Inteligencia artificial - Guía rápida
Desde la invención de las computadoras o las máquinas, su capacidad para realizar diversas tareas siguió creciendo exponencialmente. Los seres humanos han desarrollado el poder de los sistemas informáticos en términos de sus diversos dominios de trabajo, su velocidad creciente y su tamaño reducido con respecto al tiempo.
Una rama de la informática llamada Inteligencia Artificial persigue la creación de ordenadores o máquinas tan inteligentes como los seres humanos.
¿Qué es la inteligencia artificial?
Según el padre de la Inteligencia Artificial, John McCarthy, se trata de “La ciencia y la ingeniería de hacer máquinas inteligentes, especialmente programas informáticos inteligentes”.
La inteligencia artificial es una forma de making a computer, a computer-controlled robot, or a software think intelligently, de la misma manera que piensan los humanos inteligentes.
La IA se logra mediante el estudio de cómo piensa el cerebro humano y cómo los humanos aprenden, deciden y trabajan mientras intentan resolver un problema, y luego usan los resultados de este estudio como base para desarrollar software y sistemas inteligentes.
Filosofía de la IA
Mientras explota el poder de los sistemas informáticos, la curiosidad del ser humano, lo lleva a preguntarse: "¿Puede una máquina pensar y comportarse como lo hacen los humanos?"
Por lo tanto, el desarrollo de la IA comenzó con la intención de crear inteligencia similar en máquinas que encontramos y consideramos altas en los humanos.
Objetivos de la IA
To Create Expert Systems - Los sistemas que exhiben un comportamiento inteligente, aprenden, demuestran, explican y asesoran a sus usuarios.
To Implement Human Intelligence in Machines - Crear sistemas que comprendan, piensen, aprendan y se comporten como humanos.
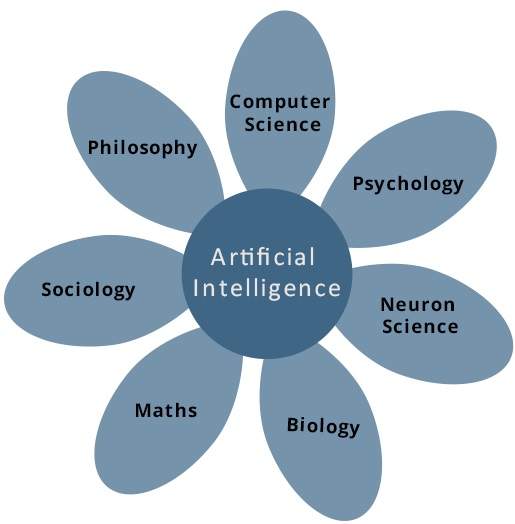
¿Qué contribuye a la IA?
La inteligencia artificial es una ciencia y tecnología basada en disciplinas como la informática, la biología, la psicología, la lingüística, las matemáticas y la ingeniería. Un impulso importante de la IA es el desarrollo de funciones informáticas asociadas con la inteligencia humana, como el razonamiento, el aprendizaje y la resolución de problemas.
De las siguientes áreas, una o varias áreas pueden contribuir a construir un sistema inteligente.
Programación sin y con IA
La programación sin y con AI es diferente en las siguientes formas:
| Programación sin IA | Programando con AI |
|---|---|
| Un programa de computadora sin IA puede responder specific preguntas que está destinado a resolver. | Un programa de computadora con IA puede responder generic preguntas que está destinado a resolver. |
| La modificación en el programa conduce a un cambio en su estructura. | Los programas de IA pueden absorber nuevas modificaciones reuniendo piezas de información altamente independientes. Por lo tanto, puede modificar incluso una pequeña información del programa sin afectar su estructura. |
| La modificación no es rápida ni sencilla. Puede llevar a afectar negativamente al programa. | Modificación de programa rápida y sencilla. |
¿Qué es la técnica de IA?
En el mundo real, el conocimiento tiene algunas propiedades no deseadas:
- Su volumen es enorme, casi inimaginable.
- No está bien organizado o bien formateado.
- Sigue cambiando constantemente.
La técnica de IA es una manera de organizar y utilizar el conocimiento de manera eficiente de tal manera que:
- Debe ser perceptible por las personas que lo proporcionan.
- Debería ser fácilmente modificable para corregir errores.
- Debería ser útil en muchas situaciones aunque sea incompleto o inexacto.
Las técnicas de IA aumentan la velocidad de ejecución del complejo programa con el que está equipado.
Aplicaciones de la IA
La IA ha sido dominante en varios campos como:
Gaming - La IA juega un papel crucial en juegos estratégicos como ajedrez, póquer, tic-tac-toe, etc., donde la máquina puede pensar en una gran cantidad de posiciones posibles basándose en el conocimiento heurístico.
Natural Language Processing - Es posible interactuar con la computadora que entiende el lenguaje natural hablado por humanos.
Expert Systems- Hay algunas aplicaciones que integran máquina, software e información especial para impartir razonamiento y asesoramiento. Proporcionan explicaciones y consejos a los usuarios.
Vision Systems- Estos sistemas comprenden, interpretan y comprenden la información visual en la computadora. Por ejemplo,
Un avión espía toma fotografías, que se utilizan para descubrir información espacial o un mapa de las áreas.
Los médicos utilizan un sistema clínico experto para diagnosticar al paciente.
La policía usa software de computadora que puede reconocer el rostro del criminal con el retrato almacenado hecho por el artista forense.
Speech Recognition- Algunos sistemas inteligentes son capaces de escuchar y comprender el lenguaje en términos de oraciones y sus significados mientras un humano le habla. Puede manejar diferentes acentos, jergas, ruido de fondo, cambios en el ruido humano debido al frío, etc.
Handwriting Recognition- El software de reconocimiento de escritura a mano lee el texto escrito en papel con un bolígrafo o en la pantalla con un lápiz. Puede reconocer las formas de las letras y convertirlas en texto editable.
Intelligent Robots- Los robots son capaces de realizar las tareas encomendadas por un humano. Tienen sensores para detectar datos físicos del mundo real, como luz, calor, temperatura, movimiento, sonido, golpes y presión. Tienen procesadores eficientes, múltiples sensores y una gran memoria para exhibir inteligencia. Además, son capaces de aprender de sus errores y pueden adaptarse al nuevo entorno.
Historia de la IA
Aquí está la historia de la IA durante el siglo XX:
| Año | Hito / Innovación |
|---|---|
| 1923 | La obra de Karel Čapek llamada “Rossum's Universal Robots” (RUR) se abre en Londres, primer uso de la palabra "robot" en inglés. |
| 1943 | Se sentaron las bases para las redes neuronales. |
| 1945 | Isaac Asimov, un alumno de la Universidad de Columbia, acuñó el término Robótica . |
| 1950 | Alan Turing presentó Turing Test para la evaluación de la inteligencia y publicó Computing Machinery and Intelligence. Claude Shannon publicó Análisis detallado del juego de ajedrez como una búsqueda. |
| 1956 | John McCarthy acuñó el término Inteligencia Artificial . Demostración del primer programa de inteligencia artificial en ejecución en la Universidad Carnegie Mellon. |
| 1958 | John McCarthy inventa el lenguaje de programación LISP para IA. |
| 1964 | La disertación de Danny Bobrow en el MIT demostró que las computadoras pueden entender el lenguaje natural lo suficientemente bien como para resolver correctamente los problemas de álgebra. |
| 1965 | Joseph Weizenbaum en MIT construyó ELIZA , un problema interactivo que lleva a cabo un diálogo en inglés. |
| 1969 | Los científicos del Instituto de Investigación de Stanford desarrollaron Shakey , un robot equipado con locomoción, percepción y resolución de problemas. |
| 1973 | El grupo Assembly Robotics de la Universidad de Edimburgo construyó a Freddy , el famoso robot escocés, capaz de usar la visión para localizar y ensamblar modelos. |
| 1979 | Se construyó el primer vehículo autónomo controlado por computadora, Stanford Cart. |
| 1985 | Harold Cohen creó y demostró el programa de dibujo, Aaron . |
| 1990 | Grandes avances en todas las áreas de la IA:
|
| 1997 | El Programa de Ajedrez Deep Blue supera al entonces campeón mundial de ajedrez, Garry Kasparov. |
| 2000 | Las mascotas robot interactivas están disponibles comercialmente. MIT muestra a Kismet , un robot con rostro que expresa emociones. El robot Nomad explora regiones remotas de la Antártida y localiza meteoritos. |
Mientras estudias inteligencia artificial, necesitas saber qué es la inteligencia. Este capítulo cubre la idea de inteligencia, tipos y componentes de la inteligencia.
¿Qué es la inteligencia?
La capacidad de un sistema para calcular, razonar, percibir relaciones y analogías, aprender de la experiencia, almacenar y recuperar información de la memoria, resolver problemas, comprender ideas complejas, usar el lenguaje natural con fluidez, clasificar, generalizar y adaptar situaciones nuevas.
Tipos de inteligencia
Como lo describe Howard Gardner, un psicólogo del desarrollo estadounidense, la Inteligencia se presenta en múltiples aspectos:
| Inteligencia | Descripción | Ejemplo |
|---|---|---|
| Inteligencia lingüística | La capacidad de hablar, reconocer y utilizar mecanismos de fonología (sonidos del habla), sintaxis (gramática) y semántica (significado). | Narradores, Oradores |
| Inteligencia musical | La capacidad de crear, comunicarse y comprender los significados del sonido, comprensión del tono y el ritmo. | Músicos, cantantes, compositores |
| Inteligencia lógico-matemática | La capacidad de utilizar y comprender las relaciones en ausencia de acciones u objetos. Comprensión de ideas complejas y abstractas. | Matemáticos, científicos |
| Inteligencia espacial | La capacidad de percibir información visual o espacial, cambiarla y recrear imágenes visuales sin hacer referencia a los objetos, construir imágenes en 3D y moverlas y rotarlas. | Lectores de mapas, astronautas, físicos |
| Inteligencia corporal-cinestésica | La capacidad de utilizar parte del cuerpo o la totalidad del cuerpo para resolver problemas o crear productos, controlar la motricidad fina y gruesa y manipular los objetos. | Jugadores, bailarines |
| Inteligencia intrapersonal | La capacidad de distinguir entre los propios sentimientos, intenciones y motivaciones. | Gautam Buddhha |
| Inteligencia interpersonal | La capacidad de reconocer y hacer distinciones entre los sentimientos, creencias e intenciones de otras personas. | Comunicadores de masas, entrevistadores |
Puede decir que una máquina o un sistema artificially intelligent cuando está equipado con al menos una y como máximo todas las inteligencias en él.
¿De qué se compone la inteligencia?
La inteligencia es intangible. Está compuesto por:
- Reasoning
- Learning
- Resolución de problemas
- Perception
- Inteligencia lingüística

Repasemos todos los componentes brevemente:
Reasoning- Es el conjunto de procesos que nos permite proporcionar una base para el juicio, la toma de decisiones y la predicción. En general, hay dos tipos:
| Razonamiento inductivo | Razonamiento deductivo |
|---|---|
| Realiza observaciones específicas para realizar declaraciones generales amplias. | Comienza con una declaración general y examina las posibilidades de llegar a una conclusión lógica específica. |
| Incluso si todas las premisas son verdaderas en un enunciado, el razonamiento inductivo permite que la conclusión sea falsa. | Si algo es cierto para una clase de cosas en general, también es cierto para todos los miembros de esa clase. |
| Ejemplo: "Nita es maestra. Nita es estudiosa. Por lo tanto, todos los maestros son estudiosos". | Ejemplo: "Todas las mujeres mayores de 60 años son abuelas. Shalini tiene 65 años. Por lo tanto, Shalini es abuela". |
Learning- Es la actividad de adquirir conocimiento o habilidad al estudiar, practicar, recibir enseñanza o experimentar algo. El aprendizaje mejora la conciencia de los sujetos de estudio.
La capacidad de aprendizaje la poseen los seres humanos, algunos animales y los sistemas habilitados por IA. El aprendizaje se clasifica como:
Auditory Learning- Es aprender escuchando y escuchando. Por ejemplo, estudiantes que escuchan conferencias grabadas en audio.
Episodic Learning- Aprender recordando secuencias de hechos que se han presenciado o experimentado. Esto es lineal y ordenado.
Motor Learning- Se aprende mediante el movimiento preciso de los músculos. Por ejemplo, recoger objetos, escribir, etc.
Observational Learning- Aprender observando e imitando a los demás. Por ejemplo, el niño intenta aprender imitando a sus padres.
Perceptual Learning- Es aprender a reconocer los estímulos que se han visto antes. Por ejemplo, identificar y clasificar objetos y situaciones.
Relational Learning- Implica aprender a diferenciar entre varios estímulos sobre la base de propiedades relacionales, en lugar de propiedades absolutas. Por ejemplo, agregando "un poco menos" de sal al momento de cocinar las papas que salieron saladas la última vez, cuando se cocieron agregando, digamos, una cucharada de sal.
Spatial Learning - Es aprender a través de estímulos visuales como imágenes, colores, mapas, etc. Por ejemplo, una persona puede crear una hoja de ruta en mente antes de seguir la ruta.
Stimulus-Response Learning- Es aprender a realizar una determinada conducta cuando se presenta un determinado estímulo. Por ejemplo, un perro levanta la oreja al escuchar el timbre.
Problem Solving - Es el proceso en el que uno percibe y trata de llegar a la solución deseada de una situación presente tomando algún camino, que está bloqueado por obstáculos conocidos o desconocidos.
La resolución de problemas también incluye decision making, que es el proceso de seleccionar la mejor alternativa adecuada entre múltiples alternativas disponibles para alcanzar la meta deseada.
Perception - Es el proceso de adquirir, interpretar, seleccionar y organizar información sensorial.
La percepción supone sensing. En los seres humanos, los órganos sensoriales ayudan a la percepción. En el dominio de la IA, el mecanismo de percepción reúne los datos adquiridos por los sensores de manera significativa.
Linguistic Intelligence- Es la capacidad de uno para usar, comprender, hablar y escribir el lenguaje verbal y escrito. Es importante en la comunicación interpersonal.
Diferencia entre inteligencia humana y mecánica
Los humanos perciben por patrones, mientras que las máquinas perciben por un conjunto de reglas y datos.
Los seres humanos almacenan y recuerdan información por patrones, las máquinas lo hacen mediante algoritmos de búsqueda. Por ejemplo, el número 40404040 es fácil de recordar, almacenar y recuperar, ya que su patrón es simple.
Los seres humanos pueden descubrir el objeto completo incluso si falta una parte o está distorsionada; mientras que las máquinas no pueden hacerlo correctamente.
El dominio de la inteligencia artificial es enorme en amplitud y amplitud. Mientras avanzamos, consideramos las áreas de investigación prósperas y ampliamente comunes en el dominio de la IA:

Reconocimiento de voz y voz
Ambos términos son comunes en robótica, sistemas expertos y procesamiento del lenguaje natural. Aunque estos términos se usan indistintamente, sus objetivos son diferentes.
| Reconocimiento de voz | Reconocimiento de voz |
|---|---|
| El reconocimiento de voz tiene como objetivo comprender y comprender WHAT fue hablado. | El objetivo del reconocimiento de voz es reconocer WHO está hablando. |
| Se utiliza en la navegación por menús, mapas o computación de manos libres. | Se utiliza para identificar a una persona analizando su tono, tono de voz y acento, etc. |
| La máquina no necesita entrenamiento para el reconocimiento de voz ya que no depende del hablante. | Este sistema de reconocimiento necesita formación ya que está orientado a las personas. |
| Los sistemas de reconocimiento de voz independientes del hablante son difíciles de desarrollar. | Los sistemas de reconocimiento de voz dependientes del hablante son comparativamente fáciles de desarrollar. |
Funcionamiento de los sistemas de reconocimiento de voz y voz
La entrada del usuario hablada en un micrófono va a la tarjeta de sonido del sistema. El convertidor convierte la señal analógica en una señal digital equivalente para el procesamiento de voz. La base de datos se utiliza para comparar los patrones de sonido para reconocer las palabras. Finalmente, se da una retroalimentación inversa a la base de datos.
Este texto en el idioma de origen se convierte en entrada para el motor de traducción, que lo convierte al texto en el idioma de destino. Están respaldados por una GUI interactiva, una gran base de datos de vocabulario, etc.
Aplicaciones de las áreas de investigación en la vida real
Existe una gran variedad de aplicaciones en las que la IA está al servicio de la gente común en su vida cotidiana:
| No Señor. | Áreas de investigación | Aplicación de la vida real |
|---|---|---|
| 1 | Expert Systems Ejemplos: sistemas de seguimiento de vuelos, sistemas clínicos. |

|
| 2 | Natural Language Processing Ejemplos: función de Google Now, reconocimiento de voz, salida de voz automática. |

|
| 3 | Neural Networks Ejemplos: sistemas de reconocimiento de patrones como reconocimiento facial, reconocimiento de caracteres, reconocimiento de escritura a mano. |

|
| 4 | Robotics Ejemplos: robots industriales para mover, pulverizar, pintar, comprobar de precisión, taladrar, limpiar, revestir, tallar, etc. |

|
| 5 | Fuzzy Logic Systems Ejemplos: electrónica de consumo, automóviles, etc. |

|
Clasificación de tareas de la IA
El dominio de la IA se clasifica en Formal tasks, Mundane tasks, y Expert tasks.

| Dominios de tareas de la inteligencia artificial | ||
|---|---|---|
| Tareas mundanas (ordinarias) | Tareas formales | Tareas de expertos |
Percepción
|
|
|
Procesamiento natural del lenguaje
|
Juegos
|
Análisis científico |
| Sentido común | Verificación | Análisis financiero |
| Razonamiento | Demostración de teoremas | Diagnostico medico |
| Cepillado | Creatividad | |
Robótica
|
||
Los humanos aprenden mundane (ordinary) tasksdesde su nacimiento. Aprenden mediante la percepción, el habla, el lenguaje y las locomotoras. Aprenden Tareas formales y Tareas de expertos más tarde, en ese orden.
Para los humanos, las tareas mundanas son las más fáciles de aprender. Lo mismo se consideró cierto antes de intentar implementar tareas mundanas en las máquinas. Anteriormente, todo el trabajo de la IA se concentraba en el dominio de tareas mundanas.
Más tarde, resultó que la máquina requiere más conocimiento, representación compleja del conocimiento y algoritmos complicados para manejar tareas mundanas. Esta es la razónwhy AI work is more prospering in the Expert Tasks domain ahora, como el dominio de tareas de los expertos necesita conocimientos de expertos sin sentido común, que pueden ser más fáciles de representar y manejar.
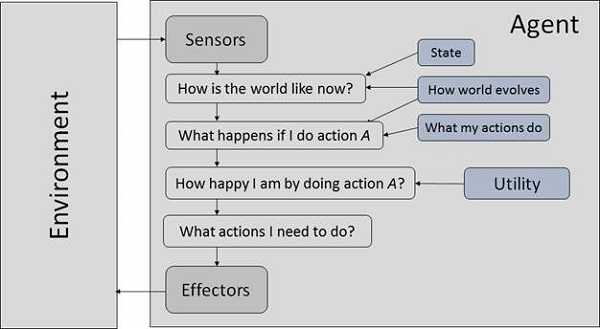
Un sistema de IA está compuesto por un agente y su entorno. Los agentes actúan en su entorno. El medio ambiente puede contener otros agentes.
¿Qué son el agente y el entorno?
Un agent es cualquier cosa que pueda percibir su entorno a través sensors y actúa sobre ese entorno a través de effectors.
UN human agent tiene órganos sensoriales como ojos, oídos, nariz, lengua y piel paralelos a los sensores, y otros órganos como manos, piernas, boca, para efectores.
UN robotic agent reemplaza cámaras y telémetros infrarrojos para los sensores, y varios motores y actuadores para los efectores.
UN software agent tiene cadenas de bits codificadas como sus programas y acciones.

Terminología del agente
Performance Measure of Agent - Es el criterio, que determina el éxito de un agente.
Behavior of Agent - Es la acción que realiza el agente después de una determinada secuencia de percepciones.
Percept - Son las entradas perceptivas del agente en una instancia determinada.
Percept Sequence - Es el historial de todo lo que un agente ha percibido hasta la fecha.
Agent Function - Es un mapa de la secuencia de precepto a una acción.
Racionalidad
La racionalidad no es más que el estado de ser razonable, sensato y tener buen sentido del juicio.
La racionalidad se ocupa de las acciones y los resultados esperados según lo que haya percibido el agente. Realizar acciones con el objetivo de obtener información útil es parte importante de la racionalidad.
¿Qué es Ideal Rational Agent?
Un agente racional ideal es aquel que es capaz de realizar las acciones esperadas para maximizar su medida de desempeño, sobre la base de:
- Su secuencia de percepción
- Su base de conocimientos incorporada
La racionalidad de un agente depende de lo siguiente:
los performance measures, que determinan el grado de éxito.
Del agente Percept Sequence hasta ahora.
El agente prior knowledge about the environment.
los actions que el agente puede realizar.
Un agente racional siempre realiza la acción correcta, donde la acción correcta significa la acción que hace que el agente tenga más éxito en la secuencia de percepción dada. El problema que resuelve el agente se caracteriza por la Medida de rendimiento, el entorno, los actuadores y los sensores (PEAS).
La estructura de los agentes inteligentes
La estructura del agente se puede ver como:
- Agente = Arquitectura + Programa de agente
- Arquitectura = la maquinaria sobre la que se ejecuta un agente.
- Programa de agente = una implementación de una función de agente.
Agentes reflejos simples
- Eligen acciones solo en función de la percepción actual.
- Son racionales solo si se toma una decisión correcta solo sobre la base del precepto actual.
- Su entorno es completamente observable.
Condition-Action Rule - Es una regla que asigna un estado (condición) a una acción.

Agentes reflejos basados en modelos
Usan un modelo del mundo para elegir sus acciones. Mantienen un estado interno.
Model - conocimiento sobre “cómo suceden las cosas en el mundo”.
Internal State - Es una representación de aspectos no observados del estado actual dependiendo del historial de percepción.
Updating the state requires the information about −
- Cómo evoluciona el mundo.
- Cómo las acciones del agente afectan al mundo.

Agentes basados en objetivos
Eligen sus acciones para alcanzar sus metas. El enfoque basado en objetivos es más flexible que el agente reflejo, ya que el conocimiento que respalda una decisión se modela explícitamente, lo que permite modificaciones.
Goal - Es la descripción de situaciones deseables.

Agentes basados en servicios públicos
Eligen acciones basadas en una preferencia (utilidad) para cada estado.
Los objetivos son inadecuados cuando:
Hay objetivos contradictorios, de los cuales solo se pueden lograr unos pocos.
Las metas tienen cierta incertidumbre de alcanzarse y es necesario sopesar la probabilidad de éxito con la importancia de una meta.
La naturaleza de los entornos
Algunos programas operan en el artificial environment confinado a la entrada de teclado, base de datos, sistemas de archivos de computadora y salida de caracteres en una pantalla.
Por el contrario, algunos agentes de software (robots de software o softbots) existen en dominios ricos e ilimitados de softbots. El simulador tiene unvery detailed, complex environment. El agente de software debe elegir entre una amplia gama de acciones en tiempo real. Un softbot diseñado para escanear las preferencias en línea del cliente y mostrar elementos interesantes al cliente trabaja en elreal así como un artificial medio ambiente.
El más famoso artificial environment es el Turing Test environment, en el que uno real y otros agentes artificiales se prueban en igualdad de condiciones. Este es un entorno muy desafiante, ya que es muy difícil para un agente de software funcionar tan bien como un humano.
Prueba de Turing
El éxito de un comportamiento inteligente de un sistema se puede medir con la prueba de Turing.
En la prueba participan dos personas y una máquina a evaluar. De las dos personas, una desempeña el papel de evaluador. Cada uno de ellos se sienta en diferentes habitaciones. El evaluador desconoce quién es una máquina y quién es un ser humano. Él interroga las preguntas mecanografiando y enviándolas a ambas inteligencias, a las que recibe respuestas mecanografiadas.
Esta prueba tiene como objetivo engañar al evaluador. Si el probador no logra determinar la respuesta de la máquina a partir de la respuesta humana, se dice que la máquina es inteligente.
Propiedades del medio ambiente
El medio ambiente tiene múltiples propiedades:
Discrete / Continuous- Si hay un número limitado de estados del entorno distintos y claramente definidos, el entorno es discreto (por ejemplo, ajedrez); de lo contrario, es continuo (por ejemplo, conducción).
Observable / Partially Observable- Si es posible determinar el estado completo del medio ambiente en cada momento a partir de las percepciones, es observable; de lo contrario, es sólo parcialmente observable.
Static / Dynamic- Si el entorno no cambia mientras un agente está actuando, entonces es estático; de lo contrario, es dinámico.
Single agent / Multiple agents - El medio ambiente puede contener otros agentes que pueden ser del mismo o diferente tipo que el del agente.
Accessible / Inaccessible - Si el aparato sensorial del agente puede tener acceso al estado completo del ambiente, entonces el ambiente es accesible para ese agente.
Deterministic / Non-deterministic- Si el siguiente estado del entorno está completamente determinado por el estado actual y las acciones del agente, entonces el entorno es determinista; de lo contrario, no es determinista.
Episodic / Non-episodic- En un entorno episódico, cada episodio consiste en que el agente percibe y luego actúa. La calidad de su acción depende solo del episodio en sí. Los episodios posteriores no dependen de las acciones de los episodios anteriores. Los entornos episódicos son mucho más simples porque el agente no necesita pensar en el futuro.
La búsqueda es la técnica universal de resolución de problemas en IA. Hay algunos juegos para un solo jugador, como juegos de fichas, sudoku, crucigramas, etc. Los algoritmos de búsqueda le ayudan a buscar una posición particular en dichos juegos.
Problemas de búsqueda de rutas de agente único
Los juegos como 3X3 de ocho fichas, 4X4 de quince fichas y 5X5 de veinticuatro fichas son desafíos de búsqueda de caminos de un solo agente. Consisten en una matriz de mosaicos con un mosaico en blanco. Se requiere que el jugador arregle las fichas deslizando una ficha ya sea vertical u horizontalmente en un espacio en blanco con el objetivo de lograr algún objetivo.
Los otros ejemplos de problemas de búsqueda de caminos de un solo agente son el problema del vendedor ambulante, el cubo de Rubik y la demostración de teoremas.
Terminología de búsqueda
Problem Space- Es el entorno en el que se desarrolla la búsqueda. (Un conjunto de estados y un conjunto de operadores para cambiar esos estados)
Problem Instance - Es el estado inicial + el estado del objetivo.
Problem Space Graph- Representa el estado del problema. Los estados se muestran por nodos y los operadores por aristas.
Depth of a problem - Longitud de la ruta más corta o la secuencia más corta de operadores desde el estado inicial hasta el estado objetivo.
Space Complexity - El número máximo de nodos que se almacenan en la memoria.
Time Complexity - El número máximo de nodos que se crean.
Admissibility - Propiedad de un algoritmo para encontrar siempre una solución óptima.
Branching Factor - El número promedio de nodos secundarios en el gráfico del espacio del problema.
Depth - Longitud de la ruta más corta desde el estado inicial al estado objetivo.
Estrategias de búsqueda de fuerza bruta
Son muy simples, ya que no necesitan ningún conocimiento específico de dominio. Funcionan bien con una pequeña cantidad de estados posibles.
Requisitos -
- Descripción del estado
- Un conjunto de operadores válidos
- Estado inicial
- Descripción del estado del objetivo
Búsqueda primero en amplitud
Comienza desde el nodo raíz, explora los nodos vecinos primero y avanza hacia los vecinos del siguiente nivel. Genera un árbol a la vez hasta que se encuentra la solución. Se puede implementar utilizando la estructura de datos de cola FIFO. Este método proporciona el camino más corto a la solución.
Si branching factor(número promedio de nodos secundarios para un nodo dado) = by profundidad = d, luego el número de nodos en el nivel d = b d .
El número total de nodos creados en el peor de los casos es b + b 2 + b 3 +… + b d .
Disadvantage- Dado que cada nivel de nodos se guarda para crear el siguiente, consume mucho espacio de memoria. El requisito de espacio para almacenar nodos es exponencial.
Su complejidad depende del número de nodos. Puede comprobar nodos duplicados.

Búsqueda en profundidad
Se implementa en recursividad con la estructura de datos de pila LIFO. Crea el mismo conjunto de nodos que el método Breadth-First, solo que en el orden diferente.
Como los nodos de la ruta única se almacenan en cada iteración desde la raíz hasta el nodo hoja, el requisito de espacio para almacenar nodos es lineal. Con el factor de ramificación by la profundidad como m , el espacio de almacenamiento es bm.
Disadvantage- Este algoritmo no puede terminar y continuar infinitamente en una ruta. La solución a este problema es elegir una profundidad de corte. Si el límite ideal es d , y si el límite elegido es menor que d , este algoritmo puede fallar. Si el límite elegido es superior a d , el tiempo de ejecución aumenta.
Su complejidad depende del número de caminos. No puede verificar nodos duplicados.

Búsqueda bidireccional
Busca hacia adelante desde el estado inicial y hacia atrás desde el estado objetivo hasta que ambos se encuentran para identificar un estado común.
La ruta desde el estado inicial se concatena con la ruta inversa desde el estado objetivo. Cada búsqueda se realiza solo hasta la mitad de la ruta total.
Búsqueda de costos uniformes
La clasificación se realiza aumentando el costo de la ruta a un nodo. Siempre expande el nodo de menor costo. Es idéntica a la búsqueda Breadth First si cada transición tiene el mismo costo.
Explora caminos en el orden creciente de costo.
Disadvantage- Puede haber múltiples rutas largas con un costo ≤ C *. La búsqueda de Costo Uniforme debe explorarlos todos.
Búsqueda iterativa de profundización en profundidad
Realiza una búsqueda en profundidad hasta el nivel 1, comienza de nuevo, ejecuta una búsqueda completa en profundidad hasta el nivel 2 y continúa de esa manera hasta que se encuentra la solución.
Nunca crea un nodo hasta que se generan todos los nodos inferiores. Solo guarda una pila de nodos. El algoritmo finaliza cuando encuentra una solución a la profundidad d . El número de nodos creados en la profundidad d es b d y en la profundidad d-1 es b d-1.
Comparación de diversas complejidades de algoritmos
Veamos el rendimiento de algoritmos basados en varios criterios:
| Criterio | Primero la amplitud | Profundidad primero | Bidireccional | Costo uniforme | Profundización interactiva |
|---|---|---|---|---|---|
| Hora | b d | b m | b d / 2 | b d | b d |
| Espacio | b d | b m | b d / 2 | b d | b d |
| Optimalidad | si | No | si | si | si |
| Lo completo | si | No | si | si | si |
Estrategias de búsqueda informadas (heurísticas)
Para resolver grandes problemas con un gran número de estados posibles, es necesario agregar conocimientos específicos del problema para aumentar la eficiencia de los algoritmos de búsqueda.
Funciones de evaluación heurística
Calculan el costo de la ruta óptima entre dos estados. Una función heurística para los juegos de fichas deslizantes se calcula contando el número de movimientos que realiza cada ficha desde su estado objetivo y sumando esta cantidad de movimientos para todas las fichas.
Búsqueda heurística pura
Expande los nodos en el orden de sus valores heurísticos. Crea dos listas, una lista cerrada para los nodos ya expandidos y una lista abierta para los nodos creados pero no expandidos.
En cada iteración, se expande un nodo con un valor heurístico mínimo, todos sus nodos secundarios se crean y se colocan en la lista cerrada. Luego, la función heurística se aplica a los nodos secundarios y se colocan en la lista abierta de acuerdo con su valor heurístico. Los caminos más cortos se guardan y los más largos se eliminan.
Una búsqueda
Es la forma más conocida de búsqueda Mejor primero. Evita expandir caminos que ya son costosos, pero primero expande los caminos más prometedores.
f (n) = g (n) + h (n), donde
- g (n) el costo (hasta ahora) para llegar al nodo
- h (n) costo estimado para ir del nodo al objetivo
- f (n) costo total estimado de la ruta a través de n hasta la meta. Se implementa usando la cola de prioridad aumentando f (n).
Greedy Mejor primera búsqueda
Expande el nodo que se estima que está más cerca del objetivo. Expande los nodos basados en f (n) = h (n). Se implementa mediante cola de prioridad.
Disadvantage- Puede atascarse en bucles. No es óptimo.
Algoritmos de búsqueda local
Parten de una solución prospectiva y luego pasan a una solución vecina. Pueden devolver una solución válida incluso si se interrumpe en cualquier momento antes de que finalice.
Búsqueda de escalada
Es un algoritmo iterativo que comienza con una solución arbitraria a un problema e intenta encontrar una mejor solución cambiando un solo elemento de la solución de forma incremental. Si el cambio produce una mejor solución, un cambio incremental se toma como una nueva solución. Este proceso se repite hasta que no haya más mejoras.
función Hill-Climbing (problema), devuelve un estado que es un máximo local.
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
endDisadvantage - Este algoritmo no es completo ni óptimo.
Búsqueda de haz local
En este algoritmo, contiene k número de estados en un momento dado. Al principio, estos estados se generan de forma aleatoria. Los sucesores de estos k estados se calculan con la ayuda de la función objetivo. Si alguno de estos sucesores es el valor máximo de la función objetivo, entonces el algoritmo se detiene.
De lo contrario, los estados (k estados iniciales y k número de sucesores de los estados = 2k) se colocan en un grupo. Luego, el grupo se ordena numéricamente. Los k estados más altos se seleccionan como nuevos estados iniciales. Este proceso continúa hasta que se alcanza un valor máximo.
función BeamSearch ( problema, k ), devuelve un estado de solución.
start with k randomly generated states
loop
generate all successors of all k states
if any of the states = solution, then return the state
else select the k best successors
endRecocido simulado
El recocido es el proceso de calentar y enfriar un metal para cambiar su estructura interna y modificar sus propiedades físicas. Cuando el metal se enfría, se agarra su nueva estructura y el metal conserva sus propiedades recién obtenidas. En el proceso de recocido simulado, la temperatura se mantiene variable.
Inicialmente establecemos la temperatura alta y luego dejamos que se "enfríe" lentamente a medida que avanza el algoritmo. Cuando la temperatura es alta, el algoritmo puede aceptar peores soluciones con alta frecuencia.
comienzo
- Inicializar k = 0; L = número entero de variables;
- De i → j, busque la diferencia de rendimiento Δ.
- Si Δ <= 0 entonces acepte else if exp (-Δ / T (k))> random (0,1) luego acepte;
- Repita los pasos 1 y 2 para los pasos L (k).
- k = k + 1;
Repita los pasos 1 a 4 hasta que se cumplan los criterios.
Fin
Problema del vendedor ambulante
En este algoritmo, el objetivo es encontrar un recorrido de bajo costo que comience en una ciudad, visite todas las ciudades en ruta exactamente una vez y termine en la misma ciudad de partida.
Start
Find out all (n -1)! Possible solutions, where n is the total number of cities.
Determine the minimum cost by finding out the cost of each of these (n -1)! solutions.
Finally, keep the one with the minimum cost.
end
Los sistemas de lógica difusa (FLS) producen una salida aceptable pero definida en respuesta a una entrada incompleta, ambigua, distorsionada o inexacta (difusa).
¿Qué es Fuzzy Logic?
La lógica difusa (FL) es un método de razonamiento que se asemeja al razonamiento humano. El enfoque de FL imita la forma de toma de decisiones en humanos que involucra todas las posibilidades intermedias entre los valores digitales SI y NO.
El bloque lógico convencional que una computadora puede entender toma una entrada precisa y produce una salida definida como VERDADERO o FALSO, que es equivalente al SÍ o NO humano.
El inventor de la lógica difusa, Lotfi Zadeh, observó que, a diferencia de las computadoras, la toma de decisiones humana incluye un rango de posibilidades entre SÍ y NO, tales como:
| CIERTAMENTE SI |
| POSIBLEMENTE SI |
| NO PUEDO DECIR |
| POSIBLEMENTE NO |
| CIERTAMENTE NO |
La lógica difusa trabaja en los niveles de posibilidades de entrada para lograr la salida definida.
Implementación
Se puede implementar en sistemas con varios tamaños y capacidades que van desde pequeños microcontroladores hasta grandes sistemas de control basados en estaciones de trabajo en red.
Puede implementarse en hardware, software o una combinación de ambos.
¿Por qué Fuzzy Logic?
La lógica difusa es útil para fines comerciales y prácticos.
- Puede controlar máquinas y productos de consumo.
- Puede que no proporcione un razonamiento preciso, pero sí un razonamiento aceptable.
- La lógica difusa ayuda a lidiar con la incertidumbre en la ingeniería.
Arquitectura de sistemas de lógica difusa
Tiene cuatro partes principales como se muestra:
Fuzzification Module- Transforma las entradas del sistema, que son números nítidos, en conjuntos difusos. Divide la señal de entrada en cinco pasos como:
| LP | x es positivo grande |
| MP | x es positivo medio |
| S | x es pequeño |
| MN | x es medio negativo |
| LN | x es grande negativo |
Knowledge Base - Almacena reglas IF-THEN proporcionadas por expertos.
Inference Engine - Simula el proceso de razonamiento humano haciendo inferencias borrosas sobre las entradas y las reglas SI-ENTONCES.
Defuzzification Module - Transforma el conjunto difuso obtenido por el motor de inferencia en un valor nítido.

los membership functions work on conjuntos difusos de variables.
Función de la membresía
Las funciones de pertenencia le permiten cuantificar términos lingüísticos y representar gráficamente un conjunto difuso. UNmembership functionpara un conjunto difuso A en el universo del discurso X se define como μ A : X → [0,1].
Aquí, cada elemento de X se asigna a un valor entre 0 y 1. Se llamamembership value o degree of membership. Se cuantifica el grado de pertenencia del elemento en X al conjunto difuso A .
- El eje x representa el universo del discurso.
- El eje y representa los grados de pertenencia en el intervalo [0, 1].
Puede haber múltiples funciones de pertenencia aplicables para fuzzificar un valor numérico. Las funciones de pertenencia simples se utilizan ya que el uso de funciones complejas no agrega más precisión en la salida.
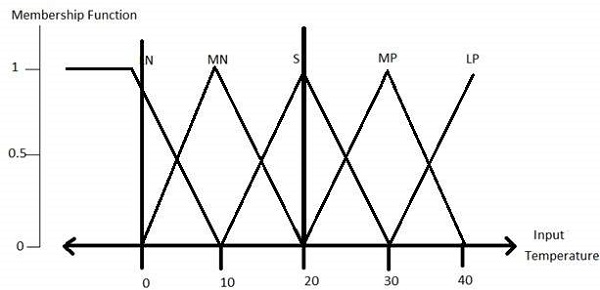
Todas las funciones de membresía para LP, MP, S, MN, y LN se muestran a continuación:

Las formas de función de pertenencia triangular son más comunes entre varias otras formas de función de pertenencia como trapezoidal, singleton y gaussiana.
Aquí, la entrada al difusor de 5 niveles varía de -10 voltios a +10 voltios. Por tanto, la salida correspondiente también cambia.
Ejemplo de un sistema de lógica difusa
Consideremos un sistema de aire acondicionado con sistema de lógica difusa de 5 niveles. Este sistema ajusta la temperatura del aire acondicionado comparando la temperatura ambiente y el valor de temperatura objetivo.
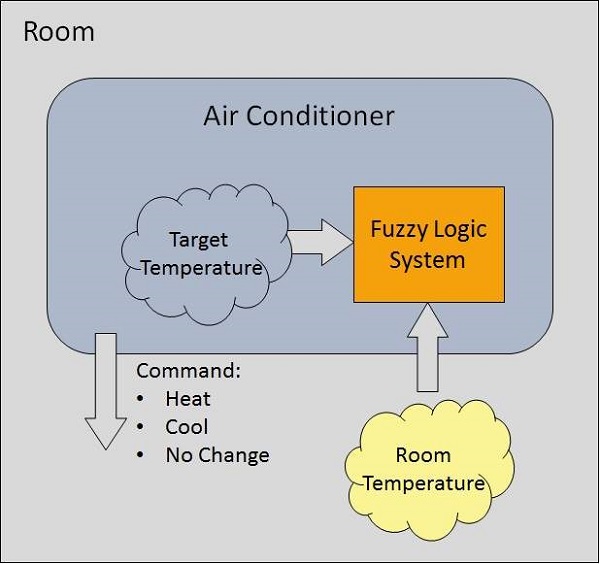
Algoritmo
- Definir variables y términos lingüísticos (inicio)
- Construya funciones de pertenencia para ellos. (comienzo)
- Construir una base de conocimientos de reglas (inicio)
- Convierta datos nítidos en conjuntos de datos difusos utilizando funciones de membresía. (fuzzificación)
- Evaluar reglas en la base de reglas. (Máquina de inferencia)
- Combine los resultados de cada regla. (Máquina de inferencia)
- Convierta los datos de salida en valores no difusos. (defuzzificación)
Desarrollo
Step 1 − Define linguistic variables and terms
Las variables lingüísticas son variables de entrada y salida en forma de palabras u oraciones simples. Para temperatura ambiente, frío, tibio, caliente, etc., son términos lingüísticos.
Temperatura (t) = {muy fría, fría, tibia, muy tibia, caliente}
Cada miembro de este conjunto es un término lingüístico y puede cubrir una parte de los valores generales de temperatura.
Step 2 − Construct membership functions for them
Las funciones de pertenencia de la variable de temperatura son las que se muestran:
Step3 − Construct knowledge base rules
Cree una matriz de valores de temperatura ambiente versus valores de temperatura objetivo que se espera que proporcione un sistema de aire acondicionado.
| Temperatura ambiente. /Objetivo | Muy frío | Frío | Calentar | Caliente | Very_Hot |
|---|---|---|---|---|---|
| Muy frío | Ningún cambio | Calor | Calor | Calor | Calor |
| Frío | Frio | Ningún cambio | Calor | Calor | Calor |
| Calentar | Frio | Frio | Ningún cambio | Calor | Calor |
| Caliente | Frio | Frio | Frio | Ningún cambio | Calor |
| Very_Hot | Frio | Frio | Frio | Frio | Ningún cambio |
Construya un conjunto de reglas en la base de conocimientos en forma de estructuras IF-THEN-ELSE.
| No Señor. | Condición | Acción |
|---|---|---|
| 1 | SI temperatura = (Fría O Muy_Fría) Y objetivo = Cálida ENTONCES | Calor |
| 2 | SI temperatura = (Caliente O Muy_caliente) Y objetivo = Caliente ENTONCES | Frio |
| 3 | SI (temperatura = cálido) Y (objetivo = cálido) ENTONCES | Ningún cambio |
Step 4 − Obtain fuzzy value
Las operaciones de conjuntos difusos realizan la evaluación de reglas. Las operaciones utilizadas para OR y AND son Max y Min respectivamente. Combine todos los resultados de la evaluación para formar un resultado final. Este resultado es un valor difuso.
Step 5 − Perform defuzzification
La defuzzificación se realiza de acuerdo con la función de pertenencia para la variable de salida.

Áreas de aplicación de la lógica difusa
Las áreas de aplicación clave de la lógica difusa son las siguientes:
Automotive Systems
- Cajas de cambios automáticas
- Dirección en las cuatro ruedas
- Control del entorno del vehículo
Consumer Electronic Goods
- Sistemas de alta fidelidad
- Photocopiers
- Cámaras fijas y de video
- Television
Domestic Goods
- Hornos de microondas
- Refrigerators
- Toasters
- Aspiradoras
- Lavadoras
Environment Control
- Aires acondicionados / secadores / calentadores
- Humidifiers
Ventajas de los FLS
Los conceptos matemáticos dentro del razonamiento difuso son muy simples.
Puede modificar un FLS simplemente agregando o eliminando reglas debido a la flexibilidad de la lógica difusa.
Los sistemas de lógica difusa pueden tomar información de entrada imprecisa, distorsionada y ruidosa.
Los FLS son fáciles de construir y comprender.
La lógica difusa es una solución a problemas complejos en todos los campos de la vida, incluida la medicina, ya que se asemeja al razonamiento y la toma de decisiones humanos.
Desventajas de los FLS
- No existe un enfoque sistemático para el diseño de sistemas difusos.
- Son comprensibles solo cuando son simples.
- Son adecuados para los problemas que no necesitan una gran precisión.
El procesamiento del lenguaje natural (PNL) se refiere al método de inteligencia artificial para comunicarse con sistemas inteligentes utilizando un lenguaje natural como el inglés.
El procesamiento de lenguaje natural es necesario cuando desea que un sistema inteligente como un robot funcione según sus instrucciones, cuando desea escuchar la decisión de un sistema clínico experto basado en el diálogo, etc.
El campo de la PNL implica la fabricación de computadoras para realizar tareas útiles con los lenguajes naturales que usan los humanos. La entrada y salida de un sistema de PNL pueden ser:
- Speech
- Texto escrito
Componentes de la PNL
Hay dos componentes de PNL como se indica:
Comprensión del lenguaje natural (NLU)
La comprensión implica las siguientes tareas:
- Mapeo de la entrada dada en lenguaje natural en representaciones útiles.
- Analizar diferentes aspectos del idioma.
Generación de lenguaje natural (NLG)
Es el proceso de producir frases y oraciones significativas en forma de lenguaje natural a partir de alguna representación interna.
Implica -
Text planning - Incluye recuperar el contenido relevante de la base de conocimientos.
Sentence planning - Incluye elegir las palabras requeridas, formar frases significativas, establecer el tono de la oración.
Text Realization - Está mapeando el plan de la oración en la estructura de la oración.
La NLU es más dura que la NLG.
Dificultades en NLU
NL tiene una forma y una estructura extremadamente ricas.
Es muy ambiguo. Puede haber diferentes niveles de ambigüedad:
Lexical ambiguity - Está en un nivel muy primitivo como el nivel de palabra.
Por ejemplo, ¿tratar la palabra "tablero" como sustantivo o verbo?
Syntax Level ambiguity - Una oración se puede analizar de diferentes formas.
Por ejemplo, "Levantó el escarabajo con gorra roja". - ¿Usó gorra para levantar el escarabajo o levantó un escarabajo que tenía gorra roja?
Referential ambiguity- Refiriéndose a algo mediante pronombres. Por ejemplo, Rima fue a Gauri. Ella dijo: "Estoy cansada". - ¿Exactamente quién está cansado?
Una entrada puede significar diferentes significados.
Muchas entradas pueden significar lo mismo.
Terminología de PNL
Phonology - Es el estudio de la organización del sonido de forma sistemática.
Morphology - Es un estudio de construcción de palabras a partir de unidades significativas primitivas.
Morpheme - Es la unidad primitiva de significado en una lengua.
Syntax- Se refiere a ordenar palabras para formar una oración. También implica determinar el papel estructural de las palabras en la oración y en las frases.
Semantics - Se preocupa por el significado de las palabras y cómo combinar palabras en frases y oraciones significativas.
Pragmatics - Se trata del uso y comprensión de frases en diferentes situaciones y cómo se ve afectada la interpretación de la frase.
Discourse - Se trata de cómo la oración inmediatamente anterior puede afectar la interpretación de la oración siguiente.
World Knowledge - Incluye el conocimiento general del mundo.
Pasos en PNL
Hay cinco pasos generales:
Lexical Analysis- Implica identificar y analizar la estructura de las palabras. Léxico de un idioma significa la colección de palabras y frases en un idioma. El análisis léxico consiste en dividir todo el texto en párrafos, oraciones y palabras.
Syntactic Analysis (Parsing)- Implica el análisis de palabras en la oración para la gramática y la ordenación de palabras de una manera que muestra la relación entre las palabras. El analizador sintáctico inglés rechaza una oración como "La escuela va al niño".

Semantic Analysis- Extrae el significado exacto o el significado del diccionario del texto. Se verifica la significación del texto. Se realiza mapeando estructuras sintácticas y objetos en el dominio de tareas. El analizador semántico ignora oraciones como "helado caliente".
Discourse Integration- El significado de cualquier oración depende del significado de la oración inmediatamente anterior. Además, también aporta el significado de la oración inmediatamente posterior.
Pragmatic Analysis- Durante esto, lo que se dijo se reinterpreta sobre lo que realmente significaba. Implica derivar aquellos aspectos del lenguaje que requieren conocimiento del mundo real.
Aspectos de implementación del análisis sintáctico
Hay una serie de algoritmos que los investigadores han desarrollado para el análisis sintáctico, pero solo consideramos los siguientes métodos simples:
- Gramática libre de contexto
- Analizador de arriba hacia abajo
Veámoslos en detalle -
Gramática libre de contexto
Es la gramática que consta de reglas con un solo símbolo en el lado izquierdo de las reglas de reescritura. Creemos gramática para analizar una oración:
"El pájaro picotea los granos"
Articles (DET)- a | un | la
Nouns- pájaro | pájaros | grano | granos
Noun Phrase (NP)- Artículo + Sustantivo | Artículo + Adjetivo + Sustantivo
= DET N | DET ADJ N
Verbs- picotazos | picoteando | picoteado
Verb Phrase (VP)- NP V | V NP
Adjectives (ADJ)- hermosa | pequeño | piar
El árbol de análisis descompone la oración en partes estructuradas para que la computadora pueda comprenderla y procesarla fácilmente. Para que el algoritmo de análisis pueda construir este árbol de análisis, se necesita construir un conjunto de reglas de reescritura, que describen qué estructuras de árbol son legales.
Estas reglas dicen que un cierto símbolo puede expandirse en el árbol mediante una secuencia de otros símbolos. De acuerdo con la regla lógica de primer orden, si hay dos cadenas Frase sustantiva (NP) y Frase verbal (VP), entonces la cadena combinada por NP seguida de VP es una oración. Las reglas de reescritura de la oración son las siguientes:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
DET → a | la
ADJ → hermoso | posarse
N → pájaro | pájaros | grano | granos
V → picotear | picotazos | picoteo
El árbol de análisis se puede crear como se muestra:

Ahora considere las reglas de reescritura anteriores. Dado que V puede ser reemplazado por ambos, "picotear" o "picotear", frases como "El pájaro picotea los granos" pueden ser incorrectamente permitidas. es decir, el error de concordancia entre sujeto y verbo se aprueba como correcto.
Merit - El estilo gramatical más simple y, por tanto, muy utilizado.
Demerits −
No son muy precisos. Por ejemplo, “Los granos picotean al pájaro”, es sintácticamente correcto según el analizador, pero incluso si no tiene sentido, el analizador lo toma como una oración correcta.
Para lograr una alta precisión, es necesario preparar varios conjuntos de gramática. Puede requerir un conjunto de reglas completamente diferente para analizar variaciones singulares y plurales, oraciones pasivas, etc., lo que puede llevar a la creación de un enorme conjunto de reglas que son inmanejables.
Analizador de arriba hacia abajo
Aquí, el analizador comienza con el símbolo S e intenta reescribirlo en una secuencia de símbolos terminales que coinciden con las clases de las palabras en la oración de entrada hasta que se compone completamente de símbolos terminales.
Luego se verifican con la oración de entrada para ver si coincide. De lo contrario, el proceso se inicia de nuevo con un conjunto de reglas diferente. Esto se repite hasta que se encuentra una regla específica que describe la estructura de la oración.
Merit - Es simple de implementar.
Demerits −
- Es ineficaz, ya que el proceso de búsqueda debe repetirse si se produce un error.
- Velocidad de trabajo lenta.
Los sistemas expertos (ES) son uno de los dominios de investigación más importantes de la IA. Lo presentan los investigadores del Departamento de Ciencias de la Computación de la Universidad de Stanford.
¿Qué son los sistemas expertos?
Los sistemas expertos son las aplicaciones informáticas desarrolladas para resolver problemas complejos en un dominio particular, al nivel de inteligencia y experiencia humanas extraordinarias.
Características de los sistemas expertos
- Alto rendimiento
- Understandable
- Reliable
- Altamente receptivo
Capacidades de los sistemas expertos
Los sistemas expertos son capaces de:
- Advising
- Instruir y ayudar al ser humano en la toma de decisiones.
- Demonstrating
- Derivando una solución
- Diagnosing
- Explaining
- Interpretación de entrada
- Predicción de resultados
- Justificando la conclusión
- Sugerir opciones alternativas a un problema
Son incapaces de ...
- Sustitución de tomadores de decisiones humanos
- Poseer capacidades humanas
- Producir resultados precisos para una base de conocimientos inadecuada
- Refinando su propio conocimiento
Componentes de sistemas expertos
Los componentes de ES incluyen:
- Base de conocimientos
- Máquina de inferencia
- Interfaz de usuario
Veámoslos brevemente uno por uno -

Base de conocimientos
Contiene conocimientos específicos de dominio y de alta calidad.
Se requiere conocimiento para exhibir inteligencia. El éxito de cualquier EE depende principalmente de la recopilación de conocimientos altamente precisos y precisos.
¿Qué es el conocimiento?
Los datos son recopilación de hechos. La información se organiza como datos y hechos sobre el dominio de la tarea.Data, information, y past experience combinados se denominan conocimientos.
Componentes de la base de conocimientos
La base de conocimientos de un EE es un almacén de conocimientos tanto fácticos como heurísticos.
Factual Knowledge - Es la información ampliamente aceptada por los ingenieros del conocimiento y los académicos en el dominio de tareas.
Heuristic Knowledge - Se trata de práctica, juicio preciso, capacidad de evaluación y conjetura.
Representación del conocimiento
Es el método utilizado para organizar y formalizar el conocimiento en la base de conocimientos. Tiene la forma de reglas IF-THEN-ELSE.
Adquisición de conocimientos
El éxito de cualquier sistema experto depende principalmente de la calidad, integridad y precisión de la información almacenada en la base de conocimientos.
La base de conocimientos está formada por lecturas de varios expertos, académicos y Knowledge Engineers. El ingeniero del conocimiento es una persona con las cualidades de empatía, aprendizaje rápido y habilidades de análisis de casos.
Adquiere información de un experto en la materia al grabarlo, entrevistarlo y observarlo en el trabajo, etc. Luego categoriza y organiza la información de manera significativa, en forma de reglas SI-ENTONCES-ELSE, para ser utilizadas por la máquina de interferencia. El ingeniero del conocimiento también supervisa el desarrollo del ES.
Máquina de inferencia
El uso de procedimientos y reglas eficientes por parte del motor de inferencia es esencial para obtener una solución correcta e impecable.
En el caso de los ES basados en el conocimiento, el motor de inferencia adquiere y manipula el conocimiento de la base de conocimiento para llegar a una solución particular.
En el caso de ES basado en reglas,
Aplica reglas repetidamente a los hechos, que se obtienen de la aplicación de reglas anterior.
Agrega nuevos conocimientos a la base de conocimientos si es necesario.
Resuelve el conflicto de reglas cuando se aplican varias reglas a un caso particular.
Para recomendar una solución, el motor de inferencia utiliza las siguientes estrategias:
- Encadenamiento directo
- Encadenamiento hacia atrás
Encadenamiento directo
Es una estrategia de un sistema experto para responder la pregunta, “What can happen next?”
Aquí, el motor de inferencia sigue la cadena de condiciones y derivaciones y finalmente deduce el resultado. Considera todos los hechos y las reglas, y los clasifica antes de llegar a una solución.
Esta estrategia se sigue para trabajar en la conclusión, el resultado o el efecto. Por ejemplo, la predicción del estado del mercado de acciones como efecto de cambios en las tasas de interés.

Encadenamiento hacia atrás
Con esta estrategia, un sistema experto encuentra la respuesta a la pregunta, “Why this happened?”
Sobre la base de lo que ya ha sucedido, el motor de inferencia intenta averiguar qué condiciones podrían haber ocurrido en el pasado para este resultado. Se sigue esta estrategia para averiguar la causa o el motivo. Por ejemplo, diagnóstico de cáncer de sangre en humanos.
Interfaz de usuario
La interfaz de usuario proporciona interacción entre el usuario del ES y el ES mismo. Por lo general, se trata de procesamiento de lenguaje natural para que lo utilice el usuario que esté bien versado en el dominio de tareas. El usuario del ES no tiene por qué ser necesariamente un experto en Inteligencia Artificial.
Explica cómo el SE ha llegado a una recomendación particular. La explicación puede aparecer en las siguientes formas:
- Lenguaje natural mostrado en pantalla.
- Narraciones verbales en lenguaje natural.
- Listado de números de reglas que se muestran en la pantalla.
La interfaz de usuario facilita el seguimiento de la credibilidad de las deducciones.
Requisitos de la interfaz de usuario de ES eficiente
Debería ayudar a los usuarios a lograr sus objetivos en la forma más breve posible.
Debe estar diseñado para que funcione con las prácticas laborales existentes o deseadas del usuario.
Su tecnología debe poder adaptarse a los requisitos del usuario; No al revés.
Debe hacer un uso eficiente de la entrada del usuario.
Limitaciones de los sistemas expertos
Ninguna tecnología puede ofrecer una solución fácil y completa. Los sistemas grandes son costosos, requieren un tiempo de desarrollo significativo y recursos informáticos. Los ES tienen sus limitaciones que incluyen:
- Limitaciones de la tecnología
- Adquisición de conocimientos difíciles
- Los ES son difíciles de mantener
- Altos costos de desarrollo
Aplicaciones del sistema experto
La siguiente tabla muestra dónde se puede aplicar ES.
| Solicitud | Descripción |
|---|---|
| Dominio de diseño | Diseño de lentes de cámara, diseño de automóviles. |
| Dominio médico | Sistemas de diagnóstico para deducir la causa de la enfermedad a partir de los datos observados, realizar operaciones médicas en humanos. |
| Sistemas de monitoreo | Comparar datos continuamente con el sistema observado o con el comportamiento prescrito, como el control de fugas en tuberías de petróleo largas. |
| Sistemas de control de procesos | Controlar un proceso físico basado en la monitorización. |
| Dominio del conocimiento | Descubrimiento de fallas en vehículos, computadoras. |
| Finanzas / Comercio | Detección de posibles fraudes, transacciones sospechosas, negociación en bolsa, programación de aerolíneas, programación de carga. |
Tecnología de sistema experto
Hay varios niveles de tecnologías ES disponibles. Las tecnologías de sistemas expertos incluyen:
Expert System Development Environment- El entorno de desarrollo de ES incluye hardware y herramientas. Ellos son -
Estaciones de trabajo, miniordenadores, mainframes.
Lenguajes de programación simbólica de alto nivel como LISt Pprogramación (LISP) y PROgramática en LOGique (PROLOG).
Grandes bases de datos.
Tools - Reducen en gran medida el esfuerzo y el coste que supone desarrollar un sistema experto.
Potentes editores y herramientas de depuración con múltiples ventanas.
Proporcionan prototipos rápidos
Tener definiciones incorporadas de modelo, representación del conocimiento y diseño de inferencia.
Shells- Un shell no es más que un sistema experto sin una base de conocimientos. Un shell proporciona a los desarrolladores la adquisición de conocimientos, el motor de inferencia, la interfaz de usuario y la facilidad de explicación. Por ejemplo, a continuación se dan algunas conchas:
Java Expert System Shell (JESS) que proporciona una API Java completamente desarrollada para crear un sistema experto.
Vidwan , un shell desarrollado en el Centro Nacional de Tecnología de Software, Mumbai en 1993. Permite la codificación del conocimiento en forma de reglas IF-THEN.
Desarrollo de sistemas expertos: pasos generales
El proceso de desarrollo de SE es iterativo. Los pasos para desarrollar el EE incluyen:
Identificar el dominio del problema
- El problema debe ser adecuado para que un sistema experto lo resuelva.
- Encuentre a los expertos en el dominio de tareas para el proyecto ES.
- Establecer la rentabilidad del sistema.
Diseñar el sistema
Identificar la tecnología ES
Conocer y establecer el grado de integración con el resto de sistemas y bases de datos.
Darse cuenta de cómo los conceptos pueden representar mejor el conocimiento del dominio.
Desarrollar el prototipo
De la base de conocimientos: el ingeniero del conocimiento trabaja para:
- Adquirir conocimientos de dominio del experto.
- Represéntelo en forma de reglas If-THEN-ELSE.
Pruebe y perfeccione el prototipo
El ingeniero del conocimiento utiliza casos de muestra para probar el prototipo en busca de deficiencias en el rendimiento.
Los usuarios finales prueban los prototipos del ES.
Desarrollar y completar el ES
Probar y garantizar la interacción del SE con todos los elementos de su entorno, incluidos los usuarios finales, las bases de datos y otros sistemas de información.
Documente bien el proyecto de ES.
Entrene al usuario para usar ES.
Mantener el sistema
Mantenga la base de conocimientos actualizada mediante revisiones y actualizaciones periódicas.
Aborde nuevas interfaces con otros sistemas de información, a medida que esos sistemas evolucionan.
Beneficios de los sistemas expertos
Availability - Están fácilmente disponibles debido a la producción masiva de software.
Less Production Cost- El costo de producción es razonable. Esto los hace asequibles.
Speed- Ofrecen una gran velocidad. Reducen la cantidad de trabajo que realiza una persona.
Less Error Rate - La tasa de error es baja en comparación con los errores humanos.
Reducing Risk - Pueden trabajar en entornos peligrosos para los seres humanos.
Steady response - Trabajan de forma constante sin moverse, tensarse o fatigarse.
La robótica es un dominio de la inteligencia artificial que se ocupa del estudio de la creación de robots inteligentes y eficientes.
¿Qué son los robots?
Los robots son los agentes artificiales que actúan en el entorno del mundo real.
Objetivo
Los robots tienen como objetivo manipular los objetos percibiendo, recogiendo, moviendo, modificando las propiedades físicas del objeto, destruyéndolo o para tener un efecto liberando así a la mano de obra de realizar funciones repetitivas sin aburrirse, distraerse o agotarse.
¿Qué es la robótica?
La robótica es una rama de la IA, que se compone de ingeniería eléctrica, ingeniería mecánica e informática para el diseño, la construcción y la aplicación de robots.
Aspectos de la robótica
Los robots tienen mechanical construction, forma o forma diseñada para realizar una tarea en particular.
Ellos tienen electrical components que alimentan y controlan la maquinaria.
Contienen cierto nivel de computer program eso determina qué, cuándo y cómo un robot hace algo.
Diferencia en el sistema de robot y otro programa de IA
Aquí está la diferencia entre los dos:
| Programas de IA | Robots |
|---|---|
| Por lo general, operan en mundos estimulados por computadora. | Operan en el mundo físico real |
| La entrada a un programa de IA está en símbolos y reglas. | Inputs to robots is analog signal in the form of speech waveform or images |
| They need general purpose computers to operate on. | They need special hardware with sensors and effectors. |
Robot Locomotion
Locomotion is the mechanism that makes a robot capable of moving in its environment. There are various types of locomotions −
- Legged
- Wheeled
- Combination of Legged and Wheeled Locomotion
- Tracked slip/skid
Legged Locomotion
This type of locomotion consumes more power while demonstrating walk, jump, trot, hop, climb up or down, etc.
It requires more number of motors to accomplish a movement. It is suited for rough as well as smooth terrain where irregular or too smooth surface makes it consume more power for a wheeled locomotion. It is little difficult to implement because of stability issues.
It comes with the variety of one, two, four, and six legs. If a robot has multiple legs then leg coordination is necessary for locomotion.
The total number of possible gaits (a periodic sequence of lift and release events for each of the total legs) a robot can travel depends upon the number of its legs.
If a robot has k legs, then the number of possible events N = (2k-1)!.
In case of a two-legged robot (k=2), the number of possible events is N = (2k-1)! = (2*2-1)! = 3! = 6.
Hence there are six possible different events −
- Lifting the Left leg
- Releasing the Left leg
- Lifting the Right leg
- Releasing the Right leg
- Lifting both the legs together
- Releasing both the legs together
In case of k=6 legs, there are 39916800 possible events. Hence the complexity of robots is directly proportional to the number of legs.

Wheeled Locomotion
It requires fewer number of motors to accomplish a movement. It is little easy to implement as there are less stability issues in case of more number of wheels. It is power efficient as compared to legged locomotion.
Standard wheel − Rotates around the wheel axle and around the contact
Castor wheel − Rotates around the wheel axle and the offset steering joint.
Swedish 45o and Swedish 90o wheels − Omni-wheel, rotates around the contact point, around the wheel axle, and around the rollers.
Ball or spherical wheel − Omnidirectional wheel, technically difficult to implement.

Slip/Skid Locomotion
In this type, the vehicles use tracks as in a tank. The robot is steered by moving the tracks with different speeds in the same or opposite direction. It offers stability because of large contact area of track and ground.

Components of a Robot
Robots are constructed with the following −
Power Supply − The robots are powered by batteries, solar power, hydraulic, or pneumatic power sources.
Actuators − They convert energy into movement.
Electric motors (AC/DC) − They are required for rotational movement.
Pneumatic Air Muscles − They contract almost 40% when air is sucked in them.
Muscle Wires − They contract by 5% when electric current is passed through them.
Piezo Motors and Ultrasonic Motors − Best for industrial robots.
Sensors − They provide knowledge of real time information on the task environment. Robots are equipped with vision sensors to be to compute the depth in the environment. A tactile sensor imitates the mechanical properties of touch receptors of human fingertips.
Computer Vision
This is a technology of AI with which the robots can see. The computer vision plays vital role in the domains of safety, security, health, access, and entertainment.
Computer vision automatically extracts, analyzes, and comprehends useful information from a single image or an array of images. This process involves development of algorithms to accomplish automatic visual comprehension.
Hardware of Computer Vision System
This involves −
- Power supply
- Image acquisition device such as camera
- A processor
- A software
- A display device for monitoring the system
- Accessories such as camera stands, cables, and connectors
Tasks of Computer Vision
OCR − In the domain of computers, Optical Character Reader, a software to convert scanned documents into editable text, which accompanies a scanner.
Face Detection − Many state-of-the-art cameras come with this feature, which enables to read the face and take the picture of that perfect expression. It is used to let a user access the software on correct match.
Object Recognition − They are installed in supermarkets, cameras, high-end cars such as BMW, GM, and Volvo.
Estimating Position − It is estimating position of an object with respect to camera as in position of tumor in human’s body.
Application Domains of Computer Vision
- Agriculture
- Autonomous vehicles
- Biometrics
- Character recognition
- Forensics, security, and surveillance
- Industrial quality inspection
- Face recognition
- Gesture analysis
- Geoscience
- Medical imagery
- Pollution monitoring
- Process control
- Remote sensing
- Robotics
- Transport
Applications of Robotics
The robotics has been instrumental in the various domains such as −
Industries − Robots are used for handling material, cutting, welding, color coating, drilling, polishing, etc.
Military − Autonomous robots can reach inaccessible and hazardous zones during war. A robot named Daksh, developed by Defense Research and Development Organization (DRDO), is in function to destroy life-threatening objects safely.
Medicine − The robots are capable of carrying out hundreds of clinical tests simultaneously, rehabilitating permanently disabled people, and performing complex surgeries such as brain tumors.
Exploration − The robot rock climbers used for space exploration, underwater drones used for ocean exploration are to name a few.
Entertainment − Disney’s engineers have created hundreds of robots for movie making.
Yet another research area in AI, neural networks, is inspired from the natural neural network of human nervous system.
What are Artificial Neural Networks (ANNs)?
The inventor of the first neurocomputer, Dr. Robert Hecht-Nielsen, defines a neural network as −
"...a computing system made up of a number of simple, highly interconnected processing elements, which process information by their dynamic state response to external inputs.”
Basic Structure of ANNs
The idea of ANNs is based on the belief that working of human brain by making the right connections, can be imitated using silicon and wires as living neurons and dendrites.
The human brain is composed of 86 billion nerve cells called neurons. They are connected to other thousand cells by Axons. Stimuli from external environment or inputs from sensory organs are accepted by dendrites. These inputs create electric impulses, which quickly travel through the neural network. A neuron can then send the message to other neuron to handle the issue or does not send it forward.

ANNs are composed of multiple nodes, which imitate biological neurons of human brain. The neurons are connected by links and they interact with each other. The nodes can take input data and perform simple operations on the data. The result of these operations is passed to other neurons. The output at each node is called its activation or node value.
Each link is associated with weight. ANNs are capable of learning, which takes place by altering weight values. The following illustration shows a simple ANN −

Types of Artificial Neural Networks
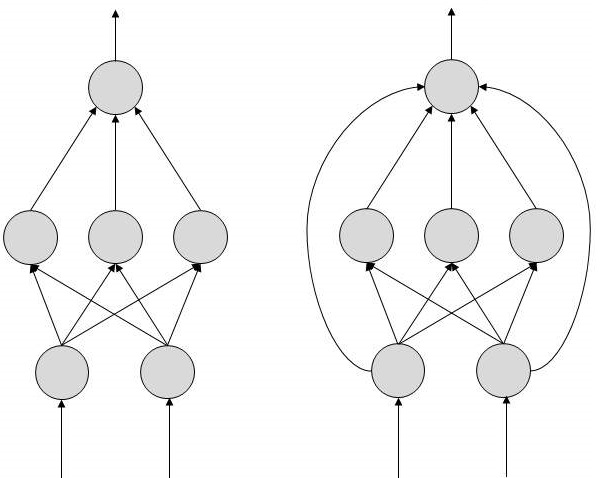
There are two Artificial Neural Network topologies − FeedForward and Feedback.
FeedForward ANN
In this ANN, the information flow is unidirectional. A unit sends information to other unit from which it does not receive any information. There are no feedback loops. They are used in pattern generation/recognition/classification. They have fixed inputs and outputs.
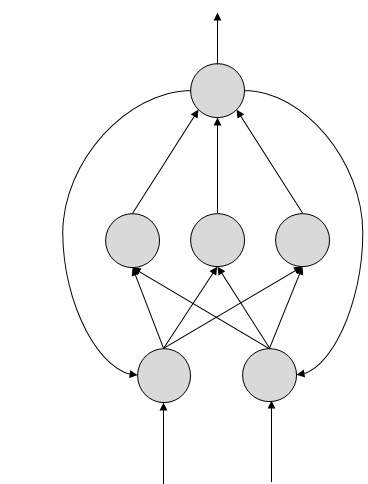
FeedBack ANN
Here, feedback loops are allowed. They are used in content addressable memories.
Working of ANNs
In the topology diagrams shown, each arrow represents a connection between two neurons and indicates the pathway for the flow of information. Each connection has a weight, an integer number that controls the signal between the two neurons.
If the network generates a “good or desired” output, there is no need to adjust the weights. However, if the network generates a “poor or undesired” output or an error, then the system alters the weights in order to improve subsequent results.
Machine Learning in ANNs
ANNs are capable of learning and they need to be trained. There are several learning strategies −
Supervised Learning − It involves a teacher that is scholar than the ANN itself. For example, the teacher feeds some example data about which the teacher already knows the answers.
For example, pattern recognizing. The ANN comes up with guesses while recognizing. Then the teacher provides the ANN with the answers. The network then compares it guesses with the teacher’s “correct” answers and makes adjustments according to errors.
Unsupervised Learning − It is required when there is no example data set with known answers. For example, searching for a hidden pattern. In this case, clustering i.e. dividing a set of elements into groups according to some unknown pattern is carried out based on the existing data sets present.
Reinforcement Learning − This strategy built on observation. The ANN makes a decision by observing its environment. If the observation is negative, the network adjusts its weights to be able to make a different required decision the next time.
Back Propagation Algorithm
It is the training or learning algorithm. It learns by example. If you submit to the algorithm the example of what you want the network to do, it changes the network’s weights so that it can produce desired output for a particular input on finishing the training.
Back Propagation networks are ideal for simple Pattern Recognition and Mapping Tasks.
Bayesian Networks (BN)
These are the graphical structures used to represent the probabilistic relationship among a set of random variables. Bayesian networks are also called Belief Networks or Bayes Nets. BNs reason about uncertain domain.
In these networks, each node represents a random variable with specific propositions. For example, in a medical diagnosis domain, the node Cancer represents the proposition that a patient has cancer.
The edges connecting the nodes represent probabilistic dependencies among those random variables. If out of two nodes, one is affecting the other then they must be directly connected in the directions of the effect. The strength of the relationship between variables is quantified by the probability associated with each node.
There is an only constraint on the arcs in a BN that you cannot return to a node simply by following directed arcs. Hence the BNs are called Directed Acyclic Graphs (DAGs).
BNs are capable of handling multivalued variables simultaneously. The BN variables are composed of two dimensions −
- Range of prepositions
- Probability assigned to each of the prepositions.
Consider a finite set X = {X1, X2, …,Xn} of discrete random variables, where each variable Xi may take values from a finite set, denoted by Val(Xi). If there is a directed link from variable Xi to variable, Xj, then variable Xi will be a parent of variable Xj showing direct dependencies between the variables.
The structure of BN is ideal for combining prior knowledge and observed data. BN can be used to learn the causal relationships and understand various problem domains and to predict future events, even in case of missing data.
Building a Bayesian Network
A knowledge engineer can build a Bayesian network. There are a number of steps the knowledge engineer needs to take while building it.
Example problem − Lung cancer. A patient has been suffering from breathlessness. He visits the doctor, suspecting he has lung cancer. The doctor knows that barring lung cancer, there are various other possible diseases the patient might have such as tuberculosis and bronchitis.
Gather Relevant Information of Problem
- Is the patient a smoker? If yes, then high chances of cancer and bronchitis.
- Is the patient exposed to air pollution? If yes, what sort of air pollution?
- Take an X-Ray positive X-ray would indicate either TB or lung cancer.
Identify Interesting Variables
The knowledge engineer tries to answer the questions −
- Which nodes to represent?
- What values can they take? In which state can they be?
For now let us consider nodes, with only discrete values. The variable must take on exactly one of these values at a time.
Common types of discrete nodes are −
Boolean nodes − They represent propositions, taking binary values TRUE (T) and FALSE (F).
Ordered values − A node Pollution might represent and take values from {low, medium, high} describing degree of a patient’s exposure to pollution.
Integral values − A node called Age might represent patient’s age with possible values from 1 to 120. Even at this early stage, modeling choices are being made.
Possible nodes and values for the lung cancer example −
| Node Name | Type | Value | Nodes Creation |
|---|---|---|---|
| Polution | Binary | {LOW, HIGH, MEDIUM} |

|
| Smoker | Boolean | {TRUE, FASLE} | |
| Lung-Cancer | Boolean | {TRUE, FASLE} | |
| X-Ray | Binary | {Positive, Negative} |
Create Arcs between Nodes
Topology of the network should capture qualitative relationships between variables.
For example, what causes a patient to have lung cancer? - Pollution and smoking. Then add arcs from node Pollution and node Smoker to node Lung-Cancer.
Similarly if patient has lung cancer, then X-ray result will be positive. Then add arcs from node Lung-Cancer to node X-Ray.

Specify Topology
Conventionally, BNs are laid out so that the arcs point from top to bottom. The set of parent nodes of a node X is given by Parents(X).
The Lung-Cancer node has two parents (reasons or causes): Pollution and Smoker, while node Smoker is an ancestor of node X-Ray. Similarly, X-Ray is a child (consequence or effects) of node Lung-Cancer and successor of nodes Smoker and Pollution.
Conditional Probabilities
Now quantify the relationships between connected nodes: this is done by specifying a conditional probability distribution for each node. As only discrete variables are considered here, this takes the form of a Conditional Probability Table (CPT).
First, for each node we need to look at all the possible combinations of values of those parent nodes. Each such combination is called an instantiation of the parent set. For each distinct instantiation of parent node values, we need to specify the probability that the child will take.
For example, the Lung-Cancer node’s parents are Pollution and Smoking. They take the possible values = { (H,T), ( H,F), (L,T), (L,F)}. The CPT specifies the probability of cancer for each of these cases as <0.05, 0.02, 0.03, 0.001> respectively.
Each node will have conditional probability associated as follows −

Applications of Neural Networks
They can perform tasks that are easy for a human but difficult for a machine −
Aerospace − Autopilot aircrafts, aircraft fault detection.
Automotive − Automobile guidance systems.
Military − Weapon orientation and steering, target tracking, object discrimination, facial recognition, signal/image identification.
Electronics − Code sequence prediction, IC chip layout, chip failure analysis, machine vision, voice synthesis.
Financial − Real estate appraisal, loan advisor, mortgage screening, corporate bond rating, portfolio trading program, corporate financial analysis, currency value prediction, document readers, credit application evaluators.
Industrial − Manufacturing process control, product design and analysis, quality inspection systems, welding quality analysis, paper quality prediction, chemical product design analysis, dynamic modeling of chemical process systems, machine maintenance analysis, project bidding, planning, and management.
Medical − Cancer cell analysis, EEG and ECG analysis, prosthetic design, transplant time optimizer.
Speech − Speech recognition, speech classification, text to speech conversion.
Telecommunications − Image and data compression, automated information services, real-time spoken language translation.
Transportation − Truck Brake system diagnosis, vehicle scheduling, routing systems.
Software − Pattern Recognition in facial recognition, optical character recognition, etc.
Time Series Prediction − ANNs are used to make predictions on stocks and natural calamities.
Signal Processing − Neural networks can be trained to process an audio signal and filter it appropriately in the hearing aids.
Control − ANNs are often used to make steering decisions of physical vehicles.
Anomaly Detection − As ANNs are expert at recognizing patterns, they can also be trained to generate an output when something unusual occurs that misfits the pattern.
AI is developing with such an incredible speed, sometimes it seems magical. There is an opinion among researchers and developers that AI could grow so immensely strong that it would be difficult for humans to control.
Humans developed AI systems by introducing into them every possible intelligence they could, for which the humans themselves now seem threatened.
Threat to Privacy
An AI program that recognizes speech and understands natural language is theoretically capable of understanding each conversation on e-mails and telephones.
Threat to Human Dignity
AI systems have already started replacing the human beings in few industries. It should not replace people in the sectors where they are holding dignified positions which are pertaining to ethics such as nursing, surgeon, judge, police officer, etc.
Threat to Safety
The self-improving AI systems can become so mighty than humans that could be very difficult to stop from achieving their goals, which may lead to unintended consequences.
Here is the list of frequently used terms in the domain of AI −
| Sr.No | Term & Meaning |
|---|---|
| 1 | Agent Agents are systems or software programs capable of autonomous, purposeful and reasoning directed towards one or more goals. They are also called assistants, brokers, bots, droids, intelligent agents, and software agents. |
| 2 | Autonomous Robot Robot free from external control or influence and able to control itself independently. |
| 3 | Backward Chaining Strategy of working backward for Reason/Cause of a problem. |
| 4 | Blackboard It is the memory inside computer, which is used for communication between the cooperating expert systems. |
| 5 | Environment It is the part of real or computational world inhabited by the agent. |
| 6 | Forward Chaining Strategy of working forward for conclusion/solution of a problem. |
| 7 | Heuristics It is the knowledge based on Trial-and-error, evaluations, and experimentation. |
| 8 | Knowledge Engineering Acquiring knowledge from human experts and other resources. |
| 9 | Percepts It is the format in which the agent obtains information about the environment. |
| 10 | Pruning Overriding unnecessary and irrelevant considerations in AI systems. |
| 11 | Rule It is a format of representing knowledge base in Expert System. It is in the form of IF-THEN-ELSE. |
| 12 | Shell A shell is a software that helps in designing inference engine, knowledge base, and user interface of an expert system. |
| 13 | Task It is the goal the agent is tries to accomplish. |
| 14 | Turing Test A test developed by Allan Turing to test the intelligence of a machine as compared to human intelligence. |