SAP BW - Kurzanleitung
In diesem Kapitel lernen wir die Grundlagen von SAP BW und SAP BI kennen. Wie es sich im Laufe der Jahre entwickelt und verbessert hat.
SAP BW und BI Einführung
SAFT Business Intelligence (BI)bedeutet die Analyse und Berichterstattung von Daten aus verschiedenen heterogenen Datenquellen. SAFTBusiness Warehouse (BW)Integriert Daten aus verschiedenen Quellen, transformiert und konsolidiert die Daten, bereinigt Daten und speichert Daten. Es umfasst auch den Bereich Datenmodellierung, -verwaltung und -bereitstellung.
Die Daten im SAP BW werden mit Hilfe eines zentralen Tools verwaltet, das als bekannt ist SAP BI Administration Workbench. Die BI-Plattform bietet Infrastruktur und Funktionen, darunter:
- OLAP-Prozessor
- Metadaten-Repository,
- Prozessdesigner und andere Funktionen.
Das Business Explorer (BEx)ist ein Berichts- und Analysetool, das Abfrage-, Analyse- und Berichtsfunktionen in BI unterstützt. Mit BEx können Sie historische und aktuelle Daten in unterschiedlichem Analysegrad analysieren.
SAP BW ist als offenes Standardtool bekannt, mit dem Sie Daten aus verschiedenen Systemen extrahieren und anschließend an das BI-System senden können. Außerdem werden die Daten mit verschiedenen Berichterstellungstools ausgewertet, und Sie können diese auf andere Systeme verteilen.
Das folgende Diagramm zeigt eine offene, breite und standardbasierte Architektur von Business Intelligence.

- BI steht für Business Intelligence
- BW steht für Business Warehouse
1997 hatte SAP erstmals ein Produkt für Berichterstellung, Analyse und Data Warehousing eingeführt, das den Namen erhielt Business Warehouse Information System (BIW).
Später wurde der Name von SAP BIW in SAP Business Warehouse (BW) geändert. Nachdem SAP Business Objects erworben hat, wurde der Name des Produkts in SAP BI geändert.
| Name | BIW-Version | Erscheinungsdatum und -jahr |
|---|---|---|
| BIW | 1.2A | Okt 1998 |
| BIW | 1.2B | September 1999 |
| BIW | 2,0A | Februar 2000 |
| BIW | 2.0B | Jun 2000 |
| BIW | 2.1C | November 2000 |
| BW (Name geändert in BW) | 3,0A | Okt 2001 |
| BW | 3.0B | Mai 2002 |
| BW | 3.1 | November 2002 |
| BW | 3.1C | April 2004 |
| BW | 3.3 | April 2004 |
| BW | 3.5 | April 2004 |
| BI (Name geändert in BI) | 7 | Jul 2005 |
Datenerfassung in SAP BI
Mit SAP BI können Sie Daten aus mehreren Datenquellen erfassen, die auf verschiedene BI-Systeme verteilt werden können. Ein SAP Business Intelligence-System kann als Zielsystem für die Datenübertragung oder als Quellsystem für die Verteilung von Daten an verschiedene BI-Ziele fungieren.

Wie im obigen Bild erwähnt, können Sie SAP BI-Quellsysteme zusammen mit anderen Systemen sehen -
- SAP-Systeme (SAP-Anwendungen / SAP ECC)
- Relationale Datenbank (Oracle, SQL Server usw.)
- Flat File (Excel, Editor)
- Mehrdimensionale Quellsysteme (Universum mit UDI-Anschluss)
- Webdienste, die Daten per Push an BI übertragen
Wenn Sie zur SAP BI Administration Workbench wechseln, wird dort das Quellsystem definiert. Gehe zuRSA1 → Source Systems


Je nach Datenquellentyp können Sie zwischen den Quellsystemen unterscheiden -
- Datenquellen für Transaktionsdaten
- Datenquellen für Stammdaten
- Datenquellen für Hierarchien
- Datenquellen für Text
- Datenquellen für Attribute
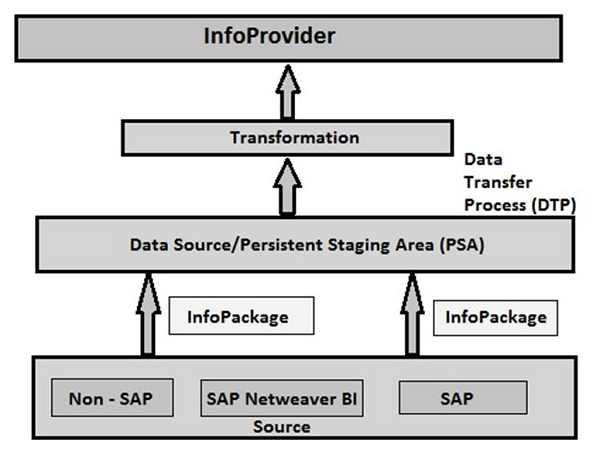
Sie können die Daten von jeder Quelle in der Datenquellenstruktur mit einem in BI laden InfoPackage. Das Zielsystem, in das die Daten geladen werden sollen, wird in der Transformation definiert.
InfoPackage
In einem InfoPackage wird angegeben, wie und wann Daten aus verschiedenen Datenquellen in das BI-System geladen werden sollen. Ein InfoPackage enthält alle Informationen darüber, wie die Daten vom Quellsystem in eine Datenquelle oder einen PSA geladen werden. InfoPackage besteht aus einer Bedingung zum Anfordern von Daten von einem Quellsystem.
Note - Mit einem InfoPackage in BW 3.5 können Sie Daten im Persistence Staging Area und auch in Zielen aus dem Quellsystem laden. Wenn Sie jedoch SAP BI 7.0 verwenden, sollte das Laden von Daten nur für die neuesten Versionen auf PSA beschränkt sein.
BI Data Flow (InfoPackage and InfoProvider)
BI-Inhalt
BI-Objekte bestehen aus folgenden Komponenten:
- Roles
- Webvorlagen und Arbeitsmappe
- Queries
- InfoProvider
- Regeln aktualisieren
- InfoSource
- Übertragungsregeln
- InfoObjects
- DataSources
BI-Objekte sind in mehrere BI-Inhaltsbereiche unterteilt, damit sie effizient verwendet werden können. Dies umfasst den Inhaltsbereich aller Schlüsselmodule in einer Organisation, einschließlich:
- SCM
- CRM
- HR
- Finanzverwaltung
- Produktlebensdauer
- Branchenlösungen
- Nicht-SAP-Datenquellen usw.
In diesem Kapitel werden wir uns mit Stern und erweitertem Sternschema befassen. Wir werden auch verstehen, was InfoArea und InfoObjects sind.
Sternschema
In Star Schema wird jede Dimension mit einer einzigen Faktentabelle verknüpft. Jede Dimension wird nur durch eine Dimension dargestellt und nicht weiter normalisiert. Eine Dimensionstabelle enthält eine Reihe von Attributen, mit denen die Daten analysiert werden.
Zum Beispiel - Wir haben eine Faktentabelle namens FactSales Das hat Primärschlüssel für alle Dim-Tabellen und Kennzahlen units_sold und dollars_sold Analyse machen.
Wir haben 4 Dimensionstabellen - DimTime, DimItem, DimBranch, DimLocation, wie in der folgenden Abbildung gezeigt.

Jede Dimensionstabelle ist mit einer Faktentabelle verbunden, da die Faktentabelle den Primärschlüssel für jede Dimensionstabelle enthält, mit der zwei Tabellen verknüpft werden.
Fakten / Kennzahlen in der Faktentabelle werden zu Analysezwecken zusammen mit dem Attribut in den Dimensionstabellen verwendet.
Erweitertes Sternschema
Im Extended Star-Schema sind Faktentabellen mit Dimensionstabellen verbunden, und diese Dimensionstabelle ist weiter mit der SID-Tabelle verbunden, und diese SID-Tabelle ist mit Stammdatentabellen verbunden. In einem erweiterten Sternschema befinden sich die Fakten- und Dimensionstabellen innerhalb des Cubes. SID-Tabellen befinden sich jedoch außerhalb des Cubes. Wenn Sie die Transaktionsdaten in den Info-Cube laden, werden die Dim-IDs basierend auf den SIDs generiert und diese Dim-IDs werden dann in den Faktentabellen verwendet.
Im erweiterten Sternschema kann eine Faktentabelle eine Verbindung zu 16 Dimensionstabellen herstellen, und jeder Dimensionstabelle werden maximal 248 SID-Tabellen zugewiesen. Diese SID-Tabellen werden auch als Merkmale bezeichnet, und jedes Merkmal kann Stammdatentabellen wie ATTR, Text usw. enthalten.
ATTR - Hier werden alle Attributdaten gespeichert.
Text - Es wird verwendet, um Beschreibungen in mehreren Sprachen zu speichern.

InfoArea und InfoObjects
InfoObjects werden als kleinste Einheit in SAP BI bezeichnet und in Info-Providern, DSOs, Multi-Providern usw. verwendet. Jeder Info-Provider enthält mehrere InfoObjects.
InfoObjects werden in Berichten verwendet, um die gespeicherten Daten zu analysieren und Entscheidungsträgern Informationen bereitzustellen. InfoObjects können in folgende Kategorien eingeteilt werden:
- Eigenschaften wie Kunde, Produkt usw.
- Einheiten wie verkaufte Menge, Währung usw.
- Kennzahlen wie Gesamtumsatz, Gewinn usw.
- Zeitmerkmale wie Jahr, Quartal usw.
InfoObjects werden im InfoObject-Katalog erstellt. Möglicherweise kann ein InfoObject einem anderen Info-Katalog zugeordnet werden.
Infobereich
Der Infobereich in SAP BI wird verwendet, um ähnliche Objekttypen zu gruppieren. Der Infobereich wird zum Verwalten von Info Cubes und InfoObjects verwendet. Jedes InfoObjects befindet sich in einem Info-Bereich und Sie können es in einem Ordner definieren, in dem ähnliche Dateien zusammengehalten werden.

In diesem Kapitel werden wir uns mit dem Datenfluss und der Datenerfassung im SAP BW befassen.
Übersicht über den Datenfluss
Der Datenfluss bei der Datenerfassung umfasst die Transformation, das Informationspaket zum Laden in PSA und den Datenübertragungsprozess zur Verteilung von Daten innerhalb von BI. In SAP BI legen Sie fest, welche Datenquellenfelder für die Entscheidungsfindung benötigt werden und übertragen werden sollen.
Wenn Sie die Datenquelle aktivieren, wird im SAP BW eine PSA-Tabelle generiert und anschließend können Daten geladen werden.
Im Transformationsprozess werden Felder für InfoObjects und deren Werte ermittelt. Dies erfolgt mithilfe der DTP-Daten, die von PSA an verschiedene Zielobjekte übertragen werden.
Der Transformationsprozess umfasst die folgenden verschiedenen Schritte:
- Datenkonsolidierung
- Datenbereinigung
- Datenintegration

Wenn Sie die Daten von einem BI-Objekt in ein anderes BI-Objekt verschieben, verwenden die Daten eine Transformation. Diese Transformation konvertiert das Quellfeld in das Format des Ziels. Die Transformation wird zwischen einem Quell- und einem Zielsystem erstellt.
BI Objects - InfoSource, DataStore-Objekte, InfoCube, InfoObjects und InfoSet fungieren als Quellobjekte, und dieselben Objekte dienen als Zielobjekte.
Eine Transformation sollte aus mindestens einer Transformationsregel bestehen. Sie können verschiedene Transformationstypen und Regeltypen aus der Liste der verfügbaren Regeln verwenden und einfache bis komplexe Transformationen erstellen.
Direkter Zugriff auf Quellsystemdaten
Auf diese Weise können Sie direkt auf Daten im BI-Quellsystem zugreifen. Sie können direkt auf die Quellsystemdaten in BI zugreifen, ohne sie mit virtuellen Anbietern zu extrahieren. Diese virtuellen Anbieter können als InfoProvider definiert werden, bei denen keine Transaktionsdaten im Objekt gespeichert sind. Virtuelle Anbieter erlauben nur Lesezugriff auf BI-Daten.
Es gibt verschiedene Arten von virtuellen Anbietern, die verfügbar sind und in verschiedenen Szenarien verwendet werden können -
- VirtualProviders basierend auf DTP
- VirtualProvider mit Funktionsbausteinen
- VirtualProviders basierend auf BAPIs
VirtualProviders Basierend auf DTP
Diese VirtualProvider basieren auf der Datenquelle oder einem InfoProvider und übernehmen Merkmale und Kennzahlen der Quelle. Dieselben Extraktoren werden zum Auswählen von Daten in einem Quellsystem verwendet, mit denen Sie Daten in das BI-System replizieren.
- Wann basieren virtuelle Anbieter auf DTP?
- Wenn nur eine bestimmte Datenmenge verwendet wird.
- Sie müssen auf aktuelle Daten aus einem SAP-Quellsystem zugreifen.
- Nur wenige Benutzer führen gleichzeitig Abfragen in der Datenbank aus.
Auf DTP basierende virtuelle Anbieter sollten unter den folgenden Bedingungen nicht verwendet werden:
Wenn mehrere Benutzer gemeinsam Abfragen ausführen.
Wenn mehrmals auf dieselben Daten zugegriffen wird.
Wenn eine große Datenmenge angefordert wird und keine Aggregationen im Quellsystem verfügbar sind.
Erstellen eines VirtualProviders basierend auf DTP
Verwenden Sie, um zur Administration Workbench zu gelangen RSA1

In dem Modeling tab → go to Info Provider tree → In Context menu → Create Virtual Provider.

Im Type Select Virtual Providerbasierend auf dem Datenübertragungsprozess für den direkten Zugriff. Sie können einen virtuellen Anbieter auch mit einem mit einer SAP-Quelle verknüpfenInfoSource 3.x.

EIN Unique Source System Assignment Indicatorwird verwendet, um die Zuordnung des Quellsystems zu steuern. Wenn Sie diesen Indikator auswählen, kann im Zuordnungsdialog nur ein Quellsystem verwendet werden. Wenn dieses Kennzeichen nicht aktiviert ist, können Sie mehr als ein Quellsystem auswählen und ein virtueller Anbieter kann als Multi-Anbieter betrachtet werden.

Klicke auf Create (F5)unten. Sie können den virtuellen Anbieter definieren, indem Sie Objekte kopieren. Klicken Sie zum Aktivieren des virtuellen Anbieters wie im folgenden Screenshot gezeigt auf.

Um Transformation zu definieren, klicken Sie mit der rechten Maustaste und gehen Sie zu Transformation erstellen.
Definieren Sie die Transformationsregeln und aktivieren Sie sie.
Der nächste Schritt ist das Erstellen eines Datenübertragungsprozesses. Rechtsklick → Datenübertragungsprozess erstellen
Der Standardtyp von DTP ist DTP für den direkten Zugriff. Sie müssen die Quelle für Virtual Provider auswählen und DTP aktivieren.
Um den direkten Zugriff zu aktivieren, context menu → Activate Direct Access.

Wählen Sie einen oder mehrere Datenübertragungsprozesse aus und aktivieren Sie die Zuordnung.
Virtuelle Anbieter mit BAPIs
Dies wird für die Berichterstellung über die Daten in externen Systemen verwendet, und Sie müssen keine Transaktionsdaten im BI-System speichern. Sie können eine Verbindung zu Nicht-SAP-Systemen wie hierarchischen Datenbanken herstellen.
Wenn dieser virtuelle Anbieter für die Berichterstellung verwendet wird, ruft er das BAPI des virtuellen Anbieters auf.
Virtueller Anbieter mit Funktionsbaustein
Dieser virtuelle Anbieter wird verwendet, um Daten aus einer Nicht-BI-Datenquelle in einem BI anzuzeigen, ohne die Daten in die BI-Struktur zu kopieren. Die Daten können lokal oder remote sein. Dies wird hauptsächlich für SEM-Anwendungen verwendet.
Wenn Sie dies mit anderen virtuellen Anbietern vergleichen, ist dies allgemeiner und bietet mehr Flexibilität. Sie müssen jedoch große Anstrengungen unternehmen, um dies zu implementieren.
Geben Sie den Namen des Funktionsbausteins ein, den Sie als Datenquelle für virtuelle Anbieter verwenden möchten.

Der Transformationsprozess wird verwendet, um Datenkonsolidierung, Bereinigung und Datenintegration durchzuführen. Wenn Daten von einem BI-Objekt in ein anderes BI-Objekt geladen werden, wird die Transformation auf die Daten angewendet. Die Transformation wird verwendet, um ein Quellfeld in das Zielobjektformat zu konvertieren.
Jede Transformation besteht aus mindestens einer Transformationsregel. Da verschiedene Regeltypen und Routinen verfügbar sind, können Sie einfache bis komplexe Transformationen erstellen.
Um eine Transformation zu erstellen, gehen Sie zum Kontext und klicken Sie mit der rechten Maustaste → Transformation erstellen.
Im nächsten Fenster werden Sie aufgefordert, die Quelle der Transformation und den Namen einzugeben und auf das Häkchen zu klicken.
Eine Regel wird vom Quell- zum Zielsystem erstellt und die Zuordnung wird angezeigt.

Transformationsregeln
Transformationsregeln werden verwendet, um Quell- und Zielfelder zuzuordnen. Für die Transformation können verschiedene Regeltypen verwendet werden.
Rule Type - Ein Regeltyp ist definiert als eine Operation, die mithilfe einer Transformationsregel auf die Felder angewendet wird.
Rule Group - Es ist als Gruppe von Transformationsregeln definiert und jedes Schlüsselfeld im Ziel enthält eine Transformationsregel.
Transformation Type - Es wird verwendet, um die Transformationswerte und die Eingabe von Daten in das Ziel zu bestimmen.
Routines- Routinen werden verwendet, um komplexe Transformationen durchzuführen. Routinen werden als lokale ABAP-Klassen definiert und bestehen aus einem vordefinierten Definitions- und Implementierungsbereich.
Im Implementierungsbereich wird eine Routine erstellt, und im Definitionsbereich werden eingehende und ausgehende Parameter definiert. Routinen können als Transformationsregel für eine Kennzahl definiert werden und sind als Regeltypen verfügbar.
Echtzeit-Datenerfassung (RDA)
Die Echtzeit-Datenerfassung basiert auf dem Verschieben von Daten in Business Warehouse in Echtzeit. Daten werden in Echtzeit an die Delta-Warteschlange oder die PSA-Tabelle gesendet. Die Echtzeit-Datenerfassung wird verwendet, wenn Sie Daten häufiger übertragen - stündlich oder jede Minute - und die Daten auf Berichtsebene mehrmals in einem einzigen Zeitintervall aktualisiert werden.
Die Echtzeit-Datenerfassung ist eine der Schlüsseleigenschaften der Datenquelle, und die Datenquelle sollte die Echtzeit-Datenerfassung unterstützen. Datenquellen, die so konfiguriert sind, dass sie Daten in Echtzeit übertragen, können nicht für die Standarddatenübertragung verwendet werden.
Die Datenerfassung in Echtzeit kann in zwei Szenarien erfolgen:
Durch Verwendung von InfoPackage für die Echtzeit-Datenerfassung mithilfe der Service-API.
Verwenden des Webdienstes zum Laden von Daten in den PSA (Persistent Storage Area) und anschließendes Verschieben der Daten in DSO mithilfe von Echtzeit-DTP.
Hintergrundprozess der Datenerfassung in Echtzeit -
Um Daten in regelmäßigen Abständen an InfoPackage und DTP zu übertragen, können Sie einen Hintergrundprozess verwenden, der als Daemon bezeichnet wird.
Der Daemon-Prozess erhält von InfoPackage und DTP alle Informationen darüber, welche Daten übertragen werden sollen und welche PSA- und Data-Wore-Objekte mit Daten geladen werden sollen.
In diesem Kapitel werden einige SAP-BW-Komponenten mit den Namen InfoArea, InfoObject und Catalog ausführlich erläutert.
InfoArea in SAP BI
InfoArea in SAP BI wird verwendet, um ähnliche Objekttypen zu gruppieren. InfoArea wird zum Verwalten von InfoCubes und InfoObjects verwendet. Jedes InfoObject befindet sich in einer InfoArea und Sie können es in einem Ordner definieren, in dem ähnliche Dateien zusammengehalten werden.
Wie erstelle ich einen Infobereich?
Um einen Infobereich zu erstellen, rufen Sie die RSA-Workbench auf. T-Code: RSA1
Gehe zu Modeling tab → InfoProvider. Right click on Context → Create InfoArea.

Geben Sie den Namen von InfoArea und die Beschreibung ein und klicken Sie auf Weiter.

Die erstellte InfoArea wird unten angezeigt.
Wie erstelle ich ein InfoObject und einen InfoObject-Katalog?
InfoObjects werden als kleinste Einheit in SAP BI bezeichnet und in InfoProvidern, DSOs, Multi-Providern usw. verwendet. Jeder InfoProvider enthält mehrere InfoObjects.
InfoObjects werden in Berichten verwendet, um die gespeicherten Daten zu analysieren und den Entscheidungsträgern Informationen bereitzustellen. InfoObjects können in folgende Kategorien eingeteilt werden:
- Eigenschaften wie Kunde, Produkt usw.
- Einheiten wie verkaufte Menge, Währung usw.
- Kennzahlen wie Gesamtumsatz, Gewinn usw.
- Zeitmerkmale wie Jahr, Quartal usw.
InfoObjects werden im InfoObject-Katalog erstellt. Möglicherweise kann ein InfoObject einem anderen Info-Katalog zugeordnet werden.
InfoObject-Katalog erstellen
T-Code: RSA1
Gehe zu Modeling → InfoObjects → Right Click → Create InfoObject Catalog.

Geben Sie den technischen Namen des InfoObject-Katalogs und die Beschreibung ein.

Select InfoObject Type - Optionsfeld "Charakteristik" - Dies ist ein charakteristischer InfoObject-Katalog.
Key Figure - Dies ist der InfoObject-Katalog, der erstellt werden würde.
Klicken Sie auf die Schaltfläche Erstellen. Der nächste Schritt ist das Speichern und Aktivieren des InfoObject-Katalogs. Ein neuer InfoObject-Katalog wird wie im folgenden Screenshot gezeigt erstellt -


InfoObject erstellen
Um ein InfoObject mit Merkmalen zu erstellen, gehen Sie zu RSA1 und öffnen Sie die Administration Workbench. Gehe zuModeling → InfoObjects.
Wählen My Sales InfoObject Catalog → Right Click → Create InfoObjects.

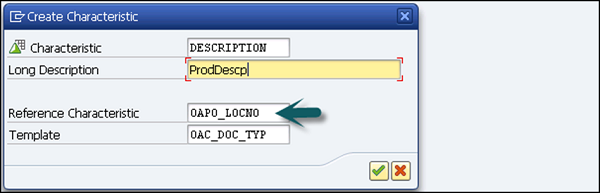
Geben Sie den technischen Namen der Merkmale und die Beschreibung ein. Sie können die Referenzmerkmale verwenden, wenn die neuen Merkmale, die erstellt werden müssen, dieselben technischen Eigenschaften eines vorhandenen Merkmals aufweisen.
Sie können Vorlagenmerkmale für ein neues Merkmal verwenden, das einige der technischen Eigenschaften eines bereits vorhandenen Merkmals aufweist. Klicken Sie auf Weiter.
Im nächsten Fenster erhalten Sie den Bearbeitungsbildschirm des InfoObjects. Der InfoObject-Bearbeitungsbildschirm verfügt über 6 folgende Registerkarten, die auch im Screenshot angezeigt werden:
- General
- Business Explorer
- Stammdaten / Texte
- Hierarchy
- Attribute
- Compounding

Wenn alle Felder definiert sind, klicken Sie auf Speichern und aktivieren.
Erstellen eines InfoObjects mit Kennzahlen
Um ein InfoObject mit Merkmalen zu erstellen, gehen Sie zu RSA1 und öffnen Sie die Administration Workbench. Gehe zuModeling → InfoObjects

Gehe zu Not Assigned Key Figures → Right Click → Create InfoObject.

Dann können Sie -
- Geben Sie den technischen Namen und die Beschreibung ein.
- Geben Sie die Referenzkennzahl ein
- Geben Sie die Referenzvorlage ein und klicken Sie auf Weiter.

Definieren Sie unter Eigenschaften bearbeiten die folgenden Felder:
- Type/Unit
- Aggregation
- Zusätzliche Eigenschaften
- Elimination

Klicken Sie auf Speichern und Aktivieren, wie im folgenden Screenshot gezeigt. Dieses InfoObject wird gespeichert und ist aktiv.

Bearbeiten eines InfoObjects
Sie können ein vorhandenes InfoObject auch in der Administration Workbench ändern. WählenInfoObject you want to maintain → Context menu → Change. Sie können das InfoObject-Symbol auch über das Symbolleistenmenü verwalten.

Mit dieser Funktion können Sie nur einige Eigenschaften eines InfoObjects ändern, wenn es im InfoProvider verwendet wird. Sie können Text und Bedeutung eines InfoObjects ändern. Das InfoObject mit Kennzahlen - ist nicht möglich, wenn im InfoProvider der Kennzahlentyp, der Datentyp oder die Aggregation der Kennzahl verwendet wird.
Sie können die Überprüfungsfunktion für inkompatible Änderungen verwenden.

In diesem Kapitel werden die verschiedenen DataStore-Objekte und ihre Untermodule erläutert.
Was ist ein DataStore-Objekt?
Ein DSO (DataStore Object) ist als Speicherort bekannt, um bereinigte und konsolidierte Transaktions- oder Stammdaten auf dem niedrigsten Granularitätsniveau zu halten. Diese Daten können mithilfe des analysiert werden BEx query.
Ein DataStore-Objekt enthält Kennzahlen, und die charakteristischen Felder und Daten eines DSO können mithilfe der Delta-Aktualisierung oder anderer DataStore-Objekte oder sogar anhand der Stammdaten aktualisiert werden. Diese DataStore-Objekte werden üblicherweise in zweidimensionalen transparenten Datenbanktabellen gespeichert.
DSO-Architektur
Die DSO-Komponente besteht aus den folgenden drei Tabellen:
Activation Queue- Hier werden die Daten gespeichert, bevor sie aktiviert werden. Der Schlüssel enthält die Anforderungs-ID, die Paket-ID und die Datensatznummer. Sobald die Aktivierung abgeschlossen ist, wird die Anforderung aus der Aktivierungswarteschlange gelöscht.
Active Data Table - In dieser Tabelle werden die aktuell aktiven Daten gespeichert. Diese Tabelle enthält den für die Datenmodellierung definierten semantischen Schlüssel.
Change Log- Wenn Sie das Objekt aktivieren, werden Änderungen an den aktiven Daten in diesem Änderungsprotokoll erneut gespeichert. Ein Änderungsprotokoll ist eine PSA-Tabelle und wird in der Administration Workbench unter der PSA-Struktur verwaltet.

Wenn Sie die neuen Daten in ein DSO laden und der technische Schlüssel den Datensätzen hinzugefügt wird. Eine Anforderung wird dann zur Aktivierungswarteschlange hinzugefügt. Es kann manuell oder automatisch ausgelöst werden.
Arten von DataStore-Objekten
Sie können die DataStore-Objekte in die folgenden Typen definieren:
- Standard DSO
- DSO direkt aktualisieren
- Schreiboptimiertes DSO
| Art | Struktur | Datenversorgung | SID-Generierung |
|---|---|---|---|
| Standard DataStore-Objekt | Besteht aus drei Tabellen: Aktivierungswarteschlange, Tabelle der aktiven Daten, Änderungsprotokoll | Aus dem Datenübertragungsprozess | Ja |
| Schreiboptimierte Datenspeicherobjekte | Besteht nur aus der Tabelle der aktiven Daten | Aus dem Datenübertragungsprozess | Nein |
| DataStore-Objekte für die direkte Aktualisierung | Besteht nur aus der Tabelle der aktiven Daten | Von APIs | Nein |
Standard DataStore-Objekte
Um ein Standard-DSO zu erstellen, rufen Sie die RSA Workbench auf.
Verwenden T-Code: RSA1

Gehe zu Modeling tab → InfoProvider → Select InfoArea → Right click and click on create DataStore Object.

Geben Sie den technischen Namen und die Beschreibung des DataStore-Objekts ein.
Type of DataStore Object→ Hiermit wird der DSO-Typ ausgewählt. Standardmäßig wird ein Standard-DSO verwendet.
Click the Create (F5) button.

Um den DSO-Typ zu ändern, wechseln Sie zur Registerkarte Einstellungen (siehe folgenden Screenshot). Klicken Sie auf das Symbol Bearbeiten. In einem neuen Fenster, das geöffnet wird, können Sie das DataStore-Objekt ändern und auch den Typ auswählen.
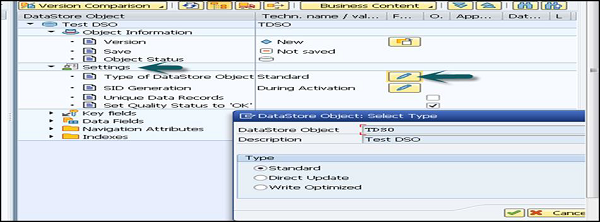
SID-Generierung
Für jeden Stammdatenwert wird eine SID generiert. Klicken Sie auf Bearbeiten, um die Einstellungen für die SID-Generierung zu ändern.

Erstellen Sie eine SID
Sie können aus folgenden Optionen auswählen:
- Während der Berichterstattung
- Während der Aktivierung oder
- Erstellen Sie niemals SIDs
Unique Data Records - Diese Option wird verwendet, um sicherzustellen, dass das DSO eindeutige Werte enthält.
Set Quality Status to OK - Auf diese Weise können Sie den Qualitätsstatus nach Abschluss des Datenladens festlegen.

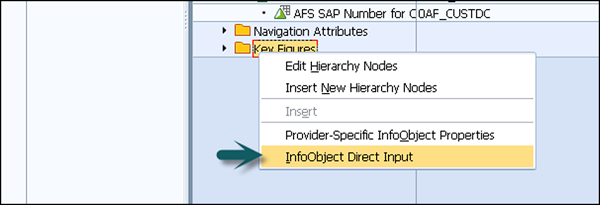
Key Fields and Data Fields- Schlüsselfelder werden verwendet, um eindeutige Datensätze hinzuzufügen. Um eine Schlüsseldatei hinzuzufügen, klicken Sie mit der rechten Maustaste auf Schlüsselfelder und wählen Sie InfoObject Direct Input.

Geben Sie in einem neuen Fenster die technischen Namen in die InfoObjects ein und klicken Sie auf Weiter. Sie können sehen, dass das InfoObject im Abschnitt Schlüsselfelder hinzugefügt wird.

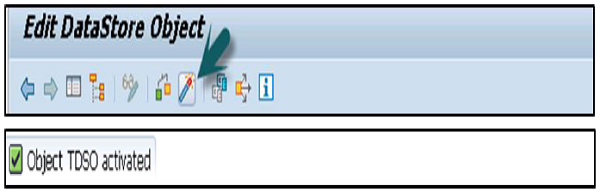
Es folgt der Schlüssel, der im DSO als InfoObject abgelegt ist. Sobald diese DSO-Struktur abgeschlossen ist, können Sie dieses DSO aktivieren.

Direkte Aktualisierung von DataStore-Objekten
Mit dem DataStore-Objekt für die direkte Aktualisierung können Sie unmittelbar nach dem Laden auf Daten für die Berichterstellung und Analyse zugreifen. Es unterscheidet sich von Standard-DSOs durch die Art und Weise, wie die Daten verarbeitet werden. Diese Daten werden in demselben Format gespeichert, in dem sie für eine direkte Aktualisierung durch die Anwendung in das DataStore-Objekt geladen wurden.
Die Struktur von Direct Update DSOs
Diese Datenspeicher enthalten eine Tabelle für aktive Daten, und es ist kein Änderungsprotokollbereich vorhanden. Die Daten werden mithilfe von APIs von externen Systemen abgerufen.
Die folgenden APIs existieren -
RSDRI_ODSO_INSERT - Diese dienen zum Einfügen neuer Daten.
RSDRI_ODSO_INSERT_RFC - Es ähnelt RSDRI_ODSO_INSERT und kann remote aufgerufen werden.
RSDRI_ODSO_MODIFY- Hiermit werden Daten mit neuen Schlüsseln eingefügt. Bei Daten mit bereits im System vorhandenen Schlüsseln werden die Daten geändert.
RSDRI_ODSO_MODIFY_RFC - Dies ähnelt RSDRI_ODSO_MODIFY und kann remote aufgerufen werden.
RSDRI_ODSO_UPDATE - Diese API wird verwendet, um die vorhandenen Daten zu aktualisieren.
RSDRI_ODSO_UPDATE_RFC - Dies ähnelt RSDRI_ODSO_UPDATE und kann remote aufgerufen werden.
RSDRI_ODSO_DELETE_RFC - Diese API wird zum Löschen der Daten verwendet.
Leistungen
Bei DSOs mit direkter Aktualisierung sind die Daten leicht zugänglich. Sie können sofort nach dem Laden auf Daten für Berichte und Analysen zugreifen.
Nachteile
Da die Struktur dieses DSO eine Tabelle für aktive Daten und kein Änderungsprotokoll enthält, ist keine Delta-Aktualisierung für InfoProvider möglich.
Da der Datenladevorgang vom BI-System nicht unterstützt wird, werden DSOs weder im Administrationsbereich noch auf dem Monitor angezeigt.
Um einen direkten Update-DataStore zu erstellen, rufen Sie die Administrations-Workbench auf. VerwendenT-Code: RSA1

Gehe zu Modeling tab → InfoProvider → Select InfoArea → Right click and click on create DataStore Object.

Geben Sie den technischen Namen und die Beschreibung des DataStore-Objekts ein.
Type of DataStore Object- Hiermit wird der DSO-Typ ausgewählt. Standardmäßig wird ein Standard-DSO verwendet.
Klick auf das Create (F5) Taste.

Um den DSO-Typ zu ändern, wechseln Sie zur Registerkarte Einstellungen (siehe folgenden Screenshot). Klicken Sie auf das Symbol Bearbeiten. In einem neuen Fenster können Sie das DataStore-Objekt ändern und dessen Typ auswählen. Wählen Sie den Direct Update DataStore aus und klicken Sie auf Weiter.

Sobald der DataStore definiert ist, klicken Sie auf die Schaltfläche Aktivieren, um DSO zu aktivieren.

Im schreiboptimierten DSO stehen die geladenen Daten sofort zur weiteren Verarbeitung zur Verfügung.
Write Optimized DSO bietet einen temporären Speicherbereich für große Datenmengen, wenn Sie komplexe Transformationen für diese Daten ausführen, bevor sie in das DataStore-Objekt geschrieben werden. Die Daten können dann auf weitere InfoProvider aktualisiert werden. Sie müssen die komplexen Transformationen nur einmal für alle Daten erstellen.
Schreiboptimierte DSOs werden als EDW-Schicht zum Speichern von Daten verwendet. Geschäftsregeln werden nur angewendet, wenn die Daten auf zusätzliche InfoProvider aktualisiert werden.
In Write Optimized DSO generiert das System keine SIDs und Sie müssen diese nicht aktivieren. Dies bedeutet, dass Sie Zeit sparen und die Daten schnell weiterverarbeiten können. Die Berichterstellung ist auf Basis dieser DataStore-Objekte möglich.
Struktur des schreiboptimierten DSO
Es enthält nur die Tabelle der aktiven Daten und es ist nicht erforderlich, die Daten wie beim Standard-DSO erforderlich zu aktivieren. Dadurch können Sie die Daten schneller verarbeiten.
In Write Optimized DSO werden geladene Daten nicht aggregiert. Wenn zwei Datensätze mit demselben logischen Schlüssel aus der Quelle extrahiert werden, werden beide Datensätze im DataStore-Objekt gespeichert. Der für die Aggregation verantwortliche Datensatz bleibt jedoch erhalten, sodass die Aggregation von Daten später in Standard-DataStore-Objekten erfolgen kann.
Das System generiert einen eindeutigen technischen Schlüssel für das schreiboptimierte DataStore-Objekt. Die Standardschlüsselfelder sind bei diesem Typ eines DataStore-Objekts nicht erforderlich. Wenn es ohnehin Standardschlüsselfelder gibt, werden diese als semantische Schlüssel bezeichnet, damit sie von den anderen technischen Schlüsseln unterschieden werden können.
Die technischen Schlüssel bestehen aus -
- Anforderungs-GUID-Feld (0REQUEST)
- Datenpaketfeld (0DATAPAKID)
- Feld Datensatznummer (0RECORD) und Sie laden nur neue Datensätze.
Verwenden T-Code: RSA1
Gehe zu Modeling tab → InfoProvider → Select InfoArea → Right click and click on create DataStore Object.
Geben Sie den technischen Namen und die Beschreibung des DataStore-Objekts ein.
Type of DataStore Object- Hiermit wird der DSO-Typ ausgewählt. Standardmäßig wird ein Standard-DSO verwendet.
Klicke auf Create (F5) Schaltfläche wie im folgenden Screenshot gezeigt.
Um den DSO-Typ zu ändern, wechseln Sie zur Registerkarte Einstellungen (siehe folgenden Screenshot). Klicken Sie auf das Symbol Bearbeiten. Wenn ein neues Fenster geöffnet wird, können Sie das DataStore-Objekt ändern und den gewünschten Typ auswählen.

In diesem Kapitel werden wir alles darüber diskutieren, was ein Infoset ist, wie man es erstellt und bearbeitet und welche verschiedenen Typen es hat.
Infoset in SAP BI
Infosets werden als spezielle Art von InfoProvidern definiert, bei denen die Datenquellen eine Verknüpfungsregel für die DataStore-Objekte, Standard-InfoCubes oder InfoObject mit Stammdatenmerkmalen enthalten. Infosets werden zum Verbinden von Daten verwendet und diese Daten werden im BI-System verwendet.
Wenn ein InfoObject zeitabhängige Merkmale enthält, wird dieser Typ eines Joins zwischen Datenquellen als temporärer Join bezeichnet.
Diese zeitlichen Verknüpfungen werden verwendet, um einen Zeitraum abzubilden. Zum Zeitpunkt der Berichterstellung verarbeiten andere InfoProvider zeitabhängige Stammdaten so, dass der Datensatz, der für ein vordefiniertes eindeutiges Stichtag gültig ist, jedes Mal verwendet wird. Sie können einen zeitlichen Join als Join definieren, der mindestens ein zeitabhängiges Merkmal oder einen pseudozeitabhängigen InfoProvider enthält.
Ein InfoSet kann auch als semantische Schicht über den Datenquellen definiert werden.
Verwendung eines Infosets
Infosets werden verwendet, um die Daten in mehreren InfoProvidern zu analysieren, indem Stammdatenmerkmale, DataStore-Objekte und InfoCubes kombiniert werden.
Sie können den zeitlichen Join mit InfoSet verwenden, um zu einem bestimmten Zeitpunkt anzugeben, wann Sie die Daten auswerten möchten.
Sie können die Berichterstellung mit dem verwenden Business Explorer BEx auf DSOs ohne Aktivierung der BEx-Anzeige.
Arten von Infoset-Verknüpfungen
Als Infoset wird definiert, wo Datenquellen die Verknüpfungsregel für DataStore-Objekte, Standard-InfoCubes oder InfoObject mit den Stammdatenmerkmalen enthalten. Die mithilfe von Infosets verknüpften Daten können in BEx-Abfragen für die Berichterstellung verwendet werden. Die Verknüpfungen können in die folgenden Abfragen unterteilt werden:
Inner Join
Dieser Join gibt Zeilen zurück, wenn in beiden Tabellen eine vollständige Übereinstimmung vorliegt.
Table - 1
| Auftragsnummer | Kundennummer | Bestelldatum |
|---|---|---|
| 1308 | 2 | 18-09-16 |
| 1009 | 17 | 19-09-16 |
| 1310 | 27 | 20-09-16 |
Table - 2
| Kundennummer | Kundenname | Kontaktname | Land |
|---|---|---|---|
| 1 | Andy | Maria | Deutschland |
| 2 | Ana | Ana T. | Kanada |
| 3 | Jason | Jason | Mexiko |
Das Ergebnis der inneren Verknüpfung in Tabelle 1 und Tabelle 2 in der Spalte CustomerID führt zu folgendem Ergebnis:
| Auftragsnummer | Kundenname | Bestelldatum |
|---|---|---|
| 1308 | Ana | 18.09.16 |
Linke äußere Verbindung
Eine linke äußere Verknüpfung oder linke Verknüpfung führt zu einer Menge, in der alle Zeilen der ersten oder linken Tabelle beibehalten werden. Die Zeilen aus der zweiten oder rechten Seitentabelle werden nur angezeigt, wenn sie mit den Zeilen aus der ersten Tabelle übereinstimmen.
Table – 1
| gid | Vorname | Familienname, Nachname | Geburtstag | Favoritentool |
|---|---|---|---|---|
| 1 | Albert | Einstein | 1879-03-14 | Verstand |
| 2 | Albert | Dachdecker | 1973-10-10 | Singulett |
| 3 | Christian | Dachdecker | 1969-08-18 | Spaten |
| 4 | Christian | Ballen | 1974-01-30 | Videobänder |
| 5 | Bruce | Wayne | 1939-02-19 | Schaufel |
| 6 | Wayne | Ritter | 1955-08-07 | Spaten |
Table – 2
| pid | gardener_id | Pflanzenname | Dünger | Pflanzdatum |
|---|---|---|---|---|
| 1 | 3 | Rose | Ja | 2001-01-15 |
| 2 | 5 | Gänseblümchen | Ja | 2020-05-16 |
| 3 | 8 | Rose | Nein | 2005-08-10 |
| 4 | 9 | violett | Ja | 2010-01-18 |
| 5 | 12 | Rose | Nein | 05.01.1991 |
| 6 | 1 | Sonnenblume | Ja | 20.08.2015 |
| 7 | 6 | violett | Ja | 1997-01-17 |
| 8 | 15 | Rose | Nein | 2007-07-22 |
Wenn Sie nun Left Outer Join on anwenden gid = gardener_idDas Ergebnis ist die folgende Tabelle:
| gid | Vorname | Familienname, Nachname | pid | gardener_id | Pflanzenname |
|---|---|---|---|---|---|
| 1 | Albert | Einstein | 6 | 1 | Sonnenblume |
| 2 | Albert | Dachdecker | Null | Null | Null |
| 3 | Christian | Dachdecker | 1 | 3 | Rose |
| 4 | Christian | Ballen | Null | Null | Null |
| 5 | Bruce | Wayne | 2 | 5 | Gänseblümchen |
| 6 | Wayne | Ritter | 7 | 6 | violett |
Auf die gleiche Weise können Sie den rechten äußeren Join verwenden, bei dem alle Zeilen aus den rechten Tabellen als gemeinsame Zeilen beibehalten werden.
Zeitlicher Beitritt
Zeitliche Verknüpfungen werden verwendet, um einen Zeitraum abzubilden. Zum Zeitpunkt der Berichterstellung verarbeiten andere InfoProvider zeitabhängige Stammdaten so, dass der Datensatz, der für ein vordefiniertes eindeutiges Stichtag gültig ist, jedes Mal verwendet wird. Sie können eine zeitliche Verknüpfung definieren, die mindestens ein zeitabhängiges Merkmal oder einen pseudozeitabhängigen InfoProvider enthält.
Selbst beitreten
Wenn eine Tabelle mit sich selbst verbunden wird, ist dies so, als würden Sie eine Tabelle zweimal verbinden.
InfoSet erstellen
Gehen Sie zur RSA Workbench und verwenden Sie die Transaction Code: RSA1
Unter Modeling → Go to InfoProvider tab → Right click → Create InfoSet.

Im nächsten Fenster können Sie die folgenden Felder ausfüllen:
- Geben Sie den technischen Namen ein.
- Geben Sie den langen und den kurzen Namen ein.
Start with the InfoProvider section- Hier können Sie das Objekt definieren, das Sie beim Definieren eines InfoSets verwenden möchten. Sie können aus folgenden Objekttypen auswählen:
- DataStore-Objekt
- Info Objekt
- InfoCube

Ändern Sie im nächsten Fenster, wie der InfoSet-Bildschirm angezeigt wird. Klicken Sie auf die Option InfoProvider auswählen. Auf diese Weise können Sie den InfoProvider auswählen, mit dem Daten verknüpft werden.

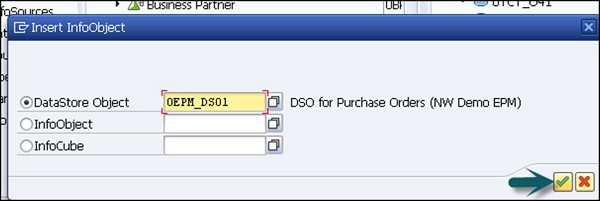
Der folgende Bildschirm wird mit zwei ausgewählten InfoProvidern angezeigt.

Um dieses InfoSet zu aktivieren, klicken Sie auf die Schaltfläche Aktivieren.

Infoset bearbeiten
Verwenden Sie zum Bearbeiten eines Infosets bitte T-Code: RSISET

Das Edit InfoSet: Initial Screen erscheint wie im folgenden Screenshot gezeigt -

Nehmen Sie die Änderungen am InfoSet vor. Wählen Sie Verbindungstyp usw. aus und klicken Sie dann auf das Symbol Aktivieren (siehe folgenden Screenshot).

Ein InfoCube ist als mehrdimensionales Dataset definiert, das zur Analyse in einer BEx-Abfrage verwendet wird. Ein InfoCube besteht aus einer Reihe relationaler Tabellen, die logisch verbunden werden, um das Sternschema zu implementieren. Eine Faktentabelle im Sternschema wird mit mehreren Dimensionstabellen verknüpft.
Sie können einem InfoCube Daten von einer oder mehreren InfoSource- oder InfoProvidern hinzufügen. Sie stehen als InfoProvider für Analyse- und Berichtszwecke zur Verfügung.
InfoCube-Struktur
Ein InfoCube wird verwendet, um die Daten physisch zu speichern. Es besteht aus einer Reihe von InfoObjects, die mit Daten aus dem Staging gefüllt sind. Es hat die Struktur eines Sternschemas.
Das Echtzeitmerkmal kann einem InfoCube zugewiesen werden. Diese Echtzeit-InfoCubes werden anders als Standard-InfoCubes verwendet.
Sternschema in BI
InfoCubes bestehen aus verschiedenen InfoObjects und sind nach dem Sternschema strukturiert. Es gibt große Faktentabellen mit Kennzahlen für InfoCube und mehrere kleinere Dimensionstabellen, die diese umgeben.
Ein InfoCube enthält Faktentabellen, die außerdem Kennzahlen und Merkmale eines InfoCubes enthalten, die in den Dimensionen gespeichert sind. Diese Dimensionen und Faktentabellen sind über Identifikationsnummern (Dimensions-IDs) miteinander verknüpft. Die Kennzahlen in einem InfoCube beziehen sich auf Merkmale seiner Dimension. Die Granularität (Detaillierungsgrad) von Kennzahlen in einem InfoCube wird durch seine Eigenschaften definiert.
Merkmale, die logisch zusammengehören, werden in einer Dimension zusammengefasst. Die Faktentabelle und die Dimensionstabellen in einem InfoCube sind relationale Datenbanktabellen.

In SAP BI enthält ein InfoCube das oben gezeigte erweiterte Sternschema.
Ein InfoCube besteht aus einer Faktentabelle, die von 16 Dimensionstabellen und Stammdaten umgeben ist, die außerhalb des Cubes liegen. Es ist ein in sich geschlossener Datensatz, der einen oder mehrere verwandte Geschäftsprozesse umfasst. Ein berichtender Benutzer kann Abfragen für einen Info-Cube definieren oder ausführen.
InfoCube speichert die zusammengefassten / aggregierten Daten über einen langen Zeitraum. In SAP BI beginnt InfoCubes mit einer Zahl, die normalerweise 0 (Null) ist. Ihr eigener InfoCube sollte mit einem Buchstaben zwischen A und Z beginnen und 3 bis 9 Zeichen lang sein.
Wie erstelle ich einen InfoCube?
Alle InfoObjects, die in einem InfoCube verwendet werden sollen, sollten in einer aktiven Version verfügbar sein. Falls es kein InfoObject gibt, das nicht existiert, können Sie es erstellen und aktivieren.
Gehen Sie zur RSA-Workbench - T-Code: RSA1
Gehe zu Modeling tab → InfoProvider → Create InfoCube.
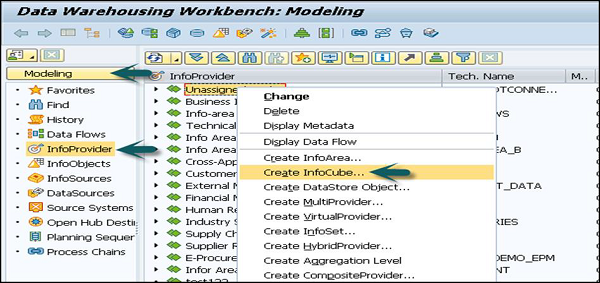
Geben Sie den technischen Namen des InfoCube ein. Sie können den Typ gemäß dem InfoCube-Typ aus Standard oder Echtzeit auswählen.
Sobald dies erledigt ist, können Sie auf Erstellen klicken, wie im folgenden Screenshot gezeigt.
Um eine Kopie eines bereits vorhandenen InfoCubes zu erstellen, können Sie einen InfoCube als Vorlage eingeben.

Rechtsklick auf Dimension 1 → Properties. Benennen Sie die Dimension gemäß InfoObject um.


Der nächste Schritt ist ein Rechtsklick auf Dimension → InfoObject Direct Input wie im folgenden Screenshot gezeigt.

Fügen Sie der Dimension InfoObject hinzu. Auf ähnliche Weise können Sie auch neue Dimensionen erstellen und InfoObjects hinzufügen.
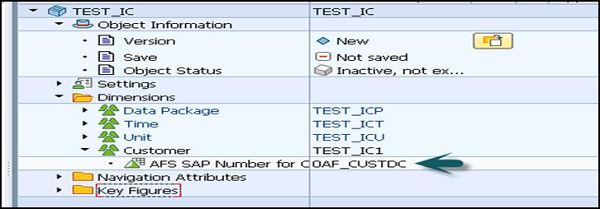
Klicken Sie mit der rechten Maustaste auf, um Kennzahlen zu InfoCube hinzuzufügen Key Figure → InfoObject Direct Input. In ähnlicher Weise können Sie auch andere Kennzahlen hinzufügen.

Sobald Sie alle Maße und Kennzahlen hinzugefügt haben, können Sie den Würfel aktivieren.

Echtzeit-InfoCubes
Echtzeit-InfoCubes werden verwendet, um den parallelen Schreibzugriff zu unterstützen. Echtzeit-InfoCubes werden in Verbindung mit der Eingabe von Planungsdaten verwendet.
Sie können die Daten in Echtzeit-InfoCubes auf zwei verschiedene Arten eingeben:
- Transaktion zur Eingabe von Planungsdaten oder von
- BI-Staging
Sie können auch einen Echtzeit-InfoCube konvertieren. Wählen Sie dazu im Kontextmenü des Echtzeit-InfoCube → Echtzeit-InfoCube konvertieren.
Standardmäßig können Sie sehen, dass ein Echtzeit-InfoCube geplant werden kann - Datenladen nicht zulässig ausgewählt. So füllen Sie diesen InfoCube mit BI-Staging → Schalten Sie diese Einstellung auf Echtzeit-Cube kann mit Daten geladen werden, Planung nicht zulässig.
Erstellen eines Echtzeit-InfoCubes
Ein Echtzeit-InfoCube kann mithilfe eines Kontrollkästchens Echtzeitanzeige erstellt werden.

Konvertieren eines Standard-InfoCubes in einen Echtzeit-InfoCube
Um einen Standard-InfoCube in einen Echtzeit-InfoCube zu konvertieren, haben Sie zwei Möglichkeiten:
Convert with loss of Transactional data - Falls Ihr Standard-InfoCube Transaktionsdaten enthält, die nicht erforderlich sind, können Sie den folgenden Ansatz verwenden:
Wählen Sie in der Administrations-Workbench die Option aus InfoCube → Delete Data Content. Dadurch werden die Transaktionsdaten gelöscht und InfoCube wird auf inaktiv gesetzt.
Conversion with Retention of Transaction Data - Falls ein Standard-InfoCube bereits die Transaktionsdaten aus der Produktion enthält, können Sie die folgenden Schritte ausführen:
Sie müssen den ABAP-Bericht ausführen SAP_CONVERT_NORMAL_TRANSunter dem Standard InfoCube. Sie können diesen Bericht als Hintergrundjob für InfoCubes mit mehr als 10.000 Datensätzen planen, da die Laufzeit möglicherweise lang sein kann.
Der virtuelle InfoProvider wird als InfoProvider bezeichnet und enthält Transaktionsdaten, die nicht im Objekt gespeichert sind und für Analyse- und Berichtszwecke direkt gelesen werden können. In Virtual Provider wird der schreibgeschützte Lesezugriff auf die Daten ermöglicht.
Die Daten in Virtual Providers können aus dem BI-System oder aus einem beliebigen SAP- / Nicht-SAP-System stammen.
Verwendet
Virtuelle InfoProvider werden verwendet, um Informationen ohne Zeitverzögerung und ohne physische Speicherung der Daten bereitzustellen.
Virtuelle InfoProvider sind Strukturen, die keinen PSA enthalten und die Berichtsanforderungen gemäß den Anforderungen im BI-System erfüllen können.
Virtuelle Anbieter sollten nur in den folgenden Szenarien verwendet werden:
Wenn nur auf eine kleine Datenmenge aus der Quelle zugegriffen werden muss.
Informationen werden nur von wenigen Benutzern gleichzeitig angefordert.
Es werden aktuelle Informationen benötigt.
Arten von virtuellen Anbietern
Wie oben erwähnt, muss herausgefunden werden, wann ein virtueller InfoProvider verwendet werden sollte. Sie müssen auch den richtigen Typ des virtuellen Anbieters finden -
VirtualProvider Basierend auf dem Datenübertragungsprozess
VirtualProvider mit BAPI
VirtualProvider mit Funktionsbausteinen
VirtualProvider basierend auf dem Datenübertragungsprozess
Virtuelle Anbieter, die auf dieser Methode basieren, sind die einfachste und transparenteste Möglichkeit, diese Art von InfoProvider zu erstellen. In diesem Fall kann ein virtueller Anbieter auf einer DataSource für den direkten Zugriff oder auf einem anderen InfoProvider basieren.
Entweder wird die BEx-Abfrage ausgeführt oder Sie navigieren innerhalb der Abfrage. Eine Anfrage wird jedoch über den virtuellen Anbieter an seine Quelle gesendet und die erforderlichen Daten werden zurückgegeben. Für die Leistungsoptimierung müssen die Daten eingeschränkt werden, damit eine Berichtsanforderung keine unnötigen Daten aus dem Quellsystem verarbeitet.
Ein auf diesem InfoProvider basierender VirtualProvider sollte verwendet werden -
Wenn nur auf eine kleine Datenmenge aus der Quelle zugegriffen werden muss.
Informationen werden nur von wenigen Benutzern gleichzeitig angefordert.
Es werden aktuelle Informationen benötigt.
Dieser Typ eines virtuellen InfoProviders sollte in den folgenden Szenarien nicht verwendet werden:
Im ersten Abfragnavigationsschritt wird auf eine große Datenmenge zugegriffen, und im Quellsystem sind keine geeigneten Aggregate verfügbar.
Es gibt mehrere Benutzer, die gleichzeitig Abfragen gleichzeitig ausführen.
Wenn häufig auf dieselben Daten zugegriffen wird.

VirtualProvider mit BAPI
In diesem virtuellen Anbieter können Sie die Transaktionsdaten für Analyse- und Berichtszwecke von einem externen System mithilfe von BAPI verwenden. Wenn Sie einen VirtualProvider mit BAPI verwenden, können Sie Berichte auf einem externen System erstellen, ohne die Transaktionsdaten im BI-System zu speichern.
Auf VirtualProvider wird eine Abfrage ausgeführt, die eine Datenanforderung mit Merkmalsauswahl auslöst. Die Quellstruktur ist dynamisch und wird durch die Auswahl bestimmt. Das Nicht-SAP-System überträgt die angeforderten Daten über das BAPI an den OLAP-Prozessor.
Wenn dieser VirtualProvider für die Berichterstellung verwendet wird, initiiert er eine Anforderung zum Aufrufen von BAPI, das die Daten sammelt, und wird dann an a übergeben BW OLAP engine.
Virtueller Anbieter basierend auf Funktionsmodul
Dies ist der komplexeste Typ eines VirtualProviders, gleichzeitig aber auch flexibler, mit dem Sie Daten aus der Quelle hinzufügen und komplexe Berechnungen oder Änderungen anwenden können, bevor sie an die OLAP-Engine übertragen werden.
Sie haben eine Reihe von Optionen, um die Eigenschaften der Datenquelle genauer zu definieren. Entsprechend diesen Eigenschaften bietet der Datenmanager verschiedene Funktionsbausteinschnittstellen zum Konvertieren der Parameter und Daten. Diese Schnittstellen müssen außerhalb des BI-Systems implementiert werden.
Verwendet
Dieser virtuelle Anbieter wird verwendet, wenn Sie Daten aus einer Nicht-BI-Datenquelle in BI anzeigen müssen, ohne das Dataset in die BI-Struktur zu kopieren. Die Daten können lokal oder remote sein.
Dies wird in SAP-Anwendungen wie der SEM-Anwendung SAP Strategic Enterprise Management verwendet.
Wenn Sie diesen VirtualProvider mit anderen Typen vergleichen, ist dieser VirtualProvider flexibler und allgemeiner, aber Sie müssen viel Aufwand für die Implementierung aufwenden.
Verwenden von InfoObjects als virtuelle Anbieter
Hiermit ermöglichen Sie einen direkten Zugriff auf das Quellsystem für einen InfoObject-Typ eines Merkmals, das Sie zur Verwendung als InfoProvider ausgewählt haben. Es ist also nicht erforderlich, die Stammdaten zu laden. Der direkte Zugriff kann sich jedoch negativ auf die Abfrageleistung auswirken.
How to setup InfoObjects as Virtual Providers?
Gehen Sie zur Seite InfoObjects Maintenance. Ordnen Sie auf der Registerkarte Stammdaten / -texte einem Merkmal eine InfoArea zu und wählen Sie direkt als Art des Stammdatenzugriffs.
Gehen Sie als Nächstes zur Registerkarte Modellierung und wählen Sie den InfoProvider-Baum aus. Navigieren Sie zu InfoArea, das Sie verwenden möchten → Transformation erstellen, wie im Thema Transformation beschrieben.

Transformationsregeln definieren und aktivieren. Klicken Sie im Kontextmenü auf Datenübertragungsprozess erstellen (DTP für direkten Zugriff ist Standardwert) → Wählen Sie die Quelle aus und aktivieren Sie den Übertragungsprozess.
Ein MultiProvider wird als InfoProvider bezeichnet, mit dem Sie Daten von mehreren InfoProvidern kombinieren und für Berichtszwecke zur Verfügung stellen können.
Eigenschaften
Ein MultiProvider enthält keine Daten für die Berichterstellung und Analyse stammt von InfoProvidern, auf denen der MultiProvider direkt basiert.
Diese InfoProvider sind durch eine Union-Operation miteinander verbunden.
Sie können die Daten basierend auf mehreren InfoProvidern melden und analysieren.
MultiProvider-Struktur
Ein MultiProvider besteht aus den folgenden verschiedenen Kombinationen von InfoProvider-Typen:
- InfoObject
- InfoCube
- DataStore-Objekt
- Virtueller Anbieter

Um die Daten zu kombinieren, wird in einem MultiProvider eine Union-Operation verwendet. Hier erstellt das System den Vereinigungssatz der beteiligten Datensätze und alle Werte dieser Datensätze werden kombiniert.
In einem InfoSet erstellen Sie das Dataset mithilfe von Joins. Diese Verknüpfungen kombinieren nur Werte, die in beiden Tabellen angezeigt werden. Im Vergleich zu einer Union bilden Verknüpfungen den Schnittpunkt der Tabellen.
Erstellen eines MultiProviders
Um einen MultiProvider mit einem InfoObject zu erstellen, sollte sich jedes InfoObject, das Sie auf den MultiProvider übertragen möchten, in einem aktiven Zustand befinden. Wenn es ein InfoObject gibt, das nicht existiert, müssen Sie es erstellen und aktivieren.
Sie können einen MultiProvider auch aus SAP Business Content installieren, wenn Sie keinen neuen MultiProvider erstellen möchten.
Um einen MultiProvider zu erstellen, können Sie die folgenden Schritte ausführen:

Erstellen Sie eine InfoArea, der Sie den neuen MultiProvider zuweisen möchten. Go to Modeling → InfoProvider
Wählen Sie im Kontextmenü der InfoArea die Option MultiProvider erstellen.

Geben Sie im nächsten Fenster einen technischen Namen und eine Beschreibung ein → Symbol erstellen

Wählen Sie den InfoProvider aus, für den Sie den MultiProvider bilden möchten → Weiter. Dann erscheint der MultiProvider-Bildschirm.

Übertragen Sie die erforderlichen InfoObjects per Drag & Drop in Ihren MultiProvider. Sie können auch die gesamten Dimensionen übertragen.
Verwenden Sie Merkmale identifizieren und Kennzahlen auswählen, um InfoObject-Zuweisungen zwischen MultiProvider und InfoProvider vorzunehmen.

Der nächste Schritt ist das Speichern und Aktivieren des MultiProviders. Nur dieser aktivierte MultiProvider steht für Berichte und Analysen zur Verfügung.
Mit diesen Flatfiles können Sie die Daten von einem externen System in BI laden. SAP BI unterstützt die Datenübertragung mithilfe von Flatfiles, Dateien im ASCII-Format oder im CSV-Format.
Die Daten aus einer Flatfile können von einer Workstation oder von einem Anwendungsserver in das BI übertragen werden.
Im Folgenden sind die Schritte für eine Flat File-Datenübertragung aufgeführt:
Definieren Sie ein Dateiquellensystem.
Erstellen Sie eine DataSource in BI und definieren Sie die Metadaten für Ihre Datei in BI.
Erstellen Sie ein InfoPackage, das die Parameter für die Datenübertragung zum PSA enthält.
Wichtige Punkte zur Datenübertragung von Flatfiles
Wenn es Zeichenfelder gibt, die nicht in einer CSV-Datei ausgefüllt sind, werden sie mit einem Leerzeichen und mit einer Null (0) gefüllt, wenn es sich um numerische Felder handelt.
Wenn Trennzeichen in einer CSV-Datei inkonsistent verwendet werden, wird das falsche Trennzeichen als Zeichen gelesen und beide Felder werden zu einem Feld zusammengeführt und können gekürzt werden. Nachfolgende Felder sind dann nicht mehr in der richtigen Reihenfolge.
Ein Zeilenumbruch kann nicht als Teil eines Werts verwendet werden, selbst wenn der Wert in ein Escapezeichen eingeschlossen ist.
Einige Hinweise zu den CSV- und ASCII-Dateien
Die Konvertierungsroutinen, mit denen bestimmt wird, ob Sie führende Nullen angeben müssen. More information - Konvertierungsroutinen im BI-System.
Für Datumsangaben verwenden Sie normalerweise das Format JJJJMMTT ohne interne Trennzeichen. Abhängig von der verwendeten Konvertierungsroutine können Sie auch andere Formate verwenden.
Definieren Sie ein Dateiquellensystem
Bevor Sie Daten von einem Dateiquellensystem übertragen können, müssen die Metadaten in BI in Form einer DataSource verfügbar sein. Gehe zuModeling tab → DataSources.

Klicken Sie mit der rechten Maustaste in den Kontextbereich → DataSource erstellen.

Geben Sie den technischen Namen der Datenquelle und den Typ der Datenquelle ein und klicken Sie dann auf Übertragen.

Gehen Sie zur Registerkarte Allgemein → Wählen Sie die Registerkarte Allgemein. Geben Sie Beschreibungen für die DataSource ein (kurz, mittel, lang).
Geben Sie bei Bedarf an, ob die DataSource anfänglich nicht kumulativ ist und möglicherweise doppelte Datensätze in einer Anforderung erzeugt.
Sie können angeben, ob Sie den PSA für die DataSource im Zeichenformat generieren möchten. Wenn der PSA nicht typisiert ist, wird er nicht in einer typisierten Struktur generiert, sondern nur mit zeichenartigen Feldern vom Typ CHAR.

Der nächste Schritt besteht darin, auf die Registerkarte Extraktion zu klicken und die folgenden Details einzugeben:
Definieren Sie den Delta-Prozess für die DataSource. Geben Sie an, ob die DataSource den direkten Zugriff auf Daten unterstützen soll (die Echtzeit-Datenerfassung wird für die Datenübertragung aus Dateien nicht unterstützt).
Wählen Sie den Adapter für die Datenübertragung. Sie können Textdateien oder Binärdateien von Ihrem lokalen Arbeitsplatz oder vom Anwendungsserver laden. Wählen Sie den Pfad zu der Datei aus, die Sie laden möchten, oder geben Sie den Namen der Datei direkt ein.
Falls Sie eine Routine erstellen müssen, um den Namen Ihrer Datei zu bestimmen. Das System liest den Dateinamen direkt aus dem Feld Dateiname. Wenn nein, wird die Routine definiert.
Gemäß dem Adapter und der zu ladenden Datei muss die folgende Einstellung vorgenommen werden:

Binary files - Geben Sie die Zeichensatzeinstellungen für die Daten an, die Sie übertragen möchten.
Text-type files- Stellen Sie für Textdateien fest, dass die Zeilen in Ihrer Datei Kopfzeilen sind und daher bei der Datenübertragung ignoriert werden können. Geben Sie die Zeichensatzeinstellungen für die Daten an, die Sie übertragen möchten.
For ASCII files - Um die Daten aus einer ASCII-Datei zu laden, werden die Daten mit einer festen Datensatzlänge angefordert.
For CSV files - Um Daten aus einer Excel-CSV-Datei zu laden, geben Sie das Datentrennzeichen und das Escape-Zeichen an.
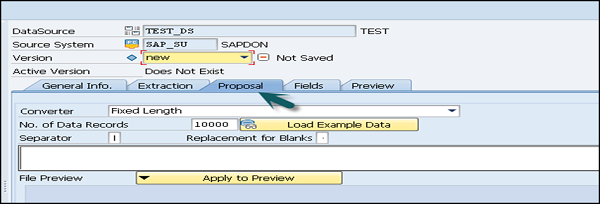
Der nächste Schritt besteht darin, zur Registerkarte Vorschlag zu wechseln. Dies ist nur für CSV-Dateien erforderlich. Definieren Sie für Dateien in verschiedenen Formaten die Feldliste auf der Registerkarte Felder.
Der nächste Schritt ist die Registerkarte Felder -
Sie können die Felder, die Sie in die Feldliste der DataSource übertragen haben, auf der Registerkarte Angebot bearbeiten. Wenn Sie die Feldliste nicht aus einem Vorschlag übertragen haben, können Sie hier die Felder der DataSource definieren, wie im folgenden Screenshot gezeigt.

Anschließend können Sie die DataSource überprüfen, speichern und aktivieren.
Sie können auch die Registerkarte Vorschau auswählen. Wenn Sie Vorschau-Daten lesen auswählen, wird die Anzahl der Datensätze, die Sie in Ihrer Feldauswahl angegeben haben, in einer Vorschau angezeigt.

DB Connect wird verwendet, um zusätzlich zur Standardverbindung eine andere Datenbankverbindung zu definieren. Diese Verbindungen werden verwendet, um Daten aus Tabellen oder Ansichten in das BI-System zu übertragen.
Um eine externe Datenbank zu verbinden, sollten Sie über die folgenden Informationen verfügen:
- Tools
- Quellanwendungswissen
- SQL-Syntax in der Datenbank
- Datenbankfunktionen
Voraussetzungen
Falls sich die Quelle Ihres Datenbankverwaltungssystems von BI DBMS unterscheidet, müssen Sie den Datenbankclient für das Quell-DBMS auf dem BI-Anwendungsserver installieren.
Die DB Connect-Schlüsselfunktion umfasst das Laden von Daten aus einer von SAP unterstützten Datenbank in das BI. Wenn Sie eine Datenbank mit BI verbinden, muss für ein Quellsystem ein direkter Zugriffspunkt auf das externe relationale Datenbankverwaltungssystem erstellt werden.
DB-Architektur
Mit der Multiconnect-Funktion der SAP NetWeaver-Komponente können Sie zusätzlich zur SAP-Standardverbindung zusätzliche Datenbankverbindungen öffnen und über diese Verbindung eine Verbindung zu externen Datenbanken herstellen.
Mit DB Connect kann eine Verbindung dieses Typs als Quellsystemverbindung zum BI hergestellt werden. Mit den DB Connect-Erweiterungen der Datenbank können Sie die Daten aus den Datenbanktabellen oder Ansichten der externen Anwendungen in das BI laden.

Für die Standardverbindung sind DB Client und DBSL für das Datenbankverwaltungssystem (DBMS) vorinstalliert. Um mit DB Connect Daten von anderen Datenbankverwaltungssystemen in das BI-System zu übertragen, müssen Sie den datenbankspezifischen DB-Client und die datenbankspezifische DBSL auf dem BI-Anwendungsserver installieren, mit dem Sie DB Connect ausführen.
DBMS als Quellsystem erstellen
Gehe zu RSA1 → Administration workbench. Unter demModeling Tab → Source Systems

Gehe zu DB Connect → Right click → Create.

Geben Sie den logischen Systemnamen (DB Connect) und die Beschreibung ein. Klicken Sie auf Weiter.
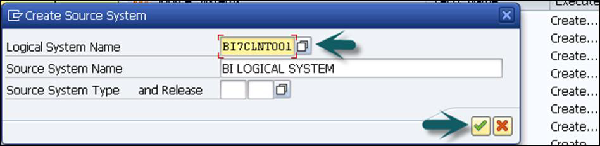
Geben Sie das Datenbankverwaltungssystem (DBMS) ein, mit dem Sie die Datenbank verwalten möchten. Geben Sie dann den Datenbankbenutzer ein, unter dessen Namen die Verbindung geöffnet werden soll, und das DB-Kennwort muss zur Authentifizierung durch die Datenbank eingegeben werden.
In den Verbindungsinformationen müssen Sie die technischen Informationen eingeben, die zum Öffnen der Datenbankverbindung erforderlich sind.
Permanenter Indikator
Sie können dieses Kennzeichen setzen, um eine dauerhafte Verbindung mit der Datenbank aufrechtzuerhalten. Wenn die erste Transaktion endet, wird jede Transaktion überprüft, um festzustellen, ob die Verbindung wieder hergestellt wurde. Sie können diese Option verwenden, wenn häufig auf die DB-Verbindung zugegriffen werden muss.
Speichern Sie diese Konfiguration und klicken Sie auf Zurück, um sie in der Tabelle anzuzeigen.
Mit Universal Data Connect (UDC) können Sie auf relationale und mehrdimensionale Datenquellen zugreifen und die Daten in Form von flachen Daten übertragen. Mehrdimensionale Daten werden in ein flaches Format konvertiert, wenn Universal Data Connect für die Datenübertragung verwendet wird.
UD verwendet a J2EE connectorum die Berichterstellung für SAP- und Nicht-SAP-Daten zu ermöglichen. Für verschiedene Treiber stehen verschiedene BI-Java-Konnektoren zur Verfügung, Protokolle als Ressourcenadapter, von denen einige wie folgt lauten:
- BI ODBO Connector
- BI JDBC Connector
- BI SAP Query Connector
- XMLA-Anschluss
So richten Sie die Verbindung zu einer Datenquelle mit Quellobjekt (Relational / OLAP) auf der J2EE-Engine ein Zunächst müssen Sie die Kommunikation zwischen der J2EE-Engine und dem BI-System aktivieren, indem Sie eine RFC-Destination von J2EE zu BI erstellen. Modellieren Sie dann die InfoObjects in BI gemäß den Quellobjektelementen und bestimmen Sie im BI-System die Datenquelle.
Erstellen eines UD Connect-Quellsystems
Wie oben erwähnt, haben Sie eine RFC-Destination erstellt, über die die J2EE-Engine und BI die Kommunikation zwischen diesen beiden Systemen ermöglichen.
Gehen Sie zur Administrations-Workbench. RSA1 → Go to Modeling tab → Source Systems.

Klicken Sie mit der rechten Maustaste auf die UD Connect → Create. Geben Sie dann im nächsten Fenster die folgenden Details ein:
- RFC-Destination für die J2EE-Engine
- Geben Sie einen logischen Systemnamen an
- Steckertyp

Dann sollten Sie die - eingeben
- Name des Steckers.
- Name des Quellsystems, wenn er nicht aus dem logischen Systemnamen ermittelt wurde.
Sobald Sie alle diese Details eingegeben haben → Wählen Sie Weiter.

In SAP BI Data Warehouse Management ist es möglich, eine Folge von Prozessen im Hintergrund für ein Ereignis zu planen, und einige dieser Prozesse können ein separates Ereignis auslösen, um die anderen Prozesse zu starten.
Eine Prozesskette bietet Ihnen in einem SAP-BI-System die folgenden Vorteile:
Sie können zur zentralen Verwaltung und Steuerung der Prozesse verwendet werden.
Sie können die Prozesse mithilfe von Grafiken visualisieren.
Mit der ereignisgesteuerten Verarbeitung können Sie die komplexen Zeitpläne automatisieren.
Features −
- Security
- Flexibility
- Openness
Struktur einer Prozesskette
Jede Prozesskette besteht aus folgenden Komponenten:
- Prozess starten
- Individuelle Bewerbungsverfahren
- Sammelprozesse
Der Startprozess wird verwendet, um die Startbedingung einer Prozesskette zu definieren, und alle anderen Kettenprozesse sollen auf ein Ereignis warten. Die Anwendungsprozesse sind die Prozesse, die in einer Sequenz definiert sind und die tatsächlichen Prozesse in einem BI-System sind. Sie können kategorisiert werden als -
- Ladevorgang
- Reporting Agent-Prozess
- Datenzielverwaltungsprozess
- Andere BI-Prozesse

Ein Prozess kann als Prozedur innerhalb oder außerhalb des SAP-Systems definiert werden und hat einen bestimmten Anfang und ein bestimmtes Ende.
Starten Sie den Prozess zum Entwerfen einer Prozesskette
Der Startprozess wird verwendet, um die Startbedingung einer Prozesskette zu definieren. Sie können eine Prozesskette zum angegebenen Zeitpunkt oder nach einem Ereignis starten, das durch einen Startprozess ausgelöst wird.
Ein Start der Prozesskette kann auch über eine Metakette konfiguriert werden. Wenn die Startbedingung einer Prozesskette in eine andere Prozesskette integriert ist, wird dies als a bezeichnetmetachain.
Im Folgenden sind die wichtigsten Funktionen eines Startvorgangs aufgeführt:
In einer Prozesskette kann nur ein Startprozess ohne Vorgängerprozess geplant werden.
Sie können nur einen Startprozess für jede Prozesskette definieren.
Ein Startprozess kann kein Nachfolger eines anderen Prozesses sein.
Sie können einen Startprozess nur in einer einzelnen Prozesskette verwenden.
Wie erstelle ich eine Prozesskette?
Verwenden T-Code: RSPC oder in der Modeling tab → Go to Process Chain.

Klicken Sie mit der rechten Maustaste in die Context area → Create Process Chain.

Geben Sie den technischen Namen und die Beschreibung der Prozesskette ein. Klicken Sie auf Weiter.

Um einen Startvorgang zu erstellen, klicken Sie im nächsten Fenster auf das neue Symbol. Geben Sie den technischen Namen und die Beschreibung des Sternprozesses ein.


Im nächsten Fenster können Sie die Planungsoptionen definieren. Bei der direkten Planung wird die Prozesskette in einem bestimmten Zeitintervall geplant.
Mit „Auswahl ändern“ können Sie Details zur Planung eingeben.

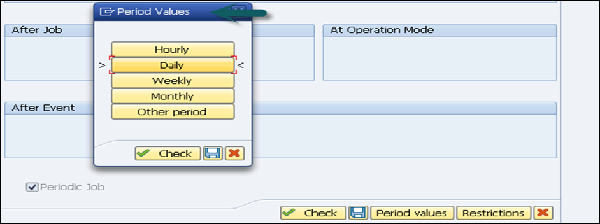
Gehen Sie zur Schaltfläche Datum / Uhrzeit. Erwähnen Sie das geplante Startdatum / die geplante Startzeit und das geplante Enddatum / die geplante Startzeit.
Um die Häufigkeit zu definieren, aktivieren Sie das Kontrollkästchen Periodischer Auftrag (siehe folgenden Screenshot). Klicke aufPeriod Values. Geben Sie die Häufigkeit ein (stündlich / täglich / wöchentlich / monatlich / andere Periode). Klicken Sie auf die Schaltfläche Speichern und zurück, um zum vorherigen RSPC-Bildschirm zurückzukehren.


Der nächste Schritt ist die Auswahl des Prozesstyps.
Verwenden Sie den Prozesstyp, um das Datenladen über ein InfoPackage durchzuführen Execute InfoPackage.
Verwenden Sie den Prozesstyp, um das Laden über ein DTP durchzuführen Data Transfer Process.

Doppelklicken Sie auf den Prozesstyp und ein neues Fenster wird geöffnet. Sie können InfoPackage aus den angegebenen Optionen auswählen.

Um die Variante mit einem InfoPackage zu verbinden, wählen Sie die „Startvariante“ und halten Sie die linke Maustaste gedrückt. Bewegen Sie dann die Maustaste zum Zielschritt. Ein Pfeil sollte Ihrer Bewegung folgen. Hören Sie auf, die Maustaste zu drücken, und eine neue Verbindung wird hergestellt.
Klicken Sie auf, um eine Konsistenzprüfung durchzuführen Goto → Checking View.

Um die Prozesskette zu aktivieren, klicken Sie auf Aktivieren oder sehen Sie sich den folgenden Screenshot an, um die zu befolgenden Schritte zu verstehen.

Um die Prozesskette zu planen, gehen Sie zu Execution → Schedule. Select Priority and Continue.

Dadurch wird die Prozesskette als Hintergrundjob geplant und kann mit der Transaktion SM37 angezeigt werden.
Überwachen Sie die Prozesskette
Verwenden T-Code: RSPCM
Dies wird verwendet, um die täglichen Prozessketten zu überwachen.

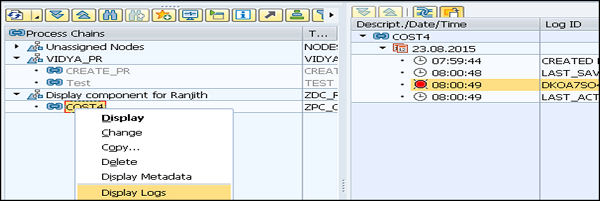
Verwenden Sie zum Anzeigen der Protokolle T-code: RSPC
Wählen Sie Prozess chain → Right Click → Display Log.
In einem SAP BI-System können Sie die ausgewählten InfoProviders-Daten per Drag & Drop oder Kontextmenü analysieren und melden, um in den im BEx Query Designer erstellten Abfragen zu navigieren.
Im heutigen wettbewerbsintensiven Markt reagieren die erfolgreichsten Unternehmen schnell und flexibel auf Marktveränderungen und -chancen. Ein Schlüssel zu dieser Reaktion ist die effektive und effiziente Nutzung von Daten und Informationen durch Analysten und Manager. Ein „Data Warehouse“ ist ein Repository mit historischen Daten, die nach Unterstützung der Entscheidungsträger in der Organisation organisiert sind. Sobald Daten in einem Data Mart oder Warehouse gespeichert sind, kann auf sie zugegriffen werden.
In SAP BI Business Explorer (BEx) ist eine der Schlüsselkomponenten, mit der Sie flexible Berichte und Analysen durchführen können, und bietet verschiedene Tools, die für die strategische Analyse verwendet werden können und die Entscheidungsträger bei der Entscheidungsfindung für zukünftige Strategien unterstützen.
Die in BEx am häufigsten verwendeten Tools sind:
- Query
- Reporting
- Analysefunktionen
Im Folgenden sind die wichtigsten Komponenten eines Business Explorers aufgeführt:
- BEx Query Designer
- BEx Web Application Designer
- BEx Broadcaster
- BEx Analyzer
BEx Query Designer
In BEx Query Designer können Sie die Daten im BI-System analysieren, indem Sie Abfragen für InfoProvider entwerfen. Sie können InfoObjects und Abfrageelemente kombinieren, um die Daten im InfoProvider zu navigieren und zu analysieren.
BEx Query Designer-Schlüsselfunktionen
Sie können Abfragen im BEx Query Designer für OLAP-Berichte und für Unternehmensberichte verwenden.
Abfragen können verschiedene Parameter wie Variablen für Merkmalswerte, Hierarchien, Formeln, Text usw. enthalten.
Sie können InfoObjects genauer auswählen, indem Sie -
Im Abfrage-Designer können Sie einen Filter anwenden, um die gesamte Abfrage einzuschränken. Während der Definition des Filters können Sie Merkmalswerte aus einem oder mehreren Merkmalen oder auch Kennzahlen in den Filter einfügen. Alle InfoProvider-Daten werden mithilfe der Filterauswahl der Abfrage aggregiert.
Sie können auch benutzerdefinierte Merkmale verwenden und den Inhalt der Zeilen und Spalten der Abfrage bestimmen. Hiermit werden die Datenbereiche des InfoProviders angegeben, durch die Sie navigieren möchten.
Sie haben die Möglichkeit, durch die Abfrage zu navigieren, um verschiedene Ansichten der InfoProvider-Daten zu generieren. Dies kann erreicht werden, indem benutzerdefinierte Merkmale in die Zeilen oder Spalten der Abfrage gezogen werden.

Wie greife ich auf Query Designer zu?
Um auf den BEx Query Designer zuzugreifen, gehen Sie zu Start → All Programs.

Wählen Sie im nächsten Schritt BI system → OK.
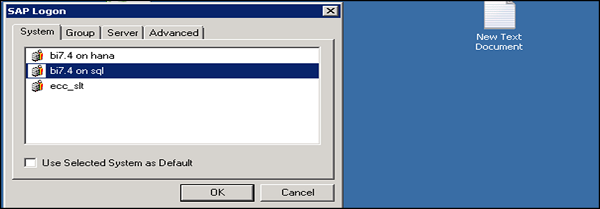
Enter the following details −
- Geben Sie den Client ein
- Nutzername
- Password
- Anmeldesprache
- Klicken Sie auf die Schaltfläche OK
You can see the following components in a Query Designer −
InfoProvider Details finden Sie hier.
Registerkarten zum Anzeigen verschiedener Berichtskomponenten.
Eigenschaftenfeld, in dem die Eigenschaften jeder in der Abfrage ausgewählten Komponente angezeigt werden.

Die oben gezeigte Standardsymbolleiste im Abfrage-Designer enthält die folgenden Schaltflächen.
- Neue Abfrage erstellen
- Abfrage öffnen
- Abfrage speichern
- Rette alle
- Abfrageeigenschaften
- Im Web veröffentlichen
- Überprüfen Sie die Abfrage und viele andere Optionen.
Abfrageelemente in InfoProvider
Key figures - Es enthält die numerischen Daten oder Kennzahlen oder KPIs für Leistungskennzahlen und kann weiter unterteilt werden in berechnete Kennzahlen CKFs und eingeschränkte Kennzahlen RKFs.
Characteristics- Sie definieren die Kriterien zur Klassifizierung der Objekte. Zum Beispiel: Produkt, Kunde, Standort usw.
Attributes - Sie definieren die zusätzlichen Eigenschaften eines Merkmals.
Abfrageeigenschaften
Variable Sequence - Hiermit steuern Sie die Reihenfolge, in der Auswahlbildschirmvariablen den Benutzern angezeigt werden.

Display - Gehen Sie zur Registerkarte Anzeige, um die Anzeigeeigenschaften wie folgt festzulegen: -
Hide Repeated Key Values - Es wird verwendet, um die Eigenschaften zu steuern, die sich in jeder Zeile wiederholen oder nicht.
Display Scaling Factors for Key Figures - Hiermit wird gesteuert, ob der Skalierungsfaktor oben in der entsprechenden Spalte angegeben wird.
Sie können auch Filter definieren und Variablen im Abfrage-Designer verwenden. Diese Filter werden verwendet, um den Datenzugriff bei der Berichterstellung, Analyse auf einen bestimmten Geschäftsbereich, eine bestimmte Produktgruppe oder einen bestimmten Zeitraum zu beschränken.
Variablen
Variablen werden im Abfrage-Designer als Parameter einer Abfrage definiert, die beim Ausführen der Abfrage mit Werten gefüllt werden. Es können verschiedene Arten von Variablen erstellt werden, von denen einige wie folgt sind:
- Hierarchievariablen
- Merkmale Wertvariablen
- Textvariable
- Formelvariable
- Hierarchieknotenvariablen
Um eine Variable zu erstellen, wechseln Sie in den Ordner Merkmalswert Variablen, die unter dem entsprechenden Merkmal verfügbar sind.
Der nächste Schritt besteht darin, mit der rechten Maustaste auf den Ordner zu klicken → die Option Neue Variable auszuwählen.
Eingeschränkte Kennzahlen
Es ist auch möglich, die Kennzahlen eines InfoProviders für die Wiederverwendung einzuschränken, indem ein oder mehrere Merkmale ausgewählt werden. Sie können die Kennzahlen durch eine oder mehrere charakteristische Auswahlen einschränken. Dies können grundlegende Kennzahlen, berechnete Kennzahlen oder bereits eingeschränkte Kennzahlen sein.
Um eine neue eingeschränkte Kennzahl zu erstellen, wählen Sie im InfoProvider-Bildschirmbereich → den Eintrag Kennzahlen und wählen Sie im Kontextmenü die Option Neue eingeschränkte Kennzahl.
Restricted Characteristics −
- Einzelwerte auswählen
- Wertebereiche auswählen
- Speichern von Werten in Favoriten
- Wertetasten anzeigen
- In der Geschichte verfügbare Werte
- Werte aus dem Auswahlfenster löschen
BEx Analyzer: Berichterstellung und Analyse
BEx Analyzer ist als in Microsoft Excel eingebettetes Designtool bekannt, das für die Berichterstellung und Analyse verwendet wird. In einem BEx Analyzer können Sie ausgewählte InfoProvider-Daten über das Kontextmenü analysieren und planen oder per Drag & Drop in Abfragen navigieren, die im BEx Query Designer erstellt wurden.
BEx Analyzer ist für verschiedene Zwecke in zwei Modi unterteilt:
Analysis mode - Es wird zum Ausführen von OLAP-Analysen für Abfragen verwendet.
Design mode - Es wird zum Entwerfen der Schnittstelle für Abfrageanwendungen verwendet.
Analysemodus
Im Analysemodus können Sie folgende Aufgaben ausführen:
Sie können auf den BEx Query Designer zugreifen, um Abfragen zu definieren.
Sie können die InfoProvider-Daten analysieren, indem Sie in den Abfragen navigieren.
Sie können verschiedene Funktionen wie Sortieren, Filtern, Bohren usw. verwenden, die in OLAP üblich sind.
Verteilung von Arbeitsmappen mit BEx Broadcaster.
Für die erweiterte Programmierung können Sie Ihre eigenen benutzerdefinierten VBA-Programme einbetten.
Sie können Arbeitsmappen auf dem Server / lokal auf Ihrem Computer oder in Favoriten speichern.
Entwurfsmodus
Im Entwurfsmodus können Sie folgende Aufgaben ausführen:
Es kann zum Entwerfen der Abfrage verwendet werden, und Sie können verschiedene Abfrageentwurfselemente wie Dropdown-Felder, Optionsfeldgruppen, Raster und Schaltflächen in Ihre Microsoft Excel-Arbeitsmappe einbetten.
Sie können Ihre Arbeitsmappe auch mit den Formatierungs- und Diagrammfunktionen von Excel anpassen.
Um BEx Analyzer zu starten, wählen Sie im Windows-Startmenü die Option Programs → Business Explorer → Analyzer.

