TIKA - Kurzanleitung
Was ist Apache Tika?
Apache Tika ist eine Bibliothek, die zur Erkennung von Dokumenttypen und zur Extraktion von Inhalten aus verschiedenen Dateiformaten verwendet wird.
Intern verwendet Tika vorhandene verschiedene Dokumentparser und Dokumenttyperkennungstechniken, um Daten zu erkennen und zu extrahieren.
Mit Tika kann ein universeller Typdetektor und Inhaltsextraktor entwickelt werden, um sowohl strukturierten Text als auch Metadaten aus verschiedenen Arten von Dokumenten wie Tabellenkalkulationen, Textdokumenten, Bildern, PDFs und bis zu einem gewissen Grad sogar Multimedia-Eingabeformaten zu extrahieren.
Tika bietet eine einzige generische API zum Parsen verschiedener Dateiformate. Es werden vorhandene spezialisierte Parser-Bibliotheken für jeden Dokumenttyp verwendet.
Alle diese Parser-Bibliotheken sind unter einer einzigen Schnittstelle namens "the" zusammengefasst Parser interface.

Warum Tika?
Laut filext.com gibt es etwa 15.000 bis 51.000 Inhaltstypen, und diese Zahl wächst von Tag zu Tag. Daten werden in verschiedenen Formaten wie Textdokumenten, Excel-Tabellen, PDFs, Bildern und Multimediadateien gespeichert, um nur einige zu nennen. Daher benötigen Anwendungen wie Suchmaschinen und Content-Management-Systeme zusätzliche Unterstützung für die einfache Extraktion von Daten aus diesen Dokumenttypen. Apache Tika dient diesem Zweck, indem es eine generische API zum Suchen und Extrahieren von Daten aus mehreren Dateiformaten bereitstellt.
Apache Tika-Anwendungen
Es gibt verschiedene Anwendungen, die Apache Tika verwenden. Hier werden wir einige wichtige Anwendungen diskutieren, die stark von Apache Tika abhängen.
Suchmaschinen
Tika wird häufig bei der Entwicklung von Suchmaschinen verwendet, um den Textinhalt digitaler Dokumente zu indizieren.
Suchmaschinen sind Informationsverarbeitungssysteme zum Suchen von Informationen und indizierten Dokumenten aus dem Web.
Crawler ist eine wichtige Komponente einer Suchmaschine, die durch das Web crawlt, um die Dokumente abzurufen, die mithilfe einer Indizierungstechnik indiziert werden sollen. Danach überträgt der Crawler diese indizierten Dokumente an eine Extraktionskomponente.
Die Aufgabe der Extraktionskomponente besteht darin, den Text und die Metadaten aus dem Dokument zu extrahieren. Solche extrahierten Inhalte und Metadaten sind für eine Suchmaschine sehr nützlich. Diese Extraktionskomponente enthält Tika.
Der extrahierte Inhalt wird dann an den Indexer der Suchmaschine übergeben, der ihn zum Erstellen eines Suchindex verwendet. Abgesehen davon verwendet die Suchmaschine den extrahierten Inhalt auch auf viele andere Arten.

Dokumentenanalyse
Auf dem Gebiet der künstlichen Intelligenz gibt es bestimmte Werkzeuge, um Dokumente automatisch auf semantischer Ebene zu analysieren und alle Arten von Daten daraus zu extrahieren.
In solchen Anwendungen werden die Dokumente anhand der im extrahierten Inhalt des Dokuments hervorgehobenen Begriffe klassifiziert.
Diese Tools verwenden Tika zur Extraktion von Inhalten, um Dokumente zu analysieren, die von Klartext bis zu digitalen Dokumenten reichen.
Digital Asset Management
Einige Unternehmen verwalten ihre digitalen Assets wie Fotos, E-Books, Zeichnungen, Musik und Videos mithilfe einer speziellen Anwendung, die als Digital Asset Management (DAM) bezeichnet wird.
Solche Anwendungen verwenden die Hilfe von Dokumenttypdetektoren und Metadatenextraktoren, um die verschiedenen Dokumente zu klassifizieren.
Inhaltsanalyse
Websites wie Amazon empfehlen neu veröffentlichten Inhalten ihrer Website einzelnen Benutzern entsprechend ihren Interessen. Dazu folgen diese Websitesmachine learning techniquesoder nutzen Sie die Hilfe von Social-Media-Websites wie Facebook, um die erforderlichen Informationen wie Vorlieben und Interessen der Benutzer zu extrahieren. Diese gesammelten Informationen werden in Form von HTML-Tags oder anderen Formaten vorliegen, die eine weitere Erkennung und Extraktion von Inhaltstypen erfordern.
Für die Inhaltsanalyse eines Dokuments verfügen wir über Technologien, die Techniken des maschinellen Lernens implementieren, wie z UIMA und Mahout. Diese Technologien sind nützlich beim Clustering und Analysieren der Daten in den Dokumenten.
Apache Mahoutist ein Framework, das ML-Algorithmen auf Apache Hadoop - einer Cloud-Computing-Plattform - bereitstellt. Mahout bietet eine Architektur, indem bestimmte Clustering- und Filtertechniken befolgt werden. Durch Befolgen dieser Architektur können Programmierer ihre eigenen ML-Algorithmen schreiben, um Empfehlungen zu erstellen, indem sie verschiedene Text- und Metadatenkombinationen verwenden. Um Eingaben für diese Algorithmen bereitzustellen, verwenden neuere Versionen von Mahout Tika, um Text und Metadaten aus binären Inhalten zu extrahieren.
Apache UIMAanalysiert und verarbeitet verschiedene Programmiersprachen und erstellt UIMA-Annotationen. Intern wird Tika Annotator zum Extrahieren von Dokumenttext und Metadaten verwendet.
Geschichte
| Jahr | Entwicklung |
|---|---|
| 2006 | Die Idee von Tika wurde vor dem Lucene Project Management Committee projiziert. |
| 2006 | Das Konzept von Tika und seine Nützlichkeit im Jackrabbit-Projekt wurde diskutiert. |
| 2007 | Tika betrat den Apache-Inkubator. |
| 2008 | Die Versionen 0.1 und 0.2 wurden veröffentlicht und Tika wechselte vom Inkubator zum Lucene-Teilprojekt. |
| 2009 | Die Versionen 0.3, 0.4 und 0.5 wurden veröffentlicht. |
| 2010 | Die Versionen 0.6 und 0.7 wurden veröffentlicht und Tika stieg in das Apache-Projekt der obersten Ebene ein. |
| 2011 | Tika 1.0 wurde veröffentlicht und das Buch über Tika "Tika in Action" wurde ebenfalls im selben Jahr veröffentlicht. |
Architektur auf Anwendungsebene von Tika
Anwendungsprogrammierer können Tika problemlos in ihre Anwendungen integrieren. Tika bietet eine Befehlszeilenschnittstelle und eine grafische Benutzeroberfläche, um sie benutzerfreundlich zu gestalten.
In diesem Kapitel werden wir die vier wichtigen Module diskutieren, die die Tika-Architektur ausmachen. Die folgende Abbildung zeigt die Architektur von Tika mit seinen vier Modulen -
- Spracherkennungsmechanismus.
- MIME-Erkennungsmechanismus.
- Parser-Schnittstelle.
- Tika Fassadenklasse.

Spracherkennungsmechanismus
Immer wenn ein Textdokument an Tika übergeben wird, erkennt es die Sprache, in der es geschrieben wurde. Es akzeptiert Dokumente ohne Sprachanmerkung und fügt diese Informationen in die Metadaten des Dokuments ein, indem die Sprache erkannt wird.
Zur Unterstützung der Sprachidentifikation hat Tika eine Klasse namens Language Identifier im Paket org.apache.tika.languageund ein Sprachidentifikations-Repository, das Algorithmen zur Spracherkennung aus einem gegebenen Text enthält. Tika verwendet intern den N-Gramm-Algorithmus zur Spracherkennung.
MIME-Erkennungsmechanismus
Tika kann den Dokumenttyp gemäß den MIME-Standards erkennen. Die Standarderkennung des MIME-Typs in Tika erfolgt mithilfe von org.apache.tika.mime.mimeTypes . Es verwendet die Schnittstelle org.apache.tika.detect.Detector für den größten Teil der Erkennung von Inhaltstypen.
Intern verwendet Tika verschiedene Techniken wie Dateiglob, Hinweise zum Inhaltstyp, magische Bytes, Zeichencodierungen und verschiedene andere Techniken.
Parser-Schnittstelle
Die Parser-Schnittstelle von org.apache.tika.parser ist die Schlüsselschnittstelle zum Parsen von Dokumenten in Tika. Diese Schnittstelle extrahiert den Text und die Metadaten aus einem Dokument und fasst sie für externe Benutzer zusammen, die bereit sind, Parser-Plugins zu schreiben.
Tika verwendet verschiedene konkrete Parser-Klassen, die für einzelne Dokumenttypen spezifisch sind, und unterstützt viele Dokumentformate. Diese formatspezifischen Klassen bieten Unterstützung für verschiedene Dokumentformate, entweder durch direkte Implementierung der Parser-Logik oder durch Verwendung externer Parser-Bibliotheken.
Tika Fassadenklasse
Die Verwendung der Tika-Fassadenklasse ist die einfachste und direkteste Methode, um Tika von Java aus aufzurufen, und folgt dem Muster der Fassadengestaltung. Sie finden die Tika-Fassadenklasse im Paket org.apache.tika der Tika-API.
Durch die Implementierung grundlegender Anwendungsfälle fungiert Tika als Vermittler von Landschaft. Es abstrahiert die zugrunde liegende Komplexität der Tika-Bibliothek wie den MIME-Erkennungsmechanismus, die Parser-Schnittstelle und den Spracherkennungsmechanismus und bietet den Benutzern eine einfache Benutzeroberfläche.
Eigenschaften von Tika
Unified parser Interface- Tika kapselt alle Parser-Bibliotheken von Drittanbietern in einer einzigen Parser-Schnittstelle. Aufgrund dieser Funktion entgeht der Benutzer der Last, die geeignete Parser-Bibliothek auszuwählen und entsprechend dem gefundenen Dateityp zu verwenden.
Low memory usage- Tika verbraucht weniger Speicherressourcen und kann daher problemlos in Java-Anwendungen eingebettet werden. Wir können Tika auch in der Anwendung verwenden, die auf Plattformen mit weniger Ressourcen wie mobilen PDAs ausgeführt wird.
Fast processing - Eine schnelle Erkennung und Extraktion von Inhalten aus Anwendungen ist zu erwarten.
Flexible metadata - Tika versteht alle Metadatenmodelle, die zur Beschreibung von Dateien verwendet werden.
Parser integration - Tika kann verschiedene Parser-Bibliotheken verwenden, die für jeden Dokumenttyp in einer einzigen Anwendung verfügbar sind.
MIME type detection - Tika kann Inhalte aus allen in den MIME-Standards enthaltenen Medientypen erkennen und extrahieren.
Language detection - Tika enthält eine Sprachidentifizierungsfunktion und kann daher in Dokumenten verwendet werden, die auf dem Sprachtyp einer mehrsprachigen Website basieren.
Funktionen von Tika
Tika unterstützt verschiedene Funktionen -
- Dokumenttyperkennung
- Extraktion von Inhalten
- Metadatenextraktion
- Spracherkennung
Dokumenttyperkennung
Tika verwendet verschiedene Erkennungstechniken und erkennt den Typ des ihm gegebenen Dokuments.

Extraktion von Inhalten
Tika verfügt über eine Parser-Bibliothek, mit der der Inhalt verschiedener Dokumentformate analysiert und extrahiert werden kann. Nachdem der Dokumenttyp erkannt wurde, wählt er den entsprechenden Parser aus dem Parser-Repository aus und übergibt das Dokument. Verschiedene Klassen von Tika haben Methoden, um verschiedene Dokumentformate zu analysieren.

Metadatenextraktion
Zusammen mit dem Inhalt extrahiert Tika die Metadaten des Dokuments nach dem gleichen Verfahren wie beim Extrahieren von Inhalten. Für einige Dokumenttypen verfügt Tika über Klassen zum Extrahieren von Metadaten.

Spracherkennung
Intern folgt Tika Algorithmen wie n-gramum die Sprache des Inhalts in einem bestimmten Dokument zu erkennen. Tika hängt von Klassen wie abLanguageidentifier und Profiler zur Sprachidentifikation.

Dieses Kapitel führt Sie durch die Einrichtung von Apache Tika unter Windows und Linux. Bei der Installation von Apache Tika ist eine Benutzerverwaltung erforderlich.
System Anforderungen
| JDK | Java SE 2 JDK 1.6 oder höher |
| Erinnerung | 1 GB RAM (empfohlen) |
| Festplattenplatz | Keine Mindestanforderung |
| Betriebssystemversion | Windows XP oder höher, Linux |
Schritt 1: Überprüfen der Java-Installation
Öffnen Sie die Konsole und führen Sie die folgenden Schritte aus, um die Java-Installation zu überprüfen java Befehl.
| Betriebssystem | Aufgabe | Befehl |
|---|---|---|
| Windows | Öffnen Sie die Befehlskonsole | \> Java-Version |
| Linux | Befehlsterminal öffnen | $ java –Version |
Wenn Java ordnungsgemäß auf Ihrem System installiert wurde, sollten Sie abhängig von der Plattform, auf der Sie arbeiten, eine der folgenden Ausgaben erhalten.
| Betriebssystem | Ausgabe |
|---|---|
| Windows | Java-Version "1.7.0_60"
Java (TM) SE-Laufzeitumgebung (Build 1.7.0_60-b19) Java Hotspot (TM) 64-Bit-Server-VM (Build 24.60-b09, gemischter Modus) |
| Lunix | Java-Version "1.7.0_25" Öffnen Sie die JDK-Laufzeitumgebung (rhel-2.3.10.4.el6_4-x86_64). Öffnen Sie die JDK 64-Bit-Server-VM (Build 23.7-b01, gemischter Modus). |
Wir gehen davon aus, dass die Leser dieses Tutorials Java 1.7.0_60 auf ihrem System installiert haben, bevor sie mit diesem Tutorial fortfahren.
Falls Sie kein Java SDK haben, laden Sie die aktuelle Version von herunter https://www.oracle.com/technetwork/java/javase/downloads/index.html and have it installed.
Schritt 2: Einstellen der Java-Umgebung
Stellen Sie die Umgebungsvariable JAVA_HOME so ein, dass sie auf den Speicherort des Basisverzeichnisses verweist, in dem Java auf Ihrem Computer installiert ist. Zum Beispiel,
| Betriebssystem | Ausgabe |
|---|---|
| Windows | Setzen Sie die Umgebungsvariable JAVA_HOME auf C: \ ProgramFiles \ java \ jdk1.7.0_60 |
| Linux | export JAVA_HOME = / usr / local / java-current |
Hängen Sie den vollständigen Pfad des Java-Compiler-Speicherorts an den Systempfad an.
| Betriebssystem | Ausgabe |
|---|---|
| Windows | Hänge den String an; C: \ Programme \ Java \ jdk1.7.0_60 \ bin bis zum Ende der Systemvariablen PATH. |
| Linux | export PATH = $ PATH: $ JAVA_HOME / bin / |
Überprüfen Sie den Befehl Java-Version an der Eingabeaufforderung wie oben erläutert.
Schritt 3: Einrichten der Apache Tika-Umgebung
Programmierer können Apache Tika mithilfe von in ihre Umgebung integrieren
- Befehlszeile,
- Tika API,
- Befehlszeilenschnittstelle (CLI) von Tika,
- Grafische Benutzeroberfläche (GUI) von Tika oder
- der Quellcode.
Für jeden dieser Ansätze müssen Sie zunächst den Quellcode von Tika herunterladen.
Den Quellcode von Tika finden Sie unter https://Tika.apache.org/download.html, wo Sie zwei Links finden -
apache-tika-1.6-src.zip - Es enthält den Quellcode von Tika und
Tika -app-1.6.jar - Es ist eine JAR-Datei, die die Tika-Anwendung enthält.
Laden Sie diese beiden Dateien herunter. Ein Schnappschuss der offiziellen Website von Tika ist unten dargestellt.
Legen Sie nach dem Herunterladen der Dateien den Klassenpfad für die JAR-Datei fest tika-app-1.6.jar. Fügen Sie den vollständigen Pfad der JAR-Datei hinzu, wie in der folgenden Tabelle gezeigt.
| Betriebssystem | Ausgabe |
|---|---|
| Windows | Hängen Sie die Zeichenfolge "C: \ jars \ Tika-app-1.6.jar" an die Benutzerumgebungsvariable CLASSPATH an |
| Linux | Export CLASSPATH = $ CLASSPATH - /usr/share/jars/Tika-app-1.6.tar - |
Apache bietet die Tika-Anwendung, eine grafische Benutzeroberfläche (GUI) mit Eclipse.
Tika-Maven Build mit Eclipse
Öffnen Sie Eclipse und erstellen Sie ein neues Projekt.
Wenn Sie Maven nicht in Ihrer Eclipse haben, richten Sie es ein, indem Sie die angegebenen Schritte ausführen.
Öffnen Sie den Link https://wiki.eclipse.org/M2E_updatesite_and_gittags . Dort finden Sie die m2e-Plugin-Releases in Tabellenform
Wählen Sie die neueste Version und speichern Sie den Pfad der URL in der Spalte p2 url.
Klicken Sie in der Menüleiste erneut auf Eclipse Help, und wähle Install New Software aus dem Dropdown-Menü

Drücke den AddGeben Sie auf die Schaltfläche einen beliebigen Namen ein, da dieser optional ist. Fügen Sie nun die gespeicherte URL in das Feld einLocation Feld.
Ein neues Plugin wird mit dem Namen hinzugefügt, den Sie im vorherigen Schritt ausgewählt haben. Aktivieren Sie das Kontrollkästchen davor und klicken Sie auf Next.

Fahren Sie mit der Installation fort. Starten Sie die Eclipse nach Abschluss neu.
Klicken Sie nun mit der rechten Maustaste auf das Projekt und in das configure Option auswählen convert to maven project.
Ein neuer Assistent zum Erstellen eines neuen Poms wird angezeigt. Geben Sie die Gruppen-ID als org.apache.tika ein, geben Sie die neueste Version von Tika ein und wählen Sie die auspackaging als Glas und klicken Finish.
Das Maven-Projekt wurde erfolgreich installiert und Ihr Projekt wird in Maven konvertiert. Jetzt müssen Sie die Datei pom.xml konfigurieren.
Konfigurieren Sie die XML-Datei
Holen Sie sich die Tika Maven-Abhängigkeit vonhttps://mvnrepository.com/artifact/org.apache.tika
Unten ist die vollständige Maven-Abhängigkeit von Apache Tika dargestellt.
<dependency>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-core</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
<artifactId> Tika-parsers</artifactId>
<version> 1.6</version>
<groupId> org.apache.Tika</groupId>
<artifactId>Tika</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
< artifactId>Tika-serialization</artifactId>
< version>1.6< /version>
< groupId>org.apache.Tika< /groupId>
< artifactId>Tika-app< /artifactId>
< version>1.6< /version>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-bundle</artifactId>
<version>1.6</version>
</dependency>Benutzer können Tika mithilfe der Tika-Fassadenklasse in ihre Anwendungen einbetten. Es verfügt über Methoden, um alle Funktionen von Tika zu erkunden. Da es sich um eine Fassadenklasse handelt, abstrahiert Tika die Komplexität hinter ihren Funktionen. Darüber hinaus können Benutzer die verschiedenen Tika-Klassen in ihren Anwendungen verwenden.
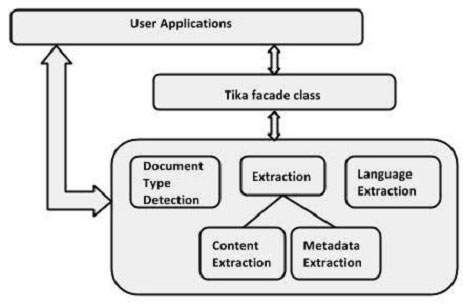
Tika-Klasse (Fassade)
Dies ist die bekannteste Klasse der Tika-Bibliothek und folgt dem Muster der Fassadengestaltung. Daher werden alle internen Implementierungen abstrahiert und einfache Methoden für den Zugriff auf die Tika-Funktionen bereitgestellt. In der folgenden Tabelle sind die Konstruktoren dieser Klasse mit ihren Beschreibungen aufgeführt.
package - org.apache.tika
class - Tika
| Sr.Nr. | Konstruktor & Beschreibung |
|---|---|
| 1 | Tika () Verwendet die Standardkonfiguration und erstellt die Tika-Klasse. |
| 2 | Tika (Detector detector) Erstellt eine Tika-Fassade, indem die Detektorinstanz als Parameter akzeptiert wird |
| 3 | Tika (Detector detector, Parser parser) Erstellt eine Tika-Fassade, indem die Detektor- und Parser-Instanzen als Parameter akzeptiert werden. |
| 4 | Tika (Detector detector, Parser parser, Translator translator) Erstellt eine Tika-Fassade, indem der Detektor, der Parser und die Übersetzerinstanz als Parameter akzeptiert werden. |
| 5 | Tika (TikaConfig config) Erstellt eine Tika-Fassade, indem das Objekt der TikaConfig-Klasse als Parameter akzeptiert wird. |
Methoden und Beschreibung
Das Folgende sind die wichtigen Methoden der Tika-Fassadenklasse -
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | analysierenToString (File Datei) Diese Methode und alle ihre Varianten analysieren die als Parameter übergebene Datei und geben den extrahierten Textinhalt im String-Format zurück. Standardmäßig ist die Länge dieses Zeichenfolgenparameters begrenzt. |
| 2 | int getMaxStringLength () Gibt die maximale Länge der von den parseToString-Methoden zurückgegebenen Zeichenfolgen zurück. |
| 3 | Leere setMaxStringLength (int maxStringLength) Legt die maximale Länge der von den parseToString-Methoden zurückgegebenen Zeichenfolgen fest. |
| 4 | Leser parse (File Datei) Diese Methode und alle ihre Varianten analysieren die als Parameter übergebene Datei und geben den extrahierten Textinhalt in Form des Objekts java.io.reader zurück. |
| 5 | String detect (InputStream Strom, Metadata Metadaten) Diese Methode und alle ihre Varianten akzeptieren ein InputStream-Objekt und ein Metadatenobjekt als Parameter, erkennen den Typ des angegebenen Dokuments und geben den Dokumenttypnamen als String-Objekt zurück. Diese Methode abstrahiert die von Tika verwendeten Erkennungsmechanismen. |
| 6 | String translate (InputStream Text, String Zielsprache) Diese Methode und alle ihre Varianten akzeptieren das InputStream-Objekt und einen String, der die Sprache darstellt, in die unser Text übersetzt werden soll, und übersetzt den angegebenen Text in die gewünschte Sprache, wobei versucht wird, die Ausgangssprache automatisch zu erkennen. |
Parser-Schnittstelle
Dies ist die Schnittstelle, die von allen Parser-Klassen des Tika-Pakets implementiert wird.
package - org.apache.tika.parser
Interface - Parser
Methoden und Beschreibung
Das Folgende ist die wichtige Methode der Tika Parser-Schnittstelle -
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | parse (InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) Diese Methode analysiert das angegebene Dokument in eine Folge von XHTML- und SAX-Ereignissen. Nach dem Parsen werden der extrahierte Dokumentinhalt im Objekt der ContentHandler-Klasse und die Metadaten im Objekt der Metadatenklasse platziert. |
Metadatenklasse
Diese Klasse implementiert verschiedene Schnittstellen wie CreativeCommons, Geographic, HttpHeaders, Message, MSOffice, ClimateForcast, TIFF, TikaMetadataKeys, TikaMimeKeys und Serializable, um verschiedene Datenmodelle zu unterstützen. In den folgenden Tabellen sind die Konstruktoren und Methoden dieser Klasse zusammen mit ihren Beschreibungen aufgeführt.
package - org.apache.tika.metadata
class - Metadaten
| Sr.Nr. | Konstruktor & Beschreibung |
|---|---|
| 1 | Metadata() Erstellt neue, leere Metadaten. |
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | add (Property property, String value) Fügt einem bestimmten Dokument eine Metadateneigenschafts- / Wertzuordnung hinzu. Mit dieser Funktion können wir den Wert auf eine Eigenschaft setzen. |
| 2 | add (String name, String value) Fügt einem bestimmten Dokument eine Metadateneigenschafts- / Wertzuordnung hinzu. Mit dieser Methode können wir einen neuen Namenswert für die vorhandenen Metadaten eines Dokuments festlegen. |
| 3 | String get (Property property) Gibt den Wert (falls vorhanden) der angegebenen Metadateneigenschaft zurück. |
| 4 | String get (String name) Gibt den Wert (falls vorhanden) des angegebenen Metadatennamens zurück. |
| 5 | Date getDate (Property property) Gibt den Wert der Date-Metadateneigenschaft zurück. |
| 6 | String[] getValues (Property property) Gibt alle Werte einer Metadateneigenschaft zurück. |
| 7 | String[] getValues (String name) Gibt alle Werte eines bestimmten Metadatennamens zurück. |
| 8 | String[] names() Gibt alle Namen von Metadatenelementen in einem Metadatenobjekt zurück. |
| 9 | set (Property property, Date date) Legt den Datumswert der angegebenen Metadateneigenschaft fest |
| 10 | set(Property property, String[] values) Legt mehrere Werte für eine Metadateneigenschaft fest. |
Sprachkennungsklasse
Diese Klasse identifiziert die Sprache des angegebenen Inhalts. In den folgenden Tabellen sind die Konstruktoren dieser Klasse zusammen mit ihren Beschreibungen aufgeführt.
package - org.apache.tika.language
class - Sprachkennung
| Sr.Nr. | Konstruktor & Beschreibung |
|---|---|
| 1 | LanguageIdentifier (LanguageProfile profile) Instanziiert die Sprachkennung. Hier müssen Sie ein LanguageProfile-Objekt als Parameter übergeben. |
| 2 | LanguageIdentifier (String content) Dieser Konstruktor kann eine Sprachkennung instanziieren, indem er einen String aus dem Textinhalt weitergibt. |
| Sr.Nr. | Methoden & Beschreibung |
|---|---|
| 1 | String getLanguage () Gibt die Sprache zurück, die dem aktuellen LanguageIdentifier-Objekt zugewiesen wurde. |
Von Tika unterstützte Dateiformate
Die folgende Tabelle zeigt die von Tika unterstützten Dateiformate.
| Datei Format | Paketbibliothek | Klasse in Tika |
|---|---|---|
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.html und verwendet die Tagsoup Library | HtmlParser |
| MS-Office-Verbunddokument Ole2 bis 2007 ab 2007 ooxml | org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml und verwendet die Apache Poi-Bibliothek |
OfficeParser (ole2) OOXMLParser (ooxml) |
| OpenDocument Format openoffice | org.apache.tika.parser.odf | OpenOfficeParser |
| tragbares Dokumentformat (PDF) | org.apache.tika.parser.pdf und dieses Paket verwendet die Apache PdfBox-Bibliothek | PDFParser |
| Elektronisches Publikationsformat (digitale Bücher) | org.apache.tika.parser.epub | EpubParser |
| Rich-text-Format | org.apache.tika.parser.rtf | RTFParser |
| Komprimierungs- und Verpackungsformate | org.apache.tika.parser.pkg und dieses Paket verwendet die Common Compress Library | PackageParser und CompressorParser und ihre Unterklassen |
| Textformat | org.apache.tika.parser.txt | TXTParser |
| Feed- und Syndication-Formate | org.apache.tika.parser.feed | FeedParser |
| Audioformate | org.apache.tika.parser.audio und org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3- für mp3parser |
| Imageparsers | org.apache.tika.parser.jpeg | JpegParser-für JPEG-Bilder |
| Videoformate | org.apache.tika.parser.mp4 und org.apache.tika.parser.video Dieser Parser verwendet intern den einfachen Algorithmus, um Flash-Videoformate zu analysieren | Mp4parser FlvParser |
| Java-Klassendateien und JAR-Dateien | org.apache.tika.parser.asm | ClassParser CompressorParser |
| Mobxformat (E-Mail-Nachrichten) | org.apache.tika.parser.mbox | MobXParser |
| Cad-Formate | org.apache.tika.parser.dwg | DWGParser |
| FontFormats | org.apache.tika.parser.font | TrueTypeParser |
| ausführbare Programme und Bibliotheken | org.apache.tika.parser.executable | ExecutableParser |
MIME-Standards
MIME-Standards (Multipurpose Internet Mail Extensions) sind die besten verfügbaren Standards zur Identifizierung von Dokumenttypen. Die Kenntnis dieser Standards hilft dem Browser bei internen Interaktionen.
Immer wenn der Browser auf eine Mediendatei stößt, wählt er eine kompatible Software aus, die zur Anzeige des Inhalts verfügbar ist. Falls es keine geeignete Anwendung zum Ausführen einer bestimmten Mediendatei gibt, empfiehlt es dem Benutzer, die geeignete Plugin-Software dafür zu erwerben.
Typerkennung in Tika
Tika unterstützt alle in MIME bereitgestellten Internetmediendokumenttypen. Immer wenn eine Datei durch Tika geleitet wird, erkennt sie die Datei und ihren Dokumenttyp. Um Medientypen zu erkennen, verwendet Tika intern die folgenden Mechanismen.
Dateierweiterungen
Das Überprüfen der Dateierweiterungen ist die einfachste und am weitesten verbreitete Methode, um das Format einer Datei zu ermitteln. Viele Anwendungen und Betriebssysteme unterstützen diese Erweiterungen. Unten sehen Sie die Erweiterung einiger bekannter Dateitypen.
| Dateiname | Erweiterung |
|---|---|
| Bild | .jpg |
| Audio- | .mp3 |
| Java-Archivdatei | .Krug |
| Java-Klassendatei | .Klasse |
Hinweise zum Inhaltstyp
Wenn Sie eine Datei aus einer Datenbank abrufen oder an ein anderes Dokument anhängen, verlieren Sie möglicherweise den Namen oder die Erweiterung der Datei. In solchen Fällen werden die mit der Datei gelieferten Metadaten verwendet, um die Dateierweiterung zu erkennen.
Magisches Byte
Wenn Sie die Rohbytes einer Datei beobachten, finden Sie für jede Datei einige eindeutige Zeichenmuster. Einige Dateien haben spezielle Byte-Präfixemagic bytes die speziell hergestellt und in einer Datei enthalten sind, um den Dateityp zu identifizieren
Beispielsweise finden Sie CA FE BA BE (Hexadezimalformat) in einer Java-Datei und% PDF (ASCII-Format) in einer PDF-Datei. Tika verwendet diese Informationen, um den Medientyp einer Datei zu identifizieren.
Zeichenkodierungen
Dateien mit einfachem Text werden mit verschiedenen Arten der Zeichenkodierung codiert. Die größte Herausforderung besteht darin, die Art der in den Dateien verwendeten Zeichenkodierung zu ermitteln. Tika folgt Zeichencodierungstechniken wieBom markers und Byte Frequencies um das vom Nur-Text-Inhalt verwendete Codierungssystem zu identifizieren.
XML-Stammzeichen
Um XML-Dokumente zu erkennen, analysiert Tika die XML-Dokumente und extrahiert die Informationen wie Stammelemente, Namespaces und referenzierte Schemas, aus denen der wahre Medientyp der Dateien stammt.
Typerkennung mit Fassadenklasse
Das detect()Die Methode der Fassadenklasse wird verwendet, um den Dokumenttyp zu erkennen. Diese Methode akzeptiert eine Datei als Eingabe. Im Folgenden sehen Sie ein Beispielprogramm für die Erkennung von Dokumenttypen mit der Tika-Fassadenklasse.
import java.io.File;
import org.apache.tika.Tika;
public class Typedetection {
public static void main(String[] args) throws Exception {
//assume example.mp3 is in your current directory
File file = new File("example.mp3");//
//Instantiating tika facade class
Tika tika = new Tika();
//detecting the file type using detect method
String filetype = tika.detect(file);
System.out.println(filetype);
}
}Speichern Sie den obigen Code als TypeDetection.java und führen Sie ihn mit den folgenden Befehlen an der Eingabeaufforderung aus:
javac TypeDetection.java
java TypeDetection
audio/mpegTika verwendet verschiedene Parser-Bibliotheken, um Inhalte aus bestimmten Parsern zu extrahieren. Es wird der richtige Parser zum Extrahieren des angegebenen Dokumenttyps ausgewählt.
Zum Parsen von Dokumenten wird im Allgemeinen die parseToString () -Methode der Tika-Fassadenklasse verwendet. Nachfolgend sind die Schritte aufgeführt, die am Parsing-Prozess beteiligt sind. Diese werden von der Tika ParsertoString () -Methode abstrahiert.

Den Analyseprozess abstrahieren -
Wenn wir ein Dokument an Tika übergeben, verwendet es zunächst einen geeigneten Typerkennungsmechanismus und erkennt den Dokumenttyp.
Sobald der Dokumenttyp bekannt ist, wählt er einen geeigneten Parser aus seinem Parser-Repository aus. Das Parser-Repository enthält Klassen, die externe Bibliotheken verwenden.
Anschließend wird das Dokument übergeben, um den Parser auszuwählen, der den Inhalt analysiert, den Text extrahiert und Ausnahmen für nicht lesbare Formate auslöst.
Inhaltsextraktion mit Tika
Im Folgenden finden Sie das Programm zum Extrahieren von Text aus einer Datei mithilfe der Tika-Fassadenklasse.
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}Speichern Sie den obigen Code als TikaExtraction.java und führen Sie ihn an der Eingabeaufforderung aus -
javac TikaExtraction.java
java TikaExtractionUnten ist der Inhalt von sample.txt angegeben.
Hi students welcome to tutorialspointEs gibt Ihnen die folgende Ausgabe -
Extracted Content: Hi students welcome to tutorialspointInhaltsextraktion über die Parser-Oberfläche
Das Parser-Paket von Tika bietet mehrere Schnittstellen und Klassen, mit denen wir ein Textdokument analysieren können. Unten ist das Blockdiagramm derorg.apache.tika.parser Paket.

Es stehen mehrere Parser-Klassen zur Verfügung, z. B. PDF-Parser, Mp3Passer, OfficeParser usw., um die jeweiligen Dokumente einzeln zu analysieren. Alle diese Klassen implementieren die Parser-Schnittstelle.
CompositeParser
Das angegebene Diagramm zeigt Tikas allgemeine Parser-Klassen: CompositeParser und AutoDetectParser. Da die CompositeParser-Klasse einem zusammengesetzten Entwurfsmuster folgt, können Sie eine Gruppe von Parser-Instanzen als einzelnen Parser verwenden. Die CompositeParser-Klasse ermöglicht auch den Zugriff auf alle Klassen, die die Parser-Schnittstelle implementieren.
AutoDetectParser
Dies ist eine Unterklasse von CompositeParser und bietet eine automatische Typerkennung. Mit dieser Funktion sendet der AutoDetectParser die eingehenden Dokumente mithilfe der zusammengesetzten Methode automatisch an die entsprechenden Parser-Klassen.
parse () -Methode
Neben parseToString () können Sie auch die parse () -Methode der Parser-Schnittstelle verwenden. Der Prototyp dieser Methode ist unten dargestellt.
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)In der folgenden Tabelle sind die vier Objekte aufgeführt, die als Parameter akzeptiert werden.
| Sr.Nr. | Objekt & Beschreibung |
|---|---|
| 1 | InputStream stream Jedes Inputstream-Objekt, das den Inhalt der Datei enthält |
| 2 | ContentHandler handler Tika übergibt das Dokument als XHTML-Inhalt an diesen Handler. Anschließend wird das Dokument mithilfe der SAX-API verarbeitet. Es bietet eine effiziente Nachbearbeitung des Inhalts eines Dokuments. |
| 3 | Metadata metadata Das Metadatenobjekt wird sowohl als Quelle als auch als Ziel für Dokumentmetadaten verwendet. |
| 4 | ParseContext context Dieses Objekt wird in Fällen verwendet, in denen die Clientanwendung den Analyseprozess anpassen möchte. |
Beispiel
Im Folgenden finden Sie ein Beispiel, das zeigt, wie die parse () -Methode verwendet wird.
Step 1 - -
Instanziieren Sie eine der Klassen, die die Implementierung für diese Schnittstelle bereitstellen, um die parse () -Methode der Parser-Schnittstelle zu verwenden.
Es gibt einzelne Parser-Klassen wie PDFParser, OfficeParser, XMLParser usw. Sie können jeden dieser einzelnen Dokument-Parser verwenden. Alternativ können Sie entweder CompositeParser oder AutoDetectParser verwenden, die alle Parser-Klassen intern verwenden und den Inhalt eines Dokuments mit einem geeigneten Parser extrahieren.
Parser parser = new AutoDetectParser();
(or)
Parser parser = new CompositeParser();
(or)
object of any individual parsers given in Tika LibraryStep 2 - -
Erstellen Sie ein Handlerklassenobjekt. Im Folgenden sind die drei Inhaltshandler aufgeführt.
| Sr.Nr. | Klasse & Beschreibung |
|---|---|
| 1 | BodyContentHandler Diese Klasse wählt den Hauptteil der XHTML-Ausgabe aus und schreibt diesen Inhalt in den Ausgabeschreiber oder Ausgabestream. Anschließend wird der XHTML-Inhalt an eine andere Content-Handler-Instanz umgeleitet. |
| 2 | LinkContentHandler Diese Klasse erkennt und wählt alle H-Ref-Tags des XHTML-Dokuments aus und leitet diese für die Verwendung von Tools wie Webcrawlern weiter. |
| 3 | TeeContentHandler Diese Klasse hilft bei der gleichzeitigen Verwendung mehrerer Werkzeuge. |
Da unser Ziel darin besteht, den Textinhalt aus einem Dokument zu extrahieren, instanziieren Sie BodyContentHandler wie unten gezeigt -
BodyContentHandler handler = new BodyContentHandler( );Step 3 - -
Erstellen Sie das Metadatenobjekt wie unten gezeigt -
Metadata metadata = new Metadata();Step 4 - -
Erstellen Sie eines der Eingabestream-Objekte und übergeben Sie Ihre zu extrahierende Datei.
FileInputstream
Instanziieren Sie ein Dateiobjekt, indem Sie den Dateipfad als Parameter übergeben und dieses Objekt an den FileInputStream-Klassenkonstruktor übergeben.
Note - Der an das Dateiobjekt übergebene Pfad sollte keine Leerzeichen enthalten.
Das Problem bei diesen Eingabestreamklassen besteht darin, dass sie keine Lesevorgänge mit wahlfreiem Zugriff unterstützen, was erforderlich ist, um einige Dateiformate effizient zu verarbeiten. Um dieses Problem zu beheben, stellt Tika TikaInputStream zur Verfügung.
File file = new File(filepath)
FileInputStream inputstream = new FileInputStream(file);
(or)
InputStream stream = TikaInputStream.get(new File(filename));Step 5 - -
Erstellen Sie ein Analysekontextobjekt wie unten gezeigt -
ParseContext context =new ParseContext();Step 6 - -
Instanziieren Sie das Parser-Objekt, rufen Sie die Analysemethode auf und übergeben Sie alle erforderlichen Objekte, wie im folgenden Prototyp gezeigt.
parser.parse(inputstream, handler, metadata, context);Im Folgenden finden Sie das Programm zum Extrahieren von Inhalten über die Parser-Oberfläche.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}Speichern Sie den obigen Code als ParserExtraction.java und führen Sie ihn an der Eingabeaufforderung aus -
javac ParserExtraction.java
java ParserExtractionUnten ist der Inhalt von sample.txt angegeben
Hi students welcome to tutorialspointWenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe:
File content : Hi students welcome to tutorialspointNeben dem Inhalt extrahiert Tika auch die Metadaten aus einer Datei. Metadaten sind nichts anderes als die zusätzlichen Informationen, die mit einer Datei geliefert werden. Wenn wir eine Audiodatei betrachten, werden der Künstlername, der Albumname und der Titel unter Metadaten angezeigt.
XMP-Standards
Die Extensible Metadata Platform (XMP) ist ein Standard zum Verarbeiten und Speichern von Informationen zum Inhalt einer Datei. Es wurde von Adobe Systems Inc. Erstellt . XMP bietet Standards zum Definieren, Erstellen und Verarbeiten von Metadaten . Sie können diesen Standard in verschiedene Dateiformate wie PDF , JPEG , JPEG , GIF , JPG , HTML usw. einbetten .
Immobilienklasse
Tika verwendet die Property-Klasse, um der XMP-Eigenschaftsdefinition zu folgen. Es enthält die Aufzählungen PropertyType und ValueType , um den Namen und den Wert von Metadaten zu erfassen.
Metadatenklasse
Diese Klasse implementiert verschiedene Schnittstellen wie ClimateForcast , CativeCommons, Geographic , TIFF usw., um verschiedene Metadatenmodelle zu unterstützen. Darüber hinaus bietet diese Klasse verschiedene Methoden zum Extrahieren des Inhalts aus einer Datei.
Metadatennamen
Mit den Methodennamen () können wir die Liste aller Metadatennamen einer Datei aus ihrem Metadatenobjekt extrahieren . Es gibt alle Namen als String-Array zurück. Mit dem Namen der Metadaten können wir den Wert mit dem abrufenget()Methode. Es nimmt einen Metadatennamen an und gibt einen damit verbundenen Wert zurück.
String[] metadaNames = metadata.names();
String value = metadata.get(name);Extrahieren von Metadaten mit der Analysemethode
Immer wenn wir eine Datei mit parse () analysieren, übergeben wir ein leeres Metadatenobjekt als einen der Parameter. Diese Methode extrahiert die Metadaten der angegebenen Datei (falls diese Datei welche enthält) und platziert sie im Metadatenobjekt. Daher können wir nach dem Parsen der Datei mit parse () die Metadaten aus diesem Objekt extrahieren.
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata(); //empty metadata object
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
// now this metadata object contains the extracted metadata of the given file.
metadata.metadata.names();Im Folgenden finden Sie das vollständige Programm zum Extrahieren von Metadaten aus einer Textdatei.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class GetMetadata {
public static void main(final String[] args) throws IOException, TikaException {
//Assume that boy.jpg is in your current directory
File file = new File("boy.jpg");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
System.out.println(handler.toString());
//getting the list of all meta data elements
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als GetMetadata.java und führen Sie ihn an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac GetMetadata .java
java GetMetadataUnten ist der Schnappschuss von boy.jpg angegeben

Wenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe:
X-Parsed-By: org.apache.tika.parser.DefaultParser
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference:
53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Content-Type: image/jpeg
Y Resolution: 300 dotsWir können auch unsere gewünschten Metadatenwerte erhalten.
Hinzufügen neuer Metadatenwerte
Wir können neue Metadatenwerte mit der add () -Methode der Metadatenklasse hinzufügen. Nachstehend ist die Syntax dieser Methode angegeben. Hier fügen wir den Autorennamen hinzu.
metadata.add(“author”,”Tutorials point”);Die Metadatenklasse verfügt über vordefinierte Eigenschaften, einschließlich der Eigenschaften, die von Klassen wie ClimateForcast , CativeCommons, Geographic usw. geerbt wurden, um verschiedene Datenmodelle zu unterstützen. Im Folgenden wird die Verwendung des SOFTWARE-Datentyps gezeigt, der von der von Tika implementierten TIFF-Schnittstelle geerbt wurde, um den XMP-Metadatenstandards für TIFF-Bildformate zu folgen.
metadata.add(Metadata.SOFTWARE,"ms paint");Im Folgenden finden Sie das vollständige Programm, das zeigt, wie Sie einer bestimmten Datei Metadatenwerte hinzufügen. Hier wird die Liste der Metadatenelemente in der Ausgabe angezeigt, damit Sie die Änderung in der Liste nach dem Hinzufügen neuer Werte beobachten können.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class AddMetadata {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//create a file object and assume sample.txt is in your current directory
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the document
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements before adding new elements
System.out.println( " metadata elements :" +Arrays.toString(metadata.names()));
//adding new meta data name value pair
metadata.add("Author","Tutorials Point");
System.out.println(" metadata name value pair is successfully added");
//printing all the meta data elements after adding new elements
System.out.println("Here is the list of all the metadata
elements after adding new elements");
System.out.println( Arrays.toString(metadata.names()));
}
}Speichern Sie den obigen Code als AddMetadata.java-Klasse und führen Sie ihn an der Eingabeaufforderung aus.
javac AddMetadata .java
java AddMetadataUnten ist der Inhalt von Example.txt angegeben
Hi students welcome to tutorialspointWenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe:
metadata elements of the given file :
[Content-Encoding, Content-Type]
enter the number of metadata name value pairs to be added 1
enter metadata1name:
Author enter metadata1value:
Tutorials point metadata name value pair is successfully added
Here is the list of all the metadata elements after adding new elements
[Content-Encoding, Author, Content-Type]Festlegen von Werten für vorhandene Metadatenelemente
Mit der Methode set () können Sie Werte für die vorhandenen Metadatenelemente festlegen. Die Syntax zum Festlegen der Datumseigenschaft mithilfe der set () -Methode lautet wie folgt:
metadata.set(Metadata.DATE, new Date());Sie können mit der set () -Methode auch mehrere Werte für die Eigenschaften festlegen. Die Syntax zum Festlegen mehrerer Werte für die Author-Eigenschaft mithilfe der set () -Methode lautet wie folgt:
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");Im Folgenden finden Sie das vollständige Programm, das die set () -Methode demonstriert.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Date;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class SetMetadata {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Create a file object and assume example.txt is in your current directory
File file = new File("example.txt");
//parameters of parse() method
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//Parsing the given file
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements elements
System.out.println( " metadata elements and values of the given file :");
String[] metadataNamesb4 = metadata.names();
for(String name : metadataNamesb4) {
System.out.println(name + ": " + metadata.get(name));
}
//setting date meta data
metadata.set(Metadata.DATE, new Date());
//setting multiple values to author property
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
//printing all the meta data elements with new elements
System.out.println("List of all the metadata elements after adding new elements ");
String[] metadataNamesafter = metadata.names();
for(String name : metadataNamesafter) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als SetMetadata.java und führen Sie ihn an der Eingabeaufforderung aus.
javac SetMetadata.java
java SetMetadataUnten ist der Inhalt von example.txt angegeben.
Hi students welcome to tutorialspointWenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe. In der Ausgabe können Sie die neu hinzugefügten Metadatenelemente beobachten.
metadata elements and values of the given file :
Content-Encoding: ISO-8859-1
Content-Type: text/plain; charset = ISO-8859-1
Here is the list of all the metadata elements after adding new elements
date: 2014-09-24T07:01:32Z
Content-Encoding: ISO-8859-1
Author: ram, raheem, robin
Content-Type: text/plain; charset = ISO-8859-1Notwendigkeit der Spracherkennung
Für die Klassifizierung von Dokumenten anhand der Sprache, in der sie auf einer mehrsprachigen Website geschrieben sind, wird ein Tool zur Spracherkennung benötigt. Dieses Tool sollte Dokumente ohne Sprachanmerkungen (Metadaten) akzeptieren und diese Informationen in die Metadaten des Dokuments einfügen, indem die Sprache erkannt wird.
Algorithmen zur Profilerstellung Corpus
Was ist Korpus?
Um die Sprache eines Dokuments zu erkennen, wird ein Sprachprofil erstellt und mit dem Profil der bekannten Sprachen verglichen. Der Textsatz dieser bekannten Sprachen ist als a bekanntcorpus.
Ein Korpus ist eine Sammlung von Texten einer geschriebenen Sprache, die erklärt, wie die Sprache in realen Situationen verwendet wird.
Der Korpus wird aus Büchern, Transkripten und anderen Datenquellen wie dem Internet entwickelt. Die Genauigkeit des Korpus hängt von dem Profilierungsalgorithmus ab, den wir zum Einrahmen des Korpus verwenden.
Was sind Profilierungsalgorithmen?
Die übliche Methode zum Erkennen von Sprachen ist die Verwendung von Wörterbüchern. Die in einem bestimmten Text verwendeten Wörter werden mit denen in den Wörterbüchern abgeglichen.
Eine Liste gebräuchlicher Wörter, die in einer Sprache verwendet werden, ist das einfachste und effektivste Korpus zum Erkennen einer bestimmten Sprache, z. B. von Artikeln a, an, the auf Englisch.
Verwenden von Wortsätzen als Korpus
Unter Verwendung von Wortsätzen wird ein einfacher Algorithmus erstellt, um den Abstand zwischen zwei Korpora zu ermitteln, der der Summe der Unterschiede zwischen den Häufigkeiten übereinstimmender Wörter entspricht.
Solche Algorithmen leiden unter den folgenden Problemen:
Da die Häufigkeit übereinstimmender Wörter sehr gering ist, kann der Algorithmus mit kleinen Texten mit wenigen Sätzen nicht effizient arbeiten. Es benötigt viel Text für eine genaue Übereinstimmung.
Es kann keine Wortgrenzen für Sprachen mit zusammengesetzten Sätzen und für Sprachen ohne Wortteiler wie Leerzeichen oder Satzzeichen erkennen.
Aufgrund dieser Schwierigkeiten bei der Verwendung von Wortsätzen als Korpus werden einzelne Zeichen oder Zeichengruppen berücksichtigt.
Zeichensätze als Korpus verwenden
Da die in einer Sprache häufig verwendeten Zeichen eine begrenzte Anzahl haben, ist es einfach, einen Algorithmus anzuwenden, der auf Worthäufigkeiten und nicht auf Zeichen basiert. Dieser Algorithmus funktioniert noch besser bei bestimmten Zeichensätzen, die in einer oder sehr wenigen Sprachen verwendet werden.
Dieser Algorithmus weist die folgenden Nachteile auf:
Es ist schwierig, zwei Sprachen mit ähnlichen Zeichenfrequenzen zu unterscheiden.
Es gibt kein spezifisches Werkzeug oder keinen spezifischen Algorithmus, um eine Sprache mithilfe (als Korpus) des von mehreren Sprachen verwendeten Zeichensatzes spezifisch zu identifizieren.
N-Gramm-Algorithmus
Die oben genannten Nachteile führten zu einem neuen Ansatz, Zeichenfolgen einer bestimmten Länge für die Profilierung des Korpus zu verwenden. Eine solche Folge von Zeichen wird im Allgemeinen als N-Gramm bezeichnet, wobei N die Länge der Zeichenfolge darstellt.
Der N-Gramm-Algorithmus ist ein effektiver Ansatz zur Spracherkennung, insbesondere bei europäischen Sprachen wie Englisch.
Dieser Algorithmus funktioniert gut mit kurzen Texten.
Obwohl es erweiterte Sprachprofilierungsalgorithmen gibt, mit denen mehrere Sprachen in einem mehrsprachigen Dokument mit attraktiveren Funktionen erkannt werden können, verwendet Tika den 3-Gramm-Algorithmus, da er in den meisten praktischen Situationen geeignet ist.
Spracherkennung in Tika
Unter allen 184 durch ISO 639-1 standardisierten Standardsprachen kann Tika 18 Sprachen erkennen. Die Spracherkennung in Tika erfolgt mit demgetLanguage() Methode der LanguageIdentifierKlasse. Diese Methode gibt den Codenamen der Sprache im String-Format zurück. Nachstehend finden Sie eine Liste der 18 von Tika erkannten Sprachcode-Paare.
| da - dänisch | de-deutsch | et-Estnisch | el - Griechisch |
| de - Englisch | es - Spanisch | fi - finnisch | fr - Französisch |
| hu - ungarisch | ist - Isländisch | es - italienisch | nl - Niederländisch |
| nein - norwegisch | pl - polnisch | pt - Portugiesisch | ru - russisch |
| sv - schwedisch | th - Thai |
Während der Instanziierung der LanguageIdentifier Klasse sollten Sie das String-Format des zu extrahierenden Inhalts übergeben, oder a LanguageProfile Klassenobjekt.
LanguageIdentifier object = new LanguageIdentifier(“this is english”);Im Folgenden finden Sie ein Beispielprogramm für die Spracherkennung in Tika.
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.language.LanguageIdentifier;
import org.xml.sax.SAXException;
public class LanguageDetection {
public static void main(String args[])throws IOException, SAXException, TikaException {
LanguageIdentifier identifier = new LanguageIdentifier("this is english ");
String language = identifier.getLanguage();
System.out.println("Language of the given content is : " + language);
}
}Speichern Sie den obigen Code als LanguageDetection.java und führen Sie es an der Eingabeaufforderung mit den folgenden Befehlen aus:
javac LanguageDetection.java
java LanguageDetectionWenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe
Language of the given content is : enSpracherkennung eines Dokuments
Um die Sprache eines bestimmten Dokuments zu erkennen, müssen Sie es mit der parse () -Methode analysieren. Die parse () -Methode analysiert den Inhalt und speichert ihn im Handler-Objekt, das als eines der Argumente an ihn übergeben wurde. Übergeben Sie das String-Format des Handler-Objekts an den Konstruktor desLanguageIdentifier Klasse wie unten gezeigt -
parser.parse(inputstream, handler, metadata, context);
LanguageIdentifier object = new LanguageIdentifier(handler.toString());Im Folgenden finden Sie das vollständige Programm, das zeigt, wie die Sprache eines bestimmten Dokuments erkannt wird.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.language.*;
import org.xml.sax.SAXException;
public class DocumentLanguageDetection {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//Instantiating a file object
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream content = new FileInputStream(file);
//Parsing the given document
parser.parse(content, handler, metadata, new ParseContext());
LanguageIdentifier object = new LanguageIdentifier(handler.toString());
System.out.println("Language name :" + object.getLanguage());
}
}Speichern Sie den obigen Code als SetMetadata.java und führen Sie ihn an der Eingabeaufforderung aus.
javac SetMetadata.java
java SetMetadataUnten ist der Inhalt von Example.txt angegeben.
Hi students welcome to tutorialspointWenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe:
Language name :enZusammen mit dem Tika-Jar bietet Tika eine grafische Benutzeroberfläche (GUI) und eine Befehlszeilenschnittstelle (CLI). Sie können eine Tika-Anwendung wie andere Java-Anwendungen auch über die Eingabeaufforderung ausführen.
Grafische Benutzeroberfläche (GUI)
Tika stellt eine JAR-Datei zusammen mit dem Quellcode unter dem folgenden Link zur Verfügung https://tika.apache.org/download.html.
Laden Sie beide Dateien herunter und legen Sie den Klassenpfad für die JAR-Datei fest.
Extrahieren Sie den Quellcode-Zip-Ordner und öffnen Sie den Tika-App-Ordner.
Im extrahierten Ordner unter "tika-1.6 \ tika-app \ src \ main \ java \ org \ apache \ Tika \ gui" sehen Sie zwei Klassendateien: ParsingTransferHandler.java und TikaGUI.java.
Kompilieren Sie beide Klassendateien und führen Sie die Klassendatei TikaGUI.java aus. Das folgende Fenster wird geöffnet.

Lassen Sie uns nun sehen, wie Sie die Tika-Benutzeroberfläche verwenden.
Klicken Sie auf der GUI auf Öffnen, durchsuchen Sie eine Datei, die extrahiert werden soll, und wählen Sie sie aus, oder ziehen Sie sie auf das Leerzeichen des Fensters.
Tika extrahiert den Inhalt der Dateien und zeigt ihn in fünf verschiedenen Formaten an, nämlich. Metadaten, formatierter Text, einfacher Text, Hauptinhalt und strukturierter Text. Sie können ein beliebiges Format auswählen.
Auf die gleiche Weise finden Sie die CLI-Klasse auch im Ordner "tika-1.6 \ tikaapp \ src \ main \ java \ org \ apache \ tika \ cli".
Die folgende Abbildung zeigt, was Tika kann. Wenn wir das Bild auf der GUI ablegen, extrahiert Tika seine Metadaten und zeigt sie an.
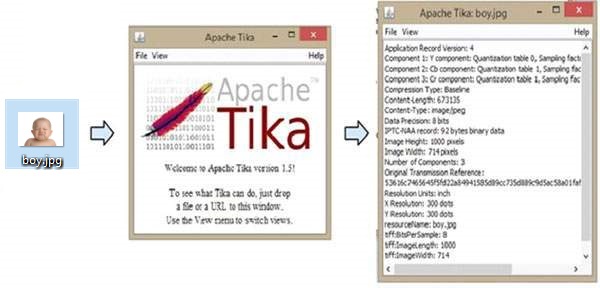
Im Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einem PDF.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class PdfParse {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF :" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als PdfParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac PdfParse.java
java PdfParseUnten finden Sie den Schnappschuss von example.pdf

Das PDF, das wir übergeben, hat die folgenden Eigenschaften:

Nach dem Kompilieren des Programms erhalten Sie die Ausgabe wie unten gezeigt.
Output - -
Contents of the PDF:
Apache Tika is a framework for content type detection and content extraction
which was designed by Apache software foundation. It detects and extracts metadata
and structured text content from different types of documents such as spreadsheets,
text documents, images or PDFs including audio or video input formats to certain extent.
Metadata of the PDF:
dcterms:modified : 2014-09-28T12:31:16Z
meta:creation-date : 2014-09-28T12:31:16Z
meta:save-date : 2014-09-28T12:31:16Z
dc:creator : Krishna Kasyap
pdf:PDFVersion : 1.5
Last-Modified : 2014-09-28T12:31:16Z
Author : Krishna Kasyap
dcterms:created : 2014-09-28T12:31:16Z
date : 2014-09-28T12:31:16Z
modified : 2014-09-28T12:31:16Z
creator : Krishna Kasyap
xmpTPg:NPages : 1
Creation-Date : 2014-09-28T12:31:16Z
pdf:encrypted : false
meta:author : Krishna Kasyap
created : Sun Sep 28 05:31:16 PDT 2014
dc:format : application/pdf; version = 1.5
producer : Microsoft® Word 2013
Content-Type : application/pdf
xmp:CreatorTool : Microsoft® Word 2013
Last-Save-Date : 2014-09-28T12:31:16ZIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus dem Open Office Document Format (ODF).
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class OpenDocumentParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_open_document_presentation.odp"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als OpenDocumentParse.javaund kompilieren Sie es in der Eingabeaufforderung mit den folgenden Befehlen:
javac OpenDocumentParse.java
java OpenDocumentParseIm Folgenden finden Sie eine Momentaufnahme der Datei example_open_document_presentation.odp.

Dieses Dokument hat die folgenden Eigenschaften:
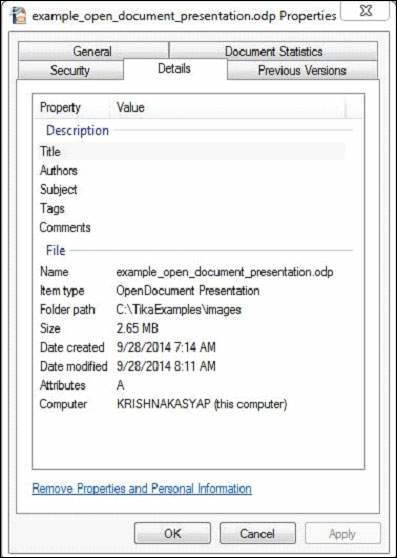
Nach dem Kompilieren des Programms erhalten Sie die folgende Ausgabe.
Output - -
Contents of the document:
Apache Tika
Apache Tika is a framework for content type detection and content extraction which was designed
by Apache software foundation. It detects and extracts metadata and structured text content from
different types of documents such as spreadsheets, text documents, images or PDFs including audio
or video input formats to certain extent.
Metadata of the document:
editing-cycles: 4
meta:creation-date: 2009-04-16T11:32:32.86
dcterms:modified: 2014-09-28T07:46:13.03
meta:save-date: 2014-09-28T07:46:13.03
Last-Modified: 2014-09-28T07:46:13.03
dcterms:created: 2009-04-16T11:32:32.86
date: 2014-09-28T07:46:13.03
modified: 2014-09-28T07:46:13.03
nbObject: 36
Edit-Time: PT32M6S
Creation-Date: 2009-04-16T11:32:32.86
Object-Count: 36
meta:object-count: 36
generator: OpenOffice/4.1.0$Win32 OpenOffice.org_project/410m18$Build-9764
Content-Type: application/vnd.oasis.opendocument.presentation
Last-Save-Date: 2014-09-28T07:46:13.03Im Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einem Microsoft Office-Dokument.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class MSExcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als MSExelParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac MSExcelParse.java
java MSExcelParseHier übergeben wir die folgende Beispiel-Excel-Datei.
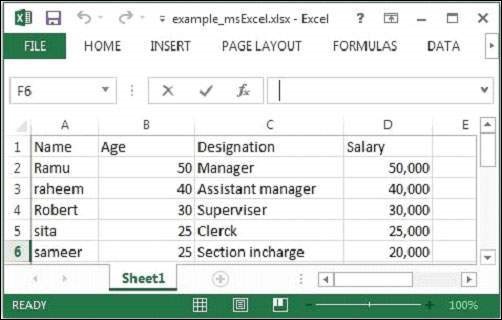
Die angegebene Excel-Datei hat die folgenden Eigenschaften:

Nach dem Ausführen des obigen Programms erhalten Sie die folgende Ausgabe.
Output - -
Contents of the document:
Sheet1
Name Age Designation Salary
Ramu 50 Manager 50,000
Raheem 40 Assistant manager 40,000
Robert 30 Superviser 30,000
sita 25 Clerk 25,000
sameer 25 Section in-charge 20,000
Metadata of the document:
meta:creation-date: 2006-09-16T00:00:00Z
dcterms:modified: 2014-09-28T15:18:41Z
meta:save-date: 2014-09-28T15:18:41Z
Application-Name: Microsoft Excel
extended-properties:Company:
dcterms:created: 2006-09-16T00:00:00Z
Last-Modified: 2014-09-28T15:18:41Z
Application-Version: 15.0300
date: 2014-09-28T15:18:41Z
publisher:
modified: 2014-09-28T15:18:41Z
Creation-Date: 2006-09-16T00:00:00Z
extended-properties:AppVersion: 15.0300
protected: false
dc:publisher:
extended-properties:Application: Microsoft Excel
Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
Last-Save-Date: 2014-09-28T15:18:41ZIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einem Textdokument.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.txt.TXTParser;
import org.xml.sax.SAXException;
public class TextParser {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.txt"));
ParseContext pcontext=new ParseContext();
//Text document parser
TXTParser TexTParser = new TXTParser();
TexTParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als TextParser.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac TextParser.java
java TextParserUnten ist der Schnappschuss der Datei sample.txt angegeben -
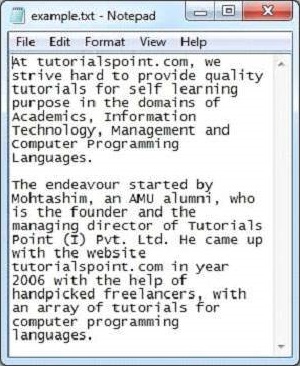
Das Textdokument hat die folgenden Eigenschaften:

Wenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe.
Output - -
Contents of the document:
At tutorialspoint.com, we strive hard to provide quality tutorials for self-learning
purpose in the domains of Academics, Information Technology, Management and Computer
Programming Languages.
The endeavour started by Mohtashim, an AMU alumni, who is the founder and the managing
director of Tutorials Point (I) Pvt. Ltd. He came up with the website tutorialspoint.com
in year 2006 with the help of handpicked freelancers, with an array of tutorials for
computer programming languages.
Metadata of the document:
Content-Encoding: windows-1252
Content-Type: text/plain; charset = windows-1252Im Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einem HTML-Dokument.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class HtmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als HtmlParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac HtmlParse.java
java HtmlParseUnten ist der Schnappschuss der Datei example.txt angegeben.
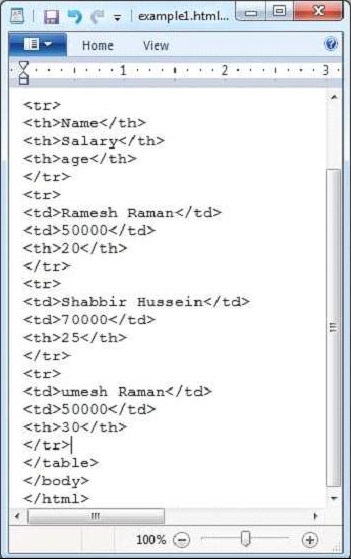
Das HTML-Dokument hat die folgenden Eigenschaften

Wenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe.
Output - -
Contents of the document:
Name Salary age
Ramesh Raman 50000 20
Shabbir Hussein 70000 25
Umesh Raman 50000 30
Somesh 50000 35
Metadata of the document:
title: HTML Table Header
Content-Encoding: windows-1252
Content-Type: text/html; charset = windows-1252
dc:title: HTML Table HeaderIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einem XML-Dokument.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.xml.XMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class XmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("pom.xml"));
ParseContext pcontext = new ParseContext();
//Xml parser
XMLParser xmlparser = new XMLParser();
xmlparser.parse(inputstream, handler, metadata, pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als XmlParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac XmlParse.java
java XmlParseUnten ist der Schnappschuss der Datei example.xml angegeben
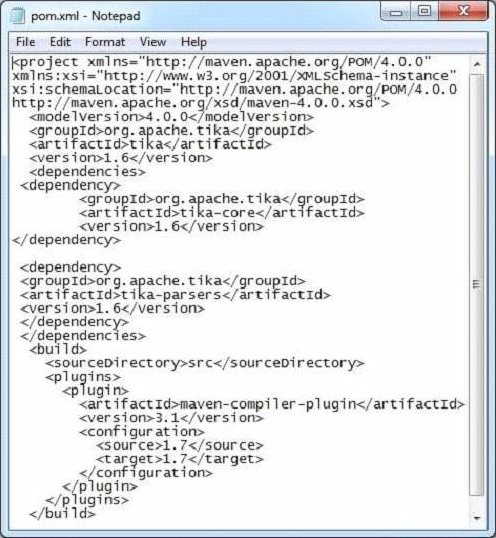
Dieses Dokument hat die folgenden Eigenschaften:

Wenn Sie das obige Programm ausführen, erhalten Sie die folgende Ausgabe:
Output - -
Contents of the document:
4.0.0
org.apache.tika
tika
1.6
org.apache.tika
tika-core
1.6
org.apache.tika
tika-parsers
1.6
src
maven-compiler-plugin
3.1
1.7
1.7
Metadata of the document:
Content-Type: application/xmlIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einer .class-Datei.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als JavaClassParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac JavaClassParse.java
java JavaClassParseUnten ist der Schnappschuss von Example.java Dadurch wird Example.class nach der Kompilierung generiert.

Example.class Datei hat die folgenden Eigenschaften -
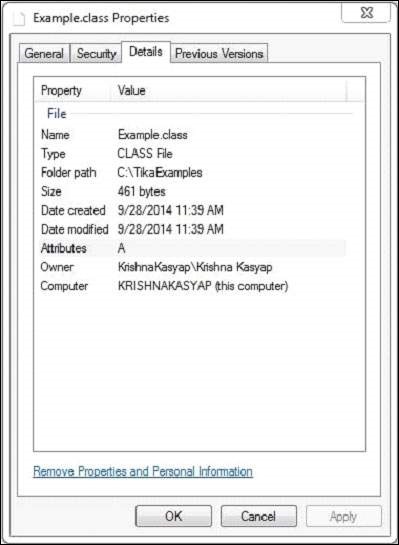
Nach dem Ausführen des obigen Programms erhalten Sie die folgende Ausgabe.
Output - -
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: ExampleIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einer Java Archive (jar) -Datei.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.pkg.PackageParser;
import org.xml.sax.SAXException;
public class PackageParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.jar"));
ParseContext pcontext = new ParseContext();
//Package parser
PackageParser packageparser = new PackageParser();
packageparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: " + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als PackageParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac PackageParse.java
java PackageParseIm Folgenden finden Sie den Snapshot von Example.java, der sich im Paket befindet.

Die JAR-Datei hat die folgenden Eigenschaften:

Nachdem Sie das obige Programm ausgeführt haben, erhalten Sie die folgende Ausgabe:
Output - -
Contents of the document:
META-INF/MANIFEST.MF
tutorialspoint/tika/examples/Example.class
Metadata of the document:
Content-Type: application/zipIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus einem JPEG-Bild.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.jpeg.JpegParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JpegParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("boy.jpg"));
ParseContext pcontext = new ParseContext();
//Jpeg Parse
JpegParser JpegParser = new JpegParser();
JpegParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als JpegParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac JpegParse.java
java JpegParseUnten ist der Schnappschuss von Example.jpeg -

Die JPEG-Datei hat die folgenden Eigenschaften:
Nach dem Ausführen des Programms erhalten Sie die folgende Ausgabe.
Output −
Contents of the document:
Meta data of the document:
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Y Resolution: 300 dotsIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus MP4-Dateien.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp4.MP4Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp4Parse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp4"));
ParseContext pcontext = new ParseContext();
//Html parser
MP4Parser MP4Parser = new MP4Parser();
MP4Parser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: :" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als JpegParse.java und kompilieren Sie ihn an der Eingabeaufforderung mit den folgenden Befehlen:
javac Mp4Parse.java
java Mp4ParseIm Folgenden finden Sie eine Momentaufnahme der Eigenschaften der Datei Example.mp4.

Nach dem Ausführen des obigen Programms erhalten Sie die folgende Ausgabe:
Output - -
Contents of the document:
Metadata of the document:
dcterms:modified: 2014-01-06T12:10:27Z
meta:creation-date: 1904-01-01T00:00:00Z
meta:save-date: 2014-01-06T12:10:27Z
Last-Modified: 2014-01-06T12:10:27Z
dcterms:created: 1904-01-01T00:00:00Z
date: 2014-01-06T12:10:27Z
tiff:ImageLength: 360
modified: 2014-01-06T12:10:27Z
Creation-Date: 1904-01-01T00:00:00Z
tiff:ImageWidth: 640
Content-Type: video/mp4
Last-Save-Date: 2014-01-06T12:10:27ZIm Folgenden finden Sie das Programm zum Extrahieren von Inhalten und Metadaten aus MP3-Dateien.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp3.LyricsHandler;
import org.apache.tika.parser.mp3.Mp3Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp3Parse {
public static void main(final String[] args) throws Exception, IOException, SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp3"));
ParseContext pcontext = new ParseContext();
//Mp3 parser
Mp3Parser Mp3Parser = new Mp3Parser();
Mp3Parser.parse(inputstream, handler, metadata, pcontext);
LyricsHandler lyrics = new LyricsHandler(inputstream,handler);
while(lyrics.hasLyrics()) {
System.out.println(lyrics.toString());
}
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Speichern Sie den obigen Code als JpegParse.javaund kompilieren Sie es an der Eingabeaufforderung mit den folgenden Befehlen:
javac Mp3Parse.java
java Mp3ParseDie Datei Example.mp3 hat die folgenden Eigenschaften:
Nach Ausführung des Programms erhalten Sie folgende Ausgabe. Wenn die angegebene Datei einen Text enthält, erfasst und zeigt unsere Anwendung diesen zusammen mit der Ausgabe an.
Output - -
Contents of the document:
Kanulanu Thaake
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Metadata of the document:
xmpDM:releaseDate: 2014
xmpDM:duration: 30171.650390625
xmpDM:audioChannelType: Stereo
dc:creator: Arijit Singh
xmpDM:album: Manam (2014)
Author: Arijit Singh
xmpDM:artist: Arijit Singh
channels: 2
xmpDM:audioSampleRate: 44100
xmpDM:logComment: eng -
DRGM
xmpDM:trackNumber: 01/06
version: MPEG 3 Layer III Version 1
creator: Arijit Singh
xmpDM:composer: Music : Anoop Rubens | Lyrics : Vanamali
xmpDM:audioCompressor: MP3
title: Kanulanu Thaake
samplerate: 44100
meta:author: Arijit Singh
xmpDM:genre: Soundtrack
Content-Type: audio/mpeg
xmpDM:albumArtist: Manam (2014)
dc:title: Kanulanu Thaake