Apache Flume - Guía rápida
¿Qué es Flume?
Apache Flume es una herramienta / servicio / mecanismo de ingesta de datos para recopilar, agregar y transportar grandes cantidades de datos de transmisión, como archivos de registro, eventos (etc.) de varias fuentes a un almacén de datos centralizado.
Flume es una herramienta altamente confiable, distribuida y configurable. Está diseñado principalmente para copiar datos de transmisión (datos de registro) de varios servidores web a HDFS.
Aplicaciones de Flume
Suponga que una aplicación web de comercio electrónico desea analizar el comportamiento del cliente de una región en particular. Para hacerlo, necesitarían mover los datos de registro disponibles a Hadoop para su análisis. Aquí, Apache Flume viene a nuestro rescate.
Flume se utiliza para mover los datos de registro generados por los servidores de aplicaciones a HDFS a mayor velocidad.
Ventajas de Flume
Estas son las ventajas de usar Flume:
Usando Apache Flume podemos almacenar los datos en cualquiera de las tiendas centralizadas (HBase, HDFS).
Cuando la tasa de datos entrantes excede la tasa a la que se pueden escribir datos en el destino, Flume actúa como mediador entre los productores de datos y los almacenes centralizados y proporciona un flujo constante de datos entre ellos.
Flume proporciona la característica de contextual routing.
Las transacciones en Flume están basadas en canales donde se mantienen dos transacciones (un remitente y un receptor) para cada mensaje. Garantiza la entrega de mensajes confiable.
Flume es confiable, tolerante a fallas, escalable, manejable y personalizable.
Características de Flume
Algunas de las características notables de Flume son las siguientes:
Flume ingiere datos de registro de varios servidores web en una tienda centralizada (HDFS, HBase) de manera eficiente.
Con Flume, podemos obtener los datos de varios servidores inmediatamente en Hadoop.
Junto con los archivos de registro, Flume también se utiliza para importar grandes volúmenes de datos de eventos producidos por sitios de redes sociales como Facebook y Twitter, y sitios web de comercio electrónico como Amazon y Flipkart.
Flume admite un gran conjunto de tipos de fuentes y destinos.
Flume admite flujos de múltiples saltos, flujos de entrada y salida, enrutamiento contextual, etc.
El canal se puede escalar horizontalmente.
Big Data,como sabemos, es una colección de grandes conjuntos de datos que no se pueden procesar mediante técnicas informáticas tradicionales. Big Data, cuando se analiza, da resultados valiosos.Hadoop es un marco de código abierto que permite almacenar y procesar Big Data en un entorno distribuido a través de grupos de computadoras utilizando modelos de programación simples.
Transmisión / registro de datos
Generalmente, la mayoría de los datos que se van a analizar serán producidos por varias fuentes de datos como servidores de aplicaciones, sitios de redes sociales, servidores en la nube y servidores empresariales. Estos datos estarán en forma delog files y events.
Log file - En general, un archivo de registro es un fileque enumera eventos / acciones que ocurren en un sistema operativo. Por ejemplo, los servidores web enumeran todas las solicitudes realizadas al servidor en los archivos de registro.
Al recolectar dichos datos de registro, podemos obtener información sobre:
- el rendimiento de la aplicación y localizar varios fallos de software y hardware.
- el comportamiento del usuario y obtener mejores conocimientos empresariales.
El método tradicional de transferir datos al sistema HDFS es utilizar el putmando. Veamos cómo usar elput mando.
Comando put HDFS
El principal desafío en el manejo de los datos de registro es mover estos registros producidos por múltiples servidores al entorno de Hadoop.
Hadoop File System Shellproporciona comandos para insertar datos en Hadoop y leerlos. Puede insertar datos en Hadoop usando elput comando como se muestra a continuación.
$ Hadoop fs –put /path of the required file /path in HDFS where to save the fileProblema con el comando put
Podemos usar el putcomando de Hadoop para transferir datos de estas fuentes a HDFS. Pero adolece de los siguientes inconvenientes:
Utilizando put comando, podemos transferir only one file at a timemientras que los generadores de datos generan datos a una velocidad mucho mayor. Dado que el análisis realizado en datos más antiguos es menos preciso, necesitamos tener una solución para transferir datos en tiempo real.
Si usamos putcomando, los datos deben ser empaquetados y deben estar listos para la carga. Dado que los servidores web generan datos de forma continua, es una tarea muy difícil.
Lo que necesitamos aquí es una solución que pueda superar los inconvenientes de put Ordene y transfiera la "transmisión de datos" de los generadores de datos a las tiendas centralizadas (especialmente HDFS) con menos demora.
Problema con HDFS
En HDFS, el archivo existe como una entrada de directorio y la longitud del archivo se considerará cero hasta que se cierre. Por ejemplo, si una fuente está escribiendo datos en HDFS y la red se interrumpió en medio de la operación (sin cerrar el archivo), los datos escritos en el archivo se perderán.
Por lo tanto, necesitamos un sistema confiable, configurable y fácil de mantener para transferir los datos de registro a HDFS.
Note- En el sistema de archivos POSIX, siempre que accedemos a un archivo (por ejemplo, realizando una operación de escritura), otros programas aún pueden leer este archivo (al menos la parte guardada del archivo). Esto se debe a que el archivo existe en el disco antes de que se cierre.
Soluciones Disponibles
Para enviar datos de transmisión (archivos de registro, eventos, etc.) desde varias fuentes a HDFS, tenemos las siguientes herramientas disponibles a nuestra disposición:
Escriba de Facebook
Scribe es una herramienta inmensamente popular que se utiliza para agregar y transmitir datos de registro. Está diseñado para escalar a una gran cantidad de nodos y ser resistente a fallas de red y nodos.
Apache Kafka
Kafka ha sido desarrollado por Apache Software Foundation. Es un corredor de mensajes de código abierto. Con Kafka, podemos manejar feeds con alto rendimiento y baja latencia.
Apache Flume
Apache Flume es una herramienta / servicio / mecanismo de ingestión de datos para recopilar, agregar y transportar grandes cantidades de datos de transmisión, como datos de registro, eventos (etc.) desde varios servidores web a un almacén de datos centralizado.
Es una herramienta altamente confiable, distribuida y configurable que está diseñada principalmente para transferir datos de transmisión desde varias fuentes a HDFS.
En este tutorial, discutiremos en detalle cómo usar Flume con algunos ejemplos.
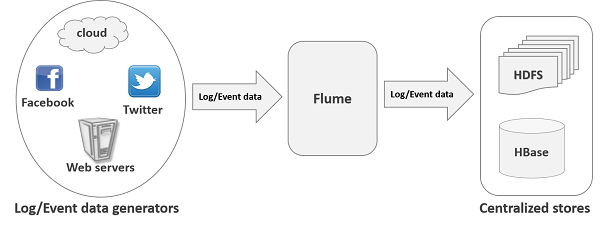
La siguiente ilustración muestra la arquitectura básica de Flume. Como se muestra en la ilustración,data generators (como Facebook, Twitter) generan datos que son recopilados por Flume individual agentscorriendo sobre ellos. A partir de entonces, undata collector (que también es un agente) recopila los datos de los agentes que se agregan y se envían a una tienda centralizada como HDFS o HBase.

Evento de canal
Un event es la unidad básica de los datos transportados dentro Flume. Contiene una carga útil de una matriz de bytes que se transportará desde el origen hasta el destino acompañada de encabezados opcionales. Un evento típico de Flume tendría la siguiente estructura:

Agente de canal
Un agentes un proceso daemon independiente (JVM) en Flume. Recibe los datos (eventos) de clientes u otros agentes y los reenvía a su próximo destino (receptor o agente). Flume puede tener más de un agente. El siguiente diagrama representa unFlume Agent

Como se muestra en el diagrama, un agente de canal contiene tres componentes principales, a saber, source, channely sink.
Fuente
UN source es el componente de un agente que recibe datos de los generadores de datos y los transfiere a uno o más canales en forma de eventos Flume.
Apache Flume admite varios tipos de fuentes y cada fuente recibe eventos de un generador de datos específico.
Example - Fuente de Avro, fuente de ahorro, fuente de twitter 1%, etc.
Canal
UN channeles un almacén transitorio que recibe los eventos de la fuente y los almacena en búfer hasta que son consumidos por los sumideros. Actúa como puente entre las fuentes y los sumideros.
Estos canales son completamente transaccionales y pueden funcionar con cualquier número de fuentes y receptores.
Example - Canal JDBC, canal del sistema de archivos, canal de memoria, etc.
Lavabo
UN sinkalmacena los datos en tiendas centralizadas como HBase y HDFS. Consume los datos (eventos) de los canales y los entrega al destino. El destino del fregadero puede ser otro agente o las tiendas centrales.
Example - Fregadero HDFS
Note- Un agente de canal puede tener múltiples fuentes, sumideros y canales. Hemos enumerado todas las fuentes, receptores y canales compatibles en el capítulo de configuración de Flume de este tutorial.
Componentes adicionales del agente de canal
Lo que hemos discutido anteriormente son los componentes primitivos del agente. Además de esto, tenemos algunos componentes más que juegan un papel vital en la transferencia de eventos desde el generador de datos a las tiendas centralizadas.
Interceptores
Los interceptores se utilizan para alterar / inspeccionar eventos de canal que se transfieren entre la fuente y el canal.
Selectores de canales
Estos se utilizan para determinar qué canal se optará para transferir los datos en el caso de varios canales. Hay dos tipos de selectores de canales:
Default channel selectors - Estos también se conocen como selectores de canal de replicación, replican todos los eventos en cada canal.
Multiplexing channel selectors - Estos deciden el canal para enviar un evento en función de la dirección en el encabezado de ese evento.
Procesadores de fregadero
Se utilizan para invocar un sumidero particular del grupo de sumideros seleccionado. Se utilizan para crear rutas de conmutación por error para sus receptores o eventos de equilibrio de carga en varios receptores de un canal.
Flume es un marco que se utiliza para mover datos de registro a HDFS. Generalmente los eventos y los datos de registro son generados por los servidores de registro y estos servidores tienen agentes Flume ejecutándose en ellos. Estos agentes reciben los datos de los generadores de datos.
Los datos de estos agentes serán recopilados por un nodo intermedio conocido como Collector. Al igual que los agentes, puede haber varios recolectores en Flume.
Finalmente, los datos de todos estos recopiladores se agregarán y se enviarán a una tienda centralizada como HBase o HDFS. El siguiente diagrama explica el flujo de datos en Flume.
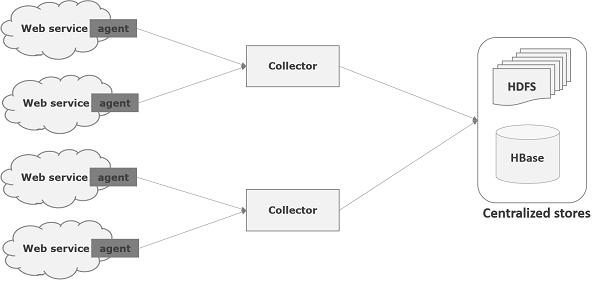
Flujo de varios saltos
Dentro de Flume, puede haber varios agentes y antes de llegar al destino final, un evento puede viajar a través de más de un agente. Esto se conoce comomulti-hop flow.
Flujo de distribución
El flujo de datos de una fuente a varios canales se conoce como fan-out flow. Es de dos tipos:
Replicating - El flujo de datos donde se replicarán los datos en todos los canales configurados.
Multiplexing - El flujo de datos donde se enviarán los datos a un canal seleccionado que se menciona en el encabezado del evento.
Flujo de ventilador
El flujo de datos en el que los datos se transferirán de muchas fuentes a un canal se conoce como fan-in flow.
Manejo de fallas
En Flume, para cada evento, se realizan dos transacciones: una en el remitente y otra en el receptor. El remitente envía eventos al receptor. Poco después de recibir los datos, el receptor realiza su propia transacción y envía una señal "recibida" al remitente. Después de recibir la señal, el remitente confirma su transacción. (El remitente no confirmará su transacción hasta que reciba una señal del receptor).
Ya discutimos la arquitectura de Flume en el capítulo anterior. En este capítulo, veamos cómo descargar y configurar Apache Flume.
Antes de continuar, debe tener un entorno Java en su sistema. Entonces, antes que nada, asegúrese de tener Java instalado en su sistema. Para algunos ejemplos en este tutorial, hemos utilizado Hadoop HDFS (como receptor). Por lo tanto, le recomendamos que instale Hadoop junto con Java. Para recopilar más información, siga el enlace -http://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
Instalación de Flume
En primer lugar, descargue la última versión del software Apache Flume del sitio web https://flume.apache.org/.
Paso 1
Abra el sitio web. Clickea en eldownloadenlace en el lado izquierdo de la página de inicio. Lo llevará a la página de descarga de Apache Flume.
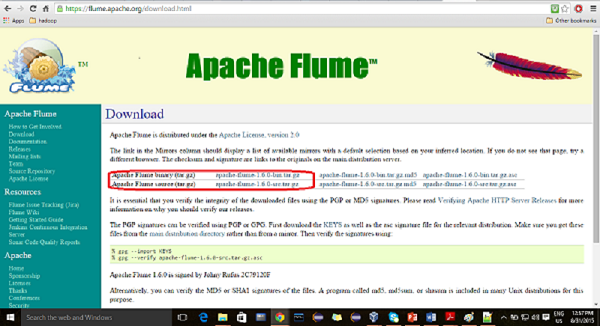
Paso 2
En la página de descargas, puede ver los enlaces para archivos binarios y fuente de Apache Flume. Haga clic en el enlace apache-flume-1.6.0-bin.tar.gz
Se le redirigirá a una lista de espejos donde podrá iniciar la descarga haciendo clic en cualquiera de estos espejos. De la misma manera, puede descargar el código fuente de Apache Flume haciendo clic en apache-flume-1.6.0-src.tar.gz .
Paso 3
Cree un directorio con el nombre Flume en el mismo directorio donde los directorios de instalación de Hadoop, HBase, y se instaló otro software (si ya ha instalado alguno) como se muestra a continuación.
$ mkdir FlumeEtapa 4
Extraiga los archivos tar descargados como se muestra a continuación.
$ cd Downloads/
$ tar zxvf apache-flume-1.6.0-bin.tar.gz
$ tar zxvf apache-flume-1.6.0-src.tar.gzPaso 5
Mover el contenido de apache-flume-1.6.0-bin.tar archivo al Flumedirectorio creado anteriormente como se muestra a continuación. (Suponga que hemos creado el directorio Flume en el usuario local llamado Hadoop).
$ mv apache-flume-1.6.0-bin.tar/* /home/Hadoop/Flume/Configuración de Flume
Para configurar Flume, tenemos que modificar tres archivos a saber, flume-env.sh, flumeconf.properties, y bash.rc.
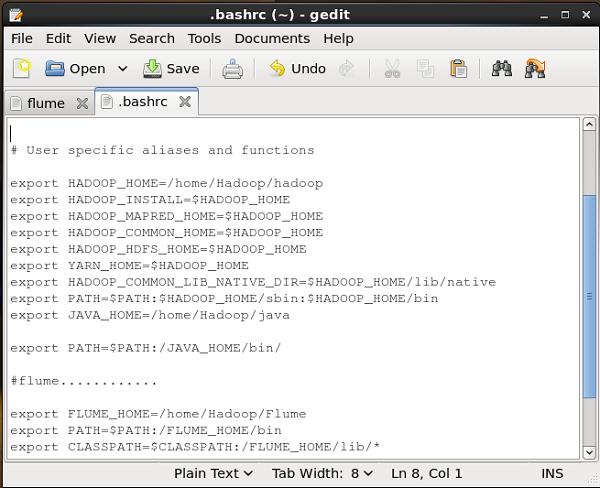
Establecer la ruta / ruta de clases
En el .bashrc , configure la carpeta de inicio, la ruta y la ruta de clases para Flume como se muestra a continuación.
conf Carpeta
Si abre el conf carpeta de Apache Flume, tendrá los siguientes cuatro archivos:
- flume-conf.properties.template,
- flume-env.sh.template,
- flume-env.ps1.template y
- log4j.properties.

Ahora cambie el nombre
flume-conf.properties.template archivar como flume-conf.properties y
flume-env.sh.template como flume-env.sh
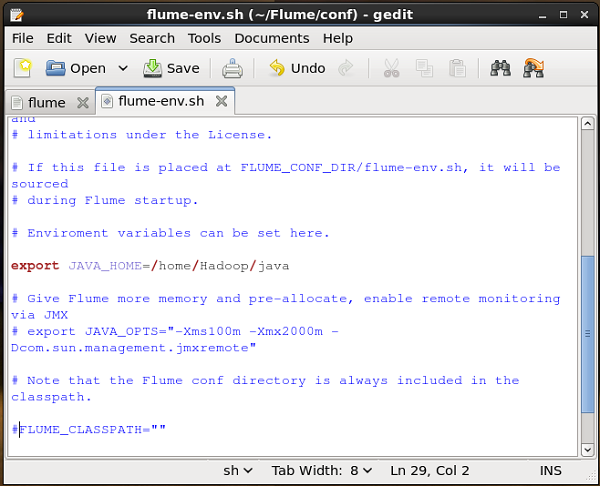
flume-env.sh
Abierto flume-env.sh archivo y configure el JAVA_Home a la carpeta donde se instaló Java en su sistema.
Verificación de la instalación
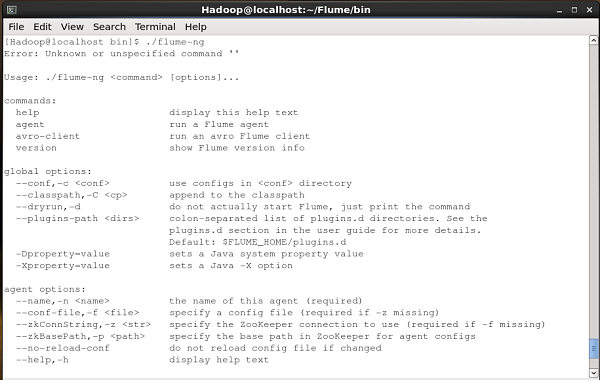
Verifique la instalación de Apache Flume navegando por el bin carpeta y escribiendo el siguiente comando.
$ ./flume-ngSi ha instalado correctamente Flume, recibirá un mensaje de ayuda de Flume como se muestra a continuación.
Después de instalar Flume, necesitamos configurarlo usando el archivo de configuración que es un archivo de propiedades de Java que tiene key-value pairs. Necesitamos pasar valores a las claves en el archivo.
En el archivo de configuración de Flume, necesitamos:
- Nombra los componentes del agente actual.
- Describe / configura la fuente.
- Describe / configura el fregadero.
- Describe / configura el canal.
- Ate la fuente y el sumidero al canal.
Por lo general, podemos tener varios agentes en Flume. Podemos diferenciar a cada agente usando un nombre único. Y usando este nombre, tenemos que configurar cada agente.
Nombrar los componentes
En primer lugar, debe nombrar / enumerar los componentes, como fuentes, receptores y canales del agente, como se muestra a continuación.
agent_name.sources = source_name
agent_name.sinks = sink_name
agent_name.channels = channel_nameFlume admite varias fuentes, sumideros y canales. Se enumeran en la tabla siguiente.
| Fuentes | Canales | Fregaderos |
|---|---|---|
|
|
|
Puedes usar cualquiera de ellos. Por ejemplo, si está transfiriendo datos de Twitter utilizando una fuente de Twitter a través de un canal de memoria a un receptor HDFS, y la identificación del nombre del agenteTwitterAgent, luego
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFSDespués de enumerar los componentes del agente, debe describir la (s) fuente (s), sumidero (s) y canal (s) proporcionando valores a sus propiedades.
Describiendo la fuente
Cada fuente tendrá una lista separada de propiedades. La propiedad denominada "tipo" es común a todas las fuentes y se utiliza para especificar el tipo de fuente que estamos utilizando.
Junto con la propiedad "tipo", es necesario proporcionar los valores de todos los required propiedades de una fuente en particular para configurarla, como se muestra a continuación.
agent_name.sources. source_name.type = value
agent_name.sources. source_name.property2 = value
agent_name.sources. source_name.property3 = valuePor ejemplo, si consideramos el twitter source, a continuación se muestran las propiedades a las que debemos proporcionar valores para configurarlo.
TwitterAgent.sources.Twitter.type = Twitter (type name)
TwitterAgent.sources.Twitter.consumerKey =
TwitterAgent.sources.Twitter.consumerSecret =
TwitterAgent.sources.Twitter.accessToken =
TwitterAgent.sources.Twitter.accessTokenSecret =Describiendo el fregadero
Al igual que la fuente, cada sumidero tendrá una lista separada de propiedades. La propiedad denominada "tipo" es común a todos los sumideros y se utiliza para especificar el tipo de sumidero que estamos usando. Junto con la propiedad "tipo", es necesario proporcionar valores a todos losrequired propiedades de un sumidero en particular para configurarlo, como se muestra a continuación.
agent_name.sinks. sink_name.type = value
agent_name.sinks. sink_name.property2 = value
agent_name.sinks. sink_name.property3 = valuePor ejemplo, si consideramos HDFS sink, a continuación se muestran las propiedades a las que debemos proporcionar valores para configurarlo.
TwitterAgent.sinks.HDFS.type = hdfs (type name)
TwitterAgent.sinks.HDFS.hdfs.path = HDFS directory’s Path to store the dataDescribiendo el canal
Flume proporciona varios canales para transferir datos entre fuentes y receptores. Por lo tanto, junto con las fuentes y los canales, es necesario describir el canal utilizado en el agente.
Para describir cada canal, debe establecer las propiedades necesarias, como se muestra a continuación.
agent_name.channels.channel_name.type = value
agent_name.channels.channel_name. property2 = value
agent_name.channels.channel_name. property3 = valuePor ejemplo, si consideramos memory channel, a continuación se muestran las propiedades a las que debemos proporcionar valores para configurarlo.
TwitterAgent.channels.MemChannel.type = memory (type name)Uniendo la fuente y el sumidero al canal
Dado que los canales conectan las fuentes y los receptores, es necesario unir ambos al canal, como se muestra a continuación.
agent_name.sources.source_name.channels = channel_name
agent_name.sinks.sink_name.channels = channel_nameEl siguiente ejemplo muestra cómo vincular las fuentes y los receptores a un canal. Aquí, consideramostwitter source, memory channel, y HDFS sink.
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channels = MemChannelInicio de un agente de canal
Después de la configuración, tenemos que iniciar el agente Flume. Se hace de la siguiente manera:
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentdonde -
agent - Comando para iniciar el agente Flume
--conf ,-c<conf> - Usar archivo de configuración en el directorio conf
-f<file> - Especifica una ruta de archivo de configuración, si falta
--name, -n <name> - Nombre del agente de twitter
-D property =value - Establece un valor de propiedad del sistema Java.
Con Flume, podemos obtener datos de varios servicios y transportarlos a tiendas centralizadas (HDFS y HBase). Este capítulo explica cómo obtener datos del servicio de Twitter y almacenarlos en HDFS usando Apache Flume.
Como se explica en Flume Architecture, un servidor web genera datos de registro y estos datos los recopila un agente en Flume. El canal almacena estos datos en un sumidero, que finalmente los envía a las tiendas centralizadas.
En el ejemplo proporcionado en este capítulo, crearemos una aplicación y obtendremos los tweets utilizando la fuente experimental de Twitter proporcionada por Apache Flume. Usaremos el canal de memoria para almacenar estos tweets en búfer y el receptor HDFS para enviar estos tweets al HDFS.

Para obtener datos de Twitter, tendremos que seguir los pasos que se detallan a continuación:
- Crea una aplicación de twitter
- Instalar / iniciar HDFS
- Configurar Flume
Crear una aplicación de Twitter
Para obtener los tweets de Twitter, es necesario crear una aplicación de Twitter. Siga los pasos que se indican a continuación para crear una aplicación de Twitter.
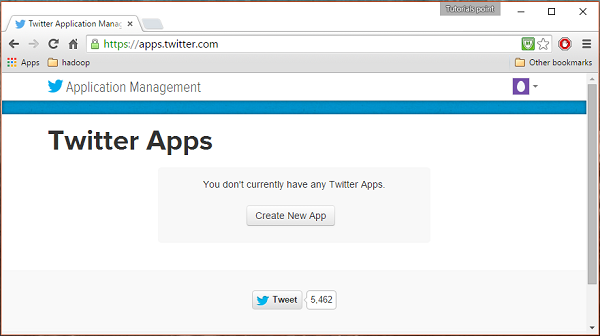
Paso 1
Para crear una aplicación de Twitter, haga clic en el siguiente enlace https://apps.twitter.com/. Inicie sesión en su cuenta de Twitter. Tendrá una ventana de administración de aplicaciones de Twitter donde puede crear, eliminar y administrar aplicaciones de Twitter.
Paso 2
Clickea en el Create New Appbotón. Será redirigido a una ventana donde obtendrá un formulario de solicitud en el que debe completar sus datos para crear la aplicación. Mientras completa la dirección del sitio web, proporcione el patrón de URL completo, por ejemplo,http://example.com.
Paso 3
Complete los datos, acepte el Developer Agreement cuando termine, haga clic en el Create your Twitter application buttonque está en la parte inferior de la página. Si todo va bien, se creará una aplicación con los detalles proporcionados como se muestra a continuación.
Etapa 4
Debajo keys and Access Tokens pestaña en la parte inferior de la página, puede observar un botón llamado Create my access token. Haga clic en él para generar el token de acceso.
Paso 5
Finalmente, haga clic en el Test OAuthbotón que se encuentra en la parte superior derecha de la página. Esto conducirá a una página que muestra suConsumer key, Consumer secret, Access token, y Access token secret. Copie estos detalles. Son útiles para configurar el agente en Flume.

Iniciando HDFS
Dado que estamos almacenando los datos en HDFS, necesitamos instalar / verificar Hadoop. Inicie Hadoop y cree una carpeta en él para almacenar los datos de Flume. Siga los pasos que se indican a continuación antes de configurar Flume.
Paso 1: instalar / verificar Hadoop
Instale Hadoop . Si Hadoop ya está instalado en su sistema, verifique la instalación usando el comando de la versión de Hadoop, como se muestra a continuación.
$ hadoop versionSi su sistema contiene Hadoop, y si ha establecido la variable de ruta, obtendrá el siguiente resultado:
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarPaso 2: iniciar Hadoop
Navegar por el sbin directorio de Hadoop e iniciar yarn y Hadoop dfs (sistema de archivos distribuido) como se muestra a continuación.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.outPaso 3: cree un directorio en HDFS
En Hadoop DFS, puede crear directorios usando el comando mkdir. Navegue a través de él y cree un directorio con el nombretwitter_data en la ruta requerida como se muestra a continuación.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataConfiguración de Flume
Tenemos que configurar la fuente, el canal y el receptor usando el archivo de configuración en el confcarpeta. El ejemplo dado en este capítulo utiliza una fuente experimental proporcionada por Apache Flume llamadaTwitter 1% Firehose Canal de memoria y disipador HDFS.
Fuente de Twitter 1% Firehose
Esta fuente es muy experimental. Se conecta al 1% de muestra de Twitter Firehose mediante API de transmisión continua y descarga tweets, los convierte al formato Avro y envía eventos Avro a un receptor Flume descendente.
Obtendremos esta fuente por defecto junto con la instalación de Flume. losjar Los archivos correspondientes a esta fuente se pueden ubicar en el lib carpeta como se muestra a continuación.

Establecer la ruta de clases
Selecciona el classpath variable a la lib carpeta de Flume en Flume-env.sh archivo como se muestra a continuación.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*Esta fuente necesita los detalles como Consumer key, Consumer secret, Access token, y Access token secretde una aplicación de Twitter. Al configurar esta fuente, debe proporcionar valores a las siguientes propiedades:
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - La clave de consumidor de OAuth
consumerSecret - Secreto de consumidor de OAuth
accessToken - Token de acceso OAuth
accessTokenSecret - Secreto de token de OAuth
maxBatchSize- Número máximo de mensajes de Twitter que deben estar en un lote de Twitter. El valor predeterminado es 1000 (opcional).
maxBatchDurationMillis- Número máximo de milisegundos a esperar antes de cerrar un lote. El valor predeterminado es 1000 (opcional).
Canal
Estamos usando el canal de memoria. Para configurar el canal de memoria, debe proporcionar valor al tipo de canal.
type- Contiene el tipo de canal. En nuestro ejemplo, el tipo esMemChannel.
Capacity- Es el número máximo de eventos almacenados en el canal. Su valor predeterminado es 100 (opcional).
TransactionCapacity- Es el número máximo de eventos que el canal acepta o envía. Su valor predeterminado es 100 (opcional).
Fregadero HDFS
Este receptor escribe datos en HDFS. Para configurar este receptor, debe proporcionar los siguientes detalles.
Channel
type - hdfs
hdfs.path - la ruta del directorio en HDFS donde se almacenarán los datos.
Y podemos proporcionar algunos valores opcionales basados en el escenario. A continuación se muestran las propiedades opcionales del receptor HDFS que estamos configurando en nuestra aplicación.
fileType - Este es el formato de archivo requerido de nuestro archivo HDFS. SequenceFile, DataStream y CompressedStreamson los tres tipos disponibles con esta secuencia. En nuestro ejemplo, estamos usando elDataStream.
writeFormat - Puede ser texto o escribible.
batchSize- Es el número de eventos escritos en un archivo antes de que se vacíe en el HDFS. Su valor predeterminado es 100.
rollsize- Es el tamaño del archivo para activar un rollo. Su valor predeterminado es 100.
rollCount- Es el número de eventos escritos en el archivo antes de que se transfiera. Su valor predeterminado es 10.
Ejemplo: archivo de configuración
A continuación se muestra un ejemplo del archivo de configuración. Copie este contenido y guárdelo comotwitter.conf en la carpeta conf de Flume.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelEjecución
Navegue por el directorio de inicio de Flume y ejecute la aplicación como se muestra a continuación.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentSi todo va bien, comenzará la transmisión de tweets a HDFS. A continuación se muestra la instantánea de la ventana del símbolo del sistema mientras se obtienen tweets.
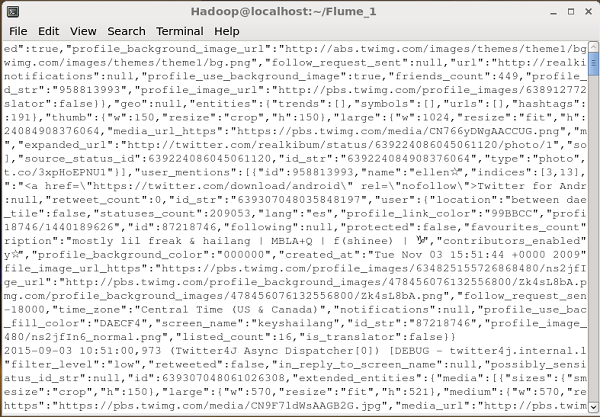
Verificación de HDFS
Puede acceder a la interfaz de usuario web de administración de Hadoop utilizando la URL que se proporciona a continuación.
http://localhost:50070/Haga clic en el menú desplegable llamado Utilitiesen el lado derecho de la página. Puede ver dos opciones como se muestra en la instantánea que se muestra a continuación.
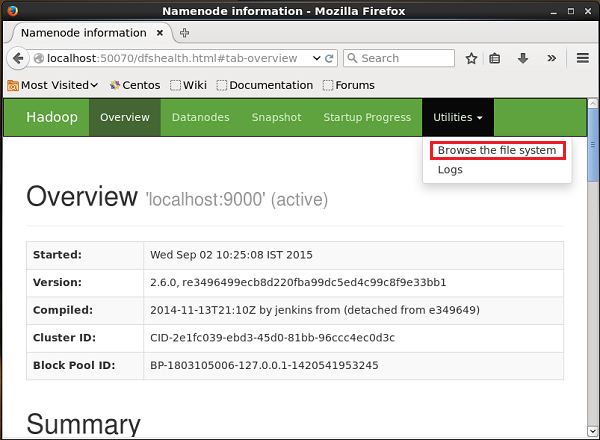
Haga clic en Browse the file systeme ingrese la ruta del directorio HDFS donde ha almacenado los tweets. En nuestro ejemplo, el camino será/user/Hadoop/twitter_data/. Luego, puede ver la lista de archivos de registro de Twitter almacenados en HDFS como se indica a continuación.

En el capítulo anterior, hemos visto cómo obtener datos de la fuente de Twitter a HDFS. Este capítulo explica cómo obtener datos deSequence generator.
Prerrequisitos
Para ejecutar el ejemplo proporcionado en este capítulo, debe instalar HDFS junto con Flume. Por lo tanto, verifique la instalación de Hadoop e inicie HDFS antes de continuar. (Consulte el capítulo anterior para saber cómo iniciar HDFS).
Configuración de Flume
Tenemos que configurar la fuente, el canal y el receptor usando el archivo de configuración en el confcarpeta. El ejemplo dado en este capítulo utiliza unsequence generator source, un memory channel, y un HDFS sink.
Fuente del generador de secuencia
Es la fuente que genera los eventos de forma continua. Mantiene un contador que comienza desde 0 y se incrementa en 1. Se utiliza con fines de prueba. Al configurar esta fuente, debe proporcionar valores a las siguientes propiedades:
Channels
Source type - seq
Canal
Estamos usando el memorycanal. Para configurar el canal de memoria, debe proporcionar un valor al tipo de canal. A continuación se muestra la lista de propiedades que debe proporcionar al configurar el canal de memoria:
type- Contiene el tipo de canal. En nuestro ejemplo, el tipo es MemChannel.
Capacity- Es el número máximo de eventos almacenados en el canal. Su valor predeterminado es 100. (opcional)
TransactionCapacity- Es el número máximo de eventos que el canal acepta o envía. Su valor predeterminado es 100 (opcional).
Fregadero HDFS
Este receptor escribe datos en HDFS. Para configurar este receptor, debe proporcionar los siguientes detalles.
Channel
type - hdfs
hdfs.path - la ruta del directorio en HDFS donde se almacenarán los datos.
Y podemos proporcionar algunos valores opcionales basados en el escenario. A continuación se muestran las propiedades opcionales del receptor HDFS que estamos configurando en nuestra aplicación.
fileType - Este es el formato de archivo requerido de nuestro archivo HDFS. SequenceFile, DataStream y CompressedStreamson los tres tipos disponibles con esta secuencia. En nuestro ejemplo, estamos usando elDataStream.
writeFormat - Puede ser texto o escribible.
batchSize- Es el número de eventos escritos en un archivo antes de que se vacíe en el HDFS. Su valor predeterminado es 100.
rollsize- Es el tamaño del archivo para activar un rollo. Su valor predeterminado es 100.
rollCount- Es el número de eventos escritos en el archivo antes de que se transfiera. Su valor predeterminado es 10.
Ejemplo: archivo de configuración
A continuación se muestra un ejemplo del archivo de configuración. Copie este contenido y guárdelo comoseq_gen .conf en la carpeta conf de Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelEjecución
Navegue por el directorio de inicio de Flume y ejecute la aplicación como se muestra a continuación.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentSi todo va bien, la fuente comienza a generar números de secuencia que se enviarán al HDFS en forma de archivos de registro.
A continuación se muestra una instantánea de la ventana del símbolo del sistema que recupera los datos generados por el generador de secuencias en el HDFS.

Verificando el HDFS
Puede acceder a la interfaz de usuario web de administración de Hadoop utilizando la siguiente URL:
http://localhost:50070/Haga clic en el menú desplegable llamado Utilitiesen el lado derecho de la página. Puede ver dos opciones como se muestra en el diagrama que se muestra a continuación.
Haga clic en Browse the file system e ingrese la ruta del directorio HDFS donde ha almacenado los datos generados por el generador de secuencias.
En nuestro ejemplo, el camino será /user/Hadoop/ seqgen_data /. Luego, puede ver la lista de archivos de registro generados por el generador de secuencias, almacenados en el HDFS como se indica a continuación.
Verificación del contenido del archivo
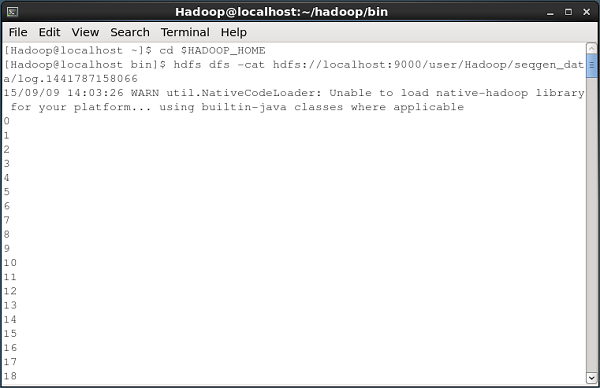
Todos estos archivos de registro contienen números en formato secuencial. Puede verificar el contenido de estos archivos en el sistema de archivos utilizando elcat comando como se muestra a continuación.
Este capítulo toma un ejemplo para explicar cómo puede generar eventos y luego registrarlos en la consola. Para esto, estamos usando elNetCat fuente y la logger lavabo.
Prerrequisitos
Para ejecutar el ejemplo proporcionado en este capítulo, debe instalar Flume.
Configuración de Flume
Tenemos que configurar la fuente, el canal y el receptor usando el archivo de configuración en el confcarpeta. El ejemplo dado en este capítulo utiliza unNetCat Source, Memory channely un logger sink.
Fuente NetCat
Al configurar la fuente de NetCat, tenemos que especificar un puerto mientras configuramos la fuente. Ahora la fuente (fuente NetCat) escucha el puerto dado y recibe cada línea que ingresamos en ese puerto como un evento individual y la transfiere al receptor a través del canal especificado.
Al configurar esta fuente, debe proporcionar valores a las siguientes propiedades:
channels
Source type - netcat
bind - Nombre de host o dirección IP para enlazar.
port - Número de puerto que queremos que escuche la fuente.
Canal
Estamos usando el memorycanal. Para configurar el canal de memoria, debe proporcionar un valor al tipo de canal. A continuación se muestra la lista de propiedades que debe proporcionar al configurar el canal de memoria:
type- Contiene el tipo de canal. En nuestro ejemplo, el tipo esMemChannel.
Capacity- Es el número máximo de eventos almacenados en el canal. Su valor predeterminado es 100. (opcional)
TransactionCapacity- Es el número máximo de eventos que el canal acepta o envía. Su valor predeterminado es 100 (opcional).
Fregadero del registrador
Este receptor registra todos los eventos que se le pasan. Generalmente, se utiliza con fines de prueba o depuración. Para configurar este receptor, debe proporcionar los siguientes detalles.
Channel
type - registrador
Archivo de configuración de ejemplo
A continuación se muestra un ejemplo del archivo de configuración. Copie este contenido y guárdelo comonetcat.conf en la carpeta conf de Flume.
# Naming the components on the current agent
NetcatAgent.sources = Netcat
NetcatAgent.channels = MemChannel
NetcatAgent.sinks = LoggerSink
# Describing/Configuring the source
NetcatAgent.sources.Netcat.type = netcat
NetcatAgent.sources.Netcat.bind = localhost
NetcatAgent.sources.Netcat.port = 56565
# Describing/Configuring the sink
NetcatAgent.sinks.LoggerSink.type = logger
# Describing/Configuring the channel
NetcatAgent.channels.MemChannel.type = memory
NetcatAgent.channels.MemChannel.capacity = 1000
NetcatAgent.channels.MemChannel.transactionCapacity = 100
# Bind the source and sink to the channel
NetcatAgent.sources.Netcat.channels = MemChannel
NetcatAgent.sinks. LoggerSink.channel = MemChannelEjecución
Navegue por el directorio de inicio de Flume y ejecute la aplicación como se muestra a continuación.
$ cd $FLUME_HOME
$ ./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/netcat.conf
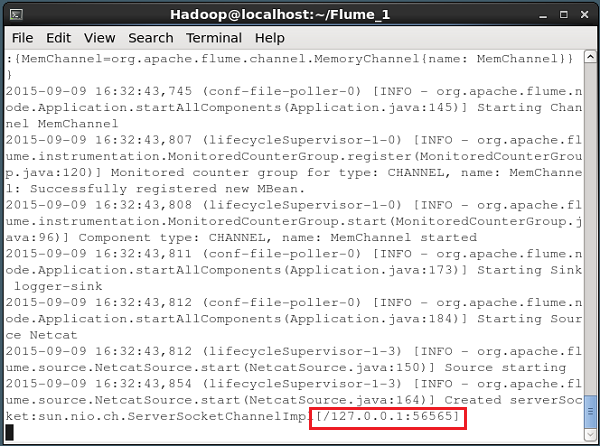
--name NetcatAgent -Dflume.root.logger=INFO,consoleSi todo va bien, la fuente comienza a escuchar el puerto indicado. En este caso lo es56565. A continuación se muestra la instantánea de la ventana del símbolo del sistema de una fuente NetCat que se ha iniciado y está escuchando el puerto 56565.
Pasar datos a la fuente
Para pasar datos a la fuente NetCat, debe abrir el puerto que se proporciona en el archivo de configuración. Abra un terminal separado y conéctelo a la fuente (56565) usando elcurlmando. Cuando la conexión sea exitosa, recibirá un mensaje "connected" Como se muestra abajo.
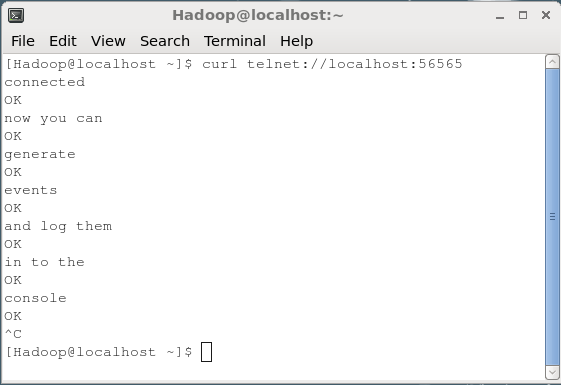
$ curl telnet://localhost:56565
connectedAhora puede ingresar sus datos línea por línea (después de cada línea, debe presionar Enter). La fuente de NetCat recibe cada línea como un evento individual y recibirá un mensaje recibido "OK”.
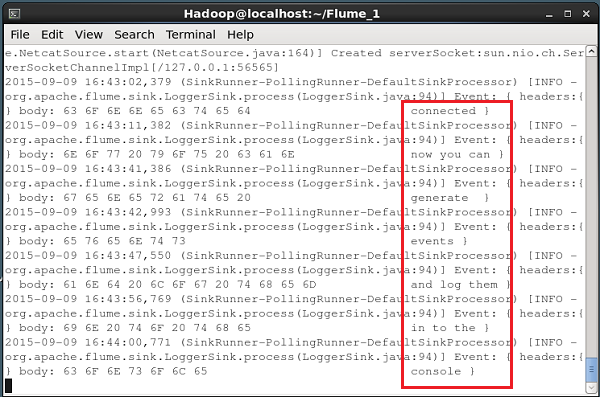
Siempre que haya terminado con el paso de datos, puede salir de la consola presionando (Ctrl+C). A continuación se muestra la instantánea de la consola donde nos hemos conectado a la fuente usando elcurl mando.
Cada línea que se ingrese en la consola anterior será recibida como un evento individual por la fuente. Dado que hemos utilizado elLogger receptor, estos eventos se registrarán en la consola (consola de origen) a través del canal especificado (canal de memoria en este caso).
La siguiente instantánea muestra la consola de NetCat donde se registran los eventos.