Beautiful Soup - Guía rápida
En el mundo actual, tenemos toneladas de datos / información no estructurados (principalmente datos web) disponibles gratuitamente. A veces, los datos disponibles gratuitamente son fáciles de leer y otras no. Independientemente de cómo estén disponibles sus datos, el web scraping es una herramienta muy útil para transformar datos no estructurados en datos estructurados que son más fáciles de leer y analizar. En otras palabras, una forma de recopilar, organizar y analizar esta enorme cantidad de datos es a través del web scraping. Primero entendamos qué es el web-scraping.
¿Qué es el web-scraping?
El raspado es simplemente un proceso de extracción (de varios medios), copia y selección de datos.
Cuando hacemos raspado o extracción de datos o feeds de la web (como de páginas web o sitios web), se denomina raspado web.
Entonces, web scraping, que también se conoce como extracción de datos web o recolección web, es la extracción de datos de la web. En resumen, el web scraping proporciona a los desarrolladores una forma de recopilar y analizar datos de Internet.
¿Por qué raspar la web?
Web-scraping proporciona una de las mejores herramientas para automatizar la mayoría de las cosas que hace un humano mientras navega. El web-scraping se utiliza en una empresa de diversas formas:
Datos para investigación
El analista inteligente (como un investigador o un periodista) utiliza el scrapper web en lugar de recopilar y limpiar manualmente los datos de los sitios web.
Comparación de precios y popularidad de productos
Actualmente, hay un par de servicios que utilizan scrappers web para recopilar datos de numerosos sitios en línea y utilizarlos para comparar la popularidad y los precios de los productos.
Monitoreo SEO
Existen numerosas herramientas de SEO como Ahrefs, Seobility, SEMrush, etc., que se utilizan para el análisis competitivo y para extraer datos de los sitios web de sus clientes.
Los motores de búsqueda
Hay algunas grandes empresas de TI cuyo negocio depende únicamente del web scraping.
Ventas y marketing
Los especialistas en marketing pueden utilizar los datos recopilados a través del web scraping para analizar diferentes nichos y competidores, o el especialista en ventas para vender servicios de promoción de redes sociales o marketing de contenidos.
¿Por qué Python para Web Scraping?
Python es uno de los lenguajes más populares para el rastreo web, ya que puede manejar la mayoría de las tareas relacionadas con el rastreo web con mucha facilidad.
A continuación se muestran algunos de los puntos sobre por qué elegir Python para web scraping:
Facilidad de uso
Como la mayoría de los desarrolladores están de acuerdo en que Python es muy fácil de codificar. No tenemos que utilizar llaves "{}" ni punto y coma ";" en cualquier lugar, lo que lo hace más legible y fácil de usar al desarrollar web scrapers.
Gran soporte de biblioteca
Python proporciona un gran conjunto de bibliotecas para diferentes requisitos, por lo que es apropiado para web scraping, así como para visualización de datos, aprendizaje automático, etc.
Sintaxis fácilmente explicable
Python es un lenguaje de programación muy legible ya que la sintaxis de Python es fácil de entender. Python es muy expresivo y la sangría del código ayuda a los usuarios a diferenciar diferentes bloques o ámbitos en el código.
Lenguaje escrito dinámicamente
Python es un lenguaje escrito dinámicamente, lo que significa que los datos asignados a una variable dicen qué tipo de variable es. Ahorra mucho tiempo y agiliza el trabajo.
Comunidad enorme
La comunidad de Python es enorme, lo que te ayuda donde sea que estés atascado mientras escribes código.
Introducción a Beautiful Soup
The Beautiful Soup es una biblioteca de pitones que lleva el nombre de un poema de Lewis Carroll del mismo nombre en "Alice's Adventures in the Wonderland". Beautiful Soup es un paquete de Python y, como su nombre indica, analiza los datos no deseados y ayuda a organizar y formatear los datos web desordenados corrigiendo HTML incorrecto y presentándonos en estructuras XML fácilmente transitables.
En resumen, Beautiful Soup es un paquete de Python que nos permite extraer datos de documentos HTML y XML.
Como BeautifulSoup no es una biblioteca estándar de Python, primero debemos instalarla. Vamos a instalar la biblioteca BeautifulSoup 4 (también conocida como BS4), que es la última.
Para aislar nuestro entorno de trabajo para no perturbar la configuración existente, primero creemos un entorno virtual.
Crear un entorno virtual (opcional)
Un entorno virtual nos permite crear una copia de trabajo aislada de Python para un proyecto específico sin afectar la configuración externa.
La mejor manera de instalar cualquier máquina de paquetes de Python es usando pip, sin embargo, si pip aún no está instalado (puede verificarlo usando - “pip –version” en su comando o línea de comandos), puede instalar dando el siguiente comando -
Entorno Linux
$sudo apt-get install python-pipEntorno Windows
Para instalar pip en Windows, haga lo siguiente:
Descargue get-pip.py de https://bootstrap.pypa.io/get-pip.py o desde el github a tu computadora.
Abra el símbolo del sistema y navegue hasta la carpeta que contiene el archivo get-pip.py.
Ejecute el siguiente comando:
>python get-pip.pyEso es todo, pip ahora está instalado en su máquina con Windows.
Puede verificar su pip instalado ejecutando el siguiente comando:
>pip --version
pip 19.2.3 from c:\users\yadur\appdata\local\programs\python\python37\lib\site-packages\pip (python 3.7)Instalación de entorno virtual
Ejecute el siguiente comando en su símbolo del sistema:
>pip install virtualenvDespués de ejecutar, verá la siguiente captura de pantalla:

El siguiente comando creará un entorno virtual ("myEnv") en su directorio actual -
>virtualenv myEnvCaptura de pantalla

Para activar su entorno virtual, ejecute el siguiente comando:
>myEnv\Scripts\activate
En la captura de pantalla anterior, puede ver que tenemos "myEnv" como prefijo que nos dice que estamos en el entorno virtual "myEnv".
Para salir del entorno virtual, ejecute deactivate.
(myEnv) C:\Users\yadur>deactivate
C:\Users\yadur>Cuando nuestro entorno virtual esté listo, ahora instalemos beautifulsoup.
Instalación de BeautifulSoup
Como BeautifulSoup no es una biblioteca estándar, necesitamos instalarla. Vamos a utilizar el paquete BeautifulSoup 4 (conocido como bs4).
Máquina Linux
Para instalar bs4 en Debian o Ubuntu linux usando el administrador de paquetes del sistema, ejecute el siguiente comando:
$sudo apt-get install python-bs4 (for python 2.x)
$sudo apt-get install python3-bs4 (for python 3.x)Puede instalar bs4 usando easy_install o pip (en caso de que encuentre problemas al instalar usando el empaquetador del sistema).
$easy_install beautifulsoup4
$pip install beautifulsoup4(Es posible que deba usar easy_install3 o pip3 respectivamente si está usando python3)
Máquina de Windows
Instalar beautifulsoup4 en Windows es muy sencillo, especialmente si ya tienes pip instalado.
>pip install beautifulsoup4
Así que ahora beautifulsoup4 está instalado en nuestra máquina. Hablemos de algunos problemas encontrados después de la instalación.
Problemas después de la instalación
En la máquina con Windows, puede encontrar una versión incorrecta que se instala error principalmente a través de:
error: ImportError “No module named HTMLParser”, entonces debe ejecutar la versión python 2 del código en Python 3.
error: ImportError “No module named html.parser” error, entonces debe ejecutar la versión Python 3 del código en Python 2.
La mejor manera de salir de las dos situaciones anteriores es reinstalar BeautifulSoup nuevamente, eliminando por completo la instalación existente.
Si obtienes el SyntaxError “Invalid syntax” en la línea ROOT_TAG_NAME = u '[documento]', entonces necesita convertir el código de python 2 a python 3, simplemente instalando el paquete -
$ python3 setup.py installo ejecutando manualmente el script de conversión 2 a 3 de python en el directorio bs4 -
$ 2to3-3.2 -w bs4Instalación de un analizador
De forma predeterminada, Beautiful Soup admite el analizador HTML incluido en la biblioteca estándar de Python, sin embargo, también admite muchos analizadores externos de Python como el analizador lxml o el analizador html5lib.
Para instalar el analizador lxml o html5lib, use el comando -
Máquina Linux
$apt-get install python-lxml
$apt-get insall python-html5libMáquina de Windows
$pip install lxml
$pip install html5lib
Generalmente, los usuarios usan lxml para la velocidad y se recomienda usar el analizador lxml o html5lib si está usando una versión anterior de python 2 (antes de la versión 2.7.3) o python 3 (antes de la 3.2.2) ya que el analizador HTML incorporado de Python es no es muy bueno en el manejo de versiones anteriores.
Corriendo hermosa sopa
Es hora de probar nuestro paquete Beautiful Soup en una de las páginas html (tomando la página web - https://www.tutorialspoint.com/index.htm, puede elegir cualquier otra página web que desee) y extraer información de ella.
En el siguiente código, intentamos extraer el título de la página web:
from bs4 import BeautifulSoup
import requests
url = "https://www.tutorialspoint.com/index.htm"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
print(soup.title)Salida
<title>H2O, Colab, Theano, Flutter, KNime, Mean.js, Weka, Solidity, Org.Json, AWS QuickSight, JSON.Simple, Jackson Annotations, Passay, Boon, MuleSoft, Nagios, Matplotlib, Java NIO, PyTorch, SLF4J, Parallax Scrolling, Java Cryptography</title>Una tarea común es extraer todas las URL dentro de una página web. Para eso, solo necesitamos agregar la siguiente línea de código:
for link in soup.find_all('a'):
print(link.get('href'))Salida
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/about/about_careers.htm
https://www.tutorialspoint.com/questions/index.php
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/codingground.htm
https://www.tutorialspoint.com/current_affairs.htm
https://www.tutorialspoint.com/upsc_ias_exams.htm
https://www.tutorialspoint.com/tutor_connect/index.php
https://www.tutorialspoint.com/whiteboard.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/tutorialslibrary.htm
https://www.tutorialspoint.com/videotutorials/index.php
https://store.tutorialspoint.com
https://www.tutorialspoint.com/gate_exams_tutorials.htm
https://www.tutorialspoint.com/html_online_training/index.asp
https://www.tutorialspoint.com/css_online_training/index.asp
https://www.tutorialspoint.com/3d_animation_online_training/index.asp
https://www.tutorialspoint.com/swift_4_online_training/index.asp
https://www.tutorialspoint.com/blockchain_online_training/index.asp
https://www.tutorialspoint.com/reactjs_online_training/index.asp
https://www.tutorix.com
https://www.tutorialspoint.com/videotutorials/top-courses.php
https://www.tutorialspoint.com/the_full_stack_web_development/index.asp
….
….
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/free_web_graphics.htm
https://www.tutorialspoint.com/online_file_conversion.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/free_online_whiteboard.htm
http://www.tutorialspoint.com
https://www.facebook.com/tutorialspointindia
https://plus.google.com/u/0/+tutorialspoint
http://www.twitter.com/tutorialspoint
http://www.linkedin.com/company/tutorialspoint
https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg
https://www.tutorialspoint.com/index.htm
/about/about_privacy.htm#cookies
/about/faq.htm
/about/about_helping.htm
/about/contact_us.htmDel mismo modo, podemos extraer información útil utilizando beautifulsoup4.
Ahora entendamos más sobre "sopa" en el ejemplo anterior.
En el ejemplo de código anterior, analizamos el documento a través de un hermoso constructor usando un método de cadena. Otra forma es pasar el documento a través de un identificador de archivo abierto.
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")Primero, el documento se convierte a Unicode y las entidades HTML se convierten a caracteres Unicode: </p>
import bs4
html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>'''
soup = bs4.BeautifulSoup(html, 'lxml')
print(soup)Salida
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>BeautifulSoup luego analiza los datos usando un analizador HTML o explícitamente le dice que los analice usando un analizador XML.
Estructura de árbol HTML
Antes de analizar los diferentes componentes de una página HTML, primero comprendamos la estructura del árbol HTML.
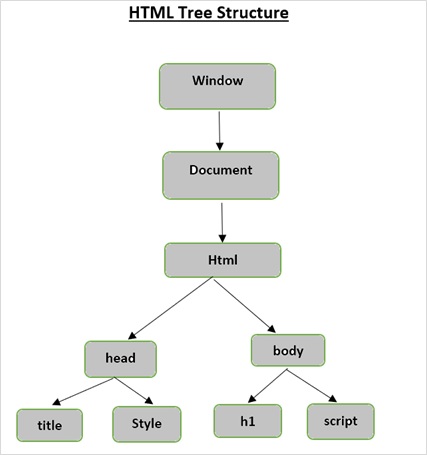
El elemento raíz en el árbol del documento es el html, que puede tener padres, hijos y hermanos y esto lo determina su posición en la estructura del árbol. Para moverse entre elementos HTML, atributos y texto, debe moverse entre los nodos en su estructura de árbol.
Supongamos que la página web es la que se muestra a continuación:
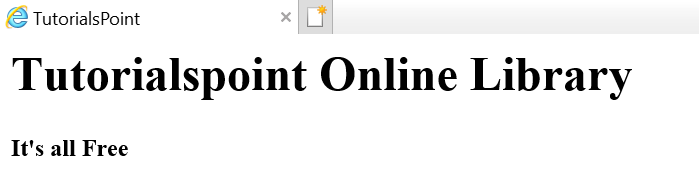
Lo que se traduce en un documento html de la siguiente manera:
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>Lo que simplemente significa que, para el documento html anterior, tenemos una estructura de árbol html de la siguiente manera:
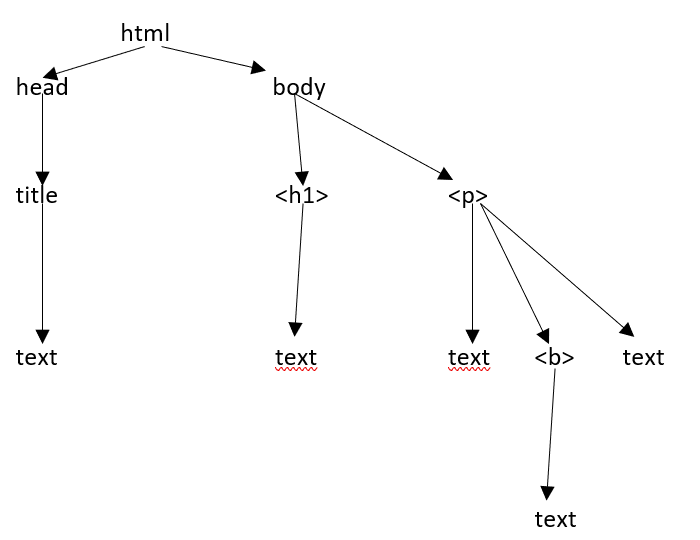
Cuando pasamos un documento html o una cadena a un constructor de beautifulsoup, beautifulsoup básicamente convierte una página html compleja en diferentes objetos de Python. A continuación, analizaremos cuatro tipos principales de objetos:
Tag
NavigableString
BeautifulSoup
Comments
Etiquetar objetos
Se utiliza una etiqueta HTML para definir varios tipos de contenido. Un objeto de etiqueta en BeautifulSoup corresponde a una etiqueta HTML o XML en la página o documento real.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>')
>>> tag = soup.html
>>> type(tag)
<class 'bs4.element.Tag'>Las etiquetas contienen muchos atributos y métodos y dos características importantes de una etiqueta son su nombre y atributos.
Nombre (tag.name)
Cada etiqueta contiene un nombre y se puede acceder a través de '.name' como sufijo. tag.name devolverá el tipo de etiqueta que es.
>>> tag.name
'html'Sin embargo, si cambiamos el nombre de la etiqueta, lo mismo se reflejará en el marcado HTML generado por BeautifulSoup.
>>> tag.name = "Strong"
>>> tag
<Strong><body><b class="boldest">TutorialsPoint</b></body></Strong>
>>> tag.name
'Strong'Atributos (tag.attrs)
Un objeto de etiqueta puede tener cualquier número de atributos. La etiqueta <b class = ”negrita”> tiene un atributo 'clase' cuyo valor es “negrita”. Todo lo que NO sea una etiqueta, es básicamente un atributo y debe contener un valor. Puede acceder a los atributos mediante el acceso a las claves (como el acceso a "clase" en el ejemplo anterior) o directamente mediante ".attrs"
>>> tutorialsP = BeautifulSoup("<div class='tutorialsP'></div>",'lxml')
>>> tag2 = tutorialsP.div
>>> tag2['class']
['tutorialsP']Podemos hacer todo tipo de modificaciones a los atributos de nuestra etiqueta (agregar / quitar / modificar).
>>> tag2['class'] = 'Online-Learning'
>>> tag2['style'] = '2007'
>>>
>>> tag2
<div class="Online-Learning" style="2007"></div>
>>> del tag2['style']
>>> tag2
<div class="Online-Learning"></div>
>>> del tag['class']
>>> tag
<b SecondAttribute="2">TutorialsPoint</b>
>>>
>>> del tag['SecondAttribute']
>>> tag
</b>
>>> tag2['class']
'Online-Learning'
>>> tag2['style']
KeyError: 'style'Atributos de varios valores
Algunos de los atributos de HTML5 pueden tener varios valores. El más utilizado es el atributo de clase, que puede tener varios valores CSS. Otros incluyen 'rel', 'rev', 'headers', 'accesskey' y 'accept-charset'. Los atributos de múltiples valores en la sopa hermosa se muestran como lista.
>>> from bs4 import BeautifulSoup
>>>
>>> css_soup = BeautifulSoup('<p class="body"></p>')
>>> css_soup.p['class']
['body']
>>>
>>> css_soup = BeautifulSoup('<p class="body bold"></p>')
>>> css_soup.p['class']
['body', 'bold']Sin embargo, si algún atributo contiene más de un valor, pero no es un atributo de valores múltiples según ninguna versión del estándar HTML, beautiful soup dejará el atributo solo:
>>> id_soup = BeautifulSoup('<p id="body bold"></p>')
>>> id_soup.p['id']
'body bold'
>>> type(id_soup.p['id'])
<class 'str'>Puede consolidar varios valores de atributos si convierte una etiqueta en una cadena.
>>> rel_soup = BeautifulSoup("<p> tutorialspoint Main <a rel='Index'> Page</a></p>")
>>> rel_soup.a['rel']
['Index']
>>> rel_soup.a['rel'] = ['Index', ' Online Library, Its all Free']
>>> print(rel_soup.p)
<p> tutorialspoint Main <a rel="Index Online Library, Its all Free"> Page</a></p>Al usar 'get_attribute_list', obtiene un valor que siempre es una lista, una cadena, independientemente de si es de varios valores o no.
id_soup.p.get_attribute_list(‘id’)Sin embargo, si analiza el documento como 'xml', no hay atributos de varios valores:
>>> xml_soup = BeautifulSoup('<p class="body bold"></p>', 'xml')
>>> xml_soup.p['class']
'body bold'NavigableString
El objeto navigablestring se utiliza para representar el contenido de una etiqueta. Para acceder a los contenidos, utilice ".string" con etiqueta.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>>
>>> soup.string
'Hello, Tutorialspoint!'
>>> type(soup.string)
>Puede reemplazar la cadena con otra cadena, pero no puede editar la cadena existente.
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> soup.string.replace_with("Online Learning!")
'Hello, Tutorialspoint!'
>>> soup.string
'Online Learning!'
>>> soup
<html><body><h2 id="message">Online Learning!</h2></body></html>Hermosa Sopa
BeautifulSoup es el objeto creado cuando intentamos raspar un recurso web. Entonces, es el documento completo el que estamos tratando de raspar. La mayoría de las veces, se trata de un objeto de etiqueta.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> type(soup)
<class 'bs4.BeautifulSoup'>
>>> soup.name
'[document]'Comentarios
El objeto de comentario ilustra la parte de comentario del documento web. Es solo un tipo especial de NavigableString.
>>> soup = BeautifulSoup('<p><!-- Everything inside it is COMMENTS --></p>')
>>> comment = soup.p.string
>>> type(comment)
<class 'bs4.element.Comment'>
>>> type(comment)
<class 'bs4.element.Comment'>
>>> print(soup.p.prettify())
<p>
<!-- Everything inside it is COMMENTS -->
</p>Objetos NavigableString
Los objetos de la cadena de navegación se utilizan para representar texto dentro de las etiquetas, en lugar de las etiquetas en sí mismas.
En este capítulo, analizaremos la navegación por etiquetas.
A continuación se muestra nuestro documento html:
>>> html_doc = """
<html><head><title>Tutorials Point</title></head>
<body>
<p class="title"><b>The Biggest Online Tutorials Library, It's all Free</b></p>
<p class="prog">Top 5 most used Programming Languages are:
<a href="https://www.tutorialspoint.com/java/java_overview.htm" class="prog" id="link1">Java</a>,
<a href="https://www.tutorialspoint.com/cprogramming/index.htm" class="prog" id="link2">C</a>,
<a href="https://www.tutorialspoint.com/python/index.htm" class="prog" id="link3">Python</a>,
<a href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" class="prog" id="link4">JavaScript</a> and
<a href="https://www.tutorialspoint.com/ruby/index.htm" class="prog" id="link5">C</a>;
as per online survey.</p>
<p class="prog">Programming Languages</p>
"""
>>>
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html_doc, 'html.parser')
>>>Basándonos en el documento anterior, intentaremos pasar de una parte del documento a otra.
Bajando
Uno de los elementos importantes de cualquier documento HTML son las etiquetas, que pueden contener otras etiquetas / cadenas (elementos secundarios de la etiqueta). Beautiful Soup ofrece diferentes formas de navegar e iterar sobre los hijos de la etiqueta.
Navegar usando nombres de etiquetas
La forma más sencilla de buscar en un árbol de análisis es buscar la etiqueta por su nombre. Si desea la etiqueta <head>, use soup.head -
>>> soup.head
<head>&t;title>Tutorials Point</title></head>
>>> soup.title
<title>Tutorials Point</title>Para obtener una etiqueta específica (como la primera etiqueta <b>) en la etiqueta <body>.
>>> soup.body.b
<b>The Biggest Online Tutorials Library, It's all Free</b>El uso de un nombre de etiqueta como atributo le dará solo la primera etiqueta con ese nombre:
>>> soup.a
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>Para obtener todos los atributos de la etiqueta, puede usar el método find_all () -
>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>]>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>].contenido y .niños
Podemos buscar los hijos de la etiqueta en una lista por su contenido.
>>> head_tag = soup.head
>>> head_tag
<head><title>Tutorials Point</title></head>
>>> Htag = soup.head
>>> Htag
<head><title>Tutorials Point</title></head>
>>>
>>> Htag.contents
[<title>Tutorials Point</title>
>>>
>>> Ttag = head_tag.contents[0]
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.contents
['Tutorials Point']El objeto BeautifulSoup en sí tiene hijos. En este caso, la etiqueta <html> es hija del objeto BeautifulSoup -
>>> len(soup.contents)
2
>>> soup.contents[1].name
'html'Una cadena no tiene .contenido, porque no puede contener nada -
>>> text = Ttag.contents[0]
>>> text.contents
self.__class__.__name__, attr))
AttributeError: 'NavigableString' object has no attribute 'contents'En lugar de obtenerlos como una lista, use el generador .children para acceder a los hijos de la etiqueta:
>>> for child in Ttag.children:
print(child)
Tutorials Point.descendientes
El atributo .descendants le permite iterar sobre todos los elementos secundarios de una etiqueta, de forma recursiva:
sus hijos directos y los hijos de sus hijos directos y así sucesivamente -
>>> for child in Htag.descendants:
print(child)
<title>Tutorials Point</title>
Tutorials PointLa etiqueta <head> tiene solo un hijo, pero tiene dos descendientes: la etiqueta <title> y el hijo de la etiqueta <title>. El objeto beautifulsoup tiene solo un hijo directo (la etiqueta <html>), pero tiene muchos descendientes:
>>> len(list(soup.children))
2
>>> len(list(soup.descendants))
33.cuerda
Si la etiqueta tiene solo un hijo, y ese hijo es NavigableString, el hijo está disponible como .string -
>>> Ttag.string
'Tutorials Point'Si el único hijo de una etiqueta es otra etiqueta, y esa etiqueta tiene un .string, entonces se considera que la etiqueta principal tiene el mismo .string que su hijo:
>>> Htag.contents
[<title>Tutorials Point</title>]
>>>
>>> Htag.string
'Tutorials Point'Sin embargo, si una etiqueta contiene más de una cosa, entonces no está claro a qué debería hacer referencia .string, por lo que .string se define como Ninguno -
>>> print(soup.html.string)
None.strings y stripped_strings
Si hay más de una cosa dentro de una etiqueta, aún puede mirar solo las cadenas. Utilice el generador .strings -
>>> for string in soup.strings:
print(repr(string))
'\n'
'Tutorials Point'
'\n'
'\n'
"The Biggest Online Tutorials Library, It's all Free"
'\n'
'Top 5 most used Programming Languages are: \n'
'Java'
',\n'
'C'
',\n'
'Python'
',\n'
'JavaScript'
' and\n'
'C'
';\n \nas per online survey.'
'\n'
'Programming Languages'
'\n'Para eliminar espacios en blanco adicionales, use el generador .stripped_strings -
>>> for string in soup.stripped_strings:
print(repr(string))
'Tutorials Point'
"The Biggest Online Tutorials Library, It's all Free"
'Top 5 most used Programming Languages are:'
'Java'
','
'C'
','
'Python'
','
'JavaScript'
'and'
'C'
';\n \nas per online survey.'
'Programming Languages'Subiendo
En una analogía del "árbol genealógico", cada etiqueta y cada cadena tiene un padre: la etiqueta que lo contiene:
.padre
Para acceder al elemento padre del elemento, use el atributo .parent.
>>> Ttag = soup.title
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.parent
<head>title>Tutorials Point</title></head>En nuestro html_doc, la cadena del título en sí tiene un padre: la etiqueta <title> que lo contiene
>>> Ttag.string.parent
<title>Tutorials Point</title>El padre de una etiqueta de nivel superior como <html> es el objeto Beautifulsoup en sí mismo:
>>> htmltag = soup.html
>>> type(htmltag.parent)
<class 'bs4.BeautifulSoup'>El .parent de un objeto Beautifulsoup se define como None -
>>> print(soup.parent)
None.padres
Para iterar sobre todos los elementos padres, use el atributo .parents.
>>> link = soup.a
>>> link
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
>>>
>>> for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p
body
html
[document]Yendo de lado
A continuación se muestra un documento simple:
>>> sibling_soup = BeautifulSoup("<a><b>TutorialsPoint</b><c><strong>The Biggest Online Tutorials Library, It's all Free</strong></b></a>")
>>> print(sibling_soup.prettify())
<html>
<body>
<a>
<b>
TutorialsPoint
</b>
<c>
<strong>
The Biggest Online Tutorials Library, It's all Free
</strong>
</c>
</a>
</body>
</html>En el documento anterior, las etiquetas <b> y <c> están en el mismo nivel y ambas son elementos secundarios de la misma etiqueta. Tanto la etiqueta <b> como la <c> son hermanas.
.next_sibling y .previous_sibling
Utilice .next_sibling y .previous_sibling para navegar entre los elementos de la página que están en el mismo nivel del árbol de análisis:
>>> sibling_soup.b.next_sibling
<c><strong>The Biggest Online Tutorials Library, It's all Free</strong></c>
>>>
>>> sibling_soup.c.previous_sibling
<b>TutorialsPoint</b>La etiqueta <b> tiene un .next_sibling pero no .previous_sibling, ya que no hay nada antes de la etiqueta <b> en el mismo nivel del árbol, el mismo caso es con la etiqueta <c>.
>>> print(sibling_soup.b.previous_sibling)
None
>>> print(sibling_soup.c.next_sibling)
NoneLas dos cadenas no son hermanos, ya que no tienen el mismo padre.
>>> sibling_soup.b.string
'TutorialsPoint'
>>>
>>> print(sibling_soup.b.string.next_sibling)
None.next_siblings y .previous_siblings
Para iterar sobre los hermanos de una etiqueta, use .next_siblings y .previous_siblings.
>>> for sibling in soup.a.next_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
>a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>
' and\n'
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm"
id="link5">C</a>
';\n \nas per online survey.'
>>> for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
'Top 5 most used Programming Languages are: \n'Yendo y viniendo
Ahora volvamos a las dos primeras líneas de nuestro ejemplo anterior "html_doc":
&t;html><head><title>Tutorials Point</title></head>
<body>
<h4 class="tagLine"><b>The Biggest Online Tutorials Library, It's all Free</b></h4>Un analizador HTML toma la cadena de caracteres anterior y la convierte en una serie de eventos como "abrir una etiqueta <html>", "abrir una etiqueta <head>", "abrir la etiqueta <title>", "agregar una cadena", "Cerrar la etiqueta </title>", "cerrar la etiqueta </head>", "abrir una etiqueta <h4>" y así sucesivamente. BeautifulSoup ofrece diferentes métodos para reconstruir el análisis inicial del documento.
.next_element y .previous_element
El atributo .next_element de una etiqueta o cadena apunta a lo que se analizó inmediatamente después. A veces se parece a .next_sibling, sin embargo, no es completamente igual. A continuación se muestra la etiqueta <a> final en nuestro documento de ejemplo "html_doc".
>>> last_a_tag = soup.find("a", id="link5")
>>> last_a_tag
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>
>>> last_a_tag.next_sibling
';\n \nas per online survey.'Sin embargo, el .next_element de esa etiqueta <a>, lo que se analizó inmediatamente después de la etiqueta <a>, no es el resto de esa oración: es la palabra "C":
>>> last_a_tag.next_element
'C'El comportamiento anterior se debe a que en el marcado original, la letra "C" apareció antes de ese punto y coma. El analizador encontró una etiqueta <a>, luego la letra "C", luego la etiqueta de cierre </a>, luego el punto y coma y el resto de la oración. El punto y coma está en el mismo nivel que la etiqueta <a>, pero la letra "C" se encontró primero.
El atributo .previous_element es exactamente lo contrario de .next_element. Apunta a cualquier elemento analizado inmediatamente antes de este.
>>> last_a_tag.previous_element
' and\n'
>>>
>>> last_a_tag.previous_element.next_element
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>.next_elements y .previous_elements
Usamos estos iteradores para avanzar y retroceder hasta un elemento.
>>> for element in last_a_tag.next_e lements:
print(repr(element))
'C'
';\n \nas per online survey.'
'\n'
<p class="prog">Programming Languages</p>
'Programming Languages'
'\n'Hay muchos métodos de Beautifulsoup, que nos permiten buscar en un árbol de análisis. Los dos métodos más comunes y usados son find () y find_all ().
Antes de hablar sobre find () y find_all (), veamos algunos ejemplos de diferentes filtros que puede pasar a estos métodos.
Tipos de filtros
Tenemos diferentes filtros que podemos pasar a estos métodos y la comprensión de estos filtros es crucial, ya que estos filtros se utilizan una y otra vez en toda la API de búsqueda. Podemos usar estos filtros basados en el nombre de la etiqueta, en sus atributos, en el texto de una cadena o una combinación de estos.
Una cuerda
Uno de los tipos de filtro más simples es una cadena. Pasando una cadena al método de búsqueda y Beautifulsoup realizará una coincidencia con esa cadena exacta.
A continuación, el código encontrará todas las etiquetas <p> en el documento:
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>> markup.find_all('p')
[<p>Top Three</p>, <p></p>, <p><b>Java, Python, Cplusplus</b></p>]Expresión regular
Puede encontrar todas las etiquetas que comiencen con una cadena / etiqueta determinada. Antes de eso, necesitamos importar el módulo re para usar expresiones regulares.
>>> import re
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>>
>>> markup.find_all(re.compile('^p'))
[<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>]Lista
Puede pasar varias etiquetas para buscar proporcionando una lista. Debajo del código se encuentran todas las etiquetas <b> y <pre> -
>>> markup.find_all(['pre', 'b'])
[<pre>Programming Languages are:</pre>, <b>Java, Python, Cplusplus</b>]Cierto
True devolverá todas las etiquetas que pueda encontrar, pero no las cadenas por sí mismas.
>>> markup.find_all(True)
[<html><body><p>Top Three</p><p></p><pre>Programming Languages are:</pre>
<p><b>Java, Python, Cplusplus</b> </p> </body></html>,
<body><p>Top Three</p><p></p><pre> Programming Languages are:</pre><p><b>Java, Python, Cplusplus</b></p>
</body>,
<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>, <b>Java, Python, Cplusplus</b>]Para devolver solo las etiquetas de la sopa anterior:
>>> for tag in markup.find_all(True):
(tag.name)
'html'
'body'
'p'
'p'
'pre'
'p'
'b'encuentra todos()
Puede usar find_all para extraer todas las apariciones de una etiqueta en particular de la respuesta de la página como:
Sintaxis
find_all(name, attrs, recursive, string, limit, **kwargs)Extraigamos algunos datos interesantes de IMDB- "Películas mejor calificadas" de todos los tiempos.
>>> url="https://www.imdb.com/chart/top/?ref_=nv_mv_250"
>>> content = requests.get(url)
>>> soup = BeautifulSoup(content.text, 'html.parser')
#Extract title Page
>>> print(soup.find('title'))
<title>IMDb Top 250 - IMDb</title>
#Extracting main heading
>>> for heading in soup.find_all('h1'):
print(heading.text)
Top Rated Movies
#Extracting sub-heading
>>> for heading in soup.find_all('h3'):
print(heading.text)
IMDb Charts
You Have Seen
IMDb Charts
Top India Charts
Top Rated Movies by Genre
Recently ViewedDesde arriba, podemos ver que find_all nos dará todos los elementos que coinciden con los criterios de búsqueda que definimos. Todos los filtros que podemos usar con find_all () se pueden usar con find () y otros métodos de búsqueda también como find_parents () o find_siblings ().
encontrar()
Hemos visto anteriormente, find_all () se usa para escanear todo el documento para encontrar todo el contenido, pero algo, el requisito es encontrar solo un resultado. Si sabe que el documento contiene solo una etiqueta <body>, es una pérdida de tiempo buscar en todo el documento. Una forma es llamar a find_all () con limit = 1 cada vez o de lo contrario podemos usar el método find () para hacer lo mismo:
Sintaxis
find(name, attrs, recursive, string, **kwargs)Entonces, a continuación, dos métodos diferentes dan el mismo resultado:
>>> soup.find_all('title',limit=1)
[<title>IMDb Top 250 - IMDb</title>]
>>>
>>> soup.find('title')
<title>IMDb Top 250 - IMDb</title>En los resultados anteriores, podemos ver que el método find_all () devuelve una lista que contiene un solo elemento, mientras que el método find () devuelve un solo resultado.
Otra diferencia entre el método find () y find_all () es:
>>> soup.find_all('h2')
[]
>>>
>>> soup.find('h2')Si el método soup.find_all () no puede encontrar nada, devuelve una lista vacía mientras que find () devuelve Ninguno.
find_parents () y find_parent ()
A diferencia de los métodos find_all () y find () que atraviesan el árbol, mirando los descendientes de la etiqueta, los métodos find_parents () y find_parents () hacen lo contrario, atraviesan el árbol hacia arriba y miran a los padres de una etiqueta (o una cadena).
Sintaxis
find_parents(name, attrs, string, limit, **kwargs)
find_parent(name, attrs, string, **kwargs)
>>> a_string = soup.find(string="The Godfather")
>>> a_string
'The Godfather'
>>> a_string.find_parents('a')
[<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>]
>>> a_string.find_parent('a')
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
>>> a_string.find_parent('tr')
<tr>
<td class="posterColumn">
<span data-value="2" name="rk"></span>
<span data-value="9.149038526210072" name="ir"></span>
<span data-value="6.93792E10" name="us"></span>
<span data-value="1485540" name="nv"></span>
<span data-value="-1.850961473789928" name="ur"></span>
<a href="/title/tt0068646/"> <img alt="The Godfather" height="67" src="https://m.media-amazon.com/images/M/MV5BM2MyNjYxNmUtYTAwNi00MTYxLWJmNWYtYzZlODY3ZTk3OTFlXkEyXkFqcGdeQXVyNzkwMjQ5NzM@._V1_UY67_CR1,0,45,67_AL_.jpg" width="45"/>
</a> </td>
<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>
<td class="ratingColumn imdbRating">
<strong title="9.1 based on 1,485,540 user ratings">9.1</strong>
</td>
<td class="ratingColumn">
<div class="seen-widget seen-widget-tt0068646 pending" data-titleid="tt0068646">
<div class="boundary">
<div class="popover">
<span class="delete"> </span><ol><li>1<li>2<li>3<li>4<li>5<li>6<li>7<li>8<li>9<li>10</li>0</li></li></li></li&td;</li></li></li></li></li></ol> </div>
</div>
<div class="inline">
<div class="pending"></div>
<div class="unseeable">NOT YET RELEASED</div>
<div class="unseen"> </div>
<div class="rating"></div>
<div class="seen">Seen</div>
</div>
</div>
</td>
<td class="watchlistColumn">
<div class="wlb_ribbon" data-recordmetrics="true" data-tconst="tt0068646"></div>
</td>
</tr>
>>>
>>> a_string.find_parents('td')
[<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>]Hay otros ocho métodos similares:
find_next_siblings(name, attrs, string, limit, **kwargs)
find_next_sibling(name, attrs, string, **kwargs)
find_previous_siblings(name, attrs, string, limit, **kwargs)
find_previous_sibling(name, attrs, string, **kwargs)
find_all_next(name, attrs, string, limit, **kwargs)
find_next(name, attrs, string, **kwargs)
find_all_previous(name, attrs, string, limit, **kwargs)
find_previous(name, attrs, string, **kwargs)Dónde,
find_next_siblings() y find_next_sibling() Los métodos iterarán sobre todos los hermanos del elemento que vienen después del actual.
find_previous_siblings() y find_previous_sibling() Los métodos iterarán sobre todos los hermanos que vienen antes del elemento actual.
find_all_next() y find_next() Los métodos iterarán sobre todas las etiquetas y cadenas que vienen después del elemento actual.
find_all_previous y find_previous() Los métodos iterarán sobre todas las etiquetas y cadenas que vienen antes del elemento actual.
Selectores de CSS
La biblioteca BeautifulSoup para admitir los selectores de CSS más utilizados. Puede buscar elementos usando selectores CSS con la ayuda del método select ().
A continuación se muestran algunos ejemplos:
>>> soup.select('title')
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>>
>>> soup.select("p:nth-of-type(1)")
[<p>The Top Rated Movie list only includes theatrical features.</p>, <p> class="imdb-footer__copyright _2-iNNCFskmr4l2OFN2DRsf">© 1990- by IMDb.com, Inc.</p>]
>>> len(soup.select("p:nth-of-type(1)"))
2
>>> len(soup.select("a"))
609
>>> len(soup.select("p"))
2
>>> soup.select("html head title")
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>> soup.select("head > title")
[<title>IMDb Top 250 - IMDb</title>]
#print HTML code of the tenth li elemnet
>>> soup.select("li:nth-of-type(10)")
[<li class="subnav_item_main">
<a href="/search/title?genres=film_noir&sort=user_rating,desc&title_type=feature&num_votes=25000,">Film-Noir
</a> </li>]Uno de los aspectos importantes de BeautifulSoup es buscar en el árbol de análisis y le permite realizar cambios en el documento web de acuerdo con sus requisitos. Podemos hacer cambios a las propiedades de la etiqueta usando sus atributos, como el método .name, .string o .append (). Le permite agregar nuevas etiquetas y cadenas a una etiqueta existente con la ayuda de los métodos .new_string () y .new_tag (). También hay otros métodos, como .insert (), .insert_before () o .insert_after () para realizar varias modificaciones en su documento HTML o XML.
Cambiar los nombres y atributos de las etiquetas
Una vez que haya creado la sopa, es fácil realizar modificaciones como cambiar el nombre de la etiqueta, hacer modificaciones a sus atributos, agregar nuevos atributos y eliminar atributos.
>>> soup = BeautifulSoup('<b class="bolder">Very Bold</b>')
>>> tag = soup.bLa modificación y la adición de nuevos atributos son las siguientes:
>>> tag.name = 'Blockquote'
>>> tag['class'] = 'Bolder'
>>> tag['id'] = 1.1
>>> tag
<Blockquote class="Bolder" id="1.1">Very Bold</Blockquote>La eliminación de atributos es la siguiente:
>>> del tag['class']
>>> tag
<Blockquote id="1.1">Very Bold</Blockquote>
>>> del tag['id']
>>> tag
<Blockquote>Very Bold</Blockquote>Modificar .string
Puede modificar fácilmente el atributo .string de la etiqueta:
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner>/i<</a>'
>>> Bsoup = BeautifulSoup(markup)
>>> tag = Bsoup.a
>>> tag.string = "My Favourite spot."
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">My Favourite spot.</a>Desde arriba, podemos ver si la etiqueta contiene alguna otra etiqueta, ellos y todo su contenido serán reemplazados por nuevos datos.
adjuntar()
Agregar nuevos datos / contenido a una etiqueta existente se realiza mediante el método tag.append (). Es muy similar al método append () en la lista de Python.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i></a>'
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.a.append(" Really Liked it")
>>> Bsoup
<html><body><a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i> Really Liked it</a></body></html>
>>> Bsoup.a.contents
['Must for every ', <i>Learner</i>, ' Really Liked it']NavigableString () y .new_tag ()
En caso de que desee agregar una cadena a un documento, esto se puede hacer fácilmente usando el constructor append () o NavigableString () -
>>> soup = BeautifulSoup("<b></b>")
>>> tag = soup.b
>>> tag.append("Start")
>>>
>>> new_string = NavigableString(" Your")
>>> tag.append(new_string)
>>> tag
<b>Start Your</b>
>>> tag.contents
['Start', ' Your']Note: Si encuentra algún error de nombre al acceder a la función NavigableString (), de la siguiente manera:
NameError: el nombre 'NavigableString' no está definido
Simplemente importe el directorio NavigableString del paquete bs4 -
>>> from bs4 import NavigableStringPodemos resolver el error anterior.
Puede agregar comentarios a sus etiquetas existentes o puede agregar alguna otra subclase de NavigableString, simplemente llame al constructor.
>>> from bs4 import Comment
>>> adding_comment = Comment("Always Learn something Good!")
>>> tag.append(adding_comment)
>>> tag
<b>Start Your<!--Always Learn something Good!--></b>
>>> tag.contents
['Start', ' Your', 'Always Learn something Good!']Se puede agregar una etiqueta completamente nueva (sin agregar a una etiqueta existente) usando el método incorporado de Beautifulsoup, BeautifulSoup.new_tag () -
>>> soup = BeautifulSoup("<b></b>")
>>> Otag = soup.b
>>>
>>> Newtag = soup.new_tag("a", href="https://www.tutorialspoint.com")
>>> Otag.append(Newtag)
>>> Otag
<b><a href="https://www.tutorialspoint.com"></a></b>Solo se requiere el primer argumento, el nombre de la etiqueta.
insertar()
Similar al método .insert () en la lista de Python, tag.insert () insertará un nuevo elemento, sin embargo, a diferencia de tag.append (), el nuevo elemento no necesariamente va al final del contenido de su padre. Se puede agregar un nuevo elemento en cualquier posición.
>>> markup = '<a href="https://www.djangoproject.com/community/">Django Official website <i>Huge Community base</i></a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>>
>>> tag.insert(1, "Love this framework ")
>>> tag
<a href="https://www.djangoproject.com/community/">Django Official website Love this framework <i>Huge Community base</i></a>
>>> tag.contents
['Django Official website ', 'Love this framework ', <i>Huge Community base</i
>]
>>>insert_before () y insert_after ()
Para insertar alguna etiqueta o cadena justo antes de algo en el árbol de análisis, usamos insert_before () -
>>> soup = BeautifulSoup("Brave")
>>> tag = soup.new_tag("i")
>>> tag.string = "Be"
>>>
>>> soup.b.string.insert_before(tag)
>>> soup.b
<b><i>Be</i>Brave</b>De manera similar, para insertar alguna etiqueta o cadena justo después de algo en el árbol de análisis, use insert_after ().
>>> soup.b.i.insert_after(soup.new_string(" Always "))
>>> soup.b
<b><i>Be</i> Always Brave</b>
>>> soup.b.contents
[<i>Be</i>, ' Always ', 'Brave']claro()
Para eliminar el contenido de una etiqueta, use tag.clear () -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical&lr;/i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> tag.clear()
>>> tag
<a href="https://www.tutorialspoint.com/index.htm"></a>extraer()
Para eliminar una etiqueta o cadenas del árbol, use PageElement.extract ().
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i&gr;technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> i_tag = soup.i.extract()
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>
>>> i_tag
<i>technical & Non-technical</i>
>>>
>>> print(i_tag.parent)
Nonedescomponer()
El tag.decompose () elimina una etiqueta del árbol y elimina todo su contenido.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> soup.i.decompose()
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>Reemplazar con()
Como sugiere el nombre, la función pageElement.replace_with () reemplazará la etiqueta o cadena anterior con la nueva etiqueta o cadena en el árbol -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Complete Python <i>Material</i></a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> new_tag = soup.new_tag("Official_site")
>>> new_tag.string = "https://www.python.org/"
>>> a_tag.i.replace_with(new_tag)
<i>Material</i>
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">Complete Python <Official_site>https://www.python.org/</Official_site></a>En la salida anterior, ha notado que replace_with () devuelve la etiqueta o cadena que fue reemplazada (como "Material" en nuestro caso), por lo que puede examinarla o agregarla nuevamente a otra parte del árbol.
envolver()
PageElement.wrap () incluyó un elemento en la etiqueta que especifique y devuelve un nuevo contenedor:
>>> soup = BeautifulSoup("<p>tutorialspoint.com</p>")
>>> soup.p.string.wrap(soup.new_tag("b"))
<b>tutorialspoint.com</b>
>>>
>>> soup.p.wrap(soup.new_tag("Div"))
<Div><p><b>tutorialspoint.com</b></p></Div>desenvolver()
El tag.unwrap () es justo lo opuesto a wrap () y reemplaza una etiqueta con lo que sea dentro de esa etiqueta.
>>> soup = BeautifulSoup('<a href="https://www.tutorialspoint.com/">I liked <i>tutorialspoint</i></a>')
>>> a_tag = soup.a
>>>
>>> a_tag.i.unwrap()
<i></i>
>>> a_tag
<a href="https://www.tutorialspoint.com/">I liked tutorialspoint</a>Desde arriba, ha notado que como replace_with (), desenvolver () devuelve la etiqueta que fue reemplazada.
A continuación se muestra un ejemplo más de desenvolver () para comprenderlo mejor:
>>> soup = BeautifulSoup("<p>I <strong>AM</strong> a <i>text</i>.</p>")
>>> soup.i.unwrap()
<i></i>
>>> soup
<html><body><p>I <strong>AM</strong> a text.</p></body></html>desenvolver () es bueno para eliminar el marcado.
Todos los documentos HTML o XML están escritos en alguna codificación específica como ASCII o UTF-8. Sin embargo, cuando carga ese documento HTML / XML en BeautifulSoup, se ha convertido a Unicode.
>>> markup = "<p>I will display £</p>"
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.p
<p>I will display £</p>
>>> Bsoup.p.string
'I will display £'El comportamiento anterior se debe a que BeautifulSoup utiliza internamente la sub-biblioteca llamada Unicode, Dammit para detectar la codificación de un documento y luego convertirlo a Unicode.
Sin embargo, no todo el tiempo, el Unicode, Dammit adivina correctamente. Como el documento se busca byte a byte para adivinar la codificación, lleva mucho tiempo. Puede ahorrar algo de tiempo y evitar errores, si ya conoce la codificación pasándola al constructor de BeautifulSoup como from_encoding.
A continuación se muestra un ejemplo en el que BeautifulSoup identifica erróneamente un documento ISO-8859-8 como ISO-8859-7 -
>>> markup = b"<h1>\xed\xe5\xec\xf9</h1>"
>>> soup = BeautifulSoup(markup)
>>> soup.h1
<h1>νεμω</h1>
>>> soup.original_encoding
'ISO-8859-7'
>>>Para resolver el problema anterior, páselo a BeautifulSoup usando from_encoding -
>>> soup = BeautifulSoup(markup, from_encoding="iso-8859-8")
>>> soup.h1
<h1>ולש </h1>
>>> soup.original_encoding
'iso-8859-8'
>>>Otra característica nueva agregada de BeautifulSoup 4.4.0 es exclude_encoding. Se puede usar cuando no conoce la codificación correcta pero está seguro de que Unicode, maldita sea, muestra un resultado incorrecto.
>>> soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"])Codificación de salida
La salida de un BeautifulSoup es un documento UTF-8, independientemente del documento introducido en BeautifulSoup. Debajo de un documento, donde están los caracteres polacos en formato ISO-8859-2.
html_markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</BODY>
</HTML>
"""
>>> soup = BeautifulSoup(html_markup)
>>> print(soup.prettify())
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type"/>
</head>
<body>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</body>
</html>En el ejemplo anterior, si observa, la etiqueta <meta> se ha reescrito para reflejar que el documento generado por BeautifulSoup ahora está en formato UTF-8.
Si no desea la salida generada en UTF-8, puede asignar la codificación deseada en prettify ().
>>> print(soup.prettify("latin-1"))
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">\n<html>\n <head>\n <meta content="text/html; charset=latin-1" http-equiv="content-type"/>\n </head>\n <body>\n ą ć ę ł ń \xf3 ś ź ż Ą Ć Ę Ł Ń \xd3 Ś Ź Ż\n </body>\n</html>\n'En el ejemplo anterior, hemos codificado el documento completo, sin embargo, puede codificar, cualquier elemento en particular en la sopa como si fuera una cadena de python -
>>> soup.p.encode("latin-1")
b'<p>0My first paragraph.</p>'
>>> soup.h1.encode("latin-1")
b'<h1>My First Heading</h1>'Cualquier carácter que no se pueda representar en la codificación elegida se convertirá en referencias numéricas de entidad XML. A continuación se muestra uno de esos ejemplos:
>>> markup = u"<b>\N{SNOWMAN}</b>"
>>> snowman_soup = BeautifulSoup(markup)
>>> tag = snowman_soup.b
>>> print(tag.encode("utf-8"))
b'<b>\xe2\x98\x83</b>'Si intenta codificar lo anterior en "latin-1" o "ascii", generará "☃", lo que indica que no hay representación para eso.
>>> print (tag.encode("latin-1"))
b'<b>☃</b>'
>>> print (tag.encode("ascii"))
b'<b>☃</b>'Unicode, maldita sea
Unicode, Dammit se usa principalmente cuando el documento entrante está en formato desconocido (principalmente en un idioma extranjero) y queremos codificar en algún formato conocido (Unicode) y tampoco necesitamos Beautifulsoup para hacer todo esto.
El punto de partida de cualquier proyecto de BeautifulSoup es el objeto BeautifulSoup. Un objeto BeautifulSoup representa el documento HTML / XML de entrada utilizado para su creación.
Podemos pasar una cadena o un objeto similar a un archivo para Beautiful Soup, donde los archivos (objetos) se almacenan localmente en nuestra máquina o en una página web.
Los objetos BeautifulSoup más comunes son:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Comparar objetos por igualdad
Según la hermosa sopa, dos objetos de cadena o etiqueta navegables son iguales si representan el mismo marcado HTML / XML.
Ahora veamos el siguiente ejemplo, donde las dos etiquetas <b> se tratan como iguales, aunque viven en diferentes partes del árbol de objetos, porque ambas se parecen a “<b> Java </b>”.
>>> markup = "<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>"
>>> soup = BeautifulSoup(markup, "html.parser")
>>> first_b, second_b = soup.find_all('b')
>>> print(first_b == second_b)
True
>>> print(first_b.previous_element == second_b.previous_element)
FalseSin embargo, para verificar si las dos variables se refieren a los mismos objetos, puede usar lo siguiente:
>>> print(first_b is second_b)
FalseCopiar objetos Beautiful Soup
Para crear una copia de cualquier etiqueta o NavigableString, use la función copy.copy (), como se muestra a continuación:
>>> import copy
>>> p_copy = copy.copy(soup.p)
>>> print(p_copy)
<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>
>>>Aunque las dos copias (la original y la copiada) contienen el mismo marcado, las dos no representan el mismo objeto:
>>> print(soup.p == p_copy)
True
>>>
>>> print(soup.p is p_copy)
False
>>>La única diferencia real es que la copia está completamente separada del árbol de objetos Beautiful Soup original, como si se hubiera llamado a extract ().
>>> print(p_copy.parent)
NoneEl comportamiento anterior se debe a dos objetos de etiqueta diferentes que no pueden ocupar el mismo espacio al mismo tiempo.
Hay varias situaciones en las que desea extraer tipos específicos de información (solo etiquetas <a>) utilizando Beautifulsoup4. La clase SoupStrainer en Beautifulsoup le permite analizar solo una parte específica de un documento entrante.
Una forma es crear un SoupStrainer y pasarlo al constructor Beautifulsoup4 como el argumento parse_only.
Colador de sopa
Un SoupStrainer le dice a BeautifulSoup qué partes extraen, y el árbol de análisis consta solo de estos elementos. Si reduce la información requerida a una parte específica del HTML, esto acelerará el resultado de la búsqueda.
product = SoupStrainer('div',{'id': 'products_list'})
soup = BeautifulSoup(html,parse_only=product)Las líneas de código anteriores analizarán solo los títulos de un sitio de producto, que puede estar dentro de un campo de etiqueta.
De manera similar, como arriba, podemos usar otros objetos soupStrainer para analizar información específica de una etiqueta HTML. A continuación se muestran algunos de los ejemplos:
from bs4 import BeautifulSoup, SoupStrainer
#Only "a" tags
only_a_tags = SoupStrainer("a")
#Will parse only the below mentioned "ids".
parse_only = SoupStrainer(id=["first", "third", "my_unique_id"])
soup = BeautifulSoup(my_document, "html.parser", parse_only=parse_only)
#parse only where string length is less than 10
def is_short_string(string):
return len(string) < 10
only_short_strings =SoupStrainer(string=is_short_string)Manejo de errores
Hay dos tipos principales de errores que deben manejarse en BeautifulSoup. Estos dos errores no son de su script sino de la estructura del fragmento porque la API de BeautifulSoup arroja un error.
Los dos errores principales son los siguientes:
AttributeError
Se produce cuando la notación de puntos no encuentra una etiqueta hermana en la etiqueta HTML actual. Por ejemplo, es posible que haya encontrado este error, debido a que falta una "etiqueta de anclaje", la clave de costo arrojará un error a medida que atraviesa y requiere una etiqueta de anclaje.
KeyError
Este error se produce si falta el atributo de etiqueta HTML necesario. Por ejemplo, si no tenemos el atributo data-pid en un fragmento, la clave pid arrojará key-error.
Para evitar los dos errores enumerados anteriormente al analizar un resultado, ese resultado se omitirá para asegurarse de que no se inserte un fragmento con formato incorrecto en las bases de datos:
except(AttributeError, KeyError) as er:
passdiagnosticar()
Siempre que encontremos alguna dificultad para entender lo que BeautifulSoup hace con nuestro documento o HTML, simplemente páselo a la función diagnostose (). Al pasar el archivo del documento a la función diagnostose (), podemos mostrar cómo la lista de diferentes analizadores maneja el documento.
A continuación se muestra un ejemplo para demostrar el uso de la función diagnosticar ():
from bs4.diagnose import diagnose
with open("20 Books.html",encoding="utf8") as fp:
data = fp.read()
diagnose(data)Salida
Error de sintáxis
Hay dos tipos principales de errores de análisis. Es posible que obtenga una excepción como HTMLParseError, cuando alimenta su documento a BeautifulSoup. También puede obtener un resultado inesperado, donde el árbol de análisis de BeautifulSoup se ve muy diferente del resultado esperado del documento de análisis.
Ninguno de los errores de análisis se debe a BeautifulSoup. Es debido al analizador externo que usamos (html5lib, lxml) ya que BeautifulSoup no contiene ningún código de analizador. Una forma de resolver el error de análisis anterior es utilizar otro analizador.
from HTMLParser import HTMLParser
try:
from HTMLParser import HTMLParseError
except ImportError, e:
# From python 3.5, HTMLParseError is removed. Since it can never be
# thrown in 3.5, we can just define our own class as a placeholder.
class HTMLParseError(Exception):
passEl analizador HTML incorporado de Python causa dos errores de análisis más comunes, HTMLParser.HTMLParserError: etiqueta de inicio mal formada y HTMLParser.HTMLParserError: etiqueta final incorrecta y para resolver esto, es usar otro analizador principalmente: lxml o html5lib.
Otro tipo común de comportamiento inesperado es que no puede encontrar una etiqueta que sabe que está en el documento. Sin embargo, cuando ejecuta find_all () devuelve [] o find () devuelve None.
Esto puede deberse a que el analizador HTML incorporado de Python a veces omite etiquetas que no comprende.
Error del analizador XML
Por defecto, el paquete BeautifulSoup analiza los documentos como HTML, sin embargo, es muy fácil de usar y maneja XML mal formado de una manera muy elegante usando beautifulsoup4.
Para analizar el documento como XML, necesita tener un analizador lxml y solo necesita pasar el "xml" como segundo argumento al constructor Beautifulsoup -
soup = BeautifulSoup(markup, "lxml-xml")o
soup = BeautifulSoup(markup, "xml")Un error común de análisis de XML es:
AttributeError: 'NoneType' object has no attribute 'attrib'Esto puede suceder en caso de que falte algún elemento o no esté definido mientras se usa la función find () o findall ().
Otros errores de análisis
A continuación se presentan algunos de los otros errores de análisis que vamos a discutir en esta sección:
Problema medioambiental
Además de los errores de análisis mencionados anteriormente, puede encontrar otros problemas de análisis, como problemas ambientales, en los que su script puede funcionar en un sistema operativo pero no en otro sistema operativo o puede funcionar en un entorno virtual pero no en otro entorno virtual o puede no funcionar fuera del entorno virtual. Todos estos problemas pueden deberse a que los dos entornos tienen diferentes bibliotecas de analizadores disponibles.
Se recomienda conocer o verificar su analizador predeterminado en su entorno de trabajo actual. Puede verificar el analizador predeterminado actual disponible para el entorno de trabajo actual o bien pasar explícitamente la biblioteca del analizador requerida como segundos argumentos al constructor BeautifulSoup.
No distingue entre mayúsculas y minúsculas
Como las etiquetas y atributos HTML no distinguen entre mayúsculas y minúsculas, los tres analizadores HTML convierten los nombres de etiquetas y atributos a minúsculas. Sin embargo, si desea conservar las etiquetas y los atributos en mayúsculas o minúsculas, es mejor analizar el documento como XML.
UnicodeEncodeError
Veamos el siguiente segmento de código:
soup = BeautifulSoup(response, "html.parser")
print (soup)Salida
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'El problema anterior puede deberse a dos situaciones principales. Es posible que esté intentando imprimir un carácter Unicode que su consola no sabe cómo mostrar. En segundo lugar, está intentando escribir en un archivo y pasa un carácter Unicode que no es compatible con su codificación predeterminada.
Una forma de resolver el problema anterior es codificar el texto / carácter de respuesta antes de preparar la sopa para obtener el resultado deseado, de la siguiente manera:
responseTxt = response.text.encode('UTF-8')KeyError: [attr]
Se debe al acceso a la etiqueta ['attr'] cuando la etiqueta en cuestión no define el atributo attr. Los errores más comunes son: “KeyError: 'href'” y “KeyError: 'class'”. Use tag.get ('attr') si no está seguro de que attr esté definido.
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback actionAttributeError
Puede encontrar AttributeError de la siguiente manera:
AttributeError: 'list' object has no attribute 'find_all'El error anterior se produce principalmente porque esperaba que find_all () devolviera una sola etiqueta o cadena. Sin embargo, soup.find_all devuelve una lista de elementos de Python.
Todo lo que necesita hacer es recorrer la lista y capturar datos de esos elementos.