Apache Storm - Guía rápida
¿Qué es Apache Storm?
Apache Storm es un sistema de procesamiento de big data distribuido en tiempo real. Storm está diseñado para procesar una gran cantidad de datos en un método escalable horizontal y tolerante a fallas. Es un marco de transmisión de datos que tiene la capacidad de las tasas de ingestión más altas. Aunque Storm no tiene estado, administra el entorno distribuido y el estado del clúster a través de Apache ZooKeeper. Es simple y puede ejecutar todo tipo de manipulaciones en datos en tiempo real en paralelo.
Apache Storm continúa siendo líder en análisis de datos en tiempo real. Storm es fácil de configurar, operar y garantiza que cada mensaje se procesará a través de la topología al menos una vez.
Apache Storm contra Hadoop
Básicamente, los frameworks Hadoop y Storm se utilizan para analizar big data. Ambos se complementan y difieren en algunos aspectos. Apache Storm realiza todas las operaciones excepto la persistencia, mientras que Hadoop es bueno en todo, pero se retrasa en el cálculo en tiempo real. La siguiente tabla compara los atributos de Storm y Hadoop.
| Tormenta | Hadoop |
|---|---|
| Procesamiento de secuencias en tiempo real | Procesamiento por lotes |
| Apátrida | Con estado |
| Arquitectura maestro / esclavo con coordinación basada en ZooKeeper. El nodo maestro se llama comonimbus y los esclavos son supervisors. | Arquitectura maestro-esclavo con / sin coordinación basada en ZooKeeper. El nodo maestro esjob tracker y el nodo esclavo es task tracker. |
| Un proceso de transmisión de Storm puede acceder a decenas de miles de mensajes por segundo en el clúster. | El sistema de archivos distribuido de Hadoop (HDFS) utiliza el marco MapReduce para procesar una gran cantidad de datos que lleva minutos u horas. |
| La topología de tormenta se ejecuta hasta que el usuario la apaga o hasta que se produce una falla irrecuperable inesperada. | Los trabajos de MapReduce se ejecutan en orden secuencial y se completan eventualmente. |
| Both are distributed and fault-tolerant | |
| Si nimbus / supervisor muere, el reinicio hace que continúe desde donde se detuvo, por lo que nada se ve afectado. | Si JobTracker muere, todos los trabajos en ejecución se pierden. |
Casos de uso de Apache Storm
Apache Storm es muy famoso por el procesamiento de flujos de big data en tiempo real. Por esta razón, la mayoría de las empresas utilizan Storm como parte integral de su sistema. Algunos ejemplos notables son los siguientes:
Twitter- Twitter está utilizando Apache Storm para su gama de "productos de Publisher Analytics". Los “Productos de análisis de editores” procesan todos y cada uno de los tweets y clics en la plataforma de Twitter. Apache Storm está profundamente integrado con la infraestructura de Twitter.
NaviSite- NaviSite utiliza Storm para el sistema de supervisión / auditoría de registros de eventos. Todos los registros generados en el sistema pasarán por Storm. Storm comparará el mensaje con el conjunto configurado de expresiones regulares y, si hay una coincidencia, ese mensaje en particular se guardará en la base de datos.
Wego- Wego es un metabuscador de viajes ubicado en Singapur. Los datos relacionados con los viajes provienen de muchas fuentes en todo el mundo con diferentes tiempos. Storm ayuda a Wego a buscar datos en tiempo real, resuelve problemas de concurrencia y encuentra la mejor coincidencia para el usuario final.
Beneficios de Apache Storm
Aquí hay una lista de los beneficios que ofrece Apache Storm:
Storm es de código abierto, robusto y fácil de usar. Podría utilizarse tanto en pequeñas empresas como en grandes corporaciones.
Storm es tolerante a fallas, flexible, confiable y es compatible con cualquier lenguaje de programación.
Permite el procesamiento de transmisiones en tiempo real.
Storm es increíblemente rápido porque tiene un enorme poder de procesamiento de datos.
Storm puede mantener el rendimiento incluso bajo una carga creciente al agregar recursos de forma lineal. Es altamente escalable.
Storm realiza la actualización de datos y la respuesta de entrega de un extremo a otro en segundos o minutos, según el problema. Tiene una latencia muy baja.
Storm tiene inteligencia operativa.
Storm proporciona un procesamiento de datos garantizado incluso si alguno de los nodos conectados en el clúster muere o se pierden mensajes.
Apache Storm lee el flujo sin procesar de datos en tiempo real desde un extremo, lo pasa a través de una secuencia de pequeñas unidades de procesamiento y genera la información procesada / útil en el otro extremo.
El siguiente diagrama muestra el concepto central de Apache Storm.

Echemos ahora un vistazo más de cerca a los componentes de Apache Storm:
| Componentes | Descripción |
|---|---|
| Tupla | Tuple es la estructura de datos principal en Storm. Es una lista de elementos ordenados. De forma predeterminada, una tupla admite todos los tipos de datos. Generalmente, se modela como un conjunto de valores separados por comas y se pasa a un clúster de Storm. |
| Corriente | Stream es una secuencia desordenada de tuplas. |
| Caños | Fuente de arroyo. Generalmente, Storm acepta datos de entrada de fuentes de datos sin procesar como Twitter Streaming API, cola de Apache Kafka, cola de Kestrel, etc. De lo contrario, puede escribir spouts para leer datos de fuentes de datos. "ISpout" es la interfaz principal para implementar spouts. Algunas de las interfaces específicas son IRichSpout, BaseRichSpout, KafkaSpout, etc. |
| Pernos | Los pernos son unidades lógicas de procesamiento. Los surtidores pasan datos al proceso de pernos y pernos y producen un nuevo flujo de salida. Bolts puede realizar las operaciones de filtrado, agregación, unión e interacción con fuentes de datos y bases de datos. Bolt recibe datos y emite a uno o más tornillos. “IBolt” es la interfaz principal para implementar pernos. Algunas de las interfaces comunes son IRichBolt, IBasicBolt, etc. |
Tomemos un ejemplo en tiempo real de “Análisis de Twitter” y veamos cómo se puede modelar en Apache Storm. El siguiente diagrama muestra la estructura.

La entrada para el "Análisis de Twitter" proviene de Twitter Streaming API. Spout leerá los tweets de los usuarios que utilizan la API de transmisión de Twitter y los generará como un flujo de tuplas. Una sola tupla del pico tendrá un nombre de usuario de Twitter y un solo tweet como valores separados por comas. Luego, este grupo de tuplas se enviará a Bolt y Bolt dividirá el tweet en palabras individuales, calculará el recuento de palabras y mantendrá la información en una fuente de datos configurada. Ahora, podemos obtener fácilmente el resultado consultando la fuente de datos.
Topología
Los picos y los pernos están conectados entre sí y forman una topología. La lógica de la aplicación en tiempo real se especifica dentro de la topología de Storm. En palabras simples, una topología es un gráfico dirigido donde los vértices son cálculos y los bordes son un flujo de datos.
Una topología simple comienza con picos. Spout emite los datos a uno o más tornillos. El perno representa un nodo en la topología que tiene la lógica de procesamiento más pequeña y la salida de un perno se puede emitir a otro perno como entrada.
Storm mantiene la topología siempre en ejecución, hasta que mata la topología. El trabajo principal de Apache Storm es ejecutar la topología y ejecutará cualquier número de topología en un momento dado.
Tareas
Ahora tienes una idea básica sobre picos y pernos. Son la unidad lógica más pequeña de la topología y una topología se construye utilizando un solo pico y una serie de pernos. Deben ejecutarse correctamente en un orden particular para que la topología se ejecute correctamente. La ejecución de todos y cada uno de los caños y cerrojos de Storm se denomina "Tareas". En palabras simples, una tarea es la ejecución de un pico o un cerrojo. En un momento dado, cada pico y perno puede tener varias instancias ejecutándose en varios subprocesos separados.
Trabajadores
Una topología se ejecuta de forma distribuida en varios nodos trabajadores. Storm distribuye las tareas de manera uniforme en todos los nodos de trabajadores. La función del nodo trabajador es escuchar trabajos e iniciar o detener los procesos cada vez que llega un nuevo trabajo.
Agrupación de transmisiones
El flujo de datos fluye de los picos a los pernos o de un perno a otro. La agrupación de flujos controla cómo se enrutan las tuplas en la topología y nos ayuda a comprender el flujo de tuplas en la topología. Hay cuatro agrupaciones integradas como se explica a continuación.
Agrupación aleatoria
En la agrupación aleatoria, se distribuye aleatoriamente un número igual de tuplas entre todos los trabajadores que ejecutan los pernos. El siguiente diagrama muestra la estructura.

Agrupación de campos
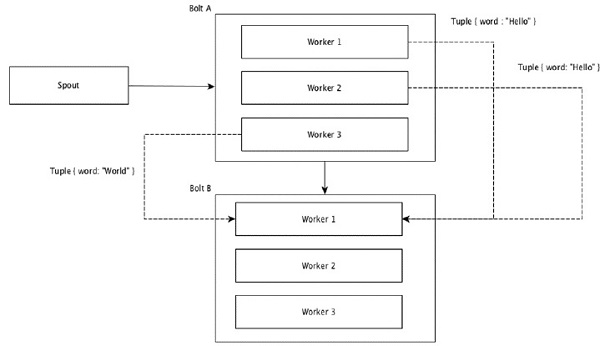
Los campos con los mismos valores en tuplas se agrupan y las tuplas restantes se mantienen fuera. Luego, las tuplas con los mismos valores de campo se envían al mismo trabajador que ejecuta los pernos. Por ejemplo, si la secuencia está agrupada por el campo "palabra", las tuplas con la misma cadena, "Hola" se moverán al mismo trabajador. El siguiente diagrama muestra cómo funciona la agrupación de campos.

Agrupación global
Todas las corrientes se pueden agrupar y enviar a un solo perno. Esta agrupación envía tuplas generadas por todas las instancias del origen a una única instancia de destino (específicamente, elija el trabajador con el ID más bajo).
Todo agrupamiento
All Grouping envía una única copia de cada tupla a todas las instancias del perno receptor. Este tipo de agrupación se utiliza para enviar señales a los tornillos. Toda la agrupación es útil para las operaciones de combinación.

Uno de los aspectos más destacados de Apache Storm es que es una aplicación distribuida rápida, tolerante a fallas y sin "punto único de falla" (SPOF). Podemos instalar Apache Storm en tantos sistemas como sea necesario para aumentar la capacidad de la aplicación.
Echemos un vistazo a cómo está diseñado el clúster de Apache Storm y su arquitectura interna. El siguiente diagrama muestra el diseño del clúster.

Apache Storm tiene dos tipos de nodos, Nimbus (nodo maestro) y Supervisor(nodo trabajador). Nimbus es el componente central de Apache Storm. El trabajo principal de Nimbus es ejecutar la topología Storm. Nimbus analiza la topología y recopila la tarea a ejecutar. Luego, distribuirá la tarea a un supervisor disponible.
Un supervisor tendrá uno o más procesos de trabajador. El supervisor delegará las tareas a los procesos de los trabajadores. El proceso de trabajo generará tantos ejecutores como sea necesario y ejecutará la tarea. Apache Storm utiliza un sistema de mensajería distribuido interno para la comunicación entre nimbus y supervisores.
| Componentes | Descripción |
|---|---|
| Nimbo | Nimbus es un nodo maestro del clúster Storm. Todos los demás nodos del clúster se denominanworker nodes. El nodo maestro es responsable de distribuir datos entre todos los nodos trabajadores, asignar tareas a los nodos trabajadores y monitorear fallas. |
| Supervisor | Los nodos que siguen las instrucciones dadas por el nimbus se denominan Supervisores. UNsupervisor tiene múltiples procesos de trabajo y gobierna los procesos de trabajo para completar las tareas asignadas por el nimbus. |
| Proceso de trabajo | Un proceso de trabajo ejecutará tareas relacionadas con una topología específica. Un proceso de trabajo no ejecutará una tarea por sí mismo, sino que creaexecutorsy les pide que realicen una tarea en particular. Un proceso de trabajo tendrá varios ejecutores. |
| Ejecutor | Un ejecutor no es más que un hilo único generado por un proceso de trabajo. Un ejecutor ejecuta una o más tareas, pero solo para un pico o cerrojo específico. |
| Tarea | Una tarea realiza el procesamiento de datos real. Entonces, es un pico o un perno. |
| Marco de ZooKeeper | Apache ZooKeeper es un servicio utilizado por un clúster (grupo de nodos) para coordinarse entre sí y mantener los datos compartidos con técnicas de sincronización sólidas. Nimbus no tiene estado, por lo que depende de ZooKeeper monitorear el estado del nodo de trabajo. ZooKeeper ayuda al supervisor a interactuar con el nimbus. Es responsable de mantener el estado de nimbus y supervisor. |
Storm es de naturaleza apátrida. Aunque la naturaleza sin estado tiene sus propias desventajas, en realidad ayuda a Storm a procesar datos en tiempo real de la mejor manera posible y más rápida.
Sin embargo, Storm no es del todo apátrida. Almacena su estado en Apache ZooKeeper. Dado que el estado está disponible en Apache ZooKeeper, un nimbus fallido se puede reiniciar y hacer que funcione desde donde salió. Por lo general, las herramientas de monitoreo de servicios comomonit monitoreará Nimbus y lo reiniciará si hay alguna falla.
Apache Storm también tiene una topología avanzada llamada Trident Topologycon mantenimiento de estado y también proporciona una API de alto nivel como Pig. Discutiremos todas estas características en los próximos capítulos.
Un clúster de Storm en funcionamiento debe tener un nimbus y uno o más supervisores. Otro nodo importante es Apache ZooKeeper, que se utilizará para la coordinación entre el nimbus y los supervisores.
Echemos ahora un vistazo de cerca al flujo de trabajo de Apache Storm:
Inicialmente, el nimbus esperará a que se le envíe la “Topología de tormenta”.
Una vez que se envía una topología, procesará la topología y recopilará todas las tareas que se van a realizar y el orden en el que se ejecutará la tarea.
Luego, el nimbus distribuirá uniformemente las tareas a todos los supervisores disponibles.
En un intervalo de tiempo particular, todos los supervisores enviarán latidos al nimbus para informar que todavía están vivos.
Cuando un supervisor muere y no envía un latido al nimbus, el nimbus asigna las tareas a otro supervisor.
Cuando el nimbus mismo muere, los supervisores trabajarán en la tarea ya asignada sin ningún problema.
Una vez completadas todas las tareas, el supervisor esperará a que entre una nueva tarea.
Mientras tanto, las herramientas de supervisión del servicio reiniciarán automáticamente el nimbus muerto.
El nimbus reiniciado continuará desde donde se detuvo. Del mismo modo, el supervisor muerto también se puede reiniciar automáticamente. Dado que tanto el nimbus como el supervisor se pueden reiniciar automáticamente y ambos continuarán como antes, Storm tiene la garantía de procesar todas las tareas al menos una vez.
Una vez que se procesan todas las topologías, el nimbus espera que llegue una nueva topología y, de manera similar, el supervisor espera nuevas tareas.
De forma predeterminada, hay dos modos en un clúster de Storm:
Local mode- Este modo se utiliza para desarrollo, pruebas y depuración porque es la forma más fácil de ver todos los componentes de topología trabajando juntos. En este modo, podemos ajustar parámetros que nos permiten ver cómo se ejecuta nuestra topología en diferentes entornos de configuración de Storm. En el modo local, las topologías de tormenta se ejecutan en la máquina local en una única JVM.
Production mode- En este modo, enviamos nuestra topología al clúster de tormenta en funcionamiento, que se compone de muchos procesos, que generalmente se ejecutan en diferentes máquinas. Como se discutió en el flujo de trabajo de Storm, un clúster en funcionamiento se ejecutará indefinidamente hasta que se cierre.
Apache Storm procesa datos en tiempo real y la entrada normalmente proviene de un sistema de cola de mensajes. Un sistema de mensajería distribuido externo proporcionará la entrada necesaria para el cálculo en tiempo real. Spout leerá los datos del sistema de mensajería y los convertirá en tuplas y los ingresará en Apache Storm. Lo interesante es que Apache Storm utiliza su propio sistema de mensajería distribuida internamente para la comunicación entre su nimbus y su supervisor.
¿Qué es el sistema de mensajería distribuida?
La mensajería distribuida se basa en el concepto de cola de mensajes confiable. Los mensajes se ponen en cola de forma asincrónica entre las aplicaciones cliente y los sistemas de mensajería. Un sistema de mensajería distribuida proporciona los beneficios de confiabilidad, escalabilidad y persistencia.
La mayoría de los patrones de mensajería siguen las publish-subscribe modelo (simplemente Pub-Sub) donde se llama a los remitentes de los mensajes publishers y los que quieran recibir los mensajes se llaman subscribers.
Una vez que el remitente ha publicado el mensaje, los suscriptores pueden recibir el mensaje seleccionado con la ayuda de una opción de filtrado. Normalmente tenemos dos tipos de filtrado, uno estopic-based filtering y otro es content-based filtering.
Tenga en cuenta que el modelo pub-sub solo puede comunicarse a través de mensajes. Es una arquitectura muy débilmente acoplada; incluso los remitentes no saben quiénes son sus suscriptores. Muchos de los patrones de mensajes permiten al intermediario de mensajes intercambiar mensajes de publicación para que muchos suscriptores tengan acceso oportuno. Un ejemplo de la vida real es Dish TV, que publica diferentes canales como deportes, películas, música, etc., y cualquiera puede suscribirse a su propio conjunto de canales y obtenerlos siempre que sus canales suscritos estén disponibles.
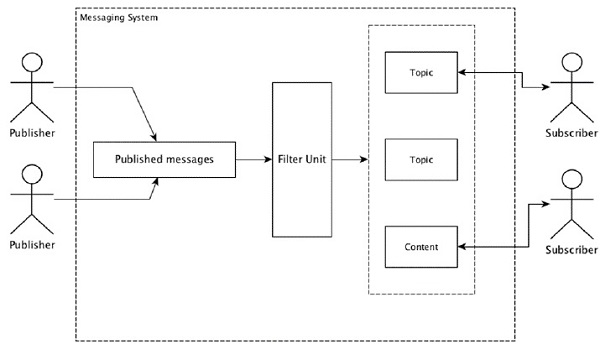
La siguiente tabla describe algunos de los sistemas de mensajería de alto rendimiento más populares:
| Sistema de mensajería distribuida | Descripción |
|---|---|
| Apache Kafka | Kafka se desarrolló en la corporación LinkedIn y luego se convirtió en un subproyecto de Apache. Apache Kafka se basa en un modelo de publicación-suscripción distribuido, persistente y habilitado para la ruptura. Kafka es rápido, escalable y altamente eficiente. |
| RabbitMQ | RabbitMQ es una aplicación de mensajería robusta distribuida de código abierto. Es fácil de usar y se ejecuta en todas las plataformas. |
| JMS (servicio de mensajes Java) | JMS es una API de código abierto que admite la creación, lectura y envío de mensajes de una aplicación a otra. Proporciona entrega de mensajes garantizada y sigue el modelo de publicación-suscripción. |
| ActiveMQ | El sistema de mensajería ActiveMQ es una API de código abierto de JMS. |
| ZeroMQ | ZeroMQ es un procesamiento de mensajes de igual a igual sin intermediario. Proporciona patrones de mensajes push-pull, enrutador-distribuidor. |
| Cernícalo | Kestrel es una cola de mensajes distribuida rápida, confiable y simple. |
Protocolo de ahorro
Thrift se creó en Facebook para el desarrollo de servicios en varios idiomas y la llamada a procedimiento remoto (RPC). Más tarde, se convirtió en un proyecto Apache de código abierto. Apache Thrift es unInterface Definition Language y permite definir nuevos tipos de datos y la implementación de servicios sobre los tipos de datos definidos de una manera sencilla.
Apache Thrift también es un marco de comunicación que admite sistemas integrados, aplicaciones móviles, aplicaciones web y muchos otros lenguajes de programación. Algunas de las características clave asociadas con Apache Thrift son su modularidad, flexibilidad y alto rendimiento. Además, puede realizar streaming, mensajería y RPC en aplicaciones distribuidas.
Storm utiliza ampliamente Thrift Protocol para su comunicación interna y definición de datos. La topología de tormenta es simplementeThrift Structs. Storm Nimbus que ejecuta la topología en Apache Storm es unaThrift service.
Veamos ahora cómo instalar el marco Apache Storm en su máquina. Aquí hay tres grandes pasos:
- Instale Java en su sistema, si aún no lo tiene.
- Instale el marco de ZooKeeper.
- Instale el marco de trabajo de Apache Storm.
Paso 1: verificar la instalación de Java
Utilice el siguiente comando para comprobar si ya tiene Java instalado en su sistema.
$ java -versionSi Java ya está allí, verá su número de versión. De lo contrario, descargue la última versión de JDK.
Paso 1.1 - Descarga JDK
Descargue la última versión de JDK utilizando el siguiente enlace: www.oracle.com
La última versión es JDK 8u 60 y el archivo es “jdk-8u60-linux-x64.tar.gz”. Descargue el archivo en su máquina.
Paso 1.2 - Extraer archivos
Generalmente, los archivos se descargan en el downloadscarpeta. Extraiga la configuración de tar usando los siguientes comandos.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzPaso 1.3 - Mover al directorio de opciones
Para que Java esté disponible para todos los usuarios, mueva el contenido java extraído a la carpeta “/ usr / local / java”.
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/Paso 1.4 - Establecer ruta
Para establecer la ruta y las variables JAVA_HOME, agregue los siguientes comandos al archivo ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binAhora aplique todos los cambios en el sistema en ejecución actual.
$ source ~/.bashrcPaso 1.5 - Alternativas de Java
Utilice el siguiente comando para cambiar las alternativas de Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Paso 1.6
Ahora verifique la instalación de Java usando el comando de verificación (java -version) explicado en el Paso 1.
Paso 2: instalación de ZooKeeper Framework
Paso 2.1 - Descarga ZooKeeper
Para instalar el framework ZooKeeper en su máquina, visite el siguiente enlace y descargue la última versión de ZooKeeper http://zookeeper.apache.org/releases.html
A partir de ahora, la última versión de ZooKeeper es 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Paso 2.2 - Extraiga el archivo tar
Extraiga el archivo tar usando los siguientes comandos:
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir dataPaso 2.3 - Crear archivo de configuración
Abra el archivo de configuración llamado "conf / zoo.cfg" usando el comando "vi conf / zoo.cfg" y estableciendo todos los siguientes parámetros como punto de partida.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Una vez que el archivo de configuración se haya guardado correctamente, puede iniciar el servidor de ZooKeeper.
Paso 2.4 - Inicie ZooKeeper Server
Utilice el siguiente comando para iniciar el servidor de ZooKeeper.
$ bin/zkServer.sh startDespués de ejecutar este comando, obtendrá una respuesta de la siguiente manera:
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTEDPaso 2.5 - Inicie CLI
Utilice el siguiente comando para iniciar la CLI.
$ bin/zkCli.shDespués de ejecutar el comando anterior, se conectará al servidor de ZooKeeper y obtendrá la siguiente respuesta.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Paso 2.6 - Detenga el servidor ZooKeeper
Después de conectar el servidor y realizar todas las operaciones, puede detener el servidor de ZooKeeper usando el siguiente comando.
bin/zkServer.sh stopHa instalado con éxito Java y ZooKeeper en su máquina. Veamos ahora los pasos para instalar el framework Apache Storm.
Paso 3: instalación de Apache Storm Framework
Paso 3.1 Descarga Storm
Para instalar Storm framework en su máquina, visite el siguiente enlace y descargue la última versión de Storm http://storm.apache.org/downloads.html
A partir de ahora, la última versión de Storm es "apache-storm-0.9.5.tar.gz".
Paso 3.2 - Extraiga el archivo tar
Extraiga el archivo tar usando los siguientes comandos:
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir dataPaso 3.3 - Abrir archivo de configuración
La versión actual de Storm contiene un archivo en “conf / storm.yaml” que configura los demonios de Storm. Agregue la siguiente información a ese archivo.
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703Después de aplicar todos los cambios, guarde y regrese a la terminal.
Paso 3.4 - Inicie el Nimbus
$ bin/storm nimbusPaso 3.5 - Inicie el supervisor
$ bin/storm supervisorPaso 3.6 Inicie la interfaz de usuario
$ bin/storm uiDespués de iniciar la aplicación de interfaz de usuario de Storm, escriba la URL http://localhost:8080en su navegador favorito y podría ver la información del clúster de Storm y su topología en ejecución. La página debe verse similar a la siguiente captura de pantalla.

Hemos revisado los detalles técnicos básicos de Apache Storm y ahora es el momento de codificar algunos escenarios simples.
Escenario: analizador de registro de llamadas móviles
La llamada móvil y su duración se proporcionarán como entrada a Apache Storm y Storm procesará y agrupará la llamada entre la misma persona que llama y el mismo receptor y su número total de llamadas.
Creación de pico
Spout es un componente que se utiliza para la generación de datos. Básicamente, un pico implementará una interfaz IRichSpout. La interfaz "IRichSpout" tiene los siguientes métodos importantes:
open- Proporciona al pico un entorno para ejecutar. Los ejecutores ejecutarán este método para inicializar el pico.
nextTuple - Emite los datos generados a través del recolector.
close - Este método se llama cuando se va a apagar un pico.
declareOutputFields - Declara el esquema de salida de la tupla.
ack - Reconoce que se procesa una tupla específica
fail - Especifica que una tupla específica no se procesa y no se reprocesará.
Abierto
La firma del open El método es el siguiente:
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf - Proporciona configuración de tormenta para este pico.
context - Proporciona información completa sobre el lugar del pico dentro de la topología, su identificación de tarea, información de entrada y salida.
collector - Nos permite emitir la tupla que será procesada por los pernos.
nextTuple
La firma del nextTuple El método es el siguiente:
nextTuple()nextTuple () se llama periódicamente desde el mismo ciclo que los métodos ack () y fail (). Debe liberar el control del hilo cuando no hay trabajo por hacer, para que los otros métodos tengan la oportunidad de ser llamados. Entonces, la primera línea de nextTuple verifica si el procesamiento ha terminado. Si es así, debería dormir durante al menos un milisegundo para reducir la carga en el procesador antes de regresar.
cerca
La firma del close El método es el siguiente:
close()declareOutputFields
La firma del declareOutputFields El método es el siguiente:
declareOutputFields(OutputFieldsDeclarer declarer)declarer - Se utiliza para declarar ID de flujo de salida, campos de salida, etc.
Este método se utiliza para especificar el esquema de salida de la tupla.
ack
La firma del ack El método es el siguiente:
ack(Object msgId)Este método reconoce que se ha procesado una tupla específica.
fallar
La firma del nextTuple El método es el siguiente:
ack(Object msgId)Este método informa que una tupla específica no se ha procesado por completo. Storm reprocesará la tupla específica.
FakeCallLogReaderSpout
En nuestro escenario, necesitamos recopilar los detalles del registro de llamadas. La información del registro de llamadas contiene.
- número de la persona que llama
- número de receptor
- duration
Dado que no tenemos información en tiempo real de los registros de llamadas, generaremos registros de llamadas falsos. La información falsa se creará usando la clase Random. El código completo del programa se proporciona a continuación.
Codificación - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Creación de pernos
Bolt es un componente que toma tuplas como entrada, procesa la tupla y produce nuevas tuplas como salida. Los pernos implementaránIRichBoltinterfaz. En este programa, dos clases de tornillosCallLogCreatorBolt y CallLogCounterBolt se utilizan para realizar las operaciones.
La interfaz IRichBolt tiene los siguientes métodos:
prepare- Proporciona al cerrojo un entorno para ejecutar. Los ejecutores ejecutarán este método para inicializar el pico.
execute - Procesar una sola tupla de entrada.
cleanup - Llamado cuando un cerrojo se va a apagar.
declareOutputFields - Declara el esquema de salida de la tupla.
Preparar
La firma del prepare El método es el siguiente:
prepare(Map conf, TopologyContext context, OutputCollector collector)conf - Proporciona configuración Storm para este perno.
context - Proporciona información completa sobre el lugar del perno dentro de la topología, su identificación de tarea, información de entrada y salida, etc.
collector - Nos permite emitir la tupla procesada.
ejecutar
La firma del execute El método es el siguiente:
execute(Tuple tuple)aquí tuple es la tupla de entrada que se procesará.
los executeEl método procesa una sola tupla a la vez. Se puede acceder a los datos de tupla mediante el método getValue de la clase Tuple. No es necesario procesar la tupla de entrada inmediatamente. Se pueden procesar múltiples tuplas y generar como una única tupla de salida. La tupla procesada se puede emitir utilizando la clase OutputCollector.
limpiar
La firma del cleanup El método es el siguiente:
cleanup()declareOutputFields
La firma del declareOutputFields El método es el siguiente:
declareOutputFields(OutputFieldsDeclarer declarer)Aquí el parámetro declarer se utiliza para declarar ID de flujo de salida, campos de salida, etc.
Este método se utiliza para especificar el esquema de salida de la tupla.
Registro de llamadas Creator Bolt
El perno del creador del registro de llamadas recibe la tupla del registro de llamadas. La tupla del registro de llamadas tiene el número de la persona que llama, el número del receptor y la duración de la llamada. Este perno simplemente crea un nuevo valor combinando el número de la persona que llama y el número del receptor. El formato del nuevo valor es "Número de llamante - Número de receptor" y se denomina como nuevo campo, "llamada". El código completo se proporciona a continuación.
Codificación - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Perno contador de registro de llamadas
El perno del contador del registro de llamadas recibe la llamada y su duración como una tupla. Este perno inicializa un objeto de diccionario (mapa) en el método de preparación. Enexecute, comprueba la tupla y crea una nueva entrada en el objeto de diccionario para cada nuevo valor de "llamada" en la tupla y establece un valor 1 en el objeto de diccionario. Para la entrada ya disponible en el diccionario, simplemente incrementa su valor. En términos simples, este perno guarda la llamada y su recuento en el objeto de diccionario. En lugar de guardar la llamada y su recuento en el diccionario, también podemos guardarla en una fuente de datos. El código completo del programa es el siguiente:
Codificación - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Crear topología
La topología de Storm es básicamente una estructura de ahorro. La clase TopologyBuilder proporciona métodos sencillos y sencillos para crear topologías complejas. La clase TopologyBuilder tiene métodos para configurar spout(setSpout) y para fijar el perno (setBolt). Finalmente, TopologyBuilder tiene createTopology para crear topología. Utilice el siguiente fragmento de código para crear una topología:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping y fieldsGrouping Los métodos ayudan a configurar la agrupación de arroyos para picos y pernos.
Clúster local
Para propósitos de desarrollo, podemos crear un clúster local usando el objeto "LocalCluster" y luego enviar la topología usando el método "submitTopology" de la clase "LocalCluster". Uno de los argumentos para "submitTopology" es una instancia de la clase "Config". La clase "Config" se utiliza para establecer opciones de configuración antes de enviar la topología. Esta opción de configuración se fusionará con la configuración del clúster en el tiempo de ejecución y se enviará a todas las tareas (pico y cerrojo) con el método de preparación. Una vez que la topología se envía al clúster, esperaremos 10 segundos para que el clúster calcule la topología enviada y luego apagaremos el clúster mediante el método de "apagado" de "LocalCluster". El código completo del programa es el siguiente:
Codificación - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}Crear y ejecutar la aplicación
La aplicación completa tiene cuatro códigos Java. Ellos son -
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
La aplicación se puede construir usando el siguiente comando:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaLa aplicación se puede ejecutar usando el siguiente comando:
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStormSalida
Una vez que se inicia la aplicación, se mostrarán los detalles completos sobre el proceso de inicio del clúster, el procesamiento del canal y el perno y, finalmente, el proceso de cierre del clúster. En "CallLogCounterBolt", hemos impreso la llamada y sus detalles de recuento. Esta información se mostrará en la consola de la siguiente manera:
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93Idiomas que no son JVM
Las topologías de tormenta se implementan mediante interfaces Thrift, lo que facilita el envío de topologías en cualquier idioma. Storm admite Ruby, Python y muchos otros lenguajes. Echemos un vistazo al enlace de Python.
Enlace de Python
Python es un lenguaje de programación de uso general interpretado, interactivo, orientado a objetos y de alto nivel. Storm admite Python para implementar su topología. Python admite operaciones de emisión, anclaje, seguimiento y registro.
Como sabe, los tornillos se pueden definir en cualquier idioma. Los pernos escritos en otro idioma se ejecutan como subprocesos, y Storm se comunica con esos subprocesos con mensajes JSON a través de stdin / stdout. Primero, tome un WordCount de perno de muestra que admita el enlace de Python.
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}Aqui la clase WordCount implementa el IRichBoltinterfaz y se ejecuta con la implementación de Python especificada como argumento del súper método "splitword.py". Ahora cree una implementación de Python llamada "splitword.py".
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()Esta es la implementación de muestra para Python que cuenta las palabras en una oración determinada. De manera similar, también puede vincularse con otros idiomas de soporte.
Trident es una extensión de Storm. Al igual que Storm, Trident también fue desarrollado por Twitter. La razón principal detrás del desarrollo de Trident es proporcionar una abstracción de alto nivel sobre Storm junto con procesamiento de flujo con estado y consultas distribuidas de baja latencia.
Trident usa pico y cerrojo, pero estos componentes de bajo nivel son generados automáticamente por Trident antes de la ejecución. Trident tiene funciones, filtros, uniones, agrupación y agregación.
Trident procesa los flujos como una serie de lotes que se denominan transacciones. Generalmente, el tamaño de esos pequeños lotes será del orden de miles o millones de tuplas, según el flujo de entrada. De esta manera, Trident es diferente de Storm, que realiza el procesamiento tupla por tupla.
El concepto de procesamiento por lotes es muy similar al de las transacciones de bases de datos. A cada transacción se le asigna un ID de transacción. La transacción se considera exitosa, una vez que se completa todo su procesamiento. Sin embargo, una falla en el procesamiento de una de las tuplas de la transacción hará que se retransmita toda la transacción. Para cada lote, Trident llamará a beginCommit al comienzo de la transacción y se comprometerá al final de la misma.
Topología tridente
Trident API expone una opción fácil para crear topología Trident usando la clase "TridentTopology". Básicamente, la topología Trident recibe el flujo de entrada del canal y realiza una secuencia ordenada de operación (filtro, agregación, agrupación, etc.) en el flujo. Storm Tuple se reemplaza por Trident Tuple y Bolts se reemplazan por operaciones. Se puede crear una topología Trident simple de la siguiente manera:
TridentTopology topology = new TridentTopology();Tuplas tridentes
La tupla tridente es una lista de valores con nombre. La interfaz TridentTuple es el modelo de datos de una topología Trident. La interfaz TridentTuple es la unidad básica de datos que puede procesar una topología Trident.
Caño tridente
El pico Trident es similar al pico Storm, con opciones adicionales para usar las funciones de Trident. De hecho, todavía podemos usar el IRichSpout, que hemos usado en la topología de Storm, pero será de naturaleza no transaccional y no podremos usar las ventajas proporcionadas por Trident.
El pico básico que tiene todas las funciones para utilizar las funciones de Trident es "ITridentSpout". Es compatible con semántica transaccional transaccional y opaca. Los otros surtidores son IBatchSpout, IPartitionedTridentSpout e IOpaquePartitionedTridentSpout.
Además de estos picos genéricos, Trident tiene muchos ejemplos de implementación del pico tridente. Uno de ellos es el pico FeederBatchSpout, que podemos usar para enviar listas nombradas de tuplas tridentes fácilmente sin preocuparnos por el procesamiento por lotes, el paralelismo, etc.
La creación de FeederBatchSpout y la alimentación de datos se pueden realizar como se muestra a continuación:
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));Operaciones de tridente
Trident se basa en la "Operación Trident" para procesar el flujo de entrada de tuplas trident. La API Trident tiene una serie de operaciones integradas para manejar el procesamiento de flujos de simples a complejos. Estas operaciones van desde la validación simple hasta la agrupación compleja y agregación de tuplas de tridentes. Repasemos las operaciones más importantes y de uso frecuente.
Filtrar
El filtro es un objeto utilizado para realizar la tarea de validación de entrada. Un filtro Trident obtiene un subconjunto de campos de tupla trident como entrada y devuelve verdadero o falso dependiendo de si se cumplen ciertas condiciones o no. Si se devuelve true, la tupla se mantiene en el flujo de salida; de lo contrario, la tupla se elimina de la secuencia. El filtro básicamente heredará delBaseFilter clase e implementar el isKeepmétodo. Aquí hay una implementación de muestra del funcionamiento del filtro:
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]La función de filtro se puede llamar en la topología utilizando el método "cada". La clase "Campos" se puede utilizar para especificar la entrada (subconjunto de la tupla tridente). El código de muestra es el siguiente:
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())Función
Functiones un objeto que se utiliza para realizar una operación simple en una tupla de un solo tridente. Toma un subconjunto de campos de tupla tridente y emite cero o más campos de tupla tridente nuevos.
Function básicamente hereda de la BaseFunction clase e implementa el executemétodo. A continuación se ofrece una implementación de muestra:
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]Al igual que la operación de filtro, la operación de función se puede llamar en una topología utilizando el eachmétodo. El código de muestra es el siguiente:
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));Agregación
La agregación es un objeto que se utiliza para realizar operaciones de agregación en un lote de entrada, una partición o un flujo. Trident tiene tres tipos de agregación. Son los siguientes:
aggregate- Agrega cada lote de tupla tridente de forma aislada. Durante el proceso de agregación, las tuplas se reparten inicialmente utilizando la agrupación global para combinar todas las particiones del mismo lote en una sola partición.
partitionAggregate- Agrega cada partición en lugar de todo el lote de tupla tridente. La salida del agregado de la partición reemplaza completamente la tupla de entrada. La salida del agregado de partición contiene una única tupla de campo.
persistentaggregate - Agrega todas las tuplas de tridentes en todos los lotes y almacena el resultado en la memoria o en la base de datos.
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));La operación de agregación se puede crear usando CombinerAggregator, ReducerAggregator o la interfaz de agregación genérica. El agregador de "recuento" utilizado en el ejemplo anterior es uno de los agregadores integrados. Se implementa mediante "CombinerAggregator". La implementación es la siguiente:
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}Agrupamiento
La operación de agrupamiento es una operación incorporada y puede ser invocada por el groupBymétodo. El método groupBy reparte la secuencia haciendo un partitionBy en los campos especificados y luego dentro de cada partición, agrupa las tuplas cuyos campos de grupo son iguales. Normalmente, usamos "groupBy" junto con "persistentAggregate" para obtener la agregación agrupada. El código de muestra es el siguiente:
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Fusión y unión
La fusión y la unión se pueden realizar mediante el método "fusionar" y "unión", respectivamente. La fusión combina una o más corrientes. La unión es similar a la fusión, excepto por el hecho de que la unión utiliza un campo de tupla tridente de ambos lados para verificar y unir dos corrientes. Además, la unión solo funcionará a nivel de lote. El código de muestra es el siguiente:
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));Mantenimiento del estado
Trident proporciona un mecanismo para el mantenimiento del estado. La información de estado se puede almacenar en la topología misma; de lo contrario, también puede almacenarla en una base de datos separada. El motivo es mantener un estado en el que si alguna tupla falla durante el procesamiento, se reintentará la tupla fallida. Esto crea un problema al actualizar el estado porque no está seguro de si el estado de esta tupla se ha actualizado previamente o no. Si la tupla ha fallado antes de actualizar el estado, volver a intentar la tupla hará que el estado sea estable. Sin embargo, si la tupla ha fallado después de actualizar el estado, volver a intentar la misma tupla aumentará nuevamente el recuento en la base de datos y hará que el estado sea inestable. Es necesario realizar los siguientes pasos para garantizar que un mensaje se procese solo una vez:
Procese las tuplas en pequeños lotes.
Asigne una identificación única a cada lote. Si se vuelve a intentar el lote, se le asigna el mismo ID único.
Las actualizaciones de estado se ordenan entre lotes. Por ejemplo, la actualización del estado del segundo lote no será posible hasta que se complete la actualización del estado del primer lote.
RPC distribuido
La RPC distribuida se utiliza para consultar y recuperar el resultado de la topología Trident. Storm tiene un servidor RPC distribuido incorporado. El servidor RPC distribuido recibe la solicitud RPC del cliente y la pasa a la topología. La topología procesa la solicitud y envía el resultado al servidor RPC distribuido, que es redirigido por el servidor RPC distribuido al cliente. La consulta RPC distribuida de Trident se ejecuta como una consulta RPC normal, excepto por el hecho de que estas consultas se ejecutan en paralelo.
¿Cuándo usar Trident?
Como en muchos casos de uso, si el requisito es procesar una consulta solo una vez, podemos lograrlo escribiendo una topología en Trident. Por otro lado, será difícil lograr exactamente una vez procesado en el caso de Storm. Por lo tanto, Trident será útil para aquellos casos de uso en los que requiera exactamente un procesamiento. Trident no es para todos los casos de uso, especialmente los casos de uso de alto rendimiento porque agrega complejidad a Storm y administra el estado.
Ejemplo de trabajo de Trident
Vamos a convertir nuestra aplicación analizadora de registro de llamadas desarrollada en la sección anterior al marco Trident. La aplicación Trident será relativamente fácil en comparación con la simple tormenta, gracias a su API de alto nivel. Básicamente, se requerirá que Storm realice cualquiera de las operaciones de Función, Filtro, Agregado, GroupBy, Join y Merge en Trident. Finalmente iniciaremos el servidor DRPC usando elLocalDRPC class y busque alguna palabra clave usando la execute método de la clase LocalDRPC.
Formatear la información de la llamada
El propósito de la clase FormatCall es formatear la información de la llamada que comprende "Número de llamante" y "Número de receptor". El código completo del programa es el siguiente:
Codificación: FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
El propósito de la clase CSVSplit es dividir la cadena de entrada basándose en "coma (,)" y emitir cada palabra en la cadena. Esta función se utiliza para analizar el argumento de entrada de la consulta distribuida. El código completo es el siguiente:
Codificación: CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}Analizador de registros
Esta es la aplicación principal. Inicialmente, la aplicación inicializará TridentTopology y alimentará la información de la persona que llama usandoFeederBatchSpout. El flujo de topología tridente se puede crear utilizando elnewStreammétodo de la clase TridentTopology. De manera similar, el flujo DRPC de topología Trident se puede crear utilizando elnewDRCPStreammétodo de la clase TridentTopology. Se puede crear un servidor DRCP simple usando la clase LocalDRPC.LocalDRPCtiene un método de ejecución para buscar alguna palabra clave. El código completo se proporciona a continuación.
Codificación: LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}Crear y ejecutar la aplicación
La aplicación completa tiene tres códigos Java. Son los siguientes:
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
La aplicación se puede construir usando el siguiente comando:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaLa aplicación se puede ejecutar usando el siguiente comando:
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTridentSalida
Una vez iniciada la aplicación, la aplicación generará los detalles completos sobre el proceso de inicio del clúster, el procesamiento de operaciones, el servidor DRPC y la información del cliente y, finalmente, el proceso de cierre del clúster. Esta salida se mostrará en la consola como se muestra a continuación.
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsAquí, en este capítulo, discutiremos una aplicación en tiempo real de Apache Storm. Veremos cómo se usa Storm en Twitter.
Gorjeo
Twitter es un servicio de redes sociales en línea que proporciona una plataforma para enviar y recibir tweets de usuarios. Los usuarios registrados pueden leer y publicar tweets, pero los usuarios no registrados solo pueden leer tweets. El hashtag se usa para categorizar tweets por palabra clave agregando # antes de la palabra clave relevante. Ahora tomemos un escenario en tiempo real para encontrar el hashtag más utilizado por tema.
Creación de pico
El propósito de spout es que las personas envíen los tweets lo antes posible. Twitter proporciona "Twitter Streaming API", una herramienta basada en servicios web para recuperar los tweets enviados por personas en tiempo real. Se puede acceder a Twitter Streaming API en cualquier lenguaje de programación.
twitter4j es una biblioteca de Java no oficial de código abierto, que proporciona un módulo basado en Java para acceder fácilmente a la API de transmisión de Twitter. twitter4jproporciona un marco basado en oyentes para acceder a los tweets. Para acceder a la API de transmisión de Twitter, debemos iniciar sesión en la cuenta de desarrollador de Twitter y obtener los siguientes detalles de autenticación de OAuth.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Storm proporciona un canal de Twitter, TwitterSampleSpout,en su kit de inicio. Lo usaremos para recuperar los tweets. El canalón necesita detalles de autenticación OAuth y al menos una palabra clave. El canal emitirá tweets en tiempo real basados en palabras clave. El código completo del programa se proporciona a continuación.
Codificación: TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}Perno del lector de hashtags
El tweet emitido por spout se reenviará a HashtagReaderBolt, que procesará el tweet y emitirá todos los hashtags disponibles. Usos de HashtagReaderBoltgetHashTagEntitiesmétodo proporcionado por twitter4j. getHashTagEntities lee el tweet y devuelve la lista de hashtag. El código completo del programa es el siguiente:
Codificación: HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Perno contador de hashtag
El hashtag emitido se reenviará a HashtagCounterBolt. Este perno procesará todos los hashtags y guardará todos y cada uno de los hashtag y su recuento en la memoria usando el objeto Java Map. El código completo del programa se proporciona a continuación.
Codificación: HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Envío de una topología
El envío de una topología es la aplicación principal. La topología de Twitter consta deTwitterSampleSpout, HashtagReaderBolty HashtagCounterBolt. El siguiente código de programa muestra cómo enviar una topología.
Codificación: TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Crear y ejecutar la aplicación
La aplicación completa tiene cuatro códigos Java. Son los siguientes:
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
Puede compilar la aplicación usando el siguiente comando:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.javaEjecute la aplicación usando los siguientes comandos:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>Salida
La aplicación imprimirá el hashtag disponible actual y su recuento. La salida debe ser similar a la siguiente:
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1Yahoo! Finance es el sitio web líder en Internet de noticias comerciales y datos financieros. Es parte de Yahoo! y brinda información sobre noticias financieras, estadísticas del mercado, datos del mercado internacional y otra información sobre recursos financieros a los que cualquiera puede acceder.
Si está registrado en Yahoo! usuario, entonces puede personalizar Yahoo! Finance para aprovechar sus determinadas ofertas. Yahoo! La API de finanzas se utiliza para consultar datos financieros de Yahoo!
Esta API muestra datos con un retraso de 15 minutos desde el tiempo real y actualiza su base de datos cada 1 minuto para acceder a la información actual relacionada con las acciones. Ahora tomemos un escenario en tiempo real de una empresa y veamos cómo generar una alerta cuando el valor de sus acciones desciende por debajo de 100.
Creación de pico
El propósito de spout es obtener los detalles de la empresa y emitir los precios a los pernos. Puede utilizar el siguiente código de programa para crear un pico.
Codificación: YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Creación de pernos
Aquí el propósito de bolt es procesar los precios de la empresa dada cuando los precios caen por debajo de 100. Utiliza el objeto Java Map para establecer la alerta de límite de precio de corte como truecuando los precios de las acciones caen por debajo de 100; de lo contrario falso. El código completo del programa es el siguiente:
Codificación: PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Envío de una topología
Esta es la aplicación principal en la que YahooFinanceSpout.java y PriceCutOffBolt.java están conectados y producen una topología. El siguiente código de programa muestra cómo enviar una topología.
Codificación: YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Crear y ejecutar la aplicación
La aplicación completa tiene tres códigos Java. Son los siguientes:
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
La aplicación se puede construir usando el siguiente comando:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaLa aplicación se puede ejecutar usando el siguiente comando:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStormSalida
La salida será similar a la siguiente:
GOOGL : false
AAPL : false
INTC : trueEl framework Apache Storm es compatible con muchas de las mejores aplicaciones industriales de la actualidad. Proporcionaremos una descripción muy breve de algunas de las aplicaciones más notables de Storm en este capítulo.
Klout
Klout es una aplicación que utiliza análisis de redes sociales para clasificar a sus usuarios en función de la influencia social en línea a través de Klout Score, que es un valor numérico entre 1 y 100. Klout utiliza la abstracción Trident incorporada de Apache Storm para crear topologías complejas que transmiten datos.
El canal del clima
El canal meteorológico utiliza topologías de tormenta para ingerir datos meteorológicos. Se ha asociado con Twitter para permitir publicidad informada sobre el clima en Twitter y aplicaciones móviles.OpenSignal es una empresa que se especializa en mapeo de cobertura inalámbrica. StormTag y WeatherSignalson proyectos basados en el clima creados por OpenSignal. StormTag es una estación meteorológica Bluetooth que se conecta a un llavero. Los datos meteorológicos recopilados por el dispositivo se envían a la aplicación WeatherSignal y a los servidores OpenSignal.
Industria de las telecomunicaciones
Los proveedores de telecomunicaciones procesan millones de llamadas telefónicas por segundo. Realizan análisis forenses en llamadas caídas y mala calidad de sonido. Los registros de detalles de llamadas fluyen a una velocidad de millones por segundo y Apache Storm los procesa en tiempo real e identifica cualquier patrón problemático. El análisis de tormentas se puede utilizar para mejorar continuamente la calidad de las llamadas.