Software Engineering - Kurzanleitung
Lassen Sie uns zunächst verstehen, wofür Software Engineering steht. Der Begriff besteht aus zwei Wörtern: Software und Engineering.
Software ist mehr als nur ein Programmcode. Ein Programm ist ein ausführbarer Code, der einem Rechenzweck dient. Software wird als Sammlung von ausführbarem Programmcode, zugehörigen Bibliotheken und Dokumentationen betrachtet. Software wird aufgerufen, wenn sie für eine bestimmte Anforderung erstellt wurdesoftware product.
Engineering Auf der anderen Seite dreht sich alles um die Entwicklung von Produkten nach genau definierten wissenschaftlichen Prinzipien und Methoden.
Software engineeringist ein technischer Zweig, der mit der Entwicklung von Softwareprodukten nach genau definierten wissenschaftlichen Prinzipien, Methoden und Verfahren verbunden ist. Das Ergebnis des Software-Engineerings ist ein effizientes und zuverlässiges Softwareprodukt.
Definitionen
IEEE definiert Software-Engineering als:
(1) Anwendung eines systematischen, disziplinierten und quantifizierbaren Ansatzes für die Entwicklung, den Betrieb und die Wartung von Software; das heißt, die Anwendung von Engineering auf Software.
(2) Die Untersuchung von Ansätzen wie in der obigen Aussage.
Der deutsche Informatiker Fritz Bauer definiert Software-Engineering als:
Software-Engineering ist die Festlegung und Anwendung solider Engineering-Prinzipien, um wirtschaftlich Software zu erhalten, die zuverlässig ist und effizient auf realen Maschinen arbeitet.
Software Evolution
Der Prozess der Entwicklung eines Softwareprodukts unter Verwendung von Prinzipien und Methoden der Softwareentwicklung wird als bezeichnet software evolution. Dies umfasst die anfängliche Entwicklung von Software sowie deren Wartung und Aktualisierung, bis das gewünschte Softwareprodukt entwickelt ist, das die erwarteten Anforderungen erfüllt.

Die Evolution beginnt mit dem Prozess der Anforderungserfassung. Anschließend erstellen Entwickler einen Prototyp der beabsichtigten Software und zeigen ihn den Benutzern, um ihr Feedback in der frühen Phase der Softwareproduktentwicklung zu erhalten. Die Benutzer schlagen Änderungen vor, bei denen sich auch mehrere aufeinanderfolgende Aktualisierungen und Wartungsarbeiten ändern. Dieser Vorgang wechselt zur ursprünglichen Software, bis die gewünschte Software erreicht ist.
Selbst nachdem der Benutzer die gewünschte Software zur Hand hat, zwingen die fortschreitende Technologie und die sich ändernden Anforderungen das Softwareprodukt, sich entsprechend zu ändern. Es ist nicht möglich, Software von Grund auf neu zu erstellen und mit den Anforderungen eins zu eins zu gehen. Die einzig praktikable und wirtschaftliche Lösung besteht darin, die vorhandene Software so zu aktualisieren, dass sie den neuesten Anforderungen entspricht.
Software-Evolutionsgesetze
Lehman hat Gesetze für die Softwareentwicklung erlassen. Er teilte die Software in drei verschiedene Kategorien ein:
- S-type (static-type) - Dies ist eine Software, die streng nach definierten Spezifikationen und Lösungen arbeitet. Die Lösung und die Methode, um dies zu erreichen, werden beide unmittelbar vor dem Codieren verstanden. Die S-Typ-Software unterliegt am wenigsten Änderungen, daher ist dies die einfachste von allen. Zum Beispiel ein Taschenrechnerprogramm für die mathematische Berechnung.
- P-type (practical-type) - Dies ist eine Software mit einer Sammlung von Verfahren. Dies wird genau dadurch definiert, was Verfahren tun können. In dieser Software können die Spezifikationen beschrieben werden, aber die Lösung ist nicht sofort offensichtlich. Zum Beispiel Spielesoftware.
- E-type (embedded-type) - Diese Software arbeitet eng mit den Anforderungen der realen Umgebung zusammen. Diese Software hat einen hohen Entwicklungsgrad, da sich in der realen Welt verschiedene Änderungen an Gesetzen, Steuern usw. ergeben. Zum Beispiel Online-Handelssoftware.
E-Type Software Evolution
Lehman hat acht Gesetze für die Entwicklung von E-Type-Software festgelegt -
- Continuing change - Ein E-Typ-Softwaresystem muss sich weiterhin an die Veränderungen in der realen Welt anpassen, sonst wird es zunehmend weniger nützlich.
- Increasing complexity - Wenn sich ein E-Typ-Softwaresystem weiterentwickelt, nimmt seine Komplexität tendenziell zu, es sei denn, es wird daran gearbeitet, es zu warten oder zu reduzieren.
- Conservation of familiarity - Die Vertrautheit mit der Software oder das Wissen darüber, wie sie entwickelt wurde, warum sie auf diese bestimmte Weise entwickelt wurde usw. muss um jeden Preis erhalten bleiben, um die Änderungen im System umzusetzen.
- Continuing growth- Damit ein E-Typ-System ein Geschäftsproblem lösen kann, wächst seine Größe bei der Implementierung der Änderungen entsprechend den Änderungen des Lebensstils des Unternehmens.
- Reducing quality - Ein E-Typ-Softwaresystem nimmt an Qualität ab, es sei denn, es wird streng gewartet und an eine sich ändernde Betriebsumgebung angepasst.
- Feedback systems- Die E-Typ-Softwaresysteme stellen Rückkopplungssysteme mit mehreren Schleifen und mehreren Ebenen dar und müssen als solche behandelt werden, um erfolgreich modifiziert oder verbessert zu werden.
- Self-regulation - E-Typ-Systementwicklungsprozesse regulieren sich selbst, wobei die Verteilung der Produkt- und Prozessmaßnahmen nahezu normal ist.
- Organizational stability - Die durchschnittliche effektive globale Aktivitätsrate in einem sich entwickelnden E-Typ-System ist über die Lebensdauer des Produkts unveränderlich.
Software-Paradigmen
Software-Paradigmen beziehen sich auf die Methoden und Schritte, die beim Entwerfen der Software ausgeführt werden. Es werden viele Methoden vorgeschlagen und sind heute in Arbeit, aber wir müssen sehen, wo in der Softwareentwicklung diese Paradigmen stehen. Diese können in verschiedene Kategorien zusammengefasst werden, obwohl jede ineinander enthalten ist:

Das Programmierparadigma ist eine Teilmenge des Software-Design-Paradigmas, das ferner eine Teilmenge des Software-Entwicklungsparadigmas ist.
Paradigma der Softwareentwicklung
Dieses Paradigma ist als Software-Engineering-Paradigma bekannt, bei dem alle Engineering-Konzepte zur Entwicklung von Software angewendet werden. Es umfasst verschiedene Untersuchungen und das Sammeln von Anforderungen, die beim Erstellen des Softwareprodukts helfen. Es besteht aus -
- Anforderungserfassung
- Software-Design
- Programming
Software-Design-Paradigma
Dieses Paradigma ist Teil der Softwareentwicklung und umfasst:
- Design
- Maintenance
- Programming
Programmierparadigma
Dieses Paradigma hängt eng mit dem Programmieraspekt der Softwareentwicklung zusammen. Das beinhaltet -
- Coding
- Testing
- Integration
Bedarf an Software-Engineering
Der Bedarf an Softwareentwicklung ergibt sich aus einer höheren Änderungsrate der Benutzeranforderungen und der Umgebung, in der die Software arbeitet.
- Large software - Es ist einfacher, eine Wand zu bauen als ein Haus oder ein Gebäude, da die Größe der Software groß wird. Das Engineering muss Schritte unternehmen, um einen wissenschaftlichen Prozess zu ermöglichen.
- Scalability- Wenn der Softwareprozess nicht auf wissenschaftlichen und technischen Konzepten basieren würde, wäre es einfacher, neue Software neu zu erstellen, als eine vorhandene zu skalieren.
- Cost- Wie die Hardware-Industrie gezeigt hat, hat die enorme Fertigung den Preis für Computer- und elektronische Hardware gesenkt. Die Kosten für Software bleiben jedoch hoch, wenn der ordnungsgemäße Prozess nicht angepasst wird.
- Dynamic Nature- Die stetig wachsende und anpassungsfähige Natur von Software hängt stark von der Umgebung ab, in der der Benutzer arbeitet. Wenn sich die Art der Software ständig ändert, müssen neue Verbesserungen an der vorhandenen vorgenommen werden. Hier spielt Software Engineering eine gute Rolle.
- Quality Management- Ein besserer Prozess der Softwareentwicklung bietet ein besseres und qualitativ hochwertiges Softwareprodukt.
Eigenschaften guter Software
Ein Softwareprodukt kann danach beurteilt werden, was es bietet und wie gut es verwendet werden kann. Diese Software muss aus folgenden Gründen erfüllen:
- Operational
- Transitional
- Maintenance
Von ausgereifter und gestalteter Software wird erwartet, dass sie die folgenden Eigenschaften aufweist:
Betriebsbereit
Dies zeigt uns, wie gut Software im Betrieb funktioniert. Es kann gemessen werden an:
- Budget
- Usability
- Efficiency
- Correctness
- Functionality
- Dependability
- Security
- Safety
Übergang
Dieser Aspekt ist wichtig, wenn die Software von einer Plattform auf eine andere verschoben wird:
- Portability
- Interoperability
- Reusability
- Adaptability
Instandhaltung
Dieser Aspekt beschreibt, wie gut eine Software in der sich ständig ändernden Umgebung in der Lage ist, sich selbst zu erhalten:
- Modularity
- Maintainability
- Flexibility
- Scalability
Kurz gesagt, Software Engineering ist ein Zweig der Informatik, der klar definierte Engineering-Konzepte verwendet, um effiziente, langlebige, skalierbare, budgetgerechte und pünktliche Softwareprodukte herzustellen.
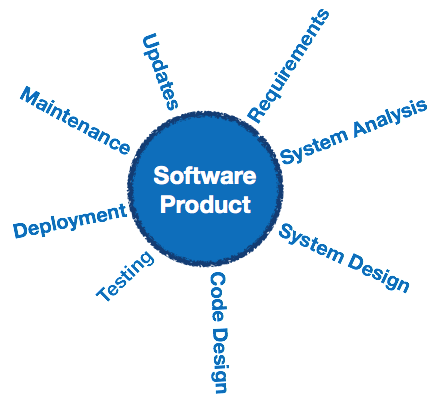
Der Software Development Life Cycle, kurz SDLC, ist eine genau definierte, strukturierte Abfolge von Schritten in der Softwareentwicklung, um das beabsichtigte Softwareprodukt zu entwickeln.
SDLC-Aktivitäten
SDLC bietet eine Reihe von Schritten, die befolgt werden müssen, um ein Softwareprodukt effizient zu entwerfen und zu entwickeln. Das SDLC-Framework umfasst die folgenden Schritte:
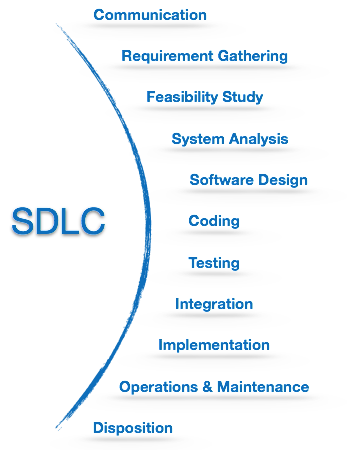
Kommunikation
Dies ist der erste Schritt, bei dem der Benutzer die Anforderung für ein gewünschtes Softwareprodukt initiiert. Er kontaktiert den Dienstleister und versucht, die Bedingungen auszuhandeln. Er reicht seine Anfrage schriftlich bei der Dienstleistungsorganisation ein.
Anforderungserfassung
Ab diesem Schritt arbeitet das Softwareentwicklungsteam daran, das Projekt fortzusetzen. Das Team führt Gespräche mit verschiedenen Stakeholdern aus dem Problembereich und versucht, so viele Informationen wie möglich über ihre Anforderungen zu erhalten. Die Anforderungen werden berücksichtigt und in Benutzeranforderungen, Systemanforderungen und funktionale Anforderungen unterteilt. Die Anforderungen werden unter Verwendung einer Reihe von Praktiken wie angegeben gesammelt -
- Studium des vorhandenen oder veralteten Systems und der Software,
- Durchführung von Interviews mit Anwendern und Entwicklern,
- unter Bezugnahme auf die Datenbank oder
- Sammeln von Antworten aus den Fragebögen.
Machbarkeitsstudie
Nach dem Sammeln der Anforderungen erstellt das Team einen groben Plan für den Softwareprozess. In diesem Schritt analysiert das Team, ob eine Software erstellt werden kann, um alle Anforderungen des Benutzers zu erfüllen, und ob die Möglichkeit besteht, dass Software nicht mehr nützlich ist. Es wird herausgefunden, ob das Projekt für die Organisation finanziell, praktisch und technologisch machbar ist. Es stehen viele Algorithmen zur Verfügung, mit denen die Entwickler die Machbarkeit eines Softwareprojekts abschließen können.
Systemanalyse
In diesem Schritt legen die Entwickler eine Roadmap für ihren Plan fest und versuchen, das beste für das Projekt geeignete Softwaremodell zu finden. Die Systemanalyse umfasst das Verständnis der Einschränkungen von Softwareprodukten, Probleme mit dem Lernsystem oder Änderungen, die in vorhandenen Systemen im Voraus vorgenommen werden müssen, das Erkennen und Behandeln der Auswirkungen des Projekts auf Organisation und Personal usw. Das Projektteam analysiert den Umfang des Projekts und plant den Zeitplan und Ressourcen entsprechend.
Software-Design
Der nächste Schritt besteht darin, das gesamte Wissen über Anforderungen und Analysen auf den Schreibtisch zu bringen und das Softwareprodukt zu entwerfen. Die Eingaben von Benutzern und Informationen, die in der Anforderungserfassungsphase gesammelt wurden, sind die Eingaben dieses Schritts. Die Ausgabe dieses Schritts erfolgt in Form von zwei Entwürfen; logisches Design und physisches Design. Ingenieure erstellen Metadaten und Datenwörterbücher, logische Diagramme, Datenflussdiagramme und in einigen Fällen Pseudocodes.
Codierung
Dieser Schritt wird auch als Programmierphase bezeichnet. Die Implementierung des Software-Designs beginnt mit dem Schreiben von Programmcode in der geeigneten Programmiersprache und der effizienten Entwicklung fehlerfreier ausführbarer Programme.
Testen
Eine Schätzung besagt, dass 50% des gesamten Softwareentwicklungsprozesses getestet werden sollten. Fehler können die Software von der kritischen Ebene bis zur eigenen Entfernung ruinieren. Softwaretests werden während der Codierung durch die Entwickler durchgeführt, und gründliche Tests werden von Testexperten auf verschiedenen Codeebenen durchgeführt, z. B. Modultests, Programmtests, Produkttests, Inhouse-Tests und Tests des Produkts beim Benutzer. Die frühzeitige Entdeckung von Fehlern und deren Behebung ist der Schlüssel zu zuverlässiger Software.
Integration
Möglicherweise muss Software in die Bibliotheken, Datenbanken und andere Programme integriert werden. Diese Phase von SDLC ist an der Integration von Software in Entitäten der Außenwelt beteiligt.
Implementierung
Dies bedeutet, dass die Software auf Benutzercomputern installiert wird. Manchmal muss die Software nach der Installation vom Benutzer konfiguriert werden. Die Software wird auf Portabilität und Anpassungsfähigkeit getestet, und Integrationsprobleme werden während der Implementierung gelöst.
Betrieb und Instandhaltung
Diese Phase bestätigt den Softwarebetrieb in Bezug auf mehr Effizienz und weniger Fehler. Bei Bedarf werden die Benutzer in der Dokumentation zur Bedienung der Software und zur Aufrechterhaltung des Betriebs der Software geschult oder unterstützt. Die Software wird rechtzeitig gewartet, indem der Code entsprechend den Änderungen in der Benutzerendumgebung oder -technologie aktualisiert wird. Diese Phase kann mit Herausforderungen aufgrund versteckter Fehler und realer, nicht identifizierter Probleme konfrontiert sein.
Anordnung
Im Laufe der Zeit kann die Software an der Leistungsfront abnehmen. Es ist möglicherweise völlig veraltet oder muss intensiv aktualisiert werden. Daher besteht ein dringender Bedarf, einen Großteil des Systems zu eliminieren. Diese Phase umfasst das Archivieren von Daten und erforderlichen Softwarekomponenten, das Herunterfahren des Systems, das Planen von Dispositionsaktivitäten und das Beenden des Systems zu einem angemessenen Zeitpunkt am Ende des Systems.
Paradigma der Softwareentwicklung
Das Softwareentwicklungsparadigma hilft Entwicklern bei der Auswahl einer Strategie zur Entwicklung der Software. Ein Softwareentwicklungsparadigma verfügt über eigene Tools, Methoden und Verfahren, die klar ausgedrückt werden und den Lebenszyklus der Softwareentwicklung definieren. Einige Paradigmen oder Prozessmodelle für die Softwareentwicklung sind wie folgt definiert:
Wasserfall-Modell
Das Wasserfallmodell ist das einfachste Modell des Softwareentwicklungsparadigmas. Es heißt, dass alle Phasen der SDLC linear nacheinander funktionieren. Das heißt, wenn die erste Phase beendet ist, beginnt nur die zweite Phase und so weiter.

Dieses Modell geht davon aus, dass alles wie geplant in der vorherigen Phase ausgeführt und durchgeführt wird und dass nicht über die Probleme der Vergangenheit nachgedacht werden muss, die in der nächsten Phase auftreten können. Dieses Modell funktioniert nicht reibungslos, wenn im vorherigen Schritt noch einige Probleme aufgetreten sind. Die sequentielle Natur des Modells erlaubt es uns nicht, zurück zu gehen und unsere Handlungen rückgängig zu machen oder zu wiederholen.
Dieses Modell eignet sich am besten, wenn Entwickler bereits in der Vergangenheit ähnliche Software entworfen und entwickelt haben und alle ihre Domänen kennen.
Iteratives Modell
Dieses Modell führt den Softwareentwicklungsprozess in Iterationen an. Es projiziert den Entwicklungsprozess zyklisch und wiederholt jeden Schritt nach jedem Zyklus des SDLC-Prozesses.

Die Software wird zunächst in sehr kleinem Maßstab entwickelt und es werden alle Schritte befolgt, die berücksichtigt werden. Bei jeder nächsten Iteration werden dann weitere Funktionen und Module entworfen, codiert, getestet und der Software hinzugefügt. Jeder Zyklus erzeugt eine Software, die für sich vollständig ist und mehr Funktionen als der vorherige bietet.
Nach jeder Iteration kann das Managementteam am Risikomanagement arbeiten und sich auf die nächste Iteration vorbereiten. Da ein Zyklus einen kleinen Teil des gesamten Softwareprozesses umfasst, ist es einfacher, den Entwicklungsprozess zu verwalten, verbraucht jedoch mehr Ressourcen.
Spiralmodell
Das Spiralmodell ist eine Kombination aus dem iterativen Modell und einem der SDLC-Modelle. Es kann so gesehen werden, als ob Sie ein SDLC-Modell auswählen und es mit einem zyklischen Prozess (iteratives Modell) kombinieren.

Dieses Modell berücksichtigt das Risiko, das von den meisten anderen Modellen häufig nicht wahrgenommen wird. Das Modell beginnt mit der Bestimmung der Ziele und Einschränkungen der Software zu Beginn einer Iteration. Die nächste Phase ist das Prototyping der Software. Dies beinhaltet eine Risikoanalyse. Anschließend wird ein Standard-SDLC-Modell zum Erstellen der Software verwendet. In der vierten Phase des Plans wird die nächste Iteration vorbereitet.
V - Modell
Der Hauptnachteil des Wasserfallmodells besteht darin, dass wir erst dann zur nächsten Stufe übergehen, wenn die vorherige abgeschlossen ist und es keine Chance gab, zurückzukehren, wenn in späteren Stufen etwas nicht gefunden wird. V-Model bietet die Möglichkeit, Software in jeder Phase in umgekehrter Weise zu testen.

In jeder Phase werden Testpläne und Testfälle erstellt, um das Produkt gemäß den Anforderungen dieser Phase zu verifizieren und zu validieren. In der Phase der Anforderungserfassung bereitet das Testteam beispielsweise alle Testfälle entsprechend den Anforderungen vor. Später, wenn das Produkt entwickelt und testbereit ist, überprüfen Testfälle dieser Phase die Software auf ihre Gültigkeit hinsichtlich der Anforderungen in dieser Phase.
Dadurch werden sowohl Verifizierung als auch Validierung parallel ausgeführt. Dieses Modell wird auch als Verifizierungs- und Validierungsmodell bezeichnet.
Urknallmodell
Dieses Modell ist das einfachste Modell in seiner Form. Es erfordert wenig Planung, viel Programmierung und viel Geld. Dieses Modell ist um den Urknall des Universums herum konzipiert. Wie Wissenschaftler sagen, haben sich nach dem Urknall viele Galaxien, Planeten und Sterne nur als Ereignis entwickelt. Wenn wir viel Programm und Geld zusammenstellen, können Sie auch das beste Softwareprodukt erzielen.

Für dieses Modell ist nur ein sehr geringer Planungsaufwand erforderlich. Es folgt keinem Prozess, oder manchmal ist sich der Kunde nicht sicher über die Anforderungen und zukünftigen Bedürfnisse. Die Eingabeanforderungen sind also beliebig.
Dieses Modell ist nicht für große Softwareprojekte geeignet, aber gut zum Lernen und Experimentieren.
Klicken Sie hier, um mehr über SDLC und seine verschiedenen Modelle zu erfahren.
Das Jobmuster eines IT-Unternehmens, das in der Softwareentwicklung tätig ist, besteht aus zwei Teilen:
- Softwareerstellung
- Software-Projektmanagement
Ein Projekt ist eine genau definierte Aufgabe, bei der mehrere Vorgänge zusammengefasst werden, um ein Ziel zu erreichen (z. B. Softwareentwicklung und -bereitstellung). Ein Projekt kann charakterisiert werden als:
- Jedes Projekt kann ein einzigartiges und eindeutiges Ziel haben.
- Projekt ist keine Routinetätigkeit oder alltäglicher Betrieb.
- Das Projekt hat eine Start- und eine Endzeit.
- Das Projekt endet, wenn sein Ziel erreicht ist, daher ist es eine vorübergehende Phase im Leben einer Organisation.
- Das Projekt benötigt angemessene Ressourcen in Bezug auf Zeit, Arbeitskräfte, Finanzen, Material und Wissensdatenbank.
Softwareprojekt
Ein Softwareprojekt ist das vollständige Verfahren der Softwareentwicklung von der Erfassung der Anforderungen bis zum Testen und zur Wartung, das gemäß den Ausführungsmethoden in einem bestimmten Zeitraum durchgeführt wird, um das beabsichtigte Softwareprodukt zu erreichen.
Bedarf an Software-Projektmanagement
Software soll ein immaterielles Produkt sein. Die Softwareentwicklung ist eine Art neuer Strom im Weltgeschäft, und es gibt nur sehr wenig Erfahrung beim Erstellen von Softwareprodukten. Die meisten Softwareprodukte sind auf die Anforderungen des Kunden zugeschnitten. Das Wichtigste ist, dass sich die zugrunde liegende Technologie so häufig und schnell ändert und weiterentwickelt, dass die Erfahrung eines Produkts möglicherweise nicht auf das andere angewendet wird. All diese geschäftlichen und ökologischen Einschränkungen bergen Risiken bei der Softwareentwicklung. Daher ist es wichtig, Softwareprojekte effizient zu verwalten.

Das obige Bild zeigt dreifache Einschränkungen für Softwareprojekte. Es ist ein wesentlicher Bestandteil der Softwareorganisation, Qualitätsprodukte zu liefern, die Kosten innerhalb des Budgetbudgets des Kunden zu halten und das Projekt wie geplant zu liefern. Es gibt verschiedene interne und externe Faktoren, die sich auf dieses Dreieck mit drei Einschränkungen auswirken können. Jeder der drei Faktoren kann die beiden anderen stark beeinflussen.
Daher ist das Management von Softwareprojekten unerlässlich, um die Benutzeranforderungen zusammen mit Budget- und Zeitbeschränkungen zu berücksichtigen.
Software-Projektmanager
Ein Softwareprojektmanager ist eine Person, die die Verantwortung für die Ausführung des Softwareprojekts übernimmt. Der Software-Projektmanager kennt alle Phasen des SDLC, die die Software durchlaufen würde. Der Projektmanager ist möglicherweise nie direkt an der Herstellung des Endprodukts beteiligt, kontrolliert und verwaltet jedoch die mit der Produktion verbundenen Aktivitäten.
Ein Projektmanager überwacht den Entwicklungsprozess genau, bereitet verschiedene Pläne vor und führt sie aus, ordnet die erforderlichen und angemessenen Ressourcen an und pflegt die Kommunikation zwischen allen Teammitgliedern, um Fragen zu Kosten, Budget, Ressourcen, Zeit, Qualität und Kundenzufriedenheit zu lösen.
Lassen Sie uns einige Verantwortlichkeiten sehen, die ein Projektmanager übernimmt -
Leute führen
- Als Projektleiter fungieren
- Läsion mit Stakeholdern
- Personalmanagement
- Einrichten der Berichtshierarchie usw.
Projekt verwalten
- Projektumfang definieren und einrichten
- Verwalten von Projektmanagementaktivitäten
- Fortschritt und Leistung überwachen
- Risikoanalyse in jeder Phase
- Ergreifen Sie die erforderlichen Maßnahmen, um Probleme zu vermeiden oder zu lösen
- Als Projektsprecher fungieren
Software-Management-Aktivitäten
Das Softwareprojektmanagement umfasst eine Reihe von Aktivitäten, darunter die Planung des Projekts, die Festlegung des Umfangs des Softwareprodukts, die Schätzung der Kosten in verschiedenen Begriffen, die Planung von Aufgaben und Ereignissen sowie das Ressourcenmanagement. Projektmanagementaktivitäten können Folgendes umfassen:
- Project Planning
- Scope Management
- Project Estimation
Projektplanung
Die Planung von Softwareprojekten ist eine Aufgabe, die ausgeführt wird, bevor die Produktion von Software tatsächlich beginnt. Es ist für die Softwareproduktion da, beinhaltet jedoch keine konkreten Aktivitäten, die in irgendeiner Richtung mit der Softwareproduktion zusammenhängen. Vielmehr handelt es sich um eine Reihe mehrerer Prozesse, die die Softwareproduktion erleichtern. Die Projektplanung kann Folgendes umfassen:
Bereichsverwaltung
Es definiert den Umfang des Projekts; Dies umfasst alle Aktivitäten und Prozesse, die ausgeführt werden müssen, um ein lieferbares Softwareprodukt zu erstellen. Das Bereichsmanagement ist wichtig, da es Grenzen des Projekts schafft, indem klar definiert wird, was im Projekt getan werden soll und was nicht. Dadurch enthält das Projekt begrenzte und quantifizierbare Aufgaben, die leicht dokumentiert werden können und Kosten- und Zeitüberschreitungen vermeiden.
Während der Verwaltung des Projektumfangs ist Folgendes erforderlich:
- Definieren Sie den Bereich
- Entscheiden Sie über die Überprüfung und Kontrolle
- Teilen Sie das Projekt zur Vereinfachung der Verwaltung in verschiedene kleinere Teile auf.
- Überprüfen Sie den Umfang
- Steuern Sie den Bereich, indem Sie Änderungen am Bereich vornehmen
Projektschätzung
Für ein effektives Management ist eine genaue Schätzung verschiedener Maßnahmen ein Muss. Mit der richtigen Schätzung können Manager das Projekt effizienter und effektiver verwalten und steuern.
Die Projektschätzung kann Folgendes umfassen:
- Software size estimation
Die Softwaregröße kann entweder anhand von KLOC (Kilo Line of Code) oder durch Berechnung der Anzahl der Funktionspunkte in der Software geschätzt werden. Codezeilen hängen von den Codierungspraktiken ab, und die Funktionspunkte variieren je nach Benutzer- oder Softwareanforderung.
- Effort estimation
Die Manager schätzen den Aufwand in Bezug auf den Personalbedarf und die für die Erstellung der Software erforderliche Arbeitszeit. Für die Aufwandsschätzung sollte die Größe der Software bekannt sein. Dies kann entweder aus der Erfahrung der Manager abgeleitet werden, die historischen Daten des Unternehmens oder die Softwaregröße kann mithilfe einiger Standardformeln in Aufwand umgewandelt werden.
- Time estimation
Sobald Größe und Aufwand geschätzt sind, kann die zur Erstellung der Software erforderliche Zeit geschätzt werden. Der erforderliche Aufwand wird gemäß den Anforderungsspezifikationen und der gegenseitigen Abhängigkeit verschiedener Softwarekomponenten in Unterkategorien unterteilt. Softwareaufgaben werden nach Work Breakthrough Structure (WBS) in kleinere Aufgaben, Aktivitäten oder Ereignisse unterteilt. Die Aufgaben werden täglich oder in Kalendermonaten geplant.
Die Zeit, die benötigt wird, um alle Aufgaben in Stunden oder Tagen zu erledigen, ist die Gesamtzeit, die für die Fertigstellung des Projekts investiert wurde.
- Cost estimation
Dies kann als das schwierigste von allen angesehen werden, da es von mehr Elementen abhängt als jedes der vorherigen. Bei der Schätzung der Projektkosten ist Folgendes zu berücksichtigen:
- Größe der Software
- Softwarequalität
- Hardware
- Zusätzliche Software oder Tools, Lizenzen usw.
- Fachpersonal mit aufgabenspezifischen Fähigkeiten
- Reisen beteiligt
- Communication
- Schulung und Unterstützung
Projektschätzungstechniken
Wir haben verschiedene Parameter diskutiert, die eine Projektschätzung beinhalten, wie Größe, Aufwand, Zeit und Kosten.
Der Projektmanager kann die aufgeführten Faktoren mithilfe von zwei allgemein anerkannten Techniken abschätzen:
Zersetzungstechnik
Diese Technik setzt die Software als Produkt verschiedener Zusammensetzungen voraus.
Es gibt zwei Hauptmodelle -
- Line of Code Die Schätzung erfolgt im Namen der Anzahl der Codezeilen im Softwareprodukt.
- Function Points Die Schätzung erfolgt im Namen der Anzahl der Funktionspunkte im Softwareprodukt.
Empirische Schätztechnik
Diese Technik verwendet empirisch abgeleitete Formeln, um eine Schätzung vorzunehmen. Diese Formeln basieren auf LOC oder FPs.
- Putnam Model
Dieses Modell wurde von Lawrence H. Putnam hergestellt, das auf der Häufigkeitsverteilung von Norden (Rayleigh-Kurve) basiert. Das Putnam-Modell bildet die Zeit und den Aufwand ab, die für die Softwaregröße erforderlich sind.
- COCOMO
COCOMO steht für COnstructive COst MOdel, entwickelt von Barry W. Boehm. Das Softwareprodukt wird in drei Kategorien von Software unterteilt: organisch, halb getrennt und eingebettet.
Projektplanung
Die Projektplanung in einem Projekt bezieht sich auf die Roadmap aller Aktivitäten, die in der angegebenen Reihenfolge und innerhalb des jeder Aktivität zugewiesenen Zeitfensters ausgeführt werden sollen. Projektmanager neigen dazu, verschiedene Aufgaben und Projektmeilensteine zu definieren und diese unter Berücksichtigung verschiedener Faktoren anzuordnen. Sie suchen nach Aufgaben, die sich im Zeitplan auf einem kritischen Pfad befinden, der auf bestimmte Weise (aufgrund der gegenseitigen Abhängigkeit der Aufgaben) und genau innerhalb der zugewiesenen Zeit ausgeführt werden muss. Die Anordnung von Aufgaben, die außerhalb des kritischen Pfades liegen, wirkt sich weniger wahrscheinlich auf den gesamten Zeitplan des Projekts aus.
Für die Planung eines Projekts ist Folgendes erforderlich:
- Teilen Sie die Projektaufgaben in eine kleinere, überschaubare Form auf
- Finden Sie verschiedene Aufgaben heraus und korrelieren Sie sie
- Schätzen Sie den für jede Aufgabe erforderlichen Zeitrahmen
- Teilen Sie die Zeit in Arbeitseinheiten auf
- Weisen Sie jeder Aufgabe eine angemessene Anzahl von Arbeitseinheiten zu
- Berechnen Sie die Gesamtzeit, die das Projekt von Anfang bis Ende benötigt
Resourcenmanagement
Alle Elemente, die zur Entwicklung eines Softwareprodukts verwendet werden, können als Ressource für dieses Projekt angenommen werden. Dies kann Personal, produktive Tools und Softwarebibliotheken umfassen.
Die Ressourcen sind in begrenzter Menge verfügbar und verbleiben als Pool von Vermögenswerten in der Organisation. Der Mangel an Ressourcen behindert die Entwicklung des Projekts und kann hinter dem Zeitplan zurückbleiben. Die Zuweisung zusätzlicher Ressourcen erhöht letztendlich die Entwicklungskosten. Es ist daher notwendig, angemessene Ressourcen für das Projekt zu schätzen und zuzuweisen.
Ressourcenmanagement umfasst -
- Definieren eines geeigneten Organisationsprojekts durch Erstellen eines Projektteams und Zuweisen von Verantwortlichkeiten zu jedem Teammitglied
- Ermittlung der zu einem bestimmten Zeitpunkt erforderlichen Ressourcen und ihrer Verfügbarkeit
- Verwalten Sie Ressourcen, indem Sie Ressourcenanforderungen generieren, wenn sie benötigt werden, und die Zuordnung aufheben, wenn sie nicht mehr benötigt werden.
Projektrisikomanagement
Das Risikomanagement umfasst alle Aktivitäten im Zusammenhang mit der Identifizierung, Analyse und Bereitstellung vorhersehbarer und nicht vorhersehbarer Risiken im Projekt. Das Risiko kann Folgendes umfassen:
- Erfahrene Mitarbeiter verlassen das Projekt und neue Mitarbeiter kommen hinzu.
- Änderung im Organisationsmanagement.
- Anforderungsänderung oder Fehlinterpretation der Anforderung.
- Unterschätzung des Zeit- und Ressourcenbedarfs.
- Technologische Veränderungen, Umweltveränderungen, geschäftlicher Wettbewerb.
Risikomanagement-Prozess
Der Risikomanagementprozess umfasst folgende Aktivitäten:
- Identification - Notieren Sie sich alle möglichen Risiken, die im Projekt auftreten können.
- Categorize - Kategorisieren Sie bekannte Risiken nach ihren möglichen Auswirkungen auf das Projekt in hohe, mittlere und niedrige Risikointensität.
- Manage - Analysieren Sie die Wahrscheinlichkeit des Auftretens von Risiken in verschiedenen Phasen. Machen Sie einen Plan, um Risiken zu vermeiden oder sich diesen zu stellen. Versuchen Sie, ihre Nebenwirkungen zu minimieren.
- Monitor - Überwachen Sie die potenziellen Risiken und ihre frühen Symptome genau. Überwachen Sie auch die Auswirkungen von Maßnahmen, die ergriffen wurden, um sie zu mindern oder zu vermeiden.
Projektdurchführung und -überwachung
In dieser Phase werden die in den Projektplänen beschriebenen Aufgaben nach ihren Zeitplänen ausgeführt.
Die Ausführung muss überwacht werden, um zu überprüfen, ob alles nach Plan verläuft. Bei der Überwachung wird beobachtet, um die Wahrscheinlichkeit eines Risikos zu überprüfen und Maßnahmen zu ergreifen, um das Risiko anzugehen oder den Status verschiedener Aufgaben zu melden.
Diese Maßnahmen umfassen -
- Activity Monitoring - Alle Aktivitäten, die innerhalb einer Aufgabe geplant sind, können täglich überwacht werden. Wenn alle Aktivitäten in einer Aufgabe abgeschlossen sind, gilt sie als abgeschlossen.
- Status Reports - Die Berichte enthalten den Status von Aktivitäten und Aufgaben, die innerhalb eines bestimmten Zeitraums, in der Regel einer Woche, ausgeführt wurden. Der Status kann als beendet, ausstehend oder in Bearbeitung usw. markiert werden.
- Milestones Checklist - Jedes Projekt ist in mehrere Phasen unterteilt, in denen wichtige Aufgaben (Meilensteine) basierend auf den Phasen von SDLC ausgeführt werden. Diese Meilenstein-Checkliste wird alle paar Wochen erstellt und gibt den Status der Meilensteine an.
Projektkommunikationsmanagement
Effektive Kommunikation spielt eine entscheidende Rolle für den Erfolg eines Projekts. Es schließt Lücken zwischen dem Kunden und der Organisation, zwischen den Teammitgliedern sowie anderen am Projekt beteiligten Akteuren wie Hardwarelieferanten.
Die Kommunikation kann mündlich oder schriftlich erfolgen. Der Kommunikationsmanagementprozess kann die folgenden Schritte umfassen:
- Planning - Dieser Schritt umfasst die Identifizierung aller am Projekt beteiligten Akteure und die Art der Kommunikation zwischen ihnen. Es wird auch geprüft, ob zusätzliche Kommunikationsmöglichkeiten erforderlich sind.
- Sharing - Nachdem verschiedene Aspekte der Planung festgelegt wurden, konzentriert sich der Manager darauf, die richtigen Informationen zur richtigen Zeit mit der richtigen Person zu teilen. Dies hält alle am Projekt Beteiligten über den Projektfortschritt und dessen Status auf dem Laufenden.
- Feedback - Projektmanager verwenden verschiedene Maßnahmen und Feedback-Mechanismen und erstellen Status- und Leistungsberichte. Dieser Mechanismus stellt sicher, dass der Input von verschiedenen Stakeholdern als Feedback an den Projektmanager gelangt.
- Closure - Am Ende jeder Großveranstaltung, am Ende einer SDLC-Phase oder am Ende des Projekts selbst wird offiziell der Abschluss der Verwaltung angekündigt, um alle Stakeholder durch Senden von E-Mails, Verteilen einer Hardcopy des Dokuments oder auf andere Weise einer effektiven Kommunikation zu aktualisieren.
Nach der Schließung geht das Team zur nächsten Phase oder zum nächsten Projekt über.
Konfigurationsmanagement
Das Konfigurationsmanagement ist ein Prozess zum Verfolgen und Steuern der Änderungen in der Software in Bezug auf Anforderungen, Design, Funktionen und Entwicklung des Produkts.
IEEE definiert es als „den Prozess des Identifizierens und Definierens der Elemente im System, des Kontrollierens der Änderung dieser Elemente während ihres gesamten Lebenszyklus, des Aufzeichnens und Meldens des Status von Elementen und Änderungsanforderungen sowie des Überprüfens der Vollständigkeit und Richtigkeit von Elementen“.
Im Allgemeinen besteht nach Abschluss des SRS eine geringere Wahrscheinlichkeit, dass vom Benutzer Änderungen erforderlich sind. Wenn sie auftreten, werden die Änderungen nur mit vorheriger Genehmigung des höheren Managements behoben, da die Möglichkeit einer Kosten- und Zeitüberschreitung besteht.
Basislinie
Eine Phase der SDLC wird als Basis angenommen, dh sie ist eine Messung, die die Vollständigkeit einer Phase definiert. Eine Phase wird festgelegt, wenn alle diesbezüglichen Aktivitäten abgeschlossen und gut dokumentiert sind. Wenn es nicht die letzte Phase wäre, würde seine Ausgabe in der nächsten unmittelbaren Phase verwendet.
Das Konfigurationsmanagement ist eine Disziplin der Organisationsadministration, die sich um das Auftreten von Änderungen (Prozesse, Anforderungen, technologische, strategische usw.) kümmert, nachdem eine Phase festgelegt wurde. CM überprüft alle Änderungen, die an der Software vorgenommen wurden.
Kontrolle ändern
Die Änderungskontrolle ist eine Funktion des Konfigurationsmanagements, das sicherstellt, dass alle am Softwaresystem vorgenommenen Änderungen konsistent sind und den organisatorischen Regeln und Vorschriften entsprechen.
Eine Änderung in der Konfiguration des Produkts führt die folgenden Schritte aus:
Identification- Eine Änderungsanforderung kommt entweder von einer internen oder einer externen Quelle. Wenn eine Änderungsanforderung formell identifiziert wird, wird sie ordnungsgemäß dokumentiert.
Validation - Die Gültigkeit der Änderungsanforderung wird überprüft und ihr Bearbeitungsverfahren bestätigt.
Analysis- Die Auswirkungen von Änderungsanforderungen werden in Bezug auf Zeitplan, Kosten und erforderlichen Aufwand analysiert. Die Gesamtauswirkung der voraussichtlichen Änderung auf das System wird analysiert.
Control- Wenn die voraussichtliche Änderung entweder zu viele Einheiten im System betrifft oder unvermeidbar ist, muss die Genehmigung der hohen Behörden eingeholt werden, bevor die Änderung in das System aufgenommen wird. Es wird entschieden, ob die Änderung eine Einbeziehung wert ist oder nicht. Ist dies nicht der Fall, wird die Änderungsanforderung offiziell abgelehnt.
Execution - Wenn in der vorherigen Phase festgelegt wurde, dass die Änderungsanforderung ausgeführt werden soll, ergreift diese Phase geeignete Maßnahmen, um die Änderung auszuführen, und führt gegebenenfalls eine gründliche Überarbeitung durch.
Close request- Die Änderung wird auf korrekte Implementierung und Zusammenführung mit dem Rest des Systems überprüft. Diese neu aufgenommene Änderung in der Software wird ordnungsgemäß dokumentiert und die Anfrage wird formell geschlossen.
Projektmanagement-Tools
Das Risiko und die Unsicherheit steigen in Bezug auf die Größe des Projekts um ein Vielfaches, selbst wenn das Projekt nach festgelegten Methoden entwickelt wird.
Es stehen Tools zur Verfügung, die ein effektives Projektmanagement unterstützen. Einige werden beschrieben -
Gantt-Diagramm
Gantt-Diagramme wurden von Henry Gantt (1917) entworfen. Es repräsentiert den Projektplan in Bezug auf Zeiträume. Es ist ein horizontales Balkendiagramm mit Balken, die Aktivitäten und die für die Projektaktivitäten geplante Zeit darstellen.

PERT-Diagramm
Das PERT-Diagramm (Program Evaluation & Review Technique) ist ein Tool, das das Projekt als Netzwerkdiagramm darstellt. Es ist in der Lage, Hauptereignisse des Projekts sowohl parallel als auch nacheinander grafisch darzustellen. Ereignisse, die nacheinander auftreten, zeigen die Abhängigkeit des späteren Ereignisses vom vorherigen.

Ereignisse werden als nummerierte Knoten angezeigt. Sie sind durch beschriftete Pfeile verbunden, die die Abfolge der Aufgaben im Projekt darstellen.
Ressourcenhistogramm
Dies ist ein grafisches Tool, das Balken oder Diagramme enthält, die die Anzahl der Ressourcen (normalerweise qualifiziertes Personal) darstellen, die im Laufe der Zeit für ein Projektereignis (oder eine Phase) benötigt werden. Das Ressourcenhistogramm ist ein wirksames Instrument für die Personalplanung und -koordination.


Analyse kritischer Pfade
Dieses Tool ist nützlich, um voneinander abhängige Aufgaben im Projekt zu erkennen. Es ist auch hilfreich, den kürzesten oder kritischen Pfad zu finden, um das Projekt erfolgreich abzuschließen. Wie beim PERT-Diagramm wird jedem Ereignis ein bestimmter Zeitrahmen zugewiesen. Dieses Tool zeigt die Abhängigkeit des Ereignisses an, vorausgesetzt, ein Ereignis kann nur dann zum nächsten übergehen, wenn das vorherige abgeschlossen ist.
Die Veranstaltungen sind nach dem frühestmöglichen Startzeitpunkt geordnet. Der Pfad zwischen Start- und Endknoten ist ein kritischer Pfad, der nicht weiter reduziert werden kann, und alle Ereignisse müssen in derselben Reihenfolge ausgeführt werden.
Die Softwareanforderungen sind eine Beschreibung der Merkmale und Funktionen des Zielsystems. Die Anforderungen vermitteln die Erwartungen der Benutzer an das Softwareprodukt. Die Anforderungen können offensichtlich oder verborgen, bekannt oder unbekannt, aus Sicht des Kunden erwartet oder unerwartet sein.
Requirement Engineering
Der Prozess zum Sammeln, Analysieren und Dokumentieren der Softwareanforderungen vom Kunden wird als Requirement Engineering bezeichnet.
Das Ziel des Requirement Engineering ist die Entwicklung und Pflege eines anspruchsvollen und beschreibenden Dokuments zur Spezifikation der Systemanforderungen.
Requirement Engineering-Prozess
Es ist ein vierstufiger Prozess, der Folgendes umfasst:
- Machbarkeitsstudie
- Anforderungserfassung
- Spezifikation der Softwareanforderungen
- Validierung der Softwareanforderungen
Lassen Sie uns den Prozess kurz sehen -
Machbarkeitsstudie
Wenn sich der Kunde an die Organisation wendet, um das gewünschte Produkt zu entwickeln, erhält er eine ungefähre Vorstellung davon, welche Funktionen die Software ausführen muss und welche Funktionen von der Software erwartet werden.
Unter Bezugnahme auf diese Informationen führen die Analysten eine detaillierte Studie darüber durch, ob die Entwicklung des gewünschten Systems und seiner Funktionalität möglich ist.
Diese Machbarkeitsstudie ist auf das Ziel der Organisation ausgerichtet. Diese Studie analysiert, ob das Softwareprodukt in Bezug auf Implementierung, Beitrag des Projekts zur Organisation, Kostenbeschränkungen und gemäß den Werten und Zielen der Organisation praktisch verwirklicht werden kann. Es werden technische Aspekte des Projekts und des Produkts wie Benutzerfreundlichkeit, Wartbarkeit, Produktivität und Integrationsfähigkeit untersucht.
Das Ergebnis dieser Phase sollte ein Machbarkeitsstudienbericht sein, der angemessene Kommentare und Empfehlungen für das Management darüber enthalten sollte, ob das Projekt durchgeführt werden sollte oder nicht.
Anforderungserfassung
Wenn der Durchführbarkeitsbericht für die Durchführung des Projekts positiv ist, beginnt die nächste Phase mit der Erfassung der Anforderungen vom Benutzer. Analysten und Ingenieure kommunizieren mit dem Kunden und den Endbenutzern, um zu erfahren, was die Software bieten soll und welche Funktionen die Software enthalten soll.
Spezifikation der Softwareanforderungen
SRS ist ein Dokument, das vom Systemanalysten erstellt wird, nachdem die Anforderungen von verschiedenen Stakeholdern gesammelt wurden.
SRS definiert, wie die beabsichtigte Software mit Hardware, externen Schnittstellen, Betriebsgeschwindigkeit, Reaktionszeit des Systems, Portabilität der Software auf verschiedenen Plattformen, Wartbarkeit, Wiederherstellungsgeschwindigkeit nach einem Absturz, Sicherheit, Qualität, Einschränkungen usw. interagiert.
Die vom Kunden erhaltenen Anforderungen sind in natürlicher Sprache verfasst. Es liegt in der Verantwortung des Systemanalysten, die Anforderungen in technischer Sprache zu dokumentieren, damit sie vom Softwareentwicklungsteam verstanden und nützlich sind.
SRS sollte folgende Funktionen bieten:
- Benutzeranforderungen werden in natürlicher Sprache ausgedrückt.
- Technische Anforderungen werden in einer strukturierten Sprache ausgedrückt, die innerhalb der Organisation verwendet wird.
- Die Entwurfsbeschreibung sollte in Pseudocode geschrieben sein.
- Format von Formularen und GUI-Siebdrucken.
- Bedingte und mathematische Notationen für DFDs usw.
Validierung der Softwareanforderungen
Nach der Entwicklung der Anforderungsspezifikationen werden die in diesem Dokument genannten Anforderungen validiert. Der Benutzer kann nach einer illegalen, unpraktischen Lösung fragen oder Experten können die Anforderungen falsch interpretieren. Dies führt zu einem enormen Kostenanstieg, wenn es nicht im Keim erstickt wird. Anforderungen können gegen folgende Bedingungen geprüft werden -
- Wenn sie praktisch umgesetzt werden können
- Wenn sie gültig sind und der Funktionalität und Domäne der Software entsprechen
- Wenn es Unklarheiten gibt
- Wenn sie vollständig sind
- Wenn sie demonstriert werden können
Anforderungserhebungsprozess
Der Anforderungserhebungsprozess kann anhand des folgenden Diagramms dargestellt werden:

- Requirements gathering - Die Entwickler diskutieren mit dem Kunden und den Endbenutzern und kennen ihre Erwartungen an die Software.
- Organizing Requirements - Die Entwickler priorisieren und ordnen die Anforderungen in der Reihenfolge ihrer Wichtigkeit, Dringlichkeit und Zweckmäßigkeit.
Negotiation & discussion - Wenn die Anforderungen nicht eindeutig sind oder es zu Konflikten bei den Anforderungen verschiedener Stakeholder kommt, werden diese ausgehandelt und mit den Stakeholdern diskutiert. Anforderungen können dann priorisiert und angemessen kompromittiert werden.
Die Anforderungen kommen von verschiedenen Stakeholdern. Um Mehrdeutigkeiten und Konflikte zu beseitigen, werden sie aus Gründen der Klarheit und Korrektheit erörtert. Unrealistische Anforderungen werden vernünftigerweise kompromittiert.
- Documentation - Alle formellen und informellen, funktionalen und nicht funktionalen Anforderungen werden dokumentiert und für die Verarbeitung in der nächsten Phase zur Verfügung gestellt.
Anforderungserhebungstechniken
Anforderungserhebung ist der Prozess zum Herausfinden der Anforderungen für ein beabsichtigtes Softwaresystem durch Kommunikation mit Kunden, Endbenutzern, Systembenutzern und anderen Personen, die an der Entwicklung von Softwaresystemen beteiligt sind.
Es gibt verschiedene Möglichkeiten, Anforderungen zu ermitteln
Interviews
Interviews sind ein starkes Medium, um Anforderungen zu sammeln. Die Organisation kann verschiedene Arten von Interviews durchführen, z.
- Strukturierte (geschlossene) Interviews, bei denen jede einzelne zu sammelnde Information im Voraus entschieden wird, folgen dem Muster und der Diskussionssache.
- Nicht strukturierte (offene) Interviews, bei denen die zu sammelnden Informationen nicht im Voraus entschieden werden, sind flexibler und weniger voreingenommen.
- Mündliche Interviews
- Schriftliche Interviews
- Einzelinterviews, die zwischen zwei Personen am Tisch stattfinden.
- Gruppeninterviews, die zwischen Teilnehmergruppen stattfinden. Sie helfen dabei, fehlende Anforderungen aufzudecken, da zahlreiche Personen beteiligt sind.
Umfragen
Die Organisation kann Umfragen unter verschiedenen Interessengruppen durchführen, indem sie ihre Erwartungen und Anforderungen an das bevorstehende System abfragt.
Fragebögen
Ein Dokument mit vordefinierten objektiven Fragen und entsprechenden Optionen wird allen Beteiligten zur Beantwortung übergeben, die gesammelt und zusammengestellt werden.
Ein Nachteil dieser Technik besteht darin, dass das Problem möglicherweise unbeaufsichtigt bleibt, wenn eine Option für ein Problem im Fragebogen nicht erwähnt wird.
Aufgabenanalyse
Ein Team von Ingenieuren und Entwicklern kann den Betrieb analysieren, für den das neue System benötigt wird. Wenn der Client bereits über Software verfügt, um bestimmte Vorgänge auszuführen, wird diese untersucht und die Anforderungen des vorgeschlagenen Systems werden erfasst.
Domänenanalyse
Jede Software fällt in eine Domain-Kategorie. Die Experten auf diesem Gebiet können eine große Hilfe bei der Analyse allgemeiner und spezifischer Anforderungen sein.
Brainstorming
Es findet eine informelle Debatte zwischen verschiedenen Interessengruppen statt, und alle ihre Beiträge werden zur weiteren Anforderungsanalyse aufgezeichnet.
Prototyp entwickeln
Beim Prototyping wird eine Benutzeroberfläche erstellt, ohne dass dem Benutzer Detailfunktionen hinzugefügt werden müssen, um die Funktionen des beabsichtigten Softwareprodukts zu interpretieren. Es hilft, eine bessere Vorstellung von den Anforderungen zu bekommen. Wenn am Ende des Clients keine Software als Referenz für den Entwickler installiert ist und der Client seine eigenen Anforderungen nicht kennt, erstellt der Entwickler einen Prototyp basierend auf den ursprünglich genannten Anforderungen. Der Prototyp wird dem Kunden gezeigt und das Feedback wird notiert. Das Kundenfeedback dient als Eingabe für das Sammeln von Anforderungen.
Überwachung
Ein Expertenteam besucht die Organisation oder den Arbeitsplatz des Kunden. Sie beobachten die tatsächliche Funktionsweise der vorhandenen installierten Systeme. Sie beobachten den Workflow am Ende des Kunden und wie Ausführungsprobleme behandelt werden. Das Team selbst zieht einige Schlussfolgerungen, die dazu beitragen, die von der Software erwarteten Anforderungen zu formulieren.
Merkmale der Softwareanforderungen
Das Sammeln von Softwareanforderungen ist die Grundlage des gesamten Softwareentwicklungsprojekts. Daher müssen sie klar, korrekt und klar definiert sein.
Eine vollständige Softwareanforderungsspezifikation muss sein:
- Clear
- Correct
- Consistent
- Coherent
- Comprehensible
- Modifiable
- Verifiable
- Prioritized
- Unambiguous
- Traceable
- Glaubwürdige Quelle
Software Anforderungen
Wir sollten versuchen zu verstehen, welche Art von Anforderungen in der Anforderungserhebungsphase auftreten können und welche Arten von Anforderungen vom Softwaresystem erwartet werden.
Allgemein sollten Softwareanforderungen in zwei Kategorien eingeteilt werden:
Funktionale Anforderungen
Anforderungen, die sich auf den Funktionsaspekt von Software beziehen, fallen in diese Kategorie.
Sie definieren Funktionen und Funktionalitäten innerhalb und außerhalb des Softwaresystems.
Beispiele -
- Suchoption für Benutzer zur Suche aus verschiedenen Rechnungen.
- Der Benutzer sollte in der Lage sein, jeden Bericht an das Management zu senden.
- Benutzer können in Gruppen unterteilt werden und Gruppen können separate Rechte zugewiesen werden.
- Sollte Geschäftsregeln und Verwaltungsfunktionen erfüllen.
- Die Software wurde unter Beibehaltung der Abwärtskompatibilität entwickelt.
Nicht-funktionale Anforderungen
Anforderungen, die sich nicht auf den Funktionsaspekt von Software beziehen, fallen in diese Kategorie. Sie sind implizite oder erwartete Merkmale von Software, von denen Benutzer ausgehen.
Nichtfunktionale Anforderungen umfassen -
- Security
- Logging
- Storage
- Configuration
- Performance
- Cost
- Interoperability
- Flexibility
- Notfallwiederherstellung
- Accessibility
Anforderungen werden logisch als kategorisiert
- Must Have : Software kann ohne sie nicht als betriebsbereit bezeichnet werden.
- Should have : Verbesserung der Funktionalität von Software.
- Could have : Software kann mit diesen Anforderungen weiterhin ordnungsgemäß funktionieren.
- Wish list : Diese Anforderungen sind keinem Softwareziel zugeordnet.
Während der Entwicklung von Software muss "Must Have" implementiert werden. "Should Have" ist eine Frage der Debatte mit den Stakeholdern und der Verneinung, während "Have Have" und "Wunschliste" für Software-Updates aufbewahrt werden können.
Anforderungen an die Benutzeroberfläche
Die Benutzeroberfläche ist ein wichtiger Bestandteil jeder Software, Hardware oder jedes Hybridsystems. Eine Software wird allgemein akzeptiert, wenn es -
- leicht zu bedienen
- schnell als Antwort
- Betriebsfehler effektiv behandeln
- Bereitstellung einer einfachen und dennoch konsistenten Benutzeroberfläche
Die Benutzerakzeptanz hängt hauptsächlich davon ab, wie der Benutzer die Software verwenden kann. Die Benutzeroberfläche ist die einzige Möglichkeit für Benutzer, das System wahrzunehmen. Ein leistungsfähiges Softwaresystem muss außerdem mit einer attraktiven, klaren, konsistenten und reaktionsschnellen Benutzeroberfläche ausgestattet sein. Andernfalls können die Funktionen des Softwaresystems nicht bequem genutzt werden. Ein System gilt als gut, wenn es Mittel zur effizienten Nutzung bietet. Die Anforderungen an die Benutzeroberfläche werden im Folgenden kurz aufgeführt.
- Inhaltspräsentation
- Einfache Navigation
- Einfache Schnittstelle
- Responsive
- Konsistente UI-Elemente
- Rückkopplungsmechanismus
- Standardeinstellungen
- Zweckmäßiges Layout
- Strategischer Einsatz von Farbe und Textur.
- Geben Sie Hilfeinformationen an
- Benutzerzentrierter Ansatz
- Gruppenbasierte Ansichtseinstellungen.
Software System Analyst
Der Systemanalyst in einer IT-Organisation ist eine Person, die die Anforderungen des vorgeschlagenen Systems analysiert und sicherstellt, dass die Anforderungen richtig und korrekt konzipiert und dokumentiert werden. Die Rolle eines Analysten beginnt während der Softwareanalysephase von SDLC. Es liegt in der Verantwortung des Analysten, sicherzustellen, dass die entwickelte Software den Anforderungen des Kunden entspricht.
Systemanalysten haben folgende Verantwortlichkeiten:
- Analysieren und Verstehen der Anforderungen der beabsichtigten Software
- Verstehen, wie das Projekt zu den Organisationszielen beitragen wird
- Anforderungsquellen identifizieren
- Validierung der Anforderung
- Entwicklung und Implementierung eines Anforderungsmanagementplans
- Dokumentation der geschäftlichen, technischen, Prozess- und Produktanforderungen
- Koordination mit Kunden, um Anforderungen zu priorisieren und Unklarheiten zu beseitigen
- Festlegung der Akzeptanzkriterien mit dem Kunden und anderen Stakeholdern
Software-Metriken und -Messungen
Software-Maßnahmen können als ein Prozess zur Quantifizierung und Symbolisierung verschiedener Attribute und Aspekte von Software verstanden werden.
Software-Metriken bieten Messwerte für verschiedene Aspekte des Softwareprozesses und des Softwareprodukts.
Softwaremaßnahmen sind eine Grundvoraussetzung für das Software-Engineering. Sie helfen nicht nur, den Softwareentwicklungsprozess zu steuern, sondern auch, die Qualität des Endprodukts ausgezeichnet zu halten.
Laut Tom DeMarco, einem (Software Engineer), können Sie nicht steuern, was Sie nicht messen können. Durch sein Sprichwort wird sehr deutlich, wie wichtig Softwaremaßnahmen sind.
Sehen wir uns einige Software-Metriken an:
Size Metrics - LOC (Lines of Code), meist berechnet in Tausenden von gelieferten Quellcodezeilen, bezeichnet als KLOC.
Die Funktionspunktzahl ist ein Maß für die von der Software bereitgestellte Funktionalität. Die Anzahl der Funktionspunkte definiert die Größe des Funktionsaspekts der Software.
- Complexity Metrics - McCabes zyklomatische Komplexität quantifiziert die Obergrenze der Anzahl unabhängiger Pfade in einem Programm, die als Komplexität des Programms oder seiner Module wahrgenommen wird. Es wird in Form von graphentheoretischen Konzepten unter Verwendung eines Kontrollflussgraphen dargestellt.
Quality Metrics - Mängel, ihre Arten und Ursachen, Folgen, Intensität der Schwere und ihre Auswirkungen bestimmen die Qualität des Produkts.
Die Anzahl der im Entwicklungsprozess festgestellten Fehler und die Anzahl der vom Kunden gemeldeten Fehler, nachdem das Produkt auf Kundenseite installiert oder geliefert wurde, bestimmen die Produktqualität.
- Process Metrics - In verschiedenen Phasen von SDLC sind die verwendeten Methoden und Werkzeuge, die Unternehmensstandards und die Leistung der Entwicklung Softwareprozessmetriken.
- Resource Metrics - Aufwand, Zeit und verschiedene verwendete Ressourcen repräsentieren Metriken für die Ressourcenmessung.
Software-Design ist ein Prozess, um Benutzeranforderungen in eine geeignete Form umzuwandeln, die dem Programmierer bei der Codierung und Implementierung von Software hilft.
Zur Bewertung der Benutzeranforderungen wird ein SRS-Dokument (Software Requirement Specification) erstellt, während für die Codierung und Implementierung spezifischere und detailliertere Anforderungen in Bezug auf die Software erforderlich sind. Die Ausgabe dieses Prozesses kann direkt in die Implementierung in Programmiersprachen verwendet werden.
Software-Design ist der erste Schritt in SDLC (Software Design Life Cycle), bei dem die Konzentration von der Problemdomäne zur Lösungsdomäne verlagert wird. Es wird versucht anzugeben, wie die in SRS genannten Anforderungen erfüllt werden sollen.
Software-Design-Levels
Das Software-Design liefert drei Ergebnisebenen:
- Architectural Design - Das architektonische Design ist die höchste abstrakte Version des Systems. Es identifiziert die Software als ein System mit vielen Komponenten, die miteinander interagieren. Auf dieser Ebene erhalten die Designer die Idee der vorgeschlagenen Lösungsdomäne.
- High-level Design- Das übergeordnete Design unterteilt das Konzept der architektonischen Gestaltung in einzelne Entitäten und mehrere Komponenten in eine weniger abstrahierte Ansicht von Subsystemen und Modulen und zeigt deren Interaktion miteinander. High-Level-Design konzentriert sich darauf, wie das System zusammen mit all seinen Komponenten in Form von Modulen implementiert werden kann. Es erkennt den modularen Aufbau jedes Subsystems und ihre Beziehung und Interaktion untereinander.
- Detailed Design- Das detaillierte Design befasst sich mit dem Implementierungsteil eines Systems und seiner Subsysteme in den beiden vorherigen Designs. Es wird detaillierter auf Module und deren Implementierungen eingegangen. Es definiert die logische Struktur jedes Moduls und seiner Schnittstellen für die Kommunikation mit anderen Modulen.
Modularisierung
Modularisierung ist eine Technik zum Aufteilen eines Softwaresystems in mehrere diskrete und unabhängige Module, von denen erwartet wird, dass sie in der Lage sind, Aufgaben unabhängig voneinander auszuführen. Diese Module können als Grundkonstrukte für die gesamte Software fungieren. Designer neigen dazu, Module so zu gestalten, dass sie separat und unabhängig ausgeführt und / oder kompiliert werden können.
Der modulare Aufbau folgt unbeabsichtigt den Regeln der Problemlösungsstrategie „Teilen und Erobern“. Dies liegt daran, dass der modulare Aufbau einer Software viele weitere Vorteile mit sich bringt.
Vorteil der Modularisierung:
- Kleinere Komponenten sind leichter zu warten
- Das Programm kann nach funktionalen Aspekten unterteilt werden
- Die gewünschte Abstraktionsebene kann in das Programm aufgenommen werden
- Komponenten mit hoher Kohäsion können wieder verwendet werden
- Die gleichzeitige Ausführung kann ermöglicht werden
- Aus Sicherheitsgründen erwünscht
Parallelität
In der Vergangenheit soll die gesamte Software nacheinander ausgeführt werden. Mit sequentieller Ausführung ist gemeint, dass der codierte Befehl nacheinander ausgeführt wird, was bedeutet, dass jeweils nur ein Teil des Programms aktiviert wird. Angenommen, eine Software verfügt über mehrere Module. Dann kann zu jedem Zeitpunkt der Ausführung nur eines der Module als aktiv befunden werden.
Beim Software-Design wird die Parallelität implementiert, indem die Software in mehrere unabhängige Ausführungseinheiten wie Module aufgeteilt und parallel ausgeführt wird. Mit anderen Worten, Parallelität bietet der Software die Möglichkeit, mehr als einen Teil des Codes parallel zueinander auszuführen.
Die Programmierer und Designer müssen die Module erkennen, die parallel ausgeführt werden können.
Beispiel
Die Rechtschreibprüfung in der Textverarbeitung ist ein Softwaremodul, das neben der Textverarbeitung selbst ausgeführt wird.
Kopplung und Zusammenhalt
Wenn ein Softwareprogramm modularisiert wird, werden seine Aufgaben basierend auf einigen Merkmalen in mehrere Module unterteilt. Wie wir wissen, sind Module eine Reihe von Anweisungen, die zusammengestellt werden, um einige Aufgaben zu erfüllen. Sie werden jedoch als eine Einheit betrachtet, können sich jedoch aufeinander beziehen, um zusammenzuarbeiten. Es gibt Maßnahmen, mit denen die Qualität eines Entwurfs von Modulen und deren Wechselwirkung zwischen ihnen gemessen werden kann. Diese Maßnahmen werden als Kopplung und Zusammenhalt bezeichnet.
Zusammenhalt
Kohäsion ist ein Maß, das den Grad der Intra-Zuverlässigkeit innerhalb von Elementen eines Moduls definiert. Je größer der Zusammenhalt, desto besser ist das Programmdesign.
Es gibt sieben Arten des Zusammenhalts, nämlich -
- Co-incidental cohesion -Es handelt sich um einen ungeplanten und zufälligen Zusammenhalt, der das Ergebnis einer Aufteilung des Programms in kleinere Module zur Modularisierung sein kann. Da es nicht geplant ist, kann es den Programmierern Verwirrung stiften und wird im Allgemeinen nicht akzeptiert.
- Logical cohesion - Wenn logisch kategorisierte Elemente zu einem Modul zusammengefügt werden, spricht man von logischem Zusammenhalt.
- emporal Cohesion - Wenn Elemente eines Moduls so organisiert sind, dass sie zu einem ähnlichen Zeitpunkt verarbeitet werden, spricht man von zeitlichem Zusammenhalt.
- Procedural cohesion - Wenn Elemente eines Moduls zusammengefasst werden, die nacheinander ausgeführt werden, um eine Aufgabe auszuführen, spricht man von prozeduralem Zusammenhalt.
- Communicational cohesion - Wenn Elemente eines Moduls zusammengefasst werden, die nacheinander ausgeführt werden und mit denselben Daten (Informationen) arbeiten, spricht man von Kommunikationszusammenhalt.
- Sequential cohesion - Wenn Elemente eines Moduls gruppiert werden, weil die Ausgabe eines Elements als Eingabe für ein anderes Element usw. dient, wird dies als sequentielle Kohäsion bezeichnet.
- Functional cohesion - Es wird als der höchste Grad an Kohäsion angesehen und wird sehr erwartet. Elemente des Moduls im funktionalen Zusammenhalt werden gruppiert, weil sie alle zu einer einzigen genau definierten Funktion beitragen. Es kann auch wiederverwendet werden.
Kupplung
Die Kopplung ist eine Maßnahme, die den Grad der gegenseitigen Zuverlässigkeit zwischen Modulen eines Programms definiert. Es zeigt an, auf welcher Ebene die Module interferieren und miteinander interagieren. Je niedriger die Kopplung, desto besser das Programm.
Es gibt fünf Kopplungsstufen, nämlich -
- Content coupling - Wenn ein Modul direkt auf den Inhalt eines anderen Moduls zugreifen oder diesen ändern oder darauf verweisen kann, spricht man von einer Kopplung auf Inhaltsebene.
- Common coupling- Wenn mehrere Module Lese- und Schreibzugriff auf einige globale Daten haben, spricht man von gemeinsamer oder globaler Kopplung.
- Control coupling- Zwei Module werden als steuerungsgekoppelt bezeichnet, wenn eines die Funktion des anderen Moduls bestimmt oder dessen Ausführungsfluss ändert.
- Stamp coupling- Wenn mehrere Module eine gemeinsame Datenstruktur verwenden und an einem anderen Teil davon arbeiten, spricht man von einer Stempelkopplung.
- Data coupling- Datenkopplung ist, wenn zwei Module durch Übergabe von Daten (als Parameter) miteinander interagieren. Wenn ein Modul die Datenstruktur als Parameter übergibt, sollte das empfangende Modul alle seine Komponenten verwenden.
Im Idealfall wird keine Kupplung als die beste angesehen.
Designüberprüfung
Die Ausgabe des Software-Entwurfsprozesses besteht aus Entwurfsdokumentation, Pseudocodes, detaillierten Logikdiagrammen, Prozessdiagrammen und einer detaillierten Beschreibung aller funktionalen oder nicht funktionalen Anforderungen.
Die nächste Phase, die Implementierung von Software, hängt von allen oben genannten Ausgaben ab.
Anschließend muss die Ausgabe überprüft werden, bevor mit der nächsten Phase fortgefahren werden kann. Je früher ein Fehler erkannt wird, desto besser ist er oder wird er möglicherweise erst beim Testen des Produkts erkannt. Wenn die Ergebnisse der Entwurfsphase in formaler Notationsform vorliegen, sollten die zugehörigen Tools zur Verifizierung verwendet werden. Andernfalls kann eine gründliche Entwurfsüberprüfung zur Verifizierung und Validierung verwendet werden.
Durch den strukturierten Überprüfungsansatz können Prüfer Fehler erkennen, die durch das Übersehen einiger Bedingungen verursacht werden können. Eine gute Entwurfsprüfung ist wichtig für ein gutes Software-Design, Genauigkeit und Qualität.
Die Softwareanalyse und das Design umfassen alle Aktivitäten, die bei der Umwandlung der Anforderungsspezifikation in die Implementierung helfen. Die Anforderungsspezifikationen spezifizieren alle funktionalen und nicht funktionalen Erwartungen an die Software. Diese Anforderungsspezifikationen bestehen aus lesbaren und verständlichen Dokumenten, mit denen ein Computer nichts zu tun hat.
Softwareanalyse und -design sind die Zwischenstufe, mit deren Hilfe von Menschen lesbare Anforderungen in tatsächlichen Code umgewandelt werden können.
Sehen wir uns einige Analyse- und Designtools an, die von Software-Designern verwendet werden:
Datenflussdiagramm
Das Datenflussdiagramm ist eine grafische Darstellung des Datenflusses in einem Informationssystem. Es ist in der Lage, eingehenden Datenfluss, ausgehenden Datenfluss und gespeicherte Daten darzustellen. Der DFD erwähnt nichts darüber, wie Daten durch das System fließen.
Es gibt einen deutlichen Unterschied zwischen DFD und Flussdiagramm. Das Flussdiagramm zeigt den Steuerungsfluss in Programmmodulen. DFDs zeigen den Datenfluss im System auf verschiedenen Ebenen. DFD enthält keine Steuerungs- oder Verzweigungselemente.
Arten von DFD
Datenflussdiagramme sind entweder logisch oder physisch.
- Logical DFD - Diese Art von DFD konzentriert sich auf den Systemprozess und den Datenfluss im System. Beispiel: In einem Banking-Softwaresystem, wie Daten zwischen verschiedenen Entitäten verschoben werden.
- Physical DFD- Diese Art von DFD zeigt, wie der Datenfluss tatsächlich im System implementiert ist. Es ist spezifischer und nah an der Implementierung.
DFD-Komponenten
DFD kann Quelle, Ziel, Speicherung und Datenfluss mithilfe der folgenden Komponenten darstellen:

- Entities- Entitäten sind Quelle und Ziel von Informationsdaten. Entitäten werden durch ein Rechteck mit ihren jeweiligen Namen dargestellt.
- Process - Aktivitäten und Aktionen, die an den Daten ausgeführt werden, werden durch kreisförmige oder rundkantige Rechtecke dargestellt.
- Data Storage - Es gibt zwei Varianten der Datenspeicherung: Sie kann entweder als Rechteck ohne beide kleineren Seiten oder als offenes Rechteck mit nur einer fehlenden Seite dargestellt werden.
- Data Flow- Die Bewegung der Daten wird durch spitze Pfeile angezeigt. Die Datenbewegung wird von der Pfeilbasis als Quelle zur Pfeilspitze als Ziel angezeigt.
DFD-Stufen
- Level 0- DFD mit der höchsten Abstraktionsebene ist als DFD der Ebene 0 bekannt. Dabei wird das gesamte Informationssystem als ein Diagramm dargestellt, in dem alle zugrunde liegenden Details verborgen sind. DFDs der Ebene 0 werden auch als DFDs der Kontextebene bezeichnet.
- Level 1- Das DFD der Stufe 0 ist in spezifischere DFD der Stufe 1 unterteilt. Level 1 DFD zeigt grundlegende Module im System und den Datenfluss zwischen verschiedenen Modulen. Level 1 DFD erwähnt auch grundlegende Prozesse und Informationsquellen.
Level 2 - Auf dieser Ebene zeigt DFD, wie Daten innerhalb der in Ebene 1 genannten Module fließen.
DFDs auf höherer Ebene können in spezifischere DFDs auf niedrigerer Ebene mit tieferem Verständnis umgewandelt werden, sofern nicht das gewünschte Spezifikationsniveau erreicht wird.


Strukturdiagramme
Das Strukturdiagramm ist ein Diagramm, das aus dem Datenflussdiagramm abgeleitet wurde. Es stellt das System detaillierter dar als DFD. Es unterteilt das gesamte System in niedrigste Funktionsmodule, beschreibt Funktionen und Unterfunktionen jedes Moduls des Systems detaillierter als DFD.
Das Strukturdiagramm repräsentiert die hierarchische Struktur der Module. Auf jeder Ebene wird eine bestimmte Aufgabe ausgeführt.
Hier sind die Symbole, die bei der Erstellung von Strukturdiagrammen verwendet werden -
- Module- Es repräsentiert einen Prozess oder ein Unterprogramm oder eine Aufgabe. Ein Steuermodul verzweigt in mehr als ein Untermodul. Bibliotheksmodule können von jedem Modul aus wiederverwendet und aufgerufen werden.

- Condition- Es wird durch einen kleinen Diamanten an der Basis des Moduls dargestellt. Es zeigt, dass das Steuermodul basierend auf einer bestimmten Bedingung eine beliebige Unterroutine auswählen kann.

- Jump - Ein Pfeil zeigt in das Modul, um anzuzeigen, dass die Steuerung in die Mitte des Untermoduls springt.

- Loop- Ein gekrümmter Pfeil repräsentiert die Schleife im Modul. Alle von der Schleife abgedeckten Untermodule wiederholen die Ausführung des Moduls.

- Data flow - Ein gerichteter Pfeil mit einem leeren Kreis am Ende repräsentiert den Datenfluss.

- Control flow - Ein gerichteter Pfeil mit einem ausgefüllten Kreis am Ende repräsentiert den Kontrollfluss.

HIPO-Diagramm
Das HIPO-Diagramm (Hierarchical Input Process Output) ist eine Kombination aus zwei organisierten Methoden zur Analyse des Systems und zur Bereitstellung der Dokumentationsmittel. Das HIPO-Modell wurde 1970 von IBM entwickelt.
Das HIPO-Diagramm repräsentiert die Hierarchie der Module im Softwaresystem. Analyst verwendet das HIPO-Diagramm, um eine allgemeine Ansicht der Systemfunktionen zu erhalten. Es zerlegt Funktionen hierarchisch in Unterfunktionen. Es zeigt die vom System ausgeführten Funktionen.
HIPO-Diagramme eignen sich gut für Dokumentationszwecke. Ihre grafische Darstellung erleichtert es Designern und Managern, sich ein Bild von der Systemstruktur zu machen.

Im Gegensatz zum IPO-Diagramm (Input Process Output), das den Steuerungs- und Datenfluss in einem Modul darstellt, liefert die HIPO keine Informationen zum Datenfluss oder Kontrollfluss.

Beispiel
Beide Teile des HIPO-Diagramms, der hierarchischen Darstellung und des IPO-Diagramms werden für das Strukturdesign eines Softwareprogramms sowie für dessen Dokumentation verwendet.
Strukturiertes Englisch
Die meisten Programmierer kennen das Gesamtbild der Software nicht und verlassen sich daher nur auf die Anweisungen ihrer Manager. Es liegt in der Verantwortung eines höheren Software-Managements, den Programmierern genaue Informationen zur Verfügung zu stellen, um genauen und dennoch schnellen Code zu entwickeln.
Andere Arten von Methoden, die Grafiken oder Diagramme verwenden, können manchmal von verschiedenen Personen unterschiedlich interpretiert werden.
Daher entwickeln Analysten und Designer der Software Tools wie Structured English. Es ist nichts anderes als die Beschreibung dessen, was zum Codieren erforderlich ist und wie es codiert wird. Strukturiertes Englisch hilft dem Programmierer, fehlerfreien Code zu schreiben.
Andere Formen von Methoden, die Grafiken oder Diagramme verwenden, können manchmal von verschiedenen Personen unterschiedlich interpretiert werden. Hier versuchen sowohl Structured English als auch Pseudo-Code, diese Verständnislücke zu schließen.
Strukturiertes Englisch ist das Es verwendet einfache englische Wörter im strukturierten Programmierparadigma. Es ist nicht der ultimative Code, sondern eine Art Beschreibung, was zum Codieren erforderlich ist und wie es codiert wird. Das Folgende sind einige Token für strukturierte Programmierung.
IF-THEN-ELSE,
DO-WHILE-UNTILAnalyst verwendet dieselbe Variable und denselben Datennamen, die im Datenwörterbuch gespeichert sind, was das Schreiben und Verstehen des Codes erheblich vereinfacht.
Beispiel
Wir nehmen das gleiche Beispiel der Kundenauthentifizierung in der Online-Einkaufsumgebung. Dieses Verfahren zur Authentifizierung des Kunden kann in strukturiertem Englisch wie folgt geschrieben werden:
Enter Customer_Name
SEEK Customer_Name in Customer_Name_DB file
IF Customer_Name found THEN
Call procedure USER_PASSWORD_AUTHENTICATE()
ELSE
PRINT error message
Call procedure NEW_CUSTOMER_REQUEST()
ENDIFDer in strukturiertem Englisch geschriebene Code ähnelt eher dem alltäglichen gesprochenen Englisch. Es kann nicht direkt als Software-Code implementiert werden. Strukturiertes Englisch ist unabhängig von der Programmiersprache.
Pseudo-Code
Pseudocode wird näher an der Programmiersprache geschrieben. Es kann als erweiterte Programmiersprache mit vielen Kommentaren und Beschreibungen betrachtet werden.
Pseudocode vermeidet die Deklaration von Variablen, sie werden jedoch mit Konstrukten einiger tatsächlicher Programmiersprachen wie C, Fortran, Pascal usw. geschrieben.
Pseudocode enthält mehr Programmierdetails als strukturiertes Englisch. Es bietet eine Methode zum Ausführen der Aufgabe, als würde ein Computer den Code ausführen.
Beispiel
Programm zum Drucken von Fibonacci mit bis zu n Zahlen.
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}Entscheidungstabellen
Eine Entscheidungstabelle enthält die Bedingungen und die entsprechenden Maßnahmen, die zu ihrer Behebung ergriffen werden müssen, in einem strukturierten Tabellenformat.
Es ist ein leistungsstarkes Tool zum Debuggen und Verhindern von Fehlern. Es hilft, ähnliche Informationen in einer einzigen Tabelle zu gruppieren, und bietet dann durch Kombinieren von Tabellen eine einfache und bequeme Entscheidungsfindung.
Entscheidungstabelle erstellen
Um die Entscheidungstabelle zu erstellen, muss der Entwickler die folgenden vier grundlegenden Schritte ausführen:
- Identifizieren Sie alle möglichen Bedingungen, die angegangen werden müssen
- Bestimmen Sie Aktionen für alle identifizierten Bedingungen
- Erstellen Sie maximal mögliche Regeln
- Definieren Sie die Aktion für jede Regel
Entscheidungstabellen sollten von Endbenutzern überprüft werden und können in letzter Zeit vereinfacht werden, indem doppelte Regeln und Aktionen beseitigt werden.
Beispiel
Nehmen wir ein einfaches Beispiel für alltägliche Probleme mit unserer Internetverbindung. Wir identifizieren zunächst alle Probleme, die beim Starten des Internets auftreten können, und ihre jeweiligen möglichen Lösungen.
Wir listen alle möglichen Probleme unter Spaltenbedingungen und die möglichen Aktionen unter Spaltenaktionen auf.
| Bedingungen / Aktionen | Regeln | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Bedingungen | Zeigt Verbunden an | N. | N. | N. | N. | Y. | Y. | Y. | Y. |
| Ping funktioniert | N. | N. | Y. | Y. | N. | N. | Y. | Y. | |
| Öffnet die Website | Y. | N. | Y. | N. | Y. | N. | Y. | N. | |
| Aktionen | Überprüfen Sie das Netzwerkkabel | X. | |||||||
| Überprüfen Sie den Internet-Router | X. | X. | X. | X. | |||||
| Starten Sie den Webbrowser neu | X. | ||||||||
| Wenden Sie sich an den Dienstanbieter | X. | X. | X. | X. | X. | X. | |||
| Mach keine Aktion | |||||||||
Entity-Relationship-Modell
Das Entity-Relationship-Modell ist eine Art Datenbankmodell, das auf dem Begriff der realen Entitäten und der Beziehung zwischen ihnen basiert. Wir können ein reales Szenario auf ein ER-Datenbankmodell abbilden. Das ER-Modell erstellt eine Reihe von Entitäten mit ihren Attributen, einer Reihe von Einschränkungen und Beziehungen zwischen ihnen.
Das ER-Modell eignet sich am besten für die Konzeption von Datenbanken. Das ER-Modell kann wie folgt dargestellt werden:

Entity - Eine Entität im ER-Modell ist ein Wesen der realen Welt, das einige Eigenschaften hat, die als bezeichnet werden attributes. Jedes Attribut wird durch den entsprechenden Wertesatz definiert, der aufgerufen wirddomain.
Betrachten Sie beispielsweise eine Schuldatenbank. Hier ist ein Student eine Einheit. Der Schüler hat verschiedene Attribute wie Name, ID, Alter und Klasse usw.
Relationship - Die logische Zuordnung zwischen Entitäten wird aufgerufen relationship. Beziehungen zu Entitäten werden auf verschiedene Arten zugeordnet. Mapping-Kardinalitäten definieren die Anzahl der Assoziationen zwischen zwei Entitäten.
Kardinalitäten abbilden:
- eins zu eins
- eins zu viele
- viele zu eins
- viel zu viel
Datenwörterbuch
Das Datenwörterbuch ist die zentralisierte Sammlung von Informationen über Daten. Es speichert die Bedeutung und Herkunft der Daten, ihre Beziehung zu anderen Daten, das Datenformat für die Verwendung usw. Das Datenwörterbuch enthält strenge Definitionen aller Namen, um Benutzer- und Softwareentwicklern die Arbeit zu erleichtern.
Das Datenwörterbuch wird häufig als Metadaten-Repository (Daten über Daten) bezeichnet. Es wird zusammen mit dem DFD-Modell (Data Flow Diagram) des Softwareprogramms erstellt und wird voraussichtlich aktualisiert, wenn DFD geändert oder aktualisiert wird.
Anforderung des Datenwörterbuchs
Die Daten werden beim Entwerfen und Implementieren von Software über ein Datenwörterbuch referenziert. Das Datenwörterbuch beseitigt alle Unklarheiten. Es hilft dabei, die Arbeit von Programmierern und Designern synchron zu halten, während überall im Programm dieselbe Objektreferenz verwendet wird.
Das Datenwörterbuch bietet eine Möglichkeit zur Dokumentation des gesamten Datenbanksystems an einem Ort. Die Validierung von DFD erfolgt mit dem Datenwörterbuch.
Inhalt
Das Datenwörterbuch sollte Informationen zu folgenden Themen enthalten
- Datenfluss
- Datenstruktur
- Datenelemente
- Datenspeicher
- Datenverarbeitung
Der Datenfluss wird mittels DFDs beschrieben, wie zuvor untersucht, und wie beschrieben in algebraischer Form dargestellt.
| = | Zusammengesetzt aus |
|---|---|
| {} | Wiederholung |
| () | Optional |
| + | Und |
| [/] | Oder |
Beispiel
Adresse = Hausnummer + (Straße / Gebiet) + Stadt + Bundesland
Kurs-ID = Kursnummer + Kursname + Kursstufe + Kursnoten
Datenelemente
Datenelemente bestehen aus Namen und Beschreibungen von Daten und Steuerelementen, internen oder externen Datenspeichern usw. mit folgenden Details:
- Primärname
- Sekundärer Name (Alias)
- Anwendungsfall (wie und wo zu verwenden)
- Inhaltsbeschreibung (Notation etc.)
- Ergänzende Informationen (voreingestellte Werte, Einschränkungen usw.)
Datenspeicher
Es speichert die Informationen, von denen aus die Daten in das System gelangen und außerhalb des Systems existieren. Der Datenspeicher kann Folgendes enthalten:
- Files
- Intern in der Software.
- Extern zur Software, aber auf demselben Computer.
- Extern zu Software und System, auf verschiedenen Maschinen.
- Tables
- Namenskonvention
- Indizierungseigenschaft
Datenverarbeitung
Es gibt zwei Arten der Datenverarbeitung:
- Logical: Wie der Benutzer es sieht
- Physical: Wie die Software es sieht
Software-Design ist ein Prozess zur Konzeption der Softwareanforderungen in die Software-Implementierung. Das Software-Design nimmt die Benutzeranforderungen als Herausforderung und versucht, eine optimale Lösung zu finden. Während der Konzeption der Software wird ein Plan erstellt, um das bestmögliche Design für die Implementierung der beabsichtigten Lösung zu finden.
Es gibt mehrere Varianten des Software-Designs. Lassen Sie uns sie kurz studieren:
Strukturiertes Design
Strukturiertes Design ist eine Konzeptualisierung des Problems in mehrere gut organisierte Lösungselemente. Grundsätzlich geht es um das Lösungsdesign. Der Vorteil von strukturiertem Design besteht darin, dass es ein besseres Verständnis dafür gibt, wie das Problem gelöst wird. Strukturiertes Design erleichtert es dem Designer auch, sich genauer auf das Problem zu konzentrieren.
Strukturiertes Design basiert hauptsächlich auf der Strategie „Teilen und Erobern“, bei der ein Problem in mehrere kleine Probleme unterteilt wird und jedes kleine Problem einzeln gelöst wird, bis das gesamte Problem gelöst ist.
Die kleinen Probleme werden mit Hilfe von Lösungsmodulen gelöst. Strukturiertes Design betont, dass diese Module gut organisiert sind, um eine präzise Lösung zu erreichen.
Diese Module sind hierarchisch angeordnet. Sie kommunizieren miteinander. Ein gut strukturiertes Design folgt immer einigen Regeln für die Kommunikation zwischen mehreren Modulen, nämlich -
Cohesion - Gruppierung aller funktional verwandten Elemente.
Coupling - Kommunikation zwischen verschiedenen Modulen.
Ein gut strukturiertes Design hat eine hohe Kohäsion und niedrige Kopplungsanordnungen.
Funktionsorientiertes Design
Beim funktionsorientierten Entwurf besteht das System aus vielen kleineren Teilsystemen, die als Funktionen bekannt sind. Diese Funktionen können wichtige Aufgaben im System ausführen. Das System wird als Draufsicht auf alle Funktionen betrachtet.
Funktionsorientiertes Design erbt einige Eigenschaften des strukturierten Designs, bei denen die Divide and Conquer-Methode verwendet wird.
Dieser Entwurfsmechanismus unterteilt das gesamte System in kleinere Funktionen, die Abstraktionsmöglichkeiten bieten, indem die Informationen und ihre Funktionsweise verborgen werden. Diese Funktionsmodule können Informationen untereinander austauschen, indem Informationen weitergegeben und global verfügbare Informationen verwendet werden.
Ein weiteres Merkmal von Funktionen ist, dass wenn ein Programm eine Funktion aufruft, die Funktion den Status des Programms ändert, was von anderen Modulen manchmal nicht akzeptiert wird. Funktionsorientiertes Design funktioniert gut, wenn der Systemstatus keine Rolle spielt und Programm / Funktionen eher auf Eingabe als auf einen Status arbeiten.
Designprozess
- Das gesamte System wird anhand eines Datenflussdiagramms als Datenfluss im System angesehen.
- DFD zeigt, wie Funktionen Daten und Status des gesamten Systems ändern.
- Das gesamte System wird aufgrund seines Betriebs im System logischerweise in kleinere Einheiten unterteilt, die als Funktionen bezeichnet werden.
- Jede Funktion wird dann allgemein beschrieben.
Objektorientiertes Design
Objektorientiertes Design arbeitet um die Entitäten und ihre Eigenschaften herum anstatt um Funktionen, die am Softwaresystem beteiligt sind. Diese Entwurfsstrategie konzentriert sich auf Entitäten und ihre Eigenschaften. Das gesamte Konzept der Softwarelösung dreht sich um die beteiligten Einheiten.
Lassen Sie uns die wichtigen Konzepte des objektorientierten Designs sehen:
- Objects - Alle am Lösungsentwurf beteiligten Entitäten werden als Objekte bezeichnet. Beispielsweise werden Personen, Banken, Unternehmen und Kunden als Objekte behandelt. Jeder Entität sind einige Attribute zugeordnet, und es gibt einige Methoden, die für die Attribute ausgeführt werden können.
Classes - Eine Klasse ist eine verallgemeinerte Beschreibung eines Objekts. Ein Objekt ist eine Instanz einer Klasse. Die Klasse definiert alle Attribute, die ein Objekt haben kann, und Methoden, die die Funktionalität des Objekts definieren.
Im Lösungsentwurf werden Attribute als Variablen gespeichert und Funktionalitäten mittels Methoden oder Prozeduren definiert.
- Encapsulation - In OOD werden die Attribute (Datenvariablen) und Methoden (Operation an den Daten) gebündelt, was als Kapselung bezeichnet wird. Durch die Kapselung werden nicht nur wichtige Informationen eines Objekts gebündelt, sondern auch der Zugriff auf die Daten und Methoden von außen eingeschränkt. Dies wird als Verstecken von Informationen bezeichnet.
- Inheritance - Mit OOD können ähnliche Klassen hierarchisch gestapelt werden, wobei die unteren oder Unterklassen zulässige Variablen und Methoden aus ihren unmittelbaren Superklassen importieren, implementieren und wiederverwenden können. Diese Eigenschaft von OOD wird als Vererbung bezeichnet. Dies erleichtert das Definieren bestimmter Klassen und das Erstellen verallgemeinerter Klassen aus bestimmten Klassen.
- Polymorphism - OOD-Sprachen bieten einen Mechanismus, bei dem Methoden, die ähnliche Aufgaben ausführen, jedoch unterschiedliche Argumente aufweisen, denselben Namen zugewiesen werden können. Dies wird als Polymorphismus bezeichnet, bei dem eine einzelne Schnittstelle Aufgaben für verschiedene Typen ausführt. Abhängig davon, wie die Funktion aufgerufen wird, wird der jeweilige Teil des Codes ausgeführt.
Designprozess
Der Software-Design-Prozess kann als eine Reihe klar definierter Schritte wahrgenommen werden. Es variiert zwar je nach Entwurfsansatz (funktionsorientiert oder objektorientiert, kann jedoch die folgenden Schritte umfassen:
- Ein Lösungsentwurf wird aus der Anforderung oder dem zuvor verwendeten System und / oder Systemsequenzdiagramm erstellt.
- Objekte werden identifiziert und in Klassen gruppiert, um die Ähnlichkeit der Attributmerkmale zu gewährleisten.
- Klassenhierarchie und Beziehung zwischen ihnen ist definiert.
- Anwendungsframework ist definiert.
Software-Design-Ansätze
Hier sind zwei generische Ansätze für das Software-Design:
Top-Down-Design
Wir wissen, dass ein System aus mehr als einem Teilsystem besteht und eine Reihe von Komponenten enthält. Ferner können diese Subsysteme und Komponenten einen Satz von Subsystemen und Komponenten haben und eine hierarchische Struktur im System erzeugen.
Beim Top-Down-Design wird das gesamte Softwaresystem als eine Einheit betrachtet und anschließend zerlegt, um basierend auf bestimmten Merkmalen mehr als ein Subsystem oder eine Komponente zu erhalten. Jedes Subsystem oder jede Komponente wird dann als System behandelt und weiter zerlegt. Dieser Prozess läuft so lange weiter, bis die niedrigste Systemebene in der Top-Down-Hierarchie erreicht ist.
Das Top-Down-Design beginnt mit einem verallgemeinerten Systemmodell und definiert weiterhin den spezifischeren Teil davon. Wenn alle Komponenten zusammengesetzt sind, entsteht das gesamte System.
Top-Down-Design ist besser geeignet, wenn die Softwarelösung von Grund auf neu entworfen werden muss und bestimmte Details unbekannt sind.
Bottom-up-Design
Das Bottom-Up-Designmodell beginnt mit den spezifischsten und grundlegendsten Komponenten. Es wird mit dem Zusammenstellen einer höheren Ebene von Komponenten fortgefahren, indem grundlegende oder niedrigere Komponenten verwendet werden. Es werden so lange übergeordnete Komponenten erstellt, bis das gewünschte System nicht mehr als eine einzige Komponente entwickelt wurde. Mit jeder höheren Ebene wird der Abstraktionsgrad erhöht.
Eine Bottom-up-Strategie ist besser geeignet, wenn ein System aus einem vorhandenen System erstellt werden muss, in dem die Grundelemente im neueren System verwendet werden können.
Sowohl Top-Down- als auch Bottom-Up-Ansätze sind für sich genommen nicht praktikabel. Stattdessen wird eine gute Kombination von beiden verwendet.
Die Benutzeroberfläche ist die Front-End-Anwendungsansicht, mit der der Benutzer interagiert, um die Software zu verwenden. Der Benutzer kann die Software sowie die Hardware über eine Benutzeroberfläche manipulieren und steuern. Heutzutage ist die Benutzeroberfläche an fast jedem Ort zu finden, an dem digitale Technologie vorhanden ist, direkt von Computern, Mobiltelefonen, Autos, Musik-Playern, Flugzeugen, Schiffen usw.
Die Benutzeroberfläche ist Teil der Software und so konzipiert, dass der Benutzer einen Einblick in die Software erhält. Die Benutzeroberfläche bietet eine grundlegende Plattform für die Interaktion zwischen Mensch und Computer.
Die Benutzeroberfläche kann je nach zugrunde liegender Hardware- und Softwarekombination grafisch, textbasiert und Audio-Video-basiert sein. Die Benutzeroberfläche kann Hardware oder Software oder eine Kombination aus beiden sein.
Die Software wird populärer, wenn ihre Benutzeroberfläche:
- Attractive
- Einfach zu benutzen
- Reaktionsschnell in kurzer Zeit
- Klar zu verstehen
- Konsistent auf allen Schnittstellenbildschirmen
Die Benutzeroberfläche ist grob in zwei Kategorien unterteilt:
- Befehlszeilenschnittstelle
- Grafische Benutzeroberfläche
Befehlszeilenschnittstelle (CLI)
CLI war ein großartiges Werkzeug für die Interaktion mit Computern, bis die Videoanzeigemonitore entstanden. CLI ist die erste Wahl vieler technischer Benutzer und Programmierer. CLI ist die Mindestschnittstelle, die eine Software ihren Benutzern bereitstellen kann.
Die CLI bietet eine Eingabeaufforderung, den Ort, an dem der Benutzer den Befehl eingibt und an das System weiterleitet. Der Benutzer muss sich die Syntax des Befehls und seine Verwendung merken. Frühere CLI wurden nicht so programmiert, dass Benutzerfehler effektiv behandelt werden.
Ein Befehl ist eine textbasierte Referenz auf einen Befehlssatz, von dem erwartet wird, dass er vom System ausgeführt wird. Es gibt Methoden wie Makros und Skripte, die dem Benutzer die Bedienung erleichtern.
Die CLI verbraucht im Vergleich zur GUI weniger Computerressourcen.
CLI-Elemente

Eine textbasierte Befehlszeilenschnittstelle kann die folgenden Elemente enthalten:
Command Prompt- Es ist ein textbasierter Notifier, der hauptsächlich den Kontext anzeigt, in dem der Benutzer arbeitet. Es wird vom Softwaresystem generiert.
Cursor- Es ist eine kleine horizontale Linie oder ein vertikaler Balken mit der Höhe der Linie, um die Position des Zeichens während der Eingabe darzustellen. Der Cursor befindet sich meist im blinkenden Zustand. Es bewegt sich, während der Benutzer etwas schreibt oder löscht.
Command- Ein Befehl ist eine ausführbare Anweisung. Es kann einen oder mehrere Parameter haben. Die Ausgabe bei der Befehlsausführung wird inline auf dem Bildschirm angezeigt. Wenn die Ausgabe erstellt wird, wird in der nächsten Zeile die Eingabeaufforderung angezeigt.
Grafische Benutzeroberfläche
Die grafische Benutzeroberfläche bietet dem Benutzer grafische Mittel zur Interaktion mit dem System. Die GUI kann eine Kombination aus Hardware und Software sein. Über die GUI interpretiert der Benutzer die Software.
In der Regel verbraucht die GUI mehr Ressourcen als die CLI. Mit fortschreitender Technologie erstellen die Programmierer und Designer komplexe GUI-Designs, die effizienter, genauer und schneller arbeiten.
GUI-Elemente
Die GUI bietet eine Reihe von Komponenten für die Interaktion mit Software oder Hardware.
Jede grafische Komponente bietet eine Möglichkeit, mit dem System zu arbeiten. Ein GUI-System enthält folgende Elemente:

Window- Ein Bereich, in dem der Inhalt der Anwendung angezeigt wird. Inhalte in einem Fenster können in Form von Symbolen oder Listen angezeigt werden, wenn das Fenster die Dateistruktur darstellt. Für einen Benutzer ist es einfacher, in einem Erkundungsfenster im Dateisystem zu navigieren. Windows kann auf die Bildschirmgröße minimiert, in der Größe geändert oder maximiert werden. Sie können an eine beliebige Stelle auf dem Bildschirm verschoben werden. Ein Fenster kann ein anderes Fenster derselben Anwendung enthalten, das als untergeordnetes Fenster bezeichnet wird.
Tabs - Wenn eine Anwendung die Ausführung mehrerer Instanzen von sich selbst zulässt, werden diese als separate Fenster auf dem Bildschirm angezeigt. Tabbed Document Interfacehat mehrere Dokumente im selben Fenster geöffnet. Diese Oberfläche hilft auch beim Anzeigen des Einstellungsfensters in der Anwendung. Alle modernen Webbrowser verwenden diese Funktion.
Menu- Das Menü besteht aus einer Reihe von Standardbefehlen, die zusammengefasst und an einer sichtbaren Stelle (normalerweise oben) im Anwendungsfenster platziert werden. Das Menü kann so programmiert werden, dass es bei Mausklicks angezeigt oder ausgeblendet wird.
Icon- Ein Symbol ist ein kleines Bild, das eine zugehörige Anwendung darstellt. Wenn Sie auf diese Symbole klicken oder darauf doppelklicken, wird das Anwendungsfenster geöffnet. Das Symbol zeigt Anwendungen und Programme, die auf einem System installiert sind, in Form kleiner Bilder an.
Cursor- Interagierende Geräte wie Maus, Touchpad und digitaler Stift werden in der GUI als Cursor dargestellt. Der Bildschirmcursor folgt den Anweisungen der Hardware in nahezu Echtzeit. Cursor werden in GUI-Systemen auch als Zeiger bezeichnet. Sie werden verwendet, um Menüs, Fenster und andere Anwendungsfunktionen auszuwählen.
Anwendungsspezifische GUI-Komponenten
Eine GUI einer Anwendung enthält eines oder mehrere der aufgelisteten GUI-Elemente:
Application Window - Die meisten Anwendungsfenster verwenden die von Betriebssystemen bereitgestellten Konstrukte, aber viele verwenden ihre eigenen vom Kunden erstellten Fenster, um den Inhalt der Anwendung zu enthalten.
Dialogue Box - Es ist ein untergeordnetes Fenster, das eine Nachricht für den Benutzer enthält und eine Aktion anfordert. Beispiel: Die Anwendung generiert einen Dialog, um vom Benutzer eine Bestätigung zum Löschen einer Datei zu erhalten.
Text-Box - Bietet dem Benutzer einen Bereich zum Eingeben und Eingeben von textbasierten Daten.
Buttons - Sie imitieren reale Schaltflächen und werden verwendet, um Eingaben an die Software zu senden.

Radio-button- Zeigt die verfügbaren Optionen zur Auswahl an. Unter allen angebotenen kann nur eine ausgewählt werden.
Check-box- Funktionen ähnlich dem Listenfeld. Wenn eine Option ausgewählt ist, wird das Kontrollkästchen als aktiviert markiert. Es können mehrere Optionen ausgewählt werden, die durch Kontrollkästchen dargestellt werden.
List-box - Bietet eine Liste der verfügbaren Elemente zur Auswahl. Es kann mehr als ein Element ausgewählt werden.

Weitere beeindruckende GUI-Komponenten sind:
- Sliders
- Combo-box
- Data-grid
- Dropdown-Liste
Designaktivitäten für Benutzeroberflächen
Es gibt eine Reihe von Aktivitäten zum Entwerfen der Benutzeroberfläche. Der Prozess des GUI-Designs und der Implementierung ist SDLC ähnlich. Jedes Modell kann für die GUI-Implementierung zwischen Wasserfall-, iterativem oder spiralförmigem Modell verwendet werden.
Ein Modell, das für das Design und die Entwicklung von GUI verwendet wird, sollte diese GUI-spezifischen Schritte erfüllen.

GUI Requirement Gathering- Die Designer möchten möglicherweise eine Liste aller funktionalen und nicht funktionalen Anforderungen der GUI haben. Dies kann dem Benutzer und seiner vorhandenen Softwarelösung entnommen werden.
User Analysis- Der Designer untersucht, wer die Software-GUI verwenden wird. Die Zielgruppe ist wichtig, da sich die Designdetails je nach Wissens- und Kompetenzniveau des Benutzers ändern. Wenn der Benutzer technisch versiert ist, kann eine erweiterte und komplexe Benutzeroberfläche integriert werden. Für Anfänger sind weitere Informationen zur Vorgehensweise bei Software enthalten.
Task Analysis- Designer müssen analysieren, welche Aufgabe die Softwarelösung erfüllen soll. Hier in der GUI spielt es keine Rolle, wie es gemacht wird. Aufgaben können hierarchisch dargestellt werden, indem eine Hauptaufgabe in kleinere Unteraufgaben unterteilt wird. Aufgaben bieten Ziele für die GUI-Präsentation. Der Informationsfluss zwischen Unteraufgaben bestimmt den Fluss der GUI-Inhalte in der Software.
GUI Design & implementation- Designer entwerfen nach Informationen zu Anforderungen, Aufgaben und Benutzerumgebung die GUI und implementieren sie in Code und binden die GUI mit funktionierender oder Dummy-Software im Hintergrund ein. Es wird dann von den Entwicklern selbst getestet.
Testing- GUI-Tests können auf verschiedene Arten durchgeführt werden. Die Organisation kann eine interne Inspektion durchführen, die direkte Einbeziehung der Benutzer und die Veröffentlichung der Beta-Version sind nur einige davon. Das Testen kann Benutzerfreundlichkeit, Kompatibilität, Benutzerakzeptanz usw. umfassen.
GUI-Implementierungstools
Es stehen verschiedene Tools zur Verfügung, mit denen die Designer per Mausklick die gesamte GUI erstellen können. Einige Tools können in die Softwareumgebung (IDE) eingebettet werden.
GUI-Implementierungstools bieten leistungsstarke GUI-Steuerelemente. Für die Softwareanpassung können Designer den Code entsprechend ändern.
Es gibt verschiedene Segmente von GUI-Tools, je nach Verwendung und Plattform.
Beispiel
Mobile GUI, Computer GUI, Touchscreen-GUI usw. Hier ist eine Liste einiger Tools, die zum Erstellen einer GUI nützlich sind:
- FLUID
- AppInventor (Android)
- LucidChart
- Wavemaker
- Visual Studio
Benutzeroberfläche Goldene Regeln
Die folgenden Regeln sind die goldenen Regeln für das GUI-Design, die von Shneiderman und Plaisant in ihrem Buch (Designing the User Interface) beschrieben wurden.
Strive for consistency- In ähnlichen Situationen sollten konsistente Aktionssequenzen erforderlich sein. In Eingabeaufforderungen, Menüs und Hilfebildschirmen sollte eine identische Terminologie verwendet werden. Konsistente Befehle sollten durchgehend verwendet werden.
Enable frequent users to use short-cuts- Der Wunsch des Benutzers, die Anzahl der Interaktionen zu reduzieren, steigt mit der Häufigkeit der Nutzung. Abkürzungen, Funktionstasten, versteckte Befehle und Makrofunktionen sind für einen erfahrenen Benutzer sehr hilfreich.
Offer informative feedback- Für jede Bedieneraktion sollte ein Systemfeedback vorhanden sein. Bei häufigen und geringfügigen Aktionen muss die Reaktion bescheiden sein, während bei seltenen und größeren Aktionen die Reaktion umfangreicher sein muss.
Design dialog to yield closure- Abfolgen von Aktionen sollten in Gruppen mit Anfang, Mitte und Ende organisiert werden. Das informative Feedback nach Abschluss einer Gruppe von Maßnahmen gibt den Bedienern die Zufriedenheit mit der Leistung, ein Gefühl der Erleichterung, das Signal, Notfallpläne und -optionen aus ihren Gedanken zu streichen, und dies zeigt, dass der Weg frei ist, um sich auf die nächste vorzubereiten Gruppe von Aktionen.
Offer simple error handling- Entwerfen Sie das System so weit wie möglich, damit der Benutzer keinen schwerwiegenden Fehler macht. Wenn ein Fehler gemacht wird, sollte das System in der Lage sein, ihn zu erkennen und einfache, verständliche Mechanismen zur Behandlung des Fehlers anzubieten.
Permit easy reversal of actions- Diese Funktion lindert Ängste, da der Benutzer weiß, dass Fehler rückgängig gemacht werden können. Die einfache Umkehrung von Aktionen fördert die Erforschung unbekannter Optionen. Die Umkehrbarkeitseinheiten können eine einzelne Aktion, eine Dateneingabe oder eine vollständige Gruppe von Aktionen sein.
Support internal locus of control- Erfahrene Bediener wünschen sich nachdrücklich das Gefühl, dass sie für das System verantwortlich sind und dass das System auf ihre Handlungen reagiert. Entwerfen Sie das System so, dass Benutzer eher zu Initiatoren von Aktionen als zu Respondern werden.
Reduce short-term memory load - Die Einschränkung der Verarbeitung menschlicher Informationen im Kurzzeitgedächtnis erfordert, dass die Anzeigen einfach gehalten, mehrseitige Anzeigen konsolidiert, die Häufigkeit von Fensterbewegungen reduziert und ausreichend Trainingszeit für Codes, Mnemoniken und Aktionssequenzen zugewiesen wird.
Der Begriff Komplexität steht für den Zustand von Ereignissen oder Dingen, die mehrere miteinander verbundene Verbindungen und hochkomplizierte Strukturen aufweisen. Bei der Softwareprogrammierung wird die Anzahl der Elemente und ihre Verbindungen mit der Realisierung des Softwareentwurfs allmählich sehr groß, was auf einmal zu schwer zu verstehen ist.
Die Komplexität des Software-Designs ist ohne Verwendung von Komplexitätsmetriken und -maßen schwer zu bewerten. Lassen Sie uns drei wichtige Maßstäbe für die Softwarekomplexität sehen.
Komplexitätsmaße von Halstead
Im Jahr 1977 führte Maurice Howard Halstead Metriken zur Messung der Softwarekomplexität ein. Die Metriken von Halstead hängen von der tatsächlichen Implementierung des Programms und seinen Maßnahmen ab, die statisch direkt von den Operatoren und Operanden aus dem Quellcode berechnet werden. Es ermöglicht die Bewertung von Testzeit, Vokabular, Größe, Schwierigkeit, Fehlern und Aufwand für C / C ++ / Java-Quellcode.
Laut Halstead ist „ein Computerprogramm eine Implementierung eines Algorithmus, der als Sammlung von Token betrachtet wird, die entweder als Operatoren oder als Operanden klassifiziert werden können“. Halstead-Metriken betrachten ein Programm als eine Folge von Operatoren und den zugehörigen Operanden.
Er definiert verschiedene Indikatoren, um die Komplexität des Moduls zu überprüfen.
| Parameter | Bedeutung |
|---|---|
| n1 | Anzahl eindeutiger Operatoren |
| n2 | Anzahl eindeutiger Operanden |
| N1 | Anzahl des gesamten Auftretens von Operatoren |
| N2 | Anzahl des gesamten Auftretens von Operanden |
Wenn wir die Quelldatei auswählen, um ihre Komplexitätsdetails im Metric Viewer anzuzeigen, wird im Metric Report das folgende Ergebnis angezeigt:
| Metrisch | Bedeutung | Mathematische Darstellung |
|---|---|---|
| n | Wortschatz | n1 + n2 |
| N. | Größe | N1 + N2 |
| V. | Volumen | Länge * Log2 Wortschatz |
| D. | Schwierigkeit | (n1 / 2) * (N1 / n2) |
| E. | Bemühungen | Schwierigkeit * Lautstärke |
| B. | Fehler | Volumen / 3000 |
| T. | Testzeit | Zeit = Aufwand / S, wobei S = 18 Sekunden. |
Zyklomatische Komplexitätsmessungen
Jedes Programm enthält Anweisungen, die ausgeführt werden müssen, um bestimmte Aufgaben und andere Entscheidungsanweisungen auszuführen, die entscheiden, welche Anweisungen ausgeführt werden müssen. Diese Entscheidungskonstrukte verändern den Programmfluss.
Wenn wir zwei Programme gleicher Größe vergleichen, wird das mit mehr Entscheidungsaussagen komplexer, da die Steuerung von Programmen häufig springt.
McCabe schlug 1976 das Cyclomatic Complexity Measure vor, um die Komplexität einer bestimmten Software zu quantifizieren. Es handelt sich um ein graphgesteuertes Modell, das auf Entscheidungskonstrukten von Programmen wie if-else-, do-while-, repeat-till-, switch-case- und goto-Anweisungen basiert.
Verfahren zur Erstellung eines Flusskontrolldiagramms:
- Unterbrechen Sie das Programm in kleinere Blöcke, die durch Entscheidungskonstrukte begrenzt sind.
- Erstellen Sie Knoten, die jeden dieser Knoten darstellen.
- Verbinden Sie die Knoten wie folgt:
Wenn die Steuerung von Block i zu Block j verzweigen kann
Zeichne einen Bogen
Vom Ausgangsknoten zum Eingangsknoten
Zeichne einen Bogen.
Um die zyklomatische Komplexität eines Programmmoduls zu berechnen, verwenden wir die Formel -
V(G) = e – n + 2
Where
e is total number of edges
n is total number of nodes
Die zyklomatische Komplexität des obigen Moduls beträgt
e = 10
n = 8
Cyclomatic Complexity = 10 - 8 + 2
= 4Nach P. Jorgensen sollte die zyklomatische Komplexität eines Moduls 10 nicht überschreiten.
Funktionspunkt
Es wird häufig verwendet, um die Größe von Software zu messen. Function Point konzentriert sich auf die vom System bereitgestellten Funktionen. Merkmale und Funktionen des Systems werden verwendet, um die Komplexität der Software zu messen.
Der Funktionspunkt zählt fünf Parameter, die als externer Eingang, externer Ausgang, logische interne Dateien, externe Schnittstellendateien und externe Anfrage bezeichnet werden. Um die Komplexität der Software zu berücksichtigen, wird jeder Parameter weiter als einfach, durchschnittlich oder komplex kategorisiert.
Lassen Sie uns die Parameter des Funktionspunkts sehen:
Externe Eingabe
Jede eindeutige Eingabe von außen in das System wird als externe Eingabe betrachtet. Die Eindeutigkeit der Eingabe wird gemessen, da keine zwei Eingaben das gleiche Format haben sollten. Diese Eingänge können entweder Daten- oder Steuerparameter sein.
Simple - wenn die Anzahl der Eingaben niedrig ist und weniger interne Dateien betrifft
Complex - Wenn die Anzahl der Eingaben hoch ist und mehr interne Dateien betrifft
Average - zwischen einfach und komplex.
Externer Ausgang
Alle vom System bereitgestellten Ausgabetypen werden in dieser Kategorie gezählt. Die Ausgabe gilt als eindeutig, wenn das Ausgabeformat und / oder die Verarbeitung eindeutig sind.
Simple - wenn die Anzahl der Ausgänge niedrig ist
Complex - wenn die Ausgangsanzahl hoch ist
Average - zwischen einfach und komplex.
Logische interne Dateien
Jedes Softwaresystem verwaltet interne Dateien, um seine Funktionsinformationen zu erhalten und ordnungsgemäß zu funktionieren. Diese Dateien enthalten logische Daten des Systems. Diese logischen Daten können sowohl Funktionsdaten als auch Steuerdaten enthalten.
Simple - wenn die Anzahl der Datensatztypen niedrig ist
Complex - wenn die Anzahl der Datensatztypen hoch ist
Average - zwischen einfach und komplex.
Externe Schnittstellendateien
Das Softwaresystem muss möglicherweise seine Dateien für eine externe Software freigeben oder die Datei zur Verarbeitung oder als Parameter an eine Funktion übergeben. Alle diese Dateien werden als externe Schnittstellendateien gezählt.
Simple - wenn die Anzahl der Datensatztypen in der freigegebenen Datei gering ist
Complex - Wenn die Anzahl der Datensatztypen in der freigegebenen Datei hoch ist
Average - zwischen einfach und komplex.
Externe Anfrage
Eine Anfrage ist eine Kombination aus Eingabe und Ausgabe, bei der der Benutzer einige Daten sendet, um sie als Eingabe abzufragen, und das System dem Benutzer mit der Ausgabe der verarbeiteten Anfrage antwortet. Die Komplexität einer Abfrage ist größer als die externe Eingabe und die externe Ausgabe. Die Abfrage gilt als eindeutig, wenn ihre Eingabe und Ausgabe in Bezug auf Format und Daten eindeutig sind.
Simple - Wenn die Abfrage nur wenig verarbeitet werden muss und nur eine geringe Menge an Ausgabedaten liefert
Complex - Wenn die Abfrage einen hohen Prozess benötigt und eine große Menge an Ausgabedaten liefert
Average - zwischen einfach und komplex.
Jeder dieser Parameter im System wird entsprechend seiner Klasse und Komplexität gewichtet. In der folgenden Tabelle ist die Gewichtung der einzelnen Parameter aufgeführt:
| Parameter | Einfach | Durchschnittlich | Komplex |
|---|---|---|---|
| Eingänge | 3 | 4 | 6 |
| Ausgänge | 4 | 5 | 7 |
| Anfrage | 3 | 4 | 6 |
| Dateien | 7 | 10 | 15 |
| Schnittstellen | 5 | 7 | 10 |
Die obige Tabelle liefert rohe Funktionspunkte. Diese Funktionspunkte werden entsprechend der Komplexität der Umgebung angepasst. Das System wird anhand von vierzehn verschiedenen Merkmalen beschrieben:
- Datenkommunikation
- Verteilte Verarbeitung
- Leistungsziele
- Betriebskonfigurationslast
- Transaktionsrate
- Online-Dateneingabe,
- Effizienz der Endbenutzer
- Online-Update
- Komplexe Verarbeitungslogik
- Re-usability
- Einfache Installation
- Bedienungsfreundlichkeit
- Mehrere Seiten
- Wunsch, Änderungen zu erleichtern
Diese charakteristischen Faktoren werden dann wie unten erwähnt von 0 bis 5 bewertet:
- Kein Einfluss
- Incidental
- Moderate
- Average
- Significant
- Essential
Alle Bewertungen werden dann als N zusammengefasst. Der Wert von N reicht von 0 bis 70 (14 Arten von Merkmalen x 5 Arten von Bewertungen). Es wird verwendet, um Komplexitätsanpassungsfaktoren (CAF) unter Verwendung der folgenden Formeln zu berechnen:
CAF = 0.65 + 0.01NDann,
Delivered Function Points (FP)= CAF x Raw FPDiese FP kann dann in verschiedenen Metriken verwendet werden, z.
Cost = $ / FP
Quality = Fehler / FP
Productivity = FP / Personenmonat
In diesem Kapitel werden wir uns mit Programmiermethoden, Dokumentation und Herausforderungen bei der Softwareimplementierung befassen.
Strukturierte Programmierung
Während des Codierungsprozesses multiplizieren sich die Codezeilen weiter, wodurch die Größe der Software zunimmt. Allmählich wird es nahezu unmöglich, sich an den Programmfluss zu erinnern. Wenn man vergisst, wie Software und ihre zugrunde liegenden Programme, Dateien und Prozeduren erstellt werden, wird es sehr schwierig, das Programm freizugeben, zu debuggen und zu ändern. Die Lösung hierfür ist die strukturierte Programmierung. Es ermutigt den Entwickler, Unterprogramme und Schleifen zu verwenden, anstatt einfache Sprünge im Code zu verwenden, wodurch der Code klarer wird und seine Effizienz verbessert wird. Die strukturierte Programmierung hilft dem Programmierer auch, die Codierungszeit zu verkürzen und den Code richtig zu organisieren.
Die strukturierte Programmierung gibt an, wie das Programm codiert werden soll. Die strukturierte Programmierung verwendet drei Hauptkonzepte:
Top-down analysis- Eine Software wird immer erstellt, um rationale Arbeit zu leisten. Diese rationale Arbeit wird im Software-Sprachgebrauch als Problem bezeichnet. Daher ist es sehr wichtig, dass wir verstehen, wie das Problem gelöst werden kann. Bei der Top-Down-Analyse wird das Problem in kleine Teile zerlegt, von denen jeder eine gewisse Bedeutung hat. Jedes Problem wird einzeln gelöst und es werden klar Schritte zur Lösung des Problems angegeben.
Modular Programming- Während der Programmierung wird der Code in eine kleinere Gruppe von Anweisungen zerlegt. Diese Gruppen werden als Module, Unterprogramme oder Unterprogramme bezeichnet. Modulare Programmierung basierend auf dem Verständnis der Top-Down-Analyse. Es wird davon abgeraten, Sprünge mit 'goto'-Anweisungen im Programm zu verwenden, wodurch der Programmfluss häufig nicht nachvollziehbar wird. Sprünge sind verboten und das modulare Format wird bei der strukturierten Programmierung empfohlen.
Structured Coding - In Bezug auf die Top-Down-Analyse unterteilt die strukturierte Codierung die Module in der Reihenfolge ihrer Ausführung in weitere kleinere Codeeinheiten. Die strukturierte Programmierung verwendet eine Kontrollstruktur, die den Programmfluss steuert, während die strukturierte Codierung eine Kontrollstruktur verwendet, um ihre Anweisungen in definierbaren Mustern zu organisieren.
Funktionale Programmierung
Funktionale Programmierung ist ein Stil der Programmiersprache, der die Konzepte mathematischer Funktionen verwendet. Eine Funktion in der Mathematik sollte beim Empfang des gleichen Arguments immer das gleiche Ergebnis liefern. In prozeduralen Sprachen durchläuft der Programmfluss Prozeduren, dh die Steuerung des Programms wird auf die aufgerufene Prozedur übertragen. Während der Steuerungsfluss von einer Prozedur zur anderen wechselt, ändert das Programm seinen Status.
Bei der prozeduralen Programmierung kann eine Prozedur unterschiedliche Ergebnisse erzielen, wenn sie mit demselben Argument aufgerufen wird, da sich das Programm selbst beim Aufrufen in einem anderen Zustand befinden kann. Dies ist sowohl eine Eigenschaft als auch ein Nachteil der prozeduralen Programmierung, bei der die Reihenfolge oder der Zeitpunkt der Prozedurausführung wichtig wird.
Die funktionale Programmierung bietet Berechnungsmöglichkeiten als mathematische Funktionen, die unabhängig vom Programmzustand Ergebnisse liefern. Dies ermöglicht es, das Verhalten des Programms vorherzusagen.
Die funktionale Programmierung verwendet die folgenden Konzepte:
First class and High-order functions - Diese Funktionen können eine andere Funktion als Argument akzeptieren oder andere Funktionen als Ergebnisse zurückgeben.
Pure functions - Diese Funktionen enthalten keine destruktiven Aktualisierungen, dh sie wirken sich nicht auf E / A oder Speicher aus. Wenn sie nicht verwendet werden, können sie leicht entfernt werden, ohne den Rest des Programms zu beeinträchtigen.
Recursion- Rekursion ist eine Programmiertechnik, bei der sich eine Funktion selbst aufruft und den darin enthaltenen Programmcode wiederholt, sofern nicht eine vordefinierte Bedingung übereinstimmt. Rekursion ist die Art und Weise, Schleifen in der funktionalen Programmierung zu erstellen.
Strict evaluation- Dies ist eine Methode zur Auswertung des Ausdrucks, der als Argument an eine Funktion übergeben wird. Die funktionale Programmierung hat zwei Arten von Bewertungsmethoden: streng (eifrig) oder nicht streng (faul). Bei einer strengen Auswertung wird der Ausdruck immer ausgewertet, bevor die Funktion aufgerufen wird. Bei einer nicht strengen Bewertung wird der Ausdruck nur bewertet, wenn er benötigt wird.
λ-calculus- Die meisten funktionalen Programmiersprachen verwenden λ-Kalkül als Typensysteme. λ-Ausdrücke werden ausgeführt, indem sie ausgewertet werden, sobald sie auftreten.
Common Lisp, Scala, Haskell, Erlang und F # sind einige Beispiele für funktionale Programmiersprachen.
Programmierstil
Der Programmierstil besteht aus Codierungsregeln, die von allen Programmierern befolgt werden, um den Code zu schreiben. Wenn mehrere Programmierer an demselben Softwareprojekt arbeiten, müssen sie häufig mit dem Programmcode arbeiten, der von einem anderen Entwickler geschrieben wurde. Dies wird mühsam oder manchmal unmöglich, wenn nicht alle Entwickler einem Standardprogrammierstil folgen, um das Programm zu codieren.
Ein geeigneter Programmierstil umfasst die Verwendung von Funktions- und Variablennamen, die für die beabsichtigte Aufgabe relevant sind, die Verwendung gut platzierter Einrückungen, das Kommentieren von Code zur Vereinfachung des Lesens und die allgemeine Darstellung von Code. Dies macht den Programmcode für alle lesbar und verständlich, was wiederum das Debuggen und die Fehlerbehebung erleichtert. Ein korrekter Codierungsstil erleichtert außerdem die Dokumentation und Aktualisierung.
Codierungsrichtlinien
Die Praxis des Codierungsstils variiert je nach Organisation, Betriebssystem und Codierungssprache.
Die folgenden Codierungselemente können unter den Codierungsrichtlinien einer Organisation definiert werden:
Naming conventions - In diesem Abschnitt wird definiert, wie Funktionen, Variablen, Konstanten und globale Variablen benannt werden.
Indenting - Dies ist der am Zeilenanfang verbleibende Platz, normalerweise 2-8 Leerzeichen oder einzelne Tabulatoren.
Whitespace - Es wird in der Regel am Zeilenende weggelassen.
Operators- Definiert die Regeln für das Schreiben von mathematischen, Zuweisungs- und logischen Operatoren. Zum Beispiel sollte der Zuweisungsoperator '=' wie und in "x = 2" Leerzeichen davor haben.
Control Structures - Die Regeln für das Schreiben von if-then-else, case-switch, while-till und für Kontrollflussanweisungen ausschließlich und verschachtelt.
Line length and wrapping- Legt fest, wie viele Zeichen in einer Zeile enthalten sein sollen. Meistens ist eine Zeile 80 Zeichen lang. Umbrechen definiert, wie eine Zeile umbrochen werden soll, wenn sie zu lang ist.
Functions - Hiermit wird festgelegt, wie Funktionen mit und ohne Parameter deklariert und aufgerufen werden sollen.
Variables - Hier wird erwähnt, wie Variablen verschiedener Datentypen deklariert und definiert werden.
Comments- Dies ist eine der wichtigen Codierungskomponenten, da die im Code enthaltenen Kommentare beschreiben, was der Code tatsächlich tut, und alle anderen zugehörigen Beschreibungen. Dieser Abschnitt hilft auch beim Erstellen von Hilfedokumentationen für andere Entwickler.
Software-Dokumentation
Die Softwaredokumentation ist ein wichtiger Bestandteil des Softwareprozesses. Ein gut geschriebenes Dokument bietet ein großartiges Werkzeug und Mittel zum Informationsspeicher, die erforderlich sind, um über Softwareprozesse Bescheid zu wissen. Die Softwaredokumentation enthält auch Informationen zur Verwendung des Produkts.
Eine gut gepflegte Dokumentation sollte folgende Dokumente enthalten:
Requirement documentation - Diese Dokumentation ist ein wichtiges Werkzeug für Softwareentwickler, Entwickler und das Testteam, um ihre jeweiligen Aufgaben auszuführen. Dieses Dokument enthält alle funktionalen, nicht funktionalen und Verhaltensbeschreibungen der beabsichtigten Software.
Quelle dieses Dokuments können zuvor gespeicherte Daten über die Software sein, die bereits am Ende des Kunden Software ausführen, Kundeninterviews, Fragebögen und Recherchen. Im Allgemeinen wird es in Form einer Tabelle oder eines Textverarbeitungsdokuments beim High-End-Software-Management-Team gespeichert.
Diese Dokumentation dient als Grundlage für die zu entwickelnde Software und wird hauptsächlich in Überprüfungs- und Validierungsphasen verwendet. Die meisten Testfälle werden direkt aus der Anforderungsdokumentation erstellt.
Software Design documentation - Diese Dokumentationen enthalten alle notwendigen Informationen, die zum Erstellen der Software benötigt werden. Es beinhaltet:(a) Hochrangige Softwarearchitektur, (b) Details zum Software-Design, (c) Datenflussdiagramme, (d) Datenbank Design
Diese Dokumente dienen als Repository für Entwickler zur Implementierung der Software. Obwohl diese Dokumente keine Details zum Codieren des Programms enthalten, enthalten sie alle erforderlichen Informationen, die für das Codieren und Implementieren erforderlich sind.
Technical documentation- Diese Dokumentationen werden von den Entwicklern und tatsächlichen Programmierern gepflegt. Diese Dokumente stellen insgesamt Informationen über den Code dar. Während des Schreibens des Codes erwähnen die Programmierer auch das Ziel des Codes, wer ihn geschrieben hat, wo er benötigt wird, was er tut und wie er funktioniert, welche anderen Ressourcen der Code verwendet usw.
Die technische Dokumentation verbessert das Verständnis zwischen verschiedenen Programmierern, die an demselben Code arbeiten. Es verbessert die Wiederverwendbarkeit des Codes. Es macht das Debuggen einfach und nachvollziehbar.
Es stehen verschiedene automatisierte Tools zur Verfügung, von denen einige mit der Programmiersprache selbst geliefert werden. Zum Beispiel kommt Java JavaDoc Tool, um technische Dokumentation von Code zu generieren.
User documentation- Diese Dokumentation unterscheidet sich von allen oben erläuterten. Alle vorherigen Dokumentationen werden gepflegt, um Informationen über die Software und ihren Entwicklungsprozess bereitzustellen. In der Benutzerdokumentation wird jedoch erläutert, wie das Softwareprodukt funktionieren und wie es verwendet werden sollte, um die gewünschten Ergebnisse zu erzielen.
Diese Dokumentationen können Softwareinstallationsverfahren, Anleitungen, Benutzerhandbücher, Deinstallationsmethoden und spezielle Verweise enthalten, um weitere Informationen wie Lizenzaktualisierungen usw. zu erhalten.
Herausforderungen bei der Softwareimplementierung
Das Entwicklungsteam steht bei der Implementierung der Software vor einigen Herausforderungen. Einige von ihnen sind unten aufgeführt:
Code-reuse- Programmierschnittstellen heutiger Sprachen sind sehr ausgefeilt und mit riesigen Bibliotheksfunktionen ausgestattet. Um die Kosten für das Endprodukt zu senken, verwendet das Organisationsmanagement den Code, der zuvor für eine andere Software erstellt wurde, lieber wieder. Programmierer haben große Probleme mit der Kompatibilitätsprüfung und der Entscheidung, wie viel Code wiederverwendet werden soll.
Version Management- Jedes Mal, wenn eine neue Software an den Kunden ausgegeben wird, müssen Entwickler die Dokumentation zu Version und Konfiguration pflegen. Diese Dokumentation muss sehr genau und rechtzeitig verfügbar sein.
Target-Host- Das Softwareprogramm, das in der Organisation entwickelt wird, muss für Host-Computer beim Kunden entwickelt werden. Manchmal ist es jedoch unmöglich, eine Software zu entwerfen, die auf den Zielcomputern funktioniert.
Beim Softwaretest wird die Software anhand der Anforderungen der Benutzer und der Systemspezifikationen bewertet. Die Tests werden auf Phasenebene im Lebenszyklus der Softwareentwicklung oder auf Modulebene im Programmcode durchgeführt. Das Testen von Software umfasst die Validierung und Verifizierung.
Software-Validierung
Bei der Validierung wird geprüft, ob die Software die Benutzeranforderungen erfüllt. Es wird am Ende des SDLC durchgeführt. Wenn die Software den Anforderungen entspricht, für die sie erstellt wurde, wird sie validiert.
- Durch die Validierung wird sichergestellt, dass das in der Entwicklung befindliche Produkt den Benutzeranforderungen entspricht.
- Die Validierung beantwortet die Frage: "Entwickeln wir das Produkt, das alle Anforderungen des Benutzers an diese Software erfüllt?".
- Die Validierung konzentriert sich auf die Benutzeranforderungen.
Softwareüberprüfung
Bei der Überprüfung wird bestätigt, ob die Software die Geschäftsanforderungen erfüllt, und sie wird unter Einhaltung der richtigen Spezifikationen und Methoden entwickelt.
- Durch die Überprüfung wird sichergestellt, dass das zu entwickelnde Produkt den Designspezifikationen entspricht.
- Die Überprüfung beantwortet die Frage: "Entwickeln wir dieses Produkt, indem wir alle Designspezifikationen genau befolgen?"
- Die Überprüfung konzentriert sich auf das Design und die Systemspezifikationen.
Ziel des Tests sind -
Errors- Dies sind tatsächliche Codierungsfehler, die von Entwicklern gemacht wurden. Darüber hinaus gibt es einen Unterschied in der Ausgabe der Software und der gewünschten Ausgabe, wird als Fehler angesehen.
Fault- Wenn ein Fehler vorliegt, tritt ein Fehler auf. Ein Fehler, auch als Fehler bezeichnet, ist das Ergebnis eines Fehlers, der zum Ausfall des Systems führen kann.
Failure - Ein Fehler soll die Unfähigkeit des Systems sein, die gewünschte Aufgabe auszuführen. Ein Fehler tritt auf, wenn ein Fehler im System vorliegt.
Manuell gegen automatisiertes Testen
Das Testen kann entweder manuell oder mit einem automatisierten Testwerkzeug erfolgen:
Manual- Diese Tests werden ohne Hilfe automatisierter Testwerkzeuge durchgeführt. Der Software-Tester bereitet Testfälle für verschiedene Abschnitte und Ebenen des Codes vor, führt die Tests aus und meldet das Ergebnis an den Manager.
Manuelles Testen ist zeit- und ressourcenintensiv. Der Tester muss bestätigen, ob die richtigen Testfälle verwendet werden. Ein Großteil der Tests umfasst manuelle Tests.
AutomatedDieses Testen ist ein Testverfahren, das mit Hilfe automatisierter Testwerkzeuge durchgeführt wird. Die Einschränkungen beim manuellen Testen können mit automatisierten Testwerkzeugen überwunden werden.
Bei einem Test muss überprüft werden, ob eine Webseite in Internet Explorer geöffnet werden kann. Dies kann leicht mit manuellen Tests durchgeführt werden. Um zu überprüfen, ob der Webserver die Last von 1 Million Benutzern aufnehmen kann, ist es unmöglich, manuell zu testen.
Es gibt Software- und Hardwaretools, die dem Tester bei der Durchführung von Lasttests, Stresstests und Regressionstests helfen.
Testansätze
Tests können basierend auf zwei Ansätzen durchgeführt werden -
- Funktionstests
- Implementierungstests
Wenn die Funktionalität getestet wird, ohne die tatsächliche Implementierung in Betracht zu ziehen, spricht man von Black-Box-Tests. Die andere Seite ist als White-Box-Test bekannt, bei dem nicht nur die Funktionalität getestet, sondern auch die Art und Weise ihrer Implementierung analysiert wird.
Vollständige Tests sind die am besten gewünschte Methode für einen perfekten Test. Jeder einzelne mögliche Wert im Bereich der Eingangs- und Ausgangswerte wird geprüft. Es ist nicht möglich, jeden einzelnen Wert im realen Szenario zu testen, wenn der Wertebereich groß ist.
Black-Box-Tests
Es wird ausgeführt, um die Funktionalität des Programms zu testen. Es wird auch als "Verhaltenstest" bezeichnet. Der Tester hat in diesem Fall eine Reihe von Eingabewerten und die entsprechenden gewünschten Ergebnisse. Wenn die Ausgabe bei der Eingabe mit den gewünschten Ergebnissen übereinstimmt, wird das Programm mit "OK" getestet und ist ansonsten problematisch.

Bei dieser Testmethode sind dem Tester das Design und die Struktur des Codes nicht bekannt, und Testingenieure und Endbenutzer führen diesen Test mit der Software durch.
Black-Box-Testtechniken:
Equivalence class- Die Eingabe ist in ähnliche Klassen unterteilt. Wenn ein Element einer Klasse den Test besteht, wird davon ausgegangen, dass die gesamte Klasse bestanden wurde.
Boundary values- Der Eingang ist in höhere und niedrigere Endwerte unterteilt. Wenn diese Werte den Test bestehen, wird davon ausgegangen, dass auch alle dazwischen liegenden Werte bestanden werden können.
Cause-effect graphing- Bei beiden vorherigen Methoden wird jeweils nur ein Eingabewert getestet. Ursache (Eingabe) - Wirkung (Ausgabe) ist eine Testtechnik, bei der Kombinationen von Eingabewerten systematisch getestet werden.
Pair-wise Testing- Das Verhalten von Software hängt von mehreren Parametern ab. Beim paarweisen Testen werden die mehreren Parameter paarweise auf ihre unterschiedlichen Werte getestet.
State-based testing- Das System ändert den Status bei Bereitstellung der Eingabe. Diese Systeme werden anhand ihrer Zustände und Eingaben getestet.
White-Box-Tests
Es wird durchgeführt, um das Programm und seine Implementierung zu testen, um die Codeeffizienz oder -struktur zu verbessern. Es wird auch als "strukturelle" Prüfung bezeichnet.

Bei dieser Testmethode sind dem Tester das Design und die Struktur des Codes bekannt. Programmierer des Codes führen diesen Test am Code durch.
Im Folgenden sind einige White-Box-Testtechniken aufgeführt:
Control-flow testing- Der Zweck des Kontrollflusstests besteht darin, Testfälle einzurichten, die alle Aussagen und Verzweigungsbedingungen abdecken. Die Verzweigungsbedingungen werden sowohl auf wahr als auch auf falsch getestet, damit alle Aussagen abgedeckt werden können.
Data-flow testing- Diese Testtechnik konzentriert sich auf alle im Programm enthaltenen Datenvariablen. Es wird getestet, wo die Variablen deklariert und definiert wurden und wo sie verwendet oder geändert wurden.
Teststufen
Das Testen selbst kann auf verschiedenen SDLC-Ebenen definiert werden. Der Testprozess läuft parallel zur Softwareentwicklung. Vor dem Sprung auf die nächste Stufe wird eine Stufe getestet, validiert und verifiziert.
Das separate Testen wird nur durchgeführt, um sicherzustellen, dass keine versteckten Fehler oder Probleme in der Software vorhanden sind. Software wird auf verschiedenen Ebenen getestet -
Unit Testing
Während des Codierens führt der Programmierer einige Tests an dieser Programmeinheit durch, um festzustellen, ob sie fehlerfrei ist. Das Testen wird unter einem White-Box-Testansatz durchgeführt. Mithilfe von Komponententests können Entwickler entscheiden, ob einzelne Einheiten des Programms gemäß den Anforderungen funktionieren und fehlerfrei sind.
Integrationstests
Selbst wenn die Softwareeinheiten einzeln einwandfrei funktionieren, muss herausgefunden werden, ob die zusammen integrierten Einheiten auch fehlerfrei funktionieren würden. Zum Beispiel Argumentübergabe und Datenaktualisierung usw.
Systemtests
Die Software wird als Produkt kompiliert und anschließend als Ganzes getestet. Dies kann mit einem oder mehreren der folgenden Tests erreicht werden:
Functionality testing - Testet alle Funktionen der Software gegen die Anforderung.
Performance testing- Dieser Test zeigt, wie effizient die Software ist. Es testet die Effektivität und die durchschnittliche Zeit, die die Software benötigt, um die gewünschte Aufgabe zu erledigen. Leistungstests werden mittels Lasttests und Stresstests durchgeführt, bei denen die Software unter verschiedenen Umgebungsbedingungen einer hohen Benutzer- und Datenlast ausgesetzt ist.
Security & Portability - Diese Tests werden durchgeführt, wenn die Software auf verschiedenen Plattformen funktionieren soll und auf die mehrere Personen zugreifen können.
Abnahmetests
Wenn die Software zur Übergabe an den Kunden bereit ist, muss sie die letzte Testphase durchlaufen, in der sie auf Benutzerinteraktion und Reaktion getestet wird. Dies ist wichtig, da die Software möglicherweise abgelehnt wird, auch wenn sie allen Benutzeranforderungen entspricht und die Darstellung oder Funktionsweise des Benutzers nicht gefällt.
Alpha testing- Das Entwicklerteam selbst führt Alpha-Tests durch, indem es das System so verwendet, als würde es in einer Arbeitsumgebung verwendet. Sie versuchen herauszufinden, wie Benutzer auf bestimmte Aktionen in der Software reagieren würden und wie das System auf Eingaben reagieren sollte.
Beta testing- Nachdem die Software intern getestet wurde, wird sie an die Benutzer übergeben, um sie in ihrer Produktionsumgebung nur zu Testzwecken zu verwenden. Dies ist noch nicht das gelieferte Produkt. Entwickler erwarten, dass Benutzer in dieser Phase winzige Probleme verursachen, die zur Teilnahme übersprungen wurden.
Regressionstests
Jedes Mal, wenn ein Softwareprodukt mit neuem Code, neuer Funktion oder Funktionalität aktualisiert wird, wird es gründlich getestet, um festzustellen, ob der hinzugefügte Code negative Auswirkungen hat. Dies wird als Regressionstest bezeichnet.
Dokumentation testen
Testdokumente werden in verschiedenen Phasen erstellt -
Vor dem Testen
Das Testen beginnt mit der Generierung von Testfällen. Folgende Dokumente werden als Referenz benötigt -
SRS document - Dokument mit den funktionalen Anforderungen
Test Policy document - Hier wird beschrieben, wie weit die Tests vor der Freigabe des Produkts erfolgen sollen.
Test Strategy document - Hier werden detaillierte Aspekte des Testteams, der Verantwortungsmatrix und der Rechte / Verantwortlichkeiten des Testmanagers und des Testingenieurs erwähnt.
Traceability Matrix document- Dies ist ein SDLC-Dokument, das sich auf den Prozess der Anforderungserfassung bezieht. Wenn neue Anforderungen kommen, werden sie dieser Matrix hinzugefügt. Diese Matrizen helfen Testern, die Quelle der Anforderung zu kennen. Sie können vorwärts und rückwärts verfolgt werden.
Während des Testens
Die folgenden Dokumente sind möglicherweise erforderlich, während der Test gestartet und durchgeführt wird:
Test Case document- Dieses Dokument enthält eine Liste der durchzuführenden Tests. Es enthält einen Unit-Testplan, einen Integrationstestplan, einen Systemtestplan und einen Abnahmetestplan.
Test description - Dieses Dokument enthält eine detaillierte Beschreibung aller Testfälle und Verfahren zu deren Ausführung.
Test case report - Dieses Dokument enthält einen Testfallbericht als Ergebnis des Tests.
Test logs - Dieses Dokument enthält Testprotokolle für jeden Testfallbericht.
Nach dem Testen
Die folgenden Dokumente können nach dem Testen erstellt werden:
Test summary- Diese Testzusammenfassung ist eine kollektive Analyse aller Testberichte und Protokolle. Es fasst zusammen und schließt, ob die Software startbereit ist. Die Software wird unter dem Versionskontrollsystem veröffentlicht, wenn sie startbereit ist.
Testen vs. Qualitätskontrolle, Qualitätssicherung und Audit
Wir müssen verstehen, dass sich Softwaretests von Softwarequalitätssicherung, Softwarequalitätskontrolle und Softwareprüfung unterscheiden.
Software quality assurance- Hierbei handelt es sich um Mittel zur Überwachung des Softwareentwicklungsprozesses, mit denen sichergestellt wird, dass alle Maßnahmen gemäß den Organisationsstandards ergriffen werden. Diese Überwachung wird durchgeführt, um sicherzustellen, dass die richtigen Softwareentwicklungsmethoden befolgt wurden.
Software quality control- Dies ist ein System zur Aufrechterhaltung der Qualität von Softwareprodukten. Es kann funktionale und nicht funktionale Aspekte des Softwareprodukts enthalten, die den guten Willen der Organisation verbessern. Dieses System stellt sicher, dass der Kunde ein Qualitätsprodukt für seine Anforderungen erhält und das Produkt als "gebrauchsfertig" zertifiziert ist.
Software audit- Dies ist eine Überprüfung des Verfahrens, das von der Organisation zur Entwicklung der Software verwendet wird. Ein vom Entwicklungsteam unabhängiges Auditorenteam untersucht den Softwareprozess, das Verfahren, die Anforderungen und andere Aspekte von SDLC. Der Zweck des Software-Audits besteht darin, zu überprüfen, ob die Software und ihr Entwicklungsprozess den Standards, Regeln und Vorschriften entsprechen.
Die Softwarewartung ist heutzutage ein weit verbreiteter Bestandteil von SDLC. Es steht für alle Änderungen und Aktualisierungen, die nach der Lieferung des Softwareprodukts vorgenommen wurden. Es gibt eine Reihe von Gründen, warum Änderungen erforderlich sind. Einige davon werden im Folgenden kurz erwähnt:
Market Conditions - Richtlinien, die sich im Laufe der Zeit ändern, wie z. B. Steuern und neu eingeführte Einschränkungen wie die Aufrechterhaltung der Buchhaltung, können Änderungen erforderlich machen.
Client Requirements - Im Laufe der Zeit kann der Kunde nach neuen Merkmalen oder Funktionen in der Software fragen.
Host Modifications - Wenn sich die Hardware und / oder Plattform (z. B. das Betriebssystem) des Zielhosts ändert, sind Softwareänderungen erforderlich, um die Anpassungsfähigkeit aufrechtzuerhalten.
Organization Changes - Wenn sich auf Kundenebene Änderungen auf Unternehmensebene ergeben, z. B. eine Verringerung der Organisationsstärke, die Übernahme eines anderen Unternehmens oder die Neugründung von Organisationen in die neue Software, kann eine Änderung der ursprünglichen Software erforderlich sein.
Arten der Wartung
Während einer Software-Lebensdauer kann die Art der Wartung je nach Art variieren. Es kann sich lediglich um routinemäßige Wartungsaufgaben handeln, da ein Fehler von einem Benutzer entdeckt wurde, oder es kann sich um ein großes Ereignis handeln, das auf der Größe oder Art der Wartung basiert. Im Folgenden sind einige Arten der Wartung aufgeführt, die auf ihren Eigenschaften basieren:
Corrective Maintenance - Dies schließt Änderungen und Aktualisierungen ein, die vorgenommen wurden, um Probleme zu beheben oder zu beheben, die entweder vom Benutzer entdeckt oder durch Benutzerfehlerberichte abgeschlossen wurden.
Adaptive Maintenance - Dies umfasst Änderungen und Aktualisierungen, die vorgenommen werden, um das Softwareprodukt auf dem neuesten Stand zu halten und auf die sich ständig ändernde Welt der Technologie und des Geschäftsumfelds abzustimmen.
Perfective Maintenance- Dies schließt Änderungen und Aktualisierungen ein, die vorgenommen werden, um die Software über einen langen Zeitraum nutzbar zu machen. Es enthält neue Funktionen, neue Benutzeranforderungen für die Verbesserung der Software und die Verbesserung ihrer Zuverlässigkeit und Leistung.
Preventive Maintenance- Dies beinhaltet Änderungen und Aktualisierungen, um zukünftige Probleme der Software zu vermeiden. Ziel ist es, Probleme zu lösen, die derzeit nicht von Bedeutung sind, aber in Zukunft schwerwiegende Probleme verursachen können.
Wartungskosten
Berichten zufolge sind die Wartungskosten hoch. Eine Studie zur Schätzung der Softwarewartung ergab, dass die Wartungskosten bis zu 67% der Kosten des gesamten Softwareprozesszyklus betragen.
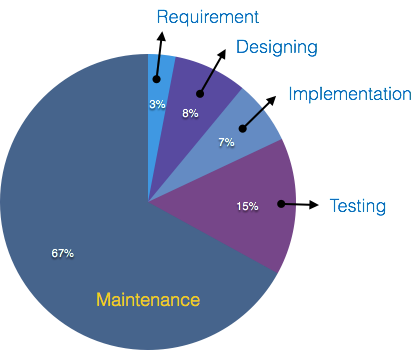
Im Durchschnitt betragen die Kosten für die Softwarewartung mehr als 50% aller SDLC-Phasen. Es gibt verschiedene Faktoren, die hohe Wartungskosten auslösen, wie z.
Reale Faktoren, die die Wartungskosten beeinflussen
- Das Standardalter einer Software beträgt 10 bis 15 Jahre.
- Ältere Software, die auf langsamen Computern mit weniger Speicher und Speicherkapazität funktionieren sollte, kann sich nicht gegen neu kommende verbesserte Software auf moderner Hardware behaupten.
- Mit fortschreitender Technologie wird die Wartung alter Software kostspielig.
- Die meisten Wartungstechniker sind Neulinge und verwenden die Trial-and-Error-Methode, um das Problem zu beheben.
- Oft können vorgenommene Änderungen die ursprüngliche Struktur der Software leicht beschädigen, was spätere Änderungen erschwert.
- Änderungen werden häufig nicht dokumentiert, was in Zukunft zu weiteren Konflikten führen kann.
Software-Endfaktoren, die die Wartungskosten beeinflussen
- Struktur des Softwareprogramms
- Programmiersprache
- Abhängigkeit von der äußeren Umgebung
- Zuverlässigkeit und Verfügbarkeit des Personals
Wartungsaktivitäten
IEEE bietet einen Rahmen für sequentielle Wartungsprozessaktivitäten. Es kann iterativ verwendet und erweitert werden, sodass benutzerdefinierte Elemente und Prozesse einbezogen werden können.

Diese Aktivitäten gehen Hand in Hand mit jeder der folgenden Phasen:
Identification & Tracing- Es handelt sich um Aktivitäten zur Identifizierung des Änderungs- oder Wartungsbedarfs. Es wird vom Benutzer generiert oder das System kann selbst über Protokolle oder Fehlermeldungen berichten. Hier wird auch der Wartungstyp klassifiziert.
Analysis- Die Änderung wird auf ihre Auswirkungen auf das System einschließlich der Auswirkungen auf die Sicherheit analysiert. Wenn die wahrscheinlichen Auswirkungen schwerwiegend sind, wird nach einer alternativen Lösung gesucht. Eine Reihe erforderlicher Änderungen wird dann in Anforderungsspezifikationen umgesetzt. Die Kosten für Änderungen / Wartung werden analysiert und die Schätzung abgeschlossen.
Design- Neue Module, die ersetzt oder geändert werden müssen, werden anhand der in der vorherigen Stufe festgelegten Anforderungsspezifikationen entwickelt. Testfälle werden zur Validierung und Verifizierung erstellt.
Implementation - Die neuen Module werden mit Hilfe des im Entwurfsschritt erstellten strukturierten Entwurfs codiert. Von jedem Programmierer wird erwartet, dass er parallel Unit-Tests durchführt.
System Testing- Integrationstests werden für neu erstellte Module durchgeführt. Integrationstests werden auch zwischen neuen Modulen und dem System durchgeführt. Schließlich wird das System als Ganzes nach regressiven Testverfahren getestet.
Acceptance Testing- Nachdem das System intern getestet wurde, wird es mithilfe von Benutzern auf Akzeptanz geprüft. In diesem Zustand beschwert sich der Benutzer über einige Probleme, die in der nächsten Iteration behoben oder behoben werden sollen.
Delivery- Nach dem Abnahmetest wird das System im gesamten Unternehmen entweder durch ein kleines Update-Paket oder durch eine Neuinstallation des Systems bereitgestellt. Der endgültige Test findet am Client-Ende nach Auslieferung der Software statt.
Bei Bedarf wird zusätzlich zum Ausdruck des Benutzerhandbuchs eine Schulungseinrichtung bereitgestellt.
Maintenance management- Das Konfigurationsmanagement ist ein wesentlicher Bestandteil der Systemwartung. Es wird mit Tools zur Versionskontrolle unterstützt, um Versionen, Halbversionen oder Patch-Management zu steuern.
Software-Re-Engineering
Wenn wir die Software aktualisieren müssen, um sie auf dem aktuellen Markt zu halten, ohne ihre Funktionalität zu beeinträchtigen, spricht man von Software-Re-Engineering. Es ist ein gründlicher Prozess, bei dem das Design von Software geändert und Programme neu geschrieben werden.
Legacy-Software kann nicht mit der neuesten auf dem Markt verfügbaren Technologie Schritt halten. Wenn die Hardware veraltet ist, bereitet das Aktualisieren der Software Kopfschmerzen. Selbst wenn Software mit der Zeit alt wird, funktioniert ihre Funktionalität nicht.
Beispielsweise wurde Unix ursprünglich in Assemblersprache entwickelt. Als Sprache C ins Leben gerufen wurde, wurde Unix in C überarbeitet, da die Arbeit in Assemblersprache schwierig war.
Abgesehen davon bemerken Programmierer manchmal, dass nur wenige Teile der Software mehr Wartung benötigen als andere, und sie müssen auch neu entwickelt werden.

Re-Engineering-Prozess
- Decidewas neu zu konstruieren. Ist es ganze Software oder ein Teil davon?
- Perform Reverse Engineering, um Spezifikationen der vorhandenen Software zu erhalten.
- Restructure ProgramFalls erforderlich. Zum Beispiel funktionsorientierte Programme in objektorientierte Programme ändern.
- Re-structure data nach Bedarf.
- Apply Forward engineering Konzepte, um überarbeitete Software zu erhalten.
Es gibt nur wenige wichtige Begriffe, die beim Software-Re-Engineering verwendet werden
Reverse Engineering
Es ist ein Prozess, um die Systemspezifikation durch gründliche Analyse und Verständnis des vorhandenen Systems zu erreichen. Dieser Prozess kann als umgekehrtes SDLC-Modell angesehen werden, dh wir versuchen, eine höhere Abstraktionsebene zu erreichen, indem wir niedrigere Abstraktionsebenen analysieren.
Ein bestehendes System ist zuvor Design implementiert, über das wir nichts wissen. Designer führen dann ein Reverse Engineering durch, indem sie sich den Code ansehen und versuchen, das Design zu erhalten. Mit dem Design in der Hand versuchen sie, die Spezifikationen abzuschließen. Umgekehrt vom Code zur Systemspezifikation.

Programmumstrukturierung
Es ist ein Prozess, um die vorhandene Software neu zu strukturieren und neu zu konstruieren. Es geht darum, den Quellcode entweder in derselben Programmiersprache oder von einer Programmiersprache in eine andere neu anzuordnen. Die Umstrukturierung kann entweder eine Umstrukturierung des Quellcodes und eine Umstrukturierung der Daten oder beides umfassen.
Eine Umstrukturierung wirkt sich nicht auf die Funktionalität der Software aus, verbessert jedoch die Zuverlässigkeit und Wartbarkeit. Programmkomponenten, die sehr häufig Fehler verursachen, können geändert oder durch Umstrukturierung aktualisiert werden.
Die Zuverlässigkeit von Software auf veralteten Hardwareplattformen kann durch Umstrukturierung beseitigt werden.
Forward Engineering
Forward Engineering ist ein Prozess zum Erhalten der gewünschten Software aus den vorliegenden Spezifikationen, die durch Reverse Engineering heruntergefahren wurden. Es wird davon ausgegangen, dass bereits in der Vergangenheit Software-Engineering durchgeführt wurde.
Forward Engineering ist mit nur einem Unterschied dasselbe wie Software Engineering-Prozess - es wird immer nach Reverse Engineering durchgeführt.

Wiederverwendbarkeit von Komponenten
Eine Komponente ist Teil des Softwareprogrammcodes, der eine unabhängige Aufgabe im System ausführt. Es kann sich um ein kleines Modul oder ein Subsystem handeln.
Beispiel
Die im Web verwendeten Anmeldeverfahren können als Komponenten betrachtet werden, das Drucksystem in der Software kann als Komponente der Software angesehen werden.
Komponenten haben eine hohe Kohäsion der Funktionalität und eine geringere Kopplungsrate, dh sie arbeiten unabhängig voneinander und können Aufgaben ausführen, ohne von anderen Modulen abhängig zu sein.
In OOP sind die entworfenen Objekte sehr spezifisch für ihr Anliegen und haben weniger Chancen, in einer anderen Software verwendet zu werden.
Bei der modularen Programmierung sind die Module so codiert, dass sie bestimmte Aufgaben ausführen, die für eine Reihe anderer Softwareprogramme verwendet werden können.
Es gibt eine völlig neue Branche, die auf der Wiederverwendung von Softwarekomponenten basiert und als Component Based Software Engineering (CBSE) bekannt ist.

Die Wiederverwendung kann auf verschiedenen Ebenen erfolgen
Application level - Wenn eine gesamte Anwendung als Teilsystem neuer Software verwendet wird.
Component level - Wenn das Subsystem einer Anwendung verwendet wird.
Modules level - Wo Funktionsmodule wiederverwendet werden.
Softwarekomponenten bieten Schnittstellen, über die die Kommunikation zwischen verschiedenen Komponenten hergestellt werden kann.
Wiederverwendungsprozess
Es gibt zwei Arten von Methoden: entweder indem die Anforderungen gleich bleiben und die Komponenten angepasst werden oder indem die Komponenten gleich bleiben und die Anforderungen geändert werden.

Requirement Specification - Es werden die funktionalen und nicht funktionalen Anforderungen festgelegt, die ein Softwareprodukt mithilfe eines vorhandenen Systems, Benutzereingaben oder beidem erfüllen muss.
Design- Dies ist auch ein Standard-SDLC-Prozessschritt, in dem Anforderungen in Bezug auf die Softwaresprache definiert werden. Die Grundarchitektur des Gesamtsystems und seiner Subsysteme wird erstellt.
Specify Components - Durch das Studium des Software-Designs trennen die Designer das gesamte System in kleinere Komponenten oder Subsysteme. Aus einem vollständigen Software-Design wird eine Sammlung einer Vielzahl von Komponenten, die zusammenarbeiten.
Search Suitable Components - Das Software-Komponenten-Repository wird von Designern zur Suche nach der passenden Komponente auf der Grundlage der Funktionalität und der beabsichtigten Softwareanforderungen verwiesen.
Incorporate Components - Alle aufeinander abgestimmten Komponenten werden zusammengepackt, um sie als vollständige Software zu formen.
CASE steht für CComputer Aided Software EEngineering. Es bedeutet, Entwicklung und Wartung von Softwareprojekten mit Hilfe verschiedener automatisierter Softwaretools.
CASE Tools
CASE-Tools bestehen aus Softwareanwendungsprogrammen, mit denen SDLC-Aktivitäten automatisiert werden. CASE-Tools werden von Software-Projektmanagern, Analysten und Ingenieuren zur Entwicklung von Softwaresystemen verwendet.
Es stehen eine Reihe von CASE-Tools zur Verfügung, um verschiedene Phasen des Softwareentwicklungs-Lebenszyklus zu vereinfachen, z. B. Analysetools, Designtools, Projektmanagement-Tools, Datenbankmanagement-Tools und Dokumentations-Tools, um nur einige zu nennen.
Die Verwendung von CASE-Tools beschleunigt die Entwicklung des Projekts, um das gewünschte Ergebnis zu erzielen, und hilft, Fehler aufzudecken, bevor die nächste Stufe der Softwareentwicklung fortgesetzt wird.
Komponenten von CASE Tools
CASE-Tools können basierend auf ihrer Verwendung in einer bestimmten SDLC-Phase grob in die folgenden Teile unterteilt werden:
Central Repository- CASE-Tools erfordern ein zentrales Repository, das als Quelle für gemeinsame, integrierte und konsistente Informationen dienen kann. Das zentrale Repository ist ein zentraler Speicherort, an dem Produktspezifikationen, Anforderungsdokumente, zugehörige Berichte und Diagramme sowie weitere nützliche Informationen zur Verwaltung gespeichert werden. Das zentrale Repository dient auch als Datenwörterbuch.

Upper Case Tools - Upper CASE-Tools werden in Planungs-, Analyse- und Entwurfsphasen von SDLC verwendet.
Lower Case Tools - Bei der Implementierung, Prüfung und Wartung werden niedrigere CASE-Tools verwendet.
Integrated Case Tools - Integrierte CASE-Tools sind in allen Phasen des SDLC hilfreich, von der Anforderungserfassung bis zum Testen und Dokumentieren.
CASE-Tools können zusammengefasst werden, wenn sie ähnliche Funktionen, Prozessaktivitäten und die Fähigkeit zur Integration in andere Tools aufweisen.
Umfang der Fallwerkzeuge
Der Umfang der CASE-Tools erstreckt sich über den gesamten SDLC.
Fallwerkzeugtypen
Jetzt gehen wir kurz verschiedene CASE-Tools durch
Diagrammwerkzeuge
Diese Tools werden verwendet, um Systemkomponenten, Daten und Steuerungsfluss zwischen verschiedenen Softwarekomponenten und der Systemstruktur in grafischer Form darzustellen. Zum Beispiel das Flow Chart Maker-Tool zum Erstellen von Flussdiagrammen auf dem neuesten Stand der Technik.
Prozessmodellierungswerkzeuge
Die Prozessmodellierung ist eine Methode zum Erstellen eines Software-Prozessmodells, mit dem die Software entwickelt wird. Tools zur Prozessmodellierung helfen den Managern, ein Prozessmodell auszuwählen oder gemäß den Anforderungen des Softwareprodukts zu ändern. Zum Beispiel EPF Composer
Projektmanagement-Tools
Diese Tools werden für die Projektplanung, Kosten- und Aufwandsschätzung, Projektplanung und Ressourcenplanung verwendet. Manager müssen die Projektausführung bei jedem genannten Schritt im Software-Projektmanagement strikt einhalten. Projektmanagement-Tools helfen beim Speichern und Teilen von Projektinformationen in Echtzeit im gesamten Unternehmen. Zum Beispiel Creative Pro Office, Trac Project, Basecamp.
Dokumentationswerkzeuge
Die Dokumentation in einem Softwareprojekt beginnt vor dem Softwareprozess, durchläuft alle Phasen des SDLC und nach Abschluss des Projekts.
Dokumentationswerkzeuge generieren Dokumente für technische Benutzer und Endbenutzer. Technische Benutzer sind meistens interne Fachleute des Entwicklungsteams, die sich auf das Systemhandbuch, das Referenzhandbuch, das Schulungshandbuch, die Installationshandbücher usw. beziehen. Die Endbenutzerdokumente beschreiben die Funktionsweise und die Vorgehensweise des Systems, z. B. das Benutzerhandbuch. Zum Beispiel Doxygen, DrExplain, Adobe RoboHelp zur Dokumentation.
Analysewerkzeuge
Diese Tools helfen dabei, Anforderungen zu erfassen, automatisch auf Inkonsistenzen, Ungenauigkeiten in den Diagrammen, Datenredundanzen oder fehlerhafte Auslassungen zu prüfen. Beispiel: Akzeptieren Sie 360, Accompa, CaseComplete für die Anforderungsanalyse und Visible Analyst für die Gesamtanalyse.
Design-Tools
Diese Tools helfen Software-Designern beim Entwerfen der Blockstruktur der Software, die mithilfe von Verfeinerungstechniken in kleinere Module unterteilt werden kann. Diese Tools bieten detaillierte Informationen zu den einzelnen Modulen und Verbindungen zwischen Modulen. Zum Beispiel animiertes Software-Design
Konfigurationsverwaltungstools
Eine Instanz von Software wird unter einer Version veröffentlicht. Konfigurationsmanagement-Tools befassen sich mit -
- Versions- und Revisionsmanagement
- Basiskonfigurationsmanagement
- Change Control Management
CASE-Tools helfen dabei durch automatische Nachverfolgung, Versionsverwaltung und Release-Verwaltung. Zum Beispiel Fossil, Git, Accu REV.
Kontrollwerkzeuge ändern
Diese Tools werden als Teil der Konfigurationsmanagement-Tools betrachtet. Sie befassen sich mit Änderungen, die an der Software vorgenommen wurden, nachdem ihre Basislinie festgelegt wurde oder wenn die Software zum ersten Mal veröffentlicht wird. CASE-Tools automatisieren die Änderungsverfolgung, Dateiverwaltung, Codeverwaltung und mehr. Es hilft auch bei der Durchsetzung der Änderungsrichtlinie der Organisation.
Programmierwerkzeuge
Diese Tools bestehen aus Programmierumgebungen wie IDE (Integrated Development Environment), integrierter Modulbibliothek und Simulationswerkzeugen. Diese Tools bieten umfassende Unterstützung beim Erstellen von Softwareprodukten und enthalten Funktionen zum Simulieren und Testen. Beispiel: Cscope zum Suchen von Code in C, Eclipse.
Prototyping-Tools
Der Software-Prototyp ist eine simulierte Version des beabsichtigten Softwareprodukts. Der Prototyp bietet ein erstes Erscheinungsbild des Produkts und simuliert nur wenige Aspekte des tatsächlichen Produkts.
Prototyping CASE-Tools werden im Wesentlichen mit grafischen Bibliotheken geliefert. Sie können hardwareunabhängige Benutzeroberflächen und Designs erstellen. Diese Tools helfen uns, schnelle Prototypen basierend auf vorhandenen Informationen zu erstellen. Darüber hinaus bieten sie eine Simulation des Software-Prototyps. Zum Beispiel Serena-Prototyp-Komponist Mockup Builder.
Webentwicklungstools
Diese Tools unterstützen Sie beim Entwerfen von Webseiten mit allen zugehörigen Elementen wie Formularen, Text, Skripten, Grafiken usw. Web-Tools bieten auch eine Live-Vorschau dessen, was entwickelt wird und wie es nach Abschluss aussehen wird. Zum Beispiel Fontello, Adobe Edge Inspect, Foundation 3, Klammern.
Qualitätssicherungstools
Die Qualitätssicherung in einer Softwareorganisation überwacht den Engineering-Prozess und die Methoden zur Entwicklung des Softwareprodukts, um die Konformität der Qualität gemäß den Organisationsstandards sicherzustellen. QS-Tools bestehen aus Tools zur Konfiguration und Änderungskontrolle sowie Tools zum Testen von Software. Zum Beispiel SoapTest, AppsWatch, JMeter.
Wartungswerkzeuge
Die Softwarewartung umfasst Änderungen am Softwareprodukt nach dessen Auslieferung. Automatische Protokollierungs- und Fehlerberichterstattungstechniken, automatische Generierung von Fehlertickets und Ursachenanalyse sind nur einige CASE-Tools, die die Softwareorganisation in der Wartungsphase von SDLC unterstützen. Zum Beispiel Bugzilla für die Fehlerverfolgung, HP Quality Center.