VSAM - Kurzanleitung
Die Virtual Storage Access Method (VSAM) ist eine leistungsstarke Zugriffsmethode und Datensatzorganisation, die Daten über eine Katalogstruktur organisiert und verwaltet. Es nutzt das Konzept des virtuellen Speichers und kann Datensätze auf verschiedenen Ebenen durch die Angabe von Kennwörtern schützen. VSAM kann in COBOL-Programmen wie physischen sequentiellen Dateien verwendet werden. VSAM sind die logischen Datensätze zum Speichern von Datensätzen. Dateien können in VSAM nacheinander und zufällig gelesen werden. Es ist eine verbesserte Methode zum Speichern von Daten, die einige der Einschränkungen herkömmlicher Dateisysteme wie sequentieller Dateien überwindet.
Eigenschaften von VSAM
Es folgen die Eigenschaften von VSAM -
VSAM schützt Daten mithilfe von Kennwörtern vor unbefugtem Zugriff.
VSAM bietet schnellen Zugriff auf Datensätze.
VSAM bietet Optionen zur Leistungsoptimierung.
VSAM ermöglicht die gemeinsame Nutzung von Datensätzen in Batch- und Online-Umgebungen.
VSAM sind beim Speichern von Daten strukturierter und organisierter.
Freier Speicherplatz wird in VSAM-Dateien automatisch wiederverwendet.
Einschränkungen von VSAM
Die einzige Einschränkung von VSAM besteht darin, dass es nicht auf dem TAPE-Volume gespeichert werden kann. Es wird immer im DASD-Speicherplatz gespeichert. Es erfordert eine Anzahl von Zylindern, um die Daten zu speichern, was nicht kosteneffektiv ist.
VSAM besteht aus folgenden Komponenten:
- VSAM-Cluster
- Kontrollbereich
- Kontrollintervall
VSAM-Cluster
VSAM sind die logischen Datensätze zum Speichern von Datensätzen und werden als Cluster bezeichnet. Ein Cluster ist eine Zuordnung des Index, des Sequenzsatzes und der Datenteile des Datensatzes. Der von einem VSAM-Cluster belegte Platz ist in zusammenhängende Bereiche unterteilt, die als Steuerintervalle bezeichnet werden. Wir werden später in diesem Modul über Kontrollintervalle diskutieren.
In einem VSAM-Cluster gibt es zwei Hauptkomponenten:
Index Componententhält den Indexteil. Indexdatensätze sind in der Indexkomponente vorhanden. Verwenden der Indexkomponente VSAM kann Datensätze von der Datenkomponente abrufen.
Data Componententhält den Datenteil. Aktuelle Datensätze sind in der Datenkomponente vorhanden.
Kontrollintervall
Steuerintervalle (CI) in VSAM entsprechen Blöcken für Nicht-VSAM-Datensätze. Bei Nicht-VSAM-Methoden wird die Dateneinheit durch den Block definiert. VSAM arbeitet mit einem logischen Datenbereich, der als Steuerintervalle bezeichnet wird.
Steuerintervalle sind die kleinste Übertragungseinheit zwischen einer Festplatte und dem Betriebssystem. Immer wenn ein Datensatz direkt aus dem Speicher abgerufen wird, wird das gesamte CI, das den Datensatz enthält, in den VSAM-Eingabe-Ausgabe-Puffer eingelesen. Der gewünschte Datensatz wird dann vom VSAM-Puffer in den Arbeitsbereich übertragen.
Das Kontrollintervall besteht aus -
- Logische Aufzeichnungen
- Kontrollinformationsfelder
- Freiraum
Wenn ein VSAM-Dataset geladen wird, werden Steuerintervalle erstellt. Die Standardgröße für das Steuerintervall beträgt 4 KB und kann bis zu 32 KB betragen.
Analyse des Kontrollintervalls
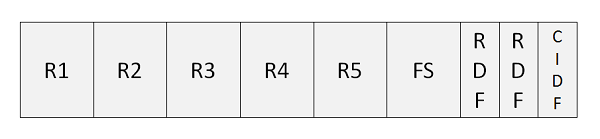
Es folgt die Beschreibung der im obigen Programm verwendeten Begriffe -
R1..R5 - Datensätze, die im Kontrollintervall gespeichert sind.
FS - FS ist freier Speicherplatz, der zur weiteren Erweiterung des Datensatzes verwendet werden kann.
RDF- RDF wird als Datensatzdefinitionsfelder bezeichnet. RDF sind 3 Bytes lang. Es beschreibt die Länge von Datensätzen und gibt an, wie viele benachbarte Datensätze dieselbe Länge haben.
CIDF- CIDF wird als Kontrollintervall-Definitionsfelder bezeichnet. CIDF sind 4 Byte lang und enthalten Informationen zum Kontrollintervall.
Kontrollbereich
Ein Kontrollbereich (CA) wird gebildet, indem zwei oder mehr Kontrollintervalle zusammengestellt werden. Ein VSAM-Datensatz besteht aus einem oder mehreren Kontrollbereichen. Die Größe von VSAM ist immer ein Vielfaches seines Kontrollbereichs. VSAM-Dateien werden in Einheiten von Kontrollbereichen erweitert.
Es folgt das Beispiel des Kontrollbereichs -

VSAM-Cluster ist in definiert JCL. JCL verwendetIDCAMSDienstprogramm zum Erstellen eines Clusters. IDCAMS ist ein von IBM entwickeltes Dienstprogramm für Access Method Services. Es wird hauptsächlich zum Definieren von VSAM-Datasets verwendet.
Cluster definieren
Die folgende Syntax zeigt die Hauptparameter, unter denen gruppiert ist Define Cluster, Data und Index.
.DEFINE CLUSTER (NAME(vsam-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
[INDEXED / NONINDEXED / NUMBERED / LINEAR] -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[KEYS(length offset)] -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE] ) -
DATA -
(NAME(vsam-file-name.data)) -
INDEX -
(NAME(vsam-file-name.index)) -
CATALOG(catalog-name[/password]))Parameter auf CLUSTER-Ebene gelten für den gesamten Cluster. Parameter auf DATA- oder INDEX-Ebene gelten nur für die Daten- oder Indexkomponente.
Wir werden jeden Parameter in der folgenden Tabelle ausführlich diskutieren -
| Sr.Nr. | Parameter mit Beschreibung |
|---|---|
| 1 | DEFINE CLUSTER Mit dem Befehl Cluster definieren wird ein Cluster definiert und Parameterattribute für den Cluster und seine Komponenten angegeben. |
| 2 | NAME NAME gibt den Namen der VSAM-Datei an, für die wir den Cluster definieren. |
| 3 | BLOCKS Blöcke gibt die Anzahl der Blöcke an, die dem Cluster zugewiesen sind. |
| 4 | VOLUMES Volumes gibt ein oder mehrere Volumes an, die den Cluster oder die Komponente enthalten. |
| 5 | INDEXED / NONINDEXED / NUMBERED / LINEAR Dieser Parameter kann je nach Art des von uns erstellten Datasets drei Werte annehmen: INDEXED, NONINDEXED oder NUMBERED. Für KSDS-Dateien (Key Sequenced) wird die Option INDEXED verwendet. Für ESDS-Dateien (Entry Sequenced) wird die Option NONINDEXED verwendet. Für RRDS-Dateien (Relative Record) ist die Option NUMBERED erforderlich. Für lineare (LDS) Dateien ist die Option LINEAR erforderlich. Der Standardwert dieses Parameters ist INDEXED. Wir werden in den kommenden Modulen mehr über KSDS, ESDS, RRDS und LDS diskutieren. |
| 6 | RECSZ Der Parameter Datensatzgröße hat zwei Werte: Durchschnittliche und Maximale Datensatzgröße. Der Durchschnitt gibt die durchschnittliche Länge der logischen Datensätze in der Datei an und das Maximum gibt die Länge der Datensätze an. |
| 7 | FREESPACE Freespace gibt den Prozentsatz des freien Speicherplatzes an, der für die Kontrollintervalle (CI) und Kontrollbereiche (CA) der Datenkomponente reserviert werden soll. Der Standardwert dieses Parameters ist null Prozent. |
| 8 | CISZ CISZ wird als Kontrollintervallgröße bezeichnet. Es gibt die Größe der Steuerintervalle an. |
| 9 | KEYS Der Schlüsselparameter wird nur in KSDS-Dateien (Key Sequenced) definiert. Es gibt die Länge und den Versatz des Primärschlüssels von der ersten Spalte an. Der Wertebereich dieses Parameters liegt zwischen 1 und 255 Byte. |
| 10 | READPW Der Wert im Parameter READPW gibt das Kennwort der Leseebene an. |
| 11 | FOR/TO Der Wert dieses Parameters gibt die Zeit in Bezug auf Datum und Tage für die Aufbewahrung der Datei an. Der Standardwert für diesen Parameter ist null Tage. |
| 12 | UPDATEPW Der Wert im Parameter UPDATEPW gibt das Kennwort der Aktualisierungsstufe an. |
| 13 | REUSE / NOREUSE Mit dem Parameter REUSE können Cluster definiert werden, die auf den leeren Status zurückgesetzt werden können, ohne sie zu löschen und neu zu definieren. |
| 14 | DATA - NAME Der DATA-Teil des Clusters enthält den Dataset-Namen, der die tatsächlichen Daten der Datei enthält. |
| 15 | INDEX-NAME Der INDEX-Teil des Clusters enthält den Primärschlüssel und den Speicherzeiger für den entsprechenden Datensatz im Datenteil. Es wird definiert, wenn ein Schlüsselsequenzierter Cluster verwendet wird. |
| 16 | CATALOG Der Katalogparameter bezeichnet den Katalog, unter dem die Datei definiert wird. Wir werden den Katalog in den kommenden Modulen separat diskutieren. |
Beispiel
Das folgende grundlegende Beispiel zeigt, wie ein Cluster in JCL definiert wird:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) -
INDEXED -
RECSZ(80 80) -
TRACKS(1,1) -
KEYS(5 0) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.KSDSFILE.DATA)) -
INDEX (NAME(MY.VSAM.KSDSFILE.INDEX))
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und erstellt die VSAM-Datei MY.VSAM.KSDSFILE.
Cluster löschen
Um eine VSAM-Datei zu löschen, muss der VSAM-Cluster mit dem Dienstprogramm IDCAMS gelöscht werden. Der Befehl DELETE entfernt den Eintrag des VSAM-Clusters aus dem Katalog und entfernt optional die Datei, wodurch der vom Objekt belegte Speicherplatz frei wird. Wenn der VSAM-Datensatz nicht abgelaufen ist, wird er nicht gelöscht. Verwenden Sie die Option PURGE, um solche Datasets zu löschen.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]Die obige Syntax zeigt die Parameter, die wir mit der Delete-Anweisung verwenden können. Wir werden jeden von ihnen in der folgenden Tabelle ausführlich besprechen -
| Sr.Nr. | Parameter mit Beschreibung |
|---|---|
| 1 | ERASE / NOERASE Die Option ERASE wird angegeben, um das für das Objekt im Katalog angegebene ERASE-Attribut zu überschreiben. Die Option NOERASE ist standardmäßig aktiviert. |
| 2 | FORCE / NOFORCE Die Option FORCE wird angegeben, um SPACE und USERCATALOG zu löschen, auch wenn sie nicht leer sind. Die Option NOFORCE ist standardmäßig aktiviert. |
| 3 | PURGE / NOPURGE Mit der Option PURGE wird das VSAM-Dataset gelöscht, wenn das Dataset nicht abgelaufen ist. Die Option NOPURGE ist standardmäßig aktiviert. |
| 4 | SCRATCH / NOSCRATCH Die Option SCRATCH wird angegeben, um den zugehörigen Eintrag für das Objekt aus dem Inhaltsverzeichnis des Volumes zu entfernen. Es wird hauptsächlich für Nicht-Vsam-Datensätze wie GDGs verwendet. Die Option NOSCRATCH ist standardmäßig aktiviert. |
Beispiel
Das folgende grundlegende Beispiel zeigt, wie ein Cluster in JCL gelöscht wird:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.KSDSFILE CLUSTER
PURGE
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und löscht die VSAM-Datei MY.VSAM.KSDSFILE.
ESDS wird als entry Sequenced Data Set bezeichnet. Ein eintragssequenzierter Datensatz verhält sich wie eine sequentielle Dateiorganisation mit einigen weiteren Funktionen. Wir können direkt auf die Aufzeichnungen zugreifen und aus Sicherheitsgründen auch Passwörter verwenden. Wir müssen codierenNONINDEXEDim Befehl DEFINE CLUSTER für ESDS-Datasets. Im Folgenden sind die wichtigsten Funktionen von ESDS aufgeführt:
Datensätze im ESDS-Cluster werden in der Reihenfolge gespeichert, in der sie in den Datensatz eingefügt wurden.
Datensätze werden durch die physikalische Adresse referenziert, die als bekannt ist Relative Byte Address (RBA). Angenommen, in einem ESDS-Dataset haben wir 80-Byte-Datensätze, die RBA des ersten Datensatzes ist 0, die RBA für den zweiten Datensatz ist 80, für den dritten Datensatz sind es 160 und so weiter.
Auf Datensätze kann nacheinander von RBA zugegriffen werden, was als bekannt ist addressed access.
Die Aufzeichnungen werden in der Reihenfolge aufbewahrt, in der sie eingefügt wurden. Neue Datensätze werden am Ende eingefügt.
Das Löschen von Datensätzen ist im ESDS-Datensatz nicht möglich. Sie können jedoch als inaktiv markiert werden.
Datensätze im ESDS-Datensatz können eine feste Länge oder eine variable Länge haben.
ESDS ist nicht indiziert. Schlüssel sind im ESDS-Dataset nicht vorhanden, daher kann es doppelte Datensätze enthalten.
ESDS kann in COBOL-Programmen wie jede andere Datei verwendet werden. Wir geben den Dateinamen in JCL an und können die ESDS-Datei für die Verarbeitung innerhalb des Programms verwenden. Geben Sie im COBOL-Programm die Dateiorganisation als anSequential und Zugriffsmodus als Sequential mit ESDS-Datensatz.
ESDS-Cluster definieren
Die folgende Syntax zeigt, welche Parameter beim Erstellen des ESDS-Clusters verwendet werden können. Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
DEFINE CLUSTER (NAME(esds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
NONINDEXED -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(esds-file-name.data))Beispiel
Das folgende Beispiel zeigt, wie Sie mit dem IDCAMS-Dienstprogramm einen ESDS-Cluster in JCL erstellen.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.ESDSFILE) -
NONINDEXED -
RECSZ(80 80) -
TRACKS(1,1) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.ESDSFILE.DATA))
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und erstellt die VSAM-Datei MY.VSAM.ESDSFILE.
ESDS-Cluster löschen
Der ESDS-Cluster wird mit dem Dienstprogramm IDCAMS gelöscht. Der Befehl DELETE entfernt den Eintrag des VSAM-Clusters aus dem Katalog und entfernt optional die Datei, wodurch der vom Objekt belegte Speicherplatz frei wird.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]Die obige Syntax zeigt, welche Parameter beim Löschen des ESDS-Clusters verwendet werden können. Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
Beispiel
Das folgende Beispiel zeigt, wie ein ESDS-Cluster in JCL mit dem Dienstprogramm IDCAMS gelöscht wird.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.ESDSFILE CLUSTER
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und löscht MY.VSAM.ESDSFILE VSAM Cluster.
KSDS wird als Key Sequenced Data Set bezeichnet. Ein schlüsselsequenzierter Datensatz (KSDS) ist komplexer als ESDS und RRDS, aber nützlicher und vielseitiger. Wir müssen codierenINDEXEDim Befehl DEFINE CLUSTER für KSDS-Datasets. Der KSDS-Cluster besteht aus zwei Komponenten:
Index- Die Indexkomponente des KSDS-Clusters enthält die Liste der Schlüsselwerte für die Datensätze im Cluster mit Zeigern auf die entsprechenden Datensätze in der Datenkomponente. Die Indexkomponente bezieht sich auf die physikalische Adresse eines KSDS-Datensatzes. Dies bezieht den Schlüssel jedes Datensatzes auf die relative Position des Datensatzes im Datensatz. Wenn ein Datensatz hinzugefügt oder gelöscht wird, wird dieser Index entsprechend aktualisiert.
Data- Die Datenkomponente des KSDS-Clusters enthält die eigentlichen Daten. Jeder Datensatz in der Datenkomponente eines KSDS-Clusters enthält ein Schlüsselfeld mit derselben Anzahl von Zeichen und tritt in jedem Datensatz an derselben relativen Position auf.
Im Folgenden sind die Hauptmerkmale von KSDS aufgeführt:
Datensätze innerhalb des KSDS-Datensatzes werden immer nach Schlüsselfeldern sortiert. Die Datensätze werden in aufsteigender Reihenfolge nach Schlüssel sortiert gespeichert.
Auf Datensätze kann nacheinander zugegriffen werden, und ein direkter Zugriff ist ebenfalls möglich.
Datensätze werden mit einem Schlüssel identifiziert. Der Schlüssel jedes Datensatzes ist ein Feld an einer vordefinierten Position innerhalb des Datensatzes. Jeder Schlüssel muss im KSDS-Datensatz eindeutig sein. Eine Vervielfältigung von Datensätzen ist daher nicht möglich.
Wenn neue Datensätze eingefügt werden, hängt die logische Reihenfolge der Datensätze von der Sortierreihenfolge des Schlüsselfelds ab.
Datensätze im KSDS-Datensatz können eine feste Länge oder eine variable Länge haben.
KSDS kann in verwendet werden COBOLProgramme wie jede andere Datei. Wir geben den Dateinamen in JCL an und können die KSDS-Datei für die Verarbeitung innerhalb des Programms verwenden. Geben Sie im COBOL-Programm die Dateiorganisation als anIndexed und Sie können jeden Zugriffsmodus verwenden (Sequential, Random or Dynamic) mit KSDS-Datensatz.
KSDS-Dateistruktur
Um nach einem bestimmten Datensatz zu suchen, geben wir einen eindeutigen Schlüsselwert an. Der Schlüsselwert wird in der Indexkomponente gesucht. Sobald der Schlüssel gefunden wurde, wird die entsprechende Speicheradresse abgerufen, die sich auf die Datenkomponente bezieht. Aus der Speicheradresse können wir die tatsächlichen Daten abrufen, die in der Datenkomponente gespeichert sind. Das folgende Beispiel zeigt die Grundstruktur von Index und Datendatei -
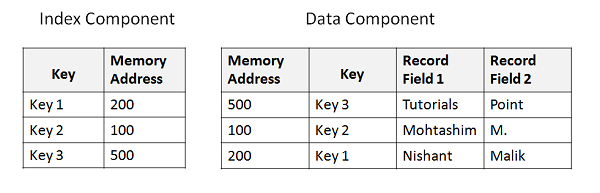
KSDS-Cluster definieren
Die folgende Syntax zeigt, welche Parameter beim Erstellen des KSDS-Clusters verwendet werden können.
Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
DEFINE CLUSTER (NAME(ksds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
INDEXED -
KEYS(length offset) -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(ksds-file-name.data)) -
INDEX -
(NAME(ksds-file-name.index))Beispiel
Das folgende Beispiel zeigt, wie Sie mit dem IDCAMS-Dienstprogramm einen KSDS-Cluster in JCL erstellen.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) -
INDEXED -
KEYS(6 1) -
RECSZ(80 80) -
TRACKS(1,1) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.KSDSFILE.DATA)) -
INDEX (NAME(MY.VSAM.KSDSFILE.INDEX)) -
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und erstellt die VSAM-Datei MY.VSAM.KSDSFILE.
KSDS-Cluster löschen
Der KSDS-Cluster wird mit dem Dienstprogramm IDCAMS gelöscht. Der Befehl DELETE entfernt den Eintrag des VSAM-Clusters aus dem Katalog und entfernt optional die Datei, wodurch der vom Objekt belegte Speicherplatz frei wird.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]Die obige Syntax zeigt, welche Parameter beim Löschen des KSDS-Clusters verwendet werden können. Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
Beispiel
Das folgende Beispiel zeigt, wie ein KSDS-Cluster in JCL mit dem Dienstprogramm IDCAMS gelöscht wird.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.KSDSFILE CLUSTER
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und löscht MY.VSAM.KSDSFILE VSAM Cluster.
RRDS wird als relativer Datensatz bezeichnet. Der RRDS-Cluster ähnelt einem ESDS-Cluster. Der einzige Unterschied besteht darin, dass auf RRDS-Datensätze zugegriffen wirdRelative Record Number (RRN)müssen wir codieren NUMBEREDinnerhalb des Befehls DEFINE CLUSTER. Im Folgenden sind die wichtigsten Funktionen von RRDS aufgeführt:
Ein relativer Datensatzdatensatz enthält Datensätze, die durch die gekennzeichnet sind Relative Record Number (RRN)Dies ist die Sequenznummer relativ zum ersten Datensatz.
RRDS ermöglicht den Zugriff auf Datensätze nach Nummern wie Datensatz 1, Datensatz 2 usw. Dies ermöglicht einen wahlfreien Zugriff und setzt voraus, dass das Anwendungsprogramm die gewünschten Datensatznummern abrufen kann.
Auf die Datensätze in einem RRDS-Datensatz kann nacheinander, in der Reihenfolge der relativen Datensatznummern oder direkt zugegriffen werden, indem die relative Datensatznummer des gewünschten Datensatzes angegeben wird.
Die Datensätze in einem RRDS-Datensatz werden in Steckplätzen mit fester Länge gespeichert. Jeder Datensatz wird durch die Nummer seines Steckplatzes referenziert. Die Anzahl kann von 1 bis zur maximalen Anzahl von Datensätzen im Datensatz variieren.
Datensätze in einem RRDS können geschrieben werden, indem ein neuer Datensatz in einen leeren Steckplatz eingefügt wird.
Datensätze können aus einem RRDS-Cluster gelöscht werden, wodurch ein leerer Steckplatz verbleibt.
Anwendungen, die Datensätze fester Länge oder eine Datensatznummer mit kontextbezogener Bedeutung verwenden, die RRDS-Datasets verwenden können.
RRDS kann in verwendet werden COBOLProgramme wie jede andere Datei. Wir geben den Dateinamen in JCL an und können die KSDS-Datei für die Verarbeitung innerhalb des Programms verwenden. Geben Sie im COBOL-Programm die Dateiorganisation als anRELATIVE und Sie können jeden Zugriffsmodus verwenden (Sequential, Random or Dynamic) mit RRDS-Datensatz.
RRDS-Dateistruktur
Der Speicherplatz ist in der RRDS-Dateistruktur in Slots mit fester Länge unterteilt. Ein Steckplatz kann entweder vollständig frei oder vollständig belegt sein. Auf diese Weise können neue Datensätze zu leeren Slots hinzugefügt und vorhandene Datensätze aus gefüllten Slots gelöscht werden. Wir können direkt auf jeden Datensatz zugreifen, indem wir die relative Datensatznummer angeben. Das folgende Beispiel zeigt die Grundstruktur der Datendatei -
Datenkomponente
| Relative Datensatznummer | Datensatzfeld 1 | Datensatzfeld 2 |
|---|---|---|
| 1 | Lernprogramm | Punkt |
| 2 | Mohtashim | M. |
| 3 | Nishant | Malik |
RRDS-Cluster definieren
Die folgende Syntax zeigt, welche Parameter beim Erstellen eines RRDS-Clusters verwendet werden können.
Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
DEFINE CLUSTER (NAME(rrds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
NUMBERED -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(rrds-file-name.data))Beispiel
Das folgende Beispiel zeigt, wie Sie mit dem Dienstprogramm IDCAMS einen RRDS-Cluster in JCL erstellen.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.RRDSFILE) -
NUMBERED -
RECSZ(80 80) -
TRACKS(1,1) -
REUSE -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.RRDSFILE.DATA))
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und erstellt die VSAM-Datei MY.VSAM.RRDSFILE.
RRDS-Cluster löschen
Der RRDS-Cluster wird mit dem Dienstprogramm IDCAMS gelöscht. Der Befehl DELETE entfernt den Eintrag des VSAM-Clusters aus dem Katalog und entfernt optional die Datei, wodurch der vom Objekt belegte Speicherplatz frei wird.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]Die obige Syntax zeigt, welche Parameter beim Löschen des RRDS-Clusters verwendet werden können. Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
Beispiel
Das folgende Beispiel zeigt, wie ein RRDS-Cluster in JCL mit dem Dienstprogramm IDCAMS gelöscht wird.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.RRDSFILE CLUSTER
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und löscht MY.VSAM.RRDSFILE VSAM Cluster.
LDS wird als linearer Datensatz bezeichnet. Das lineare Dataset ist die einzige Form des Byte-Stream-Datasets, die in herkömmlichen Betriebssystemdateien verwendet wird. Lineare Datensätze werden selten verwendet. Im Folgenden sind die Hauptmerkmale von LDS aufgeführt:
Lineare Datensätze enthalten keine RDFs und CIDFs, da keine Steuerinformationen in das CI eingebettet sind.
Daten, auf die als byteadressierbare Zeichenfolgen im virtuellen Speicher in linearen Datasets zugegriffen werden kann.
Lineare Datensätze haben eine Kontrollintervallgröße von 4 KByte.
LDS ist eine Art Nicht-Vsam-Datei mit einigen VSAM-Funktionen wie der Verwendung von IDCAMS und VSAM-spezifischen Informationen im Katalog.
DB2 ist derzeit der größte Benutzer von linearen Datensätzen.
IDCAMS wird zum Definieren eines LDS verwendet, der Zugriff erfolgt jedoch über ein Data-In-Virtual-Makro (DIV).
Der lineare Datensatz enthält keine Konzepte für Datensätze. Alle LDS-Bytes sind Datenbytes.
LDS-Cluster definieren
Die folgende Syntax zeigt, welche Parameter beim Erstellen des LDS-Clusters verwendet werden können. Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
DEFINE CLUSTER (NAME(lds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
LINEAR -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(lds-file-name.data))Beispiel
Das folgende Beispiel zeigt, wie mit dem IDCAMS-Dienstprogramm ein LDS-Cluster in JCL erstellt wird.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.LDSFILE) -
LINEAR -
TRACKS(1,1) -
CISZ(4096) ) -
DATA (NAME(MY.VSAM.LDSFILE.DATA))
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und erstellt die VSAM-Datei MY.VSAM.LDSFILE.
LDS-Cluster löschen
Der LDS-Cluster wird mit dem Dienstprogramm IDCAMS gelöscht. Der Befehl DELETE entfernt den Eintrag des VSAM-Clusters aus dem Katalog und entfernt optional die Datei, wodurch der vom Objekt belegte Speicherplatz frei wird.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]Die obige Syntax zeigt, welche Parameter beim Löschen des LDS-Clusters verwendet werden können. Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
Beispiel
Das folgende Beispiel zeigt, wie ein LDS-Cluster in JCL mit dem Dienstprogramm IDCAMS gelöscht wird.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.LDSFILE CLUSTER
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und löscht MY.VSAM.LDSFILE VSAM Cluster.
VSAM-Befehle werden verwendet, um bestimmte Vorgänge für VSAM-Datasets auszuführen. Im Folgenden sind die nützlichsten VSAM-Befehle aufgeführt:
- Alter
- Repro
- Listcat
- Examine
- Verify
Ändern
Der Befehl ALTER wird verwendet, um VSAM-Dateiattribute zu ändern. Wir können die Attribute der VSAM-Datei ändern, die wir in der VSAM-Cluster-Definition erwähnt haben. Es folgt die Syntax zum Ändern der Attribute:
ALTER file-cluster-name [password]
[ADDVOLUMES(volume-serial)]
[BUFFERSPACE(size)]
[EMPTY / NOEMPTY]
[ERASE / NOERASE]
[FREESPACE(CI-percentage CA-percentage)]
[KEYS(length offset)]
[NEWNAME(new-name)]
[RECORDSIZE(average maximum)]
[REMOVEVOLUMES(volume-serial)]
[SCRATCH / NOSCRATCH]
[TO(date) / FOR(days)]
[UPGRADE / NOUPGRADE]
[CATALOG(catalog-name [password]]Die obige Syntax zeigt, welche Parameter in einem vorhandenen VSAM-Cluster geändert werden können. Die Parameterbeschreibung bleibt die gleiche wie im VSAM - Cluster Modul.
Beispiel
Das folgende Beispiel zeigt, wie Sie mit dem Befehl ALTER den freien Speicherplatz erhöhen, weitere Volumes hinzufügen und Schlüssel ändern können.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
ALTER MY.VSAM.KSDSFILE
[ADDVOLUMES(2)]
[FREESPACE(6 6)]
[KEYS(10 2)]
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und ändert den Freiraum, die Volumes und die Schlüssel.
Repro
Mit dem Befehl REPRO werden Daten in das VSAM-Dataset geladen. Es wird auch verwendet, um Daten von einem VSAM-Datensatz in einen anderen zu kopieren. Mit diesem Befehl können wir Daten aus einer sequentiellen Datei in eine VSAM-Datei kopieren. Das Dienstprogramm IDCAMS verwendet den Befehl REPRO, um die Datasets zu laden.
REPRO INFILE(in-ddname)
OUTFILE(out-ddname)In der obigen Syntax ist der In-DD-Name der DD-Name für den Eingabedatensatz, der Datensätze enthält. Der out-ddname ist der DD-Name für den Ausgabedatensatz, in den die Eingabedatensatzdatensätze kopiert werden.
Beispiel
Das folgende Beispiel zeigt, wie Datensätze von einem Datensatz in einen anderen VSAM-Datensatz kopiert werden.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//IN DD DSN = MY.VSAM.KSDSFILE,DISP = SHR
//OUT DD DSN = MY.VSAM1.KSDSFILE,DISP = SHR
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
REPRO INFILE(IN)
OUTFILE(OUT)
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und kopiert alle Datensätze von MY.VSAM.KSDSFILE in die VSAM-Datei MY.VSAM1.KSDSFILE.
Listcat
Mit dem Befehl LISTCAT werden die Katalogdetails eines VSAM-Datasets abgerufen. Der Befehl Listcat enthält die folgenden Informationen zu VSAM-Datasets:
- SMS-Informationen
- RLS-Informationen
- Volumeninformationen
- Kugelinformationen
- Zuordnungsinformationen
- Datensatzattribute
LISTCAT ENTRY(vsam-file-name) ALLIn der obigen Syntax ist vsam-file-name der Name des VSAM-Datasets, für den wir alle Informationen benötigen. Das Schlüsselwort ALL wird angegeben, um alle Katalogdetails abzurufen.
Beispiel
Das folgende Beispiel zeigt, wie alle Details mit dem Befehl Listcat für ein VSAM-Dataset abgerufen werden.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
LISTCAT ENTRY(MY.VSAM.KSDSFILE)
ALL
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und zeigt alle Katalogdetails zum MY.VSAM.KSDSFILE-Dataset an.
Untersuchen
Mit dem Befehl "Untersuchen" wird die strukturelle Integrität eines Datensatzclusters mit Schlüsselsequenz überprüft. Es sucht nach Index- und Datenkomponenten und wenn ein Problem gefunden wird, werden die Fehlermeldungen spool gesendet. Sie können jede der IDCxxxxx-Nachrichten überprüfen.
EXAMINE NAME(vsam-ksds-name) -
INDEXTEST DATATEST -
ERRORLIMIT(50)In der obigen Syntax ist vsam-ksds-name der Name des VSAM-Datasets, für den wir den Index und den Datenteil des VSAM-Clusters untersuchen müssen.
Beispiel
Das folgende Beispiel zeigt, wie Sie überprüfen, ob der Index- und der Datenteil des KSDS-Datasets synchronisiert sind oder nicht.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
EXAMINE NAME(MY.VSAM.KSDSFILE) -
INDEXTEST DATATEST -
ERRORLIMIT(50)
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und zeigt alle Probleme mit dem VSAM-Datensatz in einer der IDCxxxxx-Nachrichten in der Spool an.
Überprüfen
Mit dem Befehl "Überprüfen" werden VSAM-Dateien überprüft und behoben, die nach einem Fehler nicht ordnungsgemäß geschlossen wurden. Der Befehl fügt der Datei korrekte Datenenddatensätze hinzu.
VERIFY DS(vsam-file-name)In der obigen Syntax ist vsam-file-name der Name des VSAM-Datasets, für den wir die Fehler überprüfen müssen.
Beispiel
Das folgende Beispiel zeigt, wie Fehler im VSAM-Dataset überprüft und behoben werden.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
VERIFY DS(MY.VSAM.KSDSFILE)
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und behebt die Fehler im VSAM-Dataset.
Alternativer Index ist der zusätzliche Index, der zusätzlich zu seinem Primärindex für KSDS / ESDS-Datasets erstellt wird. Ein alternativer Index ermöglicht den Zugriff auf Datensätze mithilfe mehrerer Schlüssel. Der Schlüssel des alternativen Index kann ein nicht eindeutiger Schlüssel sein und Duplikate enthalten.
Erstellung eines alternativen Index
Die folgenden Schritte werden verwendet, um einen alternativen Index zu erstellen:
- Alternativen Index definieren
- Pfad definieren
- Gebäudeindex
Alternativen Index definieren
Alternativer Index wird mit definiert DEFINE AIX Befehl.
DEFINE AIX -
(NAME(alternate-index-name) -
RELATE(vsam-file-name) -
CISZ(number) -
FREESPACE(CI-Percentage,CA-Percentage) -
KEYS(length offset) -
NONUNIQUEKEY / UNIQUEKEY -
UPGRADE / NOUPGRADE -
RECORDSIZE(average maximum)) -
DATA -
(NAME(vsam-file-name.data)) -
INDEX -
(NAME(vsam-file-name.index))Die obige Syntax zeigt die Parameter, die beim Definieren des alternativen Index verwendet werden. Wir haben bereits einige Parameter im Cluster-Modul definieren besprochen, und einige der neuen Parameter werden zur Definition des alternativen Index verwendet, den wir hier diskutieren werden.
| Sr.Nr. | Parameter mit Beschreibung |
|---|---|
| 1 | DEFINE AIX Der Befehl AIX definieren wird verwendet, um den alternativen Index zu definieren und Parameterattribute für seine Komponenten anzugeben. |
| 2 | NAME NAME gibt den Namen des alternativen Index an. |
| 3 | RELATE RELATE gibt den Namen des VSAM-Clusters an, für den der alternative Index erstellt wird. |
| 4 | NONUNIQUEKEY / UNIQUEKEY UNIQUEKEY gibt an, dass der alternative Index eindeutig ist, und NONUNIQUEKEY gibt an, dass möglicherweise Duplikate vorhanden sind. |
| 5 | UPGRADE / NOUPGRADE UPGRADE gibt an, dass der alternative Index geändert werden soll, wenn der Basiscluster geändert wird, und NOUPGRADE gibt an, dass die alternativen Indizes in Ruhe gelassen werden sollen, wenn der Basiscluster geändert wird. |
Beispiel
Das folgende grundlegende Beispiel zeigt, wie ein alternativer Index in JCL definiert wird:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE AIX (NAME(MY.VSAM.KSDSAIX) -
RELATE(MY.VSAM.KSDSFILE) -
CISZ(4096) -
FREESPACE(20,20) -
KEYS(20,7) -
NONUNIQUEKEY -
UPGRADE -
RECORDSIZE(80,80)) -
DATA(NAME(MY.VSAM.KSDSAIX.DATA)) -
INDEX(NAME(MY.VSAM.KSDSAIX.INDEX))
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und es wird ein alternativer Index für MY.VSAM.KSDSAIX erstellt.
Pfad definieren
Pfad definieren wird verwendet, um den alternativen Index mit dem Basiscluster zu verknüpfen. Bei der Definition des Pfads geben wir den Namen des Pfads und den alternativen Index an, auf den sich dieser Pfad bezieht.
DEFINE PATH -
NAME(alternate-index-path-name) -
PATHENTRY(alternate-index-name))Die obige Syntax hat zwei Parameter. NAME wird verwendet, um den alternativen Indexpfadnamen anzugeben, und PATHENTRY wird verwendet, um den alternativen Indexnamen anzugeben.
Beispiel
Im Folgenden finden Sie ein grundlegendes Beispiel zum Definieren des Pfads in der JCL:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE PATH -
NAME(MY.VSAM.KSDSAIX.PATH) -
PATHENTRY(MY.VSAM.KSDSAIX))
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und erstellt einen Pfad zwischen dem alternativen Index und dem Basiscluster.
Gebäudeindex
Der Befehl BLDINDEX wird zum Erstellen des alternativen Index verwendet. BLDINDEX liest alle Datensätze im VSAM-indizierten Datensatz (oder Basiscluster) und extrahiert die Daten, die zum Erstellen des alternativen Index erforderlich sind.
BLDINDEX -
INDATASET(vsam-cluster-name) -
OUTDATASET(alternate-index-name))Die obige Syntax hat zwei Parameter. INDATASET wird verwendet, um den VSAM-Clusternamen anzugeben, und OUTDATASET wird verwendet, um den alternativen Indexnamen anzugeben.
Beispiel
Im Folgenden finden Sie ein grundlegendes Beispiel für die Erstellung eines Index in JCL:
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
BLDINDEX -
INDATASET(MY.VSAM.KSDSFILE) -
OUTDATASET(MY.VSAM.KSDSAIX))
/*Wenn Sie die obige JCL auf dem Mainframes-Server ausführen. Es sollte mit MAXCC = 0 ausgeführt werden und erstellt den Index.
Der Katalog verwaltet die Einheit und das Volumen, in dem sich der Datensatz befindet. Der Katalog wird zum Abrufen von Datensätzen verwendet. Nicht-VSAM-Datasets erstellen einen Katalogeintrag mithilfe des Dispositionsparameters in JCL. VSAM-Datasets verwalten einen eigenen Katalog in Form eines KSDS-Clusters. Im folgenden Bild sehen Sie den Typ der VSAM-Kataloge -
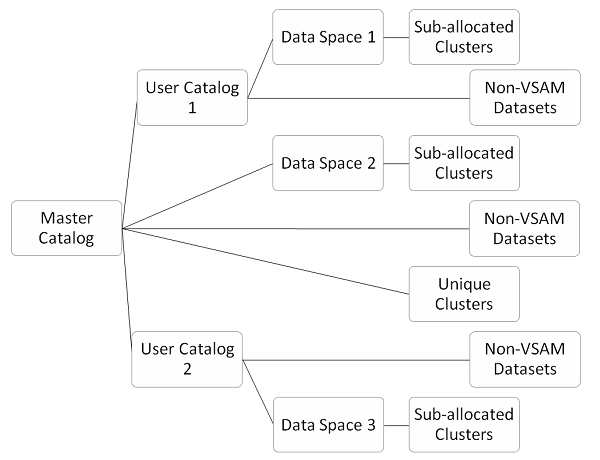
Hauptkatalog
Der Hauptkatalog ist selbst eine Datei, die den Betrieb von VSAM überwacht und verwaltet. Es gibt nur einen Hauptkatalog in einem System, der Einträge zu Systemdatensätzen und VSAM-Datensätzen enthält. VSAM- und Nicht-VSAM-Datasets haben möglicherweise einen Eintrag im Hauptkatalog, dies ist jedoch keine gute Vorgehensweise. Der Hauptkatalog wird während des Systemgenerierungsprozesses erstellt und befindet sich auf dem Systemvolume. Der Hauptkatalog besitzt alle VSAM-Ressourcen im Betriebssystem. Alle in VSAM verwendeten Dateien werden vom Hauptkatalog gesteuert. Der Hauptkatalog ist für folgende Vorgänge verantwortlich:
- Passwortautorisierung für Dateien
- Verbesserung der Sicherheit
- VSAM-Zugriff für Dateien
- Speicherplatzverwaltung der Datei
- Speicherort der Datei
- Freier Speicherplatz in Datei verfügbar
Wenn sich eines der oben genannten Dateiattribute ändert, werden sie automatisch im Hauptkatalog aktualisiert. Der Hauptkatalog wird mit IDCAMS-Programmen definiert.
Benutzerkatalog
Der Benutzerkatalog hat dieselbe Struktur und dieselben Konzepte wie der Hauptkatalog. Es ist auf der nächsten Hierarchieebene nach dem Hauptkatalog vorhanden. Der Benutzerkatalog ist im System nicht obligatorisch, wird jedoch zur Verbesserung der Sicherheit des VSAM-Systems verwendet. Der Hauptkatalog verweist auf VSAM-Dateien. Wenn jedoch ein Benutzerkatalog vorhanden ist, verweist der Hauptkatalog auf den Benutzerkatalog. Die Anzahl der Benutzerkataloge kann je nach Systemanforderung vielfältig sein. Wenn in der VSAM-Struktur der Hauptkatalog entfernt wird, hat dies keine Auswirkungen auf den Benutzerkatalog. Der Benutzerkatalog enthält Einträge zu anwendungsspezifischen Datensätzen. Die Informationen des Benutzerkatalogs werden im Hauptkatalog gespeichert.
Datenraum
Der Datenraum ist ein Bereich des Direktzugriffsspeichergeräts, der ausschließlich für die VSAM-Verwendung reserviert ist. Vor dem Erstellen von VSAM-Clustern muss ein Datenraum erstellt werden. Der vom Datenraum belegte Bereich wird im Volume-Inhaltsverzeichnis (VTOC) aufgezeichnet, sodass der Bereich nicht für eine andere Verwendung zur Verfügung steht, weder für VSAM noch für Nicht-VSAM. VTOC hat Zugang zum Bereich, der vom Raum besetzt ist. VSAM erstellt einen Datenbereich für die Benutzerkatalogeinträge. VSAM übernimmt die Kontrolle über diesen Speicherplatz und überwacht und verwaltet diesen Speicherplatz nach Bedarf für VSAM-Dateien.
Einzigartige Cluster
Einzigartige Cluster bestehen aus einem separaten Datenbereich, der von dem darin erstellten Cluster vollständig genutzt wird. Aus nicht zugewiesenem Speicherplatz im Direktzugriffsspeicher werden eindeutige Cluster erstellt.
Untergeordnete Cluster
Eine untergeordnete VSAM-Datei teilt den VSAM-Speicherplatz mit anderen untergeordneten Dateien. Es gibt an, dass die Datei innerhalb des vorhandenen VSAM-Speicherplatzes untergeordnet werden soll. Die Unterzuordnung wird zur einfacheren Verwaltung und Steuerung von VSAM-Räumen verwendet.
Nicht-VSAM-Datensätze
Nicht-VSAM-Datasets befinden sich sowohl auf Band- als auch auf Direktzugriffsspeicher. Nicht-VSAM-Datasets können Einträge sowohl im Hauptkatalog als auch im Benutzerkatalog enthalten. Die Hauptfunktion beim Katalogisieren von Nicht-VSAM-Datensätzen besteht darin, serielle Informationen zu Einheiten und Volumes beizubehalten.
Während der Arbeit mit VSAM-Datasets können Abbrüche auftreten. Im Folgenden finden Sie die allgemeinen Dateistatuscodes mit ihrer Beschreibung, mit deren Hilfe Sie die Probleme beheben können.
| Code | Beschreibung |
|---|---|
| 00 | Operation erfolgreich abgeschlossen |
| 02 | Nicht eindeutiger doppelter Schlüssel für alternativen Index gefunden |
| 04 | Ungültiger Datensatz mit fester Länge |
| 05 | Während der Ausführung von OPEN sind Datei und Datei nicht vorhanden |
| 10 | Dateiende gefunden |
| 14 | Es wurde versucht, einen relativen Datensatz außerhalb der Dateigrenze zu lesen |
| 20 | Ungültiger Schlüssel für VSAM KSDS oder RRDS |
| 21 | Sequenzfehler beim Ausführen von WRITE oder Ändern des Schlüssels bei REWRITE |
| 22 | Primärer doppelter Schlüssel gefunden |
| 23 | Datensatz nicht gefunden oder Datei nicht gefunden |
| 24 | Schlüssel außerhalb der Dateibegrenzung |
| 30 | Permanenter E / A-Fehler |
| 34 | Aufzeichnung außerhalb der Dateigrenze |
| 35 | Während der Ausführung von OPEN sind Datei und Datei nicht vorhanden |
| 37 | OPEN-Datei mit falschem Modus |
| 38 | Es wurde versucht, eine gesperrte Datei zu öffnen |
| 39 | OPEN ist aufgrund widersprüchlicher Dateiattribute fehlgeschlagen |
| 41 | Es wurde versucht, eine bereits geöffnete Datei zu öffnen |
| 42 | Es wurde versucht, eine Datei zu schließen, die nicht geöffnet ist |
| 43 | Versucht, neu zu schreiben, ohne vorher einen Datensatz zu lesen |
| 44 | Es wurde versucht, einen Datensatz mit einer anderen Länge neu zu schreiben |
| 46 | Es wurde versucht, über das Dateiende hinaus zu lesen |
| 47 | Es wurde versucht, aus einer Datei zu lesen, die nicht geöffnet wurde. IO oder INPUT |
| 48 | Es wurde versucht, in eine Datei zu schreiben, die nicht geöffnet wurde. IO oder OUTPUT |
| 49 | Es wurde versucht, eine Datei zu löschen oder neu zu schreiben, die nicht geöffnet wurde |
| 91 | Passwort oder Autorisierung fehlgeschlagen |
| 92 | Logikfehler |
| 93 | Ressourcen sind nicht verfügbar |
| 94 | Sequentieller Datensatz nicht verfügbar oder gleichzeitiger OPEN-Fehler |
| 95 | Dateiinformationen ungültig oder unvollständig |
| 96 | Keine DD-Anweisung für die Datei |
| 97 | OPEN erfolgreich und Dateiintegrität überprüft |
| 98 | Datei ist gesperrt - ÖFFNEN fehlgeschlagen |
| 99 | Datensatz gesperrt - Datensatzzugriff fehlgeschlagen |