Zookeeper - Kurzanleitung
ZooKeeper ist ein verteilter Koordinierungsdienst zur Verwaltung einer großen Anzahl von Hosts. Das Koordinieren und Verwalten eines Dienstes in einer verteilten Umgebung ist ein komplizierter Prozess. ZooKeeper löst dieses Problem mit seiner einfachen Architektur und API. Mit ZooKeeper können sich Entwickler auf die Kernanwendungslogik konzentrieren, ohne sich über die Verteilung der Anwendung Gedanken machen zu müssen.
Das ZooKeeper-Framework wurde ursprünglich bei "Yahoo!" für den einfachen und robusten Zugriff auf ihre Anwendungen. Später wurde Apache ZooKeeper zum Standard für organisierte Dienste, die von Hadoop, HBase und anderen verteilten Frameworks verwendet werden. Beispielsweise verwendet Apache HBase ZooKeeper, um den Status verteilter Daten zu verfolgen.
Bevor wir fortfahren, ist es wichtig, dass wir ein oder zwei Dinge über verteilte Anwendungen wissen. Beginnen wir die Diskussion mit einem kurzen Überblick über verteilte Anwendungen.
Verteilte Anwendung
Eine verteilte Anwendung kann gleichzeitig (gleichzeitig) auf mehreren Systemen in einem Netzwerk ausgeführt werden, indem sie sich untereinander koordiniert, um eine bestimmte Aufgabe schnell und effizient zu erledigen. Normalerweise können komplexe und zeitaufwändige Aufgaben, deren Ausführung durch eine nicht verteilte Anwendung (die in einem einzelnen System ausgeführt wird) Stunden in Anspruch nimmt, von einer verteilten Anwendung in Minuten erledigt werden, indem die Rechenfunktionen des gesamten beteiligten Systems genutzt werden.
Die Zeit zum Ausführen der Aufgabe kann weiter reduziert werden, indem die verteilte Anwendung so konfiguriert wird, dass sie auf mehreren Systemen ausgeführt wird. Eine Gruppe von Systemen, auf denen eine verteilte Anwendung ausgeführt wird, wird als a bezeichnetCluster und jeder Computer, der in einem Cluster ausgeführt wird, heißt a Node.
Eine verteilte Anwendung besteht aus zwei Teilen: Server und ClientAnwendung. Serveranwendungen sind tatsächlich verteilt und verfügen über eine gemeinsame Schnittstelle, sodass Clients eine Verbindung zu jedem Server im Cluster herstellen und das gleiche Ergebnis erzielen können. Clientanwendungen sind die Werkzeuge für die Interaktion mit einer verteilten Anwendung.

Vorteile verteilter Anwendungen
Reliability - Der Ausfall eines einzelnen oder einiger weniger Systeme führt nicht zum Ausfall des gesamten Systems.
Scalability - Die Leistung kann bei Bedarf gesteigert werden, indem weitere Computer mit geringfügigen Änderungen in der Konfiguration der Anwendung ohne Ausfallzeiten hinzugefügt werden.
Transparency - Versteckt die Komplexität des Systems und zeigt sich als eine Einheit / Anwendung.
Herausforderungen verteilter Anwendungen
Race condition- Zwei oder mehr Maschinen, die versuchen, eine bestimmte Aufgabe auszuführen, die zu einem bestimmten Zeitpunkt tatsächlich nur von einer einzelnen Maschine ausgeführt werden muss. Beispielsweise sollten gemeinsam genutzte Ressourcen zu einem bestimmten Zeitpunkt nur von einem einzelnen Computer geändert werden.
Deadlock - Zwei oder mehr Operationen, die darauf warten, dass sie auf unbestimmte Zeit abgeschlossen werden.
Inconsistency - Teilweiser Datenfehler.
Wofür ist Apache ZooKeeper gedacht?
Apache ZooKeeper ist ein Dienst, der von einem Cluster (einer Gruppe von Knoten) verwendet wird, um sich untereinander zu koordinieren und gemeinsam genutzte Daten mit robusten Synchronisationstechniken zu verwalten. ZooKeeper ist selbst eine verteilte Anwendung, die Dienste zum Schreiben einer verteilten Anwendung bereitstellt.
Die allgemeinen Dienste von ZooKeeper sind wie folgt:
Naming service- Identifizieren der Knoten in einem Cluster anhand des Namens. Es ist ähnlich wie DNS, jedoch für Knoten.
Configuration management - Neueste und aktuelle Konfigurationsinformationen des Systems für einen Verbindungsknoten.
Cluster management - Beitreten / Verlassen eines Knotens in einem Cluster und Knotenstatus in Echtzeit.
Leader election - Wahl eines Knotens als Leiter zu Koordinierungszwecken.
Locking and synchronization service- Sperren der Daten beim Ändern. Dieser Mechanismus hilft Ihnen bei der automatischen Fehlerbehebung, während Sie andere verteilte Anwendungen wie Apache HBase verbinden.
Highly reliable data registry - Verfügbarkeit von Daten, auch wenn ein oder mehrere Knoten ausgefallen sind.
Verteilte Anwendungen bieten viele Vorteile, werfen jedoch auch einige komplexe und schwer zu knackende Herausforderungen auf. Das ZooKeeper-Framework bietet einen vollständigen Mechanismus, um alle Herausforderungen zu bewältigen. Race Condition und Deadlock werden mit behandeltfail-safe synchronization approach. Ein weiterer Hauptnachteil ist die Inkonsistenz der Daten, mit der ZooKeeper behoben wirdatomicity.
Vorteile von ZooKeeper
Hier sind die Vorteile der Verwendung von ZooKeeper:
Simple distributed coordination process
Synchronization- Gegenseitiger Ausschluss und Zusammenarbeit zwischen Serverprozessen. Dieser Prozess hilft in Apache HBase bei der Konfigurationsverwaltung.
Ordered Messages
Serialization- Codieren Sie die Daten nach bestimmten Regeln. Stellen Sie sicher, dass Ihre Anwendung konsistent ausgeführt wird. Dieser Ansatz kann in MapReduce verwendet werden, um die Warteschlange zu koordinieren und laufende Threads auszuführen.
Reliability
Atomicity - Die Datenübertragung ist entweder erfolgreich oder schlägt vollständig fehl, aber keine Transaktion ist teilweise.
Bevor wir uns eingehend mit der Arbeit von ZooKeeper befassen, werfen wir einen Blick auf die grundlegenden Konzepte von ZooKeeper. Wir werden die folgenden Themen in diesem Kapitel diskutieren -
- Architecture
- Hierarchischer Namespace
- Session
- Watches
Architektur von ZooKeeper
Schauen Sie sich das folgende Diagramm an. Es zeigt die „Client-Server-Architektur“ von ZooKeeper.
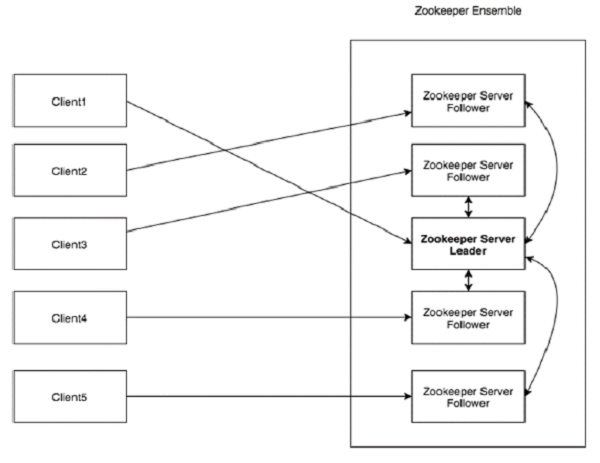
Jede der Komponenten, die Teil der ZooKeeper-Architektur sind, wurde in der folgenden Tabelle erläutert.
| Teil | Beschreibung |
|---|---|
| Klient | Clients, einer der Knoten in unserem verteilten Anwendungscluster, greifen vom Server auf Informationen zu. Für ein bestimmtes Zeitintervall sendet jeder Client eine Nachricht an den Server, um den Server darüber zu informieren, dass der Client am Leben ist. Ebenso sendet der Server eine Bestätigung, wenn ein Client eine Verbindung herstellt. Wenn der verbundene Server keine Antwort gibt, leitet der Client die Nachricht automatisch an einen anderen Server weiter. |
| Server | Server, einer der Knoten in unserem ZooKeeper-Ensemble, bietet alle Services für Clients. Gibt dem Client eine Bestätigung, dass der Server aktiv ist. |
| Ensemble | Gruppe von ZooKeeper-Servern. Die Mindestanzahl von Knoten, die zur Bildung eines Ensembles erforderlich sind, beträgt 3. |
| Führer | Serverknoten, der eine automatische Wiederherstellung durchführt, wenn einer der verbundenen Knoten ausfällt. Führungskräfte werden beim Start des Dienstes gewählt. |
| Anhänger | Serverknoten, der der Anweisung des Leiters folgt. |
Hierarchischer Namespace
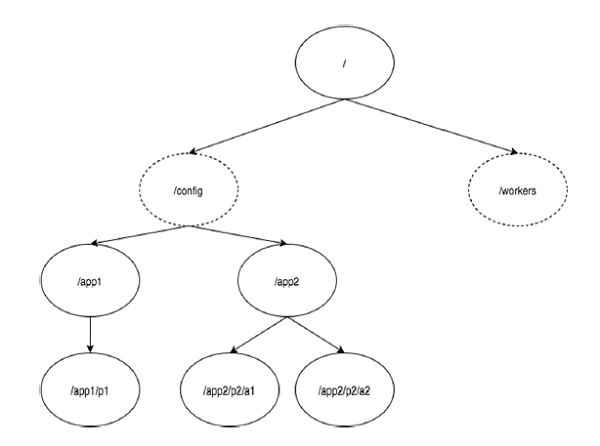
Das folgende Diagramm zeigt die Baumstruktur des ZooKeeper-Dateisystems, das für die Speicherdarstellung verwendet wird. Der ZooKeeper-Knoten wird als bezeichnetznode. Jeder Knoten wird durch einen Namen identifiziert und durch eine Folge von Pfaden (/) getrennt.
Im Diagramm haben Sie zuerst eine Wurzel znodegetrennt durch "/". Unter root haben Sie zwei logische Namespacesconfig und workers.
Das config Der Namespace wird für das zentrale Konfigurationsmanagement und das verwendet workers Der Namespace wird zur Benennung verwendet.
Unter configIm Namespace kann jeder Znode bis zu 1 MB Daten speichern. Dies ähnelt dem UNIX-Dateisystem, außer dass der übergeordnete Knoten auch Daten speichern kann. Der Hauptzweck dieser Struktur besteht darin, synchronisierte Daten zu speichern und die Metadaten des znode zu beschreiben. Diese Struktur heißtZooKeeper Data Model.
Jeder Knoten im ZooKeeper-Datenmodell verwaltet a statStruktur. Eine Statistik liefert einfach diemetadataeines znode. Es besteht aus Versionsnummer, Aktionssteuerungsliste (ACL), Zeitstempel und Datenlänge.
Version number- Jeder znode hat eine Versionsnummer, dh jedes Mal, wenn sich die mit dem znode verknüpften Daten ändern, wird auch die entsprechende Versionsnummer erhöht. Die Verwendung der Versionsnummer ist wichtig, wenn mehrere Zookeeper-Clients versuchen, Vorgänge über denselben Knoten durchzuführen.
Action Control List (ACL)- ACL ist im Grunde ein Authentifizierungsmechanismus für den Zugriff auf den znode. Es regelt alle Lese- und Schreibvorgänge von znode.
Timestamp- Der Zeitstempel repräsentiert die Zeit, die seit der Erstellung und Änderung des Knotens vergangen ist. Es wird normalerweise in Millisekunden dargestellt. ZooKeeper identifiziert jede Änderung an den Znodes anhand der „Transaktions-ID“ (zxid).Zxid ist einzigartig und behält die Zeit für jede Transaktion bei, sodass Sie die von einer Anfrage zur anderen verstrichene Zeit leicht identifizieren können.
Data length- Die Gesamtmenge der in einem Knoten gespeicherten Daten entspricht der Datenlänge. Sie können maximal 1 MB Daten speichern.
Arten von Znodes
Znodes werden in Persistenz, sequentiell und kurzlebig eingeteilt.
Persistence znode- Der Persistenz-Knoten ist auch dann aktiv, wenn der Client, der diesen bestimmten Knoten erstellt hat, die Verbindung getrennt hat. Standardmäßig sind alle Knoten dauerhaft, sofern nicht anders angegeben.
Ephemeral znode- Vergängliche Knoten sind aktiv, bis der Client lebt. Wenn ein Client vom ZooKeeper-Ensemble getrennt wird, werden die kurzlebigen Knoten automatisch gelöscht. Aus diesem Grund dürfen nur kurzlebige Knoten keine weiteren Kinder haben. Wenn ein kurzlebiger Knoten gelöscht wird, füllt der nächste geeignete Knoten seine Position. Vergängliche Knoten spielen eine wichtige Rolle bei der Wahl des Führers.
Sequential znode- Sequentielle Knoten können entweder persistent oder kurzlebig sein. Wenn ein neuer Knoten als sequentieller Knoten erstellt wird, legt ZooKeeper den Pfad des Knotens fest, indem dem ursprünglichen Namen eine 10-stellige Sequenznummer hinzugefügt wird. Zum Beispiel, wenn ein Knoten mit Pfad/myapp wird als sequentieller Znode erstellt, ZooKeeper ändert den Pfad zu /myapp0000000001und setzen Sie die nächste Sequenznummer auf 0000000002. Wenn zwei aufeinanderfolgende Knoten gleichzeitig erstellt werden, verwendet ZooKeeper niemals dieselbe Nummer für jeden Knoten. Sequentielle Knoten spielen eine wichtige Rolle beim Sperren und Synchronisieren.
Sitzungen
Sitzungen sind für den Betrieb von ZooKeeper sehr wichtig. Anforderungen in einer Sitzung werden in FIFO-Reihenfolge ausgeführt. Sobald ein Client eine Verbindung zu einem Server herstellt, wird die Sitzung eingerichtet und asession id wird dem Kunden zugewiesen.
Der Client sendet heartbeatsin einem bestimmten Zeitintervall, um die Sitzung gültig zu halten. Wenn das ZooKeeper-Ensemble nicht länger als den zu Beginn des Dienstes angegebenen Zeitraum (Sitzungszeitlimit) Herzschläge von einem Client empfängt, entscheidet es, dass der Client gestorben ist.
Sitzungszeitlimits werden normalerweise in Millisekunden dargestellt. Wenn eine Sitzung aus irgendeinem Grund endet, werden auch die kurzlebigen Knoten gelöscht, die während dieser Sitzung erstellt wurden.
Uhren
Uhren sind ein einfacher Mechanismus für den Client, um Benachrichtigungen über die Änderungen im ZooKeeper-Ensemble zu erhalten. Clients können Uhren einstellen, während sie einen bestimmten Knoten lesen. Uhren senden eine Benachrichtigung an den registrierten Client über Änderungen des Znodes (auf dem sich der Client registriert).
Znode-Änderungen sind Änderungen von Daten, die dem znode zugeordnet sind, oder Änderungen in den untergeordneten Knoten des znode. Uhren werden nur einmal ausgelöst. Wenn ein Client erneut eine Benachrichtigung wünscht, muss dies durch einen anderen Lesevorgang erfolgen. Wenn eine Verbindungssitzung abgelaufen ist, wird der Client vom Server getrennt und die zugehörigen Überwachungsfunktionen werden ebenfalls entfernt.
Sobald ein ZooKeeper-Ensemble gestartet ist, wartet es darauf, dass sich die Clients verbinden. Clients stellen eine Verbindung zu einem der Knoten im ZooKeeper-Ensemble her. Es kann ein Leader- oder ein Follower-Knoten sein. Sobald ein Client verbunden ist, weist der Knoten dem bestimmten Client eine Sitzungs-ID zu und sendet eine Bestätigung an den Client. Wenn der Client keine Bestätigung erhält, versucht er einfach, einen anderen Knoten im ZooKeeper-Ensemble zu verbinden. Sobald die Verbindung zu einem Knoten hergestellt ist, sendet der Client in regelmäßigen Abständen Herzschläge an den Knoten, um sicherzustellen, dass die Verbindung nicht unterbrochen wird.
If a client wants to read a particular znode, es sendet eine read requestan den Knoten mit dem znode-Pfad und der Knoten gibt den angeforderten znode zurück, indem er ihn aus seiner eigenen Datenbank abruft. Aus diesem Grund sind die Lesevorgänge im ZooKeeper-Ensemble schnell.
If a client wants to store data in the ZooKeeper ensemblesendet den znode-Pfad und die Daten an den Server. Der verbundene Server leitet die Anfrage an den Leiter weiter und der Leiter sendet die Schreibanforderung erneut an alle Follower. Wenn nur eine Mehrheit der Knoten erfolgreich antwortet, ist die Schreibanforderung erfolgreich und ein erfolgreicher Rückkehrcode wird an den Client gesendet. Andernfalls schlägt die Schreibanforderung fehl. Die strikte Mehrheit der Knoten wird als bezeichnetQuorum.
Knoten in einem ZooKeeper-Ensemble
Lassen Sie uns den Effekt einer unterschiedlichen Anzahl von Knoten im ZooKeeper-Ensemble analysieren.
Wenn wir haben a single nodeDann schlägt das ZooKeeper-Ensemble fehl, wenn dieser Knoten ausfällt. Es trägt zum „Single Point of Failure“ bei und wird in einer Produktionsumgebung nicht empfohlen.
Wenn wir haben two nodes und ein Knoten fällt aus, wir haben auch keine Mehrheit, da einer von zwei keine Mehrheit ist.
Wenn wir haben three nodesund ein Knoten fällt aus, wir haben die Mehrheit und so ist es die Mindestanforderung. Für ein ZooKeeper-Ensemble müssen mindestens drei Knoten in einer Live-Produktionsumgebung vorhanden sein.
Wenn wir haben four nodesund zwei Knoten fallen aus, es fällt erneut aus und es ähnelt drei Knoten. Der zusätzliche Knoten erfüllt keinen Zweck und daher ist es besser, Knoten in ungeraden Zahlen hinzuzufügen, z. B. 3, 5, 7.
Wir wissen, dass ein Schreibprozess im ZooKeeper-Ensemble teurer ist als ein Leseprozess, da alle Knoten dieselben Daten in ihre Datenbank schreiben müssen. Daher ist es für eine ausgeglichene Umgebung besser, weniger Knoten (3, 5 oder 7) zu haben als eine große Anzahl von Knoten.
Das folgende Diagramm zeigt den ZooKeeper WorkFlow. In der folgenden Tabelle werden die verschiedenen Komponenten erläutert.
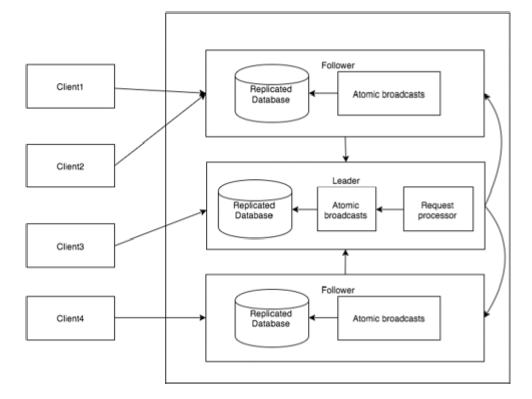
| Komponente | Beschreibung |
|---|---|
| Schreiben | Der Schreibvorgang wird vom Führungsknoten ausgeführt. Der Leiter leitet die Schreibanforderung an alle Knoten weiter und wartet auf Antworten von den Knoten. Wenn die Hälfte der Knoten antwortet, ist der Schreibvorgang abgeschlossen. |
| Lesen | Lesevorgänge werden intern von einem bestimmten verbundenen Knoten ausgeführt, sodass keine Interaktion mit dem Cluster erforderlich ist. |
| Replizierte Datenbank | Es wird verwendet, um Daten im Zookeeper zu speichern. Jeder znode hat eine eigene Datenbank und jeder znode hat zu jeder Zeit die gleichen Daten mit Hilfe der Konsistenz. |
| Führer | Leader ist der Znode, der für die Verarbeitung von Schreibanforderungen verantwortlich ist. |
| Anhänger | Follower erhalten Schreibanfragen von den Clients und leiten sie an den Leader-Knoten weiter. |
| Prozessor anfordern | Nur im Führungsknoten vorhanden. Es regelt Schreibanforderungen vom Folgeknoten. |
| Atomic Broadcasts | Verantwortlich für die Übertragung der Änderungen vom Führungsknoten an die Folgeknoten. |
Lassen Sie uns analysieren, wie ein Führungsknoten in einem ZooKeeper-Ensemble gewählt werden kann. Bedenken Sie, dass es gibtNAnzahl der Knoten in einem Cluster. Der Prozess der Führerwahl ist wie folgt:
Alle Knoten erstellen einen sequentiellen, kurzlebigen Knoten mit demselben Pfad. /app/leader_election/guid_.
Das ZooKeeper-Ensemble hängt die 10-stellige Sequenznummer an den Pfad an und der erstellte Znode wird /app/leader_election/guid_0000000001, /app/leader_election/guid_0000000002, usw.
Für eine bestimmte Instanz wird der Knoten, der die kleinste Zahl im Knoten erstellt, zum Leader, und alle anderen Knoten sind Follower.
Jeder Folgeknoten beobachtet, dass der Knoten die nächstkleinere Zahl hat. Zum Beispiel der Knoten, der znode erstellt/app/leader_election/guid_0000000008 wird den znode beobachten /app/leader_election/guid_0000000007 und der Knoten, der den Knoten erstellt /app/leader_election/guid_0000000007 wird den znode beobachten /app/leader_election/guid_0000000006.
Wenn der Anführer untergeht, dann sein entsprechender Knoten /app/leader_electionN wird gelöscht.
Der nächste Inline-Follower-Knoten erhält über den Watcher eine Benachrichtigung über das Entfernen des Leiters.
Der nächste Inline-Follower-Knoten prüft, ob es andere Knoten mit der kleinsten Anzahl gibt. Wenn keine, wird es die Rolle des Führers übernehmen. Andernfalls wird der Knoten gefunden, der den Knoten mit der kleinsten Nummer als Anführer erstellt hat.
In ähnlicher Weise wählen alle anderen Folgeknoten den Knoten, der den Knoten mit der kleinsten Zahl als Anführer erstellt hat.
Die Wahl eines Führers ist ein komplexer Prozess, wenn er von Grund auf neu durchgeführt wird. Der ZooKeeper-Service macht es jedoch sehr einfach. Fahren wir im nächsten Kapitel mit der Installation von ZooKeeper für Entwicklungszwecke fort.
Stellen Sie vor der Installation von ZooKeeper sicher, dass Ihr System auf einem der folgenden Betriebssysteme ausgeführt wird:
Any of Linux OS- Unterstützt Entwicklung und Bereitstellung. Es wird für Demo-Anwendungen bevorzugt.
Windows OS - Unterstützt nur die Entwicklung.
Mac OS - Unterstützt nur die Entwicklung.
Der ZooKeeper-Server wird in Java erstellt und auf JVM ausgeführt. Sie müssen JDK 6 oder höher verwenden.
Führen Sie nun die folgenden Schritte aus, um das ZooKeeper-Framework auf Ihrem Computer zu installieren.
Schritt 1: Überprüfen der Java-Installation
Wir glauben, dass auf Ihrem System bereits eine Java-Umgebung installiert ist. Überprüfen Sie es einfach mit dem folgenden Befehl.
$ java -versionWenn Sie Java auf Ihrem Computer installiert haben, wird möglicherweise die Version von installiertem Java angezeigt. Befolgen Sie andernfalls die folgenden einfachen Schritte, um die neueste Version von Java zu installieren.
Schritt 1.1: JDK herunterladen
Laden Sie die neueste Version von JDK herunter, indem Sie den folgenden Link besuchen und die neueste Version herunterladen. Java
Die neueste Version (während des Schreibens dieses Tutorials) ist JDK 8u 60 und die Datei lautet "jdk-8u60-linuxx64.tar.gz". Bitte laden Sie die Datei auf Ihren Computer herunter.
Schritt 1.2: Extrahieren Sie die Dateien
Im Allgemeinen werden Dateien auf die heruntergeladen downloadsMappe. Überprüfen Sie dies und extrahieren Sie das Tar-Setup mit den folgenden Befehlen.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzSchritt 1.3: Wechseln Sie in das opt-Verzeichnis
Um Java für alle Benutzer verfügbar zu machen, verschieben Sie den extrahierten Java-Inhalt in den Ordner "/ usr / local / java".
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Schritt 1.4: Pfad festlegen
Fügen Sie der Datei ~ / .bashrc die folgenden Befehle hinzu, um Pfad- und JAVA_HOME-Variablen festzulegen.
export JAVA_HOME = /usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binÜbernehmen Sie nun alle Änderungen in das aktuell ausgeführte System.
$ source ~/.bashrcSchritt 1.5: Java-Alternativen
Verwenden Sie den folgenden Befehl, um Java-Alternativen zu ändern.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Schritt 1.6
Überprüfen Sie die Java-Installation mit dem Überprüfungsbefehl (java -version) erklärt in Schritt 1.
Schritt 2: Installation von ZooKeeper Framework
Schritt 2.1: Laden Sie ZooKeeper herunter
Um das ZooKeeper-Framework auf Ihrem Computer zu installieren, besuchen Sie den folgenden Link und laden Sie die neueste Version von ZooKeeper herunter. http://zookeeper.apache.org/releases.html
Ab sofort ist die neueste Version von ZooKeeper 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Schritt 2.2: Extrahieren Sie die TAR-Datei
Extrahieren Sie die TAR-Datei mit den folgenden Befehlen:
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataSchritt 2.3: Konfigurationsdatei erstellen
Öffnen Sie die Konfigurationsdatei mit dem Namen conf/zoo.cfg mit dem Befehl vi conf/zoo.cfg und alle folgenden Parameter, die als Ausgangspunkt festgelegt werden sollen.
$ vi conf/zoo.cfg
tickTime = 2000
dataDir = /path/to/zookeeper/data
clientPort = 2181
initLimit = 5
syncLimit = 2Kehren Sie nach erfolgreicher Speicherung der Konfigurationsdatei erneut zum Terminal zurück. Sie können jetzt den Zookeeper-Server starten.
Schritt 2.4: Starten Sie den ZooKeeper-Server
Führen Sie den folgenden Befehl aus:
$ bin/zkServer.sh startNach Ausführung dieses Befehls erhalten Sie eine Antwort wie folgt:
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDSchritt 2.5: Starten Sie die CLI
Geben Sie den folgenden Befehl ein:
$ bin/zkCli.shNachdem Sie den obigen Befehl eingegeben haben, werden Sie mit dem ZooKeeper-Server verbunden und sollten die folgende Antwort erhalten.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Stoppen Sie ZooKeeper Server
Nachdem Sie den Server verbunden und alle Vorgänge ausgeführt haben, können Sie den Zookeeper-Server mit dem folgenden Befehl stoppen.
$ bin/zkServer.sh stopDie ZooKeeper-Befehlszeilenschnittstelle (CLI) wird verwendet, um zu Entwicklungszwecken mit dem ZooKeeper-Ensemble zu interagieren. Es ist nützlich zum Debuggen und Umgehen mit verschiedenen Optionen.
Um ZooKeeper-CLI-Vorgänge auszuführen, schalten Sie zuerst Ihren ZooKeeper-Server ( "bin / zkServer.sh start" ) und dann den ZooKeeper-Client ( "bin / zkCli.sh" ) ein. Sobald der Client gestartet ist, können Sie den folgenden Vorgang ausführen:
- Erstellen Sie Knoten
- Daten bekommen
- Beobachten Sie znode auf Änderungen
- Daten einstellen
- Erstellen Sie untergeordnete Elemente eines Knotens
- Listen Sie Kinder eines znode auf
- Status überprüfen
- Entfernen / Löschen eines Knotens
Lassen Sie uns nun den obigen Befehl einzeln mit einem Beispiel sehen.
Erstellen Sie Znodes
Erstellen Sie einen Knoten mit dem angegebenen Pfad. DasflagDas Argument gibt an, ob der erstellte Znode kurzlebig, persistent oder sequentiell ist. Standardmäßig sind alle Knoten dauerhaft.
Ephemeral znodes (Flag: e) wird automatisch gelöscht, wenn eine Sitzung abläuft oder wenn der Client die Verbindung trennt.
Sequential znodes Garantie, dass der znode-Pfad eindeutig ist.
Das ZooKeeper-Ensemble fügt dem znode-Pfad eine Sequenznummer sowie eine 10-stellige Auffüllung hinzu. Beispielsweise wird der Knotenpfad / myapp in / myapp0000000001 konvertiert und die nächste Sequenznummer lautet / myapp0000000002 . Wenn keine Flags angegeben sind, wird der znode als betrachtetpersistent.
Syntax
create /path /dataStichprobe
create /FirstZnode “Myfirstzookeeper-app”Ausgabe
[zk: localhost:2181(CONNECTED) 0] create /FirstZnode “Myfirstzookeeper-app”
Created /FirstZnodeSo erstellen Sie eine Sequential znode, hinzufügen -s flag Wie nachfolgend dargestellt.
Syntax
create -s /path /dataStichprobe
create -s /FirstZnode second-dataAusgabe
[zk: localhost:2181(CONNECTED) 2] create -s /FirstZnode “second-data”
Created /FirstZnode0000000023So erstellen Sie eine Ephemeral Znode, hinzufügen -e flag Wie nachfolgend dargestellt.
Syntax
create -e /path /dataStichprobe
create -e /SecondZnode “Ephemeral-data”Ausgabe
[zk: localhost:2181(CONNECTED) 2] create -e /SecondZnode “Ephemeral-data”
Created /SecondZnodeDenken Sie daran, dass bei Verlust einer Clientverbindung der kurzlebige Knoten gelöscht wird. Sie können es versuchen, indem Sie die ZooKeeper-CLI beenden und die CLI erneut öffnen.
Daten bekommen
Es gibt die zugehörigen Daten des Znodes und die Metadaten des angegebenen Znodes zurück. Sie erhalten Informationen, z. B. wann die Daten zuletzt geändert wurden, wo sie geändert wurden, und Informationen zu den Daten. Diese CLI wird auch zum Zuweisen von Uhren verwendet, um Benachrichtigungen über die Daten anzuzeigen.
Syntax
get /pathStichprobe
get /FirstZnodeAusgabe
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode
“Myfirstzookeeper-app”
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0Um auf einen sequentiellen Knoten zuzugreifen, müssen Sie den vollständigen Pfad des Knotens eingeben.
Stichprobe
get /FirstZnode0000000023Ausgabe
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode0000000023
“Second-data”
cZxid = 0x80
ctime = Tue Sep 29 16:25:47 IST 2015
mZxid = 0x80
mtime = Tue Sep 29 16:25:47 IST 2015
pZxid = 0x80
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 0Uhr
Uhren zeigen eine Benachrichtigung an, wenn sich die angegebenen untergeordneten Daten von znode oder znode ändern. Sie können a einstellenwatch nur im get Befehl.
Syntax
get /path [watch] 1Stichprobe
get /FirstZnode 1Ausgabe
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode 1
“Myfirstzookeeper-app”
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 16:15:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 22
numChildren = 0Die Ausgabe ist ähnlich wie normal getBefehl, aber es wird auf znode Änderungen im Hintergrund warten. <Hier starten>
Daten einstellen
Stellen Sie die Daten des angegebenen znode ein. Sobald Sie diesen Set-Vorgang abgeschlossen haben, können Sie die Daten mit dem überprüfenget CLI-Befehl.
Syntax
set /path /dataStichprobe
set /SecondZnode Data-updatedAusgabe
[zk: localhost:2181(CONNECTED) 1] get /SecondZnode “Data-updated”
cZxid = 0x82
ctime = Tue Sep 29 16:29:50 IST 2015
mZxid = 0x83
mtime = Tue Sep 29 16:29:50 IST 2015
pZxid = 0x82
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x15018b47db00000
dataLength = 14
numChildren = 0Wenn Sie zugewiesen haben watch Option in get Befehl (wie im vorherigen Befehl), dann ist die Ausgabe ähnlich wie unten gezeigt -
Ausgabe
[zk: localhost:2181(CONNECTED) 1] get /FirstZnode “Mysecondzookeeper-app”
WATCHER: :
WatchedEvent state:SyncConnected type:NodeDataChanged path:/FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x84
mtime = Tue Sep 29 17:14:47 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0Erstellen Sie untergeordnete Elemente / Unterknoten
Das Erstellen von Kindern ähnelt dem Erstellen neuer Knoten. Der einzige Unterschied besteht darin, dass der Pfad des untergeordneten Knotens auch den übergeordneten Pfad enthält.
Syntax
create /parent/path/subnode/path /dataStichprobe
create /FirstZnode/Child1 firstchildrenAusgabe
[zk: localhost:2181(CONNECTED) 16] create /FirstZnode/Child1 “firstchildren”
created /FirstZnode/Child1
[zk: localhost:2181(CONNECTED) 17] create /FirstZnode/Child2 “secondchildren”
created /FirstZnode/Child2Liste Kinder
Dieser Befehl wird verwendet, um die Liste aufzulisten und anzuzeigen children eines znode.
Syntax
ls /pathStichprobe
ls /MyFirstZnodeAusgabe
[zk: localhost:2181(CONNECTED) 2] ls /MyFirstZnode
[mysecondsubnode, myfirstsubnode]Status überprüfen
Statusbeschreibt die Metadaten eines angegebenen Znodes. Es enthält Details wie Zeitstempel, Versionsnummer, ACL, Datenlänge und untergeordneten Knoten.
Syntax
stat /pathStichprobe
stat /FirstZnodeAusgabe
[zk: localhost:2181(CONNECTED) 1] stat /FirstZnode
cZxid = 0x7f
ctime = Tue Sep 29 16:15:47 IST 2015
mZxid = 0x7f
mtime = Tue Sep 29 17:14:24 IST 2015
pZxid = 0x7f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 23
numChildren = 0Entfernen Sie einen Znode
Entfernt einen angegebenen Knoten und rekursiv alle seine untergeordneten Knoten. Dies würde nur passieren, wenn ein solcher Znode verfügbar ist.
Syntax
rmr /pathStichprobe
rmr /FirstZnodeAusgabe
[zk: localhost:2181(CONNECTED) 10] rmr /FirstZnode
[zk: localhost:2181(CONNECTED) 11] get /FirstZnode
Node does not exist: /FirstZnodeLöschen (delete /path) Befehl ist ähnlich wie remove Befehl, außer der Tatsache, dass es nur auf Knoten ohne Kinder funktioniert.
ZooKeeper verfügt über eine offizielle API-Bindung für Java und C. Die ZooKeeper-Community bietet für die meisten Sprachen (.NET, Python usw.) eine inoffizielle API. Mithilfe der ZooKeeper-API kann eine Anwendung eine Verbindung herstellen, interagieren, Daten bearbeiten, koordinieren und schließlich die Verbindung zu einem ZooKeeper-Ensemble trennen.
Die ZooKeeper-API verfügt über zahlreiche Funktionen, mit denen Sie alle Funktionen des ZooKeeper-Ensembles auf einfache und sichere Weise nutzen können. Die ZooKeeper-API bietet sowohl synchrone als auch asynchrone Methoden.
Das ZooKeeper-Ensemble und die ZooKeeper-API ergänzen sich in jeder Hinsicht vollständig und kommen den Entwicklern in hohem Maße zugute. Lassen Sie uns in diesem Kapitel die Java-Bindung diskutieren.
Grundlagen der ZooKeeper-API
Eine Anwendung, die mit dem ZooKeeper-Ensemble interagiert, wird als bezeichnet ZooKeeper Client oder einfach Client.
Znode ist die Kernkomponente des ZooKeeper-Ensembles, und die ZooKeeper-API bietet eine kleine Reihe von Methoden, um alle Details von znode mit dem ZooKeeper-Ensemble zu bearbeiten.
Ein Kunde sollte die folgenden Schritte ausführen, um eine klare und saubere Interaktion mit dem ZooKeeper-Ensemble zu haben.
Stellen Sie eine Verbindung zum ZooKeeper-Ensemble her. Das ZooKeeper-Ensemble weist dem Client eine Sitzungs-ID zu.
Senden Sie regelmäßig Herzschläge an den Server. Andernfalls läuft das ZooKeeper-Ensemble die Sitzungs-ID ab und der Client muss erneut eine Verbindung herstellen.
Abrufen / Festlegen der Knoten, solange eine Sitzungs-ID aktiv ist.
Trennen Sie die Verbindung zum ZooKeeper-Ensemble, sobald alle Aufgaben abgeschlossen sind. Wenn der Client längere Zeit inaktiv ist, trennt das ZooKeeper-Ensemble den Client automatisch.
Java-Bindung
Lassen Sie uns die wichtigsten ZooKeeper-APIs in diesem Kapitel verstehen. Der zentrale Teil der ZooKeeper-API istZooKeeper class. Es bietet Optionen zum Verbinden des ZooKeeper-Ensembles in seinem Konstruktor und verfügt über die folgenden Methoden:
connect - Stellen Sie eine Verbindung zum ZooKeeper-Ensemble her
create - Erstellen Sie einen Znode
exists - Überprüfen Sie, ob ein Knoten und seine Informationen vorhanden sind
getData - Daten von einem bestimmten Knoten abrufen
setData - Daten in einem bestimmten Knoten einstellen
getChildren - Alle Unterknoten in einem bestimmten Knoten verfügbar machen
delete - Holen Sie sich einen bestimmten Knoten und alle seine Kinder
close - eine Verbindung schließen
Stellen Sie eine Verbindung zum ZooKeeper Ensemble her
Die ZooKeeper-Klasse bietet über ihren Konstruktor Verbindungsfunktionen. Die Signatur des Konstruktors lautet wie folgt:
ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher)Wo,
connectionString - ZooKeeper Ensemble Host.
sessionTimeout - Sitzungszeitlimit in Millisekunden.
watcher- Ein Objekt, das die Watcher-Schnittstelle implementiert. Das ZooKeeper-Ensemble gibt den Verbindungsstatus über das Watcher-Objekt zurück.
Lassen Sie uns eine neue Hilfsklasse erstellen ZooKeeperConnection und fügen Sie eine Methode hinzu connect. Dasconnect Die Methode erstellt ein ZooKeeper-Objekt, stellt eine Verbindung zum ZooKeeper-Ensemble her und gibt das Objekt zurück.
Hier CountDownLatch wird verwendet, um den Hauptprozess anzuhalten (zu warten), bis der Client eine Verbindung zum ZooKeeper-Ensemble herstellt.
Das ZooKeeper-Ensemble antwortet auf den Verbindungsstatus über Watcher callback. Der Watcher-Rückruf wird aufgerufen, sobald der Client eine Verbindung zum ZooKeeper-Ensemble hergestellt hat und der Watcher-Rückruf dencountDown Methode der CountDownLatch um das Schloss zu lösen, await im Hauptprozess.
Hier ist der vollständige Code für die Verbindung mit einem ZooKeeper-Ensemble.
Codierung: ZooKeeperConnection.java
// import java classes
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
// import zookeeper classes
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.AsyncCallback.StatCallback;
import org.apache.zookeeper.KeeperException.Code;
import org.apache.zookeeper.data.Stat;
public class ZooKeeperConnection {
// declare zookeeper instance to access ZooKeeper ensemble
private ZooKeeper zoo;
final CountDownLatch connectedSignal = new CountDownLatch(1);
// Method to connect zookeeper ensemble.
public ZooKeeper connect(String host) throws IOException,InterruptedException {
zoo = new ZooKeeper(host,5000,new Watcher() {
public void process(WatchedEvent we) {
if (we.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
});
connectedSignal.await();
return zoo;
}
// Method to disconnect from zookeeper server
public void close() throws InterruptedException {
zoo.close();
}
}Speichern Sie den obigen Code und er wird im nächsten Abschnitt zum Verbinden des ZooKeeper-Ensembles verwendet.
Erstellen Sie einen Znode
Die ZooKeeper-Klasse bietet create methodum einen neuen Knoten im ZooKeeper-Ensemble zu erstellen. Die Unterschrift descreate Methode ist wie folgt -
create(String path, byte[] data, List<ACL> acl, CreateMode createMode)Wo,
path- Znode-Pfad. Zum Beispiel / myapp1, / myapp2, / myapp1 / mydata1, myapp2 / mydata1 / myanothersubdata
data - Daten, die in einem angegebenen znode-Pfad gespeichert werden sollen
acl- Zugriffssteuerungsliste des zu erstellenden Knotens. Die ZooKeeper-API bietet eine statische SchnittstelleZooDefs.Idsum einige der grundlegenden acl Liste zu bekommen. Beispielsweise gibt ZooDefs.Ids.OPEN_ACL_UNSAFE eine Liste von acl für geöffnete Knoten zurück.
createMode- die Art des Knotens, entweder kurzlebig, sequentiell oder beides. Das ist einenum.
Lassen Sie uns eine neue Java-Anwendung erstellen, um das zu überprüfen createFunktionalität der ZooKeeper-API. Erstellen Sie eine DateiZKCreate.java. Erstellen Sie in der Hauptmethode ein Objekt vom TypZooKeeperConnection und rufen Sie die connect Methode zum Herstellen einer Verbindung zum ZooKeeper-Ensemble.
Die Verbindungsmethode gibt das ZooKeeper-Objekt zurück zk. Rufen Sie jetzt diecreate Methode von zk Objekt mit benutzerdefinierten path und data.
Der vollständige Programmcode zum Erstellen eines Znodes lautet wie folgt:
Codierung: ZKCreate.java
import java.io.IOException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
public class ZKCreate {
// create static instance for zookeeper class.
private static ZooKeeper zk;
// create static instance for ZooKeeperConnection class.
private static ZooKeeperConnection conn;
// Method to create znode in zookeeper ensemble
public static void create(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
public static void main(String[] args) {
// znode path
String path = "/MyFirstZnode"; // Assign path to znode
// data in byte array
byte[] data = "My first zookeeper app”.getBytes(); // Declare data
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
create(path, data); // Create the data to the specified path
conn.close();
} catch (Exception e) {
System.out.println(e.getMessage()); //Catch error message
}
}
}Sobald die Anwendung kompiliert und ausgeführt wurde, wird im ZooKeeper-Ensemble ein Znode mit den angegebenen Daten erstellt. Sie können dies mithilfe der ZooKeeper-CLI überprüfenzkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnodeExists - Überprüfen Sie die Existenz eines Znode
Die ZooKeeper-Klasse bietet die exists methodum die Existenz eines znode zu überprüfen. Es gibt die Metadaten eines Znodes zurück, wenn der angegebene Znode vorhanden ist. Die Unterschrift desexists Methode ist wie folgt -
exists(String path, boolean watcher)Wo,
path - Znode-Pfad
watcher - Boolescher Wert, um anzugeben, ob ein angegebener Znode überwacht werden soll oder nicht
Lassen Sie uns eine neue Java-Anwendung erstellen, um die Funktionalität der ZooKeeper-API zu überprüfen. Erstellen Sie eine Datei "ZKExists.java" . Erstellen Sie in der Hauptmethode das ZooKeeper-Objekt "zk" mit dem Objekt "ZooKeeperConnection" . Rufen Sie dann die Methode "exist" des Objekts "zk" mit dem benutzerdefinierten Pfad "path" auf . Die vollständige Auflistung ist wie folgt -
Codierung: ZKExists.java
import java.io.IOException;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKExists {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path, true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign znode to the specified path
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path of the znode
if(stat != null) {
System.out.println("Node exists and the node version is " +
stat.getVersion());
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage()); // Catches error messages
}
}
}Sobald die Anwendung kompiliert und ausgeführt wurde, erhalten Sie die folgende Ausgabe.
Node exists and the node version is 1.getData-Methode
Die ZooKeeper-Klasse bietet getDataMethode zum Abrufen der in einem angegebenen Znode angehängten Daten und ihres Status. Die Unterschrift desgetData Methode ist wie folgt -
getData(String path, Watcher watcher, Stat stat)Wo,
path - Znode-Pfad.
watcher - Rückruffunktion vom Typ Watcher. Das ZooKeeper-Ensemble benachrichtigt Sie über den Watcher-Rückruf, wenn sich die Daten des angegebenen znode ändern. Dies ist eine einmalige Benachrichtigung.
stat - Gibt die Metadaten eines Knotens zurück.
Lassen Sie uns eine neue Java-Anwendung erstellen, um das zu verstehen getDataFunktionalität der ZooKeeper-API. Erstellen Sie eine DateiZKGetData.java. Erstellen Sie in der Hauptmethode ein ZooKeeper-Objektzk mit ihm ZooKeeperConnectionObjekt. Dann rufen Sie diegetData Methode des zk-Objekts mit benutzerdefiniertem Pfad.
Hier ist der vollständige Programmcode, um die Daten von einem bestimmten Knoten abzurufen -
Codierung: ZKGetData.java
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException, KeeperException {
String path = "/MyFirstZnode";
final CountDownLatch connectedSignal = new CountDownLatch(1);
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path);
if(stat != null) {
byte[] b = zk.getData(path, new Watcher() {
public void process(WatchedEvent we) {
if (we.getType() == Event.EventType.None) {
switch(we.getState()) {
case Expired:
connectedSignal.countDown();
break;
}
} else {
String path = "/MyFirstZnode";
try {
byte[] bn = zk.getData(path,
false, null);
String data = new String(bn,
"UTF-8");
System.out.println(data);
connectedSignal.countDown();
} catch(Exception ex) {
System.out.println(ex.getMessage());
}
}
}
}, null);
String data = new String(b, "UTF-8");
System.out.println(data);
connectedSignal.await();
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}Sobald die Anwendung kompiliert und ausgeführt wurde, erhalten Sie die folgende Ausgabe
My first zookeeper appDie Anwendung wartet auf eine weitere Benachrichtigung durch das ZooKeeper-Ensemble. Ändern Sie die Daten des angegebenen Knotens mithilfe der ZooKeeper-CLIzkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> set /MyFirstZnode HelloJetzt druckt die Anwendung die folgende Ausgabe und beendet sie.
HellosetData-Methode
Die ZooKeeper-Klasse bietet setDataMethode zum Ändern der in einem angegebenen znode angehängten Daten. Die Unterschrift dessetData Methode ist wie folgt -
setData(String path, byte[] data, int version)Wo,
path - Znode-Pfad
data - Daten, die in einem angegebenen znode-Pfad gespeichert werden sollen.
version- Aktuelle Version des znode. ZooKeeper aktualisiert die Versionsnummer des Knotens, wenn die Daten geändert werden.
Lassen Sie uns jetzt eine neue Java-Anwendung erstellen, um das zu verstehen setDataFunktionalität der ZooKeeper-API. Erstellen Sie eine DateiZKSetData.java. Erstellen Sie in der Hauptmethode ein ZooKeeper-Objektzk Verwendung der ZooKeeperConnectionObjekt. Dann rufen Sie diesetData Methode von zk Objekt mit dem angegebenen Pfad, neuen Daten und der Version des Knotens.
Hier ist der vollständige Programmcode zum Ändern der in einem angegebenen znode angehängten Daten.
Code: ZKSetData.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import java.io.IOException;
public class ZKSetData {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to update the data in a znode. Similar to getData but without watcher.
public static void update(String path, byte[] data) throws
KeeperException,InterruptedException {
zk.setData(path, data, zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path= "/MyFirstZnode";
byte[] data = "Success".getBytes(); //Assign data which is to be updated.
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
update(path, data); // Update znode data to the specified path
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}Sobald die Anwendung kompiliert und ausgeführt wurde, werden die Daten des angegebenen znode geändert und können mit der ZooKeeper-CLI überprüft werden. zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> get /MyFirstZnodegetChildrenMethod
Die ZooKeeper-Klasse bietet getChildrenMethode, um alle Unterknoten eines bestimmten Knotens abzurufen. Die Unterschrift desgetChildren Methode ist wie folgt -
getChildren(String path, Watcher watcher)Wo,
path - Znode-Pfad.
watcher- Rückruffunktion vom Typ „Watcher“. Das ZooKeeper-Ensemble benachrichtigt Sie, wenn der angegebene Znode gelöscht oder ein untergeordnetes Element unter dem Znode erstellt / gelöscht wird. Dies ist eine einmalige Benachrichtigung.
Codierung: ZKGetChildren.java
import java.io.IOException;
import java.util.*;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.data.Stat;
public class ZKGetChildren {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static Stat znode_exists(String path) throws
KeeperException,InterruptedException {
return zk.exists(path,true);
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; // Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
Stat stat = znode_exists(path); // Stat checks the path
if(stat!= null) {
//“getChildren” method- get all the children of znode.It has two
args, path and watch
List <String> children = zk.getChildren(path, false);
for(int i = 0; i < children.size(); i++)
System.out.println(children.get(i)); //Print children's
} else {
System.out.println("Node does not exists");
}
} catch(Exception e) {
System.out.println(e.getMessage());
}
}
}Bevor wir das Programm ausführen, erstellen wir zwei Unterknoten für /MyFirstZnode Verwenden der ZooKeeper-CLI, zkCli.sh.
cd /path/to/zookeeper
bin/zkCli.sh
>>> create /MyFirstZnode/myfirstsubnode Hi
>>> create /MyFirstZnode/mysecondsubmode HiBeim Kompilieren und Ausführen des Programms werden nun die oben erstellten Knoten ausgegeben.
myfirstsubnode
mysecondsubnodeLöschen Sie einen Znode
Die ZooKeeper-Klasse bietet deleteMethode zum Löschen eines angegebenen Knotens. Die Unterschrift desdelete Methode ist wie folgt -
delete(String path, int version)Wo,
path - Znode-Pfad.
version - Aktuelle Version des znode.
Lassen Sie uns eine neue Java-Anwendung erstellen, um das zu verstehen deleteFunktionalität der ZooKeeper-API. Erstellen Sie eine DateiZKDelete.java. Erstellen Sie in der Hauptmethode ein ZooKeeper-Objektzk mit ZooKeeperConnectionObjekt. Dann rufen Sie diedelete Methode von zk Objekt mit dem angegebenen path und Version des Knotens.
Der vollständige Programmcode zum Löschen eines Znodes lautet wie folgt:
Codierung: ZKDelete.java
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.KeeperException;
public class ZKDelete {
private static ZooKeeper zk;
private static ZooKeeperConnection conn;
// Method to check existence of znode and its status, if znode is available.
public static void delete(String path) throws KeeperException,InterruptedException {
zk.delete(path,zk.exists(path,true).getVersion());
}
public static void main(String[] args) throws InterruptedException,KeeperException {
String path = "/MyFirstZnode"; //Assign path to the znode
try {
conn = new ZooKeeperConnection();
zk = conn.connect("localhost");
delete(path); //delete the node with the specified path
} catch(Exception e) {
System.out.println(e.getMessage()); // catches error messages
}
}
}Zookeeper bietet eine flexible Koordinierungsinfrastruktur für verteilte Umgebungen. Das ZooKeeper-Framework unterstützt viele der besten Industrieanwendungen von heute. In diesem Kapitel werden einige der bemerkenswertesten Anwendungen von ZooKeeper erläutert.
Yahoo!
Das ZooKeeper-Framework wurde ursprünglich bei "Yahoo!" erstellt. Eine gut gestaltete verteilte Anwendung muss Anforderungen wie Datentransparenz, bessere Leistung, Robustheit, zentralisierte Konfiguration und Koordination erfüllen. Daher haben sie das ZooKeeper-Framework entwickelt, um diese Anforderungen zu erfüllen.
Apache Hadoop
Apache Hadoop ist die treibende Kraft für das Wachstum der Big Data-Branche. Hadoop verlässt sich bei der Konfigurationsverwaltung und -koordination auf ZooKeeper. Nehmen wir ein Szenario, um die Rolle von ZooKeeper in Hadoop zu verstehen.
Angenommen, a Hadoop cluster Brücken 100 or more commodity servers. Daher sind Koordinierungs- und Benennungsdienste erforderlich. Da die Berechnung einer großen Anzahl von Knoten erforderlich ist, muss jeder Knoten miteinander synchronisiert werden, wissen, wo auf Dienste zugegriffen werden muss und wie sie konfiguriert werden sollten. Zu diesem Zeitpunkt erfordern Hadoop-Cluster knotenübergreifende Dienste. ZooKeeper bietet die Einrichtungen fürcross-node synchronization und stellt sicher, dass die Aufgaben in allen Hadoop-Projekten serialisiert und synchronisiert werden.
Mehrere ZooKeeper-Server unterstützen große Hadoop-Cluster. Jeder Clientcomputer kommuniziert mit einem der ZooKeeper-Server, um seine Synchronisierungsinformationen abzurufen und zu aktualisieren. Einige der Echtzeitbeispiele sind -
Human Genome Project- Das Humangenomprojekt enthält Terabyte an Daten. Das Hadoop MapReduce-Framework kann verwendet werden, um den Datensatz zu analysieren und interessante Fakten für die menschliche Entwicklung zu finden.
Healthcare - Krankenhäuser können große Mengen von Patientenakten speichern, abrufen und analysieren, die normalerweise in Terabyte vorliegen.
Apache HBase
Apache HBase ist eine verteilte Open-Source-NoSQL-Datenbank, die für den Echtzeit-Lese- / Schreibzugriff auf große Datenmengen verwendet wird und auf dem HDFS ausgeführt wird. HBase folgtmaster-slave architecturewo der HBase Master alle Slaves regiert. Slaves werden als bezeichnetRegion servers.
Die Installation einer verteilten HBase-Anwendung hängt von einem laufenden ZooKeeper-Cluster ab. Apache HBase verwendet ZooKeeper, um mithilfe von den Status verteilter Daten auf den Master- und Regionsservern zu verfolgencentralized configuration management und distributed mutexMechanismen. Hier sind einige Anwendungsfälle von HBase:
Telecom- Die Telekommunikationsbranche speichert Milliarden von Mobilfunkaufzeichnungen (ca. 30 TB / Monat), und der Zugriff auf diese Anrufaufzeichnungen in Echtzeit wird zu einer großen Aufgabe. Mit HBase können alle Datensätze einfach und effizient in Echtzeit verarbeitet werden.
Social network- Ähnlich wie in der Telekommunikationsbranche erhalten Websites wie Twitter, LinkedIn und Facebook über die von Benutzern erstellten Beiträge riesige Datenmengen. HBase kann verwendet werden, um aktuelle Trends und andere interessante Fakten zu finden.
Apache Solr
Apache Solr ist eine schnelle Open-Source-Suchplattform, die in Java geschrieben wurde. Es ist eine blitzschnelle, fehlertolerante verteilte Suchmaschine. Gebaut aufLuceneEs ist eine leistungsstarke Textsuchmaschine mit vollem Funktionsumfang.
Solr nutzt in großem Umfang alle Funktionen von ZooKeeper, z. B. Konfigurationsverwaltung, Leader-Wahl, Knotenverwaltung, Sperren und Synchronisieren von Daten.
Solr besteht aus zwei Teilen: indexing und searching. Bei der Indizierung werden die Daten in einem geeigneten Format gespeichert, damit sie später durchsucht werden können. Solr verwendet ZooKeeper sowohl zum Indizieren der Daten in mehreren Knoten als auch zum Suchen von mehreren Knoten. ZooKeeper bietet die folgenden Funktionen:
Hinzufügen / Entfernen von Knoten nach Bedarf
Replikation von Daten zwischen Knoten und anschließende Minimierung des Datenverlusts
Teilen von Daten zwischen mehreren Knoten und anschließendes Suchen von mehreren Knoten nach schnelleren Suchergebnissen
Einige der Anwendungsfälle von Apache Solr umfassen E-Commerce, Jobsuche usw.