SAP HANA - In-Memory-Computing-Engine
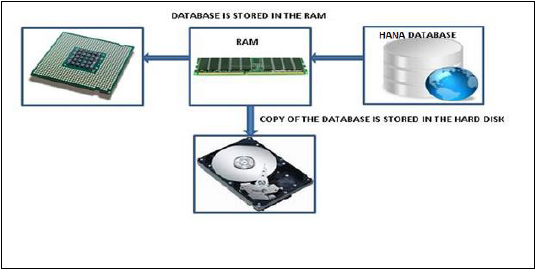
Eine In-Memory-Datenbank bedeutet, dass alle Daten aus dem Quellsystem in einem RAM-Speicher gespeichert sind. In einem herkömmlichen Datenbanksystem werden alle Daten auf der Festplatte gespeichert. Die In-Memory-Datenbank von SAP HANA verschwendet keine Zeit beim Laden der Daten von der Festplatte in den RAM. Es bietet einen schnelleren Datenzugriff auf Multicore-CPUs zur Informationsverarbeitung und -analyse.
Funktionen der In-Memory-Datenbank
Die Hauptfunktionen der In-Memory-Datenbank von SAP HANA sind:
SAP HANA ist eine hybride In-Memory-Datenbank.
Es kombiniert zeilenbasierte, spaltenbasierte und objektorientierte Basistechnologie.
Es verwendet Parallelverarbeitung mit Multicore-CPU-Architektur.
Herkömmliche Datenbank liest Speicherdaten in 5 Millisekunden. Die In-Memory-Datenbank von SAP HANA liest Daten in 5 Nanosekunden.
Dies bedeutet, dass Speicherlesevorgänge in der HANA-Datenbank 1 Million Mal schneller sind als herkömmliche Datenbank-Festplattenspeicherlesungen.
Analysten möchten aktuelle Daten sofort in Echtzeit sehen und nicht auf Daten warten, bis sie in das SAP-BW-System geladen werden. Die In-Memory-Verarbeitung von SAP HANA ermöglicht das Laden von Echtzeitdaten mithilfe verschiedener Datenbereitstellungstechniken.
Vorteile der In-Memory-Datenbank
Die HANA-Datenbank nutzt die In-Memory-Verarbeitung, um die schnellsten Datenabrufgeschwindigkeiten zu erzielen. Dies lockt Unternehmen an, die mit umfangreichen Online-Transaktionen oder zeitnahen Prognosen und Planungen zu kämpfen haben.
Festplattenbasierter Speicher ist immer noch der Unternehmensstandard, und der Preis für RAM ist stetig gesunken, sodass speicherintensive Architekturen letztendlich langsame, mechanisch drehende Festplatten ersetzen und die Kosten für die Datenspeicherung senken werden.
In-Memory Column-basierter Speicher bietet eine bis zu elffache Datenkomprimierung und reduziert so den Speicherplatz großer Datenmengen.
Diese Geschwindigkeitsvorteile, die das RAM-Speichersystem bietet, werden durch die Verwendung von Mehrkern-CPUs, mehreren CPUs pro Knoten und mehreren Knoten pro Server in einer verteilten Umgebung weiter verbessert.