SQLAlchemy - Kurzanleitung
SQLAlchemy ist ein beliebtes SQL-Toolkit und Object Relational Mapper. Es ist geschrieben inPythonund bietet einem Anwendungsentwickler die volle Leistung und Flexibilität von SQL. Es ist einopen source und cross-platform software unter MIT-Lizenz veröffentlicht.
SQLAlchemy ist berühmt für seinen objektrelationalen Mapper (ORM), mit dem Klassen der Datenbank zugeordnet werden können, wodurch sich das Objektmodell und das Datenbankschema von Anfang an sauber entkoppelt entwickeln können.
Da Größe und Leistung von SQL-Datenbanken eine Rolle spielen, verhalten sie sich weniger wie Objektsammlungen. Wenn sich die Abstraktion in Objektsammlungen jedoch von Bedeutung ist, verhalten sie sich weniger wie Tabellen und Zeilen. SQLAlchemy zielt darauf ab, diese beiden Prinzipien zu berücksichtigen.
Aus diesem Grund hat es die data mapper pattern (like Hibernate) rather than the active record pattern used by a number of other ORMs. Datenbanken und SQL werden mit SQLAlchemy aus einer anderen Perspektive betrachtet.
Michael Bayer ist der ursprüngliche Autor von SQLAlchemy. Die ursprüngliche Version wurde im Februar 2006 veröffentlicht. Die neueste Version ist mit 1.2.7 nummeriert und wurde erst im April 2018 veröffentlicht.
Was ist ORM?
ORM (Object Relational Mapping) ist eine Programmiertechnik zum Konvertieren von Daten zwischen inkompatiblen Typsystemen in objektorientierten Programmiersprachen. Normalerweise enthält das in einer objektorientierten Sprache (OO) wie Python verwendete Typsystem nicht skalare Typen. Diese können nicht als primitive Typen wie Ganzzahlen und Zeichenfolgen ausgedrückt werden. Daher muss der OO-Programmierer Objekte in Skalardaten konvertieren, um mit der Backend-Datenbank zu interagieren. Datentypen in den meisten Datenbankprodukten wie Oracle, MySQL usw. sind jedoch primär.
In einem ORM-System wird jede Klasse einer Tabelle in der zugrunde liegenden Datenbank zugeordnet. Anstatt langwierigen Code für Datenbankschnittstellen selbst zu schreiben, kümmert sich ein ORM um diese Probleme, während Sie sich auf die Programmierung der Logik des Systems konzentrieren können.
SQLAlchemy - Umgebung einrichten
Lassen Sie uns die für die Verwendung von SQLAlchemy erforderlichen Umgebungseinstellungen erörtern.
Für die Installation von SQLAlchemy ist eine höhere Version von Python als 2.7 erforderlich. Der einfachste Weg zur Installation ist die Verwendung von Python Package Manager.pip. Dieses Dienstprogramm ist in der Standarddistribution von Python enthalten.
pip install sqlalchemyMit dem obigen Befehl können wir das herunterladen latest released versionvon SQLAlchemy von python.org und installieren Sie es auf Ihrem System.
Im Falle einer Anaconda-Distribution von Python kann SQLAlchemy von installiert werden conda terminal mit dem folgenden Befehl -
conda install -c anaconda sqlalchemyEs ist auch möglich, SQLAlchemy unter dem folgenden Quellcode zu installieren -
python setup.py installSQLAlchemy wurde für den Betrieb mit einer DBAPI-Implementierung entwickelt, die für eine bestimmte Datenbank erstellt wurde. Es verwendet ein Dialektsystem, um mit verschiedenen Arten von DBAPI-Implementierungen und -Datenbanken zu kommunizieren. Für alle Dialekte muss ein entsprechender DBAPI-Treiber installiert sein.
Die folgenden Dialekte sind enthalten -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
Geben Sie den folgenden Befehl in die Python-Eingabeaufforderung ein, um zu überprüfen, ob SQLAlchemy ordnungsgemäß installiert ist, und um die Version zu ermitteln:
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.2.7'SQLAlchemy Kern enthält SQL rendering engine, DBAPI integration, transaction integration, und schema description services. Der SQLAlchemy-Kern verwendet die SQL Expression Language, die aschema-centric usage Paradigma, während SQLAlchemy ORM a domain-centric mode of usage.
Die SQL Expression Language bietet ein System zur Darstellung relationaler Datenbankstrukturen und Ausdrücke mithilfe von Python-Konstrukten. Es präsentiert ein System zur Darstellung der primitiven Konstrukte der relationalen Datenbank direkt ohne Meinung, im Gegensatz zu ORM, das ein hochrangiges und abstrahiertes Verwendungsmuster darstellt, das selbst ein Beispiel für die angewandte Verwendung der Ausdruckssprache ist.
Die Ausdruckssprache ist eine der Kernkomponenten von SQLAlchemy. Der Programmierer kann SQL-Anweisungen in Python-Code angeben und direkt in komplexeren Abfragen verwenden. Die Ausdruckssprache ist unabhängig vom Backend und deckt alle Aspekte von Raw SQL umfassend ab. Es ist näher an Raw SQL als jede andere Komponente in SQLAlchemy.
Die Ausdruckssprache repräsentiert die primitiven Konstrukte der relationalen Datenbank direkt. Da das ORM auf der Ausdruckssprache basiert, hat eine typische Python-Datenbankanwendung möglicherweise beide überlappend verwendet. Die Anwendung kann nur die Ausdruckssprache verwenden, muss jedoch ein eigenes System zur Übersetzung von Anwendungskonzepten in einzelne Datenbankabfragen definieren.
Anweisungen der Ausdruckssprache werden von der SQLAlchemy-Engine in entsprechende SQL-Rohabfragen übersetzt. Wir werden nun lernen, wie man die Engine erstellt und mit ihrer Hilfe verschiedene SQL-Abfragen ausführt.
Im vorherigen Kapitel haben wir den Ausdruck Sprache in SQLAlchemy besprochen. Fahren wir nun mit den Schritten fort, die beim Herstellen einer Verbindung zu einer Datenbank erforderlich sind.
Motorklasse verbindet a Pool and Dialect together um eine Datenbankquelle bereitzustellen connectivity and behavior. Ein Objekt der Engine-Klasse wird mit dem instanziiertcreate_engine() Funktion.
Die Funktion create_engine () verwendet die Datenbank als ein Argument. Die Datenbank muss nirgendwo definiert werden. Das Standardaufrufformular muss die URL als erstes Positionsargument senden, normalerweise eine Zeichenfolge, die Datenbankdialekt- und Verbindungsargumente angibt. Mit dem unten angegebenen Code können wir eine Datenbank erstellen.
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///college.db', echo = True)Für ein MySQL databaseVerwenden Sie den folgenden Befehl -
engine = create_engine("mysql://user:pwd@localhost/college",echo = True)Um es speziell zu erwähnen DB-API für die Verbindung verwendet werden, die URL string nimmt die Form wie folgt an -
dialect[+driver]://user:password@host/dbnameZum Beispiel, wenn Sie verwenden PyMySQL driver with MySQLVerwenden Sie den folgenden Befehl:
mysql+pymysql://<username>:<password>@<host>/<dbname>Das echo flagist eine Verknüpfung zum Einrichten der SQLAlchemy-Protokollierung, die über das Standardprotokollierungsmodul von Python erfolgt. In den folgenden Kapiteln lernen wir alle generierten SQLs kennen. Um die ausführliche Ausgabe auszublenden, setzen Sie das Echo-Attribut aufNone. Andere Argumente für die Funktion create_engine () können dialektspezifisch sein.
Die Funktion create_engine () gibt eine zurück Engine object. Einige wichtige Methoden der Motorklasse sind -
| Sr.Nr. | Methode & Beschreibung |
|---|---|
| 1 | connect() Gibt das Verbindungsobjekt zurück |
| 2 | execute() Führt ein SQL-Anweisungskonstrukt aus |
| 3 | begin() Gibt einen Kontextmanager zurück, der eine Verbindung mit einer eingerichteten Transaktion bereitstellt. Nach erfolgreichem Betrieb wird die Transaktion festgeschrieben, andernfalls wird sie zurückgesetzt |
| 4 | dispose() Entsorgt den von der Engine verwendeten Verbindungspool |
| 5 | driver() Treibername des von der Engine verwendeten Dialekts |
| 6 | table_names() Gibt eine Liste aller in der Datenbank verfügbaren Tabellennamen zurück |
| 7 | transaction() Führt die angegebene Funktion innerhalb einer Transaktionsgrenze aus |
Lassen Sie uns nun diskutieren, wie die Funktion zum Erstellen von Tabellen verwendet wird.
Die SQL-Ausdruckssprache erstellt ihre Ausdrücke anhand von Tabellenspalten. Das SQLAlchemy Column-Objekt repräsentiert acolumn in einer Datenbanktabelle, die wiederum durch a dargestellt wird Tableobject. Metadaten enthalten Definitionen von Tabellen und zugehörigen Objekten wie Index, Ansicht, Trigger usw.
Daher ist ein Objekt der MetaData-Klasse aus SQLAlchemy Metadata eine Sammlung von Tabellenobjekten und den zugehörigen Schemakonstrukten. Es enthält eine Sammlung von Tabellenobjekten sowie eine optionale Bindung an eine Engine oder Verbindung.
from sqlalchemy import MetaData
meta = MetaData()Der Konstruktor der MetaData-Klasse kann standardmäßig Bindungs- und Schemaparameter enthalten None.
Als nächstes definieren wir unsere Tabellen alle innerhalb des obigen Metadatenkatalogs unter Verwendung von the Table construct, die der regulären SQL-Anweisung CREATE TABLE ähnelt.
Ein Objekt der Tabellenklasse repräsentiert die entsprechende Tabelle in einer Datenbank. Der Konstruktor verwendet die folgenden Parameter:
| Name | Name der Tabelle |
|---|---|
| Metadaten | MetaData-Objekt, das diese Tabelle enthält |
| Säulen) | Ein oder mehrere Objekte der Spaltenklasse |
Das Spaltenobjekt repräsentiert a column in einem database table. Der Konstruktor akzeptiert Name, Typ und andere Parameter wie Primärschlüssel, automatische Inkrementierung und andere Einschränkungen.
SQLAlchemy vergleicht Python-Daten mit den darin definierten bestmöglichen generischen Spaltendatentypen. Einige der generischen Datentypen sind -
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
So erstellen Sie eine students table Verwenden Sie in der College-Datenbank das folgende Snippet:
from sqlalchemy import Table, Column, Integer, String, MetaData
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)Die Funktion create_all () verwendet das Engine-Objekt, um alle definierten Tabellenobjekte zu erstellen und die Informationen in Metadaten zu speichern.
meta.create_all(engine)Im Folgenden wird der vollständige Code angegeben, mit dem eine SQLite-Datenbank college.db mit einer Schülertabelle erstellt wird.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
meta.create_all(engine)Weil das Echo-Attribut der Funktion create_engine () auf gesetzt ist Truezeigt die Konsole die eigentliche SQL-Abfrage für die Tabellenerstellung wie folgt an:
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
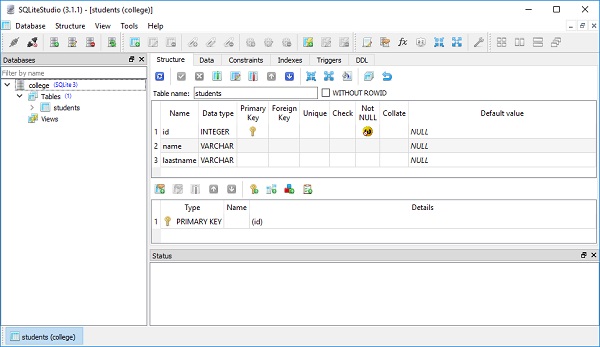
)Die Datei college.db wird im aktuellen Arbeitsverzeichnis erstellt. Um zu überprüfen, ob die Schülertabelle erstellt wurde, können Sie die Datenbank mit einem beliebigen SQLite-GUI-Tool wie zSQLiteStudio.
Das folgende Bild zeigt die in der Datenbank erstellte Schülertabelle -
In diesem Kapitel konzentrieren wir uns kurz auf die SQL-Ausdrücke und ihre Funktionen.
SQL-Ausdrücke werden mit entsprechenden Methoden relativ zum Zieltabellenobjekt erstellt. Beispielsweise wird die INSERT-Anweisung erstellt, indem die Methode insert () wie folgt ausgeführt wird:
ins = students.insert()Das Ergebnis der obigen Methode ist ein Einfügeobjekt, das mithilfe von überprüft werden kann str()Funktion. Der folgende Code fügt Details wie Schüler-ID, Name, Nachname ein.
'INSERT INTO students (id, name, lastname) VALUES (:id, :name, :lastname)'Es ist möglich, einen Wert in ein bestimmtes Feld einzufügen, indem values()Methode zum Einfügen eines Objekts. Der Code dafür ist unten angegeben -
>>> ins = users.insert().values(name = 'Karan')
>>> str(ins)
'INSERT INTO users (name) VALUES (:name)'Das auf der Python-Konsole wiedergegebene SQL zeigt nicht den tatsächlichen Wert an (in diesem Fall 'Karan'). Stattdessen generiert SQLALchemy einen Bindungsparameter, der in kompilierter Form der Anweisung sichtbar ist.
ins.compile().params
{'name': 'Karan'}Ebenso Methoden wie update(), delete() und select()Erstellen Sie die Ausdrücke UPDATE, DELETE und SELECT. Wir werden in späteren Kapiteln mehr darüber erfahren.
Im vorherigen Kapitel haben wir SQL-Ausdrücke gelernt. In diesem Kapitel werden wir uns mit der Ausführung dieser Ausdrücke befassen.
Um die resultierenden SQL-Ausdrücke auszuführen, müssen wir obtain a connection object representing an actively checked out DBAPI connection resource und dann feed the expression object wie im folgenden Code gezeigt.
conn = engine.connect()Das folgende insert () -Objekt kann für die execute () -Methode verwendet werden:
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
result = conn.execute(ins)Die Konsole zeigt das Ergebnis der Ausführung des SQL-Ausdrucks wie folgt:
INSERT INTO students (name, lastname) VALUES (?, ?)
('Ravi', 'Kapoor')
COMMITIm Folgenden finden Sie das gesamte Snippet, das die Ausführung der INSERT-Abfrage mithilfe der Kerntechnik von SQLAlchemy zeigt.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
ins = students.insert()
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
conn = engine.connect()
result = conn.execute(ins)Das Ergebnis kann überprüft werden, indem die Datenbank mit SQLite Studio geöffnet wird (siehe Abbildung unten).

Die Ergebnisvariable wird als ResultProxy bezeichnet object. Es ist analog zum DBAPI-Cursorobjekt. Mit können wir Informationen über die Primärschlüsselwerte abrufen, die aus unserer Anweisung generiert wurdenResultProxy.inserted_primary_key wie unten gezeigt -
result.inserted_primary_key
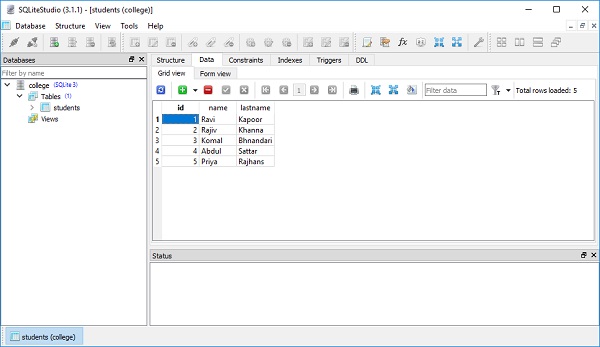
[1]Um viele Einfügungen mit der DBAPI-Methode execute many () auszugeben, können wir eine Liste von Wörterbüchern senden, die jeweils einen bestimmten Satz von einzufügenden Parametern enthalten.
conn.execute(students.insert(), [
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Dies spiegelt sich in der Datenansicht der Tabelle wider, wie in der folgenden Abbildung dargestellt -
In diesem Kapitel werden wir das Konzept der Auswahl von Zeilen im Tabellenobjekt erläutern.
Die select () -Methode des Tabellenobjekts ermöglicht es uns construct SELECT expression.
s = students.select()Das ausgewählte Objekt wird übersetzt in SELECT query by str(s) function wie unten gezeigt -
'SELECT students.id, students.name, students.lastname FROM students'Wir können dieses Auswahlobjekt als Parameter verwenden, um die () Methode des Verbindungsobjekts auszuführen, wie im folgenden Code gezeigt -
result = conn.execute(s)Wenn die obige Anweisung ausgeführt wird, wird die Python-Shell nach dem entsprechenden SQL-Ausdruck wiedergegeben:
SELECT students.id, students.name, students.lastname
FROM studentsDie resultierende Variable entspricht dem Cursor in DBAPI. Wir können jetzt Datensätze mit abrufenfetchone() method.
row = result.fetchone()Alle ausgewählten Zeilen in der Tabelle können mit a gedruckt werden for loop wie unten angegeben -
for row in result:
print (row)Der vollständige Code zum Drucken aller Zeilen aus der Schülertabelle ist unten dargestellt.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
s = students.select()
conn = engine.connect()
result = conn.execute(s)
for row in result:
print (row)Die in der Python-Shell angezeigte Ausgabe lautet wie folgt:
(1, 'Ravi', 'Kapoor')
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')Die WHERE-Klausel der SELECT-Abfrage kann mithilfe von angewendet werden Select.where(). Zum Beispiel, wenn wir Zeilen mit der ID> 2 anzeigen möchten
s = students.select().where(students.c.id>2)
result = conn.execute(s)
for row in result:
print (row)Hier c attribute is an alias for column. Die folgende Ausgabe wird auf der Shell angezeigt -
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')Hierbei ist zu beachten, dass das Auswahlobjekt auch durch die Funktion select () im Modul sqlalchemy.sql abgerufen werden kann. Die Funktion select () erfordert das Tabellenobjekt als Argument.
from sqlalchemy.sql import select
s = select([users])
result = conn.execute(s)Mit SQLAlchemy können Sie nur Zeichenfolgen verwenden, wenn SQL bereits bekannt ist und die Anweisung keine starken dynamischen Funktionen unterstützen muss. Das text () -Konstrukt wird verwendet, um eine Textanweisung zu erstellen, die größtenteils unverändert an die Datenbank übergeben wird.
Es baut ein neues auf TextClause, die eine textuelle SQL-Zeichenfolge direkt darstellt, wie im folgenden Code gezeigt -
from sqlalchemy import text
t = text("SELECT * FROM students")
result = connection.execute(t)Die Vorteile text() bietet über eine einfache Zeichenfolge sind -
- Backend-neutrale Unterstützung für Bindungsparameter
- Ausführungsoptionen pro Anweisung
- Typisierungsverhalten der Ergebnisspalte
Die Funktion text () erfordert gebundene Parameter im benannten Doppelpunktformat. Sie sind unabhängig vom Datenbank-Backend konsistent. Um Werte für die Parameter einzusenden, übergeben wir sie als zusätzliche Argumente an die Methode execute ().
Im folgenden Beispiel werden gebundene Parameter in Text-SQL verwendet.
from sqlalchemy.sql import text
s = text("select students.name, students.lastname from students where students.name between :x and :y")
conn.execute(s, x = 'A', y = 'L').fetchall()Die Funktion text () erstellt den SQL-Ausdruck wie folgt:
select students.name, students.lastname from students where students.name between ? and ?Die Werte von x = 'A' und y = 'L' werden als Parameter übergeben. Ergebnis ist eine Liste von Zeilen mit Namen zwischen 'A' und 'L' -
[('Komal', 'Bhandari'), ('Abdul', 'Sattar')]Das Konstrukt text () unterstützt vordefinierte gebundene Werte mithilfe der Methode TextClause.bindparams (). Die Parameter können auch explizit wie folgt eingegeben werden:
stmt = text("SELECT * FROM students WHERE students.name BETWEEN :x AND :y")
stmt = stmt.bindparams(
bindparam("x", type_= String),
bindparam("y", type_= String)
)
result = conn.execute(stmt, {"x": "A", "y": "L"})
The text() function also be produces fragments of SQL within a select() object that
accepts text() objects as an arguments. The “geometry” of the statement is provided by
select() construct , and the textual content by text() construct. We can build a statement
without the need to refer to any pre-established Table metadata.
from sqlalchemy.sql import select
s = select([text("students.name, students.lastname from students")]).where(text("students.name between :x and :y"))
conn.execute(s, x = 'A', y = 'L').fetchall()Sie können auch verwenden and_() Funktion zum Kombinieren mehrerer Bedingungen in der WHERE-Klausel, die mit Hilfe der Funktion text () erstellt wurde.
from sqlalchemy import and_
from sqlalchemy.sql import select
s = select([text("* from students")]) \
.where(
and_(
text("students.name between :x and :y"),
text("students.id>2")
)
)
conn.execute(s, x = 'A', y = 'L').fetchall()Der obige Code ruft Zeilen mit Namen zwischen "A" und "L" mit einer ID größer als 2 ab. Die Ausgabe des Codes ist unten angegeben -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar')]Der Alias in SQL entspricht einer "umbenannten" Version einer Tabelle oder SELECT-Anweisung, die immer dann auftritt, wenn Sie "SELECT * FROM table1 AS a" sagen. Der AS erstellt einen neuen Namen für die Tabelle. Mit Aliasen kann auf jede Tabelle oder Unterabfrage mit einem eindeutigen Namen verwiesen werden.
Auf diese Weise kann dieselbe Tabelle in der FROM-Klausel mehrmals benannt werden. Es enthält einen übergeordneten Namen für die durch die Anweisung dargestellten Spalten, sodass auf sie relativ zu diesem Namen verwiesen werden kann.
In SQLAlchemy kann jede Tabelle, jedes select () -Konstrukt oder jedes andere auswählbare Objekt mithilfe von in einen Alias umgewandelt werden From Clause.alias()Methode, die ein Alias-Konstrukt erzeugt. Die Funktion alias () im Modul sqlalchemy.sql stellt einen Alias dar, wie er normalerweise mit dem Schlüsselwort AS auf eine Tabelle oder Unterauswahl in einer SQL-Anweisung angewendet wird.
from sqlalchemy.sql import alias
st = students.alias("a")Dieser Alias kann jetzt im select () -Konstrukt verwendet werden, um auf die Schülertabelle zu verweisen -
s = select([st]).where(st.c.id>2)Dies übersetzt den SQL-Ausdruck wie folgt:
SELECT a.id, a.name, a.lastname FROM students AS a WHERE a.id > 2Wir können diese SQL-Abfrage jetzt mit der Methode execute () des Verbindungsobjekts ausführen. Der vollständige Code lautet wie folgt:
from sqlalchemy.sql import alias, select
st = students.alias("a")
s = select([st]).where(st.c.id > 2)
conn.execute(s).fetchall()Wenn die obige Codezeile ausgeführt wird, wird die folgende Ausgabe generiert:
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans')]Das update() Die Methode für das Zieltabellenobjekt erstellt einen äquivalenten UPDATE-SQL-Ausdruck.
table.update().where(conditions).values(SET expressions)Das values()Die Methode für das resultierende Aktualisierungsobjekt wird verwendet, um die SET-Bedingungen des UPDATE anzugeben. Wenn Sie Als Keine belassen, werden die SET-Bedingungen aus den Parametern bestimmt, die während der Ausführung und / oder Kompilierung der Anweisung an die Anweisung übergeben werden.
Die where-Klausel ist ein optionaler Ausdruck, der die WHERE-Bedingung der UPDATE-Anweisung beschreibt.
Das folgende Codefragment ändert den Wert der Spalte 'Nachname' in der Schülertabelle von 'Khanna' in 'Kapoor' -
stmt = students.update().where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')Das stmt-Objekt ist ein Aktualisierungsobjekt, das übersetzt in -
'UPDATE students SET lastname = :lastname WHERE students.lastname = :lastname_1'Der gebundene Parameter lastname_1 wird ersetzt, wenn execute()Methode wird aufgerufen. Der vollständige Update-Code ist unten angegeben -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students',
meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt=students.update().where(students.c.lastname=='Khanna').values(lastname='Kapoor')
conn.execute(stmt)
s = students.select()
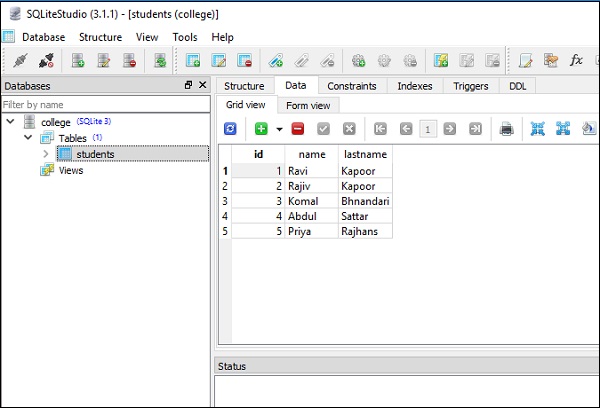
conn.execute(s).fetchall()Der obige Code zeigt die folgende Ausgabe mit der zweiten Zeile an, die den Effekt des Aktualisierungsvorgangs wie im angegebenen Screenshot zeigt -
[
(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(4, 'Abdul', 'Sattar'),
(5, 'Priya', 'Rajhans')
]
Beachten Sie, dass ähnliche Funktionen auch mit verwendet werden können update() Funktion im Modul sqlalchemy.sql.expression wie unten gezeigt -
from sqlalchemy.sql.expression import update
stmt = update(students).where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')Im vorigen Kapitel haben wir verstanden, was ein UpdateAusdruck tut. Der nächste Ausdruck, den wir lernen werden, istDelete.
Der Löschvorgang kann durch Ausführen der Methode delete () für das Zieltabellenobjekt ausgeführt werden, wie in der folgenden Anweisung angegeben:
stmt = students.delete()Im Fall einer Schülertabelle erstellt die obige Codezeile einen SQL-Ausdruck wie folgt:
'DELETE FROM students'Dadurch werden jedoch alle Zeilen in der Schülertabelle gelöscht. Normalerweise ist die DELETE-Abfrage einem logischen Ausdruck zugeordnet, der durch die WHERE-Klausel angegeben wird. Die folgende Anweisung zeigt, wo Parameter -
stmt = students.delete().where(students.c.id > 2)Der resultierende SQL-Ausdruck hat einen gebundenen Parameter, der zur Laufzeit ersetzt wird, wenn die Anweisung ausgeführt wird.
'DELETE FROM students WHERE students.id > :id_1'Das folgende Codebeispiel löscht diese Zeilen aus der Schülertabelle mit dem Nachnamen 'Khanna' -
from sqlalchemy.sql.expression import update
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt = students.delete().where(students.c.lastname == 'Khanna')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()Aktualisieren Sie die Datenansicht der Schülertabelle in SQLiteStudio, um das Ergebnis zu überprüfen.
Eines der wichtigen Merkmale von RDBMS ist das Herstellen einer Beziehung zwischen Tabellen. SQL-Operationen wie SELECT, UPDATE und DELETE können für verwandte Tabellen ausgeführt werden. In diesem Abschnitt werden diese Vorgänge mit SQLAlchemy beschrieben.
Zu diesem Zweck werden zwei Tabellen in unserer SQLite-Datenbank (college.db) erstellt. Die Schülertabelle hat dieselbe Struktur wie im vorherigen Abschnitt. während die Adresstabelle hatst_id Spalte, die zugeordnet ist id column in students table mit Fremdschlüsseleinschränkung.
Der folgende Code erstellt zwei Tabellen in college.db -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo=True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer, ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String))
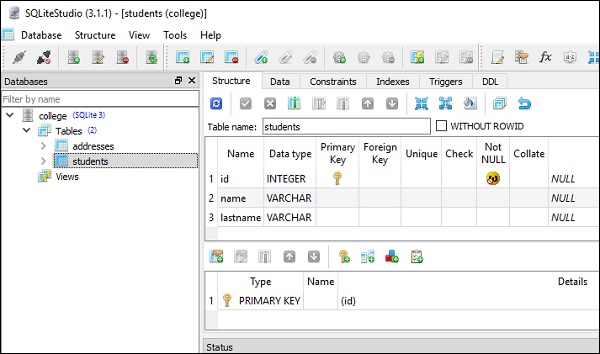
meta.create_all(engine)Der obige Code wird wie folgt in CREATE TABLE-Abfragen für Schüler und Adresstabelle übersetzt -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE addresses (
id INTEGER NOT NULL,
st_id INTEGER,
postal_add VARCHAR,
email_add VARCHAR,
PRIMARY KEY (id),
FOREIGN KEY(st_id) REFERENCES students (id)
)Die folgenden Screenshots zeigen den obigen Code sehr deutlich -
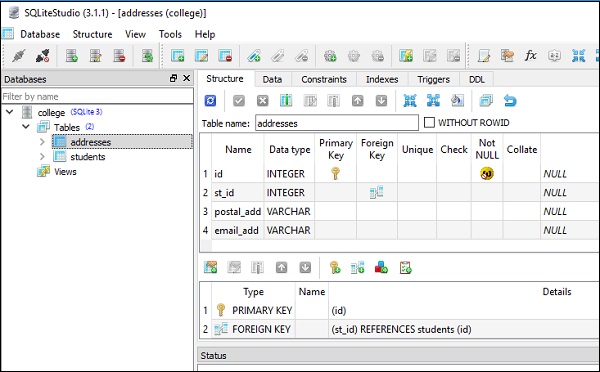
Diese Tabellen werden durch Ausführen mit Daten gefüllt insert() methodvon Tabellenobjekten. Um 5 Zeilen in die Schülertabelle einzufügen, können Sie den folgenden Code verwenden:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn.execute(students.insert(), [
{'name':'Ravi', 'lastname':'Kapoor'},
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Rows werden mit Hilfe des folgenden Codes in die Adresstabelle eingefügt -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
conn.execute(addresses.insert(), [
{'st_id':1, 'postal_add':'Shivajinagar Pune', 'email_add':'[email protected]'},
{'st_id':1, 'postal_add':'ChurchGate Mumbai', 'email_add':'[email protected]'},
{'st_id':3, 'postal_add':'Jubilee Hills Hyderabad', 'email_add':'[email protected]'},
{'st_id':5, 'postal_add':'MG Road Bangaluru', 'email_add':'[email protected]'},
{'st_id':2, 'postal_add':'Cannought Place new Delhi', 'email_add':'[email protected]'},
])Beachten Sie, dass die Spalte st_id in der Adresstabelle auf die ID-Spalte in der Schülertabelle verweist. Wir können diese Beziehung jetzt verwenden, um Daten aus beiden Tabellen abzurufen. Wir wollen holenname und lastname aus der Schülertabelle, die st_id in der Adresstabelle entspricht.
from sqlalchemy.sql import select
s = select([students, addresses]).where(students.c.id == addresses.c.st_id)
result = conn.execute(s)
for row in result:
print (row)Die ausgewählten Objekte werden effektiv in den folgenden SQL-Ausdruck übersetzt, der zwei Tabellen in einer gemeinsamen Beziehung verbindet:
SELECT students.id,
students.name,
students.lastname,
addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM students, addresses
WHERE students.id = addresses.st_idDies erzeugt eine Ausgabe, die die entsprechenden Daten aus beiden Tabellen wie folgt extrahiert:
(1, 'Ravi', 'Kapoor', 1, 1, 'Shivajinagar Pune', '[email protected]')
(1, 'Ravi', 'Kapoor', 2, 1, 'ChurchGate Mumbai', '[email protected]')
(3, 'Komal', 'Bhandari', 3, 3, 'Jubilee Hills Hyderabad', '[email protected]')
(5, 'Priya', 'Rajhans', 4, 5, 'MG Road Bangaluru', '[email protected]')
(2, 'Rajiv', 'Khanna', 5, 2, 'Cannought Place new Delhi', '[email protected]')Im vorherigen Kapitel haben wir die Verwendung mehrerer Tabellen erläutert. Also gehen wir noch einen Schritt weiter und lernenmultiple table updates in diesem Kapitel.
Mit dem Tabellenobjekt von SQLAlchemy kann in der WHERE-Klausel der update () -Methode mehr als eine Tabelle angegeben werden. PostgreSQL und Microsoft SQL Server unterstützen UPDATE-Anweisungen, die auf mehrere Tabellen verweisen. Dies implementiert“UPDATE FROM”Syntax, die jeweils eine Tabelle aktualisiert. Auf zusätzliche Tabellen kann jedoch direkt in einer zusätzlichen FROM-Klausel in der WHERE-Klausel verwiesen werden. Die folgenden Codezeilen erläutern das Konzept vonmultiple table updates deutlich.
stmt = students.update().\
values({
students.c.name:'xyz',
addresses.c.email_add:'[email protected]'
}).\
where(students.c.id == addresses.c.id)Das Aktualisierungsobjekt entspricht der folgenden UPDATE-Abfrage:
UPDATE students
SET email_add = :addresses_email_add, name = :name
FROM addresses
WHERE students.id = addresses.idIn Bezug auf den MySQL-Dialekt können mehrere Tabellen in eine einzelne UPDATE-Anweisung eingebettet werden, die wie unten angegeben durch ein Komma getrennt ist.
stmt = students.update().\
values(name = 'xyz').\
where(students.c.id == addresses.c.id)Der folgende Code zeigt die resultierende UPDATE-Abfrage -
'UPDATE students SET name = :name
FROM addresses
WHERE students.id = addresses.id'SQLite-Dialekt unterstützt jedoch keine Kriterien für mehrere Tabellen in UPDATE und zeigt den folgenden Fehler an:
NotImplementedError: This backend does not support multiple-table criteria within UPDATEDie UPDATE-Abfrage von Raw SQL hat die SET-Klausel. Es wird vom update () -Konstrukt unter Verwendung der im ursprünglichen Tabellenobjekt angegebenen Spaltenreihenfolge gerendert. Daher wird eine bestimmte UPDATE-Anweisung mit bestimmten Spalten jedes Mal gleich gerendert. Da die Parameter selbst als Python-Wörterbuchschlüssel an die Update.values () -Methode übergeben werden, ist keine andere feste Reihenfolge verfügbar.
In einigen Fällen ist die Reihenfolge der in der SET-Klausel gerenderten Parameter von Bedeutung. In MySQL basiert die Bereitstellung von Aktualisierungen für Spaltenwerte auf denen anderer Spaltenwerte.
Ergebnis der folgenden Aussage -
UPDATE table1 SET x = y + 10, y = 20wird ein anderes Ergebnis haben als -
UPDATE table1 SET y = 20, x = y + 10Die SET-Klausel in MySQL wird pro Wert und nicht pro Zeile ausgewertet. Zu diesem Zweck wird diepreserve_parameter_orderwird eingesetzt. Die Python-Liste der 2-Tupel wird als Argument für die angegebenUpdate.values() Methode -
stmt = table1.update(preserve_parameter_order = True).\
values([(table1.c.y, 20), (table1.c.x, table1.c.y + 10)])Das List-Objekt ähnelt dem Dictionary, ist jedoch geordnet. Dadurch wird sichergestellt, dass zuerst die SET-Klausel der Spalte „y“ und dann die SET-Klausel der Spalte „x“ gerendert wird.
In diesem Kapitel werden wir uns mit dem Ausdruck "Mehrere Tabellen löschen" befassen, der der Verwendung der Funktion "Mehrere Tabellenaktualisierungen" ähnelt.
In vielen DBMS-Dialekten kann in der WHERE-Klausel der DELETE-Anweisung auf mehr als eine Tabelle verwiesen werden. Für PG und MySQL wird die Syntax "DELETE USING" verwendet. und für SQL Server bezieht sich die Verwendung des Ausdrucks "DELETE FROM" auf mehr als eine Tabelle. Die SQLAlchemydelete() Konstrukt unterstützt beide Modi implizit, indem mehrere Tabellen in der WHERE-Klausel wie folgt angegeben werden:
stmt = users.delete().\
where(users.c.id == addresses.c.id).\
where(addresses.c.email_address.startswith('xyz%'))
conn.execute(stmt)In einem PostgreSQL-Backend würde das aus der obigen Anweisung resultierende SQL wie folgt gerendert:
DELETE FROM users USING addresses
WHERE users.id = addresses.id
AND (addresses.email_address LIKE %(email_address_1)s || '%%')Wenn diese Methode mit einer Datenbank verwendet wird, die dieses Verhalten nicht unterstützt, löst der Compiler NotImplementedError aus.
In diesem Kapitel erfahren Sie, wie Sie Joins in SQLAlchemy verwenden.
Der Effekt des Verbindens wird erreicht, indem nur zwei Tabellen in eine der beiden platziert werden columns clause oder der where clausedes Konstrukts select (). Jetzt verwenden wir die Methoden join () und Outerjoin ().
Die join () -Methode gibt ein Join-Objekt von einem Tabellenobjekt zu einem anderen zurück.
join(right, onclause = None, isouter = False, full = False)Die Funktionen der im obigen Code genannten Parameter sind wie folgt:
right- die rechte Seite der Verbindung; Dies ist ein beliebiges Tabellenobjekt
onclause- Ein SQL-Ausdruck, der die ON-Klausel des Joins darstellt. Wenn Sie bei Keine belassen, wird versucht, die beiden Tabellen basierend auf einer Fremdschlüsselbeziehung zu verbinden
isouter - Wenn True, wird anstelle von JOIN ein LEFT OUTER JOIN gerendert
full - Wenn True, wird anstelle von LEFT OUTER JOIN ein FULL OUTER JOIN gerendert
Wenn Sie beispielsweise die Methode join () verwenden, wird automatisch eine Verknüpfung basierend auf dem Fremdschlüssel erstellt.
>>> print(students.join(addresses))Dies entspricht dem folgenden SQL-Ausdruck:
students JOIN addresses ON students.id = addresses.st_idSie können die Beitrittskriterien wie folgt explizit angeben:
j = students.join(addresses, students.c.id == addresses.c.st_id)Wenn wir jetzt das folgende Auswahlkonstrukt erstellen, verwenden Sie diesen Join als -
stmt = select([students]).select_from(j)Dies führt zu folgendem SQL-Ausdruck:
SELECT students.id, students.name, students.lastname
FROM students JOIN addresses ON students.id = addresses.st_idWenn diese Anweisung über die Verbindung ausgeführt wird, die die Engine darstellt, werden Daten zu ausgewählten Spalten angezeigt. Der vollständige Code lautet wie folgt:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer,ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String)
)
from sqlalchemy import join
from sqlalchemy.sql import select
j = students.join(addresses, students.c.id == addresses.c.st_id)
stmt = select([students]).select_from(j)
result = conn.execute(stmt)
result.fetchall()Das Folgende ist die Ausgabe des obigen Codes -
[
(1, 'Ravi', 'Kapoor'),
(1, 'Ravi', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(5, 'Priya', 'Rajhans'),
(2, 'Rajiv', 'Khanna')
]Konjunktionen sind Funktionen im SQLAlchemy-Modul, die relationale Operatoren implementieren, die in der WHERE-Klausel von SQL-Ausdrücken verwendet werden. Die Operatoren AND, OR, NOT usw. werden verwendet, um einen zusammengesetzten Ausdruck zu bilden, der zwei einzelne logische Ausdrücke kombiniert. Ein einfaches Beispiel für die Verwendung von AND in der SELECT-Anweisung lautet wie folgt:
SELECT * from EMPLOYEE WHERE salary>10000 AND age>30SQLAlchemy-Funktionen und_ (), oder_ () und not_ () implementieren jeweils AND-, OR- und NOT-Operatoren.
und_ () Funktion
Es erzeugt eine Konjunktion von Ausdrücken, die durch UND verbunden sind. Ein Beispiel ist unten zum besseren Verständnis angegeben -
from sqlalchemy import and_
print(
and_(
students.c.name == 'Ravi',
students.c.id <3
)
)Dies bedeutet -
students.name = :name_1 AND students.id < :id_1Verwenden Sie die folgende Codezeile, um and_ () in einem select () -Konstrukt in einer Schülertabelle zu verwenden:
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))Die SELECT-Anweisung der folgenden Art wird erstellt:
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1 AND students.id < :id_1Der vollständige Code, der die Ausgabe der obigen SELECT-Abfrage anzeigt, lautet wie folgt:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import and_, or_
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
result = conn.execute(stmt)
print (result.fetchall())Die folgende Zeile wird unter der Annahme ausgewählt, dass die Schülertabelle mit den im vorherigen Beispiel verwendeten Daten gefüllt ist.
[(1, 'Ravi', 'Kapoor')]or_ () Funktion
Es erzeugt eine Konjunktion von Ausdrücken, die durch ODER verbunden sind. Wir werden das stmt-Objekt im obigen Beispiel durch das folgende mit or_ () ersetzen.
stmt = select([students]).where(or_(students.c.name == 'Ravi', students.c.id <3))Was effektiv der folgenden SELECT-Abfrage entspricht -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1
OR students.id < :id_1Sobald Sie die Ersetzung vorgenommen und den obigen Code ausgeführt haben, werden zwei Zeilen in die ODER-Bedingung fallen.
[(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Khanna')]Funktion asc ()
Es wird eine aufsteigende ORDER BY-Klausel erzeugt. Die Funktion verwendet die Spalte, um die Funktion als Parameter anzuwenden.
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))Die Anweisung implementiert den folgenden SQL-Ausdruck:
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.name ASCDer folgende Code listet alle Datensätze in der Schülertabelle in aufsteigender Reihenfolge der Namensspalte auf -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))
result = conn.execute(stmt)
for row in result:
print (row)Der obige Code erzeugt folgende Ausgabe -
(4, 'Abdul', 'Sattar')
(3, 'Komal', 'Bhandari')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')desc () Funktion
In ähnlicher Weise erzeugt die Funktion desc () eine absteigende ORDER BY-Klausel wie folgt:
from sqlalchemy import desc
stmt = select([students]).order_by(desc(students.c.lastname))Der entsprechende SQL-Ausdruck lautet -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.lastname DESCUnd die Ausgabe für die obigen Codezeilen ist -
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')
(3, 'Komal', 'Bhandari')zwischen () Funktion
Es wird eine ZWISCHEN Prädikatklausel erzeugt. Dies wird im Allgemeinen verwendet, um zu überprüfen, ob der Wert einer bestimmten Spalte zwischen einem Bereich liegt. Mit dem folgenden Code werden beispielsweise Zeilen ausgewählt, für die die ID-Spalte zwischen 2 und 4 liegt.
from sqlalchemy import between
stmt = select([students]).where(between(students.c.id,2,4))
print (stmt)Der resultierende SQL-Ausdruck ähnelt -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.id
BETWEEN :id_1 AND :id_2und das Ergebnis ist wie folgt -
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')Einige der in SQLAlchemy verwendeten wichtigen Funktionen werden in diesem Kapitel erläutert.
Standard SQL hat viele Funktionen empfohlen, die von den meisten Dialekten implementiert werden. Sie geben einen einzelnen Wert basierend auf den an sie übergebenen Argumenten zurück. Einige SQL-Funktionen verwenden Spalten als Argumente, während andere generisch sind.Thefunc keyword in SQLAlchemy API is used to generate these functions.
In SQL ist now () eine generische Funktion. Die folgenden Anweisungen rendern die Funktion now () mit func -
from sqlalchemy.sql import func
result = conn.execute(select([func.now()]))
print (result.fetchone())Das Beispielergebnis des obigen Codes kann wie folgt aussehen:
(datetime.datetime(2018, 6, 16, 6, 4, 40),)Andererseits wird die Funktion count (), die die Anzahl der aus einer Tabelle ausgewählten Zeilen zurückgibt, durch folgende Verwendung von func - gerendert.
from sqlalchemy.sql import func
result = conn.execute(select([func.count(students.c.id)]))
print (result.fetchone())Aus dem obigen Code wird die Anzahl der Zeilen in der Schülertabelle abgerufen.
Einige integrierte SQL-Funktionen werden anhand der Employee-Tabelle mit den folgenden Daten demonstriert:
| ICH WÜRDE | Name | Markierungen |
|---|---|---|
| 1 | Kamal | 56 |
| 2 | Fernandez | 85 |
| 3 | Sunil | 62 |
| 4 | Bhaskar | 76 |
Die Funktion max () wird implementiert, indem die Verwendung von func aus SQLAlchemy verwendet wird. Dies führt zu 85, den insgesamt erreichten Höchstnoten -
from sqlalchemy.sql import func
result = conn.execute(select([func.max(employee.c.marks)]))
print (result.fetchone())In ähnlicher Weise wird die Funktion min (), die 56 Mindestmarkierungen zurückgibt, durch folgenden Code gerendert:
from sqlalchemy.sql import func
result = conn.execute(select([func.min(employee.c.marks)]))
print (result.fetchone())Die AVG () -Funktion kann also auch mithilfe des folgenden Codes implementiert werden:
from sqlalchemy.sql import func
result = conn.execute(select([func.avg(employee.c.marks)]))
print (result.fetchone())
Functions are normally used in the columns clause of a select statement.
They can also be given label as well as a type. A label to function allows the result
to be targeted in a result row based on a string name, and a type is required when
you need result-set processing to occur.from sqlalchemy.sql import func
result = conn.execute(select([func.max(students.c.lastname).label('Name')]))
print (result.fetchone())Im letzten Kapitel haben wir verschiedene Funktionen wie max (), min (), count () usw. kennengelernt. Hier erfahren Sie mehr über Set-Operationen und deren Verwendung.
Set-Operationen wie UNION und INTERSECT werden von Standard-SQL und dem größten Teil seines Dialekts unterstützt. SQLAlchemy implementiert sie mit Hilfe der folgenden Funktionen:
Union()
Beim Kombinieren der Ergebnisse von zwei oder mehr SELECT-Anweisungen entfernt UNION Duplikate aus der Ergebnismenge. Die Anzahl der Spalten und der Datentyp müssen in beiden Tabellen gleich sein.
Die Funktion union () gibt ein CompoundSelect-Objekt aus mehreren Tabellen zurück. Das folgende Beispiel zeigt seine Verwendung -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, union
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
u = union(addresses.select().where(addresses.c.email_add.like('%@gmail.com addresses.select().where(addresses.c.email_add.like('%@yahoo.com'))))
result = conn.execute(u)
result.fetchall()Das Vereinigungskonstrukt übersetzt in folgenden SQL-Ausdruck:
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?In unserer Adresstabelle stellen die folgenden Zeilen die Vereinigungsoperation dar -
[
(1, 1, 'Shivajinagar Pune', '[email protected]'),
(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]'),
(4, 5, 'MG Road Bangaluru', '[email protected]')
]union_all ()
Die Operation UNION ALL kann die Duplikate nicht entfernen und die Daten in der Ergebnismenge nicht sortieren. In der obigen Abfrage wird UNION beispielsweise durch UNION ALL ersetzt, um den Effekt zu sehen.
u = union_all(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.email_add.like('%@yahoo.com')))Der entsprechende SQL-Ausdruck lautet wie folgt:
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION ALL SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?außer_()
Die SQL EXCEPTKlausel / Operator wird verwendet, um zwei SELECT-Anweisungen zu kombinieren und Zeilen aus der ersten SELECT-Anweisung zurückzugeben, die von der zweiten SELECT-Anweisung nicht zurückgegeben werden. Die Funktion exception_ () generiert einen SELECT-Ausdruck mit der EXCEPT-Klausel.
Im folgenden Beispiel gibt die Funktion exception_ () nur die Datensätze aus der Adresstabelle zurück, die im Feld email_add 'gmail.com' enthalten, schließt jedoch diejenigen aus, die im Feld postal_add 'Pune' enthalten.
u = except_(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))Das Ergebnis des obigen Codes ist der folgende SQL-Ausdruck:
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? EXCEPT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Angenommen, die Adresstabelle enthält Daten, die in früheren Beispielen verwendet wurden, wird die folgende Ausgabe angezeigt:
[(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]')]sich schneiden()
Mit dem INTERSECT-Operator zeigt SQL gemeinsame Zeilen aus beiden SELECT-Anweisungen an. Die Funktion intersect () implementiert dieses Verhalten.
In den folgenden Beispielen sind zwei SELECT-Konstrukte Parameter für die Funktion intersect (). Eine gibt Zeilen zurück, die 'gmail.com' als Teil der Spalte email_add enthalten, und andere gibt Zeilen zurück, die 'Pune' als Teil der Spalte postal_add enthalten. Das Ergebnis sind gemeinsame Zeilen aus beiden Ergebnismengen.
u = intersect(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))In der Tat entspricht dies der folgenden SQL-Anweisung:
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? INTERSECT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Die beiden gebundenen Parameter '% gmail.com' und '% Pune' generieren eine einzelne Zeile aus den Originaldaten in der Adresstabelle, wie unten gezeigt -
[(1, 1, 'Shivajinagar Pune', '[email protected]')]Das Hauptziel der Object Relational Mapper-API von SQLAlchemy besteht darin, die Zuordnung von benutzerdefinierten Python-Klassen zu Datenbanktabellen und Objekten dieser Klassen zu Zeilen in den entsprechenden Tabellen zu erleichtern. Zustandsänderungen von Objekten und Zeilen werden synchron miteinander abgeglichen. Mit SQLAlchemy können Datenbankabfragen in Form von benutzerdefinierten Klassen und deren definierten Beziehungen ausgedrückt werden.
Das ORM basiert auf der SQL Expression Language. Es ist ein hochrangiges und abstrahiertes Nutzungsmuster. Tatsächlich ist ORM eine angewandte Verwendung der Ausdruckssprache.
Obwohl eine erfolgreiche Anwendung ausschließlich mit dem Object Relational Mapper erstellt werden kann, kann eine mit dem ORM erstellte Anwendung manchmal die Ausdruckssprache direkt verwenden, wenn bestimmte Datenbankinteraktionen erforderlich sind.
Mapping deklarieren
Zunächst wird die Funktion create_engine () aufgerufen, um ein Engine-Objekt einzurichten, das anschließend zum Ausführen von SQL-Operationen verwendet wird. Die Funktion hat zwei Argumente, eines ist der Name der Datenbank und das andere ist ein Echo-Parameter, wenn auf True gesetzt, wird das Aktivitätsprotokoll generiert. Wenn es nicht existiert, wird die Datenbank erstellt. Im folgenden Beispiel wird eine SQLite-Datenbank erstellt.
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)Die Engine stellt eine echte DBAPI-Verbindung zur Datenbank her, wenn eine Methode wie Engine.execute () oder Engine.connect () aufgerufen wird. Es wird dann verwendet, um das SQLORM auszugeben, das die Engine nicht direkt verwendet. Stattdessen wird es vom ORM hinter den Kulissen verwendet.
Im Fall von ORM beginnt der Konfigurationsprozess mit der Beschreibung der Datenbanktabellen und der Definition von Klassen, die diesen Tabellen zugeordnet werden. In SQLAlchemy werden diese beiden Aufgaben zusammen ausgeführt. Dies erfolgt mithilfe des deklarativen Systems. Die erstellten Klassen enthalten Anweisungen zur Beschreibung der tatsächlichen Datenbanktabelle, der sie zugeordnet sind.
Eine Basisklasse speichert ein Catlog von Klassen und zugeordneten Tabellen im deklarativen System. Dies wird als deklarative Basisklasse bezeichnet. In einem häufig importierten Modul befindet sich normalerweise nur eine Instanz dieser Basis. Die Funktion declative_base () wird zum Erstellen der Basisklasse verwendet. Diese Funktion ist im Modul sqlalchemy.ext.declarative definiert.
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()Sobald die Basisklasse deklariert ist, kann eine beliebige Anzahl von zugeordneten Klassen definiert werden. Der folgende Code definiert die Klasse eines Kunden. Es enthält die Tabelle, der zugeordnet werden soll, sowie Namen und Datentypen der darin enthaltenen Spalten.
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)Eine deklarative Klasse muss a haben __tablename__ Attribut und mindestens eines ColumnDas ist Teil eines Primärschlüssels. Deklarativ ersetzt alleColumn Objekte mit speziellen Python-Accessoren, bekannt als descriptors. Dieser Prozess wird als Instrumentierung bezeichnet, die die Möglichkeit bietet, in einem SQL-Kontext auf die Tabelle zu verweisen, und das Fortbestehen und Laden der Werte von Spalten aus der Datenbank ermöglicht.
Diese zugeordnete Klasse verfügt wie eine normale Python-Klasse über Attribute und Methoden gemäß den Anforderungen.
Die Informationen zur Klasse im deklarativen System werden als Tabellenmetadaten bezeichnet. SQLAlchemy verwendet das Table-Objekt, um diese Informationen für eine bestimmte von Declarative erstellte Tabelle darzustellen. Das Tabellenobjekt wird gemäß den Spezifikationen erstellt und der Klasse durch Erstellen eines Mapper-Objekts zugeordnet. Dieses Mapper-Objekt wird nicht direkt verwendet, sondern intern als Schnittstelle zwischen zugeordneter Klasse und Tabelle verwendet.
Jedes Table-Objekt ist Mitglied einer größeren Sammlung, die als MetaData bezeichnet wird, und dieses Objekt ist über das verfügbar .metadataAttribut der deklarativen Basisklasse. DasMetaData.create_all()Methode ist, unsere Engine als Quelle für Datenbankkonnektivität zu übergeben. Für alle Tabellen, die noch nicht erstellt wurden, werden CREATE TABLE-Anweisungen an die Datenbank ausgegeben.
Base.metadata.create_all(engine)Das vollständige Skript zum Erstellen einer Datenbank und einer Tabelle sowie zum Zuordnen der Python-Klasse finden Sie unten:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)Bei der Ausführung wird die Python-Konsole nach dem Ausführen des SQL-Ausdrucks wiedergegeben.
CREATE TABLE customers (
id INTEGER NOT NULL,
name VARCHAR,
address VARCHAR,
email VARCHAR,
PRIMARY KEY (id)
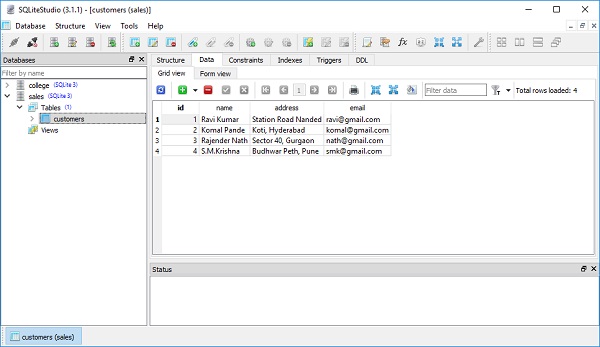
)Wenn wir die Sales.db mit dem SQLiteStudio-Grafiktool öffnen, wird die darin enthaltene Kundentabelle mit der oben genannten Struktur angezeigt.

Um mit der Datenbank zu interagieren, müssen wir ihr Handle erhalten. Ein Sitzungsobjekt ist das Handle für die Datenbank. Die Sitzungsklasse wird mit sessionmaker () definiert - einer konfigurierbaren Session Factory-Methode, die an das zuvor erstellte Engine-Objekt gebunden ist.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)Das Sitzungsobjekt wird dann mit seinem Standardkonstruktor wie folgt eingerichtet:
session = Session()Einige der häufig benötigten Methoden der Sitzungsklasse sind unten aufgeführt -
| Sr.Nr. | Methode & Beschreibung |
|---|---|
| 1 | begin() Startet eine Transaktion in dieser Sitzung |
| 2 | add() Platziert ein Objekt in der Sitzung. Sein Status bleibt beim nächsten Spülvorgang in der Datenbank erhalten |
| 3 | add_all() Fügt der Sitzung eine Sammlung von Objekten hinzu |
| 4 | commit() Leert alle Elemente und alle laufenden Transaktionen |
| 5 | delete() markiert eine Transaktion als gelöscht |
| 6 | execute() führt einen SQL-Ausdruck aus |
| 7 | expire() markiert Attribute einer Instanz als veraltet |
| 8 | flush() Leert alle Objektänderungen in die Datenbank |
| 9 | invalidate() Schließt die Sitzung mit der Ungültigmachung der Verbindung |
| 10 | rollback() setzt die aktuell laufende Transaktion zurück |
| 11 | close() Schließt die aktuelle Sitzung, indem alle Elemente gelöscht und alle laufenden Transaktionen beendet werden |
In den vorherigen Kapiteln von SQLAlchemy ORM haben wir gelernt, wie Mapping deklariert und Sitzungen erstellt werden. In diesem Kapitel erfahren Sie, wie Sie der Tabelle Objekte hinzufügen.
Wir haben die Kundenklasse deklariert, die der Kundentabelle zugeordnet wurde. Wir müssen ein Objekt dieser Klasse deklarieren und es mit der Methode add () des Sitzungsobjekts dauerhaft zur Tabelle hinzufügen.
c1 = Sales(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)Beachten Sie, dass diese Transaktion aussteht, bis dieselbe mit der Methode commit () gelöscht wird.
session.commit()Im Folgenden finden Sie das vollständige Skript zum Hinzufügen eines Datensatzes zur Kundentabelle:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
c1 = Customers(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)
session.commit()Um mehrere Datensätze hinzuzufügen, können wir verwenden add_all() Methode der Sitzungsklasse.
session.add_all([
Customers(name = 'Komal Pande', address = 'Koti, Hyderabad', email = '[email protected]'),
Customers(name = 'Rajender Nath', address = 'Sector 40, Gurgaon', email = '[email protected]'),
Customers(name = 'S.M.Krishna', address = 'Budhwar Peth, Pune', email = '[email protected]')]
)
session.commit()Die Tabellenansicht von SQLiteStudio zeigt, dass die Datensätze dauerhaft in der Kundentabelle hinzugefügt werden. Das folgende Bild zeigt das Ergebnis -
Alle von SQLAlchemy ORM generierten SELECT-Anweisungen werden vom Query-Objekt erstellt. Es bietet eine generative Schnittstelle, daher geben aufeinanderfolgende Aufrufe ein neues Abfrageobjekt zurück, eine Kopie des ersteren mit zusätzlichen Kriterien und damit verbundenen Optionen.
Abfrageobjekte werden anfänglich mit der query () -Methode der Sitzung wie folgt generiert:
q = session.query(mapped class)Die folgende Aussage entspricht auch der oben angegebenen Aussage -
q = Query(mappedClass, session)Das Abfrageobjekt verfügt über die Methode all (), die eine Ergebnismenge in Form einer Liste von Objekten zurückgibt. Wenn wir es auf unserem Kundentisch ausführen -
result = session.query(Customers).all()Diese Anweisung entspricht effektiv dem folgenden SQL-Ausdruck:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersDas Ergebnisobjekt kann mithilfe der folgenden For-Schleife durchlaufen werden, um alle Datensätze in der zugrunde liegenden Kundentabelle abzurufen. Hier ist der vollständige Code zum Anzeigen aller Datensätze in der Kundentabelle -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).all()
for row in result:
print ("Name: ",row.name, "Address:",row.address, "Email:",row.email)Die Python-Konsole zeigt die Liste der Datensätze wie folgt an:
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]
Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Das Abfrageobjekt verfügt außerdem über die folgenden nützlichen Methoden:
| Sr.Nr. | Methode & Beschreibung |
|---|---|
| 1 | add_columns() Es fügt der Liste der zurückzugebenden Ergebnisspalten einen oder mehrere Spaltenausdrücke hinzu. |
| 2 | add_entity() Es fügt der Liste der zurückzugebenden Ergebnisspalten eine zugeordnete Entität hinzu. |
| 3 | count() Es gibt eine Anzahl von Zeilen zurück, die diese Abfrage zurückgeben würde. |
| 4 | delete() Es führt eine Massenlöschabfrage durch. Löscht die mit dieser Abfrage übereinstimmenden Zeilen aus der Datenbank. |
| 5 | distinct() Es wendet eine DISTINCT-Klausel auf die Abfrage an und gibt die neu resultierende Abfrage zurück. |
| 6 | filter() Das angegebene Filterkriterium wird mithilfe von SQL-Ausdrücken auf eine Kopie dieser Abfrage angewendet. |
| 7 | first() Es gibt das erste Ergebnis dieser Abfrage oder Keine zurück, wenn das Ergebnis keine Zeile enthält. |
| 8 | get() Es gibt eine Instanz zurück, die auf der angegebenen Primärschlüssel-ID basiert und direkten Zugriff auf die Identitätszuordnung der besitzenden Sitzung bietet. |
| 9 | group_by() Es wendet ein oder mehrere GROUP BY-Kriterien auf die Abfrage an und gibt die neu resultierende Abfrage zurück |
| 10 | join() Es erstellt eine SQL-Verknüpfung anhand des Kriteriums dieses Abfrageobjekts und wird generativ angewendet, wobei die neu resultierende Abfrage zurückgegeben wird. |
| 11 | one() Es gibt genau ein Ergebnis zurück oder löst eine Ausnahme aus. |
| 12 | order_by() Es wendet ein oder mehrere ORDER BY-Kriterien auf die Abfrage an und gibt die neu resultierende Abfrage zurück. |
| 13 | update() Es führt eine Massenaktualisierungsabfrage durch und aktualisiert Zeilen, die mit dieser Abfrage in der Datenbank übereinstimmen. |
In diesem Kapitel erfahren Sie, wie Sie die Tabelle mit den gewünschten Werten ändern oder aktualisieren.
Um Daten eines bestimmten Attributs eines Objekts zu ändern, müssen wir ihm einen neuen Wert zuweisen und die Änderungen festschreiben, um die Änderung dauerhaft zu machen.
Lassen Sie uns ein Objekt aus der Tabelle mit der Primärschlüssel-ID in unserer Customers-Tabelle mit der ID = 2 abrufen. Wir können die Methode get () der Sitzung wie folgt verwenden:
x = session.query(Customers).get(2)Wir können den Inhalt des ausgewählten Objekts mit dem unten angegebenen Code anzeigen -
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Aus unserer Kundentabelle sollte folgende Ausgabe angezeigt werden:
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]Jetzt müssen wir das Adressfeld aktualisieren, indem wir einen neuen Wert wie unten angegeben zuweisen -
x.address = 'Banjara Hills Secunderabad'
session.commit()Die Änderung wird dauerhaft in der Datenbank angezeigt. Jetzt holen wir das Objekt, das der ersten Zeile in der Tabelle entspricht, mitfirst() method wie folgt -
x = session.query(Customers).first()Dies wird nach folgendem SQL-Ausdruck ausgeführt:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Die gebundenen Parameter sind LIMIT = 1 bzw. OFFSET = 0, was bedeutet, dass die erste Zeile ausgewählt wird.
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Die Ausgabe für den obigen Code, der die erste Zeile anzeigt, lautet nun wie folgt:
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]Ändern Sie nun das Namensattribut und zeigen Sie den Inhalt mit dem folgenden Code an:
x.name = 'Ravi Shrivastava'
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Die Ausgabe des obigen Codes ist -
Name: Ravi Shrivastava Address: Station Road Nanded Email: [email protected]Obwohl die Änderung angezeigt wird, wird sie nicht festgeschrieben. Sie können die frühere dauerhafte Position mithilfe von beibehaltenrollback() method mit dem Code unten.
session.rollback()
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Der ursprüngliche Inhalt des ersten Datensatzes wird angezeigt.
Für Massenaktualisierungen verwenden wir die update () -Methode des Query-Objekts. Lassen Sie uns versuchen, ein Präfix anzugeben: "Mr." in jeder Zeile zu benennen (außer ID = 2). Die entsprechende update () - Anweisung lautet wie folgt:
session.query(Customers).filter(Customers.id! = 2).
update({Customers.name:"Mr."+Customers.name}, synchronize_session = False)The update() method requires two parameters as follows −
Ein Wörterbuch mit Schlüsselwerten, wobei der Schlüssel das zu aktualisierende Attribut und der Wert der neue Inhalt des Attributs ist.
Attribut synchronize_session, das die Strategie zum Aktualisieren von Attributen in der Sitzung erwähnt. Gültige Werte sind false: Wenn die Sitzung nicht synchronisiert werden soll, führt fetch: vor der Aktualisierung eine Auswahlabfrage durch, um Objekte zu finden, die mit der Aktualisierungsabfrage übereinstimmen. und bewerten: Bewerten Sie die Kriterien für Objekte in der Sitzung.
In drei von vier Zeilen in der Tabelle wird dem Namen "Mr." vorangestellt. Die Änderungen werden jedoch nicht festgeschrieben und werden daher nicht in der Tabellenansicht von SQLiteStudio wiedergegeben. Es wird nur aktualisiert, wenn wir die Sitzung festschreiben.
In diesem Kapitel werden wir erläutern, wie Filter und bestimmte Filteroperationen zusammen mit ihren Codes angewendet werden.
Die durch das Abfrageobjekt dargestellte Ergebnismenge kann mithilfe der filter () -Methode bestimmten Kriterien unterzogen werden. Die allgemeine Verwendung der Filtermethode ist wie folgt:
session.query(class).filter(criteria)Im folgenden Beispiel wird die durch die SELECT-Abfrage in der Customers-Tabelle erhaltene Ergebnismenge durch eine Bedingung (ID> 2) gefiltert.
result = session.query(Customers).filter(Customers.id>2)Diese Anweisung wird in folgenden SQL-Ausdruck übersetzt:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ?Da der gebundene Parameter (?) Als 2 angegeben wird, werden nur die Zeilen mit der ID-Spalte> 2 angezeigt. Der vollständige Code ist unten angegeben -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).filter(Customers.id>2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Die in der Python-Konsole angezeigte Ausgabe lautet wie folgt:
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Jetzt lernen wir die Filteroperationen mit ihren jeweiligen Codes und Ausgaben.
Gleich
Der übliche verwendete Operator ist == und er wendet die Kriterien an, um die Gleichheit zu überprüfen.
result = session.query(Customers).filter(Customers.id == 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)SQLAlchemy sendet folgenden SQL-Ausdruck:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?Die Ausgabe für den obigen Code lautet wie folgt:
ID: 2 Name: Komal Pande Address: Banjara Hills Secunderabad Email: [email protected]Nicht gleich
Der Operator, der für ungleich verwendet wird, ist! = Und liefert nicht gleich Kriterien.
result = session.query(Customers).filter(Customers.id! = 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Der resultierende SQL-Ausdruck lautet -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id != ?Die Ausgabe für die obigen Codezeilen lautet wie folgt:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Mögen
Die Methode like () selbst erzeugt die LIKE-Kriterien für die WHERE-Klausel im SELECT-Ausdruck.
result = session.query(Customers).filter(Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Der obige SQLAlchemy-Code entspricht dem folgenden SQL-Ausdruck:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name LIKE ?Und die Ausgabe für den obigen Code ist -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]IM
Dieser Operator prüft, ob der Spaltenwert zu einer Sammlung von Elementen in einer Liste gehört. Es wird von der Methode in_ () bereitgestellt.
result = session.query(Customers).filter(Customers.id.in_([1,3]))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Hier lautet der von der SQLite-Engine ausgewertete SQL-Ausdruck wie folgt:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id IN (?, ?)Die Ausgabe für den obigen Code lautet wie folgt:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]UND
Diese Konjunktion wird von beiden generiert putting multiple commas separated criteria in the filter or using and_() method wie unten angegeben -
result = session.query(Customers).filter(Customers.id>2, Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)from sqlalchemy import and_
result = session.query(Customers).filter(and_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Beide oben genannten Ansätze führen zu einem ähnlichen SQL-Ausdruck -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? AND customers.name LIKE ?Die Ausgabe für die obigen Codezeilen ist -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]ODER
Diese Konjunktion wird implementiert von or_() method.
from sqlalchemy import or_
result = session.query(Customers).filter(or_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Infolgedessen erhält die SQLite-Engine den folgenden äquivalenten SQL-Ausdruck:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? OR customers.name LIKE ?Die Ausgabe für den obigen Code lautet wie folgt:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Es gibt eine Reihe von Methoden für Abfrageobjekte, die sofort SQL ausgeben und einen Wert zurückgeben, der geladene Datenbankergebnisse enthält.
Hier ist ein kurzer Überblick über die Rückgabeliste und die Skalare -
alle()
Es wird eine Liste zurückgegeben. Unten ist die Codezeile für alle () Funktionen angegeben.
session.query(Customers).all()Die Python-Konsole zeigt den folgenden ausgegebenen SQL-Ausdruck an:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customerszuerst()
Es wird ein Limit von eins angewendet und das erste Ergebnis als Skalar zurückgegeben.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Die gebundenen Parameter für LIMIT sind 1 und für OFFSET ist 0.
einer()
Dieser Befehl ruft alle Zeilen vollständig ab. Wenn im Ergebnis nicht genau eine Objektidentität oder zusammengesetzte Zeile vorhanden ist, wird ein Fehler ausgegeben.
session.query(Customers).one()Mit mehreren Zeilen gefunden -
MultipleResultsFound: Multiple rows were found for one()Keine Zeilen gefunden -
NoResultFound: No row was found for one()Die one () -Methode ist nützlich für Systeme, die erwarten, dass "keine gefundenen Elemente" im Vergleich zu "mehrere gefundene Elemente" unterschiedlich behandelt werden.
Skalar ()
Es ruft die one () -Methode auf und gibt bei Erfolg die erste Spalte der Zeile wie folgt zurück:
session.query(Customers).filter(Customers.id == 3).scalar()Dies erzeugt folgende SQL-Anweisung -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?Zuvor wurde Text-SQL mit der Funktion text () aus der Perspektive der Kernausdruckssprache von SQLAlchemy erläutert. Jetzt werden wir es aus ORM-Sicht diskutieren.
Literalzeichenfolgen können flexibel mit dem Abfrageobjekt verwendet werden, indem ihre Verwendung mit dem Konstrukt text () angegeben wird. Die meisten anwendbaren Methoden akzeptieren dies. Zum Beispiel filter () und order_by ().
Im folgenden Beispiel übersetzt die filter () -Methode die Zeichenfolge "id <3" in die WHERE-ID <3
from sqlalchemy import text
for cust in session.query(Customers).filter(text("id<3")):
print(cust.name)Der generierte SQL-Rohausdruck zeigt die Konvertierung des Filters in die WHERE-Klausel mit dem unten dargestellten Code -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id<3Aus unseren Beispieldaten in der Kundentabelle werden zwei Zeilen ausgewählt und die Namensspalte wie folgt gedruckt:
Ravi Kumar
Komal PandeVerwenden Sie einen Doppelpunkt, um Bindungsparameter mit stringbasiertem SQL anzugeben, und verwenden Sie die params () -Methode, um die Werte anzugeben.
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()Das effektive SQL, das auf der Python-Konsole angezeigt wird, ist wie folgt:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id = ?Um eine vollständig auf Zeichenfolgen basierende Anweisung zu verwenden, kann ein text () -Konstrukt, das eine vollständige Anweisung darstellt, an from_statement () übergeben werden.
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()Das Ergebnis des obigen Codes ist eine grundlegende SELECT-Anweisung wie unten angegeben -
SELECT * FROM customersNatürlich werden alle Datensätze in der Kundentabelle ausgewählt.
Das text () -Konstrukt ermöglicht es uns, sein textuelles SQL positionell mit Core- oder ORM-zugeordneten Spaltenausdrücken zu verknüpfen. Dies können wir erreichen, indem wir Spaltenausdrücke als Positionsargumente an die TextClause.columns () -Methode übergeben.
stmt = text("SELECT name, id, name, address, email FROM customers")
stmt = stmt.columns(Customers.id, Customers.name)
session.query(Customers.id, Customers.name).from_statement(stmt).all()Die ID- und Namensspalten aller Zeilen werden ausgewählt, obwohl die SQLite-Engine den folgenden Ausdruck ausführt, der durch den obigen Code generiert wurde. Alle Spalten in der text () -Methode werden angezeigt.
SELECT name, id, name, address, email FROM customersIn dieser Sitzung wird die Erstellung einer weiteren Tabelle beschrieben, die sich auf eine bereits in unserer Datenbank vorhandene Tabelle bezieht. Die Kundentabelle enthält Stammdaten von Kunden. Wir müssen jetzt eine Rechnungstabelle erstellen, die eine beliebige Anzahl von Rechnungen eines Kunden enthalten kann. Dies ist ein Fall von einer bis vielen Beziehungen.
Mit deklarativ definieren wir diese Tabelle zusammen mit der zugeordneten Klasse "Rechnungen" wie unten angegeben -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)Dadurch wird eine CREATE TABLE-Abfrage wie folgt an die SQLite-Engine gesendet:
CREATE TABLE invoices (
id INTEGER NOT NULL,
custid INTEGER,
invno INTEGER,
amount INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(custid) REFERENCES customers (id)
)Mit Hilfe des SQLiteStudio-Tools können wir überprüfen, ob eine neue Tabelle in sales.db erstellt wurde.
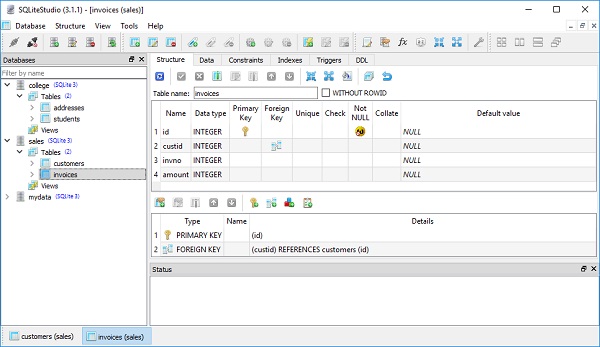
Die Invoices-Klasse wendet das ForeignKey-Konstrukt auf das custid-Attribut an. Diese Anweisung gibt an, dass die Werte in dieser Spalte auf Werte beschränkt werden sollten, die in der Spalte id in der Kundentabelle vorhanden sind. Dies ist ein Kernmerkmal relationaler Datenbanken und der „Klebstoff“, der die nicht verbundene Sammlung von Tabellen in reich überlappende Beziehungen umwandelt.
Eine zweite Anweisung, die als Relationship () bezeichnet wird, teilt dem ORM mit, dass die Invoice-Klasse mit dem Attribut Invoice.customer mit der Customer-Klasse verknüpft werden soll. Die Beziehung () verwendet die Fremdschlüsselbeziehungen zwischen den beiden Tabellen, um die Art dieser Verknüpfung zu bestimmen und festzustellen, ob es sich um viele zu eins handelt.
Eine zusätzliche Beziehungsanweisung () wird für die vom Kunden zugeordnete Klasse unter dem Attribut Customer.invoices platziert. Der Parameter Relationship.back_populate wird zugewiesen, um auf die komplementären Attributnamen zu verweisen, sodass jede Beziehung () eine intelligente Entscheidung über dieselbe Beziehung treffen kann, wie sie umgekehrt ausgedrückt wird. Auf der einen Seite bezieht sich Invoices.customer auf die Instanz Invoices, und auf der anderen Seite bezieht sich Customer.invoices auf eine Liste von Kundeninstanzen.
Die Beziehungsfunktion ist Teil der Beziehungs-API des SQLAlchemy ORM-Pakets. Es bietet eine Beziehung zwischen zwei zugeordneten Klassen. Dies entspricht einer Eltern-Kind- oder assoziativen Tabellenbeziehung.
Im Folgenden sind die grundlegenden Beziehungsmuster aufgeführt:
Eins zu viele
Eine Eins-zu-Viele-Beziehung bezieht sich auf Eltern mit Hilfe eines Fremdschlüssels in der untergeordneten Tabelle. Relationship () wird dann auf dem übergeordneten Element als Verweis auf eine Sammlung von Elementen angegeben, die vom untergeordneten Element dargestellt werden. Der Parameter ratio.back_populate wird verwendet, um eine bidirektionale Beziehung in Eins-zu-Viele herzustellen, wobei die "umgekehrte" Seite viele-zu-Eins ist.
Viele zu einem
Auf der anderen Seite platziert die Beziehung "Viele zu Eins" einen Fremdschlüssel in der übergeordneten Tabelle, um auf das untergeordnete Element zu verweisen. beziehung () wird auf dem übergeordneten Element deklariert, wo ein neues skalarhaltendes Attribut erstellt wird. Auch hier wird der Parameter ratio.back_populate für das bidirektionale Verhalten verwendet.
Eins zu eins
Eine Eins-zu-Eins-Beziehung ist im Wesentlichen eine bidirektionale Beziehung. Das Uselist-Flag zeigt die Platzierung eines skalaren Attributs anstelle einer Sammlung auf der "vielen" Seite der Beziehung an. Um eine Eins-zu-Viele-Beziehung in eine Eins-zu-Eins-Beziehung umzuwandeln, setzen Sie den Parameter uselist auf false.
Viel zu viel
Die Beziehung zwischen vielen und vielen wird hergestellt, indem eine Zuordnungstabelle hinzugefügt wird, die sich auf zwei Klassen bezieht, indem Attribute mit ihren Fremdschlüsseln definiert werden. Es wird durch das sekundäre Argument zu Beziehung () angezeigt. Normalerweise verwendet die Tabelle das MetaData-Objekt, das der deklarativen Basisklasse zugeordnet ist, sodass die ForeignKey-Anweisungen die entfernten Tabellen finden können, mit denen eine Verknüpfung hergestellt werden soll. Der Parameter education.back_populated für jede Beziehung () erstellt eine bidirektionale Beziehung. Beide Seiten der Beziehung enthalten eine Sammlung.
In diesem Kapitel konzentrieren wir uns auf die verwandten Objekte in SQLAlchemy ORM.
Wenn wir nun ein Kundenobjekt erstellen, wird eine leere Rechnungssammlung in Form einer Python-Liste angezeigt.
c1 = Customer(name = "Gopal Krishna", address = "Bank Street Hydarebad", email = "[email protected]")Das Rechnungsattribut von c1.invoices ist eine leere Liste. Wir können Elemente in der Liste als - zuweisen
c1.invoices = [Invoice(invno = 10, amount = 15000), Invoice(invno = 14, amount = 3850)]Lassen Sie uns dieses Objekt mit dem Sitzungsobjekt wie folgt in die Datenbank übertragen:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(c1)
session.commit()Dadurch werden automatisch INSERT-Abfragen für Kunden- und Rechnungstabellen generiert.
INSERT INTO customers (name, address, email) VALUES (?, ?, ?)
('Gopal Krishna', 'Bank Street Hydarebad', '[email protected]')
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 10, 15000)
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 14, 3850)Betrachten wir nun den Inhalt der Kundentabelle und der Rechnungstabelle in der Tabellenansicht von SQLiteStudio -

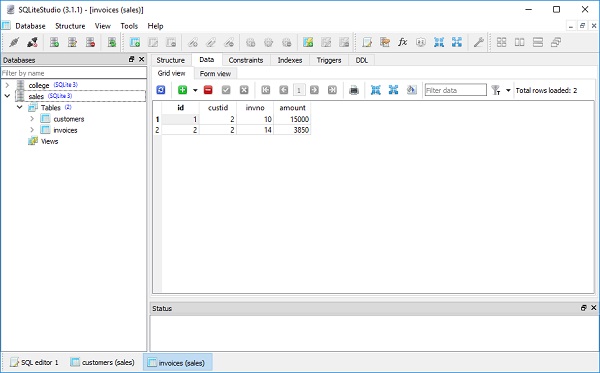
Sie können ein Kundenobjekt erstellen, indem Sie das zugeordnete Attribut von Rechnungen im Konstruktor selbst mithilfe des folgenden Befehls angeben.
c2 = [
Customer(
name = "Govind Pant",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 3, amount = 10000),
Invoice(invno = 4, amount = 5000)]
)
]Oder eine Liste der Objekte, die mit der Funktion add_all () des Sitzungsobjekts hinzugefügt werden sollen (siehe unten).
rows = [
Customer(
name = "Govind Kala",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 7, amount = 12000), Invoice(invno = 8, amount = 18500)]),
Customer(
name = "Abdul Rahman",
address = "Rohtak",
email = "[email protected]",
invoices = [Invoice(invno = 9, amount = 15000),
Invoice(invno = 11, amount = 6000)
])
]
session.add_all(rows)
session.commit()Nachdem wir nun zwei Tabellen haben, werden wir sehen, wie Abfragen für beide Tabellen gleichzeitig erstellt werden. Um eine einfache implizite Verknüpfung zwischen Kunde und Rechnung zu erstellen, können wir Query.filter () verwenden, um die zugehörigen Spalten miteinander gleichzusetzen. Im Folgenden laden wir die Kunden- und Rechnungsentitäten sofort mit dieser Methode -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for c, i in session.query(Customer, Invoice).filter(Customer.id == Invoice.custid).all():
print ("ID: {} Name: {} Invoice No: {} Amount: {}".format(c.id,c.name, i.invno, i.amount))Der von SQLAlchemy ausgegebene SQL-Ausdruck lautet wie folgt:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM customers, invoices
WHERE customers.id = invoices.custidUnd das Ergebnis der obigen Codezeilen ist wie folgt:
ID: 2 Name: Gopal Krishna Invoice No: 10 Amount: 15000
ID: 2 Name: Gopal Krishna Invoice No: 14 Amount: 3850
ID: 3 Name: Govind Pant Invoice No: 3 Amount: 10000
ID: 3 Name: Govind Pant Invoice No: 4 Amount: 5000
ID: 4 Name: Govind Kala Invoice No: 7 Amount: 12000
ID: 4 Name: Govind Kala Invoice No: 8 Amount: 8500
ID: 5 Name: Abdul Rahman Invoice No: 9 Amount: 15000
ID: 5 Name: Abdul Rahman Invoice No: 11 Amount: 6000Die eigentliche SQL JOIN-Syntax kann mit der Query.join () -Methode wie folgt erreicht werden:
session.query(Customer).join(Invoice).filter(Invoice.amount == 8500).all()Der SQL-Ausdruck für den Join wird auf der Konsole angezeigt.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers JOIN invoices ON customers.id = invoices.custid
WHERE invoices.amount = ?Wir können das Ergebnis mit for loop durchlaufen -
result = session.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
for row in result:
for inv in row.invoices:
print (row.id, row.name, inv.invno, inv.amount)Mit 8500 als Bindungsparameter wird die folgende Ausgabe angezeigt:
4 Govind Kala 8 8500Query.join () kann zwischen diesen Tabellen verknüpfen, da sich nur ein Fremdschlüssel zwischen ihnen befindet. Wenn keine oder mehrere Fremdschlüssel vorhanden waren, funktioniert Query.join () besser, wenn eines der folgenden Formulare verwendet wird:
| query.join (Rechnung, id == Address.custid) | explizite Bedingung |
| query.join (Customer.invoices) | Geben Sie die Beziehung von links nach rechts an |
| query.join (Rechnung, Kundenrechnungen) | Gleiches gilt für das explizite Ziel |
| query.join ('Rechnungen') | das gleiche, mit einem String |
In ähnlicher Weise ist die Funktion Outerjoin () verfügbar, um eine Linksaußenverknüpfung zu erreichen.
query.outerjoin(Customer.invoices)Die Methode subquery () erzeugt einen SQL-Ausdruck, der die in einen Alias eingebettete SELECT-Anweisung darstellt.
from sqlalchemy.sql import func
stmt = session.query(
Invoice.custid, func.count('*').label('invoice_count')
).group_by(Invoice.custid).subquery()Das stmt-Objekt enthält eine SQL-Anweisung wie folgt:
SELECT invoices.custid, count(:count_1) AS invoice_count FROM invoices GROUP BY invoices.custidSobald wir unsere Anweisung haben, verhält sie sich wie ein Tabellenkonstrukt. Auf die Spalten in der Anweisung kann über ein Attribut namens c zugegriffen werden, wie im folgenden Code gezeigt.
for u, count in session.query(Customer, stmt.c.invoice_count).outerjoin(stmt, Customer.id == stmt.c.custid).order_by(Customer.id):
print(u.name, count)Die obige for-Schleife zeigt die Anzahl der Rechnungen wie folgt an:
Arjun Pandit None
Gopal Krishna 2
Govind Pant 2
Govind Kala 2
Abdul Rahman 2In diesem Kapitel werden wir die Operatoren diskutieren, die auf Beziehungen aufbauen.
__eq __ ()
Der obige Operator ist ein Vergleich von vielen zu eins "gleich". Die Codezeile für diesen Operator lautet wie folgt:
s = session.query(Customer).filter(Invoice.invno.__eq__(12))Die entsprechende SQL-Abfrage für die obige Codezeile lautet -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.invno = ?__ne __ ()
Dieser Operator ist ein Eins-zu-Eins-Vergleich, der nicht gleich ist. Die Codezeile für diesen Operator lautet wie folgt:
s = session.query(Customer).filter(Invoice.custid.__ne__(2))Die entsprechende SQL-Abfrage für die obige Codezeile ist unten angegeben.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.custid != ?enthält ()
Dieser Operator wird für Eins-zu-Viele-Sammlungen verwendet. Im Folgenden wird der Code für enthält () - angegeben.
s = session.query(Invoice).filter(Invoice.invno.contains([3,4,5]))Die entsprechende SQL-Abfrage für die obige Codezeile lautet -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE (invoices.invno LIKE '%' + ? || '%')irgendein()
Jeder () Operator wird für Sammlungen verwendet, wie unten gezeigt -
s = session.query(Customer).filter(Customer.invoices.any(Invoice.invno==11))Die entsprechende SQL-Abfrage für die obige Codezeile wird unten angezeigt -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE EXISTS (
SELECT 1
FROM invoices
WHERE customers.id = invoices.custid
AND invoices.invno = ?)hat()
Dieser Operator wird für skalare Referenzen wie folgt verwendet:
s = session.query(Invoice).filter(Invoice.customer.has(name = 'Arjun Pandit'))Die entsprechende SQL-Abfrage für die obige Codezeile lautet -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE EXISTS (
SELECT 1
FROM customers
WHERE customers.id = invoices.custid
AND customers.name = ?)Eifrige Last reduziert die Anzahl der Abfragen. SQLAlchemy bietet eifrige Ladefunktionen, die über Abfrageoptionen aufgerufen werden und der Abfrage zusätzliche Anweisungen geben. Diese Optionen bestimmen, wie verschiedene Attribute über die Query.options () -Methode geladen werden.
Unterabfrage laden
Wir möchten, dass Customer.invoices eifrig geladen werden. Die Option orm.subqueryload () gibt eine zweite SELECT-Anweisung aus, die die Sammlungen, die den gerade geladenen Ergebnissen zugeordnet sind, vollständig lädt. Der Name "Unterabfrage" bewirkt, dass die SELECT-Anweisung direkt über die wiederverwendete Abfrage erstellt und als Unterabfrage in eine SELECT für die zugehörige Tabelle eingebettet wird.
from sqlalchemy.orm import subqueryload
c1 = session.query(Customer).options(subqueryload(Customer.invoices)).filter_by(name = 'Govind Pant').one()Dies führt zu den folgenden zwei SQL-Ausdrücken:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?
('Govind Pant',)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount, anon_1.customers_id
AS anon_1_customers_id
FROM (
SELECT customers.id
AS customers_id
FROM customers
WHERE customers.name = ?)
AS anon_1
JOIN invoices
ON anon_1.customers_id = invoices.custid
ORDER BY anon_1.customers_id, invoices.id 2018-06-25 18:24:47,479
INFO sqlalchemy.engine.base.Engine ('Govind Pant',)Um auf die Daten aus zwei Tabellen zuzugreifen, können wir das folgende Programm verwenden:
print (c1.name, c1.address, c1.email)
for x in c1.invoices:
print ("Invoice no : {}, Amount : {}".format(x.invno, x.amount))Die Ausgabe des obigen Programms ist wie folgt:
Govind Pant Gulmandi Aurangabad [email protected]
Invoice no : 3, Amount : 10000
Invoice no : 4, Amount : 5000Verbundenes Laden
Die andere Funktion heißt orm.joinedload (). Dies gibt einen LEFT OUTER JOIN aus. Das Hauptobjekt sowie das zugehörige Objekt oder die zugehörige Sammlung werden in einem Schritt geladen.
from sqlalchemy.orm import joinedload
c1 = session.query(Customer).options(joinedload(Customer.invoices)).filter_by(name='Govind Pant').one()Dies gibt den folgenden Ausdruck aus, der dieselbe Ausgabe wie oben ergibt -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices_1.id
AS invoices_1_id, invoices_1.custid
AS invoices_1_custid, invoices_1.invno
AS invoices_1_invno, invoices_1.amount
AS invoices_1_amount
FROM customers
LEFT OUTER JOIN invoices
AS invoices_1
ON customers.id = invoices_1.custid
WHERE customers.name = ? ORDER BY invoices_1.id
('Govind Pant',)Der OUTER JOIN führte zu zwei Zeilen, gibt jedoch eine Instanz des Kunden zurück. Dies liegt daran, dass Query eine auf der Objektidentität basierende "Eindeutigkeits" -Strategie auf die zurückgegebenen Entitäten anwendet. Verbundenes eifriges Laden kann angewendet werden, ohne die Abfrageergebnisse zu beeinflussen.
Subqueryload () eignet sich besser zum Laden verwandter Sammlungen, während joinload () besser für die Beziehung zwischen vielen Personen geeignet ist.
Es ist einfach, einen Löschvorgang für eine einzelne Tabelle durchzuführen. Sie müssen lediglich ein Objekt der zugeordneten Klasse aus einer Sitzung löschen und die Aktion festschreiben. Das Löschen mehrerer verwandter Tabellen ist jedoch wenig schwierig.
In unserer sales.db-Datenbank werden Kunden- und Rechnungsklassen Kunden- und Rechnungstabellen mit einer bis mehreren Arten von Beziehungen zugeordnet. Wir werden versuchen, das Kundenobjekt zu löschen und das Ergebnis zu sehen.
Im Folgenden finden Sie als Kurzreferenz die Definitionen der Kunden- und Rechnungsklassen.
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")Wir richten eine Sitzung ein und erhalten ein Kundenobjekt, indem wir es mit der primären ID mit dem folgenden Programm abfragen.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
x = session.query(Customer).get(2)In unserer Beispieltabelle ist x.name zufällig 'Gopal Krishna'. Löschen wir dieses x aus der Sitzung und zählen das Auftreten dieses Namens.
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()Der resultierende SQL-Ausdruck gibt 0 zurück.
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',) 0Die zugehörigen Rechnungsobjekte von x sind jedoch noch vorhanden. Es kann durch den folgenden Code überprüft werden -
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()Hier sind 10 und 14 Rechnungsnummern des Kunden Gopal Krishna. Das Ergebnis der obigen Abfrage ist 2, was bedeutet, dass die zugehörigen Objekte nicht gelöscht wurden.
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14) 2Dies liegt daran, dass SQLAlchemy nicht das Löschen der Kaskade voraussetzt. Wir müssen einen Befehl geben, um es zu löschen.
Um das Verhalten zu ändern, konfigurieren wir Kaskadenoptionen für die Beziehung User.addresses. Schließen wir die laufende Sitzung, verwenden Sie new declative_base () und deklarieren Sie die Benutzerklasse neu, indem Sie die Adressbeziehung einschließlich der Kaskadenkonfiguration hinzufügen.
Das Kaskadenattribut in der Beziehungsfunktion ist eine durch Kommas getrennte Liste von Kaskadenregeln, die bestimmt, wie Sitzungsoperationen von übergeordnet zu untergeordnet „kaskadiert“ werden sollen. Standardmäßig ist es False, was bedeutet, dass es "Update speichern, zusammenführen" ist.
Die verfügbaren Kaskaden sind wie folgt:
- save-update
- merge
- expunge
- delete
- delete-orphan
- refresh-expire
Die häufig verwendete Option ist "all, delete-orphan", um anzugeben, dass verwandte Objekte in allen Fällen zusammen mit dem übergeordneten Objekt folgen und gelöscht werden sollen, wenn die Zuordnung aufgehoben wird.
Daher wird die neu deklarierte Kundenklasse unten angezeigt -
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
invoices = relationship(
"Invoice",
order_by = Invoice.id,
back_populates = "customer",
cascade = "all,
delete, delete-orphan"
)Lassen Sie uns den Kunden mit dem Namen Gopal Krishna mit dem folgenden Programm löschen und die Anzahl der zugehörigen Rechnungsobjekte anzeigen.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
x = session.query(Customer).get(2)
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()Die Anzahl ist jetzt 0 mit folgendem SQL, das vom obigen Skript ausgegeben wird -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?
(2,)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE ? = invoices.custid
ORDER BY invoices.id (2,)
DELETE FROM invoices
WHERE invoices.id = ? ((1,), (2,))
DELETE FROM customers
WHERE customers.id = ? (2,)
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',)
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14)
0Many to Many relationshipZwischen zwei Tabellen wird erreicht, indem eine Zuordnungstabelle hinzugefügt wird, die zwei Fremdschlüssel enthält - einen aus dem Primärschlüssel jeder Tabelle. Darüber hinaus haben Klassen, die den beiden Tabellen zugeordnet sind, ein Attribut mit einer Sammlung von Objekten anderer Zuordnungstabellen, die als sekundäres Attribut der Beziehung () -Funktion zugewiesen sind.
Zu diesem Zweck erstellen wir eine SQLite-Datenbank (mycollege.db) mit zwei Tabellen - Abteilung und Mitarbeiter. Hier nehmen wir an, dass ein Mitarbeiter Teil von mehr als einer Abteilung ist und eine Abteilung mehr als einen Mitarbeiter hat. Dies ist eine Beziehung von vielen zu vielen.
Die Definition der Mitarbeiter- und Abteilungsklassen, die der Abteilungs- und Mitarbeitertabelle zugeordnet sind, lautet wie folgt:
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')Wir definieren jetzt eine Link-Klasse. Es ist mit der Verknüpfungstabelle verknüpft und enthält die Attribute department_id und employee_id, die auf Primärschlüssel der Abteilung und der Mitarbeitertabelle verweisen.
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)Hier müssen wir notieren, dass die Abteilungsklasse Mitarbeiterattribute hat, die sich auf die Mitarbeiterklasse beziehen. Dem sekundären Attribut der Beziehungsfunktion wird ein Link als Wert zugewiesen.
In ähnlicher Weise verfügt die Employee-Klasse über Abteilungsattribute, die sich auf die Abteilungsklasse beziehen. Dem sekundären Attribut der Beziehungsfunktion wird ein Link als Wert zugewiesen.
Alle diese drei Tabellen werden erstellt, wenn die folgende Anweisung ausgeführt wird:
Base.metadata.create_all(engine)Die Python-Konsole gibt folgende CREATE TABLE-Abfragen aus:
CREATE TABLE department (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE employee (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE link (
department_id INTEGER NOT NULL,
employee_id INTEGER NOT NULL,
PRIMARY KEY (department_id, employee_id),
FOREIGN KEY(department_id) REFERENCES department (id),
FOREIGN KEY(employee_id) REFERENCES employee (id)
)Wir können dies überprüfen, indem wir mycollege.db mit SQLiteStudio öffnen, wie in den folgenden Screenshots gezeigt -
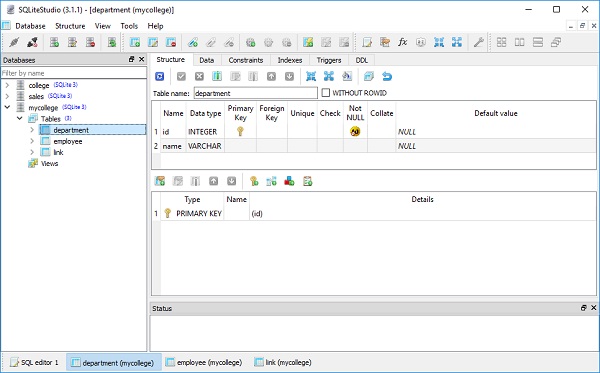
Als nächstes erstellen wir drei Objekte der Abteilungsklasse und drei Objekte der Mitarbeiterklasse, wie unten gezeigt -
d1 = Department(name = "Accounts")
d2 = Department(name = "Sales")
d3 = Department(name = "Marketing")
e1 = Employee(name = "John")
e2 = Employee(name = "Tony")
e3 = Employee(name = "Graham")Jede Tabelle verfügt über ein Auflistungsattribut mit der Methode append (). Wir können Mitarbeiterobjekte zur Mitarbeitersammlung des Abteilungsobjekts hinzufügen. Ebenso können wir Abteilungsobjekte zum Abteilungssammlungsattribut von Mitarbeiterobjekten hinzufügen.
e1.departments.append(d1)
e2.departments.append(d3)
d1.employees.append(e3)
d2.employees.append(e2)
d3.employees.append(e1)
e3.departments.append(d2)Jetzt müssen wir nur noch ein Sitzungsobjekt einrichten, alle Objekte hinzufügen und die Änderungen wie unten gezeigt festschreiben.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(e1)
session.add(e2)
session.add(d1)
session.add(d2)
session.add(d3)
session.add(e3)
session.commit()Die folgenden SQL-Anweisungen werden auf der Python-Konsole ausgegeben:
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))Verwenden Sie SQLiteStudio, um die Auswirkungen der oben genannten Vorgänge zu überprüfen und Daten in Abteilungs-, Mitarbeiter- und Verknüpfungstabellen anzuzeigen.
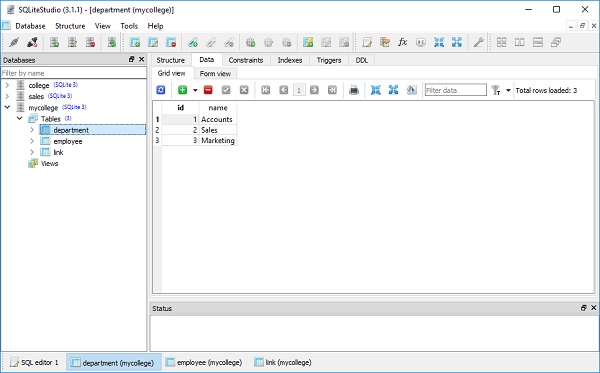
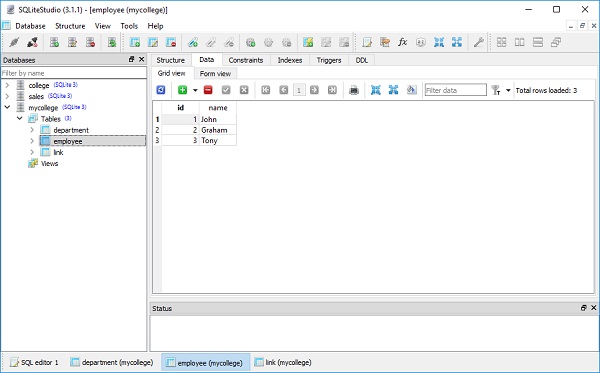
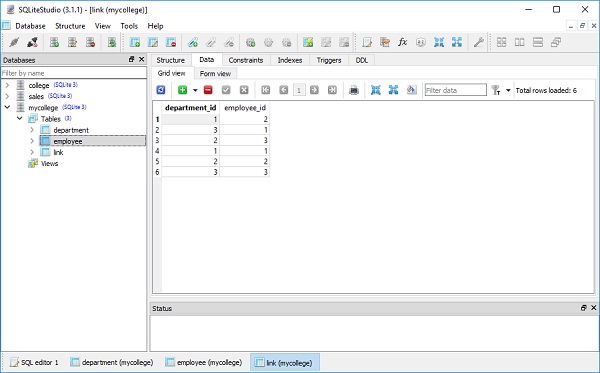
Führen Sie die folgende Abfrageanweisung aus, um die Daten anzuzeigen:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))Gemäß den in unserem Beispiel angegebenen Daten wird die Ausgabe wie folgt angezeigt:
Department: Accounts Name: John
Department: Accounts Name: Graham
Department: Sales Name: Graham
Department: Sales Name: Tony
Department: Marketing Name: John
Department: Marketing Name: TonySQLAlchemy verwendet ein Dialektsystem, um mit verschiedenen Arten von Datenbanken zu kommunizieren. Jede Datenbank verfügt über einen entsprechenden DBAPI-Wrapper. Für alle Dialekte muss ein entsprechender DBAPI-Treiber installiert sein.
Folgende Dialekte sind in der SQLAlchemy API enthalten:
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQL
- Sybase
Ein auf einer URL basierendes Engine-Objekt wird von der Funktion create_engine () erstellt. Diese URLs können Benutzername, Kennwort, Hostname und Datenbanknamen enthalten. Möglicherweise gibt es optionale Schlüsselwortargumente für die zusätzliche Konfiguration. In einigen Fällen wird ein Dateipfad akzeptiert, in anderen Fällen ersetzt ein "Datenquellenname" die Teile "Host" und "Datenbank". Die typische Form einer Datenbank-URL lautet wie folgt:
dialect+driver://username:password@host:port/databasePostgreSQL
Der PostgreSQL-Dialekt verwendet psycopg2als Standard-DBAPI. pg8000 ist auch als reiner Python-Ersatz erhältlich, wie unten gezeigt:
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')MySQL
Der MySQL-Dialekt verwendet mysql-pythonals Standard-DBAPI. Es sind viele MySQL-DBAPIs verfügbar, z. B. MySQL-Connector-Python wie folgt:
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')Orakel
Der Oracle-Dialekt verwendet cx_oracle als Standard-DBAPI wie folgt -
engine = create_engine('oracle://scott:[email protected]:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')Microsoft SQL Server
Der SQL Server-Dialekt verwendet pyodbcals Standard-DBAPI. pymssql ist ebenfalls verfügbar.
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')SQLite
SQLite stellt mithilfe des in Python integrierten Moduls eine Verbindung zu dateibasierten Datenbanken her sqlite3standardmäßig. Da SQLite eine Verbindung zu lokalen Dateien herstellt, unterscheidet sich das URL-Format geringfügig. Der "Datei" -Teil der URL ist der Dateiname der Datenbank. Für einen relativen Dateipfad sind drei Schrägstriche erforderlich (siehe unten).
engine = create_engine('sqlite:///foo.db')Und für einen absoluten Dateipfad folgt auf die drei Schrägstriche der unten angegebene absolute Pfad -
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')Geben Sie eine leere URL wie unten angegeben an, um eine SQLite: memory: -Datenbank zu verwenden.
engine = create_engine('sqlite://')Fazit
Im ersten Teil dieses Tutorials haben wir gelernt, wie man die Ausdruckssprache zum Ausführen von SQL-Anweisungen verwendet. Die Ausdruckssprache bettet SQL-Konstrukte in Python-Code ein. Im zweiten Teil haben wir die Fähigkeit zur Zuordnung von Objektbeziehungen von SQLAlchemy erörtert. Die ORM-API ordnet die SQL-Tabellen Python-Klassen zu.