Montaje - Guía rápida
¿Qué es el lenguaje ensamblador?
Cada computadora personal tiene un microprocesador que administra las actividades aritméticas, lógicas y de control de la computadora.
Cada familia de procesadores tiene su propio conjunto de instrucciones para manejar diversas operaciones, como obtener entrada desde el teclado, mostrar información en la pantalla y realizar otros trabajos. Este conjunto de instrucciones se denominan "instrucciones en lenguaje de máquina".
Un procesador solo entiende las instrucciones en lenguaje de máquina, que son cadenas de unos y ceros. Sin embargo, el lenguaje de máquina es demasiado oscuro y complejo para usarlo en el desarrollo de software. Entonces, el lenguaje ensamblador de bajo nivel está diseñado para una familia específica de procesadores que representa varias instrucciones en código simbólico y en una forma más comprensible.
Ventajas del lenguaje ensamblador
Tener una comprensión del lenguaje ensamblador hace que uno sea consciente de:
- Cómo interactúan los programas con el sistema operativo, el procesador y el BIOS;
- Cómo se representan los datos en la memoria y otros dispositivos externos;
- Cómo el procesador accede y ejecuta la instrucción;
- Cómo las instrucciones acceden y procesan los datos;
- Cómo un programa accede a dispositivos externos.
Otras ventajas de usar el lenguaje ensamblador son:
Requiere menos memoria y tiempo de ejecución;
Permite trabajos complejos específicos de hardware de una manera más sencilla;
Es adecuado para trabajos de tiempo crítico;
Es más adecuado para escribir rutinas de servicio de interrupción y otros programas residentes en memoria.
Características básicas del hardware de PC
El hardware interno principal de una PC consta de procesador, memoria y registros. Los registros son componentes del procesador que contienen datos y direcciones. Para ejecutar un programa, el sistema lo copia del dispositivo externo a la memoria interna. El procesador ejecuta las instrucciones del programa.
La unidad fundamental de almacenamiento de la computadora es un poco; podría ser ON (1) u OFF (0) y un grupo de 8 bits relacionados forma un byte en la mayoría de las computadoras modernas.
Entonces, el bit de paridad se usa para hacer que el número de bits en un byte sea impar. Si la paridad es pareja, el sistema asume que ha habido un error de paridad (aunque es poco común), que puede deberse a una falla de hardware o una perturbación eléctrica.
El procesador admite los siguientes tamaños de datos:
- Palabra: un elemento de datos de 2 bytes
- Palabra doble: un elemento de datos de 4 bytes (32 bits)
- Quadword: un elemento de datos de 8 bytes (64 bits)
- Párrafo: un área de 16 bytes (128 bits)
- Kilobyte: 1024 bytes
- Megabyte: 1.048.576 bytes
Sistema de números binarios
Cada sistema numérico usa notación posicional, es decir, cada posición en la que se escribe un dígito tiene un valor posicional diferente. Cada posición es el poder de la base, que es 2 para el sistema numérico binario, y estos poderes comienzan en 0 y aumentan en 1.
La siguiente tabla muestra los valores posicionales para un número binario de 8 bits, donde todos los bits están activados.
| Valor de bit | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| Valor de posición como potencia de base 2 | 128 | 64 | 32 | dieciséis | 8 | 4 | 2 | 1 |
| Número de bits | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
El valor de un número binario se basa en la presencia de 1 bits y su valor posicional. Entonces, el valor de un número binario dado es -
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
que es lo mismo que 2 8 - 1.
Sistema numérico hexadecimal
El sistema numérico hexadecimal usa la base 16. Los dígitos en este sistema van de 0 a 15. Por convención, las letras de la A a la F se usan para representar los dígitos hexadecimales correspondientes a los valores decimales del 10 al 15.
Los números hexadecimales en informática se utilizan para abreviar representaciones binarias extensas. Básicamente, el sistema numérico hexadecimal representa un dato binario dividiendo cada byte por la mitad y expresando el valor de cada medio byte. La siguiente tabla proporciona los equivalentes decimal, binario y hexadecimal:
| Número decimal | Representación binaria | Representación hexadecimal |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | UN |
| 11 | 1011 | segundo |
| 12 | 1100 | C |
| 13 | 1101 | re |
| 14 | 1110 | mi |
| 15 | 1111 | F |
Para convertir un número binario en su equivalente hexadecimal, divídalo en grupos de 4 grupos consecutivos cada uno, comenzando por la derecha, y escriba esos grupos sobre los dígitos correspondientes del número hexadecimal.
Example - El número binario 1000 1100 1101 0001 es equivalente a hexadecimal - 8CD1
Para convertir un número hexadecimal en binario, simplemente escriba cada dígito hexadecimal en su equivalente binario de 4 dígitos.
Example - El número hexadecimal FAD8 es equivalente a binario - 1111 1010 1101 1000
Aritmética binaria
La siguiente tabla ilustra cuatro reglas simples para la suma binaria:
| (yo) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| = 0 | = 1 | = 10 | = 11 |
Las reglas (iii) y (iv) muestran un acarreo de 1 bit a la siguiente posición izquierda.
Example
| Decimal | Binario |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
Un valor binario negativo se expresa en two's complement notation. Según esta regla, convertir un número binario a su valor negativo es invertir sus valores de bits y sumar 1 .
Example
| Número 53 | 00110101 |
| Invertir los bits | 11001010 |
| Agregar 1 | 0000000 1 |
| Número -53 | 11001011 |
Para restar un valor de otro, convierta el número que se resta al formato de complemento a dos y sume los números .
Example
Restar 42 de 53
| Número 53 | 00110101 |
| Número 42 | 00101010 |
| Invertir los bits de 42 | 11010101 |
| Agregar 1 | 0000000 1 |
| Número -42 | 11010110 |
| 53 - 42 = 11 | 00001011 |
Se pierde el desbordamiento del último bit.
Direccionamiento de datos en la memoria
El proceso a través del cual el procesador controla la ejecución de instrucciones se denomina fetch-decode-execute cycle o la execution cycle. Consta de tres pasos continuos:
- Obtener la instrucción de la memoria
- Decodificar o identificar la instrucción
- Ejecutando la instrucción
El procesador puede acceder a uno o más bytes de memoria a la vez. Consideremos un número hexadecimal 0725H. Este número requerirá dos bytes de memoria. El byte de orden superior o el byte más significativo es 07 y el byte de orden inferior es 25.
El procesador almacena datos en una secuencia de bytes inversa, es decir, un byte de orden inferior se almacena en una dirección de memoria baja y un byte de orden superior en una dirección de memoria alta. Entonces, si el procesador trae el valor 0725H del registro a la memoria, transferirá primero 25 a la dirección de memoria inferior y 07 a la siguiente dirección de memoria.
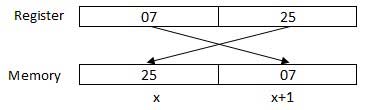
x: dirección de memoria
Cuando el procesador obtiene los datos numéricos de la memoria para registrarlos, nuevamente invierte los bytes. Hay dos tipos de direcciones de memoria:
Dirección absoluta: una referencia directa de una ubicación específica.
Dirección de segmento (o desplazamiento): dirección de inicio de un segmento de memoria con el valor de desplazamiento.
Configuración del entorno local
El lenguaje ensamblador depende del conjunto de instrucciones y la arquitectura del procesador. En este tutorial, nos enfocamos en procesadores Intel-32 como Pentium. Para seguir este tutorial, necesitará:
- Una computadora IBM o cualquier computadora compatible equivalente
- Una copia del sistema operativo Linux
- Una copia del programa ensamblador de NASM
Hay muchos programas ensambladores buenos, como:
- Ensamblador de Microsoft (MASM)
- Ensamblador de turbo Borland (TASM)
- El ensamblador GNU (GAS)
Usaremos el ensamblador NASM, tal como está:
- Gratis. Puede descargarlo de varias fuentes web.
- Bien documentado y obtendrá mucha información en la red.
- Se puede utilizar tanto en Linux como en Windows.
Instalación de NASM
Si selecciona "Herramientas de desarrollo" mientras instala Linux, es posible que instale NASM junto con el sistema operativo Linux y no necesita descargarlo e instalarlo por separado. Para verificar si ya tiene NASM instalado, siga los siguientes pasos:
Abra una terminal de Linux.
Tipo whereis nasm y presione ENTER.
Si ya está instalado, aparece una línea como nasm: / usr / bin / nasm . De lo contrario, verá solo nasm:, luego deberá instalar NASM.
Para instalar NASM, siga los siguientes pasos:
Consulte el sitio web del ensamblador netwide (NASM) para obtener la última versión.
Descargue el archivo fuente de Linux
nasm-X.XX.ta.gz, dondeX.XXestá el número de versión de NASM en el archivo.Desempaquete el archivo en un directorio que crea un subdirectorio
nasm-X. XX.cd
nasm-X.XXy escriba./configure. Este script de shell encontrará el mejor compilador de C para usar y configurará Makefiles en consecuencia.Tipo make para construir los binarios nasm y ndisasm.
Tipo make install para instalar nasm y ndisasm en / usr / local / bin e instalar las páginas del manual.
Esto debería instalar NASM en su sistema. Alternativamente, puede usar una distribución RPM para Fedora Linux. Esta versión es más sencilla de instalar, simplemente haga doble clic en el archivo RPM.
Un programa de montaje se puede dividir en tres secciones:
los data sección,
los bss sección, y
los text sección.
La sección de datos
los dataLa sección se utiliza para declarar constantes o datos inicializados. Estos datos no cambian en tiempo de ejecución. Puede declarar varios valores constantes, nombres de archivo o tamaño de búfer, etc., en esta sección.
La sintaxis para declarar la sección de datos es:
section.dataLa sección bss
los bssLa sección se utiliza para declarar variables. La sintaxis para declarar la sección bss es:
section.bssLa sección de texto
los textLa sección se utiliza para mantener el código real. Esta sección debe comenzar con la declaraciónglobal _start, que le dice al kernel dónde comienza la ejecución del programa.
La sintaxis para declarar la sección de texto es:
section.text
global _start
_start:Comentarios
El comentario en lenguaje ensamblador comienza con un punto y coma (;). Puede contener cualquier carácter imprimible, incluido el espacio en blanco. Puede aparecer en una línea por sí solo, como:
; This program displays a message on screeno, en la misma línea junto con una instrucción, como -
add eax, ebx ; adds ebx to eaxDeclaraciones en lenguaje ensamblador
Los programas en lenguaje ensamblador constan de tres tipos de declaraciones:
- Instrucciones o instrucciones ejecutables,
- Directivas de ensamblador o pseudo-operaciones, y
- Macros.
los executable instructions o simplemente instructionsdígale al procesador qué hacer. Cada instrucción consta de unoperation code(código de operación). Cada instrucción ejecutable genera una instrucción en lenguaje de máquina.
los assembler directives o pseudo-opsinformar al ensamblador sobre los diversos aspectos del proceso de ensamblaje. Estos no son ejecutables y no generan instrucciones en lenguaje de máquina.
Macros son básicamente un mecanismo de sustitución de texto.
Sintaxis de declaraciones en lenguaje ensamblador
Las declaraciones en lenguaje ensamblador se ingresan una declaración por línea. Cada declaración sigue el siguiente formato:
[label] mnemonic [operands] [;comment]Los campos entre corchetes son opcionales. Una instrucción básica tiene dos partes, la primera es el nombre de la instrucción (o el mnemónico), que se va a ejecutar, y la segunda son los operandos o los parámetros del comando.
A continuación se muestran algunos ejemplos de declaraciones típicas en lenguaje ensamblador:
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL registerEl programa Hello World en Asamblea
El siguiente código en lenguaje ensamblador muestra la cadena 'Hello World' en la pantalla:
section .text
global _start ;must be declared for linker (ld)
_start: ;tells linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Hello, world!', 0xa ;string to be printed
len equ $ - msg ;length of the stringCuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello, world!Compilar y vincular un programa de ensamblaje en NASM
Asegúrese de haber establecido el camino de nasm y ldbinarios en su variable de entorno PATH. Ahora, siga los siguientes pasos para compilar y vincular el programa anterior:
Escriba el código anterior con un editor de texto y guárdelo como hello.asm.
Asegúrese de estar en el mismo directorio donde guardó hello.asm.
Para ensamblar el programa, escriba nasm -f elf hello.asm
Si hay algún error, se le preguntará al respecto en esta etapa. De lo contrario, un archivo objeto de su programa llamadohello.o se creará.
Para vincular el archivo de objeto y crear un archivo ejecutable llamado hello, escriba ld -m elf_i386 -s -o hello hello.o
Ejecute el programa escribiendo ./hello
Si ha hecho todo correctamente, se mostrará "¡Hola, mundo!" en la pantalla.
Ya hemos hablado de las tres secciones de un programa de montaje. Estas secciones también representan varios segmentos de memoria.
Curiosamente, si reemplaza la palabra clave de la sección con segmento, obtendrá el mismo resultado. Prueba el siguiente código:
segment .text ;code segment
global _start ;must be declared for linker
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
segment .data ;data segment
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear stringCuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello, world!Segmentos de memoria
Un modelo de memoria segmentada divide la memoria del sistema en grupos de segmentos independientes referenciados por punteros ubicados en los registros de segmento. Cada segmento se utiliza para contener un tipo específico de datos. Un segmento se utiliza para contener códigos de instrucción, otro segmento almacena los elementos de datos y un tercer segmento mantiene la pila del programa.
A la luz de la discusión anterior, podemos especificar varios segmentos de memoria como:
Data segment - Está representado por .data sección y la .bss. La sección .data se utiliza para declarar la región de memoria, donde se almacenan los elementos de datos para el programa. Esta sección no se puede expandir después de que se declaran los elementos de datos y permanece estática en todo el programa.
La sección .bss también es una sección de memoria estática que contiene búferes para que los datos se declaren más adelante en el programa. Esta memoria intermedia está llena de ceros.
Code segment - Está representado por .textsección. Esto define un área en la memoria que almacena los códigos de instrucción. Esta también es un área fija.
Stack - Este segmento contiene valores de datos que se pasan a funciones y procedimientos dentro del programa.
Las operaciones del procesador implican principalmente el procesamiento de datos. Estos datos se pueden almacenar en la memoria y acceder a ellos desde allí. Sin embargo, leer y almacenar datos en la memoria ralentiza el procesador, ya que implica procesos complicados de enviar la solicitud de datos a través del bus de control y dentro de la unidad de almacenamiento de memoria y obtener los datos a través del mismo canal.
Para acelerar las operaciones del procesador, el procesador incluye algunas ubicaciones de almacenamiento de memoria interna, llamadas registers.
Los registros almacenan elementos de datos para su procesamiento sin tener que acceder a la memoria. El chip del procesador incorpora un número limitado de registros.
Registros del procesador
Hay diez registros de procesador de 32 bits y seis de 16 bits en la arquitectura IA-32. Los registros se agrupan en tres categorías:
- Registros generales,
- Registros de control y
- Registros de segmento.
Los registros generales se dividen a su vez en los siguientes grupos:
- Registros de datos,
- Registros de puntero y
- Registros de índice.
Registros de datos
Se utilizan cuatro registros de datos de 32 bits para operaciones aritméticas, lógicas y de otro tipo. Estos registros de 32 bits se pueden utilizar de tres formas:
Como registros de datos completos de 32 bits: EAX, EBX, ECX, EDX.
Las mitades inferiores de los registros de 32 bits se pueden utilizar como cuatro registros de datos de 16 bits: AX, BX, CX y DX.
Las mitades inferior y superior de los cuatro registros de 16 bits mencionados anteriormente se pueden utilizar como ocho registros de datos de 8 bits: AH, AL, BH, BL, CH, CL, DH y DL.

Algunos de estos registros de datos tienen un uso específico en operaciones aritméticas.
AX is the primary accumulator; se utiliza en entrada / salida y la mayoría de las instrucciones aritméticas. Por ejemplo, en la operación de multiplicación, un operando se almacena en el registro EAX o AX o AL según el tamaño del operando.
BX is known as the base register, ya que podría usarse en direccionamiento indexado.
CX is known as the count register, como ECX, los registros CX almacenan el recuento de bucles en operaciones iterativas.
DX is known as the data register. También se utiliza en operaciones de entrada / salida. También se usa con el registro AX junto con DX para multiplicar y dividir operaciones que involucran valores grandes.
Registros de puntero
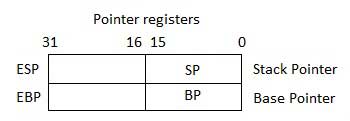
Los registros de puntero son registros EIP, ESP y EBP de 32 bits y las porciones derechas IP, SP y BP correspondientes de 16 bits. Hay tres categorías de registros de puntero:
Instruction Pointer (IP)- El registro IP de 16 bits almacena la dirección de desplazamiento de la siguiente instrucción que se ejecutará. IP en asociación con el registro CS (como CS: IP) proporciona la dirección completa de la instrucción actual en el segmento de código.
Stack Pointer (SP)- El registro SP de 16 bits proporciona el valor de compensación dentro de la pila del programa. SP en asociación con el registro SS (SS: SP) se refiere a la posición actual de los datos o la dirección dentro de la pila del programa.
Base Pointer (BP)- El registro BP de 16 bits ayuda principalmente a hacer referencia a las variables de parámetro pasadas a una subrutina. La dirección en el registro SS se combina con el desplazamiento en BP para obtener la ubicación del parámetro. BP también se puede combinar con DI y SI como registro base para direccionamiento especial.
Registros de índice
Los registros de índice de 32 bits, ESI y EDI, y sus porciones de 16 bits más a la derecha. SI y DI, se utilizan para direccionamiento indexado y, a veces, se utilizan para sumar y restar. Hay dos conjuntos de punteros de índice:
Source Index (SI) - Se utiliza como índice de origen para operaciones con cadenas.
Destination Index (DI) - Se utiliza como índice de destino para operaciones de cadenas.

Registros de control
El registro de puntero de instrucción de 32 bits y el registro de banderas de 32 bits combinados se consideran registros de control.
Muchas instrucciones involucran comparaciones y cálculos matemáticos y cambian el estado de los indicadores y algunas otras instrucciones condicionales prueban el valor de estos indicadores de estado para llevar el flujo de control a otra ubicación.
Los bits de bandera comunes son:
Overflow Flag (OF) - Indica el desbordamiento de un bit de datos de orden superior (bit más a la izquierda) después de una operación aritmética con signo.
Direction Flag (DF)- Determina la dirección izquierda o derecha para mover o comparar datos de cadenas. Cuando el valor de DF es 0, la operación de cadena toma la dirección de izquierda a derecha y cuando el valor se establece en 1, la operación de cadena toma la dirección de derecha a izquierda.
Interrupt Flag (IF)- Determina si las interrupciones externas como entrada de teclado, etc., deben ignorarse o procesarse. Deshabilita la interrupción externa cuando el valor es 0 y habilita las interrupciones cuando se establece en 1.
Trap Flag (TF)- Permite configurar el funcionamiento del procesador en modo de paso único. El programa DEBUG que usamos establece la bandera de trampa, por lo que podríamos recorrer la ejecución una instrucción a la vez.
Sign Flag (SF)- Muestra el signo del resultado de una operación aritmética. Esta bandera se establece de acuerdo con el signo de un elemento de datos después de la operación aritmética. El signo está indicado por el orden superior del bit más a la izquierda. Un resultado positivo borra el valor de SF a 0 y un resultado negativo lo establece en 1.
Zero Flag (ZF)- Indica el resultado de una operación aritmética o de comparación. Un resultado distinto de cero borra el indicador cero a 0 y un resultado cero lo establece en 1.
Auxiliary Carry Flag (AF)- Contiene el acarreo del bit 3 al bit 4 después de una operación aritmética; utilizado para aritmética especializada. El AF se establece cuando una operación aritmética de 1 byte provoca un arrastre del bit 3 al bit 4.
Parity Flag (PF)- Indica el número total de 1 bits en el resultado obtenido de una operación aritmética. Un número par de 1 bits borra el indicador de paridad a 0 y un número impar de 1 bits establece el indicador de paridad en 1.
Carry Flag (CF)- Contiene el acarreo de 0 o 1 de un bit de orden superior (más a la izquierda) después de una operación aritmética. También almacena el contenido del último bit de una operación de cambio o rotación .
La siguiente tabla indica la posición de los bits de bandera en el registro de banderas de 16 bits:
| Bandera: | O | re | yo | T | S | Z | UN | PAGS | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit no: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Registros de segmento
Los segmentos son áreas específicas definidas en un programa para contener datos, código y pila. Hay tres segmentos principales:
Code Segment- Contiene todas las instrucciones a ejecutar. Un registro de segmento de código de 16 bits o registro CS almacena la dirección de inicio del segmento de código.
Data Segment- Contiene datos, constantes y áreas de trabajo. Un registro de segmento de datos de 16 bits o registro DS almacena la dirección de inicio del segmento de datos.
Stack Segment- Contiene datos y direcciones de retorno de procedimientos o subrutinas. Se implementa como una estructura de datos de "pila". El registro de segmento de pila o registro SS almacena la dirección de inicio de la pila.
Además de los registros DS, CS y SS, existen otros registros de segmento extra: ES (segmento extra), FS y GS, que proporcionan segmentos adicionales para almacenar datos.
En la programación de ensamblaje, un programa necesita acceder a las ubicaciones de la memoria. Todas las ubicaciones de memoria dentro de un segmento son relativas a la dirección de inicio del segmento. Un segmento comienza en una dirección divisible uniformemente por 16 o hexadecimal 10. Por lo tanto, el dígito hexadecimal más a la derecha en todas esas direcciones de memoria es 0, que generalmente no se almacena en los registros de segmento.
Los registros de segmento almacenan las direcciones de inicio de un segmento. Para obtener la ubicación exacta de los datos o instrucciones dentro de un segmento, se requiere un valor de compensación (o desplazamiento). Para hacer referencia a cualquier ubicación de memoria en un segmento, el procesador combina la dirección del segmento en el registro de segmento con el valor de desplazamiento de la ubicación.
Ejemplo
Mire el siguiente programa simple para comprender el uso de registros en la programación en ensamblador. Este programa muestra 9 estrellas en la pantalla junto con un mensaje simple:
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,9 ;message length
mov ecx,s2 ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Displaying 9 stars',0xa ;a message
len equ $ - msg ;length of message
s2 times 9 db '*'Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Displaying 9 stars
*********Las llamadas al sistema son API para la interfaz entre el espacio de usuario y el espacio del kernel. Ya hemos utilizado las llamadas al sistema. sys_write y sys_exit, para escribir en la pantalla y salir del programa, respectivamente.
Llamadas al sistema Linux
Puede hacer uso de las llamadas al sistema Linux en sus programas ensambladores. Debe seguir los siguientes pasos para usar las llamadas al sistema Linux en su programa:
- Ponga el número de llamada del sistema en el registro EAX.
- Almacene los argumentos de la llamada al sistema en los registros EBX, ECX, etc.
- Llame a la interrupción correspondiente (80h).
- El resultado generalmente se devuelve en el registro EAX.
Hay seis registros que almacenan los argumentos de la llamada al sistema utilizada. Estos son EBX, ECX, EDX, ESI, EDI y EBP. Estos registros toman los argumentos consecutivos, comenzando con el registro EBX. Si hay más de seis argumentos, entonces la ubicación de memoria del primer argumento se almacena en el registro EBX.
El siguiente fragmento de código muestra el uso de la llamada al sistema sys_exit -
mov eax,1 ; system call number (sys_exit)
int 0x80 ; call kernelEl siguiente fragmento de código muestra el uso de la llamada al sistema sys_write -
mov edx,4 ; message length
mov ecx,msg ; message to write
mov ebx,1 ; file descriptor (stdout)
mov eax,4 ; system call number (sys_write)
int 0x80 ; call kernelTodas las llamadas al sistema se enumeran en /usr/include/asm/unistd.h , junto con sus números (el valor para poner en EAX antes de llamar a int 80h).
La siguiente tabla muestra algunas de las llamadas al sistema utilizadas en este tutorial:
| % eax | Nombre | % ebx | % ecx | % edx | % esx | % edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | En t | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | int sin firmar | char * | size_t | - | - |
| 4 | sys_write | int sin firmar | const char * | size_t | - | - |
| 5 | sys_open | const char * | En t | En t | - | - |
| 6 | sys_close | int sin firmar | - | - | - | - |
Ejemplo
El siguiente ejemplo lee un número del teclado y lo muestra en la pantalla:
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80hCuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Please enter a number:
1234
You have entered:1234La mayoría de las instrucciones en lenguaje ensamblador requieren que se procesen operandos. Una dirección de operando proporciona la ubicación, donde se almacenan los datos a procesar. Algunas instrucciones no requieren un operando, mientras que otras instrucciones pueden requerir uno, dos o tres operandos.
Cuando una instrucción requiere dos operandos, el primer operando es generalmente el destino, que contiene datos en un registro o ubicación de memoria y el segundo operando es la fuente. La fuente contiene los datos a entregar (direccionamiento inmediato) o la dirección (en el registro o en la memoria) de los datos. Generalmente, los datos de origen permanecen inalterados después de la operación.
Los tres modos básicos de direccionamiento son:
- Registro de direcciones
- Direccionamiento inmediato
- Direccionamiento de memoria
Registro de direcciones
En este modo de direccionamiento, un registro contiene el operando. Dependiendo de la instrucción, el registro puede ser el primer operando, el segundo operando o ambos.
Por ejemplo,
MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registersDado que el procesamiento de datos entre registros no implica memoria, proporciona un procesamiento de datos más rápido.
Direccionamiento inmediato
Un operando inmediato tiene un valor constante o una expresión. Cuando una instrucción con dos operandos usa direccionamiento inmediato, el primer operando puede ser un registro o una ubicación de memoria, y el segundo operando es una constante inmediata. El primer operando define la longitud de los datos.
Por ejemplo,
BYTE_VALUE DB 150 ; A byte value is defined
WORD_VALUE DW 300 ; A word value is defined
ADD BYTE_VALUE, 65 ; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AXDireccionamiento de memoria directo
Cuando los operandos se especifican en el modo de direccionamiento de memoria, se requiere acceso directo a la memoria principal, generalmente al segmento de datos. Esta forma de abordar da como resultado un procesamiento de datos más lento. Para localizar la ubicación exacta de los datos en la memoria, necesitamos la dirección de inicio del segmento, que normalmente se encuentra en el registro DS y un valor de compensación. Este valor de compensación también se llamaeffective address.
En el modo de direccionamiento directo, el valor de compensación se especifica directamente como parte de la instrucción, generalmente indicado por el nombre de la variable. El ensamblador calcula el valor de compensación y mantiene una tabla de símbolos, que almacena los valores de compensación de todas las variables utilizadas en el programa.
En el direccionamiento de memoria directo, uno de los operandos se refiere a una ubicación de memoria y el otro operando hace referencia a un registro.
Por ejemplo,
ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to registerDireccionamiento de compensación directa
Este modo de direccionamiento utiliza los operadores aritméticos para modificar una dirección. Por ejemplo, observe las siguientes definiciones que definen tablas de datos:
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of wordsLas siguientes operaciones acceden a los datos de las tablas en la memoria en registros:
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLEDireccionamiento de memoria indirecto
Este modo de direccionamiento utiliza la capacidad de la computadora de Segmento: direccionamiento de compensación . Generalmente, los registros base EBX, EBP (o BX, BP) y los registros de índice (DI, SI), codificados entre corchetes para referencias de memoria, se utilizan para este propósito.
El direccionamiento indirecto se usa generalmente para variables que contienen varios elementos como matrices. La dirección de inicio de la matriz se almacena, digamos, en el registro EBX.
El siguiente fragmento de código muestra cómo acceder a diferentes elementos de la variable.
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
ADD EBX, 2 ; EBX = EBX +2
MOV [EBX], 123 ; MY_TABLE[1] = 123La instrucción MOV
Ya hemos utilizado la instrucción MOV que se utiliza para mover datos de un espacio de almacenamiento a otro. La instrucción MOV toma dos operandos.
Sintaxis
La sintaxis de la instrucción MOV es:
MOV destination, sourceLa instrucción MOV puede tener una de las siguientes cinco formas:
MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, registerTenga en cuenta que -
- Ambos operandos en funcionamiento MOV deben ser del mismo tamaño
- El valor del operando fuente permanece sin cambios
La instrucción MOV provoca ambigüedad en ocasiones. Por ejemplo, mire las declaraciones:
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110No está claro si desea mover un equivalente en byte o equivalente en palabra del número 110. En tales casos, es aconsejable utilizar un type specifier.
La siguiente tabla muestra algunos de los especificadores de tipo comunes:
| Especificador de tipo | Bytes dirigidos |
|---|---|
| BYTE | 1 |
| PALABRA | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | 10 |
Ejemplo
El siguiente programa ilustra algunos de los conceptos discutidos anteriormente. Almacena un nombre 'Zara Ali' en la sección de datos de la memoria, luego cambia su valor a otro nombre 'Nuha Ali' mediante programación y muestra ambos nombres.
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
;writing the name 'Zara Ali'
mov edx,9 ;message length
mov ecx, name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov [name], dword 'Nuha' ; Changed the name to Nuha Ali
;writing the name 'Nuha Ali'
mov edx,8 ;message length
mov ecx,name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
name db 'Zara Ali 'Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Zara Ali Nuha AliNASM proporciona varios define directivespara reservar espacio de almacenamiento para variables. La directiva define ensamblador se utiliza para la asignación de espacio de almacenamiento. Se puede utilizar para reservar e inicializar uno o más bytes.
Asignación de espacio de almacenamiento para datos inicializados
La sintaxis de la declaración de asignación de almacenamiento para datos inicializados es:
[variable-name] define-directive initial-value [,initial-value]...Donde, nombre-variable es el identificador de cada espacio de almacenamiento. El ensamblador asocia un valor de compensación para cada nombre de variable definido en el segmento de datos.
Hay cinco formas básicas de la directiva define:
| Directiva | Propósito | Espacio de almacenamiento |
|---|---|---|
| DB | Definir Byte | asigna 1 byte |
| DW | Definir palabra | asigna 2 bytes |
| DD | Definir palabra doble | asigna 4 bytes |
| DQ | Definir palabra cuádruple | asigna 8 bytes |
| DT | Definir diez bytes | asigna 10 bytes |
A continuación se muestran algunos ejemplos del uso de directivas de definición:
choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456Tenga en cuenta que -
Cada byte de carácter se almacena como su valor ASCII en hexadecimal.
Cada valor decimal se convierte automáticamente a su equivalente binario de 16 bits y se almacena como un número hexadecimal.
El procesador utiliza el orden de bytes little-endian.
Los números negativos se convierten a su representación en complemento a 2.
Los números de coma flotante cortos y largos se representan utilizando 32 o 64 bits, respectivamente.
El siguiente programa muestra el uso de la directiva define:
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,1 ;message length
mov ecx,choice ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
choice DB 'y'Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
yAsignación de espacio de almacenamiento para datos no inicializados
Las directivas de reserva se utilizan para reservar espacio para datos no inicializados. Las directivas de reserva toman un solo operando que especifica el número de unidades de espacio que se reservarán. Cada directiva define tiene una directiva de reserva relacionada.
Hay cinco formas básicas de la directiva de reserva:
| Directiva | Propósito |
|---|---|
| RESB | Reserva un Byte |
| RESW | Reserva una palabra |
| RESD | Reserva una palabra doble |
| RESQ | Reserva una palabra cuádruple |
| DESCANSO | Reserva diez bytes |
Múltiples definiciones
Puede tener varias declaraciones de definición de datos en un programa. Por ejemplo
choice DB 'Y' ;ASCII of y = 79H
number1 DW 12345 ;12345D = 3039H
number2 DD 12345679 ;123456789D = 75BCD15HEl ensamblador asigna memoria contigua para múltiples definiciones de variables.
Múltiples inicializaciones
La directiva TIMES permite múltiples inicializaciones con el mismo valor. Por ejemplo, una matriz denominada marcas de tamaño 9 se puede definir e inicializar a cero utilizando la siguiente declaración:
marks TIMES 9 DW 0La directiva TIMES es útil para definir matrices y tablas. El siguiente programa muestra 9 asteriscos en la pantalla:
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
mov edx,9 ;message length
mov ecx, stars ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
stars times 9 db '*'Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
*********NASM proporciona varias directivas que definen constantes. Ya hemos utilizado la directiva EQU en capítulos anteriores. En particular, analizaremos tres directivas:
- EQU
- %assign
- %define
La Directiva EQU
los EQULa directiva se utiliza para definir constantes. La sintaxis de la directiva EQU es la siguiente:
CONSTANT_NAME EQU expressionPor ejemplo,
TOTAL_STUDENTS equ 50Luego puede usar este valor constante en su código, como:
mov ecx, TOTAL_STUDENTS
cmp eax, TOTAL_STUDENTSEl operando de una instrucción EQU puede ser una expresión:
LENGTH equ 20
WIDTH equ 10
AREA equ length * widthEl segmento de código anterior definiría AREA como 200.
Ejemplo
El siguiente ejemplo ilustra el uso de la directiva EQU:
SYS_EXIT equ 1
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
mov eax,SYS_EXIT ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $ - msg2 msg3 db 'Linux assembly programming! ' len3 equ $- msg3Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello, programmers!
Welcome to the world of,
Linux assembly programming!La directiva% asignar
los %assignLa directiva se puede usar para definir constantes numéricas como la directiva EQU. Esta directiva permite la redefinición. Por ejemplo, puede definir la constante TOTAL como -
%assign TOTAL 10Más adelante en el código, puede redefinirlo como:
%assign TOTAL 20Esta directiva distingue entre mayúsculas y minúsculas.
La Directiva% define
los %defineLa directiva permite definir tanto constantes numéricas como de cadena. Esta directiva es similar a #define en C. Por ejemplo, puede definir la constante PTR como -
%define PTR [EBP+4]El código anterior reemplaza PTR por [EBP + 4].
Esta directiva también permite la redefinición y distingue entre mayúsculas y minúsculas.
La instrucción INC
La instrucción INC se utiliza para incrementar un operando en uno. Funciona en un solo operando que puede estar en un registro o en la memoria.
Sintaxis
La instrucción INC tiene la siguiente sintaxis:
INC destinationEl destino del operando puede ser un operando de 8, 16 o 32 bits.
Ejemplo
INC EBX ; Increments 32-bit register
INC DL ; Increments 8-bit register
INC [count] ; Increments the count variableLa instrucción DEC
La instrucción DEC se utiliza para reducir un operando en uno. Funciona en un solo operando que puede estar en un registro o en la memoria.
Sintaxis
La instrucción DEC tiene la siguiente sintaxis:
DEC destinationEl destino del operando puede ser un operando de 8, 16 o 32 bits.
Ejemplo
segment .data
count dw 0
value db 15
segment .text
inc [count]
dec [value]
mov ebx, count
inc word [ebx]
mov esi, value
dec byte [esi]Las instrucciones ADD y SUB
Las instrucciones ADD y SUB se utilizan para realizar sumas / restas simples de datos binarios en tamaño de byte, palabra y palabra doble, es decir, para sumar o restar operandos de 8, 16 o 32 bits, respectivamente.
Sintaxis
Las instrucciones ADD y SUB tienen la siguiente sintaxis:
ADD/SUB destination, sourceLa instrucción ADD / SUB puede tener lugar entre -
- Regístrese para registrarse
- Memoria para registrar
- Registrarse en la memoria
- Registrarse en datos constantes
- Memoria para datos constantes
Sin embargo, al igual que otras instrucciones, las operaciones de memoria a memoria no son posibles utilizando las instrucciones ADD / SUB. Una operación ADD o SUB establece o borra las banderas de desbordamiento y acarreo.
Ejemplo
El siguiente ejemplo pedirá dos dígitos al usuario, almacenará los dígitos en el registro EAX y EBX, respectivamente, sumará los valores, almacenará el resultado en una ubicación de memoria ' res ' y finalmente mostrará el resultado.
SYS_EXIT equ 1
SYS_READ equ 3
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
segment .data
msg1 db "Enter a digit ", 0xA,0xD
len1 equ $- msg1 msg2 db "Please enter a second digit", 0xA,0xD len2 equ $- msg2
msg3 db "The sum is: "
len3 equ $- msg3
segment .bss
num1 resb 2
num2 resb 2
res resb 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num1
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num2
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
; moving the first number to eax register and second number to ebx
; and subtracting ascii '0' to convert it into a decimal number
mov eax, [num1]
sub eax, '0'
mov ebx, [num2]
sub ebx, '0'
; add eax and ebx
add eax, ebx
; add '0' to to convert the sum from decimal to ASCII
add eax, '0'
; storing the sum in memory location res
mov [res], eax
; print the sum
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, res
mov edx, 1
int 0x80
exit:
mov eax, SYS_EXIT
xor ebx, ebx
int 0x80Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Enter a digit:
3
Please enter a second digit:
4
The sum is:
7The program with hardcoded variables −
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The sum is:
7La instrucción MUL / IMUL
Hay dos instrucciones para multiplicar datos binarios. La instrucción MUL (Multiplicar) maneja datos sin firmar y la IMUL (Multiplicar enteros) maneja datos firmados. Ambas instrucciones afectan a la bandera de transporte y desbordamiento.
Sintaxis
La sintaxis de las instrucciones MUL / IMUL es la siguiente:
MUL/IMUL multiplierMultiplicando en ambos casos estará en un acumulador, dependiendo del tamaño del multiplicando y el multiplicador y el producto generado también se almacena en dos registros dependiendo del tamaño de los operandos. La siguiente sección explica las instrucciones MUL con tres casos diferentes:
| No Señor. | Escenarios |
|---|---|
| 1 | When two bytes are multiplied − El multiplicando está en el registro AL y el multiplicador es un byte en la memoria o en otro registro. El producto está en AX. Los 8 bits de orden superior del producto se almacenan en AH y los 8 bits de orden inferior se almacenan en AL.

|
| 2 | When two one-word values are multiplied − El multiplicando debe estar en el registro AX y el multiplicador es una palabra en la memoria u otro registro. Por ejemplo, para una instrucción como MUL DX, debe almacenar el multiplicador en DX y el multiplicando en AX. El producto resultante es una palabra doble, que necesitará dos registros. La parte de orden superior (más a la izquierda) se almacena en DX y la parte de orden inferior (más a la derecha) se almacena en AX.

|
| 3 | When two doubleword values are multiplied − Cuando se multiplican dos valores de dos palabras, el multiplicando debe estar en EAX y el multiplicador es un valor de dos palabras almacenado en la memoria o en otro registro. El producto generado se almacena en los registros EDX: EAX, es decir, los 32 bits de orden superior se almacenan en el registro EDX y los 32 bits de orden inferior se almacenan en el registro EAX.

|
Ejemplo
MOV AL, 10
MOV DL, 25
MUL DL
...
MOV DL, 0FFH ; DL= -1
MOV AL, 0BEH ; AL = -66
IMUL DLEjemplo
El siguiente ejemplo multiplica 3 por 2 y muestra el resultado:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al,'3'
sub al, '0'
mov bl, '2'
sub bl, '0'
mul bl
add al, '0'
mov [res], al
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The result is:
6Las instrucciones DIV / IDIV
La operación de división genera dos elementos: un quotient y un remainder. En caso de multiplicación, no se produce un desbordamiento porque se utilizan registros de doble longitud para mantener el producto. Sin embargo, en caso de división, puede producirse un desbordamiento. El procesador genera una interrupción si se produce un desbordamiento.
La instrucción DIV (Divide) se usa para datos sin firmar y el IDIV (Integer Divide) se usa para datos firmados.
Sintaxis
El formato de la instrucción DIV / IDIV -
DIV/IDIV divisorEl dividendo está en un acumulador. Ambas instrucciones pueden funcionar con operandos de 8, 16 o 32 bits. La operación afecta a los seis indicadores de estado. La siguiente sección explica tres casos de división con diferente tamaño de operando:
| No Señor. | Escenarios |
|---|---|
| 1 | When the divisor is 1 byte − Se supone que el dividendo está en el registro AX (16 bits). Después de la división, el cociente va al registro AL y el resto al registro AH.

|
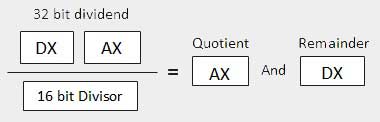
| 2 | When the divisor is 1 word − Se supone que el dividendo tiene una longitud de 32 bits y está en los registros DX: AX. Los 16 bits de orden superior están en DX y los 16 bits de orden inferior están en AX. Después de la división, el cociente de 16 bits va al registro AX y el resto de 16 bits al registro DX.
|
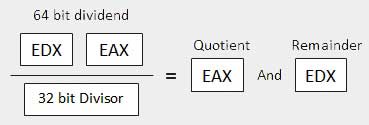
| 3 | When the divisor is doubleword − Se supone que el dividendo tiene una longitud de 64 bits y está en los registros EDX: EAX. Los 32 bits de orden superior están en EDX y los 32 bits de orden inferior están en EAX. Después de la división, el cociente de 32 bits va al registro EAX y el resto de 32 bits va al registro EDX.
|
Ejemplo
El siguiente ejemplo divide 8 por 2. El dividend 8 se almacena en el 16-bit AX register y el divisor 2 se almacena en el 8-bit BL register.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax,'8'
sub ax, '0'
mov bl, '2'
sub bl, '0'
div bl
add ax, '0'
mov [res], ax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The result is:
4El conjunto de instrucciones del procesador proporciona las instrucciones AND, OR, XOR, TEST y NOT lógica booleana, que prueba, establece y borra los bits de acuerdo con la necesidad del programa.
El formato de estas instrucciones:
| No Señor. | Instrucción | Formato |
|---|---|---|
| 1 | Y | Y operando1, operando2 |
| 2 | O | O operando1, operando2 |
| 3 | XOR | XOR operando1, operando2 |
| 4 | PRUEBA | TEST operando1, operando2 |
| 5 | NO | NO operando1 |
El primer operando en todos los casos podría estar en registro o en memoria. El segundo operando podría estar en el registro / memoria o en un valor inmediato (constante). Sin embargo, las operaciones de memoria a memoria no son posibles. Estas instrucciones comparan o hacen coincidir bits de los operandos y establecen las banderas CF, OF, PF, SF y ZF.
La instrucción AND
La instrucción AND se utiliza para admitir expresiones lógicas realizando una operación AND bit a bit. La operación AND bit a bit devuelve 1, si los bits coincidentes de ambos operandos son 1; de lo contrario, devuelve 0. Por ejemplo:
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001La operación AND se puede utilizar para borrar uno o más bits. Por ejemplo, digamos que el registro BL contiene 0011 1010. Si necesita borrar los bits de orden superior a cero, lo Y con 0FH.
AND BL, 0FH ; This sets BL to 0000 1010Tomemos otro ejemplo. Si desea verificar si un número dado es par o impar, una prueba simple sería verificar el bit menos significativo del número. Si es 1, el número es impar, de lo contrario, el número es par.
Suponiendo que el número está en el registro AL, podemos escribir:
AND AL, 01H ; ANDing with 0000 0001
JZ EVEN_NUMBEREl siguiente programa ilustra esto:
Ejemplo
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax, 8h ;getting 8 in the ax
and ax, 1 ;and ax with 1
jz evnn
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, odd_msg ;message to write
mov edx, len2 ;length of message
int 0x80 ;call kernel
jmp outprog
evnn:
mov ah, 09h
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, even_msg ;message to write
mov edx, len1 ;length of message
int 0x80 ;call kernel
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
even_msg db 'Even Number!' ;message showing even number
len1 equ $ - even_msg odd_msg db 'Odd Number!' ;message showing odd number len2 equ $ - odd_msgCuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Even Number!Cambie el valor en el registro del eje con un dígito impar, como -
mov ax, 9h ; getting 9 in the axEl programa mostraría:
Odd Number!De manera similar, para borrar todo el registro, puede Y con 00H.
La instrucción OR
La instrucción OR se utiliza para dar soporte a la expresión lógica realizando una operación OR bit a bit. El operador OR bit a bit devuelve 1, si los bits coincidentes de uno o ambos operandos son uno. Devuelve 0, si ambos bits son cero.
Por ejemplo,
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111La operación OR se puede utilizar para configurar uno o más bits. Por ejemplo, supongamos que el registro AL contiene 0011 1010, necesita establecer los cuatro bits de orden inferior, puede O con un valor 0000 1111, es decir, FH.
OR BL, 0FH ; This sets BL to 0011 1111Ejemplo
El siguiente ejemplo demuestra la instrucción OR. Guardemos el valor 5 y 3 en los registros AL y BL, respectivamente, luego la instrucción,
OR AL, BLdebe almacenar 7 en el registro AL -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
7La instrucción XOR
La instrucción XOR implementa la operación XOR bit a bit. La operación XOR establece el bit resultante en 1, si y solo si los bits de los operandos son diferentes. Si los bits de los operandos son iguales (ambos 0 o ambos 1), el bit resultante se pone a 0.
Por ejemplo,
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110XORing un operando consigo mismo cambia el operando a 0. Esto se usa para borrar un registro.
XOR EAX, EAXLa instrucción TEST
La instrucción TEST funciona igual que la operación AND, pero a diferencia de la instrucción AND, no cambia el primer operando. Entonces, si necesitamos verificar si un número en un registro es par o impar, también podemos hacerlo usando la instrucción TEST sin cambiar el número original.
TEST AL, 01H
JZ EVEN_NUMBERLa instrucción NOT
La instrucción NOT implementa la operación NOT bit a bit. La operación NO invierte los bits de un operando. El operando puede estar en un registro o en la memoria.
Por ejemplo,
Operand1: 0101 0011
After NOT -> Operand1: 1010 1100La ejecución condicional en lenguaje ensamblador se logra mediante varias instrucciones de bucle y ramificación. Estas instrucciones pueden cambiar el flujo de control en un programa. La ejecución condicional se observa en dos escenarios:
| No Señor. | Instrucciones condicionales |
|---|---|
| 1 | Unconditional jump Esto se realiza mediante la instrucción JMP. La ejecución condicional a menudo implica una transferencia de control a la dirección de una instrucción que no sigue la instrucción que se está ejecutando actualmente. La transferencia de control puede ser hacia adelante, para ejecutar un nuevo conjunto de instrucciones o hacia atrás, para volver a ejecutar los mismos pasos. |
| 2 | Conditional jump Esto se realiza mediante un conjunto de instrucciones de salto j <condición> dependiendo de la condición. Las instrucciones condicionales transfieren el control rompiendo el flujo secuencial y lo hacen cambiando el valor de compensación en IP. |
Analicemos la instrucción CMP antes de discutir las instrucciones condicionales.
Instrucción CMP
La instrucción CMP compara dos operandos. Generalmente se usa en ejecución condicional. Esta instrucción básicamente resta un operando del otro para comparar si los operandos son iguales o no. No perturba los operandos de origen o destino. Se utiliza junto con la instrucción de salto condicional para la toma de decisiones.
Sintaxis
CMP destination, sourceCMP compara dos campos de datos numéricos. El operando de destino puede estar en el registro o en la memoria. El operando de origen podría ser un registro, memoria o datos constantes (inmediatos).
Ejemplo
CMP DX, 00 ; Compare the DX value with zero
JE L7 ; If yes, then jump to label L7
.
.
L7: ...CMP se utiliza a menudo para comparar si un valor de contador ha alcanzado el número de veces que se debe ejecutar un bucle. Considere la siguiente condición típica:
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1Salto incondicional
Como se mencionó anteriormente, esto se realiza mediante la instrucción JMP. La ejecución condicional a menudo implica una transferencia de control a la dirección de una instrucción que no sigue la instrucción que se está ejecutando actualmente. La transferencia de control puede ser hacia adelante, para ejecutar un nuevo conjunto de instrucciones o hacia atrás, para volver a ejecutar los mismos pasos.
Sintaxis
La instrucción JMP proporciona un nombre de etiqueta donde el flujo de control se transfiere inmediatamente. La sintaxis de la instrucción JMP es:
JMP labelEjemplo
El siguiente fragmento de código ilustra la instrucción JMP:
MOV AX, 00 ; Initializing AX to 0
MOV BX, 00 ; Initializing BX to 0
MOV CX, 01 ; Initializing CX to 1
L20:
ADD AX, 01 ; Increment AX
ADD BX, AX ; Add AX to BX
SHL CX, 1 ; shift left CX, this in turn doubles the CX value
JMP L20 ; repeats the statementsSalto condicional
Si se satisface alguna condición especificada en el salto condicional, el flujo de control se transfiere a una instrucción de destino. Existen numerosas instrucciones de salto condicionales según la condición y los datos.
A continuación se muestran las instrucciones de salto condicional que se utilizan en datos con signo utilizados para operaciones aritméticas:
| Instrucción | Descripción | Banderas probadas |
|---|---|---|
| JE / JZ | Saltar igual o saltar cero | ZF |
| JNE / JNZ | Saltar no igual o Saltar no cero | ZF |
| JG / JNLE | Saltar mayor o no menos / igual | OF, SF, ZF |
| JGE / JNL | Saltar mayor / igual o no saltar menos | OF, SF |
| JL / JNGE | Saltar menos o saltar no mayor / igual | OF, SF |
| JLE / JNG | Saltar menos / igual o no saltar mayor | OF, SF, ZF |
A continuación se muestran las instrucciones de salto condicional que se utilizan en datos sin firmar utilizados para operaciones lógicas:
| Instrucción | Descripción | Banderas probadas |
|---|---|---|
| JE / JZ | Saltar igual o saltar cero | ZF |
| JNE / JNZ | Saltar no igual o Saltar no cero | ZF |
| JA / JNBE | Saltar por encima o no por debajo / igual | CF, ZF |
| JAE / JNB | Saltar por encima / igual o no saltar por debajo | CF |
| JB / JNAE | Saltar abajo o no saltar arriba / igual | CF |
| JBE / JNA | Saltar abajo / Igual o no saltar arriba | AF, CF |
Las siguientes instrucciones de salto condicional tienen usos especiales y verifican el valor de las banderas:
| Instrucción | Descripción | Banderas probadas |
|---|---|---|
| JXCZ | Saltar si CX es cero | ninguna |
| JC | Saltar si llevar | CF |
| JNC | Salta si no llevas | CF |
| JO | Saltar si se desborda | DE |
| JNO | Saltar si no hay desbordamiento | DE |
| JP / JPE | Saltar paridad o saltar paridad par | PF |
| JNP / JPO | Saltar sin paridad o Saltar con paridad impar | PF |
| JS | Signo de salto (valor negativo) | SF |
| JNS | Saltar sin signo (valor positivo) | SF |
La sintaxis para el conjunto de instrucciones J <condición> -
Ejemplo,
CMP AL, BL
JE EQUAL
CMP AL, BH
JE EQUAL
CMP AL, CL
JE EQUAL
NON_EQUAL: ...
EQUAL: ...Ejemplo
El siguiente programa muestra la mayor de las tres variables. Las variables son variables de dos dígitos. Las tres variables num1, num2 y num3 tienen valores 47, 22 y 31, respectivamente -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The largest digit is:
47La instrucción JMP se puede utilizar para implementar bucles. Por ejemplo, el siguiente fragmento de código se puede utilizar para ejecutar el cuerpo del bucle 10 veces.
MOV CL, 10
L1:
<LOOP-BODY>
DEC CL
JNZ L1Sin embargo, el conjunto de instrucciones del procesador incluye un grupo de instrucciones de bucle para implementar la iteración. La instrucción LOOP básica tiene la siguiente sintaxis:
LOOP labelDonde, etiqueta es la etiqueta de destino que identifica la instrucción de destino como en las instrucciones de salto. La instrucción LOOP asume que elECX register contains the loop count. Cuando se ejecuta la instrucción de bucle, el registro ECX disminuye y el control salta a la etiqueta de destino, hasta que el valor del registro ECX, es decir, el contador alcanza el valor cero.
El fragmento de código anterior podría escribirse como:
mov ECX,10
l1:
<loop body>
loop l1Ejemplo
El siguiente programa imprime el número del 1 al 9 en la pantalla:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,10
mov eax, '1'
l1:
mov [num], eax
mov eax, 4
mov ebx, 1
push ecx
mov ecx, num
mov edx, 1
int 0x80
mov eax, [num]
sub eax, '0'
inc eax
add eax, '0'
pop ecx
loop l1
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
num resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
123456789:Los datos numéricos generalmente se representan en sistema binario. Las instrucciones aritméticas operan sobre datos binarios. Cuando los números se muestran en la pantalla o se ingresan desde el teclado, están en formato ASCII.
Hasta ahora, hemos convertido estos datos de entrada en formato ASCII a binarios para cálculos aritméticos y hemos vuelto a convertir el resultado a binario. El siguiente código muestra esto:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The sum is:
7Sin embargo, tales conversiones tienen una sobrecarga, y la programación en lenguaje ensamblador permite procesar números de una manera más eficiente, en forma binaria. Los números decimales se pueden representar de dos formas:
- Formulario ASCII
- Forma decimal codificada en BCD o binaria
Representación ASCII
En la representación ASCII, los números decimales se almacenan como una cadena de caracteres ASCII. Por ejemplo, el valor decimal 1234 se almacena como -
31 32 33 34HDonde 31H es el valor ASCII para 1, 32H es el valor ASCII para 2, y así sucesivamente. Hay cuatro instrucciones para procesar números en representación ASCII:
AAA - Ajuste ASCII después de la adición
AAS - Ajuste ASCII después de la resta
AAM - Ajuste ASCII después de la multiplicación
AAD - Ajuste ASCII antes de la división
Estas instrucciones no toman ningún operando y asumen que el operando requerido está en el registro AL.
El siguiente ejemplo utiliza la instrucción AAS para demostrar el concepto:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
sub ah, ah
mov al, '9'
sub al, '3'
aas
or al, 30h
mov [res], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,res ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Result is:',0xa
len equ $ - msg
section .bss
res resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The Result is:
6Representación BCD
Hay dos tipos de representación BCD:
- Representación BCD desempaquetada
- Representación BCD empaquetada
En la representación BCD descomprimida, cada byte almacena el equivalente binario de un dígito decimal. Por ejemplo, el número 1234 se almacena como -
01 02 03 04HHay dos instrucciones para procesar estos números:
AAM - Ajuste ASCII después de la multiplicación
AAD - Ajuste ASCII antes de la división
Las cuatro instrucciones de ajuste ASCII, AAA, AAS, AAM y AAD, también se pueden utilizar con la representación BCD descomprimida. En la representación BCD empaquetada, cada dígito se almacena utilizando cuatro bits. Se empaquetan dos dígitos decimales en un byte. Por ejemplo, el número 1234 se almacena como -
12 34HHay dos instrucciones para procesar estos números:
DAA - Ajuste decimal después de la adición
DAS - Ajuste decimal después de la resta
No hay soporte para multiplicación y división en representación BCD empaquetada.
Ejemplo
El siguiente programa suma dos números decimales de 5 dígitos y muestra la suma. Utiliza los conceptos anteriores:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov esi, 4 ;pointing to the rightmost digit
mov ecx, 5 ;num of digits
clc
add_loop:
mov al, [num1 + esi]
adc al, [num2 + esi]
aaa
pushf
or al, 30h
popf
mov [sum + esi], al
dec esi
loop add_loop
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,5 ;message length
mov ecx,sum ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Sum is:',0xa
len equ $ - msg
num1 db '12345'
num2 db '23456'
sum db ' 'Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The Sum is:
35801Ya hemos utilizado cadenas de longitud variable en nuestros ejemplos anteriores. Las cadenas de longitud variable pueden tener tantos caracteres como sea necesario. Generalmente, especificamos la longitud de la cadena por cualquiera de las dos formas:
- Almacenamiento explícito de la longitud de la cadena
- Usando un personaje centinela
Podemos almacenar la longitud de la cadena de forma explícita utilizando el símbolo de contador de ubicación $ que representa el valor actual del contador de ubicación. En el siguiente ejemplo:
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string$ apunta al byte después del último carácter de la variable de cadena msg . Por lo tanto,$-msgda la longitud de la cuerda. También podemos escribir
msg db 'Hello, world!',0xa ;our dear string
len equ 13 ;length of our dear stringAlternativamente, puede almacenar cadenas con un carácter centinela final para delimitar una cadena en lugar de almacenar la longitud de la cadena explícitamente. El carácter centinela debe ser un carácter especial que no aparezca dentro de una cadena.
Por ejemplo
message DB 'I am loving it!', 0Instrucciones de cadena
Cada instrucción de cadena puede requerir un operando de origen, un operando de destino o ambos. Para segmentos de 32 bits, las instrucciones de cadena utilizan registros ESI y EDI para apuntar a los operandos de origen y destino, respectivamente.
Sin embargo, para los segmentos de 16 bits, los registros SI y DI se utilizan para apuntar al origen y al destino, respectivamente.
Hay cinco instrucciones básicas para procesar cadenas. Ellos son -
MOVS - Esta instrucción mueve 1 byte, palabra o palabra doble de datos de una ubicación de memoria a otra.
LODS- Esta instrucción se carga desde la memoria. Si el operando es de un byte, se carga en el registro AL, si el operando es una palabra, se carga en el registro AX y se carga una palabra doble en el registro EAX.
STOS - Esta instrucción almacena datos del registro (AL, AX o EAX) en la memoria.
CMPS- Esta instrucción compara dos elementos de datos en la memoria. Los datos pueden tener un tamaño de byte, palabra o palabra doble.
SCAS - Esta instrucción compara el contenido de un registro (AL, AX o EAX) con el contenido de un elemento en la memoria.
Cada una de las instrucciones anteriores tiene una versión de byte, palabra y palabra doble, y las instrucciones de cadena se pueden repetir utilizando un prefijo de repetición.
Estas instrucciones utilizan el par de registros ES: DI y DS: SI, donde los registros DI y SI contienen direcciones de compensación válidas que se refieren a bytes almacenados en la memoria. SI normalmente está asociado con DS (segmento de datos) y DI siempre está asociado con ES (segmento extra).
Los registros DS: SI (o ESI) y ES: DI (o EDI) apuntan a los operandos de origen y destino, respectivamente. Se supone que el operando de origen está en DS: SI (o ESI) y el operando de destino en ES: DI (o EDI) en la memoria.
Para direcciones de 16 bits, se utilizan los registros SI y DI, y para direcciones de 32 bits, se utilizan los registros ESI y EDI.
La siguiente tabla proporciona varias versiones de instrucciones de cadena y el espacio supuesto de los operandos.
| Instrucción básica | Operandos en | Operación Byte | Operación de palabras | Operación de palabra doble |
|---|---|---|---|---|
| MOVS | ES: DI, DS: SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS: SI | LODSB | LODSW | LODSD |
| STOS | ES: DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS: SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES: DI, AX | SCASB | SCASW | SCASD |
Prefijos de repetición
El prefijo REP, cuando se establece antes de una instrucción de cadena, por ejemplo, REP MOVSB, provoca la repetición de la instrucción basada en un contador colocado en el registro CX. REP ejecuta la instrucción, reduce CX en 1 y comprueba si CX es cero. Repite el procesamiento de la instrucción hasta que CX sea cero.
El indicador de dirección (DF) determina la dirección de la operación.
- Utilice CLD (Clear Direction Flag, DF = 0) para realizar la operación de izquierda a derecha.
- Utilice STD (Establecer indicador de dirección, DF = 1) para realizar la operación de derecha a izquierda.
El prefijo REP también tiene las siguientes variaciones:
REP: Es la repetición incondicional. Repite la operación hasta que CX sea cero.
REPE o REPZ: Es repetición condicional. Repite la operación mientras la bandera de cero indica igual / cero. Se detiene cuando ZF indica no igual / cero o cuando CX es cero.
REPNE o REPNZ: También es repetición condicional. Repite la operación mientras la bandera de cero indica no igual / cero. Se detiene cuando ZF indica igual / cero o cuando CX se reduce a cero.
Ya hemos discutido que las directivas de definición de datos para el ensamblador se utilizan para asignar almacenamiento para variables. La variable también podría inicializarse con algún valor específico. El valor inicializado se puede especificar en formato hexadecimal, decimal o binario.
Por ejemplo, podemos definir una variable de palabra 'meses' de cualquiera de las siguientes formas:
MONTHS DW 12
MONTHS DW 0CH
MONTHS DW 0110BLas directivas de definición de datos también se pueden utilizar para definir una matriz unidimensional. Definamos una matriz unidimensional de números.
NUMBERS DW 34, 45, 56, 67, 75, 89La definición anterior declara una matriz de seis palabras, cada una inicializada con los números 34, 45, 56, 67, 75, 89. Esto asigna 2x6 = 12 bytes de espacio de memoria consecutiva. La dirección simbólica del primer número será NÚMEROS y la del segundo número será NÚMEROS + 2 y así sucesivamente.
Tomemos otro ejemplo. Puede definir una matriz denominada inventario de tamaño 8 e inicializar todos los valores con cero, como:
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0Que se puede abreviar como -
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0La directiva TIMES también se puede usar para múltiples inicializaciones con el mismo valor. Usando TIEMPOS, la matriz INVENTARIO se puede definir como:
INVENTORY TIMES 8 DW 0Ejemplo
El siguiente ejemplo demuestra los conceptos anteriores definiendo una matriz de 3 elementos x, que almacena tres valores: 2, 3 y 4. Agrega los valores en la matriz y muestra la suma 9 -
section .text
global _start ;must be declared for linker (ld)
_start:
mov eax,3 ;number bytes to be summed
mov ebx,0 ;EBX will store the sum
mov ecx, x ;ECX will point to the current element to be summed
top: add ebx, [ecx]
add ecx,1 ;move pointer to next element
dec eax ;decrement counter
jnz top ;if counter not 0, then loop again
done:
add ebx, '0'
mov [sum], ebx ;done, store result in "sum"
display:
mov edx,1 ;message length
mov ecx, sum ;message to write
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
global x
x:
db 2
db 4
db 3
sum:
db 0Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
9Los procedimientos o subrutinas son muy importantes en el lenguaje ensamblador, ya que los programas en lenguaje ensamblador tienden a ser de gran tamaño. Los procedimientos se identifican con un nombre. A continuación de este nombre, se describe el cuerpo del procedimiento que realiza un trabajo bien definido. El final del procedimiento se indica mediante una declaración de devolución.
Sintaxis
A continuación se muestra la sintaxis para definir un procedimiento:
proc_name:
procedure body
...
retEl procedimiento se llama desde otra función utilizando la instrucción CALL. La instrucción CALL debe tener el nombre del procedimiento llamado como argumento, como se muestra a continuación:
CALL proc_nameEl procedimiento llamado devuelve el control al procedimiento de llamada utilizando la instrucción RET.
Ejemplo
Escribamos un procedimiento muy simple llamado suma que suma las variables almacenadas en el registro ECX y EDX y devuelve la suma en el registro EAX -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,'4'
sub ecx, '0'
mov edx, '5'
sub edx, '0'
call sum ;call sum procedure
mov [res], eax
mov ecx, msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx, res
mov edx, 1
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
sum:
mov eax, ecx
add eax, edx
add eax, '0'
ret
section .data
msg db "The sum is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
The sum is:
9Estructura de datos de pilas
Una pila es una estructura de datos similar a una matriz en la memoria en la que los datos se pueden almacenar y eliminar de una ubicación llamada 'parte superior' de la pila. Los datos que deben almacenarse se 'empujan' a la pila y los datos que se van a recuperar se 'extraen' de la pila. Stack es una estructura de datos LIFO, es decir, los datos almacenados primero se recuperan en último lugar.
El lenguaje ensamblador proporciona dos instrucciones para las operaciones de pila: PUSH y POP. Estas instrucciones tienen sintaxis como:
PUSH operand
POP address/registerEl espacio de memoria reservado en el segmento de la pila se utiliza para implementar la pila. Los registros SS y ESP (o SP) se utilizan para implementar la pila. La parte superior de la pila, que apunta al último elemento de datos insertado en la pila, es apuntada por el registro SS: ESP, donde el registro SS apunta al comienzo del segmento de la pila y el SP (o ESP) da el desplazamiento en el segmento de pila.
La implementación de la pila tiene las siguientes características:
Solamente words o doublewords podría guardarse en la pila, no en un byte.
La pila crece en la dirección inversa, es decir, hacia la dirección de memoria inferior
La parte superior de la pila apunta al último elemento insertado en la pila; apunta al byte más bajo de la última palabra insertada.
Como comentamos sobre el almacenamiento de los valores de los registros en la pila antes de usarlos para algún uso; se puede hacer de la siguiente manera:
; Save the AX and BX registers in the stack
PUSH AX
PUSH BX
; Use the registers for other purpose
MOV AX, VALUE1
MOV BX, VALUE2
...
MOV VALUE1, AX
MOV VALUE2, BX
; Restore the original values
POP BX
POP AXEjemplo
El siguiente programa muestra todo el juego de caracteres ASCII. El programa principal llama a un procedimiento llamado pantalla , que muestra el juego de caracteres ASCII.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
call display
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
display:
mov ecx, 256
next:
push ecx
mov eax, 4
mov ebx, 1
mov ecx, achar
mov edx, 1
int 80h
pop ecx
mov dx, [achar]
cmp byte [achar], 0dh
inc byte [achar]
loop next
ret
section .data
achar db '0'Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...Un procedimiento recursivo es aquel que se llama a sí mismo. Hay dos tipos de recursividad: directa e indirecta. En la recursividad directa, el procedimiento se llama a sí mismo y en la recursividad indirecta, el primer procedimiento llama a un segundo procedimiento, que a su vez llama al primer procedimiento.
La recursividad se pudo observar en numerosos algoritmos matemáticos. Por ejemplo, considere el caso de calcular el factorial de un número. El factorial de un número viene dado por la ecuación -
Fact (n) = n * fact (n-1) for n > 0Por ejemplo: el factorial de 5 es 1 x 2 x 3 x 4 x 5 = 5 x factorial de 4 y este puede ser un buen ejemplo de cómo mostrar un procedimiento recursivo. Todo algoritmo recursivo debe tener una condición de finalización, es decir, la llamada recursiva del programa debe detenerse cuando se cumple una condición. En el caso del algoritmo factorial, la condición final se alcanza cuando n es 0.
El siguiente programa muestra cómo se implementa factorial n en lenguaje ensamblador. Para mantener el programa simple, calcularemos el factorial 3.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Factorial 3 is:
6Escribir una macro es otra forma de garantizar la programación modular en lenguaje ensamblador.
Una macro es una secuencia de instrucciones, asignadas por un nombre y pueden usarse en cualquier parte del programa.
En NASM, las macros se definen con %macro y %endmacro directivas.
La macro comienza con la directiva% macro y termina con la directiva% endmacro.
La sintaxis para la definición de macros -
%macro macro_name number_of_params
<macro body>
%endmacroDonde, number_of_params especifica los parámetros numéricos , macro_name especifica el nombre de la macro.
La macro se invoca utilizando el nombre de la macro junto con los parámetros necesarios. Cuando necesite usar una secuencia de instrucciones muchas veces en un programa, puede poner esas instrucciones en una macro y usarla en lugar de escribir las instrucciones todo el tiempo.
Por ejemplo, una necesidad muy común de los programas es escribir una cadena de caracteres en la pantalla. Para mostrar una cadena de caracteres, necesita la siguiente secuencia de instrucciones:
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernelEn el ejemplo anterior de visualización de una cadena de caracteres, la llamada de función INT 80H ha utilizado los registros EAX, EBX, ECX y EDX. Por lo tanto, cada vez que necesite mostrar en pantalla, debe guardar estos registros en la pila, invocar INT 80H y luego restaurar el valor original de los registros de la pila. Por lo tanto, podría ser útil escribir dos macros para guardar y restaurar datos.
Hemos observado que algunas instrucciones como IMUL, IDIV, INT, etc., necesitan que parte de la información se almacene en algunos registros particulares e incluso devuelvan valores en algunos registros específicos. Si el programa ya estaba usando esos registros para mantener datos importantes, entonces los datos existentes de estos registros deben guardarse en la pila y restaurarse después de que se ejecute la instrucción.
Ejemplo
El siguiente ejemplo muestra la definición y el uso de macros:
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1 msg2 db 'Welcome to the world of,', 0xA,0xD len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Hello, programmers!
Welcome to the world of,
Linux assembly programming!El sistema considera cualquier dato de entrada o salida como flujo de bytes. Hay tres flujos de archivos estándar:
- Entrada estándar (stdin),
- Salida estándar (stdout) y
- Error estándar (stderr).
Descriptor de archivo
UN file descriptores un entero de 16 bits asignado a un archivo como ID de archivo. Cuando se crea un archivo nuevo o se abre un archivo existente, el descriptor de archivo se utiliza para acceder al archivo.
Descriptor de archivo de los flujos de archivos estándar - stdin, stdout y stderr son 0, 1 y 2, respectivamente.
Puntero de archivo
UN file pointerespecifica la ubicación para una operación de lectura / escritura posterior en el archivo en términos de bytes. Cada archivo se considera una secuencia de bytes. Cada archivo abierto está asociado con un puntero de archivo que especifica un desplazamiento en bytes, relativo al comienzo del archivo. Cuando se abre un archivo, el puntero del archivo se establece en cero.
Llamadas al sistema de manejo de archivos
La siguiente tabla describe brevemente las llamadas al sistema relacionadas con el manejo de archivos:
| % eax | Nombre | % ebx | % ecx | % edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - | - |
| 3 | sys_read | int sin firmar | char * | size_t |
| 4 | sys_write | int sin firmar | const char * | size_t |
| 5 | sys_open | const char * | En t | En t |
| 6 | sys_close | int sin firmar | - | - |
| 8 | sys_creat | const char * | En t | - |
| 19 | sys_lseek | int sin firmar | off_t | int sin firmar |
Los pasos necesarios para utilizar las llamadas al sistema son los mismos, como comentamos anteriormente:
- Ponga el número de llamada del sistema en el registro EAX.
- Almacene los argumentos de la llamada al sistema en los registros EBX, ECX, etc.
- Llame a la interrupción correspondiente (80h).
- El resultado generalmente se devuelve en el registro EAX.
Crear y abrir un archivo
Para crear y abrir un archivo, realice las siguientes tareas:
- Ponga la llamada al sistema sys_creat () número 8, en el registro EAX.
- Ponga el nombre del archivo en el registro EBX.
- Ponga los permisos del archivo en el registro ECX.
La llamada al sistema devuelve el descriptor de archivo del archivo creado en el registro EAX, en caso de error, el código de error está en el registro EAX.
Abrir un archivo existente
Para abrir un archivo existente, realice las siguientes tareas:
- Ponga la llamada al sistema sys_open () número 5, en el registro EAX.
- Ponga el nombre del archivo en el registro EBX.
- Ponga el modo de acceso a archivos en el registro ECX.
- Ponga los permisos del archivo en el registro EDX.
La llamada al sistema devuelve el descriptor de archivo del archivo creado en el registro EAX, en caso de error, el código de error está en el registro EAX.
Entre los modos de acceso a archivos, los más utilizados son: solo lectura (0), solo escritura (1) y lectura-escritura (2).
Leer de un archivo
Para leer de un archivo, realice las siguientes tareas:
Ponga la llamada al sistema sys_read () número 3, en el registro EAX.
Coloque el descriptor de archivo en el registro EBX.
Coloque el puntero en el búfer de entrada en el registro ECX.
Coloque el tamaño del búfer, es decir, el número de bytes a leer, en el registro EDX.
La llamada al sistema devuelve el número de bytes leídos en el registro EAX, en caso de error, el código de error está en el registro EAX.
Escribir en un archivo
Para escribir en un archivo, realice las siguientes tareas:
Ponga la llamada al sistema sys_write () número 4, en el registro EAX.
Coloque el descriptor de archivo en el registro EBX.
Coloque el puntero en el búfer de salida en el registro ECX.
Ponga el tamaño del búfer, es decir, el número de bytes a escribir, en el registro EDX.
La llamada al sistema devuelve el número real de bytes escritos en el registro EAX, en caso de error, el código de error está en el registro EAX.
Cerrar un archivo
Para cerrar un archivo, realice las siguientes tareas:
- Ponga la llamada al sistema sys_close () número 6, en el registro EAX.
- Coloque el descriptor de archivo en el registro EBX.
La llamada al sistema devuelve, en caso de error, el código de error en el registro EAX.
Actualizar un archivo
Para actualizar un archivo, realice las siguientes tareas:
- Ponga la llamada al sistema sys_lseek () número 19, en el registro EAX.
- Coloque el descriptor de archivo en el registro EBX.
- Ponga el valor de compensación en el registro ECX.
- Ponga la posición de referencia para el desplazamiento en el registro EDX.
La posición de referencia podría ser:
- Comienzo del archivo - valor 0
- Posición actual - valor 1
- Fin de archivo - valor 2
La llamada al sistema devuelve, en caso de error, el código de error en el registro EAX.
Ejemplo
El siguiente programa crea y abre un archivo llamado myfile.txt y escribe un texto 'Bienvenido a Tutorials Point' en este archivo. A continuación, el programa lee el archivo y almacena los datos en un búfer llamado info . Por último, muestra el texto almacenado en información .
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to Tutorials Point'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26Cuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Written to file
Welcome to Tutorials Pointlos sys_brk()El kernel proporciona la llamada al sistema para asignar memoria sin necesidad de moverla más tarde. Esta llamada asigna memoria justo detrás de la imagen de la aplicación en la memoria. Esta función del sistema le permite configurar la dirección más alta disponible en la sección de datos.
Esta llamada al sistema toma un parámetro, que es la dirección de memoria más alta necesaria para configurar. Este valor se almacena en el registro EBX.
En caso de cualquier error, sys_brk () devuelve -1 o devuelve el propio código de error negativo. El siguiente ejemplo demuestra la asignación de memoria dinámica.
Ejemplo
El siguiente programa asigna 16kb de memoria usando la llamada al sistema sys_brk () -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, 45 ;sys_brk
xor ebx, ebx
int 80h
add eax, 16384 ;number of bytes to be reserved
mov ebx, eax
mov eax, 45 ;sys_brk
int 80h
cmp eax, 0
jl exit ;exit, if error
mov edi, eax ;EDI = highest available address
sub edi, 4 ;pointing to the last DWORD
mov ecx, 4096 ;number of DWORDs allocated
xor eax, eax ;clear eax
std ;backward
rep stosd ;repete for entire allocated area
cld ;put DF flag to normal state
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, len
int 80h ;print a message
exit:
mov eax, 1
xor ebx, ebx
int 80h
section .data
msg db "Allocated 16 kb of memory!", 10
len equ $ - msgCuando el código anterior se compila y ejecuta, produce el siguiente resultado:
Allocated 16 kb of memory!