ArangoDB - Guía rápida
ArangoDB es aclamado por sus desarrolladores como una base de datos nativa de múltiples modelos. Esto es diferente a otras bases de datos NoSQL. En esta base de datos, los datos se pueden almacenar como documentos, pares clave / valor o gráficos. Y con un solo lenguaje de consulta declarativo, se puede acceder a todos o cualquiera de sus datos. Además, se pueden combinar diferentes modelos en una sola consulta. Y, debido a su estilo multimodelo, se pueden realizar aplicaciones ajustadas, que serán escalables horizontalmente con cualquiera o todos los tres modelos de datos.
Bases de datos multimodelo nativas o en capas
En esta sección, destacaremos una diferencia crucial entre las bases de datos nativas y multimodelo en capas.
Muchos proveedores de bases de datos llaman a su producto “multimodelo”, pero agregar una capa gráfica a una clave / valor o almacén de documentos no califica como multimodelo nativo.
Con ArangoDB, el mismo núcleo con el mismo lenguaje de consulta, se pueden agrupar diferentes modelos de datos y características en una sola consulta, como ya hemos dicho en la sección anterior. En ArangoDB, no hay "cambio" entre modelos de datos, y no hay cambio de datos de A a B para ejecutar consultas. Conduce a ventajas de rendimiento para ArangoDB en comparación con los enfoques "en capas".
La necesidad de una base de datos multimodal
La interpretación de la idea básica [de Fowler] nos lleva a darnos cuenta de los beneficios de utilizar una variedad de modelos de datos apropiados para diferentes partes de la capa de persistencia, siendo la capa parte de la arquitectura de software más grande.
De acuerdo con esto, uno podría, por ejemplo, usar una base de datos relacional para conservar datos tabulares estructurados; un almacén de documentos para datos no estructurados, similares a objetos; un almacén de clave / valor para una tabla hash; y una base de datos de gráficos para datos referenciales altamente vinculados.
Sin embargo, la implementación tradicional de este enfoque llevará a uno a utilizar varias bases de datos en el mismo proyecto. Puede provocar cierta fricción operativa (implementación más complicada, actualizaciones más frecuentes), así como problemas de duplicación y coherencia de datos.
El próximo desafío después de unificar los datos para los tres modelos de datos, es diseñar e implementar un lenguaje de consulta común que pueda permitir a los administradores de datos expresar una variedad de consultas, como consultas de documentos, búsquedas de clave / valor, consultas gráficas y combinaciones arbitrarias. de estos.
Por graphy queries, nos referimos a consultas que involucran consideraciones de teoría de grafos. En particular, estos pueden involucrar las características de conectividad particulares que provienen de los bordes. Por ejemplo,ShortestPath, GraphTraversaly Neighbors.
Los gráficos son un ajuste perfecto como modelo de datos para relaciones. En muchos casos del mundo real, como una red social, un sistema de recomendación, etc., un modelo de datos muy natural es un gráfico. Captura relaciones y puede contener información de etiqueta con cada borde y con cada vértice. Además, los documentos JSON son un ajuste natural para almacenar este tipo de datos de vértice y borde.
ArangoDB ─ Funciones
Hay varias características notables de ArangoDB. Destacaremos las características destacadas a continuación:
- Paradigma multimodelo
- Propiedades ACID
- API HTTP
ArangoDB admite todos los modelos de bases de datos populares. A continuación se muestran algunos modelos compatibles con ArangoDB:
- Modelo de documento
- Modelo clave / valor
- Modelo gráfico
Un solo lenguaje de consulta es suficiente para recuperar datos de la base de datos
Las cuatro propiedades Atomicity, Consistency, Isolationy Durability(ACID) describen las garantías de las transacciones de bases de datos. ArangoDB admite transacciones compatibles con ACID.
ArangoDB permite a los clientes, como los navegadores, interactuar con la base de datos con la API HTTP, la API está orientada a los recursos y se puede ampliar con JavaScript.
Las siguientes son las ventajas de usar ArangoDB:
Consolidación
Como base de datos nativa de múltiples modelos, ArangoDB elimina la necesidad de implementar múltiples bases de datos y, por lo tanto, disminuye la cantidad de componentes y su mantenimiento. En consecuencia, reduce la complejidad de la pila de tecnología para la aplicación. Además de consolidar sus necesidades técnicas generales, esta simplificación conduce a un menor costo total de propiedad y una mayor flexibilidad.
Escalado de rendimiento simplificado
Con aplicaciones que crecen con el tiempo, ArangoDB puede abordar las crecientes necesidades de almacenamiento y rendimiento, escalando de forma independiente con diferentes modelos de datos. Como ArangoDB puede escalar tanto vertical como horizontalmente, en caso de que su rendimiento exija una disminución (una desaceleración deliberada y deseada), su sistema de back-end se puede escalar fácilmente para ahorrar en hardware y costos operativos.
Complejidad operativa reducida
El decreto de Polyglot Persistence consiste en emplear las mejores herramientas para cada trabajo que realice. Ciertas tareas necesitan una base de datos de documentos, mientras que otras pueden necesitar una base de datos de gráficos. Como resultado de trabajar con bases de datos de un solo modelo, puede generar múltiples desafíos operativos. La integración de bases de datos de un solo modelo es un trabajo difícil en sí mismo. Pero el mayor desafío es construir una gran estructura cohesiva con consistencia de datos y tolerancia a fallas entre sistemas de bases de datos separados y no relacionados. Puede resultar casi imposible.
Polyglot Persistence se puede manejar con una base de datos nativa de múltiples modelos, ya que permite tener datos políglotas fácilmente, pero al mismo tiempo con consistencia de datos en un sistema tolerante a fallas. Con ArangoDB, podemos usar el modelo de datos correcto para el trabajo complejo.
Fuerte consistencia de datos
Si se utilizan varias bases de datos de un solo modelo, la coherencia de los datos puede convertirse en un problema. Estas bases de datos no están diseñadas para comunicarse entre sí, por lo que es necesario implementar alguna forma de funcionalidad de transacción para mantener sus datos consistentes entre diferentes modelos.
Al admitir transacciones ACID, ArangoDB administra sus diferentes modelos de datos con un solo back-end, lo que brinda una gran consistencia en una sola instancia y operaciones atómicas cuando se opera en modo de clúster.
Tolerancia a fallos
Es un desafío construir sistemas tolerantes a fallas con muchos componentes no relacionados. Este desafío se vuelve más complejo cuando se trabaja con clústeres. Se requiere experiencia para implementar y mantener dichos sistemas, utilizando diferentes tecnologías y / o pilas de tecnología. Además, la integración de varios subsistemas, diseñados para funcionar de forma independiente, genera grandes costes operativos y de ingeniería.
Como pila de tecnología consolidada, la base de datos multimodelo presenta una solución elegante. Diseñado para permitir arquitecturas modulares modernas con diferentes modelos de datos, ArangoDB también funciona para el uso de clústeres.
Menor costo total de propiedad
Cada tecnología de base de datos requiere un mantenimiento continuo, parches de corrección de errores y otros cambios de código proporcionados por el proveedor. Adoptar una base de datos de varios modelos reduce significativamente los costos de mantenimiento relacionados simplemente al eliminar la cantidad de tecnologías de base de datos en el diseño de una aplicación.
Actas
Proporcionar garantías transaccionales en múltiples máquinas es un verdadero desafío, y pocas bases de datos NoSQL brindan estas garantías. Al ser multimodelo nativo, ArangoDB impone transacciones para garantizar la coherencia de los datos.
En este capítulo, discutiremos los conceptos y terminologías básicos de ArangoDB. Es muy importante tener un conocimiento de las terminologías básicas subyacentes relacionadas con el tema técnico que estamos tratando.
Las terminologías para ArangoDB se enumeran a continuación:
- Document
- Collection
- Identificador de colección
- Nombre de la colección
- Database
- Nombre de la base de datos
- Organización de la base de datos
Desde la perspectiva del modelo de datos, ArangoDB puede considerarse una base de datos orientada a documentos, ya que la noción de documento es la idea matemática de este último. Las bases de datos orientadas a documentos son una de las principales categorías de bases de datos NoSQL.
La jerarquía es la siguiente: los documentos se agrupan en colecciones y las colecciones existen dentro de las bases de datos.
Debería ser obvio que Identificador y Nombre son dos atributos para la colección y la base de datos.
Por lo general, dos documentos (vértices) almacenados en colecciones de documentos están vinculados por un documento (borde) almacenado en una colección de bordes. Este es el modelo de datos gráficos de ArangoDB. Sigue el concepto matemático de un gráfico dirigido y etiquetado, excepto que los bordes no solo tienen etiquetas, sino que son documentos completos.
Habiéndonos familiarizado con los términos centrales de esta base de datos, comenzamos a comprender el modelo de datos de gráficos de ArangoDB. En este modelo, existen dos tipos de colecciones: colecciones de documentos y colecciones de borde. Las colecciones Edge almacenan documentos y también incluyen dos atributos especiales: el primero es el_from atributo, y el segundo es el _toatributo. Estos atributos se utilizan para crear bordes (relaciones) entre documentos esenciales para la base de datos de gráficos. Las colecciones de documentos también se denominan colecciones de vértices en el contexto de los gráficos (consulte cualquier libro de teoría de grafos).
Veamos ahora qué tan importantes son las bases de datos. Son importantes porque las colecciones existen dentro de las bases de datos. En una instancia de ArangoDB, puede haber una o muchas bases de datos. Por lo general, se utilizan diferentes bases de datos para configuraciones de múltiples inquilinos, ya que los diferentes conjuntos de datos dentro de ellas (colecciones, documentos, etc.) están aislados entre sí. La base de datos predeterminada_systemes especial, porque no se puede quitar. Los usuarios se administran en esta base de datos y sus credenciales son válidas para todas las bases de datos de una instancia de servidor.
En este capítulo, discutiremos los requisitos del sistema para ArangoDB.
Los requisitos del sistema para ArangoDB son los siguientes:
- Un servidor VPS con instalación de Ubuntu
- RAM: 1 GB; CPU: 2,2 GHz
Para todos los comandos de este tutorial, hemos utilizado una instancia de Ubuntu 16.04 (xenial) de 1 GB de RAM con una CPU con una potencia de procesamiento de 2,2 GHz. Y todos los comandos de arangosh en este tutorial fueron probados para la versión 3.1.27 de ArangoDB.
¿Cómo instalar ArangoDB?
En esta sección, veremos cómo instalar ArangoDB. ArangoDB viene prediseñado para muchos sistemas operativos y distribuciones. Para obtener más detalles, consulte la documentación de ArangoDB. Como ya se mencionó, para este tutorial usaremos Ubuntu 16.04x64.
El primer paso es descargar la clave pública para sus repositorios -
# wget https://www.arangodb.com/repositories/arangodb31/
xUbuntu_16.04/Release.keySalida
--2017-09-03 12:13:24-- https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/Release.key
Resolving https://www.arangodb.com/
(www.arangodb.com)... 104.25.1 64.21, 104.25.165.21,
2400:cb00:2048:1::6819:a415, ...
Connecting to https://www.arangodb.com/
(www.arangodb.com)|104.25. 164.21|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3924 (3.8K) [application/pgpkeys]
Saving to: ‘Release.key’
Release.key 100%[===================>] 3.83K - .-KB/s in 0.001s
2017-09-03 12:13:25 (2.61 MB/s) - ‘Release.key’ saved [39 24/3924]El punto importante es que debería ver el Release.key guardado al final de la salida.
Instalemos la clave guardada usando la siguiente línea de código:
# sudo apt-key add Release.keySalida
OKEjecute los siguientes comandos para agregar el repositorio apt y actualizar el índice:
# sudo apt-add-repository 'deb
https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/ /'
# sudo apt-get updateComo paso final, podemos instalar ArangoDB -
# sudo apt-get install arangodb3Salida
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
grub-pc-bin
Use 'sudo apt autoremove' to remove it.
The following NEW packages will be installed:
arangodb3
0 upgraded, 1 newly installed, 0 to remove and 17 not upgraded.
Need to get 55.6 MB of archives.
After this operation, 343 MB of additional disk space will be used.prensa Enter. Ahora comenzará el proceso de instalación de ArangoDB:
Get:1 https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04
arangodb3 3.1.27 [55.6 MB]
Fetched 55.6 MB in 59s (942 kB/s)
Preconfiguring packages ...
Selecting previously unselected package arangodb3.
(Reading database ... 54209 files and directories currently installed.)
Preparing to unpack .../arangodb3_3.1.27_amd64.deb ...
Unpacking arangodb3 (3.1.27) ...
Processing triggers for systemd (229-4ubuntu19) ...
Processing triggers for ureadahead (0.100.0-19) ...
Processing triggers for man-db (2.7.5-1) ...
Setting up arangodb3 (3.1.27) ...
Database files are up-to-date.Cuando la instalación de ArangoDB está a punto de completarse, aparece la siguiente pantalla:
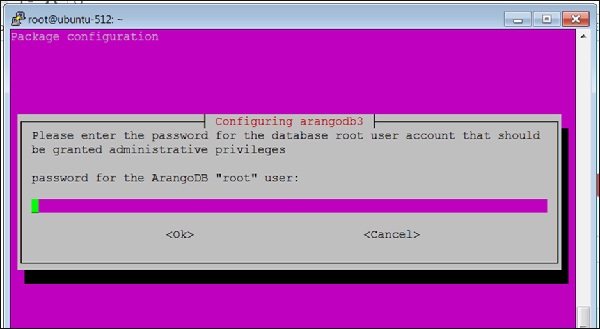
Aquí, se le pedirá que proporcione una contraseña para ArangoDB rootusuario. Anótelo con cuidado.
Selecciona el yes opción cuando aparezca el siguiente cuadro de diálogo:
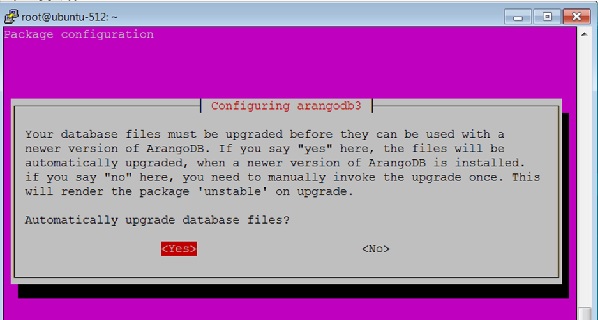
Cuando haces clic Yescomo en el cuadro de diálogo anterior, aparece el siguiente cuadro de diálogo. Hacer clicYes aquí.
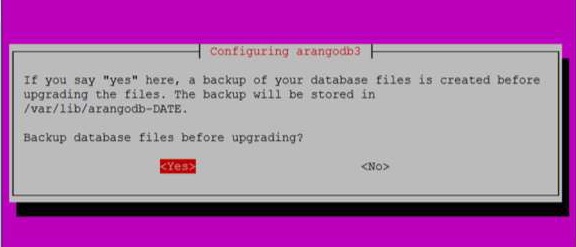
También puede verificar el estado de ArangoDB con el siguiente comando:
# sudo systemctl status arangodb3Salida
arangodb3.service - LSB: arangodb
Loaded: loaded (/etc/init.d/arangodb3; bad; vendor pre set: enabled)
Active: active (running) since Mon 2017-09-04 05:42:35 UTC;
4min 46s ago
Docs: man:systemd-sysv-generator(8)
Process: 2642 ExecStart=/etc/init.d/arangodb3 start (code = exited,
status = 0/SUC
Tasks: 22
Memory: 158.6M
CPU: 3.117s
CGroup: /system.slice/arangodb3.service
├─2689 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
└─2690 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
Sep 04 05:42:33 ubuntu-512 systemd[1]: Starting LSB: arangodb...
Sep 04 05:42:33 ubuntu-512 arangodb3[2642]: * Starting arango database server a
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: {startup} starting up in daemon mode
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: changed working directory for child
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: ...done.
Sep 04 05:42:35 ubuntu-512 systemd[1]: StartedLSB: arang odb.
Sep 04 05:46:59 ubuntu-512 systemd[1]: Started LSB: arangodb. lines 1-19/19 (END)ArangoDB ya está listo para usarse.
Para invocar la terminal arangosh, escriba el siguiente comando en la terminal:
# arangoshSalida
Please specify a password:Suministrar el root contraseña creada en el momento de la instalación -
_
__ _ _ __ __ _ _ __ __ _ ___ | |
/ | '__/ _ | ’ \ / ` |/ _ / | ’
| (| | | | (| | | | | (| | () _ \ | | |
_,|| _,|| ||_, |_/|/| ||
|__/arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server],
database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system> exit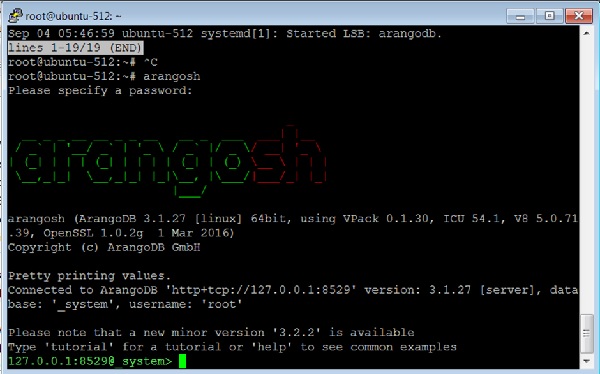
Para cerrar sesión en ArangoDB, escriba el siguiente comando:
127.0.0.1:8529@_system> exitSalida
Uf wiederluege! Na shledanou! Auf Wiedersehen! Bye Bye! Adiau! ¡Hasta luego!
Εις το επανιδείν!
להתראות ! Arrivederci! Tot ziens! Adjö! Au revoir! さようなら До свидания! Até
Breve! !خداحافظEn este capítulo, discutiremos cómo funciona Arangosh como línea de comando para ArangoDB. Comenzaremos aprendiendo cómo agregar un usuario de base de datos.
Note - Recuerde que el teclado numérico podría no funcionar en Arangosh.
Supongamos que el usuario es "harry" y la contraseña es "hpwdb".
127.0.0.1:8529@_system> require("org/arangodb/users").save("harry", "hpwdb");Salida
{
"user" : "harry",
"active" : true,
"extra" : {},
"changePassword" : false,
"code" : 201
}En este capítulo, aprenderemos cómo habilitar / deshabilitar la Autenticación y cómo vincular ArangoDB a la Interfaz de Red Pública.
# arangosh --server.endpoint tcp://127.0.0.1:8529 --server.database "_system"Le pedirá la contraseña guardada anteriormente:
Please specify a password:Utilice la contraseña que creó para root, en la configuración.
También puede usar curl para verificar que realmente está recibiendo respuestas del servidor HTTP 401 (no autorizado) para solicitudes que requieren autenticación:
# curl --dump - http://127.0.0.1:8529/_api/versionSalida
HTTP/1.1 401 Unauthorized
X-Content-Type-Options: nosniff
Www-Authenticate: Bearer token_type = "JWT", realm = "ArangoDB"
Server: ArangoDB
Connection: Keep-Alive
Content-Type: text/plain; charset = utf-8
Content-Length: 0Para evitar ingresar la contraseña cada vez durante nuestro proceso de aprendizaje, desactivaremos la autenticación. Para eso, abra el archivo de configuración -
# vim /etc/arangodb3/arangod.confDebe cambiar la combinación de colores si el código no se ve correctamente.
:colorscheme desertEstablezca la autenticación en falso como se muestra en la captura de pantalla a continuación.
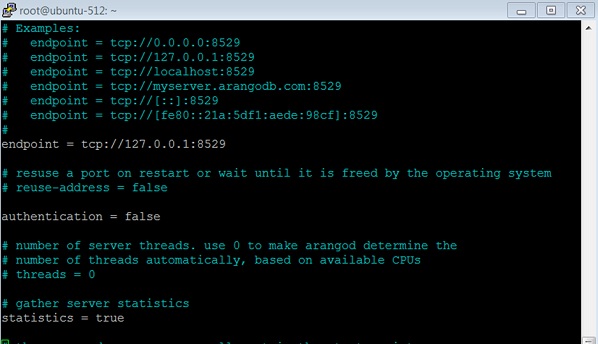
Reinicie el servicio -
# service arangodb3 restartAl hacer que la autenticación sea falsa, podrá iniciar sesión (ya sea con root o con un usuario creado como Harry en este caso) sin ingresar ninguna contraseña en please specify a password.
Vamos a comprobar el api versión cuando la autenticación está desactivada -
# curl --dump - http://127.0.0.1:8529/_api/versionSalida
HTTP/1.1 200 OK
X-Content-Type-Options: nosniff
Server: ArangoDB
Connection: Keep-Alive
Content-Type: application/json; charset=utf-8
Content-Length: 60
{"server":"arango","version":"3.1.27","license":"community"}En este capítulo, consideraremos dos escenarios de ejemplo. Estos ejemplos son más fáciles de comprender y nos ayudarán a comprender la forma en que funciona la funcionalidad de ArangoDB.
Para demostrar las API, ArangoDB viene precargado con un conjunto de gráficos fácilmente comprensibles. Hay dos métodos para crear instancias de estos gráficos en su ArangoDB:
- Agregue la pestaña Ejemplo en la ventana de creación de gráficos en la interfaz web,
- o cargar el módulo @arangodb/graph-examples/example-graph en Arangosh.
Para empezar, carguemos un gráfico con la ayuda de la interfaz web. Para eso, inicie la interfaz web y haga clic en elgraphs lengüeta.
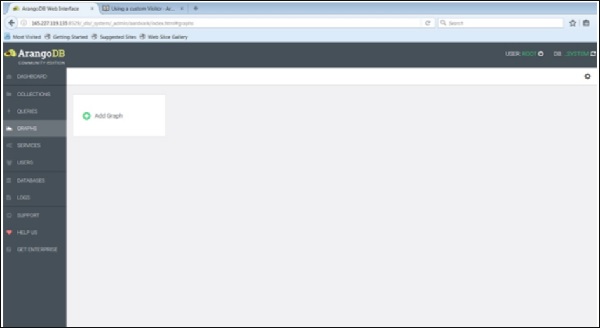
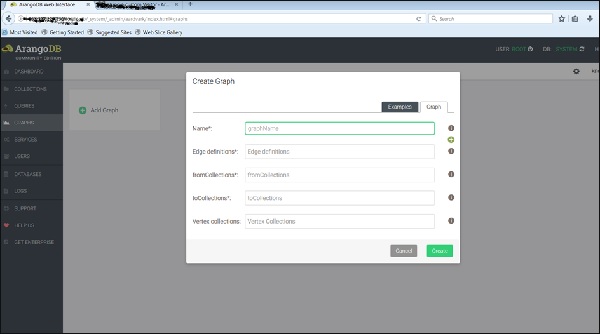
los Create Graphaparece el cuadro de diálogo. El asistente contiene dos pestañas:Examples y Graph. losGraphla pestaña está abierta por defecto; suponiendo que queramos crear un nuevo gráfico, nos pedirá el nombre y otras definiciones del gráfico.
Ahora, subiremos el gráfico ya creado. Para ello seleccionaremos elExamples lengüeta.
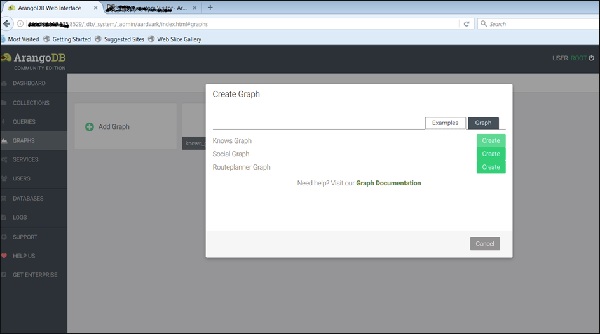
Podemos ver los tres gráficos de ejemplo. Selecciona elKnows_Graph y haga clic en el botón verde Crear.
Una vez que los haya creado, puede inspeccionarlos en la interfaz web, que se utilizó para crear las imágenes a continuación.
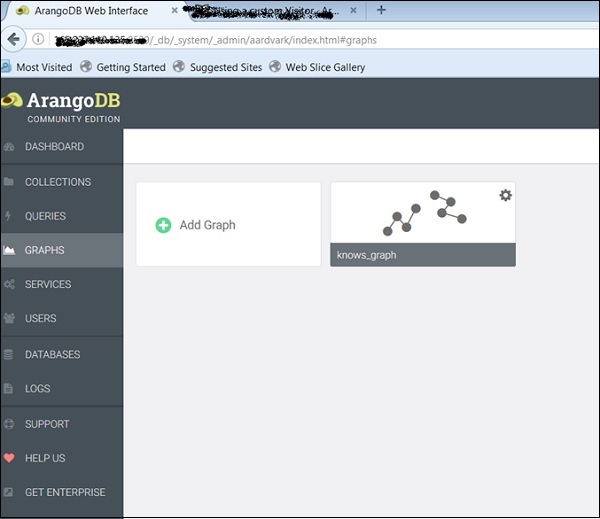
The Knows_Graph
Veamos ahora cómo Knows_Graphtrabajos. Seleccione Knows_Graph y obtendrá los datos del gráfico.
El Knows_Graph consta de una colección de vértices persons conectado a través de una colección de bordes knows. Contendrá a cinco personas Alice, Bob, Charlie, Dave y Eve como vértices. Tendremos las siguientes relaciones dirigidas
Alice knows Bob
Bob knows Charlie
Bob knows Dave
Eve knows Alice
Eve knows Bob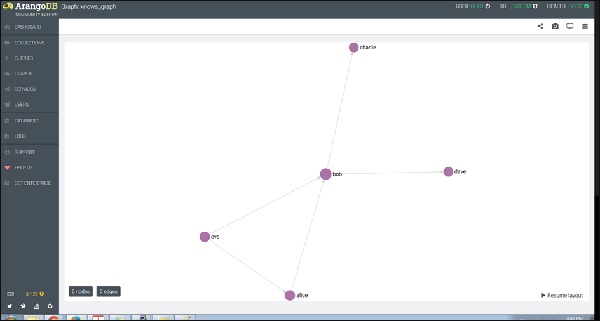
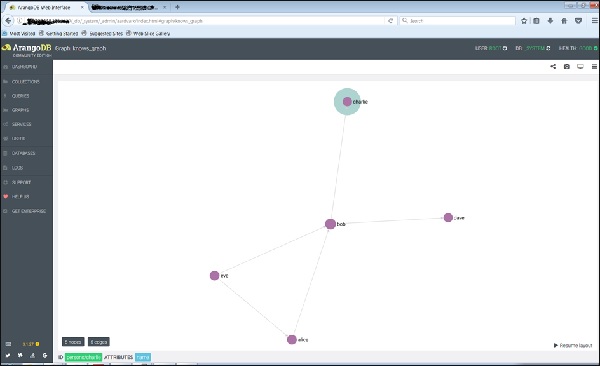
Si hace clic en un nodo (vértice), diga 'bob', se mostrará el nombre del atributo ID (personas / bob).
Y al hacer clic en cualquiera de los bordes, se mostrarán los atributos de ID (conoce / 4590).
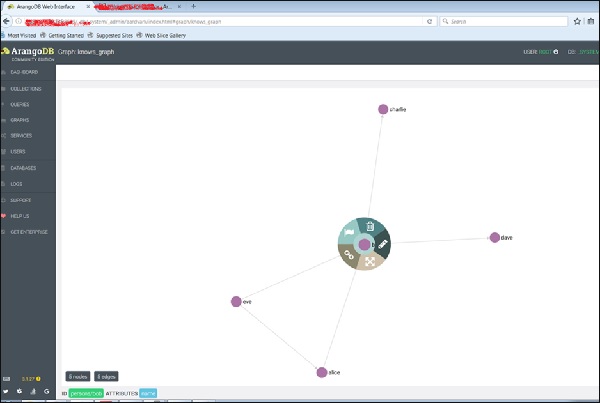
Así es como lo creamos, inspeccionamos sus vértices y aristas.
Agreguemos otro gráfico, esta vez usando Arangosh. Para eso, necesitamos incluir otro punto final en el archivo de configuración de ArangoDB.
Cómo agregar varios puntos finales
Abra el archivo de configuración -
# vim /etc/arangodb3/arangod.confAgregue otro punto final como se muestra en la captura de pantalla del terminal a continuación.
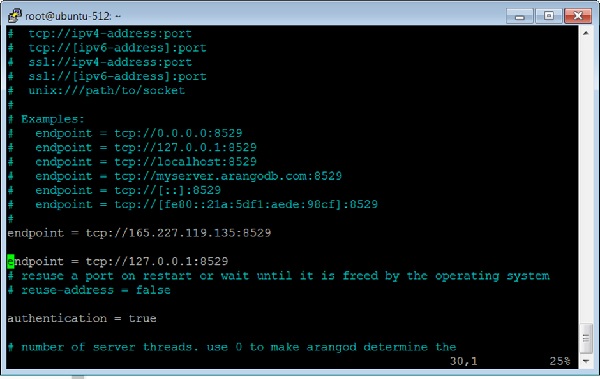
Reinicie el ArangoDB -
# service arangodb3 restartLanzar el Arangosh -
# arangosh
Please specify a password:
_
__ _ _ __ __ _ _ __ __ _ ___ ___| |__
/ _` | '__/ _` | '_ \ / _` |/ _ \/ __| '_ \
| (_| | | | (_| | | | | (_| | (_) \__ \ | | |
\__,_|_| \__,_|_| |_|\__, |\___/|___/_| |_|
|___/
arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27
[server], database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system>El Social_Graph
Ahora entendamos qué es Social_Graph y cómo funciona. El gráfico muestra un conjunto de personas y sus relaciones:
Este ejemplo tiene personas masculinas y femeninas como vértices en dos colecciones de vértices: femenino y masculino. Los bordes son sus conexiones en la colección de bordes de relación. Hemos descrito cómo crear este gráfico usando Arangosh. El lector puede solucionarlo y explorar sus atributos, como hicimos con Knows_Graph.
En este capítulo, nos centraremos en los siguientes temas:
- Interacción con la base de datos
- Modelo de datos
- Recuperación de datos
ArangoDB admite modelos de datos basados en documentos, así como modelos de datos basados en gráficos. Primero describamos el modelo de datos basado en documentos.
Los documentos de ArangoDB se parecen mucho al formato JSON. Un documento contiene cero o más atributos y se adjunta un valor a cada atributo. Un valor es de tipo atómico, como un número, booleano o nulo, una cadena literal, o de un tipo de datos compuesto, como un documento / objeto incrustado o una matriz. Las matrices o subobjetos pueden constar de estos tipos de datos, lo que implica que un solo documento puede representar estructuras de datos no triviales.
Además, en la jerarquía, los documentos se organizan en colecciones, que pueden no contener documentos (en teoría) o más de un documento. Se pueden comparar documentos con filas y colecciones con tablas (aquí, las tablas y filas se refieren a las de los sistemas de gestión de bases de datos relacionales - RDBMS).
Pero, en RDBMS, definir columnas es un requisito previo para almacenar registros en una tabla, llamando a estas definiciones esquemas. Sin embargo, como característica novedosa, ArangoDB no tiene esquema; no hay una razón a priori para especificar qué atributos tendrá el documento.
Y a diferencia de RDBMS, cada documento se puede estructurar de una manera completamente diferente a otro documento. Estos documentos se pueden guardar juntos en una sola colección. Prácticamente, pueden existir características comunes entre los documentos de la colección, sin embargo, el sistema de base de datos, es decir, ArangoDB en sí, no lo vincula a una estructura de datos en particular.
Ahora intentaremos entender el [graph data model], que requiere dos tipos de colecciones: la primera son las colecciones de documentos (conocidas como colecciones de vértices en lenguaje teórico de grupos), la segunda son las colecciones de borde. Existe una sutil diferencia entre estos dos tipos. Las colecciones Edge también almacenan documentos, pero se caracterizan por incluir dos atributos únicos,_from y _topara crear relaciones entre documentos. En la práctica, un documento (borde de lectura) vincula dos documentos (vértices de lectura), ambos almacenados en sus respectivas colecciones. Esta arquitectura se deriva del concepto de teoría de grafos de un grafo dirigido y etiquetado, excluyendo los bordes que pueden tener no solo etiquetas, sino que pueden ser un documento completo tipo JSON en sí mismo.
Para calcular datos nuevos, eliminar documentos o manipularlos, se utilizan consultas, que seleccionan o filtran documentos según los criterios dados. Ya sean simples como una "consulta de ejemplo" o tan complejas como "uniones", las consultas están codificadas en AQL - ArangoDB Query Language.
En este capítulo, discutiremos los diferentes métodos de base de datos en ArangoDB.
Para empezar, obtengamos las propiedades de la base de datos:
- Name
- ID
- Path
Primero, invocamos al Arangosh. Una vez que se invoca Arangosh, enumeraremos las bases de datos que creamos hasta ahora:
Usaremos la siguiente línea de código para invocar a Arangosh:
127.0.0.1:8529@_system> db._databases()Salida
[
"_system",
"song_collection"
]Vemos dos bases de datos, una _system creado por defecto, y el segundo song_collection que hemos creado.
Pasemos ahora a la base de datos song_collection con la siguiente línea de código:
127.0.0.1:8529@_system> db._useDatabase("song_collection")Salida
true
127.0.0.1:8529@song_collection>Exploraremos las propiedades de nuestra base de datos song_collection.
Para encontrar el nombre
Usaremos la siguiente línea de código para encontrar el nombre.
127.0.0.1:8529@song_collection> db._name()Salida
song_collectionPara encontrar la identificación -
Usaremos la siguiente línea de código para encontrar el id.
song_collectionSalida
4838Para encontrar el camino -
Usaremos la siguiente línea de código para encontrar la ruta.
127.0.0.1:8529@song_collection> db._path()Salida
/var/lib/arangodb3/databases/database-4838Comprobemos ahora si estamos en la base de datos del sistema o no utilizando la siguiente línea de código:
127.0.0.1:8529@song_collection&t; db._isSystem()Salida
falseSignifica que no estamos en la base de datos del sistema (ya que hemos creado y cambiado a song_collection). La siguiente captura de pantalla le ayudará a comprender esto.
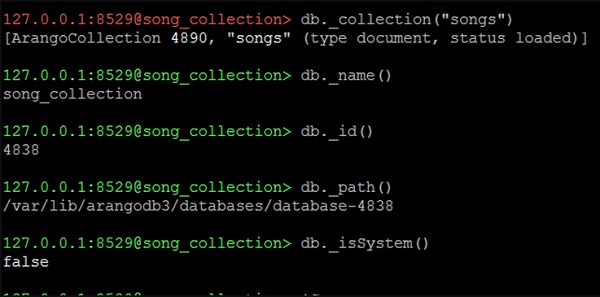
Para obtener una colección en particular, diga canciones:
Usaremos la siguiente línea de código para obtener una colección en particular.
127.0.0.1:8529@song_collection> db._collection("songs")Salida
[ArangoCollection 4890, "songs" (type document, status loaded)]La línea de código devuelve una sola colección.
Pasemos a lo esencial de las operaciones de la base de datos en los capítulos siguientes.
En este capítulo aprenderemos las diferentes operaciones con Arangosh.
Las siguientes son las posibles operaciones con Arangosh:
- Crear una colección de documentos
- Crear documentos
- Leer documentos
- Actualización de documentos
Comencemos por crear una nueva base de datos. Usaremos la siguiente línea de código para crear una nueva base de datos:
127.0.0.1:8529@_system> db._createDatabase("song_collection")
trueLa siguiente línea de código lo ayudará a cambiar a la nueva base de datos:
127.0.0.1:8529@_system> db._useDatabase("song_collection")
trueEl mensaje cambiará a "@@ song_collection"
127.0.0.1:8529@song_collection>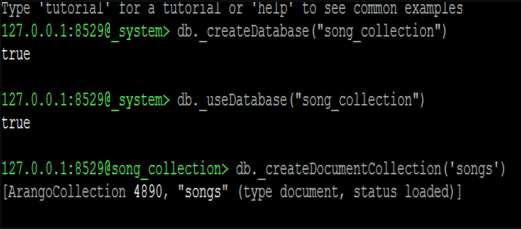
A partir de aquí estudiaremos Operaciones CRUD. Creemos una colección en la nueva base de datos:
127.0.0.1:8529@song_collection> db._createDocumentCollection('songs')Salida
[ArangoCollection 4890, "songs" (type document, status loaded)]
127.0.0.1:8529@song_collection>Agreguemos algunos documentos (objetos JSON) a nuestra colección de 'canciones'.
Agregamos el primer documento de la siguiente manera:
127.0.0.1:8529@song_collection> db.songs.save({title: "A Man's Best Friend",
lyricist: "Johnny Mercer", composer: "Johnny Mercer", Year: 1950, _key:
"A_Man"})Salida
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVClbW---"
}Agreguemos otros documentos a la base de datos. Esto nos ayudará a conocer el proceso de consulta de datos. Puede copiar estos códigos y pegar los mismos en Arangosh para emular el proceso -
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Accentchuate The Politics",
lyricist: "Johnny Mercer",
composer: "Harold Arlen", Year: 1944,
_key: "Accentchuate_The"
}
)
{
"_id" : "songs/Accentchuate_The",
"_key" : "Accentchuate_The",
"_rev" : "_VjVDnzO---"
}
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Affable Balding Me",
lyricist: "Johnny Mercer",
composer: "Robert Emmett Dolan",
Year: 1950,
_key: "Affable_Balding"
}
)
{
"_id" : "songs/Affable_Balding",
"_key" : "Affable_Balding",
"_rev" : "_VjVEFMm---"
}Cómo leer documentos
los _keyo el identificador de documentos se puede utilizar para recuperar un documento. Utilice el identificador de documentos si no es necesario recorrer la colección en sí. Si tiene una colección, la función de documento es fácil de usar:
127.0.0.1:8529@song_collection> db.songs.document("A_Man");
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVClbW---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950
}Cómo actualizar documentos
Hay dos opciones disponibles para actualizar los datos guardados: replace y update.
La función de actualización parchea un documento y lo fusiona con los atributos dados. Por otro lado, la función reemplazar reemplazará el documento anterior por uno nuevo. El reemplazo seguirá ocurriendo incluso si se proporcionan atributos completamente diferentes. Primero observaremos una actualización no destructiva, actualizando el atributo Producción` en una canción -
127.0.0.1:8529@song_collection> db.songs.update("songs/A_Man",{production:
"Top Banana"});Salida
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVOcqe---",
"_oldRev" : "_VjVClbW---"
}Leamos ahora los atributos de la canción actualizada:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Salida
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVOcqe---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950,
"production" : "Top Banana"
}Un documento grande se puede actualizar fácilmente con el update función, especialmente cuando los atributos son muy pocos.
En contraste, el replace La función eliminará sus datos al usarla con el mismo documento.
127.0.0.1:8529@song_collection> db.songs.replace("songs/A_Man",{production:
"Top Banana"});Veamos ahora la canción que acabamos de actualizar con la siguiente línea de código:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Salida
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVRhOq---",
"production" : "Top Banana"
}Ahora, puede observar que el documento ya no tiene los datos originales.
Cómo quitar documentos
La función de eliminación se utiliza en combinación con el identificador de documentos para eliminar un documento de una colección:
127.0.0.1:8529@song_collection> db.songs.remove('A_Man');Veamos ahora los atributos de la canción que acabamos de eliminar utilizando la siguiente línea de código:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Obtendremos un error de excepción como el siguiente como resultado:
JavaScript exception in file
'/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js' at 97,7:
ArangoError 1202: document not found
! throw error;
! ^
stacktrace: ArangoError: document not found
at Object.exports.checkRequestResult
(/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js:95:21)
at ArangoCollection.document
(/usr/share/arangodb3/js/client/modules/@arangodb/arango-collection.js:667:12)
at <shell command>:1:10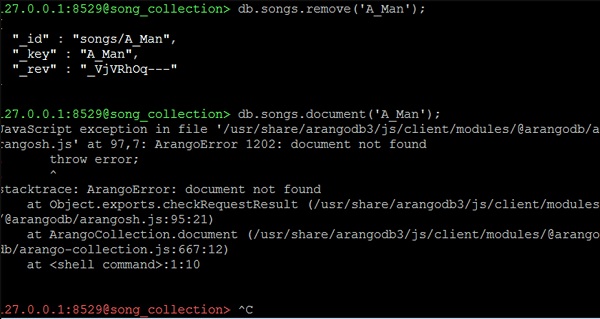
En nuestro capítulo anterior, aprendimos cómo realizar varias operaciones en documentos con Arangosh, la línea de comando. Ahora aprenderemos cómo realizar las mismas operaciones usando la interfaz web. Para empezar, ponga la siguiente dirección - http: // your_server_ip: 8529 / _db / song_collection / _admin / aardvark / index.html # login en la barra de direcciones de su navegador. Se le dirigirá a la siguiente página de inicio de sesión.
Ahora, ingrese el nombre de usuario y la contraseña.
Si tiene éxito, aparece la siguiente pantalla. Necesitamos hacer una elección para que funcione la base de datos, el_systemla base de datos es la predeterminada. Elijamos elsong_collection base de datos y haga clic en la pestaña verde -
Crear una colección
En esta sección, aprenderemos cómo crear una colección. Presione la pestaña Colecciones en la barra de navegación en la parte superior.
Nuestra colección de canciones agregadas a la línea de comandos es visible. Al hacer clic en eso, se mostrarán las entradas. Ahora agregaremos unartists’recopilación mediante la interfaz web. Colecciónsongsque creamos con Arangosh ya está ahí. En el campo Nombre, escribaartists en el New Collectioncuadro de diálogo que aparece. Las opciones avanzadas se pueden ignorar con seguridad y el tipo de colección predeterminado, es decir, Documento, está bien.

Al hacer clic en el botón Guardar finalmente se creará la colección, y ahora las dos colecciones estarán visibles en esta página.
Llenar la colección recién creada con documentos
Se le presentará una colección vacía al hacer clic en el artists colección -
Para agregar un documento, debe hacer clic en el signo + ubicado en la esquina superior derecha. Cuando se le solicite un_key, entrar Affable_Balding como la clave.
Ahora, aparecerá un formulario para agregar y editar los atributos del documento. Hay dos formas de agregar atributos:Graphical y Tree. La forma gráfica es intuitiva pero lenta, por lo tanto, cambiaremos a laCode vista, usando el menú desplegable Árbol para seleccionarlo -
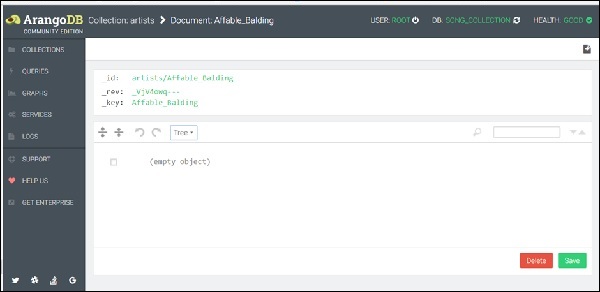
Para facilitar el proceso, hemos creado una muestra de datos en formato JSON, que puede copiar y luego pegar en el área del editor de consultas:
{"artist": "Johnny Mercer", "title": "Affable Balding Me", "composer": "Robert Emmett Dolan", "Year": 1950}
(Nota: solo se debe usar un par de llaves; vea la captura de pantalla a continuación)
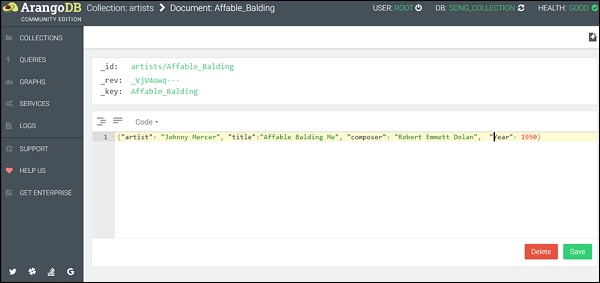
Puede observar que hemos citado las claves y también los valores en el modo de vista de código. Ahora, haga clic enSave. Una vez completado con éxito, un destello verde aparece en la página momentáneamente.
Cómo leer documentos
Para leer documentos, regrese a la página Colecciones.
Cuando uno hace clic en el artist colección, aparece una nueva entrada.
Cómo actualizar documentos
Es sencillo editar las entradas en un documento; solo tiene que hacer clic en la fila que desea editar en la descripción general del documento. Aquí nuevamente se presentará el mismo editor de consultas que al crear nuevos documentos.
Eliminar documentos
Puede eliminar los documentos presionando el icono '-'. Cada fila de documento tiene este signo al final. Le pedirá que confirme para evitar una eliminación insegura.
Además, para una colección en particular, otras operaciones como filtrar los documentos, administrar índices e importar datos también existen en el Collections Overview página.
En nuestro capítulo siguiente, discutiremos una característica importante de la Interfaz Web, es decir, el Editor de consultas AQL.
En este capítulo, discutiremos cómo consultar los datos con AQL. Ya hemos comentado en nuestros capítulos anteriores que ArangoDB ha desarrollado su propio lenguaje de consulta y que se conoce con el nombre de AQL.
Empecemos ahora a interactuar con AQL. Como se muestra en la imagen a continuación, en la interfaz web, presione elAQL Editorpestaña ubicada en la parte superior de la barra de navegación. Aparecerá un editor de consultas en blanco.
Cuando sea necesario, puede cambiar al editor desde la vista de resultados y viceversa, haciendo clic en las pestañas Consulta o Resultado en la esquina superior derecha como se muestra en la imagen a continuación:
Entre otras cosas, el editor tiene resaltado de sintaxis, funcionalidad de deshacer / rehacer y guardar consultas. Para una referencia detallada, se puede ver la documentación oficial. Destacaremos algunas características básicas y de uso común del editor de consultas AQL.
Fundamentos de AQL
En AQL, una consulta representa el resultado final que se debe lograr, pero no el proceso mediante el cual se logra el resultado final. Esta característica se conoce comúnmente como propiedad declarativa del lenguaje. Además, AQL puede consultar y modificar los datos y, por lo tanto, se pueden crear consultas complejas combinando ambos procesos.
Tenga en cuenta que AQL es totalmente compatible con ACID. La lectura o modificación de consultas concluirá en su totalidad o no concluirá en absoluto. Incluso la lectura de los datos de un documento terminará con una unidad coherente de los datos.
Agregamos dos nuevos songsa la colección de canciones que ya hemos creado. En lugar de escribir, puede copiar la siguiente consulta y pegarla en el editor AQL:
FOR song IN [
{
title: "Air-Minded Executive", lyricist: "Johnny Mercer",
composer: "Bernie Hanighen", Year: 1940, _key: "Air-Minded"
},
{
title: "All Mucked Up", lyricist: "Johnny Mercer", composer:
"Andre Previn", Year: 1974, _key: "All_Mucked"
}
]
INSERT song IN songsPresione el botón Ejecutar en la parte inferior izquierda.
Escribirá dos nuevos documentos en el songs colección.
Esta consulta describe cómo funciona el bucle FOR en AQL; itera sobre la lista de documentos codificados JSON, realizando las operaciones codificadas en cada uno de los documentos de la colección. Las diferentes operaciones pueden ser crear nuevas estructuras, filtrar, seleccionar documentos, modificar o insertar documentos en la base de datos (consulte el ejemplo instantáneo). En esencia, AQL puede realizar las operaciones CRUD de manera eficiente.
Para encontrar todas las canciones en nuestra base de datos, ejecutemos una vez más la siguiente consulta, equivalente a un SELECT * FROM songs de una base de datos de tipo SQL (debido a que el editor memoriza la última consulta, presione la *New* botón para limpiar el editor) -
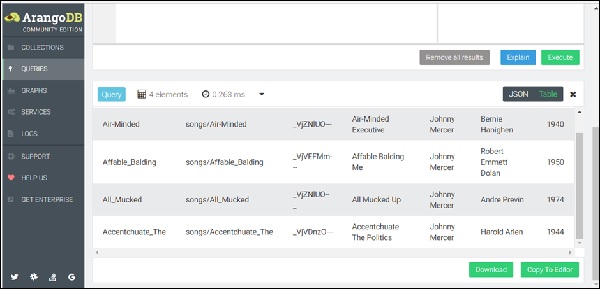
FOR song IN songs
RETURN songEl conjunto de resultados mostrará la lista de canciones guardadas hasta ahora en el songs colección como se muestra en la captura de pantalla a continuación.
Operaciones como FILTER, SORT y LIMIT se puede agregar al For loop cuerpo para estrechar y ordenar el resultado.
FOR song IN songs
FILTER song.Year > 1940
RETURN songLa consulta anterior dará canciones creadas después del año 1940 en la pestaña Resultado (ver la imagen a continuación).
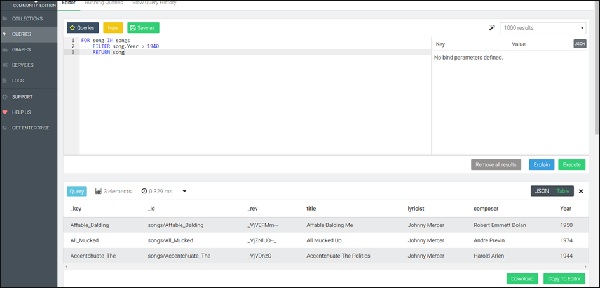
En este ejemplo se utiliza la clave del documento, pero también se puede utilizar cualquier otro atributo como equivalente para el filtrado. Dado que se garantiza que la clave del documento es única, no más de un documento coincidirá con este filtro. Para otros atributos, este puede no ser el caso. Para devolver un subconjunto de usuarios activos (determinado por un atributo llamado estado), ordenados por nombre en orden ascendente, usamos la siguiente sintaxis:
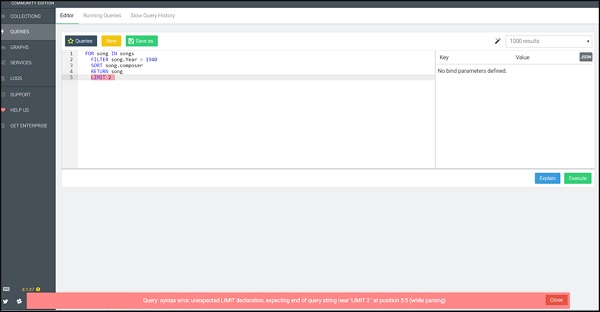
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
RETURN song
LIMIT 2Hemos incluido deliberadamente este ejemplo. Aquí, observamos un mensaje de error de sintaxis de consulta resaltado en rojo por AQL. Esta sintaxis resalta los errores y es útil para depurar sus consultas como se muestra en la captura de pantalla a continuación.
Ejecutemos ahora la consulta correcta (observe la corrección) -
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
LIMIT 2
RETURN song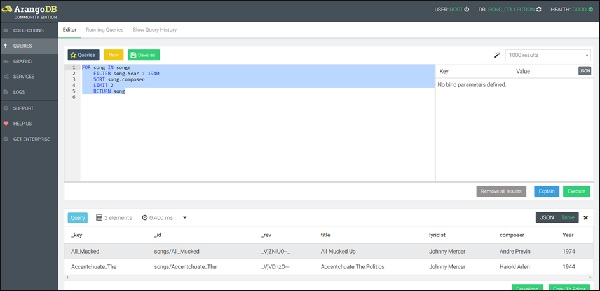
Consulta compleja en AQL
AQL está equipado con múltiples funciones para todos los tipos de datos admitidos. La asignación de variables dentro de una consulta permite construir construcciones anidadas muy complejas. De esta manera, las operaciones de uso intensivo de datos se acercan más a los datos en el backend que al cliente (como el navegador). Para entender esto, primero agreguemos las duraciones arbitrarias (longitud) a las canciones.
Comencemos con la primera función, es decir, la función Actualizar -
UPDATE { _key: "All_Mucked" }
WITH { length: 180 }
IN songs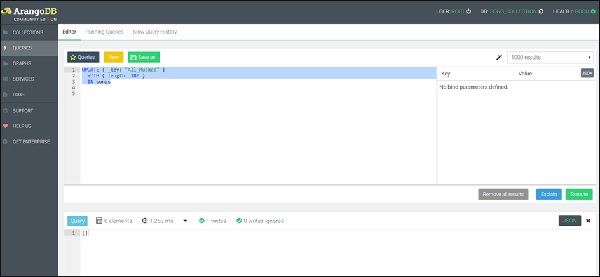
Podemos ver que se ha escrito un documento como se muestra en la captura de pantalla anterior.
Actualicemos ahora también otros documentos (canciones).
UPDATE { _key: "Affable_Balding" }
WITH { length: 200 }
IN songsAhora podemos comprobar que todas nuestras canciones tienen un nuevo atributo length -
FOR song IN songs
RETURN songSalida
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_VkC5lbS---",
"title": "Air-Minded Executive",
"lyricist": "Johnny Mercer",
"composer": "Bernie Hanighen",
"Year": 1940,
"length": 210
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_VkC4eM2---",
"title": "Affable Balding Me",
"lyricist": "Johnny Mercer",
"composer": "Robert Emmett Dolan",
"Year": 1950,
"length": 200
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vjah9Pu---",
"title": "All Mucked Up",
"lyricist": "Johnny Mercer",
"composer": "Andre Previn",
"Year": 1974,
"length": 180
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_VkC3WzW---",
"title": "Accentchuate The Politics",
"lyricist": "Johnny Mercer",
"composer": "Harold Arlen",
"Year": 1944,
"length": 190
}
]Para ilustrar el uso de otras palabras clave de AQL como LET, FILTER, SORT, etc., ahora formateamos las duraciones de la canción en el mm:ss formato.
Consulta
FOR song IN songs
FILTER song.length > 150
LET seconds = song.length % 60
LET minutes = FLOOR(song.length / 60)
SORT song.composer
RETURN
{
Title: song.title,
Composer: song.composer,
Duration: CONCAT_SEPARATOR(':',minutes, seconds)
}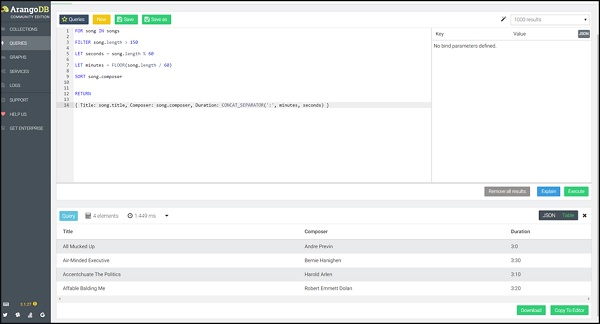
Esta vez devolveremos el título de la canción junto con la duración. losReturn La función le permite crear un nuevo objeto JSON para devolver por cada documento de entrada.
Ahora hablaremos sobre la función 'Uniones' de la base de datos AQL.
Empecemos por crear una colección. composer_dob. Además, crearemos los cuatro documentos con la fecha hipotética de nacimiento de los compositores ejecutando la siguiente consulta en el cuadro de consulta:
FOR dob IN [
{composer: "Bernie Hanighen", Year: 1909}
,
{composer: "Robert Emmett Dolan", Year: 1922}
,
{composer: "Andre Previn", Year: 1943}
,
{composer: "Harold Arlen", Year: 1910}
]
INSERT dob in composer_dob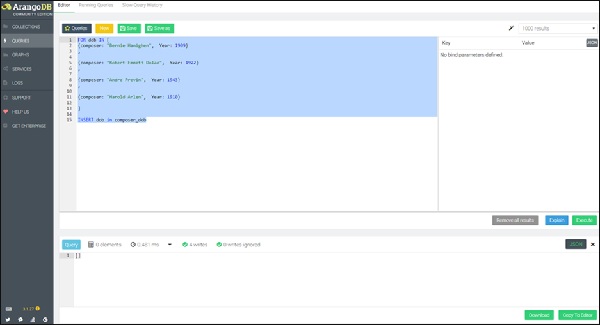
Para resaltar la similitud con SQL, presentamos una consulta de bucle FOR anidada en AQL, que conduce a la operación REPLACE, iterando primero en el bucle interno, sobre la documentación de todos los compositores y luego sobre todas las canciones asociadas, creando un nuevo documento que atributo song_with_composer_key en vez de song atributo.
Aquí va la consulta:
FOR s IN songs
FOR c IN composer_dob
FILTER s.composer == c.composer
LET song_with_composer_key = MERGE(
UNSET(s, 'composer'),
{composer_key:c._key}
)
REPLACE s with song_with_composer_key IN songs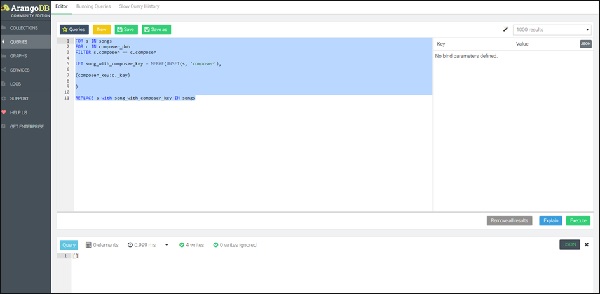
Ejecutemos ahora la consulta FOR song IN songs RETURN song nuevamente para ver cómo ha cambiado la colección de canciones.
Salida
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_Vk8kFoK---",
"Year": 1940,
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive"
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_Vk8kFoK--_",
"Year": 1950,
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me"
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vk8kFoK--A",
"Year": 1974,
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up"
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"Year": 1944,
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics"
}
]La consulta anterior completa el proceso de migración de datos, agregando el composer_key a cada canción.
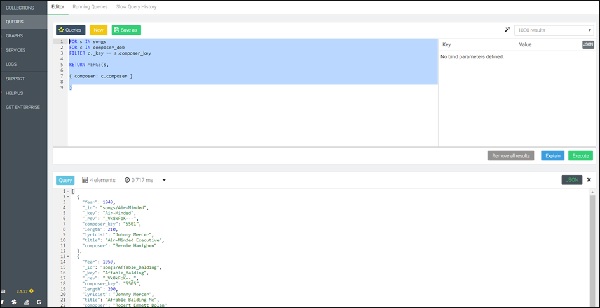
Ahora, la siguiente consulta es nuevamente una consulta de bucle FOR anidada, pero esta vez conduce a la operación Unir, agregando el nombre del compositor asociado (seleccionando con la ayuda de `composer_key`) a cada canción -
FOR s IN songs
FOR c IN composer_dob
FILTER c._key == s.composer_key
RETURN MERGE(s,
{ composer: c.composer }
)Salida
[
{
"Year": 1940,
"_id": "songs/Air-Minded",
"_key": "Air-Minded",
"_rev": "_Vk8kFoK---",
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive",
"composer": "Bernie Hanighen"
},
{
"Year": 1950,
"_id": "songs/Affable_Balding",
"_key": "Affable_Balding",
"_rev": "_Vk8kFoK--_",
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me",
"composer": "Robert Emmett Dolan"
},
{
"Year": 1974,
"_id": "songs/All_Mucked",
"_key": "All_Mucked",
"_rev": "_Vk8kFoK--A",
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up",
"composer": "Andre Previn"
},
{
"Year": 1944,
"_id": "songs/Accentchuate_The",
"_key": "Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics",
"composer": "Harold Arlen"
}
]
En este capítulo, consideraremos algunas consultas de ejemplo de AQL en un Actors and MoviesBase de datos. Estas consultas se basan en gráficos.
Problema
Dada una colección de actores y una colección de películas, y una colección actIn edge (con una propiedad de año) para conectar el vértice como se indica a continuación:
[Actor] <- act in -> [Movie]
¿Cómo llegamos?
- ¿Todos los actores que actuaron en "película1" O "película2"?
- ¿Todos los actores que actuaron tanto en "película1" como en "película2"?
- ¿Todas las películas comunes entre "actor1" y "actor2"?
- ¿Todos los actores que actuaron en 3 o más películas?
- ¿Todas las películas donde actuaron exactamente 6 actores?
- ¿El número de actores por película?
- ¿La cantidad de películas por actor?
- ¿El número de películas actuadas entre 2005 y 2010 por actor?
Solución
Durante el proceso de resolución y obtención de respuestas a las consultas anteriores, usaremos Arangosh para crear el conjunto de datos y ejecutar consultas sobre eso. Todas las consultas AQL son cadenas y simplemente se pueden copiar a su controlador favorito en lugar de Arangosh.
Comencemos por crear un conjunto de datos de prueba en Arangosh. Primero, descargue este archivo -
# wget -O dataset.js
https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharingSalida
...
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘dataset.js’
dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s
2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]Puede ver en el resultado anterior que hemos descargado un archivo JavaScript dataset.js.Este archivo contiene los comandos de Arangosh para crear el conjunto de datos en la base de datos. En lugar de copiar y pegar los comandos uno por uno, usaremos el--javascript.executeopción en Arangosh para ejecutar los múltiples comandos de forma no interactiva. ¡Considérelo el comando de salvavidas!
Ahora ejecute el siguiente comando en el shell:
$ arangosh --javascript.execute dataset.js
Proporcione la contraseña cuando se le solicite, como puede ver en la captura de pantalla anterior. Ahora que hemos guardado los datos, construiremos las consultas AQL para responder las preguntas específicas planteadas al comienzo de este capítulo.
Primera pregunta
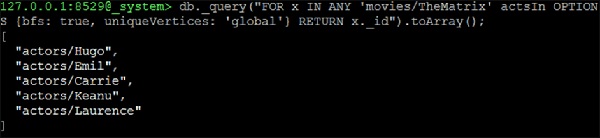
Tomemos la primera pregunta: All actors who acted in "movie1" OR "movie2". Supongamos que queremos encontrar los nombres de todos los actores que actuaron en "TheMatrix" O "TheDevilsAdvocate" -
Comenzaremos con una película a la vez para obtener los nombres de los actores:
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();Salida
Recibiremos el siguiente resultado:
[
"actors/Hugo",
"actors/Emil",
"actors/Carrie",
"actors/Keanu",
"actors/Laurence"
]
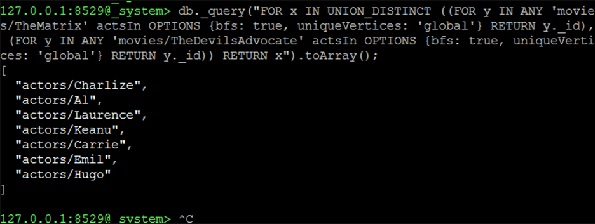
Ahora continuamos formando un UNION_DISTINCT de dos consultas NEIGHBORS que serán la solución -
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Salida
[
"actors/Charlize",
"actors/Al",
"actors/Laurence",
"actors/Keanu",
"actors/Carrie",
"actors/Emil",
"actors/Hugo"
]
Segunda pregunta
Consideremos ahora la segunda pregunta: All actors who acted in both "movie1" AND "movie2". Esto es casi idéntico a la pregunta anterior. Pero esta vez no nos interesa una UNIÓN sino una INTERSECCIÓN -
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Salida
Recibiremos el siguiente resultado:
[
"actors/Keanu"
]
Tercera pregunta
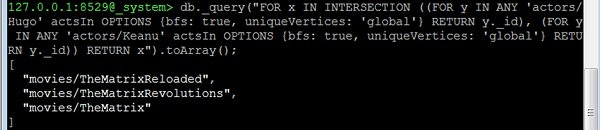
Consideremos ahora la tercera pregunta: All common movies between "actor1" and "actor2". En realidad, esto es idéntico a la pregunta sobre actores comunes en movie1 y movie2. Solo tenemos que cambiar los vértices iniciales. Como ejemplo, busquemos todas las películas en las que Hugo Weaving ("Hugo") y Keanu Reeves son coprotagonistas.
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();Salida
Recibiremos el siguiente resultado:
[
"movies/TheMatrixReloaded",
"movies/TheMatrixRevolutions",
"movies/TheMatrix"
]
Cuarta pregunta
Consideremos ahora la cuarta pregunta. All actors who acted in 3 or more movies. Esta pregunta es diferente; no podemos hacer uso de la función de vecinos aquí. En su lugar, haremos uso del índice de borde y la declaración COLLECT de AQL para agrupar. La idea básica es agrupar todos los bordes por sustartVertex(que en este conjunto de datos es siempre el actor). Luego, eliminamos a todos los actores con menos de 3 películas del resultado, ya que aquí hemos incluido la cantidad de películas en las que ha actuado un actor:
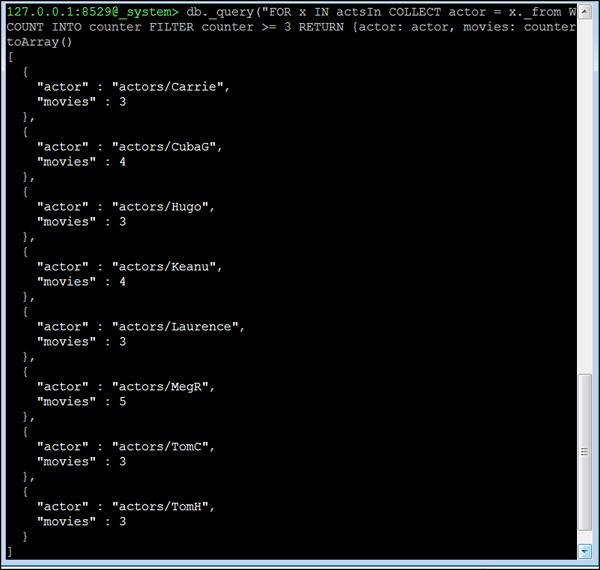
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()Salida
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
Para las preguntas restantes, discutiremos la formación de la consulta y solo proporcionaremos las consultas. El lector debe ejecutar la consulta por sí mismo en la terminal de Arangosh.
Quinta pregunta
Consideremos ahora la quinta pregunta: All movies where exactly 6 actors acted in. La misma idea que en la consulta anterior, pero con el filtro de igualdad. Sin embargo, ahora necesitamos la película en lugar del actor, así que devolvemos el_to attribute -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()¿El número de actores por película?
Recordamos en nuestro conjunto de datos _to en el borde corresponde a la película, por lo que contamos con qué frecuencia el mismo _toaparece. Este es el número de actores. La consulta es casi idéntica a las anteriores, perowithout the FILTER after COLLECT -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()Sexta pregunta
Consideremos ahora la sexta pregunta: The number of movies by an actor.
La forma en que encontramos soluciones a nuestras consultas anteriores también lo ayudará a encontrar la solución a esta consulta.
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()En este capítulo, describiremos varias posibilidades para implementar ArangoDB.
Implementación: instancia única
Ya hemos aprendido cómo implementar la instancia única de Linux (Ubuntu) en uno de nuestros capítulos anteriores. Veamos ahora cómo realizar la implementación usando Docker.
Implementación: Docker
Para la implementación usando Docker, instalaremos Docker en nuestra máquina. Para obtener más información sobre Docker, consulte nuestro tutorial sobre Docker .
Una vez que Docker esté instalado, puede usar el siguiente comando:
docker run -e ARANGO_RANDOM_ROOT_PASSWORD = 1 -d --name agdb-foo -d
arangodb/arangodbCreará y lanzará la instancia de Docker de ArangoDB con el nombre de identificación agdbfoo como un proceso en segundo plano de Docker.
Además, el terminal imprimirá el identificador del proceso.
De forma predeterminada, el puerto 8529 está reservado para que ArangoDB escuche solicitudes. Además, este puerto está disponible automáticamente para todos los contenedores de aplicaciones de Docker que pueda haber vinculado.