überhaupt nicht als Web-Sprache bezeichnet werden . Trotzdem gehören Webanwendungen und Webtools im Allgemeinen zu den häufigsten Anwendungen von Ruby.
Sie können nicht nur Ihren eigenen SMTP-Server, FTP-Daemon oder Webserver in Ruby schreiben, sondern Ruby auch für üblichere Aufgaben wie die CGI-Programmierung oder als Ersatz für PHP verwenden.
Bitte verbringen Sie einige Minuten mit dem CGI-Programmier- Tutorial, um weitere Informationen zur CGI-Programmierung zu erhalten.
Schreiben von CGI-Skripten
Das grundlegendste Ruby CGI-Skript sieht folgendermaßen aus:
#!/usr/bin/ruby
puts "HTTP/1.0 200 OK"
puts "Content-type: text/html\n\n"
puts "<html><body>This is a test</body></html>"Wenn Sie dieses Skript test.cgi aufrufen und es mit den richtigen Berechtigungen auf einen Unix-basierten Webhosting-Anbieter hochladen , können Sie es als CGI-Skript verwenden.
Zum Beispiel, wenn Sie die Website haben https://www.example.com/Bei einem Linux-Webhosting-Anbieter gehostet, laden Sie test.cgi in das Hauptverzeichnis hoch und erteilen ihm Ausführungsberechtigungen. Anschließend besuchen Siehttps://www.example.com/test.cgi sollte eine HTML-Seite zurückgeben, die sagt This is a test.
Wenn test.cgi von einem Webbrowser angefordert wird, sucht der Webserver auf der Website nach test.cgi und führt es dann mit dem Ruby-Interpreter aus. Das Ruby-Skript gibt einen grundlegenden HTTP-Header und anschließend ein grundlegendes HTML-Dokument zurück.
Verwenden von cgi.rb
Ruby wird mit einer speziellen Bibliothek geliefert cgi Dies ermöglicht komplexere Interaktionen als mit dem vorhergehenden CGI-Skript.
Lassen Sie uns ein einfaches CGI-Skript erstellen, das cgi verwendet -
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
puts cgi.header
puts "<html><body>This is a test</body></html>"Hier haben Sie ein CGI-Objekt erstellt und damit die Kopfzeile für Sie gedruckt.
Formularverarbeitung
Mit der Klassen-CGI können Sie auf zwei Arten auf HTML-Abfrageparameter zugreifen. Angenommen, wir erhalten eine URL von /cgi-bin/test.cgi?FirstName = Zara & LastName = Ali.
Sie können mit CGI # [] direkt wie folgt auf die Parameter Vorname und Nachname zugreifen :
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
cgi['FirstName'] # => ["Zara"]
cgi['LastName'] # => ["Ali"]Es gibt eine andere Möglichkeit, auf diese Formularvariablen zuzugreifen. Dieser Code gibt Ihnen einen Hash aller Schlüssel und Werte -
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
h = cgi.params # => {"FirstName"=>["Zara"],"LastName"=>["Ali"]}
h['FirstName'] # => ["Zara"]
h['LastName'] # => ["Ali"]Es folgt der Code zum Abrufen aller Schlüssel -
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
cgi.keys # => ["FirstName", "LastName"]Wenn ein Formular mehrere Felder mit demselben Namen enthält, werden die entsprechenden Werte als Array an das Skript zurückgegeben. Der Accessor [] gibt nur den ersten von diesen zurück. Indizieren Sie das Ergebnis der params-Methode, um alle abzurufen.
In diesem Beispiel wird angenommen, dass das Formular drei Felder mit dem Namen "Name" enthält und wir drei Namen "Zara", "Huma" und "Nuha" eingegeben haben.
#!/usr/bin/ruby
require 'cgi'
cgi = CGI.new
cgi['name'] # => "Zara"
cgi.params['name'] # => ["Zara", "Huma", "Nuha"]
cgi.keys # => ["name"]
cgi.params # => {"name"=>["Zara", "Huma", "Nuha"]}Note- Ruby kümmert sich automatisch um die GET- und POST-Methoden. Für diese beiden unterschiedlichen Methoden gibt es keine getrennte Behandlung.
Ein zugehöriges, aber einfaches Formular, das die richtigen Daten senden könnte, hätte den HTML-Code wie folgt:
<html>
<body>
<form method = "POST" action = "http://www.example.com/test.cgi">
First Name :<input type = "text" name = "FirstName" value = "" />
<br />
Last Name :<input type = "text" name = "LastName" value = "" />
<input type = "submit" value = "Submit Data" />
</form>
</body>
</html>Formulare und HTML erstellen
CGI enthält eine Vielzahl von Methoden zum Erstellen von HTML. Sie finden eine Methode pro Tag. Um diese Methoden zu aktivieren, müssen Sie ein CGI-Objekt erstellen, indem Sie CGI.new aufrufen.
Um das Verschachteln von Tags zu vereinfachen, verwenden diese Methoden ihren Inhalt als Codeblöcke. Die Codeblöcke sollten einen String zurückgeben , der als Inhalt für das Tag verwendet wird. Zum Beispiel -
#!/usr/bin/ruby
require "cgi"
cgi = CGI.new("html4")
cgi.out {
cgi.html {
cgi.head { "\n"+cgi.title{"This Is a Test"} } +
cgi.body { "\n"+
cgi.form {"\n"+
cgi.hr +
cgi.h1 { "A Form: " } + "\n"+
cgi.textarea("get_text") +"\n"+
cgi.br +
cgi.submit
}
}
}
}NOTE- Die Formularmethode der CGI-Klasse kann einen Methodenparameter akzeptieren, der die HTTP-Methode (GET, POST usw.) für die Formularübermittlung festlegt. Die in diesem Beispiel verwendete Standardeinstellung ist POST.
Dies führt zu folgendem Ergebnis:
Content-Type: text/html
Content-Length: 302
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Final//EN">
<HTML>
<HEAD>
<TITLE>This Is a Test</TITLE>
</HEAD>
<BODY>
<FORM METHOD = "post" ENCTYPE = "application/x-www-form-urlencoded">
<HR>
<H1>A Form: </H1>
<TEXTAREA COLS = "70" NAME = "get_text" ROWS = "10"></TEXTAREA>
<BR>
<INPUT TYPE = "submit">
</FORM>
</BODY>
</HTML>Strings zitieren
Wenn Sie mit URLs und HTML-Code arbeiten, müssen Sie darauf achten, bestimmte Zeichen in Anführungszeichen zu setzen. Zum Beispiel hat ein Schrägstrich (/) in einer URL eine besondere Bedeutung, also muss es seinescaped wenn es nicht Teil des Pfadnamens ist.
Beispielsweise wird jedes / im Abfrageteil der URL in die Zeichenfolge% 2F übersetzt und muss zurück in ein / übersetzt werden, damit Sie es verwenden können. Leerzeichen und kaufmännisches Und sind ebenfalls Sonderzeichen. Um dies zu handhaben, stellt CGI die Routinen bereitCGI.escape und CGI.unescape.
#!/usr/bin/ruby
require 'cgi'
puts CGI.escape(Zara Ali/A Sweet & Sour Girl")Dies führt zu folgendem Ergebnis:
Zara+Ali%2FA Sweet+%26+Sour+Girl")#!/usr/bin/ruby
require 'cgi'
puts CGI.escapeHTML('<h1>Zara Ali/A Sweet & Sour Girl</h1>')Dies führt zu folgendem Ergebnis:
<h1>Zara Ali/A Sweet & Sour Girl</h1>'Nützliche Methoden in der CGI-Klasse
Hier ist die Liste der Methoden, die sich auf die CGI-Klasse beziehen -
Die Ruby CGI - Methoden zur Standard CGI Bibliothek.
Cookies und Sitzungen
Wir haben diese beiden Konzepte in verschiedenen Abschnitten erläutert. Bitte folgen Sie den Abschnitten -
Die Ruby CGI Cookies - Umgang mit CGI Cookies.
Die Ruby-CGI-Sitzungen - Verwalten von CGI-Sitzungen.
Webhosting-Server
Sie können das folgende Thema im Internet überprüfen, um Ihre Website auf einem Unix-basierten Server zu hosten:
Unix-basiertes Webhosting
Das Simple Mail Transfer Protocol (SMTP) ist ein Protokoll, das das Senden von E-Mails und das Weiterleiten von E-Mails zwischen Mailservern übernimmt.
Ruby stellt die Net :: SMTP-Klasse für die clientseitige SMTP-Verbindung (Simple Mail Transfer Protocol) bereit und stellt zwei Klassenmethoden neu und start bereit .
Das new nimmt zwei Parameter -
Der Servername ist standardmäßig localhost.
Die Portnummer, die standardmäßig dem bekannten Port 25 entspricht.
Das start Methode nimmt diese Parameter -
Der Server - IP-Name des SMTP-Servers, standardmäßig localhost.
Der Port - Portnummer , standardmäßig 25.
Die Domäne - Domäne des E-Mail-Absenders, standardmäßig ENV ["HOSTNAME"].
Das Konto - Benutzername, Standard ist Null.
Das Passwort - Benutzerpasswort, standardmäßig null.
Der Authtyp - Autorisierungstyp, standardmäßig cram_md5 .
Ein SMTP-Objekt verfügt über eine Instanzmethode namens sendmail, die normalerweise zum Versenden einer Nachricht verwendet wird. Es werden drei Parameter benötigt -
Die Quelle - Eine Zeichenfolge oder ein Array oder etwas anderes, wobei jeder Iterator jeweils eine Zeichenfolge zurückgibt.
Der Absender - Eine Zeichenfolge, die im Feld from der E-Mail angezeigt wird.
Die Empfänger - Eine Zeichenfolge oder ein Array von Zeichenfolgen, die die Adressaten des Empfängers darstellen.
Beispiel
Hier ist eine einfache Möglichkeit, eine E-Mail mit dem Ruby-Skript zu senden. Probieren Sie es einmal aus -
require 'net/smtp'
message = <<MESSAGE_END
From: Private Person <[email protected]>
To: A Test User <[email protected]>
Subject: SMTP e-mail test
This is a test e-mail message.
MESSAGE_END
Net::SMTP.start('localhost') do |smtp|
smtp.send_message message, '[email protected]', '[email protected]'
endHier haben Sie mithilfe eines Dokuments eine einfache E-Mail in die Nachricht eingefügt und dabei darauf geachtet, die Überschriften korrekt zu formatieren. E-Mails erfordern aFrom, To, und Subject Kopfzeile, durch eine Leerzeile vom Text der E-Mail getrennt.
Zum Senden der E-Mail verwenden Sie Net :: SMTP, um eine Verbindung zum SMTP-Server auf dem lokalen Computer herzustellen, und verwenden dann die Methode send_message zusammen mit der Nachricht, der Absenderadresse und der Zieladresse als Parameter (obwohl die Absender- und Absenderadressen sind Innerhalb der E-Mail selbst werden diese nicht immer zum Weiterleiten von E-Mails verwendet.
Wenn Sie auf Ihrem Computer keinen SMTP-Server ausführen, können Sie mit Net :: SMTP mit einem Remote-SMTP-Server kommunizieren. Sofern Sie keinen Webmail-Dienst (wie Hotmail oder Yahoo! Mail) verwenden, hat Ihnen Ihr E-Mail-Anbieter die Details des Postausgangsservers zur Verfügung gestellt, die Sie Net :: SMTP wie folgt zur Verfügung stellen können:
Net::SMTP.start('mail.your-domain.com')Diese Codezeile stellt eine Verbindung zum SMTP-Server an Port 25 von mail.your-domain.com her, ohne einen Benutzernamen oder ein Kennwort zu verwenden. Bei Bedarf können Sie jedoch die Portnummer und andere Details angeben. Zum Beispiel -
Net::SMTP.start('mail.your-domain.com',
25,
'localhost',
'username', 'password' :plain)In diesem Beispiel wird unter Verwendung eines Benutzernamens und eines Kennworts im Nur-Text-Format eine Verbindung zum SMTP-Server unter mail.your-domain.com hergestellt. Es identifiziert den Hostnamen des Clients als localhost.
Senden einer HTML-E-Mail mit Ruby
Wenn Sie eine Textnachricht mit Ruby senden, wird der gesamte Inhalt als einfacher Text behandelt. Selbst wenn Sie HTML-Tags in eine Textnachricht aufnehmen, wird diese als einfacher Text angezeigt und HTML-Tags werden nicht gemäß der HTML-Syntax formatiert. Ruby Net :: SMTP bietet jedoch die Möglichkeit, eine HTML-Nachricht als tatsächliche HTML-Nachricht zu senden.
Beim Senden einer E-Mail-Nachricht können Sie eine Mime-Version, einen Inhaltstyp und einen Zeichensatz angeben, um eine HTML-E-Mail zu senden.
Beispiel
Es folgt das Beispiel zum Senden von HTML-Inhalten als E-Mail. Probieren Sie es einmal aus -
require 'net/smtp'
message = <<MESSAGE_END
From: Private Person <[email protected]>
To: A Test User <[email protected]>
MIME-Version: 1.0
Content-type: text/html
Subject: SMTP e-mail test
This is an e-mail message to be sent in HTML format
<b>This is HTML message.</b>
<h1>This is headline.</h1>
MESSAGE_END
Net::SMTP.start('localhost') do |smtp|
smtp.send_message message, '[email protected]', '[email protected]'
endAnhänge als E-Mail senden
Um eine E-Mail mit gemischtem Inhalt zu senden, muss festgelegt werden Content-type Header zu multipart/mixed. Dann können Text- und Anhangsabschnitte innerhalb von angegeben werdenboundaries.
Eine Grenze wird mit zwei Bindestrichen gefolgt von einer eindeutigen Nummer gestartet, die nicht im Nachrichtenteil der E-Mail erscheinen kann. Eine letzte Grenze, die den letzten Abschnitt der E-Mail kennzeichnet, muss ebenfalls mit zwei Bindestrichen enden.
Angehängte Dateien sollten mit dem verschlüsselt werden pack("m") Funktion, um vor der Übertragung eine Base64-Codierung zu haben.
Beispiel
Es folgt das Beispiel, in dem eine Datei gesendet wird /tmp/test.txt als Anhang.
require 'net/smtp'
filename = "/tmp/test.txt"
# Read a file and encode it into base64 format
filecontent = File.read(filename)
encodedcontent = [filecontent].pack("m") # base64
marker = "AUNIQUEMARKER"
body = <<EOF
This is a test email to send an attachement.
EOF
# Define the main headers.
part1 = <<EOF
From: Private Person <[email protected]>
To: A Test User <[email protected]>
Subject: Sending Attachement
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary = #{marker}
--#{marker}
EOF
# Define the message action
part2 = <<EOF
Content-Type: text/plain
Content-Transfer-Encoding:8bit
#{body}
--#{marker}
EOF
# Define the attachment section
part3 = <<EOF
Content-Type: multipart/mixed; name = \"#{filename}\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename = "#{filename}"
#{encodedcontent}
--#{marker}--
EOF
mailtext = part1 + part2 + part3
# Let's put our code in safe area
begin
Net::SMTP.start('localhost') do |smtp|
smtp.sendmail(mailtext, '[email protected]', ['[email protected]'])
end
rescue Exception => e
print "Exception occured: " + e
endNOTE - Sie können mehrere Ziele innerhalb des Arrays angeben, diese sollten jedoch durch Komma getrennt werden.
Ruby bietet zwei Zugriffsebenen auf Netzwerkdienste. Auf niedriger Ebene können Sie auf die grundlegende Socket-Unterstützung des zugrunde liegenden Betriebssystems zugreifen, mit der Sie Clients und Server sowohl für verbindungsorientierte als auch für verbindungslose Protokolle implementieren können.
Ruby verfügt auch über Bibliotheken, die übergeordneten Zugriff auf bestimmte Netzwerkprotokolle auf Anwendungsebene wie FTP, HTTP usw. bieten.
Dieses Kapitel gibt Ihnen einen Einblick in das bekannteste Konzept in Networking - Socket Programming.
Was sind Steckdosen?
Sockets sind die Endpunkte eines bidirektionalen Kommunikationskanals. Sockets können innerhalb eines Prozesses, zwischen Prozessen auf demselben Computer oder zwischen Prozessen auf verschiedenen Kontinenten kommunizieren.
Sockets können über verschiedene Kanaltypen implementiert werden: Unix-Domain-Sockets, TCP, UDP usw. Der Socket bietet spezifische Klassen für die Abwicklung der allgemeinen Transporte sowie eine generische Schnittstelle für die Abwicklung des Restes.
Steckdosen haben ihren eigenen Wortschatz -
| Sr.Nr. | Begriff & Beschreibung |
|---|---|
| 1 | domain Die Protokollfamilie, die als Transportmechanismus verwendet wird. Diese Werte sind Konstanten wie PF_INET, PF_UNIX, PF_X25 usw. |
| 2 | type Die Art der Kommunikation zwischen den beiden Endpunkten, normalerweise SOCK_STREAM für verbindungsorientierte Protokolle und SOCK_DGRAM für verbindungslose Protokolle. |
| 3 | protocol Typischerweise Null, kann dies verwendet werden, um eine Variante eines Protokolls innerhalb einer Domäne und eines Typs zu identifizieren. |
| 4 | hostname Die Kennung einer Netzwerkschnittstelle - Eine Zeichenfolge, die ein Hostname, eine gepunktete Quad-Adresse oder eine IPV6-Adresse in Doppelpunkt- (und möglicherweise Punkt-) Schreibweise sein kann Eine Zeichenfolge "<broadcast>", die eine INADDR_BROADCAST-Adresse angibt. Eine Zeichenfolge mit der Länge Null, die INADDR_ANY oder angibt Eine Ganzzahl, die als Binäradresse in der Reihenfolge der Hostbytes interpretiert wird. |
| 5 | port Jeder Server wartet auf Clients, die einen oder mehrere Ports anrufen. Ein Port kann eine Fixnum-Portnummer, eine Zeichenfolge mit einer Portnummer oder der Name eines Dienstes sein. |
Ein einfacher Client
Hier schreiben wir ein sehr einfaches Client-Programm, das eine Verbindung zu einem bestimmten Port und einem bestimmten Host herstellt. Ruby KlasseTCPSocketbietet eine offene Funktion zum Öffnen einer solchen Steckdose.
Das TCPSocket.open(hosname, port )Öffnet eine TCP-Verbindung zum Hostnamen am Port .
Sobald Sie einen Socket geöffnet haben, können Sie wie jedes E / A-Objekt daraus lesen. Wenn Sie fertig sind, denken Sie daran, es zu schließen, als würden Sie eine Datei schließen.
Der folgende Code ist ein sehr einfacher Client, der eine Verbindung zu einem bestimmten Host und Port herstellt, alle verfügbaren Daten vom Socket liest und dann beendet -
require 'socket' # Sockets are in standard library
hostname = 'localhost'
port = 2000
s = TCPSocket.open(hostname, port)
while line = s.gets # Read lines from the socket
puts line.chop # And print with platform line terminator
end
s.close # Close the socket when doneEin einfacher Server
Zum Schreiben von Internet-Servern verwenden wir die TCPServerKlasse. Ein TCPServer-Objekt ist eine Factory für TCPSocket-Objekte.
Ruf jetzt an TCPServer.open(hostname, portFunktion zum Angeben eines Ports für Ihren Dienst und Erstellen einesTCPServer Objekt.
Rufen Sie als Nächstes die Methode accept des zurückgegebenen TCPServer-Objekts auf. Diese Methode wartet, bis eine Verbindung zu dem von Ihnen angegebenen Port hergestellt ist, und gibt dann ein TCPSocket- Objekt zurück, das die Verbindung zu diesem Client darstellt.
require 'socket' # Get sockets from stdlib
server = TCPServer.open(2000) # Socket to listen on port 2000
loop { # Servers run forever
client = server.accept # Wait for a client to connect
client.puts(Time.now.ctime) # Send the time to the client
client.puts "Closing the connection. Bye!"
client.close # Disconnect from the client
}Führen Sie diesen Server nun im Hintergrund aus und führen Sie dann den obigen Client aus, um das Ergebnis anzuzeigen.
Multi-Client-TCP-Server
Die meisten Server im Internet sind für die gleichzeitige Verarbeitung einer großen Anzahl von Clients ausgelegt.
Rubys Thread- Klasse macht es einfach, einen Multithread-Server zu erstellen. Einer, der Anforderungen akzeptiert und sofort einen neuen Ausführungsthread erstellt, um die Verbindung zu verarbeiten, während das Hauptprogramm auf weitere Verbindungen warten kann.
require 'socket' # Get sockets from stdlib
server = TCPServer.open(2000) # Socket to listen on port 2000
loop { # Servers run forever
Thread.start(server.accept) do |client|
client.puts(Time.now.ctime) # Send the time to the client
client.puts "Closing the connection. Bye!"
client.close # Disconnect from the client
end
}In diesem Beispiel haben Sie eine permanente Schleife. Wenn server.accept antwortet, wird ein neuer Thread erstellt und sofort gestartet, um die gerade akzeptierte Verbindung mithilfe des an den Thread übergebenen Verbindungsobjekts zu verarbeiten. Das Hauptprogramm kehrt jedoch sofort zurück und wartet auf neue Verbindungen.
Die Verwendung von Ruby-Threads auf diese Weise bedeutet, dass der Code portabel ist und unter Linux, OS X und Windows auf dieselbe Weise ausgeführt wird.
Ein kleiner Webbrowser
Wir können die Socket-Bibliothek verwenden, um jedes Internetprotokoll zu implementieren. Hier ist zum Beispiel ein Code zum Abrufen des Inhalts einer Webseite -
require 'socket'
host = 'www.tutorialspoint.com' # The web server
port = 80 # Default HTTP port
path = "/index.htm" # The file we want
# This is the HTTP request we send to fetch a file
request = "GET #{path} HTTP/1.0\r\n\r\n"
socket = TCPSocket.open(host,port) # Connect to server
socket.print(request) # Send request
response = socket.read # Read complete response
# Split response at first blank line into headers and body
headers,body = response.split("\r\n\r\n", 2)
print body # And display itUm den ähnlichen Webclient zu implementieren, können Sie eine vorgefertigte Bibliothek wie verwenden Net::HTTPfür die Arbeit mit HTTP. Hier ist der Code, der dem vorherigen Code entspricht -
require 'net/http' # The library we need
host = 'www.tutorialspoint.com' # The web server
path = '/index.htm' # The file we want
http = Net::HTTP.new(host) # Create a connection
headers, body = http.get(path) # Request the file
if headers.code == "200" # Check the status code
print body
else
puts "#{headers.code} #{headers.message}"
endBitte überprüfen Sie ähnliche Bibliotheken, um mit FTP-, SMTP-, POP- und IMAP-Protokollen zu arbeiten.
Weitere Lesungen
Wir haben Ihnen einen schnellen Einstieg in die Socket-Programmierung gegeben. Da es sich um ein großes Thema handelt, wird empfohlen, die Ruby Socket Library und die Klassenmethoden zu lesen , um weitere Details zu finden.
Was ist XML?
Die Extensible Markup Language (XML) ist eine Markup-Sprache, die HTML oder SGML sehr ähnlich ist. Dies wird vom World Wide Web Consortium empfohlen und ist als offener Standard verfügbar.
XML ist eine tragbare Open-Source-Sprache, mit der Programmierer Anwendungen entwickeln können, die von anderen Anwendungen gelesen werden können, unabhängig vom Betriebssystem und / oder der Entwicklungssprache.
XML ist äußerst nützlich, um kleine bis mittlere Datenmengen zu verfolgen, ohne ein SQL-basiertes Backbone zu benötigen.
XML-Parser-Architekturen und APIs
Für XML-Parser stehen zwei verschiedene Varianten zur Verfügung:
SAX-like (Stream interfaces)- Hier registrieren Sie Rückrufe für Ereignisse von Interesse und lassen den Parser das Dokument durchgehen. Dies ist nützlich, wenn Ihre Dokumente groß sind oder wenn Sie über Speicherbeschränkungen verfügen, die Datei beim Lesen von der Festplatte analysiert wird und die gesamte Datei niemals im Speicher gespeichert wird.
DOM-like (Object tree interfaces) - Dies ist die Empfehlung des World Wide Web Consortium, bei der die gesamte Datei in den Speicher eingelesen und in einer hierarchischen (baumbasierten) Form gespeichert wird, um alle Funktionen eines XML-Dokuments darzustellen.
SAX kann Informationen offensichtlich nicht so schnell verarbeiten wie DOM, wenn mit großen Dateien gearbeitet wird. Auf der anderen Seite kann die ausschließliche Verwendung von DOM Ihre Ressourcen wirklich zerstören, insbesondere wenn es für viele kleine Dateien verwendet wird.
SAX ist schreibgeschützt, während DOM Änderungen an der XML-Datei zulässt. Da sich diese beiden unterschiedlichen APIs buchstäblich ergänzen, gibt es keinen Grund, warum Sie sie nicht beide für große Projekte verwenden können.
Analysieren und Erstellen von XML mit Ruby
Die häufigste Methode zur Manipulation von XML ist die REXML-Bibliothek von Sean Russell. Seit 2002 ist REXML Teil der Standard-Ruby-Distribution.
REXML ist ein reiner Ruby-XML-Prozessor, der dem XML 1.0-Standard entspricht. Es ist ein nicht validierender Prozessor, der alle nicht validierenden Konformitätstests von OASIS besteht.
Der REXML-Parser bietet gegenüber anderen verfügbaren Parsern die folgenden Vorteile:
- Es ist zu 100 Prozent in Ruby geschrieben.
- Es kann sowohl für die SAX- als auch für die DOM-Analyse verwendet werden.
- Es ist leicht, weniger als 2000 Codezeilen.
- Methoden und Klassen sind wirklich leicht zu verstehen.
- SAX2-basierte API und vollständige XPath-Unterstützung.
- Wird mit Ruby-Installation geliefert und ist keine separate Installation erforderlich.
Verwenden Sie für alle unsere XML-Codebeispiele eine einfache XML-Datei als Eingabe -
<collection shelf = "New Arrivals">
<movie title = "Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title = "Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title = "Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title = "Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>DOM-ähnliches Parsing
Lassen Sie uns zunächst unsere XML-Daten in Baumform analysieren . Wir beginnen damit, dass wir das verlangenrexml/documentBibliothek; Oft führen wir ein Include-REXML durch, um es der Einfachheit halber in den Namespace der obersten Ebene zu importieren.
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("movies.xml")
xmldoc = Document.new(xmlfile)
# Now get the root element
root = xmldoc.root
puts "Root element : " + root.attributes["shelf"]
# This will output all the movie titles.
xmldoc.elements.each("collection/movie"){
|e| puts "Movie Title : " + e.attributes["title"]
}
# This will output all the movie types.
xmldoc.elements.each("collection/movie/type") {
|e| puts "Movie Type : " + e.text
}
# This will output all the movie description.
xmldoc.elements.each("collection/movie/description") {
|e| puts "Movie Description : " + e.text
}Dies führt zu folgendem Ergebnis:
Root element : New Arrivals
Movie Title : Enemy Behind
Movie Title : Transformers
Movie Title : Trigun
Movie Title : Ishtar
Movie Type : War, Thriller
Movie Type : Anime, Science Fiction
Movie Type : Anime, Action
Movie Type : Comedy
Movie Description : Talk about a US-Japan war
Movie Description : A schientific fiction
Movie Description : Vash the Stampede!
Movie Description : Viewable boredomSAX-ähnliches Parsing
Um die gleichen Daten zu verarbeiten movies.xml , Datei in einer stromorientierten Art und Weisen wir definieren werden Zuhörer Klasse , der Methoden wird das Ziel der Rückrufe von dem Parser.
NOTE - Es wird nicht empfohlen, SAX-ähnliches Parsing für eine kleine Datei zu verwenden. Dies ist nur ein Demo-Beispiel.
#!/usr/bin/ruby -w
require 'rexml/document'
require 'rexml/streamlistener'
include REXML
class MyListener
include REXML::StreamListener
def tag_start(*args)
puts "tag_start: #{args.map {|x| x.inspect}.join(', ')}"
end
def text(data)
return if data =~ /^\w*$/ # whitespace only
abbrev = data[0..40] + (data.length > 40 ? "..." : "")
puts " text : #{abbrev.inspect}"
end
end
list = MyListener.new
xmlfile = File.new("movies.xml")
Document.parse_stream(xmlfile, list)Dies führt zu folgendem Ergebnis:
tag_start: "collection", {"shelf"=>"New Arrivals"}
tag_start: "movie", {"title"=>"Enemy Behind"}
tag_start: "type", {}
text : "War, Thriller"
tag_start: "format", {}
tag_start: "year", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Talk about a US-Japan war"
tag_start: "movie", {"title"=>"Transformers"}
tag_start: "type", {}
text : "Anime, Science Fiction"
tag_start: "format", {}
tag_start: "year", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "A schientific fiction"
tag_start: "movie", {"title"=>"Trigun"}
tag_start: "type", {}
text : "Anime, Action"
tag_start: "format", {}
tag_start: "episodes", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Vash the Stampede!"
tag_start: "movie", {"title"=>"Ishtar"}
tag_start: "type", {}
tag_start: "format", {}
tag_start: "rating", {}
tag_start: "stars", {}
tag_start: "description", {}
text : "Viewable boredom"XPath und Ruby
Eine alternative Möglichkeit zum Anzeigen von XML ist XPath. Dies ist eine Art Pseudosprache, die beschreibt, wie bestimmte Elemente und Attribute in einem XML-Dokument gefunden werden, wobei dieses Dokument als logisch geordneter Baum behandelt wird.
REXML unterstützt XPath über die XPath- Klasse. Es wird von einer baumbasierten Analyse (Dokumentobjektmodell) ausgegangen, wie wir oben gesehen haben.
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("movies.xml")
xmldoc = Document.new(xmlfile)
# Info for the first movie found
movie = XPath.first(xmldoc, "//movie")
p movie
# Print out all the movie types
XPath.each(xmldoc, "//type") { |e| puts e.text }
# Get an array of all of the movie formats.
names = XPath.match(xmldoc, "//format").map {|x| x.text }
p namesDies führt zu folgendem Ergebnis:
<movie title = 'Enemy Behind'> ... </>
War, Thriller
Anime, Science Fiction
Anime, Action
Comedy
["DVD", "DVD", "DVD", "VHS"]XSLT und Ruby
Es stehen zwei XSLT-Parser zur Verfügung, die Ruby verwenden kann. Eine kurze Beschreibung von jedem wird hier gegeben.
Ruby-Sablotron
Dieser Parser wurde von Masayoshi Takahashi geschrieben und gepflegt. Dies ist hauptsächlich für Linux-Betriebssysteme geschrieben und erfordert die folgenden Bibliotheken:
- Sablot
- Iconv
- Expat
Sie finden dieses Modul unter Ruby-Sablotron.
XSLT4R
XSLT4R wurde von Michael Neumann geschrieben und ist bei der RAA im Abschnitt Bibliothek unter XML zu finden. XSLT4R verwendet eine einfache Befehlszeilenschnittstelle, kann jedoch alternativ in einer Drittanbieteranwendung zum Transformieren eines XML-Dokuments verwendet werden.
XSLT4R benötigt zum Betrieb XMLScan, das im XSLT4R-Archiv enthalten ist und zu 100 Prozent aus Ruby besteht. Diese Module können mit der Standard-Ruby-Installationsmethode (dh ruby install.rb) installiert werden.
XSLT4R hat die folgende Syntax:
ruby xslt.rb stylesheet.xsl document.xml [arguments]Wenn Sie XSLT4R aus einer Anwendung heraus verwenden möchten, können Sie XSLT einschließen und die benötigten Parameter eingeben. Hier ist das Beispiel -
require "xslt"
stylesheet = File.readlines("stylesheet.xsl").to_s
xml_doc = File.readlines("document.xml").to_s
arguments = { 'image_dir' => '/....' }
sheet = XSLT::Stylesheet.new( stylesheet, arguments )
# output to StdOut
sheet.apply( xml_doc )
# output to 'str'
str = ""
sheet.output = [ str ]
sheet.apply( xml_doc )Weiterführende Literatur
Ausführliche Informationen zum REXML-Parser finden Sie in der Standarddokumentation zur REXML-Parser-Dokumentation .
Sie können XSLT4R aus dem RAA-Repository herunterladen .
Was ist Seife?
Das Simple Object Access Protocol (SOAP) ist ein plattformübergreifendes und sprachunabhängiges RPC-Protokoll, das auf XML und normalerweise (aber nicht unbedingt) HTTP basiert.
Es verwendet XML, um die Informationen zu codieren, die den Remoteprozeduraufruf ausführen, und HTTP, um diese Informationen über ein Netzwerk von Clients zu Servern und umgekehrt zu transportieren.
SOAP bietet gegenüber anderen Technologien wie COM, CORBA usw. mehrere Vorteile: Zum Beispiel die relativ günstigen Bereitstellungs- und Debugging-Kosten, die Erweiterbarkeit und Benutzerfreundlichkeit sowie das Vorhandensein mehrerer Implementierungen für verschiedene Sprachen und Plattformen.
Weitere Informationen finden Sie in unserem einfachen Tutorial SOAP .
Dieses Kapitel macht Sie mit der SOAP-Implementierung für Ruby (SOAP4R) vertraut. Dies ist ein grundlegendes Tutorial. Wenn Sie also ein detailliertes Detail benötigen, müssen Sie auf andere Ressourcen verweisen.
SOAP4R installieren
SOAP4R ist die von Hiroshi Nakamura entwickelte SOAP-Implementierung für Ruby und kann heruntergeladen werden von -
NOTE - Möglicherweise haben Sie diese Komponente bereits installiert.
Download SOAPWenn Sie sich dessen bewusst sind gem Dienstprogramm, dann können Sie den folgenden Befehl verwenden, um SOAP4R und verwandte Pakete zu installieren.
$ gem install soap4r --include-dependenciesWenn Sie unter Windows arbeiten, müssen Sie eine komprimierte Datei vom oben genannten Speicherort herunterladen und mithilfe der Standardinstallationsmethode installieren, indem Sie ruby install.rb ausführen .
Schreiben von SOAP4R-Servern
SOAP4R unterstützt zwei verschiedene Servertypen -
- CGI / FastCGI-basiert (SOAP :: RPC :: CGIStub)
- Standalone (SOAP :: RPC: StandaloneServer)
Dieses Kapitel enthält Einzelheiten zum Schreiben eines eigenständigen Servers. Die folgenden Schritte sind beim Schreiben eines SOAP-Servers erforderlich.
Schritt 1 - SOAP :: RPC :: StandaloneServer-Klasse erben
Um Ihren eigenen eigenständigen Server zu implementieren, müssen Sie eine neue Klasse schreiben, die SOAP :: StandaloneServer wie folgt untergeordnet ist:
class MyServer < SOAP::RPC::StandaloneServer
...............
endNOTE- Wenn Sie einen FastCGI-basierten Server schreiben möchten, müssen Sie SOAP :: RPC :: CGIStub als übergeordnete Klasse verwenden. Der Rest der Prozedur bleibt unverändert .
Schritt 2 - Handlermethoden definieren
Der zweite Schritt besteht darin, Ihre Web Services-Methoden zu schreiben, die Sie der Außenwelt zugänglich machen möchten.
Sie können als einfache Ruby-Methoden geschrieben werden. Schreiben wir zum Beispiel zwei Methoden, um zwei Zahlen hinzuzufügen und zwei Zahlen zu teilen -
class MyServer < SOAP::RPC::StandaloneServer
...............
# Handler methods
def add(a, b)
return a + b
end
def div(a, b)
return a / b
end
endSchritt 3 - Expose-Handler-Methoden
Der nächste Schritt besteht darin, unsere definierten Methoden zu unserem Server hinzuzufügen. Die Initialisierungsmethode wird verwendet, um Dienstmethoden mit einer der beiden folgenden Methoden verfügbar zu machen:
class MyServer < SOAP::RPC::StandaloneServer
def initialize(*args)
add_method(receiver, methodName, *paramArg)
end
endHier ist die Beschreibung der Parameter -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | receiver Das Objekt, das die Methode methodName enthält. Sie definieren die Servicemethoden in derselben Klasse wie die methodDef-Methode. Dieser Parameter ist self . |
| 2 | methodName Der Name der Methode, die aufgrund einer RPC-Anforderung aufgerufen wird. |
| 3 | paramArg Gibt, wenn angegeben, die Parameternamen und Parametermodi an. |
Um die Verwendung von Inout- oder Out- Parametern zu verstehen , betrachten Sie die folgende Dienstmethode, die zwei Parameter (inParam und inoutParam) verwendet, einen normalen Rückgabewert (retVal) und zwei weitere Parameter zurückgibt : inoutParam und outParam -
def aMeth(inParam, inoutParam)
retVal = inParam + inoutParam
outParam = inParam . inoutParam
inoutParam = inParam * inoutParam
return retVal, inoutParam, outParam
endJetzt können wir diese Methode wie folgt verfügbar machen:
add_method(self, 'aMeth', [
%w(in inParam),
%w(inout inoutParam),
%w(out outParam),
%w(retval return)
])Schritt 4 - Starten Sie den Server
Der letzte Schritt besteht darin, Ihren Server zu starten, indem Sie eine Instanz der abgeleiteten Klasse instanziieren und aufrufen start Methode.
myServer = MyServer.new('ServerName', 'urn:ruby:ServiceName', hostname, port)
myServer.startHier ist die Beschreibung der erforderlichen Parameter -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | ServerName Mit einem Servernamen können Sie angeben, was Ihnen am besten gefällt. |
| 2 | urn:ruby:ServiceName Hier Urne: Ruby ist konstant, aber Sie können diesem Server einen eindeutigen ServiceName-Namen geben. |
| 3 | hostname Gibt den Hostnamen an, den dieser Server abhört. |
| 4 | port Eine verfügbare Portnummer, die für den Webdienst verwendet werden soll. |
Beispiel
Lassen Sie uns nun mit den obigen Schritten einen eigenständigen Server schreiben -
require "soap/rpc/standaloneserver"
begin
class MyServer < SOAP::RPC::StandaloneServer
# Expose our services
def initialize(*args)
add_method(self, 'add', 'a', 'b')
add_method(self, 'div', 'a', 'b')
end
# Handler methods
def add(a, b)
return a + b
end
def div(a, b)
return a / b
end
end
server = MyServer.new("MyServer",
'urn:ruby:calculation', 'localhost', 8080)
trap('INT){
server.shutdown
}
server.start
rescue => err
puts err.message
endBei der Ausführung startet diese Serveranwendung einen eigenständigen SOAP-Server auf localhost und wartet auf Anforderungen auf Port 8080. Sie macht eine Dienstmethode verfügbar, add und div , die zwei Parameter verwendet und das Ergebnis zurückgibt.
Jetzt können Sie diesen Server wie folgt im Hintergrund ausführen:
$ ruby MyServer.rb&Schreiben von SOAP4R-Clients
Die SOAP :: RPC :: Driver- Klasse bietet Unterstützung für das Schreiben von SOAP-Clientanwendungen. Dieses Kapitel beschreibt diese Klasse und demonstriert ihre Verwendung anhand einer Anwendung.
Im Folgenden finden Sie die Mindestinformationen, die Sie zum Aufrufen eines SOAP-Dienstes benötigen würden:
- Die URL des SOAP-Dienstes (SOAP-Endpunkt-URL).
- Der Namespace der Dienstmethoden (Method Namespace URI).
- Die Namen der Dienstmethoden und ihre Parameter.
Jetzt schreiben wir einen SOAP-Client, der die im obigen Beispiel definierten Dienstmethoden add und div aufruft .
Hier sind die wichtigsten Schritte zum Erstellen eines SOAP-Clients.
Schritt 1 - Erstellen Sie eine SOAP-Treiberinstanz
Wir erstellen eine Instanz von SOAP :: RPC :: Driver, indem wir die neue Methode wie folgt aufrufen:
SOAP::RPC::Driver.new(endPoint, nameSpace, soapAction)Hier ist die Beschreibung der erforderlichen Parameter -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | endPoint URL des SOAP-Servers, mit dem eine Verbindung hergestellt werden soll. |
| 2 | nameSpace Der Namespace, der für alle RPCs verwendet werden soll, die mit diesem SOAP :: RPC :: Driver-Objekt erstellt wurden. |
| 3 | soapAction Ein Wert für das SOAPAction-Feld des HTTP-Headers. Wenn nil, wird standardmäßig die leere Zeichenfolge "" verwendet. |
Schritt 2 - Servicemethoden hinzufügen
Um eine SOAP - Service - Methode zu einem hinzufügen SOAP :: RPC :: Treiber können wir rufen Sie das folgende Verfahren unter Verwendung von SOAP :: RPC :: Treiber - Instanz -
driver.add_method(name, *paramArg)Hier ist die Beschreibung der Parameter -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | name Der Name der Remote-Webdienstmethode. |
| 2 | paramArg Gibt die Namen der Parameter der Remoteprozeduren an. |
Schritt 3 - Rufen Sie den SOAP-Dienst auf
Der letzte Schritt besteht darin, den SOAP-Service mithilfe der SOAP :: RPC :: Driver- Instanz wie folgt in Rechnung zu stellen :
result = driver.serviceMethod(paramArg...)Hier serviceMethod ist die eigentliche Web - Service - Methode und paramArg ... die Liste erforderlichen Parameter in der Service - Methode zu übergeben.
Example
Basierend auf den obigen Schritten schreiben wir einen SOAP-Client wie folgt:
#!/usr/bin/ruby -w
require 'soap/rpc/driver'
NAMESPACE = 'urn:ruby:calculation'
URL = 'http://localhost:8080/'
begin
driver = SOAP::RPC::Driver.new(URL, NAMESPACE)
# Add remote sevice methods
driver.add_method('add', 'a', 'b')
# Call remote service methods
puts driver.add(20, 30)
rescue => err
puts err.message
endWeitere Lesungen
Ich habe Ihnen nur sehr grundlegende Konzepte von Web Services mit Ruby erklärt. Wenn Sie einen weiteren Drilldown durchführen möchten, finden Sie unter folgendem Link weitere Informationen zu Webdiensten mit Ruby .
Einführung
Die grafische Standardbenutzeroberfläche (GUI) für Ruby ist Tk. Tk begann als GUI für die von John Ousterhout entwickelte Tcl-Skriptsprache.
Tk hat die einzigartige Auszeichnung, die einzige plattformübergreifende Benutzeroberfläche zu sein. Tk läuft unter Windows, Mac und Linux und bietet auf jedem Betriebssystem ein natives Erscheinungsbild.
Die Grundkomponente einer Tk-basierten Anwendung wird als Widget bezeichnet. Eine Komponente wird manchmal auch als Fenster bezeichnet, da in Tk "Fenster" und "Widget" häufig synonym verwendet werden.
Tk-Anwendungen folgen einer Widget-Hierarchie, in der eine beliebige Anzahl von Widgets in einem anderen Widget und diese Widgets in einem anderen Widget ad infinitum platziert werden können. Das Haupt-Widget in einem Tk-Programm wird als Root-Widget bezeichnet und kann durch Erstellen einer neuen Instanz der TkRoot-Klasse erstellt werden.
Die meisten Tk-basierten Anwendungen folgen demselben Zyklus: Erstellen Sie die Widgets, platzieren Sie sie in der Benutzeroberfläche und binden Sie schließlich die jedem Widget zugeordneten Ereignisse an eine Methode.
Es gibt drei Geometriemanager. Platz, Raster und Pack , die für die Steuerung der Größe und Position der einzelnen Widgets in der Benutzeroberfläche verantwortlich sind.
Installation
Die Ruby Tk-Bindungen werden mit Ruby verteilt, Tk ist jedoch eine separate Installation. Windows-Benutzer können eine Tk-Installation mit einem Klick von ActiveStates ActiveTcl herunterladen .
Mac- und Linux-Benutzer müssen es möglicherweise nicht installieren, da die Wahrscheinlichkeit groß ist, dass es bereits zusammen mit dem Betriebssystem installiert ist. Andernfalls können Sie vorgefertigte Pakete herunterladen oder die Quelle von Tcl Developer Xchange abrufen .
Einfache Tk-Anwendung
Eine typische Struktur für Ruby / Tk-Programme ist das Erstellen des Haupt- oder root Fügen Sie im Fenster (eine Instanz von TkRoot) Widgets hinzu, um die Benutzeroberfläche aufzubauen, und starten Sie dann die Hauptereignisschleife durch Aufrufen Tk.mainloop.
Das traditionelle Hallo, Welt! Beispiel für Ruby / Tk sieht ungefähr so aus -
require 'tk'
root = TkRoot.new { title "Hello, World!" }
TkLabel.new(root) do
text 'Hello, World!'
pack { padx 15 ; pady 15; side 'left' }
end
Tk.mainloopHier erstellen wir nach dem Laden des tk-Erweiterungsmoduls mit TkRoot.new einen Frame auf Stammebene . Anschließend erstellen wir ein TkLabel- Widget als untergeordnetes Element des Stammrahmens und legen verschiedene Optionen für die Beschriftung fest. Schließlich packen wir den Root-Frame und betreten die Haupt-GUI-Ereignisschleife.
Wenn Sie dieses Skript ausführen würden, würde es das folgende Ergebnis erzeugen:
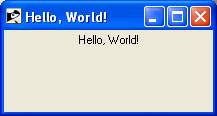
Ruby / Tk-Widget-Klassen
Es gibt eine Liste verschiedener Ruby / Tk-Klassen, mit denen mit Ruby / Tk eine gewünschte GUI erstellt werden kann.
TkFrame Erstellt und bearbeitet Frame-Widgets.
TkButton Erstellt und bearbeitet Schaltflächen-Widgets.
TkLabel Erstellt und bearbeitet Label-Widgets.
TkEntry Erstellt und bearbeitet Eintrags-Widgets.
TkCheckButton Erstellt und bearbeitet Checkbutton-Widgets.
TkRadioButton Erstellt und bearbeitet Radiobutton-Widgets.
TkListbox Erstellt und bearbeitet Listbox-Widgets.
TkComboBox Erstellt und bearbeitet Listbox-Widgets.
TkMenu Erstellt und bearbeitet Menü-Widgets.
TkMenubutton Erstellt und bearbeitet Menubutton-Widgets.
Tk.messageBox Erstellt und bearbeitet einen Nachrichtendialog.
TkScrollbar Erstellt und bearbeitet Bildlaufleisten-Widgets.
TkCanvas Erstellt und bearbeitet Canvas-Widgets.
TkScale Erstellt und bearbeitet Skalierungs-Widgets.
TkText Erstellt und bearbeitet Text-Widgets.
TkToplevel Erstellt und bearbeitet Widgets auf oberster Ebene.
TkSpinbox Erstellt und bearbeitet Spinbox-Widgets.
TkProgressBar Erstellt und bearbeitet Fortschrittsbalken-Widgets.
Dialogfeld Erstellt und bearbeitet Dialogfeld-Widgets.
Tk :: Tile :: Notebook Zeigen Sie mehrere Fenster auf engstem Raum mit Notebook-Metapher an.
Tk :: Tile :: Paned Zeigt eine Reihe von Unterfenstern an, die entweder vertikal oder horizontal gestapelt sind.
Tk :: Tile :: Separator Zeigt eine horizontale oder vertikale Trennleiste an.
Ruby / Tk-Schriftarten, Farben und Bilder Grundlegendes zu Ruby / Tk-Schriftarten, -Farben und -Bildern
Standardkonfigurationsoptionen
Alle Widgets verfügen über verschiedene Konfigurationsoptionen, die im Allgemeinen steuern, wie sie angezeigt werden oder wie sie sich verhalten. Die verfügbaren Optionen hängen natürlich von der Widget-Klasse ab.
Hier finden Sie eine Liste aller Standardkonfigurationsoptionen, die für jedes Ruby / Tk-Widget gelten können.
| Sr.Nr. | Optionen & Beschreibung |
|---|---|
| 1 | activebackground => String Gibt die Hintergrundfarbe an, die beim Zeichnen aktiver Elemente verwendet werden soll. Ein Element ist aktiv, wenn sich der Mauszeiger über dem Element befindet und durch Drücken einer Maustaste eine Aktion ausgeführt wird. Sie können Farbnamen wie "rot", "blau", "pink", "gelb" usw. verwenden. |
| 2 | activeborderwidth => Ganzzahl Gibt einen nicht negativen Wert an, der die Breite des 3D-Rahmens angibt, der um aktive Elemente gezogen wird. |
| 3 | activeforeground => String Gibt die Vordergrundfarbe an, die beim Zeichnen aktiver Elemente verwendet werden soll. |
| 4 | anchor => String Gibt an, wie die Informationen in einem Widget (z. B. Text oder eine Bitmap) im Widget angezeigt werden sollen. Muss einer der Werte seinn, ne, e, se, s, sw, w, nw, oder center. Zum Beispiel,nw bedeutet, die Informationen so anzuzeigen, dass sich die obere linke Ecke in der oberen linken Ecke des Widgets befindet. |
| 5 | background or bg => String Gibt die normale Hintergrundfarbe an, die beim Anzeigen des Widgets verwendet werden soll. |
| 6 | bitmap => Bitmap Gibt eine Bitmap an, die im Widget angezeigt werden soll. Die genaue Art und Weise, in der die Bitmap angezeigt wird, kann durch andere Optionen wie Anker oder Ausrichten beeinflusst werden. |
| 7 | borderwidth or bd => Ganzzahl Gibt einen nicht negativen Wert an, der die Breite des 3D-Rahmens angibt, der außerhalb des Widgets gezeichnet werden soll. |
| 8 | compound => String Gibt an, ob das Widget Text und Bitmaps / Bilder gleichzeitig anzeigen soll und wenn ja, wo die Bitmap / das Bild relativ zum Text platziert werden soll. Muss einer der Werte seinnone, bottom, top, left, right, oder center. |
| 9 | cursor => String Gibt den Mauszeiger an, der für das Widget verwendet werden soll. Mögliche Werte können "Uhr", "Pfeil" usw. sein. |
| 10 | disabledforeground => String Gibt die Vordergrundfarbe an, die beim Zeichnen eines deaktivierten Elements verwendet werden soll. |
| 11 | exportselection => Boolescher Wert Gibt an, ob eine Auswahl im Widget auch die X-Auswahl sein soll. Der Wert kann einen der folgenden Werte habentrue, false, 0, 1, yes, oder no. Wenn die Auswahl exportiert wird, wird durch Auswahl im Widget die aktuelle X-Auswahl abgewählt. Wenn Sie außerhalb des Widgets auswählen, wird die Auswahl aller Widgets aufgehoben. Das Widget reagiert auf Auswahlabrufanforderungen, wenn es eine Auswahl enthält. |
| 12 | font => String Gibt die Schriftart an, die beim Zeichnen von Text im Widget verwendet werden soll. |
| 13 | foreground or fg => String Gibt die normale Vordergrundfarbe an, die beim Anzeigen des Widgets verwendet werden soll. |
| 14 | highlightbackground => String Gibt die Farbe an, die im Traversal-Hervorhebungsbereich angezeigt werden soll, wenn das Widget nicht über den Eingabefokus verfügt. |
| 15 | highlightcolor => String Gibt die Farbe an, die für das Traversal-Highlight-Rechteck verwendet werden soll, das um das Widget gezeichnet wird, wenn es den Eingabefokus hat. |
| 16 | highlightthickness => Ganzzahl Gibt einen nicht negativen Wert an, der die Breite des Hervorhebungsrechtecks angibt, das außerhalb des Widgets gezeichnet werden soll, wenn es den Eingabefokus hat. |
| 17 | image => Bild Gibt ein Bild an, das im Widget angezeigt werden soll und das mit einer Bilderstellung erstellt worden sein muss. Wenn die Bildoption angegeben wird, werden andere Optionen überschrieben, die eine Bitmap oder einen Textwert angeben, der im Widget angezeigt werden soll. Die Bildoption kann auf eine leere Zeichenfolge zurückgesetzt werden, um eine Bitmap oder Textanzeige wieder zu aktivieren. |
| 18 | jump => String Bei Widgets mit einem Schieberegler, der zum Anpassen eines Werts gezogen werden kann, z. B. Bildlaufleisten und Skalen, bestimmt diese Option, wann Benachrichtigungen über Änderungen des Werts vorgenommen werden. Der Wert der Option muss ein Boolescher Wert sein. Wenn der Wert falsch ist, werden beim Ziehen des Schiebereglers kontinuierlich Aktualisierungen vorgenommen. Wenn der Wert true ist, werden Aktualisierungen verzögert, bis die Maustaste losgelassen wird, um das Ziehen zu beenden. Zu diesem Zeitpunkt erfolgt eine einzelne Benachrichtigung. |
| 19 | justify => String Wenn in einem Widget mehrere Textzeilen angezeigt werden, bestimmt diese Option, wie die Zeilen zueinander ausgerichtet sind. Muss einer von seinleft, center, oder right. Left bedeutet, dass die linken Kanten der Linien alle ausgerichtet sind, center bedeutet, dass die Linienmitten ausgerichtet sind und right bedeutet, dass die rechten Kanten der Linien ausgerichtet sind. |
| 20 | offset => String Gibt den Versatz von Kacheln an (siehe auch tileMöglichkeit). Es kann zwei verschiedene Formate habenoffset x,y oder offset side, wo Seite sein kann n, ne, e, se, s, sw, w, nw, oder center. |
| 21 | orient => String Für Widgets, die sich entweder horizontal oder vertikal ausrichten können, z. B. Bildlaufleisten, gibt diese Option an, welche Ausrichtung verwendet werden soll. Muss auch seinhorizontal oder vertical oder eine Abkürzung von einer davon. |
| 22 | padx => Ganzzahl Gibt einen nicht negativen Wert an, der angibt, wie viel zusätzlicher Speicherplatz für das Widget in X-Richtung angefordert werden soll. |
| 23 | pady => Ganzzahl Gibt einen nicht negativen Wert an, der angibt, wie viel zusätzlicher Speicherplatz für das Widget in Y-Richtung angefordert werden soll. |
| 24 | relief => Ganzzahl Gibt den für das Widget gewünschten 3D-Effekt an. Akzeptable Werte sindraised, sunken, flat, ridge, und groove. |
| 25 | repeatdelay => Ganzzahl Gibt an, wie viele Millisekunden eine Taste oder Taste gedrückt gehalten werden muss, bevor die automatische Wiederholung beginnt. Wird beispielsweise für die Aufwärts- und Abwärtspfeile in Bildlaufleisten verwendet. |
| 26 | repeatinterval => Ganzzahl Wird in Verbindung mit verwendet repeatdelay: Sobald die automatische Wiederholung beginnt, bestimmt diese Option die Anzahl der Millisekunden zwischen den automatischen Wiederholungen |
| 27 | selectbackground => String Gibt die Hintergrundfarbe an, die beim Anzeigen ausgewählter Elemente verwendet werden soll. |
| 28 | selectborderwidth => Ganzzahl Gibt einen nicht negativen Wert an, der die Breite des 3D-Rahmens angibt, der um ausgewählte Elemente gezeichnet werden soll. |
| 29 | selectforeground => String Gibt die Vordergrundfarbe an, die beim Anzeigen ausgewählter Elemente verwendet werden soll. |
| 30 | setgrid => Boolescher Wert Gibt einen booleschen Wert an, der bestimmt, ob dieses Widget das Größenänderungsraster für das Fenster der obersten Ebene steuert. Diese Option wird normalerweise in Text-Widgets verwendet, bei denen die Informationen im Widget eine natürliche Größe (die Größe eines Zeichens) haben und es sinnvoll ist, dass die Fensterabmessungen ganzzahlige Zahlen dieser Einheiten sind. |
| 31 | takefocus => Ganzzahl Bietet Informationen, die beim Verschieben des Fokus von Fenster zu Fenster über die Tastatur verwendet werden (z. B. Tab und Umschalt-Tab). Bevor Sie den Fokus auf ein Fenster setzen, überprüfen die Durchlaufskripte zunächst, ob das Fenster sichtbar ist (es und alle seine Vorfahren werden zugeordnet). Wenn nicht, wird das Fenster übersprungen. Der Wert 0 bedeutet, dass dieses Fenster beim Durchlaufen der Tastatur vollständig übersprungen werden sollte. 1 bedeutet, dass dieses Fenster immer den Eingabefokus erhalten soll. |
| 32 | text => String Gibt eine Zeichenfolge an, die im Widget angezeigt werden soll. Die Art und Weise, in der die Zeichenfolge angezeigt wird, hängt vom jeweiligen Widget ab und kann durch andere Optionen bestimmt werden, zanchor oder justify. |
| 33 | textvariable => Variable Gibt den Namen einer Variablen an. Der Wert der Variablen ist eine Textzeichenfolge, die im Widget angezeigt wird. Wenn sich der Variablenwert ändert, aktualisiert sich das Widget automatisch, um den neuen Wert wiederzugeben. Die Art und Weise, wie die Zeichenfolge im Widget angezeigt wird, hängt vom jeweiligen Widget ab und kann durch andere Optionen bestimmt werden, zanchor oder justify. |
| 34 | tile => Bild Gibt das Bild an, das zum Anzeigen des Widgets verwendet wird. Wenn das Bild die leere Zeichenfolge ist, wird die normale Hintergrundfarbe angezeigt. |
| 35 | troughcolor => String Gibt die Farbe an, die für die rechteckigen Muldenbereiche in Widgets wie Bildlaufleisten und Skalen verwendet werden soll. |
| 36 | troughtile => Bild Gibt das Bild an, das zur Anzeige in den rechteckigen Muldenbereichen in Widgets wie Bildlaufleisten und Skalen verwendet wird. |
| 37 | underline => Ganzzahl Gibt den Ganzzahlindex eines Zeichens an, das im Widget unterstrichen werden soll. Diese Option wird von den Standardbindungen verwendet, um die Tastaturüberquerung für Menüschaltflächen und Menüeinträge zu implementieren. 0 entspricht dem ersten Zeichen des im Widget angezeigten Textes, 1 dem nächsten Zeichen usw. |
| 38 | wraplength => Ganzzahl Für Widgets, die Zeilenumbrüche ausführen können, gibt diese Option die maximale Zeilenlänge an. |
| 39 | xscrollcommand => Funktion Gibt einen Rückruf an, der für die Kommunikation mit horizontalen Bildlaufleisten verwendet wird. |
| 40 | yscrollcommand => Funktion Gibt einen Rückruf an, der für die Kommunikation mit vertikalen Bildlaufleisten verwendet wird. |
Ruby / Tk-Geometriemanagement
Das Geometrie-Management befasst sich mit der Positionierung verschiedener Widgets nach Bedarf. Das Geometrie-Management in Tk basiert auf dem Konzept von Master- und Slave-Widgets.
Ein Master ist ein Widget, normalerweise ein Fenster der obersten Ebene oder ein Frame, der andere Widgets enthält, die als Slaves bezeichnet werden. Sie können sich einen Geometriemanager vorstellen, der die Kontrolle über das Master-Widget übernimmt und entscheidet, was darin angezeigt wird.
Der Geometrie-Manager fragt jedes Slave-Widget nach seiner natürlichen Größe oder nach der Größe, die es idealerweise anzeigen möchte. Diese Informationen werden dann mit allen vom Programm bereitgestellten Parametern kombiniert, wenn der Geometriemanager aufgefordert wird, dieses bestimmte Slave-Widget zu verwalten.
Es gibt drei Geometriemanager, Place, Grid und Pack , die für die Steuerung der Größe und Position der einzelnen Widgets in der Benutzeroberfläche verantwortlich sind.
Raster- Geometrie-Manager, der Widgets in einem Raster anordnet.
pack Geometrie-Manager, der um die Kanten des Hohlraums packt.
Platzieren Sie den Geometrie-Manager für die Platzierung auf festen oder Gummiplatten.
Ruby / Tk-Ereignisbehandlung
Ruby / Tk unterstützt die Ereignisschleife , die Ereignisse vom Betriebssystem empfängt. Dies sind Dinge wie Tastendruck, Tastenanschläge, Mausbewegungen, Fenstergrößenänderung und so weiter.
Ruby / Tk kümmert sich für Sie um die Verwaltung dieser Ereignisschleife. Es wird herausgefunden, für welches Widget das Ereignis gilt (hat der Benutzer auf diese Schaltfläche geklickt? Wenn eine Taste gedrückt wurde, welches Textfeld hatte den Fokus?) Und es entsprechend versendet. Einzelne Widgets wissen, wie sie auf Ereignisse reagieren. So kann beispielsweise eine Schaltfläche ihre Farbe ändern, wenn sich die Maus darüber bewegt, und beim Verlassen der Maus zurückkehren.
Auf einer höheren Ebene ruft Ruby / Tk Rückrufe in Ihrem Programm auf, um anzuzeigen, dass einem Widget etwas Wichtiges passiert ist. In beiden Fällen können Sie einen Codeblock oder ein Ruby Proc- Objekt bereitstellen , das angibt, wie die Anwendung auf das Ereignis oder den Rückruf reagiert.
Lassen Sie uns einen Blick darauf werfen, wie die Bindungsmethode verwendet wird, um grundlegende Fenstersystemereignisse den Ruby-Prozeduren zuzuordnen, die sie behandeln. Die einfachste Form der Bindung verwendet als Eingabe eine Zeichenfolge, die den Ereignisnamen und einen Codeblock angibt, mit dem Tk das Ereignis behandelt.
Um beispielsweise das ButtonRelease- Ereignis für die erste Maustaste in einem Widget abzufangen , schreiben Sie:
someWidget.bind('ButtonRelease-1') {
....code block to handle this event...
}Ein Ereignisname kann zusätzliche Modifikatoren und Details enthalten. Ein Modifikator ist eine Zeichenfolge wie Shift , Control oder Alt , die angibt, dass eine der Modifikatortasten gedrückt wurde.
So können Sie beispielsweise das Ereignis abfangen, das generiert wird, wenn der Benutzer die Strg- Taste gedrückt hält und mit der rechten Maustaste klickt.
someWidget.bind('Control-ButtonPress-3', proc { puts "Ouch!" })Viele Ruby / Tk-Widgets können Rückrufe auslösen, wenn der Benutzer sie aktiviert, und Sie können den Befehlsrückruf verwenden, um anzugeben, dass in diesem Fall ein bestimmter Codeblock oder eine bestimmte Prozedur aufgerufen wird. Wie bereits erwähnt, können Sie beim Erstellen des Widgets die Befehlsrückrufprozedur angeben.
helpButton = TkButton.new(buttonFrame) {
text "Help"
command proc { showHelp }
}Oder Sie können es später zuweisen, die das Widget mit Befehl - Methode -
helpButton.command proc { showHelp }Da die Befehlsmethode entweder Prozeduren oder Codeblöcke akzeptiert, können Sie das vorherige Codebeispiel auch als - schreiben
helpButton = TkButton.new(buttonFrame) {
text "Help"
command { showHelp }
}| Sr.Nr. | Tag & Event Beschreibung |
|---|---|
| 1 | "1" (one) Klicken Sie mit der linken Maustaste. |
| 2 | "ButtonPress-1" Klicken Sie mit der linken Maustaste. |
| 3 | "Enter" Maus nach innen bewegt. |
| 4 | "Leave" Maus nach draußen bewegt. |
| 5 | "Double-1" Doppelklick. |
| 6 | "B3-Motion" Ziehen Sie mit der rechten Maustaste von einer Position zur anderen. |
| 7 | Control-ButtonPress-3 Die rechte Taste wird zusammen mit der Strg- Taste gedrückt . |
| 8 | Alt-ButtonPress-1 Die Let-Taste wird zusammen mit der Alt- Taste gedrückt . |
Die Konfigurationsmethode
Mit der Konfigurationsmethode können Widget-Konfigurationswerte festgelegt und abgerufen werden. Um beispielsweise die Breite einer Schaltfläche zu ändern, können Sie die Konfigurationsmethode jederzeit wie folgt aufrufen:
require "tk"
button = TkButton.new {
text 'Hello World!'
pack
}
button.configure('activebackground', 'blue')
Tk.mainloopUm den Wert für ein aktuelles Widget zu erhalten, geben Sie ihn einfach wie folgt ohne Wert ein:
color = button.configure('activebackground')Sie können configure auch ohne Optionen aufrufen, wodurch Sie eine Liste aller Optionen und ihrer Werte erhalten.
Die cget-Methode
Zum einfachen Abrufen des Werts einer Option gibt configure mehr Informationen zurück, als Sie normalerweise möchten. Die cget-Methode gibt nur den aktuellen Wert zurück.
color = button.cget('activebackground')Ruby / LDAP ist eine Erweiterungsbibliothek für Ruby. Es bietet die Schnittstelle zu einigen LDAP-Bibliotheken wie OpenLDAP, UMich LDAP, Netscape SDK und ActiveDirectory.
Die allgemeine API für die Anwendungsentwicklung ist in RFC1823 beschrieben und wird von Ruby / LDAP unterstützt.
Ruby / LDAP-Installation
Sie können ein vollständiges Ruby / LDAP-Paket von SOURCEFORGE.NET herunterladen und installieren .
Stellen Sie vor der Installation von Ruby / LDAP sicher, dass Sie über die folgenden Komponenten verfügen:
- Ruby 1.8.x (mindestens 1.8.2, wenn Sie ldap / control verwenden möchten).
- OpenLDAP, Netscape SDK, Windows 2003 oder Windows XP.
Jetzt können Sie die Standard-Ruby-Installationsmethode verwenden. Wenn Sie die verfügbaren Optionen für extconf.rb anzeigen möchten, führen Sie sie vor dem Start mit der Option '--help' aus.
$ ruby extconf.rb [--with-openldap1|--with-openldap2| \
--with-netscape|--with-wldap32]
$ make $ make installNOTE- Wenn Sie die Software unter Windows erstellen , müssen Sie möglicherweise nmake anstelle von make verwenden .
Stellen Sie eine LDAP-Verbindung her
Dies ist ein zweistufiger Prozess -
Schritt 1 - Verbindungsobjekt erstellen
Im Folgenden finden Sie die Syntax zum Herstellen einer Verbindung zu einem LDAP-Verzeichnis.
LDAP::Conn.new(host = 'localhost', port = LDAP_PORT)host- Dies ist die Host-ID, auf der das LDAP-Verzeichnis ausgeführt wird. Wir werden es als localhost nehmen .
port- Dies ist der Port, der für den LDAP-Dienst verwendet wird. Standard-LDAP-Ports sind 636 und 389. Stellen Sie sicher, welcher Port auf Ihrem Server verwendet wird, andernfalls können Sie LDAP :: LDAP_PORT verwenden.
Dieser Aufruf gibt eine neue LDAP :: Conn- Verbindung zum Server, Host , am Port- Port zurück .
Schritt 2 - Bindung
Hier geben wir normalerweise den Benutzernamen und das Passwort an, die wir für den Rest der Sitzung verwenden werden.
Es folgt die Syntax zum Binden einer LDAP-Verbindung mithilfe des DN: dn, der Berechtigungsnachweis, pwdund die Bindemethode, method - -
conn.bind(dn = nil, password = nil, method = LDAP::LDAP_AUTH_SIMPLE)do
....
endSie können dieselbe Methode ohne Codeblock verwenden. In diesem Fall müssten Sie die Verbindung explizit wie folgt trennen:
conn.bind(dn = nil, password = nil, method = LDAP::LDAP_AUTH_SIMPLE)
....
conn.unbindWenn ein Codeblock angegeben ist, wird dem Block self zurückgegeben .
Wir können jetzt Such-, Hinzufügungs-, Änderungs- oder Löschvorgänge innerhalb des Blocks der Bindemethode (zwischen Binden und Aufheben der Bindung) ausführen, sofern wir über die entsprechenden Berechtigungen verfügen.
Example
Angenommen, wir arbeiten auf einem lokalen Server, lassen Sie uns die Dinge mit dem entsprechenden Host, der Domäne, der Benutzer-ID und dem Kennwort usw. zusammenstellen.
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost' $PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
....
conn.unbindHinzufügen eines LDAP-Eintrags
Das Hinzufügen eines LDPA-Eintrags erfolgt in zwei Schritten:
Schritt 1 - Erstellen eines LDAP :: Mod- Objekts
Wir benötigen eine LDAP :: Mod- Objektübergabe an die conn.add- Methode, um einen Eintrag zu erstellen. Hier ist eine einfache Syntax zum Erstellen eines LDAP :: Mod- Objekts:
Mod.new(mod_type, attr, vals)mod_type - Eine oder mehrere Optionen LDAP_MOD_ADD, LDAP_MOD_REPLACE oder LDAP_MOD_DELETE.
attr - sollte der Name des Attributs sein, mit dem gearbeitet werden soll.
vals- ist ein Array von Werten, die sich auf attr beziehen . Wenn vals Binärdaten enthält, mod_type sollte logisch ODER verknüpft werden (|) mit LDAP_MOD_BVALUES.
Dieser Aufruf gibt das LDAP :: Mod- Objekt zurück, das an Methoden in der LDAP :: Conn-Klasse übergeben werden kann, z. B. Conn # add, Conn # add_ext, Conn # modify und Conn # modify_ext.
Schritt 2 - Aufruf der conn.add- Methode
Sobald wir mit dem LDAP :: Mod- Objekt fertig sind , können wir die conn.add- Methode aufrufen , um einen Eintrag zu erstellen. Hier ist eine Syntax zum Aufrufen dieser Methode:
conn.add(dn, attrs)Diese Methode fügt einen Eintrag mit dem DN dn und den Attributen attrs hinzu . Hier sollte attrs entweder ein Array von LDAP :: Mod- Objekten oder ein Hash von Attribut / Wert-Array-Paaren sein.
Example
Hier ist ein vollständiges Beispiel, mit dem zwei Verzeichniseinträge erstellt werden:
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT $SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
entry1 = [
LDAP.mod(LDAP::LDAP_MOD_ADD,'objectclass',['top','domain']),
LDAP.mod(LDAP::LDAP_MOD_ADD,'o',['TTSKY.NET']),
LDAP.mod(LDAP::LDAP_MOD_ADD,'dc',['localhost']),
]
entry2 = [
LDAP.mod(LDAP::LDAP_MOD_ADD,'objectclass',['top','person']),
LDAP.mod(LDAP::LDAP_MOD_ADD, 'cn', ['Zara Ali']),
LDAP.mod(LDAP::LDAP_MOD_ADD | LDAP::LDAP_MOD_BVALUES, 'sn',
['ttate','ALI', "zero\000zero"]),
]
begin
conn.add("dc = localhost, dc = localdomain", entry1)
conn.add("cn = Zara Ali, dc = localhost, dc = localdomain", entry2)
rescue LDAP::ResultError
conn.perror("add")
exit
end
conn.perror("add")
conn.unbindÄndern eines LDAP-Eintrags
Das Ändern eines Eintrags ähnelt dem Hinzufügen eines Eintrags. Rufen Sie einfach die Änderungsmethode auf , anstatt sie mit den zu ändernden Attributen hinzuzufügen . Hier ist eine einfache Syntax der Änderungsmethode .
conn.modify(dn, mods)Diese Methode ändert einen Eintrag mit den Mods DN, dn und den Attributen mods . Hier sollten Mods entweder ein Array von LDAP :: Mod- Objekten oder ein Hash von Attribut / Wert-Array-Paaren sein.
Beispiel
Um den Nachnamen des Eintrags zu ändern, den wir im vorherigen Abschnitt hinzugefügt haben, schreiben wir:
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost' $PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
entry1 = [
LDAP.mod(LDAP::LDAP_MOD_REPLACE, 'sn', ['Mohtashim']),
]
begin
conn.modify("cn = Zara Ali, dc = localhost, dc = localdomain", entry1)
rescue LDAP::ResultError
conn.perror("modify")
exit
end
conn.perror("modify")
conn.unbindLöschen eines LDAP-Eintrags
Um einen Eintrag zu löschen, rufen Sie die Löschmethode mit dem definierten Namen als Parameter auf. Hier ist eine einfache Syntax der Löschmethode .
conn.delete(dn)Diese Methode löscht einen Eintrag mit dem DN, dn .
Beispiel
Um den Zara Mohtashim- Eintrag zu löschen , den wir im vorherigen Abschnitt hinzugefügt haben, würden wir schreiben:
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT $SSLPORT = LDAP::LDAPS_PORT
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.delete("cn = Zara-Mohtashim, dc = localhost, dc = localdomain")
rescue LDAP::ResultError
conn.perror("delete")
exit
end
conn.perror("delete")
conn.unbindÄndern des Distinguished Name
Es ist nicht möglich, den definierten Namen eines Eintrags mit der Änderungsmethode zu ändern . Verwenden Sie stattdessen die modrdn- Methode. Hier ist die einfache Syntax der modrdn- Methode -
conn.modrdn(dn, new_rdn, delete_old_rdn)Diese Methode ändert die RDN des Eintrags mit DN, dn , und gibt ihm die neue RDN, new_rdn . Wenn delete_old_rdn ist wahr , wird der alte RDN - Wert aus dem Eintrag gelöscht werden.
Beispiel
Angenommen, wir haben den folgenden Eintrag -
dn: cn = Zara Ali,dc = localhost,dc = localdomain
cn: Zara Ali
sn: Ali
objectclass: personDann können wir den definierten Namen mit dem folgenden Code ändern:
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost' $PORT = LDAP::LDAP_PORT
$SSLPORT = LDAP::LDAPS_PORT conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.modrdn("cn = Zara Ali, dc = localhost, dc = localdomain", "cn = Zara Mohtashim", true)
rescue LDAP::ResultError
conn.perror("modrdn")
exit
end
conn.perror("modrdn")
conn.unbindDurchführen einer Suche
Verwenden Sie die Suchmethode mit einem der drei verschiedenen Suchmodi, um eine Suche in einem LDAP-Verzeichnis durchzuführen.
LDAP_SCOPE_BASEM - Suchen Sie nur den Basisknoten.
LDAP_SCOPE_ONELEVEL - Durchsuchen Sie alle untergeordneten Elemente des Basisknotens.
LDAP_SCOPE_SUBTREE - Durchsuchen Sie den gesamten Teilbaum einschließlich des Basisknotens.
Beispiel
Hier durchsuchen wir den gesamten Teilbaum des Eintrags dc = localhost, dc = localdomain nach Personenobjekten -
#/usr/bin/ruby -w
require 'ldap'
$HOST = 'localhost'
$PORT = LDAP::LDAP_PORT $SSLPORT = LDAP::LDAPS_PORT
base = 'dc = localhost,dc = localdomain'
scope = LDAP::LDAP_SCOPE_SUBTREE
filter = '(objectclass = person)'
attrs = ['sn', 'cn']
conn = LDAP::Conn.new($HOST, $PORT)
conn.bind('cn = root, dc = localhost, dc = localdomain','secret')
conn.perror("bind")
begin
conn.search(base, scope, filter, attrs) { |entry|
# print distinguished name
p entry.dn
# print all attribute names
p entry.attrs
# print values of attribute 'sn'
p entry.vals('sn')
# print entry as Hash
p entry.to_hash
}
rescue LDAP::ResultError
conn.perror("search")
exit
end
conn.perror("search")
conn.unbindDies ruft den angegebenen Codeblock für jeden übereinstimmenden Eintrag auf, wobei der LDAP-Eintrag durch eine Instanz der LDAP :: Entry-Klasse dargestellt wird. Mit dem letzten Parameter der Suche können Sie die Attribute angeben, an denen Sie interessiert sind, wobei alle anderen weggelassen werden. Wenn Sie hier null übergeben, werden alle Attribute in relationalen Datenbanken wie "SELECT *" zurückgegeben.
Die dn-Methode (Alias für get_dn) der LDAP :: Entry-Klasse gibt den definierten Namen des Eintrags zurück. Mit der to_hash-Methode können Sie eine Hash-Darstellung ihrer Attribute (einschließlich des definierten Namens) abrufen. Verwenden Sie die attrs-Methode (Alias für get_attributes), um eine Liste der Attribute eines Eintrags abzurufen. Verwenden Sie außerdem die Methode vals (Alias für get_values), um die Liste der Werte eines bestimmten Attributs abzurufen.
Fehler behandeln
Ruby / LDAP definiert zwei verschiedene Ausnahmeklassen -
Im Fehlerfall lösen die neuen Methoden bind oder unbind eine LDAP :: Error-Ausnahme aus.
Wenn Sie ein LDAP-Verzeichnis hinzufügen, ändern, löschen oder durchsuchen, wird ein LDAP :: ResultError ausgelöst.
Weiterführende Literatur
Ausführliche Informationen zu LDAP-Methoden finden Sie in der Standarddokumentation zur LDAP-Dokumentation .
Herkömmliche Programme haben einen einzigen Ausführungsthread. Die Anweisungen oder Anweisungen, aus denen das Programm besteht, werden nacheinander ausgeführt, bis das Programm beendet wird.
Ein Multithread-Programm hat mehr als einen Ausführungsthread. Innerhalb jedes Threads werden Anweisungen nacheinander ausgeführt, aber die Threads selbst können beispielsweise auf einer Multicore-CPU parallel ausgeführt werden. Auf einem einzelnen CPU-Computer werden häufig nicht mehrere Threads parallel ausgeführt, sondern die Parallelität wird simuliert, indem die Ausführung der Threads verschachtelt wird.
Ruby macht es einfach, Multithread-Programme mit der Thread- Klasse zu schreiben . Ruby-Threads sind eine einfache und effiziente Methode, um Parallelität in Ihrem Code zu erreichen.
Ruby-Threads erstellen
Um einen neuen Thread zu starten, verknüpfen Sie einfach einen Block mit einem Aufruf von Thread.new . Ein neuer Thread wird erstellt, um den Code im Block auszuführen, und der ursprüngliche Thread wird sofort von Thread.new zurückgegeben und die Ausführung mit der nächsten Anweisung fortgesetzt -
# Thread #1 is running here
Thread.new {
# Thread #2 runs this code
}
# Thread #1 runs this codeBeispiel
Hier ist ein Beispiel, das zeigt, wie wir ein Ruby-Programm mit mehreren Threads verwenden können.
#!/usr/bin/ruby
def func1
i = 0
while i<=2
puts "func1 at: #{Time.now}"
sleep(2)
i = i+1
end
end
def func2
j = 0
while j<=2
puts "func2 at: #{Time.now}"
sleep(1)
j = j+1
end
end
puts "Started At #{Time.now}"
t1 = Thread.new{func1()}
t2 = Thread.new{func2()}
t1.join
t2.join
puts "End at #{Time.now}"Dies führt zu folgendem Ergebnis:
Started At Wed May 14 08:21:54 -0700 2008
func1 at: Wed May 14 08:21:54 -0700 2008
func2 at: Wed May 14 08:21:54 -0700 2008
func2 at: Wed May 14 08:21:55 -0700 2008
func1 at: Wed May 14 08:21:56 -0700 2008
func2 at: Wed May 14 08:21:56 -0700 2008
func1 at: Wed May 14 08:21:58 -0700 2008
End at Wed May 14 08:22:00 -0700 2008Thread-Lebenszyklus
Mit Thread.new werden neue Threads erstellt . Sie können auch die Synonyme Thread.start und Thread.fork verwenden .
Es ist nicht erforderlich, einen Thread nach dem Erstellen zu starten. Er wird automatisch ausgeführt, sobald CPU-Ressourcen verfügbar werden.
Die Thread-Klasse definiert eine Reihe von Methoden zum Abfragen und Bearbeiten des Threads, während er ausgeführt wird. Ein Thread führt den Code in dem Block aus, der dem Aufruf von Thread.new zugeordnet ist, und wird dann nicht mehr ausgeführt.
Der Wert des letzten Ausdrucks in diesem Block ist der Wert des Threads und kann durch Aufrufen der value- Methode des Thread-Objekts abgerufen werden . Wenn der Thread vollständig ausgeführt wurde, gibt der Wert sofort den Wert des Threads zurück. Andernfalls wird der Wert nicht Methode blockiert und nicht zurück , bis der Thread beendet hat.
Die Klassenmethode Thread.current gibt das Thread-Objekt zurück, das den aktuellen Thread darstellt. Dadurch können sich Threads selbst manipulieren. Die Klassenmethode Thread.main gibt das Thread-Objekt zurück, das den Hauptthread darstellt. Dies ist der erste Thread der Ausführung, der mit dem Start des Ruby-Programms begann.
Sie können warten, bis ein bestimmter Thread fertig ist, indem Sie die Thread.join- Methode dieses Threads aufrufen . Der aufrufende Thread wird blockiert, bis der angegebene Thread beendet ist.
Themen und Ausnahmen
Wenn im Hauptthread eine Ausnahme ausgelöst wird und nirgendwo behandelt wird, druckt der Ruby-Interpreter eine Nachricht und wird beendet. In anderen Threads als dem Hauptthread führen nicht behandelte Ausnahmen dazu, dass der Thread nicht mehr ausgeführt wird.
Wenn ein Thread t wird aufgrund einer nicht behandelten Ausnahme und eines anderen Threads beendet sruft t.join oder t.value auf, dann die Ausnahme, die in aufgetreten istt wird im Faden angehoben s.
Wenn Thread.abort_on_exception ist falsch , die Standardbedingung, eine nicht behandelte Ausnahme einfach tötet den aktuellen Thread und der ganze Rest laufen weiter.
Wenn Sie möchten, dass eine nicht behandelte Ausnahme in einem Thread den Interpreter beendet, setzen Sie die Klassenmethode Thread.abort_on_exception auf true .
t = Thread.new { ... }
t.abort_on_exception = trueThread-Variablen
Ein Thread kann normalerweise auf alle Variablen zugreifen, die sich beim Erstellen des Threads im Gültigkeitsbereich befinden. Lokale Variablen, die für den Block eines Threads lokal sind, sind lokal für den Thread und werden nicht gemeinsam genutzt.
Die Thread-Klasse verfügt über eine spezielle Funktion, mit der thread-lokale Variablen erstellt und namentlich aufgerufen werden können. Sie behandeln das Thread-Objekt einfach wie einen Hash, schreiben mit [] = in Elemente und lesen sie mit [] zurück.
In diesem Beispiel zeichnet jeder Thread den aktuellen Wert der Variablenanzahl in einer threadlokalen Variablen mit dem Schlüssel mycount auf .
#!/usr/bin/ruby
count = 0
arr = []
10.times do |i|
arr[i] = Thread.new {
sleep(rand(0)/10.0)
Thread.current["mycount"] = count
count += 1
}
end
arr.each {|t| t.join; print t["mycount"], ", " }
puts "count = #{count}"Dies ergibt das folgende Ergebnis:
8, 0, 3, 7, 2, 1, 6, 5, 4, 9, count = 10Der Haupt-Thread wartet, bis die Unterfäden fertig sind, und druckt dann den von jedem erfassten Zählwert aus.
Thread-Prioritäten
Der erste Faktor, der die Thread-Planung beeinflusst, ist die Thread-Priorität: Threads mit hoher Priorität werden vor Threads mit niedriger Priorität geplant. Genauer gesagt, ein Thread erhält nur dann CPU-Zeit, wenn keine Threads mit höherer Priorität auf die Ausführung warten.
Sie können die Priorität eines Ruby Thread-Objekts mit priority = und priority festlegen und abfragen . Ein neu erstellter Thread beginnt mit derselben Priorität wie der Thread, der ihn erstellt hat. Der Haupt-Thread startet mit Priorität 0.
Es gibt keine Möglichkeit, die Priorität eines Threads festzulegen, bevor er ausgeführt wird. Ein Thread kann jedoch seine eigene Priorität als erste Aktion erhöhen oder verringern.
Thread-Ausschluss
Wenn zwei Threads gemeinsam auf dieselben Daten zugreifen und mindestens einer der Threads diese Daten ändert, müssen Sie besonders darauf achten, dass kein Thread die Daten jemals in einem inkonsistenten Zustand sehen kann. Dies wird als Thread-Ausschluss bezeichnet .
Mutexist eine Klasse, die eine einfache Semaphorsperre für den sich gegenseitig ausschließenden Zugriff auf eine gemeinsam genutzte Ressource implementiert. Das heißt, zu einem bestimmten Zeitpunkt darf nur ein Thread die Sperre halten. Andere Threads warten möglicherweise in der Schlange, bis die Sperre verfügbar ist, oder sie erhalten einfach einen sofortigen Fehler, der darauf hinweist, dass die Sperre nicht verfügbar ist.
Indem wir alle Zugriffe auf die gemeinsam genutzten Daten unter die Kontrolle eines Mutex stellen , stellen wir Konsistenz und atomaren Betrieb sicher. Versuchen wir es mit Beispielen, erstens ohne Mutax und zweitens mit Mutax -
Beispiel ohne Mutax
#!/usr/bin/ruby
require 'thread'
count1 = count2 = 0
difference = 0
counter = Thread.new do
loop do
count1 += 1
count2 += 1
end
end
spy = Thread.new do
loop do
difference += (count1 - count2).abs
end
end
sleep 1
puts "count1 : #{count1}"
puts "count2 : #{count2}"
puts "difference : #{difference}"Dies führt zu folgendem Ergebnis:
count1 : 1583766
count2 : 1583766
difference : 0#!/usr/bin/ruby
require 'thread'
mutex = Mutex.new
count1 = count2 = 0
difference = 0
counter = Thread.new do
loop do
mutex.synchronize do
count1 += 1
count2 += 1
end
end
end
spy = Thread.new do
loop do
mutex.synchronize do
difference += (count1 - count2).abs
end
end
end
sleep 1
mutex.lock
puts "count1 : #{count1}"
puts "count2 : #{count2}"
puts "difference : #{difference}"Dies führt zu folgendem Ergebnis:
count1 : 696591
count2 : 696591
difference : 0Umgang mit Deadlock
Wenn wir Mutex- Objekte zum Ausschließen von Threads verwenden, müssen wir darauf achten, Deadlocks zu vermeiden . Deadlock ist die Bedingung, die auftritt, wenn alle Threads darauf warten, eine von einem anderen Thread gehaltene Ressource abzurufen. Da alle Threads blockiert sind, können sie die von ihnen gehaltenen Sperren nicht aufheben. Und weil sie die Sperren nicht aufheben können, kann kein anderer Thread diese Sperren erwerben.
Hier kommen Bedingungsvariablen ins Spiel. Eine Bedingungsvariable ist einfach ein Semaphor, das einer Ressource zugeordnet ist und zum Schutz eines bestimmten Mutex verwendet wird . Wenn Sie eine Ressource benötigen, die nicht verfügbar ist, warten Sie auf eine Bedingungsvariable. Diese Aktion hebt die Sperre für den entsprechenden Mutex auf . Wenn ein anderer Thread signalisiert, dass die Ressource verfügbar ist, verlässt der ursprüngliche Thread die Wartezeit und stellt gleichzeitig die Sperre für den kritischen Bereich wieder her.
Beispiel
#!/usr/bin/ruby
require 'thread'
mutex = Mutex.new
cv = ConditionVariable.new
a = Thread.new {
mutex.synchronize {
puts "A: I have critical section, but will wait for cv"
cv.wait(mutex)
puts "A: I have critical section again! I rule!"
}
}
puts "(Later, back at the ranch...)"
b = Thread.new {
mutex.synchronize {
puts "B: Now I am critical, but am done with cv"
cv.signal
puts "B: I am still critical, finishing up"
}
}
a.join
b.joinDies führt zu folgendem Ergebnis:
A: I have critical section, but will wait for cv
(Later, back at the ranch...)
B: Now I am critical, but am done with cv
B: I am still critical, finishing up
A: I have critical section again! I rule!Thread-Zustände
Es gibt fünf mögliche Rückgabewerte, die den fünf möglichen Zuständen entsprechen, wie in der folgenden Tabelle gezeigt. Die Statusmethode gibt den Status des Threads zurück.
| Thread-Status | Rückgabewert |
|---|---|
| Runnable | Lauf |
| Schlafen | Schlafen |
| Abbruch | abbrechen |
| Normal beendet | falsch |
| Mit Ausnahme beendet | Null |
Thread-Klassenmethoden
Die folgenden Methoden werden von der Thread- Klasse bereitgestellt und gelten für alle im Programm verfügbaren Threads. Diese Methoden werden unter Verwendung des Thread- Klassennamens wie folgt aufgerufen :
Thread.abort_on_exception = true| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | Thread.abort_on_exception Gibt den Status des globalen Abbruchs bei Ausnahmebedingung zurück . Der Standardwert ist false . Wenn true festgelegt ist , werden alle Threads abgebrochen (der Prozess wird beendet (0)), wenn in einem Thread eine Ausnahme ausgelöst wird |
| 2 | Thread.abort_on_exception= Wenn true festgelegt ist , werden alle Threads abgebrochen, wenn eine Ausnahme ausgelöst wird. Gibt den neuen Status zurück. |
| 3 | Thread.critical Gibt den Status der kritischen Bedingung des globalen Threads zurück . |
| 4 | Thread.critical= Legt den Status der globalen Thread-kritischen Bedingung fest und gibt sie zurück. Wenn der Wert auf true gesetzt ist , wird die Planung eines vorhandenen Threads verhindert. Blockiert nicht das Erstellen und Ausführen neuer Threads. Bestimmte Thread-Vorgänge (z. B. Stoppen oder Beenden eines Threads, Schlafen im aktuellen Thread und Auslösen einer Ausnahme) können dazu führen, dass ein Thread auch in einem kritischen Abschnitt geplant wird. |
| 5 | Thread.current Gibt den aktuell ausgeführten Thread zurück. |
| 6 | Thread.exit Beendet den aktuell ausgeführten Thread und plant die Ausführung eines anderen Threads. Wenn dieser Thread bereits als beendet markiert ist, gibt exit den Thread zurück. Wenn dies der Hauptthread oder der letzte Thread ist, beenden Sie den Prozess. |
| 7 | Thread.fork { block } Synonym für Thread.new. |
| 8 | Thread.kill( aThread ) Bewirkt , dass der gegebenen einen Thread zu verlassen |
| 9 | Thread.list Gibt ein Array von Thread- Objekten für alle Threads zurück, die entweder ausgeführt oder gestoppt werden können. Faden. |
| 10 | Thread.main Gibt den Hauptthread für den Prozess zurück. |
| 11 | Thread.new( [ arg ]* ) {| args | block } Erstellt einen neuen Thread, um die im Block angegebenen Anweisungen auszuführen, und beginnt mit der Ausführung. Alle an Thread.new übergebenen Argumente werden an den Block übergeben. |
| 12 | Thread.pass Ruft den Thread-Scheduler auf, um die Ausführung an einen anderen Thread zu übergeben. |
| 13 | Thread.start( [ args ]* ) {| args | block } Grundsätzlich das gleiche wie Thread.new . Wenn die Klasse Thread jedoch in eine Unterklasse unterteilt ist, ruft der Aufruf von start in dieser Unterklasse nicht die Initialisierungsmethode der Unterklasse auf . |
| 14 | Thread.stop Stoppt die Ausführung des aktuellen Threads, versetzt ihn in einen Ruhezustand und plant die Ausführung eines anderen Threads. Setzt die kritische Bedingung auf false zurück. |
Thread-Instanzmethoden
Diese Methoden sind auf eine Instanz eines Threads anwendbar. Diese Methoden werden so aufgerufen, dass eine Instanz eines Threads wie folgt verwendet wird:
#!/usr/bin/ruby
thr = Thread.new do # Calling a class method new
puts "In second thread"
raise "Raise exception"
end
thr.join # Calling an instance method join| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | thr[ aSymbol ] Attributreferenz - Gibt den Wert einer threadlokalen Variablen zurück, wobei entweder ein Symbol oder ein aSymbol- Name verwendet wird. Wenn die angegebene Variable nicht vorhanden ist, wird nil zurückgegeben . |
| 2 | thr[ aSymbol ] = Attributzuweisung - Legt den Wert einer threadlokalen Variablen fest oder erstellt ihn mithilfe eines Symbols oder einer Zeichenfolge. |
| 3 | thr.abort_on_exception Gibt den Status des Abbruchs bei Ausnahmebedingung für thr zurück . Der Standardwert ist false . |
| 4 | thr.abort_on_exception= Wenn auf true gesetzt , werden alle Threads (einschließlich des Hauptprogramms) abgebrochen, wenn eine Ausnahme in thr ausgelöst wird . Der Prozess wird effektiv beendet (0) . |
| 5 | thr.alive? Gibt true zurück, wenn thr läuft oder schläft. |
| 6 | thr.exit Beendet thr und plant die Ausführung eines anderen Threads. Wenn dieser Thread bereits als beendet markiert ist, gibt exit den Thread zurück . Wenn dies der Hauptthread oder der letzte Thread ist, wird der Prozess beendet. |
| 7 | thr.join Der aufrufende Thread unterbricht die Ausführung und führt thr aus . Kommt erst zurück, wenn der Ausgang beendet ist . Nicht verbundene Threads werden beim Beenden des Hauptprogramms beendet. |
| 8 | thr.key? Gibt true zurück, wenn die angegebene Zeichenfolge (oder das angegebene Symbol) als threadlokale Variable vorhanden ist. |
| 9 | thr.kill Synonym für Thread.exit . |
| 10 | thr.priority Gibt die Priorität von thr zurück . Standard ist Null; Threads mit höherer Priorität werden vor Threads mit niedrigerer Priorität ausgeführt. |
| 11 | thr.priority= Setzt die Priorität von thr auf eine Ganzzahl. Threads mit höherer Priorität werden vor Threads mit niedrigerer Priorität ausgeführt. |
| 12 | thr.raise( anException ) Löst eine Ausnahme von thr aus . Der Anrufer muss nicht thr sein . |
| 13 | thr.run Aufwacht thr , es für den Scheduler zu machen. Wenn nicht in einem kritischen Abschnitt, wird der Scheduler aufgerufen. |
| 14 | thr.safe_level Gibt die für thr gültige Sicherheitsstufe zurück . |
| 15 | thr.status Gibt den Status von thr zurück : sleep, wenn thr schläft oder auf E / A wartet, run, wenn thr ausgeführt wird, false, wenn thr normal beendet wird, und nil, wenn thr mit einer Ausnahme beendet wird. |
| 16 | thr.stop? Gibt true zurück, wenn thr tot ist oder schläft. |
| 17 | thr.value Wartet, bis der Vorgang über Thread.join abgeschlossen ist, und gibt seinen Wert zurück. |
| 18 | thr.wakeup Marks thr als für Terminplanung, noch kann jedoch auf I / O gesperrt bleiben. |
Da das Kernel- Modul in der Object- Klasse enthalten ist, sind seine Methoden überall im Ruby-Programm verfügbar. Sie können ohne Empfänger aufgerufen werden (Funktionsform). Daher werden sie oft als Funktionen bezeichnet.
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | abort Beendet das Programm. Wenn eine Ausnahme ausgelöst wird (dh $! Ist nicht Null), wird die Fehlermeldung angezeigt. |
| 2 | Array( obj) Gibt obj zurück, nachdem es mit to_ary oder to_a in ein Array konvertiert wurde. |
| 3 | at_exit {...} Registriert einen Block zur Ausführung, wenn das Programm beendet wird. Ähnlich wie bei der END-Anweisung, jedoch registriert die END-Anweisung den Block nur einmal. |
| 4 | autoload( classname, file) Registriert einen Klassenklassennamen, der bei der ersten Verwendung aus der Datei geladen werden soll. Klassenname kann eine Zeichenfolge oder ein Symbol sein. |
| 5 | binding Gibt die aktuellen Variablen- und Methodenbindungen zurück. Das zurückgegebene Bindungsobjekt kann als zweites Argument an die eval- Methode übergeben werden. |
| 6 | block_given? Gibt true zurück, wenn die Methode mit einem Block aufgerufen wurde . |
| 7 | callcc {| c|...} Übergibt ein Continuation- Objekt c an den Block und führt den Block aus. callcc kann für das globale Exit- oder Loop-Konstrukt verwendet werden. |
| 8 | caller([ n]) Gibt den aktuellen Ausführungsstapel in einem Array der Zeichenfolgen in der Formulardatei zurück : line . Wenn n angegeben ist, werden Stapeleinträge ab der n-ten Ebene zurückgegeben. |
| 9 | catch( tag) {...} Fängt einen nichtlokalen Ausgang durch einen Wurf ab, der während der Ausführung seines Blocks aufgerufen wird. |
| 10 | chomp([ rs = $/]) Gibt den Wert der Variablen zurück $_ with the ending newline removed, assigning the result back to $_. Der Wert der Zeilenumbruchzeichenfolge kann mit rs angegeben werden. |
| 11 | chomp!([ rs = $/]) Entfernt Zeilenumbrüche aus $ _ und ändert die vorhandene Zeichenfolge. |
| 12 | chop Gibt den Wert von zurück $_ with its last character (one byte) removed, assigning the result back to $_. |
| 13 | chop! Entfernt das letzte Zeichen aus $ _ und ändert die vorhandene Zeichenfolge. |
| 14 | eval( str[, scope[, file, line]]) Führt str als Ruby-Code aus. Die Bindung, in der die Bewertung durchgeführt werden soll, kann mit Umfang angegeben werden . Der Dateiname und die Zeilennummer des zu kompilierenden Codes können mit Datei und Zeile angegeben werden . |
| 15 | exec( cmd[, arg...]) Ersetzt den aktuellen Prozess durch Ausführen des Befehls cmd . Wenn mehrere Argumente angegeben werden, wird der Befehl ohne Shell-Erweiterung ausgeführt. |
| 16 | exit([ result = 0]) Beendet das Programm mit dem Ergebnis als zurückgegebenem Statuscode. |
| 17 | exit!([ result = 0]) Beendet das Programm unter Umgehung der Exit-Behandlung, z. B. Sicherstellen usw. |
| 18 | fail(...) Siehe erhöhen (...) |
| 19 | Float( obj) Gibt obj zurück, nachdem es in einen Float konvertiert wurde. Numerische Objekte werden direkt konvertiert. nil wird in 0.0 umgewandelt; Zeichenfolgen werden unter Berücksichtigung des Radix-Präfixes 0x, 0b konvertiert. Der Rest wird mit obj.to_f konvertiert. |
| 20 | fork fork {...} Erstellt einen untergeordneten Prozess. Im untergeordneten Prozess wird nil zurückgegeben, und die ID (Ganzzahl) des untergeordneten Prozesses wird im übergeordneten Prozess zurückgegeben. Wenn ein Block angegeben wird, wird er im untergeordneten Prozess ausgeführt. |
| 21 | format( fmt[, arg...]) Siehe sprintf. |
| 22 | gets([ rs = $/]) Liest den in der Befehlszeile oder einer Zeile angegebenen Dateinamen von der Standardeingabe. Die Datensatztrennzeichenfolge kann explizit mit rs angegeben werden. |
| 23 | global_variables Gibt ein Array globaler Variablennamen zurück. |
| 24 | gsub( x, y) gsub( x) {...} Ersetzt alle Zeichenfolgen, die mit x in übereinstimmen $_ with y. If a block is specified, matched strings are replaced with the result of the block. The modified result is assigned to $_. |
| 25 | gsub!( x, y) gsub!( x) {...} Führt die gleiche Ersetzung wie gsub durch, außer dass die Zeichenfolge an Ort und Stelle geändert wird. |
| 26 | Integer( obj) Gibt obj zurück, nachdem es in eine Ganzzahl konvertiert wurde. Numerische Objekte werden direkt konvertiert. nil wird in 0 umgewandelt; Zeichenfolgen werden unter Berücksichtigung des Radix-Präfixes 0x, 0b konvertiert. Der Rest wird mit obj.to_i konvertiert. |
| 27 | lambda {| x|...} proc {| x|...} lambda proc Konvertiert einen Block in ein Proc- Objekt. Wenn kein Block angegeben ist, wird der der aufrufenden Methode zugeordnete Block konvertiert. |
| 28 | load( file[, private = false]) Lädt ein Ruby-Programm aus einer Datei . Im Gegensatz zu require werden keine Erweiterungsbibliotheken geladen. Wenn privat ist wahr , wird das Programm in eine anonyme Modul geladen, so dass der Namensraum des rufenden Programms zu schützen. |
| 29 | local_variables Gibt ein Array lokaler Variablennamen zurück. |
| 30 | loop {...} Wiederholt einen Codeblock. |
| 31 | open( path[, mode = "r"]) open( path[, mode = "r"]) {| f|...} Öffnet eine Datei . Wenn ein Block angegeben wird, wird der Block mit dem geöffneten Stream ausgeführt, der als Argument übergeben wird. Die Datei wird automatisch geschlossen, wenn der Block beendet wird. Wenn der Pfad mit einer Pipe | beginnt, wird die folgende Zeichenfolge als Befehl ausgeführt und der diesem Prozess zugeordnete Stream wird zurückgegeben. |
| 32 | p( obj) Zeigt obj mit seiner Inspect-Methode an (häufig zum Debuggen verwendet). |
| 33 | print([ arg...]) Druckt arg auf $ defout . Wenn keine Argumente angegeben werden, wird der Wert von $ _ gedruckt. |
| 34 | printf( fmt[, arg...]) Formatiert arg gemäß fmt mit sprintf und druckt das Ergebnis in $ defout . Einzelheiten zur Formatierung finden Sie unter sprintf. |
| 35 | proc {| x|...} proc Siehe Lamda. |
| 36 | putc( c) Druckt ein Zeichen in die Standardausgabe ( $ defout ). |
| 37 | puts([ str]) Druckt eine Zeichenfolge in die Standardausgabe ( $ defout ). Wenn die Zeichenfolge nicht mit einer neuen Zeile endet, wird eine neue Zeile an die Zeichenfolge angehängt. |
| 38 | raise(...) fail(...) Löst eine Ausnahme aus. Geht davon aus Runtime wenn keine Ausnahmeklasse angegeben wird. Wenn Sie in einer Rettungsklausel Raise ohne Argumente aufrufen, wird die Ausnahme erneut ausgelöst. Wenn Sie dies außerhalb einer Rettungsklausel tun, wird ein RuntimeError ohne Nachricht ausgelöst .fail ist ein veralteter Name für Raise. |
| 39 | rand([ max = 0]) Erzeugt eine Pseudozufallszahl größer oder gleich 0 und kleiner als max. Wenn max entweder nicht angegeben oder auf 0 gesetzt ist, wird eine Zufallszahl als Gleitkommazahl größer oder gleich 0 und kleiner als 1 zurückgegeben. Mit srand kann ein Pseudozufallsstrom initialisiert werden. |
| 40 | readline([ rs = $/]) Entspricht get, außer dass beim Lesen von EOF eine EOFError-Ausnahme ausgelöst wird. |
| 41 | readlines([ rs = $/]) Gibt ein Array von Zeichenfolgen zurück, die entweder die als Befehlszeilenargumente angegebenen Dateinamen oder den Inhalt der Standardeingabe enthalten. |
| 42 | require( lib) Lädt die Bibliothek (einschließlich der Erweiterungsbibliotheken) lib, wenn sie zum ersten Mal aufgerufen wird. require lädt dieselbe Bibliothek nicht mehr als einmal. Wenn in lib keine Erweiterung angegeben ist , müssen Sie versuchen, .rb, .so usw. hinzuzufügen. |
| 43 | scan( re) scan( re) {|x|...} Entspricht $ _. Scan. |
| 44 | select( reads[, writes = nil[, excepts = nil[, timeout = nil]]]) Überprüft, ob sich der Status von drei Arten von E / A-Objekten ändert, die als Arrays von E / A-Objekten übergeben werden. nil wird für Argumente übergeben, die nicht überprüft werden müssen. Ein Array mit drei Elementen, das Arrays der E / A-Objekte enthält, für die sich der Status geändert hat, wird zurückgegeben. Bei Zeitüberschreitung wird nil zurückgegeben. |
| 45 | set_trace_func( proc) Legt einen Handler für die Ablaufverfolgung fest. proc kann eine Zeichenfolge oder ein proc- Objekt sein. set_trace_func wird vom Debugger und Profiler verwendet. |
| 46 | sleep([ sec]) Unterbricht die Programmausführung für Sekunden. Wenn sec nicht angegeben ist, wird das Programm für immer angehalten. |
| 47 | split([ sep[, max]]) Entspricht $ _. Split. |
| 48 | sprintf( fmt[, arg...]) format( fmt[, arg...]) Gibt eine Zeichenfolge zurück, in der arg gemäß fmt formatiert ist. Die Formatierungsspezifikationen sind im Wesentlichen dieselben wie für sprintf in der Programmiersprache C. Konvertierungsspezifizierer (% gefolgt von Konvertierungsfeldspezifizierer) in fmt werden durch eine formatierte Zeichenfolge des entsprechenden Arguments ersetzt. Eine Liste der eingereichten Konvertierungen finden Sie weiter unten im nächsten Abschnitt. |
| 49 | srand([ seed]) Initialisiert ein Array von Zufallszahlen. Wenn Samen nicht angegeben ist, eine Initialisierung durchgeführt für die Saat , die Zeit und andere Systeminformationen. |
| 50 | String( obj) Gibt obj zurück, nachdem es mit obj.to_s in einen String konvertiert wurde. |
| 51 | syscall( sys[, arg...]) Ruft eine durch die Nummer sys angegebene Aufruffunktion des Betriebssystems auf . Die Anzahl und Bedeutung von sys ist systemabhängig. |
| 52 | system( cmd[, arg...]) Führt cmd als Aufruf an die Befehlszeile. Wenn mehrere Argumente angegeben werden, wird der Befehl direkt ohne Shell-Erweiterung ausgeführt. Gibt true zurück, wenn der Rückgabestatus 0 ist (Erfolg). |
| 53 | sub( x, y) sub( x) {...} Ersetzt die erste Zeichenfolge, die mit x in $ _ übereinstimmt, durch y. Wenn ein Block angegeben wird, werden übereinstimmende Zeichenfolgen durch das Ergebnis des Blocks ersetzt. Das geänderte Ergebnis wird $ _ zugewiesen. |
| 54 | sub!( x, y) sub!( x) {...} Führt den gleichen Austausch wie sub durch, außer dass die Zeichenfolge an Ort und Stelle geändert wird. |
| 55 | test( test, f1[, f2]) Führt verschiedene Datei - Tests durch das Zeichen angegeben Test . Um die Lesbarkeit zu verbessern, sollten Sie anstelle dieser Funktion Dateiklassenmethoden (z. B. File :: readable?) Verwenden. Eine Liste der Argumente finden Sie weiter unten im nächsten Abschnitt. |
| 56 | throw( tag[, value = nil]) Springt zur Catch-Funktion, die mit dem Symbol oder dem String- Tag wartet . value ist der Rückgabewert, der von catch verwendet werden soll . |
| 57 | trace_var( var, cmd) trace_var( var) {...} Legt die Ablaufverfolgung für eine globale Variable fest. Der Variablenname wird als Symbol angegeben. cmd kann eine Zeichenfolge oder ein Proc-Objekt sein. |
| 58 | trap( sig, cmd) trap( sig) {...} Legt einen Signalhandler fest. sig kann eine Zeichenfolge (wie SIGUSR1) oder eine Ganzzahl sein. SIG kann im Signalnamen weggelassen werden. Der Signalhandler für das EXIT-Signal oder die Signalnummer 0 wird unmittelbar vor dem Beenden des Prozesses aufgerufen. |
| 59 | untrace_var( var[, cmd]) Entfernt die Ablaufverfolgung für eine globale Variable. Wenn cmd angegeben ist, wird nur dieser Befehl entfernt. |
Funktionen für Zahlen
Hier ist eine Liste der integrierten Funktionen in Bezug auf die Nummer. Sie sollten wie folgt verwendet werden:
#!/usr/bin/ruby
num = 12.40
puts num.floor # 12
puts num + 10 # 22.40
puts num.integer? # false as num is a float.Dies führt zu folgendem Ergebnis:
12
22.4
false| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | n + num n - num n * num n / num Führt arithmetische Operationen aus: Addition, Subtraktion, Multiplikation und Division. |
| 2 | n % num Gibt den Modul von n zurück. |
| 3 | n ** num Potenzierung. |
| 4 | n.abs Gibt den absoluten Wert von n zurück. |
| 5 | n.ceil Gibt die kleinste Ganzzahl zurück, die größer oder gleich n ist. |
| 6 | n.coerce( num) Gibt ein Array zurück, das num und n enthält, die möglicherweise in einen Typ konvertiert wurden, mit dem sie gegenseitig bearbeitet werden können. Wird bei der automatischen Typkonvertierung in numerischen Operatoren verwendet. |
| 7 | n.divmod( num) Gibt ein Array zurück, das den Quotienten und den Modul enthält, indem n durch num geteilt wird. |
| 8 | n.floor Gibt die größte Ganzzahl zurück, die kleiner oder gleich n ist. |
| 9 | n.integer? Gibt true zurück, wenn n eine Ganzzahl ist. |
| 10 | n.modulo( num) Gibt den Modul zurück, der durch Teilen von n durch num und Runden des Quotienten mit dem Boden erhalten wird |
| 11 | n.nonzero? Gibt n zurück, wenn es nicht Null ist, andernfalls Null. |
| 12 | n.remainder( num) Gibt den durch Teilen erhaltenen Rest zurück n durch numund Entfernen von Dezimalstellen aus dem Quotienten. Dasresult und n habe immer das gleiche Zeichen. |
| 13 | n.round Gibt n auf die nächste Ganzzahl gerundet zurück. |
| 14 | n.truncate Gibt n als Ganzzahl mit entfernten Dezimalstellen zurück. |
| 15 | n.zero? Gibt Null zurück, wenn n 0 ist. |
| 16 | n & num n | num n ^ num Bitweise Operationen: AND, OR, XOR und Inversion. |
| 17 | n << num n >> num Bitweise Links- und Rechtsverschiebung. |
| 18 | n[num] Gibt den Wert von zurück numth Bit vom niedrigstwertigen Bit, das n [0] ist. |
| 19 | n.chr Gibt eine Zeichenfolge zurück, die das Zeichen für den Zeichencode enthält n. |
| 20 | n.next n.succ Gibt die nächste Ganzzahl nach n zurück. Entspricht n + 1. |
| 21 | n.size Gibt die Anzahl der Bytes in der Maschinendarstellung von zurück n. |
| 22 | n.step( upto, step) {|n| ...} Iteriert den Block von n zu upto, inkrementierend um step jedes Mal. |
| 23 | n.times {|n| ...} Iteriert den Block n mal. |
| 24 | n.to_f Konvertiert nin eine Gleitkommazahl. Bei der Float-Konvertierung können Präzisionsinformationen verloren gehen. |
| 25 | n.to_int Kehrt zurück n nach der Umwandlung in eine Interger-Nummer. |
Funktionen für Float
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | Float::induced_from(num) Gibt das Ergebnis der Konvertierung von num in eine Gleitkommazahl zurück. |
| 2 | f.finite? Gibt true zurück, wenn f nicht unendlich ist und f.nan false ist. |
| 3 | f.infinite? Gibt 1 zurück, wenn f eine positive Unendlichkeit ist, -1, wenn eine negative Unendlichkeit vorliegt, oder Null, wenn etwas anderes. |
| 4 | f.nan? Gibt true zurück, wenn f keine gültige IEEE-Gleitkommazahl ist. |
Funktionen für Mathe
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | atan2( x, y) Berechnet die Bogentangente. |
| 2 | cos( x) Berechnet den Cosinus von x. |
| 3 | exp( x) Berechnet eine Exponentialfunktion (e erhöht auf die Potenz von x). |
| 4 | frexp( x) Gibt ein Array mit zwei Elementen zurück, das den nominalisierten Bruch und den Exponenten von x enthält. |
| 5 | ldexp( x, exp) Gibt den Wert von x mal 2 hoch von exp zurück. |
| 6 | log( x) Berechnet den natürlichen Logarithmus von x. |
| 7 | log10( x) Berechnet den Logarithmus zur Basis 10 von x. |
| 8 | sin( x) Berechnet den Sinus von x. |
| 9 | sqrt( x) Gibt die Quadratwurzel von x zurück. x muss positiv sein. |
| 10 | tan( x) Berechnet die Tangente von x. |
Konvertierungsfeldspezifizierer
Die Funktionen sprintf (fmt [, arg ...]) und format (fmt [, arg ...]) geben eine Zeichenfolge zurück, in der arg gemäß fmt formatiert ist. Die Formatierungsspezifikationen sind im Wesentlichen dieselben wie für sprintf in der Programmiersprache C. Konvertierungsspezifizierer (% gefolgt von Konvertierungsfeldspezifizierer) in fmt werden durch eine formatierte Zeichenfolge des entsprechenden Arguments ersetzt.
| Sr.Nr. | Spezifizierer & Beschreibung |
|---|---|
| 1 | b Binäre Ganzzahl |
| 2 | c Einzelzeichen |
| 3 | d,i Dezimalzahl |
| 4 | e Exponentielle Notation (z. B. 2.44e6) |
| 5 | E Exponentielle Notation (z. B. 2.44E6) |
| 6 | f Gleitkommazahl (z. B. 2,44) |
| 7 | g Verwenden Sie% e, wenn der Exponent kleiner als -4 ist, andernfalls% f |
| 8 | G Verwenden Sie% E, wenn der Exponent kleiner als -4 ist, andernfalls% f |
| 9 | o Oktale Ganzzahl |
| 10 | s String oder ein beliebiges Objekt, das mit to_s konvertiert wurde |
| 11 | u Dezimalzahl ohne Vorzeichen |
| 12. | x Hexadezimale Ganzzahl (z. B. 39ff) |
| 13 | X Hexadezimale Ganzzahl (z. B. 39FF) |
Es folgt das Verwendungsbeispiel -
#!/usr/bin/ruby
str = sprintf("%s\n", "abc") # => "abc\n" (simplest form)
puts str
str = sprintf("d=%d", 42) # => "d=42" (decimal output)
puts str
str = sprintf("%04x", 255) # => "00ff" (width 4, zero padded)
puts str
str = sprintf("%8s", "hello") # => " hello" (space padded)
puts str
str = sprintf("%.2s", "hello") # => "he" (trimmed by precision)
puts strDies führt zu folgendem Ergebnis:
abc
d = 42
00ff
hello
heTestfunktionsargumente
Der Funktionstest (Test, f1 [, f2]) führt eine der folgenden Datei Tests durch das Zeichen angegeben Test . Um die Lesbarkeit zu verbessern, sollten Sie anstelle dieser Funktion Dateiklassenmethoden (z. B. File :: readable?) Verwenden.
| Sr.Nr. | Argument & Beschreibung |
|---|---|
| 1 | ?r Ist f1 für die effektive UID des Anrufers lesbar? |
| 2 | ?w Ist f1 durch die effektive UID des Anrufers beschreibbar? |
| 3 | ?x Ist f1 von der effektiven UID des Anrufers ausführbar? |
| 4 | ?o Ist f1 im Besitz der effektiven UID des Anrufers? |
| 5 | ?R Ist f1 für die reale UID des Anrufers lesbar? |
| 6 | ?W Ist f1 für die reale UID des Anrufers beschreibbar? |
| 7 | ?X Ist f1 von der realen UID des Anrufers ausführbar? |
| 8 | ?O Ist f1 im Besitz der echten UID des Anrufers? |
| 9 | ?e Existiert f1? |
| 10 | ?z Hat f1 eine Länge von Null? |
| 11 | ?s Dateigröße von f1 (null wenn 0) |
| 12 | ?f Ist f1 eine reguläre Datei? |
| 13 | ?d Ist f1 ein Verzeichnis? |
| 14 | ?l Ist f1 eine symbolische Verbindung? |
| 15 | ?p Ist f1 eine Named Pipe (FIFO)? |
| 16 | ?S Ist f1 eine Steckdose? |
| 17 | ?b Ist f1 ein Blockgerät? |
| 18 | ?c Ist f1 ein Zeichengerät? |
| 19 | ?u Hat f1 das Setuid-Bit gesetzt? |
| 20 | ?g Hat f1 das setgid-Bit gesetzt? |
| 21 | ?k Hat f1 das Sticky Bit gesetzt? |
| 22 | ?M Letzte Änderungszeit für f1. |
| 23 | ?A Letzte Zugriffszeit für f1. |
| 24 | ?C Letzte Inode-Änderungszeit für f1. |
| Sr.Nr. | Argument & Beschreibung |
|---|---|
| 1 | ?= Sind die Modifikationszeiten von f1 und f2 gleich? |
| 2 | ?> Ist die Änderungszeit von f1 aktueller als f2? |
| 3 | ?< Ist die Änderungszeit von f1 älter als f2? |
| 4 | ?- Ist f1 eine harte Verbindung zu f2? |
Es folgt das Verwendungsbeispiel. Angenommen, main.rb existiert mit Lese-, Schreib- und nicht Ausführungsberechtigungen -
#!/usr/bin/ruby
puts test(?r, "main.rb" ) # => true
puts test(?w, "main.rb" ) # => true
puts test(?x, "main.rb" ) # => falseDies führt zu folgendem Ergebnis:
true
false
falseRuby - Vordefinierte Variablen
Rubys vordefinierte Variablen wirken sich auf das Verhalten des gesamten Programms aus, daher wird ihre Verwendung in Bibliotheken nicht empfohlen.
Auf die Werte in den meisten vordefinierten Variablen kann auf alternative Weise zugegriffen werden.
In der folgenden Tabelle sind alle vordefinierten Variablen von Ruby aufgeführt.
| Sr.Nr. | Variablenname & Beschreibung |
|---|---|
| 1 | $! Das letzte Ausnahmeobjekt, das ausgelöst wurde. Auf das Ausnahmeobjekt kann auch mit => in der Rettungsklausel zugegriffen werden . |
| 2 | $@ Der Stack- Backtrace für die letzte Ausnahme wurde ausgelöst. Die Stack- Backtrace- Informationen können mit der Exception # Backtrace-Methode der letzten Ausnahme abgerufen werden. |
| 3 | $/ Das Trennzeichen für Eingabedatensätze (standardmäßig Zeilenumbruch). get, readline usw. verwenden das Trennzeichen für den Eingabedatensatz als optionales Argument. |
| 4 | $\ Das Trennzeichen für den Ausgabedatensatz (standardmäßig null). |
| 5 | $, Das Ausgabetrennzeichen zwischen den zu druckenden Argumenten und dem Array # join (standardmäßig null). Sie können das Trennzeichen explizit für Array # join angeben. |
| 6 | $; Das Standardtrennzeichen für die Aufteilung (standardmäßig null). Sie können das Trennzeichen explizit für String # split angeben. |
| 7 | $. Die Nummer der letzten Zeile, die aus der aktuellen Eingabedatei gelesen wurde. Entspricht ARGF.lineno. |
| 8 | $< Synonym für ARGF. |
| 9 | $> Synonym für $ defout. |
| 10 | $0 Der Name des aktuell ausgeführten Ruby-Programms. |
| 11 | $$ Die Prozess-PID des aktuell ausgeführten Ruby-Programms. |
| 12 | $? Der Exit-Status des letzten Prozesses wurde beendet. |
| 13 | $: Synonym für $ LOAD_PATH. |
| 14 | $DEBUG True, wenn die Befehlszeilenoption -d oder --debug angegeben ist. |
| 15 | $defout Die Zielausgabe für print und printf ( standardmäßig $ stdout ). |
| 16 | $F Die Variable, die die Ausgabe von split empfängt, wenn -a angegeben wird. Diese Variable wird festgelegt, wenn die Befehlszeilenoption -a zusammen mit der Option -p oder -n angegeben wird. |
| 17 | $FILENAME Der Name der Datei, die gerade aus ARGF gelesen wird. Entspricht ARGF.Dateiname. |
| 18 | $LOAD_PATH Ein Array mit den Verzeichnissen, die beim Laden von Dateien mit dem Laden durchsucht werden sollen, und erfordert Methoden. |
| 19 | $SAFE Die Sicherheitsstufe 0 → Es werden keine Überprüfungen von extern gelieferten (verdorbenen) Daten durchgeführt. (Standard) 1 → Potenziell gefährliche Vorgänge mit verschmutzten Daten sind verboten. 2 → Potenziell gefährliche Vorgänge an Prozessen und Dateien sind verboten. 3 → Alle neu erstellten Objekte gelten als verschmutzt. 4 → Änderungen globaler Daten sind verboten. |
| 20 | $stdin Standardeingabe (standardmäßig STDIN). |
| 21 | $stdout Standardausgabe (standardmäßig STDOUT). |
| 22 | $stderr Standardfehler (standardmäßig STDERR). |
| 23 | $VERBOSE True, wenn die Befehlszeilenoption -v, -w oder --verbose angegeben ist. |
| 24 | $- x Der Wert der Interpreteroption -x (x = 0, a, d, F, i, K, l, p, v). Diese Optionen sind unten aufgeführt |
| 25 | $-0 Der Wert der Interpreteroption -x und der Alias $ /. |
| 26 | $-a Der Wert der Interpreteroption -x und true, wenn die Option -a festgelegt ist. Schreibgeschützt. |
| 27 | $-d Der Wert der Interpreteroption -x und der Alias von $ DEBUG |
| 28 | $-F Der Wert der Interpreteroption -x und der Alias $;. |
| 29 | $-i Der Wert der Interpreteroption -x und im direkten Bearbeitungsmodus enthält die Erweiterung, andernfalls null. Kann den In-Place-Bearbeitungsmodus aktivieren oder deaktivieren. |
| 30 | $-I Der Wert der Interpreteroption -x und der Alias $:. |
| 31 | $-l Der Wert der Interpreteroption -x und true, wenn die Option -l gesetzt ist. Schreibgeschützt. |
| 32 | $-p Der Wert der Interpreteroption -x und true, wenn die Option -p gesetzt ist. Schreibgeschützt. |
| 33 | $_ Die lokale Variable, letzte Zeichenfolge, die von get oder readline im aktuellen Bereich gelesen wurde. |
| 34 | $~ Die lokale Variable MatchData, die sich auf die letzte Übereinstimmung bezieht . Die Regex # -Match-Methode gibt die letzten Match-Informationen zurück. |
| 35 | $ n ($1, $2, $3...) Die Zeichenfolge stimmte in der n-ten Gruppe der letzten Musterübereinstimmung überein. Entspricht m [n], wobei m ein MatchData- Objekt ist. |
| 36 | $& Die Zeichenfolge, die in der letzten Musterübereinstimmung übereinstimmt. Entspricht m [0], wobei m ein MatchData- Objekt ist. |
| 37 | $` Die Zeichenfolge vor der Übereinstimmung in der letzten Musterübereinstimmung. Entspricht m.pre_match, wobei m ein MatchData- Objekt ist. |
| 38 | $' Die Zeichenfolge nach der Übereinstimmung in der letzten Musterübereinstimmung. Entspricht m.post_match, wobei m ein MatchData-Objekt ist. |
| 39 | $+ Die Zeichenfolge, die der zuletzt erfolgreich übereinstimmenden Gruppe in der letzten Musterübereinstimmung entspricht. |
Ruby - Vordefinierte Konstanten
In der folgenden Tabelle sind alle vordefinierten Konstanten von Ruby aufgeführt.
NOTE- TRUE, FALSE und NIL sind abwärtskompatibel. Es ist vorzuziehen, wahr, falsch und null zu verwenden.
| Sr.Nr. | Konstanter Name & Beschreibung |
|---|---|
| 1 | TRUE Synonym für wahr. |
| 2 | FALSE Synonym für falsch. |
| 3 | NIL Synonym für Null. |
| 4 | ARGF Ein Objekt, das den Zugriff auf die virtuelle Verkettung von Dateien ermöglicht, die als Befehlszeilenargumente oder Standardeingabe übergeben werden, wenn keine Befehlszeilenargumente vorhanden sind. Ein Synonym für $ <. |
| 5 | ARGV Ein Array mit den an das Programm übergebenen Befehlszeilenargumenten. Ein Synonym für $ *. |
| 6 | DATA Ein Eingabestream zum Lesen der Codezeilen gemäß der Anweisung __END__. Nicht definiert, wenn __END__ im Code nicht vorhanden ist. |
| 7 | ENV Ein Hash-ähnliches Objekt, das die Umgebungsvariablen des Programms enthält. ENV kann als Hash behandelt werden. |
| 8 | RUBY_PLATFORM Eine Zeichenfolge, die die Plattform des Ruby-Interpreters angibt. |
| 9 | RUBY_RELEASE_DATE Eine Zeichenfolge, die das Veröffentlichungsdatum des Ruby-Interpreters angibt |
| 10 | RUBY_VERSION Eine Zeichenfolge, die die Version des Ruby-Interpreters angibt. |
| 11 | STDERR Standardfehlerausgabestream. Standardwert von $ stderr . |
| 12 | STDIN Standardeingabestream. Standardwert von $ stdin. |
| 13 | STDOUT Standardausgabestream. Standardwert von $ stdout. |
| 14 | TOPLEVEL_BINDING Ein verbindliches Objekt auf Rubys oberster Ebene. |
Ruby - Zugehörige Tools
Standard Ruby Tools
Die Standard-Ruby-Distribution enthält nützliche Tools sowie den Interpreter und die Standardbibliotheken.
Mit diesen Tools können Sie Ihre Ruby-Programme ohne großen Aufwand debuggen und verbessern. Dieses Tutorial gibt Ihnen einen sehr guten Einstieg in diese Tools.
RubyGems - -
RubyGems ist ein Paketdienstprogramm für Ruby, das Ruby-Softwarepakete installiert und auf dem neuesten Stand hält.
Ruby Debugger - -
Zur Behebung von Fehlern enthält die Standarddistribution von Ruby einen Debugger. Dies ist dem Dienstprogramm gdb sehr ähnlich , mit dem komplexe Programme debuggt werden können.
Interactive Ruby (irb) - -
irb (Interactive Ruby) wurde von Keiju Ishitsuka entwickelt. Sie können an der Eingabeaufforderung Befehle eingeben und den Interpreter so reagieren lassen, als würden Sie ein Programm ausführen. irb ist nützlich, um mit Ruby zu experimentieren oder es zu erkunden.
Ruby Profiler - -
Mit dem Ruby-Profiler können Sie die Leistung eines langsamen Programms verbessern, indem Sie den Engpass ermitteln.
Zusätzliche Ruby-Tools
Es gibt andere nützliche Tools, die nicht in der Ruby-Standarddistribution enthalten sind. Sie müssen sie jedoch selbst installieren.
eRuby: Embeded Ruby - -
eRuby steht für Embedded Ruby. Es ist ein Tool, das Fragmente von Ruby-Code in andere Dateien einbettet, z. B. HTML-Dateien, die ASP, JSP und PHP ähneln.
ri: Ruby Interactive Reference - -
Wenn Sie eine Frage zum Verhalten einer bestimmten Methode haben, können Sie ri aufrufen, um die kurze Erläuterung der Methode zu lesen.
Weitere Informationen zu Ruby-Tools und -Ressourcen finden Sie unter Ruby Useful Resources.